
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 600M
2.05B
| node_id
stringlengths 18
32
| number
int64 2
6.51k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
sequencelengths 0
30
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/656/comments | https://api.github.com/repos/huggingface/datasets/issues/656/events | https://github.com/huggingface/datasets/pull/656 | 705,736,319 | MDExOlB1bGxSZXF1ZXN0NDkwNDEwODAz | 656 | Use multiprocess from pathos for multiprocessing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"We can just install multiprocess actually, I'll change that",
"Just an FYI: I remember that I wanted to try pathos a couple of years back and I ran into issues considering cross-platform; the code would just break on Windows. If I can verify this PR by running CPU tests on Windows, let me know!",
"That's good to know thanks\r\nI guess we can just wait for #644 to be merged first. I'm working on fixing the tests for windows",
"Looks like all the CI jobs on windows passed !\r\nI also tested locally on my windows and it works great :) \r\n\r\nI think this is ready to merge, let me know if you have any remarks @thomwolf @BramVanroy "
] | "2020-09-21T16:12:19Z" | "2020-09-28T14:45:40Z" | "2020-09-28T14:45:39Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/656.diff",
"html_url": "https://github.com/huggingface/datasets/pull/656",
"merged_at": "2020-09-28T14:45:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/656.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/656"
} | [Multiprocess](https://github.com/uqfoundation/multiprocess) (from the [pathos](https://github.com/uqfoundation/pathos) project) allows to use lambda functions in multiprocessed map.
It was suggested to use it by @kandorm.
We're already using dill which is its only dependency. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/656/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2061 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2061/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2061/comments | https://api.github.com/repos/huggingface/datasets/issues/2061/events | https://github.com/huggingface/datasets/issues/2061 | 832,596,228 | MDU6SXNzdWU4MzI1OTYyMjg= | 2,061 | Cannot load udpos subsets from xtreme dataset using load_dataset() | {
"avatar_url": "https://avatars.githubusercontent.com/u/55791365?v=4",
"events_url": "https://api.github.com/users/adzcodez/events{/privacy}",
"followers_url": "https://api.github.com/users/adzcodez/followers",
"following_url": "https://api.github.com/users/adzcodez/following{/other_user}",
"gists_url": "https://api.github.com/users/adzcodez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adzcodez",
"id": 55791365,
"login": "adzcodez",
"node_id": "MDQ6VXNlcjU1NzkxMzY1",
"organizations_url": "https://api.github.com/users/adzcodez/orgs",
"received_events_url": "https://api.github.com/users/adzcodez/received_events",
"repos_url": "https://api.github.com/users/adzcodez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adzcodez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adzcodez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adzcodez"
} | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"@lhoestq Adding \"_\" to the class labels in the dataset script will fix the issue.\r\n\r\nThe bigger issue IMO is that the data files are in conll format, but the examples are tokens, not sentences.",
"Hi ! Thanks for reporting @adzcodez \r\n\r\n\r\n> @lhoestq Adding \"_\" to the class labels in the dataset script will fix the issue.\r\n> \r\n> The bigger issue IMO is that the data files are in conll format, but the examples are tokens, not sentences.\r\n\r\nYou're right: \"_\" should be added to the list of labels, and the examples must be sequences of tokens, not singles tokens.\r\n",
"@lhoestq Can you please label this issue with the \"good first issue\" label? I'm not sure I'll find time to fix this.\r\n\r\nTo resolve it, the user should:\r\n1. add `\"_\"` to the list of labels\r\n2. transform the udpos subset to the conll format (I think the preprocessing logic can be borrowed from [the original repo](https://github.com/google-research/xtreme/blob/58a76a0d02458c4b3b6a742d3fd4ffaca80ff0de/utils_preprocess.py#L187-L204))\r\n3. update the dummy data\r\n4. update the dataset info\r\n5. [optional] add info about the data fields structure of the udpos subset to the dataset readme",
"I tried fixing this issue, but its working fine in the dev version : \"1.6.2.dev0\"\r\n\r\nI think somebody already fixed it. ",
"Hi,\r\n\r\nafter #2326, the lines with pos tags equal to `\"_\"` are filtered out when generating the dataset, so this fixes the KeyError described above. However, the udpos subset should be in the conll format i.e. it should yield sequences of tokens and not single tokens, so it would be great to see this fixed (feel free to borrow the logic from [here](https://github.com/google-research/xtreme/blob/58a76a0d02458c4b3b6a742d3fd4ffaca80ff0de/utils_preprocess.py#L187-L204) if you decide to work on this). ",
"Closed by #2466."
] | "2021-03-16T09:32:13Z" | "2021-06-18T11:54:11Z" | "2021-06-18T11:54:10Z" | NONE | null | null | null | Hello,
I am trying to load the udpos English subset from xtreme dataset, but this faces an error during loading. I am using datasets v1.4.1, pip install. I have tried with other udpos languages which also fail, though loading a different subset altogether (such as XNLI) has no issue. I have also tried on Colab and faced the same error.
Reprex is:
`from datasets import load_dataset `
`dataset = load_dataset('xtreme', 'udpos.English')`
The error is:
`KeyError: '_'`
The full traceback is:
KeyError Traceback (most recent call last)
<ipython-input-5-7181359ea09d> in <module>
1 from datasets import load_dataset
----> 2 dataset = load_dataset('xtreme', 'udpos.English')
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, **config_kwargs)
738
739 # Download and prepare data
--> 740 builder_instance.download_and_prepare(
741 download_config=download_config,
742 download_mode=download_mode,
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
576 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
577 if not downloaded_from_gcs:
--> 578 self._download_and_prepare(
579 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
580 )
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
654 try:
655 # Prepare split will record examples associated to the split
--> 656 self._prepare_split(split_generator, **prepare_split_kwargs)
657 except OSError as e:
658 raise OSError(
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\builder.py in _prepare_split(self, split_generator)
977 generator, unit=" examples", total=split_info.num_examples, leave=False, disable=not_verbose
978 ):
--> 979 example = self.info.features.encode_example(record)
980 writer.write(example)
981 finally:
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\features.py in encode_example(self, example)
946 def encode_example(self, example):
947 example = cast_to_python_objects(example)
--> 948 return encode_nested_example(self, example)
949
950 def encode_batch(self, batch):
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\features.py in encode_nested_example(schema, obj)
840 # Nested structures: we allow dict, list/tuples, sequences
841 if isinstance(schema, dict):
--> 842 return {
843 k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
844 }
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\features.py in <dictcomp>(.0)
841 if isinstance(schema, dict):
842 return {
--> 843 k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
844 }
845 elif isinstance(schema, (list, tuple)):
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\features.py in encode_nested_example(schema, obj)
868 # ClassLabel will convert from string to int, TranslationVariableLanguages does some checks
869 elif isinstance(schema, (ClassLabel, TranslationVariableLanguages, Value, _ArrayXD)):
--> 870 return schema.encode_example(obj)
871 # Other object should be directly convertible to a native Arrow type (like Translation and Translation)
872 return obj
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\features.py in encode_example(self, example_data)
647 # If a string is given, convert to associated integer
648 if isinstance(example_data, str):
--> 649 example_data = self.str2int(example_data)
650
651 # Allowing -1 to mean no label.
~\Anaconda3\envs\mlenv\lib\site-packages\datasets\features.py in str2int(self, values)
605 if value not in self._str2int:
606 value = value.strip()
--> 607 output.append(self._str2int[str(value)])
608 else:
609 # No names provided, try to integerize
KeyError: '_'
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2061/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2061/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3304/comments | https://api.github.com/repos/huggingface/datasets/issues/3304/events | https://github.com/huggingface/datasets/issues/3304 | 1,059,130,494 | I_kwDODunzps4_IQx- | 3,304 | Dataset object has no attribute `to_tf_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59993678?v=4",
"events_url": "https://api.github.com/users/RajkumarGalaxy/events{/privacy}",
"followers_url": "https://api.github.com/users/RajkumarGalaxy/followers",
"following_url": "https://api.github.com/users/RajkumarGalaxy/following{/other_user}",
"gists_url": "https://api.github.com/users/RajkumarGalaxy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/RajkumarGalaxy",
"id": 59993678,
"login": "RajkumarGalaxy",
"node_id": "MDQ6VXNlcjU5OTkzNjc4",
"organizations_url": "https://api.github.com/users/RajkumarGalaxy/orgs",
"received_events_url": "https://api.github.com/users/RajkumarGalaxy/received_events",
"repos_url": "https://api.github.com/users/RajkumarGalaxy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/RajkumarGalaxy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RajkumarGalaxy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/RajkumarGalaxy"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"The issue is due to the older version of transformers and datasets. It has been resolved by upgrading their versions.\r\n\r\n```\r\n# upgrade transformers and datasets to latest versions\r\n!pip install --upgrade transformers\r\n!pip install --upgrade datasets\r\n```\r\n\r\nRegards!"
] | "2021-11-20T12:03:59Z" | "2021-11-21T07:07:25Z" | "2021-11-21T07:07:25Z" | NONE | null | null | null | I am following HuggingFace Course. I am at Fine-tuning a model.
Link: https://huggingface.co/course/chapter3/2?fw=tf
I use tokenize_function and `map` as mentioned in the course to process data.
`# define a tokenize function`
`def Tokenize_function(example):`
` return tokenizer(example['sentence'], truncation=True)`
`# tokenize entire data`
`tokenized_data = raw_data.map(Tokenize_function, batched=True)`
I get Dataset object at this point. When I try converting this to a TF dataset object as mentioned in the course, it throws the following error.
`# convert to TF dataset`
`train_data = tokenized_data["train"].to_tf_dataset( `
` columns = ['attention_mask', 'input_ids', 'token_type_ids'], `
` label_cols = ['label'], `
` shuffle = True, `
` collate_fn = data_collator, `
` batch_size = 8 `
`)`
Output:
`---------------------------------------------------------------------------`
`AttributeError Traceback (most recent call last)`
`/tmp/ipykernel_42/103099799.py in <module>`
` 1 # convert to TF dataset`
`----> 2 train_data = tokenized_data["train"].to_tf_dataset( \`
` 3 columns = ['attention_mask', 'input_ids', 'token_type_ids'], \`
` 4 label_cols = ['label'], \`
` 5 shuffle = True, \`
`AttributeError: 'Dataset' object has no attribute 'to_tf_dataset'`
When I look for `dir(tokenized_data["train"])`, there is no method or attribute in the name of `to_tf_dataset`.
Why do I get this error? And how to clear this?
Please help me. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3304/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/591/comments | https://api.github.com/repos/huggingface/datasets/issues/591/events | https://github.com/huggingface/datasets/pull/591 | 696,530,413 | MDExOlB1bGxSZXF1ZXN0NDgyNjAxMzc1 | 591 | fix #589 (backward compat) | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | [] | "2020-09-09T07:33:13Z" | "2020-09-09T08:57:56Z" | "2020-09-09T08:57:55Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/591.diff",
"html_url": "https://github.com/huggingface/datasets/pull/591",
"merged_at": "2020-09-09T08:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/591.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/591"
} | Fix #589 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/591/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/591/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3691/comments | https://api.github.com/repos/huggingface/datasets/issues/3691/events | https://github.com/huggingface/datasets/pull/3691 | 1,127,629,306 | PR_kwDODunzps4yQThV | 3,691 | Upgrade black to version ~=22.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LysandreJik",
"id": 30755778,
"login": "LysandreJik",
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LysandreJik"
} | [] | closed | false | null | [] | null | [] | "2022-02-08T18:45:19Z" | "2022-02-08T19:56:40Z" | "2022-02-08T19:56:39Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3691.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3691",
"merged_at": "2022-02-08T19:56:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3691.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3691"
} | Upgrades the `datasets` library quality tool `black` to use the first stable release of `black`, version 22.0. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3691/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/862 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/862/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/862/comments | https://api.github.com/repos/huggingface/datasets/issues/862/events | https://github.com/huggingface/datasets/pull/862 | 744,906,131 | MDExOlB1bGxSZXF1ZXN0NTIyNTUzMzY1 | 862 | Update head requests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-11-17T16:49:06Z" | "2020-11-18T14:43:53Z" | "2020-11-18T14:43:50Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/862",
"merged_at": "2020-11-18T14:43:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/862"
} | Get requests and Head requests didn't have the same parameters. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/862/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/862/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4615/comments | https://api.github.com/repos/huggingface/datasets/issues/4615/events | https://github.com/huggingface/datasets/pull/4615 | 1,291,307,428 | PR_kwDODunzps46tADt | 4,615 | Fix `embed_storage` on features inside lists/sequences | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-07-01T11:52:08Z" | "2022-07-08T12:13:10Z" | "2022-07-08T12:01:36Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4615.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4615",
"merged_at": "2022-07-08T12:01:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4615.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4615"
} | Add a dedicated function for embed_storage to always preserve the embedded/casted arrays (and to have more control over `embed_storage` in general).
Fix #4591
~~(Waiting for #4608 to be merged to mark this PR as ready for review - required for fixing `xgetsize` in private repos)~~ Done! | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4615/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5457/comments | https://api.github.com/repos/huggingface/datasets/issues/5457/events | https://github.com/huggingface/datasets/issues/5457 | 1,554,171,264 | I_kwDODunzps5cosWA | 5,457 | prebuilt dataset relies on `downloads/extracted` | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00"
} | [] | open | false | null | [] | null | [
"Hi! \r\n\r\nThis issue is due to our audio/image datasets not being self-contained. This allows us to save disk space (files are written only once) but also leads to the issues like this one. We plan to make all our datasets self-contained in Datasets 3.0.\r\n\r\nIn the meantime, you can run the following map to ensure your dataset is self-contained:\r\n```python\r\nfrom datasets.table import embed_table_storage\r\n# load_dataset ...\r\ndset = dset.with_format(\"arrow\")\r\ndset.map(embed_table_storage, batched=True)\r\ndset = dset.with_format(\"python\")\r\n```\r\n",
"Understood. Thank you, Mario.\r\n\r\nPerhaps the solution could be very simple - move the extracted files into the directory of the cached dataset? Which would make it self-contained already and won't require waiting for a new major release. Unless I'm missing some back-compat nuance.\r\n\r\nBut regardless if X relies on Y - it could check if Y is still there when loading X. so not checking full consistency but just the top-level directory it relies on."
] | "2023-01-24T02:09:32Z" | "2023-01-24T18:14:10Z" | null | CONTRIBUTOR | null | null | null | ### Describe the bug
I pre-built the dataset:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
and it can be used just fine.
now I wipe out `downloads/extracted` and it no longer works.
```
rm -r ~/.cache/huggingface/datasets/downloads
```
That is I can still load it:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
No config specified, defaulting to: general-pmd-synthetic-testing/100.unique
Found cached dataset general-pmd-synthetic-testing (/home/stas/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing/100.unique/1.1.1/86bc445e3e48cb5ef79de109eb4e54ff85b318cd55c3835c4ee8f86eae33d9d2)
```
but if I try to use it:
```
E stderr: Traceback (most recent call last):
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/main.py", line 116, in <module>
E stderr: train_loader, val_loader = get_dataloaders(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 170, in get_dataloaders
E stderr: train_loader = get_dataloader_from_config(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 443, in get_dataloader_from_config
E stderr: dataloader = get_dataloader(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 264, in get_dataloader
E stderr: is_pmd = "meta" in hf_dataset[0] and "source" in hf_dataset[0]
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/arrow_dataset.py", line 2601, in __getitem__
E stderr: return self._getitem(
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/arrow_dataset.py", line 2586, in _getitem
E stderr: formatted_output = format_table(
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 634, in format_table
E stderr: return formatter(pa_table, query_type=query_type)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 406, in __call__
E stderr: return self.format_row(pa_table)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 442, in format_row
E stderr: row = self.python_features_decoder.decode_row(row)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 225, in decode_row
E stderr: return self.features.decode_example(row) if self.features else row
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1846, in decode_example
E stderr: return {
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1847, in <dictcomp>
E stderr: column_name: decode_nested_example(feature, value, token_per_repo_id=token_per_repo_id)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1304, in decode_nested_example
E stderr: return decode_nested_example([schema.feature], obj)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1296, in decode_nested_example
E stderr: if decode_nested_example(sub_schema, first_elmt) != first_elmt:
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1309, in decode_nested_example
E stderr: return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/image.py", line 144, in decode_example
E stderr: image = PIL.Image.open(path)
E stderr: File "/home/stas/anaconda3/envs/py38-pt113/lib/python3.8/site-packages/PIL/Image.py", line 3092, in open
E stderr: fp = builtins.open(filename, "rb")
E stderr: FileNotFoundError: [Errno 2] No such file or directory: '/mnt/nvme0/code/data/cache/huggingface/datasets/downloads/extracted/134227b9b94c4eccf19b205bf3021d4492d0227b9be6c2ddb6bf517d8d55a8cb/data/101/images_01.jpg'
```
Only if I wipe out the cached dir and rebuild then it starts working as `download/extracted` is back again with extracted files.
```
rm -r ~/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
I think there are 2 issues here:
1. why does it still rely on extracted files after `arrow` files were printed - did I do something incorrectly when creating this dataset?
2. why doesn't the dataset know that it has been gutted and loads just fine? If it has a dependency on `download/extracted` then `load_dataset` should check if it's there and fail or force rebuilding. I am sure this could be a very expensive operation, so probably really solving #1 will not require this check. and this second item is probably an overkill. Other than perhaps if it had an optional `check_consistency` flag to do that.
### Environment info
datasets@main | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5457/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1356/comments | https://api.github.com/repos/huggingface/datasets/issues/1356/events | https://github.com/huggingface/datasets/pull/1356 | 759,994,457 | MDExOlB1bGxSZXF1ZXN0NTM0ODk3OTQ1 | 1,356 | Add StackOverflow StackSample dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7613470?v=4",
"events_url": "https://api.github.com/users/ncoop57/events{/privacy}",
"followers_url": "https://api.github.com/users/ncoop57/followers",
"following_url": "https://api.github.com/users/ncoop57/following{/other_user}",
"gists_url": "https://api.github.com/users/ncoop57/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ncoop57",
"id": 7613470,
"login": "ncoop57",
"node_id": "MDQ6VXNlcjc2MTM0NzA=",
"organizations_url": "https://api.github.com/users/ncoop57/orgs",
"received_events_url": "https://api.github.com/users/ncoop57/received_events",
"repos_url": "https://api.github.com/users/ncoop57/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ncoop57/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ncoop57/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ncoop57"
} | [] | closed | false | null | [] | null | [
"@lhoestq Thanks for the review and suggestions! I've added your comments and pushed the changes. I'm having issues with the dummy data still. When I run the dummy data test\r\n\r\n```bash\r\nRUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_so_stacksample\r\n```\r\nI get this error: \r\n\r\n```\r\n___________________________________________ LocalDatasetTest.test_load_dataset_all_configs_so_stacksample ____________________________________________\r\n\r\nself = <tests.test_dataset_common.LocalDatasetTest testMethod=test_load_dataset_all_configs_so_stacksample>, dataset_name = 'so_stacksample'\r\n\r\n @slow\r\n def test_load_dataset_all_configs(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True)\r\n\r\ntests/test_dataset_common.py:237: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:198: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n\r\nFAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_so_stacksample - AssertionError: False is not true\r\n```\r\n\r\nI tried formatting the data similar to other datasets, but I think I don't have my csv's in the zip folder with the proper name. I also ran the command that's supposed to outline the exact steps I need to perform to get them into the correct format, but I followed them and they don't seem to be working still :/. Any help would be greatly appreciated!\r\n",
"Ok I found the issue with the dummy data.\r\nIt's currently failing because it's not generating a single example using the dummy csv file.\r\nThat's because there's only only line in the dummy csv file, and this line is skipped using the `next()` call used to ignore the headers of the csv.\r\n\r\nTo fix the dummy data you must add headers to the dummy csv files.",
"Also can you make sure that all the original CSV files have headers ? i.e. check that their first line is just the column names",
"> Ok I found the issue with the dummy data.\r\n> It's currently failing because it's not generating a single example using the dummy csv file.\r\n> That's because there's only only line in the dummy csv file, and this line is skipped using the `next()` call used to ignore the headers of the csv.\r\n> \r\n> To fix the dummy data you must add headers to the dummy csv files.\r\n\r\nOh man, I bamboozled myself! Thank you @lhoestq for catching that! I've updated the dummy csv's to include headers and also confirmed that they all have headers, so I am not throwing away any information with that `next()` call. When I run the test locally for the dummy data it passes, so hopefully it is good to go :D",
"merging since the Ci is fixed on master"
] | "2020-12-09T04:59:51Z" | "2020-12-21T14:48:21Z" | "2020-12-21T14:48:21Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1356",
"merged_at": "2020-12-21T14:48:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1356"
} | This PR adds the StackOverflow StackSample dataset from Kaggle: https://www.kaggle.com/stackoverflow/stacksample
Ran through all of the steps. However, since my dataset requires manually downloading the data, I was unable to run the pytest on the real dataset (the dummy data pytest passed). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5550/comments | https://api.github.com/repos/huggingface/datasets/issues/5550/events | https://github.com/huggingface/datasets/pull/5550 | 1,591,409,475 | PR_kwDODunzps5KUl5i | 5,550 | Resolve four broken refs in the docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/37621491?v=4",
"events_url": "https://api.github.com/users/tomaarsen/events{/privacy}",
"followers_url": "https://api.github.com/users/tomaarsen/followers",
"following_url": "https://api.github.com/users/tomaarsen/following{/other_user}",
"gists_url": "https://api.github.com/users/tomaarsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tomaarsen",
"id": 37621491,
"login": "tomaarsen",
"node_id": "MDQ6VXNlcjM3NjIxNDkx",
"organizations_url": "https://api.github.com/users/tomaarsen/orgs",
"received_events_url": "https://api.github.com/users/tomaarsen/received_events",
"repos_url": "https://api.github.com/users/tomaarsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tomaarsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomaarsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tomaarsen"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"See the resolved changes [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5550/en/package_reference/main_classes#datasets.Dataset.class_encode_column), [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5550/en/package_reference/main_classes#datasets.Dataset.unique) and [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5550/en/package_reference/main_classes#datasets.DatasetDict.class_encode_column), respectively",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008256 / 0.011353 (-0.003097) | 0.004400 / 0.011008 (-0.006608) | 0.098676 / 0.038508 (0.060168) | 0.028937 / 0.023109 (0.005828) | 0.302578 / 0.275898 (0.026680) | 0.334170 / 0.323480 (0.010690) | 0.006657 / 0.007986 (-0.001329) | 0.004581 / 0.004328 (0.000253) | 0.076874 / 0.004250 (0.072624) | 0.034401 / 0.037052 (-0.002652) | 0.303928 / 0.258489 (0.045439) | 0.348421 / 0.293841 (0.054580) | 0.033303 / 0.128546 (-0.095243) | 0.011445 / 0.075646 (-0.064202) | 0.322137 / 0.419271 (-0.097135) | 0.041072 / 0.043533 (-0.002461) | 0.306007 / 0.255139 (0.050868) | 0.325945 / 0.283200 (0.042745) | 0.086685 / 0.141683 (-0.054998) | 1.454956 / 1.452155 (0.002801) | 1.545525 / 1.492716 (0.052809) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.175536 / 0.018006 (0.157530) | 0.400203 / 0.000490 (0.399713) | 0.002103 / 0.000200 (0.001903) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022750 / 0.037411 (-0.014661) | 0.095163 / 0.014526 (0.080637) | 0.103995 / 0.176557 (-0.072561) | 0.138806 / 0.737135 (-0.598330) | 0.105711 / 0.296338 (-0.190628) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.427860 / 0.215209 (0.212651) | 4.259594 / 2.077655 (2.181940) | 2.157986 / 1.504120 (0.653866) | 1.913814 / 1.541195 (0.372619) | 1.793455 / 1.468490 (0.324965) | 0.702341 / 4.584777 (-3.882436) | 3.353086 / 3.745712 (-0.392626) | 1.856952 / 5.269862 (-3.412909) | 1.149963 / 4.565676 (-3.415713) | 0.082926 / 0.424275 (-0.341349) | 0.012307 / 0.007607 (0.004700) | 0.524531 / 0.226044 (0.298487) | 5.254766 / 2.268929 (2.985838) | 2.590157 / 55.444624 (-52.854468) | 2.272613 / 6.876477 (-4.603864) | 2.304367 / 2.142072 (0.162294) | 0.819298 / 4.805227 (-3.985929) | 0.152170 / 6.500664 (-6.348494) | 0.066563 / 0.075469 (-0.008906) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.205054 / 1.841788 (-0.636733) | 13.729073 / 8.074308 (5.654765) | 14.061037 / 10.191392 (3.869645) | 0.138020 / 0.680424 (-0.542404) | 0.028042 / 0.534201 (-0.506159) | 0.392260 / 0.579283 (-0.187024) | 0.405632 / 0.434364 (-0.028732) | 0.469583 / 0.540337 (-0.070755) | 0.563110 / 1.386936 (-0.823826) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006513 / 0.011353 (-0.004839) | 0.004402 / 0.011008 (-0.006606) | 0.076339 / 0.038508 (0.037831) | 0.027222 / 0.023109 (0.004112) | 0.338968 / 0.275898 (0.063070) | 0.378475 / 0.323480 (0.054995) | 0.005443 / 0.007986 (-0.002542) | 0.003312 / 0.004328 (-0.001016) | 0.075352 / 0.004250 (0.071102) | 0.034951 / 0.037052 (-0.002102) | 0.342268 / 0.258489 (0.083779) | 0.381024 / 0.293841 (0.087183) | 0.031568 / 0.128546 (-0.096979) | 0.011558 / 0.075646 (-0.064088) | 0.085267 / 0.419271 (-0.334005) | 0.041248 / 0.043533 (-0.002284) | 0.340422 / 0.255139 (0.085283) | 0.365497 / 0.283200 (0.082297) | 0.088278 / 0.141683 (-0.053405) | 1.479838 / 1.452155 (0.027683) | 1.554440 / 1.492716 (0.061724) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223240 / 0.018006 (0.205234) | 0.394771 / 0.000490 (0.394282) | 0.003022 / 0.000200 (0.002822) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024842 / 0.037411 (-0.012570) | 0.099167 / 0.014526 (0.084641) | 0.106376 / 0.176557 (-0.070180) | 0.141397 / 0.737135 (-0.595738) | 0.110355 / 0.296338 (-0.185983) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437598 / 0.215209 (0.222389) | 4.394964 / 2.077655 (2.317310) | 2.082660 / 1.504120 (0.578540) | 1.868690 / 1.541195 (0.327496) | 1.915190 / 1.468490 (0.446700) | 0.701035 / 4.584777 (-3.883742) | 3.306594 / 3.745712 (-0.439118) | 1.842681 / 5.269862 (-3.427181) | 1.155022 / 4.565676 (-3.410654) | 0.083310 / 0.424275 (-0.340965) | 0.012413 / 0.007607 (0.004806) | 0.543179 / 0.226044 (0.317135) | 5.445605 / 2.268929 (3.176676) | 2.545080 / 55.444624 (-52.899544) | 2.188741 / 6.876477 (-4.687736) | 2.205561 / 2.142072 (0.063489) | 0.804967 / 4.805227 (-4.000261) | 0.151024 / 6.500664 (-6.349640) | 0.066448 / 0.075469 (-0.009021) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.304671 / 1.841788 (-0.537117) | 13.996631 / 8.074308 (5.922323) | 13.617626 / 10.191392 (3.426234) | 0.141512 / 0.680424 (-0.538912) | 0.016527 / 0.534201 (-0.517674) | 0.384981 / 0.579283 (-0.194302) | 0.385198 / 0.434364 (-0.049166) | 0.469033 / 0.540337 (-0.071305) | 0.554738 / 1.386936 (-0.832198) |\n\n</details>\n</details>\n\n\n"
] | "2023-02-20T08:52:11Z" | "2023-02-20T15:16:13Z" | "2023-02-20T15:09:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5550",
"merged_at": "2023-02-20T15:09:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5550"
} | Hello!
## Pull Request overview
* Resolve 4 broken references in the docs
## The problems
Two broken references [here](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.class_encode_column):

---
One broken reference [here](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.unique):

---
One missing reference [here](https://huggingface.co/docs/datasets/v2.9.0/en/package_reference/main_classes#datasets.DatasetDict.class_encode_column):

- Tom Aarsen | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5550/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3291 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3291/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3291/comments | https://api.github.com/repos/huggingface/datasets/issues/3291/events | https://github.com/huggingface/datasets/pull/3291 | 1,056,689,876 | PR_kwDODunzps4urikR | 3,291 | Use f-strings in the dataset scripts | {
"avatar_url": "https://avatars.githubusercontent.com/u/84228424?v=4",
"events_url": "https://api.github.com/users/Carlosbogo/events{/privacy}",
"followers_url": "https://api.github.com/users/Carlosbogo/followers",
"following_url": "https://api.github.com/users/Carlosbogo/following{/other_user}",
"gists_url": "https://api.github.com/users/Carlosbogo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Carlosbogo",
"id": 84228424,
"login": "Carlosbogo",
"node_id": "MDQ6VXNlcjg0MjI4NDI0",
"organizations_url": "https://api.github.com/users/Carlosbogo/orgs",
"received_events_url": "https://api.github.com/users/Carlosbogo/received_events",
"repos_url": "https://api.github.com/users/Carlosbogo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Carlosbogo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Carlosbogo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Carlosbogo"
} | [] | closed | false | null | [] | null | [] | "2021-11-17T22:20:19Z" | "2021-11-22T16:40:16Z" | "2021-11-22T16:40:16Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3291.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3291",
"merged_at": "2021-11-22T16:40:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3291.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3291"
} | Uses f-strings to format the .py files in the dataset folder | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3291/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3291/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4402/comments | https://api.github.com/repos/huggingface/datasets/issues/4402/events | https://github.com/huggingface/datasets/pull/4402 | 1,248,078,067 | PR_kwDODunzps44cdR5 | 4,402 | Skip identical files in `push_to_hub` instead of overwriting | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-25T13:12:51Z" | "2022-05-25T15:16:36Z" | "2022-05-25T15:08:03Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4402",
"merged_at": "2022-05-25T15:08:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4402"
} | Skip identical files instead of overwriting them to save bandwidth and circumvent (user-side/server-side) errors, which can arise when working with large datasets due to long-lasting HTTP connections, by repeating calls to `push_to_hub` to resume an upload.
To be able to check if an upload can be resumed, this PR modifies the shard naming scheme from:
```
data/{split}-[0-9][0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9].parquet
```
to:
```
data/{split}-[0-9][0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9]-<SHARD_FINGERPRINT>.parquet
```
cc @LysandreJik | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4402/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4554/comments | https://api.github.com/repos/huggingface/datasets/issues/4554/events | https://github.com/huggingface/datasets/pull/4554 | 1,283,369,453 | PR_kwDODunzps46Sv_f | 4,554 | Fix WMT dataset loading issue and docs update (Re-opened) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8711912?v=4",
"events_url": "https://api.github.com/users/khushmeeet/events{/privacy}",
"followers_url": "https://api.github.com/users/khushmeeet/followers",
"following_url": "https://api.github.com/users/khushmeeet/following{/other_user}",
"gists_url": "https://api.github.com/users/khushmeeet/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/khushmeeet",
"id": 8711912,
"login": "khushmeeet",
"node_id": "MDQ6VXNlcjg3MTE5MTI=",
"organizations_url": "https://api.github.com/users/khushmeeet/orgs",
"received_events_url": "https://api.github.com/users/khushmeeet/received_events",
"repos_url": "https://api.github.com/users/khushmeeet/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/khushmeeet/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/khushmeeet/subscriptions",
"type": "User",
"url": "https://api.github.com/users/khushmeeet"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-06-24T07:26:16Z" | "2022-07-08T15:39:20Z" | "2022-07-08T15:27:44Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4554.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4554",
"merged_at": "2022-07-08T15:27:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4554.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4554"
} | This PR is a fix for #4354
Changes are made for `wmt14`, `wmt15`, `wmt16`, `wmt17`, `wmt18`, `wmt19` and `wmt_t2t`. And READMEs are updated for the corresponding datasets.
Let me know, if any additional changes are required.
Thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4554/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4554/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4594/comments | https://api.github.com/repos/huggingface/datasets/issues/4594/events | https://github.com/huggingface/datasets/issues/4594 | 1,288,070,023 | I_kwDODunzps5MxmOH | 4,594 | load_from_disk suggests incorrect fix when used to load DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/11157811?v=4",
"events_url": "https://api.github.com/users/dvsth/events{/privacy}",
"followers_url": "https://api.github.com/users/dvsth/followers",
"following_url": "https://api.github.com/users/dvsth/following{/other_user}",
"gists_url": "https://api.github.com/users/dvsth/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dvsth",
"id": 11157811,
"login": "dvsth",
"node_id": "MDQ6VXNlcjExMTU3ODEx",
"organizations_url": "https://api.github.com/users/dvsth/orgs",
"received_events_url": "https://api.github.com/users/dvsth/received_events",
"repos_url": "https://api.github.com/users/dvsth/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dvsth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dvsth/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dvsth"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | "2022-06-29T01:40:01Z" | "2022-06-29T04:03:44Z" | "2022-06-29T04:03:44Z" | NONE | null | null | null | Edit: Please feel free to remove this issue. The problem was not the error message but the fact that the DatasetDict.load_from_disk does not support loading nested splits, i.e. if one of the splits is itself a DatasetDict. If nesting splits is an antipattern, perhaps the load_from_disk function can throw a warning indicating that? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4594/timeline | null | not_planned | false |
https://api.github.com/repos/huggingface/datasets/issues/3027 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3027/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3027/comments | https://api.github.com/repos/huggingface/datasets/issues/3027/events | https://github.com/huggingface/datasets/issues/3027 | 1,016,150,117 | I_kwDODunzps48kThl | 3,027 | Resolve data_files by split name | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"Awesome @lhoestq I like the proposal and it works great on my JSON community dataset. Here is the [log](https://gist.github.com/vblagoje/714babc325bcbdd5de579fd8e1648892). ",
"From my discussion with @borisdayma it would be more general the files match if their paths contains the split name - not only if the filename contains the split name. For example for a dataset like this:\r\n```\r\ntrain/\r\n└── data.csv\r\ntest/\r\n└── data.csv\r\n```\r\n\r\nBut IMO the default should be \r\n```\r\ndata/\r\n├── train.csv\r\n└── test.csv\r\n```\r\nbecause it allows people to have other directories if they have different subsets of their data (different configurations, not splits)",
"I just created a PR for this at https://github.com/huggingface/datasets/pull/3221, let me know what you think :)"
] | "2021-10-05T10:24:36Z" | "2021-11-05T17:49:58Z" | "2021-11-05T17:49:57Z" | MEMBER | null | null | null | This issue is about discussing the default behavior when someone loads a dataset that consists in data files. For example:
```python
load_dataset("lhoestq/demo1")
```
should return two splits "train" and "test" since the dataset repostiory is like
```
data/
├── train.csv
└── test.csv
```
Currently it returns only one split "train" which contains the data of both files
I started playing with this idea on this branch btw: `resolve-data_files-by-split-name`
Basically the idea is that if you named you data files after split names then the default pattern is
```python
{
"train": ["*train*"],
"test": ["*test*"],
"validation": ["*dev*", "valid"],
}
```
otherwise it's
```python
{
"train": ["*"]
}
```
Let me know what you think !
cc @albertvillanova @LysandreJik @vblagoje | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3027/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3027/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2855 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2855/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2855/comments | https://api.github.com/repos/huggingface/datasets/issues/2855/events | https://github.com/huggingface/datasets/pull/2855 | 983,858,229 | MDExOlB1bGxSZXF1ZXN0NzIzMzcxMTIy | 2,855 | Fix windows CI CondaError | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-08-31T13:22:02Z" | "2021-08-31T13:35:34Z" | "2021-08-31T13:35:33Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2855.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2855",
"merged_at": "2021-08-31T13:35:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2855.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2855"
} | From this thread: https://github.com/conda/conda/issues/6057
We can fix the conda error
```
CondaError: Cannot link a source that does not exist.
C:\Users\...\Anaconda3\Scripts\conda.exe
```
by doing
```bash
conda update conda
```
before doing any install in the windows CI | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2855/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2855/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/554/comments | https://api.github.com/repos/huggingface/datasets/issues/554/events | https://github.com/huggingface/datasets/issues/554 | 690,173,214 | MDU6SXNzdWU2OTAxNzMyMTQ= | 554 | nlp downloads to its module path | {
"avatar_url": "https://avatars.githubusercontent.com/u/49398?v=4",
"events_url": "https://api.github.com/users/danieldk/events{/privacy}",
"followers_url": "https://api.github.com/users/danieldk/followers",
"following_url": "https://api.github.com/users/danieldk/following{/other_user}",
"gists_url": "https://api.github.com/users/danieldk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danieldk",
"id": 49398,
"login": "danieldk",
"node_id": "MDQ6VXNlcjQ5Mzk4",
"organizations_url": "https://api.github.com/users/danieldk/orgs",
"received_events_url": "https://api.github.com/users/danieldk/received_events",
"repos_url": "https://api.github.com/users/danieldk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danieldk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danieldk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danieldk"
} | [] | closed | false | null | [] | null | [
"Indeed this is a known issue arising from the fact that we try to be compatible with cloupickle.\r\n\r\nDoes this also happen if you are installing in a virtual environment?",
"> Indeed this is a know issue with the fact that we try to be compatible with cloupickle.\r\n> \r\n> Does this also happen if you are installing in a virtual environment?\r\n\r\nThen it would work, because the package is in a writable path.",
"If it's fine for you then this is the recommended way to solve this issue.",
"> If it's fine for you then this is the recommended way to solve this issue.\r\n\r\nI don't want to use a virtual environment, because Nix is fully reproducible, and virtual environments are not. And I am the maintainer of the `transformers` in nixpkgs, so sooner or later I will have to package `nlp`, since it is becoming a dependency of `transformers` ;).",
"Ok interesting. We could have another check to see if it's possible to download and import the datasets script at another location than the module path. I think this would probably involve tweaking the python system path dynamically.\r\n\r\nI don't know anything about Nix so if you want to give this a try your self we can guide you or you can give us more information on your general project and how this works.\r\n\r\nRegarding `nlp` and `transformers`, we are not sure `nlp` will become a required dependency for `transformers`. It will probably be used a lot in the examples but I think it probably won't be a required dependency for the main package since we try to keep it as light as possible in terms of deps.\r\n\r\nHappy to help you make all these things work better for your use-case ",
"@danieldk modules are now installed in a different location (by default in the cache directory of the lib, in `~/.cache/huggingface/modules`). You can also change that using the environment variable `HF_MODULES_PATH`\r\n\r\nFeel free to play with this change from the master branch for now, and let us know if it sounds good for you :)\r\nWe plan to do a release in the next coming days",
"Awesome! I’ll hopefully have some time in the coming days to try this.",
"> Feel free to play with this change from the master branch for now, and let us know if it sounds good for you :)\r\n> We plan to do a release in the next coming days\r\n\r\nThanks for making this change! I just packaged the latest commit on master and it works like a charm now! :partying_face: "
] | "2020-09-01T14:06:14Z" | "2020-09-11T06:19:24Z" | "2020-09-11T06:19:24Z" | NONE | null | null | null | I am trying to package `nlp` for Nix, because it is now an optional dependency for `transformers`. The problem that I encounter is that the `nlp` library downloads to the module path, which is typically not writable in most package management systems:
```>>> import nlp
>>> squad_dataset = nlp.load_dataset('squad')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/nix/store/2yhik0hhqayksmkkfb0ylqp8cf5wa5wp-python3-3.8.5-env/lib/python3.8/site-packages/nlp/load.py", line 530, in load_dataset
module_path, hash = prepare_module(path, download_config=download_config, dataset=True)
File "/nix/store/2yhik0hhqayksmkkfb0ylqp8cf5wa5wp-python3-3.8.5-env/lib/python3.8/site-packages/nlp/load.py", line 329, in prepare_module
os.makedirs(main_folder_path, exist_ok=True)
File "/nix/store/685kq8pyhrvajah1hdsfn4q7gm3j4yd4-python3-3.8.5/lib/python3.8/os.py", line 223, in makedirs
mkdir(name, mode)
OSError: [Errno 30] Read-only file system: '/nix/store/2yhik0hhqayksmkkfb0ylqp8cf5wa5wp-python3-3.8.5-env/lib/python3.8/site-packages/nlp/datasets/squad'
```
Do you have any suggested workaround for this issue?
Perhaps overriding the default value for `force_local_path` of `prepare_module`? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/554/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/554/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2826 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2826/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2826/comments | https://api.github.com/repos/huggingface/datasets/issues/2826/events | https://github.com/huggingface/datasets/issues/2826 | 976,974,254 | MDU6SXNzdWU5NzY5NzQyNTQ= | 2,826 | Add a Text Classification dataset: KanHope | {
"avatar_url": "https://avatars.githubusercontent.com/u/46108405?v=4",
"events_url": "https://api.github.com/users/adeepH/events{/privacy}",
"followers_url": "https://api.github.com/users/adeepH/followers",
"following_url": "https://api.github.com/users/adeepH/following{/other_user}",
"gists_url": "https://api.github.com/users/adeepH/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adeepH",
"id": 46108405,
"login": "adeepH",
"node_id": "MDQ6VXNlcjQ2MTA4NDA1",
"organizations_url": "https://api.github.com/users/adeepH/orgs",
"received_events_url": "https://api.github.com/users/adeepH/received_events",
"repos_url": "https://api.github.com/users/adeepH/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adeepH/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adeepH/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adeepH"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hi ! In your script it looks like you're trying to load the dataset `bn_hate_speech,`, not KanHope.\r\n\r\nMoreover the error `KeyError: ' '` means that you have a feature of type ClassLabel, but for a certain example of the dataset, it looks like the label is empty (it's just a string with a space). Can you make sure that the data don't have missing labels, and that your dataset script parses the labels correctly ?"
] | "2021-08-23T12:21:58Z" | "2021-10-01T18:06:59Z" | "2021-10-01T18:06:59Z" | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** *KanHope*
- **Description:** *A code-mixed English-Kannada dataset for Hope speech detection*
- **Paper:** *https://arxiv.org/abs/2108.04616* (I am the author of the paper}
- **Author:** *[AdeepH](https://github.com/adeepH)*
- **Data:** *https://github.com/adeepH/KanHope/tree/main/dataset*
- **Motivation:** *The dataset is amongst the very few resources available for code-mixed Dravidian languages*
- I tried following the steps as per the instructions. However, could not resolve an error. Any help would be appreciated.
- The dataset card and the scripts for the dataset *https://github.com/adeepH/datasets/tree/multilingual-hope-speech/datasets/mhs_eval*
```
Using custom data configuration default
Downloading and preparing dataset bn_hate_speech/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/bn_hate_speech/default/0.0.0/5f417ddc89777278abd29988f909f39495f0ec802090f7d8fa63b5bffb121762...
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-114-4a9cdb519e4c> in <module>()
1 from datasets import load_dataset
2
----> 3 data = load_dataset('/content/bn')
9 frames
/usr/local/lib/python3.7/dist-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
850 ignore_verifications=ignore_verifications,
851 try_from_hf_gcs=try_from_hf_gcs,
--> 852 use_auth_token=use_auth_token,
853 )
854
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
614 if not downloaded_from_gcs:
615 self._download_and_prepare(
--> 616 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
617 )
618 # Sync info
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
691 try:
692 # Prepare split will record examples associated to the split
--> 693 self._prepare_split(split_generator, **prepare_split_kwargs)
694 except OSError as e:
695 raise OSError(
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _prepare_split(self, split_generator)
1107 disable=bool(logging.get_verbosity() == logging.NOTSET),
1108 ):
-> 1109 example = self.info.features.encode_example(record)
1110 writer.write(example, key)
1111 finally:
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_example(self, example)
1015 """
1016 example = cast_to_python_objects(example)
-> 1017 return encode_nested_example(self, example)
1018
1019 def encode_batch(self, batch):
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_nested_example(schema, obj)
863 if isinstance(schema, dict):
864 return {
--> 865 k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
866 }
867 elif isinstance(schema, (list, tuple)):
/usr/local/lib/python3.7/dist-packages/datasets/features.py in <dictcomp>(.0)
863 if isinstance(schema, dict):
864 return {
--> 865 k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
866 }
867 elif isinstance(schema, (list, tuple)):
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_nested_example(schema, obj)
890 # ClassLabel will convert from string to int, TranslationVariableLanguages does some checks
891 elif isinstance(schema, (ClassLabel, TranslationVariableLanguages, Value, _ArrayXD)):
--> 892 return schema.encode_example(obj)
893 # Other object should be directly convertible to a native Arrow type (like Translation and Translation)
894 return obj
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_example(self, example_data)
665 # If a string is given, convert to associated integer
666 if isinstance(example_data, str):
--> 667 example_data = self.str2int(example_data)
668
669 # Allowing -1 to mean no label.
/usr/local/lib/python3.7/dist-packages/datasets/features.py in str2int(self, values)
623 if value not in self._str2int:
624 value = str(value).strip()
--> 625 output.append(self._str2int[str(value)])
626 else:
627 # No names provided, try to integerize
KeyError: ' '
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2826/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2826/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6354/comments | https://api.github.com/repos/huggingface/datasets/issues/6354/events | https://github.com/huggingface/datasets/issues/6354 | 1,963,483,324 | I_kwDODunzps51CGC8 | 6,354 | `IterableDataset.from_spark` does not support multiple workers in pytorch `Dataloader` | {
"avatar_url": "https://avatars.githubusercontent.com/u/50199774?v=4",
"events_url": "https://api.github.com/users/NazyS/events{/privacy}",
"followers_url": "https://api.github.com/users/NazyS/followers",
"following_url": "https://api.github.com/users/NazyS/following{/other_user}",
"gists_url": "https://api.github.com/users/NazyS/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NazyS",
"id": 50199774,
"login": "NazyS",
"node_id": "MDQ6VXNlcjUwMTk5Nzc0",
"organizations_url": "https://api.github.com/users/NazyS/orgs",
"received_events_url": "https://api.github.com/users/NazyS/received_events",
"repos_url": "https://api.github.com/users/NazyS/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NazyS/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NazyS/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NazyS"
} | [] | open | false | null | [] | null | [
"I am having issues as well with this. \r\n\r\nHowever, the error I am getting is :\r\n`RuntimeError: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transformation. SparkContext can only be used on the driver, not in code that it run on workers. For more information, see SPARK-5063.`\r\n\r\nAlso did not work with pyspark==3.3.0 and py4j==0.10.9.5"
] | "2023-10-26T12:43:36Z" | "2023-11-14T18:46:03Z" | null | NONE | null | null | null | ### Describe the bug
Looks like `IterableDataset.from_spark` does not support multiple workers in pytorch `Dataloader` if I'm not missing anything.
Also, returns not consistent error messages, which probably depend on the nondeterministic order of worker executions
Some exampes I've encountered:
```
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-68c05436-3512-41c4-88ca-5630012b70d1/lib/python3.10/site-packages/datasets/packaged_modules/spark/spark.py", line 79, in __iter__
yield from self.generate_examples_fn()
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-68c05436-3512-41c4-88ca-5630012b70d1/lib/python3.10/site-packages/datasets/packaged_modules/spark/spark.py", line 49, in generate_fn
df_with_partition_id = df.select("*", pyspark.sql.functions.spark_partition_id().alias("part_id"))
File "/databricks/spark/python/pyspark/instrumentation_utils.py", line 54, in wrapper
logger.log_failure(
File "/databricks/spark/python/pyspark/databricks/usage_logger.py", line 70, in log_failure
self.logger.recordFunctionCallFailureEvent(
File "/databricks/spark/python/lib/py4j-0.10.9.7-src.zip/py4j/java_gateway.py", line 1322, in __call__
return_value = get_return_value(
File "/databricks/spark/python/pyspark/errors/exceptions/captured.py", line 188, in deco
return f(*a, **kw)
File "/databricks/spark/python/lib/py4j-0.10.9.7-src.zip/py4j/protocol.py", line 342, in get_return_value
return OUTPUT_CONVERTER[type](answer[2:], gateway_client)
KeyError: 'c'
```
```
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-68c05436-3512-41c4-88ca-5630012b70d1/lib/python3.10/site-packages/datasets/packaged_modules/spark/spark.py", line 79, in __iter__
yield from self.generate_examples_fn()
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-68c05436-3512-41c4-88ca-5630012b70d1/lib/python3.10/site-packages/datasets/packaged_modules/spark/spark.py", line 49, in generate_fn
df_with_partition_id = df.select("*", pyspark.sql.functions.spark_partition_id().alias("part_id"))
File "/databricks/spark/python/pyspark/sql/utils.py", line 162, in wrapped
return f(*args, **kwargs)
File "/databricks/spark/python/pyspark/sql/functions.py", line 4893, in spark_partition_id
return _invoke_function("spark_partition_id")
File "/databricks/spark/python/pyspark/sql/functions.py", line 98, in _invoke_function
return Column(jf(*args))
File "/databricks/spark/python/lib/py4j-0.10.9.7-src.zip/py4j/java_gateway.py", line 1322, in __call__
return_value = get_return_value(
File "/databricks/spark/python/pyspark/errors/exceptions/captured.py", line 188, in deco
return f(*a, **kw)
File "/databricks/spark/python/lib/py4j-0.10.9.7-src.zip/py4j/protocol.py", line 342, in get_return_value
return OUTPUT_CONVERTER[type](answer[2:], gateway_client)
KeyError: 'm'
```
```
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-68c05436-3512-41c4-88ca-5630012b70d1/lib/python3.10/site-packages/datasets/packaged_modules/spark/spark.py", line 79, in __iter__
yield from self.generate_examples_fn()
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-68c05436-3512-41c4-88ca-5630012b70d1/lib/python3.10/site-packages/datasets/packaged_modules/spark/spark.py", line 49, in generate_fn
df_with_partition_id = df.select("*", pyspark.sql.functions.spark_partition_id().alias("part_id"))
File "/databricks/spark/python/pyspark/sql/utils.py", line 162, in wrapped
return f(*args, **kwargs)
File "/databricks/spark/python/pyspark/sql/functions.py", line 4893, in spark_partition_id
return _invoke_function("spark_partition_id")
File "/databricks/spark/python/pyspark/sql/functions.py", line 97, in _invoke_function
jf = _get_jvm_function(name, SparkContext._active_spark_context)
File "/databricks/spark/python/pyspark/sql/functions.py", line 88, in _get_jvm_function
return getattr(sc._jvm.functions, name)
File "/databricks/spark/python/lib/py4j-0.10.9.7-src.zip/py4j/java_gateway.py", line 1725, in __getattr__
raise Py4JError(message)
py4j.protocol.Py4JError: functions does not exist in the JVM
```
### Steps to reproduce the bug
```python
import pandas as pd
import numpy as np
batch_size = 16
pdf = pd.DataFrame({
key: np.random.rand(16*100) for key in ['feature', 'target']
})
test_df = spark.createDataFrame(pdf)
from datasets import IterableDataset
from torch.utils.data import DataLoader
ids = IterableDataset.from_spark(test_df)
for batch in DataLoader(ids, batch_size=16, num_workers=4):
for k, b in batch.items():
print(k, b.shape, sep='\t')
print('\n')
```
### Expected behavior
For `num_workers` equal to 0 or 1 works fine as expected:
```
feature torch.Size([16])
target torch.Size([16])
feature torch.Size([16])
target torch.Size([16])
....
```
Expected to support workers >1.
### Environment info
Databricks 13.3 LTS ML runtime - Spark 3.4.1
pyspark==3.4.1
py4j==0.10.9.7
datasets==2.13.1 and also tested with datasets==2.14.6 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6354/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4870 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4870/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4870/comments | https://api.github.com/repos/huggingface/datasets/issues/4870/events | https://github.com/huggingface/datasets/pull/4870 | 1,346,160,498 | PR_kwDODunzps49jGxD | 4,870 | audio folder check CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-08-22T10:15:53Z" | "2022-11-02T11:54:35Z" | "2022-08-22T12:19:40Z" | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4870.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4870",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4870.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4870"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4870/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4870/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1474/comments | https://api.github.com/repos/huggingface/datasets/issues/1474/events | https://github.com/huggingface/datasets/pull/1474 | 762,083,706 | MDExOlB1bGxSZXF1ZXN0NTM2NjY4MjU3 | 1,474 | Create JSON dummy data without loading all dataset in memory | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | open | false | null | [] | null | [] | "2020-12-11T08:44:23Z" | "2022-07-06T15:19:47Z" | null | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1474.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1474",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1474.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1474"
} | See #1442.
The statement `json.load()` loads **all the file content in memory**.
In order to avoid this, file content should be parsed **iteratively**, by using the library `ijson` e.g.
I have refactorized the code into a function `_create_json_dummy_data` and I have added some tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1474/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1474/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1700/comments | https://api.github.com/repos/huggingface/datasets/issues/1700/events | https://github.com/huggingface/datasets/pull/1700 | 781,333,589 | MDExOlB1bGxSZXF1ZXN0NTUxMDc1NTg2 | 1,700 | Update Curiosity dialogs DatasetCard | {
"avatar_url": "https://avatars.githubusercontent.com/u/50873201?v=4",
"events_url": "https://api.github.com/users/vineeths96/events{/privacy}",
"followers_url": "https://api.github.com/users/vineeths96/followers",
"following_url": "https://api.github.com/users/vineeths96/following{/other_user}",
"gists_url": "https://api.github.com/users/vineeths96/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vineeths96",
"id": 50873201,
"login": "vineeths96",
"node_id": "MDQ6VXNlcjUwODczMjAx",
"organizations_url": "https://api.github.com/users/vineeths96/orgs",
"received_events_url": "https://api.github.com/users/vineeths96/received_events",
"repos_url": "https://api.github.com/users/vineeths96/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vineeths96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vineeths96/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vineeths96"
} | [] | closed | false | null | [] | null | [] | "2021-01-07T13:59:27Z" | "2021-01-12T18:51:32Z" | "2021-01-12T18:51:32Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1700.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1700",
"merged_at": "2021-01-12T18:51:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1700.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1700"
} | Update Curiosity dialogs DatasetCard
There are some entries in the data fields section yet to be filled. There is little information regarding those fields. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1700/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1700/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3385/comments | https://api.github.com/repos/huggingface/datasets/issues/3385/events | https://github.com/huggingface/datasets/issues/3385 | 1,071,742,310 | I_kwDODunzps4_4X1m | 3,385 | None batched `with_transform`, `set_transform` | {
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cccntu",
"id": 31893406,
"login": "cccntu",
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"repos_url": "https://api.github.com/users/cccntu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cccntu"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! Thanks for the suggestion :)\r\nIt makes sense to me, and it can surely be implemented by wrapping the user's function to make it a batched function. However I'm not a big fan of the inconsistency it would create with `map`: `with_transform` is batched by default while `map` isn't.\r\n\r\nIs there something you would like to contribute ? I can give you some pointers if you want",
"Hi @lhoestq ,\r\nSorry I missed your reply.\r\n\r\nI would love to contribute. But I don't know which solution would be the best for this repo.\r\n\r\n> However I'm not a big fan of the inconsistency it would create with map: with_transform is batched by default while map isn't.\r\n\r\nI agree. What do you think about the alternative solutions?\r\n\r\n> * Convert a non-batched transform function to batched one myself.\r\n\r\nThis won't be able to use torch loader multi-worker.\r\n\r\n> * Wrap a 🤗 Dataset with torch Dataset, and add a __getitem__. 🙄\r\n\r\nThis is actually pretty simple.\r\n\r\n```python\r\nimport torch\r\n\r\nclass LazyMapTorchDataset(torch.utils.data.Dataset):\r\n def __init__(self, ds, fn):\r\n self.ds = ds\r\n self.fn = fn\r\n def __getitem__(self, i):\r\n return self.fn(self.ds[i])\r\n\r\nd = [{1:2, 2:3}, {1:3, 2:4}]\r\nds = LazyMapTorchDataset(d, lambda x:{k:v*2 for k,v in x.items()})\r\nfor i in range(2):\r\n print(f'before {d[i]}')\r\n print(f'after {ds[i]}')\r\n```\r\n```\r\nbefore {1: 2, 2: 3}\r\nafter {1: 4, 2: 6}\r\nbefore {1: 3, 2: 4}\r\nafter {1: 6, 2: 8}\r\n```\r\n\r\nBut this requires converting data to torch tensor myself. And this is really similar to `.map()`, why not just use it? So I have the next solution.\r\n\r\n> * Have lazy=False in Dataset.map, and returns a LazyDataset if lazy=True. This way the same map interface can be used, and existing code can be updated with one argument change.\r\n\r\nI think I like this solution best. Because `.with_transform` is entangled with `.with_format`, so seems more flexible to modify the `.map` than to modify `.with_transform`.\r\n\r\nThe usage looks nice, too.\r\n```python\r\n# lazy, one to one, can be parallelized via torch loader, no need to set `num_worker` beforehand.\r\ndataset = dataset.map(fn, lazy=True, batched=False)\r\n# collate_fn\r\ndataloader = Dataloader(dataset.with_format('torch'), collate_fn=collate_fn, num_workers=...) \r\n```\r\n\r\nThere are some minor decisions like whether a lazy map should be allowed before another map, but I think we can work it out later. The implementation can probably borrow from `IterableDataset`.",
"I like the idea of lazy map. On the other hand we should only have either lazy map or `with_transform` (not both). That's why I'd rather stick with `with_transform` for now (but maybe we can consider it for later major releases like `datasets` v2).\r\n\r\nI understand the issue with `with_transform` and `with_format` being exclusive, maybe we can separate them: first transform, them format.\r\n\r\nFinally I think what's also going to be important in the end will be the addition of multiprocessing to transforms"
] | "2021-12-06T05:20:54Z" | "2022-01-17T15:25:01Z" | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
A `torch.utils.data.Dataset.__getitem__` operates on a single example.
But 🤗 `Datasets.with_transform` doesn't seem to allow non-batched transform.
**Describe the solution you'd like**
Have a `batched=True` argument in `Datasets.with_transform`
**Describe alternatives you've considered**
* Convert a non-batched transform function to batched one myself.
* Wrap a 🤗 Dataset with torch Dataset, and add a `__getitem__`. 🙄
* Have `lazy=False` in `Dataset.map`, and returns a `LazyDataset` if `lazy=True`. This way the same `map` interface can be used, and existing code can be updated with one argument change. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3385/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/487/comments | https://api.github.com/repos/huggingface/datasets/issues/487/events | https://github.com/huggingface/datasets/pull/487 | 676,143,029 | MDExOlB1bGxSZXF1ZXN0NDY1NTA1NjQy | 487 | Fix elasticsearch result ids returning as strings | {
"avatar_url": "https://avatars.githubusercontent.com/u/3595526?v=4",
"events_url": "https://api.github.com/users/sai-prasanna/events{/privacy}",
"followers_url": "https://api.github.com/users/sai-prasanna/followers",
"following_url": "https://api.github.com/users/sai-prasanna/following{/other_user}",
"gists_url": "https://api.github.com/users/sai-prasanna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sai-prasanna",
"id": 3595526,
"login": "sai-prasanna",
"node_id": "MDQ6VXNlcjM1OTU1MjY=",
"organizations_url": "https://api.github.com/users/sai-prasanna/orgs",
"received_events_url": "https://api.github.com/users/sai-prasanna/received_events",
"repos_url": "https://api.github.com/users/sai-prasanna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sai-prasanna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sai-prasanna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sai-prasanna"
} | [] | closed | false | null | [] | null | [
"It looks like you need to rebase from master to fix the CI. Could you do that please ?"
] | "2020-08-10T13:37:11Z" | "2020-08-31T10:42:46Z" | "2020-08-31T10:42:46Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/487",
"merged_at": "2020-08-31T10:42:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/487"
} | I am using the latest elasticsearch binary and master of nlp. For me elasticsearch searches failed because the resultant "id_" returned for searches are strings, but our library assumes them to be integers. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/487/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6270/comments | https://api.github.com/repos/huggingface/datasets/issues/6270/events | https://github.com/huggingface/datasets/issues/6270 | 1,920,329,373 | I_kwDODunzps5ydead | 6,270 | Dataset.from_generator raises with sharded gen_args | {
"avatar_url": "https://avatars.githubusercontent.com/u/53510?v=4",
"events_url": "https://api.github.com/users/hartmans/events{/privacy}",
"followers_url": "https://api.github.com/users/hartmans/followers",
"following_url": "https://api.github.com/users/hartmans/following{/other_user}",
"gists_url": "https://api.github.com/users/hartmans/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hartmans",
"id": 53510,
"login": "hartmans",
"node_id": "MDQ6VXNlcjUzNTEw",
"organizations_url": "https://api.github.com/users/hartmans/orgs",
"received_events_url": "https://api.github.com/users/hartmans/received_events",
"repos_url": "https://api.github.com/users/hartmans/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hartmans/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hartmans/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hartmans"
} | [] | closed | false | null | [] | null | [
"`gen_kwargs` should be a `dict`, as stated in the docstring, but you are passing a `list`.\r\n\r\nSo, to fix the error, replace the list of dicts with a dict of lists (and slightly modify the generator function):\r\n```python\r\nfrom pathlib import Path\r\nimport datasets\r\n\r\ndef process_yaml(files):\r\n for f in files:\r\n # process\r\n yield dict(...)\r\n\r\n\r\nif __name__ == '__main__':\r\n import sys\r\n dir = Path(sys.argv[0]).parent\r\n ds = datasets.Dataset.from_generator(process_yaml, gen_kwargs={'files': [f for f in dir.glob('*.yml')]})\r\n ds.to_json('training.jsonl')\r\n```",
"That runs, and because my dataset is small, it's what I did to get past the problem.\r\nHowever, it does not produce a sharded dataset. From the doc string I expect there ought to be a way to call from_generator such that num_shards in the resulting data set is equal to the number of items in the list.\r\nThe part of the doc string that your suggestion is not responsive to is:\r\n` You can define a sharded dataset by passing the list of shards in *g\r\nen_kwargs*.\r\n`\r\n\r\nWhat your suggestion does is calls the generator once, with the list argument, and produces a single shard dataset.\r\n",
"The sharding mentioned here refers to using this function with `num_proc` (multiprocessing splits the `kwargs` into shards and passes them to the generator function)\r\n\r\n> That runs, and because my dataset is small, it's what I did to get past the problem.\r\n\r\n`from_generator` generates a memory-mapped dataset (can be larger than RAM), so the dataset size should not be an issue unless the generator function's implementation does not properly free the memory.\r\n",
"It sounds like you are saying that num_proc affects the form of gen_kwargs.\r\nAre you saying that for non-zero num_proc gen_kwargs should be a list whose length is the same as num_proc?\r\nOr are you saying that for non-zero num_proc, gen_kwargs should be a dict whose elements are lists the length of num_proc?\r\n",
"I ran some tests. So, it looks like with num_proc greater than 1, gen_kwargs is expected to be a dict of lists. It calls the generator also with a dict of lists, but the lists are split.\r\nI.E. if my original has `gen_kwargs=dict(a=[0,1,2])`, then my generator might get called with `gen_kwalrgs=dict([0])`.\r\nThat all makes sense, but I definitely think there is room for improvement in the doc string here.\r\nIn order to suggest improvements to the doc string, I need to look at how the gen_kwargs are split, and figure out if:\r\n* num_proc needs to exactly equal the length of the lists\r\n* num_proc needs to evenly divide the length of the lists\r\n* Or there's no required relationship.\r\nI'll look into that and then propose an improved doc string if no one else gets to it first.",
"Okay, that was fun; I took a dive through the dataset code and feel like I have a much better understanding.\r\nHere is my understanding of the behavior:\r\n* max_proc is an upper limit on the number of shards that `from_generator` produces\r\n* If `max_proc` is greater than 1, then all lists in *gen_kwargs* must be the same length\r\n* If the lists in *gen_kwargs* are shorter than *num_proc* elements, *num_proc* will be reduced and a warning produced. Put another way, `min(list_length, num_shards)` shards will be produced\r\n* The members of the lists in *gen_kwargs* will be partitioned among the created jobs.\r\nTo validate the above, take a look at\r\n`_number_of_shards_in_gen_kwargs` and `_distribute_shards` and `_split_gen_kwargs` in utils/sharding.py.\r\nI've also chased down starting at *from_generator* all the way through to GeneratorBuilder and the calls to the functions in sharding.py.\r\nTomorrow I'll take a look at the contributing guidelines and see what's involved in putting together a PR to improve the doc string."
] | "2023-09-30T16:50:06Z" | "2023-10-11T20:29:12Z" | "2023-10-11T20:29:11Z" | CONTRIBUTOR | null | null | null | ### Describe the bug
According to the docs of Datasets.from_generator:
```
gen_kwargs(`dict`, *optional*):
Keyword arguments to be passed to the `generator` callable.
You can define a sharded dataset by passing the list of shards in `gen_kwargs`.
```
So I'd expect that if gen_kwargs was a list, then my generator would be called once for each element in the list with the dict in the list for that element.
It doesn't work that way though.
### Steps to reproduce the bug
```python
#!/usr/bin/python
from pathlib import Path
import datasets
def process_yaml(file):
yield dict(example=42)
if __name__ == '__main__':
import sys
dir = Path(sys.argv[0]).parent
ds = datasets.Dataset.from_generator(process_yaml, gen_kwargs=[{'file':f} for f in dir.glob('*.yml')],
)
ds.to_json('training.jsonl')
```
```
Generating train split: 0 examples [00:00, ? examples/s]
Traceback (most recent call last):
File "/tmp/dataset_bug.py", line 13, in <module>
ds = datasets.Dataset.from_generator(process_yaml, gen_kwargs=[{'file':f} for f in dir.glob('*.yml')],
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 1072, in from_generator
).read()
^^^^^^
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/io/generator.py", line 47, in read
self.builder.download_and_prepare(
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/builder.py", line 954, in download_and_prepare
self._download_and_prepare(
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/builder.py", line 1717, in _download_and_prepare
super()._download_and_prepare(
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/builder.py", line 1049, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/builder.py", line 1555, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/hartmans/ai/venv/lib/python3.11/site-packages/datasets/builder.py", line 1656, in _prepare_split_single
generator = self._generate_examples(**gen_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: datasets.packaged_modules.generator.generator.Generator._generate_examples() argument after ** must be a ```
mapping, not list
### Expected behavior
I would expect that process_yaml would be called once for each yaml file in the directory where the script is run.
I also tried with the list being in gen_kwargs, but in that case process_yaml gets called with a list.
### Environment info
- `datasets` version: 2.14.6.dev0 (git commit 0cc77d7f45c7369; also tested with 2.14.0)
- Platform: Linux-6.1.0-10-amd64-x86_64-with-glibc2.36
- Python version: 3.11.2
- Huggingface_hub version: 0.16.4
- PyArrow version: 12.0.1
- Pandas version: 2.0.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6270/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5886 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5886/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5886/comments | https://api.github.com/repos/huggingface/datasets/issues/5886/events | https://github.com/huggingface/datasets/issues/5886 | 1,721,070,225 | I_kwDODunzps5mlXKR | 5,886 | Use work-stealing algorithm when parallel computing | {
"avatar_url": "https://avatars.githubusercontent.com/u/46060451?v=4",
"events_url": "https://api.github.com/users/1014661165/events{/privacy}",
"followers_url": "https://api.github.com/users/1014661165/followers",
"following_url": "https://api.github.com/users/1014661165/following{/other_user}",
"gists_url": "https://api.github.com/users/1014661165/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/1014661165",
"id": 46060451,
"login": "1014661165",
"node_id": "MDQ6VXNlcjQ2MDYwNDUx",
"organizations_url": "https://api.github.com/users/1014661165/orgs",
"received_events_url": "https://api.github.com/users/1014661165/received_events",
"repos_url": "https://api.github.com/users/1014661165/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/1014661165/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/1014661165/subscriptions",
"type": "User",
"url": "https://api.github.com/users/1014661165"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Alternatively we could set the number of shards to be a factor than the number of processes (current they're equal) - this way it will be less likely to end up with a shard that is significantly slower than all the other ones."
] | "2023-05-23T03:08:44Z" | "2023-05-24T15:30:09Z" | null | NONE | null | null | null | ### Feature request
when i used Dataset.map api to process data concurrently, i found that
it gets slower and slower as it gets closer to completion. Then i read the source code of arrow_dataset.py and found that it shard the dataset and use multiprocessing pool to execute each shard.It may cause the slowest task to drag out the entire program's execution time,especially when processing huge dataset.
### Motivation
using work-stealing algorithm instead of sharding and parallel computing to optimize performance.
### Your contribution
just an idea. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5886/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5886/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6446 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6446/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6446/comments | https://api.github.com/repos/huggingface/datasets/issues/6446/events | https://github.com/huggingface/datasets/issues/6446 | 2,007,092,708 | I_kwDODunzps53oc3k | 6,446 | Speech Commands v2 dataset doesn't match AST-v2 config | {
"avatar_url": "https://avatars.githubusercontent.com/u/18024303?v=4",
"events_url": "https://api.github.com/users/vymao/events{/privacy}",
"followers_url": "https://api.github.com/users/vymao/followers",
"following_url": "https://api.github.com/users/vymao/following{/other_user}",
"gists_url": "https://api.github.com/users/vymao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vymao",
"id": 18024303,
"login": "vymao",
"node_id": "MDQ6VXNlcjE4MDI0MzAz",
"organizations_url": "https://api.github.com/users/vymao/orgs",
"received_events_url": "https://api.github.com/users/vymao/received_events",
"repos_url": "https://api.github.com/users/vymao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vymao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vymao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vymao"
} | [] | closed | false | null | [] | null | [
"You can use `.align_labels_with_mapping` on the dataset to align the labels with the model config.\r\n\r\nRegarding the number of labels, only the special `_silence_` label corresponding to noise is missing, which is consistent with the model paper (reports training on 35 labels). You can run a `.filter` to drop it.\r\n\r\nPS: You should create a discussion on a model/dataset repo (on the Hub) for these kinds of questions",
"Thanks, will keep that in mind. But I tried running `dataset_aligned = dataset.align_labels_with_mapping(model.config.id2label, 'label')`, and received this error: \r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/victor/anaconda3/envs/transformers-v2/lib/python3.9/site-packages/datasets/arrow_dataset.py\", line 5928, in align_labels_with_mapping\r\n label2id = {k.lower(): v for k, v in label2id.items()}\r\n File \"/Users/victor/anaconda3/envs/transformers-v2/lib/python3.9/site-packages/datasets/arrow_dataset.py\", line 5928, in <dictcomp>\r\n label2id = {k.lower(): v for k, v in label2id.items()}\r\nAttributeError: 'int' object has no attribute 'lower'\r\n```\r\nMy guess is that the dataset `label` column is purely an int ID, and I'm not sure there's a way to identify which class label the ID belongs to in the dataset easily.",
"Replacing `model.config.id2label` with `model.config.label2id` should fix the issue.\r\n\r\nSo, the full code to align the labels with the model config is as follows:\r\n```python\r\nfrom datasets import load_dataset\r\nfrom transformers import AutoFeatureExtractor, AutoModelForAudioClassification\r\n\r\n# extractor = AutoFeatureExtractor.from_pretrained(\"MIT/ast-finetuned-speech-commands-v2\")\r\nmodel = AutoModelForAudioClassification.from_pretrained(\"MIT/ast-finetuned-speech-commands-v2\")\r\n\r\nds = load_dataset(\"speech_commands\", \"v0.02\")\r\nds = ds.filter(lambda label: label != ds[\"train\"].features[\"label\"].str2int(\"_silence_\"), input_columns=\"label\")\r\nds = ds.align_labels_with_mapping(model.config.label2id, \"label\")\r\n```"
] | "2023-11-22T20:46:36Z" | "2023-11-28T14:46:08Z" | "2023-11-28T14:46:08Z" | NONE | null | null | null | ### Describe the bug
[According](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2) to `MIT/ast-finetuned-speech-commands-v2`, the model was trained on the Speech Commands v2 dataset. However, while the model config says the model should have 35 class labels, the dataset itself has 36 class labels. Moreover, the class labels themselves don't match between the model config and the dataset. It is difficult to reproduce the data used to fine tune `MIT/ast-finetuned-speech-commands-v2`.
### Steps to reproduce the bug
```
>>> model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-speech-commands-v2")
>>> model.config.id2label
{0: 'backward', 1: 'follow', 2: 'five', 3: 'bed', 4: 'zero', 5: 'on', 6: 'learn', 7: 'two', 8: 'house', 9: 'tree', 10: 'dog', 11: 'stop', 12: 'seven', 13: 'eight', 14: 'down', 15: 'six', 16: 'forward', 17: 'cat', 18: 'right', 19: 'visual', 20: 'four', 21: 'wow', 22: 'no', 23: 'nine', 24: 'off', 25: 'three', 26: 'left', 27: 'marvin', 28: 'yes', 29: 'up', 30: 'sheila', 31: 'happy', 32: 'bird', 33: 'go', 34: 'one'}
>>> dataset = load_dataset("speech_commands", "v0.02", split="test")
>>> torch.unique(torch.Tensor(dataset['label']))
tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26., 27.,
28., 29., 30., 31., 32., 33., 34., 35.])
```
If you try to explore the [dataset itself](https://huggingface.co/datasets/speech_commands/viewer/v0.02/test), you can see that the id to label does not match what is provided by `model.config.id2label`.
### Expected behavior
The labels should match completely and there should be the same number of label classes between the model config and the dataset itself.
### Environment info
datasets = 2.14.6, transformers = 4.33.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6446/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6446/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6366/comments | https://api.github.com/repos/huggingface/datasets/issues/6366/events | https://github.com/huggingface/datasets/issues/6366 | 1,970,213,490 | I_kwDODunzps51bxJy | 6,366 | with_format() function returns bytes instead of PIL images even when image column is not part of "columns" | {
"avatar_url": "https://avatars.githubusercontent.com/u/17809020?v=4",
"events_url": "https://api.github.com/users/leot13/events{/privacy}",
"followers_url": "https://api.github.com/users/leot13/followers",
"following_url": "https://api.github.com/users/leot13/following{/other_user}",
"gists_url": "https://api.github.com/users/leot13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/leot13",
"id": 17809020,
"login": "leot13",
"node_id": "MDQ6VXNlcjE3ODA5MDIw",
"organizations_url": "https://api.github.com/users/leot13/orgs",
"received_events_url": "https://api.github.com/users/leot13/received_events",
"repos_url": "https://api.github.com/users/leot13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/leot13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leot13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/leot13"
} | [] | closed | false | null | [] | null | [
"Thanks for reporting! I've opened a PR with a fix."
] | "2023-10-31T11:10:48Z" | "2023-11-02T14:21:17Z" | "2023-11-02T14:21:17Z" | NONE | null | null | null | ### Describe the bug
When using the with_format() function on a dataset containing images, even if the image column is not part of the columns provided in the function, its type will be changed to bytes.
Here is a minimal reproduction of the bug:
https://colab.research.google.com/drive/1hyaOspgyhB41oiR1-tXE3k_gJCdJUQCf?usp=sharing
### Steps to reproduce the bug
1. Load the image dataset
2. apply with_format(columns=["text"])
3. Check the type of images in the "image" column before and after applying with_format
### Expected behavior
The type should stay the same, but it does not
### Environment info
datasets==2.14.6
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6366/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1716/comments | https://api.github.com/repos/huggingface/datasets/issues/1716/events | https://github.com/huggingface/datasets/pull/1716 | 782,819,006 | MDExOlB1bGxSZXF1ZXN0NTUyMjgzNzE5 | 1,716 | Add Hatexplain Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/48222101?v=4",
"events_url": "https://api.github.com/users/kushal2000/events{/privacy}",
"followers_url": "https://api.github.com/users/kushal2000/followers",
"following_url": "https://api.github.com/users/kushal2000/following{/other_user}",
"gists_url": "https://api.github.com/users/kushal2000/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kushal2000",
"id": 48222101,
"login": "kushal2000",
"node_id": "MDQ6VXNlcjQ4MjIyMTAx",
"organizations_url": "https://api.github.com/users/kushal2000/orgs",
"received_events_url": "https://api.github.com/users/kushal2000/received_events",
"repos_url": "https://api.github.com/users/kushal2000/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kushal2000/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kushal2000/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kushal2000"
} | [] | closed | false | null | [] | null | [] | "2021-01-10T13:30:01Z" | "2021-01-18T14:21:42Z" | "2021-01-18T14:21:42Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1716.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1716",
"merged_at": "2021-01-18T14:21:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1716.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1716"
} | Adding Hatexplain - the first benchmark hate speech dataset covering multiple aspects of the issue | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1716/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4408/comments | https://api.github.com/repos/huggingface/datasets/issues/4408/events | https://github.com/huggingface/datasets/pull/4408 | 1,248,687,574 | PR_kwDODunzps44ecNI | 4,408 | Update imagenet gate | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-25T20:32:19Z" | "2022-05-25T20:45:11Z" | "2022-05-25T20:36:47Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4408.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4408",
"merged_at": "2022-05-25T20:36:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4408.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4408"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4408/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1004 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1004/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1004/comments | https://api.github.com/repos/huggingface/datasets/issues/1004/events | https://github.com/huggingface/datasets/issues/1004 | 755,325,368 | MDU6SXNzdWU3NTUzMjUzNjg= | 1,004 | how large datasets are handled under the hood | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehkarimimahabadi",
"id": 73364383,
"login": "rabeehkarimimahabadi",
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehkarimimahabadi"
} | [] | closed | false | null | [] | null | [
"This library uses Apache Arrow under the hood to store datasets on disk.\r\nThe advantage of Apache Arrow is that it allows to memory map the dataset. This allows to load datasets bigger than memory and with almost no RAM usage. It also offers excellent I/O speed.\r\n\r\nFor example when you access one element or one batch\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nsquad = load_dataset(\"squad\", split=\"train\")\r\nfirst_element = squad[0]\r\none_batch = squad[:8]\r\n```\r\n\r\nthen only this element/batch is loaded in memory, while the rest of the dataset is memory mapped.",
"How can we change how much data is loaded to memory with Arrow? I think that I am having some performance issue with it. When Arrow loads the data from disk it does it in multiprocess? It's almost twice slower training with arrow than in memory.\r\n\r\nEDIT:\r\nMy fault! I had not seen the `dataloader_num_workers` in `TrainingArguments` ! Now I can parallelize and go fast! Sorry, and thanks.",
"> How can we change how much data is loaded to memory with Arrow? I think that I am having some performance issue with it. When Arrow loads the data from disk it does it in multiprocess? It's almost twice slower training with arrow than in memory.\r\n\r\nLoading arrow data from disk is done with memory-mapping. This allows to load huge datasets without filling your RAM.\r\nMemory mapping is almost instantaneous and is done within one process.\r\n\r\nThen, the speed of querying examples from the dataset is I/O bounded depending on your disk. If it's an SSD then fetching examples from the dataset will be very fast.\r\nBut since the I/O speed of an SSD is lower than the one of RAM it's expected to be slower to fetch data from disk than from memory.\r\nStill, if you load the dataset in different processes then it can be faster but there will still be the I/O bottleneck of the disk.\r\n\r\n> EDIT:\r\n> My fault! I had not seen the `dataloader_num_workers` in `TrainingArguments` ! Now I can parallelize and go fast! Sorry, and thanks.\r\n\r\nOk let me know if that helps !\r\n"
] | "2020-12-02T14:32:40Z" | "2022-10-05T12:13:29Z" | "2022-10-05T12:13:29Z" | NONE | null | null | null | Hi
I want to use multiple large datasets with a mapping style dataloader, where they cannot fit into memory, could you tell me how you handled the datasets under the hood? is this you bring all in memory in case of mapping style ones? or is this some sharding under the hood and you bring in memory when necessary, thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1004/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1004/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4004 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4004/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4004/comments | https://api.github.com/repos/huggingface/datasets/issues/4004/events | https://github.com/huggingface/datasets/pull/4004 | 1,179,320,795 | PR_kwDODunzps408Onj | 4,004 | ASSIN 2 dataset: replace broken Google Drive _URLS by links on github | {
"avatar_url": "https://avatars.githubusercontent.com/u/14352388?v=4",
"events_url": "https://api.github.com/users/ruanchaves/events{/privacy}",
"followers_url": "https://api.github.com/users/ruanchaves/followers",
"following_url": "https://api.github.com/users/ruanchaves/following{/other_user}",
"gists_url": "https://api.github.com/users/ruanchaves/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ruanchaves",
"id": 14352388,
"login": "ruanchaves",
"node_id": "MDQ6VXNlcjE0MzUyMzg4",
"organizations_url": "https://api.github.com/users/ruanchaves/orgs",
"received_events_url": "https://api.github.com/users/ruanchaves/received_events",
"repos_url": "https://api.github.com/users/ruanchaves/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ruanchaves/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ruanchaves/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ruanchaves"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-24T10:37:39Z" | "2022-03-28T14:01:46Z" | "2022-03-28T13:56:39Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4004.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4004",
"merged_at": "2022-03-28T13:56:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4004.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4004"
} | Closes #4003 .
Fixes checksum error. Replaces Google Drive urls by the files hosted here: [Multilingual Transformer Ensembles for Portuguese Natural Language Tasks](https://github.com/ruanchaves/assin) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4004/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4004/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1230/comments | https://api.github.com/repos/huggingface/datasets/issues/1230/events | https://github.com/huggingface/datasets/pull/1230 | 758,119,342 | MDExOlB1bGxSZXF1ZXN0NTMzMzQxNTg0 | 1,230 | Add Urdu fake news dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44389205?v=4",
"events_url": "https://api.github.com/users/chaitnayabasava/events{/privacy}",
"followers_url": "https://api.github.com/users/chaitnayabasava/followers",
"following_url": "https://api.github.com/users/chaitnayabasava/following{/other_user}",
"gists_url": "https://api.github.com/users/chaitnayabasava/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/chaitnayabasava",
"id": 44389205,
"login": "chaitnayabasava",
"node_id": "MDQ6VXNlcjQ0Mzg5MjA1",
"organizations_url": "https://api.github.com/users/chaitnayabasava/orgs",
"received_events_url": "https://api.github.com/users/chaitnayabasava/received_events",
"repos_url": "https://api.github.com/users/chaitnayabasava/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/chaitnayabasava/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chaitnayabasava/subscriptions",
"type": "User",
"url": "https://api.github.com/users/chaitnayabasava"
} | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | "2020-12-07T03:19:50Z" | "2020-12-07T18:04:55Z" | "2020-12-07T16:57:54Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1230.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1230",
"merged_at": "2020-12-07T16:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1230.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1230"
} | @lhoestq opened a clean PR containing only relevant files.
old PR #1125 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1230/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3161/comments | https://api.github.com/repos/huggingface/datasets/issues/3161/events | https://github.com/huggingface/datasets/pull/3161 | 1,035,444,292 | PR_kwDODunzps4tpCsm | 3,161 | Add riddle_sense dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44691149?v=4",
"events_url": "https://api.github.com/users/ziyiwu9494/events{/privacy}",
"followers_url": "https://api.github.com/users/ziyiwu9494/followers",
"following_url": "https://api.github.com/users/ziyiwu9494/following{/other_user}",
"gists_url": "https://api.github.com/users/ziyiwu9494/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ziyiwu9494",
"id": 44691149,
"login": "ziyiwu9494",
"node_id": "MDQ6VXNlcjQ0NjkxMTQ5",
"organizations_url": "https://api.github.com/users/ziyiwu9494/orgs",
"received_events_url": "https://api.github.com/users/ziyiwu9494/received_events",
"repos_url": "https://api.github.com/users/ziyiwu9494/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ziyiwu9494/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ziyiwu9494/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ziyiwu9494"
} | [] | closed | false | null | [] | null | [
"@lhoestq \r\nI address all the comments, I think. Thanks! \r\n",
"The five test fails are unrelated to this PR and fixed on master so we can ignore them"
] | "2021-10-25T18:30:56Z" | "2021-11-04T14:01:15Z" | "2021-11-04T14:01:15Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3161.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3161",
"merged_at": "2021-11-04T14:01:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3161.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3161"
} | Adding a new dataset for QA with riddles. I'm confused about the tagging process because it looks like the streamlit app loads data from the current repo, so is it something that should be done after merging or off my fork? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3161/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3517 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3517/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3517/comments | https://api.github.com/repos/huggingface/datasets/issues/3517/events | https://github.com/huggingface/datasets/pull/3517 | 1,092,726,651 | PR_kwDODunzps4wemwU | 3,517 | Add CPPE-5 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"Thanks so much, @mariosasko and @lhoestq , much appreciated!"
] | "2022-01-03T18:31:20Z" | "2022-01-19T02:23:37Z" | "2022-01-05T18:53:02Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3517.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3517",
"merged_at": "2022-01-05T18:53:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3517.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3517"
} | Adds the recently released CPPE-5 dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3517/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3517/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/130/comments | https://api.github.com/repos/huggingface/datasets/issues/130/events | https://github.com/huggingface/datasets/issues/130 | 619,035,440 | MDU6SXNzdWU2MTkwMzU0NDA= | 130 | Loading GLUE dataset loads CoLA by default | {
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zphang",
"id": 1668462,
"login": "zphang",
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"repos_url": "https://api.github.com/users/zphang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zphang"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"As a follow-up to this: It looks like the actual GLUE task name is supplied as the `name` argument. Is there a way to check what `name`s/sub-datasets are available under a grouping like GLUE? That information doesn't seem to be readily available in info from `nlp.list_datasets()`.\r\n\r\nEdit: I found the info under `Glue.BUILDER_CONFIGS`",
"Yes so the first config is loaded by default when no `name` is supplied but for GLUE this should probably throw an error indeed.\r\n\r\nWe can probably just add an `__init__` at the top of the `class Glue(nlp.GeneratorBasedBuilder)` in the `glue.py` script which does this check:\r\n```\r\nclass Glue(nlp.GeneratorBasedBuilder):\r\n def __init__(self, *args, **kwargs):\r\n assert 'name' in kwargs and kwargs[name] is not None, \"Glue has to be called with a configuration name\"\r\n super(Glue, self).__init__(*args, **kwargs)\r\n```",
"An error is raised if the sub-dataset is not specified :)\r\n```\r\nValueError: Config name is missing.\r\nPlease pick one among the available configs: ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']\r\nExample of usage:\r\n\t`load_dataset('glue', 'cola')`\r\n```"
] | "2020-05-15T14:55:50Z" | "2020-05-27T22:08:15Z" | "2020-05-27T22:08:15Z" | NONE | null | null | null | If I run:
```python
dataset = nlp.load_dataset('glue')
```
The resultant dataset seems to be CoLA be default, without throwing any error. This is in contrast to calling:
```python
metric = nlp.load_metric("glue")
```
which throws an error telling the user that they need to specify a task in GLUE. Should the same apply for loading datasets? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/130/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/130/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/712/comments | https://api.github.com/repos/huggingface/datasets/issues/712/events | https://github.com/huggingface/datasets/issues/712 | 714,242,316 | MDU6SXNzdWU3MTQyNDIzMTY= | 712 | Error in the notebooks/Overview.ipynb notebook | {
"avatar_url": "https://avatars.githubusercontent.com/u/850012?v=4",
"events_url": "https://api.github.com/users/subhrm/events{/privacy}",
"followers_url": "https://api.github.com/users/subhrm/followers",
"following_url": "https://api.github.com/users/subhrm/following{/other_user}",
"gists_url": "https://api.github.com/users/subhrm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/subhrm",
"id": 850012,
"login": "subhrm",
"node_id": "MDQ6VXNlcjg1MDAxMg==",
"organizations_url": "https://api.github.com/users/subhrm/orgs",
"received_events_url": "https://api.github.com/users/subhrm/received_events",
"repos_url": "https://api.github.com/users/subhrm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/subhrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/subhrm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/subhrm"
} | [] | closed | false | null | [] | null | [
"Do this:\r\n``` python\r\nsquad_dataset = list_datasets(with_details=True)[datasets.index('squad')]\r\npprint(squad_dataset.__dict__) # It's a simple python dataclass\r\n```",
"Thanks! This worked. I have created a PR to fix this in the notebook. "
] | "2020-10-04T05:58:31Z" | "2020-10-05T16:25:40Z" | "2020-10-05T16:25:40Z" | CONTRIBUTOR | null | null | null | Hi,
I got the following error in **cell number 3** while exploring the **Overview.ipynb** notebook in google colab. I used the [link ](https://colab.research.google.com/github/huggingface/datasets/blob/master/notebooks/Overview.ipynb) provided in the main README file to open it in colab.
```python
# You can access various attributes of the datasets before downloading them
squad_dataset = list_datasets()[datasets.index('squad')]
pprint(squad_dataset.__dict__) # It's a simple python dataclass
```
Error message
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-5-8dc805c4949c> in <module>()
2 squad_dataset = list_datasets()[datasets.index('squad')]
3
----> 4 pprint(squad_dataset.__dict__) # It's a simple python dataclass
AttributeError: 'str' object has no attribute '__dict__'
```
The object `squad_dataset` is a `str` not a `dataclass` . | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/712/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/712/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/607/comments | https://api.github.com/repos/huggingface/datasets/issues/607/events | https://github.com/huggingface/datasets/pull/607 | 698,094,442 | MDExOlB1bGxSZXF1ZXN0NDgzOTcyMDg4 | 607 | Add transmit_format wrapper and tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-09-10T15:03:50Z" | "2020-09-10T15:21:48Z" | "2020-09-10T15:21:47Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/607.diff",
"html_url": "https://github.com/huggingface/datasets/pull/607",
"merged_at": "2020-09-10T15:21:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/607.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/607"
} | Same as #605 but using a decorator on-top of dataset transforms that are not in place | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/607/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1180/comments | https://api.github.com/repos/huggingface/datasets/issues/1180/events | https://github.com/huggingface/datasets/pull/1180 | 757,784,612 | MDExOlB1bGxSZXF1ZXN0NTMzMDk1MzI2 | 1,180 | Add KorQuAD v2 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/15624271?v=4",
"events_url": "https://api.github.com/users/cceyda/events{/privacy}",
"followers_url": "https://api.github.com/users/cceyda/followers",
"following_url": "https://api.github.com/users/cceyda/following{/other_user}",
"gists_url": "https://api.github.com/users/cceyda/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cceyda",
"id": 15624271,
"login": "cceyda",
"node_id": "MDQ6VXNlcjE1NjI0Mjcx",
"organizations_url": "https://api.github.com/users/cceyda/orgs",
"received_events_url": "https://api.github.com/users/cceyda/received_events",
"repos_url": "https://api.github.com/users/cceyda/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cceyda/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cceyda/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cceyda"
} | [] | closed | false | null | [] | null | [
"looks like this PR also includes the changes for the V1\r\nCould you only include the files of the V2 ?",
"hmm I have made the dummy data lighter retested on local and it passed not sure why it fails here?",
"merging since the CI is fixed on master"
] | "2020-12-05T21:33:34Z" | "2020-12-16T16:10:30Z" | "2020-12-16T16:10:30Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1180.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1180",
"merged_at": "2020-12-16T16:10:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1180.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1180"
} | # The Korean Question Answering Dataset v2
Adding the [KorQuAD](https://korquad.github.io/) v2 dataset as part of the sprint 🎉
This dataset is very similar to SQuAD and is an extension of [squad_kor_v1](https://github.com/huggingface/datasets/pull/1178) which is why I added it as `squad_kor_v2`.
- Crowd generated questions and answer (1-answer per question) for Wikipedia articles. Differently from V1 it includes the html structure and markup, which makes it a different enough dataset. (doesn't share ids between v1 and v2 either)
- [x] All tests passed
- [x] Added dummy data
- [x] Added data card (as much as I could)
Edit: 🤦 looks like squad_kor_v1 commit sneaked in here too | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1180/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6171/comments | https://api.github.com/repos/huggingface/datasets/issues/6171/events | https://github.com/huggingface/datasets/pull/6171 | 1,862,922,767 | PR_kwDODunzps5Yk4AS | 6,171 | Fix typo in about_mapstyle_vs_iterable.mdx | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6171). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009315 / 0.011353 (-0.002038) | 0.004931 / 0.011008 (-0.006077) | 0.100534 / 0.038508 (0.062026) | 0.089270 / 0.023109 (0.066161) | 0.394995 / 0.275898 (0.119097) | 0.440244 / 0.323480 (0.116764) | 0.006026 / 0.007986 (-0.001959) | 0.004252 / 0.004328 (-0.000077) | 0.078828 / 0.004250 (0.074577) | 0.066770 / 0.037052 (0.029718) | 0.411152 / 0.258489 (0.152663) | 0.445616 / 0.293841 (0.151775) | 0.048344 / 0.128546 (-0.080203) | 0.013700 / 0.075646 (-0.061946) | 0.361205 / 0.419271 (-0.058066) | 0.072085 / 0.043533 (0.028552) | 0.399173 / 0.255139 (0.144034) | 0.439334 / 0.283200 (0.156134) | 0.035815 / 0.141683 (-0.105868) | 1.779023 / 1.452155 (0.326868) | 1.865099 / 1.492716 (0.372383) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.275978 / 0.018006 (0.257972) | 0.588850 / 0.000490 (0.588360) | 0.004953 / 0.000200 (0.004754) | 0.000109 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031329 / 0.037411 (-0.006082) | 0.095435 / 0.014526 (0.080910) | 0.111182 / 0.176557 (-0.065375) | 0.177692 / 0.737135 (-0.559444) | 0.113345 / 0.296338 (-0.182993) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.577882 / 0.215209 (0.362673) | 5.865872 / 2.077655 (3.788217) | 2.664218 / 1.504120 (1.160098) | 2.383354 / 1.541195 (0.842159) | 2.336821 / 1.468490 (0.868331) | 0.834585 / 4.584777 (-3.750192) | 5.418720 / 3.745712 (1.673008) | 4.551790 / 5.269862 (-0.718072) | 2.921874 / 4.565676 (-1.643803) | 0.095738 / 0.424275 (-0.328537) | 0.009625 / 0.007607 (0.002018) | 0.688317 / 0.226044 (0.462273) | 6.831826 / 2.268929 (4.562897) | 3.482607 / 55.444624 (-51.962017) | 2.633482 / 6.876477 (-4.242995) | 2.878786 / 2.142072 (0.736714) | 0.971615 / 4.805227 (-3.833613) | 0.208661 / 6.500664 (-6.292003) | 0.080271 / 0.075469 (0.004802) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.661193 / 1.841788 (-0.180594) | 24.223041 / 8.074308 (16.148733) | 21.621791 / 10.191392 (11.430399) | 0.243809 / 0.680424 (-0.436614) | 0.031630 / 0.534201 (-0.502571) | 0.501408 / 0.579283 (-0.077875) | 0.600002 / 0.434364 (0.165638) | 0.572066 / 0.540337 (0.031728) | 0.791992 / 1.386936 (-0.594944) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009410 / 0.011353 (-0.001943) | 0.005255 / 0.011008 (-0.005753) | 0.079202 / 0.038508 (0.040693) | 0.078973 / 0.023109 (0.055863) | 0.557416 / 0.275898 (0.281518) | 0.560417 / 0.323480 (0.236937) | 0.007066 / 0.007986 (-0.000920) | 0.004560 / 0.004328 (0.000232) | 0.080359 / 0.004250 (0.076109) | 0.060071 / 0.037052 (0.023019) | 0.538441 / 0.258489 (0.279952) | 0.592486 / 0.293841 (0.298645) | 0.053221 / 0.128546 (-0.075325) | 0.014056 / 0.075646 (-0.061591) | 0.094084 / 0.419271 (-0.325188) | 0.066721 / 0.043533 (0.023188) | 0.521873 / 0.255139 (0.266734) | 0.579637 / 0.283200 (0.296437) | 0.041476 / 0.141683 (-0.100206) | 1.829681 / 1.452155 (0.377527) | 1.948418 / 1.492716 (0.455702) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.347594 / 0.018006 (0.329588) | 0.606906 / 0.000490 (0.606417) | 0.035413 / 0.000200 (0.035213) | 0.000371 / 0.000054 (0.000317) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031987 / 0.037411 (-0.005425) | 0.096985 / 0.014526 (0.082459) | 0.109275 / 0.176557 (-0.067282) | 0.175340 / 0.737135 (-0.561795) | 0.110763 / 0.296338 (-0.185575) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.634823 / 0.215209 (0.419614) | 6.527172 / 2.077655 (4.449517) | 3.135709 / 1.504120 (1.631589) | 2.634357 / 1.541195 (1.093162) | 2.670583 / 1.468490 (1.202093) | 0.888686 / 4.584777 (-3.696091) | 5.382289 / 3.745712 (1.636577) | 4.701189 / 5.269862 (-0.568673) | 3.161290 / 4.565676 (-1.404386) | 0.112414 / 0.424275 (-0.311861) | 0.009443 / 0.007607 (0.001836) | 0.774703 / 0.226044 (0.548658) | 7.905334 / 2.268929 (5.636405) | 3.689548 / 55.444624 (-51.755076) | 3.087263 / 6.876477 (-3.789214) | 3.366568 / 2.142072 (1.224496) | 1.185951 / 4.805227 (-3.619277) | 0.248638 / 6.500664 (-6.252026) | 0.104598 / 0.075469 (0.029129) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.820667 / 1.841788 (-0.021120) | 24.536703 / 8.074308 (16.462395) | 23.083964 / 10.191392 (12.892572) | 0.252897 / 0.680424 (-0.427527) | 0.032954 / 0.534201 (-0.501247) | 0.482467 / 0.579283 (-0.096816) | 0.602247 / 0.434364 (0.167883) | 0.600563 / 0.540337 (0.060225) | 0.824013 / 1.386936 (-0.562923) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009242 / 0.011353 (-0.002111) | 0.005244 / 0.011008 (-0.005764) | 0.112678 / 0.038508 (0.074170) | 0.089176 / 0.023109 (0.066067) | 0.405823 / 0.275898 (0.129925) | 0.465703 / 0.323480 (0.142223) | 0.005227 / 0.007986 (-0.002758) | 0.004296 / 0.004328 (-0.000032) | 0.082961 / 0.004250 (0.078711) | 0.063144 / 0.037052 (0.026092) | 0.422369 / 0.258489 (0.163880) | 0.478185 / 0.293841 (0.184344) | 0.049770 / 0.128546 (-0.078776) | 0.016561 / 0.075646 (-0.059086) | 0.380172 / 0.419271 (-0.039100) | 0.068698 / 0.043533 (0.025165) | 0.397773 / 0.255139 (0.142634) | 0.461284 / 0.283200 (0.178084) | 0.036907 / 0.141683 (-0.104775) | 1.828017 / 1.452155 (0.375862) | 2.028385 / 1.492716 (0.535669) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291245 / 0.018006 (0.273239) | 0.605519 / 0.000490 (0.605030) | 0.003790 / 0.000200 (0.003590) | 0.000094 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029269 / 0.037411 (-0.008142) | 0.087014 / 0.014526 (0.072488) | 0.116984 / 0.176557 (-0.059573) | 0.170644 / 0.737135 (-0.566491) | 0.109011 / 0.296338 (-0.187328) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.603045 / 0.215209 (0.387836) | 6.125308 / 2.077655 (4.047653) | 2.637127 / 1.504120 (1.133007) | 2.468636 / 1.541195 (0.927441) | 2.383773 / 1.468490 (0.915283) | 0.838139 / 4.584777 (-3.746638) | 5.355777 / 3.745712 (1.610065) | 4.753015 / 5.269862 (-0.516846) | 3.097486 / 4.565676 (-1.468191) | 0.094749 / 0.424275 (-0.329526) | 0.009040 / 0.007607 (0.001433) | 0.699987 / 0.226044 (0.473942) | 7.111671 / 2.268929 (4.842742) | 3.297798 / 55.444624 (-52.146827) | 2.614578 / 6.876477 (-4.261898) | 2.927717 / 2.142072 (0.785645) | 1.037292 / 4.805227 (-3.767935) | 0.218025 / 6.500664 (-6.282639) | 0.086306 / 0.075469 (0.010836) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.645146 / 1.841788 (-0.196642) | 24.191875 / 8.074308 (16.117567) | 21.844371 / 10.191392 (11.652979) | 0.245369 / 0.680424 (-0.435055) | 0.031776 / 0.534201 (-0.502425) | 0.465634 / 0.579283 (-0.113649) | 0.565498 / 0.434364 (0.131134) | 0.497409 / 0.540337 (-0.042929) | 0.748048 / 1.386936 (-0.638889) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009239 / 0.011353 (-0.002114) | 0.005345 / 0.011008 (-0.005663) | 0.072732 / 0.038508 (0.034224) | 0.099880 / 0.023109 (0.076770) | 0.466933 / 0.275898 (0.191035) | 0.471730 / 0.323480 (0.148250) | 0.006164 / 0.007986 (-0.001821) | 0.004486 / 0.004328 (0.000158) | 0.075475 / 0.004250 (0.071224) | 0.068291 / 0.037052 (0.031238) | 0.465925 / 0.258489 (0.207436) | 0.469198 / 0.293841 (0.175357) | 0.047304 / 0.128546 (-0.081242) | 0.013368 / 0.075646 (-0.062278) | 0.083563 / 0.419271 (-0.335708) | 0.063204 / 0.043533 (0.019671) | 0.457422 / 0.255139 (0.202283) | 0.478793 / 0.283200 (0.195593) | 0.036120 / 0.141683 (-0.105563) | 1.841209 / 1.452155 (0.389054) | 1.955984 / 1.492716 (0.463267) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.369160 / 0.018006 (0.351154) | 0.607140 / 0.000490 (0.606650) | 0.047253 / 0.000200 (0.047054) | 0.000475 / 0.000054 (0.000420) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.040226 / 0.037411 (0.002815) | 0.107361 / 0.014526 (0.092835) | 0.122424 / 0.176557 (-0.054133) | 0.186447 / 0.737135 (-0.550688) | 0.127060 / 0.296338 (-0.169279) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.706737 / 0.215209 (0.491528) | 6.791287 / 2.077655 (4.713632) | 3.194471 / 1.504120 (1.690352) | 2.928145 / 1.541195 (1.386950) | 2.829078 / 1.468490 (1.360588) | 0.929797 / 4.584777 (-3.654980) | 5.484638 / 3.745712 (1.738926) | 4.841570 / 5.269862 (-0.428292) | 2.995247 / 4.565676 (-1.570430) | 0.104709 / 0.424275 (-0.319566) | 0.009543 / 0.007607 (0.001936) | 0.817605 / 0.226044 (0.591561) | 7.879234 / 2.268929 (5.610305) | 3.838073 / 55.444624 (-51.606551) | 3.189728 / 6.876477 (-3.686749) | 3.483775 / 2.142072 (1.341703) | 1.092823 / 4.805227 (-3.712404) | 0.227660 / 6.500664 (-6.273004) | 0.082452 / 0.075469 (0.006983) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.750413 / 1.841788 (-0.091374) | 27.078082 / 8.074308 (19.003774) | 23.968038 / 10.191392 (13.776646) | 0.248065 / 0.680424 (-0.432359) | 0.029961 / 0.534201 (-0.504240) | 0.508630 / 0.579283 (-0.070653) | 0.608707 / 0.434364 (0.174343) | 0.611062 / 0.540337 (0.070725) | 0.830797 / 1.386936 (-0.556139) |\n\n</details>\n</details>\n\n\n"
] | "2023-08-23T09:21:11Z" | "2023-08-23T09:32:59Z" | "2023-08-23T09:21:19Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6171.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6171",
"merged_at": "2023-08-23T09:21:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6171.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6171"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6171/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6171/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "https://api.github.com/users/thenerd31/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thenerd31",
"id": 53668030,
"login": "thenerd31",
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"organizations_url": "https://api.github.com/users/thenerd31/orgs",
"received_events_url": "https://api.github.com/users/thenerd31/received_events",
"repos_url": "https://api.github.com/users/thenerd31/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thenerd31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thenerd31/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thenerd31"
} | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n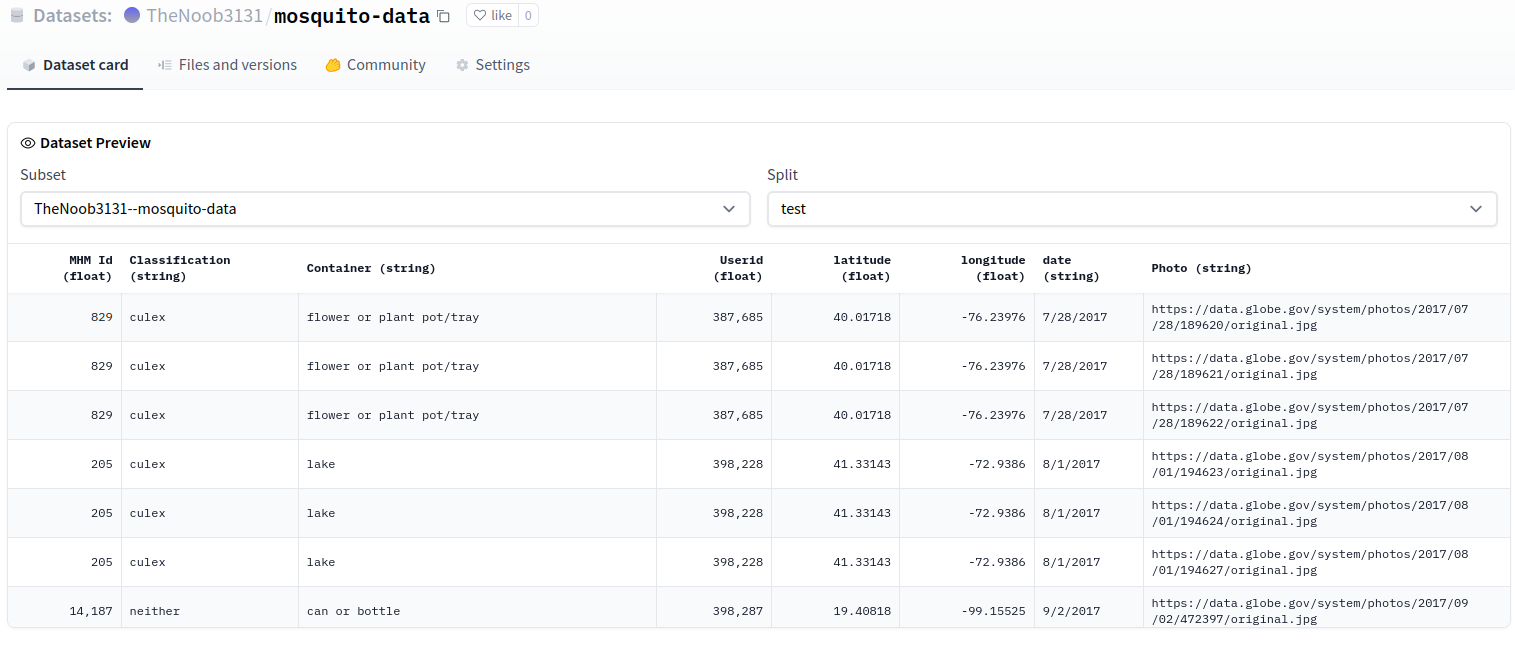\r\n\r\n"
] | "2022-07-21T05:24:48Z" | "2022-07-21T07:51:56Z" | "2022-07-21T07:45:01Z" | NONE | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1000 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1000/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1000/comments | https://api.github.com/repos/huggingface/datasets/issues/1000/events | https://github.com/huggingface/datasets/pull/1000 | 755,292,066 | MDExOlB1bGxSZXF1ZXN0NTMxMDMxMTE1 | 1,000 | UM005: Urdu <> English Translation Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [] | "2020-12-02T13:51:35Z" | "2020-12-04T15:34:30Z" | "2020-12-04T15:34:29Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1000.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1000",
"merged_at": "2020-12-04T15:34:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1000.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1000"
} | Adds Urdu-English dataset for machine translation: http://ufal.ms.mff.cuni.cz/umc/005-en-ur/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1000/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1000/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/482/comments | https://api.github.com/repos/huggingface/datasets/issues/482/events | https://github.com/huggingface/datasets/issues/482 | 674,851,147 | MDU6SXNzdWU2NzQ4NTExNDc= | 482 | Bugs : dataset.map() is frozen on ELI5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/56621342?v=4",
"events_url": "https://api.github.com/users/ratthachat/events{/privacy}",
"followers_url": "https://api.github.com/users/ratthachat/followers",
"following_url": "https://api.github.com/users/ratthachat/following{/other_user}",
"gists_url": "https://api.github.com/users/ratthachat/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ratthachat",
"id": 56621342,
"login": "ratthachat",
"node_id": "MDQ6VXNlcjU2NjIxMzQy",
"organizations_url": "https://api.github.com/users/ratthachat/orgs",
"received_events_url": "https://api.github.com/users/ratthachat/received_events",
"repos_url": "https://api.github.com/users/ratthachat/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ratthachat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ratthachat/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ratthachat"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"This comes from an overflow in pyarrow's array.\r\nIt is stuck inside the loop that reduces the batch size to avoid the overflow.\r\nI'll take a look",
"I created a PR to fix the issue.\r\nIt was due to an overflow check that handled badly an empty list.\r\n\r\nYou can try the changes by using \r\n```\r\n!pip install git+https://github.com/huggingface/nlp.git@fix-bad-type-in-overflow-check\r\n```\r\n\r\nAlso I noticed that the first 1000 examples have an empty list in the `title_urls` field. The feature type inference in `.map` will consider it `null` because of that, and it will crash when it encounter the next example with a `title_urls` that is not empty.\r\n\r\nTherefore to fix that, what you can do for now is increase the writer batch size so that the feature inference will take into account at least one example with a non-empty `title_urls`:\r\n\r\n```python\r\n# default batch size is 1_000 and it's not enough for feature type inference because of empty lists\r\nvalid_dataset = valid_dataset.map(make_input_target, writer_batch_size=3_000) \r\n```\r\n\r\nI was able to run the frozen cell with these changes.",
"@lhoestq Perfect and thank you very much!!\r\nClose the issue.",
"@lhoestq mapping the function `make_input_target` was passed by your fixing.\r\n\r\nHowever, there is another error in the final step of `valid_dataset.map(convert_to_features, batched=True)`\r\n\r\n`ArrowInvalid: Could not convert Thepiratebay.vg with type str: converting to null type`\r\n(The [same colab notebook above with new error message](https://colab.research.google.com/drive/14wttOTv3ky74B_c0kv5WrbgQjCF2fYQk?usp=sharing#scrollTo=5sRrJ3_C8rLt))\r\n\r\nDo you have some ideas? (I am really sorry I could not debug it by myself since I never used `pyarrow` before) \r\nNote that `train_dataset.map(convert_to_features, batched=True)` can be run successfully even though train_dataset is 27x bigger than `valid_dataset` so I believe the problem lies in some field of `valid_dataset` again .",
"I got this issue too and fixed it by specifying `writer_batch_size=3_000` in `.map`.\r\nThis is because Arrow didn't expect `Thepiratebay.vg` in `title_urls `, as all previous examples have empty lists in `title_urls `",
"I am clear now . Thank so much again Quentin!",
"I'm getting a hanging `dataset.map()` when running a gradio app with `gradio` for auto-reloading instead of `python`",
"Maybe this is an issue with gradio, could you open an issue on their repo ? `Dataset.map` simply uses `multiprocess.Pool` for multiprocessing\r\n\r\nIf you interrupt the program mayeb the stack trace would give some information of where it was hanging in the code (maybe a lock somewhere ?)"
] | "2020-08-07T08:23:35Z" | "2023-04-06T09:39:59Z" | "2020-08-11T23:55:15Z" | NONE | null | null | null | Hi Huggingface Team!
Thank you guys once again for this amazing repo.
I have tried to prepare ELI5 to train with T5, based on [this wonderful notebook of Suraj Patil](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb)
However, when I run `dataset.map()` on ELI5 to prepare `input_text, target_text`, `dataset.map` is **frozen** in the first hundreds examples. On the contrary, this works totally fine on SQUAD (80,000 examples). Both `nlp` version 0.3.0 and 0.4.0 cause frozen process . Also try various `pyarrow` versions from 0.16.0 / 0.17.0 / 1.0.0 also have the same frozen process.
Reproducible code can be found on [this colab notebook ](https://colab.research.google.com/drive/14wttOTv3ky74B_c0kv5WrbgQjCF2fYQk?usp=sharing), where I also show that the same mapping function works fine on SQUAD, so the problem is likely due to ELI5 somehow.
----------------------------------------
**More Info :** instead of `map`, if I run `for` loop and apply function by myself, there's no error and can finish within 10 seconds. However, `nlp dataset` is immutable (I couldn't manually assign a new key-value to `dataset `object)
I also notice that SQUAD texts are quite clean while ELI5 texts contain many special characters, not sure if this is the cause ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/482/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1534 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1534/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1534/comments | https://api.github.com/repos/huggingface/datasets/issues/1534/events | https://github.com/huggingface/datasets/pull/1534 | 764,934,681 | MDExOlB1bGxSZXF1ZXN0NTM4Nzc1Njky | 1,534 | adding dataset for diplomacy detection | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MisbahKhan789",
"id": 15351802,
"login": "MisbahKhan789",
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MisbahKhan789"
} | [] | closed | false | null | [] | null | [
"Requested changes made and new PR submitted here: https://github.com/huggingface/datasets/pull/1580 "
] | "2020-12-13T04:38:43Z" | "2020-12-15T19:52:52Z" | "2020-12-15T19:52:25Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1534.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1534",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1534.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1534"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1534/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1534/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2715/comments | https://api.github.com/repos/huggingface/datasets/issues/2715/events | https://github.com/huggingface/datasets/pull/2715 | 952,845,229 | MDExOlB1bGxSZXF1ZXN0Njk2OTc5MjQ1 | 2,715 | Update PAN-X data URL in XTREME dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"Merging since the CI is just about missing infos in the dataset card"
] | "2021-07-26T12:21:17Z" | "2021-07-26T13:27:59Z" | "2021-07-26T13:27:59Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2715.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2715",
"merged_at": "2021-07-26T13:27:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2715.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2715"
} | Related to #2710, #2691. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2715/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2715/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3731/comments | https://api.github.com/repos/huggingface/datasets/issues/3731/events | https://github.com/huggingface/datasets/pull/3731 | 1,139,626,362 | PR_kwDODunzps4y5-hi | 3,731 | Fix Multi-News dataset metadata and card | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2022-02-16T07:14:57Z" | "2022-02-16T08:48:47Z" | "2022-02-16T08:48:47Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3731.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3731",
"merged_at": "2022-02-16T08:48:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3731.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3731"
} | Fix #3730. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3731/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3194 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3194/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3194/comments | https://api.github.com/repos/huggingface/datasets/issues/3194/events | https://github.com/huggingface/datasets/pull/3194 | 1,041,999,535 | PR_kwDODunzps4t91Eg | 3,194 | Update link to Datasets Tagging app in Spaces | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-11-02T08:13:50Z" | "2021-11-08T10:36:23Z" | "2021-11-08T10:36:22Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3194.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3194",
"merged_at": "2021-11-08T10:36:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3194.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3194"
} | Fix #3193. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3194/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3194/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/378/comments | https://api.github.com/repos/huggingface/datasets/issues/378/events | https://github.com/huggingface/datasets/issues/378 | 655,226,316 | MDU6SXNzdWU2NTUyMjYzMTY= | 378 | [dataset] Structure of MLQA seems unecessary nested | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | [
"Same for the RACE dataset: https://github.com/huggingface/nlp/blob/master/datasets/race/race.py\r\n\r\nShould we scan all the datasets to remove this pattern of un-necessary nesting?",
"You're right, I think we don't need to use the nested dictionary. \r\n"
] | "2020-07-11T15:16:08Z" | "2020-07-15T16:17:20Z" | "2020-07-15T16:17:20Z" | MEMBER | null | null | null | The features of the MLQA dataset comprise several nested dictionaries with a single element inside (for `questions` and `ids`): https://github.com/huggingface/nlp/blob/master/datasets/mlqa/mlqa.py#L90-L97
Should we keep this @mariamabarham @patrickvonplaten? Was this added for compatibility with tfds?
```python
features=nlp.Features(
{
"context": nlp.Value("string"),
"questions": nlp.features.Sequence({"question": nlp.Value("string")}),
"answers": nlp.features.Sequence(
{"text": nlp.Value("string"), "answer_start": nlp.Value("int32"),}
),
"ids": nlp.features.Sequence({"idx": nlp.Value("string")})
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/378/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6079/comments | https://api.github.com/repos/huggingface/datasets/issues/6079/events | https://github.com/huggingface/datasets/issues/6079 | 1,822,597,471 | I_kwDODunzps5soqFf | 6,079 | Iterating over DataLoader based on HF datasets is stuck forever | {
"avatar_url": "https://avatars.githubusercontent.com/u/5454868?v=4",
"events_url": "https://api.github.com/users/arindamsarkar93/events{/privacy}",
"followers_url": "https://api.github.com/users/arindamsarkar93/followers",
"following_url": "https://api.github.com/users/arindamsarkar93/following{/other_user}",
"gists_url": "https://api.github.com/users/arindamsarkar93/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/arindamsarkar93",
"id": 5454868,
"login": "arindamsarkar93",
"node_id": "MDQ6VXNlcjU0NTQ4Njg=",
"organizations_url": "https://api.github.com/users/arindamsarkar93/orgs",
"received_events_url": "https://api.github.com/users/arindamsarkar93/received_events",
"repos_url": "https://api.github.com/users/arindamsarkar93/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/arindamsarkar93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arindamsarkar93/subscriptions",
"type": "User",
"url": "https://api.github.com/users/arindamsarkar93"
} | [] | closed | false | null | [] | null | [
"When the process starts to hang, can you interrupt it with CTRL + C and paste the error stack trace here? ",
"Thanks @mariosasko for your prompt response, here's the stack trace:\r\n\r\n```\r\nKeyboardInterrupt Traceback (most recent call last)\r\nCell In[12], line 4\r\n 2 t = time.time()\r\n 3 iter_ = 0\r\n----> 4 for batch in train_dataloader:\r\n 5 #batch_proc = streaming_obj.collect_streaming_data_batch(batch)\r\n 6 iter_ += 1\r\n 8 if iter_ == 1:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:634, in _BaseDataLoaderIter.__next__(self)\r\n 631 if self._sampler_iter is None:\r\n 632 # TODO(https://github.com/pytorch/pytorch/issues/76750)\r\n 633 self._reset() # type: ignore[call-arg]\r\n--> 634 data = self._next_data()\r\n 635 self._num_yielded += 1\r\n 636 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n 637 self._IterableDataset_len_called is not None and \\\r\n 638 self._num_yielded > self._IterableDataset_len_called:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:678, in _SingleProcessDataLoaderIter._next_data(self)\r\n 676 def _next_data(self):\r\n 677 index = self._next_index() # may raise StopIteration\r\n--> 678 data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n 679 if self._pin_memory:\r\n 680 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:32, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)\r\n 30 for _ in possibly_batched_index:\r\n 31 try:\r\n---> 32 data.append(next(self.dataset_iter))\r\n 33 except StopIteration:\r\n 34 self.ended = True\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:1353, in IterableDataset.__iter__(self)\r\n 1350 yield formatter.format_row(pa_table)\r\n 1351 return\r\n-> 1353 for key, example in ex_iterable:\r\n 1354 if self.features:\r\n 1355 # `IterableDataset` automatically fills missing columns with None.\r\n 1356 # This is done with `_apply_feature_types_on_example`.\r\n 1357 example = _apply_feature_types_on_example(\r\n 1358 example, self.features, token_per_repo_id=self._token_per_repo_id\r\n 1359 )\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:956, in BufferShuffledExamplesIterable.__iter__(self)\r\n 954 # this is the shuffle buffer that we keep in memory\r\n 955 mem_buffer = []\r\n--> 956 for x in self.ex_iterable:\r\n 957 if len(mem_buffer) == buffer_size: # if the buffer is full, pick and example from it\r\n 958 i = next(indices_iterator)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:296, in ShuffledDataSourcesArrowExamplesIterable.__iter__(self)\r\n 294 for key, pa_table in self.generate_tables_fn(**kwargs_with_shuffled_shards):\r\n 295 for pa_subtable in pa_table.to_reader(max_chunksize=config.ARROW_READER_BATCH_SIZE_IN_DATASET_ITER):\r\n--> 296 formatted_batch = formatter.format_batch(pa_subtable)\r\n 297 for example in _batch_to_examples(formatted_batch):\r\n 298 yield key, example\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/formatting.py:448, in PythonFormatter.format_batch(self, pa_table)\r\n 446 if self.lazy:\r\n 447 return LazyBatch(pa_table, self)\r\n--> 448 batch = self.python_arrow_extractor().extract_batch(pa_table)\r\n 449 batch = self.python_features_decoder.decode_batch(batch)\r\n 450 return batch\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/formatting.py:150, in PythonArrowExtractor.extract_batch(self, pa_table)\r\n 149 def extract_batch(self, pa_table: pa.Table) -> dict:\r\n--> 150 return pa_table.to_pydict()\r\n\r\nKeyboardInterrupt: \r\n```\r\n",
"Update: If i let it run, it eventually fails with:\r\n\r\n```\r\nRuntimeError Traceback (most recent call last)\r\nCell In[16], line 4\r\n 2 t = time.time()\r\n 3 iter_ = 0\r\n----> 4 for batch in train_dataloader:\r\n 5 #batch_proc = streaming_obj.collect_streaming_data_batch(batch)\r\n 6 iter_ += 1\r\n 8 if iter_ == 1:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:634, in _BaseDataLoaderIter.__next__(self)\r\n 631 if self._sampler_iter is None:\r\n 632 # TODO(https://github.com/pytorch/pytorch/issues/76750)\r\n 633 self._reset() # type: ignore[call-arg]\r\n--> 634 data = self._next_data()\r\n 635 self._num_yielded += 1\r\n 636 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n 637 self._IterableDataset_len_called is not None and \\\r\n 638 self._num_yielded > self._IterableDataset_len_called:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:678, in _SingleProcessDataLoaderIter._next_data(self)\r\n 676 def _next_data(self):\r\n 677 index = self._next_index() # may raise StopIteration\r\n--> 678 data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n 679 if self._pin_memory:\r\n 680 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:32, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)\r\n 30 for _ in possibly_batched_index:\r\n 31 try:\r\n---> 32 data.append(next(self.dataset_iter))\r\n 33 except StopIteration:\r\n 34 self.ended = True\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:1360, in IterableDataset.__iter__(self)\r\n 1354 if self.features:\r\n 1355 # `IterableDataset` automatically fills missing columns with None.\r\n 1356 # This is done with `_apply_feature_types_on_example`.\r\n 1357 example = _apply_feature_types_on_example(\r\n 1358 example, self.features, token_per_repo_id=self._token_per_repo_id\r\n 1359 )\r\n-> 1360 yield format_dict(example) if format_dict else example\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/torch_formatter.py:85, in TorchFormatter.recursive_tensorize(self, data_struct)\r\n 84 def recursive_tensorize(self, data_struct: dict):\r\n---> 85 return map_nested(self._recursive_tensorize, data_struct, map_list=False)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/utils/py_utils.py:463, in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, parallel_min_length, types, disable_tqdm, desc)\r\n 461 num_proc = 1\r\n 462 if num_proc != -1 and num_proc <= 1 or len(iterable) < parallel_min_length:\r\n--> 463 mapped = [\r\n 464 _single_map_nested((function, obj, types, None, True, None))\r\n 465 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)\r\n 466 ]\r\n 467 else:\r\n 468 mapped = parallel_map(function, iterable, num_proc, types, disable_tqdm, desc, _single_map_nested)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/utils/py_utils.py:464, in <listcomp>(.0)\r\n 461 num_proc = 1\r\n 462 if num_proc != -1 and num_proc <= 1 or len(iterable) < parallel_min_length:\r\n 463 mapped = [\r\n--> 464 _single_map_nested((function, obj, types, None, True, None))\r\n 465 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)\r\n 466 ]\r\n 467 else:\r\n 468 mapped = parallel_map(function, iterable, num_proc, types, disable_tqdm, desc, _single_map_nested)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/utils/py_utils.py:366, in _single_map_nested(args)\r\n 364 # Singleton first to spare some computation\r\n 365 if not isinstance(data_struct, dict) and not isinstance(data_struct, types):\r\n--> 366 return function(data_struct)\r\n 368 # Reduce logging to keep things readable in multiprocessing with tqdm\r\n 369 if rank is not None and logging.get_verbosity() < logging.WARNING:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/torch_formatter.py:82, in TorchFormatter._recursive_tensorize(self, data_struct)\r\n 80 elif isinstance(data_struct, (list, tuple)):\r\n 81 return self._consolidate([self.recursive_tensorize(substruct) for substruct in data_struct])\r\n---> 82 return self._tensorize(data_struct)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/torch_formatter.py:68, in TorchFormatter._tensorize(self, value)\r\n 66 if isinstance(value, PIL.Image.Image):\r\n 67 value = np.asarray(value)\r\n---> 68 return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})\r\n\r\nRuntimeError: Could not infer dtype of decimal.Decimal\r\n```",
"PyTorch tensors cannot store `Decimal` objects. Casting the column with decimals to `float` should fix the issue.",
"I already have cast in collate_fn, in which I perform .astype(float) for each numerical field.\r\nOn the same instance, I installed a conda env with python 3.6, and this works well.\r\n\r\nSample:\r\n\r\n```\r\ndef streaming_data_collate_fn(batch):\r\n df = pd.DataFrame.from_dict(batch)\r\n feat_vals = torch.FloatTensor(np.nan_to_num(np.array(df[feats].astype(float))))\r\n\r\n```",
"`collate_fn` is applied after the `torch` formatting step, so I think the only option when working with an `IterableDataset` is to remove the `with_format` call and perform the conversion from Python values to PyTorch tensors in `collate_fn`. The standard `Dataset` supports `with_format(\"numpy\")`, which should make this conversion faster.",
"Thanks! \r\nPython 3.10 conda-env: After replacing with_format(\"torch\") with with_format(\"numpy\"), the error went away. However, it was still taking over 2 minutes to load a very small batch of 64 samples with num_workers set to 32. Once I removed with_format call altogether, it is finishing in 11 seconds.\r\n\r\nPython 3.6 based conda-env: When I switch the kernel , neither of the above work, and with_format(\"torch\") is the only thing that works, and executes in 1.6 seconds.\r\n\r\nI feel something else is also amiss here.",
"Can you share the `datasets` and `torch` versions installed in these conda envs?\r\n\r\n> Once I removed with_format call altogether, it is finishing in 11 seconds.\r\n\r\nHmm, that's surprising. What are your dataset's `.features`?",
"Python 3.6: \r\ndatasets.__version__ 2.4.0\r\ntorch.__version__ 1.10.1+cu102\r\n\r\nPython 3.10:\r\ndatasets.__version__ 2.14.0\r\ntorch.__version__ 2.0.0\r\n\r\nAnonymized features are of the form (subset shown here):\r\n{\r\n'string_feature_i': Value(dtype='string', id=None),\r\n'numerical_feature_i': Value(dtype='decimal128(38, 0)', id=None),\r\n'numerical_feature_series_i': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None),\r\n}\r\n\r\n\r\nThere is no output from .features in python 3.6 kernel BTW.",
"One more thing, in python 3.10 based kernel, interestingly increasing num_workers seem to be increasing the runtime of iterating I was trying out. In python 3.10 kernel execution, I do not even see multiple CPU cores spiking unlike in 3.6.\r\n\r\n512 batch size on 32 workers executes in 2.4 seconds on python 3.6 kernel, while it takes ~118 seconds on 3.10!",
"**Update**: It seems the latency part is more of a multiprocessing issue with torch and some host specific issue, and I had to scourge through relevant pytorch issues, when I stumbled across these threads:\r\n1. https://github.com/pytorch/pytorch/issues/102494\r\n2. https://github.com/pytorch/pytorch/issues/102269\r\n3. https://github.com/pytorch/pytorch/issues/99625\r\n\r\nOut of the suggested solutions, the one that worked in my case was:\r\n```\r\nos.environ['KMP_AFFINITY'] = \"disabled\"\r\n```\r\nIt is working for now, though I have no clue why, just I hope it does not get stuck when I do actual model training, will update by tomorrow.\r\n\r\n\r\n",
"I'm facing a similar situation in the local VS Code. \r\n\r\nDatasets version 2.14.4\r\nTorch 2.0.1+cu118\r\n\r\nSame code runs without issues in Colab\r\n\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"Supermaxman/esa-hubble\", streaming=True)\r\nsample = next(iter(dataset[\"train\"]))\r\n```\r\n\r\nis stuck for minutes. If I interrupt, I get\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nKeyboardInterrupt Traceback (most recent call last)\r\nCell In[5], line 5\r\n 1 from datasets import load_dataset\r\n 3 dataset = load_dataset(\"Supermaxman/esa-hubble\", streaming=True)\r\n----> 5 sample = next(iter(dataset[\"train\"]))\r\n 6 print(sample[\"text\"])\r\n 7 sample[\"image\"]\r\n\r\nFile [~/miniconda3/envs/book/lib/python3.10/site-packages/datasets/iterable_dataset.py:1353](https://file+.vscode-resource.vscode-cdn.net/home/osanseviero/Desktop/workspace/genai/nbs/~/miniconda3/envs/book/lib/python3.10/site-packages/datasets/iterable_dataset.py:1353), in IterableDataset.__iter__(self)\r\n 1350 yield formatter.format_row(pa_table)\r\n 1351 return\r\n-> 1353 for key, example in ex_iterable:\r\n 1354 if self.features:\r\n 1355 # `IterableDataset` automatically fills missing columns with None.\r\n 1356 # This is done with `_apply_feature_types_on_example`.\r\n 1357 example = _apply_feature_types_on_example(\r\n 1358 example, self.features, token_per_repo_id=self._token_per_repo_id\r\n 1359 )\r\n\r\nFile [~/miniconda3/envs/book/lib/python3.10/site-packages/datasets/iterable_dataset.py:255](https://file+.vscode-resource.vscode-cdn.net/home/osanseviero/Desktop/workspace/genai/nbs/~/miniconda3/envs/book/lib/python3.10/site-packages/datasets/iterable_dataset.py:255), in ArrowExamplesIterable.__iter__(self)\r\n 253 def __iter__(self):\r\n 254 formatter = PythonFormatter()\r\n--> 255 for key, pa_table in self.generate_tables_fn(**self.kwargs):\r\n 256 for pa_subtable in pa_table.to_reader(max_chunksize=config.ARROW_READER_BATCH_SIZE_IN_DATASET_ITER):\r\n...\r\n-> 1130 return self._sslobj.read(len, buffer)\r\n 1131 else:\r\n 1132 return self._sslobj.read(len)\r\n```",
"@osanseviero I assume the `self._sslobj.read(len, buffer)` line comes from the built-in `ssl` module, so this probably has something to do with your network. Please open a new issue with the full stack trace in case you haven't resolved this yet.",
"Thank you reporting this and sharing the solution, I ran into this as well!"
] | "2023-07-26T14:52:37Z" | "2023-10-05T02:58:43Z" | "2023-07-30T14:09:06Z" | NONE | null | null | null | ### Describe the bug
I am using Amazon Sagemaker notebook (Amazon Linux 2) with python 3.10 based Conda environment.
I have a dataset in parquet format locally. When I try to iterate over it, the loader is stuck forever. Note that the same code is working for python 3.6 based conda environment seamlessly. What should be my next steps here?
### Steps to reproduce the bug
```
train_dataset = load_dataset(
"parquet", data_files = {'train': tr_data_path + '*.parquet'},
split = 'train',
collate_fn = streaming_data_collate_fn,
streaming = True
).with_format('torch')
train_dataloader = DataLoader(train_dataset, batch_size = 2, num_workers = 0)
t = time.time()
iter_ = 0
for batch in train_dataloader:
iter_ += 1
if iter_ == 1000:
break
print (time.time() - t)
```
### Expected behavior
The snippet should work normally and load the next batch of data.
### Environment info
datasets: '2.14.0'
pyarrow: '12.0.0'
torch: '2.0.0'
Python: 3.10.10 | packaged by conda-forge | (main, Mar 24 2023, 20:08:06) [GCC 11.3.0]
!uname -r
5.10.178-162.673.amzn2.x86_64 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6079/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6079/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3997/comments | https://api.github.com/repos/huggingface/datasets/issues/3997/events | https://github.com/huggingface/datasets/pull/3997 | 1,178,566,568 | PR_kwDODunzps4058xr | 3,997 | Sync Features dictionaries | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-23T19:23:51Z" | "2022-04-13T15:52:27Z" | "2022-04-13T15:46:19Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3997.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3997",
"merged_at": "2022-04-13T15:46:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3997.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3997"
} | This PR adds a wrapper to the `Features` class to keep the secondary dict, `_column_requires_decoding`, aligned with the main dict (as discussed in https://github.com/huggingface/datasets/pull/3723#discussion_r806912731).
A more elegant approach would be to subclass `UserDict` and override `__setitem__` and `__delitem__`, but this PR doesn't implement it for the following reasons:
* it requires replacing all occurrences of `isinstance(obj, dict)` with `isinstance(obj, Mapping)`, which is five times slower than `isinstance(obj, dict)` on my machine, in `features.py`
* is a breaking change, i.e., `isinstance(Features(...), dict)` would return `False` after it
* IMO, it makes sense to be consistent in the user-facing API and subclass either `dict` or `UserDict`. The problem with the latter is that it can't be used for `DatasetDict` because `DatasetDict` exposes the `data` property, which is also used by `UserDict`, so this would result in a collision.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3997/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/388/comments | https://api.github.com/repos/huggingface/datasets/issues/388/events | https://github.com/huggingface/datasets/issues/388 | 656,707,497 | MDU6SXNzdWU2NTY3MDc0OTc= | 388 | 🐛 [Dataset] Cannot download wmt14, wmt15 and wmt17 | {
"avatar_url": "https://avatars.githubusercontent.com/u/2826602?v=4",
"events_url": "https://api.github.com/users/SamuelCahyawijaya/events{/privacy}",
"followers_url": "https://api.github.com/users/SamuelCahyawijaya/followers",
"following_url": "https://api.github.com/users/SamuelCahyawijaya/following{/other_user}",
"gists_url": "https://api.github.com/users/SamuelCahyawijaya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SamuelCahyawijaya",
"id": 2826602,
"login": "SamuelCahyawijaya",
"node_id": "MDQ6VXNlcjI4MjY2MDI=",
"organizations_url": "https://api.github.com/users/SamuelCahyawijaya/orgs",
"received_events_url": "https://api.github.com/users/SamuelCahyawijaya/received_events",
"repos_url": "https://api.github.com/users/SamuelCahyawijaya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SamuelCahyawijaya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SamuelCahyawijaya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SamuelCahyawijaya"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
}
] | null | [
"similar slow download speed here for nlp.load_dataset('wmt14', 'fr-en')\r\n`\r\nDownloading: 100%|██████████████████████████████████████████████████████████| 658M/658M [1:00:42<00:00, 181kB/s]\r\nDownloading: 100%|██████████████████████████████████████████████████████████| 918M/918M [1:39:38<00:00, 154kB/s]\r\nDownloading: 2%|▉ | 40.9M/2.37G [04:48<5:03:06, 128kB/s]\r\n`\r\nCould we just download a specific subdataset in 'wmt14', such as 'newstest14'? ",
"> The code runs but the download speed is extremely slow, the same behaviour is not observed on wmt16 and wmt18\r\n\r\nThe original source for the files may provide slow download speeds.\r\nWe can probably host these files ourselves.\r\n\r\n> When trying to download wmt17 zh-en, I got the following error:\r\n> ConnectionError: Couldn't reach https://storage.googleapis.com/tfdataset-data/downloadataset/uncorpus/UNv1.0.en-zh.tar.gz\r\n\r\nLooks like the file`UNv1.0.en-zh.tar.gz` is missing, or the url changed. We need to fix that\r\n\r\n> Could we just download a specific subdataset in 'wmt14', such as 'newstest14'?\r\n\r\nRight now I don't think it's possible. Maybe @patrickvonplaten knows more about it\r\n",
"Yeah, the download speed is sadly always extremely slow :-/. \r\nI will try to check out the `wmt17 zh-en` bug :-) ",
"Maybe this can be used - https://stuncorpusprod.blob.core.windows.net/corpusfiles/UNv1.0.en-zh.tar.gz.00 ",
"These issues seem to be fixed now."
] | "2020-07-14T15:36:41Z" | "2022-10-04T18:01:28Z" | "2022-10-04T18:01:28Z" | NONE | null | null | null | 1. I try downloading `wmt14`, `wmt15`, `wmt17`, `wmt19` with the following code:
```
nlp.load_dataset('wmt14','de-en')
nlp.load_dataset('wmt15','de-en')
nlp.load_dataset('wmt17','de-en')
nlp.load_dataset('wmt19','de-en')
```
The code runs but the download speed is **extremely slow**, the same behaviour is not observed on `wmt16` and `wmt18`
2. When trying to download `wmt17 zh-en`, I got the following error:
> ConnectionError: Couldn't reach https://storage.googleapis.com/tfdataset-data/downloadataset/uncorpus/UNv1.0.en-zh.tar.gz | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/388/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2875 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2875/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2875/comments | https://api.github.com/repos/huggingface/datasets/issues/2875/events | https://github.com/huggingface/datasets/issues/2875 | 989,919,398 | MDU6SXNzdWU5ODk5MTkzOTg= | 2,875 | Add Congolese Swahili speech datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/osanseviero",
"id": 7246357,
"login": "osanseviero",
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"type": "User",
"url": "https://api.github.com/users/osanseviero"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] | open | false | null | [] | null | [] | "2021-09-07T12:13:50Z" | "2021-09-07T12:13:50Z" | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Congolese Swahili speech corpora
- **Data:** https://gamayun.translatorswb.org/data/
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Also related: https://mobile.twitter.com/OktemAlp/status/1435196393631764482 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2875/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2875/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4056/comments | https://api.github.com/repos/huggingface/datasets/issues/4056/events | https://github.com/huggingface/datasets/issues/4056 | 1,185,155,775 | I_kwDODunzps5GpAq_ | 4,056 | Unexpected behavior of _TempDirWithCustomCleanup | {
"avatar_url": "https://avatars.githubusercontent.com/u/22680696?v=4",
"events_url": "https://api.github.com/users/JonasGeiping/events{/privacy}",
"followers_url": "https://api.github.com/users/JonasGeiping/followers",
"following_url": "https://api.github.com/users/JonasGeiping/following{/other_user}",
"gists_url": "https://api.github.com/users/JonasGeiping/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JonasGeiping",
"id": 22680696,
"login": "JonasGeiping",
"node_id": "MDQ6VXNlcjIyNjgwNjk2",
"organizations_url": "https://api.github.com/users/JonasGeiping/orgs",
"received_events_url": "https://api.github.com/users/JonasGeiping/received_events",
"repos_url": "https://api.github.com/users/JonasGeiping/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JonasGeiping/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JonasGeiping/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JonasGeiping"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! Would setting TMPDIR at the beginning of your python script/session work ? I mean, even before importing transformers, datasets, etc. and using them ? I think this would be the most robust solution given any library that uses `tempfile`. I don't think we aim to support environment variables to be changed at run time",
"Hi, yeah setting the environment variable before the imports / as environment variable outside is another way to fix this. I am just arguing that `datasets` already uses its own global variable to track temporary files: `_TEMP_DIR_FOR_TEMP_CACHE_FILES`, and the creation of this global variable should respect TMPDIR instead of relying on tempfile to do so."
] | "2022-03-29T16:58:22Z" | "2022-03-30T15:08:04Z" | null | NONE | null | null | null | ## Describe the bug
This is not 100% a bug in `datasets`, but behavior that surprised me and I think this could be made more robust on the `datasets`side.
When using `datasets.disable_caching()`, cache files are written to a temporary directory. This directory should be based on the environment variable TMPDIR. I want to set TMPDIR at runtime using os.ENVIRON["TMPDIR"] = something, but depending on other imported modules this can fail to take effect.
## Steps to reproduce the bug
`_TempDirWithCustomCleanup` relies on `tempfile` to generate a path to a temporary directory. However, `tempfile` generates the path only once. This can be a problem when trying to set TMPDIR at runtime whenever other code imports `tempfile` first and does something unexpected.
For example (after too much trial and error) I found out that a different part of the code base I work with defines a class `PatchedDataCollatorForLanguageModeling(transformers.DataCollatorForLanguageModeling)` based on a `transformers` class. This import is enough to trigger `tempfile` to generate `tempfile` to generate a temporary path and leading to the wrong path being cached in `tempfile.tempdir`.
## Suggestion:
I could file this also as bug with `transformers`, but I think fixing this on the datasets would be much more robust:
Datasets could recompute the temporary path once (technically possible via `tempfile._get_default_tempdir` or resetting
the global variable `tempfile.tmpdir` to None) before setting its own global `_TEMP_DIR_FOR_TEMP_CACHE_FILES`.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4056/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6412/comments | https://api.github.com/repos/huggingface/datasets/issues/6412/events | https://github.com/huggingface/datasets/issues/6412 | 1,992,401,594 | I_kwDODunzps52waK6 | 6,412 | User token is printed out! | {
"avatar_url": "https://avatars.githubusercontent.com/u/25702692?v=4",
"events_url": "https://api.github.com/users/mohsen-goodarzi/events{/privacy}",
"followers_url": "https://api.github.com/users/mohsen-goodarzi/followers",
"following_url": "https://api.github.com/users/mohsen-goodarzi/following{/other_user}",
"gists_url": "https://api.github.com/users/mohsen-goodarzi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mohsen-goodarzi",
"id": 25702692,
"login": "mohsen-goodarzi",
"node_id": "MDQ6VXNlcjI1NzAyNjky",
"organizations_url": "https://api.github.com/users/mohsen-goodarzi/orgs",
"received_events_url": "https://api.github.com/users/mohsen-goodarzi/received_events",
"repos_url": "https://api.github.com/users/mohsen-goodarzi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mohsen-goodarzi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mohsen-goodarzi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mohsen-goodarzi"
} | [] | closed | false | null | [] | null | [
"Indeed, this is not a good practice. I've opened a PR that removes the token value from the (deprecation) warning."
] | "2023-11-14T10:01:34Z" | "2023-11-14T22:19:46Z" | "2023-11-14T22:19:46Z" | NONE | null | null | null | This line prints user token on command line! Is it safe?
https://github.com/huggingface/datasets/blob/12ebe695b4748c5a26e08b44ed51955f74f5801d/src/datasets/load.py#L2091 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6412/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5461/comments | https://api.github.com/repos/huggingface/datasets/issues/5461/events | https://github.com/huggingface/datasets/issues/5461 | 1,555,532,719 | I_kwDODunzps5ct4uv | 5,461 | Discrepancy in `nyu_depth_v2` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/36858976?v=4",
"events_url": "https://api.github.com/users/awsaf49/events{/privacy}",
"followers_url": "https://api.github.com/users/awsaf49/followers",
"following_url": "https://api.github.com/users/awsaf49/following{/other_user}",
"gists_url": "https://api.github.com/users/awsaf49/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/awsaf49",
"id": 36858976,
"login": "awsaf49",
"node_id": "MDQ6VXNlcjM2ODU4OTc2",
"organizations_url": "https://api.github.com/users/awsaf49/orgs",
"received_events_url": "https://api.github.com/users/awsaf49/received_events",
"repos_url": "https://api.github.com/users/awsaf49/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/awsaf49/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/awsaf49/subscriptions",
"type": "User",
"url": "https://api.github.com/users/awsaf49"
} | [] | open | false | null | [] | null | [
"Ccing @dwofk (the author of `fast-depth`). \r\n\r\nThanks, @awsaf49 for reporting this. I believe this is because the NYU Depth V2 shipped from `fast-depth` is already preprocessed. \r\n\r\nIf you think it might be better to have the NYU Depth V2 dataset from BTS [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2) feel free to open a PR, I am happy to provide guidance :) ",
"Good catch ! Ideally it would be nice to have the datasets in the raw form, this way users can choose whatever processing they want to apply",
"> Ccing @dwofk (the author of `fast-depth`).\r\n> \r\n> Thanks, @awsaf49 for reporting this. I believe this is because the NYU Depth V2 shipped from `fast-depth` is already preprocessed.\r\n> \r\n> If you think it might be better to have the NYU Depth V2 dataset from BTS [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2) feel free to open a PR, I am happy to provide guidance :)\r\n\r\n@sayakpaul I would love to create a PR on this. As this will be my first PR here, some guidance would be helpful.\r\n\r\nNeed a bit of advice on the dataset, there are three publicly available datasets. Which one should I consider for PR?\r\n1. [BTS](https://github.com/cleinc/bts): Containst train/test: 36K/654 data, dtype = `uint16` hence more precise\r\n2. [DenseDepth](https://github.com/ialhashim/DenseDepth) It contains train/test: 50K/654 data, dtype = `uint8` hence less precise\r\n3. [Official](https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html#raw_parts): Size is big 400GB+, requires **MatLab** code for fixing **projection** and **sync**, DataType: `pgm` and `dump` hence can't be used directly.\r\n\r\ncc: @lhoestq\r\n\r\n",
"I think BTS. Repositories like https://github.com/vinvino02/GLPDepth usually use BTS. Also, just for clarity, the PR will be to https://huggingface.co/datasets/sayakpaul/nyu_depth_v2. Once we have worked it out, we can update the following things:\r\n\r\n* https://github.com/huggingface/blog/pull/718\r\n* https://huggingface.co/docs/datasets/main/en/depth_estimation\r\n\r\nDon't worry about it if it seems overwhelming. We will work it out together :) \r\n\r\n@lhoestq what do you think? ",
"@sayakpaul If I get this right I have to,\r\n1. Create a PR on https://huggingface.co/datasets/sayakpaul/nyu_depth_v2\r\n2. Create a PR on https://github.com/huggingface/blog\r\n3. Create a PR on https://github.com/huggingface/datasets to update https://github.com/huggingface/datasets/blob/main/docs/source/depth_estimation.mdx",
"The last two are low-hanging fruits. Don't worry about them. ",
"Yup opening a PR to use BTS on https://huggingface.co/datasets/sayakpaul/nyu_depth_v2 sounds good :) Thanks for the help !",
"Finally, I have found the origin of the **discretized depth map**. When I first loaded the datasets from HF I noticed it was 30GB but in DenseDepth data is only 4GB with dtype=uint8. This means data from fast-depth (before loading to HF) must have high precision. So when I tried to dig deeper by directly loading depth_map from `h5py`, I found depth_map from `h5py` came with `float32`. But when the data is processed in HF with `datasets.Image()` it was directly converted to `uint8` from `float32` hence the **discretized** depth map.\r\nhttps://github.com/huggingface/datasets/blob/c78559cacbb0ca6e0bc8bfc313cc0359f8c23ead/src/datasets/features/image.py#L91-L93\r\n\r\n## Solutions:\r\n\r\n#### 1. Array2D\r\nUse `Array2D` feature with `float32` for depth_map \r\n\r\n* Code:\r\n```py\r\nFeatures({'depth_map': Array2D(shape=(480, 640), dtype='float32')})\r\n```\r\n* Pros:\r\nNo precision loss.\r\n\r\n* Cons:\r\nAs depth_map is saved as Array I think it can't be visuzlied in [hf.co/dataset](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2) page like segmentation mask.\r\n\r\n#### 2. Uint16\r\nUse `uint16` as dtype for Image in `_h5_loader` for saving depth maps and accept `uint16` dtype in `datasets.Image()` feature.\r\n\r\n* Code\r\n```py\r\ndepth = np.array(h5f[\"depth\"])\r\ndepth /= 10.0 # [0, max_depth] -> [0, 1]\r\ndepth *= (2**16 -1) # transform from [0, 1] -> [0, 2^16 - 1]\r\ndepth = depth.astype('uint16')\r\n```\r\n* Pros:\r\n * We can visualize depth map in hf.co/datasets page like segmentation mask.\r\n * No need for post-processing.\r\n\r\n* Cons:\r\n * We need to make two change\r\n * Modify `_h5_loader` in https://huggingface.co/datasets/sayakpaul/nyu_depth_v2 to convert depth_map from `float32` to `uint16`.\r\n * Make sure `datasets.Image()` converts `np.ndarray` to `uint16` checking max value\r\n * Precision loss due to `float32` to `uint16`\r\n * Post-processing required for depth_map to transform from `[0, 2^16 - 1]` to `[0, max_depth]` before feeding them to model.",
"Thanks so much for digging into this. \r\n\r\nSince the second solution entails changes to core datatypes in `datasets`, I think it's better to go with the first solution. \r\n\r\n@lhoestq WDYT?",
"@sayakpaul Yes, Solution 1 requires minimal change and provides no precision loss. But I think support for `uint16` image would be a great addition as many datasets come with `uint16` image. For example [UW-Madison GI Tract Image Segmentation](https://www.kaggle.com/competitions/uw-madison-gi-tract-image-segmentation) dataset, here the image itself comes with `uint16` dtype rather than mask. So, saving `uint16` image with `uint8` will result in precision loss.\r\n\r\nPerhaps we can adapt solution 1 for this issue and Add support for `uint16` image separately?",
"Using Array2D makes it not practical to use to train a model - in `transformers` we expect an image type.\r\n\r\nThere is a pull request to support more precision than uint8 in Image() here: https://github.com/huggingface/datasets/pull/5365/files\r\n\r\nwe can probably merge it today and do a release right away",
"Fantastic, @lhoestq! \r\n\r\n@awsaf49 then let's wait for the PR to get merged and then take the next steps? ",
"Sure",
"The PR adds support for uint16 which is ok for BTS if I understand correctly, would it be ok for you ?",
"If the main issue with the current version of NYU we have on the Hub is related to the precision loss stemming from `Image()`, I'd prefer if `Image()` supported float32 as well. ",
"I also prefer `float32` as it offers more precision. But I'm not sure if we'll be able to visualize image with `float32` precision.",
"We could have a separate loading for the float32 one using Array2D, but I feel like it's less convenient to use due to the amount of disk space and because it's not an Image() type. That's why I think uint16 is a better solution for users",
"A bit confused here, If https://github.com/huggingface/datasets/pull/5365 gets merged won't this issue will be resolved automatically?",
"Yes in theory :)",
"actually float32 also seems to work in this PR (it just doesn't work for multi-channel)",
"In that case, a new PR isn't necessary, right?",
"Yep. I just tested from the PR and it works:\r\n```python\r\n>>> train_dataset = load_dataset(\"sayakpaul/nyu_depth_v2\", split=\"train\", streaming=True) \r\nDownloading readme: 100%|██████████████████| 8.71k/8.71k [00:00<00:00, 3.60MB/s]\r\n>>> next(iter(train_dataset))\r\n{'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=640x480 at 0x1382ED7F0>,\r\n 'depth_map': <PIL.TiffImagePlugin.TiffImageFile image mode=F size=640x480 at 0x1382EDF28>}\r\n>>> x = next(iter(train_dataset))\r\n>>> np.asarray(x[\"depth_map\"]) \r\narray([[0. , 0. , 0. , ..., 0. , 0. ,\r\n 0. ],\r\n [0. , 0. , 0. , ..., 0. , 0. ,\r\n 0. ],\r\n [0. , 0. , 0. , ..., 0. , 0. ,\r\n 0. ],\r\n ...,\r\n [0. , 2.2861192, 2.2861192, ..., 2.234162 , 2.234162 ,\r\n 0. ],\r\n [0. , 2.2861192, 2.2861192, ..., 2.234162 , 2.234162 ,\r\n 0. ],\r\n [0. , 2.2861192, 2.2861192, ..., 2.234162 , 2.234162 ,\r\n 0. ]], dtype=float32)\r\n```",
"Great! the case is closed! This issue has been solved and I have to say, it was quite the thrill ride. I felt like Sherlock Holmes, solving a mystery and finding the bug🕵️♂️. But in all seriousness, it was a pleasure working on this issue and I'm glad we could get to the bottom of it.\r\n\r\nOn another note, should I consider closing the issue? I think we still need to make updates on https://github.com/huggingface/blog and https://github.com/huggingface/datasets/blob/main/docs/source/depth_estimation.mdx",
"Haha thanks Mr Holmes :p\r\n\r\nmaybe let's close this issue when we're done updating the blog post and the documentation",
"@awsaf49 thank you for your hard work! \r\n\r\nI am a little unsure why the other links need to be updated, though. They all rely on datasets internally. ",
"I think depth_map still shows discretized version. It would be nice to have corrected one.\r\n<img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/depth_est_target_viz.png\" width = 300>",
"Also, I think we need to make some changes in the code to visualize depth_map as it is `float32` . `plot.imshow()` supports either [0, 1] + float32 or [0. 255] + uint8",
"Oh yes! Do you want to start with the fixes? Please feel free to say no but I wanted to make sure your contributions are reflected properly in our doc and the blog :)",
"Yes I think that would be nice :)",
"I'll make the changes tomorrow. I hope it's okay..."
] | "2023-01-24T19:15:46Z" | "2023-02-06T20:52:00Z" | null | CONTRIBUTOR | null | null | null | ### Describe the bug
I think there is a discrepancy between depth map of `nyu_depth_v2` dataset [here](https://huggingface.co/docs/datasets/main/en/depth_estimation) and actual depth map. Depth values somehow got **discretized/clipped** resulting in depth maps that are different from actual ones. Here is a side-by-side comparison,

I tried to find the origin of this issue but sadly as I mentioned in tensorflow/datasets/issues/4674, the download link from `fast-depth` doesn't work anymore hence couldn't verify if the error originated there or during porting data from there to HF.
Hi @sayakpaul, as you worked on huggingface/datasets/issues/5255, if you still have access to that data could you please share the data or perhaps checkout this issue?
### Steps to reproduce the bug
This [notebook](https://colab.research.google.com/drive/1K3ZU8XUPRDOYD38MQS9nreQXJYitlKSW?usp=sharing#scrollTo=UEW7QSh0jf0i) from @sayakpaul could be used to generate depth maps and actual ground truths could be checked from this [dataset](https://www.kaggle.com/datasets/awsaf49/nyuv2-bts-dataset) from BTS repo.
> Note: BTS dataset has only 36K data compared to the train-test 50K. They sampled the data as adjacent frames look quite the same
### Expected behavior
Expected depth maps should be smooth rather than discrete/clipped.
### Environment info
- `datasets` version: 2.8.1.dev0
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5461/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5461/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2209/comments | https://api.github.com/repos/huggingface/datasets/issues/2209/events | https://github.com/huggingface/datasets/pull/2209 | 855,638,232 | MDExOlB1bGxSZXF1ZXN0NjEzMzQwMTI2 | 2,209 | Add code of conduct to the project | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [] | "2021-04-12T07:16:14Z" | "2021-04-12T17:55:52Z" | "2021-04-12T17:55:52Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2209.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2209",
"merged_at": "2021-04-12T17:55:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2209.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2209"
} | Add code of conduct to the project and link it from README and CONTRIBUTING.
This was already done in `transformers`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2209/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2209/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2231/comments | https://api.github.com/repos/huggingface/datasets/issues/2231/events | https://github.com/huggingface/datasets/pull/2231 | 859,850,488 | MDExOlB1bGxSZXF1ZXN0NjE2ODYyNTEx | 2,231 | Fix map when removing columns on a formatted dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-04-16T14:08:55Z" | "2021-04-16T15:10:05Z" | "2021-04-16T15:10:04Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2231",
"merged_at": "2021-04-16T15:10:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2231"
} | This should fix issue #2226
The `remove_columns` argument was ignored on formatted datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2231/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6300/comments | https://api.github.com/repos/huggingface/datasets/issues/6300/events | https://github.com/huggingface/datasets/pull/6300 | 1,940,153,432 | PR_kwDODunzps5cpIoG | 6,300 | Unpin `jax` maximum version | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008410 / 0.011353 (-0.002943) | 0.004888 / 0.011008 (-0.006120) | 0.103342 / 0.038508 (0.064834) | 0.103697 / 0.023109 (0.080587) | 0.416445 / 0.275898 (0.140547) | 0.454604 / 0.323480 (0.131124) | 0.004976 / 0.007986 (-0.003010) | 0.003957 / 0.004328 (-0.000371) | 0.077398 / 0.004250 (0.073148) | 0.069026 / 0.037052 (0.031973) | 0.420484 / 0.258489 (0.161995) | 0.471828 / 0.293841 (0.177987) | 0.037133 / 0.128546 (-0.091413) | 0.010009 / 0.075646 (-0.065637) | 0.349573 / 0.419271 (-0.069698) | 0.063240 / 0.043533 (0.019708) | 0.421554 / 0.255139 (0.166415) | 0.433548 / 0.283200 (0.150348) | 0.029397 / 0.141683 (-0.112286) | 1.716860 / 1.452155 (0.264705) | 1.851264 / 1.492716 (0.358547) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269733 / 0.018006 (0.251727) | 0.493313 / 0.000490 (0.492823) | 0.010438 / 0.000200 (0.010238) | 0.000401 / 0.000054 (0.000347) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034690 / 0.037411 (-0.002722) | 0.105304 / 0.014526 (0.090778) | 0.115831 / 0.176557 (-0.060726) | 0.185017 / 0.737135 (-0.552118) | 0.117480 / 0.296338 (-0.178859) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.479414 / 0.215209 (0.264205) | 4.785526 / 2.077655 (2.707871) | 2.388412 / 1.504120 (0.884292) | 2.178222 / 1.541195 (0.637027) | 2.248214 / 1.468490 (0.779723) | 0.571723 / 4.584777 (-4.013054) | 4.721250 / 3.745712 (0.975538) | 4.073893 / 5.269862 (-1.195969) | 2.618131 / 4.565676 (-1.947546) | 0.068406 / 0.424275 (-0.355869) | 0.008890 / 0.007607 (0.001283) | 0.564224 / 0.226044 (0.338180) | 5.631412 / 2.268929 (3.362483) | 3.072212 / 55.444624 (-52.372412) | 2.760574 / 6.876477 (-4.115903) | 2.963060 / 2.142072 (0.820987) | 0.708150 / 4.805227 (-4.097077) | 0.160324 / 6.500664 (-6.340340) | 0.075402 / 0.075469 (-0.000067) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.649965 / 1.841788 (-0.191823) | 24.297517 / 8.074308 (16.223209) | 17.658675 / 10.191392 (7.467283) | 0.171399 / 0.680424 (-0.509025) | 0.021172 / 0.534201 (-0.513029) | 0.477196 / 0.579283 (-0.102087) | 0.503900 / 0.434364 (0.069536) | 0.555858 / 0.540337 (0.015520) | 0.824302 / 1.386936 (-0.562634) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008613 / 0.011353 (-0.002740) | 0.004848 / 0.011008 (-0.006160) | 0.078344 / 0.038508 (0.039836) | 0.098976 / 0.023109 (0.075867) | 0.520713 / 0.275898 (0.244815) | 0.566350 / 0.323480 (0.242870) | 0.006658 / 0.007986 (-0.001327) | 0.004043 / 0.004328 (-0.000285) | 0.077881 / 0.004250 (0.073631) | 0.070731 / 0.037052 (0.033678) | 0.519717 / 0.258489 (0.261228) | 0.575623 / 0.293841 (0.281782) | 0.038542 / 0.128546 (-0.090004) | 0.010277 / 0.075646 (-0.065369) | 0.084269 / 0.419271 (-0.335002) | 0.058088 / 0.043533 (0.014555) | 0.541790 / 0.255139 (0.286651) | 0.534915 / 0.283200 (0.251715) | 0.027851 / 0.141683 (-0.113831) | 1.814827 / 1.452155 (0.362672) | 1.898208 / 1.492716 (0.405492) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.244162 / 0.018006 (0.226156) | 0.482895 / 0.000490 (0.482405) | 0.005734 / 0.000200 (0.005534) | 0.000127 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.039328 / 0.037411 (0.001917) | 0.119795 / 0.014526 (0.105269) | 0.128570 / 0.176557 (-0.047986) | 0.191207 / 0.737135 (-0.545929) | 0.127147 / 0.296338 (-0.169192) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.533545 / 0.215209 (0.318336) | 5.320135 / 2.077655 (3.242480) | 2.924573 / 1.504120 (1.420453) | 2.741351 / 1.541195 (1.200156) | 2.824217 / 1.468490 (1.355727) | 0.595842 / 4.584777 (-3.988935) | 4.343499 / 3.745712 (0.597787) | 3.976546 / 5.269862 (-1.293316) | 2.532541 / 4.565676 (-2.033135) | 0.070480 / 0.424275 (-0.353795) | 0.008868 / 0.007607 (0.001260) | 0.634297 / 0.226044 (0.408253) | 6.327314 / 2.268929 (4.058386) | 3.530741 / 55.444624 (-51.913883) | 3.121435 / 6.876477 (-3.755042) | 3.344473 / 2.142072 (1.202401) | 0.719413 / 4.805227 (-4.085814) | 0.162348 / 6.500664 (-6.338316) | 0.074964 / 0.075469 (-0.000505) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.679095 / 1.841788 (-0.162693) | 25.071620 / 8.074308 (16.997312) | 18.422398 / 10.191392 (8.231006) | 0.223981 / 0.680424 (-0.456443) | 0.026537 / 0.534201 (-0.507664) | 0.513867 / 0.579283 (-0.065416) | 0.535874 / 0.434364 (0.101510) | 0.567971 / 0.540337 (0.027634) | 0.842545 / 1.386936 (-0.544391) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006445 / 0.011353 (-0.004908) | 0.003978 / 0.011008 (-0.007030) | 0.084542 / 0.038508 (0.046034) | 0.069231 / 0.023109 (0.046122) | 0.308794 / 0.275898 (0.032896) | 0.339246 / 0.323480 (0.015766) | 0.005269 / 0.007986 (-0.002716) | 0.003285 / 0.004328 (-0.001043) | 0.065336 / 0.004250 (0.061086) | 0.053480 / 0.037052 (0.016428) | 0.316775 / 0.258489 (0.058286) | 0.357885 / 0.293841 (0.064044) | 0.031309 / 0.128546 (-0.097237) | 0.008450 / 0.075646 (-0.067196) | 0.287911 / 0.419271 (-0.131361) | 0.052756 / 0.043533 (0.009223) | 0.321516 / 0.255139 (0.066377) | 0.331998 / 0.283200 (0.048799) | 0.024129 / 0.141683 (-0.117553) | 1.507718 / 1.452155 (0.055563) | 1.571400 / 1.492716 (0.078683) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237536 / 0.018006 (0.219530) | 0.499691 / 0.000490 (0.499201) | 0.007644 / 0.000200 (0.007444) | 0.000284 / 0.000054 (0.000230) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028243 / 0.037411 (-0.009168) | 0.081556 / 0.014526 (0.067030) | 0.096877 / 0.176557 (-0.079680) | 0.149985 / 0.737135 (-0.587150) | 0.095556 / 0.296338 (-0.200783) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.383215 / 0.215209 (0.168006) | 3.815800 / 2.077655 (1.738145) | 1.832227 / 1.504120 (0.328107) | 1.664001 / 1.541195 (0.122806) | 1.698786 / 1.468490 (0.230296) | 0.487594 / 4.584777 (-4.097183) | 3.569767 / 3.745712 (-0.175945) | 3.262387 / 5.269862 (-2.007475) | 2.017105 / 4.565676 (-2.548572) | 0.057555 / 0.424275 (-0.366720) | 0.007170 / 0.007607 (-0.000437) | 0.460134 / 0.226044 (0.234090) | 4.629800 / 2.268929 (2.360871) | 2.357126 / 55.444624 (-53.087499) | 1.970144 / 6.876477 (-4.906332) | 2.123520 / 2.142072 (-0.018552) | 0.613058 / 4.805227 (-4.192169) | 0.135869 / 6.500664 (-6.364795) | 0.061292 / 0.075469 (-0.014177) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.311294 / 1.841788 (-0.530494) | 18.640807 / 8.074308 (10.566499) | 13.946834 / 10.191392 (3.755442) | 0.163976 / 0.680424 (-0.516448) | 0.018527 / 0.534201 (-0.515674) | 0.390530 / 0.579283 (-0.188753) | 0.412661 / 0.434364 (-0.021703) | 0.459514 / 0.540337 (-0.080823) | 0.635026 / 1.386936 (-0.751910) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006645 / 0.011353 (-0.004708) | 0.003943 / 0.011008 (-0.007066) | 0.064470 / 0.038508 (0.025962) | 0.069895 / 0.023109 (0.046786) | 0.411091 / 0.275898 (0.135193) | 0.437628 / 0.323480 (0.114148) | 0.005214 / 0.007986 (-0.002772) | 0.003281 / 0.004328 (-0.001047) | 0.064434 / 0.004250 (0.060183) | 0.054294 / 0.037052 (0.017241) | 0.413576 / 0.258489 (0.155087) | 0.448793 / 0.293841 (0.154952) | 0.031754 / 0.128546 (-0.096793) | 0.008530 / 0.075646 (-0.067117) | 0.069950 / 0.419271 (-0.349322) | 0.047747 / 0.043533 (0.004214) | 0.411241 / 0.255139 (0.156102) | 0.430076 / 0.283200 (0.146876) | 0.023462 / 0.141683 (-0.118220) | 1.519501 / 1.452155 (0.067346) | 1.575782 / 1.492716 (0.083066) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231816 / 0.018006 (0.213810) | 0.442802 / 0.000490 (0.442312) | 0.005738 / 0.000200 (0.005539) | 0.000087 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031426 / 0.037411 (-0.005985) | 0.090758 / 0.014526 (0.076233) | 0.103414 / 0.176557 (-0.073142) | 0.156409 / 0.737135 (-0.580726) | 0.103900 / 0.296338 (-0.192439) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.438897 / 0.215209 (0.223688) | 4.385318 / 2.077655 (2.307663) | 2.352042 / 1.504120 (0.847923) | 2.182228 / 1.541195 (0.641033) | 2.266256 / 1.468490 (0.797766) | 0.492780 / 4.584777 (-4.091997) | 3.665787 / 3.745712 (-0.079925) | 3.315329 / 5.269862 (-1.954533) | 2.027993 / 4.565676 (-2.537684) | 0.058220 / 0.424275 (-0.366055) | 0.007429 / 0.007607 (-0.000178) | 0.508790 / 0.226044 (0.282746) | 5.107093 / 2.268929 (2.838164) | 2.799789 / 55.444624 (-52.644836) | 2.462828 / 6.876477 (-4.413649) | 2.610193 / 2.142072 (0.468120) | 0.588133 / 4.805227 (-4.217094) | 0.133418 / 6.500664 (-6.367246) | 0.059793 / 0.075469 (-0.015676) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.363358 / 1.841788 (-0.478430) | 19.258372 / 8.074308 (11.184064) | 14.730977 / 10.191392 (4.539584) | 0.169493 / 0.680424 (-0.510931) | 0.020462 / 0.534201 (-0.513739) | 0.397980 / 0.579283 (-0.181303) | 0.426638 / 0.434364 (-0.007726) | 0.474249 / 0.540337 (-0.066088) | 0.677640 / 1.386936 (-0.709296) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006536 / 0.011353 (-0.004817) | 0.003827 / 0.011008 (-0.007181) | 0.084394 / 0.038508 (0.045886) | 0.073166 / 0.023109 (0.050056) | 0.309380 / 0.275898 (0.033482) | 0.338501 / 0.323480 (0.015021) | 0.005346 / 0.007986 (-0.002640) | 0.003273 / 0.004328 (-0.001056) | 0.064606 / 0.004250 (0.060356) | 0.053500 / 0.037052 (0.016447) | 0.313143 / 0.258489 (0.054654) | 0.354364 / 0.293841 (0.060523) | 0.030919 / 0.128546 (-0.097627) | 0.008512 / 0.075646 (-0.067134) | 0.292774 / 0.419271 (-0.126498) | 0.052441 / 0.043533 (0.008908) | 0.310503 / 0.255139 (0.055364) | 0.341211 / 0.283200 (0.058011) | 0.023608 / 0.141683 (-0.118074) | 1.456220 / 1.452155 (0.004065) | 1.540189 / 1.492716 (0.047473) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.234321 / 0.018006 (0.216315) | 0.451809 / 0.000490 (0.451319) | 0.008560 / 0.000200 (0.008360) | 0.000085 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028165 / 0.037411 (-0.009246) | 0.082548 / 0.014526 (0.068023) | 0.752621 / 0.176557 (0.576065) | 0.263949 / 0.737135 (-0.473187) | 0.097635 / 0.296338 (-0.198704) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.386611 / 0.215209 (0.171402) | 3.847528 / 2.077655 (1.769873) | 1.859173 / 1.504120 (0.355053) | 1.685269 / 1.541195 (0.144074) | 1.715823 / 1.468490 (0.247333) | 0.485272 / 4.584777 (-4.099505) | 3.500724 / 3.745712 (-0.244988) | 3.252149 / 5.269862 (-2.017713) | 2.052914 / 4.565676 (-2.512762) | 0.056794 / 0.424275 (-0.367481) | 0.007317 / 0.007607 (-0.000291) | 0.457924 / 0.226044 (0.231879) | 4.570092 / 2.268929 (2.301163) | 2.328829 / 55.444624 (-53.115796) | 1.986502 / 6.876477 (-4.889975) | 2.164645 / 2.142072 (0.022573) | 0.580455 / 4.805227 (-4.224772) | 0.134415 / 6.500664 (-6.366249) | 0.060506 / 0.075469 (-0.014963) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.267423 / 1.841788 (-0.574364) | 18.653450 / 8.074308 (10.579142) | 13.919682 / 10.191392 (3.728290) | 0.144001 / 0.680424 (-0.536423) | 0.018218 / 0.534201 (-0.515983) | 0.389933 / 0.579283 (-0.189350) | 0.418366 / 0.434364 (-0.015998) | 0.456341 / 0.540337 (-0.083997) | 0.631401 / 1.386936 (-0.755535) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006838 / 0.011353 (-0.004515) | 0.003973 / 0.011008 (-0.007036) | 0.065217 / 0.038508 (0.026709) | 0.068357 / 0.023109 (0.045248) | 0.407960 / 0.275898 (0.132062) | 0.437794 / 0.323480 (0.114314) | 0.005398 / 0.007986 (-0.002587) | 0.003360 / 0.004328 (-0.000969) | 0.065503 / 0.004250 (0.061253) | 0.055676 / 0.037052 (0.018623) | 0.411381 / 0.258489 (0.152892) | 0.446902 / 0.293841 (0.153061) | 0.032156 / 0.128546 (-0.096390) | 0.008702 / 0.075646 (-0.066944) | 0.072295 / 0.419271 (-0.346976) | 0.047722 / 0.043533 (0.004189) | 0.406125 / 0.255139 (0.150986) | 0.428359 / 0.283200 (0.145160) | 0.021901 / 0.141683 (-0.119782) | 1.464186 / 1.452155 (0.012032) | 1.532809 / 1.492716 (0.040093) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.218505 / 0.018006 (0.200499) | 0.447450 / 0.000490 (0.446961) | 0.006509 / 0.000200 (0.006309) | 0.000099 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031789 / 0.037411 (-0.005622) | 0.091100 / 0.014526 (0.076574) | 0.102812 / 0.176557 (-0.073745) | 0.155988 / 0.737135 (-0.581147) | 0.103983 / 0.296338 (-0.192355) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436431 / 0.215209 (0.221222) | 4.336072 / 2.077655 (2.258417) | 2.344613 / 1.504120 (0.840493) | 2.173513 / 1.541195 (0.632319) | 2.313134 / 1.468490 (0.844644) | 0.493651 / 4.584777 (-4.091126) | 3.657541 / 3.745712 (-0.088171) | 3.289933 / 5.269862 (-1.979928) | 2.040271 / 4.565676 (-2.525406) | 0.058092 / 0.424275 (-0.366183) | 0.007348 / 0.007607 (-0.000259) | 0.507506 / 0.226044 (0.281462) | 5.093477 / 2.268929 (2.824548) | 2.770579 / 55.444624 (-52.674046) | 2.449507 / 6.876477 (-4.426970) | 2.645470 / 2.142072 (0.503397) | 0.590799 / 4.805227 (-4.214429) | 0.133411 / 6.500664 (-6.367253) | 0.059507 / 0.075469 (-0.015962) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.381148 / 1.841788 (-0.460639) | 19.188716 / 8.074308 (11.114408) | 14.709111 / 10.191392 (4.517719) | 0.191104 / 0.680424 (-0.489320) | 0.019862 / 0.534201 (-0.514339) | 0.395380 / 0.579283 (-0.183903) | 0.424757 / 0.434364 (-0.009607) | 0.468810 / 0.540337 (-0.071527) | 0.687058 / 1.386936 (-0.699878) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008872 / 0.011353 (-0.002481) | 0.004824 / 0.011008 (-0.006184) | 0.097012 / 0.038508 (0.058504) | 0.074728 / 0.023109 (0.051619) | 0.400604 / 0.275898 (0.124706) | 0.434316 / 0.323480 (0.110836) | 0.006025 / 0.007986 (-0.001961) | 0.004153 / 0.004328 (-0.000176) | 0.074093 / 0.004250 (0.069842) | 0.057239 / 0.037052 (0.020187) | 0.420611 / 0.258489 (0.162122) | 0.457779 / 0.293841 (0.163938) | 0.047610 / 0.128546 (-0.080936) | 0.014577 / 0.075646 (-0.061069) | 0.414351 / 0.419271 (-0.004921) | 0.063072 / 0.043533 (0.019539) | 0.426141 / 0.255139 (0.171002) | 0.429844 / 0.283200 (0.146644) | 0.034754 / 0.141683 (-0.106929) | 1.620946 / 1.452155 (0.168792) | 1.725831 / 1.492716 (0.233115) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304712 / 0.018006 (0.286706) | 0.646924 / 0.000490 (0.646434) | 0.014486 / 0.000200 (0.014286) | 0.000626 / 0.000054 (0.000572) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034935 / 0.037411 (-0.002477) | 0.085788 / 0.014526 (0.071262) | 0.107749 / 0.176557 (-0.068807) | 0.170924 / 0.737135 (-0.566211) | 0.134985 / 0.296338 (-0.161354) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.602913 / 0.215209 (0.387704) | 6.041700 / 2.077655 (3.964045) | 2.539970 / 1.504120 (1.035850) | 2.184166 / 1.541195 (0.642972) | 2.241783 / 1.468490 (0.773293) | 0.864601 / 4.584777 (-3.720176) | 5.246955 / 3.745712 (1.501243) | 4.850458 / 5.269862 (-0.419404) | 3.101497 / 4.565676 (-1.464179) | 0.098591 / 0.424275 (-0.325684) | 0.008902 / 0.007607 (0.001295) | 0.732278 / 0.226044 (0.506234) | 7.163557 / 2.268929 (4.894629) | 3.226444 / 55.444624 (-52.218180) | 2.578737 / 6.876477 (-4.297740) | 2.850212 / 2.142072 (0.708140) | 1.026390 / 4.805227 (-3.778837) | 0.217077 / 6.500664 (-6.283587) | 0.080344 / 0.075469 (0.004875) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.687488 / 1.841788 (-0.154300) | 24.686337 / 8.074308 (16.612029) | 21.315989 / 10.191392 (11.124597) | 0.226176 / 0.680424 (-0.454248) | 0.035774 / 0.534201 (-0.498427) | 0.477807 / 0.579283 (-0.101476) | 0.636305 / 0.434364 (0.201941) | 0.553341 / 0.540337 (0.013003) | 0.797267 / 1.386936 (-0.589669) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008955 / 0.011353 (-0.002398) | 0.006099 / 0.011008 (-0.004909) | 0.086306 / 0.038508 (0.047798) | 0.090783 / 0.023109 (0.067674) | 0.554802 / 0.275898 (0.278904) | 0.598778 / 0.323480 (0.275299) | 0.008656 / 0.007986 (0.000670) | 0.004487 / 0.004328 (0.000159) | 0.084194 / 0.004250 (0.079943) | 0.076048 / 0.037052 (0.038996) | 0.533212 / 0.258489 (0.274723) | 0.584029 / 0.293841 (0.290188) | 0.051913 / 0.128546 (-0.076634) | 0.014253 / 0.075646 (-0.061393) | 0.100500 / 0.419271 (-0.318772) | 0.061092 / 0.043533 (0.017560) | 0.516955 / 0.255139 (0.261816) | 0.562754 / 0.283200 (0.279554) | 0.036673 / 0.141683 (-0.105010) | 1.853655 / 1.452155 (0.401501) | 1.968358 / 1.492716 (0.475642) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.308258 / 0.018006 (0.290252) | 0.630492 / 0.000490 (0.630002) | 0.010575 / 0.000200 (0.010375) | 0.000271 / 0.000054 (0.000217) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034762 / 0.037411 (-0.002649) | 0.107314 / 0.014526 (0.092788) | 0.132160 / 0.176557 (-0.044396) | 0.178737 / 0.737135 (-0.558398) | 0.125988 / 0.296338 (-0.170351) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.730738 / 0.215209 (0.515528) | 7.240393 / 2.077655 (5.162738) | 3.557665 / 1.504120 (2.053545) | 3.541425 / 1.541195 (2.000230) | 3.103849 / 1.468490 (1.635359) | 0.926843 / 4.584777 (-3.657934) | 5.818264 / 3.745712 (2.072552) | 5.012984 / 5.269862 (-0.256878) | 3.286085 / 4.565676 (-1.279591) | 0.104879 / 0.424275 (-0.319396) | 0.009010 / 0.007607 (0.001403) | 0.806145 / 0.226044 (0.580101) | 8.263655 / 2.268929 (5.994727) | 4.108932 / 55.444624 (-51.335693) | 3.454613 / 6.876477 (-3.421864) | 3.629045 / 2.142072 (1.486973) | 1.062325 / 4.805227 (-3.742902) | 0.220482 / 6.500664 (-6.280182) | 0.081440 / 0.075469 (0.005970) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.665587 / 1.841788 (-0.176201) | 23.695299 / 8.074308 (15.620991) | 22.917493 / 10.191392 (12.726101) | 0.259033 / 0.680424 (-0.421391) | 0.040118 / 0.534201 (-0.494083) | 0.487329 / 0.579283 (-0.091954) | 0.607482 / 0.434364 (0.173118) | 0.568383 / 0.540337 (0.028045) | 0.824486 / 1.386936 (-0.562450) |\n\n</details>\n</details>\n\n\n",
"CI failures are unrelated",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007095 / 0.011353 (-0.004258) | 0.004260 / 0.011008 (-0.006748) | 0.084729 / 0.038508 (0.046221) | 0.076498 / 0.023109 (0.053389) | 0.325981 / 0.275898 (0.050083) | 0.357140 / 0.323480 (0.033661) | 0.004325 / 0.007986 (-0.003660) | 0.003632 / 0.004328 (-0.000696) | 0.065075 / 0.004250 (0.060824) | 0.059058 / 0.037052 (0.022006) | 0.331895 / 0.258489 (0.073406) | 0.370782 / 0.293841 (0.076941) | 0.031886 / 0.128546 (-0.096660) | 0.008782 / 0.075646 (-0.066864) | 0.288159 / 0.419271 (-0.131113) | 0.053012 / 0.043533 (0.009479) | 0.319992 / 0.255139 (0.064853) | 0.347061 / 0.283200 (0.063861) | 0.026365 / 0.141683 (-0.115317) | 1.486112 / 1.452155 (0.033958) | 1.570150 / 1.492716 (0.077434) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.277155 / 0.018006 (0.259149) | 0.573507 / 0.000490 (0.573017) | 0.010122 / 0.000200 (0.009922) | 0.000322 / 0.000054 (0.000268) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029076 / 0.037411 (-0.008335) | 0.082517 / 0.014526 (0.067991) | 0.100710 / 0.176557 (-0.075847) | 0.154529 / 0.737135 (-0.582606) | 0.099531 / 0.296338 (-0.196807) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.382058 / 0.215209 (0.166849) | 3.803307 / 2.077655 (1.725652) | 1.834107 / 1.504120 (0.329987) | 1.665703 / 1.541195 (0.124508) | 1.739520 / 1.468490 (0.271030) | 0.490544 / 4.584777 (-4.094233) | 3.577874 / 3.745712 (-0.167838) | 3.327631 / 5.269862 (-1.942231) | 2.056634 / 4.565676 (-2.509043) | 0.057871 / 0.424275 (-0.366404) | 0.007326 / 0.007607 (-0.000281) | 0.453993 / 0.226044 (0.227949) | 4.549179 / 2.268929 (2.280250) | 2.320304 / 55.444624 (-53.124321) | 1.966082 / 6.876477 (-4.910395) | 2.189979 / 2.142072 (0.047907) | 0.586678 / 4.805227 (-4.218549) | 0.134919 / 6.500664 (-6.365745) | 0.061649 / 0.075469 (-0.013820) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.286228 / 1.841788 (-0.555560) | 19.409674 / 8.074308 (11.335366) | 14.290463 / 10.191392 (4.099071) | 0.165766 / 0.680424 (-0.514658) | 0.018200 / 0.534201 (-0.516001) | 0.390526 / 0.579283 (-0.188757) | 0.410953 / 0.434364 (-0.023411) | 0.455921 / 0.540337 (-0.084416) | 0.642271 / 1.386936 (-0.744665) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007288 / 0.011353 (-0.004064) | 0.004348 / 0.011008 (-0.006660) | 0.065935 / 0.038508 (0.027427) | 0.087327 / 0.023109 (0.064218) | 0.413461 / 0.275898 (0.137563) | 0.458904 / 0.323480 (0.135424) | 0.005996 / 0.007986 (-0.001990) | 0.003648 / 0.004328 (-0.000680) | 0.066578 / 0.004250 (0.062328) | 0.062072 / 0.037052 (0.025020) | 0.418469 / 0.258489 (0.159980) | 0.468960 / 0.293841 (0.175119) | 0.032616 / 0.128546 (-0.095930) | 0.008961 / 0.075646 (-0.066686) | 0.072537 / 0.419271 (-0.346734) | 0.048302 / 0.043533 (0.004769) | 0.411845 / 0.255139 (0.156706) | 0.441730 / 0.283200 (0.158530) | 0.025038 / 0.141683 (-0.116645) | 1.519402 / 1.452155 (0.067248) | 1.601791 / 1.492716 (0.109074) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.322494 / 0.018006 (0.304488) | 0.570210 / 0.000490 (0.569720) | 0.025815 / 0.000200 (0.025615) | 0.000166 / 0.000054 (0.000111) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034657 / 0.037411 (-0.002754) | 0.096024 / 0.014526 (0.081498) | 0.109134 / 0.176557 (-0.067422) | 0.162170 / 0.737135 (-0.574965) | 0.110472 / 0.296338 (-0.185866) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439032 / 0.215209 (0.223823) | 4.385768 / 2.077655 (2.308113) | 2.343261 / 1.504120 (0.839142) | 2.157926 / 1.541195 (0.616731) | 2.299193 / 1.468490 (0.830703) | 0.498961 / 4.584777 (-4.085816) | 3.651909 / 3.745712 (-0.093803) | 3.387587 / 5.269862 (-1.882275) | 2.144553 / 4.565676 (-2.421123) | 0.058242 / 0.424275 (-0.366033) | 0.007416 / 0.007607 (-0.000191) | 0.512714 / 0.226044 (0.286670) | 5.138569 / 2.268929 (2.869641) | 2.778683 / 55.444624 (-52.665941) | 2.532990 / 6.876477 (-4.343487) | 2.782211 / 2.142072 (0.640139) | 0.591881 / 4.805227 (-4.213346) | 0.135005 / 6.500664 (-6.365660) | 0.060965 / 0.075469 (-0.014504) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.356311 / 1.841788 (-0.485477) | 20.029994 / 8.074308 (11.955686) | 14.666570 / 10.191392 (4.475178) | 0.164363 / 0.680424 (-0.516061) | 0.020685 / 0.534201 (-0.513516) | 0.396020 / 0.579283 (-0.183263) | 0.429407 / 0.434364 (-0.004957) | 0.476924 / 0.540337 (-0.063413) | 0.693389 / 1.386936 (-0.693547) |\n\n</details>\n</details>\n\n\n"
] | "2023-10-12T14:42:40Z" | "2023-10-12T16:37:55Z" | "2023-10-12T16:28:57Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6300",
"merged_at": "2023-10-12T16:28:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6300"
} | fix #6299
fix #6202 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6300/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/594/comments | https://api.github.com/repos/huggingface/datasets/issues/594/events | https://github.com/huggingface/datasets/pull/594 | 696,816,893 | MDExOlB1bGxSZXF1ZXN0NDgyODQ1OTc5 | 594 | Fix germeval url | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-09-09T13:29:35Z" | "2020-09-09T13:34:35Z" | "2020-09-09T13:34:34Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/594.diff",
"html_url": "https://github.com/huggingface/datasets/pull/594",
"merged_at": "2020-09-09T13:34:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/594.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/594"
} | Continuation of #593 but without the dummy data hack | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/594/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1444/comments | https://api.github.com/repos/huggingface/datasets/issues/1444/events | https://github.com/huggingface/datasets/issues/1444 | 761,055,651 | MDU6SXNzdWU3NjEwNTU2NTE= | 1,444 | FileNotFound remotly, can't load a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/18331629?v=4",
"events_url": "https://api.github.com/users/sadakmed/events{/privacy}",
"followers_url": "https://api.github.com/users/sadakmed/followers",
"following_url": "https://api.github.com/users/sadakmed/following{/other_user}",
"gists_url": "https://api.github.com/users/sadakmed/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sadakmed",
"id": 18331629,
"login": "sadakmed",
"node_id": "MDQ6VXNlcjE4MzMxNjI5",
"organizations_url": "https://api.github.com/users/sadakmed/orgs",
"received_events_url": "https://api.github.com/users/sadakmed/received_events",
"repos_url": "https://api.github.com/users/sadakmed/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sadakmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sadakmed/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sadakmed"
} | [] | closed | false | null | [] | null | [
"This dataset will be available in version-2 of the library. If you want to use this dataset now, install datasets from `master` branch rather.\r\n\r\nCommand to install datasets from `master` branch:\r\n`!pip install git+https://github.com/huggingface/datasets.git@master`",
"Closing this, thanks @VasudevGupta7 "
] | "2020-12-10T09:14:47Z" | "2020-12-15T17:41:14Z" | "2020-12-15T17:41:14Z" | NONE | null | null | null | ```py
!pip install datasets
import datasets as ds
corpus = ds.load_dataset('large_spanish_corpus')
```
gives the error
> FileNotFoundError: Couldn't find file locally at large_spanish_corpus/large_spanish_corpus.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/large_spanish_corpus/large_spanish_corpus.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/large_spanish_corpus/large_spanish_corpus.py
not just `large_spanish_corpus`, `zest` too, but `squad` is available.
this was using colab and localy | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1444/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/954/comments | https://api.github.com/repos/huggingface/datasets/issues/954/events | https://github.com/huggingface/datasets/pull/954 | 754,362,012 | MDExOlB1bGxSZXF1ZXN0NTMwMjc1MDY4 | 954 | add prachathai67k | {
"avatar_url": "https://avatars.githubusercontent.com/u/15519308?v=4",
"events_url": "https://api.github.com/users/cstorm125/events{/privacy}",
"followers_url": "https://api.github.com/users/cstorm125/followers",
"following_url": "https://api.github.com/users/cstorm125/following{/other_user}",
"gists_url": "https://api.github.com/users/cstorm125/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cstorm125",
"id": 15519308,
"login": "cstorm125",
"node_id": "MDQ6VXNlcjE1NTE5MzA4",
"organizations_url": "https://api.github.com/users/cstorm125/orgs",
"received_events_url": "https://api.github.com/users/cstorm125/received_events",
"repos_url": "https://api.github.com/users/cstorm125/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cstorm125/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cstorm125/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cstorm125"
} | [] | closed | false | null | [] | null | [
"Test failing for same issues as https://github.com/huggingface/datasets/pull/939\r\nPlease advise.\r\n\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_builder_class_flue\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_builder_class_norwegian_ner\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_builder_configs_flue\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_builder_configs_norwegian_ner\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_flue\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_norwegian_ner\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_xglue\r\n===== 7 failed, 1309 passed, 932 skipped, 11 warnings in 166.71s (0:02:46) =====\r\n```",
"Closing and opening a new pull request to solve rebase issues",
"To be continued on https://github.com/huggingface/datasets/pull/982"
] | "2020-12-01T12:40:55Z" | "2020-12-02T05:12:11Z" | "2020-12-02T04:43:52Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/954.diff",
"html_url": "https://github.com/huggingface/datasets/pull/954",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/954.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/954"
} | `prachathai-67k`: News Article Corpus and Multi-label Text Classificdation from Prachathai.com
The prachathai-67k dataset was scraped from the news site Prachathai.
We filtered out those articles with less than 500 characters of body text, mostly images and cartoons.
It contains 67,889 articles wtih 12 curated tags from August 24, 2004 to November 15, 2018.
The dataset was originally scraped by @lukkiddd and cleaned by @cstorm125.
You can also see preliminary exploration at https://github.com/PyThaiNLP/prachathai-67k/blob/master/exploration.ipynb | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/954/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/585/comments | https://api.github.com/repos/huggingface/datasets/issues/585/events | https://github.com/huggingface/datasets/pull/585 | 695,191,209 | MDExOlB1bGxSZXF1ZXN0NDgxNDY4NTM4 | 585 | Fix select for pyarrow < 1.0.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-09-07T15:02:52Z" | "2020-09-08T07:43:17Z" | "2020-09-08T07:43:15Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/585.diff",
"html_url": "https://github.com/huggingface/datasets/pull/585",
"merged_at": "2020-09-08T07:43:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/585.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/585"
} | Fix #583 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/585/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4673/comments | https://api.github.com/repos/huggingface/datasets/issues/4673/events | https://github.com/huggingface/datasets/issues/4673 | 1,301,010,331 | I_kwDODunzps5Ni9eb | 4,673 | load_datasets on csv returns everything as a string | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}",
"gists_url": "https://api.github.com/users/courtneysprouse/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/courtneysprouse",
"id": 25102613,
"login": "courtneysprouse",
"node_id": "MDQ6VXNlcjI1MTAyNjEz",
"organizations_url": "https://api.github.com/users/courtneysprouse/orgs",
"received_events_url": "https://api.github.com/users/courtneysprouse/received_events",
"repos_url": "https://api.github.com/users/courtneysprouse/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/courtneysprouse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/courtneysprouse/subscriptions",
"type": "User",
"url": "https://api.github.com/users/courtneysprouse"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to lacking of implementation in PyArrow. For example:\r\n```python\r\nimport datasets\r\n\r\nfeatures = datasets.Features(\r\n {\r\n \"tokens\": datasets.Sequence(datasets.Value(\"string\")),\r\n \"ner_tags\": datasets.Sequence(datasets.Value(\"int32\")),\r\n }\r\n)\r\n\r\nnew_conll = datasets.load_dataset(\"csv\", data_files=\"ner_conll.csv\", features=features)\r\n```\r\ngives `ArrowNotImplementedError` error:\r\n```\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowNotImplementedError: Unsupported cast from string to list using function cast_list\r\n```\r\n\r\nOn the other hand, if you just would like to save and afterwards load your dataset, you could use `save_to_disk` and `load_from_disk` instead. These functions preserve all data types.\r\n```python\r\n>>> orig_conll.save_to_disk(\"ner_conll\")\r\n\r\n>>> from datasets import load_from_disk\r\n\r\n>>> new_conll = load_from_disk(\"ner_conll\")\r\n>>> new_conll\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 14042\r\n })\r\n validation: Dataset({\r\n features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 3251\r\n })\r\n test: Dataset({\r\n features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 3454\r\n })\r\n})\r\n>>> new_conll[\"train\"][0]\r\n{'chunk_tags': [11, 21, 11, 12, 21, 22, 11, 12, 0],\r\n 'id': '0',\r\n 'ner_tags': [3, 0, 7, 0, 0, 0, 7, 0, 0],\r\n 'pos_tags': [22, 42, 16, 21, 35, 37, 16, 21, 7],\r\n 'tokens': ['EU',\r\n 'rejects',\r\n 'German',\r\n 'call',\r\n 'to',\r\n 'boycott',\r\n 'British',\r\n 'lamb',\r\n '.']}\r\n>>> new_conll[\"train\"].features\r\n{'chunk_tags': Sequence(feature=ClassLabel(num_classes=23, names=['O', 'B-ADJP', 'I-ADJP', 'B-ADVP', 'I-ADVP', 'B-CONJP', 'I-CONJP', 'B-INTJ', 'I-INTJ', 'B-LST', 'I-LST', 'B-NP', 'I-NP', 'B-PP', 'I-PP', 'B-PRT', 'I-PRT', 'B-SBAR', 'I-SBAR', 'B-UCP', 'I-UCP', 'B-VP', 'I-VP'], id=None), length=-1, id=None),\r\n 'id': Value(dtype='string', id=None),\r\n 'ner_tags': Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], id=None), length=-1, id=None),\r\n 'pos_tags': Sequence(feature=ClassLabel(num_classes=47, names=['\"', \"''\", '#', '$', '(', ')', ',', '.', ':', '``', 'CC', 'CD', 'DT', 'EX', 'FW', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NN', 'NNP', 'NNPS', 'NNS', 'NN|SYM', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB'], id=None), length=-1, id=None),\r\n 'tokens': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}\r\n```",
"Hi @albertvillanova!\r\n\r\nThanks so much for your suggestions! That worked! "
] | "2022-07-11T17:30:24Z" | "2022-07-12T13:33:09Z" | "2022-07-12T13:33:08Z" | NONE | null | null | null | ## Describe the bug
If you use:
`conll_dataset.to_csv("ner_conll.csv")`
It will create a csv file with all of your data as expected, however when you load it with:
`conll_dataset = load_dataset("csv", data_files="ner_conll.csv")`
everything is read in as a string. For example if I look at everything in 'ner_tags' I get back `['[3 0 7 0 0 0 7 0 0]', '[1 2]', '[5 0]']` instead of what I originally saved which was `[[3, 0, 7, 0, 0, 0, 7, 0, 0], [1, 2], [5, 0]]`
I think maybe there is something funky going on with the csv delimiter
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
#load original conll dataset
orig_conll = load_dataset("conll2003")
#save original conll as a csv
orig_conll.to_csv("ner_conll.csv")
#reload conll data as a csv
new_conll = load_dataset("csv", data_files="ner_conll.csv")`
```
## Expected results
A clear and concise description of the expected results.
I would expect the data be returned as the data type I saved it as. I.e. if I save a list of ints
[[3, 0, 7, 0, 0, 0, 7, 0, 0]], I shouldnt get back a string ['[3 0 7 0 0 0 7 0 0]']
I also get back a string when I pass a list of strings ['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
## Actual results
A list of strings `['[3 0 7 0 0 0 7 0 0]', '[1 2]', '[5 0]']`
A string "['EU' 'rejects' 'German' 'call' 'to' 'boycott' 'British' 'lamb' '.']"
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-5.4.0-121-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 8.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5452 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5452/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5452/comments | https://api.github.com/repos/huggingface/datasets/issues/5452/events | https://github.com/huggingface/datasets/pull/5452 | 1,552,655,939 | PR_kwDODunzps5ITcA3 | 5,452 | Swap log messages for symbolic/hard links in tar extractor | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011848 / 0.011353 (0.000495) | 0.006988 / 0.011008 (-0.004020) | 0.138078 / 0.038508 (0.099570) | 0.040310 / 0.023109 (0.017201) | 0.411857 / 0.275898 (0.135959) | 0.509496 / 0.323480 (0.186016) | 0.010695 / 0.007986 (0.002709) | 0.005275 / 0.004328 (0.000946) | 0.107157 / 0.004250 (0.102907) | 0.050987 / 0.037052 (0.013935) | 0.432387 / 0.258489 (0.173898) | 0.495136 / 0.293841 (0.201295) | 0.055273 / 0.128546 (-0.073273) | 0.019573 / 0.075646 (-0.056074) | 0.460356 / 0.419271 (0.041084) | 0.060916 / 0.043533 (0.017383) | 0.426140 / 0.255139 (0.171002) | 0.430461 / 0.283200 (0.147261) | 0.124569 / 0.141683 (-0.017114) | 1.989404 / 1.452155 (0.537250) | 1.942052 / 1.492716 (0.449335) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287233 / 0.018006 (0.269227) | 0.606056 / 0.000490 (0.605566) | 0.004435 / 0.000200 (0.004235) | 0.000144 / 0.000054 (0.000090) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032353 / 0.037411 (-0.005058) | 0.124237 / 0.014526 (0.109711) | 0.143280 / 0.176557 (-0.033276) | 0.182081 / 0.737135 (-0.555055) | 0.148085 / 0.296338 (-0.148253) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.613550 / 0.215209 (0.398341) | 6.172421 / 2.077655 (4.094766) | 2.466018 / 1.504120 (0.961898) | 2.166433 / 1.541195 (0.625238) | 2.192511 / 1.468490 (0.724021) | 1.248777 / 4.584777 (-3.336000) | 5.746150 / 3.745712 (2.000438) | 3.097184 / 5.269862 (-2.172678) | 2.078176 / 4.565676 (-2.487501) | 0.144351 / 0.424275 (-0.279924) | 0.014830 / 0.007607 (0.007223) | 0.761699 / 0.226044 (0.535655) | 7.713201 / 2.268929 (5.444272) | 3.359647 / 55.444624 (-52.084977) | 2.652595 / 6.876477 (-4.223882) | 2.721952 / 2.142072 (0.579880) | 1.493036 / 4.805227 (-3.312192) | 0.252336 / 6.500664 (-6.248328) | 0.082906 / 0.075469 (0.007436) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.643887 / 1.841788 (-0.197901) | 18.762775 / 8.074308 (10.688466) | 22.003583 / 10.191392 (11.812191) | 0.256361 / 0.680424 (-0.424062) | 0.048048 / 0.534201 (-0.486153) | 0.601971 / 0.579283 (0.022688) | 0.712801 / 0.434364 (0.278438) | 0.684473 / 0.540337 (0.144136) | 0.802566 / 1.386936 (-0.584370) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010410 / 0.011353 (-0.000943) | 0.006719 / 0.011008 (-0.004289) | 0.132862 / 0.038508 (0.094354) | 0.036973 / 0.023109 (0.013863) | 0.470925 / 0.275898 (0.195027) | 0.502864 / 0.323480 (0.179384) | 0.007447 / 0.007986 (-0.000539) | 0.005629 / 0.004328 (0.001301) | 0.091985 / 0.004250 (0.087734) | 0.057537 / 0.037052 (0.020485) | 0.458362 / 0.258489 (0.199873) | 0.518324 / 0.293841 (0.224483) | 0.056540 / 0.128546 (-0.072007) | 0.021266 / 0.075646 (-0.054380) | 0.448289 / 0.419271 (0.029018) | 0.064211 / 0.043533 (0.020678) | 0.492596 / 0.255139 (0.237457) | 0.495030 / 0.283200 (0.211830) | 0.121858 / 0.141683 (-0.019825) | 1.823821 / 1.452155 (0.371667) | 2.012165 / 1.492716 (0.519449) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296252 / 0.018006 (0.278245) | 0.601688 / 0.000490 (0.601198) | 0.006369 / 0.000200 (0.006169) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035821 / 0.037411 (-0.001590) | 0.132722 / 0.014526 (0.118196) | 0.141819 / 0.176557 (-0.034738) | 0.205115 / 0.737135 (-0.532020) | 0.148917 / 0.296338 (-0.147422) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.678207 / 0.215209 (0.462998) | 6.969918 / 2.077655 (4.892263) | 3.077831 / 1.504120 (1.573711) | 2.689296 / 1.541195 (1.148102) | 2.706462 / 1.468490 (1.237972) | 1.249125 / 4.584777 (-3.335652) | 5.793917 / 3.745712 (2.048205) | 3.137565 / 5.269862 (-2.132297) | 2.056880 / 4.565676 (-2.508796) | 0.151918 / 0.424275 (-0.272357) | 0.015029 / 0.007607 (0.007422) | 0.833975 / 0.226044 (0.607930) | 8.575649 / 2.268929 (6.306720) | 3.812115 / 55.444624 (-51.632509) | 3.124219 / 6.876477 (-3.752258) | 3.178645 / 2.142072 (1.036572) | 1.488260 / 4.805227 (-3.316967) | 0.268239 / 6.500664 (-6.232425) | 0.089463 / 0.075469 (0.013993) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.645461 / 1.841788 (-0.196327) | 19.074412 / 8.074308 (11.000104) | 21.626726 / 10.191392 (11.435334) | 0.210525 / 0.680424 (-0.469899) | 0.032166 / 0.534201 (-0.502035) | 0.555572 / 0.579283 (-0.023711) | 0.654667 / 0.434364 (0.220303) | 0.632471 / 0.540337 (0.092133) | 0.756510 / 1.386936 (-0.630426) |\n\n</details>\n</details>\n\n\n"
] | "2023-01-23T07:53:38Z" | "2023-01-23T09:40:55Z" | "2023-01-23T08:31:17Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5452.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5452",
"merged_at": "2023-01-23T08:31:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5452.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5452"
} | The log messages do not match their if-condition. This PR swaps them.
Found while investigating:
- #5441
CC: @lhoestq | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5452/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5452/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5987 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5987/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5987/comments | https://api.github.com/repos/huggingface/datasets/issues/5987/events | https://github.com/huggingface/datasets/issues/5987 | 1,773,047,909 | I_kwDODunzps5prpBl | 5,987 | Why max_shard_size is not supported in load_dataset and passed to download_and_prepare | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "https://api.github.com/users/npuichigo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/npuichigo",
"id": 11533479,
"login": "npuichigo",
"node_id": "MDQ6VXNlcjExNTMzNDc5",
"organizations_url": "https://api.github.com/users/npuichigo/orgs",
"received_events_url": "https://api.github.com/users/npuichigo/received_events",
"repos_url": "https://api.github.com/users/npuichigo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/npuichigo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/npuichigo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/npuichigo"
} | [] | closed | false | null | [] | null | [
"Can you explain your use case for `max_shard_size`? \r\n\r\nOn some systems, there is a limit to the size of a memory-mapped file, so we could consider exposing this parameter in `load_dataset`.",
"In my use case, users may choose a proper size to balance the cost and benefit of using large shard size. (On azure blob or hdfs which may automatically download the shard from background)",
"But `load_dataset` doesn't support caching (and reading) Arrow datasets from remote storage. \r\n\r\n`load_datset_builder` + `download_and_prepare` is not equal to `load_dataset`. The latter has one more step, `builder.as_dataset`, that memory-maps Arrow files, which only works for local files.",
"Thanks. So if I want to use `IterableDataset` and control the size of single arrow file, how should I organize the data loader? Maybe `load_dataset_build` + `download_and_prepare` + `builder.as_dataset` + `dataset.to_iterable_dataset`?",
"Yes, this should work.\r\n\r\nI think we can expose `max_shard_size` in `load_dataset`, so feel free to open a PR."
] | "2023-06-25T04:19:13Z" | "2023-06-29T16:06:08Z" | "2023-06-29T16:06:08Z" | CONTRIBUTOR | null | null | null | ### Describe the bug
https://github.com/huggingface/datasets/blob/a8a797cc92e860c8d0df71e0aa826f4d2690713e/src/datasets/load.py#L1809
What I can to is break the `load_dataset` and use `load_datset_builder` + `download_and_prepare` instead.
### Steps to reproduce the bug
https://github.com/huggingface/datasets/blob/a8a797cc92e860c8d0df71e0aa826f4d2690713e/src/datasets/load.py#L1809
### Expected behavior
Users can define the max shard size.
### Environment info
datasets==2.13.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5987/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5987/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4369/comments | https://api.github.com/repos/huggingface/datasets/issues/4369/events | https://github.com/huggingface/datasets/pull/4369 | 1,240,245,642 | PR_kwDODunzps44CpCe | 4,369 | Add redirect to dataset script in the repo structure page | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-18T17:05:33Z" | "2022-05-19T08:19:01Z" | "2022-05-19T08:10:51Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4369.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4369",
"merged_at": "2022-05-19T08:10:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4369.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4369"
} | Following https://github.com/huggingface/hub-docs/pull/146 I added a redirection to the dataset scripts documentation in the repository structure page. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4369/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4369/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4611/comments | https://api.github.com/repos/huggingface/datasets/issues/4611/events | https://github.com/huggingface/datasets/pull/4611 | 1,290,940,874 | PR_kwDODunzps46rxIX | 4,611 | Preserve member order by MockDownloadManager.iter_archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-07-01T05:48:20Z" | "2022-07-01T16:59:11Z" | "2022-07-01T16:48:28Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4611.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4611",
"merged_at": "2022-07-01T16:48:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4611.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4611"
} | Currently, `MockDownloadManager.iter_archive` yields paths to archive members in an order given by `path.rglob("*")`, which migh not be the same order as in the original archive.
See issue in:
- https://github.com/huggingface/datasets/pull/4579#issuecomment-1172135027
This PR fixes the order of the members yielded by `MockDownloadManager.iter_archive` so that it is the same as in the original archive. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/616/comments | https://api.github.com/repos/huggingface/datasets/issues/616/events | https://github.com/huggingface/datasets/issues/616 | 699,462,293 | MDU6SXNzdWU2OTk0NjIyOTM= | 616 | UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/BramVanroy",
"id": 2779410,
"login": "BramVanroy",
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/BramVanroy"
} | [] | open | false | null | [] | null | [
"I have the same issue",
"Same issue here when Trying to load a dataset from disk.",
"I am also experiencing this issue, and don't know if it's affecting my training.",
"Same here. I hope the dataset is not being modified in-place.",
"I think the only way to avoid this warning would be to do a copy of the numpy array before providing it.\r\n\r\nThis would slow down a bit the iteration over the dataset but maybe it would be safer. We could disable the copy with a flag on the `set_format` command.\r\n\r\nIn most typical cases of training a NLP model, PyTorch shouldn't modify the input so it's ok to have a non-writable array but I can understand the warning is a bit scary so maybe we could choose the side of non-warning/slower by default and have an option to speedup.\r\n\r\nWhat do you think @lhoestq ? ",
"@thomwolf Would it be possible to have the array look writeable, but raise an error if it is actually written to?\r\n\r\nI would like to keep my code free of warning, but I also wouldn't like to slow down the program because of unnecessary copy operations. ",
"@AndreasMadsen probably not I would guess (no free lunch hahah)",
"@thomwolf Why not? Writable is checked with `arr.flags.writeable`, and writing is done via magic methods.",
"Well because I don't know the internal of numpy as well as you I guess hahahah, do you want to try to open a PR proposing a solution?",
"@thomwolf @AndreasMadsen I think this is a terrible idea, n/o, and I am very much against it. Modifying internals of an array in such a hacky way is bound to run into other (user) issues down the line. To users it would not be clear at all what is going on e.g. when they check for write access (which will return True) but then they get a warning that the array is not writeable. That's extremely confusing. \r\n\r\nIf your only goal is to get rid of warnings in your code, then you can just use a [simplefilter](https://docs.python.org/3.8/library/warnings.html#temporarily-suppressing-warnings) for UserWarnings in your own code. Changing the code-base in such an intuitive way does not seem like a good way to go and sets a bad precedent, imo. \r\n\r\n(Feel free to disagree, of course.)\r\n\r\nIMO a warning can stay (as they can be filtered by users anyway), but it can be clarified why the warning takes place.",
"> To users it would not be clear at all what is going on e.g. when they check for write access (which will return True) but then they get a warning that the array is not writeable. That's extremely confusing.\r\n\r\nConfusion can be resolved with a helpful error message. In this case, that error message can be controlled by huggingface/datasets. The right argument here is that if code depends on `.flags.writable` being truthful (not just for warnings), then it will cause unavoidable errors. Although, I can't imagine such a use-case.\r\n\r\n> If your only goal is to get rid of warnings in your code, then you can just use a simplefilter for UserWarnings in your own code. Changing the code-base in such an intuitive way does not seem like a good way to go and sets a bad precedent, imo.\r\n\r\nI don't want to ignore all `UserWarnings`, nor all warnings regarding non-writable arrays. Ignoring warnings leads to hard to debug issues.\r\n\r\n> IMO a warning can stay (as they can be filtered by users anyway), but it can be clarified why the warning takes place.\r\n\r\nPlain use cases should really not generate warnings. It teaches developers to ignore warnings which is a terrible practice.\r\n\r\n---\r\n\r\nThe best solution would be to allow non-writable arrays in `DataLoader`, but that is a PyTorch issue.",
"> The right argument here is that if code depends on `.flags.writable` being truthful (not just for warnings), then it will cause unavoidable errors. Although, I can't imagine such a use-case.\r\n\r\nThat's exactly the argument in my first sentence. Too often someone \"cannot think of a use-case\", but you can not foresee the use-cases of a whole research community.\r\n \r\n> I don't want to ignore all `UserWarnings`, nor all warnings regarding non-writable arrays. Ignoring warnings leads to hard to debug issues.\r\n\r\nThat's fair.\r\n\r\n> Plain use cases should really not generate warnings. It teaches developers to ignore warnings which is a terrible practice.\r\n\r\nBut this is not a plain use-case (because Pytorch does not support these read-only tensors). Manually setting the flag to writable will solve the issue on the surface but is basically just a hack to compensate for something that is not allowed in another library. \r\n\r\nWhat about an \"ignore_warnings\" flag in `set_format` that when True wraps the offending code in a block to ignore userwarnings at that specific step in [_convert_outputs](https://github.com/huggingface/datasets/blob/880c2c76a8223a00c303eab2909371e857113063/src/datasets/arrow_dataset.py#L821)? Something like:\r\n\r\n```python\r\ndef _convert_outputs(..., ignore_warnings=True):\r\n ...\r\n with warnings.catch_warnings():\r\n if ignore_warnings:\r\n warnings.simplefilter(\"ignore\", UserWarning)\r\n return torch.tensor(...)\r\n# continues without warning filter after context manager...\r\n```",
"> But this is not a plain use-case (because Pytorch does not support these read-only tensors).\r\n\r\nBy \"plain\", I mean the recommended way to use `datasets` with PyTorch according to the `datasets` documentation.",
"This error is what I see when I run the first lines of the Pytorch Quickstart. It should also say that it should be ignored and/or how to fix it. BTW, this is a Pytorch error message -- not a Huggingface error message. My code runs anyway."
] | "2020-09-11T15:39:16Z" | "2021-07-22T21:12:21Z" | null | CONTRIBUTOR | null | null | null | I am trying out the library and want to load in pickled data with `from_dict`. In that dict, one column `text` should be tokenized and the other (an embedding vector) should be retained. All other columns should be removed. When I eventually try to set the format for the columns with `set_format` I am getting this strange Userwarning without a stack trace:
> Set __getitem__(key) output type to torch for ['input_ids', 'sembedding'] columns (when key is int or slice) and don't output other (un-formatted) columns.
> C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\datasets\arrow_dataset.py:835: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:141.)
> return torch.tensor(x, **format_kwargs)
The first one might not be related to the warning, but it is odd that it is shown, too. It is unclear whether that is something that I should do or something that that the program is doing at that moment.
Snippet:
```
dataset = Dataset.from_dict(torch.load("data/dummy.pt.pt"))
print(dataset)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
keys_to_retain = {"input_ids", "sembedding"}
dataset = dataset.map(lambda example: tokenizer(example["text"], padding='max_length'), batched=True)
dataset.remove_columns_(set(dataset.column_names) - keys_to_retain)
dataset.set_format(type="torch", columns=["input_ids", "sembedding"])
dataloader = torch.utils.data.DataLoader(dataset, batch_size=2)
print(next(iter(dataloader)))
```
PS: the input type for `remove_columns_` should probably be an Iterable rather than just a List. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/616/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2474/comments | https://api.github.com/repos/huggingface/datasets/issues/2474/events | https://github.com/huggingface/datasets/issues/2474 | 917,622,055 | MDU6SXNzdWU5MTc2MjIwNTU= | 2,474 | cache_dir parameter for load_from_disk ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/7063207?v=4",
"events_url": "https://api.github.com/users/chbensch/events{/privacy}",
"followers_url": "https://api.github.com/users/chbensch/followers",
"following_url": "https://api.github.com/users/chbensch/following{/other_user}",
"gists_url": "https://api.github.com/users/chbensch/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/chbensch",
"id": 7063207,
"login": "chbensch",
"node_id": "MDQ6VXNlcjcwNjMyMDc=",
"organizations_url": "https://api.github.com/users/chbensch/orgs",
"received_events_url": "https://api.github.com/users/chbensch/received_events",
"repos_url": "https://api.github.com/users/chbensch/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/chbensch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chbensch/subscriptions",
"type": "User",
"url": "https://api.github.com/users/chbensch"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi ! `load_from_disk` doesn't move the data. If you specify a local path to your mounted drive, then the dataset is going to be loaded directly from the arrow file in this directory. The cache files that result from `map` operations are also stored in the same directory by default.\r\n\r\nHowever note than writing data to your google drive actually fills the VM's disk (see https://github.com/huggingface/datasets/issues/643)\r\n\r\nGiven that, I don't think that changing the cache directory changes anything.\r\n\r\nLet me know what you think",
"Thanks for your answer! I am a little surprised since I just want to read the dataset.\r\n\r\nAfter debugging a bit, I noticed that the VM’s disk fills up when the tables (generator) are converted to a list:\r\n\r\nhttps://github.com/huggingface/datasets/blob/5ba149773d23369617563d752aca922081277ec2/src/datasets/table.py#L850\r\n\r\nIf I try to iterate through the table’s generator e.g.: \r\n\r\n`length = sum(1 for x in tables)`\r\n\r\nthe VM’s disk fills up as well.\r\n\r\nI’m running out of Ideas 😄 ",
"Indeed reading the data shouldn't increase the VM's disk. Not sure what google colab does under the hood for that to happen",
"Apparently, Colab uses a local cache of the data files read/written from Google Drive. See:\r\n- https://github.com/googlecolab/colabtools/issues/2087#issuecomment-860818457\r\n- https://github.com/googlecolab/colabtools/issues/1915#issuecomment-804234540\r\n- https://github.com/googlecolab/colabtools/issues/2147#issuecomment-885052636"
] | "2021-06-10T17:39:36Z" | "2022-02-16T14:55:01Z" | "2022-02-16T14:55:00Z" | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
When using Google Colab big datasets can be an issue, as they won't fit on the VM's disk. Therefore mounting google drive could be a possible solution. Unfortunatly when loading my own dataset by using the _load_from_disk_ function, the data gets cached to the VM's disk:
`
from datasets import load_from_disk
myPreprocessedData = load_from_disk("/content/gdrive/MyDrive/ASR_data/myPreprocessedData")
`
I know that chaching on google drive could slow down learning. But at least it would run.
**Describe the solution you'd like**
Add cache_Dir parameter to the load_from_disk function.
**Describe alternatives you've considered**
It looks like you could write a custom loading script for the load_dataset function. But this seems to be much too complex for my use case. Is there perhaps a template here that uses the load_from_disk function?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2474/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2474/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4601/comments | https://api.github.com/repos/huggingface/datasets/issues/4601/events | https://github.com/huggingface/datasets/pull/4601 | 1,289,924,715 | PR_kwDODunzps46oWF8 | 4,601 | Upgrade pip in WIN CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"It failed terribly"
] | "2022-06-30T10:25:42Z" | "2023-09-24T10:04:25Z" | "2022-06-30T10:43:38Z" | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4601.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4601",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4601.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4601"
} | The windows CI is currently flaky: some dependencies like aiobotocore, multiprocess and seqeval sometimes fail to install.
In particular it seems that building the wheels fail. Here is an example of logs
```
Building wheel for seqeval (setup.py): started
Running command 'C:\tools\miniconda3\envs\py37\python.exe' -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\circleci\\AppData\\Local\\Temp\\pip-install-h55pfgbv\\seqeval_d6cdb9d23ff6490b98b6c4bcaecb516e\\setup.py'"'"'; __file__='"'"'C:\\Users\\circleci\\AppData\\Local\\Temp\\pip-install-h55pfgbv\\seqeval_d6cdb9d23ff6490b98b6c4bcaecb516e\\setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' bdist_wheel -d 'C:\Users\circleci\AppData\Local\Temp\pip-wheel-x3cc8ym6'
No parent package detected, impossible to derive `name`
running bdist_wheel
running build
running build_py
package init file 'seqeval\__init__.py' not found (or not a regular file)
package init file 'seqeval\metrics\__init__.py' not found (or not a regular file)
C:\tools\miniconda3\envs\py37\lib\site-packages\setuptools\command\install.py:37: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
setuptools.SetuptoolsDeprecationWarning,
installing to build\bdist.win-amd64\wheel
running install
running install_lib
warning: install_lib: 'build\lib' does not exist -- no Python modules to install
running install_egg_info
running egg_info
creating UNKNOWN.egg-info
writing UNKNOWN.egg-info\PKG-INFO
writing dependency_links to UNKNOWN.egg-info\dependency_links.txt
writing top-level names to UNKNOWN.egg-info\top_level.txt
writing manifest file 'UNKNOWN.egg-info\SOURCES.txt'
reading manifest file 'UNKNOWN.egg-info\SOURCES.txt'
writing manifest file 'UNKNOWN.egg-info\SOURCES.txt'
Copying UNKNOWN.egg-info to build\bdist.win-amd64\wheel\.\UNKNOWN-0.0.0-py3.7.egg-info
running install_scripts
creating build\bdist.win-amd64\wheel\UNKNOWN-0.0.0.dist-info\WHEEL
creating 'C:\Users\circleci\AppData\Local\Temp\pip-wheel-x3cc8ym6\UNKNOWN-0.0.0-py3-none-any.whl' and adding 'build\bdist.win-amd64\wheel' to it
adding 'UNKNOWN-0.0.0.dist-info/METADATA'
adding 'UNKNOWN-0.0.0.dist-info/WHEEL'
adding 'UNKNOWN-0.0.0.dist-info/top_level.txt'
adding 'UNKNOWN-0.0.0.dist-info/RECORD'
removing build\bdist.win-amd64\wheel
Building wheel for seqeval (setup.py): finished with status 'done'
Created wheel for seqeval: filename=UNKNOWN-0.0.0-py3-none-any.whl size=963 sha256=67eb93a6e1ff4796c5882a13f9fa25bb0d3d103796e2525f9cecf3b2ef26d4b1
Stored in directory: c:\users\circleci\appdata\local\pip\cache\wheels\05\96\ee\7cac4e74f3b19e3158dce26a20a1c86b3533c43ec72a549fd7
WARNING: Built wheel for seqeval is invalid: Wheel has unexpected file name: expected 'seqeval', got 'UNKNOWN'
```
I tried to update pip and re-run the CI several times and I couldn't re-experience this issue for now, so I think upgrading pip may solve the issue | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4601/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1593/comments | https://api.github.com/repos/huggingface/datasets/issues/1593/events | https://github.com/huggingface/datasets/issues/1593 | 769,611,386 | MDU6SXNzdWU3Njk2MTEzODY= | 1,593 | Access to key in DatasetDict map | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ZhaofengWu",
"id": 11954789,
"login": "ZhaofengWu",
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ZhaofengWu"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Indeed that would be cool\r\n\r\nAlso FYI right now the easiest way to do this is\r\n```python\r\ndataset_dict[\"train\"] = dataset_dict[\"train\"].map(my_transform_for_the_train_set)\r\ndataset_dict[\"test\"] = dataset_dict[\"test\"].map(my_transform_for_the_test_set)\r\n```",
"I don't feel like adding an extra param for this simple usage makes sense, considering how many args `map` already has. \r\n\r\n(Feel free to re-open this issue if you don't agree with me)",
"I still think this is useful, since it's common that the data processing is different for training/dev/testing. And I don't know if the fact that `map` currently takes many arguments is a good reason not to support a useful feature."
] | "2020-12-17T07:02:20Z" | "2022-10-05T13:47:28Z" | "2022-10-05T12:33:06Z" | NONE | null | null | null | It is possible that we want to do different things in the `map` function (and possibly other functions too) of a `DatasetDict`, depending on the key. I understand that `DatasetDict.map` is a really thin wrapper of `Dataset.map`, so it is easy to directly implement this functionality in the client code. Still, it'd be nice if there can be a flag, similar to `with_indices`, that allows the callable to know the key inside `DatasetDict`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1593/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1593/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3640/comments | https://api.github.com/repos/huggingface/datasets/issues/3640/events | https://github.com/huggingface/datasets/issues/3640 | 1,116,133,769 | I_kwDODunzps5ChtmJ | 3,640 | Issues with custom dataset in Wav2Vec2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"events_url": "https://api.github.com/users/peregilk/events{/privacy}",
"followers_url": "https://api.github.com/users/peregilk/followers",
"following_url": "https://api.github.com/users/peregilk/following{/other_user}",
"gists_url": "https://api.github.com/users/peregilk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/peregilk",
"id": 9079808,
"login": "peregilk",
"node_id": "MDQ6VXNlcjkwNzk4MDg=",
"organizations_url": "https://api.github.com/users/peregilk/orgs",
"received_events_url": "https://api.github.com/users/peregilk/received_events",
"repos_url": "https://api.github.com/users/peregilk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/peregilk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/peregilk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/peregilk"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Closed and moved to transformers."
] | "2022-01-27T12:09:05Z" | "2022-01-27T12:29:48Z" | "2022-01-27T12:29:48Z" | NONE | null | null | null | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:

We are able to work around the issue, for instance by adding this check in line#222 in transformers/models/wav2vec2/modeling_wav2vec2.py:
```python
if input_length - (mask_length - 1) < num_masked_span:
num_masked_span = input_length - (mask_length - 1)
```
Interestingly, these are the variable values before the adjustment:
```
input_length=10
mask_length=10
num_masked_span=2
````
After adjusting num_masked_spin to 1, the training script runs. The issue is also fixed by setting “replace=True” in the same function.
Do you have any idea what is causing this, and how to fix this error permanently? If you do not think this is an Datasets issue, feel free to move the issue.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3640/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3640/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2426/comments | https://api.github.com/repos/huggingface/datasets/issues/2426/events | https://github.com/huggingface/datasets/issues/2426 | 906,473,546 | MDU6SXNzdWU5MDY0NzM1NDY= | 2,426 | Saving Graph/Structured Data in Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/3295342?v=4",
"events_url": "https://api.github.com/users/gsh199449/events{/privacy}",
"followers_url": "https://api.github.com/users/gsh199449/followers",
"following_url": "https://api.github.com/users/gsh199449/following{/other_user}",
"gists_url": "https://api.github.com/users/gsh199449/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gsh199449",
"id": 3295342,
"login": "gsh199449",
"node_id": "MDQ6VXNlcjMyOTUzNDI=",
"organizations_url": "https://api.github.com/users/gsh199449/orgs",
"received_events_url": "https://api.github.com/users/gsh199449/received_events",
"repos_url": "https://api.github.com/users/gsh199449/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gsh199449/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gsh199449/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gsh199449"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"It should probably work out of the box to save structured data. If you want to show an example we can help you.",
"An example of a toy dataset is like:\r\n```json\r\n[\r\n {\r\n \"name\": \"mike\",\r\n \"friends\": [\r\n \"tom\",\r\n \"lily\"\r\n ],\r\n \"articles\": [\r\n {\r\n \"title\": \"aaaaa\",\r\n \"reader\": [\r\n \"tom\",\r\n \"lucy\"\r\n ]\r\n }\r\n ]\r\n },\r\n {\r\n \"name\": \"tom\",\r\n \"friends\": [\r\n \"mike\",\r\n \"bbb\"\r\n ],\r\n \"articles\": [\r\n {\r\n \"title\": \"xxxxx\",\r\n \"reader\": [\r\n \"tom\",\r\n \"qqqq\"\r\n ]\r\n }\r\n ]\r\n }\r\n]\r\n```\r\nWe can use the friendship relation to build a directional graph, and a user node can be represented using the articles written by himself. And the relationship between articles can be built when the article has read by the same user.\r\nThis dataset can be used to model the heterogeneous relationship between users and articles, and this graph can be used to build recommendation systems to recommend articles to the user, or potential friends to the user.",
"Hi,\r\n\r\nyou can do the following to load this data into a `Dataset`:\r\n```python\r\nfrom datasets import Dataset\r\nexamples = [\r\n {\r\n \"name\": \"mike\",\r\n \"friends\": [\r\n \"tom\",\r\n \"lily\"\r\n ],\r\n \"articles\": [\r\n {\r\n \"title\": \"aaaaa\",\r\n \"reader\": [\r\n \"tom\",\r\n \"lucy\"\r\n ]\r\n }\r\n ]\r\n },\r\n {\r\n \"name\": \"tom\",\r\n \"friends\": [\r\n \"mike\",\r\n \"bbb\"\r\n ],\r\n \"articles\": [\r\n {\r\n \"title\": \"xxxxx\",\r\n \"reader\": [\r\n \"tom\",\r\n \"qqqq\"\r\n ]\r\n }\r\n ]\r\n }\r\n]\r\n\r\nkeys = examples[0].keys()\r\nvalues = [ex.values() for ex in examples]\r\ndataset = Dataset.from_dict({k: list(v) for k, v in zip(keys, zip(*values))})\r\n```\r\n\r\nLet us know if this works for you.",
"Thank you so much, and that works! I also have a question that if the dataset is very large, that cannot be loaded into the memory. How to create the Dataset?",
"If your dataset doesn't fit in memory, store it in a local file and load it from there. Check out [this chapter](https://huggingface.co/docs/datasets/master/loading_datasets.html#from-local-files) in the docs for more info.",
"Nice! Thanks for your help."
] | "2021-05-29T13:35:21Z" | "2021-06-02T01:21:03Z" | "2021-06-02T01:21:03Z" | NONE | null | null | null | Thanks for this amazing library! And my question is I have structured data that is organized with a graph. For example, a dataset with users' friendship relations and user's articles. When I try to save a python dict in the dataset, an error occurred ``did not recognize Python value type when inferring an Arrow data type''.
Although I also know that storing a python dict in pyarrow datasets is not the best practice, but I have no idea about how to save structured data in the Datasets.
Thank you very much for your help. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2426/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2426/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3115 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3115/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3115/comments | https://api.github.com/repos/huggingface/datasets/issues/3115/events | https://github.com/huggingface/datasets/pull/3115 | 1,030,737,524 | PR_kwDODunzps4tZ-Vr | 3,115 | Fill in dataset card for NCBI disease dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/17855740?v=4",
"events_url": "https://api.github.com/users/edugp/events{/privacy}",
"followers_url": "https://api.github.com/users/edugp/followers",
"following_url": "https://api.github.com/users/edugp/following{/other_user}",
"gists_url": "https://api.github.com/users/edugp/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/edugp",
"id": 17855740,
"login": "edugp",
"node_id": "MDQ6VXNlcjE3ODU1NzQw",
"organizations_url": "https://api.github.com/users/edugp/orgs",
"received_events_url": "https://api.github.com/users/edugp/received_events",
"repos_url": "https://api.github.com/users/edugp/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/edugp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edugp/subscriptions",
"type": "User",
"url": "https://api.github.com/users/edugp"
} | [] | closed | false | null | [] | null | [] | "2021-10-19T20:57:05Z" | "2021-10-22T08:25:07Z" | "2021-10-22T08:25:07Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3115.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3115",
"merged_at": "2021-10-22T08:25:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3115.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3115"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3115/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3115/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/609/comments | https://api.github.com/repos/huggingface/datasets/issues/609/events | https://github.com/huggingface/datasets/pull/609 | 698,323,989 | MDExOlB1bGxSZXF1ZXN0NDg0MTc4Nzky | 609 | Update GLUE URLs (now hosted on FB) | {
"avatar_url": "https://avatars.githubusercontent.com/u/57466294?v=4",
"events_url": "https://api.github.com/users/jeswan/events{/privacy}",
"followers_url": "https://api.github.com/users/jeswan/followers",
"following_url": "https://api.github.com/users/jeswan/following{/other_user}",
"gists_url": "https://api.github.com/users/jeswan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jeswan",
"id": 57466294,
"login": "jeswan",
"node_id": "MDQ6VXNlcjU3NDY2Mjk0",
"organizations_url": "https://api.github.com/users/jeswan/orgs",
"received_events_url": "https://api.github.com/users/jeswan/received_events",
"repos_url": "https://api.github.com/users/jeswan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jeswan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeswan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jeswan"
} | [] | closed | false | null | [] | null | [
"Thanks for opening this PR :) \r\n\r\nWe changed the name of the lib from nlp to datasets yesterday.\r\nCould you rebase from master and re-generate the dataset_info.json file to fix the name changes ?",
"Rebased changes here: https://github.com/huggingface/datasets/pull/626"
] | "2020-09-10T18:16:32Z" | "2020-09-14T19:06:02Z" | "2020-09-14T19:06:01Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/609.diff",
"html_url": "https://github.com/huggingface/datasets/pull/609",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/609.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/609"
} | NYU is switching dataset hosting from Google to FB. This PR closes https://github.com/huggingface/datasets/issues/608 and is necessary for https://github.com/jiant-dev/jiant/issues/161. This PR updates the data URLs based on changes made in https://github.com/nyu-mll/jiant/pull/1112. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/609/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/377/comments | https://api.github.com/repos/huggingface/datasets/issues/377/events | https://github.com/huggingface/datasets/issues/377 | 655,215,790 | MDU6SXNzdWU2NTUyMTU3OTA= | 377 | Iyy!!! | {
"avatar_url": "https://avatars.githubusercontent.com/u/68154535?v=4",
"events_url": "https://api.github.com/users/ajinomoh/events{/privacy}",
"followers_url": "https://api.github.com/users/ajinomoh/followers",
"following_url": "https://api.github.com/users/ajinomoh/following{/other_user}",
"gists_url": "https://api.github.com/users/ajinomoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ajinomoh",
"id": 68154535,
"login": "ajinomoh",
"node_id": "MDQ6VXNlcjY4MTU0NTM1",
"organizations_url": "https://api.github.com/users/ajinomoh/orgs",
"received_events_url": "https://api.github.com/users/ajinomoh/received_events",
"repos_url": "https://api.github.com/users/ajinomoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ajinomoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ajinomoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ajinomoh"
} | [] | closed | false | null | [] | null | [] | "2020-07-11T14:11:07Z" | "2020-07-11T14:30:51Z" | "2020-07-11T14:30:51Z" | NONE | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/377/timeline | null | completed | false |
|
https://api.github.com/repos/huggingface/datasets/issues/2218 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2218/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2218/comments | https://api.github.com/repos/huggingface/datasets/issues/2218/events | https://github.com/huggingface/datasets/issues/2218 | 857,238,435 | MDU6SXNzdWU4NTcyMzg0MzU= | 2,218 | Duplicates in the LAMA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7276193?v=4",
"events_url": "https://api.github.com/users/amarasovic/events{/privacy}",
"followers_url": "https://api.github.com/users/amarasovic/followers",
"following_url": "https://api.github.com/users/amarasovic/following{/other_user}",
"gists_url": "https://api.github.com/users/amarasovic/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/amarasovic",
"id": 7276193,
"login": "amarasovic",
"node_id": "MDQ6VXNlcjcyNzYxOTM=",
"organizations_url": "https://api.github.com/users/amarasovic/orgs",
"received_events_url": "https://api.github.com/users/amarasovic/received_events",
"repos_url": "https://api.github.com/users/amarasovic/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/amarasovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amarasovic/subscriptions",
"type": "User",
"url": "https://api.github.com/users/amarasovic"
} | [] | open | false | null | [] | null | [
"Hi,\r\n\r\ncurrently the datasets API doesn't have a dedicated function to remove duplicate rows, but since the LAMA dataset is not too big (it fits in RAM), we can leverage pandas to help us remove duplicates:\r\n```python\r\n>>> from datasets import load_dataset, Dataset\r\n>>> dataset = load_dataset('lama', split='train')\r\n>>> dataset = Dataset.from_pandas(dataset.to_pandas().drop_duplicates(subset=...)) # specify a subset of the columns to consider in a list or use all of the columns if None\r\n```\r\n\r\nNote that the same can be achieved with the `Dataset.filter` method but this would requrie some extra work (filter function, speed?).",
"Oh, seems like my question wasn't specified well. I'm _not_ asking how to remove duplicates, but whether duplicates should be removed if I want to do the evaluation on the LAMA dataset as it was proposed in the original paper/repository? In other words, will I get the same result if evaluate on the de-duplicated dataset loaded from HF's `datasets` as the results I'd get if I use the original data format and data processing script in https://github.com/facebookresearch/LAMA? ",
"So it looks like the person who added LAMA to the library chose to have one item per piece of evidence rather than one per relation - and in this case, there are duplicate pieces of evidence for the target relation\r\n\r\nIf I understand correctly, to reproduce reported results, you would have to aggregate predictions for the several pieces of evidence provided for each relation (each unique `uuid`), but the original authors will know better \r\n\r\ncc @fabiopetroni "
] | "2021-04-13T18:59:49Z" | "2021-04-14T21:42:27Z" | null | NONE | null | null | null | I observed duplicates in the LAMA probing dataset, see a minimal code below.
```
>>> import datasets
>>> dataset = datasets.load_dataset('lama')
No config specified, defaulting to: lama/trex
Reusing dataset lama (/home/anam/.cache/huggingface/datasets/lama/trex/1.1.0/97deffae13eca0a18e77dfb3960bb31741e973586f5c1fe1ec0d6b5eece7bddc)
>>> train_dataset = dataset['train']
>>> train_dataset[0]
{'description': 'language or languages a person has learned from early childhood', 'label': 'native language', 'masked_sentence': 'Louis Jules Trochu ([lwi ʒyl tʁɔʃy]; 12 March 1815 – 7 October 1896) was a [MASK] military leader and politician.', 'obj_label': 'French', 'obj_surface': 'French', 'obj_uri': 'Q150', 'predicate_id': 'P103', 'sub_label': 'Louis Jules Trochu', 'sub_surface': 'Louis Jules Trochu', 'sub_uri': 'Q441235', 'template': 'The native language of [X] is [Y] .', 'template_negated': '[X] is not owned by [Y] .', 'type': 'N-1', 'uuid': '40b2ed1c-0961-482e-844e-32596b6117c8'}
>>> train_dataset[1]
{'description': 'language or languages a person has learned from early childhood', 'label': 'native language', 'masked_sentence': 'Louis Jules Trochu ([lwi ʒyl tʁɔʃy]; 12 March 1815 – 7 October 1896) was a [MASK] military leader and politician.', 'obj_label': 'French', 'obj_surface': 'French', 'obj_uri': 'Q150', 'predicate_id': 'P103', 'sub_label': 'Louis Jules Trochu', 'sub_surface': 'Louis Jules Trochu', 'sub_uri': 'Q441235', 'template': 'The native language of [X] is [Y] .', 'template_negated': '[X] is not owned by [Y] .', 'type': 'N-1', 'uuid': '40b2ed1c-0961-482e-844e-32596b6117c8'}
```
I checked the original data available at https://dl.fbaipublicfiles.com/LAMA/data.zip. This particular duplicated comes from:
```
{"uuid": "40b2ed1c-0961-482e-844e-32596b6117c8", "obj_uri": "Q150", "obj_label": "French", "sub_uri": "Q441235", "sub_label": "Louis Jules Trochu", "predicate_id": "P103", "evidences": [{"sub_surface": "Louis Jules Trochu", "obj_surface": "French", "masked_sentence": "Louis Jules Trochu ([lwi \u0292yl t\u0281\u0254\u0283y]; 12 March 1815 \u2013 7 October 1896) was a [MASK] military leader and politician."}, {"sub_surface": "Louis Jules Trochu", "obj_surface": "French", "masked_sentence": "Louis Jules Trochu ([lwi \u0292yl t\u0281\u0254\u0283y]; 12 March 1815 \u2013 7 October 1896) was a [MASK] military leader and politician."}]}
```
What is the best way to deal with these duplicates if I want to use `datasets` to probe with LAMA? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2218/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2218/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4583/comments | https://api.github.com/repos/huggingface/datasets/issues/4583/events | https://github.com/huggingface/datasets/pull/4583 | 1,286,790,871 | PR_kwDODunzps46d7xo | 4,583 | <code> implementation of FLAC support using torchaudio | {
"avatar_url": "https://avatars.githubusercontent.com/u/45745870?v=4",
"events_url": "https://api.github.com/users/rafael-ariascalles/events{/privacy}",
"followers_url": "https://api.github.com/users/rafael-ariascalles/followers",
"following_url": "https://api.github.com/users/rafael-ariascalles/following{/other_user}",
"gists_url": "https://api.github.com/users/rafael-ariascalles/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rafael-ariascalles",
"id": 45745870,
"login": "rafael-ariascalles",
"node_id": "MDQ6VXNlcjQ1NzQ1ODcw",
"organizations_url": "https://api.github.com/users/rafael-ariascalles/orgs",
"received_events_url": "https://api.github.com/users/rafael-ariascalles/received_events",
"repos_url": "https://api.github.com/users/rafael-ariascalles/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rafael-ariascalles/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rafael-ariascalles/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rafael-ariascalles"
} | [] | closed | false | null | [] | null | [] | "2022-06-28T05:24:21Z" | "2022-06-28T05:47:02Z" | "2022-06-28T05:47:02Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4583",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4583"
} | I had added Audio FLAC support with torchaudio given that Librosa and SoundFile can give problems. Also, FLAC is been used as audio from https://mlcommons.org/en/peoples-speech/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4583/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3615/comments | https://api.github.com/repos/huggingface/datasets/issues/3615/events | https://github.com/huggingface/datasets/issues/3615 | 1,111,576,876 | I_kwDODunzps5CQVEs | 3,615 | Dataset BnL Historical Newspapers does not work in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"@albertvillanova let me know if there is anything I can do to help with this. I had a quick look at the code again and though I could try the following changes:\r\n- use `download` instead of `download_and_extract`\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bnl_newspapers/bnl_newspapers.py#L136\r\n- swith to using `iter_archive` to loop through downloaded data to replace\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bnl_newspapers/bnl_newspapers.py#L159\r\n\r\nLet me know if it's useful for me to try and make those changes. ",
"Thanks @davanstrien.\r\n\r\nI have already been working on it so that it can be used in the BigScience workshop.\r\n\r\nI agree that the `rglob()` is not efficient in this case.\r\n\r\nI tried different solutions without success:\r\n- `iter_archive` cannot be used in this case because it does not support ZIP files yet\r\n\r\nFinally I have used `iter_files()`.",
"I see this is fixed now 🙂. I also picked up a few other tips from your redactors so hopefully my next attempts will support streaming from the start. "
] | "2022-01-22T14:12:59Z" | "2022-02-04T14:05:21Z" | "2022-02-04T14:05:21Z" | MEMBER | null | null | null | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3615/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2134 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2134/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2134/comments | https://api.github.com/repos/huggingface/datasets/issues/2134/events | https://github.com/huggingface/datasets/issues/2134 | 843,242,849 | MDU6SXNzdWU4NDMyNDI4NDk= | 2,134 | Saving large in-memory datasets with save_to_disk crashes because of pickling | {
"avatar_url": "https://avatars.githubusercontent.com/u/5815801?v=4",
"events_url": "https://api.github.com/users/prokopCerny/events{/privacy}",
"followers_url": "https://api.github.com/users/prokopCerny/followers",
"following_url": "https://api.github.com/users/prokopCerny/following{/other_user}",
"gists_url": "https://api.github.com/users/prokopCerny/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/prokopCerny",
"id": 5815801,
"login": "prokopCerny",
"node_id": "MDQ6VXNlcjU4MTU4MDE=",
"organizations_url": "https://api.github.com/users/prokopCerny/orgs",
"received_events_url": "https://api.github.com/users/prokopCerny/received_events",
"repos_url": "https://api.github.com/users/prokopCerny/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/prokopCerny/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prokopCerny/subscriptions",
"type": "User",
"url": "https://api.github.com/users/prokopCerny"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"Hi !\r\nIndeed `save_to_disk` doesn't call pickle anymore. Though the `OverflowError` can still appear for in-memory datasets bigger than 4GB. This happens when doing this for example:\r\n```python\r\nimport pyarrow as pa\r\nimport pickle\r\n\r\narr = pa.array([0] * ((4 * 8 << 30) // 64))\r\ntable = pa.Table.from_arrays([a], names=[\"foo\"])\r\npickle.dumps(table) # fails with an OverflowError\r\npickle.dumps(table, 4) # works !\r\n```\r\nWe'll do the change to use `protocol=4`.\r\n\r\nMoreover I've also seen other users complain about this error\r\n```\r\nstruct.error: 'I' format requires 0 <= number <= 4294967295\r\n```\r\n\r\nIt looks like something related to the 4GB limit as well but I'm not able to reproduce on my side.\r\nDo you think you can provide a script that reproduces the issue ?\r\nHow big is your dataset ? (number of bytes, number of rows)\r\n\r\n",
"Hi!\r\nSo I've managed to created a minimum working (well technically crashing) example for the multiprocessing case, I create a huge list of zeros, like in your example, and then I try to .map(None, num_proc=2) over it, which then crashes, here's the code:\r\n\r\n```python\r\nfrom datasets import Dataset\r\n\r\nif __name__ == '__main__':\r\n ton_of_zeroes = [0] * ((12 * 8 << 30) // 64)\r\n large_dataset = Dataset.from_dict({'col': ton_of_zeroes})\r\n print(\"Start\")\r\n large_dataset.map(function=None, num_proc=2)\r\n print(\"Done - should not print\")\r\n```\r\n\r\nThe amount of zeros could probably be reduced, I haven't tried to minimize it to find the breaking point, I just increased it from your code (which by quick glance I assumed tried to allocate over 4 GiB)\r\n\r\nRunning this results in the following traceback:\r\n\r\n```\r\nParameter 'indices'=[ 0 1 2 ... 805306365 805306366 805306367] of the transform datasets.arrow_dataset.Dataset.select couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.\r\nTraceback (most recent call last):\r\n File \"./crash_multiproc_pickle.py\", line 7, in <module>\r\n large_dataset.map(function=None, num_proc=2)\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py\", line 1485, in map\r\n transformed_shards = [r.get() for r in results]\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py\", line 1485, in <listcomp>\r\n transformed_shards = [r.get() for r in results]\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/pool.py\", line 657, in get\r\n raise self._value\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/pool.py\", line 431, in _handle_tasks\r\n put(task)\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/connection.py\", line 209, in send\r\n self._send_bytes(_ForkingPickler.dumps(obj))\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/reduction.py\", line 54, in dumps\r\n cls(buf, protocol, *args, **kwds).dump(obj)\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py\", line 454, in dump\r\n StockPickler.dump(self, obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 437, in dump\r\n self.save(obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 789, in save_tuple\r\n save(element)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py\", line 941, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 859, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 885, in _batch_setitems\r\n save(v)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 549, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 662, in save_reduce\r\n save(state)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py\", line 941, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 859, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 885, in _batch_setitems\r\n save(v)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 549, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 638, in save_reduce\r\n save(args)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 774, in save_tuple\r\n save(element)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 819, in save_list\r\n self._batch_appends(obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 846, in _batch_appends\r\n save(tmp[0])\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 549, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 638, in save_reduce\r\n save(args)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 774, in save_tuple\r\n save(element)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 819, in save_list\r\n self._batch_appends(obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 846, in _batch_appends\r\n save(tmp[0])\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 549, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 638, in save_reduce\r\n save(args)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 774, in save_tuple\r\n save(element)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 789, in save_tuple\r\n save(element)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 819, in save_list\r\n self._batch_appends(obj)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 843, in _batch_appends\r\n save(x)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 549, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 638, in save_reduce\r\n save(args)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 774, in save_tuple\r\n save(element)\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py\", line 732, in save_bytes\r\n self._write_large_bytes(BINBYTES + pack(\"<I\", n), obj)\r\nstruct.error: 'I' format requires 0 <= number <= 4294967295\r\n```\r\n\r\nMy datasets usually have hundreds of thousands to low millions of rows, with each row containing a list of 10 strings and list of vectors of different length (the strings tokenized), which in the worst case have 10\\*512\\*8 = 40960 bytes (but usually it is much smaller, as the vectors tend to be shorter. I need these groups of text lines to create training data for the Inverse Cloze Task.\r\n\r\nAnyway I don't think my particular dataset is relevant, as the tiny script I created also manages to crash.\r\nBut I think the issue is the same as the save_to_disk, from the traceback it seems that in multiprocessing, it tries to use dill to return the result of the map workers, which tries to pickle the data and can't do it, probably because it's again using the older pickle protocol. That's my guess anyway.",
"I just merged a fix #2150 that allows to pickle tables bigger than 4GiB\r\nFeel free to try it on the `master` branch !",
"awesome! I started getting this error as well when I tried to tokenize with a longer sequence length",
"@prokopCerny does this fix work for you? I found that with the latest master, my container with 500GB RAM starts crashing when I try to map a large dataset using `num_proc`.\r\n\r\n@lhoestq would it be possible to implement some logic to keep the individual cache files small (say below 100mb)? I find this helps with loading large datasets, but the \"hack\" I was using (increasing `num_proc` to a large number) doesn't work anymore with the latest master; my container crashes even with `num_proc=200` now",
"Closing since the original issue was fixed in #2150 \r\nFeel free to reopen if you are still experiencing it.\r\nFor the other problems, please open separate issues"
] | "2021-03-29T10:43:15Z" | "2021-05-03T17:59:21Z" | "2021-05-03T17:59:21Z" | NONE | null | null | null | Using Datasets 1.5.0 on Python 3.7.
Recently I've been working on medium to large size datasets (pretokenized raw text sizes from few gigabytes to low tens of gigabytes), and have found out that several preprocessing steps are massively faster when done in memory, and I have the ability to requisition a lot of RAM, so I decided to do these steps completely out of the datasets library.
So my workflow is to do several .map() on datasets object, then for the operation which is faster in memory to extract the necessary columns from the dataset and then drop it whole, do the transformation in memory, and then create a fresh Dataset object using .from_dict() or other method.
When I then try to call save_to_disk(path) on the dataset, it crashes because of pickling, which appears to be because of using old pickle protocol which doesn't support large files (over 4 GiB).
```
Traceback (most recent call last):
File "./tokenize_and_chunkify_in_memory.py", line 80, in <module>
main()
File "./tokenize_and_chunkify_in_memory.py", line 75, in main
tokenize_and_chunkify(config)
File "./tokenize_and_chunkify_in_memory.py", line 60, in tokenize_and_chunkify
contexts_dataset.save_to_disk(chunked_path)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 457, in save_to_disk
self = pickle.loads(pickle.dumps(self))
OverflowError: cannot serialize a bytes object larger than 4 GiB
```
From what I've seen this issue may be possibly fixed, as the line `self = pickle.loads(pickle.dumps(self))` does not appear to be present in the current state of the repository.
To save these datasets to disk, I've resorted to calling .map() over them with `function=None` and specifying the .arrow cache file, and then creating a new dataset using the .from_file() method, which I can then safely save to disk.
Additional issue when working with these large in-memory datasets is when using multiprocessing, is again to do with pickling. I've tried to speed up the mapping with function=None by specifying num_proc to the available cpu count, and I again get issues with transferring the dataset, with the following traceback. I am not sure if I should open a separate issue for that.
```
Traceback (most recent call last):
File "./tokenize_and_chunkify_in_memory.py", line 94, in <module>
main()
File "./tokenize_and_chunkify_in_memory.py", line 89, in main
tokenize_and_chunkify(config)
File "./tokenize_and_chunkify_in_memory.py", line 67, in tokenize_and_chunkify
contexts_dataset.map(function=None, cache_file_name=str(output_dir_path / "tmp.arrow"), writer_batch_size=50000, num_proc=config.threads)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1485, in map
transformed_shards = [r.get() for r in results]
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1485, in <listcomp>
transformed_shards = [r.get() for r in results]
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/pool.py", line 657, in get
raise self._value
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/pool.py", line 431, in _handle_tasks
put(task)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/connection.py", line 209, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/reduction.py", line 54, in dumps
cls(buf, protocol, *args, **kwds).dump(obj)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py", line 454, in dump
StockPickler.dump(self, obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 437, in dump
self.save(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py", line 941, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 859, in save_dict
self._batch_setitems(obj.items())
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 885, in _batch_setitems
save(v)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 662, in save_reduce
save(state)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py", line 941, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 859, in save_dict
self._batch_setitems(obj.items())
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 885, in _batch_setitems
save(v)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 843, in _batch_appends
save(x)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 846, in _batch_appends
save(tmp[0])
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 846, in _batch_appends
save(tmp[0])
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 846, in _batch_appends
save(tmp[0])
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 843, in _batch_appends
save(x)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 732, in save_bytes
self._write_large_bytes(BINBYTES + pack("<I", n), obj)
struct.error: 'I' format requires 0 <= number <= 4294967295Traceback (most recent call last):
File "./tokenize_and_chunkify_in_memory.py", line 94, in <module>
main()
File "./tokenize_and_chunkify_in_memory.py", line 89, in main
tokenize_and_chunkify(config)
File "./tokenize_and_chunkify_in_memory.py", line 67, in tokenize_and_chunkify
contexts_dataset.map(function=None, cache_file_name=str(output_dir_path / "tmp.arrow"), writer_batch_size=50000, num_proc=config.threads)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1485, in map
transformed_shards = [r.get() for r in results]
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1485, in <listcomp>
transformed_shards = [r.get() for r in results]
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/pool.py", line 657, in get
raise self._value
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/pool.py", line 431, in _handle_tasks
put(task)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/connection.py", line 209, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/multiprocess/reduction.py", line 54, in dumps
cls(buf, protocol, *args, **kwds).dump(obj)
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py", line 454, in dump
StockPickler.dump(self, obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 437, in dump
self.save(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py", line 941, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 859, in save_dict
self._batch_setitems(obj.items())
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 885, in _batch_setitems
save(v)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 662, in save_reduce
save(state)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/home/cernypro/dev/envs/huggingface_gpu/lib/python3.7/site-packages/dill/_dill.py", line 941, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 859, in save_dict
self._batch_setitems(obj.items())
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 885, in _batch_setitems
save(v)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 843, in _batch_appends
save(x)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 846, in _batch_appends
save(tmp[0])
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 846, in _batch_appends
save(tmp[0])
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 846, in _batch_appends
save(tmp[0])
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 789, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 819, in save_list
self._batch_appends(obj)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 843, in _batch_appends
save(x)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 549, in save
self.save_reduce(obj=obj, *rv)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 638, in save_reduce
save(args)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 774, in save_tuple
save(element)
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 504, in save
f(self, obj) # Call unbound method with explicit self
File "/mnt/appl/software/Python/3.7.4-GCCcore-8.3.0/lib/python3.7/pickle.py", line 732, in save_bytes
self._write_large_bytes(BINBYTES + pack("<I", n), obj)
struct.error: 'I' format requires 0 <= number <= 4294967295
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2134/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2134/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2382/comments | https://api.github.com/repos/huggingface/datasets/issues/2382/events | https://github.com/huggingface/datasets/issues/2382 | 895,610,216 | MDU6SXNzdWU4OTU2MTAyMTY= | 2,382 | DuplicatedKeysError: FAILURE TO GENERATE DATASET ! load_dataset('head_qa', 'en') | {
"avatar_url": "https://avatars.githubusercontent.com/u/75953751?v=4",
"events_url": "https://api.github.com/users/helloworld123-lab/events{/privacy}",
"followers_url": "https://api.github.com/users/helloworld123-lab/followers",
"following_url": "https://api.github.com/users/helloworld123-lab/following{/other_user}",
"gists_url": "https://api.github.com/users/helloworld123-lab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/helloworld123-lab",
"id": 75953751,
"login": "helloworld123-lab",
"node_id": "MDQ6VXNlcjc1OTUzNzUx",
"organizations_url": "https://api.github.com/users/helloworld123-lab/orgs",
"received_events_url": "https://api.github.com/users/helloworld123-lab/received_events",
"repos_url": "https://api.github.com/users/helloworld123-lab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/helloworld123-lab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/helloworld123-lab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/helloworld123-lab"
} | [] | closed | false | null | [] | null | [] | "2021-05-19T15:49:48Z" | "2021-05-30T13:26:16Z" | "2021-05-30T13:26:16Z" | NONE | null | null | null | Hello everyone,
I try to use head_qa dataset in [https://huggingface.co/datasets/viewer/?dataset=head_qa&config=en](url)
```
!pip install datasets
from datasets import load_dataset
dataset = load_dataset(
'head_qa', 'en')
```
When I write above load_dataset(.), it throws the following:
```
DuplicatedKeysError Traceback (most recent call last)
<ipython-input-6-ea87002d32f0> in <module>()
2 from datasets import load_dataset
3 dataset = load_dataset(
----> 4 'head_qa', 'en')
5 frames
/usr/local/lib/python3.7/dist-packages/datasets/arrow_writer.py in check_duplicate_keys(self)
347 for hash, key in self.hkey_record:
348 if hash in tmp_record:
--> 349 raise DuplicatedKeysError(key)
350 else:
351 tmp_record.add(hash)
DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: 1
Keys should be unique and deterministic in nature
```
How can I fix the error? Thanks
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2382/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/163 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/163/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/163/comments | https://api.github.com/repos/huggingface/datasets/issues/163/events | https://github.com/huggingface/datasets/issues/163 | 620,534,307 | MDU6SXNzdWU2MjA1MzQzMDc= | 163 | [Feature request] Add cos-e v1.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Sounds good, @mariamabarham do you want to give a look?\r\nI think we should have two configurations so we can allow either version of the dataset to be loaded with the `1.0` version being the default maybe.\r\n\r\nCc some authors of the great cos-e: @nazneenrajani @bmccann",
"cos_e v1.0 is related to CQA v1.0 but only CQA v1.11 dataset is available on their website. Indeed their is lots of ids in cos_e v1, which are not in CQA v1.11 or the other way around.\r\n@sarahwie, @thomwolf, @nazneenrajani, @bmccann do you know where I can find CQA v1.0\r\n",
"@mariamabarham I'm also not sure where to find CQA 1.0. Perhaps it's not possible to include this version of the dataset. I'll close the issue if that's the case.",
"I do have a copy of the dataset. I can upload it to our repo.",
"Great @nazneenrajani. let me know once done.\r\nThanks",
"@mariamabarham @sarahwie I added them to the cos-e repo https://github.com/salesforce/cos-e/tree/master/data/v1.0",
"You can now do\r\n```python\r\nfrom nlp import load_dataset\r\ncos_e = load_dataset(\"cos_e\", \"v1.0\")\r\n```\r\nThanks @mariamabarham !",
"Thanks!",
"@mariamabarham Just wanted to note that default behavior `cos_e = load_dataset(\"cos_e\")` now loads `v1.0`. Not sure if this is intentional (but the flag specification does work as intended). ",
"> @mariamabarham Just wanted to note that default behavior `cos_e = load_dataset(\"cos_e\")` now loads `v1.0`. Not sure if this is intentional (but the flag specification does work as intended).\r\n\r\nIn the new version of `nlp`, if you try `cos_e = load_dataset(\"cos_e\")` it throws this error:\r\n```\r\nValueError: Config name is missing.\r\nPlease pick one among the available configs: ['v1.0', 'v1.11']\r\nExample of usage:\r\n\t`load_dataset('cos_e', 'v1.0')`\r\n```\r\nFor datasets with at least two configurations, we now force the user to pick one (no default)"
] | "2020-05-18T22:05:26Z" | "2020-06-16T23:15:25Z" | "2020-06-16T18:52:06Z" | NONE | null | null | null | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](https://arxiv.org/pdf/2004.14546.pdf). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/163/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/163/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/356/comments | https://api.github.com/repos/huggingface/datasets/issues/356/events | https://github.com/huggingface/datasets/pull/356 | 653,537,388 | MDExOlB1bGxSZXF1ZXN0NDQ2NDM3MDQ5 | 356 | Add text dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen"
} | [] | closed | false | null | [] | null | [] | "2020-07-08T19:21:53Z" | "2020-07-10T14:19:03Z" | "2020-07-10T14:19:03Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/356",
"merged_at": "2020-07-10T14:19:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/356"
} | Usage:
```python
from nlp import load_dataset
dset = load_dataset("text", data_files="/path/to/file.txt")["train"]
```
I created a dummy_data.zip which contains three files: `train.txt`, `test.txt`, `dev.txt`. Each of these contains two lines. It passes
```bash
RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_text
```
but I would like a second set of eyes to ensure I did it right.
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 3,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1440/comments | https://api.github.com/repos/huggingface/datasets/issues/1440/events | https://github.com/huggingface/datasets/pull/1440 | 760,973,057 | MDExOlB1bGxSZXF1ZXN0NTM1NzEyNDY1 | 1,440 | Adding english plaintext jokes dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22298787?v=4",
"events_url": "https://api.github.com/users/purvimisal/events{/privacy}",
"followers_url": "https://api.github.com/users/purvimisal/followers",
"following_url": "https://api.github.com/users/purvimisal/following{/other_user}",
"gists_url": "https://api.github.com/users/purvimisal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/purvimisal",
"id": 22298787,
"login": "purvimisal",
"node_id": "MDQ6VXNlcjIyMjk4Nzg3",
"organizations_url": "https://api.github.com/users/purvimisal/orgs",
"received_events_url": "https://api.github.com/users/purvimisal/received_events",
"repos_url": "https://api.github.com/users/purvimisal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/purvimisal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/purvimisal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/purvimisal"
} | [] | closed | false | null | [] | null | [
"Hi @purvimisal, thanks for your contributions!\r\n\r\nThis jokes dataset has come up before, and after a conversation with the initial submitter, we decided not to add it then. Humor is important, but looking at the actual data points in this set raises several concerns :) \r\n\r\nThe main issue is the Reddit part of the dataset which has most of the examples. A cursory look at the data shows a large number of highly offensive jokes that reproduce some pretty harmful biases (the second one from the top is a Holocaust joke). \r\n\r\nThe other two sources have similar issues (especially the \"Blond Jokes\") to a slightly lesser extent.\r\n\r\nWhile such datasets can be useful in the right context, there is a real concern that people using the library might miss some of this context (however much we outline it), and end up unwittingly training models that rely on some pretty racist and sexist associations.\r\n\r\nWe would recommend skipping this dataset altogether.\r\n\r\nIf you feel really strongly about having a joke dataset, then we would ask that you:\r\n- remove the Reddit part of the dataset altogether\r\n- write an in-depth description of the social biases present in the remaining data\r\n\r\nLet us know which of the two you decide! And if you want recommendations on other datasets to add, hit us up on Slack 🤗 ",
"Hi @yjernite, thanks so much. I should've totally thought about this earlier. The harmful biases make so much sense. I should've consulted before making a PR. \r\nI will be closing this one and skipping this dataset altogether. \r\nThanks again \r\n"
] | "2020-12-10T07:04:17Z" | "2020-12-13T05:22:00Z" | "2020-12-12T05:55:43Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1440.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1440",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1440.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1440"
} | This PR adds a dataset of 200k English plaintext Jokes from three sources: Reddit, Stupidstuff, and Wocka.
Link: https://github.com/taivop/joke-dataset
This is my second PR.
First was: [#1269 ](https://github.com/huggingface/datasets/pull/1269) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1440/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1801 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1801/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1801/comments | https://api.github.com/repos/huggingface/datasets/issues/1801/events | https://github.com/huggingface/datasets/pull/1801 | 797,814,275 | MDExOlB1bGxSZXF1ZXN0NTY0NzMwODYw | 1,801 | [GEM] Updated the source link of the data to update correct tokenized version. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11708999?v=4",
"events_url": "https://api.github.com/users/mounicam/events{/privacy}",
"followers_url": "https://api.github.com/users/mounicam/followers",
"following_url": "https://api.github.com/users/mounicam/following{/other_user}",
"gists_url": "https://api.github.com/users/mounicam/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mounicam",
"id": 11708999,
"login": "mounicam",
"node_id": "MDQ6VXNlcjExNzA4OTk5",
"organizations_url": "https://api.github.com/users/mounicam/orgs",
"received_events_url": "https://api.github.com/users/mounicam/received_events",
"repos_url": "https://api.github.com/users/mounicam/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mounicam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mounicam/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mounicam"
} | [] | closed | false | null | [] | null | [
"@mounicam we'll keep the original version in the Turk dataset proper, and use the updated file in the GEM aggregated dataset which I'll add later today\r\n\r\n@lhoestq do not merge, I'll close when I've submitted the GEM dataset PR :) ",
"Closed by https://github.com/huggingface/datasets/pull/1807"
] | "2021-01-31T21:17:19Z" | "2021-02-02T13:17:38Z" | "2021-02-02T13:17:28Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1801.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1801",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1801.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1801"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1801/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1801/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2161/comments | https://api.github.com/repos/huggingface/datasets/issues/2161/events | https://github.com/huggingface/datasets/issues/2161 | 849,127,041 | MDU6SXNzdWU4NDkxMjcwNDE= | 2,161 | any possibility to download part of large datasets only? | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234"
} | [] | closed | false | null | [] | null | [
"Not yet but it’s on the short/mid-term roadmap (requested by many indeed).",
"oh, great, really awesome feature to have, thank you very much for the great, fabulous work",
"We'll work on dataset streaming soon. This should allow you to only load the examples you need ;)",
"thanks a lot Quentin, this would be really really a great feature to have\n\nOn Wed, Apr 7, 2021 at 12:14 PM Quentin Lhoest ***@***.***>\nwrote:\n\n> We'll work on dataset streaming soon. This should allow you to only load\n> the examples you need ;)\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/2161#issuecomment-814791922>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AS37NMROD62QAKIJMAKWISTTHQWBVANCNFSM42IUI5JQ>\n> .\n>\n",
"Is streaming completed? On the 1.8.0 docs it is mentioned (https://huggingface.co/docs/datasets/dataset_streaming.html), but when following the example I get the following error:\r\n\r\n```\r\n>>> dataset2 = load_dataset(\"amazon_us_reviews\", \"Pet_Products_v1_00\", split='train', streaming=True)\r\n\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-21-1eedab26cff1> in <module>()\r\n----> 1 en_dataset = load_dataset('oscar', \"unshuffled_deduplicated_en\", split='train', streaming=True)\r\n\r\n3 frames\r\n/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _create_builder_config(self, name, custom_features, **config_kwargs)\r\n 339 if value is not None:\r\n 340 if not hasattr(builder_config, key):\r\n--> 341 raise ValueError(f\"BuilderConfig {builder_config} doesn't have a '{key}' key.\")\r\n 342 setattr(builder_config, key, value)\r\n 343 \r\n\r\nValueError: BuilderConfig OscarConfig(name='unshuffled_deduplicated_en', version=1.0.0, data_dir=None, data_files=None, description='Unshuffled and deduplicated, English OSCAR dataset') doesn't have a 'streaming' key.\r\n```\r\n\r\nUPDATE: Managed to get streaming working by building from source and installing the additional `datasets[streaming]` package:\r\n\r\n```\r\n!pip install git+https://github.com/huggingface/datasets.git\r\n!pip install datasets[streaming]\r\n```",
"Hi ! Streaming is available on `master` only right now. We'll make a new release 1.9.0 on Monday :)"
] | "2021-04-02T10:06:46Z" | "2022-10-05T13:26:51Z" | "2022-10-05T13:26:51Z" | NONE | null | null | null | Hi
Some of the datasets I need like cc100 are very large, and then I wonder if I can download first X samples of the shuffled/unshuffled data without going through first downloading the whole data then sampling? thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2161/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1754/comments | https://api.github.com/repos/huggingface/datasets/issues/1754/events | https://github.com/huggingface/datasets/pull/1754 | 789,881,730 | MDExOlB1bGxSZXF1ZXN0NTU4MTU5NjEw | 1,754 | Use a config id in the cache directory names for custom configs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-01-20T11:11:00Z" | "2021-01-25T09:12:07Z" | "2021-01-25T09:12:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1754.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1754",
"merged_at": "2021-01-25T09:12:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1754.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1754"
} | As noticed by @JetRunner there was some issues when trying to generate a dataset using a custom config that is based on an existing config.
For example in the following code the `mnli_custom` would reuse the cache used to create `mnli` instead of generating a new dataset with the new label classes:
```python
from datasets import load_dataset
mnli = load_dataset("glue", "mnli")
mnli_custom = load_dataset("glue", "mnli", label_classes=["contradiction", "entailment", "neutral"])
```
I fixed that by extending the cache directory definition of a dataset that is being generated.
Instead of using the config name in the cache directory name, I switched to using a `config_id`.
By default it is equal to the config name.
However the name of a config is not sufficent to have a unique identifier for the dataset being generated since it doesn't take into account:
- the config kwargs that can be used to overwrite attributes
- the custom features used to write the dataset
- the data_files for json/text/csv/pandas datasets
Therefore the config id is just the config name with an optional suffix based on these.
In particular taking into account the config kwargs fixes the issue with the `label_classes` above.
I completed the current test cases by adding the case that was missing: overwriting an already existing config. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1754/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1754/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3576/comments | https://api.github.com/repos/huggingface/datasets/issues/3576/events | https://github.com/huggingface/datasets/pull/3576 | 1,102,059,651 | PR_kwDODunzps4w8sUm | 3,576 | Add PASS dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [] | "2022-01-13T17:16:07Z" | "2022-01-20T16:50:48Z" | "2022-01-20T16:50:47Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3576.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3576",
"merged_at": "2022-01-20T16:50:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3576.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3576"
} | This PR adds the PASS dataset.
Closes #3043 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3576/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4837 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4837/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4837/comments | https://api.github.com/repos/huggingface/datasets/issues/4837/events | https://github.com/huggingface/datasets/pull/4837 | 1,337,079,723 | PR_kwDODunzps49Fb6l | 4,837 | Add support for CSV metadata files to ImageFolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Maybe let's include this change after the refactoring from FolderBasedBuilder in #3963 to avoid dealing with too many unpleasant conflicts ?",
"@lhoestq I resolved the conflicts (AudioFolder also supports CSV metadata now). Let me know what you think.\r\n",
"@lhoestq Thanks for the suggestion! Indeed it makes more sense to use CSV as the default format in the folder-based builders."
] | "2022-08-12T11:19:18Z" | "2022-08-31T12:01:27Z" | "2022-08-31T11:59:07Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4837.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4837",
"merged_at": "2022-08-31T11:59:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4837.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4837"
} | Fix #4814 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4837/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4837/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5125 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5125/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5125/comments | https://api.github.com/repos/huggingface/datasets/issues/5125/events | https://github.com/huggingface/datasets/pull/5125 | 1,411,602,813 | PR_kwDODunzps5A7nr8 | 5,125 | Add `pyproject.toml` for `black` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-17T13:38:47Z" | "2022-10-17T14:23:27Z" | "2022-10-17T14:21:09Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5125.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5125",
"merged_at": "2022-10-17T14:21:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5125.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5125"
} | Add `pyproject.toml` as a config file for the `black` tool to support VS Code's auto-formatting on save (and to be more consistent with the other HF projects).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5125/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5125/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6063 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6063/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6063/comments | https://api.github.com/repos/huggingface/datasets/issues/6063/events | https://github.com/huggingface/datasets/pull/6063 | 1,818,679,485 | PR_kwDODunzps5WPtxi | 6,063 | Release: 2.14.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007703 / 0.011353 (-0.003650) | 0.004699 / 0.011008 (-0.006309) | 0.090195 / 0.038508 (0.051687) | 0.119165 / 0.023109 (0.096056) | 0.361435 / 0.275898 (0.085537) | 0.404429 / 0.323480 (0.080949) | 0.006172 / 0.007986 (-0.001814) | 0.003932 / 0.004328 (-0.000397) | 0.068384 / 0.004250 (0.064133) | 0.066730 / 0.037052 (0.029678) | 0.360978 / 0.258489 (0.102489) | 0.401301 / 0.293841 (0.107460) | 0.032836 / 0.128546 (-0.095710) | 0.010821 / 0.075646 (-0.064825) | 0.294526 / 0.419271 (-0.124745) | 0.068751 / 0.043533 (0.025218) | 0.368427 / 0.255139 (0.113288) | 0.376969 / 0.283200 (0.093770) | 0.040538 / 0.141683 (-0.101145) | 1.509966 / 1.452155 (0.057811) | 1.564885 / 1.492716 (0.072169) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.292243 / 0.018006 (0.274237) | 0.662067 / 0.000490 (0.661577) | 0.004966 / 0.000200 (0.004766) | 0.000103 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029050 / 0.037411 (-0.008361) | 0.099880 / 0.014526 (0.085354) | 0.109277 / 0.176557 (-0.067280) | 0.167877 / 0.737135 (-0.569258) | 0.110770 / 0.296338 (-0.185569) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395742 / 0.215209 (0.180533) | 3.944152 / 2.077655 (1.866498) | 1.875295 / 1.504120 (0.371175) | 1.705088 / 1.541195 (0.163893) | 1.884443 / 1.468490 (0.415953) | 0.497243 / 4.584777 (-4.087534) | 3.749287 / 3.745712 (0.003575) | 4.418826 / 5.269862 (-0.851035) | 2.481149 / 4.565676 (-2.084528) | 0.058260 / 0.424275 (-0.366015) | 0.007744 / 0.007607 (0.000137) | 0.472531 / 0.226044 (0.246486) | 4.716022 / 2.268929 (2.447094) | 2.480446 / 55.444624 (-52.964179) | 2.163098 / 6.876477 (-4.713379) | 2.217555 / 2.142072 (0.075482) | 0.601965 / 4.805227 (-4.203262) | 0.139364 / 6.500664 (-6.361301) | 0.067097 / 0.075469 (-0.008372) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.330537 / 1.841788 (-0.511251) | 22.176270 / 8.074308 (14.101962) | 16.224981 / 10.191392 (6.033589) | 0.173708 / 0.680424 (-0.506715) | 0.019402 / 0.534201 (-0.514799) | 0.401994 / 0.579283 (-0.177289) | 0.432597 / 0.434364 (-0.001767) | 0.489933 / 0.540337 (-0.050404) | 0.672334 / 1.386936 (-0.714602) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008622 / 0.011353 (-0.002731) | 0.004609 / 0.011008 (-0.006399) | 0.067791 / 0.038508 (0.029283) | 0.112770 / 0.023109 (0.089661) | 0.380939 / 0.275898 (0.105041) | 0.416940 / 0.323480 (0.093460) | 0.006170 / 0.007986 (-0.001815) | 0.003876 / 0.004328 (-0.000452) | 0.066227 / 0.004250 (0.061976) | 0.073132 / 0.037052 (0.036080) | 0.390120 / 0.258489 (0.131631) | 0.420893 / 0.293841 (0.127052) | 0.033235 / 0.128546 (-0.095311) | 0.009659 / 0.075646 (-0.065987) | 0.072668 / 0.419271 (-0.346604) | 0.051333 / 0.043533 (0.007801) | 0.393828 / 0.255139 (0.138689) | 0.412376 / 0.283200 (0.129176) | 0.027760 / 0.141683 (-0.113923) | 1.494369 / 1.452155 (0.042214) | 1.592862 / 1.492716 (0.100145) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.345376 / 0.018006 (0.327369) | 0.609399 / 0.000490 (0.608909) | 0.000546 / 0.000200 (0.000346) | 0.000061 / 0.000054 (0.000007) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035601 / 0.037411 (-0.001810) | 0.106527 / 0.014526 (0.092001) | 0.114388 / 0.176557 (-0.062168) | 0.175607 / 0.737135 (-0.561529) | 0.113009 / 0.296338 (-0.183329) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417237 / 0.215209 (0.202028) | 4.136329 / 2.077655 (2.058675) | 2.147134 / 1.504120 (0.643014) | 2.009501 / 1.541195 (0.468306) | 2.139499 / 1.468490 (0.671009) | 0.491593 / 4.584777 (-4.093184) | 3.766734 / 3.745712 (0.021022) | 5.652446 / 5.269862 (0.382585) | 3.021654 / 4.565676 (-1.544022) | 0.058458 / 0.424275 (-0.365817) | 0.008271 / 0.007607 (0.000664) | 0.488229 / 0.226044 (0.262184) | 4.861343 / 2.268929 (2.592415) | 2.694142 / 55.444624 (-52.750482) | 2.489130 / 6.876477 (-4.387346) | 2.679376 / 2.142072 (0.537304) | 0.589959 / 4.805227 (-4.215268) | 0.137939 / 6.500664 (-6.362725) | 0.066833 / 0.075469 (-0.008636) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.444871 / 1.841788 (-0.396916) | 22.874961 / 8.074308 (14.800653) | 15.842130 / 10.191392 (5.650738) | 0.175529 / 0.680424 (-0.504895) | 0.019024 / 0.534201 (-0.515177) | 0.406551 / 0.579283 (-0.172732) | 0.430335 / 0.434364 (-0.004029) | 0.475750 / 0.540337 (-0.064587) | 0.624836 / 1.386936 (-0.762100) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006068 / 0.011353 (-0.005285) | 0.003694 / 0.011008 (-0.007315) | 0.080321 / 0.038508 (0.041813) | 0.061738 / 0.023109 (0.038629) | 0.329675 / 0.275898 (0.053777) | 0.364008 / 0.323480 (0.040528) | 0.004722 / 0.007986 (-0.003263) | 0.002857 / 0.004328 (-0.001471) | 0.062447 / 0.004250 (0.058197) | 0.047006 / 0.037052 (0.009953) | 0.335730 / 0.258489 (0.077241) | 0.373047 / 0.293841 (0.079206) | 0.027273 / 0.128546 (-0.101274) | 0.007979 / 0.075646 (-0.067667) | 0.262693 / 0.419271 (-0.156579) | 0.045416 / 0.043533 (0.001883) | 0.340774 / 0.255139 (0.085635) | 0.359667 / 0.283200 (0.076468) | 0.020848 / 0.141683 (-0.120835) | 1.450110 / 1.452155 (-0.002045) | 1.489511 / 1.492716 (-0.003206) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185090 / 0.018006 (0.167084) | 0.429823 / 0.000490 (0.429334) | 0.000703 / 0.000200 (0.000503) | 0.000058 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024398 / 0.037411 (-0.013013) | 0.072983 / 0.014526 (0.058457) | 0.084012 / 0.176557 (-0.092544) | 0.146160 / 0.737135 (-0.590975) | 0.084068 / 0.296338 (-0.212270) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432204 / 0.215209 (0.216995) | 4.320593 / 2.077655 (2.242939) | 2.261260 / 1.504120 (0.757140) | 2.087148 / 1.541195 (0.545954) | 2.144520 / 1.468490 (0.676029) | 0.501477 / 4.584777 (-4.083300) | 3.119557 / 3.745712 (-0.626156) | 3.572527 / 5.269862 (-1.697335) | 2.208836 / 4.565676 (-2.356840) | 0.057232 / 0.424275 (-0.367043) | 0.006494 / 0.007607 (-0.001113) | 0.508135 / 0.226044 (0.282091) | 5.090416 / 2.268929 (2.821488) | 2.739800 / 55.444624 (-52.704824) | 2.416105 / 6.876477 (-4.460372) | 2.616037 / 2.142072 (0.473965) | 0.583730 / 4.805227 (-4.221497) | 0.124312 / 6.500664 (-6.376352) | 0.060760 / 0.075469 (-0.014709) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256097 / 1.841788 (-0.585691) | 18.326073 / 8.074308 (10.251765) | 13.859173 / 10.191392 (3.667781) | 0.143639 / 0.680424 (-0.536785) | 0.016649 / 0.534201 (-0.517552) | 0.331671 / 0.579283 (-0.247612) | 0.365370 / 0.434364 (-0.068994) | 0.392753 / 0.540337 (-0.147584) | 0.549302 / 1.386936 (-0.837634) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006054 / 0.011353 (-0.005299) | 0.003641 / 0.011008 (-0.007367) | 0.063109 / 0.038508 (0.024601) | 0.060482 / 0.023109 (0.037372) | 0.404047 / 0.275898 (0.128149) | 0.425436 / 0.323480 (0.101956) | 0.004603 / 0.007986 (-0.003382) | 0.002905 / 0.004328 (-0.001423) | 0.063207 / 0.004250 (0.058956) | 0.048248 / 0.037052 (0.011196) | 0.404325 / 0.258489 (0.145836) | 0.432652 / 0.293841 (0.138811) | 0.027630 / 0.128546 (-0.100916) | 0.008062 / 0.075646 (-0.067584) | 0.068367 / 0.419271 (-0.350905) | 0.042169 / 0.043533 (-0.001364) | 0.384903 / 0.255139 (0.129764) | 0.418617 / 0.283200 (0.135417) | 0.020767 / 0.141683 (-0.120915) | 1.463606 / 1.452155 (0.011451) | 1.512081 / 1.492716 (0.019365) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229601 / 0.018006 (0.211594) | 0.417878 / 0.000490 (0.417388) | 0.000373 / 0.000200 (0.000173) | 0.000053 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026354 / 0.037411 (-0.011057) | 0.078100 / 0.014526 (0.063574) | 0.087122 / 0.176557 (-0.089434) | 0.140017 / 0.737135 (-0.597118) | 0.089923 / 0.296338 (-0.206415) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422405 / 0.215209 (0.207196) | 4.237383 / 2.077655 (2.159728) | 2.161104 / 1.504120 (0.656984) | 1.982337 / 1.541195 (0.441142) | 2.050216 / 1.468490 (0.581726) | 0.499281 / 4.584777 (-4.085496) | 2.996953 / 3.745712 (-0.748759) | 5.027069 / 5.269862 (-0.242792) | 2.804703 / 4.565676 (-1.760974) | 0.057707 / 0.424275 (-0.366568) | 0.006809 / 0.007607 (-0.000798) | 0.495196 / 0.226044 (0.269152) | 4.946593 / 2.268929 (2.677665) | 2.598965 / 55.444624 (-52.845660) | 2.349871 / 6.876477 (-4.526606) | 2.451665 / 2.142072 (0.309593) | 0.592314 / 4.805227 (-4.212913) | 0.125685 / 6.500664 (-6.374979) | 0.063252 / 0.075469 (-0.012217) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.325422 / 1.841788 (-0.516366) | 18.521059 / 8.074308 (10.446751) | 14.046757 / 10.191392 (3.855365) | 0.133009 / 0.680424 (-0.547415) | 0.017097 / 0.534201 (-0.517104) | 0.339804 / 0.579283 (-0.239479) | 0.345464 / 0.434364 (-0.088900) | 0.387623 / 0.540337 (-0.152714) | 0.519880 / 1.386936 (-0.867056) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008671 / 0.011353 (-0.002682) | 0.004681 / 0.011008 (-0.006327) | 0.107517 / 0.038508 (0.069008) | 0.078846 / 0.023109 (0.055737) | 0.449745 / 0.275898 (0.173847) | 0.504075 / 0.323480 (0.180596) | 0.005837 / 0.007986 (-0.002148) | 0.004031 / 0.004328 (-0.000297) | 0.092021 / 0.004250 (0.087771) | 0.065954 / 0.037052 (0.028902) | 0.442082 / 0.258489 (0.183593) | 0.529349 / 0.293841 (0.235508) | 0.052527 / 0.128546 (-0.076019) | 0.013854 / 0.075646 (-0.061792) | 0.367315 / 0.419271 (-0.051956) | 0.068731 / 0.043533 (0.025199) | 0.494733 / 0.255139 (0.239594) | 0.472801 / 0.283200 (0.189601) | 0.036791 / 0.141683 (-0.104892) | 1.877648 / 1.452155 (0.425493) | 1.928399 / 1.492716 (0.435683) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231910 / 0.018006 (0.213904) | 0.553464 / 0.000490 (0.552974) | 0.011915 / 0.000200 (0.011715) | 0.000378 / 0.000054 (0.000324) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028232 / 0.037411 (-0.009179) | 0.091441 / 0.014526 (0.076916) | 0.110394 / 0.176557 (-0.066162) | 0.187638 / 0.737135 (-0.549497) | 0.111810 / 0.296338 (-0.184529) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.599987 / 0.215209 (0.384778) | 6.008709 / 2.077655 (3.931054) | 2.518769 / 1.504120 (1.014650) | 2.197029 / 1.541195 (0.655834) | 2.217165 / 1.468490 (0.748675) | 0.894939 / 4.584777 (-3.689837) | 5.001217 / 3.745712 (1.255505) | 4.636482 / 5.269862 (-0.633379) | 3.237613 / 4.565676 (-1.328063) | 0.104227 / 0.424275 (-0.320048) | 0.008504 / 0.007607 (0.000897) | 0.750190 / 0.226044 (0.524145) | 7.514571 / 2.268929 (5.245642) | 3.358003 / 55.444624 (-52.086621) | 2.585649 / 6.876477 (-4.290827) | 2.731129 / 2.142072 (0.589056) | 1.088828 / 4.805227 (-3.716400) | 0.217308 / 6.500664 (-6.283356) | 0.076410 / 0.075469 (0.000941) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.620087 / 1.841788 (-0.221701) | 23.145743 / 8.074308 (15.071435) | 20.583403 / 10.191392 (10.392011) | 0.225467 / 0.680424 (-0.454956) | 0.029063 / 0.534201 (-0.505138) | 0.480563 / 0.579283 (-0.098720) | 0.539083 / 0.434364 (0.104719) | 0.563787 / 0.540337 (0.023449) | 0.782902 / 1.386936 (-0.604034) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010113 / 0.011353 (-0.001239) | 0.004997 / 0.011008 (-0.006011) | 0.082974 / 0.038508 (0.044466) | 0.090375 / 0.023109 (0.067266) | 0.440273 / 0.275898 (0.164375) | 0.476939 / 0.323480 (0.153459) | 0.005955 / 0.007986 (-0.002031) | 0.004375 / 0.004328 (0.000046) | 0.080459 / 0.004250 (0.076209) | 0.061787 / 0.037052 (0.024734) | 0.477211 / 0.258489 (0.218722) | 0.487164 / 0.293841 (0.193323) | 0.054198 / 0.128546 (-0.074348) | 0.013945 / 0.075646 (-0.061701) | 0.093006 / 0.419271 (-0.326266) | 0.062685 / 0.043533 (0.019152) | 0.461373 / 0.255139 (0.206234) | 0.475766 / 0.283200 (0.192567) | 0.032059 / 0.141683 (-0.109623) | 1.857989 / 1.452155 (0.405834) | 1.837993 / 1.492716 (0.345277) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.243048 / 0.018006 (0.225042) | 0.535850 / 0.000490 (0.535360) | 0.007204 / 0.000200 (0.007004) | 0.000104 / 0.000054 (0.000049) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032584 / 0.037411 (-0.004827) | 0.098151 / 0.014526 (0.083625) | 0.109691 / 0.176557 (-0.066866) | 0.172803 / 0.737135 (-0.564333) | 0.110469 / 0.296338 (-0.185869) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.635086 / 0.215209 (0.419877) | 6.500864 / 2.077655 (4.423210) | 2.996727 / 1.504120 (1.492607) | 2.537218 / 1.541195 (0.996023) | 2.572310 / 1.468490 (1.103820) | 0.870868 / 4.584777 (-3.713909) | 4.989744 / 3.745712 (1.244032) | 4.422174 / 5.269862 (-0.847687) | 2.935874 / 4.565676 (-1.629803) | 0.097118 / 0.424275 (-0.327157) | 0.009360 / 0.007607 (0.001753) | 0.790447 / 0.226044 (0.564403) | 7.859519 / 2.268929 (5.590591) | 3.975616 / 55.444624 (-51.469009) | 3.018271 / 6.876477 (-3.858206) | 3.111173 / 2.142072 (0.969101) | 1.085577 / 4.805227 (-3.719651) | 0.225719 / 6.500664 (-6.274945) | 0.080576 / 0.075469 (0.005107) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.802284 / 1.841788 (-0.039504) | 23.487921 / 8.074308 (15.413613) | 20.595171 / 10.191392 (10.403779) | 0.196610 / 0.680424 (-0.483814) | 0.027483 / 0.534201 (-0.506718) | 0.485840 / 0.579283 (-0.093443) | 0.542661 / 0.434364 (0.108297) | 0.580602 / 0.540337 (0.040265) | 0.768195 / 1.386936 (-0.618741) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-24T15:41:19Z" | "2023-07-24T16:05:16Z" | "2023-07-24T15:47:51Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6063.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6063",
"merged_at": "2023-07-24T15:47:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6063.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6063"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6063/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6063/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1875 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1875/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1875/comments | https://api.github.com/repos/huggingface/datasets/issues/1875/events | https://github.com/huggingface/datasets/pull/1875 | 807,887,267 | MDExOlB1bGxSZXF1ZXN0NTczMDM2NzE0 | 1,875 | Adding sari metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/6061911?v=4",
"events_url": "https://api.github.com/users/ddhruvkr/events{/privacy}",
"followers_url": "https://api.github.com/users/ddhruvkr/followers",
"following_url": "https://api.github.com/users/ddhruvkr/following{/other_user}",
"gists_url": "https://api.github.com/users/ddhruvkr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ddhruvkr",
"id": 6061911,
"login": "ddhruvkr",
"node_id": "MDQ6VXNlcjYwNjE5MTE=",
"organizations_url": "https://api.github.com/users/ddhruvkr/orgs",
"received_events_url": "https://api.github.com/users/ddhruvkr/received_events",
"repos_url": "https://api.github.com/users/ddhruvkr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ddhruvkr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ddhruvkr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ddhruvkr"
} | [] | closed | false | null | [] | null | [] | "2021-02-14T04:38:35Z" | "2021-02-17T15:56:27Z" | "2021-02-17T15:56:27Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1875.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1875",
"merged_at": "2021-02-17T15:56:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1875.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1875"
} | Adding SARI metric that is used in evaluation of text simplification. This is required as part of the GEM benchmark. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1875/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1875/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1596/comments | https://api.github.com/repos/huggingface/datasets/issues/1596/events | https://github.com/huggingface/datasets/pull/1596 | 770,260,531 | MDExOlB1bGxSZXF1ZXN0NTQyMDM3NTU0 | 1,596 | made suggested changes to hate-speech-and-offensive-language | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MisbahKhan789",
"id": 15351802,
"login": "MisbahKhan789",
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MisbahKhan789"
} | [] | closed | false | null | [] | null | [] | "2020-12-17T18:09:26Z" | "2020-12-17T18:36:02Z" | "2020-12-17T18:35:53Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1596.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1596",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1596.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1596"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1596/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3056/comments | https://api.github.com/repos/huggingface/datasets/issues/3056/events | https://github.com/huggingface/datasets/pull/3056 | 1,022,345,564 | PR_kwDODunzps4tAB9h | 3,056 | Fix meteor metric for version >= 3.6.4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-10-11T07:11:44Z" | "2021-10-11T07:29:20Z" | "2021-10-11T07:29:19Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3056.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3056",
"merged_at": "2021-10-11T07:29:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3056.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3056"
} | After `nltk` update, the meteor metric expects pre-tokenized inputs (breaking change).
This PR fixes this issue, while maintaining compatibility with older versions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3056/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4071/comments | https://api.github.com/repos/huggingface/datasets/issues/4071/events | https://github.com/huggingface/datasets/issues/4071 | 1,187,587,683 | I_kwDODunzps5GySZj | 4,071 | Loading issue for xuyeliu/notebookCDG dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/46160972?v=4",
"events_url": "https://api.github.com/users/Jun-jie-Huang/events{/privacy}",
"followers_url": "https://api.github.com/users/Jun-jie-Huang/followers",
"following_url": "https://api.github.com/users/Jun-jie-Huang/following{/other_user}",
"gists_url": "https://api.github.com/users/Jun-jie-Huang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Jun-jie-Huang",
"id": 46160972,
"login": "Jun-jie-Huang",
"node_id": "MDQ6VXNlcjQ2MTYwOTcy",
"organizations_url": "https://api.github.com/users/Jun-jie-Huang/orgs",
"received_events_url": "https://api.github.com/users/Jun-jie-Huang/received_events",
"repos_url": "https://api.github.com/users/Jun-jie-Huang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Jun-jie-Huang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jun-jie-Huang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Jun-jie-Huang"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"Hi @Jun-jie-Huang,\r\n\r\nAs the error message says, \".pkl\" data files are not supported.\r\n\r\nIf you would like to share your dataset on the Hub, you would need:\r\n- either to create a Python loading script, that loads the data in any format\r\n- or to transform your data files to one of the supported formats (listed in the error message above: CSV, JSON, Parquet, TXT,...)\r\n\r\nYou can find the details in our docs: \r\n- How to share a dataset: https://huggingface.co/docs/datasets/share\r\n- How to create a dataset loading script: https://huggingface.co/docs/datasets/dataset_script\r\n\r\nFeel free to re-open this issue and ping us if you need further assistance."
] | "2022-03-31T06:36:29Z" | "2022-03-31T08:17:01Z" | "2022-03-31T08:16:16Z" | NONE | null | null | null | ## Dataset viewer issue for '*xuyeliu/notebookCDG*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/xuyeliu/notebookCDG)*
*Couldn't load the xuyeliu/notebookCDG with provided scripts: *
```
from datasets import load_dataset
dataset = load_dataset("xuyeliu/notebookCDG/dataset_notebook.pkl")
```
I get an error message as follows:
FileNotFoundError: Couldn't find a dataset script at /home/code_documentation/code/xuyeliu/notebookCDG/notebookCDG.py or any data file in the same directory. Couldn't find 'xuyeliu/notebookCDG' on the Hugging Face Hub either: FileNotFoundError: Unable to resolve any data file that matches ['**train*'] in dataset repository xuyeliu/notebookCDG with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'zip']
Am I the one who added this dataset ? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4071/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4071/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2016 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2016/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2016/comments | https://api.github.com/repos/huggingface/datasets/issues/2016/events | https://github.com/huggingface/datasets/pull/2016 | 825,965,493 | MDExOlB1bGxSZXF1ZXN0NTg4MDA5NjEz | 2,016 | Not all languages have 2 digit codes. | {
"avatar_url": "https://avatars.githubusercontent.com/u/13891775?v=4",
"events_url": "https://api.github.com/users/asiddhant/events{/privacy}",
"followers_url": "https://api.github.com/users/asiddhant/followers",
"following_url": "https://api.github.com/users/asiddhant/following{/other_user}",
"gists_url": "https://api.github.com/users/asiddhant/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/asiddhant",
"id": 13891775,
"login": "asiddhant",
"node_id": "MDQ6VXNlcjEzODkxNzc1",
"organizations_url": "https://api.github.com/users/asiddhant/orgs",
"received_events_url": "https://api.github.com/users/asiddhant/received_events",
"repos_url": "https://api.github.com/users/asiddhant/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/asiddhant/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asiddhant/subscriptions",
"type": "User",
"url": "https://api.github.com/users/asiddhant"
} | [] | closed | false | null | [] | null | [] | "2021-03-09T13:53:39Z" | "2021-03-11T18:01:03Z" | "2021-03-11T18:01:03Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2016.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2016",
"merged_at": "2021-03-11T18:01:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2016.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2016"
} | . | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2016/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2016/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3431/comments | https://api.github.com/repos/huggingface/datasets/issues/3431/events | https://github.com/huggingface/datasets/issues/3431 | 1,079,866,083 | I_kwDODunzps5AXXLj | 3,431 | Unable to resolve any data file after loading once | {
"avatar_url": "https://avatars.githubusercontent.com/u/84694183?v=4",
"events_url": "https://api.github.com/users/LzyFischer/events{/privacy}",
"followers_url": "https://api.github.com/users/LzyFischer/followers",
"following_url": "https://api.github.com/users/LzyFischer/following{/other_user}",
"gists_url": "https://api.github.com/users/LzyFischer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LzyFischer",
"id": 84694183,
"login": "LzyFischer",
"node_id": "MDQ6VXNlcjg0Njk0MTgz",
"organizations_url": "https://api.github.com/users/LzyFischer/orgs",
"received_events_url": "https://api.github.com/users/LzyFischer/received_events",
"repos_url": "https://api.github.com/users/LzyFischer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LzyFischer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LzyFischer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LzyFischer"
} | [] | closed | false | null | [] | null | [
"Hi ! `load_dataset` accepts as input either a local dataset directory or a dataset name from the Hugging Face Hub.\r\n\r\nSo here you are getting this error the second time because it tries to load the local `wiki_dpr` directory, instead of `wiki_dpr` from the Hub. It doesn't work since it's a **cache** directory, not a **dataset** directory in itself.\r\n\r\nTo fix that you can use another cache directory like `cache_dir=\"/data2/whr/lzy/open_domain_data/retrieval/cache\"`",
"thx a lot"
] | "2021-12-14T15:02:15Z" | "2022-12-11T10:53:04Z" | "2022-02-24T09:13:52Z" | NONE | null | null | null | when I rerun my program, it occurs this error
" Unable to resolve any data file that matches '['**train*']' at /data2/whr/lzy/open_domain_data/retrieval/wiki_dpr with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'zip']", so how could i deal with this problem?
thx.
And below is my code .

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3431/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4192 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4192/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4192/comments | https://api.github.com/repos/huggingface/datasets/issues/4192/events | https://github.com/huggingface/datasets/issues/4192 | 1,210,692,554 | I_kwDODunzps5IKbPK | 4,192 | load_dataset can't load local dataset,Unable to find ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/33253979?v=4",
"events_url": "https://api.github.com/users/ahf876828330/events{/privacy}",
"followers_url": "https://api.github.com/users/ahf876828330/followers",
"following_url": "https://api.github.com/users/ahf876828330/following{/other_user}",
"gists_url": "https://api.github.com/users/ahf876828330/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ahf876828330",
"id": 33253979,
"login": "ahf876828330",
"node_id": "MDQ6VXNlcjMzMjUzOTc5",
"organizations_url": "https://api.github.com/users/ahf876828330/orgs",
"received_events_url": "https://api.github.com/users/ahf876828330/received_events",
"repos_url": "https://api.github.com/users/ahf876828330/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ahf876828330/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahf876828330/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ahf876828330"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! :)\r\n\r\nI believe that should work unless `dataset_infos.json` isn't actually a dataset. For Hugging Face datasets, there is usually a file named `dataset_infos.json` which contains metadata about the dataset (eg. the dataset citation, license, description, etc). Can you double-check that `dataset_infos.json` isn't just metadata please?",
"Hi @ahf876828330, \r\n\r\nAs @stevhliu pointed out, the proper way to load a dataset is not trying to load its metadata file.\r\n\r\nIn your case, as the dataset script is local, you should better point to your local loading script:\r\n```python\r\ndataset = load_dataset(\"dataset/opus_books.py\")\r\n```\r\n\r\nPlease, feel free to re-open this issue if the previous code snippet does not work for you.",
"> Hi! :)\r\n> \r\n> I believe that should work unless `dataset_infos.json` isn't actually a dataset. For Hugging Face datasets, there is usually a file named `dataset_infos.json` which contains metadata about the dataset (eg. the dataset citation, license, description, etc). Can you double-check that `dataset_infos.json` isn't just metadata please?\r\n\r\nYes,you are right!So if I have a metadata dataset local,How can I turn it to a dataset that can be used by the load_dataset() function?Are there some examples?",
"The metadata file isn't a dataset so you can't turn it into one. You should try @albertvillanova's code snippet above (now merged in the docs [here](https://huggingface.co/docs/datasets/master/en/loading#local-loading-script)), which uses your local loading script `opus_books.py` to:\r\n\r\n1. Download the actual dataset. \r\n2. Once the dataset is downloaded, `load_dataset` will load it for you."
] | "2022-04-21T08:28:58Z" | "2022-04-25T16:51:57Z" | "2022-04-22T07:39:53Z" | NONE | null | null | null |
Traceback (most recent call last):
File "/home/gs603/ahf/pretrained/model.py", line 48, in <module>
dataset = load_dataset("json",data_files="dataset/dataset_infos.json")
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1675, in load_dataset
**config_kwargs,
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1496, in load_dataset_builder
data_files=data_files,
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1155, in dataset_module_factory
download_mode=download_mode,
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 800, in get_module
data_files = DataFilesDict.from_local_or_remote(patterns, use_auth_token=self.downnload_config.use_auth_token)
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 582, in from_local_or_remote
if not isinstance(patterns_for_key, DataFilesList)
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 544, in from_local_or_remote
data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 194, in resolve_patterns_locally_or_by_urls
for path in _resolve_single_pattern_locally(base_path, pattern, allowed_extensions):
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 144, in _resolve_single_pattern_locally
raise FileNotFoundError(error_msg)
FileNotFoundError: Unable to find '/home/gs603/ahf/pretrained/dataset/dataset_infos.json' at /home/gs603/ahf/pretrained


the code is in the model.py,why I can't use the load_dataset function to load my local dataset? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4192/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4192/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1298 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1298/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1298/comments | https://api.github.com/repos/huggingface/datasets/issues/1298/events | https://github.com/huggingface/datasets/pull/1298 | 759,412,451 | MDExOlB1bGxSZXF1ZXN0NTM0NDIyODQy | 1,298 | Add OPUS Ted Talks 2013 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | "2020-12-08T12:38:38Z" | "2020-12-16T16:57:50Z" | "2020-12-16T16:57:49Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1298.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1298",
"merged_at": "2020-12-16T16:57:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1298.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1298"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1298/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1298/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3453/comments | https://api.github.com/repos/huggingface/datasets/issues/3453/events | https://github.com/huggingface/datasets/issues/3453 | 1,084,515,911 | I_kwDODunzps5ApGZH | 3,453 | ValueError while iter_archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2021-12-20T08:46:18Z" | "2021-12-20T10:04:59Z" | "2021-12-20T10:04:59Z" | MEMBER | null | null | null | ## Describe the bug
After the merge of:
- #3443
the method `iter_archive` throws a ValueError:
```
ValueError: read of closed file
```
## Steps to reproduce the bug
```python
for path, file in dl_manager.iter_archive(archive_path):
pass
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3453/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3453/timeline | null | completed | false |