

TheBloke's LLM work is generously supported by a grant from andreessen horowitz (a16z)
Openchat 3.5 0106 - GGUF
- Model creator: OpenChat
- Original model: Openchat 3.5 0106
Description
This repo contains GGUF format model files for OpenChat's Openchat 3.5 0106.
These files were quantised using hardware kindly provided by Massed Compute.
About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
- llama.cpp. The source project for GGUF. Offers a CLI and a server option.
- text-generation-webui, the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
- KoboldCpp, a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
- GPT4All, a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
- LM Studio, an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
- LoLLMS Web UI, a great web UI with many interesting and unique features, including a full model library for easy model selection.
- Faraday.dev, an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
- llama-cpp-python, a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
- candle, a Rust ML framework with a focus on performance, including GPU support, and ease of use.
- ctransformers, a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
Repositories available
- AWQ model(s) for GPU inference.
- GPTQ models for GPU inference, with multiple quantisation parameter options.
- 2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference
- OpenChat's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions
Prompt template: OpenChat-Correct
GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:
Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit d0cee0d
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
Explanation of quantisation methods
Click to see details
The new methods available are:
- GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
- GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
- GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
- GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
- GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
|---|---|---|---|---|---|
| openchat-3.5-0106.Q2_K.gguf | Q2_K | 2 | 3.08 GB | 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| openchat-3.5-0106.Q3_K_S.gguf | Q3_K_S | 3 | 3.16 GB | 5.66 GB | very small, high quality loss |
| openchat-3.5-0106.Q3_K_M.gguf | Q3_K_M | 3 | 3.52 GB | 6.02 GB | very small, high quality loss |
| openchat-3.5-0106.Q3_K_L.gguf | Q3_K_L | 3 | 3.82 GB | 6.32 GB | small, substantial quality loss |
| openchat-3.5-0106.Q4_0.gguf | Q4_0 | 4 | 4.11 GB | 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| openchat-3.5-0106.Q4_K_S.gguf | Q4_K_S | 4 | 4.14 GB | 6.64 GB | small, greater quality loss |
| openchat-3.5-0106.Q4_K_M.gguf | Q4_K_M | 4 | 4.37 GB | 6.87 GB | medium, balanced quality - recommended |
| openchat-3.5-0106.Q5_0.gguf | Q5_0 | 5 | 5.00 GB | 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| openchat-3.5-0106.Q5_K_S.gguf | Q5_K_S | 5 | 5.00 GB | 7.50 GB | large, low quality loss - recommended |
| openchat-3.5-0106.Q5_K_M.gguf | Q5_K_M | 5 | 5.13 GB | 7.63 GB | large, very low quality loss - recommended |
| openchat-3.5-0106.Q6_K.gguf | Q6_K | 6 | 5.94 GB | 8.44 GB | very large, extremely low quality loss |
| openchat-3.5-0106.Q8_0.gguf | Q8_0 | 8 | 7.70 GB | 10.20 GB | very large, extremely low quality loss - not recommended |
Note: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
How to download GGUF files
Note for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
In text-generation-webui
Under Download Model, you can enter the model repo: TheBloke/openchat-3.5-0106-GGUF and below it, a specific filename to download, such as: openchat-3.5-0106.Q4_K_M.gguf.
Then click Download.
On the command line, including multiple files at once
I recommend using the huggingface-hub Python library:
pip3 install huggingface-hub
Then you can download any individual model file to the current directory, at high speed, with a command like this:
huggingface-cli download TheBloke/openchat-3.5-0106-GGUF openchat-3.5-0106.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
More advanced huggingface-cli download usage (click to read)
You can also download multiple files at once with a pattern:
huggingface-cli download TheBloke/openchat-3.5-0106-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
For more documentation on downloading with huggingface-cli, please see: HF -> Hub Python Library -> Download files -> Download from the CLI.
To accelerate downloads on fast connections (1Gbit/s or higher), install hf_transfer:
pip3 install hf_transfer
And set environment variable HF_HUB_ENABLE_HF_TRANSFER to 1:
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/openchat-3.5-0106-GGUF openchat-3.5-0106.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
Windows Command Line users: You can set the environment variable by running set HF_HUB_ENABLE_HF_TRANSFER=1 before the download command.
Example llama.cpp command
Make sure you are using llama.cpp from commit d0cee0d or later.
./main -ngl 35 -m openchat-3.5-0106.Q4_K_M.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:"
Change -ngl 32 to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change -c 8192 to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the -p <PROMPT> argument with -i -ins
For other parameters and how to use them, please refer to the llama.cpp documentation
How to run in text-generation-webui
Further instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model Tab.md.
How to run from Python code
You can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
How to load this model in Python code, using llama-cpp-python
For full documentation, please see: llama-cpp-python docs.
First install the package
Run one of the following commands, according to your system:
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
Simple llama-cpp-python example code
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./openchat-3.5-0106.Q4_K_M.gguf", # Download the model file first
n_ctx=8192, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./openchat-3.5-0106.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
Discord
For further support, and discussions on these models and AI in general, join us at:
Thanks, and how to contribute
Thanks to the chirper.ai team!
Thanks to Clay from gpus.llm-utils.org!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
Special thanks to: Aemon Algiz.
Patreon special mentions: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
Original model card: OpenChat's Openchat 3.5 0106
Advancing Open-source Language Models with Mixed-Quality Data
![]() Online Demo
|
Online Demo
|
 GitHub
|
GitHub
|
 Paper
|
Paper
|
 Discord
Discord
Sponsored by RunPod

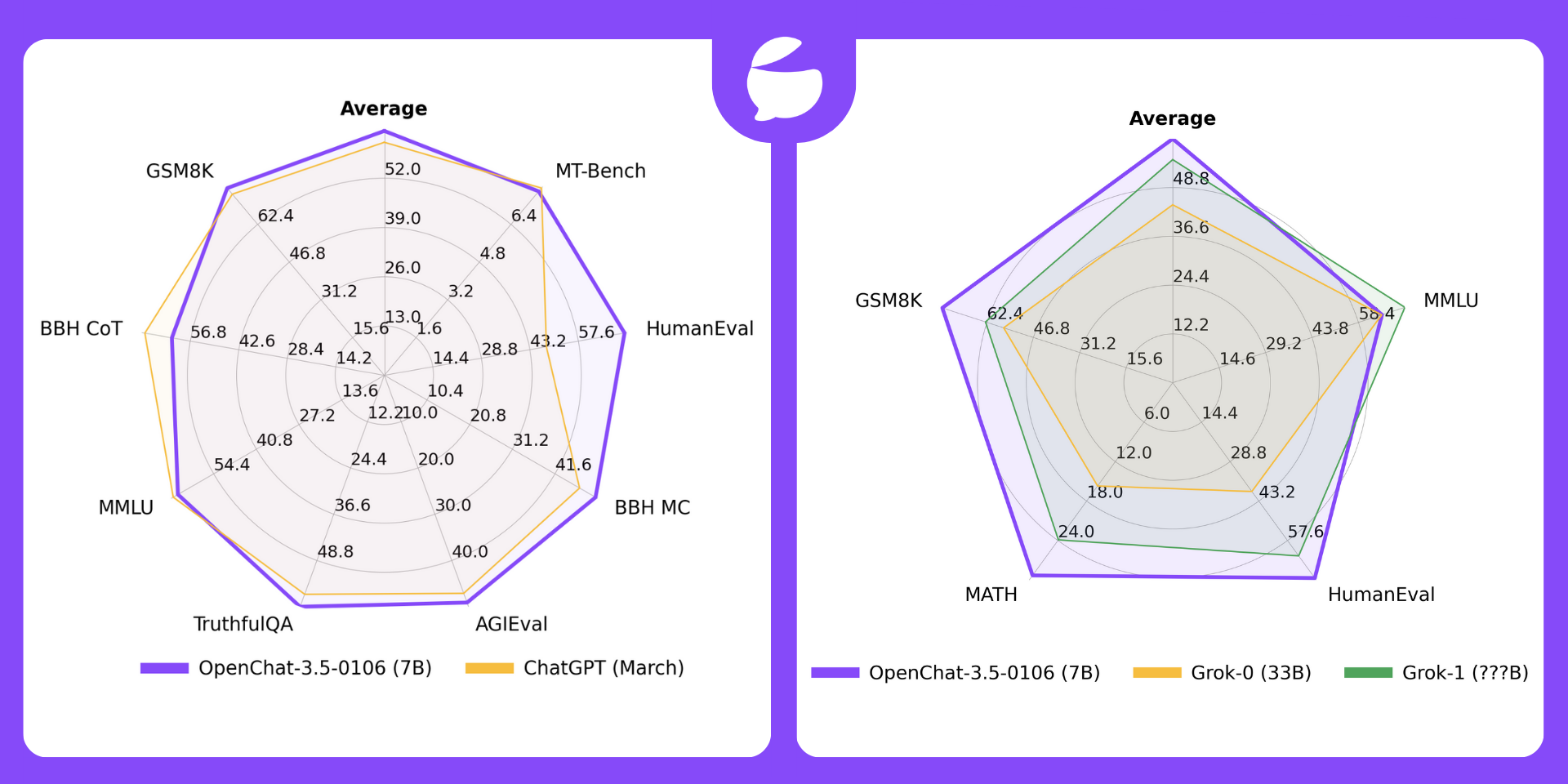
Table of Contents
Usage
To use this model, we highly recommend installing the OpenChat package by following the installation guide in our repository and using the OpenChat OpenAI-compatible API server by running the serving command from the table below. The server is optimized for high-throughput deployment using vLLM and can run on a consumer GPU with 24GB RAM. To enable tensor parallelism, append --tensor-parallel-size N to the serving command.
Once started, the server listens at localhost:18888 for requests and is compatible with the OpenAI ChatCompletion API specifications. Please refer to the example request below for reference. Additionally, you can use the OpenChat Web UI for a user-friendly experience.
If you want to deploy the server as an online service, you can use --api-keys sk-KEY1 sk-KEY2 ... to specify allowed API keys and --disable-log-requests --disable-log-stats --log-file openchat.log for logging only to a file. For security purposes, we recommend using an HTTPS gateway in front of the server.
| Model | Size | Context | Weights | Serving |
|---|---|---|---|---|
| OpenChat-3.5-0106 | 7B | 8192 | Huggingface | python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-0106 --engine-use-ray --worker-use-ray |
Example request (click to expand)
💡 Default Mode (GPT4 Correct): Best for coding, chat and general tasks
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'
🧮 Mathematical Reasoning Mode: Tailored for solving math problems
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"condition": "Math Correct",
"messages": [{"role": "user", "content": "10.3 − 7988.8133 = "}]
}'
Conversation templates
💡 Default Mode (GPT4 Correct): Best for coding, chat and general tasks
GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant: Hi<|end_of_turn|>GPT4 Correct User: How are you today?<|end_of_turn|>GPT4 Correct Assistant:
🧮 Mathematical Reasoning Mode: Tailored for solving math problems
Math Correct User: 10.3 − 7988.8133=<|end_of_turn|>Math Correct Assistant:
⚠️ Notice: Remember to set <|end_of_turn|> as end of generation token.
The default (GPT4 Correct) template is also available as the integrated tokenizer.chat_template,
which can be used instead of manually specifying the template:
messages = [
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hi"},
{"role": "user", "content": "How are you today?"}
]
tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
assert tokens == [1, 420, 6316, 28781, 3198, 3123, 1247, 28747, 22557, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747, 15359, 32000, 420, 6316, 28781, 3198, 3123, 1247, 28747, 1602, 460, 368, 3154, 28804, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747]
(Experimental) Evaluator / Feedback Capabilities
We've included evaluator capabilities in this release to advance open-source models as evaluators. You can use Default Mode (GPT4 Correct) with the following prompt (same as Prometheus) to evaluate a response.
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{orig_instruction}
###Response to evaluate:
{orig_response}
###Reference Answer (Score 5):
{orig_reference_answer}
###Score Rubrics:
[{orig_criteria}]
Score 1: {orig_score1_description}
Score 2: {orig_score2_description}
Score 3: {orig_score3_description}
Score 4: {orig_score4_description}
Score 5: {orig_score5_description}
###Feedback:
Benchmarks
| Model | # Params | Average | MT-Bench | HumanEval | BBH MC | AGIEval | TruthfulQA | MMLU | GSM8K | BBH CoT |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenChat-3.5-0106 | 7B | 64.5 | 7.8 | 71.3 | 51.5 | 49.1 | 61.0 | 65.8 | 77.4 | 62.2 |
| OpenChat-3.5-1210 | 7B | 63.8 | 7.76 | 68.9 | 49.5 | 48.0 | 61.8 | 65.3 | 77.3 | 61.8 |
| OpenChat-3.5 | 7B | 61.6 | 7.81 | 55.5 | 47.6 | 47.4 | 59.1 | 64.3 | 77.3 | 63.5 |
| ChatGPT (March)* | ???B | 61.5 | 7.94 | 48.1 | 47.6 | 47.1 | 57.7 | 67.3 | 74.9 | 70.1 |
| OpenHermes 2.5 | 7B | 59.3 | 7.54 | 48.2 | 49.4 | 46.5 | 57.5 | 63.8 | 73.5 | 59.9 |
| OpenOrca Mistral | 7B | 52.7 | 6.86 | 38.4 | 49.4 | 42.9 | 45.9 | 59.3 | 59.1 | 58.1 |
| Zephyr-β^ | 7B | 34.6 | 7.34 | 22.0 | 40.6 | 39.0 | 40.8 | 39.8 | 5.1 | 16.0 |
| Mistral | 7B | - | 6.84 | 30.5 | 39.0 | 38.0 | - | 60.1 | 52.2 | - |
Evaluation Details(click to expand)
*: ChatGPT (March) results are from GPT-4 Technical Report, Chain-of-Thought Hub, and our evaluation. Please note that ChatGPT is not a fixed baseline and evolves rapidly over time.
^: Zephyr-β often fails to follow few-shot CoT instructions, likely because it was aligned with only chat data but not trained on few-shot data.
**: Mistral and Open-source SOTA results are taken from reported results in instruction-tuned model papers and official repositories.
All models are evaluated in chat mode (e.g. with the respective conversation template applied). All zero-shot benchmarks follow the same setting as in the AGIEval paper and Orca paper. CoT tasks use the same configuration as Chain-of-Thought Hub, HumanEval is evaluated with EvalPlus, and MT-bench is run using FastChat. To reproduce our results, follow the instructions in our repository.
HumanEval+
| Model | Size | HumanEval+ pass@1 |
|---|---|---|
| OpenChat-3.5-0106 | 7B | 65.9 |
| ChatGPT (December 12, 2023) | ???B | 64.6 |
| WizardCoder-Python-34B-V1.0 | 34B | 64.6 |
| OpenChat 3.5 1210 | 7B | 63.4 |
| OpenHermes 2.5 | 7B | 41.5 |
OpenChat-3.5 vs. Grok
🔥 OpenChat-3.5-0106 (7B) now outperforms Grok-0 (33B) on all 4 benchmarks and Grok-1 (???B) on average and 3/4 benchmarks.
| License | # Param | Average | MMLU | HumanEval | MATH | GSM8k | |
|---|---|---|---|---|---|---|---|
| OpenChat-3.5-0106 | Apache-2.0 | 7B | 61.0 | 65.8 | 71.3 | 29.3 | 77.4 |
| OpenChat-3.5-1210 | Apache-2.0 | 7B | 60.1 | 65.3 | 68.9 | 28.9 | 77.3 |
| OpenChat-3.5 | Apache-2.0 | 7B | 56.4 | 64.3 | 55.5 | 28.6 | 77.3 |
| Grok-0 | Proprietary | 33B | 44.5 | 65.7 | 39.7 | 15.7 | 56.8 |
| Grok-1 | Proprietary | ???B | 55.8 | 73 | 63.2 | 23.9 | 62.9 |
*: Grok results are reported by X.AI.
Limitations
Foundation Model Limitations Despite its advanced capabilities, OpenChat is still bound by the limitations inherent in its foundation models. These limitations may impact the model's performance in areas such as:
- Complex reasoning
- Mathematical and arithmetic tasks
- Programming and coding challenges
Hallucination of Non-existent Information OpenChat may sometimes generate information that does not exist or is not accurate, also known as "hallucination". Users should be aware of this possibility and verify any critical information obtained from the model.
Safety OpenChat may sometimes generate harmful, hate speech, biased responses, or answer unsafe questions. It's crucial to apply additional AI safety measures in use cases that require safe and moderated responses.
License
Our OpenChat 3.5 code and models are distributed under the Apache License 2.0.
Citation
@article{wang2023openchat,
title={OpenChat: Advancing Open-source Language Models with Mixed-Quality Data},
author={Wang, Guan and Cheng, Sijie and Zhan, Xianyuan and Li, Xiangang and Song, Sen and Liu, Yang},
journal={arXiv preprint arXiv:2309.11235},
year={2023}
}
💌 Main Contributor
- Wang Guan [[email protected]], Cheng Sijie [[email protected]], Alpay Ariyak [[email protected]]
- We look forward to hearing you and collaborating on this exciting project!
- Downloads last month
- 214