
This is fashion image feature extractor model.
1. Model Architecture
I used microsoft/swin-base-patch4-window7-224 for base image encoder model. Just added a 128 size fully connected layer to lower embedding size. The dataset used anchor (product areas detected from posts) - positive (product thumbnail) image pairs. Within each batch, all samples except one's own positive were used as negative samples, training to minimize the distance between anchor-positive pairs while maximizing the distance between anchor-negative pairs. This method is known as contrastive learning, which is the training method used by OpenAI's CLIP model. Initially, anchor - positive - negative pairs were explicitly constructed in a 1:1:1 ratio using triplet loss, but training with in-batch negative sampling and contrastive loss showed much better performance as it allowed learning from more negative samples.
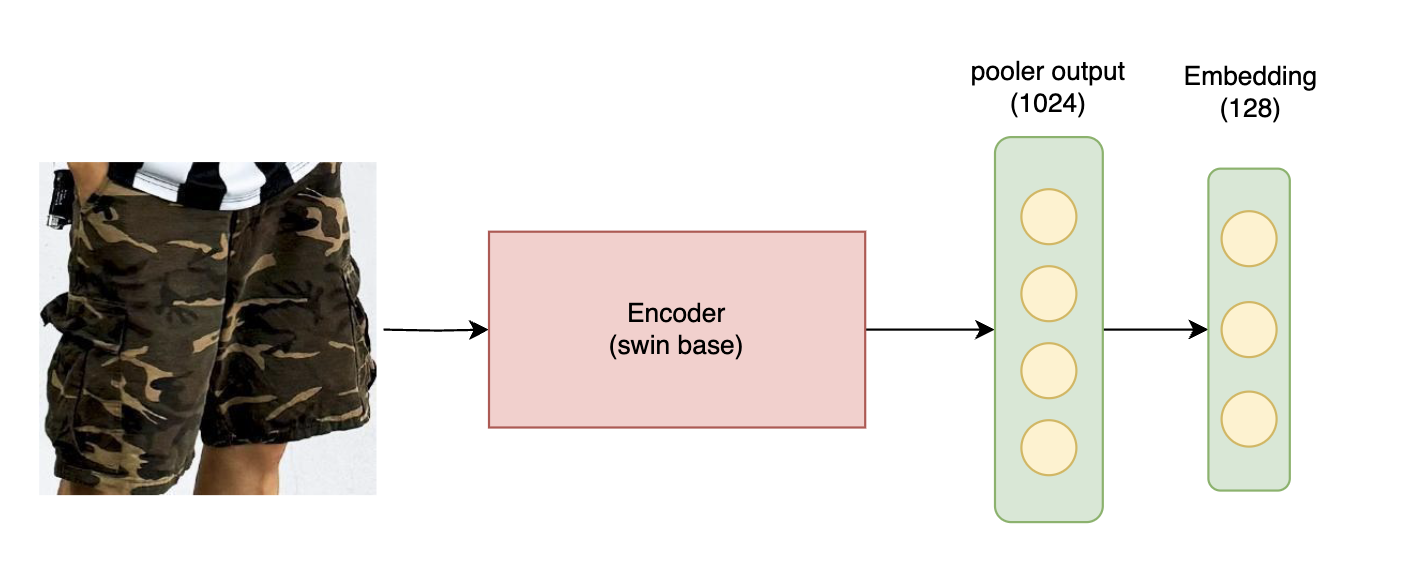

2. Training dataset
User posting images from onthelook and kream were crawled and preprocessed. First, raw data of image-product thumbnail combinations from posts were collected. Then, object detection was performed on posting images, and category classification was performed on product thumbnails to pair images of the same category together. For thumbnail category classification, a trained category classifier was used. Finally, about 290,000 anchor-positive image pairs were created for 6 categories: tops, bottoms, outer, shoes, bags, and hats. Finally, approximately 290,000 anchor-positive image pairs were created for 6 categories: tops, bottoms, outer, shoes, bags, and hats.
You can find object-detection model -> https://huggingface.co/yainage90/fashion-object-detection
You can find details of model in this github repo -> fashion-visual-search
from PIL import Image
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as v2
from transformers import AutoImageProcessor, SwinModel, SwinConfig
from huggingface_hub import PyTorchModelHubMixin
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
ckpt = "yainage90/fashion-image-feature-extractor"
encoder_config = SwinConfig.from_pretrained(ckpt)
encoder_image_processor = AutoImageProcessor.from_pretrained(ckpt)
class ImageEncoder(nn.Module, PyTorchModelHubMixin):
def __init__(self):
super(ImageEncoder, self).__init__()
self.swin = SwinModel(config=encoder_config)
self.embedding_layer = nn.Linear(encoder_config.hidden_size, 128)
def forward(self, image_tensor):
features = self.swin(image_tensor).pooler_output
embeddings = self.embedding_layer(features)
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
encoder = ImageEncoder().from_pretrained('yainage90/fashion-image-feature-extractor').to(device)
transform = v2.Compose([
v2.Resize((encoder_config.image_size, encoder_config.image_size)),
v2.ToTensor(),
v2.Normalize(mean=encoder_image_processor.image_mean, std=encoder_image_processor.image_std),
])
image = Image.open('<path/to/image>').convert('RGB')
image = transform(image)
with torch.no_grad():
embedding = encoder(image.unsqueeze(0).to(device)).cpu().numpy()




- Downloads last month
- 305