

Update README.md
Browse files
README.md
CHANGED
|
@@ -38,25 +38,22 @@ Transformer-based approach, the Word2Vec-based approach improved the accuracy ra
|
|
| 38 |
|
| 39 |
## Model description
|
| 40 |
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
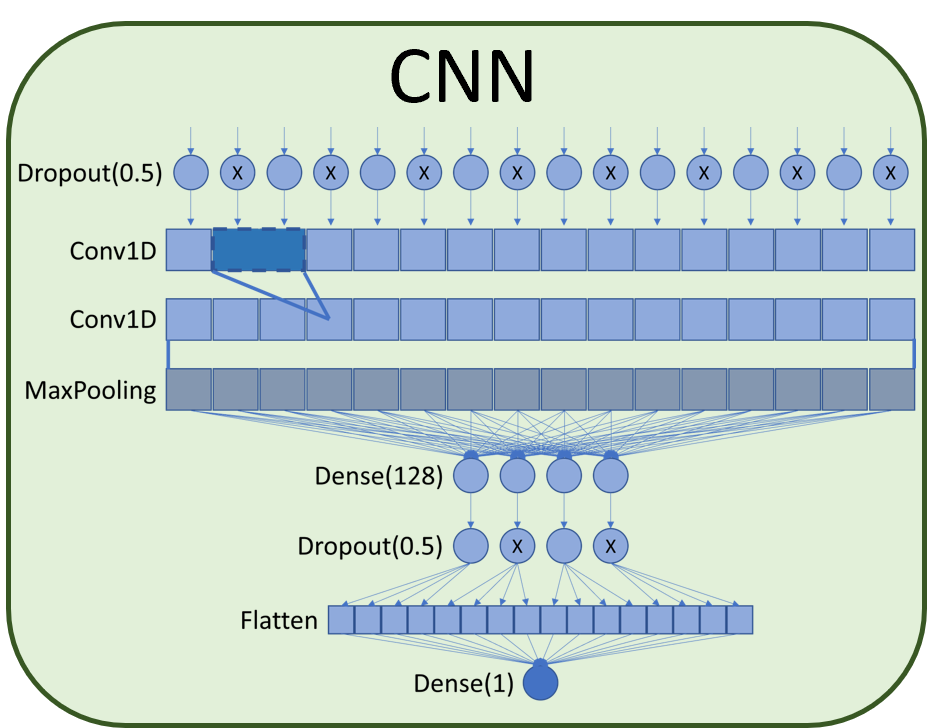
layers associated with a MaxPooling layer. After max pooling a dense layer of size 128 was added connected
|
| 58 |
-
to a 50% dropout which finally connects to a flatten layer and the final classification dense layer. Dropout
|
| 59 |
-
layers help to avoid overfitting the network by masking part of the data so that the network learns to create
|
| 60 |
redundancies in the analysis of the inputs.
|
| 61 |
|
| 62 |
|
|
|
|
| 38 |
|
| 39 |
## Model description
|
| 40 |
|
| 41 |
+
The work consists of a machine learning model with word embedding and Convolutional Neural Network (CNN).
|
| 42 |
+
For the project, a Convolutional Neural Network (CNN) was chosen, as it presents better accuracy in empirical
|
| 43 |
+
comparison with 3 other different architectures: Neural Network (NN), Deep Neural Network (DNN) and Long-Term
|
| 44 |
+
Memory (LSTM).
|
| 45 |
+
|
| 46 |
+
As the input data is compose of unstructured and nonuniform texts it is essential normalize the data to study
|
| 47 |
+
little insights and valuable relationships to work with the best features of them. In this way, learning is
|
| 48 |
+
facilitated and allows the gradient descent to converge more quickly.
|
| 49 |
+
|
| 50 |
+
The first layer of the model is an embedding layer as a method of extracting features from the data that can
|
| 51 |
+
replace one-hot coding with dimensional reduction.
|
| 52 |
+
|
| 53 |
+
The architecture of the CNN network is composed of a 50% dropout layer followed by two 1D convolution layers
|
| 54 |
+
associated with a MaxPooling layer. After maximum grouping, a dense layer of size 128 is added connected to
|
| 55 |
+
a 50% dropout which finally connects to a flattened layer and the final sort dense layer. The dropout layers
|
| 56 |
+
helped to avoid network overfitting by masking part of the data so that the network learned to create
|
|
|
|
|
|
|
|
|
|
| 57 |
redundancies in the analysis of the inputs.
|
| 58 |
|
| 59 |

|