

Update README.md
Browse files
README.md
CHANGED
|
@@ -19,7 +19,7 @@ thumbnail: https://github.com/Marcosdib/S2Query/Classification_Architecture_mode
|
|
| 19 |

|
| 20 |
|
| 21 |
|
| 22 |
-
# MCTI Text Classification Task (uncased)
|
| 23 |
|
| 24 |
Disclaimer: The Brazilian Ministry of Science, Technology, and Innovation (MCTI) has partially supported this project.
|
| 25 |
|
|
@@ -38,24 +38,28 @@ Transformer-based approach, the Word2Vec-based approach improved the accuracy ra
|
|
| 38 |
|
| 39 |
## Model description
|
| 40 |
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
bibendum cursus. Nunc volutpat vitae neque ut bibendum:
|
| 45 |
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
- Nullam congue hendrerit turpis et facilisis. Cras accumsan ante mi, eu hendrerit nulla finibus at. Donec imperdiet,
|
| 50 |
-
nisi nec pulvinar suscipit, dolor nulla sagittis massa, et vehicula ante felis quis nibh. Lorem ipsum dolor sit amet,
|
| 51 |
-
consectetur adipiscing elit.
|
| 52 |
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
consectetur adipiscing elit. Maecenas viverra tempus risus non ornare. Donec in vehicula est. Pellentesque vulputate
|
| 56 |
-
bibendum cursus. Nunc volutpat vitae neque ut bibendum.
|
| 57 |
|
| 58 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
|
| 60 |
## Model variations
|
| 61 |
|
|
@@ -74,30 +78,9 @@ Table 1: Templates using Word2Vec and Longformer
|
|
| 74 |
| Longformer | 10.9GB |
|
| 75 |
| Word2Vec | 56.1MB |
|
| 76 |
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
| Keras Embedding + SNN | 92.47 | 88.46 | 79.66 | 100 | 0.2 | 0.7 | 1.8 |
|
| 80 |
-
| Keras Embedding + DNN | 89.78 | 84.41 | 77.81 | 92.57 | 1 | 1.4 | 7.6 |
|
| 81 |
-
| Keras Embedding + CNN | 93.01 | 89.91 | 85.18 | 95.69 | 0.4 | 1.1 | 3.2 |
|
| 82 |
-
| Keras Embedding + LSTM| 93.01 | 88.94 | 83.32 | 95.54 | 1.4 | 2 | 1.8 |
|
| 83 |
-
| Word2Vec + SNN | 89.25 | 83.82 | 74.15 | 97.10 | 1.4 | 1.2 | 9.6 |
|
| 84 |
-
| Word2Vec + DNN | 90.32 | 86.52 | 85.18 | 88.70 | 2 | 6.8 | 7.8 |
|
| 85 |
-
| Word2Vec + CNN | 92.47 | 88.42 | 80.85 | 98.72 | 1.9 | 3.4 | 4.7 |
|
| 86 |
-
| Word2Vec + LSTM | 89.78 | 84.36 | 75.36 | 95.81 | 2.6 | 14.3 | 1.2 |
|
| 87 |
-
| Longformer + SNN | 61.29 | 0 | 0 | 0 | 128 | 1.5 | 36.8 |
|
| 88 |
-
| Longformer + DNN | 91.93 | 87.62 | 80.37 | 97.62 | 81 | 8.4 | 12.7 |
|
| 89 |
-
| Longformer + CNN | 94.09 | 90.69 | 83.41 | 100 | 57 | 4.5 | 9.6 |
|
| 90 |
-
| Longformer + LSTM | 61.29 | 0 | 0 | 0 | 135 | 8.6 | 2.6 |
|
| 91 |
-
|
| 92 |
## Intended uses
|
| 93 |
|
| 94 |
-
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
|
| 95 |
-
be fine-tuned on a downstream task. See the [model hub](https://www.google.com) to look for
|
| 96 |
-
fine-tuned versions of a task that interests you.
|
| 97 |
|
| 98 |
-
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
|
| 99 |
-
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
|
| 100 |
-
generation you should look at model like XXX.
|
| 101 |
|
| 102 |
### How to use
|
| 103 |
|
|
@@ -125,6 +108,15 @@ This model is uncased: it does not make a difference between english and English
|
|
| 125 |
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
|
| 126 |
predictions:
|
| 127 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 128 |
-
|
| 129 |
-
|
| 130 |
This bias will also affect all fine-tuned versions of this model.
|
|
@@ -144,14 +136,6 @@ it was coupled to the classification model to train it with the labeled data in
|
|
| 144 |
obtained with related metrics. With this implementation, was reached new levels of accuracy with 86% for CNN architecture
|
| 145 |
and 88% for the LSTM architecture.
|
| 146 |
|
| 147 |
-
Table 6: Results from Pre-trained WE + ML models
|
| 148 |
-
| ML Model | Accuracy | F1 Score | Precision | Recall |
|
| 149 |
-
|:--------:|:---------:|:---------:|:---------:|:---------:|
|
| 150 |
-
| NN | 0.8269 | 0.8545 | 0.8392 | 0.8712 |
|
| 151 |
-
| DNN | 0.7115 | 0.7794 | 0.7255 | 0.8485 |
|
| 152 |
-
| CNN | 0.8654 | 0.9083 | 0.8486 | 0.9773 |
|
| 153 |
-
| LSTM | 0.8846 | 0.9139 | 0.9056 | 0.9318 |
|
| 154 |
-
|
| 155 |
### Preprocessing
|
| 156 |
|
| 157 |
Pre-processing was used to standardize the texts for the English language, reduce the number of insignificant tokens and
|
|
@@ -250,9 +234,58 @@ Table 5: Compatibility results (*base = labeled MCTI dataset entries)
|
|
| 250 |
| BBC News Articles | 56.77% |
|
| 251 |
| New unlabeled MCTI | 75.26% |
|
| 252 |
|
| 253 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 254 |
|
|
|
|
| 255 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 256 |
|
| 257 |
## Benchmarks
|
| 258 |
|
|
|
|
| 19 |

|
| 20 |
|
| 21 |
|
| 22 |
+
# MCTI Text Classification Task (uncased)
|
| 23 |
|
| 24 |
Disclaimer: The Brazilian Ministry of Science, Technology, and Innovation (MCTI) has partially supported this project.
|
| 25 |
|
|
|
|
| 38 |
|
| 39 |
## Model description
|
| 40 |
|
| 41 |
+
After the embedding, which is just essentially data preprocessing, it is necessary to develop the Project
|
| 42 |
+
further to analyze the input text and classify whether it is a valid research funding opportunity for
|
| 43 |
+
Brazilian or not.
|
|
|
|
| 44 |
|
| 45 |
+
For the project, the best option would be chosen empirically upon comparing the results of 4 distinct architectures:
|
| 46 |
+
Neural Network (NN), Deep Neural Network (DNN), Long Short-Term Memory (LSTM), and Convolutional Neural Network (CNN).
|
| 47 |
+
Figure 4 shows the structure of the models.
|
|
|
|
|
|
|
|
|
|
| 48 |
|
| 49 |
+
A neural network (NN) here is a simple feedforward neural network with only a single hidden layer, usually called
|
| 50 |
+
”shallow”. Shallow NNs are often limited in the complexity of the problems they can be trained to solve well.
|
|
|
|
|
|
|
| 51 |
|
| 52 |
+
Our CNN model uses a dropout layer feeding into a couple of Conv1D layers and then a MaxPooling layer. After that,
|
| 53 |
+
we Figure 4: Classification models use a hidden layer composed of a dense layer of size 128, followed by another
|
| 54 |
+
dropout layer, and finally, the Flatten and final dense classification layer.
|
| 55 |
+
|
| 56 |
+
The architecture of the CNN network used is composed of a 50% dropout layer followed by two 1D convolution
|
| 57 |
+
layers associated with a MaxPooling layer. After max pooling a dense layer of size 128 was added connected
|
| 58 |
+
to a 50% dropout which finally connects to a flatten layer and the final classification dense layer. Dropout
|
| 59 |
+
layers help to avoid overfitting the network by masking part of the data so that the network learns to create
|
| 60 |
+
redundancies in the analysis of the inputs.
|
| 61 |
+
|
| 62 |
+
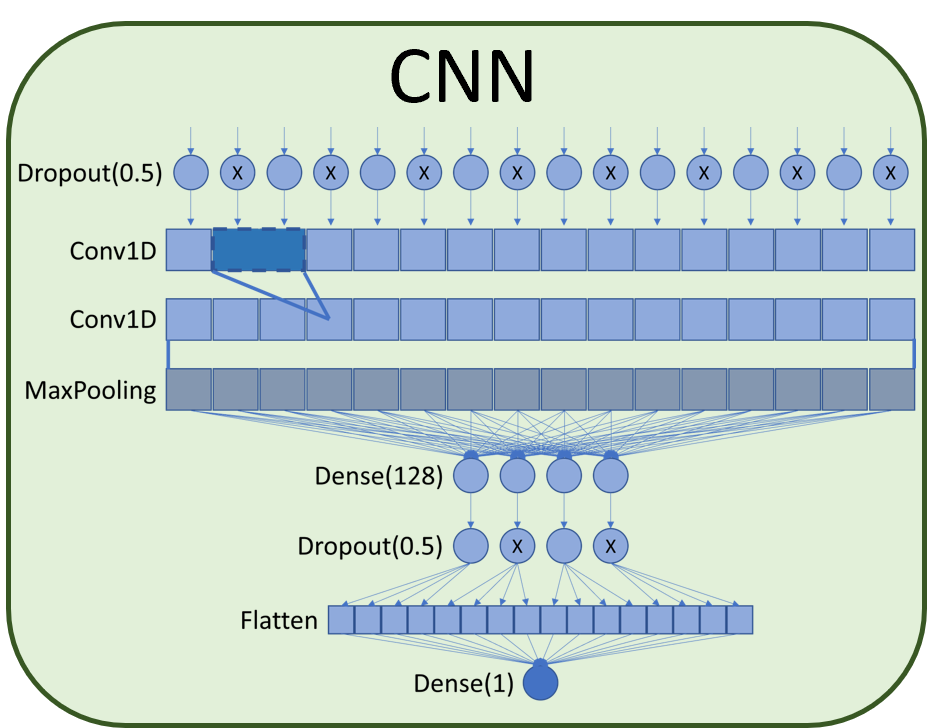
|
| 63 |
|
| 64 |
## Model variations
|
| 65 |
|
|
|
|
| 78 |
| Longformer | 10.9GB |
|
| 79 |
| Word2Vec | 56.1MB |
|
| 80 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 81 |
## Intended uses
|
| 82 |
|
|
|
|
|
|
|
|
|
|
| 83 |
|
|
|
|
|
|
|
|
|
|
| 84 |
|
| 85 |
### How to use
|
| 86 |
|
|
|
|
| 108 |
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
|
| 109 |
predictions:
|
| 110 |
|
| 111 |
+
Performance limiting: Loading the longformer model in memory means needing 11Gb available only for the model,
|
| 112 |
+
without considering the weight of the deep learning network. For training this means we need a 20+ Gb GPU to
|
| 113 |
+
perform the training. Here this was resolved using the high RAM environment of google Colab Pro and training
|
| 114 |
+
using CPU which justifies the longer training time per season.
|
| 115 |
+
|
| 116 |
+
Replicability limitation: Due to the simplicity of the keras embedding model, we are using one hot encoding,
|
| 117 |
+
and it has a delicate problem for replication in production. This detail is pending further study to define
|
| 118 |
+
whether it is possible to use one of these models.
|
| 119 |
+
|
| 120 |
-
|
| 121 |
-
|
| 122 |
This bias will also affect all fine-tuned versions of this model.
|
|
|
|
| 136 |
obtained with related metrics. With this implementation, was reached new levels of accuracy with 86% for CNN architecture
|
| 137 |
and 88% for the LSTM architecture.
|
| 138 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 139 |
### Preprocessing
|
| 140 |
|
| 141 |
Pre-processing was used to standardize the texts for the English language, reduce the number of insignificant tokens and
|
|
|
|
| 234 |
| BBC News Articles | 56.77% |
|
| 235 |
| New unlabeled MCTI | 75.26% |
|
| 236 |
|
| 237 |
+
Table 6: Results from Pre-trained WE + ML models
|
| 238 |
+
| ML Model | Accuracy | F1 Score | Precision | Recall |
|
| 239 |
+
|:--------:|:---------:|:---------:|:---------:|:---------:|
|
| 240 |
+
| NN | 0.8269 | 0.8545 | 0.8392 | 0.8712 |
|
| 241 |
+
| DNN | 0.7115 | 0.7794 | 0.7255 | 0.8485 |
|
| 242 |
+
| CNN | 0.8654 | 0.9083 | 0.8486 | 0.9773 |
|
| 243 |
+
| LSTM | 0.8846 | 0.9139 | 0.9056 | 0.9318 |
|
| 244 |
|
| 245 |
+
## Evaluation results
|
| 246 |
|
| 247 |
+
The table below presents the results of accuracy, f1-score, recall and precision obtained in the training of each network.
|
| 248 |
+
In addition, the necessary times for training each epoch, the data validation execution time and the weight of the deep
|
| 249 |
+
learning model associated with each implementation were added.
|
| 250 |
+
|
| 251 |
+
Table 7: Results of experiments
|
| 252 |
+
| Model | Accuracy | F1-score | Recall | Precision | Training time epoch(s) | Validation time (s) | Weight(MB) |
|
| 253 |
+
|------------------------|----------|----------|--------|-----------|------------------------|---------------------|------------|
|
| 254 |
+
| Keras Embedding + SNN | 92.47 | 88.46 | 79.66 | 100.00 | 0.2 | 0.7 | 1.8 |
|
| 255 |
+
| Keras Embedding + DNN | 89.78 | 84.41 | 77.81 | 92.57 | 1.0 | 1.4 | 7.6 |
|
| 256 |
+
| Keras Embedding + CNN | 93.01 | 89.91 | 85.18 | 95.69 | 0.4 | 1.1 | 3.2 |
|
| 257 |
+
| Keras Embedding + LSTM | 93.01 | 88.94 | 83.32 | 95.54 | 1.4 | 2.0 | 1.8 |
|
| 258 |
+
| Word2Vec + SNN | 89.25 | 83.82 | 74.15 | 97.10 | 1.4 | 1.2 | 9.6 |
|
| 259 |
+
| Word2Vec + DNN | 90.32 | 86.52 | 85.18 | 88.70 | 2.0 | 6.8 | 7.8 |
|
| 260 |
+
| Word2Vec + CNN | 92.47 | 88.42 | 80.85 | 98.72 | 1.9 | 3.4 | 4.7 |
|
| 261 |
+
| Word2Vec + LSTM | 89.78 | 84.36 | 75.36 | 95.81 | 2.6 | 14.3 | 1.2 |
|
| 262 |
+
| Longformer + SNN | 61.29 | 0 | 0 | 0 | 128.0 | 1.5 | 36.8 |
|
| 263 |
+
| Longformer + DNN | 91.93 | 87.62 | 80.37 | 97.62 | 81.0 | 8.4 | 12.7 |
|
| 264 |
+
| Longformer + CNN | 94.09 | 90.69 | 83.41 | 100.00 | 57.0 | 4.5 | 9.6 |
|
| 265 |
+
| Longformer + LSTM | 61.29 | 0 | 0 | 0 | 13.0 | 8.6 | 2.6 |
|
| 266 |
+
|
| 267 |
+
The results obtained surpassed those achieved in goal 6 and goal 9, with the best accuracy obtained of 94%
|
| 268 |
+
in the longformer + CNN model. We can also observe that the models that achieved the best results were those
|
| 269 |
+
that used the CNN network for deep learning.
|
| 270 |
+
|
| 271 |
+
In addition, it was possible to notice that the model of longformer + SNN and longformer + LSTM were not able
|
| 272 |
+
to learn. Perhaps the models need some adjustments, but each training attempt took between 5 and 8 hours, which
|
| 273 |
+
made it impossible to try to adjust when other models were already showing promising results.
|
| 274 |
+
|
| 275 |
+
Above the results obtained, it is also necessary to highlight two limitations found for the replication and
|
| 276 |
+
training of networks:
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
These 10Gb of the model exceed the Github limit and did not go to the repository, so to run the system we need
|
| 280 |
+
to download the pre-trained network in the notebook and run the encoder-decoder with the data to create the model.
|
| 281 |
+
It is advisable to do this in a GPU environment and save the file on the drive. After that change the environment to
|
| 282 |
+
CPU to perform the training. Trying to generate the model in CPU will take more than 3 hours of processing.
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
The best model that does not have any limitations is Word2Vec + CNN. However, we need to study the limitations to
|
| 286 |
+
understand whether it is possible to introduce a new model with better accuracy and indicators. These adjustments
|
| 287 |
+
will be worked on during goals 13 and 14 where the main objective will be to encapsulate the solution in the most
|
| 288 |
+
suitable way for use in production.
|
| 289 |
|
| 290 |
## Benchmarks
|
| 291 |
|