
Teapot LLM
Website | Try out our demo on Discord
Teapot is an open-source small language model (~800 million parameters) fine-tuned on synthetic data and optimized to run locally on resource-constrained devices such as smartphones and CPUs. Teapot is trained to only answer using context from documents, reducing hallucinations. Teapot can perform a variety of tasks, including hallucination-resistant Question Answering (QnA), Retrieval-Augmented Generation (RAG), and JSON extraction. Teapot is a model built by and for the community.
Conversational Question Answering
Teapot is fine-tuned to provide friendly, conversational answers using context and documents provided as references.
Hallucination Resistance
Teapot is trained to only output answers that can be derived from the provided context, ensuring that even though it is a small model, it performs demonstrably better by refusing to answer questions when there is insufficient data.
Retrieval Augmented Generation
Teapot is further fine-tuned on the task of retrieval augmented generation by utilizing a custom embedding model. We perform RAG across multiple documents from our training data and the model is able to learn to extract relevant details for question answering.
Information Extraction
Teapot has been trained to extract succint answers in a variety of format enabling efficient document parsing. Teapot is trained natively to output standard data types such as numbers, strings, and even json.
Getting Started
We recommend using our library teapotai to quickly integrate our models into production environments, as it handles the overhead of model configuration, document embeddings, error handling and prompt formatting. However, you can directly use the model from the transformers library on huggingface.
Installation
! pip install teapotai
1. General Question Answering (QnA)
Teapot can be used for general question answering based on a provided context. The model is optimized to respond conversationally and is trained to avoid answering questions that can't be answered from the given context, reducing hallucinations.
Example:
from teapotai import TeapotAI
# Sample context
context = """
The Eiffel Tower is a wrought iron lattice tower in Paris, France. It was designed by Gustave Eiffel and completed in 1889.
It stands at a height of 330 meters and is one of the most recognizable structures in the world.
"""
teapot_ai = TeapotAI()
answer = teapot_ai.query(
query="What is the height of the Eiffel Tower?",
context=context
)
print(answer) # => "The Eiffel Tower stands at a height of 330 meters. "
Hallucination Example:
from teapotai import TeapotAI
# Sample context without height information
context = """
The Eiffel Tower is a wrought iron lattice tower in Paris, France. It was designed by Gustave Eiffel and completed in 1889.
"""
teapot_ai = TeapotAI()
answer = teapot_ai.query(
query="What is the height of the Eiffel Tower?",
context=context
)
print(answer) # => "I don't have information on the height of the Eiffel Tower."
2. Chat with Retrieval Augmented Generation (RAG)
Teapot can also use Retrieval-Augmented Generation (RAG) to determine which documents are relevant before answering a question. This is useful when you have many documents you want to use as context, ensuring the model answers based on the most relevant ones.
Example:
from teapotai import TeapotAI
# Sample documents (in practice, these could be articles or longer documents)
documents = [
"The Eiffel Tower is located in Paris, France. It was built in 1889 and stands 330 meters tall.",
"The Great Wall of China is a historic fortification that stretches over 13,000 miles.",
"The Amazon Rainforest is the largest tropical rainforest in the world, covering over 5.5 million square kilometers.",
"The Grand Canyon is a natural landmark located in Arizona, USA, carved by the Colorado River.",
"Mount Everest is the tallest mountain on Earth, located in the Himalayas along the border between Nepal and China.",
"The Colosseum in Rome, Italy, is an ancient amphitheater known for its gladiator battles.",
"The Sahara Desert is the largest hot desert in the world, located in North Africa.",
"The Nile River is the longest river in the world, flowing through northeastern Africa.",
"The Empire State Building is an iconic skyscraper in New York City that was completed in 1931 and stands at 1454 feet tall."
]
# Initialize TeapotAI with documents for RAG
teapot_ai = TeapotAI(documents=documents)
# Get the answer using RAG
answer = teapot_ai.chat([
{
"role":"system",
"content": "You are an agent designed to answer facts about famous landmarks."
},
{
"role":"user",
"content": "What landmark was constructed in the 1800s?"
}
])
print(answer) # => The Eiffel Tower was constructed in the 1800s.
Loading RAG Model:
You can save a model with pre-computed embeddings to reduce loading times. TeapotAI is pickle-compatible and can be saved and loaded as shown below.
import pickle
# Pickle the TeapotAI model to a file with pre-computed embeddings
with open("teapot_ai.pkl", "wb") as f:
pickle.dump(teapot_ai, f)
# Load the pickled model
with open("teapot_ai.pkl", "rb") as f:
loaded_teapot_ai = pickle.load(f)
# You can now use the loaded instance as you would normally
print(len(loaded_teapot_ai.documents)) # => 10 Documents with precomputed embeddings
loaded_teapot_ai.query("What city is the Eiffel Tower in?") # => "The Eiffel Tower is located in Paris, France."
3. Information Extraction
Teapot can be used to extract structured information from context using pre-defined JSON structures. The extract method takes a Pydantic model to ensure Teapot extracts the correct types. Teapot can infer fields based on names and will also leverage descriptions if available. This method can also be used with RAG and query functionalities natively.
Example:
from teapotai import TeapotAI
from pydantic import BaseModel
# Sample text containing apartment details
apartment_description = """
This spacious 2-bedroom apartment is available for rent in downtown New York. The monthly rent is $2500.
It includes 1 bathrooms and a fully equipped kitchen with modern appliances.
Pets are welcome!
Please reach out to us at 555-123-4567 or [email protected]
"""
# Define a Pydantic model for the data you want to extract
class ApartmentInfo(BaseModel):
rent: float = Field(..., description="the monthly rent in dollars")
bedrooms: int = Field(..., description="the number of bedrooms")
bathrooms: int = Field(..., description="the number of bathrooms")
phone_number: str
# Initialize TeapotAI
teapot_ai = TeapotAI()
# Extract the apartment details
extracted_info = teapot_ai.extract(
ApartmentInfo,
context=apartment_description
)
print(extracted_info) # => ApartmentInfo(rent=2500.0 bedrooms=2 bathrooms=1 phone_number='555-123-4567')
Native Transformer Support
While we recommend using TeapotAI's library, you can load the base model directly with Hugging Face's Transformers library as follows:
from transformers import pipeline
# Load the model
teapot_ai = pipeline("text2text-generation", "teapotai/teapotllm")
context = """
The Eiffel Tower is a wrought iron lattice tower in Paris, France. It was designed by Gustave Eiffel and completed in 1889.
It stands at a height of 330 meters and is one of the most recognizable structures in the world.
"""
question = "What is the height of the Eiffel Tower?"
answer = teapot_ai(context+"\n"+question)
print(answer[0].get('generated_text')) # => The Eiffel Tower stands at a height of 330 meters.
Model Details
Teapot LLM is fine-tuned from flan-t5-large on a synthetic dataset of LLM tasks generated using DeepSeek-V3.
Training Details
- [Dataset] ~10mb synthetic dataset consisting of QnA pairs with a variety of task specific formats.
- [Methodology] The model is trained to mimic task specific output formats, and is scored based on its ability to output relevant, succint and verifiable answers in the requested format.
- [Hardware] Teapot was trained for ~10hr on an A100 provided by Google Colab.
- [Hyperparameters] The model was trained with various learning rates and monitored to ensure task specific performance was learned without catastrophic forgetting.
Model Evaluation
TeapotLLM is focused on in-context reasoning tasks, and therefore most benchmarks are not suitable for evaluation. We want TeapotLLM to be a practical tool for QnA and information extraction, so we have developed custom datasets to benchmark performance.
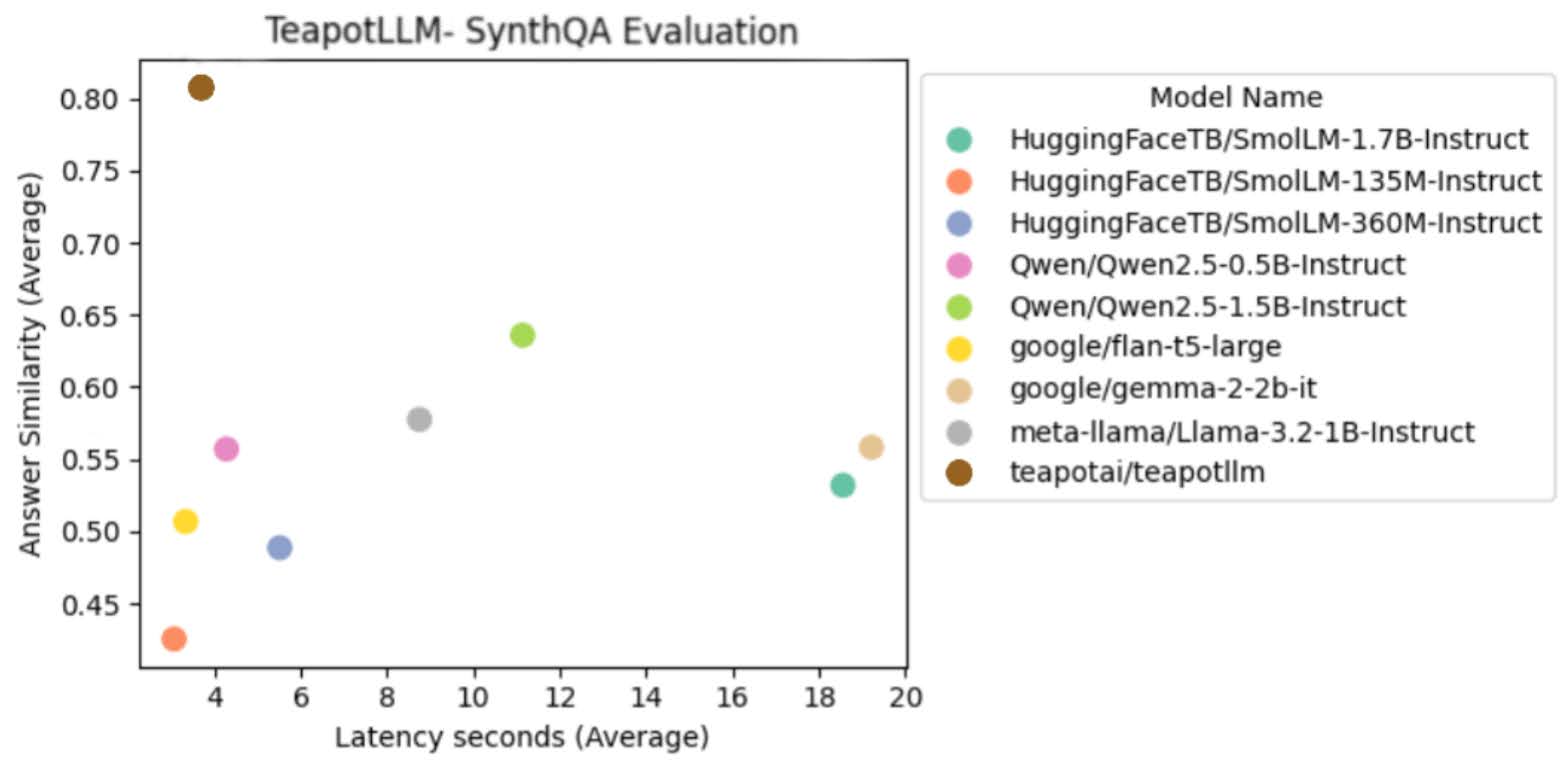
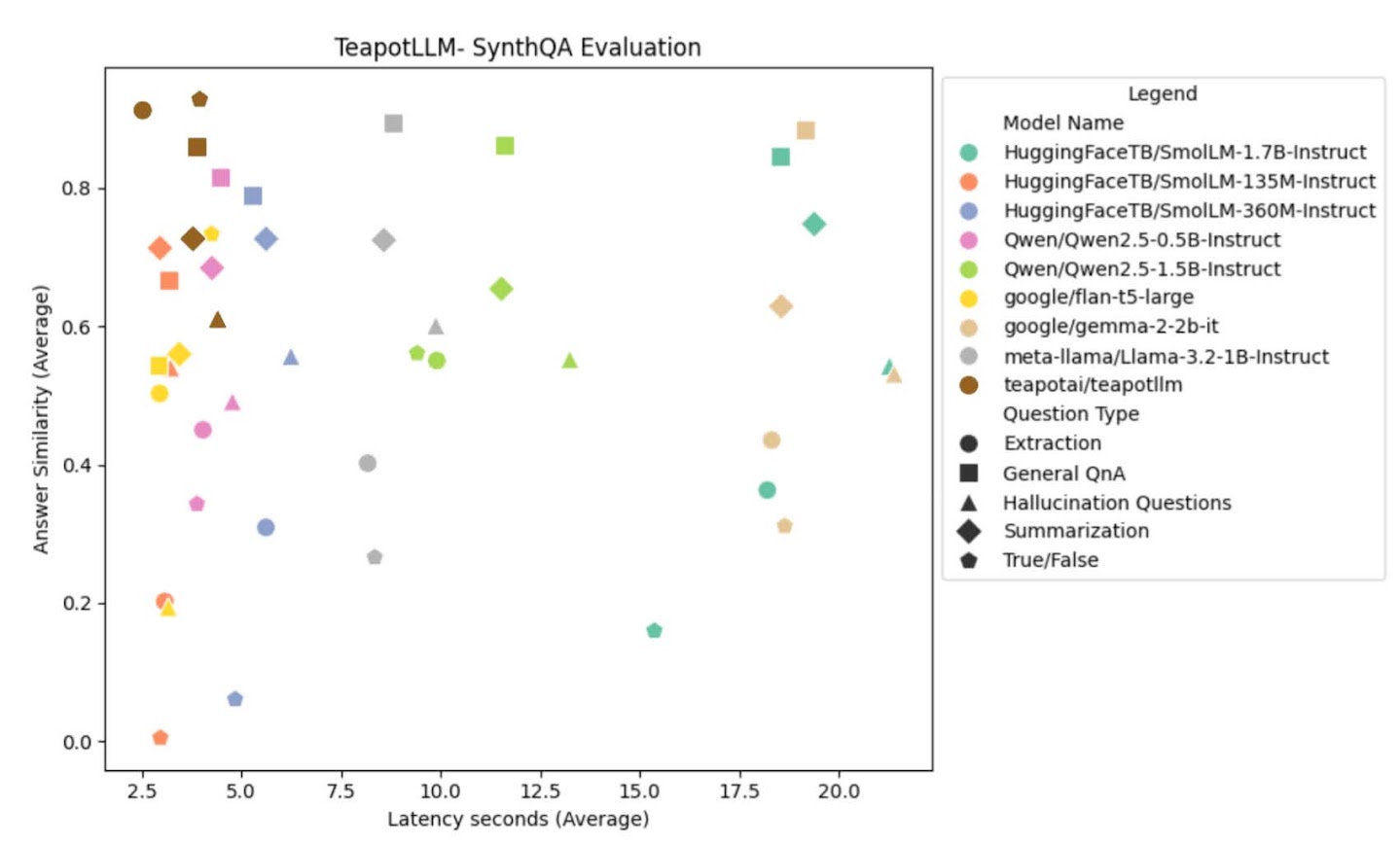
Synthqa Evaluation
Synthqa is a dataset focused on in-context QnA and information extraction tasks. We use the validation set to benchmark TeapotLLM against other models of similar size. All benchmarks were run using a Google Colab Notebook running on CPU with High Ram. Teapot significantly outperforms models of similar size, with low latency CPU inference and improved accuracy.
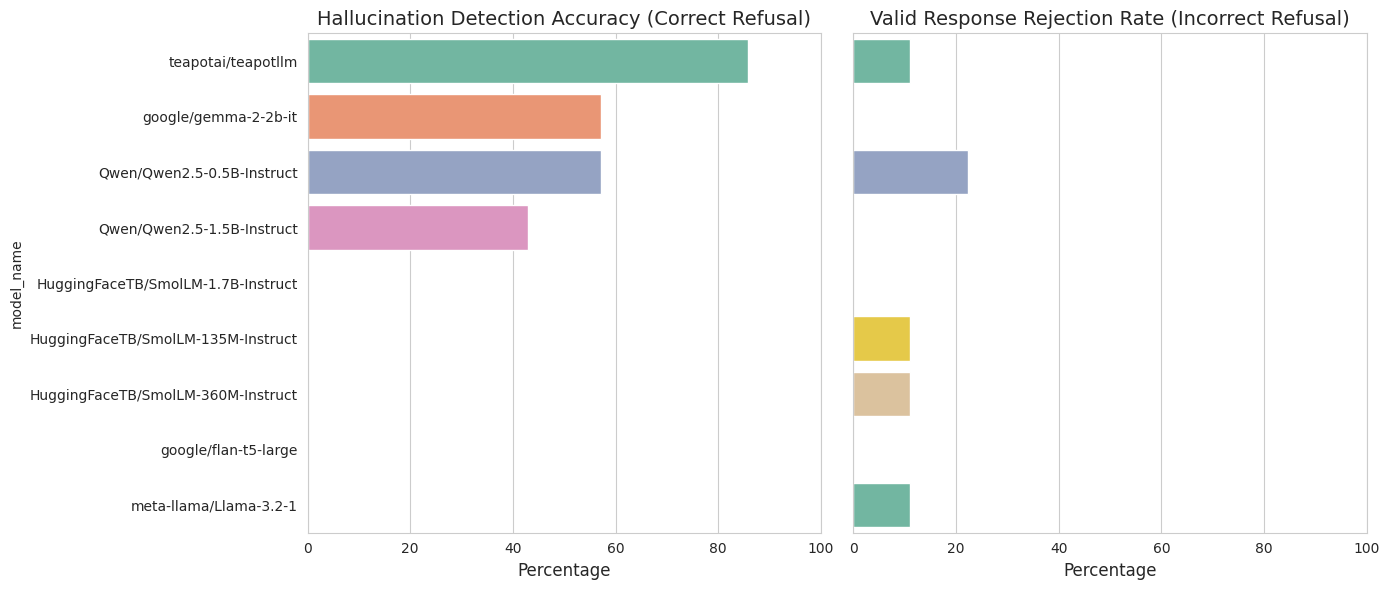
We also manually annotated hallucination refusals from models. All models were asked to not answer if the answer could not be derived from the provided context. TeapotLLM exhibits significantly stronger hallucination resistant behavior, without compromising on incorrect refusals.
Limitations and Risks
Teapot is trained specifically for question answering use cases and is not intended to be used for code generation, creative writing or critical decision applications. Teapot has only been trained on specific languages supported by flan-t5 and has not been evaluated for performance in languages other than English.
License
This model, the embedding model and the synthetic dataset are all provided open source under the MIT LICENSE.
Questions, Feature Requests?
We hope you find TeapotAI useful and are continuosuly working to improve our models. Please reach out to us on our Discord for any technical help or feature requrests. We look forwarding to seeing what our community can build!
- Downloads last month
- 8,373