
XLMali |
|
|
Вишејезични модел, 279 милиона параметара Обучаван над корпусима српског и српскохрватског језика - 20 милијарди речи Једнака подршка уноса на ћирилици и латиници! |
Multilingual model, 279 million parameters Trained on Serbian and Serbo-Croatian corpora - 20 billion words Equal support for Cyrillic and Latin input! |
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='te-sla/teslaXLM')
>>> unmasker("Kada bi čovek znao gde će pasti on bi<mask>.")
>>> from transformers import AutoTokenizer, AutoModelForMaskedLM
>>> from torch import LongTensor, no_grad
>>> from scipy import spatial
>>> tokenizer = AutoTokenizer.from_pretrained('te-sla/teslaXLM')
>>> model = AutoModelForMaskedLM.from_pretrained('te-sla/teslaXLM', output_hidden_states=True)
>>> x = " pas"
>>> y = " mačka"
>>> z = " svemir"
>>> tensor_x = LongTensor(tokenizer.encode(x, add_special_tokens=False)).unsqueeze(0)
>>> tensor_y = LongTensor(tokenizer.encode(y, add_special_tokens=False)).unsqueeze(0)
>>> tensor_z = LongTensor(tokenizer.encode(z, add_special_tokens=False)).unsqueeze(0)
>>> model.eval()
>>> with no_grad():
>>> vektor_x = model(input_ids=tensor_x).hidden_states[-1].squeeze()
>>> vektor_y = model(input_ids=tensor_y).hidden_states[-1].squeeze()
>>> vektor_z = model(input_ids=tensor_z).hidden_states[-1].squeeze()
>>> print(spatial.distance.cosine(vektor_x, vektor_y))
>>> print(spatial.distance.cosine(vektor_x, vektor_z))
Евалуација XLMR-base модела за српски језик |
Serbian XLMR-base models evaluation results |
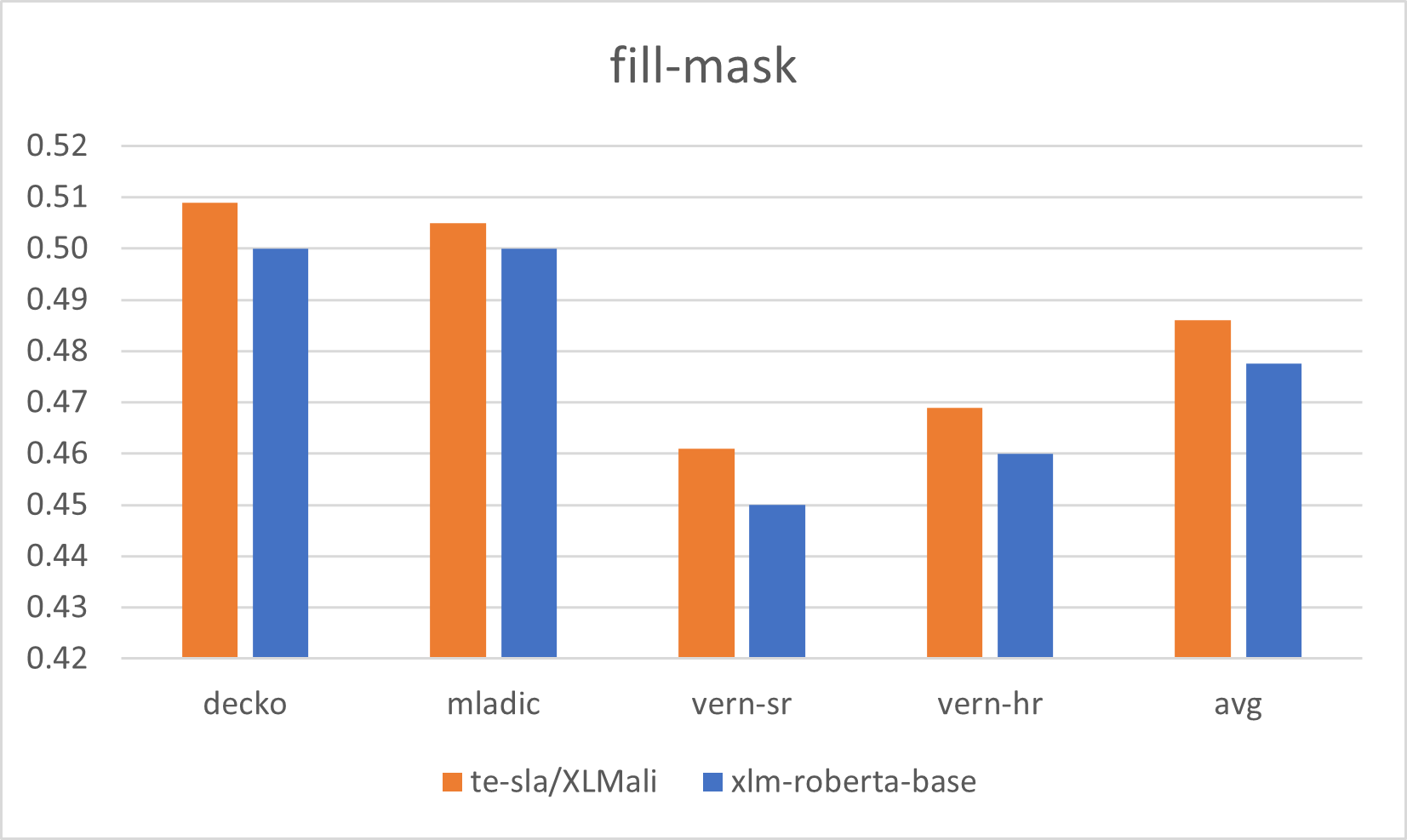
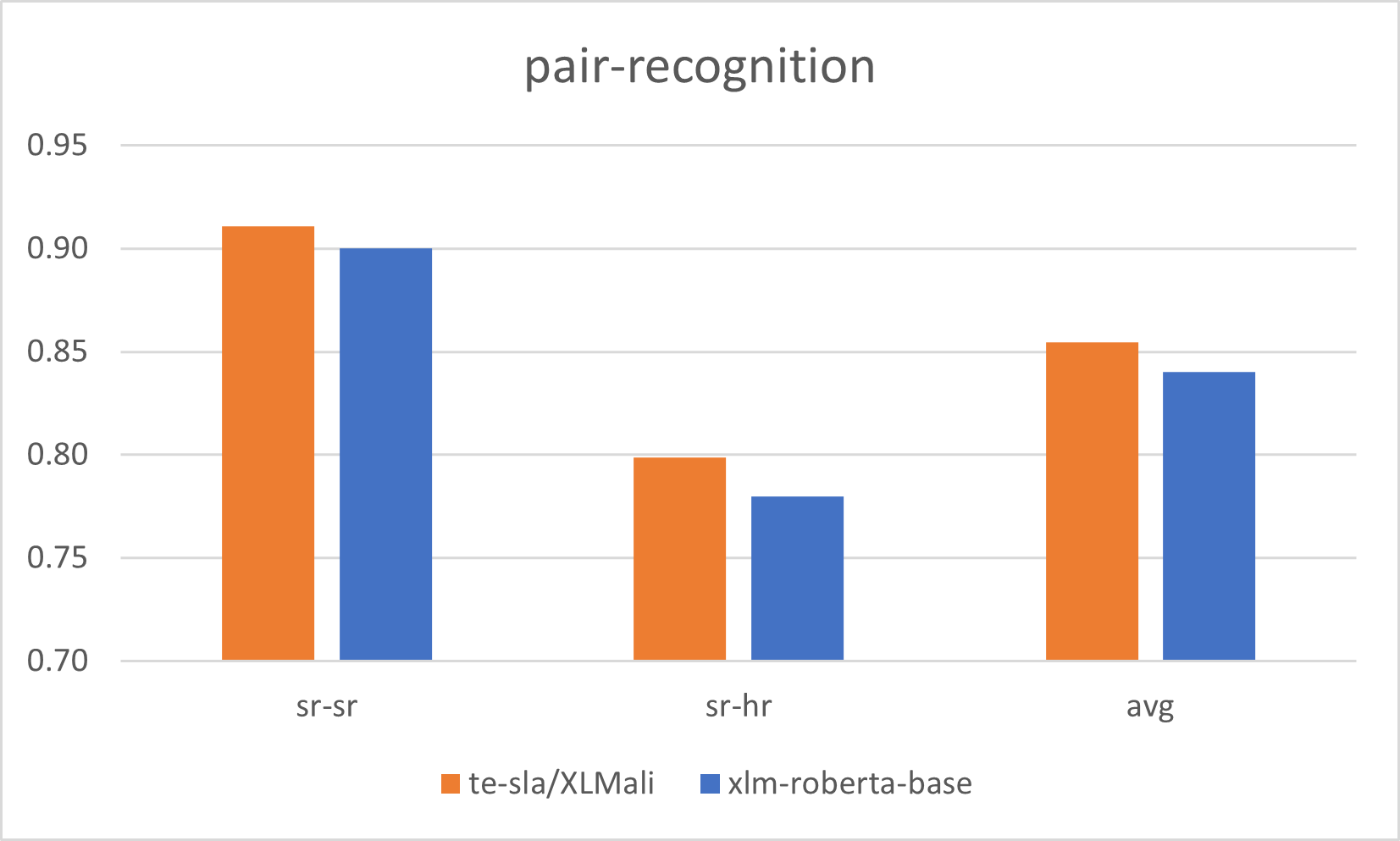
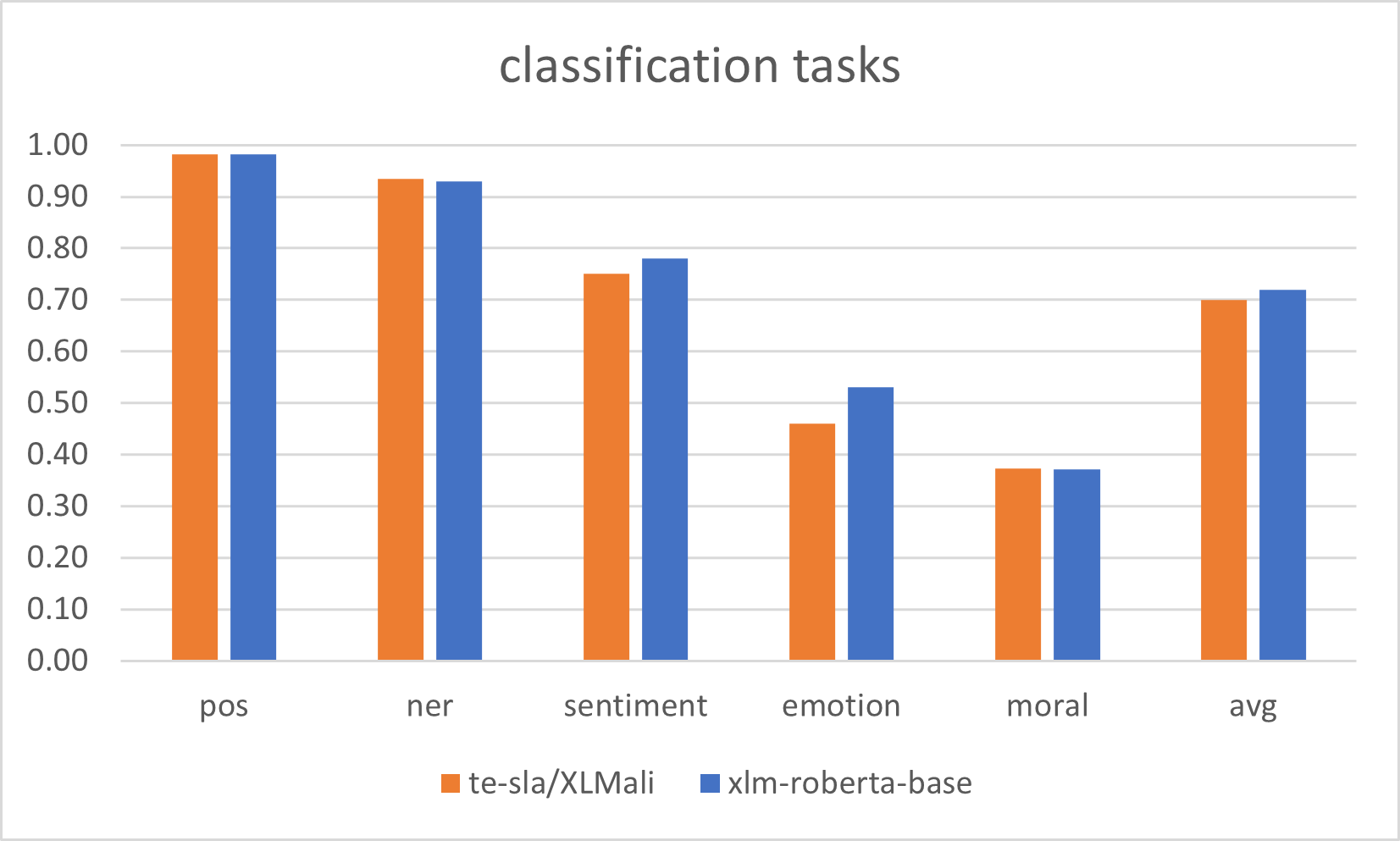
|
|
Cit.
@inproceedings{skoricxlm,
author = {Mihailo Škorić, Saša Petalinkar},
title = {New XLM-R-based language models for Serbian and Serbo-Croatian},
booktitle = {ARTIFICAL INTELLIGENCE CONFERENCE},
year = {2024},
address = {Belgrade}
publisher = {SASA, Belgrade},
url = {}
}
|
Истраживање jе спроведено уз подршку Фонда за науку Републике Србиjе, #7276, Text Embeddings – Serbian Language Applications – TESLA |
This research was supported by the Science Fund of the Republic of Serbia, #7276, Text Embeddings - Serbian Language Applications - TESLA |
- Downloads last month
- 13
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.
Model tree for te-sla/XLMali
Base model
FacebookAI/xlm-roberta-base