Spaces:
Sleeping

Sleeping
A newer version of the Streamlit SDK is available:
1.41.1
metadata
title: Who killed Laura Palmer?
emoji: 🗻🗻
colorFrom: blue
colorTo: green
sdk: streamlit
sdk_version: 1.2.0
app_file: app.py
pinned: false
license: apache-2.0
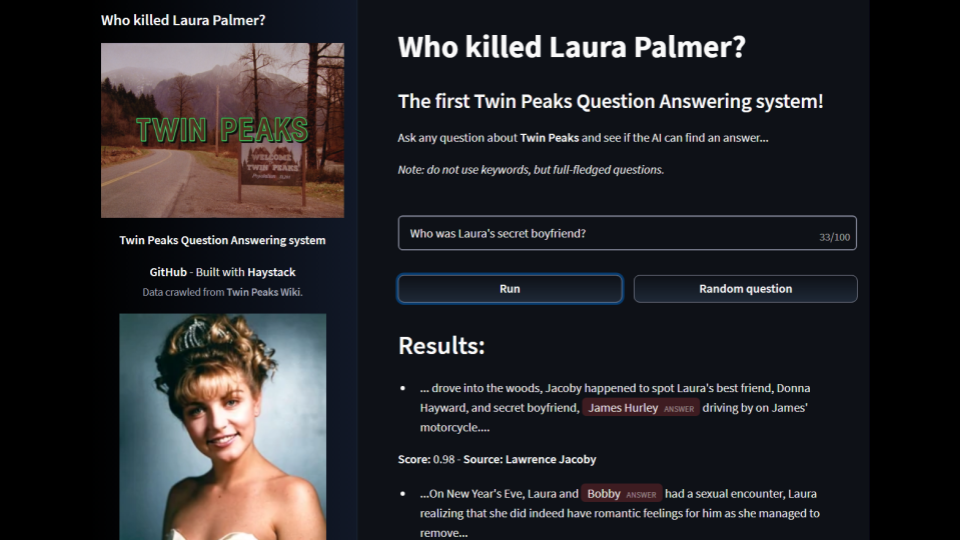
Who killed Laura Palmer? 

![]()
🗻🗻 Twin Peaks Question Answering system
WKLP is a simple Question Answering system, based on data crawled from Twin Peaks Wiki. It is built using 🔍 Haystack, an awesome open-source framework for building search systems that work intelligently over large document collections.
- Project architecture 🧱
- What can I learn from this project? 📚
- Repository structure 📁
- Installation 💻
- Possible improvements ✨
Project architecture 🧱
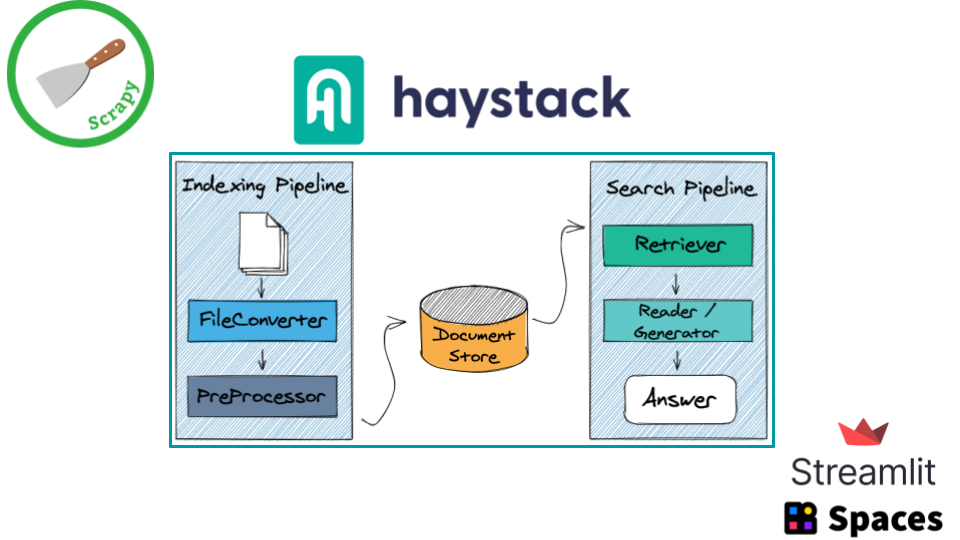
- Crawler: implemented using Scrapy and fandom-py
- Question Answering pipelines: created with Haystack
- Web app: developed with Streamlit
- Free hosting: Hugging Face Spaces
What can I learn from this project? 📚
- How to quickly ⌚ build a modern Question Answering system using 🔍 Haystack
- How to generate questions based on your documents
- How to build a nice Streamlit web app to show your QA system
- How to optimize the web app to 🚀 deploy in 🤗 Spaces
Repository structure 📁
- app.py: Streamlit web app
- app_utils folder: python modules used in the web app
- crawler folder: Twin Peaks crawler, developed with Scrapy and fandom-py
- notebooks folder: Jupyter/Colab notebooks to create the Search pipeline and generate questions (using Haystack)
- data folder: all necessary data
- presentations: Video presentation and slides (PyCon Italy 2022)
Within each folder, you can find more in-depth explanations.
Installation 💻
To install this project locally, follow these steps:
git clone https://github.com/anakin87/who-killed-laura-palmercd who-killed-laura-palmerpip install -r requirements.txt
To run the web app, simply type: streamlit run app.py
Possible improvements ✨
Project structure
- The project is optimized to be deployed in Hugging Face Spaces and consists of an all-in-one Streamlit web app. In more structured production environments, I suggest dividing the software into three parts:
- Haystack backend API (as explained in the official documentation)
- Document store service
- Streamlit web app
Reader
- The reader model (
deepset/roberta-base-squad2) is a good compromise between speed and accuracy, running on CPU. There are certainly better (and more computationally expensive) models, as you can read in the Haystack documentation. - You can also think about preparing a Twin Peaks QA dataset and fine-tuning the reader model to get better accuracy, as explained in this Haystack tutorial.