
Typhoon 2 Text
Collection
Latest Official Text ThaiLLM release by SCB 10X.
•
11 items
•
Updated
•
2
Llama3.1-Typhoon2-8B: Thai Large Language Model (Instruct)
Llama3.1-Typhoon2-8B-instruct is a instruct Thai 🇹🇭 large language model with 8 billion parameters, and it is based on Llama3.1-8B.
For technical-report. please see our arxiv. *To acknowledge Meta's effort in creating the foundation model and to comply with the license, we explicitly include "llama-3.1" in the model name.
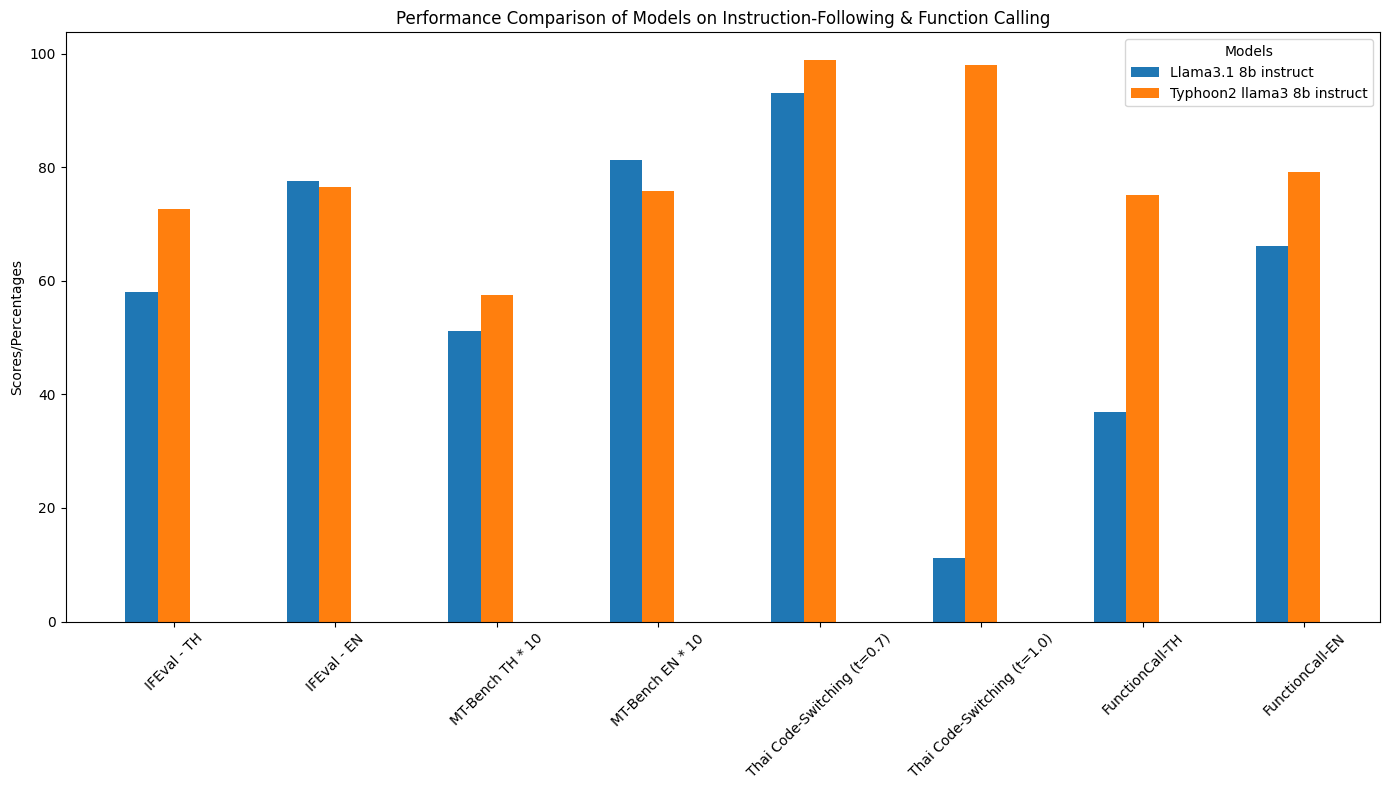
Instruction-Following & Function Call Performance
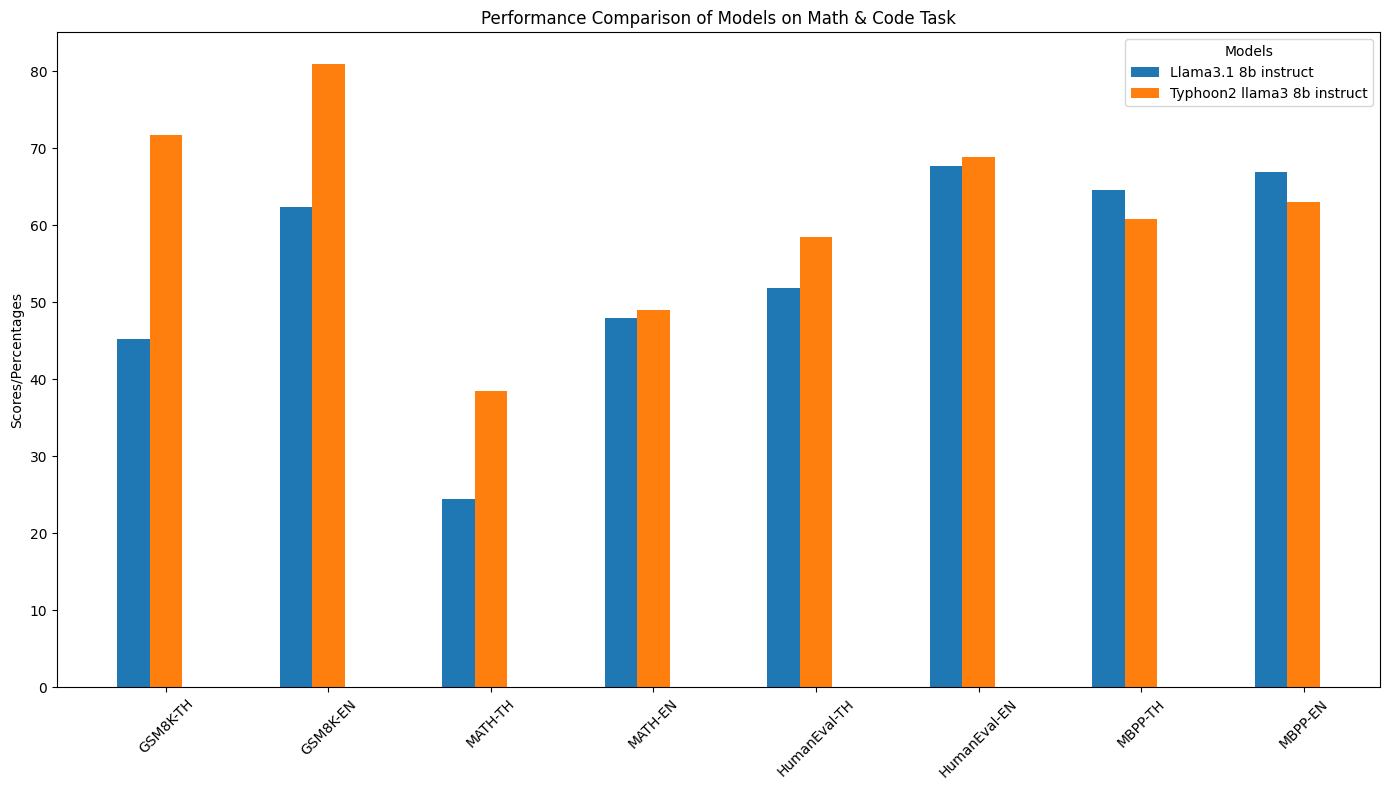
Specific Domain Performance (Math & Coding)
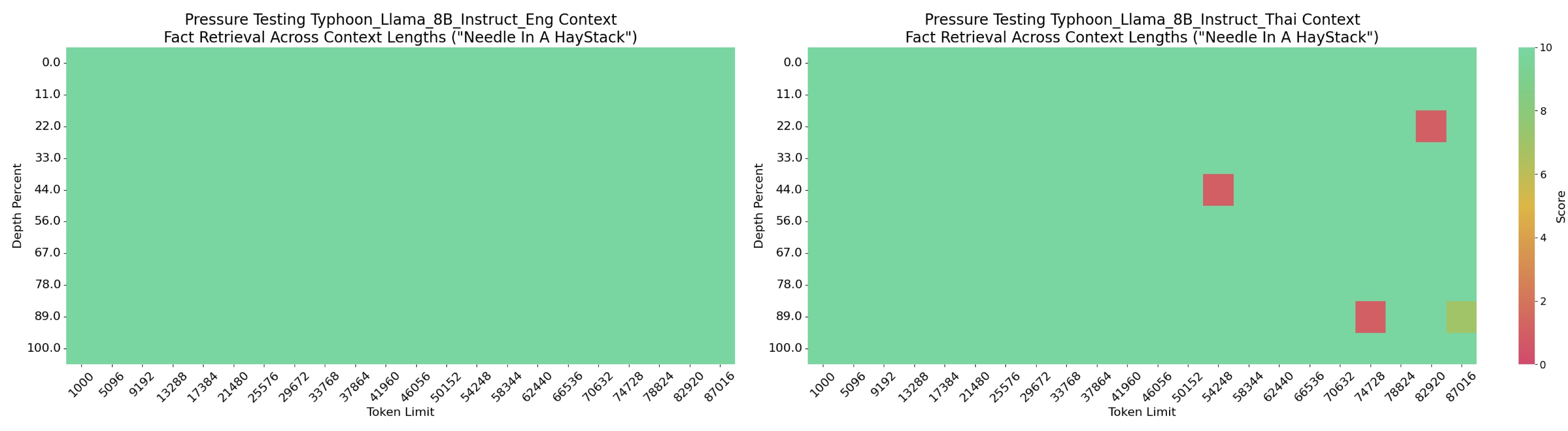
Long Context Performance
Detail Performance
| Model | IFEval - TH | IFEval - EN | MT-Bench TH | MT-Bench EN | Thai Code-Switching(t=0.7) | Thai Code-Switching(t=1.0) | FunctionCall-TH | FunctionCall-EN | GSM8K-TH | GSM8K-EN | MATH-TH | MATH-EN | HumanEval-TH | HumanEval-EN | MBPP-TH | MBPP-EN |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama3.1 8B Instruct | 58.04% | 77.64% | 5.109 | 8.118 | 93% | 11.2% | 36.92% | 66.06% | 45.18% | 62.4% | 24.42% | 48% | 51.8% | 67.7% | 64.6% | 66.9% |
| Typhoon2 Llama3 8B Instruct | 72.60% | 76.43% | 5.7417 | 7.584 | 98.8% | 98% | 75.12% | 79.08% | 71.72% | 81.0% | 38.48% | 49.04% | 58.5% | 68.9% | 60.8% | 63.0% |
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/llama3.1-typhoon2-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.7,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
pip install vllm
vllm serve scb10x/llama3.1-typhoon2-8b-instruct
# see more information at https://docs.vllm.ai/
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import ast
model_name = "scb10x/llama3.1-typhoon2-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype=torch.bfloat16, device_map='auto'
)
get_weather_api = {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, New York",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return",
},
},
"required": ["location"],
},
}
search_api = {
"name": "search",
"description": "Search for information on the internet",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query, e.g. 'latest news on AI'",
}
},
"required": ["query"],
},
}
get_stock = {
"name": "get_stock_price",
"description": "Get the stock price",
"parameters": {
"type": "object",
"properties": {
"symbol": {
"type": "string",
"description": "The stock symbol, e.g. AAPL, GOOG",
}
},
"required": ["symbol"],
},
}
# Tool input are same format with OpenAI tools
openai_format_tools = [get_weather_api, search_api, get_stock]
messages = [
{"role": "system", "content": "You are an expert in composing functions."},
{"role": "user", "content": "ขอราคาหุ้น Tasla (TLS) และ Amazon (AMZ) ?"},
]
inputs = tokenizer.apply_chat_template(
messages, tools=openai_format_tools, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
num_return_sequences=1,
eos_token_id=[tokenizer.eos_token_id, 128009],
)
response = outputs[0][inputs.shape[-1]:]
print("Here Output:", tokenizer.decode(response, skip_special_tokens=True))
# Decoding function utility
def resolve_ast_by_type(value):
if isinstance(value, ast.Constant):
if value.value is Ellipsis:
output = "..."
else:
output = value.value
elif isinstance(value, ast.UnaryOp):
output = -value.operand.value
elif isinstance(value, ast.List):
output = [resolve_ast_by_type(v) for v in value.elts]
elif isinstance(value, ast.Dict):
output = {
resolve_ast_by_type(k): resolve_ast_by_type(v)
for k, v in zip(value.keys, value.values)
}
elif isinstance(
value, ast.NameConstant
): # Added this condition to handle boolean values
output = value.value
elif isinstance(
value, ast.BinOp
): # Added this condition to handle function calls as arguments
output = eval(ast.unparse(value))
elif isinstance(value, ast.Name):
output = value.id
elif isinstance(value, ast.Call):
if len(value.keywords) == 0:
output = ast.unparse(value)
else:
output = resolve_ast_call(value)
elif isinstance(value, ast.Tuple):
output = tuple(resolve_ast_by_type(v) for v in value.elts)
elif isinstance(value, ast.Lambda):
output = eval(ast.unparse(value.body[0].value))
elif isinstance(value, ast.Ellipsis):
output = "..."
elif isinstance(value, ast.Subscript):
try:
output = ast.unparse(value.body[0].value)
except:
output = ast.unparse(value.value) + "[" + ast.unparse(value.slice) + "]"
else:
raise Exception(f"Unsupported AST type: {type(value)}")
return output
def resolve_ast_call(elem):
func_parts = []
func_part = elem.func
while isinstance(func_part, ast.Attribute):
func_parts.append(func_part.attr)
func_part = func_part.value
if isinstance(func_part, ast.Name):
func_parts.append(func_part.id)
func_name = ".".join(reversed(func_parts))
args_dict = {}
for arg in elem.keywords:
output = resolve_ast_by_type(arg.value)
args_dict[arg.arg] = output
return {func_name: args_dict}
def ast_parse(input_str, language="Python"):
if language == "Python":
cleaned_input = input_str.strip("[]'")
parsed = ast.parse(cleaned_input, mode="eval")
extracted = []
if isinstance(parsed.body, ast.Call):
extracted.append(resolve_ast_call(parsed.body))
else:
for elem in parsed.body.elts:
assert isinstance(elem, ast.Call)
extracted.append(resolve_ast_call(elem))
return extracted
else:
raise NotImplementedError(f"Unsupported language: {language}")
def parse_nested_value(value):
"""
Parse a potentially nested value from the AST output.
Args:
value: The value to parse, which could be a nested dictionary, which includes another function call, or a simple value.
Returns:
str: A string representation of the value, handling nested function calls and nested dictionary function arguments.
"""
if isinstance(value, dict):
# Check if the dictionary represents a function call (i.e., the value is another dictionary or complex structure)
if all(isinstance(v, dict) for v in value.values()):
func_name = list(value.keys())[0]
args = value[func_name]
args_str = ", ".join(
f"{k}={parse_nested_value(v)}" for k, v in args.items()
)
return f"{func_name}({args_str})"
else:
# If it's a simple dictionary, treat it as key-value pairs
return (
"{"
+ ", ".join(f"'{k}': {parse_nested_value(v)}" for k, v in value.items())
+ "}"
)
return repr(value)
def default_decode_ast_prompting(result, language="Python"):
result = result.strip("`\n ")
if not result.startswith("["):
result = "[" + result
if not result.endswith("]"):
result = result + "]"
decoded_output = ast_parse(result, language)
return decoded_output
fc_result = default_decode_ast_prompting(tokenizer.decode(response, skip_special_tokens=True))
print(fc_result) # [{'Function': {'arguments': '{"symbol": "TLS"}', 'name': 'get_stock_price'}}, {'Function': {'arguments': '{"symbol": "AMZ"}', 'name': 'get_stock_price'}}]
This model is an instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
https://twitter.com/opentyphoon
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}