
Efficient Stable Diffusion
Collection
Block-removed Knowledge-distilled SD models; https://github.com/Nota-NetsPresso/BK-SDM
•
9 items
•
Updated
•
2
Block-removed Knowledge-distilled Stable Diffusion Model (BK-SDM) is an architecturally compressed SDM for efficient general-purpose text-to-image synthesis. This model is bulit with (i) removing several residual and attention blocks from the U-Net of Stable Diffusion v1.4 and (ii) distillation pretraining on only 0.22M LAION pairs (fewer than 0.1% of the full training set). Despite being trained with very limited resources, our compact model can imitate the original SDM by benefiting from transferred knowledge.
An inference code with the default PNDM scheduler and 50 denoising steps is as follows.
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("nota-ai/bk-sdm-small", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a tropical bird sitting on a branch of a tree"
image = pipe(prompt).images[0]
image.save("example.png")
The following code is also runnable, because we compressed the U-Net of Stable Diffusion v1.4 while keeping the other parts (i.e., Text Encoder and Image Decoder) unchanged:
import torch
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet = UNet2DConditionModel.from_pretrained("nota-ai/bk-sdm-small", subfolder="unet", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a tropical bird sitting on a branch of a tree"
image = pipe(prompt).images[0]
image.save("example.png")
Certain residual and attention blocks were eliminated from the U-Net of SDM-v1.4:
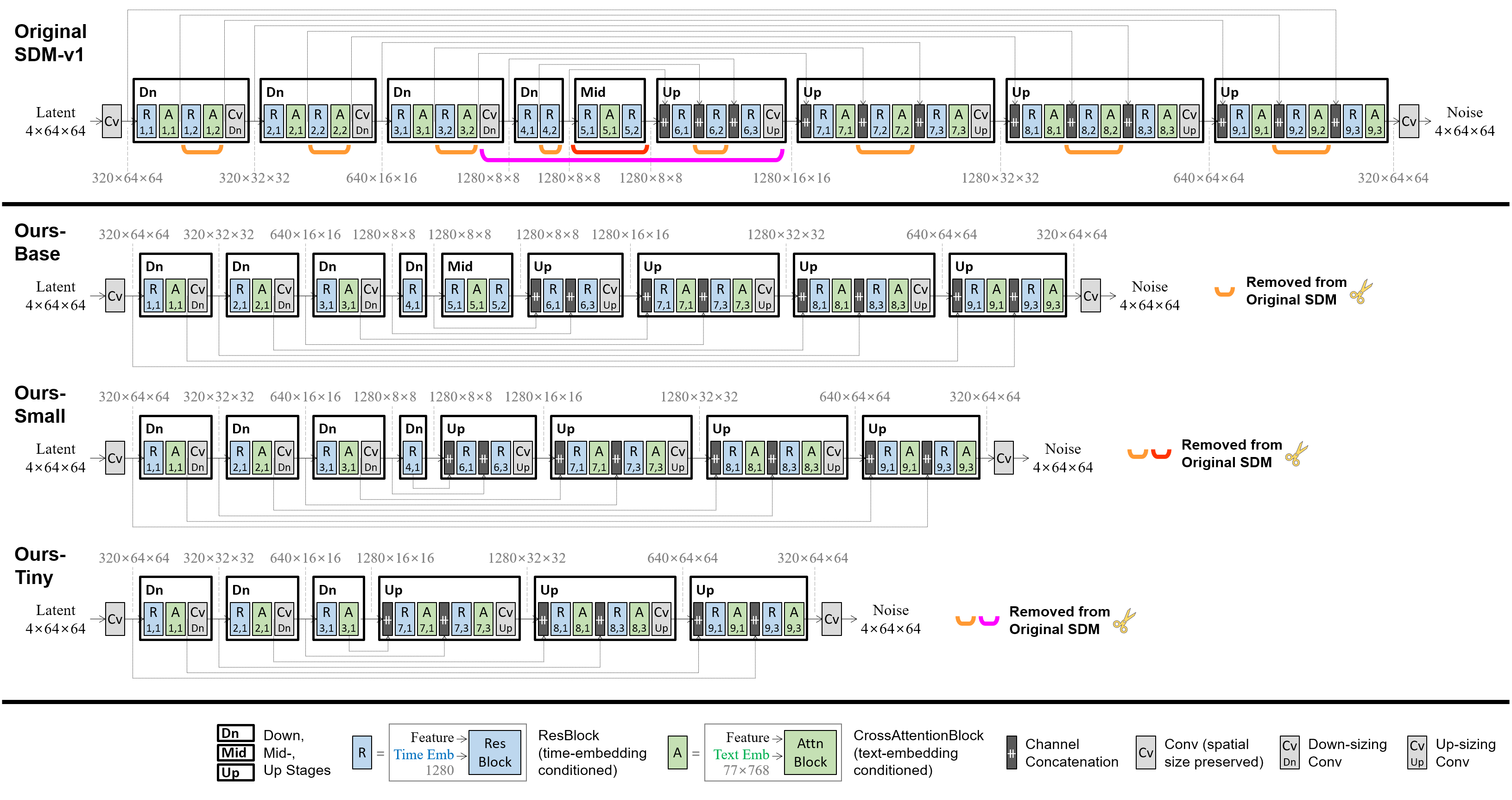
The compact U-Net was trained to mimic the behavior of the original U-Net. We leveraged feature-level and output-level distillation, along with the denoising task loss.

The following table shows the zero-shot results on 30K samples from the MS-COCO validation split. After generating 512×512 images with the PNDM scheduler and 25 denoising steps, we downsampled them to 256×256 for evaluating generation scores. Our models were drawn at the 50K-th training iteration.
| Model | FID↓ | IS↑ | CLIP Score↑ (ViT-g/14) |
# Params, U-Net |
# Params, Whole SDM |
|---|---|---|---|---|---|
| Stable Diffusion v1.4 | 13.05 | 36.76 | 0.2958 | 0.86B | 1.04B |
| BK-SDM-Base (Ours) | 15.76 | 33.79 | 0.2878 | 0.58B | 0.76B |
| BK-SDM-Small (Ours) | 16.98 | 31.68 | 0.2677 | 0.49B | 0.66B |
| BK-SDM-Tiny (Ours) | 17.12 | 30.09 | 0.2653 | 0.33B | 0.50B |
The following figure depicts synthesized images with some MS-COCO captions.

Note: This section is taken from the Stable Diffusion v1 model card) (which was based on the DALLE-MINI model card) and applies in the same way to BK-SDMs.
The model is intended for research purposes only. Possible research areas and tasks include
Excluded uses are described below.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. Stable Diffusion v1 was trained on subsets of LAION-2B(en), which consists of images that are primarily limited to English descriptions. Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for. This affects the overall output of the model, as white and western cultures are often set as the default. Further, the ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
The intended use of this model is with the Safety Checker in Diffusers. This checker works by checking model outputs against known hard-coded NSFW concepts. The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter. Specifically, the checker compares the class probability of harmful concepts in the embedding space of the CLIPTextModel after generation of the images. The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
@article{kim2023architectural,
title={BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={arXiv preprint arXiv:2305.15798},
year={2023},
url={https://arxiv.org/abs/2305.15798}
}
@article{kim2023bksdm,
title={BK-SDM: Architecturally Compressed Stable Diffusion for Efficient Text-to-Image Generation},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={ICML Workshop on Efficient Systems for Foundation Models (ES-FoMo)},
year={2023},
url={https://openreview.net/forum?id=bOVydU0XKC}
}
This model card was written by Bo-Kyeong Kim and is based on the Stable Diffusion v1 model card.