
Bonito(支持中文版本)
Bonito is an open-source model for conditional task generation: the task of converting unannotated text into task-specific training datasets for instruction tuning. This repo is a lightweight library for Bonito to easily create synthetic datasets built on top of the Hugging Face transformers and vllm libraries.
- Paper: Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
- Model: bonito-v1(English)
- Model: bonito-chinese-v1(中文)
- Demo: Bonito on Spaces (English)
- Demo: Google Colab(正文)
- Dataset: ctga-v1
- Code: To reproduce experiments in our paper, see nayak-aclfindings24-code.
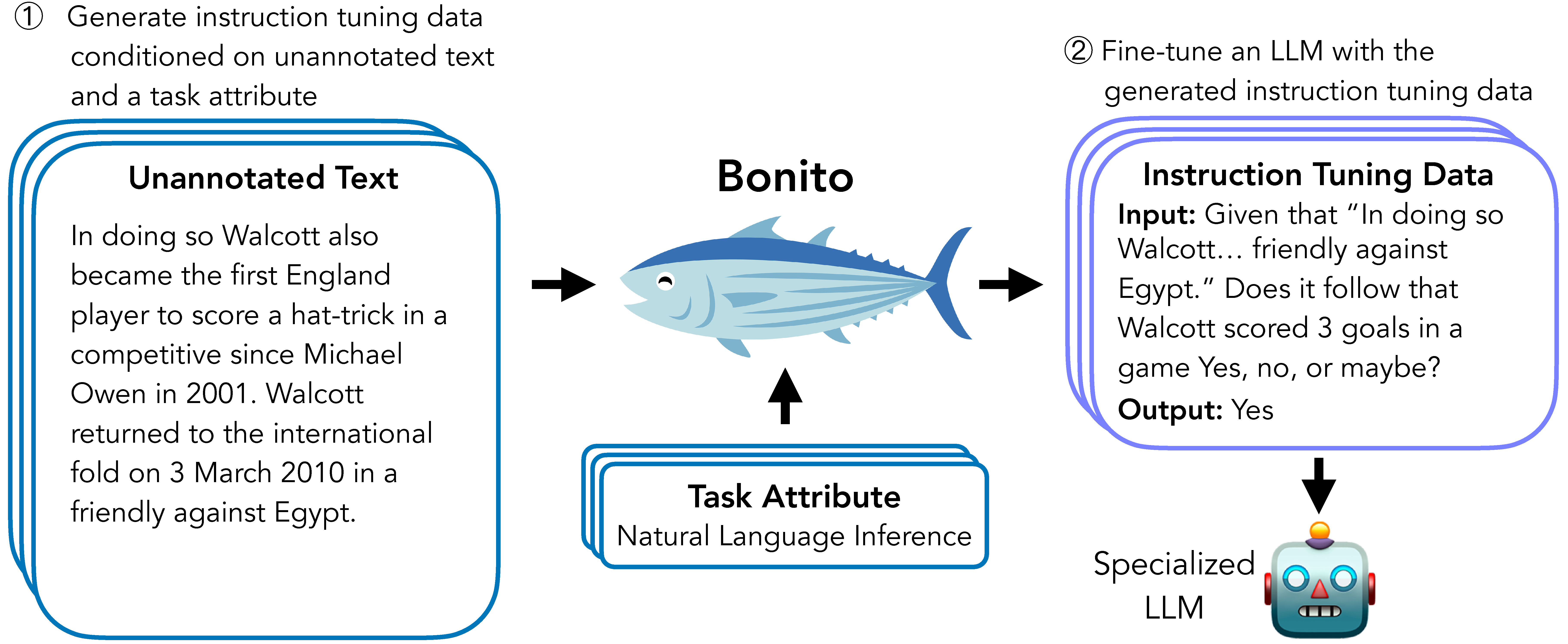
This version supports the Chinese language
Because of the training data limitations, this version supports only the 3 task types
- 🐠 1.question generation.
- 🐡 2.multiple-choice question answering.
- 🐟 3.question answering without choices.
Google Colab: Demo
Basic Usage
To generate synthetic instruction tuning dataset using Bonito, you can use the following code:
pip3 install bonito-llm
from pprint import pprint
from datasets import Dataset
from vllm import SamplingParams
from transformers import set_seed
from bonito import Bonito
unannotated_paragraph = """灌区以往的闸门控制系统在实际应用过程中普遍以人工操作为主,容易受到多种因素的影响,不可避免出现较多缺陷。如操作人员自身的综合能力、业务水平、工作态度等对工作质量和效率产生较大影响;工作人员实践操作中遇到极端气候、工作环境恶劣等问题,大大增加了工作难度,并存在较多安全隐患。"""
pprint(unannotated_paragraph)
bonito = Bonito("kitsdk/bonito-chinese-v1")
set_seed(2)
def convert_to_dataset(text):
dataset = Dataset.from_list([{"input": text}])
return dataset
sampling_params = SamplingParams(max_tokens=256, top_p=0.95, temperature=0.5, n=1)
synthetic_dataset = bonito.generate_tasks(
convert_to_dataset(unannotated_paragraph),
context_col="input",
task_type="mcqa",
sampling_params=sampling_params
)
pprint("----Generated Instructions----")
pprint(f'Input: {synthetic_dataset[0]["input"]}')
pprint(f'Output: {synthetic_dataset[0]["output"]}')
- Downloads last month
- 22
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.
Model tree for kitsdk/bonito-chinese-v1
Base model
Qwen/Qwen2.5-3B