
JiuZhou: Open Foundation Language Models for Geoscience
🎉 News
- [2024-12-31] Article JiuZhou: Open Foundation Language Models and Effective Pre-training Framework for Geoscience has been accepted for publication in the International Journal of Digital Earth. Code and Data.
- [2024-10-11] WeChat article: PreparedLLM: Effective Pre-pretraining Framework for Domain-specific Large Language Models.
- [2024-09-06] Released ClimateChat instruct model.
- [2024-08-31] Article PreparedLLM: Effective Pre-pretraining Framework for Domain-specific Large Language Models has been accepted for publication in the Big Earth Data journal.
- [2024-08-31] Released Chinese-Mistral-7B-Instruct-v0.2 instruct model. Significant improvements in language understanding and multi-turn dialogue capabilities.
- [2024-06-30] Released JiuZhou-Instruct-v0.2 instruct model. Significant improvements in language understanding and multi-turn dialogue capabilities.
- [2024-05-15] WeChat Article: Chinese Vocabulary Expansion Incremental Pretraining for Large Language Models: Chinese-Mistral Released.
- [2024-04-04] Released Chinese-Mistral-7B-Instruct-v0.1 instruct model.
- [2024-03-31] Released Chinese-Mistral-7B-v0.1 base model.
- [2024-03-15] Released the base version JiuZhou-base, instruct version JiuZhou-instruct-v0.1, and intermediate checkpoints.
Table of Contents
- Introduction
- Download
- Inference
- Model Performance
- Model Training Process
- Model Training Code
- Citations
- Acknowledgments
Introduction
The field of geoscience has amassed a vast amount of data, necessitating the extraction and integration of diverse knowledge from this data to address global change challenges, promote sustainable development, and accelerate scientific discovery. Foundation language models initially learn and integrate knowledge autonomously through self-supervised pre-training on extensive text data. Subsequently, they acquire the capability to solve geoscience problems through instruction tuning. However, when the foundational language models lack sufficient geoscience expertise, instruction tuning with relevant data can lead to the generation of content that is inconsistent with established facts. To improve the model's accuracy and practicality, a robust geoscience foundational language model is urgently needed.
This study uses Mistral-7B-v0.1 as the base model and continues pretraining on a large geoscience corpus. It also incorporates the domain-specific large language model pre-pretraining framework (PreparedLLM) and the "two-stage pre-adaptation pre-training" algorithm to build the geoscience large language model, JiuZhou.
Download
| Model Series | Model | Download Link | Description |
|---|---|---|---|
| JiuZhou | JiuZhou-base | Huggingface | Base model (Rich in geoscience knowledge) |
| JiuZhou | JiuZhou-Instruct-v0.1 | Huggingface | Instruct model (Instruction alignment caused a loss of some geoscience knowledge, but it has instruction-following ability) LoRA fine-tuned on Alpaca_GPT4 in both Chinese and English and GeoSignal |
| JiuZhou | JiuZhou-Instruct-v0.2 | HuggingFace Wisemodel |
Instruct model (Instruction alignment caused a loss of some geoscience knowledge, but it has instruction-following ability) Fine-tuned with high-quality general instruction data |
| ClimateChat | ClimateChat | HuggingFace Wisemodel |
Instruct model Fine-tuned on JiuZhou-base for instruction following |
| Chinese-Mistral | Chinese-Mistral-7B | HuggingFace Wisemodel ModelScope |
Base model |
| Chinese-Mistral | Chinese-Mistral-7B-Instruct-v0.1 | HuggingFace Wisemodel ModelScope |
Instruct model LoRA fine-tuned with Alpaca_GPT4 in both Chinese and English |
| Chinese-Mistral | Chinese-Mistral-7B-Instruct-v0.2 | HuggingFace Wisemodel |
Instruct model LoRA fine-tuned with a million high-quality instructions |
| PreparedLLM | Prepared-Llama | Huggingface Wisemodel |
Base model Continual pretraining with a small number of geoscience data Recommended to use JiuZhou |
Inference
Below is an example of inference code using JiuZhou-Instruct-v0.2.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
model_path = "itpossible/JiuZhou-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map=device)
text = "What is geoscience?"
messages = [{"role": "user", "content": text}]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(device)
outputs_id = model.generate(inputs, max_new_tokens=600, do_sample=True)
outputs = tokenizer.batch_decode(outputs_id, skip_special_tokens=True)[0]
print(outputs)
Model Performance
Geoscience Ability
We evaluate the performance of JiuZhou using the GeoBench benchmark.
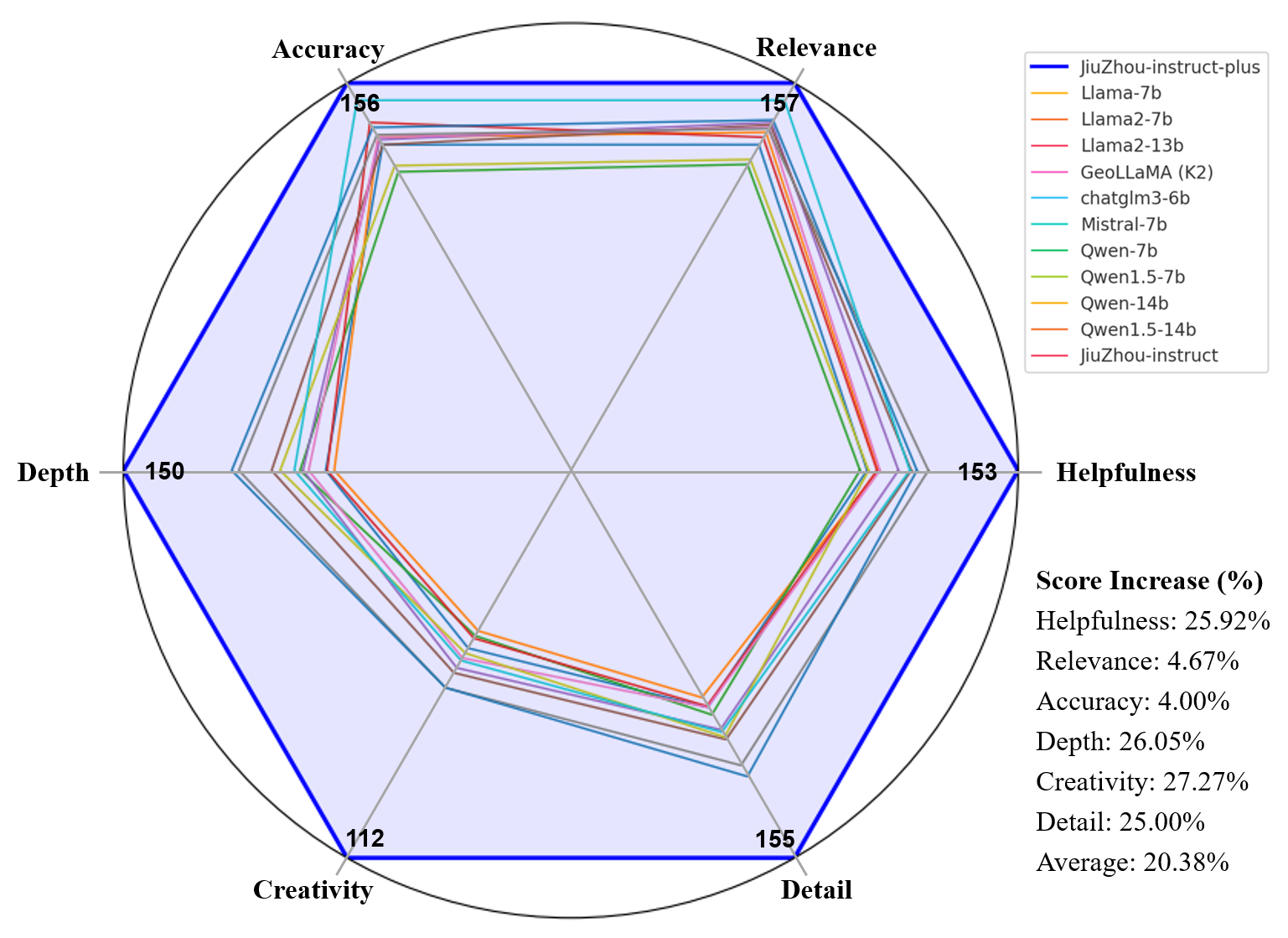
JiuZhou outperforms GPT-3.5 in objective tasks:

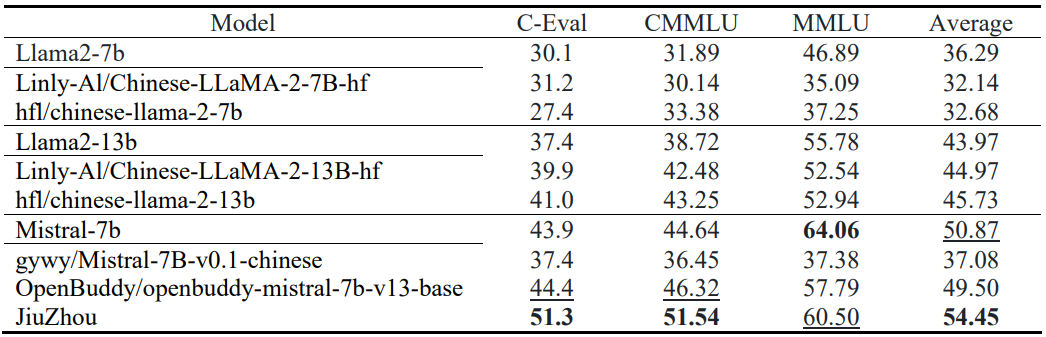
Compared to other variants of Llama and Mistral models, JiuZhou shows outstanding performance:


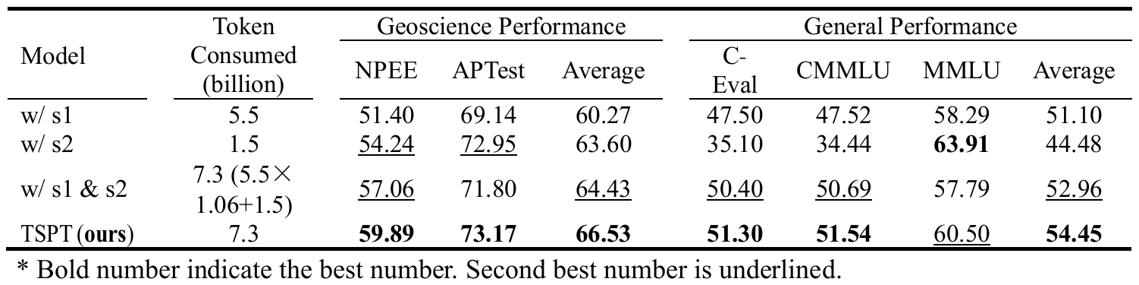
The difference between TSPT and single-stage training algorithms:

Project Deployment
git clone https://github.com/THU-ESIS/JiuZhou.git
cd JiuZhou
pip install -e ".[torch,metrics]"
Model Training
Pre-training:
llamafactory-cli train examples/train_lora/JiuZhou_pretrain_sft.yaml
Instruction-tuning:
llamafactory-cli train examples/train_lora/JiuZhou_lora_sft.yaml
Chat with the fine-tuned JiuZhou::
llamafactory-cli chat examples/inference/JiuZhou_lora_sft.yaml
Merge the instruction-tuned LoRA weights with the original JiuZhou weights:
llamafactory-cli export examples/merge_lora/JiuZhou_lora_sft.yaml
Citations
@article{chen2024preparedllm,
author = {Chen, Zhou and Lin, Ming and Wang, Zimeng and Zang, Mingrun and Bai, Yuqi},
title = {PreparedLLM: Effective Pre-pretraining Framework for Domain-specific Large Language Models},
year = {2024},
journal = {Big Earth Data},
pages = {1--24},
doi = {10.1080/20964471.2024.2396159},
url = {https://doi.org/10.1080/20964471.2024.2396159}
}
Acknowledgments
- Downloads last month
- 16