File size: 3,257 Bytes
dc42511 0aa04ca dc42511 09c6657 c37ff5c 09c6657 6b07ba8 dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 c37ff5c dc42511 0aa04ca 09c6657 dc42511 5dec1c8 0aa04ca 5dec1c8 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca 28f7e02 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca dc42511 0aa04ca 65e24d1 0aa04ca |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen2.5-1.5B-Instruct
- laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-soup
pipeline_tag: question-answering
metrics:
- accuracy
library_name: transformers
---
[Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions](https://arxiv.org/abs/2412.08737)
# Model Card for Euclid-convnext-xxlarge (Version on 12/05/2024)
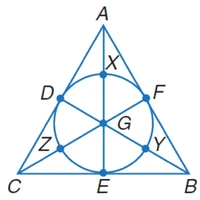
A multimodal large language models specifically trained for strong low-level geometric perception.
## Model Details
### Model Description
Euclid is trained on 1.6M synthetic geometry images with high-fidelity question-answer pairs using a curriculum learning approach.
It combines a ConvNeXt visual encoder with a Qwen-2.5 language model, connected through a 2-layer MLP multimodal connector.
### Model Sources
- **Repository:** https://github.com/euclid-multimodal/Euclid
- **Paper:** https://arxiv.org/abs/2412.08737
- **Demo:** https://euclid-multimodal.github.io/
## Uses
The model is trained for precise low-level geometric perception tasks which is able to perform
- Point-on-line detection
- Point-on-circle detection
- Angle classification
- Length comparison
- Geometric annotation understanding
Please refer to our [repo](https://github.com/euclid-multimodal/Euclid) for full input format.
### Limitations and Applications
Our model is not designed to handle:
- Comprehensive image understanding tasks
- Advanced cognitive reasoning beyond geometric analysis
However, the model demonstrates strength in low-level visual perception.
This capability makes it potentially valuable for serving as a base model for specialized downstream fintuning including:
- Robotic vision and automation systems
- Medical imaging and diagnostic support
- Industrial quality assurance and inspection
- Geometric education and visualization tools
### Example Usage
Clone our Euclid [repo](https://github.com/euclid-multimodal/Euclid) first, set up the environment, then run:
```
pip install -U "huggingface_hub[cli]"
huggingface-cli download --cache-dir $MODEL_PATH EuclidAI/Euclid-convnext-xxlarge
python euclid/eval/run_euclid_geo.py --model_path $MODEL_PATH --device cuda
```
## Evaluation Results
Performance on Geoperception benchmark tasks:
| Model | POL | POC | ALC | LHC | PEP | PRA | EQL | Overall |
|-------|-----|-----|-----|-----|-----|-----|-----|----------|
| Random Baseline | 0.43 | 2.63 | 59.92 | 51.36 | 0.25 | 0.00 | 0.02 | 16.37 |
| Pixtral-12B | 22.85 | 53.21 | 47.33 | 51.43 | 22.53 | 37.11 | **58.45** | 41.84 |
| Gemini-1.5-Pro | 24.42 | **69.80** | 57.96 | 79.05 | **39.60** | **77.59** | 52.27 | 57.24 |
| EUCLID-ConvNeXt-Large | 80.54 | 57.76 | 86.37 | 88.24 | 42.23 | 64.94 | 34.45 | 64.93 |
| EUCLID-ConvNeXt-XXLarge | **82.98** | 61.45 | **90.56** | **90.82** | **46.96** | 70.52 | 31.94 | **67.89** |
## Citation
If you find Euclid useful for your research and applications, please cite using this BibTeX:
```bibtex
@article{zhang2024euclid,
title={Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions},
author={Zhang, Jiarui and Liu, Ollie and Yu, Tianyu and Hu, Jinyi and Neiswanger, Willie},
journal={arXiv preprint arXiv:2412.08737},
year={2024}
} |