
license: apache-2.0
language:
- zh
- en
size_categories:
- 100B<n<1T
介绍/Introduction
本数据集源自雅意训练语料,我们精选了约100B数据,数据大小约为500GB。我们期望通过雅意预训练数据的开源推动中文预训练大模型开源社区的发展,并积极为此贡献力量。通过开源,我们与每一位合作伙伴共同构建雅意大模型生态。
We opensource the pre-trained dataset in this release, it should contain more than 100B tokens depending on the tokenizer you use, requiring more than 500GB of local storage. By open-sourcing the pre-trained dataset, we aim to contribute to the development of the Chinese pre-trained large language model open-source community. Through open-source, we aspire to collaborate with every partner in building the YAYI large language model ecosystem.
组成
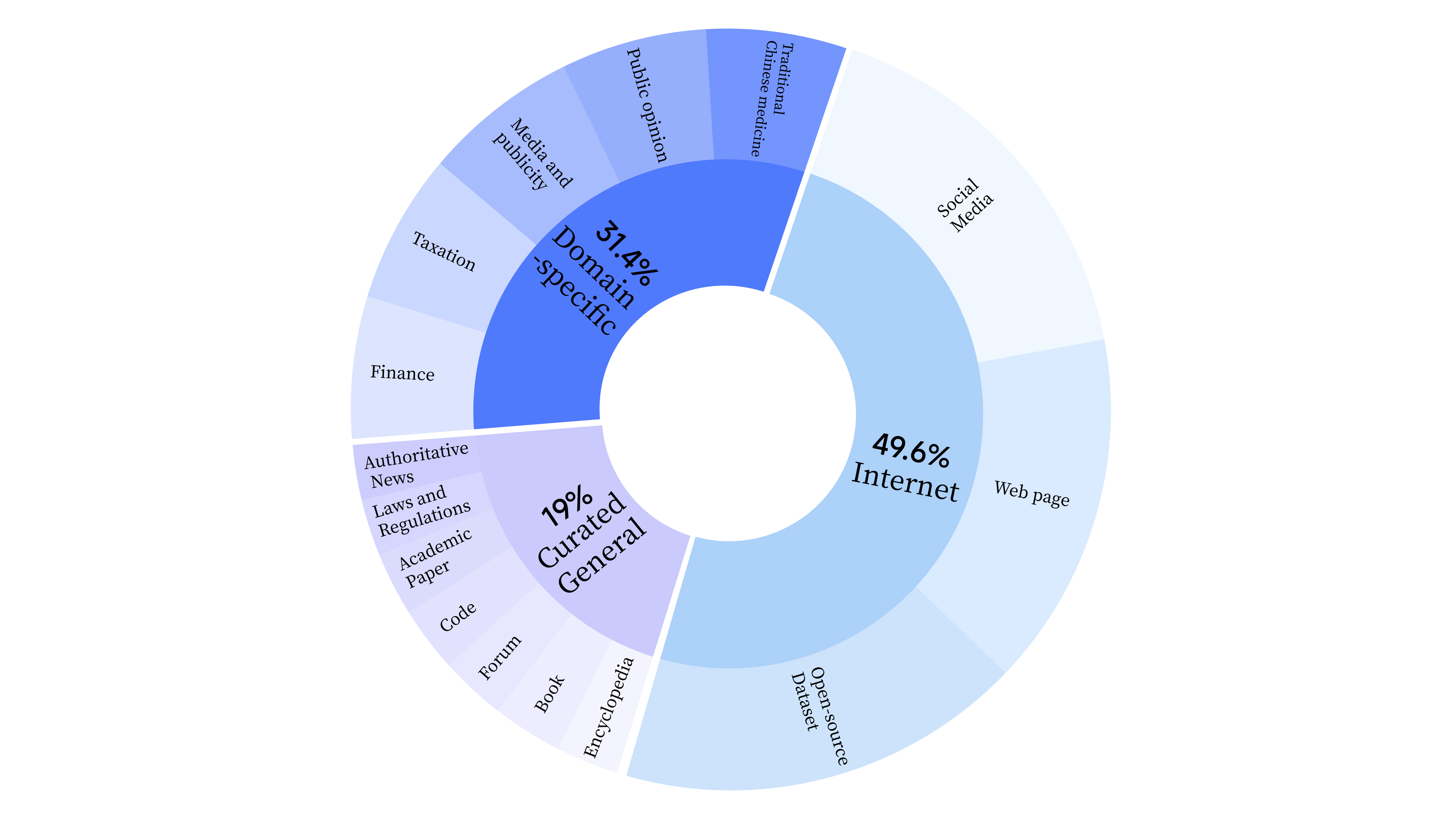
- 在预训练阶段,我们不仅使用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据包含人工收集和整理的高质量数据。涵盖了报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据。其中,报纸类数据包括广泛的新闻报道和专栏文章,这类数据通常结构化程度高,信息量丰富。文献类数据包括学术论文和研究报告,为我们的数据集注入了专业和深度。代码类数据包括各种编程语言的源码,有助于构建和优化技术类数据的处理模型。书籍类数据涵盖了小说、诗歌、古文、教材等内容,提供丰富的语境和词汇,增强语言模型的理解能力。数据分布情况如下:
- During the pre-training phase, we not only utilized internet data to train the model's language abilities but also incorporated curated general data and domain-specific information to enhance the model's expertise. Curated general data covers a wide range of categories including books (e.g., textbooks, novels), codes, encyclopedias, forums, academic papers, authoritative news, laws and regulations. Details of the data distribution are as follows:
数据清洗
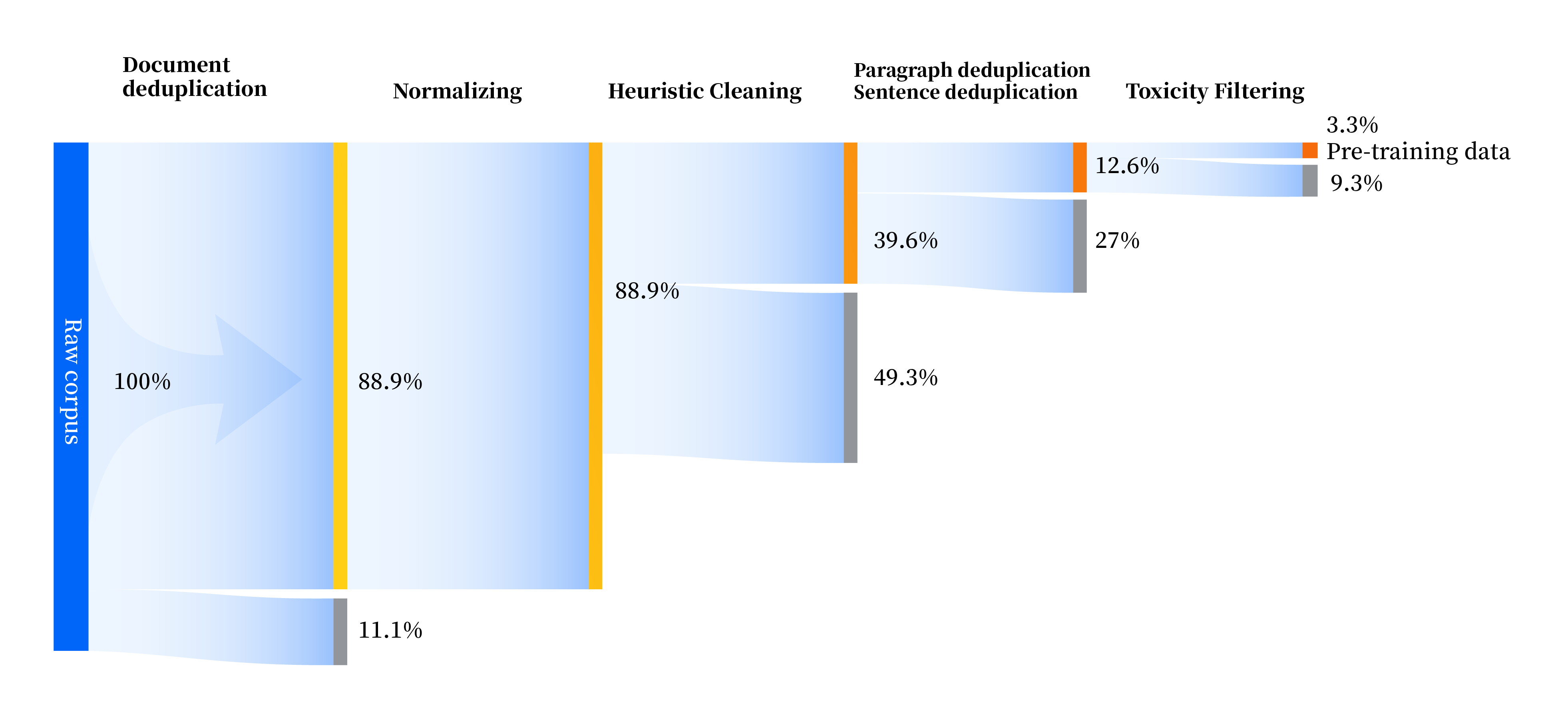
我们构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。我们共收集了 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。整体流程如下:
We establish a comprehensive data processing pipeline to enhance data quality in all aspects. This pipeline comprises four modules: normalizing, heuristic cleaning, multi-level deduplication, and toxicity filtering. 240 terabytes of raw data are collected for pre-training, and only 10.6 terabytes of high-quality data remain after preprocessing. Details of the data processing pipeline are as follows:
协议/License
本项目中的代码依照 Apache-2.0 协议开源,社区使用 YAYI 2 模型和数据需要遵循雅意YAYI 2 模型社区许可协议。若您需要将雅意 YAYI 2系列模型或其衍生品用作商业用途,请根据《雅意 YAYI 2 模型商用许可协议》将商用许可申请登记信息发送至指定邮箱 [email protected]。审核通过后,雅意将授予您商用版权许可,请遵循协议中的商业许可限制。
The code in this project is open-sourced under the Apache-2.0 license. The use of YaYi series model weights and data must adhere to the YAYI 2 Community License. If you intend to use the YAYI 2 series models or their derivatives for commercial purposes, please submit your commercial license application and registration information to [email protected], following the YAYI 2 Commercial License. Upon approval, YAYI will grant you a commercial copyright license, subject to the commercial license restrictions outlined in the agreement.
引用/Citation
如果您在工作中使用了我们的模型或者数据,请引用我们的论文。
If you are using the resource for your work, please cite our paper.
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}