

license: cc-by-4.0
task_categories:
- audio-classification
pretty_name: Enriched DCASE 2023 Challenge Task 2 Dataset
size_categories:
- 1K<n<10K
tags:
- anomaly detection
- anomalous sound detection
- acoustic condition monitoring
- sound machine fault diagnosis
- machine learning
- unsupervised learning
- acoustic scene classification
- acoustic event detection
- acoustic signal processing
- audio domain shift
- domain generalization
Dataset Card for the Enriched "DCASE 2023 Challenge Task 2 Dataset".
Table of contents
- Dataset Description
- Dataset Structure
- Dataset Creation
- Considerations for Using the Data
- Additional Information
Dataset Description
- Homepage: Renumics Homepage
- Homepage DCASE23 Task 2 Challenge
- Homepage: HF Dataset Creator
- Original Dataset Upload (Dev) ZENODO: DCASE 2023 Challenge Task 2 Development Dataset
- Paper MIMII DG
- Paper ToyADMOS2
- Paper First-shot anomaly detection for machine condition monitoring: A domain generalization baseline
Dataset Summary
Data-centric AI principles have become increasingly important for real-world use cases. At Renumics we believe that classical benchmark datasets and competitions should be extended to reflect this development.
This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
- Enable new researchers to quickly develop a profound understanding of the dataset.
- Popularize data-centric AI principles and tooling in the ML community.
- Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
This dataset is an enriched version of the dataset provided in the context of the anomalous sound detection task of the DCASE2023 challenge. The enrichment include an embedding generated by a pre-trained Audio Spectrogram Transformer and results of the official challenge baseline implementation.
DCASE23 Task2 Dataset
Once a year, the DCASE community publishes a challenge with several tasks in the context of acoustic event detection and classification. Task 2 of this challenge deals with anomalous sound detection for machine condition monitoring. The original dataset is based on the MIMII DG and the ToyADMOS2 datasets. Please cite the papers by Harada et al. and Dohi et al. if you use this dataset and the paper by Harada et al. if you use the baseline results.
Explore Dataset
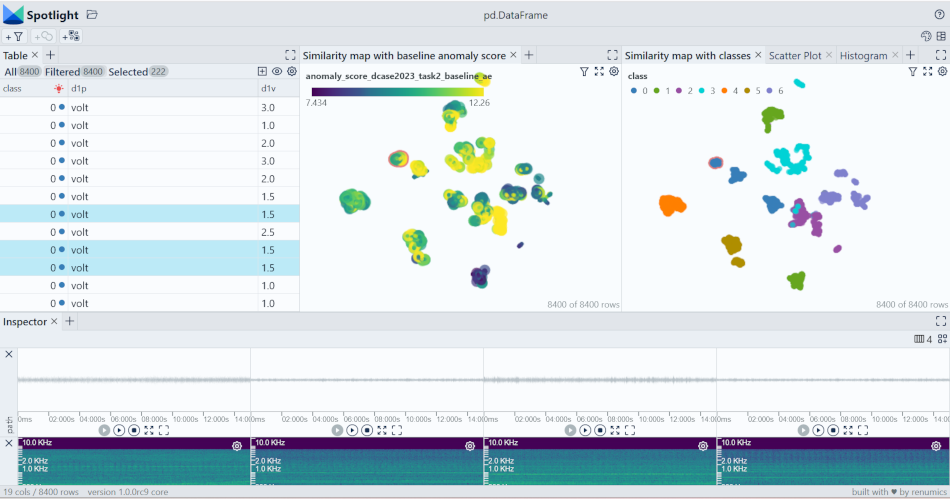
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool Renumics Spotlight enables that with just a few lines of code:
Install datasets and Spotlight via pip:
!pip install renumics-spotlight datasets[audio]
Notice: On Linux, non-Python dependency on libsndfile package must be installed manually. See Datasets - Installation for more information.
Load the dataset from huggingface in your notebook:
import datasets
dataset = datasets.load_dataset("renumics/dcase23-task2-enriched", "dev", split="all", streaming=False)
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
from renumics import spotlight
df = dataset.to_pandas()
simple_layout = datasets.load_dataset_builder("renumics/dcase23-task2-enriched", "dev").config.get_layout(config="simple")
spotlight.show(df, dtype={'path': spotlight.Audio, "embeddings_ast-finetuned-audioset-10-10-0.4593": spotlight.Embedding}, layout=simple_layout)
You can use the UI to interactively configure the view on the data. Depending on the concrete taks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
In this example we focus on the valve class. We specifically look at normal data points that have high anomaly scores in both models. This is one example on how to find difficult example or edge cases:
from renumics import spotlight
extended_layout = datasets.load_dataset_builder("renumics/dcase23-task2-enriched", "dev").config.get_layout(config="extended")
spotlight.show(df, dtype={'path': spotlight.Audio, "embeddings_ast-finetuned-audioset-10-10-0.4593": spotlight.Embedding}, layout=extended_layout)

Using custom model results and enrichments
When developing your custom model you want to use different kinds of information from you model (e.g. embedding, anomaly scores etc.) to gain further insights into the dataset and the model behvior.
Suppose you have your model's embeddings for each datapoint as a 2D-Numpy array called embeddings and your anomaly score as a 1D-Numpy array called anomaly_scores. Then you can add this information to the dataset:
df['my_model_embedding'] = embeddings
df['anomaly_score'] = anomaly_scores
Depending on your concrete task you might want to use different enrichments. For a good overview on great open source tooling for uncertainty quantification, explainability and outlier detection, you can take a look at our curated list for open source data-centric AI tooling on Github.
You can also save your view configuration in Spotlight in a JSON configuration file by clicking on the respective icon:

For more information how to configure the Spotlight UI please refer to the documentation.
Dataset Structure
Data Instances
For each instance, there is a Audio for the audio, a string for the path, an integer for the section, a string for the d1p (parameter), a string for the d1v (value), a ClassLabel for the label and a ClassLabel for the class.
{'audio': {'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': 'train/fan_section_01_source_train_normal_0592_f-n_A.wav',
'sampling_rate': 16000
}
'path': 'train/fan_section_01_source_train_normal_0592_f-n_A.wav'
'section': 1
'd1p': 'f-n'
'd1v': 'A'
'd2p': 'nan'
'd2v': 'nan'
'd3p': 'nan'
'd3v': 'nan'
'domain': 0 (source)
'label': 0 (normal)
'class': 1 (fan)
'dev_train_lof_anomaly': 0
'dev_train_lof_anomaly_score': 1.241023
'add_train_lof_anomaly': 1
'add_train_lof_anomaly_score': 1.806289
'ast-finetuned-audioset-10-10-0.4593-embeddings': [0.8152204155921936,
1.5862374305725098, ...,
1.7154160737991333]
}
The length of each audio file is 10 seconds.
Data Fields
audio: andatasets.Audiopath: a string representing the path of the audio file inside the tar.gz.-archive.section: an integer representing the section, see Definitiond*p: a string representing the name of the d*-parameterd*v: a string representing the value of the corresponding d*-parameterdomain: an integer whose value may be either 0, indicating that the audio sample is from the source domain, 1, indicating that the audio sample is from the target.class: an integer as class label.label: an integer whose value may be either 0, indicating that the audio sample is normal, 1, indicating that the audio sample contains an anomaly.- '[X]_lof_anomaly': an integer as anomaly indicator. The anomaly prediction is computed with the Local Outlier Factor algorithm based on the "[X]"-dataset.
- '[X]_lof_anomaly_score': a float as anomaly score. The anomaly score is computed with the Local Outlier Factor algorithm based on the "[X]"-dataset.
embeddings_ast-finetuned-audioset-10-10-0.4593: andatasets.Sequence(Value("float32"), shape=(1, 768))representing audio embeddings that are generated with an Audio Spectrogram Transformer.
Data Splits
The development dataset has 2 splits: train and test.
| Dataset Split | Number of Instances in Split | Source Domain / Target Domain Samples |
|---|---|---|
| Train | 7000 | 6930 / 70 |
| Test | 1400 | 700 / 700 |
The additional training dataset has 1 split: train.
| Dataset Split | Number of Instances in Split | Source Domain / Target Domain Samples |
|---|---|---|
| Train | 7000 | 6930 / 70 |
The evaluation dataset has 1 split: test.
| Dataset Split | Number of Instances in Split | Source Domain / Target Domain Samples |
|---|---|---|
| Test | 1400 | ? |
Dataset Creation
The following information is copied from the original dataset upload on zenodo.org
Curation Rationale
This dataset is the "development dataset" for the DCASE 2023 Challenge Task 2 "First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring".
The data consists of the normal/anomalous operating sounds of seven types of real/toy machines. Each recording is a single-channel 10-second audio that includes both a machine's operating sound and environmental noise. The following seven types of real/toy machines are used in this task:
- ToyCar
- ToyTrain
- Fan
- Gearbox
- Bearing
- Slide rail
- Valve
The "additional training data" and "evaluation data" datasets contain the following classes:
- bandsaw
- grinder
- shaker
- ToyDrone
- ToyNscale
- ToyTank
- Vacuum
Source Data
Definition
We first define key terms in this task: "machine type," "section," "source domain," "target domain," and "attributes.".
- "Machine type" indicates the type of machine, which in the development dataset is one of seven: fan, gearbox, bearing, slide rail, valve, ToyCar, and ToyTrain.
- A section is defined as a subset of the dataset for calculating performance metrics.
- The source domain is the domain under which most of the training data and some of the test data were recorded, and the target domain is a different set of domains under which some of the training data and some of the test data were recorded. There are differences between the source and target domains in terms of operating speed, machine load, viscosity, heating temperature, type of environmental noise, signal-to-noise ratio, etc.
- Attributes are parameters that define states of machines or types of noise.
Description
This dataset consists of seven machine types. For each machine type, one section is provided, and the section is a complete set of training and test data. For each section, this dataset provides (i) 990 clips of normal sounds in the source domain for training, (ii) ten clips of normal sounds in the target domain for training, and (iii) 100 clips each of normal and anomalous sounds for the test. The source/target domain of each sample is provided. Additionally, the attributes of each sample in the training and test data are provided in the file names and attribute csv files.
Recording procedure
Normal/anomalous operating sounds of machines and its related equipment are recorded. Anomalous sounds were collected by deliberately damaging target machines. For simplifying the task, we use only the first channel of multi-channel recordings; all recordings are regarded as single-channel recordings of a fixed microphone. We mixed a target machine sound with environmental noise, and only noisy recordings are provided as training/test data. The environmental noise samples were recorded in several real factory environments. We will publish papers on the dataset to explain the details of the recording procedure by the submission deadline.
Supported Tasks and Leaderboards
Anomalous sound detection (ASD) is the task of identifying whether the sound emitted from a target machine is normal or anomalous. Automatic detection of mechanical failure is an essential technology in the fourth industrial revolution, which involves artificial-intelligence-based factory automation. Prompt detection of machine anomalies by observing sounds is useful for monitoring the condition of machines.
This task is the follow-up from DCASE 2020 Task 2 to DCASE 2022 Task 2. The task this year is to develop an ASD system that meets the following four requirements.
1. Train a model using only normal sound (unsupervised learning scenario)
Because anomalies rarely occur and are highly diverse in real-world factories, it can be difficult to collect exhaustive patterns of anomalous sounds. Therefore, the system must detect unknown types of anomalous sounds that are not provided in the training data. This is the same requirement as in the previous tasks.
2. Detect anomalies regardless of domain shifts (domain generalization task)
In real-world cases, the operational states of a machine or the environmental noise can change to cause domain shifts. Domain-generalization techniques can be useful for handling domain shifts that occur frequently or are hard-to-notice. In this task, the system is required to use domain-generalization techniques for handling these domain shifts. This requirement is the same as in DCASE 2022 Task 2.
3. Train a model for a completely new machine type
For a completely new machine type, hyperparameters of the trained model cannot be tuned. Therefore, the system should have the ability to train models without additional hyperparameter tuning.
4. Train a model using only one machine from its machine type
While sounds from multiple machines of the same machine type can be used to enhance detection performance, it is often the case that sound data from only one machine are available for a machine type. In such a case, the system should be able to train models using only one machine from a machine type.
Considerations for Using the Data
Social Impact of Dataset
[More Information Needed]
Discussion of Biases
[More Information Needed]
Other Known Limitations
[More Information Needed]
Additional Information
Baseline system
The baseline system is available on the Github repository dcase2023_task2_baseline_ae.The baseline systems provide a simple entry-level approach that gives a reasonable performance in the dataset of Task 2. They are good starting points, especially for entry-level researchers who want to get familiar with the anomalous-sound-detection task.
Dataset Curators
[More Information Needed]
Licensing Information - Condition of use
This is a feature/embeddings-enriched version of the "DCASE 2023 Challenge Task 2 Development Dataset". The original dataset was created jointly by Hitachi, Ltd. and NTT Corporation and is available under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license.
Citation Information (original)
If you use this dataset, please cite all the following papers. We will publish a paper on DCASE 2023 Task 2, so pleasure make sure to cite the paper, too.
- Kota Dohi, Tomoya Nishida, Harsh Purohit, Ryo Tanabe, Takashi Endo, Masaaki Yamamoto, Yuki Nikaido, and Yohei Kawaguchi. MIMII DG: sound dataset for malfunctioning industrial machine investigation and inspection for domain generalization task. In arXiv e-prints: 2205.13879, 2022. [URL]
- Noboru Harada, Daisuke Niizumi, Daiki Takeuchi, Yasunori Ohishi, Masahiro Yasuda, and Shoichiro Saito. ToyADMOS2: another dataset of miniature-machine operating sounds for anomalous sound detection under domain shift conditions. In Proceedings of the 6th Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), 1–5. Barcelona, Spain, November 2021. [URL]
- Noboru Harada, Daisuke Niizumi, Daiki Takeuchi, Yasunori Ohishi, and Masahiro Yasuda. First-shot anomaly detection for machine condition monitoring: a domain generalization baseline. In arXiv e-prints: 2303.00455, 2023. [URL]
@dataset{kota_dohi_2023_7882613,
author = {Kota Dohi and
Keisuke Imoto and
Noboru Harada and
Daisuke Niizumi and
Yuma Koizumi and
Tomoya Nishida and
Harsh Purohit and
Takashi Endo and
Yohei Kawaguchi},
title = {DCASE 2023 Challenge Task 2 Development Dataset},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {3.0},
doi = {10.5281/zenodo.7882613},
url = {https://doi.org/10.5281/zenodo.7882613}
}