Hugging Face
Models
Datasets
Spaces
Posts
Docs
Enterprise
Pricing
Log In
Sign Up
cerebras
/
btlm-3b-8k-base
like
260
Follow
Cerebras
415
Text Generation
Transformers
PyTorch
cerebras/SlimPajama-627B
English
btlm
causal-lm
Cerebras
BTLM
custom_code
arxiv:
6 papers
License:
apache-2.0
Model card
Files
Files and versions
Community
27
Train
Use this model
refs/pr/24
btlm-3b-8k-base
3 contributors
History:
24 commits
SFconvertbot
Adding `safetensors` variant of this model
8522159
over 1 year ago
.gitattributes
1.52 kB
initial commit
over 1 year ago
README.md
11.1 kB
update generation samples
over 1 year ago
config.json
1.24 kB
change mup param names
over 1 year ago
configuration_btlm.py
7.58 kB
change mup param names
over 1 year ago
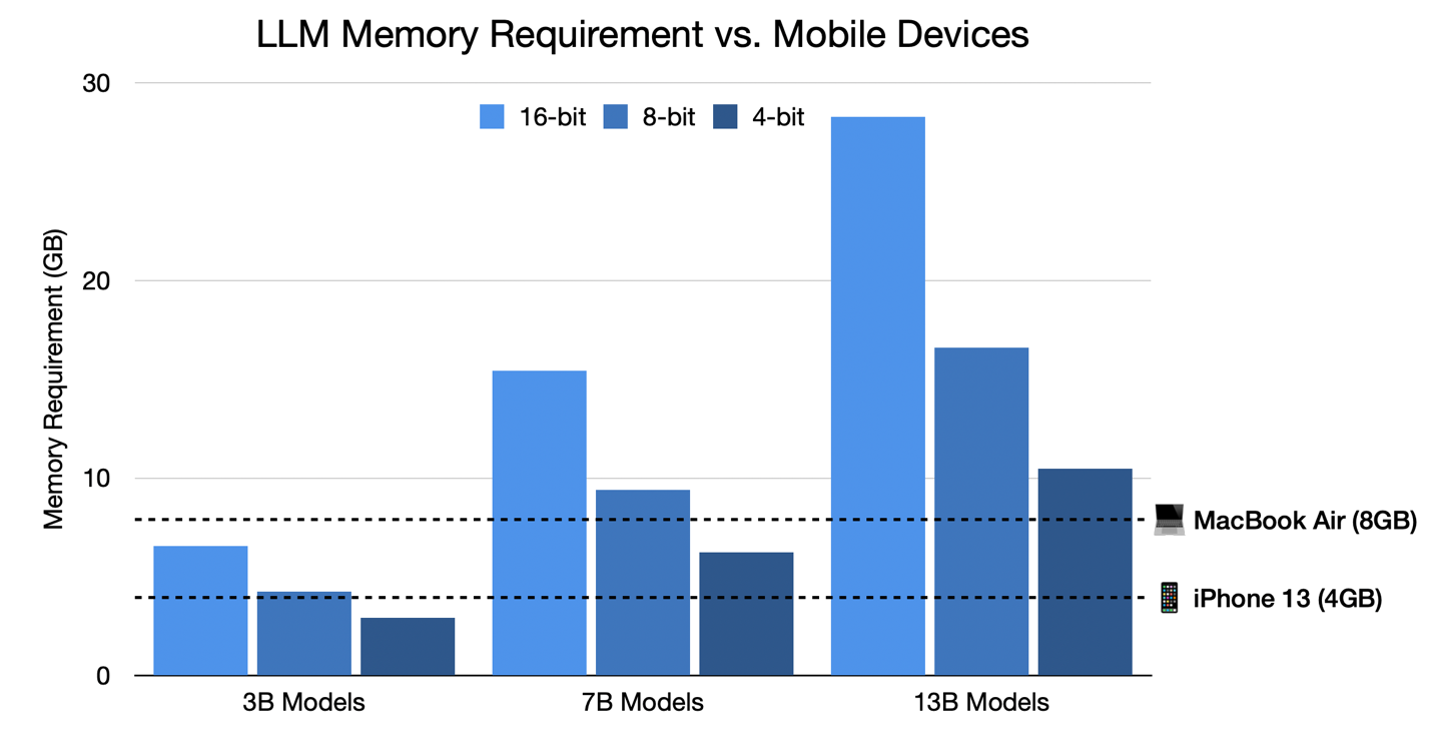
figure_1_memory_footprint.png
301 kB
fix three images (#4)
over 1 year ago
figure_2_half_the_size_twice_the_speed.png
342 kB
upload images from blog (#2)
over 1 year ago
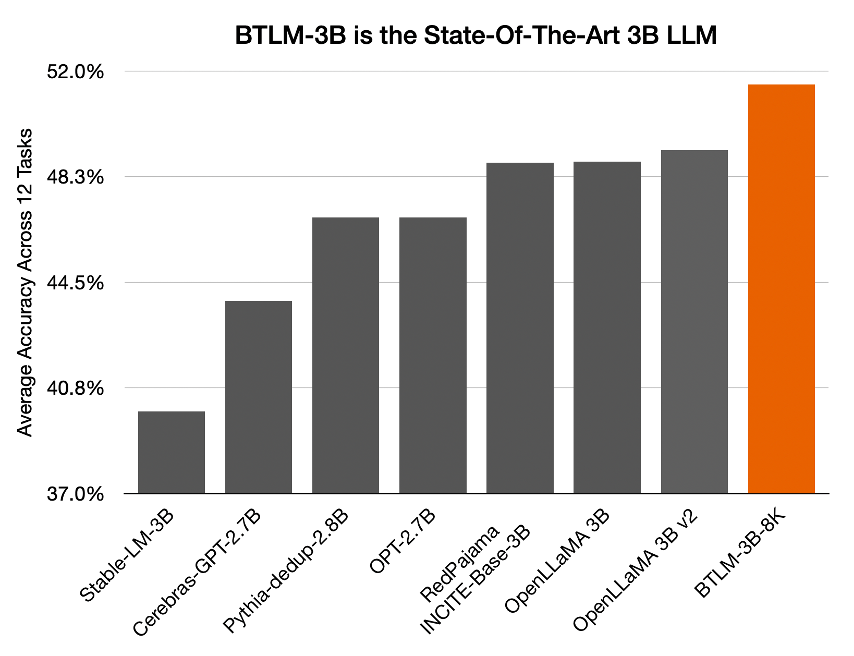
figure_3_performance_vs_3b_models.png
238 kB
upload images from blog (#2)
over 1 year ago
figure_4_performance_vs_7b_models.jpg
102 kB
upload images from blog (#2)
over 1 year ago
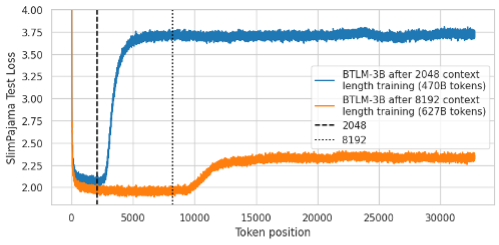
figure_5_xentropy_with_sequence_lengths.png
52.1 kB
upload images from blog (#2)
over 1 year ago
figure_5_xentropy_with_sequence_lengths.svg
520 kB
upload svg for long msl xentropy
over 1 year ago
generation_config.json
119 Bytes
add bfloat16 checkpoint
over 1 year ago
merges.txt
456 kB
add the tokenizer
over 1 year ago
model.safetensors
5.29 GB
LFS
Adding `safetensors` variant of this model
over 1 year ago
modeling_btlm.py
71.5 kB
update ALiBi with kv caching
over 1 year ago
pytorch_model.bin
pickle
Detected Pickle imports (3)
"torch._utils._rebuild_tensor_v2"
,
"torch.BFloat16Storage"
,
"collections.OrderedDict"
What is a pickle import?
5.29 GB
LFS
add bfloat16 checkpoint
over 1 year ago
special_tokens_map.json
99 Bytes
add the tokenizer
over 1 year ago
table_1_downstream_performance_3b.png
590 kB
fix three images (#4)
over 1 year ago
table_2_downstream_performance_7b.png
243 kB
upload images from blog (#2)
over 1 year ago
tokenizer_config.json
234 Bytes
add the tokenizer
over 1 year ago
vocab.json
1.04 MB
add the tokenizer
over 1 year ago




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}