
metadata
base_model: stabilityai/stable-diffusion-3.5-medium
library_name: diffusers
license: other
instance_prompt: A beautiful UI for music app
widget:
- text: An elegant UI for an eccomerce website
output:
url: image_0.png
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- sd3
- sd3-diffusers
SD3 DreamBooth LoRA - bhomik7/output_dir
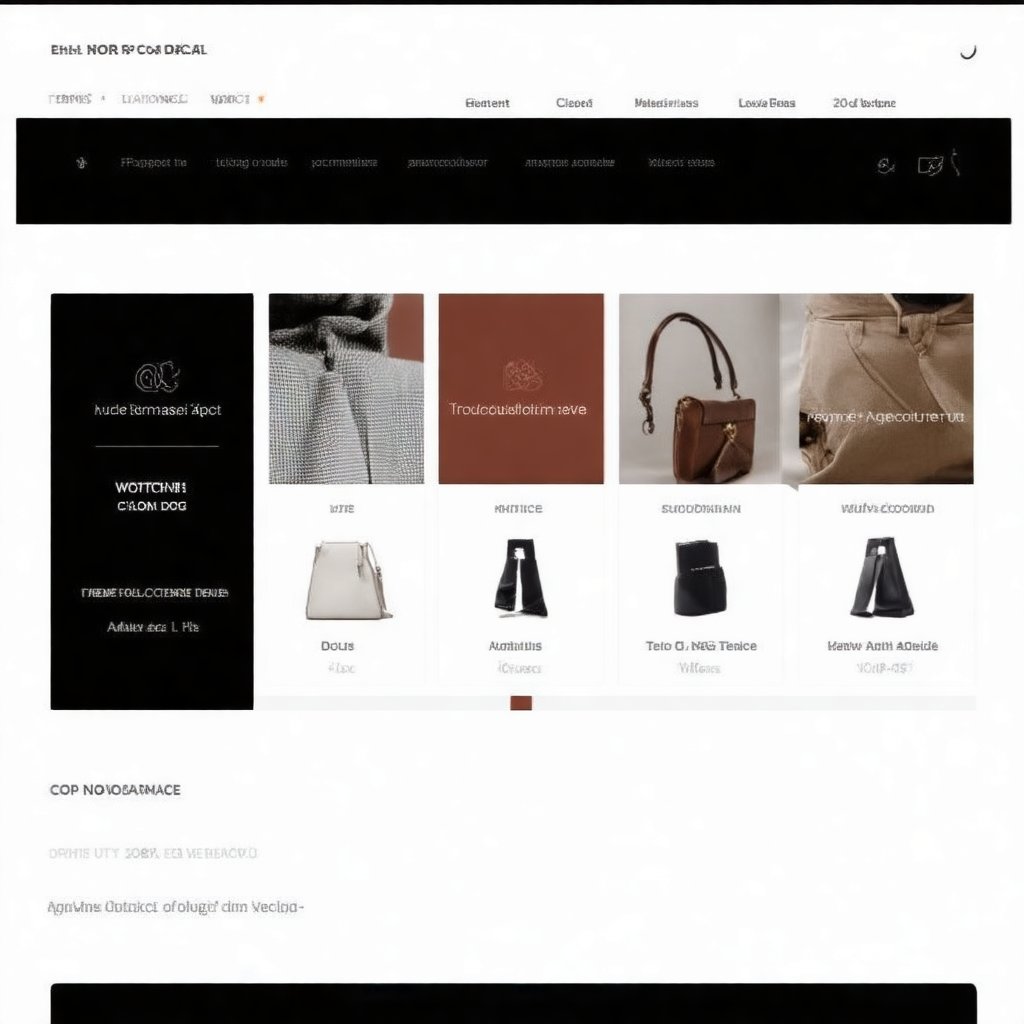
- Prompt
- An elegant UI for an eccomerce website
Model description
These are bhomik7/output_dir DreamBooth LoRA weights for stabilityai/stable-diffusion-3.5-medium.
The weights were trained using DreamBooth with the SD3 diffusers trainer.
Was LoRA for the text encoder enabled? False.
Trigger words
You should use A beautiful UI for music app to trigger the image generation.
Download model
Download the *.safetensors LoRA in the Files & versions tab.
Use it with the 🧨 diffusers library
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(stabilityai/stable-diffusion-3.5-medium, torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('bhomik7/output_dir', weight_name='pytorch_lora_weights.safetensors')
image = pipeline('An elegant UI for an eccomerce website').images[0]
Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- LoRA: download
diffusers_lora_weights.safetensorshere 💾.- Rename it and place it on your
models/Lorafolder. - On AUTOMATIC1111, load the LoRA by adding
<lora:your_new_name:1>to your prompt. On ComfyUI just load it as a regular LoRA.
- Rename it and place it on your
For more details, including weighting, merging and fusing LoRAs, check the documentation on loading LoRAs in diffusers
License
Please adhere to the licensing terms as described here.
Intended uses & limitations
How to use
# TODO: add an example code snippet for running this diffusion pipeline
Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
Training details
[TODO: describe the data used to train the model]