|
--- |
|
frameworks: |
|
- Pytorch |
|
license: other |
|
tasks: |
|
- text-to-video-synthesis |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
--- |
|
|
|
# EasyAnimate | 高分辨率长视频生成的端到端解决方案 |
|
😊 EasyAnimate是一个用于生成高分辨率和长视频的端到端解决方案。我们可以训练基于转换器的扩散生成器,训练用于处理长视频的VAE,以及预处理元数据。 |
|
|
|
😊 我们基于DIT,使用transformer进行作为扩散器进行视频与图片生成。 |
|
|
|
😊 Welcome! |
|
|
|
[](https://arxiv.org/abs/2405.18991) |
|
[](https://easyanimate.github.io/) |
|
[](https://modelscope.cn/studios/PAI/EasyAnimate/summary) |
|
[](https://huggingface.co/spaces/alibaba-pai/EasyAnimate) |
|
[](https://discord.gg/UzkpB4Bn) |
|
|
|
[English](./README.md) | 简体中文 |
|
|
|
# 目录 |
|
- [目录](#目录) |
|
- [简介](#简介) |
|
- [快速启动](#快速启动) |
|
- [视频作品](#视频作品) |
|
- [如何使用](#如何使用) |
|
- [模型地址](#模型地址) |
|
- [未来计划](#未来计划) |
|
- [联系我们](#联系我们) |
|
- [参考文献](#参考文献) |
|
- [许可证](#许可证) |
|
|
|
# 简介 |
|
EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI图片与视频、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的EasyAnimate模型直接进行预测,生成不同分辨率,6秒左右、fps8的视频(EasyAnimateV5,1 ~ 49帧),也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。 |
|
|
|
我们会逐渐支持从不同平台快速启动,请参阅 [快速启动](#快速启动)。 |
|
|
|
新特性: |
|
- 更新到v5版本,最大支持1024x1024,49帧, 6s, 8fps视频生成,拓展模型规模到12B,应用MMDIT结构,支持不同输入的控制模型,支持中文与英文双语预测。[ 2024.11.08 ] |
|
- 更新到v4版本,最大支持1024x1024,144帧, 6s, 24fps视频生成,支持文、图、视频生视频,单个模型可支持512到1280任意分辨率,支持中文与英文双语预测。[ 2024.08.15 ] |
|
- 更新到v3版本,最大支持960x960,144帧,6s, 24fps视频生成,支持文与图生视频模型。[ 2024.07.01 ] |
|
- ModelScope-Sora“数据导演”创意竞速——第三届Data-Juicer大模型数据挑战赛已经正式启动!其使用EasyAnimate作为基础模型,探究数据处理对于模型训练的作用。立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532219),了解赛事详情。[ 2024.06.17 ] |
|
- 更新到v2版本,最大支持768x768,144帧,6s, 24fps视频生成。[ 2024.05.26 ] |
|
- 创建代码!现在支持 Windows 和 Linux。[ 2024.04.12 ] |
|
|
|
功能概览: |
|
- [数据预处理](#data-preprocess) |
|
- [训练VAE](#vae-train) |
|
- [训练DiT](#dit-train) |
|
- [模型生成](#video-gen) |
|
|
|
我们的ui界面如下: |
|
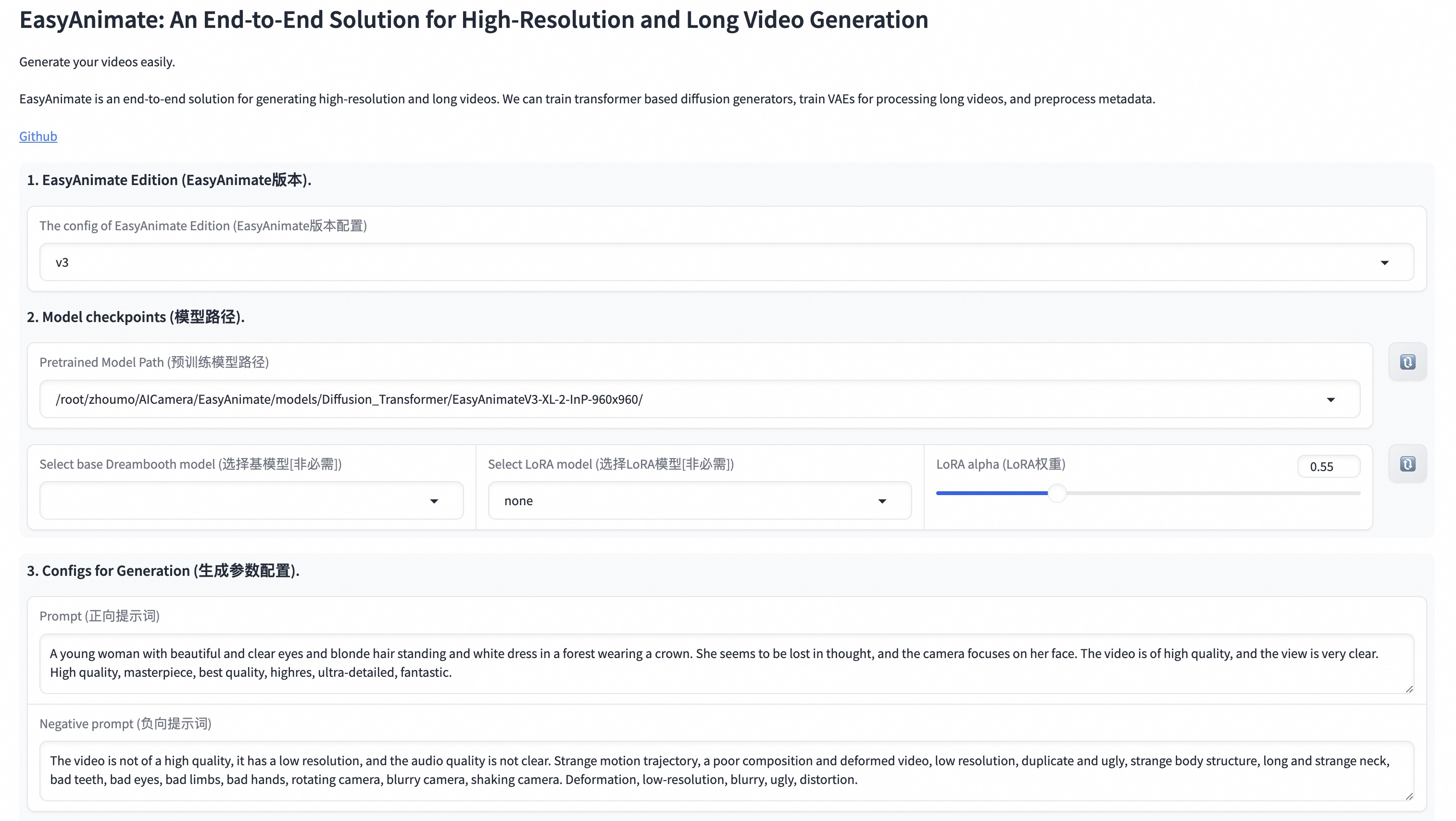 |
|
|
|
# 快速启动 |
|
### 1. 云使用: AliyunDSW/Docker |
|
#### a. 通过阿里云 DSW |
|
DSW 有免费 GPU 时间,用户可申请一次,申请后3个月内有效。 |
|
|
|
阿里云在[Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1)提供免费GPU时间,获取并在阿里云PAI-DSW中使用,5分钟内即可启动EasyAnimate |
|
|
|
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate) |
|
|
|
#### b. 通过ComfyUI |
|
我们的ComfyUI界面如下,具体查看[ComfyUI README](comfyui/README.md)。 |
|
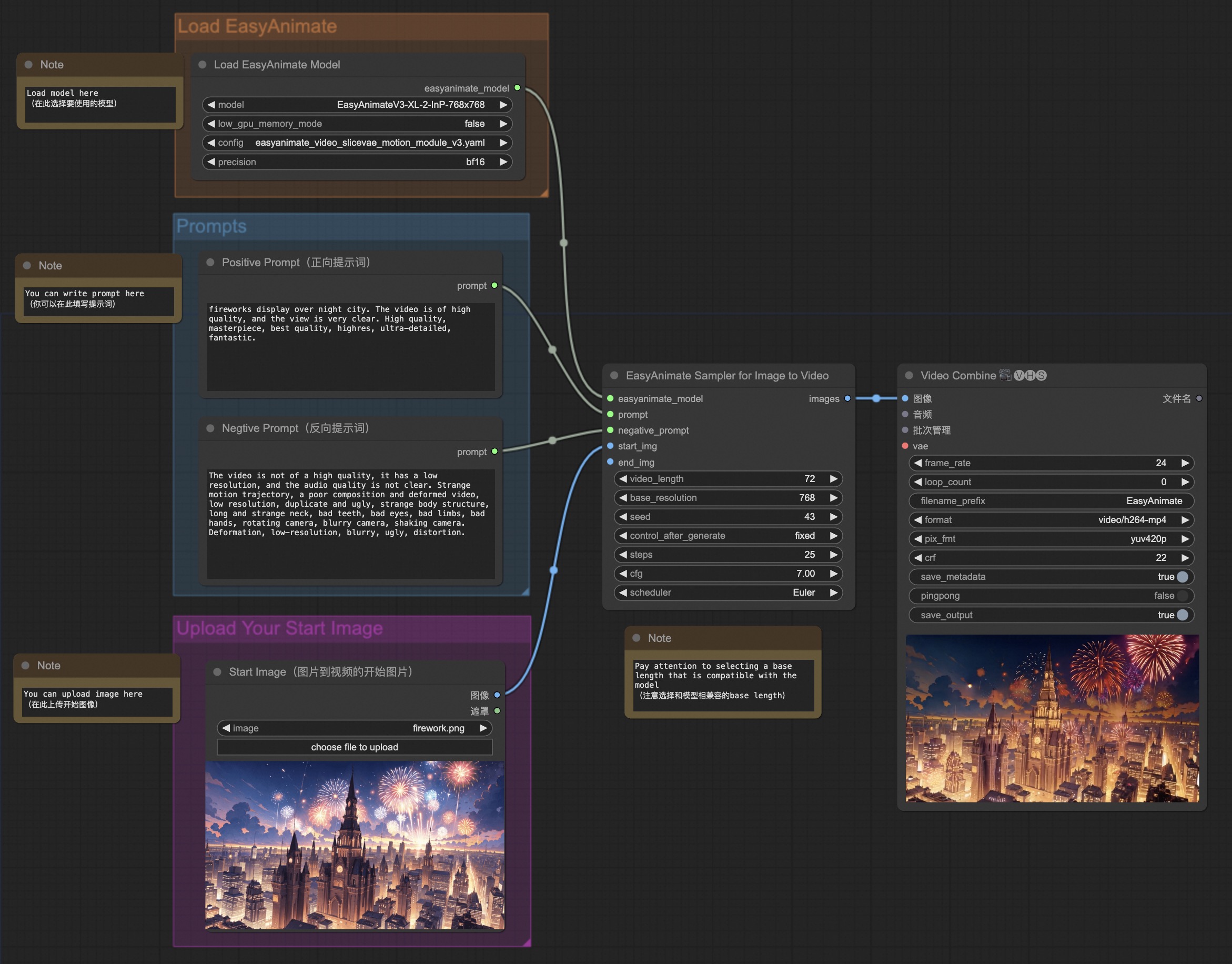 |
|
|
|
#### c. 通过docker |
|
使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令: |
|
``` |
|
# pull image |
|
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate |
|
|
|
# enter image |
|
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate |
|
|
|
# clone code |
|
git clone https://github.com/aigc-apps/EasyAnimate.git |
|
|
|
# enter EasyAnimate's dir |
|
cd EasyAnimate |
|
|
|
# download weights |
|
mkdir models/Diffusion_Transformer |
|
mkdir models/Motion_Module |
|
mkdir models/Personalized_Model |
|
|
|
# Please use the hugginface link or modelscope link to download the EasyAnimateV5 model. |
|
# I2V models |
|
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP |
|
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP |
|
# T2V models |
|
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh |
|
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh |
|
``` |
|
|
|
### 2. 本地安装: 环境检查/下载/安装 |
|
#### a. 环境检查 |
|
我们已验证EasyAnimate可在以下环境中执行: |
|
|
|
Windows 的详细信息: |
|
- 操作系统 Windows 10 |
|
- python: python3.10 & python3.11 |
|
- pytorch: torch2.2.0 |
|
- CUDA: 11.8 & 12.1 |
|
- CUDNN: 8+ |
|
- GPU: Nvidia-3060 12G |
|
|
|
Linux 的详细信息: |
|
- 操作系统 Ubuntu 20.04, CentOS |
|
- python: python3.10 & python3.11 |
|
- pytorch: torch2.2.0 |
|
- CUDA: 11.8 & 12.1 |
|
- CUDNN: 8+ |
|
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G |
|
|
|
我们需要大约 60GB 的可用磁盘空间,请检查! |
|
|
|
EasyAnimateV5-12B的视频大小可以由不同的GPU Memory生成,包括: |
|
| GPU memory |384x672x72|384x672x49|576x1008x25|576x1008x49|768x1344x25|768x1344x49| |
|
|----------|----------|----------|----------|----------|----------|----------| |
|
| 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ | |
|
| 24GB | 🧡 | 🧡 | 🧡 | 🧡 | ❌ | ❌ | |
|
| 40GB | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | |
|
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
|
|
|
✅ 表示它可以在"model_cpu_offload"的情况下运行,🧡代表它可以在"model_cpu_offload_and_qfloat8"的情况下运行,⭕️ 表示它可以在"sequential_cpu_offload"的情况下运行,❌ 表示它无法运行。请注意,使用sequential_cpu_offload运行会更慢。 |
|
|
|
有一些不支持torch.bfloat16的卡型,如2080ti、V100,需要将app.py、predict文件中的weight_dtype修改为torch.float16才可以运行。 |
|
|
|
EasyAnimateV5-12B使用不同GPU在25个steps中的生成时间如下: |
|
| GPU |384x672x72|384x672x49|576x1008x25|576x1008x49|768x1344x25|768x1344x49| |
|
|----------|----------|----------|----------|----------|----------|----------| |
|
| A10 24GB |约120秒 (4.8s/it)|约240秒 (9.6s/it)|约320秒 (12.7s/it)| 约750秒 (29.8s/it)| ❌ | ❌ | |
|
| A100 80GB |约45秒 (1.75s/it)|约90秒 (3.7s/it)|约120秒 (4.7s/it)|约300秒 (11.4s/it)|约265秒 (10.6s/it)| 约710秒 (28.3s/it)| |
|
|
|
(⭕️) 表示它可以在low_gpu_memory_mode=True的情况下运行,但速度较慢,同时❌ 表示它无法运行。 |
|
|
|
<details> |
|
<summary>(Obsolete) EasyAnimateV3:</summary> |
|
|
|
EasyAnimateV3的视频大小可以由不同的GPU Memory生成,包括: |
|
| GPU memory | 384x672x72 | 384x672x144 | 576x1008x72 | 576x1008x144 | 720x1280x72 | 720x1280x144 | |
|
|----------|----------|----------|----------|----------|----------|----------| |
|
| 12GB | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ❌ | ❌ | |
|
| 16GB | ✅ | ✅ | ⭕️ | ⭕️ | ⭕️ | ❌ | |
|
| 24GB | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | |
|
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
|
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
|
</details> |
|
|
|
#### b. 权重放置 |
|
我们最好将[权重](#model-zoo)按照指定路径进行放置: |
|
|
|
EasyAnimateV5: |
|
``` |
|
📦 models/ |
|
├── 📂 Diffusion_Transformer/ |
|
│ ├── 📂 EasyAnimateV5-12b-zh-InP/ |
|
│ └── 📂 EasyAnimateV5-12b-zh/ |
|
├── 📂 Personalized_Model/ |
|
│ └── your trained trainformer model / your trained lora model (for UI load) |
|
``` |
|
|
|
# 视频作品 |
|
所展示的结果都是图生视频获得。 |
|
|
|
### EasyAnimateV5-12b-zh-InP |
|
|
|
#### I2V |
|
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/bb393b7c-ba33-494c-ab06-b314adea9fc1" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/cb0d0253-919d-4dd6-9dc1-5cd94443c7f1" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/09ed361f-c0c5-4025-aad7-71fe1a1a52b1" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/9f42848d-34eb-473f-97ea-a5ebd0268106" width="100%" controls autoplay loop></video> |
|
</td> |
|
</tr> |
|
</table> |
|
|
|
|
|
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/903fda91-a0bd-48ee-bf64-fff4e4d96f17" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/407c6628-9688-44b6-b12d-77de10fbbe95" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/ccf30ec1-91d2-4d82-9ce0-fcc585fc2f21" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/5dfe0f92-7d0d-43e0-b7df-0ff7b325663c" width="100%" controls autoplay loop></video> |
|
</td> |
|
</tr> |
|
</table> |
|
|
|
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/2b542b85-be19-4537-9607-9d28ea7e932e" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/c1662745-752d-4ad2-92bc-fe53734347b2" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/8bec3d66-50a3-4af5-a381-be2c865825a0" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/bcec22f4-732c-446f-958c-2ebbfd8f94be" width="100%" controls autoplay loop></video> |
|
</td> |
|
</tr> |
|
</table> |
|
|
|
#### T2V |
|
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/eccb0797-4feb-48e9-91d3-5769ce30142b" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/76b3db64-9c7a-4d38-8854-dba940240ceb" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/0b8fab66-8de7-44ff-bd43-8f701bad6bb7" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/9fbddf5f-7fcd-4cc6-9d7c-3bdf1d4ce59e" width="100%" controls autoplay loop></video> |
|
</td> |
|
</tr> |
|
</table> |
|
|
|
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/19c1742b-e417-45ac-97d6-8bf3a80d8e13" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/641e56c8-a3d9-489d-a3a6-42c50a9aeca1" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/2b16be76-518b-44c6-a69b-5c49d76df365" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/e7d9c0fc-136f-405c-9fab-629389e196be" width="100%" controls autoplay loop></video> |
|
</td> |
|
</tr> |
|
</table> |
|
|
|
### EasyAnimateV5-12b-zh-Control |
|
|
|
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/fce43c0b-81fa-4ab2-9ca7-78d786f520e6" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/b208b92c-5add-4ece-a200-3dbbe47b93c3" width="100%" controls autoplay loop></video> |
|
</td> |
|
<tr> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/3aec95d5-d240-49fb-a9e9-914446c7a4cf" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/60fa063b-5c1f-485f-b663-09bd6669de3f" width="100%" controls autoplay loop></video> |
|
</td> |
|
<td> |
|
<video src="https://github.com/user-attachments/assets/4adde728-8397-42f3-8a2a-23f7b39e9a1e" width="100%" controls autoplay loop></video> |
|
</td> |
|
</tr> |
|
</table> |
|
|
|
# 如何使用 |
|
|
|
<h3 id="video-gen">1. 生成 </h3> |
|
|
|
#### a、运行python文件 |
|
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。 |
|
- 步骤2:在predict_t2v.py文件中修改prompt、neg_prompt、guidance_scale和seed。 |
|
- 步骤3:运行predict_t2v.py文件,等待生成结果,结果保存在samples/easyanimate-videos文件夹中。 |
|
- 步骤4:如果想结合自己训练的其他backbone与Lora,则看情况修改predict_t2v.py中的predict_t2v.py和lora_path。 |
|
|
|
#### b、通过ui界面 |
|
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。 |
|
- 步骤2:运行app.py文件,进入gradio页面。 |
|
- 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。 |
|
|
|
#### c、通过comfyui |
|
具体查看[ComfyUI README](comfyui/README.md)。 |
|
|
|
#### d、显存节省方案 |
|
由于EasyAnimateV5的参数非常大,我们需要考虑显存节省方案,以节省显存适应消费级显卡。我们给每个预测文件都提供了GPU_memory_mode,可以在model_cpu_offload,model_cpu_offload_and_qfloat8,sequential_cpu_offload中进行选择。 |
|
|
|
- model_cpu_offload代表整个模型在使用后会进入cpu,可以节省部分显存。 |
|
- model_cpu_offload_and_qfloat8代表整个模型在使用后会进入cpu,并且对transformer模型进行了float8的量化,可以节省更多的显存。 |
|
- sequential_cpu_offload代表模型的每一层在使用后会进入cpu,速度较慢,节省大量显存。 |
|
|
|
qfloat8会降低模型的性能,但可以节省更多的显存。如果显存足够,推荐使用model_cpu_offload。 |
|
|
|
### 2. 模型训练 |
|
一个完整的EasyAnimate训练链路应该包括数据预处理、Video VAE训练、Video DiT训练。其中Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。 |
|
|
|
<h4 id="data-preprocess">a.数据预处理</h4> |
|
|
|
我们给出了一个简单的demo通过图片数据训练lora模型,详情可以查看[wiki](https://github.com/aigc-apps/EasyAnimate/wiki/Training-Lora)。 |
|
|
|
一个完整的长视频切分、清洗、描述的数据预处理链路可以参考video caption部分的[README](easyanimate/video_caption/README.md)进行。 |
|
|
|
如果期望训练一个文生图视频的生成模型,您需要以这种格式排列数据集。 |
|
``` |
|
📦 project/ |
|
├── 📂 datasets/ |
|
│ ├── 📂 internal_datasets/ |
|
│ ├── 📂 train/ |
|
│ │ ├── 📄 00000001.mp4 |
|
│ │ ├── 📄 00000002.jpg |
|
│ │ └── 📄 ..... |
|
│ └── 📄 json_of_internal_datasets.json |
|
``` |
|
|
|
json_of_internal_datasets.json是一个标准的json文件。json中的file_path可以被设置为相对路径,如下所示: |
|
```json |
|
[ |
|
{ |
|
"file_path": "train/00000001.mp4", |
|
"text": "A group of young men in suits and sunglasses are walking down a city street.", |
|
"type": "video" |
|
}, |
|
{ |
|
"file_path": "train/00000002.jpg", |
|
"text": "A group of young men in suits and sunglasses are walking down a city street.", |
|
"type": "image" |
|
}, |
|
..... |
|
] |
|
``` |
|
|
|
你也可以将路径设置为绝对路径: |
|
```json |
|
[ |
|
{ |
|
"file_path": "/mnt/data/videos/00000001.mp4", |
|
"text": "A group of young men in suits and sunglasses are walking down a city street.", |
|
"type": "video" |
|
}, |
|
{ |
|
"file_path": "/mnt/data/train/00000001.jpg", |
|
"text": "A group of young men in suits and sunglasses are walking down a city street.", |
|
"type": "image" |
|
}, |
|
..... |
|
] |
|
``` |
|
<h4 id="vae-train">b. Video VAE训练 (可选)</h4> |
|
Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。 |
|
|
|
如果想要进行训练,可以参考video vae部分的[README](easyanimate/vae/README.md)进行。 |
|
|
|
<h4 id="dit-train">c. Video DiT训练 </h4> |
|
|
|
如果数据预处理时,数据的格式为相对路径,则进入scripts/train.sh进行如下设置。 |
|
``` |
|
export DATASET_NAME="datasets/internal_datasets/" |
|
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json" |
|
|
|
... |
|
|
|
train_data_format="normal" |
|
``` |
|
|
|
如果数据的格式为绝对路径,则进入scripts/train.sh进行如下设置。 |
|
``` |
|
export DATASET_NAME="" |
|
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json" |
|
``` |
|
|
|
最后运行scripts/train.sh。 |
|
```sh |
|
sh scripts/train.sh |
|
``` |
|
|
|
关于一些参数的设置细节,可以查看[Readme Train](scripts/README_TRAIN.md)与[Readme Lora](scripts/README_TRAIN_LORA.md) |
|
|
|
<details> |
|
<summary>(Obsolete) EasyAnimateV1:</summary> |
|
如果你想训练EasyAnimateV1。请切换到git分支v1。 |
|
</details> |
|
|
|
# 模型地址 |
|
EasyAnimateV5: |
|
|
|
7B: |
|
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 | |
|
|--|--|--|--|--|--| |
|
| EasyAnimateV5-7b-zh-InP | EasyAnimateV5 | 22 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-7b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-7b-zh-InP)| 官方的7B图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 | |
|
| EasyAnimateV5-7b-zh | EasyAnimateV5 | 22 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-7b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh)| 官方的7B文生视频权重。可用于进行下游任务的fientune。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 | |
|
|
|
12B: |
|
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 | |
|
|--|--|--|--|--|--| |
|
| EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP)| 官方的图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 | |
|
| EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-Control) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-Control)| 官方的视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 | |
|
| EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh)| 官方的文生视频权重。可用于进行下游任务的fientune。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 | |
|
|
|
<details> |
|
<summary>(Obsolete) EasyAnimateV4:</summary> |
|
|
|
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 | |
|
|--|--|--|--|--|--| |
|
| EasyAnimateV4-XL-2-InP.tar.gz | EasyAnimateV4 | 解压前 8.9 GB / 解压后 14.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV4-XL-2-InP)| [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV4-XL-2-InP)| 官方的图生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以144帧、每秒24帧进行训练 | |
|
</details> |
|
|
|
<details> |
|
<summary>(Obsolete) EasyAnimateV3:</summary> |
|
|
|
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 | |
|
|--|--|--|--|--|--| |
|
| EasyAnimateV3-XL-2-InP-512x512.tar | EasyAnimateV3 | 18.2GB| [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-512x512)| [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV3-XL-2-InP-512x512)| 官方的512x512分辨率的图生视频权重。以144帧、每秒24帧进行训练 | |
|
| EasyAnimateV3-XL-2-InP-768x768.tar | EasyAnimateV3 | 18.2GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-768x768) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV3-XL-2-InP-768x768)| 官方的768x768分辨率的图生视频权重。以144帧、每秒24帧进行训练 | |
|
| EasyAnimateV3-XL-2-InP-960x960.tar | EasyAnimateV3 | 18.2GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-960x960) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV3-XL-2-InP-960x960)| 官方的960x960(720P)分辨率的图生视频权重。以144帧、每秒24帧进行训练 | |
|
</details> |
|
|
|
<details> |
|
<summary>(Obsolete) EasyAnimateV2:</summary> |
|
|
|
| 名称 | 种类 | 存储空间 | 下载地址 | Hugging Face | Model Scope | 描述 | |
|
|--|--|--|--|--|--|--| |
|
| EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | - | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-512x512)| [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV2-XL-2-512x512)| 官方的512x512分辨率的重量。以144帧、每秒24帧进行训练 | |
|
| EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | - | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-768x768) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV2-XL-2-768x768)| 官方的768x768分辨率的重量。以144帧、每秒24帧进行训练 | |
|
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimatev2_minimalism_lora.safetensors)| - | - | 使用特定类型的图像进行lora训练的结果。图片可从这里[下载](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/Minimalism.zip). | |
|
</details> |
|
|
|
<details> |
|
<summary>(Obsolete) EasyAnimateV1:</summary> |
|
|
|
### 1、运动权重 |
|
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 | |
|
|--|--|--|--|--| |
|
| easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 | |
|
|
|
### 2、其他权重 |
|
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 | |
|
|--|--|--|--|--| |
|
| PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights | |
|
| easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets | |
|
| easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets | |
|
</details> |
|
|
|
# 未来计划 |
|
- 支持更大规模参数量的文视频生成模型。 |
|
|
|
# 联系我们 |
|
1. 扫描下方二维码或搜索群号:77450006752 来加入钉钉群。 |
|
2. 扫描下方二维码来加入微信群(如果二维码失效,可扫描最右边同学的微信,邀请您入群) |
|
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/> |
|
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/wechat.jpg" alt="Wechat group" width="30%"/> |
|
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/person.jpg" alt="Person" width="30%"/> |
|
|
|
# 参考文献 |
|
- CogVideo: https://github.com/THUDM/CogVideo/ |
|
- Flux: https://github.com/black-forest-labs/flux |
|
- magvit: https://github.com/google-research/magvit |
|
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha |
|
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan |
|
- Open-Sora: https://github.com/hpcaitech/Open-Sora |
|
- Animatediff: https://github.com/guoyww/AnimateDiff |
|
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper |
|
- HunYuan DiT: https://github.com/tencent/HunyuanDiT |
|
|
|
# 许可证 |
|
本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE). |
|
|
