
EasyAnimate-V5
Collection
5 items
•
Updated
EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI图片与视频、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的EasyAnimate模型直接进行预测,生成不同分辨率,6秒左右、fps8的视频(EasyAnimateV5,1 ~ 49帧),也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。
我们会逐渐支持从不同平台快速启动,请参阅 快速启动。
新特性:
功能概览:
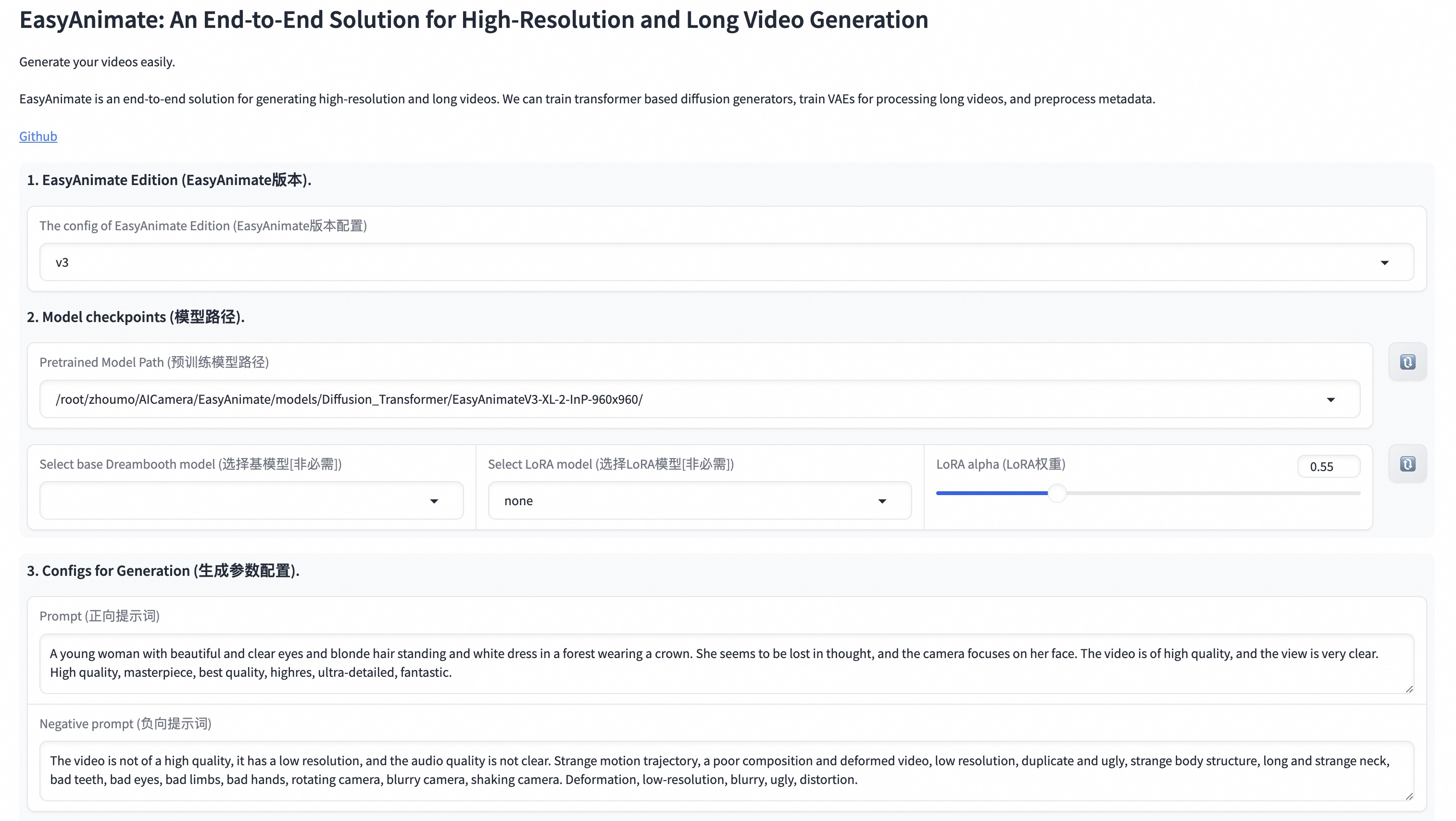
我们的ui界面如下:
DSW 有免费 GPU 时间,用户可申请一次,申请后3个月内有效。
阿里云在Freetier提供免费GPU时间,获取并在阿里云PAI-DSW中使用,5分钟内即可启动EasyAnimate

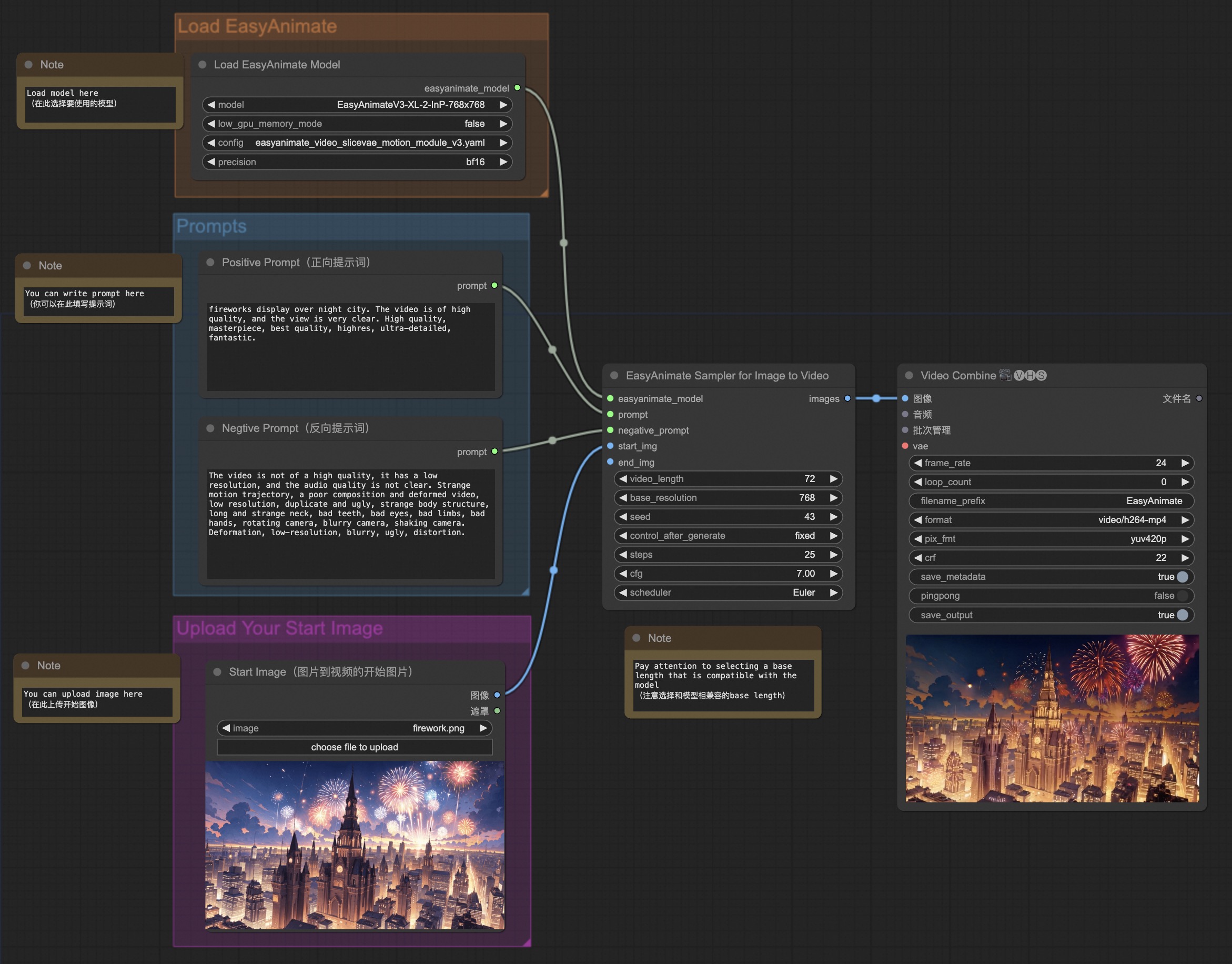
我们的ComfyUI界面如下,具体查看ComfyUI README。
使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git
# enter EasyAnimate's dir
cd EasyAnimate
# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
# Please use the hugginface link or modelscope link to download the EasyAnimateV5 model.
# I2V models
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP
# T2V models
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh
我们已验证EasyAnimate可在以下环境中执行:
Windows 的详细信息:
Linux 的详细信息:
我们需要大约 60GB 的可用磁盘空间,请检查!
EasyAnimateV5-12B的视频大小可以由不同的GPU Memory生成,包括:
| GPU memory | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|---|---|---|---|---|---|---|
| 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ |
| 24GB | 🧡 | 🧡 | 🧡 | 🧡 | ❌ | ❌ |
| 40GB | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
✅ 表示它可以在"model_cpu_offload"的情况下运行,🧡代表它可以在"model_cpu_offload_and_qfloat8"的情况下运行,⭕️ 表示它可以在"sequential_cpu_offload"的情况下运行,❌ 表示它无法运行。请注意,使用sequential_cpu_offload运行会更慢。
有一些不支持torch.bfloat16的卡型,如2080ti、V100,需要将app.py、predict文件中的weight_dtype修改为torch.float16才可以运行。
EasyAnimateV5-12B使用不同GPU在25个steps中的生成时间如下:
| GPU | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|---|---|---|---|---|---|---|
| A10 24GB | 约120秒 (4.8s/it) | 约240秒 (9.6s/it) | 约320秒 (12.7s/it) | 约750秒 (29.8s/it) | ❌ | ❌ |
| A100 80GB | 约45秒 (1.75s/it) | 约90秒 (3.7s/it) | 约120秒 (4.7s/it) | 约300秒 (11.4s/it) | 约265秒 (10.6s/it) | 约710秒 (28.3s/it) |
(⭕️) 表示它可以在low_gpu_memory_mode=True的情况下运行,但速度较慢,同时❌ 表示它无法运行。
EasyAnimateV3的视频大小可以由不同的GPU Memory生成,包括:
| GPU memory | 384x672x72 | 384x672x144 | 576x1008x72 | 576x1008x144 | 720x1280x72 | 720x1280x144 |
|---|---|---|---|---|---|---|
| 12GB | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ❌ | ❌ |
| 16GB | ✅ | ✅ | ⭕️ | ⭕️ | ⭕️ | ❌ |
| 24GB | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
我们最好将权重按照指定路径进行放置:
EasyAnimateV5:
📦 models/
├── 📂 Diffusion_Transformer/
│ ├── 📂 EasyAnimateV5-12b-zh-InP/
│ └── 📂 EasyAnimateV5-12b-zh/
├── 📂 Personalized_Model/
│ └── your trained trainformer model / your trained lora model (for UI load)
所展示的结果都是图生视频获得。
具体查看ComfyUI README。
由于EasyAnimateV5的参数非常大,我们需要考虑显存节省方案,以节省显存适应消费级显卡。我们给每个预测文件都提供了GPU_memory_mode,可以在model_cpu_offload,model_cpu_offload_and_qfloat8,sequential_cpu_offload中进行选择。
qfloat8会降低模型的性能,但可以节省更多的显存。如果显存足够,推荐使用model_cpu_offload。
一个完整的EasyAnimate训练链路应该包括数据预处理、Video VAE训练、Video DiT训练。其中Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。
我们给出了一个简单的demo通过图片数据训练lora模型,详情可以查看wiki。
一个完整的长视频切分、清洗、描述的数据预处理链路可以参考video caption部分的README进行。
如果期望训练一个文生图视频的生成模型,您需要以这种格式排列数据集。
📦 project/
├── 📂 datasets/
│ ├── 📂 internal_datasets/
│ ├── 📂 train/
│ │ ├── 📄 00000001.mp4
│ │ ├── 📄 00000002.jpg
│ │ └── 📄 .....
│ └── 📄 json_of_internal_datasets.json
json_of_internal_datasets.json是一个标准的json文件。json中的file_path可以被设置为相对路径,如下所示:
[
{
"file_path": "train/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "train/00000002.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]
你也可以将路径设置为绝对路径:
[
{
"file_path": "/mnt/data/videos/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "/mnt/data/train/00000001.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]
如果想要进行训练,可以参考video vae部分的README进行。
如果数据预处理时,数据的格式为相对路径,则进入scripts/train.sh进行如下设置。
export DATASET_NAME="datasets/internal_datasets/"
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
...
train_data_format="normal"
如果数据的格式为绝对路径,则进入scripts/train.sh进行如下设置。
export DATASET_NAME=""
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
最后运行scripts/train.sh。
sh scripts/train.sh
关于一些参数的设置细节,可以查看Readme Train与Readme Lora
EasyAnimateV5:
7B:
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 |
|---|---|---|---|---|---|
| EasyAnimateV5-7b-zh-InP | EasyAnimateV5 | 22 GB | 🤗Link | 😄Link | 官方的7B图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
| EasyAnimateV5-7b-zh | EasyAnimateV5 | 22 GB | 🤗Link | 😄Link | 官方的7B文生视频权重。可用于进行下游任务的fientune。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
12B:
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 |
|---|---|---|---|---|---|
| EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | 官方的图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
| EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | 官方的视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
| EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | 官方的文生视频权重。可用于进行下游任务的fientune。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 |
|---|---|---|---|---|---|
| EasyAnimateV3-XL-2-InP-512x512.tar | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | 官方的512x512分辨率的图生视频权重。以144帧、每秒24帧进行训练 |
| EasyAnimateV3-XL-2-InP-768x768.tar | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | 官方的768x768分辨率的图生视频权重。以144帧、每秒24帧进行训练 |
| EasyAnimateV3-XL-2-InP-960x960.tar | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | 官方的960x960(720P)分辨率的图生视频权重。以144帧、每秒24帧进行训练 |
| 名称 | 种类 | 存储空间 | 下载地址 | Hugging Face | Model Scope | 描述 |
|---|---|---|---|---|---|---|
| EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | - | 🤗Link | 😄Link | 官方的512x512分辨率的重量。以144帧、每秒24帧进行训练 |
| EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | - | 🤗Link | 😄Link | 官方的768x768分辨率的重量。以144帧、每秒24帧进行训练 |
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | Download | - | - | 使用特定类型的图像进行lora训练的结果。图片可从这里下载. |
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
|---|---|---|---|---|
| easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | download | Training with 80 frames and fps 12 |
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
|---|---|---|---|---|
| PixArt-XL-2-512x512.tar | Pixart | 11.4GB | download | Pixart-Alpha official weights |
| easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | download | Training with internal portrait datasets |
| easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | download | Training with internal portrait datasets |


本项目采用 Apache License (Version 2.0).