

TheBloke's LLM work is generously supported by a grant from andreessen horowitz (a16z)
Sonya 7B - GPTQ
- Model creator: Sanji Watsuki
- Original model: Sonya 7B
Description
This repo contains GPTQ model files for Sanji Watsuki's Sonya 7B.
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by Massed Compute.
Repositories available
- AWQ model(s) for GPU inference.
- GPTQ models for GPU inference, with multiple quantisation parameter options.
- 2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference
- Sanji Watsuki's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions
Prompt template: Alpaca
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
Known compatible clients / servers
GPTQ models are currently supported on Linux (NVidia/AMD) and Windows (NVidia only). macOS users: please use GGUF models.
These GPTQ models are known to work in the following inference servers/webuis.
This may not be a complete list; if you know of others, please let me know!
Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
Explanation of GPTQ parameters
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as
desc_act. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now. - Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
|---|---|---|---|---|---|---|---|---|---|
| main | 4 | 128 | Yes | 0.1 | VMware Open Instruct | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| gptq-4bit-32g-actorder_True | 4 | 32 | Yes | 0.1 | VMware Open Instruct | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| gptq-8bit--1g-actorder_True | 8 | None | Yes | 0.1 | VMware Open Instruct | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| gptq-8bit-128g-actorder_True | 8 | 128 | Yes | 0.1 | VMware Open Instruct | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| gptq-8bit-32g-actorder_True | 8 | 32 | Yes | 0.1 | VMware Open Instruct | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| gptq-4bit-64g-actorder_True | 4 | 64 | Yes | 0.1 | VMware Open Instruct | 4096 | 4.29 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
How to download, including from branches
In text-generation-webui
To download from the main branch, enter TheBloke/Sonya-7B-GPTQ in the "Download model" box.
To download from another branch, add :branchname to the end of the download name, eg TheBloke/Sonya-7B-GPTQ:gptq-4bit-32g-actorder_True
From the command line
I recommend using the huggingface-hub Python library:
pip3 install huggingface-hub
To download the main branch to a folder called Sonya-7B-GPTQ:
mkdir Sonya-7B-GPTQ
huggingface-cli download TheBloke/Sonya-7B-GPTQ --local-dir Sonya-7B-GPTQ --local-dir-use-symlinks False
To download from a different branch, add the --revision parameter:
mkdir Sonya-7B-GPTQ
huggingface-cli download TheBloke/Sonya-7B-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Sonya-7B-GPTQ --local-dir-use-symlinks False
More advanced huggingface-cli download usage
If you remove the --local-dir-use-symlinks False parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: ~/.cache/huggingface), and symlinks will be added to the specified --local-dir, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the HF_HOME environment variable, and/or the --cache-dir parameter to huggingface-cli.
For more documentation on downloading with huggingface-cli, please see: HF -> Hub Python Library -> Download files -> Download from the CLI.
To accelerate downloads on fast connections (1Gbit/s or higher), install hf_transfer:
pip3 install hf_transfer
And set environment variable HF_HUB_ENABLE_HF_TRANSFER to 1:
mkdir Sonya-7B-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Sonya-7B-GPTQ --local-dir Sonya-7B-GPTQ --local-dir-use-symlinks False
Windows Command Line users: You can set the environment variable by running set HF_HUB_ENABLE_HF_TRANSFER=1 before the download command.
With git (not recommended)
To clone a specific branch with git, use a command like this:
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Sonya-7B-GPTQ
Note that using Git with HF repos is strongly discouraged. It will be much slower than using huggingface-hub, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the .git folder as a blob.)
How to easily download and use this model in text-generation-webui
Please make sure you're using the latest version of text-generation-webui.
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
Click the Model tab.
Under Download custom model or LoRA, enter
TheBloke/Sonya-7B-GPTQ.- To download from a specific branch, enter for example
TheBloke/Sonya-7B-GPTQ:gptq-4bit-32g-actorder_True - see Provided Files above for the list of branches for each option.
- To download from a specific branch, enter for example
Click Download.
The model will start downloading. Once it's finished it will say "Done".
In the top left, click the refresh icon next to Model.
In the Model dropdown, choose the model you just downloaded:
Sonya-7B-GPTQThe model will automatically load, and is now ready for use!
If you want any custom settings, set them and then click Save settings for this model followed by Reload the Model in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file
quantize_config.json.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file
Once you're ready, click the Text Generation tab and enter a prompt to get started!
Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: ghcr.io/huggingface/text-generation-inference:1.1.0
Example Docker parameters:
--model-id TheBloke/Sonya-7B-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
pip3 install huggingface-hub
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(
prompt_template,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(f"Model output: {response}")
Python code example: inference from this GPTQ model
Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
pip3 install --upgrade transformers optimum
# If using PyTorch 2.1 + CUDA 12.x:
pip3 install --upgrade auto-gptq
# or, if using PyTorch 2.1 + CUDA 11.x:
pip3 install --upgrade auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
If you are using PyTorch 2.0, you will need to install AutoGPTQ from source. Likewise if you have problems with the pre-built wheels, you should try building from source:
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.5.1
pip3 install .
Example Python code
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Sonya-7B-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Write a story about llamas"
system_message = "You are a story writing assistant"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
ExLlama is compatible with Llama architecture models (including Mistral, Yi, DeepSeek, SOLAR, etc) in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
Discord
For further support, and discussions on these models and AI in general, join us at:
Thanks, and how to contribute
Thanks to the chirper.ai team!
Thanks to Clay from gpus.llm-utils.org!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
Special thanks to: Aemon Algiz.
Patreon special mentions: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
Original model card: Sanji Watsuki's Sonya 7B

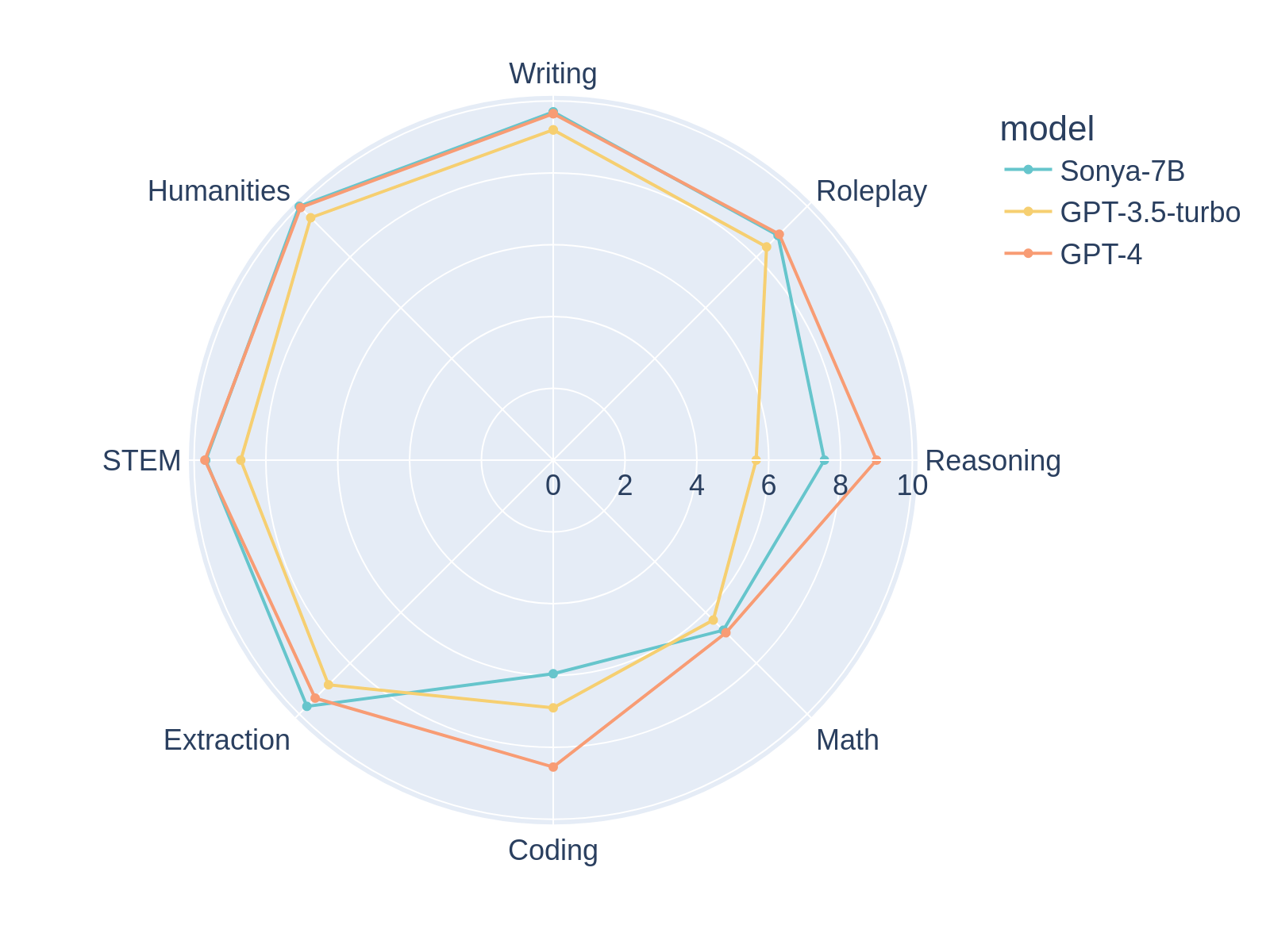
Top 1 Performer MT-bench 🤪
WTF is This?
Sonya-7B is, at the time of writing, the #1 performing model in MT-Bench first turn, ahead of GPT-4, and overall the #2 model in MT-Bench, to the best of my knowledge. Sonya-7B should be a good all-purpose model for all tasks including assistant, RP, etc.
Sonya-7B has a similar structure to my previous model, Silicon-Maid-7B, and uses a very similar merge. It's a merge of xDAN-AI/xDAN-L1-Chat-RL-v1, Jan-Ai's Stealth v1.2, chargoddard/piano-medley-7b, NeverSleep/Noromaid-7B-v0.2, and athirdpath/NSFW_DPO_vmgb-7b. Sauce is below. Somehow, by combining these pieces, it substantially outscores any of its parents on MT-Bench.
I picked these models because:
- MT-Bench normally correlates well with real world model quality and xDAN performs well on it.
- Almost all models in the mix were Alpaca prompt formatted which gives prompt consistency.
- Stealth v1.2 has been a magic sprinkle that seems to increase my MT-Bench scores.
- I added RP models because it boosted the Writing and Roleplay benchmarks 👀
Based on the parent models, I expect this model to be used with an 8192 context window. Please use NTK scaling alpha of 2.6 to experimentally try out 16384 context.
Let me be candid: Despite the test scores, this model is NOT is a GPT killer. I think it's a very sharp model for a 7B, it probably punches way above its weight for a 7B, but it's still a 7B model. Even for a 7B model, I think it's quirky and has some weird outputs, probably due to how Frankenstein this merge is. Keep your expectations in check 😉
MT-Bench Average Turn
| model | score | size |
|---|---|---|
| gpt-4 | 8.99 | - |
| Sonya-7B | 8.52 | 7b |
| xDAN-L1-Chat-RL-v1 | 8.34 | 7b |
| Starling-7B | 8.09 | 7b |
| Claude-2 | 8.06 | - |
| Silicon-Maid | 7.96 | 7b |
| Loyal-Macaroni-Maid | 7.95 | 7b |
| gpt-3.5-turbo | 7.94 | 20b? |
| Claude-1 | 7.90 | - |
| OpenChat-3.5 | 7.81 | - |
| vicuna-33b-v1.3 | 7.12 | 33b |
| wizardlm-30b | 7.01 | 30b |
| Llama-2-70b-chat | 6.86 | 70b |
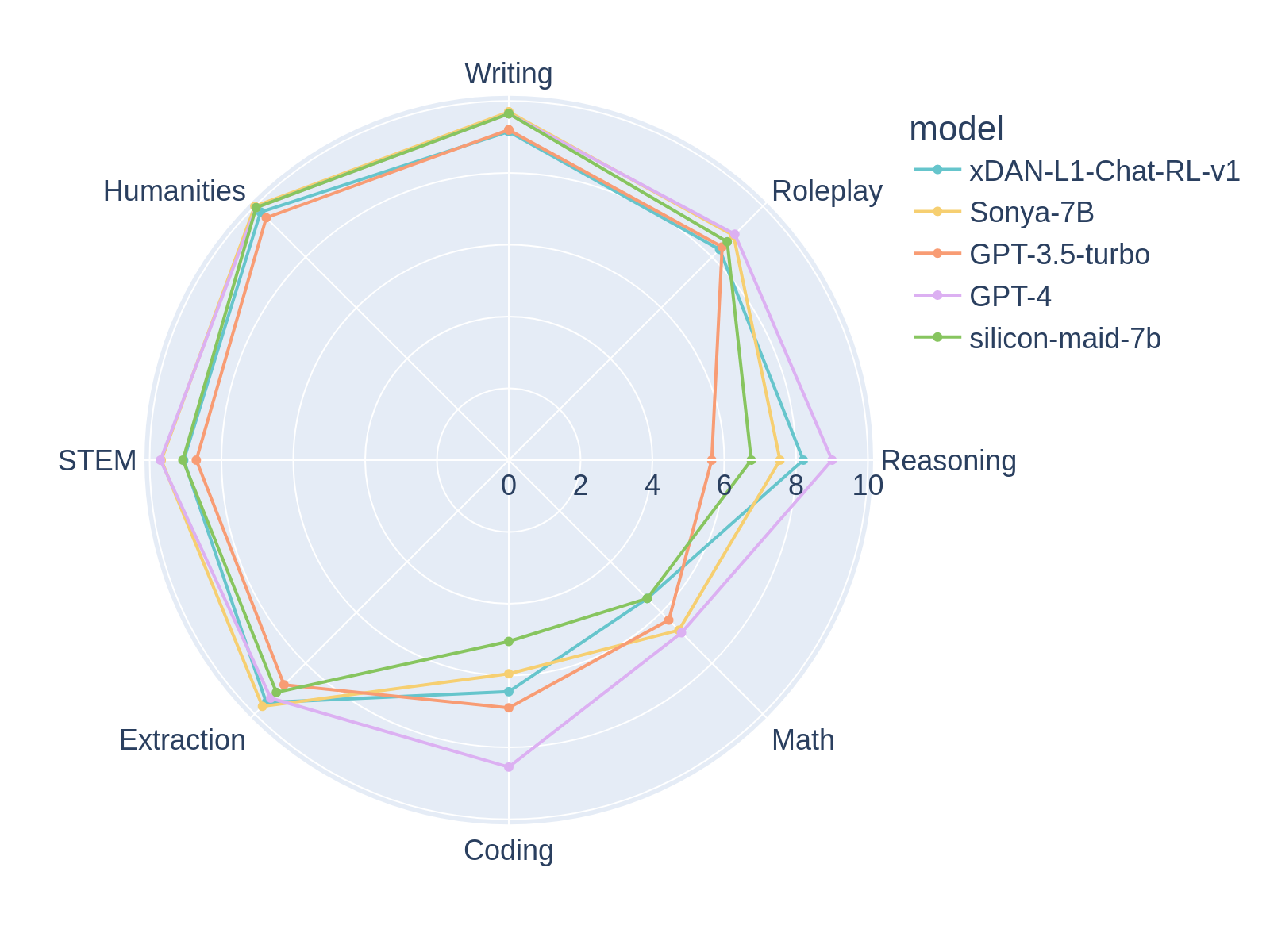
The Sauce
models:
- model: xDAN-AI/xDAN-L1-Chat-RL-v1
parameters:
weight: 1
density: 1
- model: chargoddard/piano-medley-7b
parameters:
weight: 0.3
- model: jan-hq/stealth-v1.2
parameters:
weight: 0.2
- model: NeverSleep/Noromaid-7b-v0.2
parameters:
weight: 0.2
- model: athirdpath/NSFW_DPO_vmgb-7b
parameters:
weight: 0.2
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
density: 0.4
int8_mask: true
normalize: true
dtype: bfloat16
There was no additional training, finetuning, or DPO. This is a straight merger.
Prompt Template (Alpaca)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
I found that this model performed worse with the xDAN prompt format so, despite the heavy weight of xDAN in this merger, I recommeend against its use.
Other Benchmark Stuff
########## First turn ##########
| model | turn | score | size |
|---|---|---|---|
| Sonya-7B | 1 | 9.06875 | 7b |
| gpt-4 | 1 | 8.95625 | - |
| xDAN-L1-Chat-RL-v1 | 1 | 8.87500 | 7b |
| xDAN-L2-Chat-RL-v2 | 1 | 8.78750 | 30b |
| claude-v1 | 1 | 8.15000 | - |
| gpt-3.5-turbo | 1 | 8.07500 | 20b |
| vicuna-33b-v1.3 | 1 | 7.45625 | 33b |
| wizardlm-30b | 1 | 7.13125 | 30b |
| oasst-sft-7-llama-30b | 1 | 7.10625 | 30b |
| Llama-2-70b-chat | 1 | 6.98750 | 70b |
########## Second turn ##########
| model | turn | score | size |
|---|---|---|---|
| gpt-4 | 2 | 9.025000 | - |
| xDAN-L2-Chat-RL-v2 | 2 | 8.087500 | 30b |
| Sonya-7B | 2 | 7.962500 | 7b |
| xDAN-L1-Chat-RL-v1 | 2 | 7.825000 | 7b |
| gpt-3.5-turbo | 2 | 7.812500 | 20b |
| claude-v1 | 2 | 7.650000 | - |
| wizardlm-30b | 2 | 6.887500 | 30b |
| vicuna-33b-v1.3 | 2 | 6.787500 | 33b |
| Llama-2-70b-chat | 2 | 6.725000 | 70b |
If you'd like to replicate the MT-Bench run, please ensure that the Alpaca prompt template is applied to the model. I did this by putting "alpaca" in the model path to trigger the AlpacaAdapter.
- Downloads last month
- 20
Model tree for TheBloke/Sonya-7B-GPTQ
Base model
SanjiWatsuki/Sonya-7B