
Model Cards: Driver Drowsiness Detection System
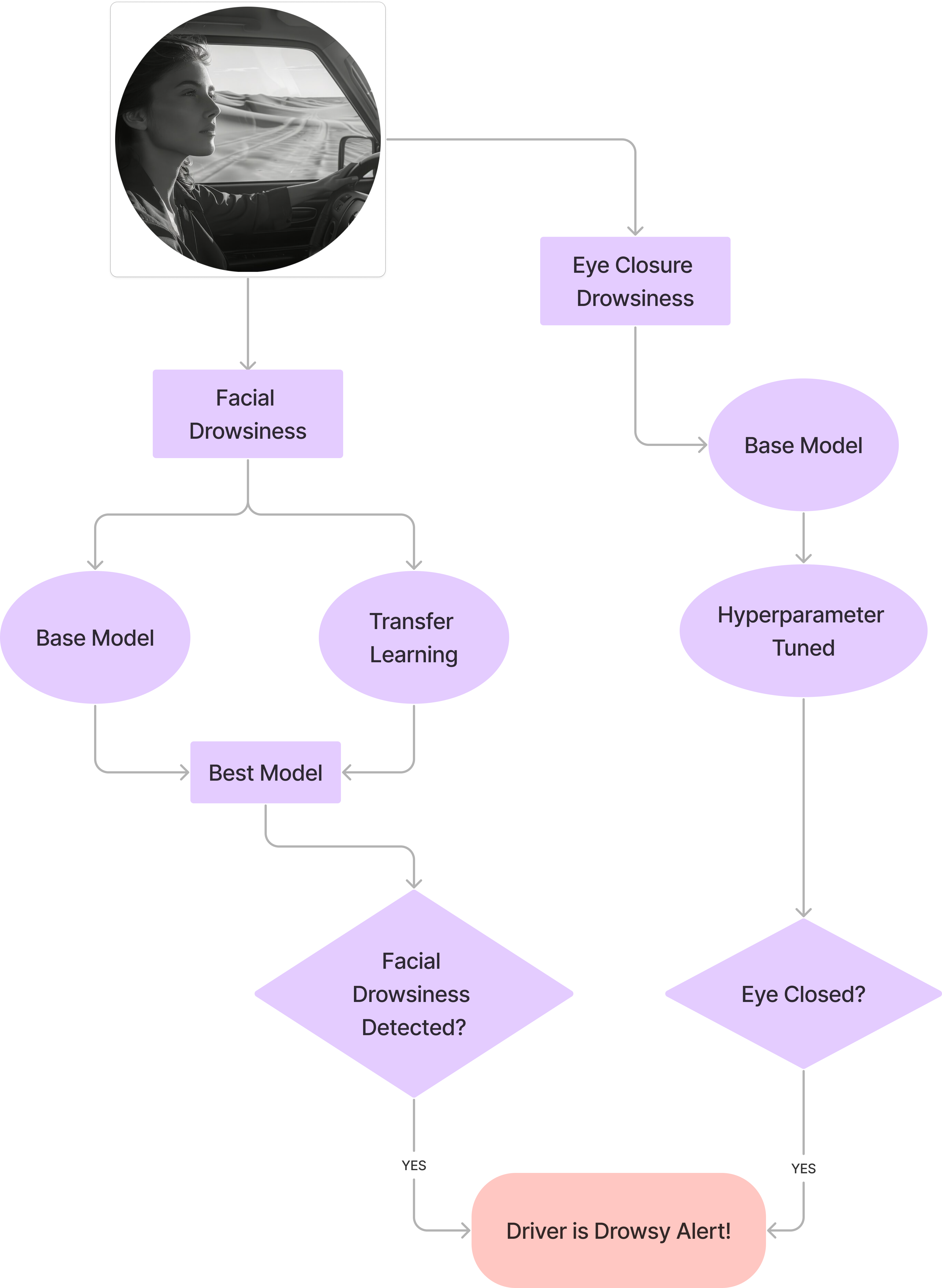
This repository contains models developed for the Driver Drowsiness Detection System project. The goal is to enhance vehicular safety by identifying signs of driver fatigue and drowsiness in real-time using deep learning. The system employs two main approaches:
- Facial Features Drowsiness Detection (Dataset 1): Analyzes overall facial images for signs of drowsiness (e.g., yawning, general expression).
- Eye Closure Drowsiness Detection (Dataset 2): Specifically focuses on detecting whether the driver's eyes are open or closed.
The report suggests combining these approaches for a more robust system, potentially using MobileNetV2 for facial features and the tuned CNN for eye closure.
Model Card: Facial Drowsiness Detection - Base CNN
- Model File:
trained_model_weights_BASE_DATASET1.pth
Model Details
- Description: A custom Convolutional Neural Network (CNN) trained from scratch to classify facial images as 'Drowsy' or 'Natural' (alert). This is the initial baseline model for Dataset 1.
- Architecture:
Model_OurArchitecture(4 Conv2D layers: 1->32, 32->64, 64->128, 128->128; MaxPool2D after first 3 Conv layers; 1 FC layer: 12866 -> 256; Output FC layer: 256 -> 1; ReLU activations; Single Dropout(0.5) layer before final output). - Input: 48x48 Grayscale images.
- Output: Single logit predicting drowsiness (Binary Classification).
- Framework: PyTorch.
Intended Use
- Intended for detecting drowsiness based on static facial images. Serves as a baseline for comparison.
- Not recommended for deployment due to significant overfitting.
Training Data
- Dataset: Drowsy Detection Dataset (Kaggle Link)
- Classes: DROWSY, NATURAL.
- Size: 5,859 training images.
- Preprocessing: Resize (48x48), Grayscale, ToTensor, Normalize (calculated mean/std from dataset), RandomHorizontalFlip.

Evaluation Data
- Dataset: Test split of the Drowsy Detection Dataset.
- Size: 1,483 testing images.
- Preprocessing: Resize (48x48), Grayscale, ToTensor, Normalize (same as training).
Quantitative Analyses
- Training Performance: Accuracy: 99.51%, Loss: 0.0148
- Evaluation Performance: Accuracy: 86.24%, Loss: 0.9170
- Metrics: Accuracy, Binary Cross-Entropy with Logits Loss.
Limitations and Ethical Considerations
- Overfitting: Shows significant overfitting (large gap between training and testing accuracy). Generalizes poorly to unseen data.
- Bias: Performance may vary across different demographics, lighting conditions, camera angles, and accessories (e.g., glasses) not equally represented in the dataset.
- Misuse Potential: Could be used for surveillance, though not designed for it. False negatives (missing drowsiness) could lead to accidents; false positives (incorrect alerts) could be annoying or lead to user distrust.
Model Card: Facial Drowsiness Detection - Base CNN + Dropout
- Model File:
trained_model_weights_BASE_DROPOUT_DATASET1.pth
Model Details
- Description: The same custom CNN architecture as the base model (
Model_OurArchitecture) but explicitly trained with the described dropout layer active to mitigate overfitting observed in the baseline. - Architecture:
Model_OurArchitecture(As described above, including the Dropout(0.5) layer). - Input: 48x48 Grayscale images.
- Output: Single logit predicting drowsiness.
- Framework: PyTorch.
Intended Use
- Intended for detecting drowsiness based on static facial images. Shows improvement over the baseline by using dropout for regularization.
- Better generalization than the baseline, but transfer learning models performed better.
Training Data
- Same as the Base CNN model (Dataset 1).
Evaluation Data
- Same as the Base CNN model (Dataset 1).
Quantitative Analyses
- Training Performance: Accuracy: 96.36%, Loss: 0.0960
- Evaluation Performance: Accuracy: 90.42%, Loss: 0.1969
- Metrics: Accuracy, BCEWithLogitsLoss.
Limitations and Ethical Considerations
- Overfitting Reduced: Overfitting is reduced compared to the baseline, but a gap still exists.
- Bias: Same potential biases as the base model regarding demographics, lighting, etc.
- Misuse Potential: Same as the base model.
Model Card: Facial Drowsiness Detection - Base CNN + Dropout + Early Stopping
- Model File:
trained_model_weights_BASE_DROPOUT_EARLYSTOPPING_DATASET1.pth
Model Details
- Description: The same custom CNN architecture (
Model_OurArchitecturewith dropout) trained using Dropout and Early Stopping (patience=5) to further prevent overfitting. Training stopped at epoch 9 out of 25 planned. - Architecture:
Model_OurArchitecture(As described above, including the Dropout(0.5) layer). - Input: 48x48 Grayscale images.
- Output: Single logit predicting drowsiness.
- Framework: PyTorch.
Intended Use
- Intended for detecting drowsiness based on static facial images. Represents the best-performing version of the custom CNN architecture due to regularization techniques.
- Performance is closer between training and testing compared to previous versions.
Training Data
- Same as the Base CNN model (Dataset 1).
Evaluation Data
- Same as the Base CNN model (Dataset 1).
Quantitative Analyses
- Best Training Performance (at Epoch 9): Accuracy: 97.87%, Loss: 0.0617
- Evaluation Performance: Accuracy: 91.64%, Loss: 0.1899
- Metrics: Accuracy, BCEWithLogitsLoss.
Limitations and Ethical Considerations
- Generalization: While improved, may not perform as well as the best transfer learning models on diverse unseen data.
- Bias: Same potential biases as the base model.
- Misuse Potential: Same as the base model.
Model Card: Facial Drowsiness Detection - Fine-tuned VGG16
- Model File:
trained_model_weights_VGG16_DATASET1.pth
Model Details
- Description: A VGG16 model, pre-trained on ImageNet, fine-tuned for binary classification of facial images ('Drowsy' vs 'Natural') on Dataset 1.
- Architecture: Standard VGG16 architecture with the final fully connected layer replaced by a single output unit for binary classification.
- Input: 224x224 RGB images (Normalized using ImageNet stats).
- Output: Single logit predicting drowsiness.
- Framework: PyTorch.
Intended Use
- Detecting drowsiness from facial images. Leverages transfer learning for potentially better feature extraction and generalization compared to the custom CNN. Good performance on the test set.
Training Data
- Dataset: Drowsy Detection Dataset (Kaggle Link)
- Classes: DROWSY, NATURAL.
- Size: 5,859 training images.
- Preprocessing: Resize (224x224), RandomHorizontalFlip, ToTensor, Normalize (ImageNet mean/std).
Evaluation Data
- Dataset: Test split of the Drowsy Detection Dataset.
- Size: 1,483 testing images.
- Preprocessing: Resize (224x224), ToTensor, Normalize (ImageNet mean/std).
Quantitative Analyses
- Training Performance: Accuracy: 96.69%, Loss: 0.1067
- Evaluation Performance: Accuracy: 97.51%, Loss: 0.1033
- Metrics: Accuracy, BCEWithLogitsLoss.
Limitations and Ethical Considerations
- Model Size: VGG16 is relatively large, potentially impacting inference speed and deployment on resource-constrained devices.
- Bias: Potential biases inherited from ImageNet pre-training and the fine-tuning dataset (demographics, lighting, etc.).
- Misuse Potential: Same as the base model.
Model Card: Facial Drowsiness Detection - Fine-tuned ResNet18
- Model File:
trained_model_weights_RESNET18_DATASET1.pth
Model Details
- Description: A ResNet18 model, pre-trained on ImageNet, fine-tuned for binary classification of facial images ('Drowsy' vs 'Natural') on Dataset 1.
- Architecture: Standard ResNet18 architecture with the final fully connected layer replaced by a single output unit.
- Input: 224x224 RGB images (Normalized using ImageNet stats).
- Output: Single logit predicting drowsiness.
- Framework: PyTorch.
Intended Use
- Detecting drowsiness from facial images using transfer learning. Offers a balance between performance and model size compared to VGG16.
Training Data
- Same as the Fine-tuned VGG16 model (Dataset 1, 224x224 RGB, ImageNet Norm).
Evaluation Data
- Same as the Fine-tuned VGG16 model (Dataset 1 Test Set).
Quantitative Analyses
- Training Performance: Accuracy: 99.42%, Loss: 0.0197
- Evaluation Performance: Accuracy: 95.28%, Loss: 0.1118
- Metrics: Accuracy, BCEWithLogitsLoss.
Limitations and Ethical Considerations
- Overfitting: Shows a slightly larger gap between training and test performance compared to VGG16/MobileNetV2 on this task, indicating some overfitting.
- Bias: Potential biases from ImageNet and the fine-tuning dataset.
- Misuse Potential: Same as the base model.
Model Card: Facial Drowsiness Detection - Fine-tuned MobileNetV2 (Recommended for Facial Features)
- Model File:
trained_model_weights_MOBILENETV2_DATASET1.pth
Model Details
- Description: A MobileNetV2 model, pre-trained on ImageNet, fine-tuned for binary classification of facial images ('Drowsy' vs 'Natural') on Dataset 1. Achieved the highest test accuracy among models tested on Dataset 1.
- Architecture: Standard MobileNetV2 architecture with the final classifier replaced for a single output unit. Designed for efficiency.
- Input: 224x224 RGB images (Normalized using ImageNet stats).
- Output: Single logit predicting drowsiness.
- Framework: PyTorch.
Intended Use
- Recommended model for facial drowsiness detection. Offers high accuracy and efficiency, suitable for real-time applications.
Training Data
- Same as the Fine-tuned VGG16 model (Dataset 1, 224x224 RGB, ImageNet Norm).
Evaluation Data
- Same as the Fine-tuned VGG16 model (Dataset 1 Test Set).
Quantitative Analyses
- Training Performance: Accuracy: 99.61%, Loss: 0.0175
- Evaluation Performance: Accuracy: 98.99%, Loss: 0.0317
- Metrics: Accuracy, BCEWithLogitsLoss.
Limitations and Ethical Considerations
- Efficiency vs. Complexity: While efficient, it might be less robust to extreme variations than larger models in some scenarios.
- Bias: Potential biases from ImageNet and the fine-tuning dataset.
- Misuse Potential: Same as the base model. Performance under challenging real-world conditions (e.g., poor lighting, partial occlusion) should be carefully validated.
Model Card: Eye Closure Detection - Tuned CNN (Recommended for Eye Closure)
- Model File:
trained_model_weights_FINAL_DATASET2.pth
Model Details
- Description: A custom CNN (
Model_NewArchitecture) trained to detect whether eyes are 'Open' or 'Closed'. This model is the result of hyperparameter tuning (Adam optimizer, Dropout rate 0.5) on the baseline architecture for Dataset 2. - Architecture:
Model_NewArchitecture(4 Conv2D layers: 3->64, 64->128, 128->256, 256->256; MaxPool2D after first 3 Conv layers; 1 FC layer: 2562828 -> 512; Output FC layer: 512 -> 1; ReLU activations; Dropout(0.5) before final output). - Input: 224x224 Grayscale images (potentially replicated to 3 channels based on report's transform description, normalized using dataset stats).
- Output: Single logit predicting eye closure (Binary Classification).
- Framework: PyTorch.
Intended Use
- Recommended model for eye closure detection. Specifically designed to classify eye state, intended to be used alongside the facial feature model for a more robust drowsiness detection system.
Training Data
- Dataset: Openned Closed Eyes Dataset (Kaggle Link) - UnityEyes synthetic data.
- Classes: Opened, Closed.
- Size: 5,807 training images.
- Preprocessing: Resize (224x224), Grayscale (num_output_channels=3), Augmentations (RandomHorizontalFlip, RandomRotation(10), ColorJitter), ToTensor, Normalize (calculated mean/std from dataset).

Evaluation Data
- Dataset: Test split of the Openned Closed Eyes Dataset.
- Size: 4,232 testing images.
- Preprocessing: Resize (224x224), Grayscale (num_output_channels=3), ToTensor, Normalize (same as training).
Quantitative Analyses (Hyperparameter Tuned Model: Adam, Dropout 0.5)
- Final Training Performance: Accuracy: 95.52%, Loss: 0.1303 (from table pg 23)
- Evaluation Performance: Accuracy: 96.79%, Loss: 0.0935 (from table pg 23)
- Metrics: Accuracy, BCEWithLogitsLoss.
Limitations and Ethical Considerations
- Synthetic Data: Trained primarily on synthetic eye images (UnityEyes). Performance on diverse real-world eyes (different ethnicities, lighting, glasses, occlusions, extreme angles) needs validation. Domain gap might exist.
- Bias: Potential biases related to the distribution of eye types/states in the synthetic dataset.
- Misuse Potential: Could be part of a surveillance system monitoring eye state. False negatives/positives have safety implications as described for other models.
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.