


TongGu LLM
Introduction
Tonggu is a classical Chinese LLM developed by the Deep Learning and Visual Computing Laboratory (SCUT-DLVCLab) at South China University of Technology. It has strong capabilities in understanding and processing ancient texts. Tonggu uses multi-stage instruction fine-tuning and innovatively proposes a Redundancy-Aware Tuning (RAT) method, which greatly retains the capabilities of the base model while enhancing the performance of downstream tasks.

Evaluation
Tonggu has surpassed existing models in a wide range of classical Chinese understanding and processing tasks. A comparison with its base model Baichuan2-7B-Chat demonstrates the effectiveness of Tonggu's training process and methods. In the future, Tonggu will continue to update its model and benefit from even more powerful base models.
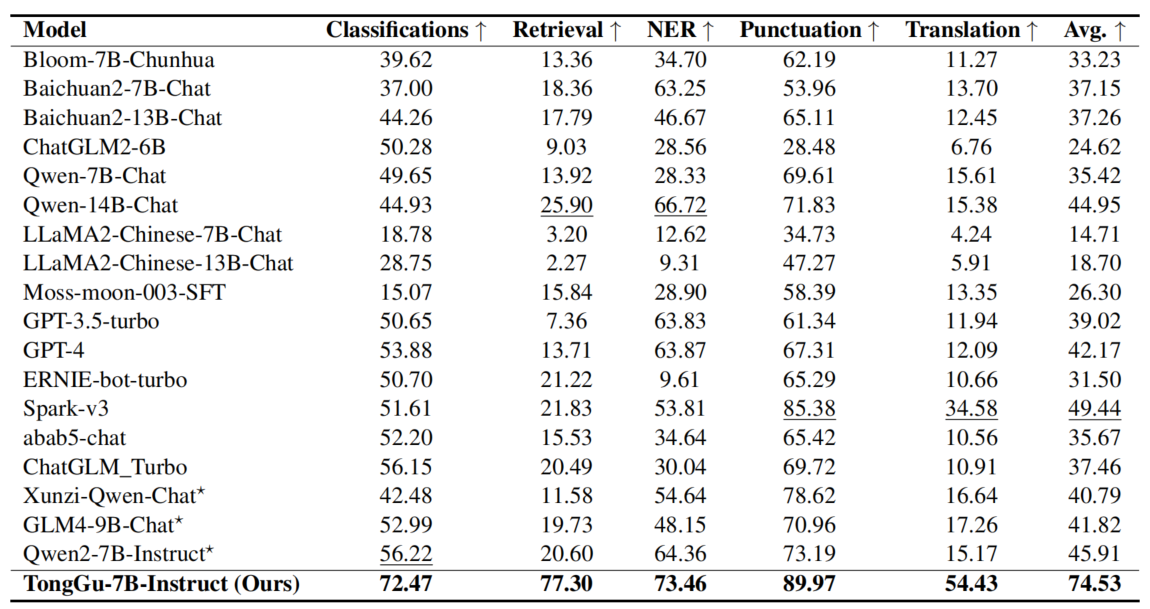

Open-source List
Model
TongGu-7B-Instruct: The 7B classical Chinese language model is based on Baichuan2-7B-Base, which has undergone unsupervised incremental pre-training on a corpus of 2.41 billion classical Chinese texts, and fine-tuned on 4 million classical Chinese dialogue data, possessing functions such as ancient text annotation, translation, and appreciation.
Data
ACCN-INS: 4 million classical Chinese instruction data, covering 24 estimated tasks across three dimensions of ancient text understanding, generation, and knowledge.
The ACCN-INS dataset can only be used for non-commercial research purposes. For scholar or organization who wants to use the MSDS dataset, please first fill in this Application Form and email them to us. When submitting the application form to us, please list or attached 1-2 of your publications in the recent 6 years to indicate that you (or your team) do research in the related research fields of classical Chinese. We will give you the download link and the decompression password after your application has been received and approved. All users must follow all use conditions; otherwise, the authorization will be revoked.
News
- 2024/9/21 The paper of Tonggu has been accepted by EMNLP 2024.
- 2024/9/26 Tonggu model and instruction data have been opened sourced.
Examples
句读

成语解释

文白翻译

白文翻译

诗词创作

Inference
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "SCUT-DLVCLab/TongGu-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path, device_map='auto', torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
system_message = "你是通古,由华南理工大学DLVCLab训练而来的古文大模型。你具备丰富的古文知识,为用户提供有用、准确的回答。"
user_query = "翻译成白话文:大学之道,在明明德,在亲民,在止于至善。"
prompt = f"{system_message}\n<用户> {user_query}\n<通古> "
inputs = tokenizer(prompt, return_tensors='pt')
generate_ids = model.generate(
inputs.input_ids.cuda(),
max_new_tokens=128
)
generate_text = tokenizer.batch_decode(
generate_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)[0][len(prompt):]
print(generate_text)
Citation
@article{cao2024tonggu,
title={TongGu: Mastering Classical Chinese Understanding with Knowledge-Grounded Large Language Models},
author={Cao, Jiahuan and Peng, Dezhi and Zhang, Peirong and Shi, Yongxin and Liu, Yang and Ding, Kai and Jin, Lianwen},
journal={EMNLP 2024},
year={2024}
}
Statement:
After extensive data incremental pre-training and instruction fine-tuning, Tonggu has strong capabilities in processing ancient texts, such as punctuation and translation. However, due to limitations in model size and the autoregressive generation paradigm, Tonggu may still generate misleading replies containing factual errors or harmful content that includes bias or discrimination. Please use it cautiously and be aware of discerning such content. Do not spread harmful content generated by Tonggu on the Internet. If any adverse consequences arise, the disseminator shall bear the responsibility.