|
--- |
|
license: apache-2.0 |
|
language: |
|
- en |
|
pipeline_tag: text-classification |
|
--- |
|
|
|
# Fine-tune and Train a custom dataset for sentiment_analysis on top of Vicuna |
|
Vicuna_finetune_sentiment_analysis through PEFT and LoRA. |
|
|
|
To Run the app: https://huggingface.co/spaces/RinInori/vicuna_finetuned_6_sentiments?logs=build |
|
|
|
Github fine-tune code link: https://github.com/hennypurwadi/Vicuna_finetune_sentiment_analysis |
|
|
|
#Fine-tuned Vicuna model for sentiment analysis, trained using dataset from Kaggle: |
|
https://www.kaggle.com/datasets/praveengovi/emotions-dataset-for-nlp |
|
|
|
BASE_MODEL = "TheBloke/vicuna-7B-1.1-HF" |
|
|
|
LORA_WEIGHTS = "RinInori/vicuna_finetuned_6_sentiments" |
|
|
|
--- |
|
|
|
Vicuna is created by fine-tuning a LLaMA base model using approximately 70K user-shared conversations gathered from ShareGPT.com with public APIs. |
|
To find more about Vicuna here: https://lmsys.org/blog/2023-03-30-vicuna/ |
|
|
|
To train a custom dataset on top of Vicuna if we don’t have good access to data-center grade GPU, is to fine-tune it through PEFT and LoRA. |
|
|
|
PEFT = parameter-Efficient Fine_Tuning of Billion-Scale Models on Low-Resource hardware. |
|
|
|
LoRA = Low-Rank Adaptation of Large Language Models is a training method that accelerates the training of large models while consuming less memory. |
|
It adds pairs of rank-decomposition weight matrices (called update matrices) to existing weights, and only trains those newly added weights. |
|
|
|
--- |
|
|
|
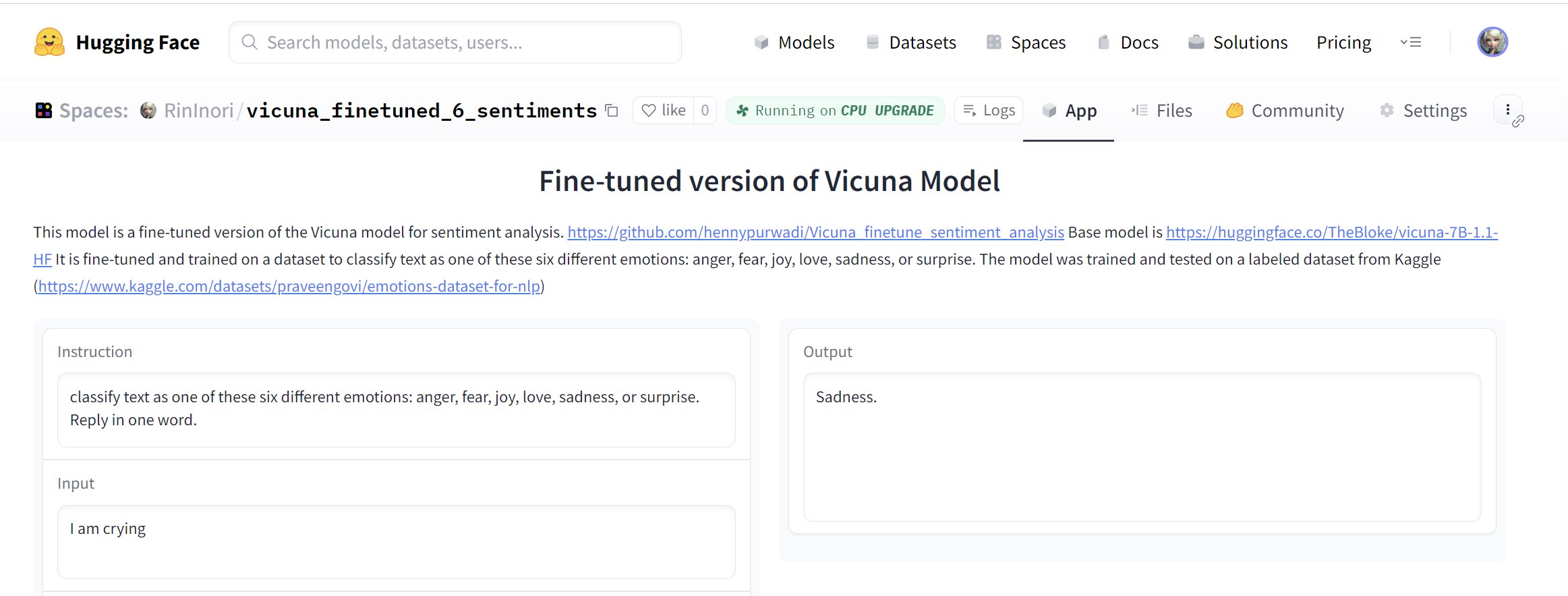
### To RUN APP: https://huggingface.co/spaces/RinInori/vicuna_finetuned_6_sentiments |
|
|
|
 |
|
|
|
----------------- |
|
### Model Hub: https://huggingface.co/RinInori/vicuna_finetuned_6_sentimentsis/blob/main/images/SaveModel_Tokenizer_To_Huggingface.jpg?raw=true) |
|
|
|
--- |
|
|
|
Ref: https://www.youtube.com/watch?v=Us5ZFp16PaU |
|
|
|
Ref: https://arxiv.org/abs/2106.09685 |
|
|
|
Ref: https://huggingface.co/docs/diffusers/training/lora#lowrank-adaptation-of-large-language-models-lora |
|
|
|
Ref: Hutchinson, B., Ostendorf, M., & Fazel, M. (2011, September). Low Rank Language Models for Small Training Sets. IEEE Signal Processing Letters, 18(9), 489–492. https://doi.org/10.1109/lsp.2011.2160850 |
|
|
