
license: mit
license: mit pipeline_tag: image-text-to-text library_name: transformers base_model: - internlm/internlm2-chat-1_8b base_model_relation: merge language: - multilingual tags: - internvl - vision-language model - monolithic
HoVLE
[📜 HoVLE Paper] [🚀 Quick Start]
Introduction
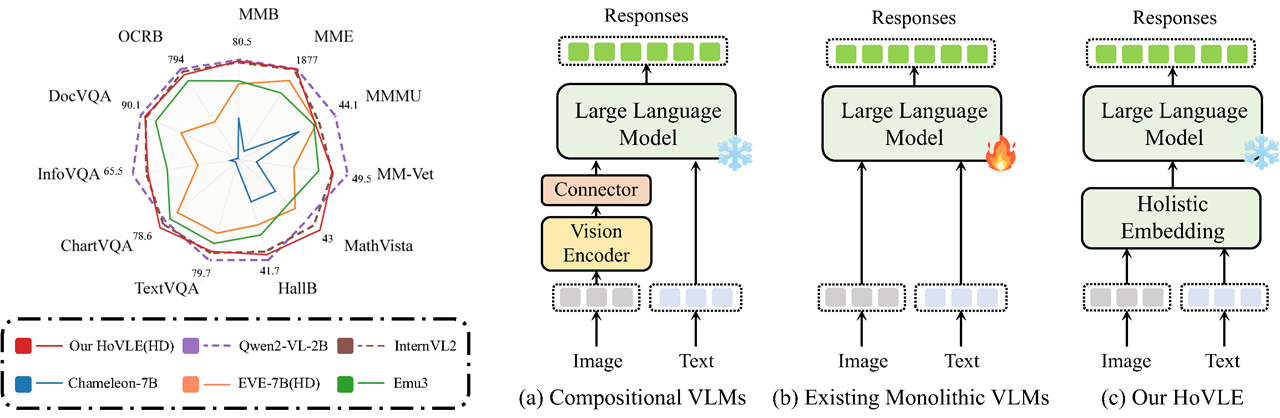
We introduce HoVLE, a novel monolithic vision-language model (VLM) that processes images and texts in a unified manner. HoVLE introduces a holistic embedding module that projects image and text inputs into a shared embedding space, allowing the Large Language Model (LLM) to interpret images in the same way as texts.
HoVLE significantly surpasses previous monolithic VLMs and demonstrates competitive performance with compositional VLMs. This work narrows the gap between monolithic and compositional VLMs, providing a promising direction for the development of monolithic VLMs.
This repository releases the HoVLE model with 2.6B parameters. It is built upon internlm2-chat-1_8b. Please refer to HoVLE (HD) for the high-definition version. For more details, please refer to our paper.
Model Details
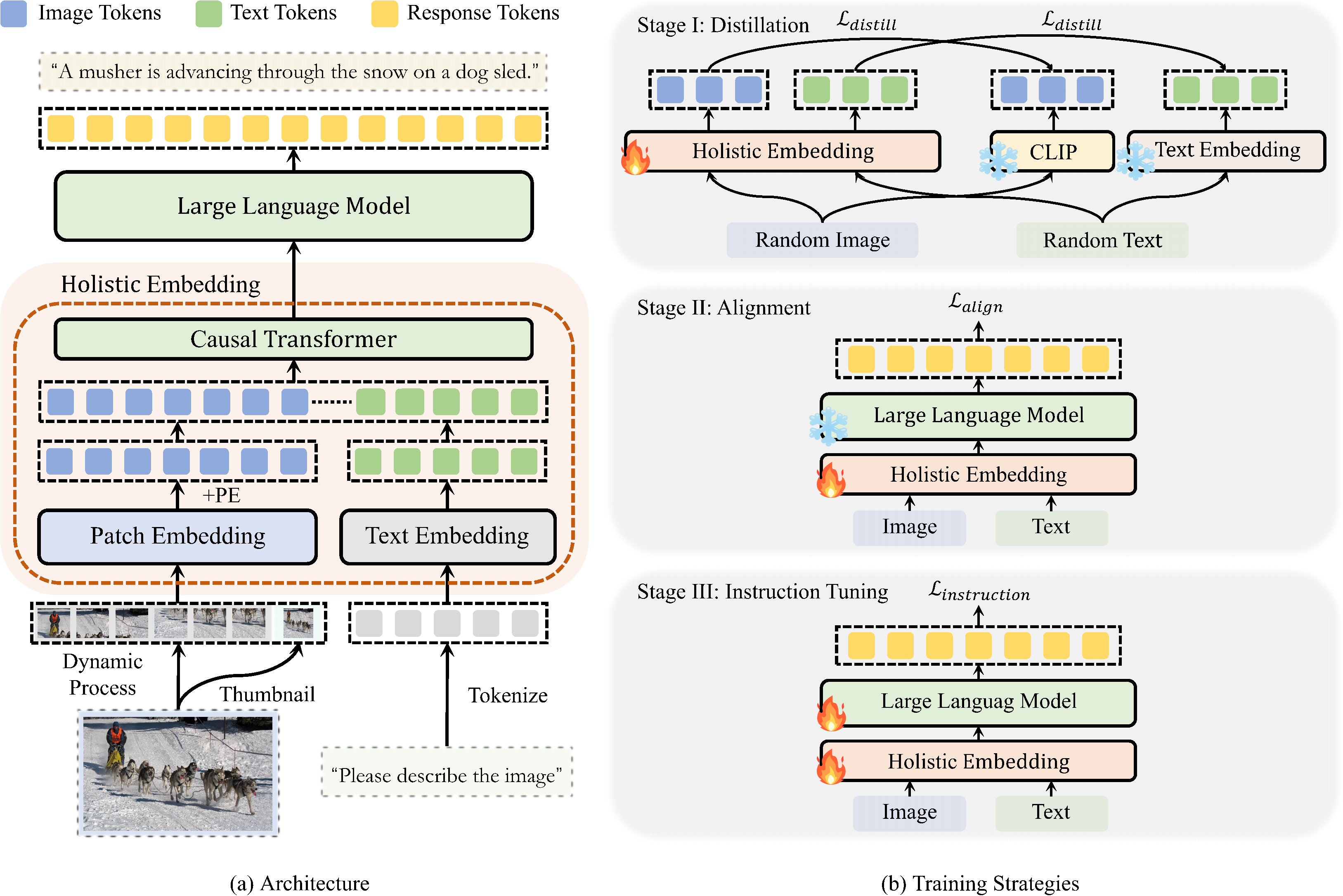
| Details | |
|---|---|
| Architecture | The whole model consists of a holistic embedding module and an LLM. The holistic embedding module consists of the same causal Transformer layers as the LLM. It accepts both images and texts as input, and projects them into a unified embedding space. These embeddings are then forwarded into the LLM, constituting a monolithic VLM. |
| Stage I (Distillation) | The first stage trains the holistic embedding module to distill the image feature from a pre-trained visual encoder and the text embeddings from an LLM, providing general encoding abilities. Only the holistic embedding module is trainable. |
| Stage II (Alignment) | The second stage combines the holistic embedding module with the LLM to perform auto-regressive training, aligning different modalities to a shared embedding space. Only the holistic embedding module is trainable. |
| Stage III (Instruction Tuning) | A visual instruction tuning stage is incorporated to further strengthen the whole VLM to follow instructions. The whole model is trainable. |
Performance
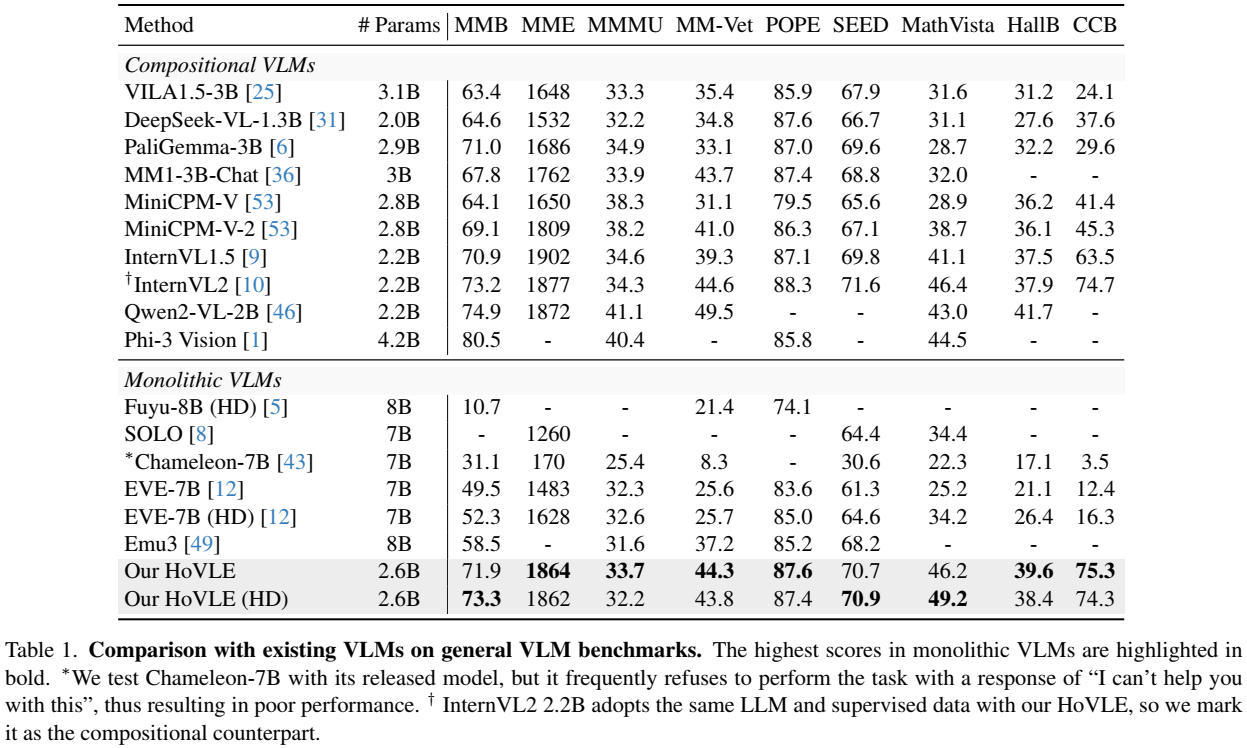
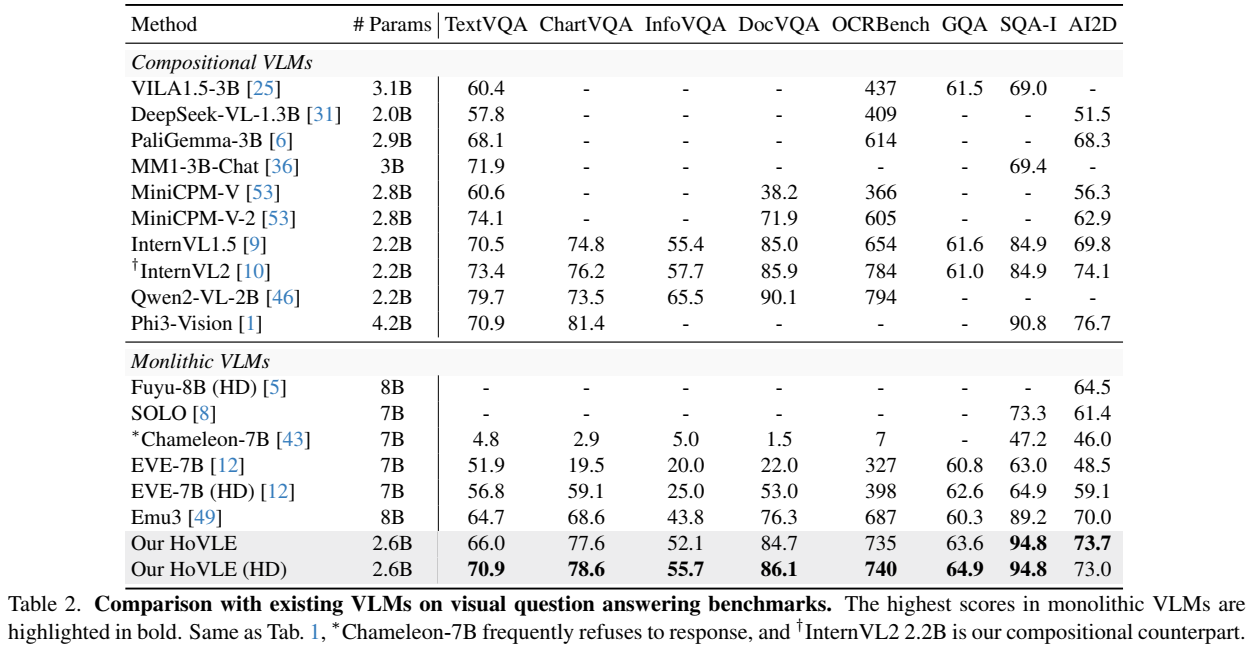
- Sources of the results include the original papers, our evaluation with VLMEvalKit, and OpenCompass.
- Please note that evaluating the same model using different testing toolkits can result in slight differences, which is normal. Updates to code versions and variations in environment and hardware can also cause minor discrepancies in results.
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
Quick Start
We provide an example code to run HoVLE inference using transformers.
Please use transformers==4.37.2 to ensure the model works normally.
Inference with Transformers
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'taochenxin/HoVLE/'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples_image.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
License
This project is released under the MIT license, while InternLM2 is licensed under the Apache-2.0 license.
Citation
If you find this project useful in your research, please consider citing:
@article{tao2024hovle,
title={HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding},
author={Tao, Chenxin and Su, Shiqian and Zhu, Xizhou and Zhang, Chenyu and Chen, Zhe and Liu, Jiawen and Wang, Wenhai and Lu, Lewei and Huang, Gao and Qiao, Yu and Dai, Jifeng},
journal={},
year={2024}
}