
File size: 7,860 Bytes
0d860ab 2e02a55 286c902 2e02a55 286c902 2e02a55 286c902 2e02a55 6c1ece3 f252fee 2e02a55 286c902 2e02a55 286c902 2e02a55 286c902 2e02a55 fb63999 2e02a55 fb63999 2e02a55 fb63999 2e02a55 fb63999 2e02a55 ac4d1f6 2e02a55 fb63999 2e02a55 fb63999 2e02a55 fb63999 2e02a55 fb63999 2e02a55 6c1ece3 2e02a55 286c902 2e02a55 6c1ece3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 |
---
tags:
- pytorch
- diffusers
- unconditional-image-generation
- image-generation
- denoising-diffusion
- stable-diffusion
license: apache-2.0
library_name: diffusers
model_name: ddpm-celebahq-256
---
# DDPM CelebAHQ 256 with Safetensors
This repository contains a **denoising diffusion probabilistic model (DDPM)** trained on the CelebA HQ dataset at a resolution of 256x256. The model is based on the original `google/ddpm-celebahq-256` implementation and has been updated to support **safetensors** for model storage.
## Model Information
- **Model Type**: `UNet2DModel`
- **Diffusion Process**: DDPM (Denoising Diffusion Probabilistic Models)
- **Training Data**: CelebA HQ dataset
- **Resolution**: 256x256
- **Format**: The model weights are available in `safetensors`.
## Features
- **Safetensors Support**: The model weights are stored in the `safetensors` format, a safer and more efficient.
- **Pretrained Model**: This model is pretrained on the CelebA HQ dataset and is designed for high-quality image generation.
- **Model Formats**: Available in safetensors formats for easy integration into your workflow.
## Example Images
Here are some sample images generated by the model at different diffusion steps:
### DDPM:
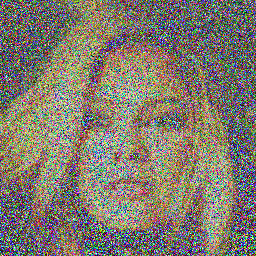



### DDIM:

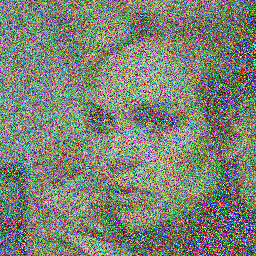



### PNDM:
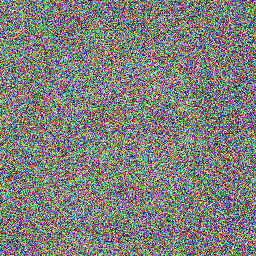
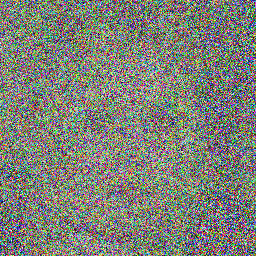
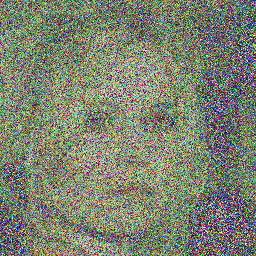



## How to Use
To use this model, you can load it using the `diffusers` library from Hugging Face. You can load the model in `safetensors` format.
### Requirements (2 ways to install)
- Install the required dependencies:
```bash
pip install torch diffusers safetensors
```
- OR install same environment as me
To recreate the same environment used for this project, you can use the provided `environment.yml` file.
1. Download the environment.yml file from [here](https://huggingface.co/Mou11209203/ddpm-celebahq-256/resolve/main/environment.yml).
2. Run the following command to create the environment:
```bash
conda env create --file environment.yml
```
3. Activate the environment:
```bash
conda activate inpaint
```
### Loading the Model
To load the model and run inference, you can use the following code:
```python
import torch
import numpy as np
import PIL.Image
from diffusers import UNet2DModel, DDPMScheduler
import tqdm
# 1. Initialize the model
# Choose a model ID, use google's with use_safetensors=False, use Mou11209203's with use_safetensors=True
repo_id = "google/ddpm-celebahq-256"
repo_id1 = "Mou11209203/ddpm-celebahq-256"
model = UNet2DModel.from_pretrained(repo_id1, use_safetensors=True)
model.to("cuda") # Move the model to GPU
print("model.config: ", model.config)
# 2. Initialize the scheduler
scheduler = DDPMScheduler.from_pretrained(repo_id1)
print("scheduler.config: ", scheduler.config)
# 3. Create an image with Gaussian noise
torch.manual_seed(1733783271) # Fix the random seed for reproducibility
noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size).to("cuda")
print(f"Noisy sample shape: {noisy_sample.shape}")
# 4. Define a function to display the image
def display_sample(sample, i):
image_processed = sample.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
print(f"Image at step {i}")
image_pil.show()
# 5. Reverse diffusion process
sample = noisy_sample
for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
# 1. Predict the noise residual
with torch.no_grad():
residual = model(sample, t).sample
# 2. Compute the less noisy image and move x_t -> x_t-1
sample = scheduler.step(residual, t, sample).prev_sample
# 3. Optionally display the image (every 50 steps)
if (i + 1) % 50 == 0:
display_sample(sample, i + 1)
print("Denoising complete.")
```
## Scheduler
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
```
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Model Storage
The following files are available for download:
- **Model Weights (Safetensors format)**: `diffusion_pytorch_model.safetensors`
- **Environment File**: `environment.yml`
- **Model Configuration**: `config.json`
- **Scheduler Configuration**: `scheduler_config.json`
- **Generated Images**: Various steps from 50 to 1000
- **README.md**: This document for usage and setup instructions
## Citation
If you use this model in your research or project, please cite the original `google/ddpm-celebahq-256` repository:
```bibtex
@misc{google/ddpm-celebahq-256,
author = {Google Research},
title = {DDPM CelebAHQ 256},
year = {2022},
url = {https://huggingface.co/google/ddpm-celebahq-256}
}
```
## License
This model is provided under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0). |