
Huozi 3.5
Collection
活字 3.5 系列
•
4 items
•
Updated
| 章节 | 说明 |
|---|---|
| 💁🏻♂ 开源清单 | 本仓库开源项目清单 |
| 💡 模型介绍 | 简要介绍活字模型结构和训练过程 |
| 📥 模型下载 | 活字模型下载链接 |
| 💻 模型推理 | 活字模型推理样例,包括vLLM、llama.cpp、Ollama等推理框架的使用流程 |
| 📈 模型性能 | 活字模型在主流评测任务上的性能 |
| 🗂 生成样例 | 活字模型实际生成效果样例 |

大规模语言模型(LLM)在自然语言处理领域取得了显著的进展,并在广泛的应用场景中展现了其强大的潜力。这一技术不仅吸引了学术界的广泛关注,也成为了工业界的热点。在此背景下,哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)近期推出了最新成果——活字3.5,致力于为自然语言处理的研究和实际应用提供更多可能性和选择。
活字3.5是在活字3.0和Chinese-Mixtral-8x7B基础上,进行进一步性能增强得到的模型。活字3.5支持32K长上下文,继承了活字3.0强大的综合能力,并在中英文知识、数学推理、代码生成、指令遵循能力、内容安全性等诸多方面实现了性能提升。
活字系列模型仍然可能生成包含事实性错误的误导性回复或包含偏见/歧视的有害内容,请谨慎鉴别和使用生成的内容,请勿将生成的有害内容传播至互联网。
活字3.5是一个稀疏混合专家模型(SMoE),每个专家层包含8个FFN,每次前向计算采用top-2稀疏激活。活字3.5共拥有46.7B参数,得益于其稀疏激活的特性,实际推理时仅需激活13B参数,有效提升了计算效率和处理速度。
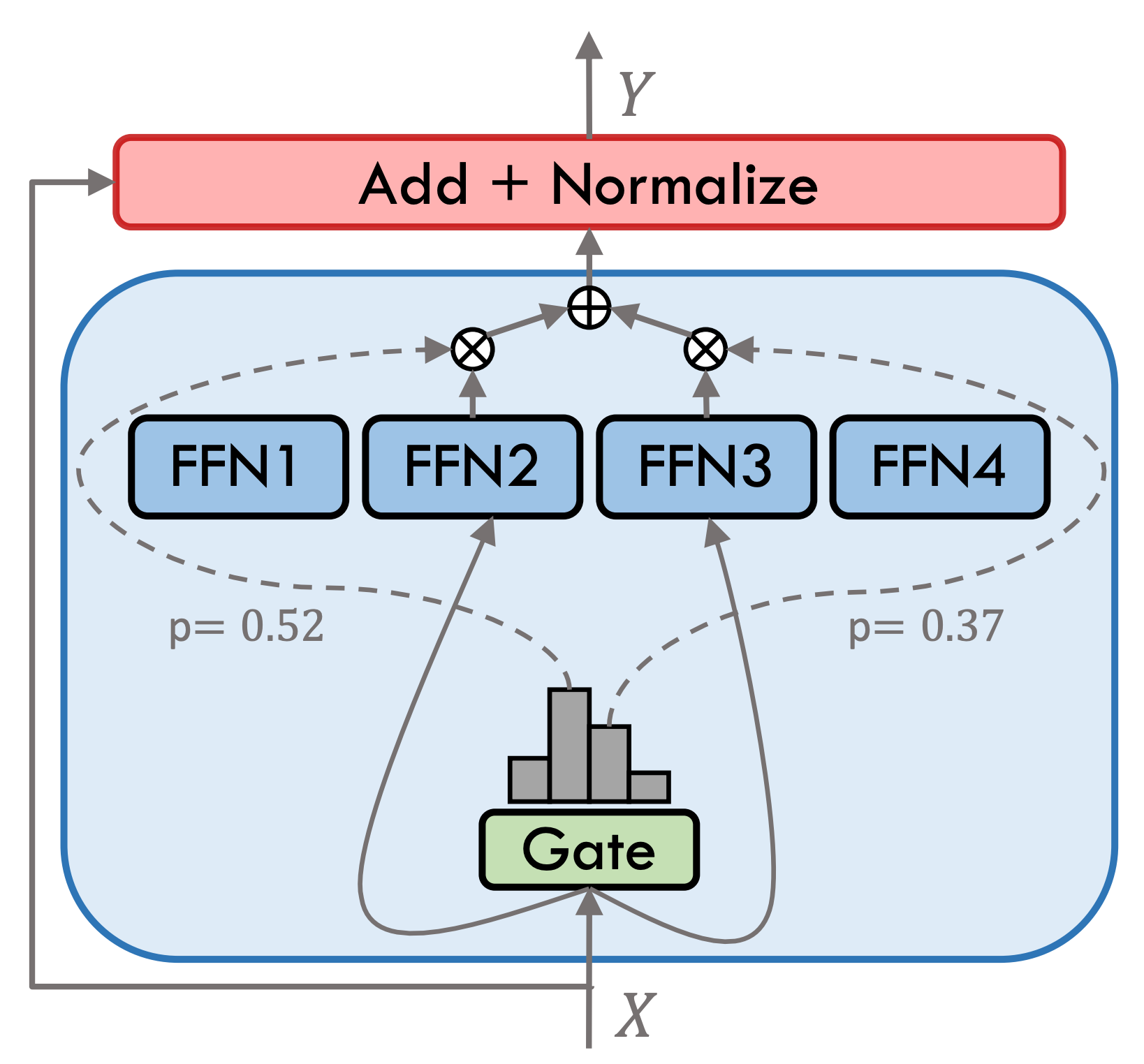
活字3.5经过了多步训练,如下图所示:

其训练过程为:
| 模型名称 | 文件大小 | 下载地址 | 备注 |
|---|---|---|---|
| huozi3.5 | 88GB | 🤗HuggingFace ModelScope |
活字3.5 完整模型 |
| huozi3.5-ckpt-1 | 88GB | 🤗HuggingFace ModelScope |
活字3.5 中间检查点 1 |
| huozi3.5-ckpt-2 | 88GB | 🤗HuggingFace ModelScope |
活字3.5 中间检查点 2 |
| huozi3.5-ckpt-3 | 88GB | 🤗HuggingFace ModelScope |
活字3.5 中间检查点 3 |
如果您希望微调活字3.5或Chinese-Mixtral-8x7B,请参考此处训练代码。
活字3.5采用ChatML格式的prompt模板,格式为:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
使用活字3.5进行推理的示例代码如下:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))
活字3.5支持全部Mixtral模型生态,包括Transformers、vLLM、llama.cpp、Ollama、Text generation web UI等框架。
如果您在下载模型时遇到网络问题,可以使用我们在ModelScope上提供的检查点。
transformers支持为tokenizer添加聊天模板,并支持流式生成。示例代码如下:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + '\n' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + '\n'}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手\n' }}{% endif %}"""
chat = [
{"role": "系统", "content": "你是一个智能助手"},
{"role": "用户", "content": "请你用python写一段快速排序的代码"},
]
inputs = tokenizer.apply_chat_template(
chat,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to(0)
stream_output = model.generate(
inputs,
streamer=TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True),
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
ModelScope的接口与Transformers非常相似,只需将transformers替换为modelscope即可:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))
活字3.5支持通过vLLM实现推理加速,示例代码如下:
# example/vllm-generate/generate.py
from vllm import LLM, SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""",
]
sampling_params = SamplingParams(
temperature=0.8, top_p=0.95, stop_token_ids=[57001], max_tokens=2048
)
llm = LLM(
model="HIT-SCIR/huozi3.5",
tensor_parallel_size=4,
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)
活字3.5可以部署为支持OpenAI API协议的服务,这使得活字3.5可以直接通过OpenAI API进行调用。
环境准备:
$ pip install vllm openai
启动服务:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048
使用OpenAI API发送请求:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="huozi",
messages=[
{"role": "系统", "content": "你是一个智能助手"},
{"role": "用户", "content": "请你用python写一段快速排序的代码"},
],
extra_body={"stop_token_ids": [57001]},
)
print("Chat response:", chat_response.choices[0].message.content)
下面是一个使用OpenAI API + Gradio + 流式生成的示例代码:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
def predict(message, history):
history_openai_format = [
{"role": "系统", "content": "你是一个智能助手"},
]
for human, assistant in history:
history_openai_format.append({"role": "用户", "content": human})
history_openai_format.append({"role": "助手", "content": assistant})
history_openai_format.append({"role": "用户", "content": message})
models = client.models.list()
stream = client.chat.completions.create(
model=models.data[0].id,
messages=history_openai_format,
temperature=0.8,
stream=True,
extra_body={"repetition_penalty": 1, "stop_token_ids": [57001]},
)
partial_message = ""
for chunk in stream:
partial_message += chunk.choices[0].delta.content or ""
yield partial_message
gr.ChatInterface(predict).queue().launch()
GGUF格式旨在快速加载和保存模型,由llama.cpp团队推出,适用于llama.cpp、Ollama等框架。您可以手动将HuggingFace格式的活字3.5转换到GGUF格式。
首先需要下载llama.cpp的源码。我们在仓库中提供了llama.cpp的submodule,这个版本的llama.cpp已经过测试,可以成功进行推理:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cpp
您也可以下载最新版本的llama.cpp源码:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cpp
然后需要进行编译。根据您的硬件平台,编译命令有细微差异:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试
以下命令需要在llama.cpp/目录下:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0
以下命令需要在llama.cpp/目录下:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix "<|beginofutterance|>用户\n" --in-suffix "<|endofutterance|>\n<|beginofutterance|>助手" -r "<|endofutterance|>"
-ngl参数表示向GPU中offload的层数,降低这个值可以缓解GPU显存压力。经过我们的实际测试,q2_k量化的模型offload 16层,显存占用可降低至9.6GB,可在消费级GPU上运行模型:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix "<|beginofutterance|>用户\n" --in-suffix "<|endofutterance|>\n<|beginofutterance|>助手" -r "<|endofutterance|>"
关于main的更多参数,可以参考llama.cpp的官方文档。
使用Ollama框架进行推理,可以参考Ollama的README说明。

针对大模型综合能力评价,我们分别使用以下评测数据集对活字3.5进行评测:
活字3.5在推理时仅激活13B参数。下表为活字3.5与其他13B规模的中文模型以及旧版活字在各个评测数据集上的结果:

我们在C-Eval、CMMLU、MMLU采用5-shot,GSM8K采用4-shot,HellaSwag、HumanEval采用0-shot,HumanEval采用pass@1指标。所有测试均采用greedy策略。
我们使用OpenCompass作为评测框架,commit hash为4c87e77。评测代码位于此处。
在活字3.0的性能评测中,我们在HumanEval错误使用了base模型的评测方法,正确的评测结果已在上表内更新。
根据上表中的测试结果,活字3.5较活字3.0取得了较稳定的性能提升,活字3.5的中英文知识、数学推理、代码生成、中文指令遵循能力、中文内容安全性等多方面能力均得到了加强。
下面是活字3.5在MT-Bench-zh评测集上的生成效果展示:






对本仓库源码的使用遵循开源许可协议 Apache 2.0。
活字支持商用。如果将活字模型或其衍生品用作商业用途,请您按照如下方式联系许可方,以进行登记并向许可方申请书面授权:联系邮箱:[email protected]。
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = {\url{https://github.com/HIT-SCIR/huozi}}
}