

DGSpitzer Art Diffusion
DGSpitzer Art Diffusion is a unique AI model that is trained to draw like my art style!
Online Demo
You can try the Online Web UI demo build with Gradio:
Hello folks! This is DGSpitzer, I'm a game developer, music composer and digital artist based in New York, you can check out my artworks/games/etc at here: Games Arts Music
I've been working on AI related stuff on my Youtube Channel since 2020 , especially for colorizing old black & white footage using a series of AI technologies.
I always portrait artificial intelligence as an assist tool for extending my creativity. Nevertheless, whatever how powerful AI will be, us humans will be the leading role during the creative process as usual, and AI will provide suggestions / generate drafts as a helper. In my opinion, there is huge potential to adapt AI into the modern-age digital artist's work pipeline, therefore I trained this AI model with my art style as an experiment to try it out! And share it with you for free!
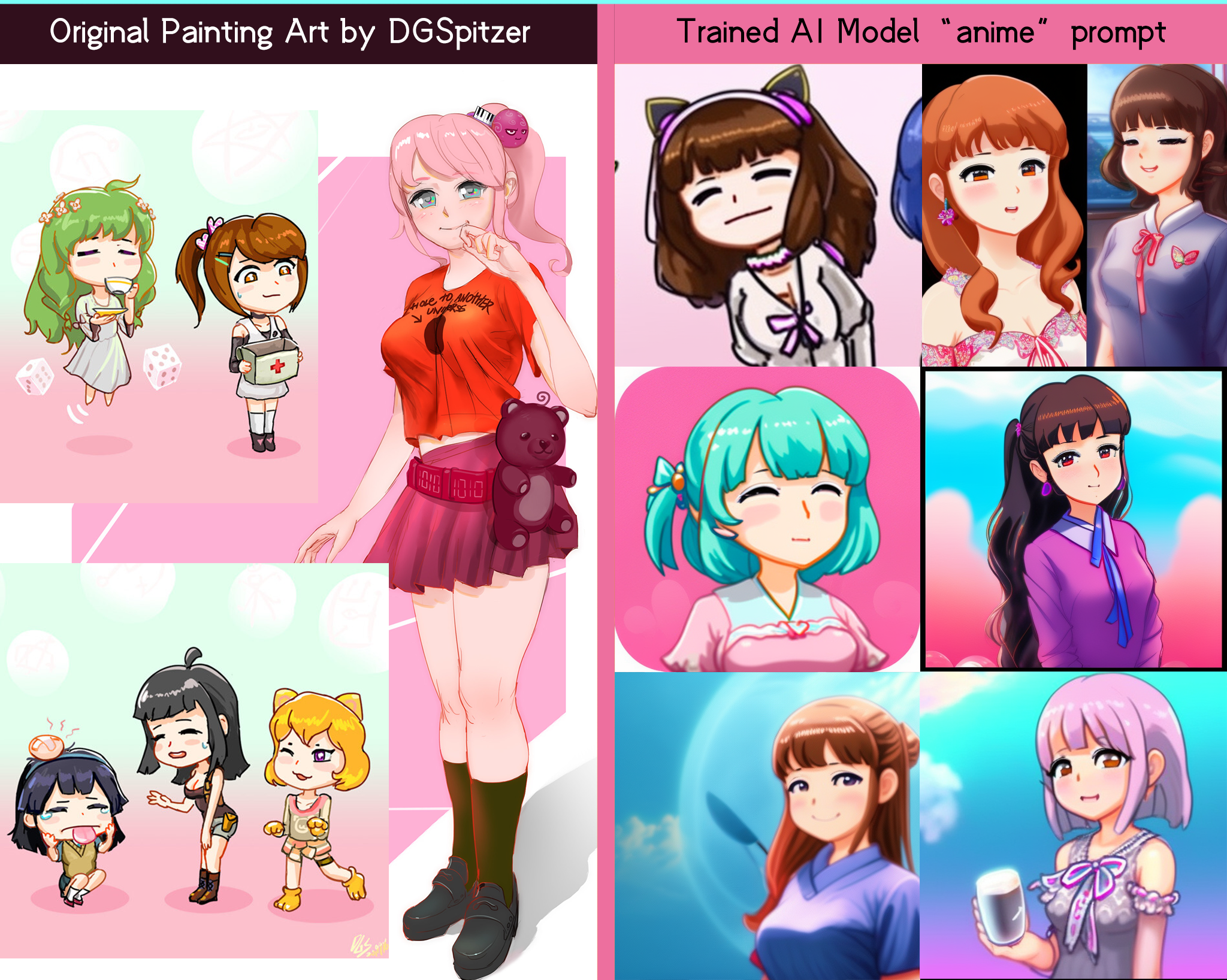
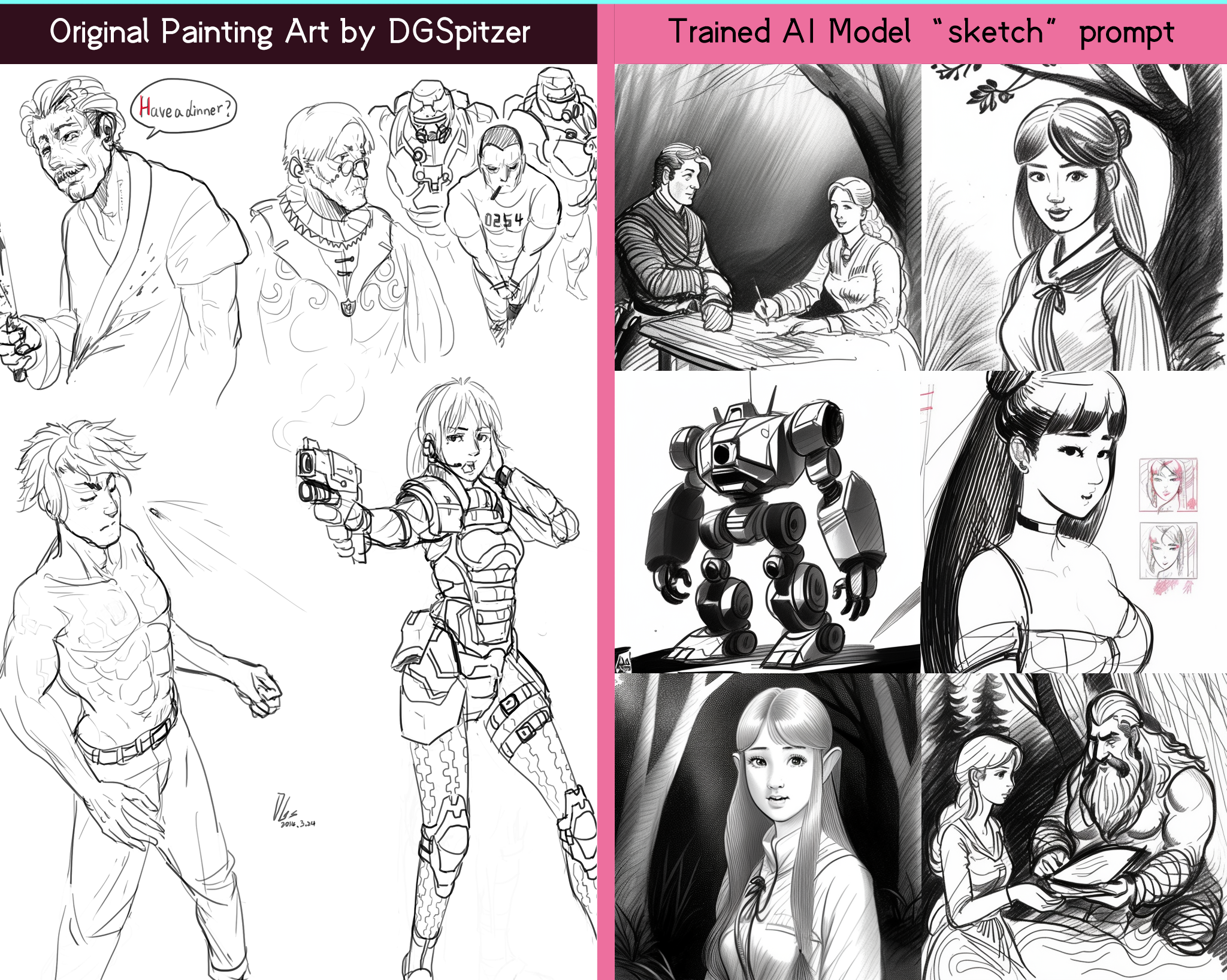
All of the datasets (as the training images for building this AI model) is from my own digital paintings & game concept arts, no other artists’ names involved. I separated my artworks into detailed categories such as “outline”, “sketch”, “anime”, “landscape”. As a result, this AI model supports multiple keywords in prompt as different styles of mine! The model is fine-tuned based on Vintedois diffusion-v0-1 Model though, but I totally overwrite the style of the vintedois diffusion model by using “arts”, “paintings” as keywords with my dataset during Dreambooth training.
You are free to use/fine-tune this model even commercially as long as you follow the CreativeML Open RAIL-M license. Additionally, you can use all my artworks as dataset in your training, giving a credit should be cool ;P
It’s welcome to share your results using this model! Looking forward to creating something truly amazing!
Buy me a coffee if you like this project ;P ♥






🧨 Diffusers
This repo contains both .ckpt and Diffuser model files. It's compatible to be used as any Stable Diffusion model, using standard Stable Diffusion Pipelines.
You can convert this model to ONNX, MPS and/or FLAX/JAX.
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "DGSpitzer/DGSpitzer-Art-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "dgspitzer painting of a beautiful mech girl, 4k, photorealistic"
image = pipe(prompt).images[0]
image.save("./dgspitzer_ai_art.png")
👇Model👇
AI Model Weights available at huggingface: https://huggingface.co/DGSpitzer/DGSpitzer-Art-Diffusion
Usage
After model loaded, there are multiple keywords supported (represent as different styles):
painting a general style from my paintings, good for portraits
outline a character painting with outline and flat color, slight anime style
landscape general landscape style
anime cute simple anime characters
whiteshape a character with stylized white color body silhouette and pure color background
sketch a sketch style from my draft paintings
arts & dgspitzer extra prompts work as painting keyword to create the general style of my paintings
For sampler, use DPM++ SDE Karras or Euler A for the best result (DDIM kinda works too), CFG Scale 7, steps 20 should be fine
Example 1:
dgspitzer painting portrait of a girl, draw photorealistic painting full body portrait of stunningly attractive female soldier working, cleavage, perfect face, dark ponytail curvy hair, intricate, 8k, highly detailed, shy, digital painting, intense, sharp focus
Example 2:
outline anime portrait of a beautiful martial art girl
Example 3 (with Stable Diffusion WebUI):
If using AUTOMATIC1111's Stable Diffusion WebUI
You can simply use this as prompt with Euler A Sampler, CFG Scale 7, steps 20, 704 x 704px output res:
an anime girl with cute face holding an apple in dessert island
And always recommend to set the negative prompt as similar to this to get much better result:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet
If the result too purple/colorful (which I draw quite a lot...), you can add this keyword in the negative prompt as well:
saturation, purple, red
NOTE: usage of this model implies accpetance of stable diffusion's CreativeML Open RAIL-M license





- Downloads last month
- 327