

license: apache-2.0
language:
- en
- zh
pipeline_tag: visual-question-answering
tags:
- multimodal
library_name: transformers

Introduction
Xinyuan-VL-2B is a high-performance multimodal large model for the end-side from the Cylingo Group, which is fine-tuned with Qwen/Qwen2-VL-2B-Instruct, and uses more than 5M of multimodal data as well as a small amount of plain text data.
It performs well on several authoritative Benchmarks.
How to use
In order to rely on the thriving ecology of the open source community, we chose to fine-tune Qwen/Qwen2-VL-2B-Instruct to form our Cylingo/Xinyuan-VL- 2B.
Thus, using Cylingo/Xinyuan-VL-2B is consistent with using Qwen/Qwen2-VL-2B-Instruct:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Cylingo/Xinyuan-VL-2B", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Cylingo/Xinyuan-VL-2B")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Evaluation
We evaluated XinYuan-VL-2B using the VLMEvalKit toolkit across the following benchmarks and found that XinYuan-VL-2B outperformed Qwen/Qwen2-VL-2B-Instruct released by Alibaba Cloud, as well as other models of comparable parameter scale that have significant influence in the open-source community.
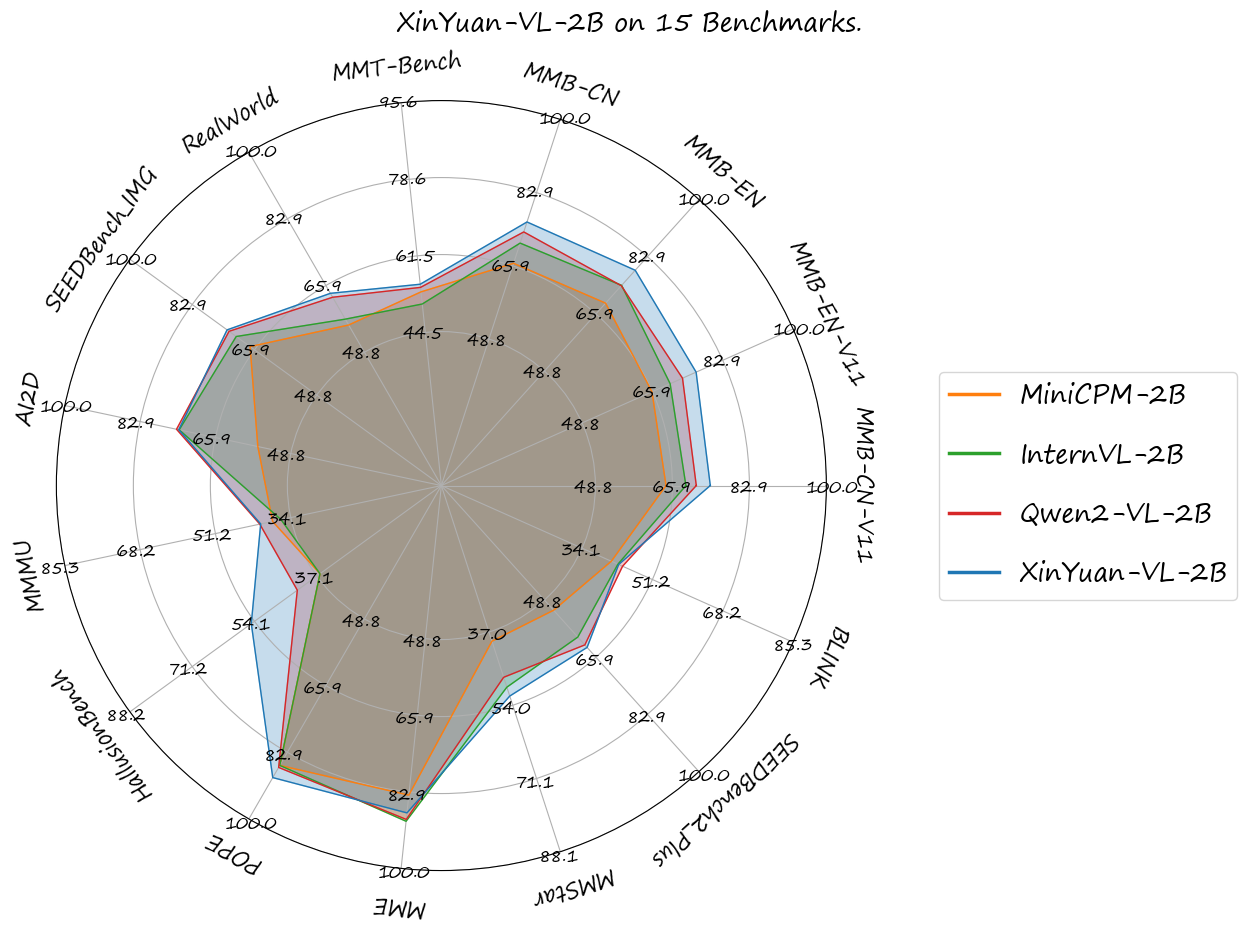
You can see the results in opencompass/open_vlm_leaderboard:
| Benchamrk | MiniCPM-2B | InternVL-2B | Qwen2-VL-2B | XinYuan-VL-2B |
|---|---|---|---|---|
| MMB-CN-V11-Test | 64.5 | 68.9 | 71.2 | 74.3 |
| MMB-EN-V11-Test | 65.8 | 70.2 | 73.2 | 76.5 |
| MMB-EN | 69.1 | 74.4 | 74.3 | 78.9 |
| MMB-CN | 66.5 | 71.2 | 73.8 | 76.12 |
| CCBench | 45.3 | 74.7 | 53.7 | 55.5 |
| MMT-Bench | 53.5 | 50.8 | 54.5 | 55.2 |
| RealWorld | 55.8 | 57.3 | 62.9 | 63.9 |
| SEEDBench_IMG | 67.1 | 70.9 | 72.86 | 73.4 |
| AI2D | 56.3 | 74.1 | 74.7 | 74.2 |
| MMMU | 38.2 | 36.3 | 41.1 | 40.9 |
| HallusionBench | 36.2 | 36.2 | 42.4 | 55.00 |
| POPE | 86.3 | 86.3 | 86.82 | 89.42 |
| MME | 1808.6 | 1876.8 | 1872.0 | 1854.9 |
| MMStar | 39.1 | 49.8 | 47.5 | 51.87 |
| SEEDBench2_Plus | 51.9 | 59.9 | 62.23 | 62.98 |
| BLINK | 41.2 | 42.8 | 43.92 | 42.98 |
| OCRBench | 605 | 781 | 794 | 782 |
| TextVQA | 74.1 | 73.4 | 79.7 | 77.6 |