
BenevolenceMessiah/Yi-Coder-9B-Chat-Instruct-TIES-Q8_0-GGUF
This model was converted to GGUF format from BenevolenceMessiah/Yi-Coder-9B-Chat-Instruct-TIES using llama.cpp via the ggml.ai's GGUF-my-repo space.
Refer to the original model card for more details on the model.
Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
brew install llama.cpp
Invoke the llama.cpp server or the CLI.
CLI:
llama-cli --hf-repo BenevolenceMessiah/Yi-Coder-9B-Chat-Instruct-TIES-Q8_0-GGUF --hf-file yi-coder-9b-chat-instruct-ties-q8_0.gguf -p "The meaning to life and the universe is"
Server:
llama-server --hf-repo BenevolenceMessiah/Yi-Coder-9B-Chat-Instruct-TIES-Q8_0-GGUF --hf-file yi-coder-9b-chat-instruct-ties-q8_0.gguf -c 2048
Note: You can also use this checkpoint directly through the usage steps listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
git clone https://github.com/ggerganov/llama.cpp
Step 2: Move into the llama.cpp folder and build it with LLAMA_CURL=1 flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
cd llama.cpp && LLAMA_CURL=1 make
Step 3: Run inference through the main binary.
./llama-cli --hf-repo BenevolenceMessiah/Yi-Coder-9B-Chat-Instruct-TIES-Q8_0-GGUF --hf-file yi-coder-9b-chat-instruct-ties-q8_0.gguf -p "The meaning to life and the universe is"
or
./llama-server --hf-repo BenevolenceMessiah/Yi-Coder-9B-Chat-Instruct-TIES-Q8_0-GGUF --hf-file yi-coder-9b-chat-instruct-ties-q8_0.gguf -c 2048
base_model: - 01-ai/Yi-Coder-9B-Chat - 01-ai/Yi-Coder-9B library_name: transformers tags: - mergekit - merge license: apache-2.0
merge
This is a merge of pre-trained language models created using mergekit.
Merge Details
Merge Method
This model was merged using the TIES merge method using 01-ai/Yi-Coder-9B as a base.
Models Merged
The following models were included in the merge:
Configuration
The following YAML configuration was used to produce this model:
models:
- model: 01-ai/Yi-Coder-9B
parameters:
density: 0.5
weight: 0.5
- model: 01-ai/Yi-Coder-9B-Chat
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: 01-ai/Yi-Coder-9B
parameters:
normalize: false
int8_mask: true
dtype: float16
🐙 GitHub •
👾 Discord •
🐤 Twitter •
💬 WeChat
📝 Paper •
💪 Tech Blog •
🙌 FAQ •
📗 Learning Hub
Intro
Yi-Coder is a series of open-source code language models that delivers state-of-the-art coding performance with fewer than 10 billion parameters.
Key features:
- Excelling in long-context understanding with a maximum context length of 128K tokens.
- Supporting 52 major programming languages:
'java', 'markdown', 'python', 'php', 'javascript', 'c++', 'c#', 'c', 'typescript', 'html', 'go', 'java_server_pages', 'dart', 'objective-c', 'kotlin', 'tex', 'swift', 'ruby', 'sql', 'rust', 'css', 'yaml', 'matlab', 'lua', 'json', 'shell', 'visual_basic', 'scala', 'rmarkdown', 'pascal', 'fortran', 'haskell', 'assembly', 'perl', 'julia', 'cmake', 'groovy', 'ocaml', 'powershell', 'elixir', 'clojure', 'makefile', 'coffeescript', 'erlang', 'lisp', 'toml', 'batchfile', 'cobol', 'dockerfile', 'r', 'prolog', 'verilog'
For model details and benchmarks, see Yi-Coder blog and Yi-Coder README.

Models
| Name | Type | Length | Download |
|---|---|---|---|
| Yi-Coder-9B-Chat | Chat | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-Coder-1.5B-Chat | Chat | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-Coder-9B | Base | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-Coder-1.5B | Base | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
Benchmarks
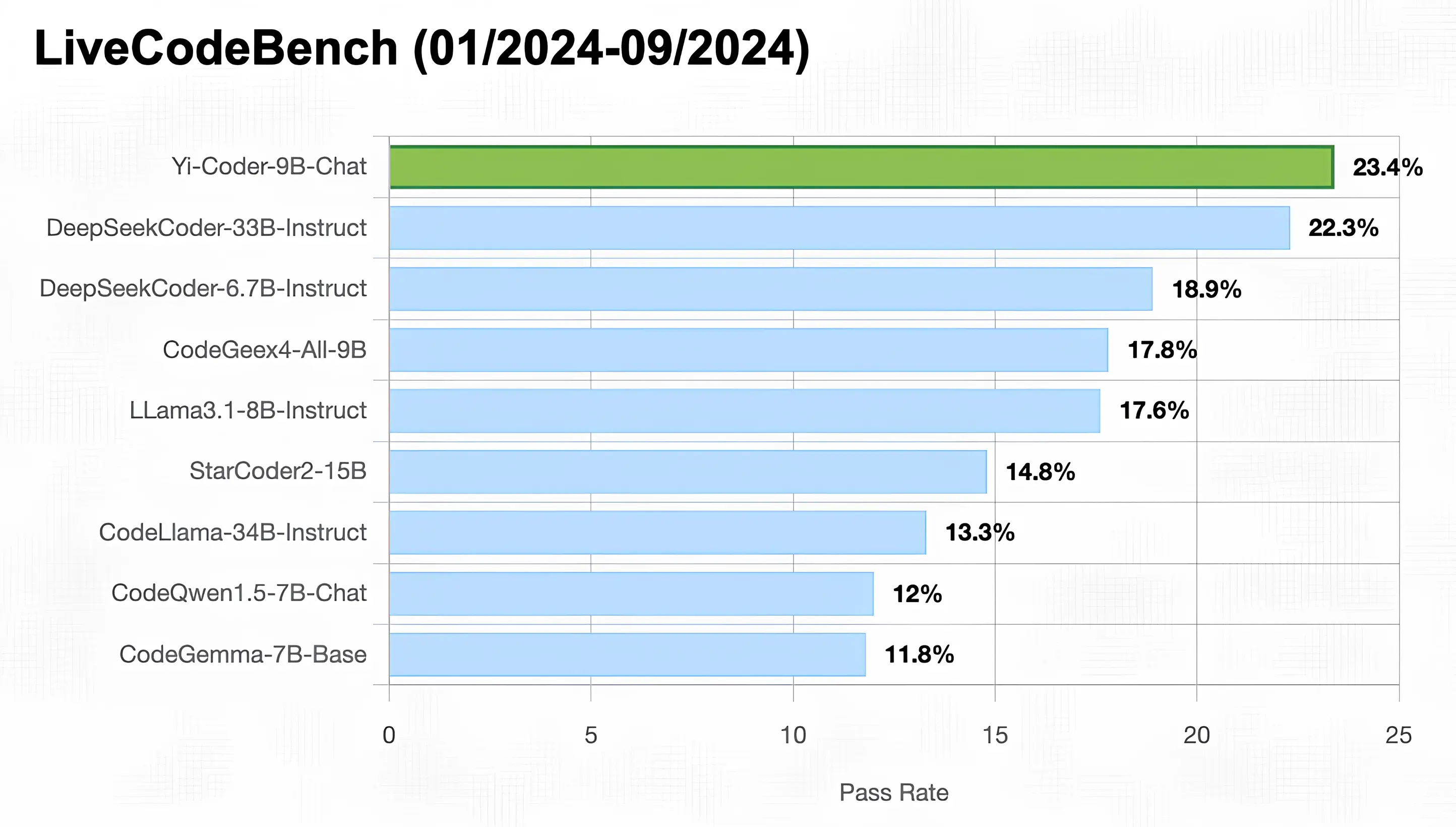
As illustrated in the figure below, Yi-Coder-9B-Chat achieved an impressive 23% pass rate in LiveCodeBench, making it the only model with under 10B parameters to surpass 20%. It also outperforms DeepSeekCoder-33B-Ins at 22.3%, CodeGeex4-9B-all at 17.8%, CodeLLama-34B-Ins at 13.3%, and CodeQwen1.5-7B-Chat at 12%.
Quick Start
You can use transformers to run inference with Yi-Coder models (both chat and base versions) as follows:
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # the device to load the model onto
model_path = "01-ai/Yi-Coder-9B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto").eval()
prompt = "Write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1024,
eos_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
For getting up and running with Yi-Coder series models quickly, see Yi-Coder README.
- Downloads last month
- 25