

Update README.md
Browse files
README.md
CHANGED
|
@@ -33,35 +33,35 @@ models were applied to improve the understanding of each sentence.
|
|
| 33 |
## According to the abstract,
|
| 34 |
|
| 35 |
"The research results serve as a successful case of artificial intelligence in a federal government application".
|
| 36 |
-
More details about the project, architecture model, training model and classifications process can be found in the article
|
| 37 |
["Using transfer learning to classify long unstructured texts with small amounts of labeled data"](https://www.scitepress.org/Link.aspx?doi=10.5220/0011527700003318).
|
| 38 |
|
| 39 |
## Model description
|
| 40 |
|
| 41 |
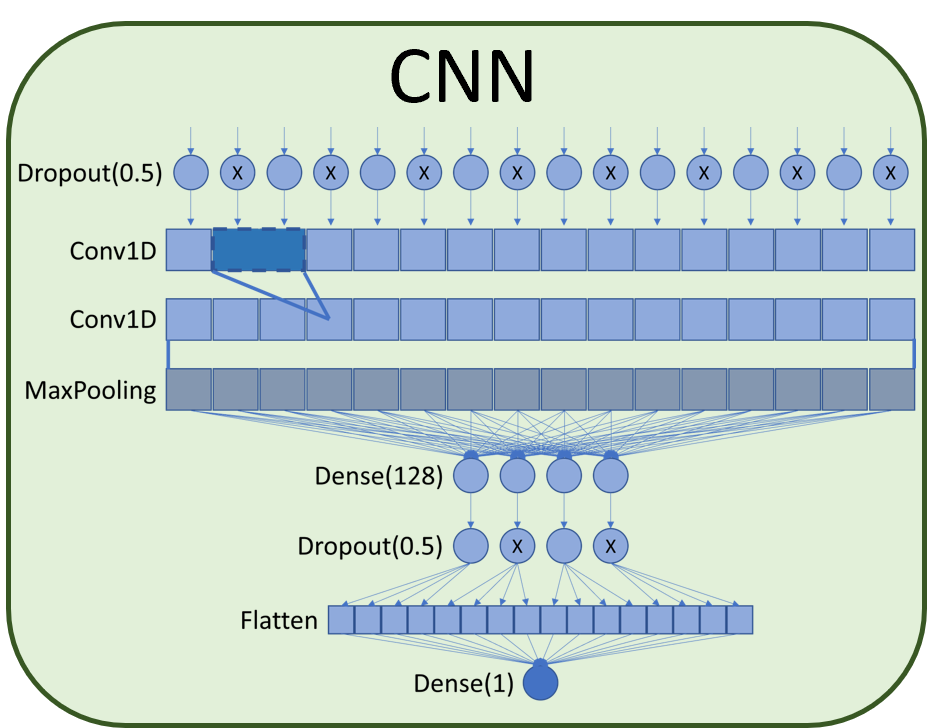
The work consists of a machine learning model with word embedding and Convolutional Neural Network (CNN).
|
| 42 |
For the project, a Convolutional Neural Network (CNN) was chosen, as it presents better accuracy in empirical
|
| 43 |
-
comparison with 3 other different architectures: Neural Network (NN), Deep Neural Network (DNN) and Long-Term
|
| 44 |
Memory (LSTM).
|
| 45 |
|
| 46 |
-
As the input data is
|
| 47 |
-
little insights and valuable relationships to work with
|
| 48 |
facilitated and allows the gradient descent to converge more quickly.
|
| 49 |
|
| 50 |
The first layer of the model is a pre-trained Word2Vec embedding layer as a method of extracting features from the data that can
|
| 51 |
replace one-hot coding with dimensional reduction. The pre-training of this model is explained further in this document.
|
| 52 |
|
| 53 |
After the embedding layer, there is the CNN classification model. The architecture of the CNN network is composed of a 50% dropout layer followed by two 1D convolution layers
|
| 54 |
-
associated with a MaxPooling layer. After maximum grouping, a dense layer of size 128 is added connected to
|
| 55 |
a 50% dropout which finally connects to a flattened layer and the final sort dense layer. The dropout layers
|
| 56 |
-
helped
|
| 57 |
-
redundancies in
|
| 58 |
|
| 59 |
|
| 60 |
|
| 61 |
## Model variations
|
| 62 |
|
| 63 |
Table 1 below presents the results of several implementations with different architectures, highlighting the
|
| 64 |
-
accuracy, f1-score, recall and precision results obtained in
|
| 65 |
|
| 66 |
Table 1: Results of experiments
|
| 67 |
| Model | Accuracy | F1-score | Recall | Precision |
|
|
@@ -79,10 +79,10 @@ Table 1: Results of experiments
|
|
| 79 |
| Longformer + CNN | 94.09 | 90.69 | 83.41 | 100.00 |
|
| 80 |
| Longformer + LSTM | 61.29 | 0 | 0 | 0 |
|
| 81 |
|
| 82 |
-
Table 2
|
| 83 |
model associated with each implementation.
|
| 84 |
|
| 85 |
-
Table 2: Results of Training time epoch, Validation time and Weight
|
| 86 |
| Model | Training time epoch(s) | Validation time (s) | Weight(MB) |
|
| 87 |
|------------------------|:-----------------------:|:-------------------:|:----------:|
|
| 88 |
| Keras Embedding + SNN | 100.00 | 0.2 | 0.7 | 1.8 |
|
|
@@ -99,15 +99,15 @@ Table 2: Results of Training time epoch, Validation time and Weight
|
|
| 99 |
| Longformer + LSTM | 0 | 13.0 | 8.6 | 2.6 |
|
| 100 |
|
| 101 |
In addition, it is possible to notice that the model of Longformer + SNN and Longformer + LSTM were not able
|
| 102 |
-
to learn. Perhaps the models need some adjustments
|
| 103 |
-
which made
|
| 104 |
|
| 105 |
-
With Longformer the problems caused by the size
|
| 106 |
actively deallocate unused chunks of memory right after use so that the next steps could be loaded. Then, it
|
| 107 |
-
was necessary to use a CPU environment for training the networks because the weight
|
| 108 |
16GB of video memory available on the P100 board, available in Colab during training. In this case, the high
|
| 109 |
-
RAM environment was used, which delivers 25GB of memory for use with the CPU, and this means a longer time
|
| 110 |
-
required for training since the GPU performs matrix operations faster
|
| 111 |
5x with 100 training epochs each.
|
| 112 |
|
| 113 |
## Intended uses
|
|
@@ -116,10 +116,10 @@ required for training since the GPU performs matrix operations faster then a CPU
|
|
| 116 |
|
| 117 |
### How to use
|
| 118 |
|
| 119 |
-
This model is available in
|
| 120 |
- [NLP MCTI Classification Multi](https://huggingface.co/spaces/unb-lamfo-nlp-mcti/NLP-W2V-CNN-Multi)
|
| 121 |
|
| 122 |
-
|
| 123 |
- [PPF-MCTI Repository](https://github.com/chap0lin/PPF-MCTI)
|
| 124 |
|
| 125 |
|
|
@@ -133,12 +133,12 @@ have little to no wrong encodings and abstract markdowns so that the preprocessi
|
|
| 133 |
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
|
| 134 |
predictions:
|
| 135 |
|
| 136 |
-
Performance limiting: Loading the longformer model in memory means needing 11Gb available only for the model
|
| 137 |
-
without considering the weight of the deep learning network. For training this means we need a 20+ Gb GPU to
|
| 138 |
perform the training. Here this was resolved using the high RAM environment of google Colab Pro and training
|
| 139 |
-
using CPU which justifies the longer training time per season.
|
| 140 |
|
| 141 |
-
Replicability limitation: Due to the simplicity of the
|
| 142 |
and it has a delicate problem for replication in production. This detail is pending further study to define
|
| 143 |
whether it is possible to use one of these models.
|
| 144 |
|
|
@@ -146,7 +146,7 @@ This bias will also affect all fine-tuned versions of this model.
|
|
| 146 |
|
| 147 |
## Training data
|
| 148 |
|
| 149 |
-
The [inputted training data](https://github.com/chap0lin/PPF-MCTI/tree/master/Datasets) was obtained from scrapping techniques
|
| 150 |
Annenberg foundation, and contained 928 labeled entries (928 rows x 21 columns). Of the data gathered, was used only
|
| 151 |
the main text content (column u). Text content averages 800 tokens in length, but with high variance, up to 5,000 tokens.
|
| 152 |
|
|
@@ -156,7 +156,7 @@ the main text content (column u). Text content averages 800 tokens in length, bu
|
|
| 156 |
|
| 157 |
After the pre-trained model of word2vec embeddings had already learned meanings relevant to the classification problem,
|
| 158 |
it was coupled to the classification model to train it with the labeled data in a supervised way. Table 6 shows the results
|
| 159 |
-
obtained with related metrics.
|
| 160 |
and 88% for the LSTM architecture.
|
| 161 |
|
| 162 |
### Preprocessing
|
|
@@ -180,7 +180,7 @@ Table 3: Python packages used
|
|
| 180 |
|--------------------------------------------------------|--------------|
|
| 181 |
| Resolve contractions and slang usage in text | [contractions](https://pypi.org/project/contractions) |
|
| 182 |
| Natural Language Processing | [nltk](https://pypi.org/project/nltk) |
|
| 183 |
-
|
|
| 184 |
| Data manipulation and analysis | [pandas](https://pypi.org/project/pandas) |
|
| 185 |
| http library | [requests](https://pypi.org/project/requests) |
|
| 186 |
| Training model | [scikit-learn](https://pypi.org/project/scikit-learn) |
|
|
@@ -211,7 +211,7 @@ evaluation of the first four bases (xp1, xp2, xp3, xp4).
|
|
| 211 |
Then, the content simplification was evaluated, from the xp4 base, considering stemming (xp5), Lemmatization (xp6),
|
| 212 |
stemming + stopwords removal (xp7), and Lemmatization + stopwords removal (xp8).
|
| 213 |
|
| 214 |
-
All eight bases were evaluated to classify the eligibility of the opportunity
|
| 215 |
neural network (SNN – Shallow Neural Network). The metrics for the eight bases were evaluated. The results are
|
| 216 |
shown in Table 5.
|
| 217 |
|
|
@@ -229,20 +229,20 @@ Table 5: Results obtained in Preprocessing
|
|
| 229 |
| xp8 | ap4 + Lemmatization + Stopwords Removal | 92,47% | 88,46% | 79,66% | 100,00% | 225,580 | 16081 | 2726 |
|
| 230 |
|
| 231 |
Even so, between these two excellent options, one can judge which one to choose. XP7: It has less training time,
|
| 232 |
-
less number of unique tokens. XP8: It has smaller maximum sizes. In this case, the criterion used for the choice
|
| 233 |
was the computational cost required to train the vector representation models (word-embedding, sentence-embeddings,
|
| 234 |
document-embedding). The training time is so close that it did not have such a large weight for the analysis.
|
| 235 |
|
| 236 |
-
As
|
| 237 |
preprocessed text in sentence format and tokens, respectively. This [database](https://github.com/mcti-sefip/mcti-sefip-ppfcd2020/blob/pre-processamento/Pre_Processamento/oportunidades_final_pre_processado.xlsx) was made
|
| 238 |
available on the project's GitHub with the inclusion of columns opo_pre (text) and opo_pre_tkn (tokenized).
|
| 239 |
|
| 240 |
### Pretraining
|
| 241 |
|
| 242 |
-
Since labeled data is scarce, word-embeddings
|
| 243 |
contain most of the words it needs to learn. The idea implemented was based on introducing better and better-trained
|
| 244 |
word embeddings in the model. For an additional dataset to be applied to improve word-embedding training, it must be
|
| 245 |
-
compatible with the dataset used to train the classifier.
|
| 246 |
over a thousand available NLP datasets, and the closest we found was the BBC News Articles dataset, which achieved
|
| 247 |
only 56% compatibility.
|
| 248 |
|
|
@@ -267,8 +267,8 @@ Table 7: Results from Pre-trained WE + ML models
|
|
| 267 |
|
| 268 |
## Evaluation results
|
| 269 |
|
| 270 |
-
The table below presents the results of accuracy, f1-score, recall and precision obtained in the training of each network.
|
| 271 |
-
In addition, the necessary times for training each epoch, the data validation execution time and the weight of the deep
|
| 272 |
learning model associated with each implementation were added.
|
| 273 |
|
| 274 |
Table 8: Results of experiments
|
|
@@ -293,7 +293,7 @@ that used the CNN network for deep learning.
|
|
| 293 |
|
| 294 |
With the motivation to increase accuracy obtained with baseline implementation, was implemented a transfer learning
|
| 295 |
strategy under the assumption that small data available for training was insufficient for adequate embedding training.
|
| 296 |
-
In this context,
|
| 297 |
|
| 298 |
- Pre-training word embeddings using similar datasets for text classification;
|
| 299 |
- Using transformers and attention mechanisms (Longformer) to create contextualized embeddings.
|
|
@@ -314,15 +314,15 @@ Above the results obtained, it is also necessary to highlight two limitations fo
|
|
| 314 |
training of networks:
|
| 315 |
|
| 316 |
|
| 317 |
-
These 10Gb of the model
|
| 318 |
to download the pre-trained network in the notebook and run the encoder-decoder with the data to create the model.
|
| 319 |
-
It is advisable to do this in a GPU environment and save the file on the drive. After that change the environment to
|
| 320 |
-
CPU to perform the training. Trying to generate the model
|
| 321 |
|
| 322 |
|
| 323 |
The best model that does not have any limitations is Word2Vec + CNN. However, we need to study the limitations to
|
| 324 |
understand whether it is possible to introduce a new model with better accuracy and indicators. These adjustments
|
| 325 |
-
will be worked on during goals 13 and 14 where the main objective will be to encapsulate the solution in the most
|
| 326 |
suitable way for use in production.
|
| 327 |
|
| 328 |
## Benchmarks
|
|
|
|
| 33 |
## According to the abstract,
|
| 34 |
|
| 35 |
"The research results serve as a successful case of artificial intelligence in a federal government application".
|
| 36 |
+
More details about the project, architecture model, training model, and classifications process can be found in the article
|
| 37 |
["Using transfer learning to classify long unstructured texts with small amounts of labeled data"](https://www.scitepress.org/Link.aspx?doi=10.5220/0011527700003318).
|
| 38 |
|
| 39 |
## Model description
|
| 40 |
|
| 41 |
The work consists of a machine learning model with word embedding and Convolutional Neural Network (CNN).
|
| 42 |
For the project, a Convolutional Neural Network (CNN) was chosen, as it presents better accuracy in empirical
|
| 43 |
+
comparison with 3 other different architectures: Neural Network (NN), Deep Neural Network (DNN), and Long-Term
|
| 44 |
Memory (LSTM).
|
| 45 |
|
| 46 |
+
As the input data is composed of unstructured and nonuniform texts, it is essential to normalize the data to study
|
| 47 |
+
little insights and valuable relationships to work with their best features. In this way, learning is
|
| 48 |
facilitated and allows the gradient descent to converge more quickly.
|
| 49 |
|
| 50 |
The first layer of the model is a pre-trained Word2Vec embedding layer as a method of extracting features from the data that can
|
| 51 |
replace one-hot coding with dimensional reduction. The pre-training of this model is explained further in this document.
|
| 52 |
|
| 53 |
After the embedding layer, there is the CNN classification model. The architecture of the CNN network is composed of a 50% dropout layer followed by two 1D convolution layers
|
| 54 |
+
associated with a MaxPooling layer. After maximum grouping, a dense layer of size 128 is added and connected to
|
| 55 |
a 50% dropout which finally connects to a flattened layer and the final sort dense layer. The dropout layers
|
| 56 |
+
helped avoid network overfitting by masking part of the data so that the network learned to create
|
| 57 |
+
redundancies in analyzing the inputs.
|
| 58 |
|
| 59 |

|
| 60 |
|
| 61 |
## Model variations
|
| 62 |
|
| 63 |
Table 1 below presents the results of several implementations with different architectures, highlighting the
|
| 64 |
+
accuracy, f1-score, recall, and precision results obtained in each network training.
|
| 65 |
|
| 66 |
Table 1: Results of experiments
|
| 67 |
| Model | Accuracy | F1-score | Recall | Precision |
|
|
|
|
| 79 |
| Longformer + CNN | 94.09 | 90.69 | 83.41 | 100.00 |
|
| 80 |
| Longformer + LSTM | 61.29 | 0 | 0 | 0 |
|
| 81 |
|
| 82 |
+
Table 2 below shows the times required for training each epoch, the data validation execution time and the weight of the deep learning
|
| 83 |
model associated with each implementation.
|
| 84 |
|
| 85 |
+
Table 2: Results of Training time epoch, Validation time, and Weight
|
| 86 |
| Model | Training time epoch(s) | Validation time (s) | Weight(MB) |
|
| 87 |
|------------------------|:-----------------------:|:-------------------:|:----------:|
|
| 88 |
| Keras Embedding + SNN | 100.00 | 0.2 | 0.7 | 1.8 |
|
|
|
|
| 99 |
| Longformer + LSTM | 0 | 13.0 | 8.6 | 2.6 |
|
| 100 |
|
| 101 |
In addition, it is possible to notice that the model of Longformer + SNN and Longformer + LSTM were not able
|
| 102 |
+
to learn. Perhaps the models need some adjustments; however, each training attempt takes between 5 and 8 hours,
|
| 103 |
+
which made an attempt to adjust unfeasible because of other models already showing promising results.
|
| 104 |
|
| 105 |
+
With Longformer, the problems caused by the size the model's size became more visible. First, it was necessary to
|
| 106 |
actively deallocate unused chunks of memory right after use so that the next steps could be loaded. Then, it
|
| 107 |
+
was necessary to use a CPU environment for training the networks because the model's weight exceeded the
|
| 108 |
16GB of video memory available on the P100 board, available in Colab during training. In this case, the high
|
| 109 |
+
RAM environment was used, which delivers 25GB of memory for use with the CPU, and this means a longer time is
|
| 110 |
+
required for training since the GPU performs matrix operations faster than the CPU. These models were trained
|
| 111 |
5x with 100 training epochs each.
|
| 112 |
|
| 113 |
## Intended uses
|
|
|
|
| 116 |
|
| 117 |
### How to use
|
| 118 |
|
| 119 |
+
This model is available in Hugging Face spaces to be applied to excel files containing scrapped opportunity data.
|
| 120 |
- [NLP MCTI Classification Multi](https://huggingface.co/spaces/unb-lamfo-nlp-mcti/NLP-W2V-CNN-Multi)
|
| 121 |
|
| 122 |
+
The training and evaluation notebooks can be found in the github repository:
|
| 123 |
- [PPF-MCTI Repository](https://github.com/chap0lin/PPF-MCTI)
|
| 124 |
|
| 125 |
|
|
|
|
| 133 |
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
|
| 134 |
predictions:
|
| 135 |
|
| 136 |
+
Performance limiting: Loading the longformer model in the memory means needing 11Gb available only for the model
|
| 137 |
+
without considering the weight of the deep learning network. For training, this means we need a 20+ Gb GPU to
|
| 138 |
perform the training. Here this was resolved using the high RAM environment of google Colab Pro and training
|
| 139 |
+
using CPU, which justifies the longer training time per season.
|
| 140 |
|
| 141 |
+
Replicability limitation: Due to the simplicity of the Keras embedding model, we are using one-hot encoding,
|
| 142 |
and it has a delicate problem for replication in production. This detail is pending further study to define
|
| 143 |
whether it is possible to use one of these models.
|
| 144 |
|
|
|
|
| 146 |
|
| 147 |
## Training data
|
| 148 |
|
| 149 |
+
The [inputted training data](https://github.com/chap0lin/PPF-MCTI/tree/master/Datasets) was obtained from scrapping techniques over 30 different platforms, e.g., The Royal Society,
|
| 150 |
Annenberg foundation, and contained 928 labeled entries (928 rows x 21 columns). Of the data gathered, was used only
|
| 151 |
the main text content (column u). Text content averages 800 tokens in length, but with high variance, up to 5,000 tokens.
|
| 152 |
|
|
|
|
| 156 |
|
| 157 |
After the pre-trained model of word2vec embeddings had already learned meanings relevant to the classification problem,
|
| 158 |
it was coupled to the classification model to train it with the labeled data in a supervised way. Table 6 shows the results
|
| 159 |
+
obtained with related metrics. This implementation reached new levels of accuracy, with 86% for CNN architecture
|
| 160 |
and 88% for the LSTM architecture.
|
| 161 |
|
| 162 |
### Preprocessing
|
|
|
|
| 180 |
|--------------------------------------------------------|--------------|
|
| 181 |
| Resolve contractions and slang usage in text | [contractions](https://pypi.org/project/contractions) |
|
| 182 |
| Natural Language Processing | [nltk](https://pypi.org/project/nltk) |
|
| 183 |
+
| Other data manipulations and calculations included in Python 3.10: io, json, math, re (regular expressions), shutil, time, unicodedata; | [numpy](https://pypi.org/project/numpy) |
|
| 184 |
| Data manipulation and analysis | [pandas](https://pypi.org/project/pandas) |
|
| 185 |
| http library | [requests](https://pypi.org/project/requests) |
|
| 186 |
| Training model | [scikit-learn](https://pypi.org/project/scikit-learn) |
|
|
|
|
| 211 |
Then, the content simplification was evaluated, from the xp4 base, considering stemming (xp5), Lemmatization (xp6),
|
| 212 |
stemming + stopwords removal (xp7), and Lemmatization + stopwords removal (xp8).
|
| 213 |
|
| 214 |
+
All eight bases were evaluated to classify the eligibility of the opportunity through the training of a shallow
|
| 215 |
neural network (SNN – Shallow Neural Network). The metrics for the eight bases were evaluated. The results are
|
| 216 |
shown in Table 5.
|
| 217 |
|
|
|
|
| 229 |
| xp8 | ap4 + Lemmatization + Stopwords Removal | 92,47% | 88,46% | 79,66% | 100,00% | 225,580 | 16081 | 2726 |
|
| 230 |
|
| 231 |
Even so, between these two excellent options, one can judge which one to choose. XP7: It has less training time,
|
| 232 |
+
and less number of unique tokens. XP8: It has smaller maximum sizes. In this case, the criterion used for the choice
|
| 233 |
was the computational cost required to train the vector representation models (word-embedding, sentence-embeddings,
|
| 234 |
document-embedding). The training time is so close that it did not have such a large weight for the analysis.
|
| 235 |
|
| 236 |
+
As the last step, a spreadsheet was generated for the model (xp8) with the fields opo_pre and opo_pre_tkn, containing the
|
| 237 |
preprocessed text in sentence format and tokens, respectively. This [database](https://github.com/mcti-sefip/mcti-sefip-ppfcd2020/blob/pre-processamento/Pre_Processamento/oportunidades_final_pre_processado.xlsx) was made
|
| 238 |
available on the project's GitHub with the inclusion of columns opo_pre (text) and opo_pre_tkn (tokenized).
|
| 239 |
|
| 240 |
### Pretraining
|
| 241 |
|
| 242 |
+
Since labeled data is scarce, word-embeddings were trained in an unsupervised manner using other datasets that
|
| 243 |
contain most of the words it needs to learn. The idea implemented was based on introducing better and better-trained
|
| 244 |
word embeddings in the model. For an additional dataset to be applied to improve word-embedding training, it must be
|
| 245 |
+
compatible with the dataset used to train the classifier. We searched for datasets from the Kaggle, a platform with
|
| 246 |
over a thousand available NLP datasets, and the closest we found was the BBC News Articles dataset, which achieved
|
| 247 |
only 56% compatibility.
|
| 248 |
|
|
|
|
| 267 |
|
| 268 |
## Evaluation results
|
| 269 |
|
| 270 |
+
The table below presents the results of accuracy, f1-score, recall, and precision obtained in the training of each network.
|
| 271 |
+
In addition, the necessary times for training each epoch, the data validation execution time, and the weight of the deep
|
| 272 |
learning model associated with each implementation were added.
|
| 273 |
|
| 274 |
Table 8: Results of experiments
|
|
|
|
| 293 |
|
| 294 |
With the motivation to increase accuracy obtained with baseline implementation, was implemented a transfer learning
|
| 295 |
strategy under the assumption that small data available for training was insufficient for adequate embedding training.
|
| 296 |
+
In this context, were considered two approaches:
|
| 297 |
|
| 298 |
- Pre-training word embeddings using similar datasets for text classification;
|
| 299 |
- Using transformers and attention mechanisms (Longformer) to create contextualized embeddings.
|
|
|
|
| 314 |
training of networks:
|
| 315 |
|
| 316 |
|
| 317 |
+
These 10Gb of the model exceeded the Github limit and did not go to the repository, so to run the system, we need
|
| 318 |
to download the pre-trained network in the notebook and run the encoder-decoder with the data to create the model.
|
| 319 |
+
It is advisable to do this in a GPU environment and save the file on the drive. After that, change the environment to
|
| 320 |
+
CPU to perform the training. Trying to generate the model unsing the CPU will take more than 3 hours of processing.
|
| 321 |
|
| 322 |
|
| 323 |
The best model that does not have any limitations is Word2Vec + CNN. However, we need to study the limitations to
|
| 324 |
understand whether it is possible to introduce a new model with better accuracy and indicators. These adjustments
|
| 325 |
+
will be worked on during goals 13 and 14, where the main objective will be to encapsulate the solution in the most
|
| 326 |
suitable way for use in production.
|
| 327 |
|
| 328 |
## Benchmarks
|