
Commit
•
df09d7f
1
Parent(s):
49bb575
Update readme
Browse files- README.md +173 -1
- readme_images/image.png +0 -0
- readme_images/unet.png +0 -0
README.md
CHANGED
|
@@ -10,4 +10,176 @@ pinned: false
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
-
# Image Segmentation Web App
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# Image Segmentation Web App
|
| 14 |
+
[](https://huggingface.co/spaces/soumyaprabhamaiti/image_segmentation_web_app)
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
This is a web app that segments the image of a pet animal into three regions - foreground (pet), background and boundary. It uses a [U-Net](https://arxiv.org/abs/1505.04597) model trained on [Oxford-IIIT Pet Dataset](https://www.robots.ox.ac.uk/~vgg/data/pets/) and is deployed using [Gradio](https://gradio.app/).
|
| 18 |
+
|
| 19 |
+
## Demo
|
| 20 |
+
|
| 21 |
+
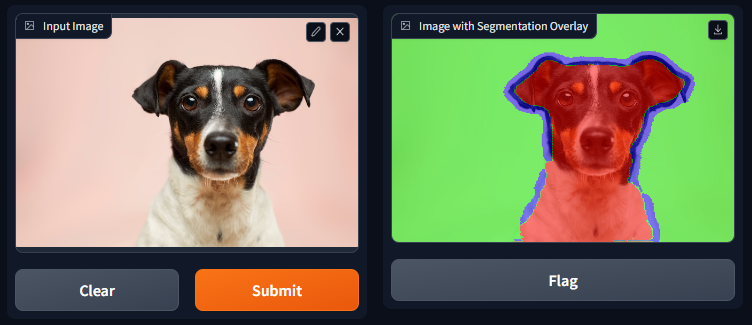
The deployed version of this project can be accessed at [Hugging Face Spaces](https://huggingface.co/spaces/soumyaprabhamaiti/image_segmentation_web_app). Segmentation on a sample image is shown below:
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
## Installing Locally
|
| 25 |
+
|
| 26 |
+
To run this project locally, please follow these steps:
|
| 27 |
+
|
| 28 |
+
1. Clone the repository:
|
| 29 |
+
|
| 30 |
+
```
|
| 31 |
+
git clone https://github.com/soumya-prabha-maiti/image-segmentation-web-app
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
2. Navigate to the project folder:
|
| 35 |
+
|
| 36 |
+
```
|
| 37 |
+
cd image-segmentation-web-app
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
3. Install the required libraries:
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
pip install -r requirements.txt
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
4. Run the application:
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
python app.py
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
5. Access the application in your web browser at the specified port.
|
| 53 |
+
|
| 54 |
+
## Dataset
|
| 55 |
+
|
| 56 |
+
The [Oxford-IIIT Pet Dataset](https://www.robots.ox.ac.uk/~vgg/data/pets/) contains 37 categories of pets with roughly 200 images for each category. The images have a large variation in scale, pose and lighting. All images have an associated ground truth annotation of breed, head ROI, and pixel level trimap segmentation. Here the dataset was obtained using [TensorFlow Datasets](https://www.tensorflow.org/datasets/catalog/oxford_iiit_pet).
|
| 57 |
+
|
| 58 |
+
## Model Architecture
|
| 59 |
+
|
| 60 |
+
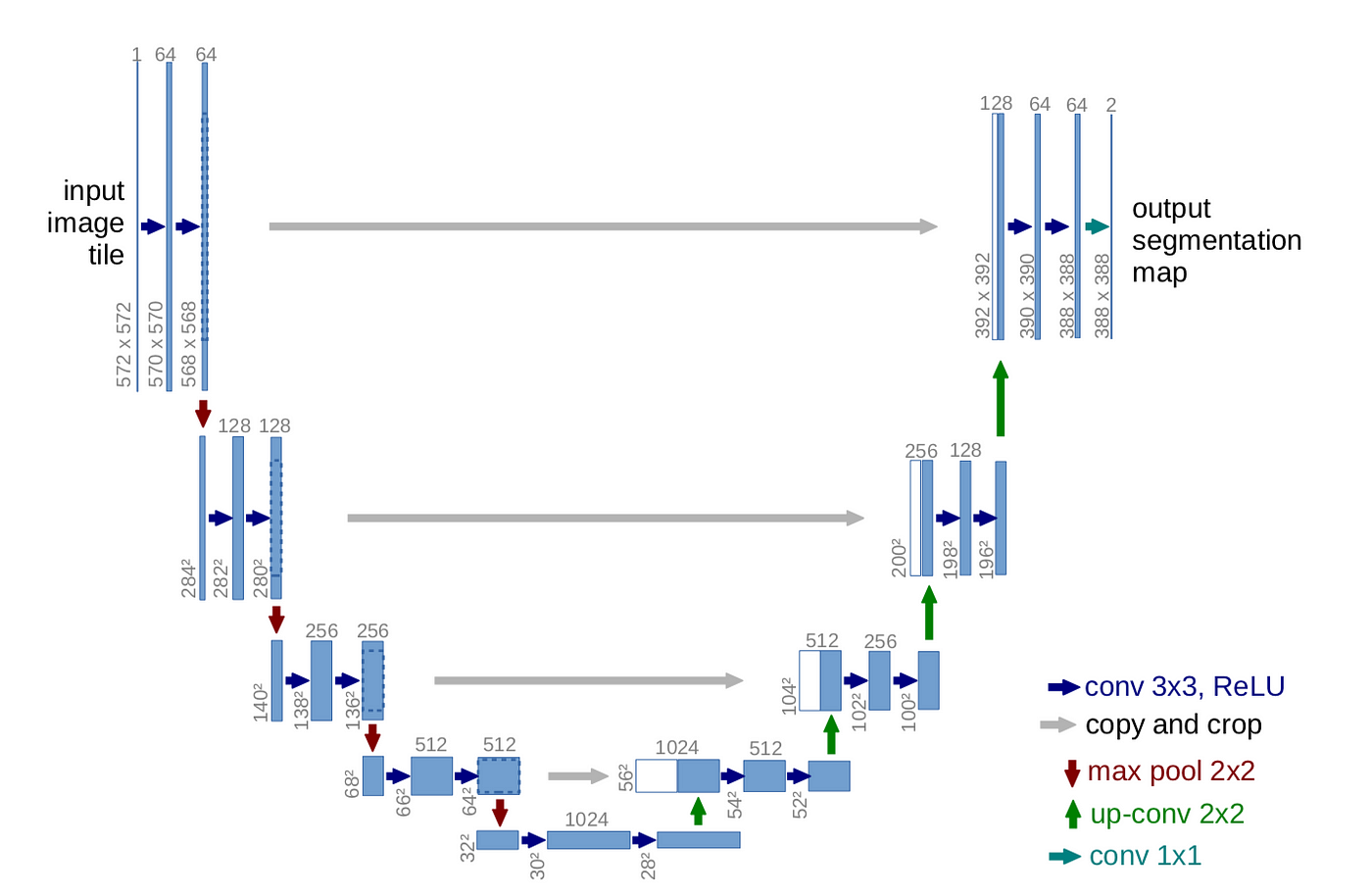
The segmentation model uses the UNET architecture. The basic architecture of the UNET model is shown below:
|
| 61 |
+

|
| 62 |
+
The UNET model consists of an encoder and a decoder. The encoder is a series of convolutional layers that extract features from the input image. The decoder is a series of transposed convolutional layers that upsample the features to the original image size. Skip connections are used to connect the encoder and decoder layers. The skip connections concatenate the feature maps from the encoder to the corresponding feature maps in the decoder. This helps the decoder to recover the spatial information lost during the encoding process.
|
| 63 |
+
|
| 64 |
+
The detailed architecture of the UNET model used in this project is shown below:
|
| 65 |
+
```
|
| 66 |
+
Model: "model"
|
| 67 |
+
__________________________________________________________________________________________________
|
| 68 |
+
Layer (type) Output Shape Param # Connected to
|
| 69 |
+
==================================================================================================
|
| 70 |
+
input_1 (InputLayer) [(None, 256, 256, 3 0 []
|
| 71 |
+
)]
|
| 72 |
+
|
| 73 |
+
conv2d (Conv2D) (None, 256, 256, 16 448 ['input_1[0][0]']
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
conv2d_1 (Conv2D) (None, 256, 256, 16 2320 ['conv2d[0][0]']
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
max_pooling2d (MaxPooling2D) (None, 128, 128, 16 0 ['conv2d_1[0][0]']
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
dropout (Dropout) (None, 128, 128, 16 0 ['max_pooling2d[0][0]']
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
conv2d_2 (Conv2D) (None, 128, 128, 32 4640 ['dropout[0][0]']
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
conv2d_3 (Conv2D) (None, 128, 128, 32 9248 ['conv2d_2[0][0]']
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
max_pooling2d_1 (MaxPooling2D) (None, 64, 64, 32) 0 ['conv2d_3[0][0]']
|
| 92 |
+
|
| 93 |
+
dropout_1 (Dropout) (None, 64, 64, 32) 0 ['max_pooling2d_1[0][0]']
|
| 94 |
+
|
| 95 |
+
conv2d_4 (Conv2D) (None, 64, 64, 64) 18496 ['dropout_1[0][0]']
|
| 96 |
+
|
| 97 |
+
conv2d_5 (Conv2D) (None, 64, 64, 64) 36928 ['conv2d_4[0][0]']
|
| 98 |
+
|
| 99 |
+
max_pooling2d_2 (MaxPooling2D) (None, 32, 32, 64) 0 ['conv2d_5[0][0]']
|
| 100 |
+
|
| 101 |
+
dropout_2 (Dropout) (None, 32, 32, 64) 0 ['max_pooling2d_2[0][0]']
|
| 102 |
+
|
| 103 |
+
conv2d_6 (Conv2D) (None, 32, 32, 128) 73856 ['dropout_2[0][0]']
|
| 104 |
+
|
| 105 |
+
conv2d_7 (Conv2D) (None, 32, 32, 128) 147584 ['conv2d_6[0][0]']
|
| 106 |
+
|
| 107 |
+
max_pooling2d_3 (MaxPooling2D) (None, 16, 16, 128) 0 ['conv2d_7[0][0]']
|
| 108 |
+
|
| 109 |
+
dropout_3 (Dropout) (None, 16, 16, 128) 0 ['max_pooling2d_3[0][0]']
|
| 110 |
+
|
| 111 |
+
conv2d_8 (Conv2D) (None, 16, 16, 256) 295168 ['dropout_3[0][0]']
|
| 112 |
+
|
| 113 |
+
conv2d_9 (Conv2D) (None, 16, 16, 256) 590080 ['conv2d_8[0][0]']
|
| 114 |
+
|
| 115 |
+
conv2d_transpose (Conv2DTransp (None, 32, 32, 128) 295040 ['conv2d_9[0][0]']
|
| 116 |
+
ose)
|
| 117 |
+
|
| 118 |
+
concatenate (Concatenate) (None, 32, 32, 256) 0 ['conv2d_transpose[0][0]',
|
| 119 |
+
'conv2d_7[0][0]']
|
| 120 |
+
|
| 121 |
+
dropout_4 (Dropout) (None, 32, 32, 256) 0 ['concatenate[0][0]']
|
| 122 |
+
|
| 123 |
+
conv2d_10 (Conv2D) (None, 32, 32, 128) 295040 ['dropout_4[0][0]']
|
| 124 |
+
|
| 125 |
+
conv2d_11 (Conv2D) (None, 32, 32, 128) 147584 ['conv2d_10[0][0]']
|
| 126 |
+
|
| 127 |
+
conv2d_transpose_1 (Conv2DTran (None, 64, 64, 64) 73792 ['conv2d_11[0][0]']
|
| 128 |
+
spose)
|
| 129 |
+
|
| 130 |
+
concatenate_1 (Concatenate) (None, 64, 64, 128) 0 ['conv2d_transpose_1[0][0]',
|
| 131 |
+
'conv2d_5[0][0]']
|
| 132 |
+
|
| 133 |
+
dropout_5 (Dropout) (None, 64, 64, 128) 0 ['concatenate_1[0][0]']
|
| 134 |
+
|
| 135 |
+
conv2d_12 (Conv2D) (None, 64, 64, 64) 73792 ['dropout_5[0][0]']
|
| 136 |
+
|
| 137 |
+
conv2d_13 (Conv2D) (None, 64, 64, 64) 36928 ['conv2d_12[0][0]']
|
| 138 |
+
|
| 139 |
+
conv2d_transpose_2 (Conv2DTran (None, 128, 128, 32 18464 ['conv2d_13[0][0]']
|
| 140 |
+
spose) )
|
| 141 |
+
|
| 142 |
+
concatenate_2 (Concatenate) (None, 128, 128, 64 0 ['conv2d_transpose_2[0][0]',
|
| 143 |
+
) 'conv2d_3[0][0]']
|
| 144 |
+
|
| 145 |
+
dropout_6 (Dropout) (None, 128, 128, 64 0 ['concatenate_2[0][0]']
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
conv2d_14 (Conv2D) (None, 128, 128, 32 18464 ['dropout_6[0][0]']
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
conv2d_15 (Conv2D) (None, 128, 128, 32 9248 ['conv2d_14[0][0]']
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
conv2d_transpose_3 (Conv2DTran (None, 256, 256, 16 4624 ['conv2d_15[0][0]']
|
| 155 |
+
spose) )
|
| 156 |
+
|
| 157 |
+
concatenate_3 (Concatenate) (None, 256, 256, 32 0 ['conv2d_transpose_3[0][0]',
|
| 158 |
+
) 'conv2d_1[0][0]']
|
| 159 |
+
|
| 160 |
+
dropout_7 (Dropout) (None, 256, 256, 32 0 ['concatenate_3[0][0]']
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
conv2d_16 (Conv2D) (None, 256, 256, 16 4624 ['dropout_7[0][0]']
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
conv2d_17 (Conv2D) (None, 256, 256, 16 2320 ['conv2d_16[0][0]']
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
conv2d_18 (Conv2D) (None, 256, 256, 3) 51 ['conv2d_17[0][0]']
|
| 170 |
+
|
| 171 |
+
==================================================================================================
|
| 172 |
+
Total params: 2,158,739
|
| 173 |
+
Trainable params: 2,158,739
|
| 174 |
+
Non-trainable params: 0
|
| 175 |
+
```
|
| 176 |
+
## Libraries Used
|
| 177 |
+
|
| 178 |
+
The following libraries were used in this project:
|
| 179 |
+
|
| 180 |
+
- TensorFlow: To build segmentation model.
|
| 181 |
+
- Gradio: To create the user interface for the segmentation app.
|
| 182 |
+
|
| 183 |
+
## License
|
| 184 |
+
|
| 185 |
+
This project is licensed under the [MIT License](LICENSE).
|
readme_images/image.png
ADDED
|
readme_images/unet.png
ADDED
|