Spaces:
Runtime error

Runtime error
Commit
•
8bcd401
1
Parent(s):
3abbcfd
Update readme
Browse files- README.md +91 -1
- readme_images/demo.jpg +0 -0
README.md
CHANGED
|
@@ -8,4 +8,94 @@ sdk_version: 3.42.0
|
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# Hate Speech Classification
|
| 14 |
+
[](https://huggingface.co/spaces/soumyaprabhamaiti/hate_speech_classifier)
|
| 15 |
+
|
| 16 |
+
This is a web app that classifies the input text as hate speech or not. The app uses a LSTM model trained on the [Hate Speech and Offensive Language dataset](https://www.kaggle.com/mrmorj/hate-speech-and-offensive-language-dataset) and [Twitter hate speech](https://www.kaggle.com/datasets/vkrahul/twitter-hate-speech) dataset.
|
| 17 |
+
|
| 18 |
+
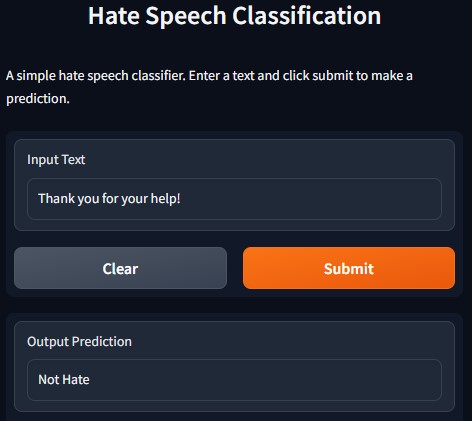
## Demo
|
| 19 |
+
The deployed version of this project can be accessed at [Hugging Face Spaces](https://huggingface.co/spaces/soumyaprabhamaiti/hate_speech_classifier). A demo of the app is shown below:
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Dataset
|
| 24 |
+
|
| 25 |
+
The dataset used in this project is a combination of the [Hate Speech and Offensive Language dataset](https://www.kaggle.com/mrmorj/hate-speech-and-offensive-language-dataset) and [Twitter hate speech](https://www.kaggle.com/datasets/vkrahul/twitter-hate-speech) dataset. The combined dataset contains 56,745 tweets belonging to 3 classes: hate speech, offensive language, and neither, among which the first two are merged to form the final hate speech class. The modified dataset thus formed is an almost balanced dataset with 2 classes - hate speech and not a hate speech. The dataset is split into 80% training and 20% validation sets.
|
| 26 |
+
|
| 27 |
+
## Model Architecture
|
| 28 |
+
|
| 29 |
+
The model used in this project is a simple LSTM model with an embedding layer, a dropout layer and a dense layer.
|
| 30 |
+
|
| 31 |
+
The detailed architecture of the model used in this project is shown below:
|
| 32 |
+
```
|
| 33 |
+
Model: "sequential"
|
| 34 |
+
_________________________________________________________________
|
| 35 |
+
Layer (type) Output Shape Param #
|
| 36 |
+
=================================================================
|
| 37 |
+
embedding (Embedding) (None, 300, 100) 5000000
|
| 38 |
+
|
| 39 |
+
spatial_dropout1d (SpatialD (None, 300, 100) 0
|
| 40 |
+
ropout1D)
|
| 41 |
+
|
| 42 |
+
lstm (LSTM) (None, 100) 80400
|
| 43 |
+
|
| 44 |
+
dense (Dense) (None, 1) 101
|
| 45 |
+
|
| 46 |
+
=================================================================
|
| 47 |
+
Total params: 5,080,501
|
| 48 |
+
Trainable params: 5,080,501
|
| 49 |
+
Non-trainable params: 0
|
| 50 |
+
_________________________________________________________________
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
<!-- ## Performance
|
| 54 |
+
|
| 55 |
+
The model was trained for 10 epochs with a batch size of 64. The training and validation accuracy and loss curves are shown below:
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+

|
| 59 |
+
|
| 60 |
+
The model achieved an accuracy of 96.5% on the validation set. -->
|
| 61 |
+
|
| 62 |
+
## Libraries Used
|
| 63 |
+
|
| 64 |
+
The following libraries were used in this project:
|
| 65 |
+
|
| 66 |
+
- TensorFlow: To build segmentation model.
|
| 67 |
+
- Gradio: To create the user interface for the segmentation app.
|
| 68 |
+
|
| 69 |
+
## Installing Locally
|
| 70 |
+
|
| 71 |
+
To run this project locally, please follow these steps:
|
| 72 |
+
|
| 73 |
+
1. Clone the repository:
|
| 74 |
+
|
| 75 |
+
```
|
| 76 |
+
git clone https://github.com/soumya-prabha-maiti/hate-speech-classification
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
2. Navigate to the project folder:
|
| 80 |
+
|
| 81 |
+
```
|
| 82 |
+
cd hate-speech-classification
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
3. Install the required libraries:
|
| 86 |
+
|
| 87 |
+
```
|
| 88 |
+
pip install -r requirements.txt
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
4. Run the application:
|
| 92 |
+
|
| 93 |
+
```
|
| 94 |
+
python app.py
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
5. Access the application in your web browser at the specified port.
|
| 98 |
+
|
| 99 |
+
## License
|
| 100 |
+
|
| 101 |
+
This project is licensed under the [MIT License](LICENSE).
|
readme_images/demo.jpg
ADDED
|