
Merge pull request #7 from seanpedrick-case/dev
Browse filesUpdated documentation with an advanced user guide detailing new features
INDEX.md
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
layout: default
|
| 3 |
+
title: Home
|
| 4 |
+
redirect_from:
|
| 5 |
+
- "/"
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
{% include_relative README.md %}
|
README.md
CHANGED
|
@@ -34,6 +34,8 @@ NOTE: The app is not 100% accurate, and it will miss some personal information.
|
|
| 34 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 35 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 36 |
|
|
|
|
|
|
|
| 37 |
## Example data files
|
| 38 |
|
| 39 |
Please refer to these example files to follow this guide:
|
|
@@ -170,3 +172,124 @@ Once you happy with your modified changes throughout the document, click 'Apply
|
|
| 170 |

|
| 171 |
|
| 172 |
Any feedback or comments on the app, please get in touch!
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 35 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 36 |
|
| 37 |
+
See the [advanced user guide here](#advanced-user-guide).
|
| 38 |
+
|
| 39 |
## Example data files
|
| 40 |
|
| 41 |
Please refer to these example files to follow this guide:
|
|
|
|
| 172 |

|
| 173 |
|
| 174 |
Any feedback or comments on the app, please get in touch!
|
| 175 |
+
|
| 176 |
+
# ADVANCED USER GUIDE
|
| 177 |
+
|
| 178 |
+
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
| 179 |
+
|
| 180 |
+
## Table of contents
|
| 181 |
+
|
| 182 |
+
- [Modifying and merging redaction review files](#modifying-and-merging-redaction-review-files)
|
| 183 |
+
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 184 |
+
- [Merging existing redaction review files](#merging-existing-redaction-review-files)
|
| 185 |
+
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 186 |
+
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 187 |
+
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 188 |
+
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 189 |
+
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
## Modifying and merging redaction review files
|
| 193 |
+
|
| 194 |
+
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 195 |
+
|
| 196 |
+
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
| 197 |
+
|
| 198 |
+
### Modifying existing redaction review files
|
| 199 |
+
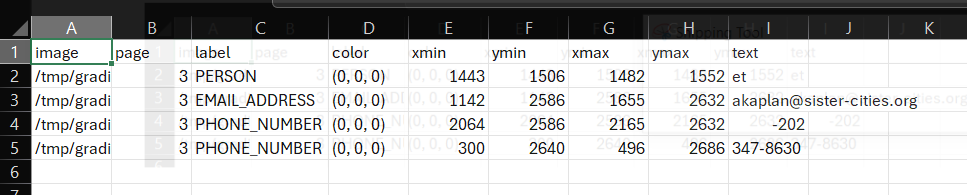
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local.csv)', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use 'Finad & Select' -> 'Replace' from the top ribbon menu if you wanted to change a number of labels simultaneously.
|
| 204 |
+
|
| 205 |
+
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. [You can find suitable colours here](https://rgbcolorpicker.com). Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
|
| 206 |
+
|
| 207 |
+
Imagine that a redaction box was slightly too small, and I didn't want to use the in-app options to change the size. In the review file csv, we can modify e.g. the ymin and ymax values for any box to increase the extent of the redaction box. For the 'email address' entry, let's decrease ymin by 5, and increase ymax by 5.
|
| 208 |
+
|
| 209 |
+
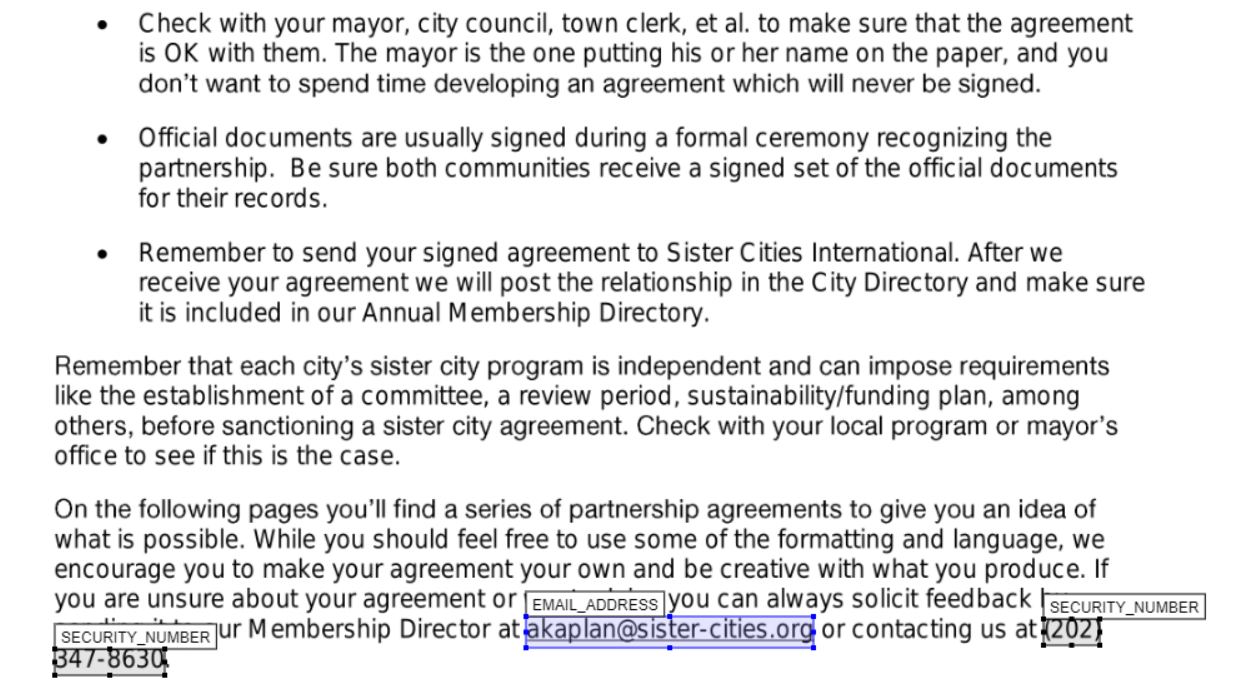
I have saved an output file following the above steps as '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local_mod.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/outputs/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local_mod.csv)' in the same folder that the original was found. Let's upload this file to the app along with the original pdf to see how the redactions look now.
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.
|
| 214 |
+
|
| 215 |
+
### Merging existing redaction review files
|
| 216 |
+
|
| 217 |
+
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.
|
| 218 |
+
|
| 219 |
+

|
| 220 |
+
|
| 221 |
+
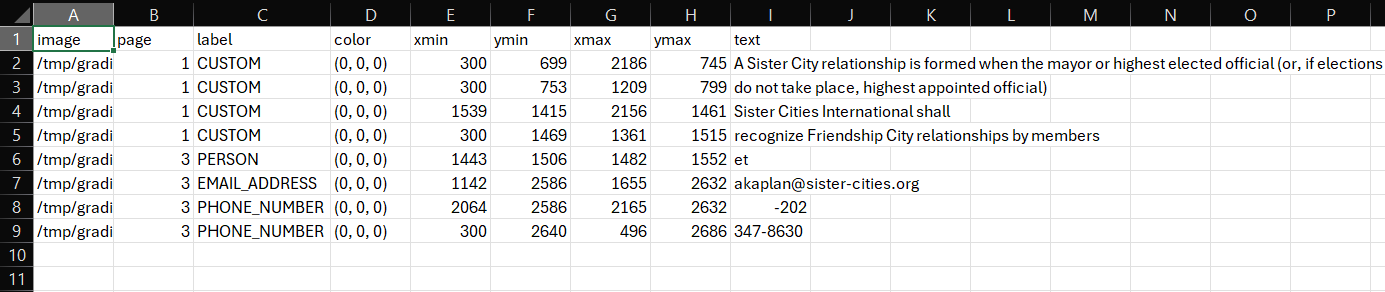
You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
## Identifying and redacting duplicate pages
|
| 226 |
+
|
| 227 |
+
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 228 |
+
|
| 229 |
+
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature calculates the similarity of text in all pages of input PDFs, calculates a similarity score, and then flags pages above a certain similarity score (90%) for removal by creating a 'whole page' redaction list file for each input PDF.
|
| 230 |
+
|
| 231 |
+

|
| 232 |
+
|
| 233 |
+
The similarity calculation is based on using the 'ocr_outputs.csv' file that is output every time that you perform a redaction task. From the file folder, upload the four 'ocr_output.csv' files provided in the example folder into the file area. Click 'Identify duplicate pages' and you will see a number of files returned. In case you want to see the original PDFs, they are available [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/input_pdfs/).
|
| 234 |
+
|
| 235 |
+

|
| 236 |
+
|
| 237 |
+
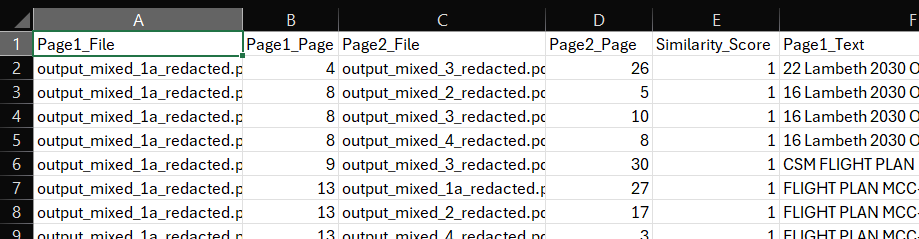
First, there is a 'combined_ocr_result...' file that just merges together all the text from the input files. 'page_similarity_results.csv' shows a breakdown of the pages from each file that are most similar to each other above the threshold (90% similarity). You can compare the text in the two columns 'Page_1_Text' and 'Page_2_Text'.
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
The remaining output files are suffixed with '_whole_page.csv'. These are the same files that can be used to redact whole pages as described in the ['Full page redaction list example' section](#full-page-redaction-list-example). For each PDF involved in the duplicate detection process, you can upload the relevant '_whole_page.csv' file into the relevant area, then do a new redaction task for the PDF file without any entity types selected. This way, only the suggested whole pages will be suggested for redaction and nothing else.
|
| 242 |
+
|
| 243 |
+

|
| 244 |
+
|
| 245 |
+
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 246 |
+
|
| 247 |
+
## Fuzzy search and redaction
|
| 248 |
+
|
| 249 |
+
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/).
|
| 250 |
+
|
| 251 |
+
Sometimes you may be searching for terns that are slightly mispelled throughout a document, for example names. The document redaction app gives the option for searching for long phrases that may contain spelling mistakes, a method called 'fuzzy matching'.
|
| 252 |
+
|
| 253 |
+
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
|
| 254 |
+
|
| 255 |
+
The other option we can leave as is (should fuzzy search match on entire phrases in deny list) - this option would allow you to fuzzy search on each individual word in the search phrase (apart from stop words).
|
| 256 |
+
|
| 257 |
+
Next, we can upload a deny list on the same page to do the fuzzy search. A relevant deny list file can be found [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/Partnership-Agreement-Toolkit_test_deny_list_para_single_spell.csv) - you can upload it following [these steps](#deny-list-example). You will notice that the suggested deny list has spelling mistakes compared to phrases found in the example document.
|
| 258 |
+
|
| 259 |
+

|
| 260 |
+
|
| 261 |
+
Upload the [Partnership-Agreement-Toolkit file](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf) into the 'Redact document' area on the first tab. Now, press the 'Redact document' button.
|
| 262 |
+
|
| 263 |
+
Using these deny list with spelling mistakes, the app fuzzy match these terms to the correct text in the document. After redaction is complete, go to the Review Redactions tab to check the first tabs. You should see that the phrases in the deny list have been successfully matched.
|
| 264 |
+
|
| 265 |
+

|
| 266 |
+
|
| 267 |
+
## Export to and import from Adobe
|
| 268 |
+
|
| 269 |
+
Files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/export_to_adobe/).
|
| 270 |
+
|
| 271 |
+
### Exporting to Adobe Acrobat
|
| 272 |
+
|
| 273 |
+
The Document Redaction app has a feature to export suggested redactions to Adobe, and likewise to import Adobe comment files into the app. The file format used is the .xfdf Adobe comment file format - [you can find more information about how to use these files here](https://helpx.adobe.com/uk/acrobat/using/importing-exporting-comments.html).
|
| 274 |
+
|
| 275 |
+
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.
|
| 276 |
+
|
| 277 |
+

|
| 278 |
+
|
| 279 |
+
Then, you can find the export to Adobe option at the bottom of the Review redactions tab. Adobe comment files will be output here.
|
| 280 |
+
|
| 281 |
+

|
| 282 |
+
|
| 283 |
+
Once the input files are ready, you can click on the 'Convert review file to Adobe comment format'. You should see a file appear in the output box with a '.xfdf' file type. To use this in Adobe, after download to your computer, you should be able to double click on it, and a pop-up box will appear asking you to find the PDF file associated with it. Find the original PDF file used for your redaction task. The file should be opened up in Adobe Acrobat with the suggested redactions.
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
### Importing from Adobe Acrobat
|
| 288 |
+
|
| 289 |
+
The app also allows you to import .xfdf files from Adobe Acrobat. To do this, go to the same Adobe import/export area as described above at the bottom of the Review Redactions tab. In this box, you need to upload a .xfdf Adobe comment file, along with the relevant original PDF for redaction.
|
| 290 |
+
|
| 291 |
+

|
| 292 |
+
|
| 293 |
+
When you click the 'convert .xfdf comment file to review_file.csv' button, the app should take you up to the top of the screen where the new review file has been created and can be downloaded.
|
| 294 |
+
|
| 295 |
+

|
app.py
CHANGED
|
@@ -329,7 +329,7 @@ with app:
|
|
| 329 |
|
| 330 |
with gr.Row():
|
| 331 |
max_fuzzy_spelling_mistakes_num = gr.Number(label="Maximum number of spelling mistakes allowed for fuzzy matching (CUSTOM_FUZZY entity).", value=1, minimum=0, maximum=9, precision=0)
|
| 332 |
-
match_fuzzy_whole_phrase_bool = gr.Checkbox(label="Should fuzzy match on entire phrases in deny list (as opposed to each word individually)?", value=True)
|
| 333 |
|
| 334 |
with gr.Accordion("Redact only selected pages", open = False):
|
| 335 |
with gr.Row():
|
|
|
|
| 329 |
|
| 330 |
with gr.Row():
|
| 331 |
max_fuzzy_spelling_mistakes_num = gr.Number(label="Maximum number of spelling mistakes allowed for fuzzy matching (CUSTOM_FUZZY entity).", value=1, minimum=0, maximum=9, precision=0)
|
| 332 |
+
match_fuzzy_whole_phrase_bool = gr.Checkbox(label="Should fuzzy search match on entire phrases in deny list (as opposed to each word individually)?", value=True)
|
| 333 |
|
| 334 |
with gr.Accordion("Redact only selected pages", open = False):
|
| 335 |
with gr.Row():
|