
Commit
·
1b13393
1
Parent(s):
b1b0e04
Update app layout, user guide, and Gradio upgrade.
Browse files- Dockerfile_old +0 -82
- README.md +107 -28
- app.py +30 -35
- requirements.txt +1 -1
Dockerfile_old
DELETED
|
@@ -1,82 +0,0 @@
|
|
| 1 |
-
# Define custom function directory as root
|
| 2 |
-
ARG FUNCTION_DIR=""
|
| 3 |
-
|
| 4 |
-
# Stage 1: Build dependencies and download models
|
| 5 |
-
FROM public.ecr.aws/docker/library/python:3.11.9-slim-bookworm AS builder
|
| 6 |
-
|
| 7 |
-
# Install system dependencies. Need to specify -y for poppler to get it to install
|
| 8 |
-
RUN apt-get update \
|
| 9 |
-
&& apt-get clean \
|
| 10 |
-
&& g++ \
|
| 11 |
-
&& make \
|
| 12 |
-
&& cmake \
|
| 13 |
-
&& unzip \
|
| 14 |
-
&& libcurl4-openssl-dev \
|
| 15 |
-
&& rm -rf /var/lib/apt/lists/*
|
| 16 |
-
|
| 17 |
-
WORKDIR /src
|
| 18 |
-
|
| 19 |
-
COPY requirements.txt .
|
| 20 |
-
|
| 21 |
-
RUN pip install --no-cache-dir --target=/install -r requirements.txt
|
| 22 |
-
|
| 23 |
-
RUN rm requirements.txt
|
| 24 |
-
|
| 25 |
-
# Add lambda_entrypoint.py to the container
|
| 26 |
-
COPY lambda_entrypoint.py .
|
| 27 |
-
|
| 28 |
-
# Stage 2: Final runtime image
|
| 29 |
-
FROM public.ecr.aws/docker/library/python:3.11.9-slim-bookworm
|
| 30 |
-
|
| 31 |
-
# Install Lambda web adapter in case you want to run with with an AWS Lamba function URL (not essential if not using Lambda)
|
| 32 |
-
COPY --from=public.ecr.aws/awsguru/aws-lambda-adapter:0.8.4 /lambda-adapter /opt/extensions/lambda-adapter
|
| 33 |
-
|
| 34 |
-
# Install system dependencies. Need to specify -y for poppler to get it to install
|
| 35 |
-
RUN apt-get update \
|
| 36 |
-
&& apt-get install -y \
|
| 37 |
-
tesseract-ocr \
|
| 38 |
-
poppler-utils \
|
| 39 |
-
libgl1-mesa-glx \
|
| 40 |
-
libglib2.0-0 \
|
| 41 |
-
&& apt-get clean \
|
| 42 |
-
&& rm -rf /var/lib/apt/lists/*
|
| 43 |
-
|
| 44 |
-
# Set up a new user named "user" with user ID 1000
|
| 45 |
-
RUN useradd -m -u 1000 user
|
| 46 |
-
|
| 47 |
-
# Make output folder
|
| 48 |
-
RUN mkdir -p /home/user/app/output \
|
| 49 |
-
&& mkdir -p /home/user/app/tld \
|
| 50 |
-
&& mkdir -p /home/user/app/logs \
|
| 51 |
-
&& chown -R user:user /home/user/app
|
| 52 |
-
|
| 53 |
-
# Copy installed packages from builder stage
|
| 54 |
-
COPY --from=builder /install /usr/local/lib/python3.11/site-packages/
|
| 55 |
-
|
| 56 |
-
# Switch to the "user" user
|
| 57 |
-
USER user
|
| 58 |
-
|
| 59 |
-
# Set environmental variables
|
| 60 |
-
ENV HOME=/home/user \
|
| 61 |
-
PATH=/home/user/.local/bin:$PATH \
|
| 62 |
-
PYTHONPATH=/home/user/app \
|
| 63 |
-
PYTHONUNBUFFERED=1 \
|
| 64 |
-
PYTHONDONTWRITEBYTECODE=1 \
|
| 65 |
-
GRADIO_ALLOW_FLAGGING=never \
|
| 66 |
-
GRADIO_NUM_PORTS=1 \
|
| 67 |
-
GRADIO_SERVER_NAME=0.0.0.0 \
|
| 68 |
-
GRADIO_SERVER_PORT=7860 \
|
| 69 |
-
GRADIO_THEME=huggingface \
|
| 70 |
-
TLDEXTRACT_CACHE=$HOME/app/tld/.tld_set_snapshot \
|
| 71 |
-
SYSTEM=spaces
|
| 72 |
-
|
| 73 |
-
# Set the working directory to the user's home directory
|
| 74 |
-
WORKDIR $HOME/app
|
| 75 |
-
|
| 76 |
-
# Copy the current directory contents into the container at $HOME/app setting the owner to the user
|
| 77 |
-
COPY --chown=user . $HOME/app
|
| 78 |
-
|
| 79 |
-
# Keep the default entrypoint as flexible
|
| 80 |
-
ENTRYPOINT ["python", "-u", "lambda_entrypoint.py"]
|
| 81 |
-
|
| 82 |
-
#CMD ["python", "app.py"]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
README.md
CHANGED
|
@@ -8,68 +8,146 @@ app_file: app.py
|
|
| 8 |
pinned: false
|
| 9 |
license: agpl-3.0
|
| 10 |
---
|
| 11 |
-
|
| 12 |
# Document redaction
|
| 13 |
|
| 14 |
-
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet).
|
| 15 |
|
| 16 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
-
NOTE:
|
| 19 |
|
| 20 |
# USER GUIDE
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
Please refer to these example files to follow this guide:
|
| 23 |
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 24 |
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 25 |
-
- [Partnership Agreement Toolkit (for signatures)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
|
|
|
|
|
|
| 26 |
|
| 27 |
-
|
| 28 |
|
| 29 |
-
Download the
|
| 30 |
|
| 31 |
|
| 32 |
|
| 33 |
Click on the upload files area, and select the three different files (they should all be stored in the same folder if you want them to be redacted at the same time).
|
| 34 |
|
| 35 |
-
|
| 36 |
-
- '
|
| 37 |
-
- '
|
| 38 |
-
- '
|
|
|
|
|
|
|
|
|
|
|
|
|
| 39 |
|
| 40 |
-
Hit 'Redact document
|
| 41 |
|
| 42 |

|
| 43 |
|
| 44 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |

|
| 47 |
|
| 48 |
-
|
|
|
|
|
|
|
| 49 |
|
| 50 |
-
|
| 51 |
|
| 52 |
-
|
| 53 |
|
| 54 |
-
|
| 55 |
|
| 56 |
-
|
| 57 |
|
| 58 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
|
| 60 |
-
|
| 61 |
|
| 62 |
-
|
| 63 |
|
| 64 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
|
| 66 |
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
|
| 67 |
|
| 68 |
|
| 69 |
|
| 70 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
|
| 72 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
|
| 74 |
On this tab you have a visual interface that allows you to inspect and modify redactions suggested by the app.
|
| 75 |
|
|
@@ -83,13 +161,14 @@ To change to 'add new redactions' mode, scroll to the bottom of the page. Click
|
|
| 83 |
|
| 84 |
|
| 85 |
|
| 86 |
-
|
| 87 |
|
| 88 |
-
 for a walkthrough on how to use the app. Below is a very brief overview.
|
| 14 |
|
| 15 |
+
To identify text in documents, the 'local' text/OCR image analysis uses spacy/tesseract, and works ok for documents with typed text. If available, choose 'AWS Textract service' to redact more complex elements e.g. signatures or handwriting.
|
| 16 |
+
|
| 17 |
+
Then, choose a method for PII identification. 'Local' is quick and gives good results if you are primarily looking for a custom list of terms to redact (see Redaction settings). If available, AWS Comprehend gives better results at a small cost.
|
| 18 |
+
|
| 19 |
+
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...redaction_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
|
| 20 |
|
| 21 |
+
NOTE: The app is not 100% accurate, and it will miss some personal information. It is essential that all outputs are reviewed **by a human** before using the final outputs.
|
| 22 |
|
| 23 |
# USER GUIDE
|
| 24 |
|
| 25 |
+
## Table of contents
|
| 26 |
+
|
| 27 |
+
- [Example data files](#example-data-files)
|
| 28 |
+
- [Basic redaction](#basic-redaction)
|
| 29 |
+
- [Customising redaction options](#customising-redaction-options)
|
| 30 |
+
- [Custom allow, deny, and page redaction lists](#custom-allow-deny-and-page-redaction-lists)
|
| 31 |
+
- [Allow list example](#allow-list-example)
|
| 32 |
+
- [Deny list example](#deny-list-example)
|
| 33 |
+
- [Full page redaction list example](#full-page-redaction-list-example)
|
| 34 |
+
- [Redacting additional types of personal information](#redacting-additional-types-of-personal-information)
|
| 35 |
+
- [Redacting only specific pages](#redacting-only-specific-pages)
|
| 36 |
+
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 37 |
+
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 38 |
+
|
| 39 |
+
## Example data files
|
| 40 |
+
|
| 41 |
Please refer to these example files to follow this guide:
|
| 42 |
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 43 |
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 44 |
+
- [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
| 45 |
+
|
| 46 |
+
## Basic redaction
|
| 47 |
|
| 48 |
+
The document redaction app can detect personally-identifiable information (PII) in documents. Documents can be redacted directly, or suggested redactions can be reviewed and modified using a grapical user interface.
|
| 49 |
|
| 50 |
+
Download the example PDFs above to your computer. Open up the redaction app at [Hugging Face](https://huggingface.co/spaces/seanpedrickcase/document_redaction) to use the public version (not for use with private documents), or the link provided by email if using with secure documents. Note that the AWS service functions will not be visible in the public Hugging Face version of the app.
|
| 51 |
|
| 52 |

|
| 53 |
|
| 54 |
Click on the upload files area, and select the three different files (they should all be stored in the same folder if you want them to be redacted at the same time).
|
| 55 |
|
| 56 |
+
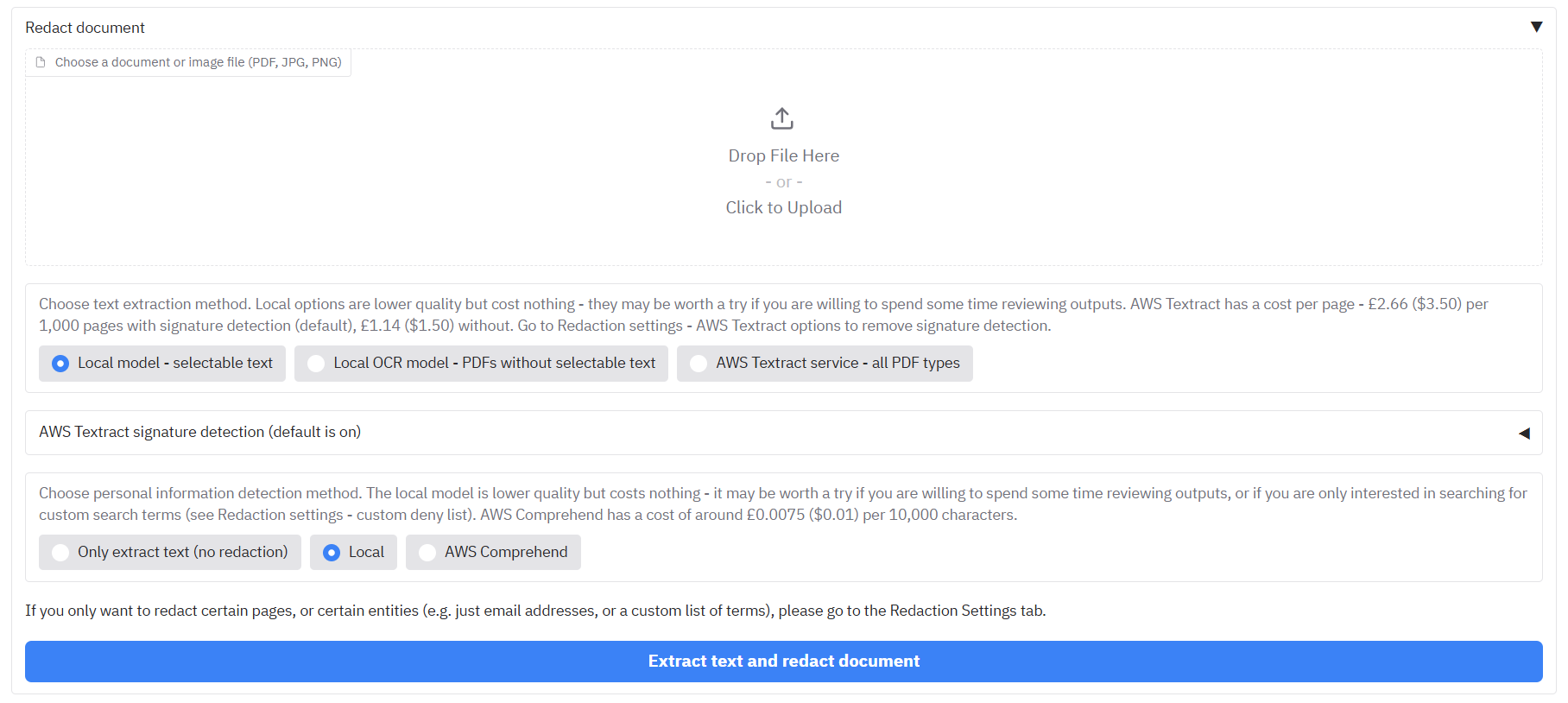
First, select one of the three text extraction options below:
|
| 57 |
+
- 'Local model - selectable text' - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
|
| 58 |
+
- 'Local OCR model - PDFs without selectable text' - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
|
| 59 |
+
- 'AWS Textract service - all PDF types' - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
|
| 60 |
+
|
| 61 |
+
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
|
| 62 |
+
- 'Local' - This uses the spacy package to rapidly detect PII in extracted text. This method is often sufficient if you are just interested in redacting specific terms defined in a custom list.
|
| 63 |
+
- 'AWS Comprehend' - This method calls an AWS service to provide more accurate identification of PII in extracted text.
|
| 64 |
|
| 65 |
+
Hit 'Redact document'. After loading in the document, the app should be able to process about 30 pages per minute (depending on redaction methods chose above). When ready, you should see a message saying that processing is complete, with output files appearing in the bottom right.
|
| 66 |
|
| 67 |

|
| 68 |
|
| 69 |
+
- '...redacted.pdf' files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
|
| 70 |
+
- '...ocr_results.csv' files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 71 |
+
- '...review_file.csv' files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-suggested-redactions-and-modifying), and should be downloaded to use later for this.
|
| 72 |
+
|
| 73 |
+
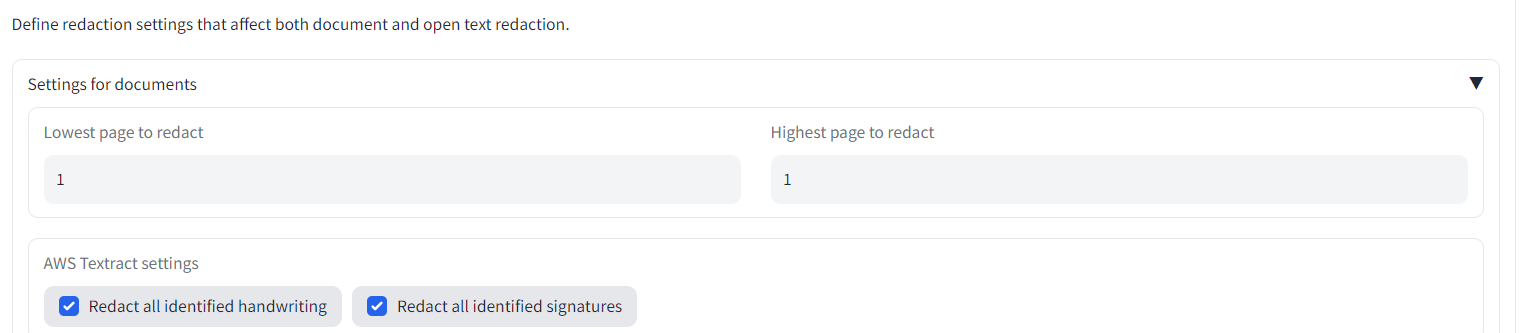
Additional outputs are available under the 'Redaction settings' tab. Scroll to the bottom and you should see more files:
|
| 74 |
|
| 75 |

|
| 76 |
|
| 77 |
+
- '...review_file.json' is the same file as the review file above, but in .json format.
|
| 78 |
+
- '...decision_process_output.csv' is also similar to the review file above, with a few more details on the location and scores of identified PII in the document.
|
| 79 |
+
- If you are using AWS Textract, you should also get a .json file with the Textract outputs. It could be useful to retain this document to avoid having to repeatedly analyse the same document in future (this .json file can be uploaded into the app on the first redaction tab to load into local memory before redaction).
|
| 80 |
|
| 81 |
+
We have covered redacting documents with the default redaction options. The '...redacted.pdf' file output may be enough for your purposes. But it is very likely that you will need to customise your redaction options, which we will cover below.
|
| 82 |
|
| 83 |
+
## Customising redaction options
|
| 84 |
|
| 85 |
+
On the 'Redaction settings' page, there are a number of options that you can tweak to better match your use case and needs.
|
| 86 |
|
| 87 |
+
### Custom allow, deny, and page redaction lists
|
| 88 |
|
| 89 |
+
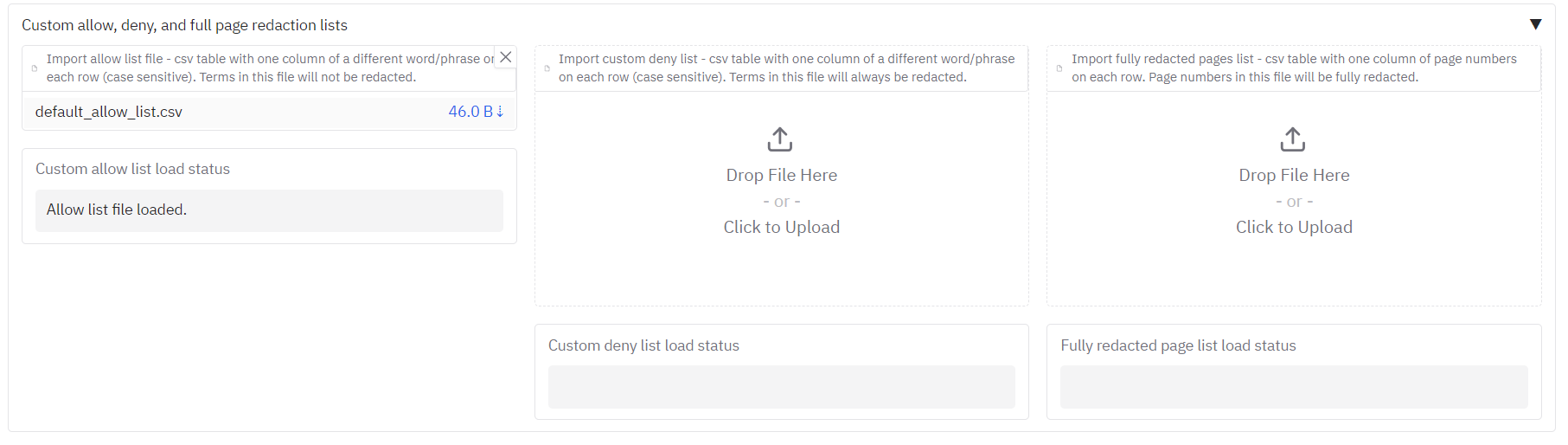
The app allows you to specify terms that should never be redacted (an allow list), terms that should always be redacted (a deny list), and also to provide a list of page numbers for pages that should be fully redacted.
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
#### Allow list example
|
| 94 |
+
|
| 95 |
+
It may be the case that specific terms that are frequently redacted are not interesting to
|
| 96 |
+
|
| 97 |
+
In the redacted outputs of the 'Example of files sent to a professor before applying' PDF, you can see that it is frequently redacting references to Dr Hyde's lab in the main body of the text. Let's say that references to Dr Hyde were not considered personal information in this context. You can exclude this term from redaction (and others) by providing an 'allow list' file. This is simply a csv that contains the case sensitive terms to exclude in the first column, in our example, 'Hyde' and 'Muller glia'. The example file is provided [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/allow_list.csv).
|
| 98 |
+
|
| 99 |
+
To import this to use with your redaction tasks, go to the 'Redaction settings' tab, click on the 'Import allow list file' button halfway down, and select the csv file you have created. It should be loaded for next time you hit the redact button. Go back to the first tab and do this.
|
| 100 |
+
|
| 101 |
+
#### Deny list example
|
| 102 |
+
|
| 103 |
+
Say you wanted to remove specific terms from a document. In this app you can do this by providing a custom deny list as a csv. Like for the allow list described above, this should be a one-column csv without a column header. The app will suggest each individual term in the list with exact spelling as whole words. So it won't select text from within words. To enable this feature, the 'CUSTOM' tag needs to be chosen as a redaction entity [(the process for adding/removing entity types to redact is described below)](#redacting-additional-types-of-personal-information).
|
| 104 |
+
|
| 105 |
+
Here is an example using the [Partnership Agreement Toolkit file](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf). This is an [example of a custom deny list file](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/partnership_toolkit_redact_custom_deny_list.csv). 'Sister', 'Sister City'
|
| 106 |
+
'Sister Cities', 'Friendship City' have been listed as specific terms to redact. You can see the outputs of this redaction process on the review page:
|
| 107 |
|
| 108 |
+
.
|
| 109 |
|
| 110 |
+
You can see that the app has highlighted all instances of these terms on the page shown. You can then consider each of these terms for modification or removal on the review page [explained here](#reviewing-and-modifying-suggested-redactions).
|
| 111 |
|
| 112 |
+
#### Full page redaction list example
|
| 113 |
+
|
| 114 |
+
There may be full pages in a document that you want to redact. The app also provides the capability of redacting pages completely based on a list of input page numbers in a csv. The format of the input file is the same as that for the allow and deny lists described above - a one-column csv without a column header. An [example of this is here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/partnership_toolkit_redact_some_pages.csv). You can see an example of the redacted page on the review page:
|
| 115 |
+
|
| 116 |
+
.
|
| 117 |
+
|
| 118 |
+
Using the above approaches to allow, deny, and full page redaction lists will give you an output [like this](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/Partnership-Agreement-Toolkit_0_0_redacted.pdf).
|
| 119 |
+
|
| 120 |
+
### Redacting additional types of personal information
|
| 121 |
+
|
| 122 |
+
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
| 123 |
+
|
| 124 |
+
Under the 'Redaction settings' tab, go to 'Entities to redact (click close to down arrow for full list)'. Different dropdowns are provided according to whether you are using the Local service to redact PII, or the AWS Comprehend service. Click within the empty box close to the dropdown arrow and you should see a list of possible 'entities' to redact. Select 'DATE_TIME' and it should appear in the main list. To remove items, click on the 'x' next to their name.
|
| 125 |
+
|
| 126 |
+
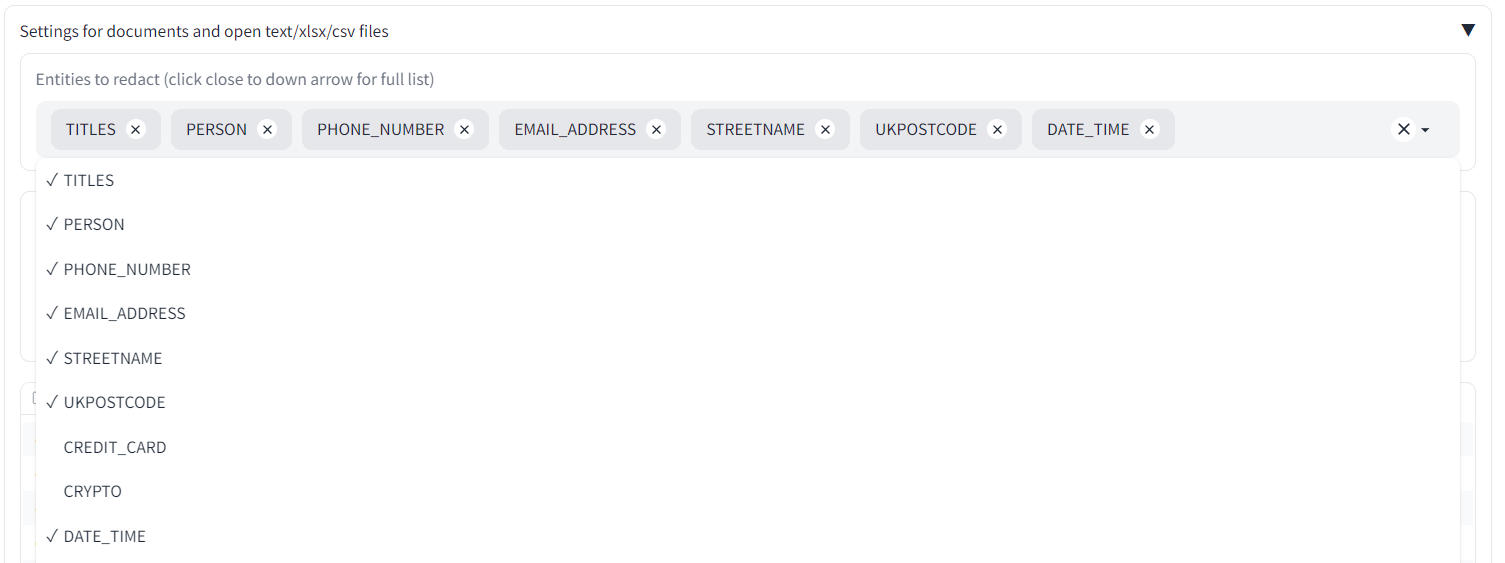
|
| 127 |
+
|
| 128 |
+
Now, go back to the main screen and click 'Redact Document' again. You should now get a redacted version of 'Example complaint letter' that has the dates and times removed.
|
| 129 |
+
|
| 130 |
+
If you want to redact different files, I suggest you refresh your browser page to start a new session and unload all previous data.
|
| 131 |
+
|
| 132 |
+
## Redacting only specific pages
|
| 133 |
|
| 134 |
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
|
| 135 |
|
| 136 |

|
| 137 |
|
| 138 |
+
## Handwriting and signature redaction
|
| 139 |
+
|
| 140 |
+
The file [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf) is provided as an example document to test AWS Textract + redaction with a document that has signatures in. If you have access to AWS Textract in the app, try removing all entity types from redaction on the Redaction settings and clicking the big X to the right of 'Entities to redact'. Ensure that handwriting and signatures are enabled for redaction on the Redaction Settings tab(enabled by default):
|
| 141 |
+
|
| 142 |
+
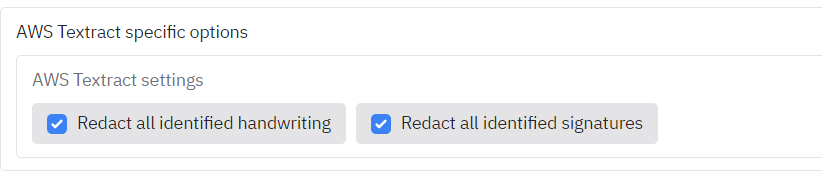
|
| 143 |
+
|
| 144 |
+
The outputs should show handwriting/signatures redacted (see pages 5 - 7), which you can inspect and modify on the 'Review redactions' tab.
|
| 145 |
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+
## Reviewing and modifying suggested redactions
|
| 149 |
+
|
| 150 |
+
Quite often there are certain terms suggested for redaction by the model that don't match quite what you intended. The app allows you to review and modify suggested redactions for the last file redacted. Refresh your browser tab. On the first tab 'PDFs/images' upload the ['Example of files sent to a professor before applying.pdf'](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf) file. Let's stick with the 'Local model - selectable text' option, and click 'Redact document'. Once the outputs are created, go to the 'Review redactions' tab.
|
| 151 |
|
| 152 |
On this tab you have a visual interface that allows you to inspect and modify redactions suggested by the app.
|
| 153 |
|
|
|
|
| 161 |
|
| 162 |

|
| 163 |
|
| 164 |
+
On the right of the screen there is a dropdown and table where you can filter to entity types that have been found throughout the document. You can choose a specific entity type to see which pages the entity is present on. If you want to go to the page specified in the table, you can click on a cell in the table and the review page will be changed to that page.
|
| 165 |
|
| 166 |
+
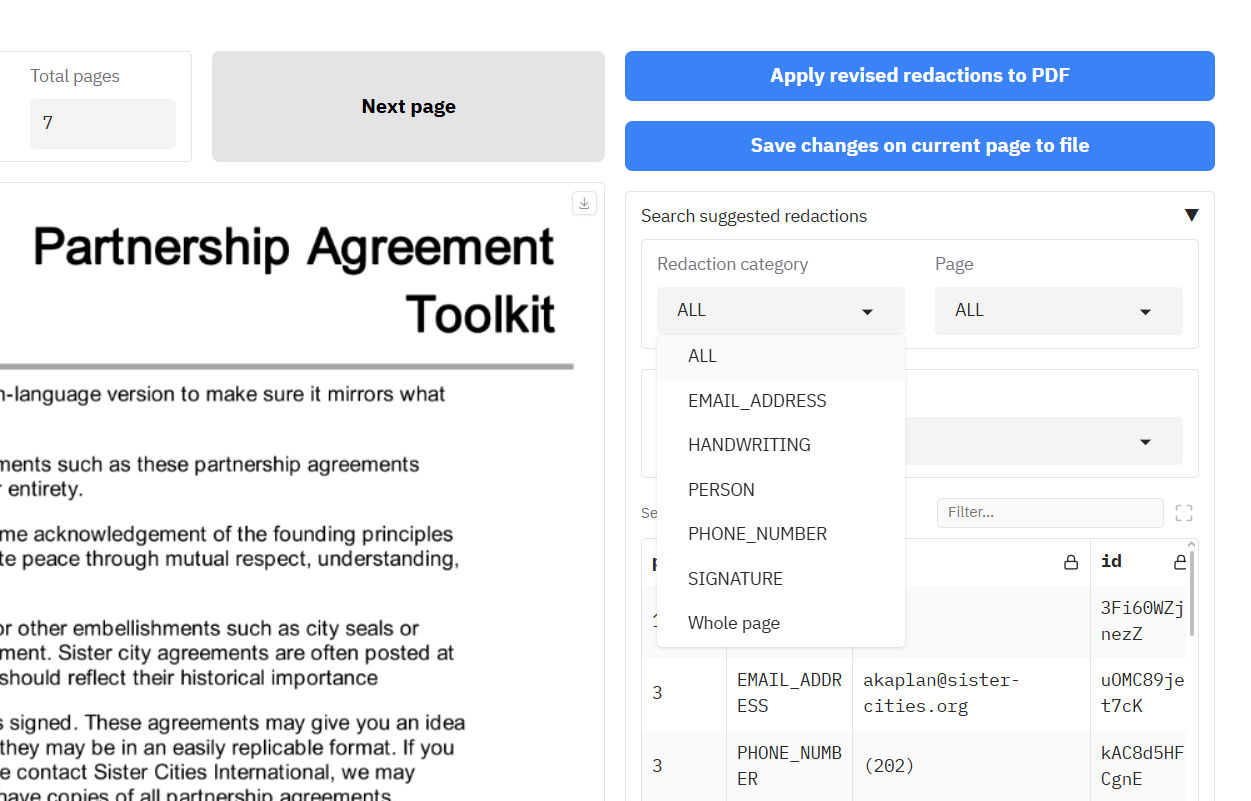
|
| 167 |
|
| 168 |
+
Note that the table currently only shows entity types, and not specific found text. So for instance if you provide a list of specific terms to redact in the [deny list](#deny-list-example), they will all be labelled just as 'CUSTOM'. A feature to include in the near term will include being able to view specific redacted text in this table to get a better sense of the PII entities found.
|
| 169 |
|
| 170 |
+
Once you happy with your modified changes throughout the document, click 'Apply revised redactions' at the top of the page. The app will then run through all the pages in the document to update the redactions, and will output a modified PDF file. The modified PDF will appear at the top of the page in the file area.
|
| 171 |
|
| 172 |
+

|
| 173 |
|
| 174 |
Any feedback or comments on the app, please get in touch!
|
app.py
CHANGED
|
@@ -46,6 +46,7 @@ feedback_logs_folder = 'feedback/' + today_rev + '/' + host_name + '/'
|
|
| 46 |
access_logs_folder = 'logs/' + today_rev + '/' + host_name + '/'
|
| 47 |
usage_logs_folder = 'usage/' + today_rev + '/' + host_name + '/'
|
| 48 |
|
|
|
|
| 49 |
|
| 50 |
if RUN_AWS_FUNCTIONS == "1":
|
| 51 |
default_ocr_val = textract_option
|
|
@@ -153,18 +154,20 @@ with app:
|
|
| 153 |
gr.Markdown(
|
| 154 |
"""# Document redaction
|
| 155 |
|
| 156 |
-
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet).
|
| 157 |
|
| 158 |
-
|
| 159 |
|
| 160 |
-
|
|
|
|
|
|
|
| 161 |
|
| 162 |
-
NOTE:
|
| 163 |
|
| 164 |
# PDF / IMAGES TAB
|
| 165 |
with gr.Tab("PDFs/images"):
|
| 166 |
with gr.Accordion("Redact document", open = True):
|
| 167 |
-
in_doc_files = gr.File(label="Choose a document or image file (PDF, JPG, PNG)", file_count= "single", file_types=['.pdf', '.jpg', '.png', '.json'])
|
| 168 |
if RUN_AWS_FUNCTIONS == "1":
|
| 169 |
in_redaction_method = gr.Radio(label="Choose text extraction method. AWS Textract has a cost per page.", value = default_ocr_val, choices=[text_ocr_option, tesseract_ocr_option, textract_option])
|
| 170 |
pii_identification_method_drop = gr.Radio(label = "Choose PII detection method. AWS Comprehend has a cost per 100 characters.", value = default_pii_detector, choices=[local_pii_detector, aws_pii_detector])
|
|
@@ -172,14 +175,14 @@ with app:
|
|
| 172 |
in_redaction_method = gr.Radio(label="Choose text extraction method.", value = default_ocr_val, choices=[text_ocr_option, tesseract_ocr_option])
|
| 173 |
pii_identification_method_drop = gr.Radio(label = "Choose PII detection method.", value = default_pii_detector, choices=[local_pii_detector], visible=False)
|
| 174 |
|
| 175 |
-
gr.Markdown("""If you only want to redact certain pages, or certain entities (e.g. just email addresses), please go to the redaction settings tab.""")
|
| 176 |
-
document_redact_btn = gr.Button("Redact document
|
| 177 |
current_loop_page_number = gr.Number(value=0,precision=0, interactive=False, label = "Last redacted page in document", visible=False)
|
| 178 |
page_break_return = gr.Checkbox(value = False, label="Page break reached", visible=False)
|
| 179 |
|
| 180 |
with gr.Row():
|
| 181 |
output_summary = gr.Textbox(label="Output summary", scale=1)
|
| 182 |
-
output_file = gr.File(label="Output files", scale = 2)
|
| 183 |
latest_file_completed_text = gr.Number(value=0, label="Number of documents redacted", interactive=False, visible=False)
|
| 184 |
|
| 185 |
with gr.Row():
|
|
@@ -195,7 +198,7 @@ with app:
|
|
| 195 |
with gr.Tab("Review redactions", id="tab_object_annotation"):
|
| 196 |
|
| 197 |
with gr.Accordion(label = "Review redaction file", open=True):
|
| 198 |
-
output_review_files = gr.File(label="Review output files", file_count='multiple')
|
| 199 |
upload_previous_review_file_btn = gr.Button("Review previously created redaction file (upload original PDF and ...review_file.csv)")
|
| 200 |
|
| 201 |
with gr.Row():
|
|
@@ -245,10 +248,6 @@ with app:
|
|
| 245 |
annotate_max_pages_bottom = gr.Number(value=1, label="Total pages", precision=0, interactive=False, scale = 1)
|
| 246 |
annotation_next_page_button_bottom = gr.Button("Next page", scale = 3)
|
| 247 |
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
| 252 |
# TEXT / TABULAR DATA TAB
|
| 253 |
with gr.Tab(label="Open text or Excel/csv files"):
|
| 254 |
gr.Markdown(
|
|
@@ -259,7 +258,7 @@ with app:
|
|
| 259 |
with gr.Accordion("Paste open text", open = False):
|
| 260 |
in_text = gr.Textbox(label="Enter open text", lines=10)
|
| 261 |
with gr.Accordion("Upload xlsx or csv files", open = True):
|
| 262 |
-
in_data_files = gr.File(label="Choose Excel or csv files", file_count= "multiple", file_types=['.xlsx', '.xls', '.csv', '.parquet', '.csv.gz'])
|
| 263 |
|
| 264 |
in_excel_sheets = gr.Dropdown(choices=["Choose Excel sheets to anonymise"], multiselect = True, label="Select Excel sheets that you want to anonymise (showing sheets present across all Excel files).", visible=False, allow_custom_value=True)
|
| 265 |
|
|
@@ -280,39 +279,35 @@ with app:
|
|
| 280 |
data_submit_feedback_btn = gr.Button(value="Submit feedback", visible=False)
|
| 281 |
|
| 282 |
# SETTINGS TAB
|
| 283 |
-
with gr.Tab(label="Redaction settings"):
|
| 284 |
-
gr.
|
| 285 |
-
"""
|
| 286 |
-
Define redaction settings that affect both document and open text redaction.
|
| 287 |
-
""")
|
| 288 |
-
with gr.Accordion("Settings for documents", open = True):
|
| 289 |
-
|
| 290 |
-
with gr.Row():
|
| 291 |
-
page_min = gr.Number(precision=0,minimum=0,maximum=9999, label="Lowest page to redact")
|
| 292 |
-
page_max = gr.Number(precision=0,minimum=0,maximum=9999, label="Highest page to redact")
|
| 293 |
-
|
| 294 |
-
with gr.Accordion("Settings for documents and open text/xlsx/csv files", open = True):
|
| 295 |
with gr.Row():
|
| 296 |
with gr.Column():
|
| 297 |
-
in_allow_list = gr.File(label="Import allow list file - csv table with one column of a different word/phrase on each row (case sensitive). Terms in this file will not be redacted.", file_count="multiple", height=
|
| 298 |
in_allow_list_text = gr.Textbox(label="Custom allow list load status")
|
| 299 |
with gr.Column():
|
| 300 |
-
in_deny_list = gr.File(label="Import custom deny list - csv table with one column of a different word/phrase on each row (case sensitive). Terms in this file will always be redacted.", file_count="multiple", height=
|
| 301 |
in_deny_list_text = gr.Textbox(label="Custom deny list load status")
|
| 302 |
with gr.Column():
|
| 303 |
-
in_fully_redacted_list = gr.File(label="Import fully redacted pages list - csv table with one column of page numbers on each row. Page numbers in this file will be fully redacted.", file_count="multiple", height=
|
| 304 |
in_fully_redacted_list_text = gr.Textbox(label="Fully redacted page list load status")
|
| 305 |
|
| 306 |
-
|
| 307 |
-
|
| 308 |
|
| 309 |
-
|
| 310 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 311 |
handwrite_signature_checkbox = gr.CheckboxGroup(label="AWS Textract settings", choices=["Redact all identified handwriting", "Redact all identified signatures"], value=["Redact all identified handwriting", "Redact all identified signatures"])
|
| 312 |
#with gr.Row():
|
| 313 |
in_redact_language = gr.Dropdown(value = "en", choices = ["en"], label="Redaction language (only English currently supported)", multiselect=False, visible=False)
|
| 314 |
|
| 315 |
-
with gr.Accordion("Settings for open text or xlsx/csv files", open =
|
| 316 |
anon_strat = gr.Radio(choices=["replace with <REDACTED>", "replace with <ENTITY_NAME>", "redact", "hash", "mask", "encrypt", "fake_first_name"], label="Select an anonymisation method.", value = "replace with <REDACTED>")
|
| 317 |
|
| 318 |
log_files_output = gr.File(label="Log file output", interactive=False)
|
|
@@ -458,7 +453,7 @@ with app:
|
|
| 458 |
then(fn = upload_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 459 |
|
| 460 |
# Get some environment variables and Launch the Gradio app
|
| 461 |
-
COGNITO_AUTH = get_or_create_env_var('COGNITO_AUTH', '
|
| 462 |
print(f'The value of COGNITO_AUTH is {COGNITO_AUTH}')
|
| 463 |
1
|
| 464 |
RUN_DIRECT_MODE = get_or_create_env_var('RUN_DIRECT_MODE', '0')
|
|
|
|
| 46 |
access_logs_folder = 'logs/' + today_rev + '/' + host_name + '/'
|
| 47 |
usage_logs_folder = 'usage/' + today_rev + '/' + host_name + '/'
|
| 48 |
|
| 49 |
+
file_input_height = 200
|
| 50 |
|
| 51 |
if RUN_AWS_FUNCTIONS == "1":
|
| 52 |
default_ocr_val = textract_option
|
|
|
|
| 154 |
gr.Markdown(
|
| 155 |
"""# Document redaction
|
| 156 |
|
| 157 |
+
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](https://github.com/seanpedrick-case/doc_redaction/blob/main/README.md) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 158 |
|
| 159 |
+
To identify text in documents, the 'local' text/OCR image analysis uses spacy/tesseract, and works ok for documents with typed text. If available, choose 'AWS Textract service' to redact more complex elements e.g. signatures or handwriting.
|
| 160 |
|
| 161 |
+
Then, choose a method for PII identification. 'Local' is quick and gives good results if you are primarily looking for a custom list of terms to redact (see Redaction settings). If available, AWS Comprehend gives better results at a small cost.
|
| 162 |
+
|
| 163 |
+
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...redaction_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
|
| 164 |
|
| 165 |
+
NOTE: The app is not 100% accurate, and it will miss some personal information. It is essential that all outputs are reviewed **by a human** before using the final outputs.""")
|
| 166 |
|
| 167 |
# PDF / IMAGES TAB
|
| 168 |
with gr.Tab("PDFs/images"):
|
| 169 |
with gr.Accordion("Redact document", open = True):
|
| 170 |
+
in_doc_files = gr.File(label="Choose a document or image file (PDF, JPG, PNG)", file_count= "single", file_types=['.pdf', '.jpg', '.png', '.json'], height=file_input_height)
|
| 171 |
if RUN_AWS_FUNCTIONS == "1":
|
| 172 |
in_redaction_method = gr.Radio(label="Choose text extraction method. AWS Textract has a cost per page.", value = default_ocr_val, choices=[text_ocr_option, tesseract_ocr_option, textract_option])
|
| 173 |
pii_identification_method_drop = gr.Radio(label = "Choose PII detection method. AWS Comprehend has a cost per 100 characters.", value = default_pii_detector, choices=[local_pii_detector, aws_pii_detector])
|
|
|
|
| 175 |
in_redaction_method = gr.Radio(label="Choose text extraction method.", value = default_ocr_val, choices=[text_ocr_option, tesseract_ocr_option])
|
| 176 |
pii_identification_method_drop = gr.Radio(label = "Choose PII detection method.", value = default_pii_detector, choices=[local_pii_detector], visible=False)
|
| 177 |
|
| 178 |
+
gr.Markdown("""If you only want to redact certain pages, or certain entities (e.g. just email addresses, or a custom list of terms), please go to the redaction settings tab.""")
|
| 179 |
+
document_redact_btn = gr.Button("Redact document", variant="primary")
|
| 180 |
current_loop_page_number = gr.Number(value=0,precision=0, interactive=False, label = "Last redacted page in document", visible=False)
|
| 181 |
page_break_return = gr.Checkbox(value = False, label="Page break reached", visible=False)
|
| 182 |
|
| 183 |
with gr.Row():
|
| 184 |
output_summary = gr.Textbox(label="Output summary", scale=1)
|
| 185 |
+
output_file = gr.File(label="Output files", scale = 2, height=file_input_height)
|
| 186 |
latest_file_completed_text = gr.Number(value=0, label="Number of documents redacted", interactive=False, visible=False)
|
| 187 |
|
| 188 |
with gr.Row():
|
|
|
|
| 198 |
with gr.Tab("Review redactions", id="tab_object_annotation"):
|
| 199 |
|
| 200 |
with gr.Accordion(label = "Review redaction file", open=True):
|
| 201 |
+
output_review_files = gr.File(label="Review output files", file_count='multiple', height=file_input_height)
|
| 202 |
upload_previous_review_file_btn = gr.Button("Review previously created redaction file (upload original PDF and ...review_file.csv)")
|
| 203 |
|
| 204 |
with gr.Row():
|
|
|
|
| 248 |
annotate_max_pages_bottom = gr.Number(value=1, label="Total pages", precision=0, interactive=False, scale = 1)
|
| 249 |
annotation_next_page_button_bottom = gr.Button("Next page", scale = 3)
|
| 250 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 251 |
# TEXT / TABULAR DATA TAB
|
| 252 |
with gr.Tab(label="Open text or Excel/csv files"):
|
| 253 |
gr.Markdown(
|
|
|
|
| 258 |
with gr.Accordion("Paste open text", open = False):
|
| 259 |
in_text = gr.Textbox(label="Enter open text", lines=10)
|
| 260 |
with gr.Accordion("Upload xlsx or csv files", open = True):
|
| 261 |
+
in_data_files = gr.File(label="Choose Excel or csv files", file_count= "multiple", file_types=['.xlsx', '.xls', '.csv', '.parquet', '.csv.gz'], height=file_input_height)
|
| 262 |
|
| 263 |
in_excel_sheets = gr.Dropdown(choices=["Choose Excel sheets to anonymise"], multiselect = True, label="Select Excel sheets that you want to anonymise (showing sheets present across all Excel files).", visible=False, allow_custom_value=True)
|
| 264 |
|
|
|
|
| 279 |
data_submit_feedback_btn = gr.Button(value="Submit feedback", visible=False)
|
| 280 |
|
| 281 |
# SETTINGS TAB
|
| 282 |
+
with gr.Tab(label="Redaction settings"):
|
| 283 |
+
with gr.Accordion("Custom allow, deny, and full page redaction lists", open = True):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 284 |
with gr.Row():
|
| 285 |
with gr.Column():
|
| 286 |
+
in_allow_list = gr.File(label="Import allow list file - csv table with one column of a different word/phrase on each row (case sensitive). Terms in this file will not be redacted.", file_count="multiple", height=file_input_height)
|
| 287 |
in_allow_list_text = gr.Textbox(label="Custom allow list load status")
|
| 288 |
with gr.Column():
|
| 289 |
+
in_deny_list = gr.File(label="Import custom deny list - csv table with one column of a different word/phrase on each row (case sensitive). Terms in this file will always be redacted.", file_count="multiple", height=file_input_height)
|
| 290 |
in_deny_list_text = gr.Textbox(label="Custom deny list load status")
|
| 291 |
with gr.Column():
|
| 292 |
+
in_fully_redacted_list = gr.File(label="Import fully redacted pages list - csv table with one column of page numbers on each row. Page numbers in this file will be fully redacted.", file_count="multiple", height=file_input_height)
|
| 293 |
in_fully_redacted_list_text = gr.Textbox(label="Fully redacted page list load status")
|
| 294 |
|
| 295 |
+
with gr.Accordion("Select entity types to redact", open = True):
|
| 296 |
+
in_redact_entities = gr.Dropdown(value=chosen_redact_entities, choices=full_entity_list, multiselect=True, label="Local PII identification model (click empty space in box for full list)")
|
| 297 |
|
| 298 |
+
in_redact_comprehend_entities = gr.Dropdown(value=chosen_comprehend_entities, choices=full_comprehend_entity_list, multiselect=True, label="AWS Comprehend PII identification model (click empty space in box for full list)")
|
| 299 |
+
|
| 300 |
+
with gr.Accordion("Redact only selected pages", open = False):
|
| 301 |
+
with gr.Row():
|
| 302 |
+
page_min = gr.Number(precision=0,minimum=0,maximum=9999, label="Lowest page to redact")
|
| 303 |
+
page_max = gr.Number(precision=0,minimum=0,maximum=9999, label="Highest page to redact")
|
| 304 |
+
|
| 305 |
+
with gr.Accordion("AWS Textract specific options", open = False):
|
| 306 |
handwrite_signature_checkbox = gr.CheckboxGroup(label="AWS Textract settings", choices=["Redact all identified handwriting", "Redact all identified signatures"], value=["Redact all identified handwriting", "Redact all identified signatures"])
|
| 307 |
#with gr.Row():
|
| 308 |
in_redact_language = gr.Dropdown(value = "en", choices = ["en"], label="Redaction language (only English currently supported)", multiselect=False, visible=False)
|
| 309 |
|
| 310 |
+
with gr.Accordion("Settings for open text or xlsx/csv files", open = False):
|
| 311 |
anon_strat = gr.Radio(choices=["replace with <REDACTED>", "replace with <ENTITY_NAME>", "redact", "hash", "mask", "encrypt", "fake_first_name"], label="Select an anonymisation method.", value = "replace with <REDACTED>")
|
| 312 |
|
| 313 |
log_files_output = gr.File(label="Log file output", interactive=False)
|
|
|
|
| 453 |
then(fn = upload_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 454 |
|
| 455 |
# Get some environment variables and Launch the Gradio app
|
| 456 |
+
COGNITO_AUTH = get_or_create_env_var('COGNITO_AUTH', '0')
|
| 457 |
print(f'The value of COGNITO_AUTH is {COGNITO_AUTH}')
|
| 458 |
1
|
| 459 |
RUN_DIRECT_MODE = get_or_create_env_var('RUN_DIRECT_MODE', '0')
|
requirements.txt
CHANGED
|
@@ -10,7 +10,7 @@ pandas==2.2.3
|
|
| 10 |
spacy==3.8.3
|
| 11 |
#en_core_web_lg @ https://github.com/explosion/spacy-#models/releases/download/en_core_web_lg-3.8.0/en_core_web_sm-#3.8.0.tar.gz
|
| 12 |
en_core_web_sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.8.0/en_core_web_sm-3.8.0.tar.gz
|
| 13 |
-
gradio==5.
|
| 14 |
boto3==1.35.83
|
| 15 |
pyarrow==18.1.0
|
| 16 |
openpyxl==3.1.2
|
|
|
|
| 10 |
spacy==3.8.3
|
| 11 |
#en_core_web_lg @ https://github.com/explosion/spacy-#models/releases/download/en_core_web_lg-3.8.0/en_core_web_sm-#3.8.0.tar.gz
|
| 12 |
en_core_web_sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.8.0/en_core_web_sm-3.8.0.tar.gz
|
| 13 |
+
gradio==5.10.0
|
| 14 |
boto3==1.35.83
|
| 15 |
pyarrow==18.1.0
|
| 16 |
openpyxl==3.1.2
|