
Caleb Spradlin
commited on
Commit
·
76005a3
1
Parent(s):
ab687e7
added text and image
Browse files- app.py +5 -0
- data/.DS_Store +0 -0
- data/figures/reconstruction.png +0 -0
- text.py +22 -0
app.py
CHANGED
|
@@ -3,6 +3,7 @@ import numpy as np
|
|
| 3 |
import os
|
| 4 |
import pathlib
|
| 5 |
from inference import infer, InferenceModel
|
|
|
|
| 6 |
|
| 7 |
# -----------------------------------------------------------------------------
|
| 8 |
# class SatvisionDemoApp
|
|
@@ -77,6 +78,10 @@ class SatvisionDemoApp:
|
|
| 77 |
with col3:
|
| 78 |
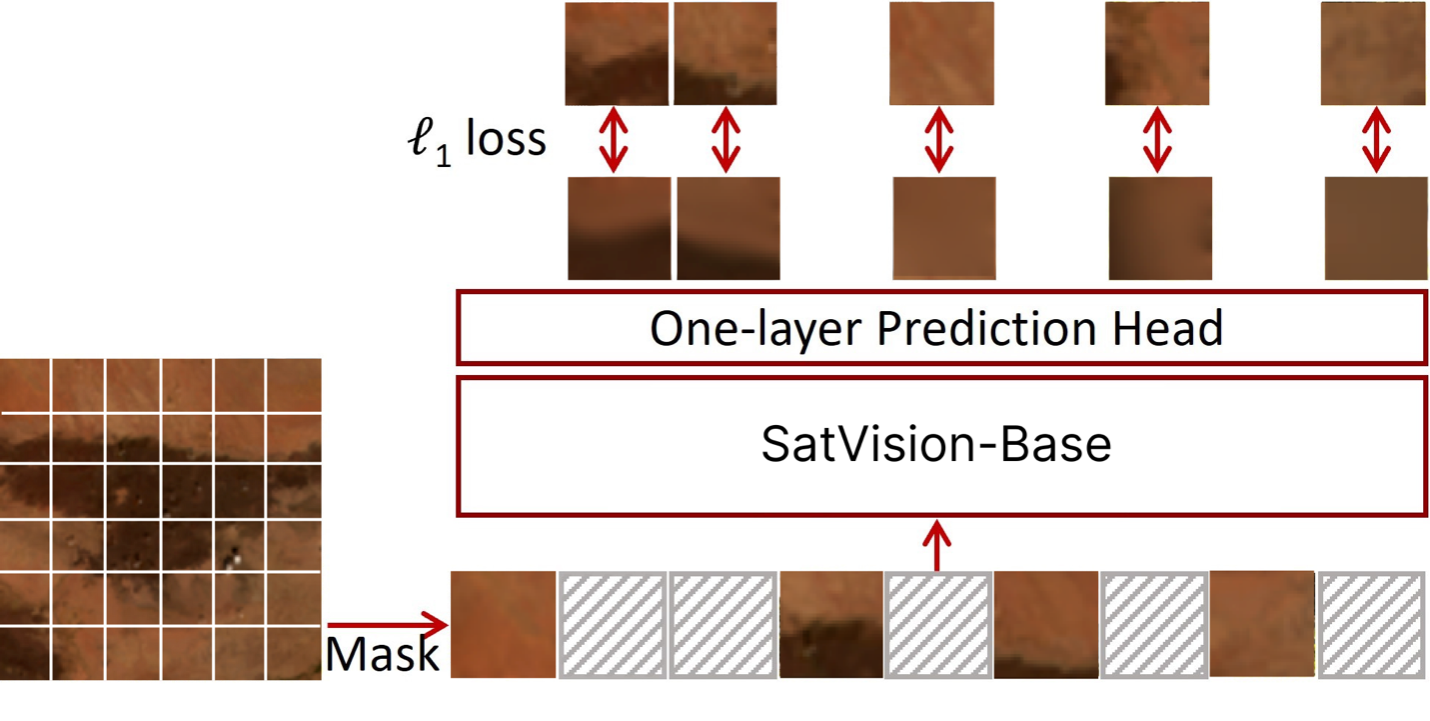
st.image(output, use_column_width=True, caption="Reconstruction")
|
| 79 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 80 |
# -------------------------------------------------------------------------
|
| 81 |
# load_selected_image
|
| 82 |
# -------------------------------------------------------------------------
|
|
|
|
| 3 |
import os
|
| 4 |
import pathlib
|
| 5 |
from inference import infer, InferenceModel
|
| 6 |
+
from text import intro
|
| 7 |
|
| 8 |
# -----------------------------------------------------------------------------
|
| 9 |
# class SatvisionDemoApp
|
|
|
|
| 78 |
with col3:
|
| 79 |
st.image(output, use_column_width=True, caption="Reconstruction")
|
| 80 |
|
| 81 |
+
st.markdown(intro)
|
| 82 |
+
|
| 83 |
+
st.image('data/figures/reconstruction.png')
|
| 84 |
+
|
| 85 |
# -------------------------------------------------------------------------
|
| 86 |
# load_selected_image
|
| 87 |
# -------------------------------------------------------------------------
|
data/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
data/figures/reconstruction.png
ADDED
|
text.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
intro = '''Remote sensing images from NASA's fleet of Earth-observing satellites are pivotal for applications as broad as land cover mapping,
|
| 4 |
+
disaster monitoring, urban planning, and environmental analysis. The potential of AI-based geospatial foundation models for performing
|
| 5 |
+
visual analysis tasks on these remote sensing images has garnered significant attention. To realize that potential, the crucial first
|
| 6 |
+
step is to develop foundation models – computer models that acquire competence in a broad range of tasks, which can then be specialized
|
| 7 |
+
with further training for specific applications. In this case, the foundation model is based on a large-scale vision transformer model
|
| 8 |
+
trained with satellite imagery.
|
| 9 |
+
|
| 10 |
+
Vision transformers employ AI/deep learning techniques to fine-tune the model to answer specific science questions. Through training
|
| 11 |
+
on extensive remote sensing datasets, vision transformers can learn general relationships between the spectral data given as inputs,
|
| 12 |
+
as well as capture high-level visual patterns, semantics, and spatial relationships that can be leveraged for a wide range of analysis tasks.
|
| 13 |
+
Trained vision transformers can handle large-scale, high-resolution data; learn global reorientations; extract robust features; and support
|
| 14 |
+
multi-modal data fusion – all with improved performance.
|
| 15 |
+
|
| 16 |
+
The Data Science Group at NASA Goddard Space Flight Center's Computational and Information Sciences and Technology Office (CISTO)
|
| 17 |
+
has implemented an end-to-end workflow to generate a pre-trained vision transformer which could evolve into a foundation model.
|
| 18 |
+
A training dataset of over 2 million 128x128 pixel “chips” has been created from NASA’s Moderate Resolution Imaging Spectroradiometer (MODIS)
|
| 19 |
+
surface reflectance products (MOD09). These data were used to train a SwinV2 vision transformer that we call SatVision.
|
| 20 |
+
'''
|
| 21 |
+
|
| 22 |
+
|