Spaces:
Sleeping

Sleeping
tmlinhdinh
commited on
Commit
•
b8e2ff5
1
Parent(s):
80e747e
clean up git messages
Browse files- Dockerfile +3 -1
- README.md +5 -5
- app.py +2 -5
- report/.DS_Store +0 -0
- report/ragas_finetune.png +0 -0
- report/ragas_prototype.png +0 -0
- report/report.md +114 -0
- requirements.txt +7 -7
Dockerfile
CHANGED
|
@@ -1,10 +1,12 @@
|
|
| 1 |
-
FROM python:3.
|
| 2 |
RUN useradd -m -u 1000 user
|
| 3 |
USER user
|
| 4 |
ENV HOME=/home/user \
|
| 5 |
PATH=/home/user/.local/bin:$PATH
|
| 6 |
WORKDIR $HOME/app
|
| 7 |
COPY --chown=user . $HOME/app
|
|
|
|
|
|
|
| 8 |
COPY ./requirements.txt ~/app/requirements.txt
|
| 9 |
RUN pip install -r requirements.txt
|
| 10 |
COPY . .
|
|
|
|
| 1 |
+
FROM python:3.11
|
| 2 |
RUN useradd -m -u 1000 user
|
| 3 |
USER user
|
| 4 |
ENV HOME=/home/user \
|
| 5 |
PATH=/home/user/.local/bin:$PATH
|
| 6 |
WORKDIR $HOME/app
|
| 7 |
COPY --chown=user . $HOME/app
|
| 8 |
+
RUN mkdir -p $HOME/app/.chainlit/translations && \
|
| 9 |
+
chown -R user:user $HOME/app/.chainlit
|
| 10 |
COPY ./requirements.txt ~/app/requirements.txt
|
| 11 |
RUN pip install -r requirements.txt
|
| 12 |
COPY . .
|
README.md
CHANGED
|
@@ -1,11 +1,11 @@
|
|
| 1 |
---
|
| 2 |
-
title: AI
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
-
license:
|
| 9 |
---
|
| 10 |
|
| 11 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: AI Industry Insights
|
| 3 |
+
emoji: 👁
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
+
license: mit
|
| 9 |
---
|
| 10 |
|
| 11 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
CHANGED
|
@@ -62,8 +62,7 @@ rag_documents_2 = PyMuPDFLoader(file_path=DATA_LINK2).load()
|
|
| 62 |
|
| 63 |
chunked_rag_documents = chunk_documents(rag_documents_1, CHUNK_SIZE, CHUNK_OVERLAP) + \
|
| 64 |
chunk_documents(rag_documents_2, CHUNK_SIZE, CHUNK_OVERLAP)
|
| 65 |
-
|
| 66 |
-
|
| 67 |
@cl.on_chat_start
|
| 68 |
async def on_chat_start():
|
| 69 |
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
|
|
@@ -79,8 +78,6 @@ async def on_chat_start():
|
|
| 79 |
|
| 80 |
cl.user_session.set("chain", rag_chain)
|
| 81 |
|
| 82 |
-
|
| 83 |
-
|
| 84 |
# Chainlit app
|
| 85 |
@cl.on_message
|
| 86 |
async def main(message):
|
|
@@ -90,4 +87,4 @@ async def main(message):
|
|
| 90 |
await cl.Message(
|
| 91 |
content=result, # Extract the response from the chain
|
| 92 |
author="AI"
|
| 93 |
-
).send()
|
|
|
|
| 62 |
|
| 63 |
chunked_rag_documents = chunk_documents(rag_documents_1, CHUNK_SIZE, CHUNK_OVERLAP) + \
|
| 64 |
chunk_documents(rag_documents_2, CHUNK_SIZE, CHUNK_OVERLAP)
|
| 65 |
+
|
|
|
|
| 66 |
@cl.on_chat_start
|
| 67 |
async def on_chat_start():
|
| 68 |
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
|
|
|
|
| 78 |
|
| 79 |
cl.user_session.set("chain", rag_chain)
|
| 80 |
|
|
|
|
|
|
|
| 81 |
# Chainlit app
|
| 82 |
@cl.on_message
|
| 83 |
async def main(message):
|
|
|
|
| 87 |
await cl.Message(
|
| 88 |
content=result, # Extract the response from the chain
|
| 89 |
author="AI"
|
| 90 |
+
).send()
|
report/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
report/ragas_finetune.png
ADDED
|
report/ragas_prototype.png
ADDED

|
report/report.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Task 1: Dealing with the Data
|
| 2 |
+
|
| 3 |
+
### 1. Describe the default chunking strategy that you will use.
|
| 4 |
+
I'm going to use **Recursive Chunking** (RecursiveCharacterTextSplitter) from LangChain.
|
| 5 |
+
|
| 6 |
+
### 2. Articulate a chunking strategy that you would also like to test out.
|
| 7 |
+
I would also like to test out **Semantic Chunking** ([LangChain Documentation](https://python.langchain.com/docs/how_to/semantic-chunker/)).
|
| 8 |
+
|
| 9 |
+
### 3. Describe how and why you made these decisions.
|
| 10 |
+
I'm choosing **Recursive Chunking** as the default because, according to LangChain:
|
| 11 |
+
|
| 12 |
+
> "Recursive chunking divides the input text into smaller chunks in a hierarchical and iterative manner using a set of separators. If the initial attempt at splitting the text doesn’t produce chunks of the desired size or structure, the method recursively calls itself on the resulting chunks with a different separator or criterion until the desired chunk size or structure is achieved. This means that while the chunks aren’t going to be exactly the same size, they’ll still ‘aspire’ to be of a similar size."
|
| 13 |
+
|
| 14 |
+
This strategy is simple to implement and allows for consistent chunk sizes, which I believe will make our RAG pipeline perform more predictably compared to using irregular chunk sizes. I reviewed the two documents, and they appear to be standard with no unusual formatting, making this method suitable.
|
| 15 |
+
|
| 16 |
+
I would also like to test out **Semantic Chunking** because it focuses on dividing text based on semantic meaning rather than just character count or separators. This approach could lead to more meaningful chunks, which might improve the quality of document retrieval in the RAG pipeline, especially when dealing with documents with varied lengths and complex content.
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# Task 2: Building a Quick End-to-End Prototype
|
| 20 |
+
|
| 21 |
+
### 1. Build a prototype and deploy to a Hugging Face Space, and create a short (< 2 min) loom video demonstrating some initial testing inputs and outputs.
|
| 22 |
+
<<<<<<< HEAD
|
| 23 |
+
Loom link: https://www.loom.com/share/2ee6825aed60424da6aadc414bbc800a?sid=1994ecda-c52e-4e71-afe9-166e862296e4
|
| 24 |
+
=======
|
| 25 |
+
Link:
|
| 26 |
+
>>>>>>> e107018 (add report)
|
| 27 |
+
|
| 28 |
+
### 2. How did you choose your stack, and why did you select each tool the way you did?
|
| 29 |
+
I built a Retrieval-Augmented Generation (RAG) system with:
|
| 30 |
+
|
| 31 |
+
- **Recursive Chunking**: I used recursive splitting to maintain context across document chunks, ensuring important information isn't cut off while keeping manageable sizes for processing.
|
| 32 |
+
|
| 33 |
+
- **Text-Embedding-3-Small**: This model offers a good balance between performance and efficiency, generating compact embeddings for fast similarity searches without heavy computational costs.
|
| 34 |
+
|
| 35 |
+
- **Qdrant**: I chose Qdrant for its optimized vector similarity search, scalability, and seamless integration with the embedding model, making it ideal for fast, precise retrieval.
|
| 36 |
+
|
| 37 |
+
- **GPT-4o**: As the QA LLM, GPT-4o provides excellent generalization and context-based answers, making it perfect for handling complex queries in this RAG setup.
|
| 38 |
+
|
| 39 |
+
Each tool was selected to balance performance, scalability, and efficiency for the system’s needs and the quick turnaround of a prototype.
|
| 40 |
+
|
| 41 |
+
# Task 3: Creating a Golden Test Data Set
|
| 42 |
+
|
| 43 |
+
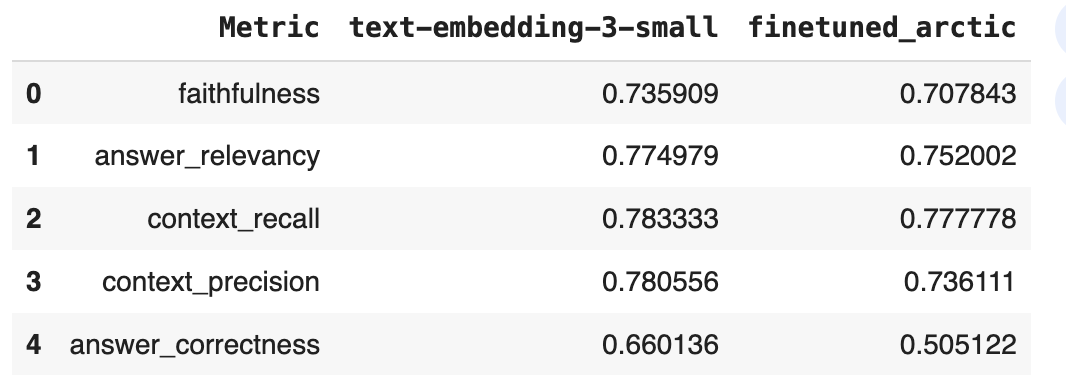
### 1. Assess your pipeline using the RAGAS framework including key metrics faithfulness, answer relevancy, context precision, and context recall. Provide a table of your output results.
|
| 44 |
+

|
| 45 |
+
|
| 46 |
+
### 2. What conclusions can you draw about performance and effectiveness of your pipeline with this information?
|
| 47 |
+
The pipeline shows strong retrieval performance but needs improvement in generating accurate answers:
|
| 48 |
+
|
| 49 |
+
<<<<<<< HEAD
|
| 50 |
+
### What conclusions can you draw about performance and effectiveness of your pipeline with this information?
|
| 51 |
+
|
| 52 |
+
The pipeline demonstrates reasonably strong retrieval capabilities but reveals areas for improvement in the accuracy and relevance of generated answers:
|
| 53 |
+
|
| 54 |
+
- **Context Recall (0.783)** and **Context Precision (0.781)** indicate that the system is retrieving relevant information consistently, suggesting effective document chunking and vector search.
|
| 55 |
+
- **Faithfulness (0.736)** is decent but shows that roughly a quarter of the generated answers are not fully grounded in the retrieved information, which can be problematic in applications requiring high accuracy.
|
| 56 |
+
- **Answer Relevancy (0.775)** is solid, meaning the answers are usually related to the input queries, but there is room for improvement to make responses more directly relevant.
|
| 57 |
+
- **Answer Correctness (0.660)** is relatively low, suggesting that the system often produces answers that aren’t fully correct, likely due to limitations in how well the system understands or interprets the retrieved context.
|
| 58 |
+
|
| 59 |
+
### Summary:
|
| 60 |
+
- The pipeline is doing well at retrieving relevant context, but the generation of accurate and faithful answers needs refinement. This suggests a potential need for either a more advanced QA model or improvements in how retrieved chunks are passed to the answer generation process.
|
| 61 |
+
=======
|
| 62 |
+
### Strengths:
|
| 63 |
+
- **Context Recall (92.2%)** and **Precision (91.9%)** are high, meaning the system effectively retrieves relevant information.
|
| 64 |
+
- **Faithfulness (75.9%)** indicates that the generated answers are mostly grounded in retrieved data.
|
| 65 |
+
|
| 66 |
+
### Weaknesses:
|
| 67 |
+
- **Answer Correctness (52.6%)** and **Relevancy (67.6%)** need improvement, as the system struggles to generate consistently correct and relevant responses.
|
| 68 |
+
|
| 69 |
+
**Summary**: Retrieval is excellent, but the QA generation needs refinement for more accurate answers.
|
| 70 |
+
>>>>>>> e107018 (add report)
|
| 71 |
+
|
| 72 |
+
# Task 4: Fine-Tuning Open-Source Embeddings
|
| 73 |
+
|
| 74 |
+
### 1. Swap out your existing embedding model for the new fine-tuned version. Provide a link to your fine-tuned embedding model on the Hugging Face Hub.
|
| 75 |
+
<<<<<<< HEAD
|
| 76 |
+
Fine-tuning model link: https://huggingface.co/ldldld/snowflake-arctic-embed-m-finetuned
|
| 77 |
+
|
| 78 |
+
### 2. How did you choose the embedding model for this application?
|
| 79 |
+
I selected `Snowflake/snowflake-arctic-embed-m` as the model for fine-tuning. To make this choice, I referred to the `mteb/leaderboard`, filtered for models with fewer than 250M parameters. Then I looked at all the top ranking models, filtered out models from personal accounts and models that require me to execute some suspicious executable. That ultimately left me with `Snowflake/snowflake-arctic-embed-m`, which is actually the one we used in class.
|
| 80 |
+
=======
|
| 81 |
+
|
| 82 |
+
### 2. How did you choose the embedding model for this application?
|
| 83 |
+
>>>>>>> e107018 (add report)
|
| 84 |
+
|
| 85 |
+
# Task 5: Assessing Performance
|
| 86 |
+
|
| 87 |
+
### 1. Test the fine-tuned embedding model using the RAGAS frameworks to quantify any improvements. Provide results in a table.
|
| 88 |
+
<<<<<<< HEAD
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
It seems that off-the-shelve embedding model from OpenAI `text-embedding-3-small` is still better for our RAG, which honestly isn't too surprising.
|
| 92 |
+
=======
|
| 93 |
+
>>>>>>> e107018 (add report)
|
| 94 |
+
|
| 95 |
+
### 2. Test the two chunking strategies using the RAGAS frameworks to quantify any improvements. Provide results in a table.
|
| 96 |
+
|
| 97 |
+
### 3. The AI Solutions Engineer asks you “Which one is the best to test with internal stakeholders next week, and why?”
|
| 98 |
+
<<<<<<< HEAD
|
| 99 |
+
The original prototype is ideal for testing with internal stakeholders next week: it offers strong performance and is straightforward to implement. The only drawback is that it's not open-sourced. If this is a critical requirement, we can confirm with stakeholders and then explore the fine-tuning path. Based on initial results, we could likely fine-tune open-source models to achieve performance similar to that of OpenAI's `text-embedding-3-small`.
|
| 100 |
+
=======
|
| 101 |
+
>>>>>>> e107018 (add report)
|
| 102 |
+
|
| 103 |
+
# Task 6: Managing Your Boss and User Expectations
|
| 104 |
+
|
| 105 |
+
### 1. What is the story that you will give to the CEO to tell the whole company at the launch next month?
|
| 106 |
+
<<<<<<< HEAD
|
| 107 |
+
We're excited to introduce our **AI Industry Insights chatbot**, designed to provide real-time, nuanced guidance on the rapidly evolving impact of AI—especially in the context of politics and ethical enterprise applications. As we move through an election cycle and navigate the uncertainties around AI regulations, our chatbot empowers users to stay informed and make confident decisions. The tool leverages cutting-edge technology, offering insightful, up-to-date information on how AI is shaping industries and government policies. It’s a reliable companion for anyone looking to understand the future of AI in business and governance.
|
| 108 |
+
|
| 109 |
+
### 2. There appears to be important information not included in our build, for instance, the 270-day update on the 2023 executive order on Safe, Secure, and Trustworthy AI. How might you incorporate relevant white-house briefing information into future versions?
|
| 110 |
+
I'd add the new relevant white-house briefing information into the QDrant vectorstore. Then depending on if we use an open-sourced model or not, I'd proceed with re-finetuning the embedding model and evaluate with RAGAS.
|
| 111 |
+
=======
|
| 112 |
+
|
| 113 |
+
### 2. There appears to be important information not included in our build, for instance, the 270-day update on the 2023 executive order on Safe, Secure, and Trustworthy AI. How might you incorporate relevant white-house briefing information into future versions?
|
| 114 |
+
>>>>>>> e107018 (add report)
|
requirements.txt
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
chainlit==0.7.700
|
| 2 |
-
langchain
|
| 3 |
-
langchain-
|
| 4 |
-
langchain-
|
| 5 |
-
langchain-
|
| 6 |
-
langchain-
|
| 7 |
-
langchain-
|
| 8 |
qdrant-client
|
| 9 |
-
|
|
|
|
| 1 |
chainlit==0.7.700
|
| 2 |
+
langchain
|
| 3 |
+
langchain-community
|
| 4 |
+
langchain-core
|
| 5 |
+
langchain-openai
|
| 6 |
+
langchain-qdrant
|
| 7 |
+
langchain-text-splitters
|
| 8 |
qdrant-client
|
| 9 |
+
PyMuPDF
|