
Commit
·
ed0720f
1
Parent(s):
e25e0f3
Upload 43 files
Browse files- .gitattributes +1 -0
- app.ipynb +274 -0
- db/97372335-8399-4edb-90ed-bcaf83a48591/data_level0.bin +3 -0
- db/97372335-8399-4edb-90ed-bcaf83a48591/header.bin +3 -0
- db/97372335-8399-4edb-90ed-bcaf83a48591/index_metadata.pickle +3 -0
- db/97372335-8399-4edb-90ed-bcaf83a48591/length.bin +3 -0
- db/97372335-8399-4edb-90ed-bcaf83a48591/link_lists.bin +3 -0
- db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/data_level0.bin +3 -0
- db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/header.bin +3 -0
- db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/index_metadata.pickle +3 -0
- db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/length.bin +3 -0
- db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/link_lists.bin +3 -0
- db/aa5bd886-4fdf-4d66-965d-18ffddafee21/data_level0.bin +3 -0
- db/aa5bd886-4fdf-4d66-965d-18ffddafee21/header.bin +3 -0
- db/aa5bd886-4fdf-4d66-965d-18ffddafee21/index_metadata.pickle +3 -0
- db/aa5bd886-4fdf-4d66-965d-18ffddafee21/length.bin +3 -0
- db/aa5bd886-4fdf-4d66-965d-18ffddafee21/link_lists.bin +3 -0
- db/b402ad0c-87fe-4eff-b65e-58777a7face5/data_level0.bin +3 -0
- db/b402ad0c-87fe-4eff-b65e-58777a7face5/header.bin +3 -0
- db/b402ad0c-87fe-4eff-b65e-58777a7face5/index_metadata.pickle +3 -0
- db/b402ad0c-87fe-4eff-b65e-58777a7face5/length.bin +3 -0
- db/b402ad0c-87fe-4eff-b65e-58777a7face5/link_lists.bin +3 -0
- db/chroma.sqlite3 +3 -0
- db/e90dea15-53e7-4b41-b502-0ab854ae08d8/data_level0.bin +3 -0
- db/e90dea15-53e7-4b41-b502-0ab854ae08d8/header.bin +3 -0
- db/e90dea15-53e7-4b41-b502-0ab854ae08d8/index_metadata.pickle +3 -0
- db/e90dea15-53e7-4b41-b502-0ab854ae08d8/length.bin +3 -0
- db/e90dea15-53e7-4b41-b502-0ab854ae08d8/link_lists.bin +3 -0
- docs/КоАП РФ.txt +0 -0
- examples/1.png +0 -0
- examples/10.png +0 -0
- examples/11.png +0 -0
- examples/2.png +0 -0
- examples/3.png +0 -0
- examples/4.png +0 -0
- examples/5.png +0 -0
- examples/6.png +0 -0
- examples/7.png +0 -0
- examples/8.png +0 -0
- examples/9.png +0 -0
- generated_additional_llm_answer.csv +0 -0
- generated_questions.csv +0 -0
- preprocess_doc.ipynb +220 -0
- question_generation.ipynb +179 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
db/chroma.sqlite3 filter=lfs diff=lfs merge=lfs -text
|
app.ipynb
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"id": "276ff8dc-703d-4966-918b-983c592e7938",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": [
|
| 10 |
+
"__import__('pysqlite3')\n",
|
| 11 |
+
"import sys\n",
|
| 12 |
+
"sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')\n",
|
| 13 |
+
"import chromadb\n",
|
| 14 |
+
"import torch\n",
|
| 15 |
+
"import gradio as gr\n",
|
| 16 |
+
"from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification, pipeline\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"from langchain.llms import OpenAI, GigaChat\n",
|
| 19 |
+
"from langchain.chains import LLMChain\n",
|
| 20 |
+
"from langchain.prompts import PromptTemplate\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"chatgpt = OpenAI(\n",
|
| 23 |
+
" api_key='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',\n",
|
| 24 |
+
")\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"gigachat = GigaChat(\n",
|
| 27 |
+
" credentials='Y2Y4Yjk5ODUtNThmMC00ODdjLTk5ODItNDdmYzhmNDdmNzE0OjQ5Y2RjNTVkLWFmMGQtNGJlYy04OGNiLTI1Yzc3MmJkMzYwYw==',\n",
|
| 28 |
+
" scope='GIGACHAT_API_PERS',\n",
|
| 29 |
+
" verify_ssl_certs=False\n",
|
| 30 |
+
")\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"llms = {\n",
|
| 33 |
+
" 'ChatGPT': chatgpt,\n",
|
| 34 |
+
" 'GigaChat': gigachat,\n",
|
| 35 |
+
"}\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"# задаем формат вывода модели\n",
|
| 38 |
+
"answer_task_types = {\n",
|
| 39 |
+
" 'Развернутый ответ': 'Ответь достаточно подробно, но не используй ничего лишнего.',\n",
|
| 40 |
+
" 'Только цифры штрафа': 'Ответь в виде <количество> рублей или <диапазон> рублей, и больше ничего не пиши.'\n",
|
| 41 |
+
"}\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"# проверяем с помощью LLM валидность запроса, исключая обработку бессмысленного входа\n",
|
| 44 |
+
"validity_template = '{query}\\n\\nЭто валидный запрос? Ответь да или нет, больше ничего не пиши.'\n",
|
| 45 |
+
"validity_prompt = PromptTemplate(template=validity_template, input_variables=['query'])\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"# получаем ответ модели на запрос, используем его для более качественного поиска Retriever'ом и Cross-Encoder'ом\n",
|
| 48 |
+
"query_template = '{query} Ответь текстом, похожим на закон, не пиши ничего лишнего. Не используй в ответе слово КоАП РФ. Не используй слово \"Россия\".'\n",
|
| 49 |
+
"query_prompt = PromptTemplate(template=query_template, input_variables=['query'])\n",
|
| 50 |
+
"\n",
|
| 51 |
+
"# просим LLM выбрать один из 3 фрагментов текста, выбранных поисковыми моделями, где по мнению модели есть ответ. Если ответа нет, модель нам об этом сообщает\n",
|
| 52 |
+
"choose_answer_template = '1. {text_1}\\n\\n2. {text_2}\\n\\n3. {text_3}\\n\\nЗадание: выбери из перечисленных выше отрывков тот, где есть ответ на вопрос: \"{query}\". В качестве ответа напиши только номер 1, 2 или 3 и все. Если в данных отрывках нет ответа, то напиши \"Нет ответа\".'\n",
|
| 53 |
+
"choose_answer_prompt = PromptTemplate(template=choose_answer_template, input_variables=['text_1', 'text_2', 'text_3', 'query'])\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"# просим LLM ответить на вопрос, опираясь на найденный фрагмент, и в нужном формате, или сообщить, что ответа все-таки нет\n",
|
| 56 |
+
"answer_template = '{text}\\n\\nЗадание: ответь на вопрос по тексту: \"{query}\". {answer_type} Если в данном тексте нет ответа, то напиши \"Нет ответа\".'\n",
|
| 57 |
+
"answer_prompt = PromptTemplate(template=answer_template, input_variables=['text', 'query', 'answer_type'])\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"client = chromadb.PersistentClient(path='db')\n",
|
| 60 |
+
"collection = client.get_collection(name=\"administrative_codex\")\n",
|
| 61 |
+
"\n",
|
| 62 |
+
"retriever_checkpoint = 'sentence-transformers/LaBSE'\n",
|
| 63 |
+
"retriever_tokenizer = AutoTokenizer.from_pretrained(retriever_checkpoint)\n",
|
| 64 |
+
"retriever_model = AutoModel.from_pretrained(retriever_checkpoint)\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"cross_encoder_checkpoint = 'jeffwan/mmarco-mMiniLMv2-L12-H384-v1'\n",
|
| 67 |
+
"cross_encoder_model = AutoModelForSequenceClassification.from_pretrained(cross_encoder_checkpoint)\n",
|
| 68 |
+
"cross_encoder_tokenizer = AutoTokenizer.from_pretrained(cross_encoder_checkpoint)\n",
|
| 69 |
+
"cross_encoder = pipeline('text-classification', model=cross_encoder_model, tokenizer=cross_encoder_tokenizer)"
|
| 70 |
+
]
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"cell_type": "code",
|
| 74 |
+
"execution_count": 6,
|
| 75 |
+
"id": "ca60b616-97f4-4d01-b0f5-4a994d11e216",
|
| 76 |
+
"metadata": {
|
| 77 |
+
"scrolled": true
|
| 78 |
+
},
|
| 79 |
+
"outputs": [
|
| 80 |
+
{
|
| 81 |
+
"name": "stdout",
|
| 82 |
+
"output_type": "stream",
|
| 83 |
+
"text": [
|
| 84 |
+
"Running on local URL: http://127.0.0.1:7864\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"To create a public link, set `share=True` in `launch()`.\n"
|
| 87 |
+
]
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"data": {
|
| 91 |
+
"text/html": [
|
| 92 |
+
"<div><iframe src=\"http://127.0.0.1:7864/\" width=\"100%\" height=\"500\" allow=\"autoplay; camera; microphone; clipboard-read; clipboard-write;\" frameborder=\"0\" allowfullscreen></iframe></div>"
|
| 93 |
+
],
|
| 94 |
+
"text/plain": [
|
| 95 |
+
"<IPython.core.display.HTML object>"
|
| 96 |
+
]
|
| 97 |
+
},
|
| 98 |
+
"metadata": {},
|
| 99 |
+
"output_type": "display_data"
|
| 100 |
+
},
|
| 101 |
+
{
|
| 102 |
+
"data": {
|
| 103 |
+
"text/plain": []
|
| 104 |
+
},
|
| 105 |
+
"execution_count": 6,
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"output_type": "execute_result"
|
| 108 |
+
}
|
| 109 |
+
],
|
| 110 |
+
"source": [
|
| 111 |
+
"def encode(docs):\n",
|
| 112 |
+
" if type(docs) == str:\n",
|
| 113 |
+
" docs = [docs]\n",
|
| 114 |
+
"\n",
|
| 115 |
+
" encoded_input = retriever_tokenizer(\n",
|
| 116 |
+
" docs,\n",
|
| 117 |
+
" padding=True,\n",
|
| 118 |
+
" truncation=True,\n",
|
| 119 |
+
" max_length=512,\n",
|
| 120 |
+
" return_tensors='pt'\n",
|
| 121 |
+
" )\n",
|
| 122 |
+
" \n",
|
| 123 |
+
" with torch.no_grad():\n",
|
| 124 |
+
" model_output = retriever_model(**encoded_input)\n",
|
| 125 |
+
" \n",
|
| 126 |
+
" embeddings = model_output.pooler_output\n",
|
| 127 |
+
" embeddings = torch.nn.functional.normalize(embeddings)\n",
|
| 128 |
+
" return embeddings.detach().cpu().tolist()\n",
|
| 129 |
+
"\n",
|
| 130 |
+
"\n",
|
| 131 |
+
"def re_rank(sentence, docs):\n",
|
| 132 |
+
" return [res['score'] for res in cross_encoder([{'text': sentence, 'text_pair': doc} for doc in docs], max_length=512, truncation=True)]\n",
|
| 133 |
+
"\n",
|
| 134 |
+
"\n",
|
| 135 |
+
"def update_query_with_llm(query, llm_type, use_llm_for_retriever):\n",
|
| 136 |
+
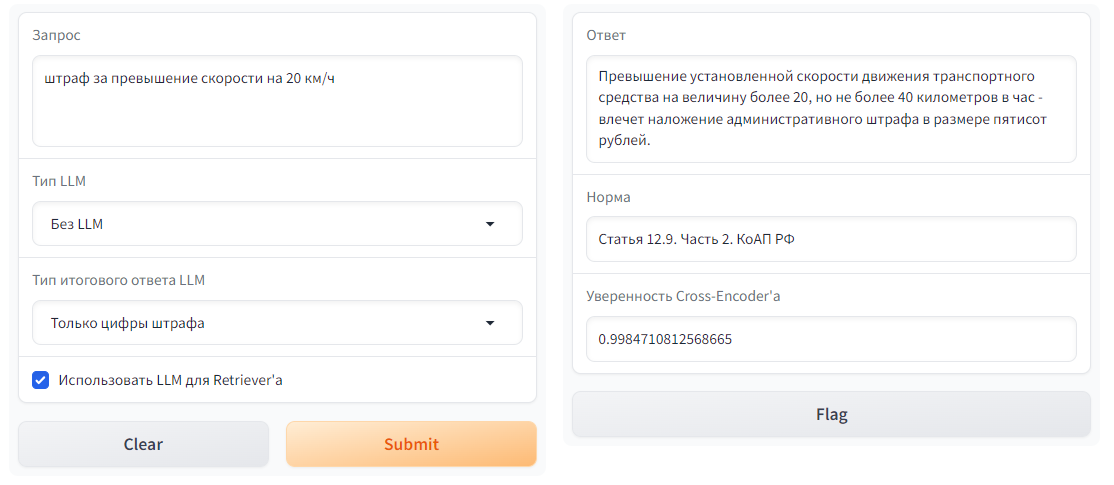
" if llm_type == 'Без LLM' or not use_llm_for_retriever:\n",
|
| 137 |
+
" return query\n",
|
| 138 |
+
" \n",
|
| 139 |
+
" llm_chain = LLMChain(prompt=query_prompt, llm=llms[llm_type])\n",
|
| 140 |
+
" return f'{query} {llm_chain.run(query).strip()}'\n",
|
| 141 |
+
"\n",
|
| 142 |
+
"\n",
|
| 143 |
+
"def answer_with_llm(query, re_ranked_res, llm_type, llm_answer_type):\n",
|
| 144 |
+
" if llm_type == 'Без LLM':\n",
|
| 145 |
+
" answer, metadata, re_ranker_score = re_ranked_res[0]\n",
|
| 146 |
+
" else:\n",
|
| 147 |
+
" llm_chain = LLMChain(prompt=choose_answer_prompt, llm=llms[llm_type])\n",
|
| 148 |
+
" llm_chain_dict = {f'text_{i}': res[0] for i, res in enumerate(re_ranked_res, start=1)}\n",
|
| 149 |
+
" llm_chain_dict['query'] = query\n",
|
| 150 |
+
"\n",
|
| 151 |
+
" llm_res = llm_chain.run(llm_chain_dict).strip()\n",
|
| 152 |
+
"\n",
|
| 153 |
+
" if 'нет ответа' in llm_res.lower() or not llm_res[0].isnumeric():\n",
|
| 154 |
+
" return 'Нет ответа', '', ''\n",
|
| 155 |
+
" \n",
|
| 156 |
+
" most_suitable_text, metadata, re_ranker_score = re_ranked_res[int(llm_res[0]) - 1]\n",
|
| 157 |
+
"\n",
|
| 158 |
+
" llm_chain = LLMChain(prompt=answer_prompt, llm=llms[llm_type])\n",
|
| 159 |
+
" answer = llm_chain.run({'text': most_suitable_text, 'query': query, 'answer_type': llm_answer_type}).strip()\n",
|
| 160 |
+
"\n",
|
| 161 |
+
" if 'нет ответа' in answer.lower():\n",
|
| 162 |
+
" answer = 'Нет ответа'\n",
|
| 163 |
+
"\n",
|
| 164 |
+
" # если LLM сначала выбрала фрагмент, где есть ответ, а потом не смогла ответить на вопрос (что бывает редко), то все равно порекомендуем пользователю обратиться к норме\n",
|
| 165 |
+
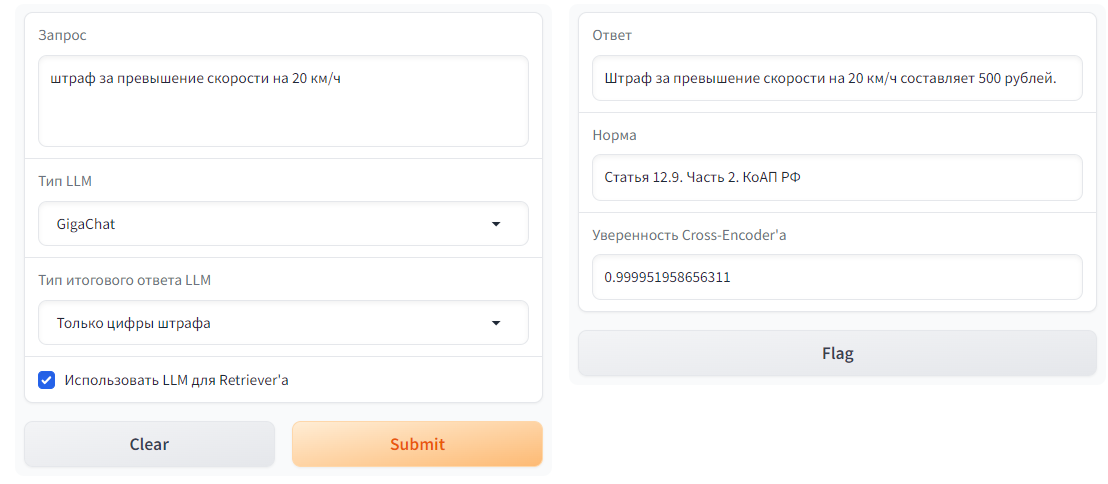
" law_norm = f\"{'Попробуйте обратиться к этому источнику: ' if answer == 'Нет ответа' else ''}{metadata['article']} {metadata['point']} {metadata['doc']}\"\n",
|
| 166 |
+
" return answer, law_norm, re_ranker_score\n",
|
| 167 |
+
"\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"def check_request_validity(func):\n",
|
| 170 |
+
" def wrapper(\n",
|
| 171 |
+
" query,\n",
|
| 172 |
+
" llm_type,\n",
|
| 173 |
+
" llm_answer_type,\n",
|
| 174 |
+
" use_llm_for_retriever,\n",
|
| 175 |
+
" use_llm_for_request_validation\n",
|
| 176 |
+
" ):\n",
|
| 177 |
+
" query = query.strip()\n",
|
| 178 |
+
" \n",
|
| 179 |
+
" if not query:\n",
|
| 180 |
+
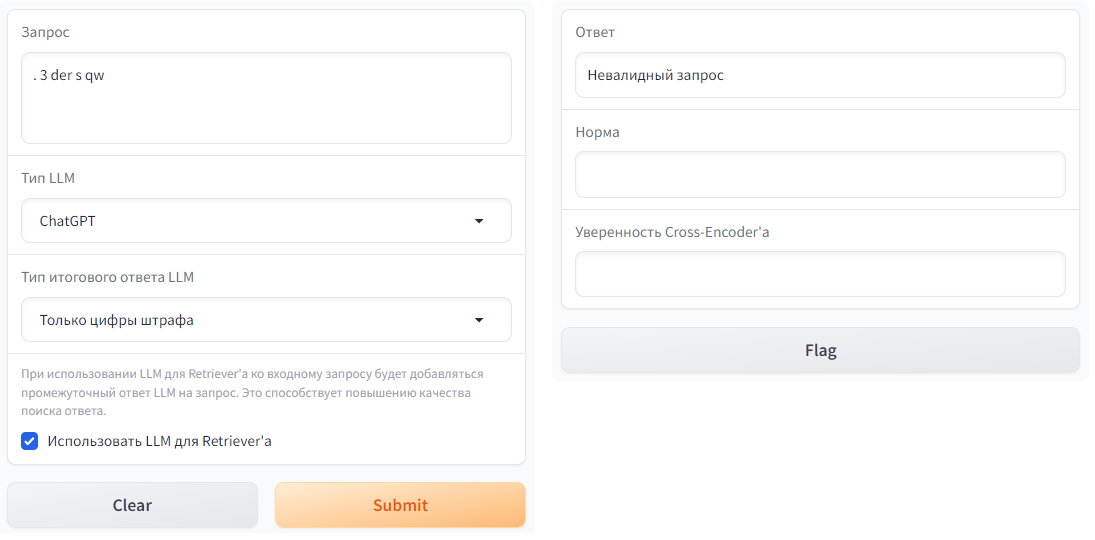
" return 'Невалидный запрос', '', ''\n",
|
| 181 |
+
" \n",
|
| 182 |
+
" if llm_type == 'Без LLM' or not use_llm_for_request_validation:\n",
|
| 183 |
+
" return func(query, llm_type, llm_answer_type, use_llm_for_retriever)\n",
|
| 184 |
+
" \n",
|
| 185 |
+
" llm_chain = LLMChain(prompt=validity_prompt, llm=llms[llm_type])\n",
|
| 186 |
+
"\n",
|
| 187 |
+
" if 'нет' in llm_chain.run(query).lower():\n",
|
| 188 |
+
" return 'Невалидный запрос', '', ''\n",
|
| 189 |
+
" \n",
|
| 190 |
+
" return func(query, llm_type, llm_answer_type, use_llm_for_retriever)\n",
|
| 191 |
+
" \n",
|
| 192 |
+
" return wrapper\n",
|
| 193 |
+
"\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"@check_request_validity\n",
|
| 196 |
+
"def fn(\n",
|
| 197 |
+
" query,\n",
|
| 198 |
+
" llm_type,\n",
|
| 199 |
+
" llm_answer_type,\n",
|
| 200 |
+
" use_llm_for_retriever\n",
|
| 201 |
+
"):\n",
|
| 202 |
+
" # обогатим запрос с помощью LLM, чтобы поис��овым моделям было проще найти нужный фрагмент с ответом\n",
|
| 203 |
+
" retriever_ranker_query = update_query_with_llm(query, llm_type, use_llm_for_retriever)\n",
|
| 204 |
+
"\n",
|
| 205 |
+
" # Retriever-поиск по базе данных\n",
|
| 206 |
+
" retriever_res = collection.query(\n",
|
| 207 |
+
" query_embeddings=encode(retriever_ranker_query),\n",
|
| 208 |
+
" n_results=10,\n",
|
| 209 |
+
" )\n",
|
| 210 |
+
"\n",
|
| 211 |
+
" top_k_docs = retriever_res['documents'][0]\n",
|
| 212 |
+
"\n",
|
| 213 |
+
" # re-ranking с помощью Cross-Encoder'а и отбор лучших кандидатов\n",
|
| 214 |
+
" re_rank_scores = re_rank(retriever_ranker_query, top_k_docs)\n",
|
| 215 |
+
" re_ranked_res = sorted(\n",
|
| 216 |
+
" [[doc, meta, score] for doc, meta, score in zip(retriever_res['documents'][0], retriever_res['metadatas'][0], re_rank_scores)],\n",
|
| 217 |
+
" key=lambda x: x[-1],\n",
|
| 218 |
+
" reverse=True,\n",
|
| 219 |
+
" )[:3]\n",
|
| 220 |
+
"\n",
|
| 221 |
+
" # поиск ответа и нормы с помощью LLM\n",
|
| 222 |
+
" return answer_with_llm(query, re_ranked_res, llm_type, llm_answer_type)\n",
|
| 223 |
+
"\n",
|
| 224 |
+
"\n",
|
| 225 |
+
"demo = gr.Interface(\n",
|
| 226 |
+
" fn=fn,\n",
|
| 227 |
+
" inputs=[\n",
|
| 228 |
+
" gr.Textbox(lines=3, label='Запрос', placeholder='Введите запрос'),\n",
|
| 229 |
+
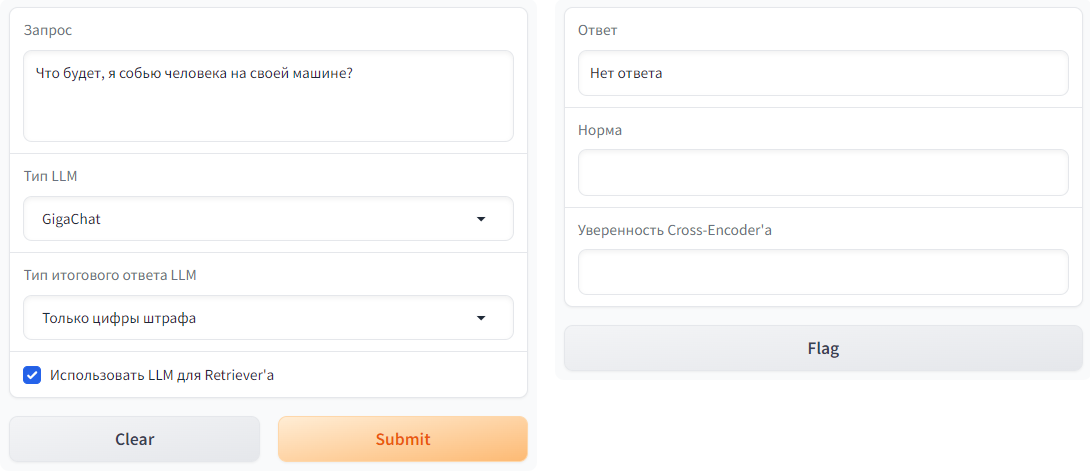
" gr.Dropdown(label='Тип LLM', choices=['ChatGPT', 'GigaChat', 'Без LLM'], value='ChatGPT'),\n",
|
| 230 |
+
" gr.Dropdown(label='Тип итогового ответа LLM', choices=['Только цифры штрафа', 'Развернутый ответ'], value='Только цифры штрафа'),\n",
|
| 231 |
+
" gr.Checkbox(label=\"Использовать LLM для Retriever'а\", value=True, info=\"При использовании LLM для Retriever'а ко входному запросу будет добавляться промежуточный ответ LLM на запрос. Это способствует повышению качества поиска ответа.\"),\n",
|
| 232 |
+
" gr.Checkbox(label=\"Использовать LLM для проверки валидности запроса\", value=False)\n",
|
| 233 |
+
" ],\n",
|
| 234 |
+
" outputs=[\n",
|
| 235 |
+
" gr.Textbox(label='Ответ'),\n",
|
| 236 |
+
" gr.Textbox(label='Норма'),\n",
|
| 237 |
+
" gr.Textbox(label=\"Уверенность Cross-Encoder'а\"),\n",
|
| 238 |
+
" ],\n",
|
| 239 |
+
")\n",
|
| 240 |
+
"\n",
|
| 241 |
+
"demo.launch()"
|
| 242 |
+
]
|
| 243 |
+
},
|
| 244 |
+
{
|
| 245 |
+
"cell_type": "code",
|
| 246 |
+
"execution_count": null,
|
| 247 |
+
"id": "17ebff84-9312-46ae-9972-cd859fad36f9",
|
| 248 |
+
"metadata": {},
|
| 249 |
+
"outputs": [],
|
| 250 |
+
"source": []
|
| 251 |
+
}
|
| 252 |
+
],
|
| 253 |
+
"metadata": {
|
| 254 |
+
"kernelspec": {
|
| 255 |
+
"display_name": "Python 3 (ipykernel)",
|
| 256 |
+
"language": "python",
|
| 257 |
+
"name": "python3"
|
| 258 |
+
},
|
| 259 |
+
"language_info": {
|
| 260 |
+
"codemirror_mode": {
|
| 261 |
+
"name": "ipython",
|
| 262 |
+
"version": 3
|
| 263 |
+
},
|
| 264 |
+
"file_extension": ".py",
|
| 265 |
+
"mimetype": "text/x-python",
|
| 266 |
+
"name": "python",
|
| 267 |
+
"nbconvert_exporter": "python",
|
| 268 |
+
"pygments_lexer": "ipython3",
|
| 269 |
+
"version": "3.8.10"
|
| 270 |
+
}
|
| 271 |
+
},
|
| 272 |
+
"nbformat": 4,
|
| 273 |
+
"nbformat_minor": 5
|
| 274 |
+
}
|
db/97372335-8399-4edb-90ed-bcaf83a48591/data_level0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e861bdd7817a442cd756c01729685476c6d03bf7320edfa45a9d31217dc60f89
|
| 3 |
+
size 6424000
|
db/97372335-8399-4edb-90ed-bcaf83a48591/header.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:995285888fae05329c795e15bef4387c9003f7ed65af6bd46fc6a1220b9e2265
|
| 3 |
+
size 100
|
db/97372335-8399-4edb-90ed-bcaf83a48591/index_metadata.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:659f72af1aa9a4dc9bba946c9c62147869d7b1eaef779684a67821dd6ba565bf
|
| 3 |
+
size 52870
|
db/97372335-8399-4edb-90ed-bcaf83a48591/length.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:135cb2913a715740c00acafbd2a392317f77955f782a1e2974ded7c7f0d769e6
|
| 3 |
+
size 8000
|
db/97372335-8399-4edb-90ed-bcaf83a48591/link_lists.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4c44a130f362f4e7bd70389814b9d8d8889d0d1262ca68d6c5fd7ae2fb11e707
|
| 3 |
+
size 16976
|
db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/data_level0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aef8dfed4c15fb14fd74ce9f26f2aecf739df73b7ae473f2e4a36baa830770d0
|
| 3 |
+
size 6424000
|
db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/header.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:91a34e115568431e60861fa63dee2fbc5eba7750376a27655abbd690383acc8a
|
| 3 |
+
size 100
|
db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/index_metadata.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
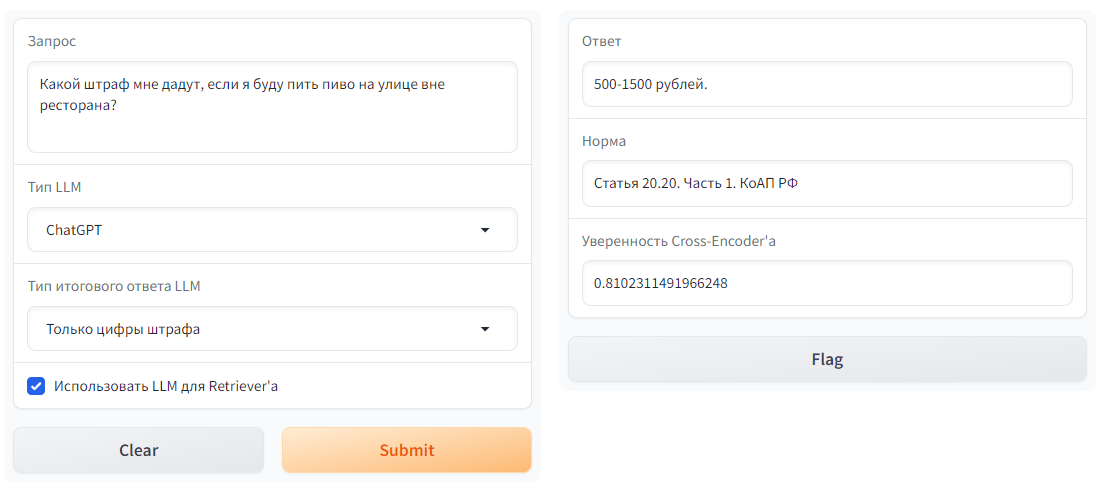
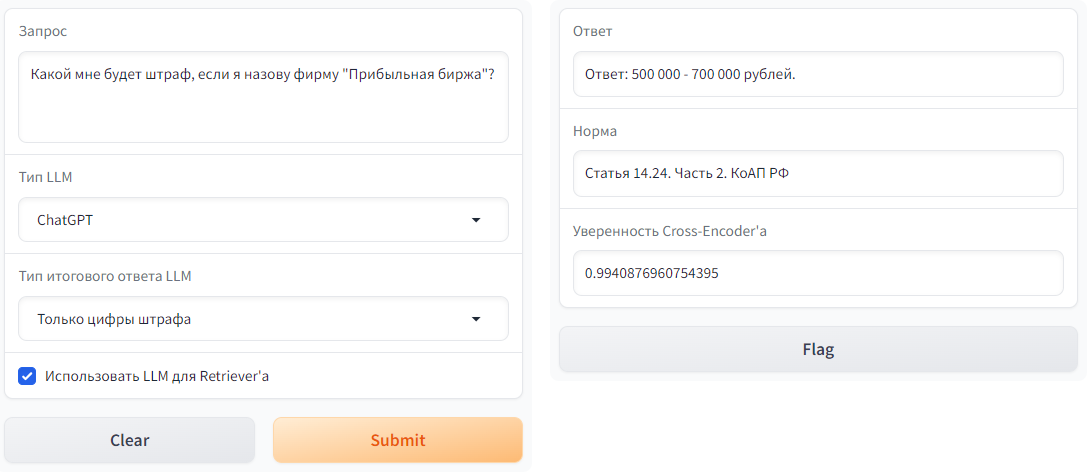
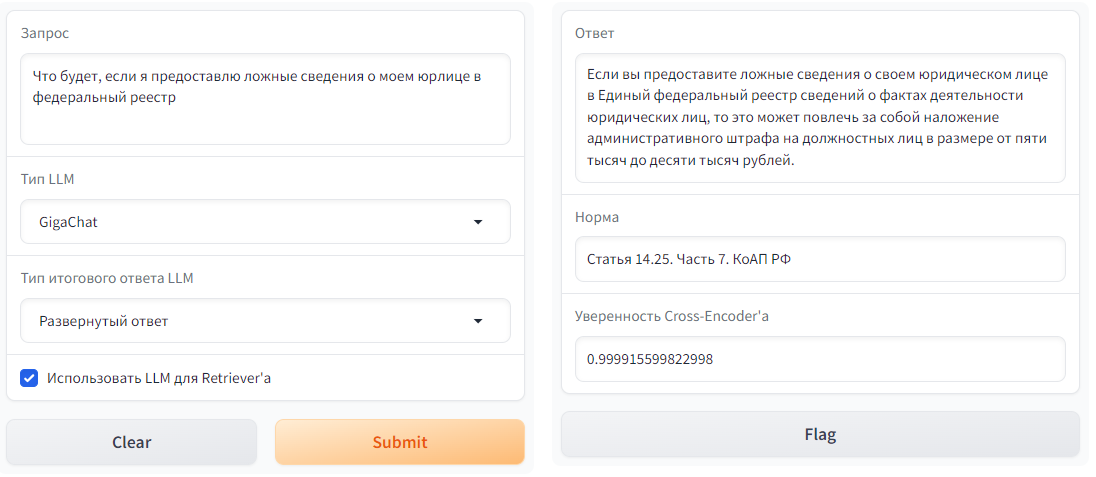
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e015a6c87c458effc1fb3105fbdb92b3681df738b60f2d64624af959b206afe0
|
| 3 |
+
size 52870
|
db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/length.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dd2b7f4046e646fb88c6d837cb3d2067ba3b0d82f256c7f3afe4a5fd4f26a655
|
| 3 |
+
size 8000
|
db/9dc5e8eb-9345-462f-a1fa-938aec17a9a0/link_lists.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6209ce61c94144576d5851341ac04d85cf6b558c02da410e983b3f9290e411bc
|
| 3 |
+
size 16976
|
db/aa5bd886-4fdf-4d66-965d-18ffddafee21/data_level0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d1e1753e5819ae5dffa99158015f31ba066c12ee0e4f657e64dc64660dd7b77f
|
| 3 |
+
size 6424000
|
db/aa5bd886-4fdf-4d66-965d-18ffddafee21/header.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:995285888fae05329c795e15bef4387c9003f7ed65af6bd46fc6a1220b9e2265
|
| 3 |
+
size 100
|
db/aa5bd886-4fdf-4d66-965d-18ffddafee21/index_metadata.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0086f16ab6934ed3c2a5b99a1e9595e150623259c8396e0faf2f26023f20c757
|
| 3 |
+
size 52870
|
db/aa5bd886-4fdf-4d66-965d-18ffddafee21/length.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:38c55df27ec0a8adb0ac1e2d55377a84ddbb939c3f3f9704a150952b067108e5
|
| 3 |
+
size 8000
|
db/aa5bd886-4fdf-4d66-965d-18ffddafee21/link_lists.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6de5ffb84a9d65860195295c241ed10a8618676c290dfa8379158bef5c308f5e
|
| 3 |
+
size 16976
|
db/b402ad0c-87fe-4eff-b65e-58777a7face5/data_level0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b72c643cdc6cdf14f5bf99407c6df138da0ce720c6b2127ee36aea4fe57a3b50
|
| 3 |
+
size 6424000
|
db/b402ad0c-87fe-4eff-b65e-58777a7face5/header.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:995285888fae05329c795e15bef4387c9003f7ed65af6bd46fc6a1220b9e2265
|
| 3 |
+
size 100
|
db/b402ad0c-87fe-4eff-b65e-58777a7face5/index_metadata.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ddf8414b24f52bb480445ed59c48b82cd02324d2668f74f8582e8d16d1558ab
|
| 3 |
+
size 52870
|
db/b402ad0c-87fe-4eff-b65e-58777a7face5/length.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:287895f1d9f79674f38d9748c5e8a38edef18d74567d51b7790eb3094d959605
|
| 3 |
+
size 8000
|
db/b402ad0c-87fe-4eff-b65e-58777a7face5/link_lists.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0c4b1a82fceed2e2b272bffdc76f6dd30062dfa5fcdf3ca1292fd739a764cfdb
|
| 3 |
+
size 16976
|
db/chroma.sqlite3
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c29da25687cacaa124ee55421db14f74f971e5e185a029e7113f3d047bac697f
|
| 3 |
+
size 29159424
|
db/e90dea15-53e7-4b41-b502-0ab854ae08d8/data_level0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:02d382a284aa159c52564b0fc03080a00b4ecbbbbe383781d81f004a21c7e61a
|
| 3 |
+
size 6424000
|
db/e90dea15-53e7-4b41-b502-0ab854ae08d8/header.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:995285888fae05329c795e15bef4387c9003f7ed65af6bd46fc6a1220b9e2265
|
| 3 |
+
size 100
|
db/e90dea15-53e7-4b41-b502-0ab854ae08d8/index_metadata.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ccf1f97bd21b051c83e0e8a19d1e4f7de0972d3095b7b1807f94dfeafc99db89
|
| 3 |
+
size 52870
|
db/e90dea15-53e7-4b41-b502-0ab854ae08d8/length.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cc538b666ab7415eda93fabfb42aa70ec82d57f19509da8eb899e10faa21a153
|
| 3 |
+
size 8000
|
db/e90dea15-53e7-4b41-b502-0ab854ae08d8/link_lists.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:94b06e796bcc2b6f1959f2575e260cc9ed17950526af440de41f1bb7f148ed0f
|
| 3 |
+
size 16976
|
docs/КоАП РФ.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
examples/1.png
ADDED

|
examples/10.png
ADDED
|
examples/11.png
ADDED
|
examples/2.png
ADDED
|
examples/3.png
ADDED
|
examples/4.png
ADDED
|
examples/5.png
ADDED

|
examples/6.png
ADDED

|
examples/7.png
ADDED

|
examples/8.png
ADDED
|
examples/9.png
ADDED
|
generated_additional_llm_answer.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
generated_questions.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
preprocess_doc.ipynb
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"id": "bc1b8947-4397-4fb8-b3ae-310fdb44c056",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": [
|
| 10 |
+
"__import__('pysqlite3')\n",
|
| 11 |
+
"import sys\n",
|
| 12 |
+
"import os\n",
|
| 13 |
+
"sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')\n",
|
| 14 |
+
"os.environ['ALLOW_RESET'] = 'True'\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"import torch\n",
|
| 17 |
+
"from torch.utils.data import DataLoader\n",
|
| 18 |
+
"from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification, pipeline\n",
|
| 19 |
+
"import numpy as np\n",
|
| 20 |
+
"from tqdm import tqdm\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"import chromadb"
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "markdown",
|
| 27 |
+
"id": "c0af096a-f302-4df9-9f26-63213ad44b8f",
|
| 28 |
+
"metadata": {},
|
| 29 |
+
"source": [
|
| 30 |
+
"### Подготавливаем базу данных"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"cell_type": "code",
|
| 35 |
+
"execution_count": 12,
|
| 36 |
+
"id": "e5a2886c-586a-49f7-8833-0972407bf1fa",
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"client = chromadb.PersistentClient(path='db')\n",
|
| 41 |
+
"client.reset()\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"collection = client.create_collection(\n",
|
| 44 |
+
" name=\"administrative_codex\",\n",
|
| 45 |
+
" metadata={\"hnsw:space\": \"cosine\"}\n",
|
| 46 |
+
")"
|
| 47 |
+
]
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"cell_type": "markdown",
|
| 51 |
+
"id": "329c4f86-c514-4039-9494-621cb7042f77",
|
| 52 |
+
"metadata": {},
|
| 53 |
+
"source": [
|
| 54 |
+
"### Открываем и предобрабатываем КоАП"
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"cell_type": "code",
|
| 59 |
+
"execution_count": 3,
|
| 60 |
+
"id": "f057b53d-5a50-4a92-bbda-4c8396aca107",
|
| 61 |
+
"metadata": {},
|
| 62 |
+
"outputs": [],
|
| 63 |
+
"source": [
|
| 64 |
+
"with open('docs/КоАП РФ.txt', encoding='utf-8') as r:\n",
|
| 65 |
+
" raw_text = r.read().split('\\n\\n')"
|
| 66 |
+
]
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"cell_type": "markdown",
|
| 70 |
+
"id": "5589508c-5be9-403d-ba68-7a0e60658136",
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"source": [
|
| 73 |
+
"### Делим документ по частям статей, исключаем лишнее"
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"cell_type": "code",
|
| 78 |
+
"execution_count": 9,
|
| 79 |
+
"id": "d7b87b89-5cc2-4c3b-8cee-8ea59b4778a5",
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"outputs": [],
|
| 82 |
+
"source": [
|
| 83 |
+
"paragraphs = []\n",
|
| 84 |
+
"index = 0\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"while index != len(raw_text):\n",
|
| 87 |
+
" if raw_text[index].startswith('Статья'):\n",
|
| 88 |
+
" article = ' '.join(raw_text[index].strip().split()[:2])\n",
|
| 89 |
+
" article_points = raw_text[index + 1].split('\\n')\n",
|
| 90 |
+
"\n",
|
| 91 |
+
" cur_point = ''\n",
|
| 92 |
+
" for i in range(len(article_points)):\n",
|
| 93 |
+
" cur_point_part = article_points[i].strip()\n",
|
| 94 |
+
" \n",
|
| 95 |
+
" if 'КонсультантПлюс' in article_points[i] + article_points[i - 1]:\n",
|
| 96 |
+
" continue\n",
|
| 97 |
+
" elif cur_point_part.split()[0].strip().replace('.', '').isnumeric() or cur_point_part.startswith('Примечание. '):\n",
|
| 98 |
+
" if cur_point:\n",
|
| 99 |
+
" if cur_point.startswith('Примечание. '):\n",
|
| 100 |
+
" paragraphs.append([cur_point, article, 'Примечание.'])\n",
|
| 101 |
+
" elif cur_point[0].isnumeric():\n",
|
| 102 |
+
" paragraphs.append([' '.join(cur_point.split()[1:]), article, f'Часть {cur_point.split()[0]}'])\n",
|
| 103 |
+
" else:\n",
|
| 104 |
+
" paragraphs.append([cur_point, article, ''])\n",
|
| 105 |
+
" \n",
|
| 106 |
+
" cur_point = cur_point_part\n",
|
| 107 |
+
" elif cur_point_part[0] != '(' and cur_point_part[-1] != ')' and 'утратил силу' not in cur_point_part[:20].lower():\n",
|
| 108 |
+
" cur_point += ' ' + cur_point_part\n",
|
| 109 |
+
" \n",
|
| 110 |
+
" index += 2\n",
|
| 111 |
+
" else:\n",
|
| 112 |
+
" index += 1"
|
| 113 |
+
]
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
"cell_type": "markdown",
|
| 117 |
+
"id": "5e574c65-8100-45e3-9d8b-e7a15bfec242",
|
| 118 |
+
"metadata": {},
|
| 119 |
+
"source": [
|
| 120 |
+
"### Получаем эмбеддинги из извлеченных фрагментов и сохраняем их в базу данных"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"cell_type": "code",
|
| 125 |
+
"execution_count": 5,
|
| 126 |
+
"id": "35204261-c2a0-43bc-b167-931154cfb77f",
|
| 127 |
+
"metadata": {},
|
| 128 |
+
"outputs": [],
|
| 129 |
+
"source": [
|
| 130 |
+
"checkpoint = 'sentence-transformers/LaBSE'\n",
|
| 131 |
+
"tokenizer = AutoTokenizer.from_pretrained(checkpoint)\n",
|
| 132 |
+
"model = AutoModel.from_pretrained(checkpoint, device_map='cuda:0')"
|
| 133 |
+
]
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"cell_type": "code",
|
| 137 |
+
"execution_count": 6,
|
| 138 |
+
"id": "7aad08e2-fca0-4cf8-b568-17e5c2b4ffff",
|
| 139 |
+
"metadata": {},
|
| 140 |
+
"outputs": [],
|
| 141 |
+
"source": [
|
| 142 |
+
"def encode(docs):\n",
|
| 143 |
+
" if type(docs) == str:\n",
|
| 144 |
+
" docs = [docs]\n",
|
| 145 |
+
"\n",
|
| 146 |
+
" encoded_input = tokenizer(\n",
|
| 147 |
+
" docs,\n",
|
| 148 |
+
" padding=True,\n",
|
| 149 |
+
" truncation=True,\n",
|
| 150 |
+
" max_length=512,\n",
|
| 151 |
+
" return_tensors='pt'\n",
|
| 152 |
+
" )\n",
|
| 153 |
+
" \n",
|
| 154 |
+
" with torch.no_grad():\n",
|
| 155 |
+
" model_output = model(**encoded_input.to('cuda'))\n",
|
| 156 |
+
" \n",
|
| 157 |
+
" embeddings = model_output.pooler_output\n",
|
| 158 |
+
" embeddings = torch.nn.functional.normalize(embeddings)\n",
|
| 159 |
+
" return embeddings.detach().cpu().tolist()"
|
| 160 |
+
]
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"cell_type": "code",
|
| 164 |
+
"execution_count": 10,
|
| 165 |
+
"id": "f118299e-c57a-40ce-a060-5a86b452cfec",
|
| 166 |
+
"metadata": {},
|
| 167 |
+
"outputs": [],
|
| 168 |
+
"source": [
|
| 169 |
+
"BATCH_SIZE = 128\n",
|
| 170 |
+
"loader = DataLoader(paragraphs, batch_size=BATCH_SIZE)"
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"cell_type": "code",
|
| 175 |
+
"execution_count": 13,
|
| 176 |
+
"id": "95dafd67-f6f8-41e1-a209-6325a23e066f",
|
| 177 |
+
"metadata": {},
|
| 178 |
+
"outputs": [
|
| 179 |
+
{
|
| 180 |
+
"name": "stderr",
|
| 181 |
+
"output_type": "stream",
|
| 182 |
+
"text": [
|
| 183 |
+
"100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 17/17 [00:11<00:00, 1.48it/s]\n"
|
| 184 |
+
]
|
| 185 |
+
}
|
| 186 |
+
],
|
| 187 |
+
"source": [
|
| 188 |
+
"for i, docs in enumerate(tqdm(loader)):\n",
|
| 189 |
+
" embeddings = encode(docs[0])\n",
|
| 190 |
+
" collection.add(\n",
|
| 191 |
+
" documents=docs[0],\n",
|
| 192 |
+
" metadatas=[{'doc': 'КоАП РФ', 'article': a, 'point': p} for a, p in zip(docs[1], docs[2])],\n",
|
| 193 |
+
" embeddings=embeddings,\n",
|
| 194 |
+
" ids=[f'id{i * BATCH_SIZE + j}' for j in range(len(docs[0]))],\n",
|
| 195 |
+
" )"
|
| 196 |
+
]
|
| 197 |
+
}
|
| 198 |
+
],
|
| 199 |
+
"metadata": {
|
| 200 |
+
"kernelspec": {
|
| 201 |
+
"display_name": "Python 3 (ipykernel)",
|
| 202 |
+
"language": "python",
|
| 203 |
+
"name": "python3"
|
| 204 |
+
},
|
| 205 |
+
"language_info": {
|
| 206 |
+
"codemirror_mode": {
|
| 207 |
+
"name": "ipython",
|
| 208 |
+
"version": 3
|
| 209 |
+
},
|
| 210 |
+
"file_extension": ".py",
|
| 211 |
+
"mimetype": "text/x-python",
|
| 212 |
+
"name": "python",
|
| 213 |
+
"nbconvert_exporter": "python",
|
| 214 |
+
"pygments_lexer": "ipython3",
|
| 215 |
+
"version": "3.8.10"
|
| 216 |
+
}
|
| 217 |
+
},
|
| 218 |
+
"nbformat": 4,
|
| 219 |
+
"nbformat_minor": 5
|
| 220 |
+
}
|
question_generation.ipynb
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 14,
|
| 6 |
+
"id": "d024645c",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": [
|
| 10 |
+
"__import__('pysqlite3')\n",
|
| 11 |
+
"import sys\n",
|
| 12 |
+
"import os\n",
|
| 13 |
+
"sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')\n",
|
| 14 |
+
"os.environ['ALLOW_RESET'] = 'True'\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"import pandas as pd\n",
|
| 17 |
+
"from tqdm import tqdm\n",
|
| 18 |
+
"import time\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"import chromadb\n",
|
| 21 |
+
"from gigachat import GigaChat\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"client = chromadb.PersistentClient(path='db')\n",
|
| 24 |
+
"collection = client.get_collection(name=\"administrative_codex\")"
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "code",
|
| 29 |
+
"execution_count": 25,
|
| 30 |
+
"id": "17dae6a5",
|
| 31 |
+
"metadata": {},
|
| 32 |
+
"outputs": [],
|
| 33 |
+
"source": [
|
| 34 |
+
"docs = collection.get()['documents']\n",
|
| 35 |
+
"prompt = 'Задание: напиши в виде нумерованного списка 3 конкретных независимых друг от друга вопроса, ответ на которые можно найти в приведенном тексте. Не упоминай федеральные законы. Не упоминай КоАП.'"
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "markdown",
|
| 40 |
+
"id": "91549726-3c7a-44ef-8519-c1afc3adde0f",
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"source": [
|
| 43 |
+
"### Генерируем вопросы к каждому фрагменту текста"
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"execution_count": 29,
|
| 49 |
+
"id": "06f82948",
|
| 50 |
+
"metadata": {},
|
| 51 |
+
"outputs": [
|
| 52 |
+
{
|
| 53 |
+
"name": "stderr",
|
| 54 |
+
"output_type": "stream",
|
| 55 |
+
"text": [
|
| 56 |
+
"100%|███████████████████████████████████████████████████████████████████████████████| 2130/2130 [54:44<00:00, 1.54s/it]\n"
|
| 57 |
+
]
|
| 58 |
+
}
|
| 59 |
+
],
|
| 60 |
+
"source": [
|
| 61 |
+
"for doc in tqdm(docs[1:]):\n",
|
| 62 |
+
" question_ready = False\n",
|
| 63 |
+
" \n",
|
| 64 |
+
" while not question_ready:\n",
|
| 65 |
+
" try:\n",
|
| 66 |
+
" text = f'{doc}\\n\\n{prompt}'\n",
|
| 67 |
+
" \n",
|
| 68 |
+
" with GigaChat(credentials='N2ZiNDIxZTgtM2Y4Yy00MGJjLWI4OTgtN2M5NGM5MTYzZTNiOmFmYjJmZTUwLTc1OWItNGQ5MC1iMGVmLTMwYTNlODU3YzVmZg==', scope='GIGACHAT_API_PERS', verify_ssl_certs=False) as giga:\n",
|
| 69 |
+
" questions = giga.chat(text).choices[0].message.content\n",
|
| 70 |
+
" \n",
|
| 71 |
+
" question_ready = True\n",
|
| 72 |
+
" except:\n",
|
| 73 |
+
" time.sleep(5)\n",
|
| 74 |
+
"\n",
|
| 75 |
+
" df = pd.read_csv('generated_questions.csv')\n",
|
| 76 |
+
" new_df = pd.DataFrame({'text': [doc], 'questions': [questions]})\n",
|
| 77 |
+
" pd.concat([df, new_df], ignore_index=True).to_csv('generated_questions.csv', index=False)"
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"cell_type": "code",
|
| 82 |
+
"execution_count": 31,
|
| 83 |
+
"id": "2f44eac2-7ce0-4d26-9f4a-41f5bfe0fa44",
|
| 84 |
+
"metadata": {},
|
| 85 |
+
"outputs": [],
|
| 86 |
+
"source": [
|
| 87 |
+
"generated_questions_df = pd.read_csv('generated_questions.csv')\n",
|
| 88 |
+
"docs = generated_questions_df['text'].tolist()\n",
|
| 89 |
+
"generated_questions = generated_questions_df['questions'].tolist()\n",
|
| 90 |
+
"\n",
|
| 91 |
+
"prompt = 'В России. Дай подробный ответ текстом, похожим на закон, не пиши ничего лишнего.'"
|
| 92 |
+
]
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"cell_type": "markdown",
|
| 96 |
+
"id": "90b543f8-0b94-4c0c-8a69-9574b7c54db9",
|
| 97 |
+
"metadata": {},
|
| 98 |
+
"source": [
|
| 99 |
+
"### Генерируем ответы к вопросам, в которых есть слово штраф"
|
| 100 |
+
]
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"cell_type": "code",
|
| 104 |
+
"execution_count": 39,
|
| 105 |
+
"id": "a7937078-6200-44ba-b43f-4867e947b750",
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"outputs": [
|
| 108 |
+
{
|
| 109 |
+
"name": "stderr",
|
| 110 |
+
"output_type": "stream",
|
| 111 |
+
"text": [
|
| 112 |
+
"100%|███████████████████████████████████████████████████████████████████████████████| 1978/1978 [50:30<00:00, 1.53s/it]\n"
|
| 113 |
+
]
|
| 114 |
+
}
|
| 115 |
+
],
|
| 116 |
+
"source": [
|
| 117 |
+
"for doc, g_questions in zip(tqdm(docs[153:]), generated_questions[153:]):\n",
|
| 118 |
+
" llm_answer_ready = False\n",
|
| 119 |
+
" fine_question = ''\n",
|
| 120 |
+
"\n",
|
| 121 |
+
" for question in g_questions.split('\\n'):\n",
|
| 122 |
+
" question = ' '.join(question.split()[1:])\n",
|
| 123 |
+
" \n",
|
| 124 |
+
" if 'штраф' in question:\n",
|
| 125 |
+
" fine_question = question\n",
|
| 126 |
+
" break\n",
|
| 127 |
+
"\n",
|
| 128 |
+
" if not fine_question:\n",
|
| 129 |
+
" continue\n",
|
| 130 |
+
" \n",
|
| 131 |
+
" while not llm_answer_ready:\n",
|
| 132 |
+
" try:\n",
|
| 133 |
+
" text = f'Помоги, пожалуйста. {fine_question} {prompt}'\n",
|
| 134 |
+
" \n",
|
| 135 |
+
" with GigaChat(credentials='MmU3OTdhNmItMTQzYy00NGQzLWEyYTctZjcxOWJmYThiMWE5OmE1ZDdhNDkxLWI5ZTEtNGFkZS04N2JjLTExZjE5MTYwNGQ5Yg==', scope='GIGACHAT_API_PERS', verify_ssl_certs=False) as giga:\n",
|
| 136 |
+
" llm_answer = giga.chat(text).choices[0].message.content.split('\\n')[0]\n",
|
| 137 |
+
" \n",
|
| 138 |
+
" llm_answer_ready = True\n",
|
| 139 |
+
" except:\n",
|
| 140 |
+
" time.sleep(5)\n",
|
| 141 |
+
"\n",
|
| 142 |
+
" \n",
|
| 143 |
+
" if len(llm_answer) > 100:\n",
|
| 144 |
+
" df = pd.read_csv('generated_additional_llm_answer.csv')\n",
|
| 145 |
+
" new_df = pd.DataFrame({'text': [doc], 'question': [fine_question], 'llm_answer': [llm_answer]})\n",
|
| 146 |
+
" pd.concat([df, new_df], ignore_index=True).to_csv('generated_additional_llm_answer.csv', index=False)"
|
| 147 |
+
]
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"cell_type": "code",
|
| 151 |
+
"execution_count": null,
|
| 152 |
+
"id": "5fd64855-01b5-4c66-a425-b6d91b355a22",
|
| 153 |
+
"metadata": {},
|
| 154 |
+
"outputs": [],
|
| 155 |
+
"source": []
|
| 156 |
+
}
|
| 157 |
+
],
|
| 158 |
+
"metadata": {
|
| 159 |
+
"kernelspec": {
|
| 160 |
+
"display_name": "Python 3 (ipykernel)",
|
| 161 |
+
"language": "python",
|
| 162 |
+
"name": "python3"
|
| 163 |
+
},
|
| 164 |
+
"language_info": {
|
| 165 |
+
"codemirror_mode": {
|
| 166 |
+
"name": "ipython",
|
| 167 |
+
"version": 3
|
| 168 |
+
},
|
| 169 |
+
"file_extension": ".py",
|
| 170 |
+
"mimetype": "text/x-python",
|
| 171 |
+
"name": "python",
|
| 172 |
+
"nbconvert_exporter": "python",
|
| 173 |
+
"pygments_lexer": "ipython3",
|
| 174 |
+
"version": "3.8.10"
|
| 175 |
+
}
|
| 176 |
+
},
|
| 177 |
+
"nbformat": 4,
|
| 178 |
+
"nbformat_minor": 5
|
| 179 |
+
}
|