
(Speech recognition) Implement sampling (#1)
Browse files* (Speech recognition) Implement sampling
* Self-review
- .readthedocs.yaml +4 -1
- docs/source/img/hello-sampling.png +0 -0
- docs/source/img/hello-sound.png +0 -0
- docs/source/img/real-vs-sampling.png +0 -0
- docs/source/img/sampling-sound-wave.gif +0 -0
- docs/source/img/sound-wave.png +0 -0
- docs/source/img/speech-processing.png +0 -0
- docs/source/lamassu.rst +1 -4
- docs/source/speech/sampling.rst +68 -0
- lamassu/__init__.py +0 -0
- lamassu/speech/__init__.py +0 -0
- lamassu/speech/sampling.py +16 -0
- setup.py +1 -1
.readthedocs.yaml
CHANGED
|
@@ -23,4 +23,7 @@ sphinx:
|
|
| 23 |
|
| 24 |
python:
|
| 25 |
install:
|
| 26 |
-
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
|
| 24 |
python:
|
| 25 |
install:
|
| 26 |
+
- method: pip
|
| 27 |
+
path: .
|
| 28 |
+
- requirements: requirements.txt
|
| 29 |
+
- requirements: docs/source/requirements.txt
|
docs/source/img/hello-sampling.png
ADDED

|
docs/source/img/hello-sound.png
ADDED
|
docs/source/img/real-vs-sampling.png
ADDED
|
docs/source/img/sampling-sound-wave.gif
ADDED
|
docs/source/img/sound-wave.png
ADDED
|
docs/source/img/speech-processing.png
ADDED
|
docs/source/lamassu.rst
CHANGED
|
@@ -2,11 +2,8 @@
|
|
| 2 |
Lamassu
|
| 3 |
=======
|
| 4 |
|
| 5 |
-
|
| 6 |
-
Machine Learning
|
| 7 |
-
================
|
| 8 |
-
|
| 9 |
.. toctree::
|
| 10 |
:maxdepth: 100
|
| 11 |
|
| 12 |
machine_learning/rnn
|
|
|
|
|
|
| 2 |
Lamassu
|
| 3 |
=======
|
| 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
.. toctree::
|
| 6 |
:maxdepth: 100
|
| 7 |
|
| 8 |
machine_learning/rnn
|
| 9 |
+
speech/sampling.rst
|
docs/source/speech/sampling.rst
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
===============================
|
| 2 |
+
Speech Recognition with Lamassu
|
| 3 |
+
===============================
|
| 4 |
+
|
| 5 |
+
.. contents:: Table of Contents
|
| 6 |
+
:depth: 2
|
| 7 |
+
|
| 8 |
+
Speech recognition will become a primary way that we interact with computers.
|
| 9 |
+
|
| 10 |
+
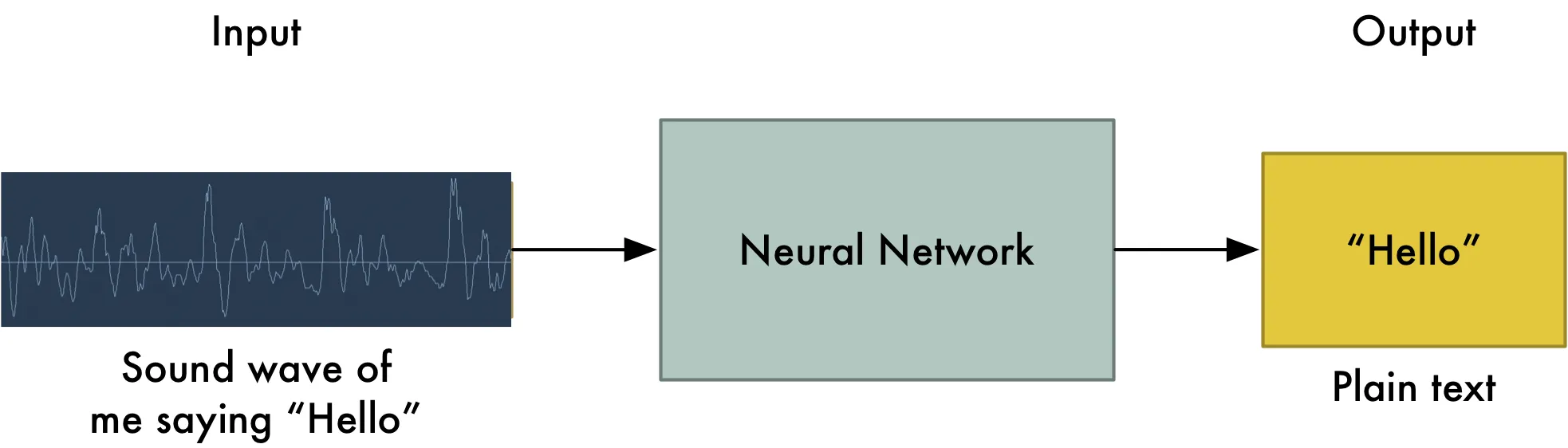
One might guess that we could simply feed sound recordings into a neural network and train it to produce text:
|
| 11 |
+
|
| 12 |
+
.. figure:: ../img/speech-processing.png
|
| 13 |
+
:align: center
|
| 14 |
+
|
| 15 |
+
That's the holy grail of speech recognition with deep learning, but we aren't quite there yet. The big problem is that
|
| 16 |
+
speech varies in speed. One person might say "hello!" very quickly and another person might say
|
| 17 |
+
"heeeelllllllllllllooooo!" very slowly, producing a much longer sound file with much more data. Both sounds should be
|
| 18 |
+
recognized as exactly the same text - "hello!" Automatically aligning audio files of various lengths to a fixed-length
|
| 19 |
+
piece of text turns out to be pretty hard. To work around this, we have to use some special tricks and extra precessing.
|
| 20 |
+
|
| 21 |
+
Turning Sounds into Bits
|
| 22 |
+
========================
|
| 23 |
+
|
| 24 |
+
The first step in speech recognition is obvious — we need to feed sound waves into a computer. Sound is transmitted as
|
| 25 |
+
waves. A sound clip of someone saying "Hello" looks like
|
| 26 |
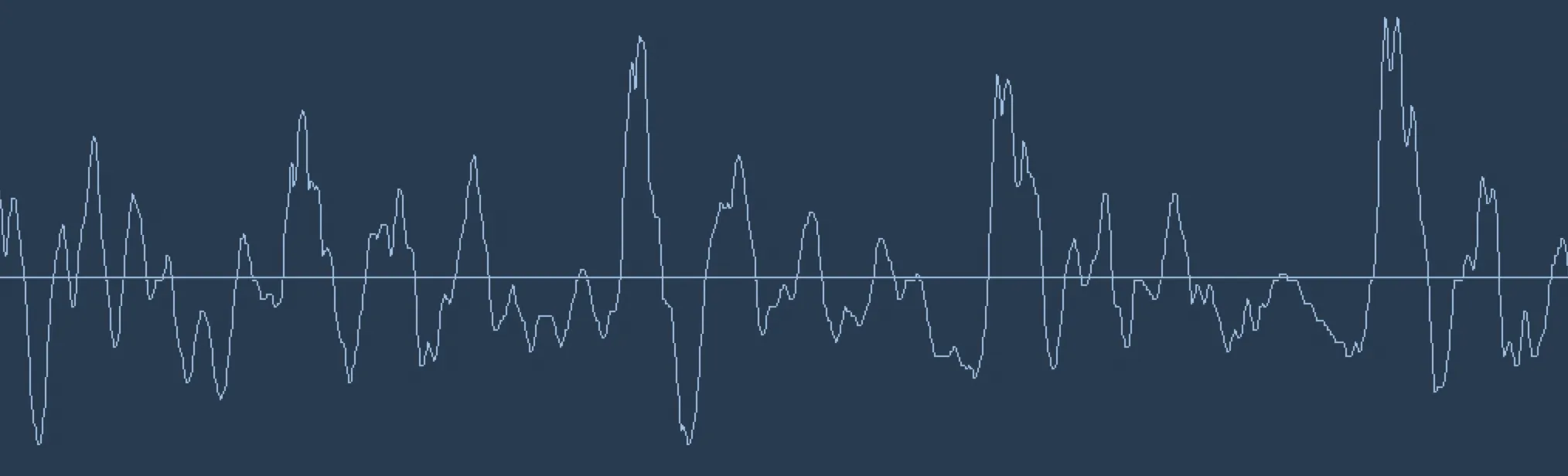
+
|
| 27 |
+
.. figure:: ../img/hello-sound.png
|
| 28 |
+
:align: center
|
| 29 |
+
|
| 30 |
+
Sound waves are one-dimensional. At every moment in time, they have a single value based on the height of the wave.
|
| 31 |
+
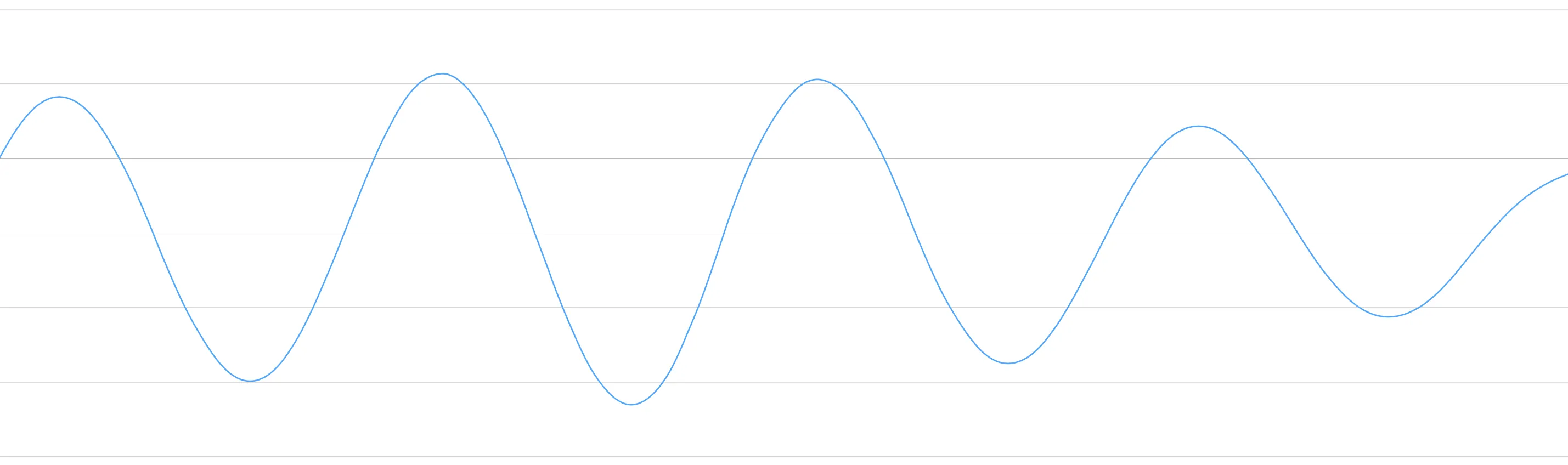
Let's zoom in on one tiny part of the sound wave and take a look:
|
| 32 |
+
|
| 33 |
+
.. figure:: ../img/sound-wave.png
|
| 34 |
+
:align: center
|
| 35 |
+
|
| 36 |
+
To turn this sound wave into numbers, we just record of the height of the wave at equally-spaced points:
|
| 37 |
+
|
| 38 |
+
.. figure:: ../img/sampling-sound-wave.gif
|
| 39 |
+
:align: center
|
| 40 |
+
|
| 41 |
+
This is called *sampling*. We are taking a reading thousands of times a second and recording a number representing the
|
| 42 |
+
height of the sound wave at that point in time. That's basically all an uncompressed .wav audio file is.
|
| 43 |
+
|
| 44 |
+
"CD Quality" audio is sampled at 44.1khz (44,100 readings per second). But for speech recognition, a sampling rate of
|
| 45 |
+
16khz (16,000 samples per second) is enough to cover the frequency range of human speech.
|
| 46 |
+
|
| 47 |
+
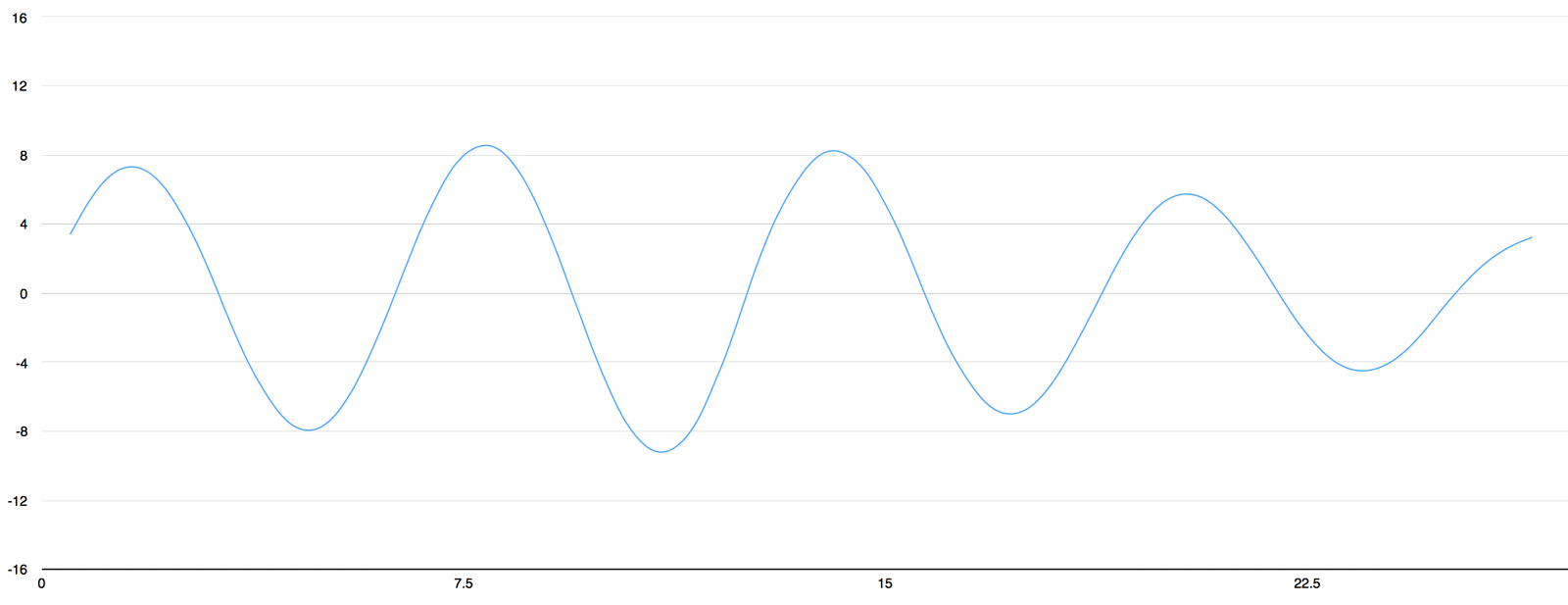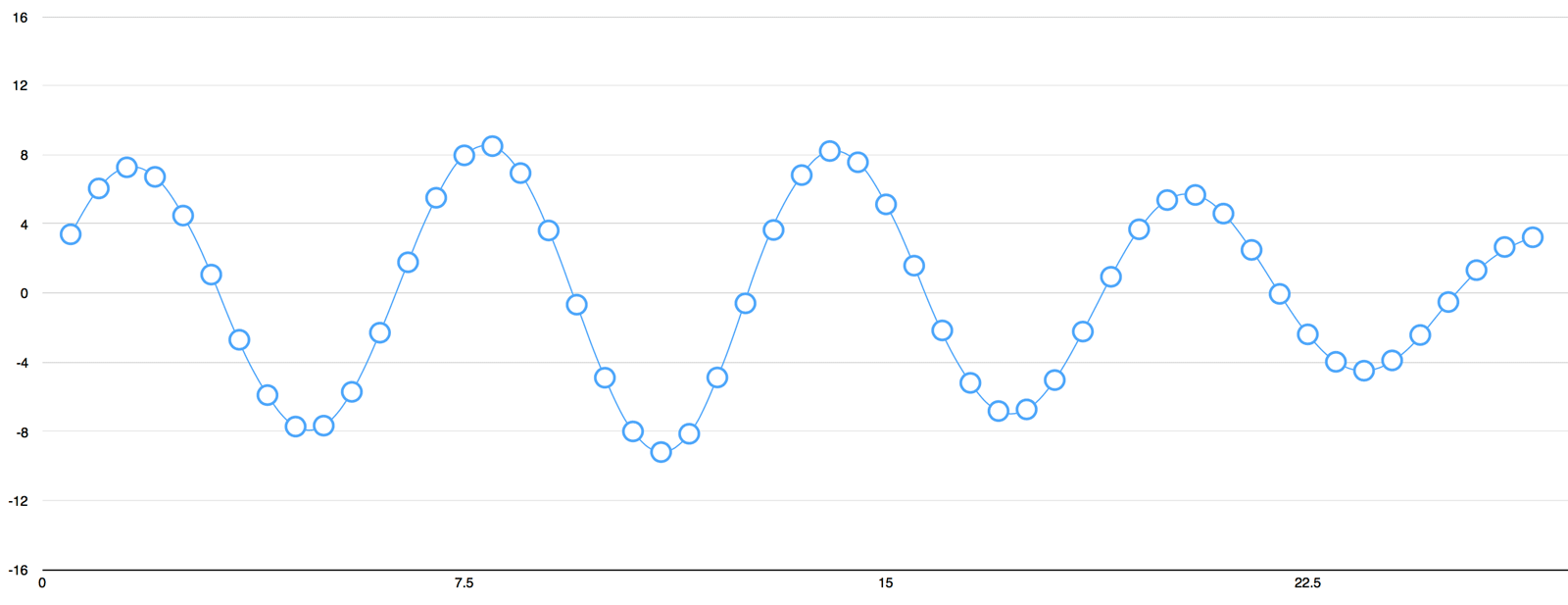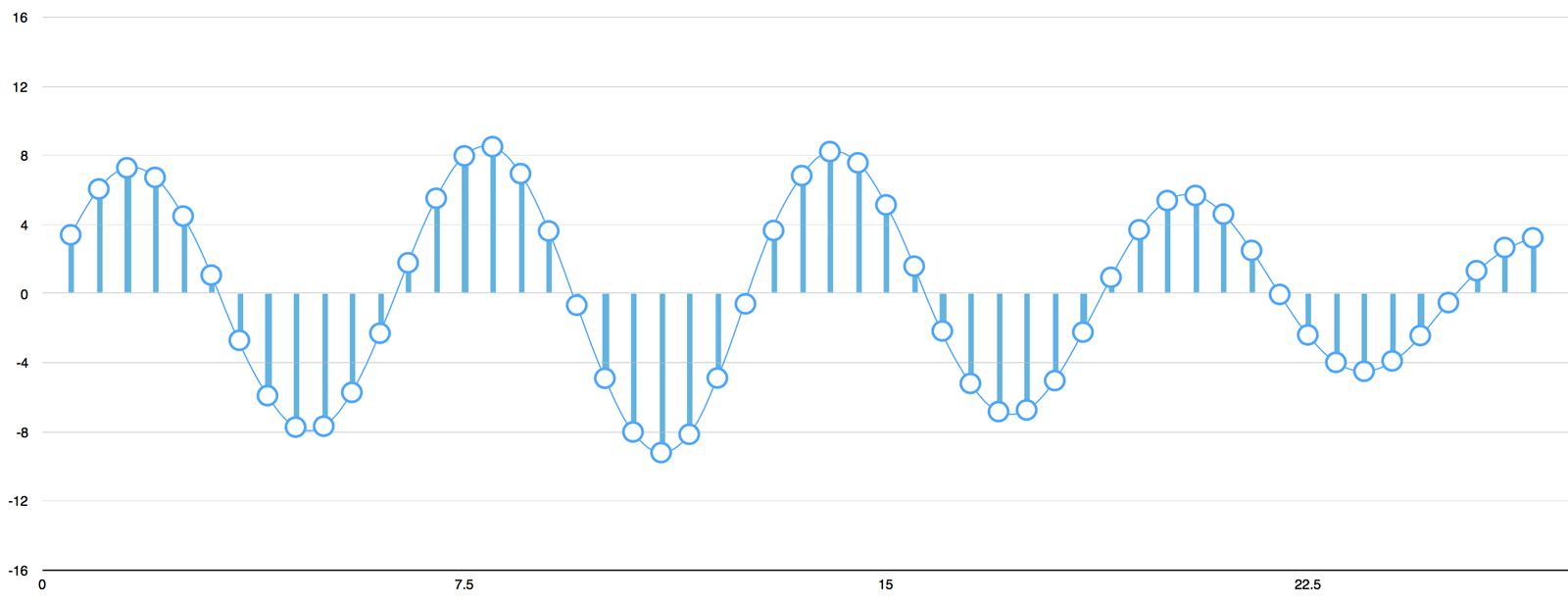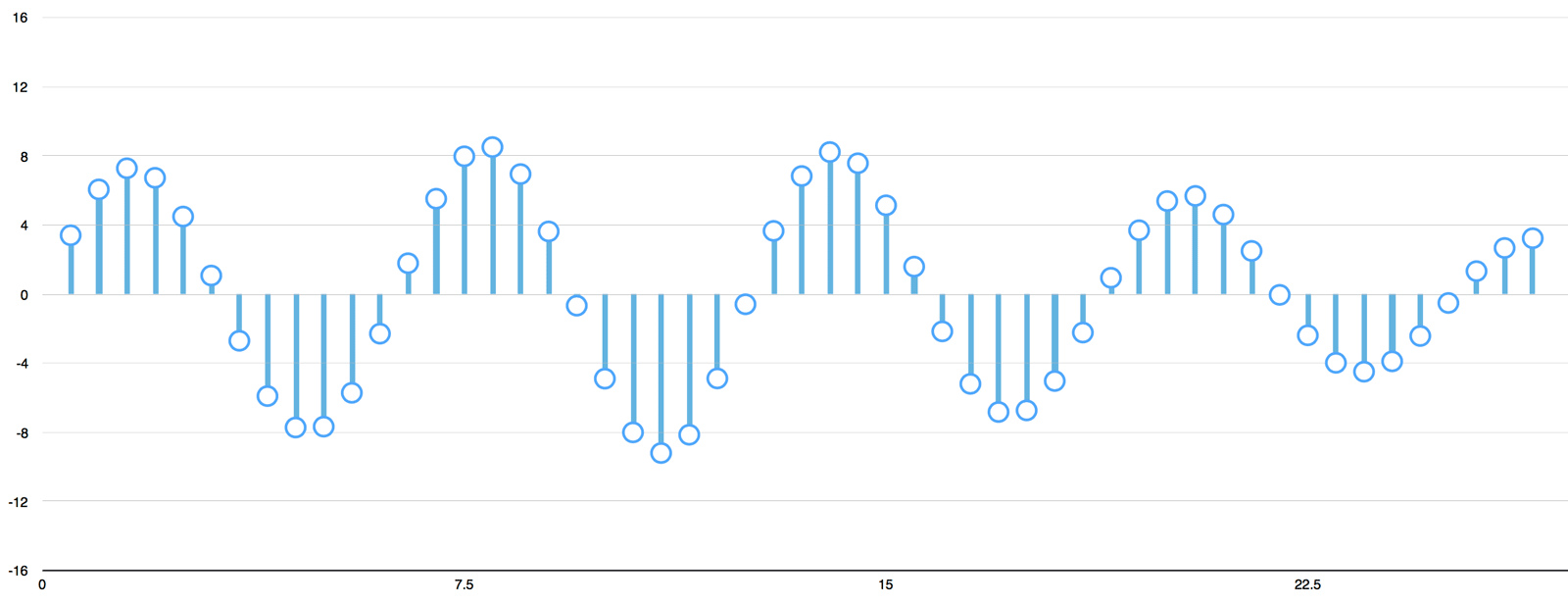
Lets sample our "Hello" sound wave 16,000 times per second. Here's the first 100 samples:
|
| 48 |
+
|
| 49 |
+
.. figure:: ../img/hello-sampling.png
|
| 50 |
+
:align: center
|
| 51 |
+
|
| 52 |
+
.. note:: Can digital samples perfectly recreate the original analog sound wave? What about those gaps?
|
| 53 |
+
|
| 54 |
+
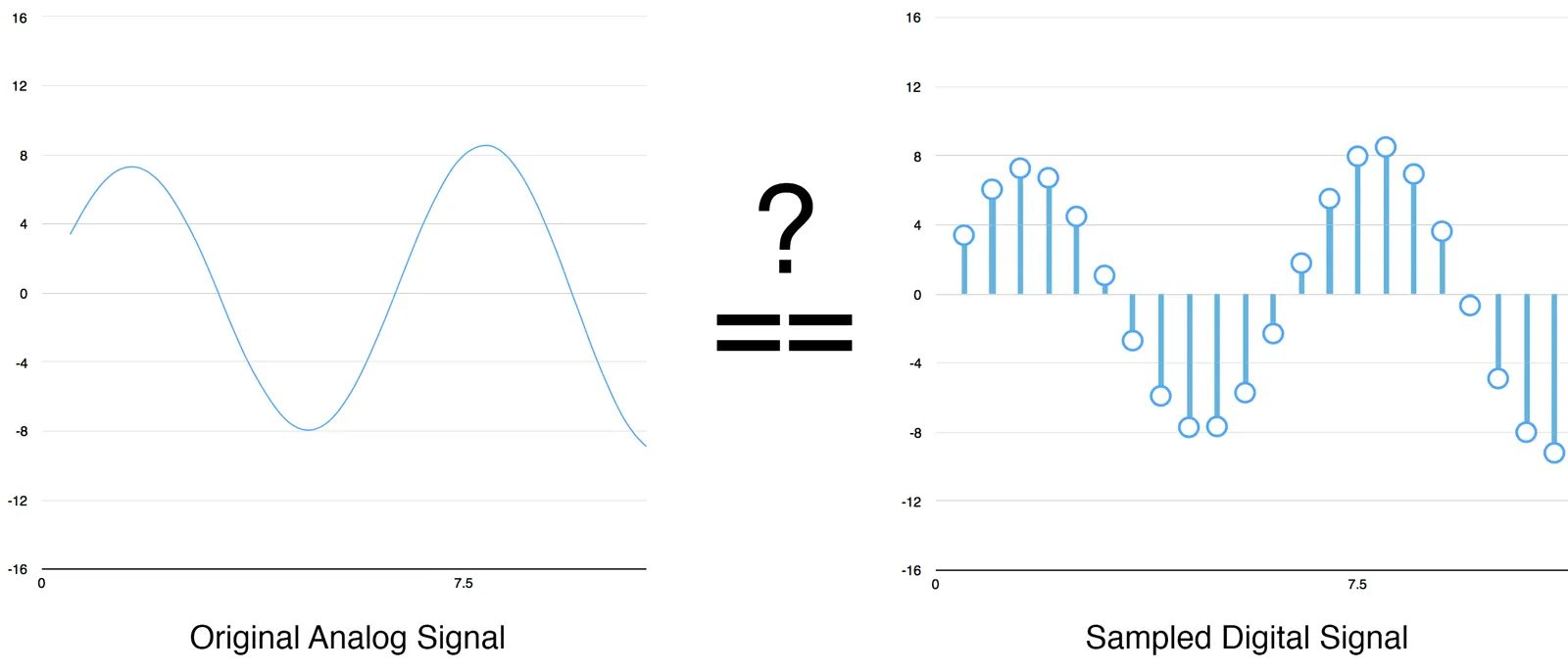
You might be thinking that sampling is only creating a rough approximation of the original sound wave because it's
|
| 55 |
+
only taking occasional readings. There's gaps in between our readings so we must be losing data, right?
|
| 56 |
+
|
| 57 |
+
.. figure:: ../img/real-vs-sampling.png
|
| 58 |
+
:align: center
|
| 59 |
+
|
| 60 |
+
But thanks to the `Nyquist theorem`_, we know that we can use math to perfectly reconstruct the original sound wave
|
| 61 |
+
from the spaced-out samples — as long as we sample at least twice as fast as the highest frequency we want to record.
|
| 62 |
+
|
| 63 |
+
.. automodule:: lamassu.speech.sampling
|
| 64 |
+
:members:
|
| 65 |
+
:undoc-members:
|
| 66 |
+
:show-inheritance:
|
| 67 |
+
|
| 68 |
+
.. _`Nyquist theorem`: https://en.wikipedia.org/wiki/Nyquist%E2%80%93Shannon_sampling_theorem
|
lamassu/__init__.py
ADDED
|
File without changes
|
lamassu/speech/__init__.py
ADDED
|
File without changes
|
lamassu/speech/sampling.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import wave
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def sample_wav(file_path: str):
|
| 7 |
+
"""
|
| 8 |
+
Sampling a .wav file
|
| 9 |
+
|
| 10 |
+
:param file_path: The absolute path to the .wav file to be sampled
|
| 11 |
+
|
| 12 |
+
:return: an array of sampled points
|
| 13 |
+
"""
|
| 14 |
+
with wave.open(file_path, "rb") as f:
|
| 15 |
+
frames = f.readframes(f.getnframes())
|
| 16 |
+
return np.frombuffer(frames, dtype=np.int16)
|
setup.py
CHANGED
|
@@ -2,7 +2,7 @@ from setuptools import setup, find_packages
|
|
| 2 |
|
| 3 |
setup(
|
| 4 |
name="lamassu",
|
| 5 |
-
version="0.0.
|
| 6 |
description="Empowering individual to agnostically run machine learning algorithms to produce ad-hoc AI features",
|
| 7 |
url="https://github.com/QubitPi/lamassu",
|
| 8 |
author="Jiaqi liu",
|
|
|
|
| 2 |
|
| 3 |
setup(
|
| 4 |
name="lamassu",
|
| 5 |
+
version="0.0.9",
|
| 6 |
description="Empowering individual to agnostically run machine learning algorithms to produce ad-hoc AI features",
|
| 7 |
url="https://github.com/QubitPi/lamassu",
|
| 8 |
author="Jiaqi liu",
|