Spaces:
Sleeping

Sleeping

first commit
Browse files- Benchmark1/dataset.jsonl +0 -0
- Benchmark1/gemini.ipynb +0 -0
- Benchmark1/gemini_cm.png +0 -0
- Benchmark1/leaderboard.csv +10 -0
- Benchmark1/openhermes.ipynb +0 -0
- Benchmark1/openhermes_cm.png +0 -0
- Benchmark1/part1.ipynb +0 -0
- Benchmark1/part2.ipynb +0 -0
- Benchmark1/part3.ipynb +0 -0
- Benchmark1/part4.ipynb +0 -0
- Benchmark1/part5.ipynb +0 -0
- Benchmark2/benchmark-2-gemini-pro-and-openhermes-mistral.ipynb +0 -0
- Benchmark2/benchmark-2-llama-2-7b-and-llama-2-13b.ipynb +0 -0
- Benchmark2/benchmark-2-mistral-7b-instruct-v0-2.ipynb +0 -0
- Benchmark2/benchmark-2-openchat-3-5-1210-and-dolphin-2-2-1.ipynb +0 -0
- Benchmark2/leaderboard.csv +8 -0
- README.md +7 -6
- app.py +259 -0
- requirements.txt +3 -0
Benchmark1/dataset.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/gemini.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/gemini_cm.png
ADDED
|
Benchmark1/leaderboard.csv
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Model, Percentage of keys, Percentage of values,Average time (s),Notebook link,License,Link
|
| 2 |
+
Mistral-7B-v0.1,40.68,5.2,90.59,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part1.ipynb,Apache-2.0,https://huggingface.co/mistralai/Mistral-7B-v0.1
|
| 3 |
+
Gemini Pro,96.61,63.37,13.08,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/gemini.ipynb,Google,https://blog.google/technology/ai/gemini-api-developers-cloud/
|
| 4 |
+
Mistral-7B-Instruct-v0.2,62.71,20.52,56.41,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part2.ipynb,Apache-2.0,https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
|
| 5 |
+
Yi-34B-Chat,60.98,19.21,504.82,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part2.ipynb,Yi-license,https://huggingface.co/01-ai/Yi-34B-Chat
|
| 6 |
+
Llama-2-7b-chat-hf,38.98,4.36,144.45,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part3.ipynb,Llama 2 Community,https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
|
| 7 |
+
Llama-2-13b-chat-hf,23.73,2.79,132.26,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part3.ipynb,Llama 2 Community,https://huggingface.co/meta-llama/Llama-2-13b-chat-hf
|
| 8 |
+
OpenHermes-2.5-Mistral-7B,62.71,32.13,55.34,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/openhermes.ipynb,Apache-2.0,https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B
|
| 9 |
+
Openchat-3.5-1210,42.37,19.47,90.98,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part4.ipynb,Apache-2.0,https://huggingface.co/openchat/openchat-3.5-1210
|
| 10 |
+
Dolphin-2.2.1-Mistral-7b,57.63,14.41,51.22,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/part4.ipynb,Apache-2.0,https://huggingface.co/cognitivecomputations/dolphin-2.2.1-mistral-7b
|
Benchmark1/openhermes.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/openhermes_cm.png
ADDED
|
Benchmark1/part1.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/part2.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/part3.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/part4.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark1/part5.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark2/benchmark-2-gemini-pro-and-openhermes-mistral.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark2/benchmark-2-llama-2-7b-and-llama-2-13b.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark2/benchmark-2-mistral-7b-instruct-v0-2.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark2/benchmark-2-openchat-3-5-1210-and-dolphin-2-2-1.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Benchmark2/leaderboard.csv
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Model, Percentage of keys, Percentage of values,Average time (s),Notebook link,License,Link
|
| 2 |
+
OpenHermes-2.5-Mistral-7B,96.17,57.22,114.01,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/benchmark-2-gemini-pro-and-openhermes-mistral.ipynb,Apache-2.0,https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B
|
| 3 |
+
Gemini Pro,98.65,66.76,19.72,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/benchmark-2-gemini-pro-and-openhermes-mistral.ipynb,Google,https://blog.google/technology/ai/gemini-api-developers-cloud/
|
| 4 |
+
Mistral-7B-Instruct-v0.2,95.55,53.47,101.29,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/benchmark-2-mistral-7b-instruct-v0-2.ipynb,Apache-2.0,https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
|
| 5 |
+
Llama-2-7b-chat-hf,57.63,7.5,359.56,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/Benchmark 2: LLama-2-7B and LLama-2-13B.ipynb,Llama 2 Community,https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
|
| 6 |
+
Llama-2-13b-chat-hf,66.95,36.88,476.71,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/Benchmark 2: LLama-2-7B and LLama-2-13B.ipynb,Llama 2 Community,https://huggingface.co/meta-llama/Llama-2-13b-chat-hf
|
| 7 |
+
Openchat-3.5-1210,75.41,46.46,131.16,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/benchmark-2-openchat-3-5-1210-and-dolphin-2-2-1.ipynb,Apache-2.0,https://huggingface.co/openchat/openchat-3.5-1210
|
| 8 |
+
Dolphin-2.2.1-Mistral-7b,94.98,60.47,99.36,https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark2/benchmark-2-openchat-3-5-1210-and-dolphin-2-2-1.ipynb,Apache-2.0,https://huggingface.co/cognitivecomputations/dolphin-2.2.1-mistral-7b
|
README.md
CHANGED
|
@@ -1,13 +1,14 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version:
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: apache-2.0
|
|
|
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: LLms Benchmark
|
| 3 |
+
emoji: 🏆🤖
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: green
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 3.50.2
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: apache-2.0
|
| 11 |
+
tags:
|
| 12 |
+
- leaderboard
|
| 13 |
---
|
| 14 |
|
|
|
app.py
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import numpy as np
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import argparse
|
| 5 |
+
|
| 6 |
+
def make_default_md():
|
| 7 |
+
leaderboard_md = f"""
|
| 8 |
+
# 🏆 LLms Benchmark
|
| 9 |
+
|
| 10 |
+
The main goal of this project is to utilize Large Language Models (LLMs) to extract specific information from PDF documents and organize it into a structured JSON format.
|
| 11 |
+
|
| 12 |
+
To achieve this objective, we are assessing various LLMs on two benchmarks:
|
| 13 |
+
|
| 14 |
+
1. [Benchmark1](https://huggingface.co/spaces/Nechba/LLms-Benchmark/blob/main/dataset.jsonl):
|
| 15 |
+
This benchmark consists of a dataset of 59 pages as context and corresponding JSON extracts from "Interchange and Service Fees Manual: Europe Region".
|
| 16 |
+
|
| 17 |
+
2. [Benchmark2](https://huggingface.co/datasets/Effyis/Table-Extraction):
|
| 18 |
+
This benchmark comprises a dataset of 16573 tables as context and corresponding JSON extracts.
|
| 19 |
+
"""
|
| 20 |
+
return leaderboard_md
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def make_arena_leaderboard_md(total_models):
|
| 24 |
+
leaderboard_md = f"""
|
| 25 |
+
Total #models: **{total_models}**. Last updated: Avril 04, 2024.
|
| 26 |
+
|
| 27 |
+
"""
|
| 28 |
+
return leaderboard_md
|
| 29 |
+
|
| 30 |
+
def model_hyperlink(model_name, link):
|
| 31 |
+
return f'<a target="_blank" href="{link}" style="color: var(--link-text-color); text-decoration: underline;text-decoration-style: dotted;">{model_name}</a>'
|
| 32 |
+
|
| 33 |
+
def load_leaderboard_table_csv(filename, add_hyperlink=True):
|
| 34 |
+
rows = []
|
| 35 |
+
with open(filename, 'r') as file:
|
| 36 |
+
lines = file.readlines()
|
| 37 |
+
heads = [v.strip() for v in lines[0].split(",")]
|
| 38 |
+
for line in lines[1:]:
|
| 39 |
+
row = [v.strip() for v in line.split(",")]
|
| 40 |
+
item = {}
|
| 41 |
+
for h, v in zip(heads, row):
|
| 42 |
+
item[h] = v
|
| 43 |
+
if add_hyperlink:
|
| 44 |
+
item["Model"] = model_hyperlink(item["Model"], item["Link"])
|
| 45 |
+
item["Notebook link"] = model_hyperlink("Notebook", item["Notebook link"])
|
| 46 |
+
rows.append(item)
|
| 47 |
+
return rows
|
| 48 |
+
|
| 49 |
+
def get_arena_table(model_table_df):
|
| 50 |
+
# change type Percentage of values column of df
|
| 51 |
+
model_table_df["Percentage of values"] = model_table_df["Percentage of values"].astype(float)
|
| 52 |
+
model_table_df["Percentage of keys"] = model_table_df["Percentage of keys"].astype(float)
|
| 53 |
+
model_table_df["Average time (s)"] = model_table_df["Average time (s)"].astype(float)
|
| 54 |
+
arena_df = model_table_df.sort_values(by=["Percentage of values"], ascending=False)
|
| 55 |
+
values = []
|
| 56 |
+
if not arena_df.empty: # Check if arena_df is not empty
|
| 57 |
+
for i in range(len(arena_df)):
|
| 58 |
+
row = []
|
| 59 |
+
model_name = arena_df["Model"].values[i] # Access model name directly without index 0
|
| 60 |
+
row.append(model_name)
|
| 61 |
+
row.append(arena_df.iloc[i]["Percentage of values"])
|
| 62 |
+
row.append(arena_df.iloc[i]["Percentage of keys"])
|
| 63 |
+
row.append(arena_df.iloc[i]["Average time (s)"])
|
| 64 |
+
row.append(arena_df.iloc[i]["Notebook link"])
|
| 65 |
+
row.append(arena_df.iloc[i]["License"])
|
| 66 |
+
# row.append(arena_df.iloc[i]["Link"])
|
| 67 |
+
values.append(row)
|
| 68 |
+
return values
|
| 69 |
+
|
| 70 |
+
def build_leaderboard_tab(leaderboard_table_file1,leaderboard_table_file2, show_plot=False):
|
| 71 |
+
default_md = make_default_md()
|
| 72 |
+
md_1 = gr.Markdown(default_md, elem_id="leaderboard_markdown")
|
| 73 |
+
if leaderboard_table_file1:
|
| 74 |
+
data1 = load_leaderboard_table_csv(leaderboard_table_file1)
|
| 75 |
+
model_table_df1 = pd.DataFrame(data1)
|
| 76 |
+
data2 = load_leaderboard_table_csv(leaderboard_table_file2)
|
| 77 |
+
model_table_df2 = pd.DataFrame(data2)
|
| 78 |
+
with gr.Tabs() as tabs:
|
| 79 |
+
with gr.Tab(" 🏅 Benchmark 1", id=0):
|
| 80 |
+
arena_table_vals = get_arena_table(model_table_df1)
|
| 81 |
+
md = make_arena_leaderboard_md(len(arena_table_vals))
|
| 82 |
+
gr.Markdown(md, elem_id="leaderboard_markdown")
|
| 83 |
+
gr.Dataframe(
|
| 84 |
+
headers=[
|
| 85 |
+
"Model",
|
| 86 |
+
"Percentage of values (%)",
|
| 87 |
+
"Percentage of keys (%)",
|
| 88 |
+
"Average time (s)",
|
| 89 |
+
"Code",
|
| 90 |
+
"License",
|
| 91 |
+
],
|
| 92 |
+
datatype=[
|
| 93 |
+
"markdown",
|
| 94 |
+
"number",
|
| 95 |
+
"number",
|
| 96 |
+
"number",
|
| 97 |
+
"markdown",
|
| 98 |
+
"str"
|
| 99 |
+
],
|
| 100 |
+
value=arena_table_vals,
|
| 101 |
+
elem_id="arena_leaderboard_dataframe",
|
| 102 |
+
height=700,
|
| 103 |
+
column_widths=[200, 150, 150, 130, 100, 140],
|
| 104 |
+
wrap=True,
|
| 105 |
+
)
|
| 106 |
+
# Displaying a note about the leaderboard analysis
|
| 107 |
+
gr.Markdown(
|
| 108 |
+
f"""Note: Upon reviewing the leaderboard, it's evident that two models, Gemini and OpenHermes, outperform the others. Our next step involves a detailed analysis and comparison of the results obtained by these two models.""",
|
| 109 |
+
elem_id="leaderboard_markdown"
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
# Displaying additional statistics for Gemini and OpenHermes
|
| 113 |
+
gr.Markdown(
|
| 114 |
+
f"""## More Statistics for Gemini and OpenHermes\n
|
| 115 |
+
Now we will focus on Gemini and OpenHermes, diving deeper into their performance for a comprehensive comparison.""",
|
| 116 |
+
elem_id=0
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
# Displaying the confusion matrices for Gemini and OpenHermes
|
| 120 |
+
with gr.Row():
|
| 121 |
+
with gr.Column():
|
| 122 |
+
gr.Markdown(
|
| 123 |
+
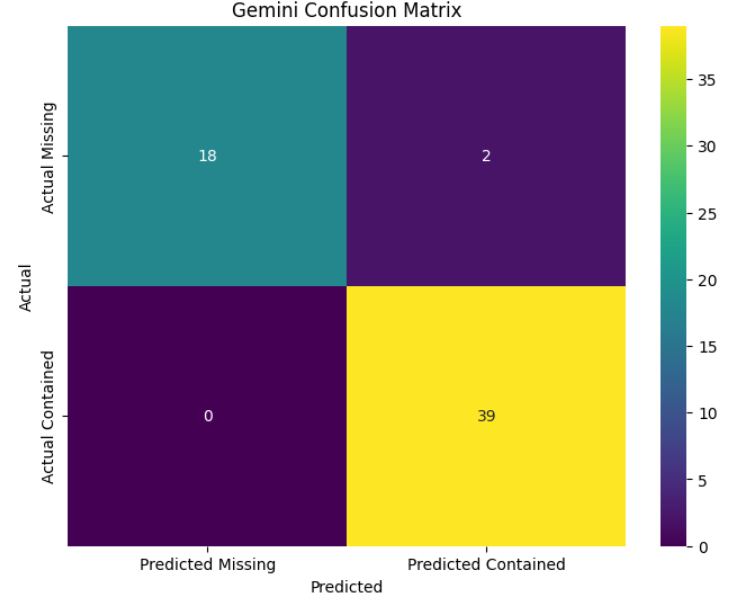
"#### Figure 1: Gemini Confusion Matrix"
|
| 124 |
+
)
|
| 125 |
+
plot_1 = gr.Image("./Benchmark1/gemini_cm.png", show_label=False)
|
| 126 |
+
# Detailed analysis of Gemini's performance
|
| 127 |
+
gr.Markdown(
|
| 128 |
+
"""### True Positives:
|
| 129 |
+
Our model correctly identified all 18 pages lacking the desired information (Payment product, FeeTier, and Rate).
|
| 130 |
+
|
| 131 |
+
### True Negatives:
|
| 132 |
+
The model successfully predicted desired information on 39 out of 41 pages with an accuracy ranging from 12% to 100%. (For more details about accuracy, check the Notebook [here](https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/gemini.ipynb))
|
| 133 |
+
|
| 134 |
+
### False Negatives:
|
| 135 |
+
In 2 instances, the model incorrectly predicted that pages lacked the desired information when they actually contained it.
|
| 136 |
+
|
| 137 |
+
### False Positives:
|
| 138 |
+
The model incorrectly predicted that 0 pages contained the desired information when they were actually missing it."""
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
with gr.Column():
|
| 142 |
+
gr.Markdown(
|
| 143 |
+
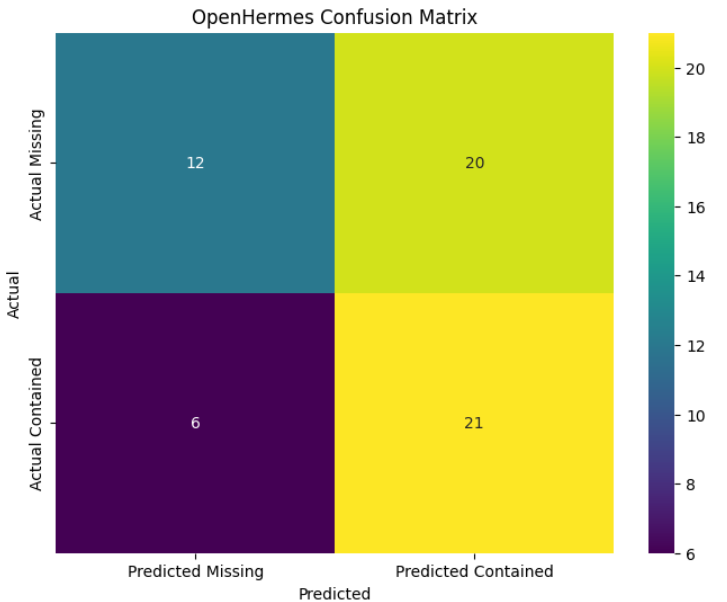
"#### Figure 2: OpenHermes Confusion Matrix"
|
| 144 |
+
)
|
| 145 |
+
plot_2 = gr.Image("./Benchmark1/openhermes_cm.png", show_label=False)
|
| 146 |
+
# Detailed analysis of OpenHermes's performance
|
| 147 |
+
gr.Markdown(
|
| 148 |
+
"""### True Positives:
|
| 149 |
+
Our model correctly identified 12 out of 18 pages lacking the desired information (Payment product, FeeTier, and Rate).
|
| 150 |
+
|
| 151 |
+
### True Negatives:
|
| 152 |
+
The model successfully predicted desired information on 21 out of 41 pages with an accuracy ranging from 5% to 66%. (For more details about accuracy, check the Notebook [here](https://huggingface.co/spaces/Effyis/LLms-Benchmark/blob/main/Benchmark1/openhermes.ipynb))
|
| 153 |
+
|
| 154 |
+
### False Negatives:
|
| 155 |
+
In 20 instances, the model incorrectly predicted that pages lacked the desired information when they actually contained it.
|
| 156 |
+
|
| 157 |
+
### False Positives:
|
| 158 |
+
The model incorrectly predicted that 6 pages contained the desired information when they were actually missing it."""
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
# Conclusion based on the analysis
|
| 162 |
+
gr.Markdown(
|
| 163 |
+
"""## Conclusion\n
|
| 164 |
+
Upon analyzing the performance of Gemini and OpenHermes, it becomes evident that both models exhibit strengths and weaknesses. Gemini demonstrates higher accuracy in identifying pages lacking desired information and also performs better in predicting pages containing the desired information. On the other hand, while OpenHermes shows good results in identifying pages lacking desired information, it achieves only 50% accuracy in predicting pages containing the desired information. Further fine-tuning of both models could lead to enhanced overall performance."""
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
with gr.Tab("🏅 Benchmark 2", id=1):
|
| 169 |
+
arena_table_vals = get_arena_table(model_table_df2)
|
| 170 |
+
md = make_arena_leaderboard_md(len(arena_table_vals))
|
| 171 |
+
gr.Markdown(md, elem_id="leaderboard_markdown")
|
| 172 |
+
gr.Dataframe(
|
| 173 |
+
headers=[
|
| 174 |
+
"Model",
|
| 175 |
+
"Percentage of values (%)",
|
| 176 |
+
"Percentage of keys (%)",
|
| 177 |
+
"Average time (s)",
|
| 178 |
+
"Code",
|
| 179 |
+
"License",
|
| 180 |
+
],
|
| 181 |
+
datatype=[
|
| 182 |
+
"markdown",
|
| 183 |
+
"number",
|
| 184 |
+
"number",
|
| 185 |
+
"number",
|
| 186 |
+
"markdown",
|
| 187 |
+
"str"
|
| 188 |
+
],
|
| 189 |
+
value=arena_table_vals,
|
| 190 |
+
elem_id="arena_leaderboard_dataframe",
|
| 191 |
+
height=700,
|
| 192 |
+
column_widths=[200, 150, 150, 130, 100, 140],
|
| 193 |
+
wrap=True,
|
| 194 |
+
)
|
| 195 |
+
gr.Markdown(
|
| 196 |
+
f"""
|
| 197 |
+
Note: For this benchmark, only a sample of 100 points from the dataset is utilized. It's evident that the data context is straightforward, yet it includes Arabic names. This could explain the lower performance scores of the models, as they may lack robust capabilities in handling Arabic names.""",
|
| 198 |
+
elem_id="leaderboard_markdown"
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
else:
|
| 202 |
+
pass
|
| 203 |
+
return [md_1,plot_1, plot_2]
|
| 204 |
+
|
| 205 |
+
block_css = """
|
| 206 |
+
#notice_markdown {
|
| 207 |
+
font-size: 104%
|
| 208 |
+
}
|
| 209 |
+
#notice_markdown th {
|
| 210 |
+
display: none;
|
| 211 |
+
}
|
| 212 |
+
#notice_markdown td {
|
| 213 |
+
padding-top: 6px;
|
| 214 |
+
padding-bottom: 6px;
|
| 215 |
+
}
|
| 216 |
+
#leaderboard_markdown {
|
| 217 |
+
font-size: 104%
|
| 218 |
+
}
|
| 219 |
+
#leaderboard_markdown td {
|
| 220 |
+
padding-top: 6px;
|
| 221 |
+
padding-bottom: 6px;
|
| 222 |
+
}
|
| 223 |
+
#leaderboard_dataframe td {
|
| 224 |
+
line-height: 0.1em;
|
| 225 |
+
}
|
| 226 |
+
footer {
|
| 227 |
+
display:none !important
|
| 228 |
+
}
|
| 229 |
+
.sponsor-image-about img {
|
| 230 |
+
margin: 0 20px;
|
| 231 |
+
margin-top: 20px;
|
| 232 |
+
height: 40px;
|
| 233 |
+
max-height: 100%;
|
| 234 |
+
width: auto;
|
| 235 |
+
float: left;
|
| 236 |
+
}
|
| 237 |
+
"""
|
| 238 |
+
|
| 239 |
+
def build_demo(leaderboard_table_file1, leaderboard_table_file2):
|
| 240 |
+
text_size = gr.themes.sizes.text_lg
|
| 241 |
+
with gr.Blocks(
|
| 242 |
+
title="LLMS Benchmark",
|
| 243 |
+
theme=gr.themes.Base(text_size=text_size),
|
| 244 |
+
css=block_css,
|
| 245 |
+
) as demo:
|
| 246 |
+
leader_components = build_leaderboard_tab(
|
| 247 |
+
leaderboard_table_file1,leaderboard_table_file2, show_plot=True
|
| 248 |
+
)
|
| 249 |
+
return demo
|
| 250 |
+
|
| 251 |
+
if __name__ == "__main__":
|
| 252 |
+
parser = argparse.ArgumentParser()
|
| 253 |
+
parser.add_argument("--share", action="store_true")
|
| 254 |
+
args = parser.parse_args()
|
| 255 |
+
|
| 256 |
+
leaderboard_table_file1 = "./Benchmark1/leaderboard.csv"
|
| 257 |
+
leaderboard_table_file2 = "./Benchmark2/leaderboard.csv"
|
| 258 |
+
demo = build_demo(leaderboard_table_file1,leaderboard_table_file2)
|
| 259 |
+
demo.launch(share=args.share)
|
requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio
|
| 2 |
+
numpy
|
| 3 |
+
pandas
|