
File size: 3,103 Bytes
806f077 820c520 806f077 f858628 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
---
language:
- ko
---
# KR-FinBert & KR-FinBert-SC
Much progress has been made in the NLP (Natural Language Processing) field, with numerous studies showing that domain adaptation using small-scale corpus and fine-tuning with labeled data is effective for overall performance improvement.
we proposed KR-FinBert for the financial domain by further pre-training it on a financial corpus and fine-tuning it for sentiment analysis. As many studies have shown, the performance improvement through adaptation and conducting the downstream task was also clear in this experiment.
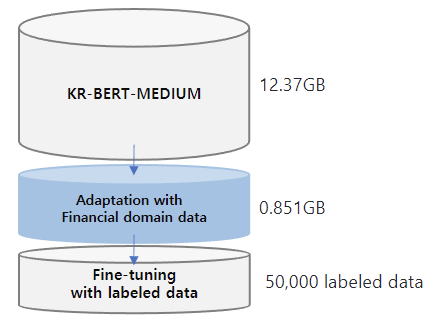
## Data
The training data for this model is expanded from those of **[KR-BERT-MEDIUM](https://huggingface.co/snunlp/KR-Medium)**, texts from Korean Wikipedia, general news articles, legal texts crawled from the National Law Information Center and [Korean Comments dataset](https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments). For the transfer learning, **corporate related economic news articles from 72 media sources** such as the Financial Times, The Korean Economy Daily, etc and **analyst reports from 16 securities companies** such as Kiwoom Securities, Samsung Securities, etc are added. Included in the dataset is 440,067 news titles with their content and 11,237 analyst reports. **The total data size is about 13.22GB.** For mlm training, we split the data line by line and **the total no. of lines is 6,379,315.**
KR-FinBert is trained for 5.5M steps with the maxlen of 512, training batch size of 32, and learning rate of 5e-5, taking 67.48 hours to train the model using NVIDIA TITAN XP.
## Downstream tasks
### Sentimental Classification model
Downstream task performances with 50,000 labeled data.
|Model|Accuracy|
|-|-|
|KR-FinBert|0.963|
|KR-BERT-MEDIUM|0.958|
|KcBert-large|0.955|
|KcBert-base|0.953|
|KoBert|0.817|
### Inference sample
|Positive|Negative|
|-|-|
|현대바이오, '폴리탁셀' 코로나19 치료 가능성에 19% 급등 | 영화관株 '코로나 빙하기' 언제 끝나나…"CJ CGV 올 4000억 손실 날수도" |
|이수화학, 3분기 영업익 176억…전년比 80%↑ | C쇼크에 멈춘 흑자비행…대한항공 1분기 영업적자 566억 |
|"GKL, 7년 만에 두 자릿수 매출성장 예상" | '1000억대 횡령·배임' 최신원 회장 구속… SK네트웍스 "경영 공백 방지 최선" |
|위지윅스튜디오, 콘텐츠 활약에 사상 첫 매출 1000억원 돌파 | 부품 공급 차질에…기아차 광주공장 전면 가동 중단 |
|삼성전자, 2년 만에 인도 스마트폰 시장 점유율 1위 '왕좌 탈환' | 현대제철, 지난해 영업익 3,313억원···전년比 67.7% 감소 |
### Citation
```
@misc{kr-FinBert-SC,
author = {Kim, Eunhee and Hyopil Shin},
title = {KR-FinBert: Fine-tuning KR-FinBert for Sentiment Analysis},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://huggingface.co/snunlp/KR-FinBert-SC}}
}
``` |