
Upload 35 files
Browse files- .gitattributes +1 -0
- CyclicGAN_Inference.ipynb +208 -0
- Fog_Effect_Generator.py +113 -0
- LICENSE +201 -0
- MiDaS_Depth_Estimation.py +110 -0
- Neural_Style_Transfer.py +121 -0
- Rain_Effect_Generator.py +177 -0
- Snow_Effect_Generator.py +178 -0
- checkpoints/clear2rainy.pth +3 -0
- checkpoints/clear2snowy.pth +3 -0
- gen_depth_map.sh +5 -0
- gen_rain_image.sh +5 -0
- gen_rain_image_ag.sh +4 -0
- gen_rain_nst.sh +9 -0
- gen_snow_image.sh +5 -0
- gen_snow_image_ag.sh +4 -0
- gen_snow_nst.sh +9 -0
- lib/fog_gen.py +143 -0
- lib/gan_networks.py +616 -0
- lib/gen_utils.py +263 -0
- lib/lime.py +111 -0
- lib/motionblur.py +419 -0
- lib/rain_gen.py +162 -0
- lib/snow_gen.py +83 -0
- lib/style_transfer_utils.py +239 -0
- presentation.ipynb +3 -0
- requirements.txt +6 -0
- resources/error_0.png +0 -0
- resources/error_1.png +0 -0
- resources/error_2.png +0 -0
- resources/exploding_gradient.png +0 -0
- resources/rain_0.jpg +0 -0
- resources/rain_1.jpg +0 -0
- resources/resnet_gan.png +0 -0
- resources/snow_0.jpg +0 -0
- resources/snow_1.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
presentation.ipynb filter=lfs diff=lfs merge=lfs -text
|
CyclicGAN_Inference.ipynb
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 11,
|
| 6 |
+
"id": "10ee1bf4",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": [
|
| 10 |
+
"import os\n",
|
| 11 |
+
"import torch\n",
|
| 12 |
+
"import numpy as np\n",
|
| 13 |
+
"from PIL import Image\n",
|
| 14 |
+
"from tqdm import tqdm\n",
|
| 15 |
+
"from lib.gan_networks import define_G\n",
|
| 16 |
+
"import torchvision.transforms as transforms"
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": 12,
|
| 22 |
+
"id": "59797ab5",
|
| 23 |
+
"metadata": {},
|
| 24 |
+
"outputs": [],
|
| 25 |
+
"source": [
|
| 26 |
+
"def __transforms2pil_resize(method):\n",
|
| 27 |
+
" mapper = {\n",
|
| 28 |
+
" transforms.InterpolationMode.BILINEAR: Image.BILINEAR,\n",
|
| 29 |
+
" transforms.InterpolationMode.BICUBIC: Image.BICUBIC,\n",
|
| 30 |
+
" transforms.InterpolationMode.NEAREST: Image.NEAREST,\n",
|
| 31 |
+
" transforms.InterpolationMode.LANCZOS: Image.LANCZOS,\n",
|
| 32 |
+
" }\n",
|
| 33 |
+
" return mapper[method]\n",
|
| 34 |
+
"\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"def __scale_width(\n",
|
| 37 |
+
" img, target_size, crop_size, method=transforms.InterpolationMode.BICUBIC\n",
|
| 38 |
+
"):\n",
|
| 39 |
+
" method = __transforms2pil_resize(method)\n",
|
| 40 |
+
" ow, oh = img.size\n",
|
| 41 |
+
" if ow == target_size and oh >= crop_size:\n",
|
| 42 |
+
" return img\n",
|
| 43 |
+
" w = target_size\n",
|
| 44 |
+
" h = int(max(target_size * oh / ow, crop_size))\n",
|
| 45 |
+
" return img.resize((w, h), method)\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"\n",
|
| 48 |
+
"def get_transform(load_size, crop_size, method=transforms.InterpolationMode.BICUBIC):\n",
|
| 49 |
+
" transform_list = [\n",
|
| 50 |
+
" transforms.Lambda(lambda img: __scale_width(img, load_size, crop_size, method)),\n",
|
| 51 |
+
" transforms.ToTensor(),\n",
|
| 52 |
+
" transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n",
|
| 53 |
+
" ]\n",
|
| 54 |
+
" return transforms.Compose(transform_list)\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"\n",
|
| 57 |
+
"def tensor2im(input_image, imtype=np.uint8):\n",
|
| 58 |
+
" \"\"\" \"Converts a Tensor array into a numpy image array.\n",
|
| 59 |
+
"\n",
|
| 60 |
+
" Parameters:\n",
|
| 61 |
+
" input_image (tensor) -- the input image tensor array\n",
|
| 62 |
+
" imtype (type) -- the desired type of the converted numpy array\n",
|
| 63 |
+
" \"\"\"\n",
|
| 64 |
+
" if not isinstance(input_image, np.ndarray):\n",
|
| 65 |
+
" if isinstance(input_image, torch.Tensor): # get the data from a variable\n",
|
| 66 |
+
" image_tensor = input_image.data\n",
|
| 67 |
+
" else:\n",
|
| 68 |
+
" return input_image\n",
|
| 69 |
+
" image_numpy = (\n",
|
| 70 |
+
" image_tensor[0].cpu().float().numpy()\n",
|
| 71 |
+
" ) # convert it into a numpy array\n",
|
| 72 |
+
" if image_numpy.shape[0] == 1: # grayscale to RGB\n",
|
| 73 |
+
" image_numpy = np.tile(image_numpy, (3, 1, 1))\n",
|
| 74 |
+
" image_numpy = (\n",
|
| 75 |
+
" (np.transpose(image_numpy, (1, 2, 0)) + 1) / 2.0 * 255.0\n",
|
| 76 |
+
" ) # post-processing: tranpose and scaling\n",
|
| 77 |
+
" else: # if it is a numpy array, do nothing\n",
|
| 78 |
+
" image_numpy = input_image\n",
|
| 79 |
+
" return image_numpy.astype(imtype)\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"def create_model_and_transform(pretrained: str = None):\n",
|
| 83 |
+
" # Creating model\n",
|
| 84 |
+
" input_nc = 3\n",
|
| 85 |
+
" output_nc = 3\n",
|
| 86 |
+
" ngf = 64\n",
|
| 87 |
+
" netG = \"resnet_9blocks\"\n",
|
| 88 |
+
" norm = \"instance\"\n",
|
| 89 |
+
" no_dropout = True\n",
|
| 90 |
+
" init_type = \"normal\"\n",
|
| 91 |
+
" init_gain = 0.02\n",
|
| 92 |
+
" gpu_ids = []\n",
|
| 93 |
+
"\n",
|
| 94 |
+
" netG_A = define_G(\n",
|
| 95 |
+
" input_nc,\n",
|
| 96 |
+
" output_nc,\n",
|
| 97 |
+
" ngf,\n",
|
| 98 |
+
" netG,\n",
|
| 99 |
+
" norm,\n",
|
| 100 |
+
" not no_dropout,\n",
|
| 101 |
+
" init_type,\n",
|
| 102 |
+
" init_gain,\n",
|
| 103 |
+
" gpu_ids,\n",
|
| 104 |
+
" )\n",
|
| 105 |
+
" if pretrained:\n",
|
| 106 |
+
" chkpntA = torch.load(pretrained)\n",
|
| 107 |
+
" netG_A.load_state_dict(chkpntA)\n",
|
| 108 |
+
" netG_A.eval()\n",
|
| 109 |
+
"\n",
|
| 110 |
+
" netG_A = netG_A.cuda()\n",
|
| 111 |
+
"\n",
|
| 112 |
+
" # Creating transform\n",
|
| 113 |
+
" load_size = 1280\n",
|
| 114 |
+
" crop_size = 224\n",
|
| 115 |
+
" image_transforms = get_transform(load_size=load_size, crop_size=crop_size)\n",
|
| 116 |
+
" return netG_A, image_transforms\n",
|
| 117 |
+
"\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"def run_inference(img_path, model, transform):\n",
|
| 120 |
+
" image = Image.open(img_path)\n",
|
| 121 |
+
" inputs = image_transforms(image).unsqueeze(0).to(\"cuda\")\n",
|
| 122 |
+
"\n",
|
| 123 |
+
" with torch.no_grad():\n",
|
| 124 |
+
" out = model(inputs)\n",
|
| 125 |
+
" out = tensor2im(out)\n",
|
| 126 |
+
" return Image.fromarray(out)"
|
| 127 |
+
]
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"cell_type": "code",
|
| 131 |
+
"execution_count": 13,
|
| 132 |
+
"id": "6fc20d26",
|
| 133 |
+
"metadata": {},
|
| 134 |
+
"outputs": [
|
| 135 |
+
{
|
| 136 |
+
"name": "stdout",
|
| 137 |
+
"output_type": "stream",
|
| 138 |
+
"text": [
|
| 139 |
+
"initialize network with normal\n"
|
| 140 |
+
]
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"ename": "RuntimeError",
|
| 144 |
+
"evalue": "Error(s) in loading state_dict for UnetGenerator:\n\tMissing key(s) in state_dict: \"model.model.0.weight\", \"model.model.0.bias\", \"model.model.1.model.1.weight\", \"model.model.1.model.1.bias\", \"model.model.1.model.3.model.1.weight\", \"model.model.1.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.3.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.3.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.5.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.5.bias\", \"model.model.1.model.3.model.3.model.3.model.5.weight\", \"model.model.1.model.3.model.3.model.3.model.5.bias\", \"model.model.1.model.3.model.3.model.5.weight\", \"model.model.1.model.3.model.3.model.5.bias\", \"model.model.1.model.3.model.5.weight\", \"model.model.1.model.3.model.5.bias\", \"model.model.1.model.5.weight\", \"model.model.1.model.5.bias\", \"model.model.3.weight\", \"model.model.3.bias\". \n\tUnexpected key(s) in state_dict: \"model.1.weight\", \"model.1.bias\", \"model.4.weight\", \"model.4.bias\", \"model.7.weight\", \"model.7.bias\", \"model.10.conv_block.1.weight\", \"model.10.conv_block.1.bias\", \"model.10.conv_block.5.weight\", \"model.10.conv_block.5.bias\", \"model.11.conv_block.1.weight\", \"model.11.conv_block.1.bias\", \"model.11.conv_block.5.weight\", \"model.11.conv_block.5.bias\", \"model.12.conv_block.1.weight\", \"model.12.conv_block.1.bias\", \"model.12.conv_block.5.weight\", \"model.12.conv_block.5.bias\", \"model.13.conv_block.1.weight\", \"model.13.conv_block.1.bias\", \"model.13.conv_block.5.weight\", \"model.13.conv_block.5.bias\", \"model.14.conv_block.1.weight\", \"model.14.conv_block.1.bias\", \"model.14.conv_block.5.weight\", \"model.14.conv_block.5.bias\", \"model.15.conv_block.1.weight\", \"model.15.conv_block.1.bias\", \"model.15.conv_block.5.weight\", \"model.15.conv_block.5.bias\", \"model.16.conv_block.1.weight\", \"model.16.conv_block.1.bias\", \"model.16.conv_block.5.weight\", \"model.16.conv_block.5.bias\", \"model.17.conv_block.1.weight\", \"model.17.conv_block.1.bias\", \"model.17.conv_block.5.weight\", \"model.17.conv_block.5.bias\", \"model.18.conv_block.1.weight\", \"model.18.conv_block.1.bias\", \"model.18.conv_block.5.weight\", \"model.18.conv_block.5.bias\", \"model.19.weight\", \"model.19.bias\", \"model.22.weight\", \"model.22.bias\", \"model.26.weight\", \"model.26.bias\". ",
|
| 145 |
+
"output_type": "error",
|
| 146 |
+
"traceback": [
|
| 147 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 148 |
+
"\u001b[0;31mRuntimeError\u001b[0m Traceback (most recent call last)",
|
| 149 |
+
"Cell \u001b[0;32mIn[13], line 1\u001b[0m\n\u001b[0;32m----> 1\u001b[0m gan, image_transforms \u001b[38;5;241m=\u001b[39m \u001b[43mcreate_model_and_transform\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43m./checkpoints/clear2snowy.pth\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m)\u001b[49m\n",
|
| 150 |
+
"Cell \u001b[0;32mIn[12], line 82\u001b[0m, in \u001b[0;36mcreate_model_and_transform\u001b[0;34m(pretrained)\u001b[0m\n\u001b[1;32m 80\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m pretrained:\n\u001b[1;32m 81\u001b[0m chkpntA \u001b[38;5;241m=\u001b[39m torch\u001b[38;5;241m.\u001b[39mload(pretrained)\n\u001b[0;32m---> 82\u001b[0m \u001b[43mnetG_A\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mload_state_dict\u001b[49m\u001b[43m(\u001b[49m\u001b[43mchkpntA\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 83\u001b[0m netG_A\u001b[38;5;241m.\u001b[39meval()\n\u001b[1;32m 85\u001b[0m netG_A \u001b[38;5;241m=\u001b[39m netG_A\u001b[38;5;241m.\u001b[39mcuda()\n",
|
| 151 |
+
"File \u001b[0;32m~/miniconda3/lib/python3.10/site-packages/torch/nn/modules/module.py:2189\u001b[0m, in \u001b[0;36mModule.load_state_dict\u001b[0;34m(self, state_dict, strict, assign)\u001b[0m\n\u001b[1;32m 2184\u001b[0m error_msgs\u001b[38;5;241m.\u001b[39minsert(\n\u001b[1;32m 2185\u001b[0m \u001b[38;5;241m0\u001b[39m, \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mMissing key(s) in state_dict: \u001b[39m\u001b[38;5;132;01m{}\u001b[39;00m\u001b[38;5;124m. \u001b[39m\u001b[38;5;124m'\u001b[39m\u001b[38;5;241m.\u001b[39mformat(\n\u001b[1;32m 2186\u001b[0m \u001b[38;5;124m'\u001b[39m\u001b[38;5;124m, \u001b[39m\u001b[38;5;124m'\u001b[39m\u001b[38;5;241m.\u001b[39mjoin(\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m'\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;132;01m{\u001b[39;00mk\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124m'\u001b[39m \u001b[38;5;28;01mfor\u001b[39;00m k \u001b[38;5;129;01min\u001b[39;00m missing_keys)))\n\u001b[1;32m 2188\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mlen\u001b[39m(error_msgs) \u001b[38;5;241m>\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[0;32m-> 2189\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mRuntimeError\u001b[39;00m(\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mError(s) in loading state_dict for \u001b[39m\u001b[38;5;132;01m{}\u001b[39;00m\u001b[38;5;124m:\u001b[39m\u001b[38;5;130;01m\\n\u001b[39;00m\u001b[38;5;130;01m\\t\u001b[39;00m\u001b[38;5;132;01m{}\u001b[39;00m\u001b[38;5;124m'\u001b[39m\u001b[38;5;241m.\u001b[39mformat(\n\u001b[1;32m 2190\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m\u001b[38;5;18m__class__\u001b[39m\u001b[38;5;241m.\u001b[39m\u001b[38;5;18m__name__\u001b[39m, \u001b[38;5;124m\"\u001b[39m\u001b[38;5;130;01m\\n\u001b[39;00m\u001b[38;5;130;01m\\t\u001b[39;00m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;241m.\u001b[39mjoin(error_msgs)))\n\u001b[1;32m 2191\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m _IncompatibleKeys(missing_keys, unexpected_keys)\n",
|
| 152 |
+
"\u001b[0;31mRuntimeError\u001b[0m: Error(s) in loading state_dict for UnetGenerator:\n\tMissing key(s) in state_dict: \"model.model.0.weight\", \"model.model.0.bias\", \"model.model.1.model.1.weight\", \"model.model.1.model.1.bias\", \"model.model.1.model.3.model.1.weight\", \"model.model.1.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.1.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.1.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.3.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.3.model.3.bias\", \"model.model.1.model.3.model.3.model.3.model.3.model.5.weight\", \"model.model.1.model.3.model.3.model.3.model.3.model.5.bias\", \"model.model.1.model.3.model.3.model.3.model.5.weight\", \"model.model.1.model.3.model.3.model.3.model.5.bias\", \"model.model.1.model.3.model.3.model.5.weight\", \"model.model.1.model.3.model.3.model.5.bias\", \"model.model.1.model.3.model.5.weight\", \"model.model.1.model.3.model.5.bias\", \"model.model.1.model.5.weight\", \"model.model.1.model.5.bias\", \"model.model.3.weight\", \"model.model.3.bias\". \n\tUnexpected key(s) in state_dict: \"model.1.weight\", \"model.1.bias\", \"model.4.weight\", \"model.4.bias\", \"model.7.weight\", \"model.7.bias\", \"model.10.conv_block.1.weight\", \"model.10.conv_block.1.bias\", \"model.10.conv_block.5.weight\", \"model.10.conv_block.5.bias\", \"model.11.conv_block.1.weight\", \"model.11.conv_block.1.bias\", \"model.11.conv_block.5.weight\", \"model.11.conv_block.5.bias\", \"model.12.conv_block.1.weight\", \"model.12.conv_block.1.bias\", \"model.12.conv_block.5.weight\", \"model.12.conv_block.5.bias\", \"model.13.conv_block.1.weight\", \"model.13.conv_block.1.bias\", \"model.13.conv_block.5.weight\", \"model.13.conv_block.5.bias\", \"model.14.conv_block.1.weight\", \"model.14.conv_block.1.bias\", \"model.14.conv_block.5.weight\", \"model.14.conv_block.5.bias\", \"model.15.conv_block.1.weight\", \"model.15.conv_block.1.bias\", \"model.15.conv_block.5.weight\", \"model.15.conv_block.5.bias\", \"model.16.conv_block.1.weight\", \"model.16.conv_block.1.bias\", \"model.16.conv_block.5.weight\", \"model.16.conv_block.5.bias\", \"model.17.conv_block.1.weight\", \"model.17.conv_block.1.bias\", \"model.17.conv_block.5.weight\", \"model.17.conv_block.5.bias\", \"model.18.conv_block.1.weight\", \"model.18.conv_block.1.bias\", \"model.18.conv_block.5.weight\", \"model.18.conv_block.5.bias\", \"model.19.weight\", \"model.19.bias\", \"model.22.weight\", \"model.22.bias\", \"model.26.weight\", \"model.26.bias\". "
|
| 153 |
+
]
|
| 154 |
+
}
|
| 155 |
+
],
|
| 156 |
+
"source": [
|
| 157 |
+
"gan, image_transforms = create_model_and_transform(\"./checkpoints/clear2snowy.pth\")"
|
| 158 |
+
]
|
| 159 |
+
},
|
| 160 |
+
{
|
| 161 |
+
"cell_type": "code",
|
| 162 |
+
"execution_count": null,
|
| 163 |
+
"id": "d44ebf97",
|
| 164 |
+
"metadata": {},
|
| 165 |
+
"outputs": [
|
| 166 |
+
{
|
| 167 |
+
"name": "stderr",
|
| 168 |
+
"output_type": "stream",
|
| 169 |
+
"text": [
|
| 170 |
+
"100%|██████████| 100/100 [00:39<00:00, 2.51it/s]\n"
|
| 171 |
+
]
|
| 172 |
+
}
|
| 173 |
+
],
|
| 174 |
+
"source": [
|
| 175 |
+
"image_path = os.listdir(\"./data/images\")\n",
|
| 176 |
+
"save_folder = \"./data/gan/snow_images\"\n",
|
| 177 |
+
"\n",
|
| 178 |
+
"for img in tqdm(image_path):\n",
|
| 179 |
+
" trg = os.path.join(\"./data/images\", img)\n",
|
| 180 |
+
" src = os.path.join(f\"./data/gan/snow_images/\", img.split(\".\")[0] + \".jpg\")\n",
|
| 181 |
+
" if not (os.path.exists(src)):\n",
|
| 182 |
+
" out = run_inference(img_path=trg, model=gan, transform=image_transforms)\n",
|
| 183 |
+
" out.save(src)"
|
| 184 |
+
]
|
| 185 |
+
}
|
| 186 |
+
],
|
| 187 |
+
"metadata": {
|
| 188 |
+
"kernelspec": {
|
| 189 |
+
"display_name": "Python 3 (ipykernel)",
|
| 190 |
+
"language": "python",
|
| 191 |
+
"name": "python3"
|
| 192 |
+
},
|
| 193 |
+
"language_info": {
|
| 194 |
+
"codemirror_mode": {
|
| 195 |
+
"name": "ipython",
|
| 196 |
+
"version": 3
|
| 197 |
+
},
|
| 198 |
+
"file_extension": ".py",
|
| 199 |
+
"mimetype": "text/x-python",
|
| 200 |
+
"name": "python",
|
| 201 |
+
"nbconvert_exporter": "python",
|
| 202 |
+
"pygments_lexer": "ipython3",
|
| 203 |
+
"version": "3.10.14"
|
| 204 |
+
}
|
| 205 |
+
},
|
| 206 |
+
"nbformat": 4,
|
| 207 |
+
"nbformat_minor": 5
|
| 208 |
+
}
|
Fog_Effect_Generator.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from skimage import color
|
| 8 |
+
from tqdm.auto import tqdm
|
| 9 |
+
|
| 10 |
+
from lib.lime import LIME
|
| 11 |
+
from lib.fog_gen import fogAttenuation
|
| 12 |
+
|
| 13 |
+
from lib.gen_utils import (
|
| 14 |
+
illumination2opacity,
|
| 15 |
+
reduce_lightHSV,
|
| 16 |
+
scale_depth)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def parse_arguments():
|
| 20 |
+
parser = argparse.ArgumentParser()
|
| 21 |
+
parser.add_argument("--clear_path", type=str, required=True, help="path to the file or the folder")
|
| 22 |
+
parser.add_argument("--depth_path", type=str, required=True, help="path to the file or the folder")
|
| 23 |
+
parser.add_argument("--save_folder", type=str, default="./generated/", help="path to the folder")
|
| 24 |
+
parser.add_argument("--txt_file", default=None, help="path to the folder")
|
| 25 |
+
parser.add_argument("--show", action="store_true")
|
| 26 |
+
return parser.parse_args()
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class FogEffectGenerator:
|
| 31 |
+
def __init__(self):
|
| 32 |
+
self._lime = LIME(iterations=25, alpha=1.0)
|
| 33 |
+
# self._illumination2darkness = {0: 1, 1: 0.75, 2: 0.65, 3:0.5}
|
| 34 |
+
self._illumination2darkness = {0: 1, 1: 0.9, 2: 0.8, 3: 0.7}
|
| 35 |
+
self._weather2visibility = (500, 2000)
|
| 36 |
+
# self._illumination2fogcolor = {0: (80, 120), 1: (120, 160), 2: (160, 200), 3: (200, 240)}
|
| 37 |
+
self._illumination2fogcolor = {0: (150, 180), 1: (180, 200), 2: (200, 240), 3: (200, 240)}
|
| 38 |
+
|
| 39 |
+
def getIlluminationMap(self, img: np.ndarray) -> np.ndarray:
|
| 40 |
+
self._lime.load(img)
|
| 41 |
+
T = self._lime.illumMap()
|
| 42 |
+
return T
|
| 43 |
+
|
| 44 |
+
def getIlluminationMapCheat(self, img: np.ndarray) -> np.ndarray:
|
| 45 |
+
T = color.rgb2gray(img)
|
| 46 |
+
return T
|
| 47 |
+
|
| 48 |
+
def genEffect(self, img_path: str, depth_path: str):
|
| 49 |
+
I = np.array(Image.open(img_path))
|
| 50 |
+
D = np.load(depth_path)
|
| 51 |
+
|
| 52 |
+
hI, wI, _ = I.shape
|
| 53 |
+
hD, wD = D.shape
|
| 54 |
+
|
| 55 |
+
if hI!=hD or wI!=wD:
|
| 56 |
+
D = scale_depth(D, hI, wI)
|
| 57 |
+
|
| 58 |
+
# T = self.getIlluminationMap(I)
|
| 59 |
+
T = self.getIlluminationMapCheat(I)
|
| 60 |
+
illumination_array = np.histogram(T, bins=4, range=(0,1))[0]/(T.size)
|
| 61 |
+
illumination = illumination_array.argmax()
|
| 62 |
+
|
| 63 |
+
if illumination>0:
|
| 64 |
+
vmax = self._weather2visibility[1] if self._weather2visibility[1]<=D.max() else D.max()
|
| 65 |
+
if vmax<= self._weather2visibility[0]:
|
| 66 |
+
visibility = self._weather2visibility[0]
|
| 67 |
+
else:
|
| 68 |
+
visibility = random.randint(self._weather2visibility[0], int(vmax))
|
| 69 |
+
fog_color = random.randint(self._illumination2fogcolor[illumination][0], self._illumination2fogcolor[illumination][1])
|
| 70 |
+
I_dark = reduce_lightHSV(I, sat_red=self._illumination2darkness[illumination], val_red=self._illumination2darkness[illumination])
|
| 71 |
+
I_fog = fogAttenuation(I_dark, D, visibility=visibility, fog_color=fog_color)
|
| 72 |
+
else:
|
| 73 |
+
fog_color = 75
|
| 74 |
+
visibility = 150 #D.max()*0.75
|
| 75 |
+
I_fog = fogAttenuation(I, D, visibility=visibility, fog_color=fog_color)
|
| 76 |
+
|
| 77 |
+
return I_fog
|
| 78 |
+
|
| 79 |
+
def main():
|
| 80 |
+
args = parse_arguments()
|
| 81 |
+
foggen = FogEffectGenerator()
|
| 82 |
+
|
| 83 |
+
clearP = Path(args.clear_path)
|
| 84 |
+
depthP = Path(args.depth_path)
|
| 85 |
+
if clearP.is_file() and (depthP.is_file() and depthP.suffix==".npy"):
|
| 86 |
+
snowy = foggen.genEffect(clearP, depthP)
|
| 87 |
+
if args.show:
|
| 88 |
+
Image.fromarray(snowy).show()
|
| 89 |
+
|
| 90 |
+
if clearP.is_dir() and depthP.is_dir():
|
| 91 |
+
if args.txt_file:
|
| 92 |
+
with open(args.txt_file, 'r') as f:
|
| 93 |
+
files = f.read().split('\n')
|
| 94 |
+
image_files = [clearP / f for f in files]
|
| 95 |
+
else:
|
| 96 |
+
image_files = sorted(Path(clearP).glob("*"))
|
| 97 |
+
|
| 98 |
+
depth_files = [Path(depthP) / ("-".join(imgf.name.split('-')[:2])+".npy") for imgf in image_files]
|
| 99 |
+
|
| 100 |
+
valid_files = [idx for idx, f in enumerate(depth_files) if f.exists()]
|
| 101 |
+
image_files = [image_files[idx] for idx in valid_files]
|
| 102 |
+
depth_files = [depth_files[idx] for idx in valid_files]
|
| 103 |
+
|
| 104 |
+
save_folder = Path(args.save_folder)
|
| 105 |
+
if not save_folder.exists():
|
| 106 |
+
os.makedirs(str(save_folder))
|
| 107 |
+
|
| 108 |
+
for imgp, depthp in tqdm(zip(image_files, depth_files), total=len(image_files)):
|
| 109 |
+
foggy = foggen.genEffect(imgp, depthp)
|
| 110 |
+
Image.fromarray(foggy).save(save_folder / (imgp.stem+"-fsyn.jpg"))
|
| 111 |
+
|
| 112 |
+
if __name__=='__main__':
|
| 113 |
+
main()
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
MiDaS_Depth_Estimation.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import cv2
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from tqdm.auto import tqdm
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def parse_arguments():
|
| 11 |
+
parser = argparse.ArgumentParser()
|
| 12 |
+
parser.add_argument(
|
| 13 |
+
"--img_path", type=str, required=True, help="path to the file or the folder"
|
| 14 |
+
)
|
| 15 |
+
parser.add_argument(
|
| 16 |
+
"--save_folder", type=str, default="./depth/", help="path to the folder"
|
| 17 |
+
)
|
| 18 |
+
parser.add_argument(
|
| 19 |
+
"--midas_model", type=str, default="DPT_Large", help="Midas model name"
|
| 20 |
+
)
|
| 21 |
+
parser.add_argument("--use_cuda", action="store_true")
|
| 22 |
+
parser.add_argument("--baseline", type=float, default=0.54)
|
| 23 |
+
parser.add_argument("--focal", type=float, default=721.09)
|
| 24 |
+
parser.add_argument("--img_scale", type=float, default=1)
|
| 25 |
+
return parser.parse_args()
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_depth_estimation_model(model_name: str, device="cpu"):
|
| 29 |
+
assert model_name in ["DPT_Large", "DPT_Hybrid", "MiDaS_small"]
|
| 30 |
+
|
| 31 |
+
midas = torch.hub.load("intel-isl/MiDaS", model_name)
|
| 32 |
+
midas.eval()
|
| 33 |
+
midas.to(device)
|
| 34 |
+
|
| 35 |
+
midas_transforms = torch.hub.load("intel-isl/MiDaS", "transforms")
|
| 36 |
+
if model_name in ["DPT_Large", "DPT_Hybrid"]:
|
| 37 |
+
transform = midas_transforms.dpt_transform
|
| 38 |
+
else:
|
| 39 |
+
transform = midas_transforms.small_transform
|
| 40 |
+
return midas, transform
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def getDisparityMap(model, transform, img_path):
|
| 44 |
+
img = cv2.imread(str(img_path))
|
| 45 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 46 |
+
input_batch = transform(img)
|
| 47 |
+
|
| 48 |
+
with torch.no_grad():
|
| 49 |
+
prediction = model(input_batch.cuda())
|
| 50 |
+
|
| 51 |
+
prediction = torch.nn.functional.interpolate(
|
| 52 |
+
prediction.unsqueeze(1),
|
| 53 |
+
size=img.shape[:2],
|
| 54 |
+
mode="bicubic",
|
| 55 |
+
align_corners=False,
|
| 56 |
+
).squeeze()
|
| 57 |
+
return prediction.cpu().numpy()
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def get_depth_map(
|
| 61 |
+
midas, midas_transform, imgp, baseline=0.54, focal=721.09, img_scale=1
|
| 62 |
+
):
|
| 63 |
+
disp = getDisparityMap(midas, midas_transform, imgp)
|
| 64 |
+
disp[disp < 0] = 0
|
| 65 |
+
disp = disp + 1e-3
|
| 66 |
+
depth = baseline * focal / (disp * img_scale)
|
| 67 |
+
|
| 68 |
+
return depth
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def get_depth_map_new(midas, midas_transform, imgp):
|
| 72 |
+
depth = getDisparityMap(midas, midas_transform, imgp)
|
| 73 |
+
depth[depth < 0] = 0
|
| 74 |
+
depth = depth + 1e-3
|
| 75 |
+
depth = depth
|
| 76 |
+
return depth.max() - depth
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def main():
|
| 80 |
+
args = parse_arguments()
|
| 81 |
+
|
| 82 |
+
device = torch.device("cpu")
|
| 83 |
+
if args.use_cuda:
|
| 84 |
+
device = torch.device("cuda")
|
| 85 |
+
|
| 86 |
+
### kitti
|
| 87 |
+
baseline = args.baseline
|
| 88 |
+
focal = args.focal
|
| 89 |
+
img_scale = args.img_scale
|
| 90 |
+
|
| 91 |
+
imgP = Path(args.img_path)
|
| 92 |
+
save_folder = Path(args.save_folder)
|
| 93 |
+
if not save_folder.exists():
|
| 94 |
+
os.makedirs(str(save_folder))
|
| 95 |
+
|
| 96 |
+
midas, midas_transform = get_depth_estimation_model(
|
| 97 |
+
model_name=args.midas_model, device=device
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
if imgP.is_dir():
|
| 101 |
+
image_files = sorted(Path(imgP).glob("*"))
|
| 102 |
+
for imgp in tqdm(image_files):
|
| 103 |
+
depth = get_depth_map(
|
| 104 |
+
midas, midas_transform, imgp, baseline, focal, img_scale
|
| 105 |
+
)
|
| 106 |
+
np.save(save_folder / imgp.stem, depth)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
if __name__ == "__main__":
|
| 110 |
+
main()
|
Neural_Style_Transfer.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import copy
|
| 3 |
+
import torch
|
| 4 |
+
import random
|
| 5 |
+
import argparse
|
| 6 |
+
import numpy as np
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
from tqdm.auto import tqdm
|
| 10 |
+
from lib.style_transfer_utils import (
|
| 11 |
+
tensor2pil,
|
| 12 |
+
load_style_transfer_model,
|
| 13 |
+
run_style_transfer,
|
| 14 |
+
style_content_image_loader,
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def parse_arguments():
|
| 19 |
+
parser = argparse.ArgumentParser()
|
| 20 |
+
parser.add_argument(
|
| 21 |
+
"--content-imgs", type=str, help="Path to the content images.", required=True
|
| 22 |
+
)
|
| 23 |
+
parser.add_argument(
|
| 24 |
+
"--style-imgs", type=str, help="Path to the style images.", required=True
|
| 25 |
+
)
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--save-folder",
|
| 28 |
+
type=str,
|
| 29 |
+
help="Path to the save the generated images.",
|
| 30 |
+
required=True,
|
| 31 |
+
)
|
| 32 |
+
parser.add_argument(
|
| 33 |
+
"--vgg", type=str, help="Path to the pretrained VGG model.", required=True
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
parser.add_argument("--cuda", action="store_true", help="use cuda.")
|
| 37 |
+
parser.add_argument(
|
| 38 |
+
"--ext", type=str, default="stl", help="extension for generated image."
|
| 39 |
+
)
|
| 40 |
+
parser.add_argument(
|
| 41 |
+
"--min-step", type=int, default=100, help="minimum iteration steps"
|
| 42 |
+
)
|
| 43 |
+
parser.add_argument(
|
| 44 |
+
"--max-step", type=int, default=200, help="maximum iteration steps"
|
| 45 |
+
)
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"--style-weight", type=float, default=100000, help="weight for style loss"
|
| 48 |
+
)
|
| 49 |
+
parser.add_argument(
|
| 50 |
+
"--content-weight", type=float, default=2, help="weight for content loss"
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
return parser.parse_args()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def transfer_style(
|
| 57 |
+
cnn_path,
|
| 58 |
+
cimg,
|
| 59 |
+
simg,
|
| 60 |
+
min_step=100,
|
| 61 |
+
max_step=200,
|
| 62 |
+
style_weight=100000,
|
| 63 |
+
content_weight=2,
|
| 64 |
+
device="cpu",
|
| 65 |
+
):
|
| 66 |
+
cnn = load_style_transfer_model(pretrained=cnn_path)
|
| 67 |
+
|
| 68 |
+
content_img, style_img = style_content_image_loader(cimg, simg)
|
| 69 |
+
input_img = copy.deepcopy(content_img).to(device, torch.float)
|
| 70 |
+
|
| 71 |
+
output = run_style_transfer(
|
| 72 |
+
cnn,
|
| 73 |
+
content_img,
|
| 74 |
+
style_img,
|
| 75 |
+
input_img,
|
| 76 |
+
num_steps=random.randint(min_step, max_step),
|
| 77 |
+
style_weight=style_weight,
|
| 78 |
+
content_weight=content_weight,
|
| 79 |
+
device=device,
|
| 80 |
+
)
|
| 81 |
+
return tensor2pil(output[0].detach().cpu())
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def main():
|
| 85 |
+
args = parse_arguments()
|
| 86 |
+
if args.cuda and torch.cuda.is_available():
|
| 87 |
+
device = torch.device("cuda:0")
|
| 88 |
+
else:
|
| 89 |
+
device = torch.device("cpu")
|
| 90 |
+
|
| 91 |
+
content_images = sorted(Path(args.content_imgs).glob("*"))
|
| 92 |
+
# with open(Path(args.content_imgs), "r") as f:
|
| 93 |
+
# lines = f.read()
|
| 94 |
+
# content_images = lines.split("\n")
|
| 95 |
+
# content_images = [Path("./content_images") / f for f in content_images]
|
| 96 |
+
style_images = sorted(Path(args.style_imgs).glob("*"))
|
| 97 |
+
|
| 98 |
+
save_folder = Path(args.save_folder)
|
| 99 |
+
if not os.path.exists(args.save_folder):
|
| 100 |
+
print(f"Creating {args.save_folder}")
|
| 101 |
+
os.makedirs(str(save_folder))
|
| 102 |
+
|
| 103 |
+
for i, cimg in enumerate(content_images):
|
| 104 |
+
name, extension = cimg.name.split(".")
|
| 105 |
+
simg = style_images[i % len(style_images)]
|
| 106 |
+
|
| 107 |
+
output_img = transfer_style(
|
| 108 |
+
cnn_path=args.vgg,
|
| 109 |
+
cimg=cimg,
|
| 110 |
+
simg=simg,
|
| 111 |
+
min_step=args.min_step,
|
| 112 |
+
max_step=args.max_step,
|
| 113 |
+
style_weight=args.style_weight,
|
| 114 |
+
content_weight=args.content_weight,
|
| 115 |
+
device=device,
|
| 116 |
+
)
|
| 117 |
+
output_img.save(save_folder / f"{name}.{extension}")
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
if __name__ == "__main__":
|
| 121 |
+
main()
|
Rain_Effect_Generator.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import argparse
|
| 5 |
+
import numpy as np
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
from skimage import color
|
| 9 |
+
from tqdm.auto import tqdm
|
| 10 |
+
|
| 11 |
+
from lib.lime import LIME
|
| 12 |
+
from lib.fog_gen import fogAttenuation
|
| 13 |
+
from lib.rain_gen import RainGenUsingNoise
|
| 14 |
+
from lib.gen_utils import (
|
| 15 |
+
illumination2opacity,
|
| 16 |
+
layer_blend,
|
| 17 |
+
alpha_blend,
|
| 18 |
+
reduce_lightHSV,
|
| 19 |
+
scale_depth,
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def parse_arguments():
|
| 24 |
+
parser = argparse.ArgumentParser()
|
| 25 |
+
parser.add_argument(
|
| 26 |
+
"--clear_path", type=str, required=True, help="path to the file or the folder"
|
| 27 |
+
)
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--depth_path", type=str, required=True, help="path to the file or the folder"
|
| 30 |
+
)
|
| 31 |
+
parser.add_argument(
|
| 32 |
+
"--save_folder", type=str, default="./generated/", help="path to the folder"
|
| 33 |
+
)
|
| 34 |
+
parser.add_argument("--txt_file", default=None, help="path to the folder")
|
| 35 |
+
parser.add_argument("--show", action="store_true")
|
| 36 |
+
parser.add_argument("--fog", action="store_true")
|
| 37 |
+
return parser.parse_args()
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class RainEffectGenerator:
|
| 41 |
+
def __init__(self, fog=True):
|
| 42 |
+
self._lime = LIME(iterations=25, alpha=1.0)
|
| 43 |
+
# self._illumination2darkness = {0: 1, 1: 0.75, 2: 0.65, 3: 0.5}
|
| 44 |
+
self._illumination2darkness = {0: 1, 1: 0.95, 2: 0.85, 3: 0.8}
|
| 45 |
+
self._weather2visibility = (1000, 2000)
|
| 46 |
+
# self._weather2visibility = {'fog': (100,250), 'rain': (1000,2000), 'snow': (500, 1000)}
|
| 47 |
+
# self._illumination2fogcolor = {0: (80, 120), 1: (120, 160), 2: (160, 200), 3: (200, 240)}
|
| 48 |
+
self._illumination2fogcolor = {
|
| 49 |
+
0: (150, 180),
|
| 50 |
+
1: (180, 200),
|
| 51 |
+
2: (200, 240),
|
| 52 |
+
3: (200, 240),
|
| 53 |
+
}
|
| 54 |
+
self._rain_layer_gen = RainGenUsingNoise()
|
| 55 |
+
self._fog = fog
|
| 56 |
+
|
| 57 |
+
def getIlluminationMap(self, img: np.ndarray) -> np.ndarray:
|
| 58 |
+
self._lime.load(img)
|
| 59 |
+
T = self._lime.illumMap()
|
| 60 |
+
return T
|
| 61 |
+
|
| 62 |
+
def getIlluminationMapCheat(self, img: np.ndarray) -> np.ndarray:
|
| 63 |
+
T = color.rgb2gray(img)
|
| 64 |
+
return T
|
| 65 |
+
|
| 66 |
+
def genRainLayer(self, h=720, w=1280):
|
| 67 |
+
blur_angle = random.choice([-1, 1]) * random.randint(60, 90)
|
| 68 |
+
layer_large = self._rain_layer_gen.genRainLayer(
|
| 69 |
+
h=720,
|
| 70 |
+
w=1280,
|
| 71 |
+
noise_scale=random.uniform(0.35, 0.55),
|
| 72 |
+
noise_amount=0.2,
|
| 73 |
+
zoom_layer=random.uniform(1.0, 3.5),
|
| 74 |
+
blur_kernel_size=random.choice([15, 17, 19, 21, 23]),
|
| 75 |
+
blur_angle=blur_angle,
|
| 76 |
+
) # large
|
| 77 |
+
|
| 78 |
+
layer_small = self._rain_layer_gen.genRainLayer(
|
| 79 |
+
h=720,
|
| 80 |
+
w=1280,
|
| 81 |
+
noise_scale=random.uniform(0.35, 0.55),
|
| 82 |
+
noise_amount=0.15,
|
| 83 |
+
zoom_layer=random.uniform(1.0, 3.5),
|
| 84 |
+
blur_kernel_size=random.choice([7, 9, 11, 13]),
|
| 85 |
+
blur_angle=blur_angle,
|
| 86 |
+
) # small
|
| 87 |
+
layer = layer_blend(layer_small, layer_large)
|
| 88 |
+
hl, wl = layer.shape
|
| 89 |
+
|
| 90 |
+
if h != hl or w != wl:
|
| 91 |
+
layer = np.asarray(Image.fromarray(layer).resize((w, h)))
|
| 92 |
+
return layer
|
| 93 |
+
|
| 94 |
+
def genEffect(self, img_path: str, depth_path: str):
|
| 95 |
+
I = np.array(Image.open(img_path))
|
| 96 |
+
D = np.load(depth_path)
|
| 97 |
+
|
| 98 |
+
return self.genEffect_(I, D)
|
| 99 |
+
|
| 100 |
+
def genEffect_(self, I, D):
|
| 101 |
+
hI, wI, _ = I.shape
|
| 102 |
+
hD, wD = D.shape
|
| 103 |
+
|
| 104 |
+
if hI != hD or wI != wD:
|
| 105 |
+
D = scale_depth(D, hI, wI)
|
| 106 |
+
|
| 107 |
+
T = self.getIlluminationMap(I)
|
| 108 |
+
illumination_array = np.histogram(T, bins=4, range=(0, 1))[0] / (T.size)
|
| 109 |
+
illumination = illumination_array.argmax()
|
| 110 |
+
|
| 111 |
+
if self._fog:
|
| 112 |
+
if illumination > 0:
|
| 113 |
+
visibility = visibility = random.randint(
|
| 114 |
+
self._weather2visibility[0], self._weather2visibility[1]
|
| 115 |
+
)
|
| 116 |
+
fog_color = random.randint(
|
| 117 |
+
self._illumination2fogcolor[illumination][0],
|
| 118 |
+
self._illumination2fogcolor[illumination][1],
|
| 119 |
+
)
|
| 120 |
+
I_dark = reduce_lightHSV(
|
| 121 |
+
I,
|
| 122 |
+
sat_red=self._illumination2darkness[illumination],
|
| 123 |
+
val_red=self._illumination2darkness[illumination],
|
| 124 |
+
)
|
| 125 |
+
I_fog = fogAttenuation(
|
| 126 |
+
I_dark, D, visibility=visibility, fog_color=fog_color
|
| 127 |
+
)
|
| 128 |
+
else:
|
| 129 |
+
fog_color = 75
|
| 130 |
+
visibility = D.max() * 0.75 if D.max() < 1000 else 750
|
| 131 |
+
I_fog = fogAttenuation(I, D, visibility=visibility, fog_color=fog_color)
|
| 132 |
+
else:
|
| 133 |
+
I_fog = I
|
| 134 |
+
|
| 135 |
+
alpha = illumination2opacity(I, illumination) * random.uniform(0.3, 0.5)
|
| 136 |
+
rain_layer = self.genRainLayer(h=hI, w=wI)
|
| 137 |
+
I_rain = alpha_blend(I_fog, rain_layer, alpha)
|
| 138 |
+
return I_rain.astype(np.uint8)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def main():
|
| 142 |
+
args = parse_arguments()
|
| 143 |
+
raingen = RainEffectGenerator(fog=args.fog)
|
| 144 |
+
|
| 145 |
+
clearP = Path(args.clear_path)
|
| 146 |
+
depthP = Path(args.depth_path)
|
| 147 |
+
if clearP.is_file() and (depthP.is_file() and depthP.suffix == ".npy"):
|
| 148 |
+
rainy = raingen.genEffect(clearP, depthP)
|
| 149 |
+
if args.show:
|
| 150 |
+
Image.fromarray(rainy).show()
|
| 151 |
+
|
| 152 |
+
if clearP.is_dir() and depthP.is_dir():
|
| 153 |
+
if args.txt_file:
|
| 154 |
+
with open(args.txt_file, "r") as f:
|
| 155 |
+
files = f.read().split("\n")
|
| 156 |
+
image_files = [clearP / f for f in files]
|
| 157 |
+
else:
|
| 158 |
+
image_files = sorted(Path(clearP).glob("*"))
|
| 159 |
+
depth_files = [
|
| 160 |
+
Path(depthP) / (imgf.name.split(".")[0] + ".npy") for imgf in image_files
|
| 161 |
+
]
|
| 162 |
+
|
| 163 |
+
valid_files = [idx for idx, f in enumerate(depth_files) if f.exists()]
|
| 164 |
+
image_files = [image_files[idx] for idx in valid_files]
|
| 165 |
+
depth_files = [depth_files[idx] for idx in valid_files]
|
| 166 |
+
|
| 167 |
+
save_folder = Path(args.save_folder)
|
| 168 |
+
if not save_folder.exists():
|
| 169 |
+
os.makedirs(str(save_folder))
|
| 170 |
+
|
| 171 |
+
for imgp, depthp in tqdm(zip(image_files, depth_files), total=len(image_files)):
|
| 172 |
+
rainy = raingen.genEffect(imgp, depthp)
|
| 173 |
+
Image.fromarray(rainy).save(save_folder / (imgp.stem + ".jpg"))
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
if __name__ == "__main__":
|
| 177 |
+
main()
|
Snow_Effect_Generator.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import argparse
|
| 5 |
+
import numpy as np
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
from skimage import color
|
| 9 |
+
from tqdm.auto import tqdm
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
from lib.lime import LIME
|
| 13 |
+
from lib.fog_gen import fogAttenuation
|
| 14 |
+
from lib.snow_gen import SnowGenUsingNoise
|
| 15 |
+
from lib.gen_utils import (
|
| 16 |
+
screen_blend,
|
| 17 |
+
layer_blend,
|
| 18 |
+
illumination2opacity,
|
| 19 |
+
reduce_lightHSV,
|
| 20 |
+
scale_depth,
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def parse_arguments():
|
| 25 |
+
parser = argparse.ArgumentParser()
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--clear_path", type=str, required=True, help="path to the file or the folder"
|
| 28 |
+
)
|
| 29 |
+
parser.add_argument(
|
| 30 |
+
"--depth_path", type=str, required=True, help="path to the file or the folder"
|
| 31 |
+
)
|
| 32 |
+
parser.add_argument(
|
| 33 |
+
"--save_folder", type=str, default="./generated/", help="path to the folder"
|
| 34 |
+
)
|
| 35 |
+
parser.add_argument("--txt_file", default=None, help="path to the folder")
|
| 36 |
+
parser.add_argument("--show", action="store_true")
|
| 37 |
+
parser.add_argument("--fog", action="store_true")
|
| 38 |
+
|
| 39 |
+
return parser.parse_args()
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class SnowEffectGenerator:
|
| 43 |
+
def __init__(self, fog=True):
|
| 44 |
+
self._lime = LIME(iterations=25, alpha=1.0)
|
| 45 |
+
# self._illumination2darkness = {0: 1, 1: 0.75, 2: 0.65, 3: 0.5}
|
| 46 |
+
self._illumination2darkness = {0: 1, 1: 0.9, 2: 0.8, 3: 0.7}
|
| 47 |
+
self._weather2visibility = (1000, 2500) # (500, 1000)
|
| 48 |
+
# self._illumination2fogcolor = {0: (80, 120), 1: (120, 160), 2: (160, 200), 3: (200, 240)}
|
| 49 |
+
self._illumination2fogcolor = {
|
| 50 |
+
0: (150, 180),
|
| 51 |
+
1: (180, 200),
|
| 52 |
+
2: (200, 240),
|
| 53 |
+
3: (200, 240),
|
| 54 |
+
}
|
| 55 |
+
self._snow_layer_gen = SnowGenUsingNoise()
|
| 56 |
+
self._fog = fog
|
| 57 |
+
|
| 58 |
+
def getIlluminationMap(self, img: np.ndarray) -> np.ndarray:
|
| 59 |
+
self._lime.load(img)
|
| 60 |
+
T = self._lime.illumMap()
|
| 61 |
+
return T
|
| 62 |
+
|
| 63 |
+
def getIlluminationMapCheat(self, img: np.ndarray) -> np.ndarray:
|
| 64 |
+
T = color.rgb2gray(img)
|
| 65 |
+
return T
|
| 66 |
+
|
| 67 |
+
def genSnowLayer(self, h=720, w=1280): # alpha,
|
| 68 |
+
num_itr_small = 2 # random.randint(1,3)
|
| 69 |
+
num_itr_large = 1 # random.randint(1,4)
|
| 70 |
+
blur_angle = random.choice([-1, 1]) * random.randint(60, 90)
|
| 71 |
+
layer_small = self._snow_layer_gen.genSnowMultiLayer(
|
| 72 |
+
h=720,
|
| 73 |
+
w=1280,
|
| 74 |
+
blur_angle=blur_angle,
|
| 75 |
+
intensity="small",
|
| 76 |
+
num_itr=num_itr_small,
|
| 77 |
+
) # small
|
| 78 |
+
|
| 79 |
+
layer_large = self._snow_layer_gen.genSnowMultiLayer(
|
| 80 |
+
h=720,
|
| 81 |
+
w=1280,
|
| 82 |
+
blur_angle=blur_angle,
|
| 83 |
+
intensity="large",
|
| 84 |
+
num_itr=num_itr_large,
|
| 85 |
+
) # large
|
| 86 |
+
layer = layer_blend(layer_small, layer_large)
|
| 87 |
+
hl, wl = layer.shape
|
| 88 |
+
|
| 89 |
+
if h != hl or w != wl:
|
| 90 |
+
layer = np.asarray(Image.fromarray(layer).resize((w, h)))
|
| 91 |
+
return layer # (layer.astype(float)*alpha).astype(np.uint8)
|
| 92 |
+
|
| 93 |
+
def genEffect(self, img_path: str, depth_path: str):
|
| 94 |
+
I = np.array(Image.open(img_path))
|
| 95 |
+
D = np.load(depth_path)
|
| 96 |
+
|
| 97 |
+
return self.genEffect_(I, D)
|
| 98 |
+
|
| 99 |
+
def genEffect_(self, I, D):
|
| 100 |
+
hI, wI, _ = I.shape
|
| 101 |
+
hD, wD = D.shape
|
| 102 |
+
|
| 103 |
+
if hI != hD or wI != wD:
|
| 104 |
+
D = scale_depth(D, hI, wI)
|
| 105 |
+
|
| 106 |
+
T = self.getIlluminationMapCheat(I)
|
| 107 |
+
illumination_array = np.histogram(T, bins=4, range=(0, 1))[0] / (T.size)
|
| 108 |
+
illumination = illumination_array.argmax()
|
| 109 |
+
|
| 110 |
+
if self._fog:
|
| 111 |
+
if illumination > 0:
|
| 112 |
+
visibility = random.randint(
|
| 113 |
+
self._weather2visibility[0], self._weather2visibility[1]
|
| 114 |
+
)
|
| 115 |
+
fog_color = random.randint(
|
| 116 |
+
self._illumination2fogcolor[illumination][0],
|
| 117 |
+
self._illumination2fogcolor[illumination][1],
|
| 118 |
+
)
|
| 119 |
+
I_dark = reduce_lightHSV(
|
| 120 |
+
I,
|
| 121 |
+
sat_red=self._illumination2darkness[illumination],
|
| 122 |
+
val_red=self._illumination2darkness[illumination],
|
| 123 |
+
)
|
| 124 |
+
I_fog = fogAttenuation(
|
| 125 |
+
I_dark, D, visibility=visibility, fog_color=fog_color
|
| 126 |
+
)
|
| 127 |
+
else:
|
| 128 |
+
fog_color = 75
|
| 129 |
+
visibility = D.max() * 0.75 if D.max() < 1000 else 750
|
| 130 |
+
I_fog = fogAttenuation(I, D, visibility=visibility, fog_color=fog_color)
|
| 131 |
+
else:
|
| 132 |
+
I_fog = I
|
| 133 |
+
|
| 134 |
+
snow_layer = self.genSnowLayer(h=hI, w=wI) # , alpha=alpha) #, alpha
|
| 135 |
+
I_snow = screen_blend(
|
| 136 |
+
I_fog, snow_layer
|
| 137 |
+
) # screen_blend(I_fog, snow_layer) , alpha
|
| 138 |
+
return I_snow.astype(np.uint8)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def main():
|
| 142 |
+
args = parse_arguments()
|
| 143 |
+
snowgen = SnowEffectGenerator(fog=args.fog)
|
| 144 |
+
|
| 145 |
+
clearP = Path(args.clear_path)
|
| 146 |
+
depthP = Path(args.depth_path)
|
| 147 |
+
if clearP.is_file() and (depthP.is_file() and depthP.suffix == ".npy"):
|
| 148 |
+
snowy = snowgen.genEffect(clearP, depthP)
|
| 149 |
+
if args.show:
|
| 150 |
+
Image.fromarray(snowy).show()
|
| 151 |
+
|
| 152 |
+
if clearP.is_dir() and depthP.is_dir():
|
| 153 |
+
if args.txt_file:
|
| 154 |
+
with open(args.txt_file, "r") as f:
|
| 155 |
+
files = f.read().split("\n")
|
| 156 |
+
image_files = [clearP / f for f in files]
|
| 157 |
+
else:
|
| 158 |
+
image_files = sorted(Path(clearP).glob("*"))
|
| 159 |
+
|
| 160 |
+
depth_files = [
|
| 161 |
+
Path(depthP) / (imgf.name.split(".")[0] + ".npy") for imgf in image_files
|
| 162 |
+
]
|
| 163 |
+
|
| 164 |
+
valid_files = [idx for idx, f in enumerate(depth_files) if f.exists()]
|
| 165 |
+
image_files = [image_files[idx] for idx in valid_files]
|
| 166 |
+
depth_files = [depth_files[idx] for idx in valid_files]
|
| 167 |
+
|
| 168 |
+
save_folder = Path(args.save_folder)
|
| 169 |
+
if not save_folder.exists():
|
| 170 |
+
os.makedirs(str(save_folder))
|
| 171 |
+
|
| 172 |
+
for imgp, depthp in tqdm(zip(image_files, depth_files), total=len(image_files)):
|
| 173 |
+
snowy = snowgen.genEffect(imgp, depthp)
|
| 174 |
+
Image.fromarray(snowy).save(save_folder / (imgp.stem + ".jpg"))
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
if __name__ == "__main__":
|
| 178 |
+
main()
|
checkpoints/clear2rainy.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2e9b90303e5876bb391be11a16b5fae9d3a58f83d5ff0e299a2d2a8ea3f175e
|
| 3 |
+
size 45531485
|
checkpoints/clear2snowy.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:90fd7de992455241c5f7ce7fa0bb92a01bb53b6fb422c4558a7a0231bfdd7104
|
| 3 |
+
size 45531485
|
gen_depth_map.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python MiDaS_Depth_Estimation.py \
|
| 2 |
+
--img_path ./data/images \
|
| 3 |
+
--save_folder ./data/depth_maps \
|
| 4 |
+
--use_cuda
|
| 5 |
+
|
gen_rain_image.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python Rain_Effect_Generator.py \
|
| 2 |
+
--clear_path ./data/images \
|
| 3 |
+
--depth_path ./data/depth_maps \
|
| 4 |
+
--save_folder ./data/analyticity/rain_images \
|
| 5 |
+
--fog
|
gen_rain_image_ag.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python Rain_Effect_Generator.py \
|
| 2 |
+
--clear_path ./data/gan/rain_images \
|
| 3 |
+
--depth_path ./data/depth_maps \
|
| 4 |
+
--save_folder ./data/analytical_gan/rain_images
|
gen_rain_nst.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python Neural_Style_Transfer.py \
|
| 2 |
+
--content-imgs ./data/images/ \
|
| 3 |
+
--style-imgs ./data/styles/rain_images \
|
| 4 |
+
--save-folder ./data/nst/rain_images \
|
| 5 |
+
--vgg ./checkpoints/rain_vgg_512 \
|
| 6 |
+
--min-step 10 \
|
| 7 |
+
--max-step 10 \
|
| 8 |
+
--style-weight 10 \
|
| 9 |
+
--cuda
|
gen_snow_image.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python Snow_Effect_Generator.py \
|
| 2 |
+
--clear_path ./data/images \
|
| 3 |
+
--depth_path ./data/depth_maps \
|
| 4 |
+
--save_folder ./data/analyticity/snow_images \
|
| 5 |
+
--fog
|
gen_snow_image_ag.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python Snow_Effect_Generator.py \
|
| 2 |
+
--clear_path ./data/gan/snow_images \
|
| 3 |
+
--depth_path ./data/depth_maps \
|
| 4 |
+
--save_folder ./data/analytical_gan/snow_images
|
gen_snow_nst.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python Neural_Style_Transfer.py \
|
| 2 |
+
--content-imgs ./data/images/ \
|
| 3 |
+
--style-imgs ./data/styles/ \
|
| 4 |
+
--save-folder ./data/nst/snow_images \
|
| 5 |
+
--vgg ./checkpoints/snow_vgg_512 \
|
| 6 |
+
--min-step 100 \
|
| 7 |
+
--max-step 200 \
|
| 8 |
+
--style-weight 10 \
|
| 9 |
+
--cuda
|
lib/fog_gen.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from PIL import Image
|
| 3 |
+
from noise import pnoise3
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def perlin_noise(w, h, depth):
|
| 7 |
+
p1 = Image.new("L", (w, h))
|
| 8 |
+
p2 = Image.new("L", (w, h))
|
| 9 |
+
p3 = Image.new("L", (w, h))
|
| 10 |
+
|
| 11 |
+
scale = 1 / 130.0
|
| 12 |
+
for y in range(h):
|
| 13 |
+
for x in range(w):
|
| 14 |
+
v = pnoise3(
|
| 15 |
+
x * scale,
|
| 16 |
+
y * scale,
|
| 17 |
+
depth[y, x] * scale,
|
| 18 |
+
octaves=1,
|
| 19 |
+
persistence=0.5,
|
| 20 |
+
lacunarity=2.0,
|
| 21 |
+
)
|
| 22 |
+
color = int((v + 1) * 128.0)
|
| 23 |
+
p1.putpixel((x, y), color)
|
| 24 |
+
|
| 25 |
+
scale = 1 / 60.0
|
| 26 |
+
for y in range(h):
|
| 27 |
+
for x in range(w):
|
| 28 |
+
v = pnoise3(
|
| 29 |
+
x * scale,
|
| 30 |
+
y * scale,
|
| 31 |
+
depth[y, x] * scale,
|
| 32 |
+
octaves=1,
|
| 33 |
+
persistence=0.5,
|
| 34 |
+
lacunarity=2.0,
|
| 35 |
+
)
|
| 36 |
+
color = int((v + 0.5) * 128)
|
| 37 |
+
p2.putpixel((x, y), color)
|
| 38 |
+
|
| 39 |
+
scale = 1 / 10.0
|
| 40 |
+
for y in range(h):
|
| 41 |
+
for x in range(w):
|
| 42 |
+
v = pnoise3(
|
| 43 |
+
x * scale,
|
| 44 |
+
y * scale,
|
| 45 |
+
depth[y, x] * scale,
|
| 46 |
+
octaves=1,
|
| 47 |
+
persistence=0.5,
|
| 48 |
+
lacunarity=2.0,
|
| 49 |
+
)
|
| 50 |
+
color = int((v + 1.2) * 128)
|
| 51 |
+
p3.putpixel((x, y), color)
|
| 52 |
+
|
| 53 |
+
perlin = (np.array(p1) + np.array(p2) / 2 + np.array(p3) / 4) / 3
|
| 54 |
+
|
| 55 |
+
return perlin
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def generate_fog(image, depth, visibility=None, fog_color=None):
|
| 59 |
+
"""
|
| 60 |
+
input:
|
| 61 |
+
image - numpy array (h, w, c)
|
| 62 |
+
depth - numpy array (h, w)
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
height, width = depth.shape
|
| 66 |
+
perlin = perlin_noise(width, height, depth)
|
| 67 |
+
|
| 68 |
+
depth_max = depth.max()
|
| 69 |
+
|
| 70 |
+
if visibility:
|
| 71 |
+
fog_visibility = visibility
|
| 72 |
+
else:
|
| 73 |
+
fog_visibility = float(
|
| 74 |
+
np.random.randint(
|
| 75 |
+
int(depth_max - 0.2 * depth_max), int(depth_max + 0.2 * depth_max)
|
| 76 |
+
)
|
| 77 |
+
)
|
| 78 |
+
fog_visibility = np.clip(fog_visibility, 60, 200)
|
| 79 |
+
|
| 80 |
+
VERTICLE_FOV = 60 # degrees
|
| 81 |
+
CAMERA_ALTITUDE = 1.8 # meters
|
| 82 |
+
VISIBILITY_RANGE_MOLECULE = 12 # m 12
|
| 83 |
+
VISIBILITY_RANGE_AEROSOL = fog_visibility # m 450
|
| 84 |
+
ECM_ = 3.912 / VISIBILITY_RANGE_MOLECULE # EXTINCTION_COEFFICIENT_MOLECULE /m
|
| 85 |
+
ECA_ = 3.912 / VISIBILITY_RANGE_AEROSOL # EXTINCTION_COEFFICIENT_AEROSOL /m
|
| 86 |
+
|
| 87 |
+
FT = 70 # FOG_TOP m 31 70
|
| 88 |
+
HT = 34 # HAZE_TOP m 300 34
|
| 89 |
+
|
| 90 |
+
angle = np.repeat(
|
| 91 |
+
-1
|
| 92 |
+
* np.linspace(-0.5 * VERTICLE_FOV, 0.5 * VERTICLE_FOV, height).reshape(-1, 1),
|
| 93 |
+
axis=1,
|
| 94 |
+
repeats=width,
|
| 95 |
+
)
|
| 96 |
+
distance = depth / np.cos(np.radians(angle))
|
| 97 |
+
elevation = CAMERA_ALTITUDE + distance * np.sin(np.radians(angle))
|
| 98 |
+
|
| 99 |
+
distance_through_fog = np.zeros_like(distance)
|
| 100 |
+
distance_through_haze = np.zeros_like(distance)
|
| 101 |
+
distance_through_haze_free = np.zeros_like(distance)
|
| 102 |
+
|
| 103 |
+
ECA = ECA_
|
| 104 |
+
c = 1 - elevation / (FT + 0.00001)
|
| 105 |
+
c[c < 0] = 0
|
| 106 |
+
ECM = (ECM_ * c + (1 - c) * ECA_) * (perlin / 255)
|
| 107 |
+
|
| 108 |
+
idx1 = np.logical_and(FT > elevation, elevation > HT)
|
| 109 |
+
idx2 = elevation <= HT
|
| 110 |
+
idx3 = elevation >= FT
|
| 111 |
+
|
| 112 |
+
distance_through_haze[idx2] = distance[idx2]
|
| 113 |
+
distance_through_fog[idx1] = (
|
| 114 |
+
(elevation[idx1] - HT) * distance[idx1] / (elevation[idx1] - CAMERA_ALTITUDE)
|
| 115 |
+
)
|
| 116 |
+
distance_through_haze[idx1] = distance[idx1] - distance_through_fog[idx1]
|
| 117 |
+
distance_through_haze[idx3] = (
|
| 118 |
+
(HT - CAMERA_ALTITUDE) * distance[idx3] / (elevation[idx3] - CAMERA_ALTITUDE)
|
| 119 |
+
)
|
| 120 |
+
distance_through_fog[idx3] = (
|
| 121 |
+
(FT - HT) * distance[idx3] / (elevation[idx3] - CAMERA_ALTITUDE)
|
| 122 |
+
)
|
| 123 |
+
distance_through_haze_free[idx3] = (
|
| 124 |
+
distance[idx3] - distance_through_haze[idx3] - distance_through_fog[idx3]
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
attenuation = np.exp(-ECA * distance_through_haze - ECM * distance_through_fog)
|
| 128 |
+
|
| 129 |
+
I_ex = image * attenuation[:, :, None]
|
| 130 |
+
O_p = 1 - attenuation
|
| 131 |
+
if fog_color is None:
|
| 132 |
+
fog_color = np.random.randint(200, 255)
|
| 133 |
+
I_al = np.array([[[fog_color, fog_color, fog_color]]])
|
| 134 |
+
|
| 135 |
+
I = I_ex + O_p[:, :, None] * I_al
|
| 136 |
+
return I.astype(np.uint8)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def fogAttenuation(img: np.ndarray, depth: np.ndarray, visibility=1000, fog_color=200):
|
| 140 |
+
img_fog = generate_fog(
|
| 141 |
+
img.copy(), depth.copy(), visibility=visibility, fog_color=fog_color
|
| 142 |
+
)
|
| 143 |
+
return img_fog
|
lib/gan_networks.py
ADDED
|
@@ -0,0 +1,616 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.nn import init
|
| 4 |
+
import functools
|
| 5 |
+
from torch.optim import lr_scheduler
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
###############################################################################
|
| 9 |
+
# Helper Functions
|
| 10 |
+
###############################################################################
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Identity(nn.Module):
|
| 14 |
+
def forward(self, x):
|
| 15 |
+
return x
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_norm_layer(norm_type='instance'):
|
| 19 |
+
"""Return a normalization layer
|
| 20 |
+
|
| 21 |
+
Parameters:
|
| 22 |
+
norm_type (str) -- the name of the normalization layer: batch | instance | none
|
| 23 |
+
|
| 24 |
+
For BatchNorm, we use learnable affine parameters and track running statistics (mean/stddev).
|
| 25 |
+
For InstanceNorm, we do not use learnable affine parameters. We do not track running statistics.
|
| 26 |
+
"""
|
| 27 |
+
if norm_type == 'batch':
|
| 28 |
+
norm_layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
|
| 29 |
+
elif norm_type == 'instance':
|
| 30 |
+
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
|
| 31 |
+
elif norm_type == 'none':
|
| 32 |
+
def norm_layer(x):
|
| 33 |
+
return Identity()
|
| 34 |
+
else:
|
| 35 |
+
raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
|
| 36 |
+
return norm_layer
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def get_scheduler(optimizer, opt):
|
| 40 |
+
"""Return a learning rate scheduler
|
| 41 |
+
|
| 42 |
+
Parameters:
|
| 43 |
+
optimizer -- the optimizer of the network
|
| 44 |
+
opt (option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions.
|
| 45 |
+
opt.lr_policy is the name of learning rate policy: linear | step | plateau | cosine
|
| 46 |
+
|
| 47 |
+
For 'linear', we keep the same learning rate for the first <opt.n_epochs> epochs
|
| 48 |
+
and linearly decay the rate to zero over the next <opt.n_epochs_decay> epochs.
|
| 49 |
+
For other schedulers (step, plateau, and cosine), we use the default PyTorch schedulers.
|
| 50 |
+
See https://pytorch.org/docs/stable/optim.html for more details.
|
| 51 |
+
"""
|
| 52 |
+
if opt.lr_policy == 'linear':
|
| 53 |
+
def lambda_rule(epoch):
|
| 54 |
+
lr_l = 1.0 - max(0, epoch + opt.epoch_count - opt.n_epochs) / float(opt.n_epochs_decay + 1)
|
| 55 |
+
return lr_l
|
| 56 |
+
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
|
| 57 |
+
elif opt.lr_policy == 'step':
|
| 58 |
+
scheduler = lr_scheduler.StepLR(optimizer, step_size=opt.lr_decay_iters, gamma=0.1)
|
| 59 |
+
elif opt.lr_policy == 'plateau':
|
| 60 |
+
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, threshold=0.01, patience=5)
|
| 61 |
+
elif opt.lr_policy == 'cosine':
|
| 62 |
+
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=opt.n_epochs, eta_min=0)
|
| 63 |
+
else:
|
| 64 |
+
return NotImplementedError('learning rate policy [%s] is not implemented', opt.lr_policy)
|
| 65 |
+
return scheduler
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def init_weights(net, init_type='normal', init_gain=0.02):
|
| 69 |
+
"""Initialize network weights.
|
| 70 |
+
|
| 71 |
+
Parameters:
|
| 72 |
+
net (network) -- network to be initialized
|
| 73 |
+
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
|
| 74 |
+
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
| 75 |
+
|
| 76 |
+
We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
|
| 77 |
+
work better for some applications. Feel free to try yourself.
|
| 78 |
+
"""
|
| 79 |
+
def init_func(m): # define the initialization function
|
| 80 |
+
classname = m.__class__.__name__
|
| 81 |
+
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
|
| 82 |
+
if init_type == 'normal':
|
| 83 |
+
init.normal_(m.weight.data, 0.0, init_gain)
|
| 84 |
+
elif init_type == 'xavier':
|
| 85 |
+
init.xavier_normal_(m.weight.data, gain=init_gain)
|
| 86 |
+
elif init_type == 'kaiming':
|
| 87 |
+
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
| 88 |
+
elif init_type == 'orthogonal':
|
| 89 |
+
init.orthogonal_(m.weight.data, gain=init_gain)
|
| 90 |
+
else:
|
| 91 |
+
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
|
| 92 |
+
if hasattr(m, 'bias') and m.bias is not None:
|
| 93 |
+
init.constant_(m.bias.data, 0.0)
|
| 94 |
+
elif classname.find('BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
|
| 95 |
+
init.normal_(m.weight.data, 1.0, init_gain)
|
| 96 |
+
init.constant_(m.bias.data, 0.0)
|
| 97 |
+
|
| 98 |
+
print('initialize network with %s' % init_type)
|
| 99 |
+
net.apply(init_func) # apply the initialization function <init_func>
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def init_net(net, init_type='normal', init_gain=0.02, gpu_ids=[]):
|
| 103 |
+
"""Initialize a network: 1. register CPU/GPU device (with multi-GPU support); 2. initialize the network weights
|
| 104 |
+
Parameters:
|
| 105 |
+
net (network) -- the network to be initialized
|
| 106 |
+
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
|
| 107 |
+
gain (float) -- scaling factor for normal, xavier and orthogonal.
|
| 108 |
+
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
|
| 109 |
+
|
| 110 |
+
Return an initialized network.
|
| 111 |
+
"""
|
| 112 |
+
if len(gpu_ids) > 0:
|
| 113 |
+
assert(torch.cuda.is_available())
|
| 114 |
+
net.to(gpu_ids[0])
|
| 115 |
+
net = torch.nn.DataParallel(net, gpu_ids) # multi-GPUs
|
| 116 |
+
init_weights(net, init_type, init_gain=init_gain)
|
| 117 |
+
return net
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def define_G(input_nc, output_nc, ngf, netG, norm='batch', use_dropout=False, init_type='normal', init_gain=0.02, gpu_ids=[]):
|
| 121 |
+
"""Create a generator
|
| 122 |
+
|
| 123 |
+
Parameters:
|
| 124 |
+
input_nc (int) -- the number of channels in input images
|
| 125 |
+
output_nc (int) -- the number of channels in output images
|
| 126 |
+
ngf (int) -- the number of filters in the last conv layer
|
| 127 |
+
netG (str) -- the architecture's name: resnet_9blocks | resnet_6blocks | unet_256 | unet_128
|
| 128 |
+
norm (str) -- the name of normalization layers used in the network: batch | instance | none
|
| 129 |
+
use_dropout (bool) -- if use dropout layers.
|
| 130 |
+
init_type (str) -- the name of our initialization method.
|
| 131 |
+
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
| 132 |
+
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
|
| 133 |
+
|
| 134 |
+
Returns a generator
|
| 135 |
+
|
| 136 |
+
Our current implementation provides two types of generators:
|
| 137 |
+
U-Net: [unet_128] (for 128x128 input images) and [unet_256] (for 256x256 input images)
|
| 138 |
+
The original U-Net paper: https://arxiv.org/abs/1505.04597
|
| 139 |
+
|
| 140 |
+
Resnet-based generator: [resnet_6blocks] (with 6 Resnet blocks) and [resnet_9blocks] (with 9 Resnet blocks)
|
| 141 |
+
Resnet-based generator consists of several Resnet blocks between a few downsampling/upsampling operations.
|
| 142 |
+
We adapt Torch code from Justin Johnson's neural style transfer project (https://github.com/jcjohnson/fast-neural-style).
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
The generator has been initialized by <init_net>. It uses RELU for non-linearity.
|
| 146 |
+
"""
|
| 147 |
+
net = None
|
| 148 |
+
norm_layer = get_norm_layer(norm_type=norm)
|
| 149 |
+
|
| 150 |
+
if netG == 'resnet_9blocks':
|
| 151 |
+
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=9)
|
| 152 |
+
elif netG == 'resnet_6blocks':
|
| 153 |
+
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=6)
|
| 154 |
+
elif netG == 'unet_128':
|
| 155 |
+
net = UnetGenerator(input_nc, output_nc, 7, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
| 156 |
+
elif netG == 'unet_256':
|
| 157 |
+
net = UnetGenerator(input_nc, output_nc, 8, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
| 158 |
+
else:
|
| 159 |
+
raise NotImplementedError('Generator model name [%s] is not recognized' % netG)
|
| 160 |
+
return init_net(net, init_type, init_gain, gpu_ids)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def define_D(input_nc, ndf, netD, n_layers_D=3, norm='batch', init_type='normal', init_gain=0.02, gpu_ids=[]):
|
| 164 |
+
"""Create a discriminator
|
| 165 |
+
|
| 166 |
+
Parameters:
|
| 167 |
+
input_nc (int) -- the number of channels in input images
|
| 168 |
+
ndf (int) -- the number of filters in the first conv layer
|
| 169 |
+
netD (str) -- the architecture's name: basic | n_layers | pixel
|
| 170 |
+
n_layers_D (int) -- the number of conv layers in the discriminator; effective when netD=='n_layers'
|
| 171 |
+
norm (str) -- the type of normalization layers used in the network.
|
| 172 |
+
init_type (str) -- the name of the initialization method.
|
| 173 |
+
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
| 174 |
+
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
|
| 175 |
+
|
| 176 |
+
Returns a discriminator
|
| 177 |
+
|
| 178 |
+
Our current implementation provides three types of discriminators:
|
| 179 |
+
[basic]: 'PatchGAN' classifier described in the original pix2pix paper.
|
| 180 |
+
It can classify whether 70×70 overlapping patches are real or fake.
|
| 181 |
+
Such a patch-level discriminator architecture has fewer parameters
|
| 182 |
+
than a full-image discriminator and can work on arbitrarily-sized images
|
| 183 |
+
in a fully convolutional fashion.
|
| 184 |
+
|
| 185 |
+
[n_layers]: With this mode, you can specify the number of conv layers in the discriminator
|
| 186 |
+
with the parameter <n_layers_D> (default=3 as used in [basic] (PatchGAN).)
|
| 187 |
+
|
| 188 |
+
[pixel]: 1x1 PixelGAN discriminator can classify whether a pixel is real or not.
|
| 189 |
+
It encourages greater color diversity but has no effect on spatial statistics.
|
| 190 |
+
|
| 191 |
+
The discriminator has been initialized by <init_net>. It uses Leakly RELU for non-linearity.
|
| 192 |
+
"""
|
| 193 |
+
net = None
|
| 194 |
+
norm_layer = get_norm_layer(norm_type=norm)
|
| 195 |
+
|
| 196 |
+
if netD == 'basic': # default PatchGAN classifier
|
| 197 |
+
net = NLayerDiscriminator(input_nc, ndf, n_layers=3, norm_layer=norm_layer)
|
| 198 |
+
elif netD == 'n_layers': # more options
|
| 199 |
+
net = NLayerDiscriminator(input_nc, ndf, n_layers_D, norm_layer=norm_layer)
|
| 200 |
+
elif netD == 'pixel': # classify if each pixel is real or fake
|
| 201 |
+
net = PixelDiscriminator(input_nc, ndf, norm_layer=norm_layer)
|
| 202 |
+
else:
|
| 203 |
+
raise NotImplementedError('Discriminator model name [%s] is not recognized' % netD)
|
| 204 |
+
return init_net(net, init_type, init_gain, gpu_ids)
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
##############################################################################
|
| 208 |
+
# Classes
|
| 209 |
+
##############################################################################
|
| 210 |
+
class GANLoss(nn.Module):
|
| 211 |
+
"""Define different GAN objectives.
|
| 212 |
+
|
| 213 |
+
The GANLoss class abstracts away the need to create the target label tensor
|
| 214 |
+
that has the same size as the input.
|
| 215 |
+
"""
|
| 216 |
+
|
| 217 |
+
def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
|
| 218 |
+
""" Initialize the GANLoss class.
|
| 219 |
+
|
| 220 |
+
Parameters:
|
| 221 |
+
gan_mode (str) - - the type of GAN objective. It currently supports vanilla, lsgan, and wgangp.
|
| 222 |
+
target_real_label (bool) - - label for a real image
|
| 223 |
+
target_fake_label (bool) - - label of a fake image
|
| 224 |
+
|
| 225 |
+
Note: Do not use sigmoid as the last layer of Discriminator.
|
| 226 |
+
LSGAN needs no sigmoid. vanilla GANs will handle it with BCEWithLogitsLoss.
|
| 227 |
+
"""
|
| 228 |
+
super(GANLoss, self).__init__()
|
| 229 |
+
self.register_buffer('real_label', torch.tensor(target_real_label))
|
| 230 |
+
self.register_buffer('fake_label', torch.tensor(target_fake_label))
|
| 231 |
+
self.gan_mode = gan_mode
|
| 232 |
+
if gan_mode == 'lsgan':
|
| 233 |
+
self.loss = nn.MSELoss()
|
| 234 |
+
elif gan_mode == 'vanilla':
|
| 235 |
+
self.loss = nn.BCEWithLogitsLoss()
|
| 236 |
+
elif gan_mode in ['wgangp']:
|
| 237 |
+
self.loss = None
|
| 238 |
+
else:
|
| 239 |
+
raise NotImplementedError('gan mode %s not implemented' % gan_mode)
|
| 240 |
+
|
| 241 |
+
def get_target_tensor(self, prediction, target_is_real):
|
| 242 |
+
"""Create label tensors with the same size as the input.
|
| 243 |
+
|
| 244 |
+
Parameters:
|
| 245 |
+
prediction (tensor) - - tpyically the prediction from a discriminator
|
| 246 |
+
target_is_real (bool) - - if the ground truth label is for real images or fake images
|
| 247 |
+
|
| 248 |
+
Returns:
|
| 249 |
+
A label tensor filled with ground truth label, and with the size of the input
|
| 250 |
+
"""
|
| 251 |
+
|
| 252 |
+
if target_is_real:
|
| 253 |
+
target_tensor = self.real_label
|
| 254 |
+
else:
|
| 255 |
+
target_tensor = self.fake_label
|
| 256 |
+
return target_tensor.expand_as(prediction)
|
| 257 |
+
|
| 258 |
+
def __call__(self, prediction, target_is_real):
|
| 259 |
+
"""Calculate loss given Discriminator's output and grount truth labels.
|
| 260 |
+
|
| 261 |
+
Parameters:
|
| 262 |
+
prediction (tensor) - - tpyically the prediction output from a discriminator
|
| 263 |
+
target_is_real (bool) - - if the ground truth label is for real images or fake images
|
| 264 |
+
|
| 265 |
+
Returns:
|
| 266 |
+
the calculated loss.
|
| 267 |
+
"""
|
| 268 |
+
if self.gan_mode in ['lsgan', 'vanilla']:
|
| 269 |
+
target_tensor = self.get_target_tensor(prediction, target_is_real)
|
| 270 |
+
loss = self.loss(prediction, target_tensor)
|
| 271 |
+
elif self.gan_mode == 'wgangp':
|
| 272 |
+
if target_is_real:
|
| 273 |
+
loss = -prediction.mean()
|
| 274 |
+
else:
|
| 275 |
+
loss = prediction.mean()
|
| 276 |
+
return loss
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def cal_gradient_penalty(netD, real_data, fake_data, device, type='mixed', constant=1.0, lambda_gp=10.0):
|
| 280 |
+
"""Calculate the gradient penalty loss, used in WGAN-GP paper https://arxiv.org/abs/1704.00028
|
| 281 |
+
|
| 282 |
+
Arguments:
|
| 283 |
+
netD (network) -- discriminator network
|
| 284 |
+
real_data (tensor array) -- real images
|
| 285 |
+
fake_data (tensor array) -- generated images from the generator
|
| 286 |
+
device (str) -- GPU / CPU: from torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu')
|
| 287 |
+
type (str) -- if we mix real and fake data or not [real | fake | mixed].
|
| 288 |
+
constant (float) -- the constant used in formula ( ||gradient||_2 - constant)^2
|
| 289 |
+
lambda_gp (float) -- weight for this loss
|
| 290 |
+
|
| 291 |
+
Returns the gradient penalty loss
|
| 292 |
+
"""
|
| 293 |
+
if lambda_gp > 0.0:
|
| 294 |
+
if type == 'real': # either use real images, fake images, or a linear interpolation of two.
|
| 295 |
+
interpolatesv = real_data
|
| 296 |
+
elif type == 'fake':
|
| 297 |
+
interpolatesv = fake_data
|
| 298 |
+
elif type == 'mixed':
|
| 299 |
+
alpha = torch.rand(real_data.shape[0], 1, device=device)
|
| 300 |
+
alpha = alpha.expand(real_data.shape[0], real_data.nelement() // real_data.shape[0]).contiguous().view(*real_data.shape)
|
| 301 |
+
interpolatesv = alpha * real_data + ((1 - alpha) * fake_data)
|
| 302 |
+
else:
|
| 303 |
+
raise NotImplementedError('{} not implemented'.format(type))
|
| 304 |
+
interpolatesv.requires_grad_(True)
|
| 305 |
+
disc_interpolates = netD(interpolatesv)
|
| 306 |
+
gradients = torch.autograd.grad(outputs=disc_interpolates, inputs=interpolatesv,
|
| 307 |
+
grad_outputs=torch.ones(disc_interpolates.size()).to(device),
|
| 308 |
+
create_graph=True, retain_graph=True, only_inputs=True)
|
| 309 |
+
gradients = gradients[0].view(real_data.size(0), -1) # flat the data
|
| 310 |
+
gradient_penalty = (((gradients + 1e-16).norm(2, dim=1) - constant) ** 2).mean() * lambda_gp # added eps
|
| 311 |
+
return gradient_penalty, gradients
|
| 312 |
+
else:
|
| 313 |
+
return 0.0, None
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
class ResnetGenerator(nn.Module):
|
| 317 |
+
"""Resnet-based generator that consists of Resnet blocks between a few downsampling/upsampling operations.
|
| 318 |
+
|
| 319 |
+
We adapt Torch code and idea from Justin Johnson's neural style transfer project(https://github.com/jcjohnson/fast-neural-style)
|
| 320 |
+
"""
|
| 321 |
+
|
| 322 |
+
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect'):
|
| 323 |
+
"""Construct a Resnet-based generator
|
| 324 |
+
|
| 325 |
+
Parameters:
|
| 326 |
+
input_nc (int) -- the number of channels in input images
|
| 327 |
+
output_nc (int) -- the number of channels in output images
|
| 328 |
+
ngf (int) -- the number of filters in the last conv layer
|
| 329 |
+
norm_layer -- normalization layer
|
| 330 |
+
use_dropout (bool) -- if use dropout layers
|
| 331 |
+
n_blocks (int) -- the number of ResNet blocks
|
| 332 |
+
padding_type (str) -- the name of padding layer in conv layers: reflect | replicate | zero
|
| 333 |
+
"""
|
| 334 |
+
assert(n_blocks >= 0)
|
| 335 |
+
super(ResnetGenerator, self).__init__()
|
| 336 |
+
if type(norm_layer) == functools.partial:
|
| 337 |
+
use_bias = norm_layer.func == nn.InstanceNorm2d
|
| 338 |
+
else:
|
| 339 |
+
use_bias = norm_layer == nn.InstanceNorm2d
|
| 340 |
+
|
| 341 |
+
model = [nn.ReflectionPad2d(3),
|
| 342 |
+
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
|
| 343 |
+
norm_layer(ngf),
|
| 344 |
+
nn.ReLU(True)]
|
| 345 |
+
|
| 346 |
+
n_downsampling = 2
|
| 347 |
+
for i in range(n_downsampling): # add downsampling layers
|
| 348 |
+
mult = 2 ** i
|
| 349 |
+
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
|
| 350 |
+
norm_layer(ngf * mult * 2),
|
| 351 |
+
nn.ReLU(True)]
|
| 352 |
+
|
| 353 |
+
mult = 2 ** n_downsampling
|
| 354 |
+
for i in range(n_blocks): # add ResNet blocks
|
| 355 |
+
|
| 356 |
+
model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
|
| 357 |
+
|
| 358 |
+
for i in range(n_downsampling): # add upsampling layers
|
| 359 |
+
mult = 2 ** (n_downsampling - i)
|
| 360 |
+
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
|
| 361 |
+
kernel_size=3, stride=2,
|
| 362 |
+
padding=1, output_padding=1,
|
| 363 |
+
bias=use_bias),
|
| 364 |
+
norm_layer(int(ngf * mult / 2)),
|
| 365 |
+
nn.ReLU(True)]
|
| 366 |
+
model += [nn.ReflectionPad2d(3)]
|
| 367 |
+
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
| 368 |
+
model += [nn.Tanh()]
|
| 369 |
+
|
| 370 |
+
self.model = nn.Sequential(*model)
|
| 371 |
+
|
| 372 |
+
def forward(self, input):
|
| 373 |
+
"""Standard forward"""
|
| 374 |
+
return self.model(input)
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
class ResnetBlock(nn.Module):
|
| 378 |
+
"""Define a Resnet block"""
|
| 379 |
+
|
| 380 |
+
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
|
| 381 |
+
"""Initialize the Resnet block
|
| 382 |
+
|
| 383 |
+
A resnet block is a conv block with skip connections
|
| 384 |
+
We construct a conv block with build_conv_block function,
|
| 385 |
+
and implement skip connections in <forward> function.
|
| 386 |
+
Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
|
| 387 |
+
"""
|
| 388 |
+
super(ResnetBlock, self).__init__()
|
| 389 |
+
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
|
| 390 |
+
|
| 391 |
+
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
|
| 392 |
+
"""Construct a convolutional block.
|
| 393 |
+
|
| 394 |
+
Parameters:
|
| 395 |
+
dim (int) -- the number of channels in the conv layer.
|
| 396 |
+
padding_type (str) -- the name of padding layer: reflect | replicate | zero
|
| 397 |
+
norm_layer -- normalization layer
|
| 398 |
+
use_dropout (bool) -- if use dropout layers.
|
| 399 |
+
use_bias (bool) -- if the conv layer uses bias or not
|
| 400 |
+
|
| 401 |
+
Returns a conv block (with a conv layer, a normalization layer, and a non-linearity layer (ReLU))
|
| 402 |
+
"""
|
| 403 |
+
conv_block = []
|
| 404 |
+
p = 0
|
| 405 |
+
if padding_type == 'reflect':
|
| 406 |
+
conv_block += [nn.ReflectionPad2d(1)]
|
| 407 |
+
elif padding_type == 'replicate':
|
| 408 |
+
conv_block += [nn.ReplicationPad2d(1)]
|
| 409 |
+
elif padding_type == 'zero':
|
| 410 |
+
p = 1
|
| 411 |
+
else:
|
| 412 |
+
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
| 413 |
+
|
| 414 |
+
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
|
| 415 |
+
if use_dropout:
|
| 416 |
+
conv_block += [nn.Dropout(0.5)]
|
| 417 |
+
|
| 418 |
+
p = 0
|
| 419 |
+
if padding_type == 'reflect':
|
| 420 |
+
conv_block += [nn.ReflectionPad2d(1)]
|
| 421 |
+
elif padding_type == 'replicate':
|
| 422 |
+
conv_block += [nn.ReplicationPad2d(1)]
|
| 423 |
+
elif padding_type == 'zero':
|
| 424 |
+
p = 1
|
| 425 |
+
else:
|
| 426 |
+
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
| 427 |
+
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
|
| 428 |
+
|
| 429 |
+
return nn.Sequential(*conv_block)
|
| 430 |
+
|
| 431 |
+
def forward(self, x):
|
| 432 |
+
"""Forward function (with skip connections)"""
|
| 433 |
+
out = x + self.conv_block(x) # add skip connections
|
| 434 |
+
return out
|
| 435 |
+
|
| 436 |
+
|
| 437 |
+
class UnetGenerator(nn.Module):
|
| 438 |
+
"""Create a Unet-based generator"""
|
| 439 |
+
|
| 440 |
+
def __init__(self, input_nc, output_nc, num_downs, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False):
|
| 441 |
+
"""Construct a Unet generator
|
| 442 |
+
Parameters:
|
| 443 |
+
input_nc (int) -- the number of channels in input images
|
| 444 |
+
output_nc (int) -- the number of channels in output images
|
| 445 |
+
num_downs (int) -- the number of downsamplings in UNet. For example, # if |num_downs| == 7,
|
| 446 |
+
image of size 128x128 will become of size 1x1 # at the bottleneck
|
| 447 |
+
ngf (int) -- the number of filters in the last conv layer
|
| 448 |
+
norm_layer -- normalization layer
|
| 449 |
+
|
| 450 |
+
We construct the U-Net from the innermost layer to the outermost layer.
|
| 451 |
+
It is a recursive process.
|
| 452 |
+
"""
|
| 453 |
+
super(UnetGenerator, self).__init__()
|
| 454 |
+
# construct unet structure
|
| 455 |
+
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True) # add the innermost layer
|
| 456 |
+
for i in range(num_downs - 5): # add intermediate layers with ngf * 8 filters
|
| 457 |
+
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout)
|
| 458 |
+
# gradually reduce the number of filters from ngf * 8 to ngf
|
| 459 |
+
unet_block = UnetSkipConnectionBlock(ngf * 4, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
| 460 |
+
unet_block = UnetSkipConnectionBlock(ngf * 2, ngf * 4, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
| 461 |
+
unet_block = UnetSkipConnectionBlock(ngf, ngf * 2, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
| 462 |
+
self.model = UnetSkipConnectionBlock(output_nc, ngf, input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer) # add the outermost layer
|
| 463 |
+
|
| 464 |
+
def forward(self, input):
|
| 465 |
+
"""Standard forward"""
|
| 466 |
+
return self.model(input)
|
| 467 |
+
|
| 468 |
+
|
| 469 |
+
class UnetSkipConnectionBlock(nn.Module):
|
| 470 |
+
"""Defines the Unet submodule with skip connection.
|
| 471 |
+
X -------------------identity----------------------
|
| 472 |
+
|-- downsampling -- |submodule| -- upsampling --|
|
| 473 |
+
"""
|
| 474 |
+
|
| 475 |
+
def __init__(self, outer_nc, inner_nc, input_nc=None,
|
| 476 |
+
submodule=None, outermost=False, innermost=False, norm_layer=nn.BatchNorm2d, use_dropout=False):
|
| 477 |
+
"""Construct a Unet submodule with skip connections.
|
| 478 |
+
|
| 479 |
+
Parameters:
|
| 480 |
+
outer_nc (int) -- the number of filters in the outer conv layer
|
| 481 |
+
inner_nc (int) -- the number of filters in the inner conv layer
|
| 482 |
+
input_nc (int) -- the number of channels in input images/features
|
| 483 |
+
submodule (UnetSkipConnectionBlock) -- previously defined submodules
|
| 484 |
+
outermost (bool) -- if this module is the outermost module
|
| 485 |
+
innermost (bool) -- if this module is the innermost module
|
| 486 |
+
norm_layer -- normalization layer
|
| 487 |
+
use_dropout (bool) -- if use dropout layers.
|
| 488 |
+
"""
|
| 489 |
+
super(UnetSkipConnectionBlock, self).__init__()
|
| 490 |
+
self.outermost = outermost
|
| 491 |
+
if type(norm_layer) == functools.partial:
|
| 492 |
+
use_bias = norm_layer.func == nn.InstanceNorm2d
|
| 493 |
+
else:
|
| 494 |
+
use_bias = norm_layer == nn.InstanceNorm2d
|
| 495 |
+
if input_nc is None:
|
| 496 |
+
input_nc = outer_nc
|
| 497 |
+
downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4,
|
| 498 |
+
stride=2, padding=1, bias=use_bias)
|
| 499 |
+
downrelu = nn.LeakyReLU(0.2, True)
|
| 500 |
+
downnorm = norm_layer(inner_nc)
|
| 501 |
+
uprelu = nn.ReLU(True)
|
| 502 |
+
upnorm = norm_layer(outer_nc)
|
| 503 |
+
|
| 504 |
+
if outermost:
|
| 505 |
+
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
|
| 506 |
+
kernel_size=4, stride=2,
|
| 507 |
+
padding=1)
|
| 508 |
+
down = [downconv]
|
| 509 |
+
up = [uprelu, upconv, nn.Tanh()]
|
| 510 |
+
model = down + [submodule] + up
|
| 511 |
+
elif innermost:
|
| 512 |
+
upconv = nn.ConvTranspose2d(inner_nc, outer_nc,
|
| 513 |
+
kernel_size=4, stride=2,
|
| 514 |
+
padding=1, bias=use_bias)
|
| 515 |
+
down = [downrelu, downconv]
|
| 516 |
+
up = [uprelu, upconv, upnorm]
|
| 517 |
+
model = down + up
|
| 518 |
+
else:
|
| 519 |
+
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
|
| 520 |
+
kernel_size=4, stride=2,
|
| 521 |
+
padding=1, bias=use_bias)
|
| 522 |
+
down = [downrelu, downconv, downnorm]
|
| 523 |
+
up = [uprelu, upconv, upnorm]
|
| 524 |
+
|
| 525 |
+
if use_dropout:
|
| 526 |
+
model = down + [submodule] + up + [nn.Dropout(0.5)]
|
| 527 |
+
else:
|
| 528 |
+
model = down + [submodule] + up
|
| 529 |
+
|
| 530 |
+
self.model = nn.Sequential(*model)
|
| 531 |
+
|
| 532 |
+
def forward(self, x):
|
| 533 |
+
if self.outermost:
|
| 534 |
+
return self.model(x)
|
| 535 |
+
else: # add skip connections
|
| 536 |
+
return torch.cat([x, self.model(x)], 1)
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
class NLayerDiscriminator(nn.Module):
|
| 540 |
+
"""Defines a PatchGAN discriminator"""
|
| 541 |
+
|
| 542 |
+
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
|
| 543 |
+
"""Construct a PatchGAN discriminator
|
| 544 |
+
|
| 545 |
+
Parameters:
|
| 546 |
+
input_nc (int) -- the number of channels in input images
|
| 547 |
+
ndf (int) -- the number of filters in the last conv layer
|
| 548 |
+
n_layers (int) -- the number of conv layers in the discriminator
|
| 549 |
+
norm_layer -- normalization layer
|
| 550 |
+
"""
|
| 551 |
+
super(NLayerDiscriminator, self).__init__()
|
| 552 |
+
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
|
| 553 |
+
use_bias = norm_layer.func == nn.InstanceNorm2d
|
| 554 |
+
else:
|
| 555 |
+
use_bias = norm_layer == nn.InstanceNorm2d
|
| 556 |
+
|
| 557 |
+
kw = 4
|
| 558 |
+
padw = 1
|
| 559 |
+
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
|
| 560 |
+
nf_mult = 1
|
| 561 |
+
nf_mult_prev = 1
|
| 562 |
+
for n in range(1, n_layers): # gradually increase the number of filters
|
| 563 |
+
nf_mult_prev = nf_mult
|
| 564 |
+
nf_mult = min(2 ** n, 8)
|
| 565 |
+
sequence += [
|
| 566 |
+
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
|
| 567 |
+
norm_layer(ndf * nf_mult),
|
| 568 |
+
nn.LeakyReLU(0.2, True)
|
| 569 |
+
]
|
| 570 |
+
|
| 571 |
+
nf_mult_prev = nf_mult
|
| 572 |
+
nf_mult = min(2 ** n_layers, 8)
|
| 573 |
+
sequence += [
|
| 574 |
+
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
|
| 575 |
+
norm_layer(ndf * nf_mult),
|
| 576 |
+
nn.LeakyReLU(0.2, True)
|
| 577 |
+
]
|
| 578 |
+
|
| 579 |
+
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
|
| 580 |
+
self.model = nn.Sequential(*sequence)
|
| 581 |
+
|
| 582 |
+
def forward(self, input):
|
| 583 |
+
"""Standard forward."""
|
| 584 |
+
return self.model(input)
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
class PixelDiscriminator(nn.Module):
|
| 588 |
+
"""Defines a 1x1 PatchGAN discriminator (pixelGAN)"""
|
| 589 |
+
|
| 590 |
+
def __init__(self, input_nc, ndf=64, norm_layer=nn.BatchNorm2d):
|
| 591 |
+
"""Construct a 1x1 PatchGAN discriminator
|
| 592 |
+
|
| 593 |
+
Parameters:
|
| 594 |
+
input_nc (int) -- the number of channels in input images
|
| 595 |
+
ndf (int) -- the number of filters in the last conv layer
|
| 596 |
+
norm_layer -- normalization layer
|
| 597 |
+
"""
|
| 598 |
+
super(PixelDiscriminator, self).__init__()
|
| 599 |
+
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
|
| 600 |
+
use_bias = norm_layer.func == nn.InstanceNorm2d
|
| 601 |
+
else:
|
| 602 |
+
use_bias = norm_layer == nn.InstanceNorm2d
|
| 603 |
+
|
| 604 |
+
self.net = [
|
| 605 |
+
nn.Conv2d(input_nc, ndf, kernel_size=1, stride=1, padding=0),
|
| 606 |
+
nn.LeakyReLU(0.2, True),
|
| 607 |
+
nn.Conv2d(ndf, ndf * 2, kernel_size=1, stride=1, padding=0, bias=use_bias),
|
| 608 |
+
norm_layer(ndf * 2),
|
| 609 |
+
nn.LeakyReLU(0.2, True),
|
| 610 |
+
nn.Conv2d(ndf * 2, 1, kernel_size=1, stride=1, padding=0, bias=use_bias)]
|
| 611 |
+
|
| 612 |
+
self.net = nn.Sequential(*self.net)
|
| 613 |
+
|
| 614 |
+
def forward(self, input):
|
| 615 |
+
"""Standard forward."""
|
| 616 |
+
return self.net(input)
|
lib/gen_utils.py
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
from skimage import measure
|
| 4 |
+
from skimage import color, filters
|
| 5 |
+
from sklearn.neighbors import NearestNeighbors
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def get_otsu_threshold(image):
|
| 9 |
+
image = cv2.GaussianBlur(image.astype(float), (7, 7), 0)
|
| 10 |
+
ret, _ = cv2.threshold(
|
| 11 |
+
image.astype(np.uint8), 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU
|
| 12 |
+
)
|
| 13 |
+
return ret
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def reduce_lightHSV(rgb, sat_red=0.5, val_red=0.5):
|
| 17 |
+
hsv = color.rgb2hsv(rgb / 255)
|
| 18 |
+
hsv[..., 1] *= sat_red
|
| 19 |
+
hsv[..., 2] *= val_red
|
| 20 |
+
return (color.hsv2rgb(hsv) * 255).astype(np.uint8)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def apply_motion_blur_(image, size):
|
| 24 |
+
"""
|
| 25 |
+
input:
|
| 26 |
+
image - numpy array of image
|
| 27 |
+
size - in pixels, size of motion blur
|
| 28 |
+
output:
|
| 29 |
+
blurred image as numpy array
|
| 30 |
+
"""
|
| 31 |
+
k = np.zeros((size, size), dtype=np.float32)
|
| 32 |
+
k[(size - 1) // 2, :] = np.ones(size, dtype=np.float32)
|
| 33 |
+
k = k * (1.0 / np.sum(k))
|
| 34 |
+
return cv2.filter2D(image, -1, k).astype(np.uint8)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def apply_motion_blur(image, size, angle):
|
| 38 |
+
"""
|
| 39 |
+
input:
|
| 40 |
+
image - numpy array of image
|
| 41 |
+
size - in pixels, size of motion blur
|
| 42 |
+
angel - in degrees, direction of motion blur
|
| 43 |
+
output:
|
| 44 |
+
blurred image as numpy array
|
| 45 |
+
"""
|
| 46 |
+
k = np.zeros((size, size), dtype=np.float32)
|
| 47 |
+
k[(size - 1) // 2, :] = np.ones(size, dtype=np.float32)
|
| 48 |
+
k = cv2.warpAffine(
|
| 49 |
+
k,
|
| 50 |
+
cv2.getRotationMatrix2D((size / 2 - 0.5, size / 2 - 0.5), angle, 1.0),
|
| 51 |
+
(size, size),
|
| 52 |
+
)
|
| 53 |
+
k = k * (1.0 / np.sum(k))
|
| 54 |
+
return cv2.filter2D(image, -1, k).astype(np.uint8)
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def illumination2opacity(img: np.ndarray, illumination):
|
| 58 |
+
alpha = color.rgb2gray(img)
|
| 59 |
+
if illumination > 0:
|
| 60 |
+
alpha = np.clip(
|
| 61 |
+
filters.gaussian((1 - alpha), sigma=20, channel_axis=None), 0, 1
|
| 62 |
+
)
|
| 63 |
+
else:
|
| 64 |
+
alpha = np.clip(
|
| 65 |
+
2 * filters.gaussian((alpha), sigma=20, channel_axis=None), 0, 1
|
| 66 |
+
)
|
| 67 |
+
return alpha
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def color_level_adjustment(
|
| 71 |
+
image, inBlack=0, inWhite=255, inGamma=1.0, outBlack=0, outWhite=255
|
| 72 |
+
):
|
| 73 |
+
"""
|
| 74 |
+
Adjust color level.
|
| 75 |
+
input:
|
| 76 |
+
image - numpy array of greyscale image
|
| 77 |
+
inBlack - lower limit of intensity
|
| 78 |
+
inWhite - upper limit of intensity
|
| 79 |
+
inGamma - scaling the intensity values by Gamma value
|
| 80 |
+
outBlack - lower intensity value for scaling
|
| 81 |
+
outWhite - upper intensity value for scaling
|
| 82 |
+
"""
|
| 83 |
+
assert image.ndim == 2
|
| 84 |
+
|
| 85 |
+
# image = np.clip( (image - inBlack) / (inWhite - inBlack), 0, 1)
|
| 86 |
+
image = (image - inBlack) / (inWhite - inBlack)
|
| 87 |
+
image[image < 0] = 0
|
| 88 |
+
image[image > 1] = 0
|
| 89 |
+
image = (image ** (1 / inGamma)) * (outWhite - outBlack) + outBlack
|
| 90 |
+
image = np.clip(image, 0, 255).astype(np.uint8)
|
| 91 |
+
return image.astype(np.uint8)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def crystallize(img, r):
|
| 95 |
+
"""
|
| 96 |
+
Crystallization Effect
|
| 97 |
+
input: img - Numpy Array
|
| 98 |
+
r - fraction of pixels to select as center for crystallization
|
| 99 |
+
outpur: res- Numpy Array for crystallized filter
|
| 100 |
+
"""
|
| 101 |
+
if img.ndim == 2:
|
| 102 |
+
h, w = img.shape
|
| 103 |
+
elif img.ndim == 3:
|
| 104 |
+
h, w, _ = img.shape
|
| 105 |
+
|
| 106 |
+
# Get the center for crystallization
|
| 107 |
+
pixels = np.zeros((h * w, 2), dtype=np.uint16)
|
| 108 |
+
pixels[:, 0] = np.tile(np.arange(h), (w, 1)).T.reshape(-1)
|
| 109 |
+
pixels[:, 1] = (np.tile(np.arange(w), (h, 1))).reshape(-1)
|
| 110 |
+
|
| 111 |
+
sel_pixels = pixels.copy()
|
| 112 |
+
sel_pixels = sel_pixels[np.random.randint(0, h * w, int(len(sel_pixels) * r))]
|
| 113 |
+
|
| 114 |
+
# Perform nearest neighbour for all pixels
|
| 115 |
+
nbrs = NearestNeighbors(n_neighbors=1, algorithm="ball_tree", n_jobs=4).fit(
|
| 116 |
+
sel_pixels
|
| 117 |
+
)
|
| 118 |
+
distances, indices = nbrs.kneighbors(pixels)
|
| 119 |
+
color_pixels = sel_pixels[indices[:, 0]]
|
| 120 |
+
|
| 121 |
+
# Perform crystallization (copy the color pixels of crystal center)
|
| 122 |
+
res = np.zeros_like(img)
|
| 123 |
+
res[pixels[:, 0], pixels[:, 1]] = img[color_pixels[:, 0], color_pixels[:, 1]]
|
| 124 |
+
return res
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def zoom_image_and_crop(image, r=1.5):
|
| 128 |
+
"""
|
| 129 |
+
input:
|
| 130 |
+
image: numpy array
|
| 131 |
+
r = upscale fraction >1.0
|
| 132 |
+
output:
|
| 133 |
+
image: scale image as numpy array
|
| 134 |
+
"""
|
| 135 |
+
if image.ndim == 2:
|
| 136 |
+
h, w = image.shape
|
| 137 |
+
elif image.ndim == 3:
|
| 138 |
+
h, w, _ = image.shape
|
| 139 |
+
image_resize = cv2.resize(
|
| 140 |
+
image.astype(np.uint8),
|
| 141 |
+
(int(w * r), int(h * r)),
|
| 142 |
+
interpolation=cv2.INTER_LANCZOS4,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
x = int(r * w / 2 - w / 2)
|
| 146 |
+
y = int(r * h / 2 - h / 2)
|
| 147 |
+
crop_img = image_resize[int(y) : int(y + h), int(x) : int(x + w)]
|
| 148 |
+
|
| 149 |
+
return crop_img.astype(np.uint8)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def repeat_and_combine(layer, repeat_scale=2):
|
| 153 |
+
orgh, orgw = layer.shape
|
| 154 |
+
compressh = int(np.floor(orgh / repeat_scale))
|
| 155 |
+
compressw = int(np.floor(orgw / repeat_scale))
|
| 156 |
+
|
| 157 |
+
resize_layer = cv2.resize(
|
| 158 |
+
layer, (compressw, compressh), interpolation=cv2.INTER_LANCZOS4
|
| 159 |
+
)
|
| 160 |
+
layer_tile = np.tile(resize_layer, (repeat_scale, repeat_scale))
|
| 161 |
+
h, w = layer_tile.shape
|
| 162 |
+
|
| 163 |
+
repeat = np.zeros_like(layer)
|
| 164 |
+
repeat[:h, :w] = layer_tile
|
| 165 |
+
return repeat.astype(np.uint8)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def generate_noisy_image(h, w, sigma=0.5, p=0.5):
|
| 169 |
+
"""
|
| 170 |
+
input:
|
| 171 |
+
h - height of the image
|
| 172 |
+
w - width of the image
|
| 173 |
+
scale - scale of Gaussian noise
|
| 174 |
+
output:
|
| 175 |
+
im_noisy - uint8 array with Gaussian noise
|
| 176 |
+
"""
|
| 177 |
+
im_array = np.zeros((h, w))
|
| 178 |
+
|
| 179 |
+
# Generate random Gaussian noise
|
| 180 |
+
noise = np.random.normal(scale=sigma, size=(h, w))
|
| 181 |
+
prob = np.random.rand(h, w)
|
| 182 |
+
im_array[prob < p] = 255 * noise[prob < p]
|
| 183 |
+
im_array = np.clip(im_array, 0, 255)
|
| 184 |
+
return im_array.astype(np.uint8)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def binarizeImage(image: np.ndarray):
|
| 188 |
+
"""Binarize grey image using OTSU threshold"""
|
| 189 |
+
if image.ndim == 3:
|
| 190 |
+
if image.shape[2] == 3:
|
| 191 |
+
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
| 192 |
+
else:
|
| 193 |
+
image = image[:, :, 0]
|
| 194 |
+
binarize = np.copy(image)
|
| 195 |
+
ret = get_otsu_threshold(image=image)
|
| 196 |
+
binarize[binarize < ret] = 0
|
| 197 |
+
binarize[binarize > ret] = 255
|
| 198 |
+
return binarize
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def bwAreaFilter(mask, area_range=(0, np.inf)):
|
| 202 |
+
"""Extract objects from binary image by size"""
|
| 203 |
+
labels = measure.label(mask.astype("uint8"), background=0)
|
| 204 |
+
unq, areas = np.unique(labels, return_counts=True)
|
| 205 |
+
areas = areas[1:]
|
| 206 |
+
area_idx = np.arange(1, np.max(labels) + 1)
|
| 207 |
+
|
| 208 |
+
inside_range_idx = np.logical_and(areas >= area_range[0], areas <= area_range[1])
|
| 209 |
+
area_idx = area_idx[inside_range_idx]
|
| 210 |
+
areas = areas[inside_range_idx]
|
| 211 |
+
layer = np.isin(labels, area_idx)
|
| 212 |
+
return layer.astype(int)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def centreCrop(image, reqH, reqW):
|
| 216 |
+
center = image.shape
|
| 217 |
+
x = center[1] / 2 - reqW / 2
|
| 218 |
+
y = center[0] / 2 - reqH / 2
|
| 219 |
+
|
| 220 |
+
crop_img = image[int(y) : int(y + reqH), int(x) : int(x + reqW)]
|
| 221 |
+
return crop_img
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def alpha_blend(img, layer, alpha):
|
| 225 |
+
if layer.ndim == 3:
|
| 226 |
+
layer = cv2.cvtColor(layer.astype(np.uint8), cv2.COLOR_RGB2GRAY)
|
| 227 |
+
|
| 228 |
+
assert alpha.ndim == 2
|
| 229 |
+
assert layer.ndim == 2
|
| 230 |
+
blended = img * (1 - alpha[:, :, None]) + layer[:, :, None] * alpha[:, :, None]
|
| 231 |
+
return blended
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def screen_blend(image, layer):
|
| 235 |
+
"""
|
| 236 |
+
input:
|
| 237 |
+
image - numpy array of RGB image
|
| 238 |
+
layer - numpy array of layer to blend
|
| 239 |
+
"""
|
| 240 |
+
result = 255.0 * (1 - (1 - image / 255.0) * (1 - layer[:, :, None] / 255.0))
|
| 241 |
+
return result.astype(np.uint8)
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def layer_blend(layer1, layer2):
|
| 245 |
+
"""
|
| 246 |
+
input:
|
| 247 |
+
layer1 - numpy array of RGB image
|
| 248 |
+
layer2 - numpy array of layer to blend
|
| 249 |
+
"""
|
| 250 |
+
assert layer1.shape == layer2.shape
|
| 251 |
+
result = 255.0 * (1 - (1 - layer1 / 255.0) * (1 - layer2 / 255.0))
|
| 252 |
+
return result.astype(np.uint8)
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def scale_depth(im, nR, nC):
|
| 256 |
+
nR0 = len(im) # source number of rows
|
| 257 |
+
nC0 = len(im[0]) # source number of columns
|
| 258 |
+
return np.asarray(
|
| 259 |
+
[
|
| 260 |
+
[im[int(nR0 * r / nR)][int(nC0 * c / nC)] for c in range(nC)]
|
| 261 |
+
for r in range(nR)
|
| 262 |
+
]
|
| 263 |
+
)
|
lib/lime.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tqdm
|
| 2 |
+
import numpy as np
|
| 3 |
+
from scipy import fft
|
| 4 |
+
from skimage import io, exposure, img_as_ubyte, img_as_float
|
| 5 |
+
|
| 6 |
+
def firstOrderDerivative(n, k=1):
|
| 7 |
+
return np.eye(n) * (-1) + np.eye(n, k=k)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def toeplitizMatrix(n, row):
|
| 11 |
+
vecDD = np.zeros(n)
|
| 12 |
+
vecDD[0] = 4
|
| 13 |
+
vecDD[1] = -1
|
| 14 |
+
vecDD[row] = -1
|
| 15 |
+
vecDD[-1] = -1
|
| 16 |
+
vecDD[-row] = -1
|
| 17 |
+
return vecDD
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def vectorize(matrix):
|
| 21 |
+
return matrix.T.ravel()
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def reshape(vector, row, col):
|
| 25 |
+
return vector.reshape((row, col), order='F')
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class LIME:
|
| 29 |
+
def __init__(self, iterations=10, alpha=2, rho=1.5, gamma=0.7, strategy=2, *args, **kwargs):
|
| 30 |
+
self.iterations = iterations
|
| 31 |
+
self.alpha = alpha
|
| 32 |
+
self.rho = rho
|
| 33 |
+
self.gamma = gamma
|
| 34 |
+
self.strategy = strategy
|
| 35 |
+
|
| 36 |
+
def load(self, imgPath):
|
| 37 |
+
if isinstance(imgPath, str):
|
| 38 |
+
self.L = img_as_float(io.imread(imgPath))
|
| 39 |
+
elif isinstance(imgPath, np.ndarray):
|
| 40 |
+
self.L = img_as_float(imgPath)
|
| 41 |
+
else:
|
| 42 |
+
print(f"The input should be path to image of numpy array.")
|
| 43 |
+
|
| 44 |
+
self.row = self.L.shape[0]
|
| 45 |
+
self.col = self.L.shape[1]
|
| 46 |
+
|
| 47 |
+
self.T_hat = np.max(self.L, axis=2)
|
| 48 |
+
self.dv = firstOrderDerivative(self.row)
|
| 49 |
+
self.dh = firstOrderDerivative(self.col, -1)
|
| 50 |
+
self.vecDD = toeplitizMatrix(self.row * self.col, self.row)
|
| 51 |
+
self.W = self.weightingStrategy()
|
| 52 |
+
|
| 53 |
+
def weightingStrategy(self):
|
| 54 |
+
if self.strategy == 2:
|
| 55 |
+
dTv = self.dv @ self.T_hat
|
| 56 |
+
dTh = self.T_hat @ self.dh
|
| 57 |
+
Wv = 1 / (np.abs(dTv) + 1)
|
| 58 |
+
Wh = 1 / (np.abs(dTh) + 1)
|
| 59 |
+
return np.vstack([Wv, Wh])
|
| 60 |
+
else:
|
| 61 |
+
return np.ones((self.row * 2, self.col))
|
| 62 |
+
|
| 63 |
+
def __T_subproblem(self, G, Z, u):
|
| 64 |
+
X = G - Z / u
|
| 65 |
+
Xv = X[:self.row, :]
|
| 66 |
+
Xh = X[self.row:, :]
|
| 67 |
+
temp = self.dv @ Xv + Xh @ self.dh
|
| 68 |
+
numerator = fft.fft(vectorize(2 * self.T_hat + u * temp))
|
| 69 |
+
denominator = fft.fft(self.vecDD * u) + 2
|
| 70 |
+
T = fft.ifft(numerator / denominator)
|
| 71 |
+
T = np.real(reshape(T, self.row, self.col))
|
| 72 |
+
return exposure.rescale_intensity(T, (0, 1), (0.001, 1))
|
| 73 |
+
|
| 74 |
+
def __G_subproblem(self, T, Z, u, W):
|
| 75 |
+
dT = self.__derivative(T)
|
| 76 |
+
epsilon = self.alpha * W / u
|
| 77 |
+
X = dT + Z / u
|
| 78 |
+
return np.sign(X) * np.maximum(np.abs(X) - epsilon, 0)
|
| 79 |
+
|
| 80 |
+
def __Z_subproblem(self, T, G, Z, u):
|
| 81 |
+
dT = self.__derivative(T)
|
| 82 |
+
return Z + u * (dT - G)
|
| 83 |
+
|
| 84 |
+
def __u_subproblem(self, u):
|
| 85 |
+
return u * self.rho
|
| 86 |
+
|
| 87 |
+
def __derivative(self, matrix):
|
| 88 |
+
v = self.dv @ matrix
|
| 89 |
+
h = matrix @ self.dh
|
| 90 |
+
return np.vstack([v, h])
|
| 91 |
+
|
| 92 |
+
def illumMap(self):
|
| 93 |
+
T = np.zeros((self.row, self.col))
|
| 94 |
+
G = np.zeros((self.row * 2, self.col))
|
| 95 |
+
Z = np.zeros((self.row * 2, self.col))
|
| 96 |
+
u = 1
|
| 97 |
+
|
| 98 |
+
for _ in tqdm.trange(0, self.iterations):
|
| 99 |
+
T = self.__T_subproblem(G, Z, u)
|
| 100 |
+
G = self.__G_subproblem(T, Z, u, self.W)
|
| 101 |
+
Z = self.__Z_subproblem(T, G, Z, u)
|
| 102 |
+
u = self.__u_subproblem(u)
|
| 103 |
+
|
| 104 |
+
return T ** self.gamma
|
| 105 |
+
|
| 106 |
+
def enhance(self):
|
| 107 |
+
self.T = self.illumMap()
|
| 108 |
+
self.R = self.L / np.repeat(self.T[:, :, np.newaxis], 3, axis=2)
|
| 109 |
+
self.R = exposure.rescale_intensity(self.R, (0, 1))
|
| 110 |
+
self.R = img_as_ubyte(self.R)
|
| 111 |
+
return self.R
|
lib/motionblur.py
ADDED
|
@@ -0,0 +1,419 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from PIL import Image, ImageDraw, ImageFilter
|
| 3 |
+
from numpy.random import uniform, triangular, beta
|
| 4 |
+
from math import pi
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from scipy.signal import convolve
|
| 7 |
+
|
| 8 |
+
# tiny error used for nummerical stability
|
| 9 |
+
eps = 0.1
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def softmax(x):
|
| 13 |
+
"""Compute softmax values for each sets of scores in x."""
|
| 14 |
+
e_x = np.exp(x - np.max(x))
|
| 15 |
+
return e_x / e_x.sum()
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def norm(lst: list) -> float:
|
| 19 |
+
"""[summary]
|
| 20 |
+
L^2 norm of a list
|
| 21 |
+
[description]
|
| 22 |
+
Used for internals
|
| 23 |
+
Arguments:
|
| 24 |
+
lst {list} -- vector
|
| 25 |
+
"""
|
| 26 |
+
if not isinstance(lst, list):
|
| 27 |
+
raise ValueError("Norm takes a list as its argument")
|
| 28 |
+
|
| 29 |
+
if lst == []:
|
| 30 |
+
return 0
|
| 31 |
+
|
| 32 |
+
return (sum((i**2 for i in lst)))**0.5
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def polar2z(r: np.ndarray, θ: np.ndarray) -> np.ndarray:
|
| 36 |
+
"""[summary]
|
| 37 |
+
Takes a list of radii and angles (radians) and
|
| 38 |
+
converts them into a corresponding list of complex
|
| 39 |
+
numbers x + yi.
|
| 40 |
+
[description]
|
| 41 |
+
|
| 42 |
+
Arguments:
|
| 43 |
+
r {np.ndarray} -- radius
|
| 44 |
+
θ {np.ndarray} -- angle
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
[np.ndarray] -- list of complex numbers r e^(i theta) as x + iy
|
| 48 |
+
"""
|
| 49 |
+
return r * np.exp(1j * θ)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class Kernel(object):
|
| 53 |
+
"""[summary]
|
| 54 |
+
Class representing a motion blur kernel of a given intensity.
|
| 55 |
+
|
| 56 |
+
[description]
|
| 57 |
+
Keyword Arguments:
|
| 58 |
+
size {tuple} -- Size of the kernel in px times px
|
| 59 |
+
(default: {(100, 100)})
|
| 60 |
+
|
| 61 |
+
intensity {float} -- Float between 0 and 1.
|
| 62 |
+
Intensity of the motion blur.
|
| 63 |
+
|
| 64 |
+
: 0 means linear motion blur and 1 is a highly non linear
|
| 65 |
+
and often convex motion blur path. (default: {0})
|
| 66 |
+
|
| 67 |
+
Attribute:
|
| 68 |
+
kernelMatrix -- Numpy matrix of the kernel of given intensity
|
| 69 |
+
|
| 70 |
+
Properties:
|
| 71 |
+
applyTo -- Applies kernel to image
|
| 72 |
+
(pass as path, pillow image or np array)
|
| 73 |
+
|
| 74 |
+
Raises:
|
| 75 |
+
ValueError
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
def __init__(self, size: tuple = (100, 100), intensity: float=0):
|
| 79 |
+
|
| 80 |
+
# checking if size is correctly given
|
| 81 |
+
if not isinstance(size, tuple):
|
| 82 |
+
raise ValueError("Size must be TUPLE of 2 positive integers")
|
| 83 |
+
elif len(size) != 2 or type(size[0]) != type(size[1]) != int:
|
| 84 |
+
raise ValueError("Size must be tuple of 2 positive INTEGERS")
|
| 85 |
+
elif size[0] < 0 or size[1] < 0:
|
| 86 |
+
raise ValueError("Size must be tuple of 2 POSITIVE integers")
|
| 87 |
+
|
| 88 |
+
# check if intensity is float (int) between 0 and 1
|
| 89 |
+
if type(intensity) not in [int, float, np.float32, np.float64]:
|
| 90 |
+
raise ValueError("Intensity must be a number between 0 and 1")
|
| 91 |
+
elif intensity < 0 or intensity > 1:
|
| 92 |
+
raise ValueError("Intensity must be a number between 0 and 1")
|
| 93 |
+
|
| 94 |
+
# saving args
|
| 95 |
+
self.SIZE = size
|
| 96 |
+
self.INTENSITY = intensity
|
| 97 |
+
|
| 98 |
+
# deriving quantities
|
| 99 |
+
|
| 100 |
+
# we super size first and then downscale at the end for better
|
| 101 |
+
# anti-aliasing
|
| 102 |
+
self.SIZEx2 = tuple([2 * i for i in size])
|
| 103 |
+
self.x, self.y = self.SIZEx2
|
| 104 |
+
|
| 105 |
+
# getting length of kernel diagonal
|
| 106 |
+
self.DIAGONAL = (self.x**2 + self.y**2)**0.5
|
| 107 |
+
|
| 108 |
+
# flag to see if kernel has been calculated already
|
| 109 |
+
self.kernel_is_generated = False
|
| 110 |
+
|
| 111 |
+
def _createPath(self):
|
| 112 |
+
"""[summary]
|
| 113 |
+
creates a motion blur path with the given intensity.
|
| 114 |
+
[description]
|
| 115 |
+
Proceede in 5 steps
|
| 116 |
+
1. Get a random number of random step sizes
|
| 117 |
+
2. For each step get a random angle
|
| 118 |
+
3. combine steps and angles into a sequence of increments
|
| 119 |
+
4. create path out of increments
|
| 120 |
+
5. translate path to fit the kernel dimensions
|
| 121 |
+
|
| 122 |
+
NOTE: "random" means random but might depend on the given intensity
|
| 123 |
+
"""
|
| 124 |
+
|
| 125 |
+
# first we find the lengths of the motion blur steps
|
| 126 |
+
def getSteps():
|
| 127 |
+
"""[summary]
|
| 128 |
+
Here we calculate the length of the steps taken by
|
| 129 |
+
the motion blur
|
| 130 |
+
[description]
|
| 131 |
+
We want a higher intensity lead to a longer total motion
|
| 132 |
+
blur path and more different steps along the way.
|
| 133 |
+
|
| 134 |
+
Hence we sample
|
| 135 |
+
|
| 136 |
+
MAX_PATH_LEN =[U(0,1) + U(0, intensity^2)] * diagonal * 0.75
|
| 137 |
+
|
| 138 |
+
and each step: beta(1, 30) * (1 - self.INTENSITY + eps) * diagonal)
|
| 139 |
+
"""
|
| 140 |
+
|
| 141 |
+
# getting max length of blur motion
|
| 142 |
+
self.MAX_PATH_LEN = 0.75 * self.DIAGONAL * \
|
| 143 |
+
(uniform() + uniform(0, self.INTENSITY**2))
|
| 144 |
+
|
| 145 |
+
# getting step
|
| 146 |
+
steps = []
|
| 147 |
+
|
| 148 |
+
while sum(steps) < self.MAX_PATH_LEN:
|
| 149 |
+
|
| 150 |
+
# sample next step
|
| 151 |
+
step = beta(1, 30) * (1 - self.INTENSITY + eps) * self.DIAGONAL
|
| 152 |
+
if step < self.MAX_PATH_LEN:
|
| 153 |
+
steps.append(step)
|
| 154 |
+
|
| 155 |
+
# note the steps and the total number of steps
|
| 156 |
+
self.NUM_STEPS = len(steps)
|
| 157 |
+
self.STEPS = np.asarray(steps)
|
| 158 |
+
|
| 159 |
+
def getAngles():
|
| 160 |
+
"""[summary]
|
| 161 |
+
Gets an angle for each step
|
| 162 |
+
[description]
|
| 163 |
+
The maximal angle should be larger the more
|
| 164 |
+
intense the motion is. So we sample it from a
|
| 165 |
+
U(0, intensity * pi)
|
| 166 |
+
|
| 167 |
+
We sample "jitter" from a beta(2,20) which is the probability
|
| 168 |
+
that the next angle has a different sign than the previous one.
|
| 169 |
+
"""
|
| 170 |
+
|
| 171 |
+
# same as with the steps
|
| 172 |
+
|
| 173 |
+
# first we get the max angle in radians
|
| 174 |
+
self.MAX_ANGLE = uniform(0, self.INTENSITY * pi)
|
| 175 |
+
|
| 176 |
+
# now we sample "jitter" which is the probability that the
|
| 177 |
+
# next angle has a different sign than the previous one
|
| 178 |
+
self.JITTER = beta(2, 20)
|
| 179 |
+
|
| 180 |
+
# initialising angles (and sign of angle)
|
| 181 |
+
angles = [uniform(low=-self.MAX_ANGLE, high=self.MAX_ANGLE)]
|
| 182 |
+
|
| 183 |
+
while len(angles) < self.NUM_STEPS:
|
| 184 |
+
|
| 185 |
+
# sample next angle (absolute value)
|
| 186 |
+
angle = triangular(0, self.INTENSITY *
|
| 187 |
+
self.MAX_ANGLE, self.MAX_ANGLE + eps)
|
| 188 |
+
|
| 189 |
+
# with jitter probability change sign wrt previous angle
|
| 190 |
+
if uniform() < self.JITTER:
|
| 191 |
+
angle *= - np.sign(angles[-1])
|
| 192 |
+
else:
|
| 193 |
+
angle *= np.sign(angles[-1])
|
| 194 |
+
|
| 195 |
+
angles.append(angle)
|
| 196 |
+
|
| 197 |
+
# save angles
|
| 198 |
+
self.ANGLES = np.asarray(angles)
|
| 199 |
+
|
| 200 |
+
# Get steps and angles
|
| 201 |
+
getSteps()
|
| 202 |
+
getAngles()
|
| 203 |
+
|
| 204 |
+
# Turn them into a path
|
| 205 |
+
####
|
| 206 |
+
|
| 207 |
+
# we turn angles and steps into complex numbers
|
| 208 |
+
complex_increments = polar2z(self.STEPS, self.ANGLES)
|
| 209 |
+
|
| 210 |
+
# generate path as the cumsum of these increments
|
| 211 |
+
self.path_complex = np.cumsum(complex_increments)
|
| 212 |
+
|
| 213 |
+
# find center of mass of path
|
| 214 |
+
self.com_complex = sum(self.path_complex) / self.NUM_STEPS
|
| 215 |
+
|
| 216 |
+
# Shift path s.t. center of mass lies in the middle of
|
| 217 |
+
# the kernel and a apply a random rotation
|
| 218 |
+
###
|
| 219 |
+
|
| 220 |
+
# center it on COM
|
| 221 |
+
center_of_kernel = (self.x + 1j * self.y) / 2
|
| 222 |
+
self.path_complex -= self.com_complex
|
| 223 |
+
|
| 224 |
+
# randomly rotate path by an angle a in (0, pi)
|
| 225 |
+
self.path_complex *= np.exp(1j * uniform(0, pi))
|
| 226 |
+
|
| 227 |
+
# center COM on center of kernel
|
| 228 |
+
self.path_complex += center_of_kernel
|
| 229 |
+
|
| 230 |
+
# convert complex path to final list of coordinate tuples
|
| 231 |
+
self.path = [(i.real, i.imag) for i in self.path_complex]
|
| 232 |
+
|
| 233 |
+
def _createKernel(self, save_to: Path=None, show: bool=False):
|
| 234 |
+
"""[summary]
|
| 235 |
+
Finds a kernel (psf) of given intensity.
|
| 236 |
+
[description]
|
| 237 |
+
use displayKernel to actually see the kernel.
|
| 238 |
+
|
| 239 |
+
Keyword Arguments:
|
| 240 |
+
save_to {Path} -- Image file to save the kernel to. {None}
|
| 241 |
+
show {bool} -- shows kernel if true
|
| 242 |
+
"""
|
| 243 |
+
|
| 244 |
+
# check if we haven't already generated a kernel
|
| 245 |
+
if self.kernel_is_generated:
|
| 246 |
+
return None
|
| 247 |
+
|
| 248 |
+
# get the path
|
| 249 |
+
self._createPath()
|
| 250 |
+
|
| 251 |
+
# Initialise an image with super-sized dimensions
|
| 252 |
+
# (pillow Image object)
|
| 253 |
+
self.kernel_image = Image.new("RGB", self.SIZEx2)
|
| 254 |
+
|
| 255 |
+
# ImageDraw instance that is linked to the kernel image that
|
| 256 |
+
# we can use to draw on our kernel_image
|
| 257 |
+
self.painter = ImageDraw.Draw(self.kernel_image)
|
| 258 |
+
|
| 259 |
+
# draw the path
|
| 260 |
+
self.painter.line(xy=self.path, width=int(self.DIAGONAL / 150))
|
| 261 |
+
|
| 262 |
+
# applying gaussian blur for realism
|
| 263 |
+
self.kernel_image = self.kernel_image.filter(
|
| 264 |
+
ImageFilter.GaussianBlur(radius=int(self.DIAGONAL * 0.01)))
|
| 265 |
+
|
| 266 |
+
# Resize to actual size
|
| 267 |
+
self.kernel_image = self.kernel_image.resize(
|
| 268 |
+
self.SIZE, resample=Image.LANCZOS)
|
| 269 |
+
|
| 270 |
+
# convert to gray scale
|
| 271 |
+
self.kernel_image = self.kernel_image.convert("L")
|
| 272 |
+
|
| 273 |
+
# flag that we have generated a kernel
|
| 274 |
+
self.kernel_is_generated = True
|
| 275 |
+
|
| 276 |
+
def displayKernel(self, save_to: Path=None, show: bool=True):
|
| 277 |
+
"""[summary]
|
| 278 |
+
Finds a kernel (psf) of given intensity.
|
| 279 |
+
[description]
|
| 280 |
+
Saves the kernel to save_to if needed or shows it
|
| 281 |
+
is show true
|
| 282 |
+
|
| 283 |
+
Keyword Arguments:
|
| 284 |
+
save_to {Path} -- Image file to save the kernel to. {None}
|
| 285 |
+
show {bool} -- shows kernel if true
|
| 286 |
+
"""
|
| 287 |
+
|
| 288 |
+
# generate kernel if needed
|
| 289 |
+
self._createKernel()
|
| 290 |
+
|
| 291 |
+
# save if needed
|
| 292 |
+
if save_to is not None:
|
| 293 |
+
|
| 294 |
+
save_to_file = Path(save_to)
|
| 295 |
+
|
| 296 |
+
# save Kernel image
|
| 297 |
+
self.kernel_image.save(save_to_file)
|
| 298 |
+
else:
|
| 299 |
+
# Show kernel
|
| 300 |
+
self.kernel_image.show()
|
| 301 |
+
|
| 302 |
+
@property
|
| 303 |
+
def kernelMatrix(self) -> np.ndarray:
|
| 304 |
+
"""[summary]
|
| 305 |
+
Kernel matrix of motion blur of given intensity.
|
| 306 |
+
[description]
|
| 307 |
+
Once generated, it stays the same.
|
| 308 |
+
Returns:
|
| 309 |
+
numpy ndarray
|
| 310 |
+
"""
|
| 311 |
+
|
| 312 |
+
# generate kernel if needed
|
| 313 |
+
self._createKernel()
|
| 314 |
+
kernel = np.asarray(self.kernel_image, dtype=np.float32)
|
| 315 |
+
kernel /= np.sum(kernel)
|
| 316 |
+
|
| 317 |
+
return kernel
|
| 318 |
+
|
| 319 |
+
@kernelMatrix.setter
|
| 320 |
+
def kernelMatrix(self, *kargs):
|
| 321 |
+
raise NotImplementedError("Can't manually set kernel matrix yet")
|
| 322 |
+
|
| 323 |
+
def applyTo(self, image, keep_image_dim: bool = False) -> Image:
|
| 324 |
+
"""[summary]
|
| 325 |
+
Applies kernel to one of the following:
|
| 326 |
+
|
| 327 |
+
1. Path to image file
|
| 328 |
+
2. Pillow image object
|
| 329 |
+
3. (H,W,3)-shaped numpy array
|
| 330 |
+
[description]
|
| 331 |
+
|
| 332 |
+
Arguments:
|
| 333 |
+
image {[str, Path, Image, np.ndarray]}
|
| 334 |
+
keep_image_dim {bool} -- If true, then we will
|
| 335 |
+
conserve the image dimension after blurring
|
| 336 |
+
by using "same" convolution instead of "valid"
|
| 337 |
+
convolution inside the scipy convolve function.
|
| 338 |
+
|
| 339 |
+
Returns:
|
| 340 |
+
Image -- [description]
|
| 341 |
+
"""
|
| 342 |
+
# calculate kernel if haven't already
|
| 343 |
+
self._createKernel()
|
| 344 |
+
|
| 345 |
+
def applyToPIL(image: Image, keep_image_dim: bool = False) -> Image:
|
| 346 |
+
"""[summary]
|
| 347 |
+
Applies the kernel to an PIL.Image instance
|
| 348 |
+
[description]
|
| 349 |
+
converts to RGB and applies the kernel to each
|
| 350 |
+
band before recombining them.
|
| 351 |
+
Arguments:
|
| 352 |
+
image {Image} -- Image to convolve
|
| 353 |
+
keep_image_dim {bool} -- If true, then we will
|
| 354 |
+
conserve the image dimension after blurring
|
| 355 |
+
by using "same" convolution instead of "valid"
|
| 356 |
+
convolution inside the scipy convolve function.
|
| 357 |
+
|
| 358 |
+
Returns:
|
| 359 |
+
Image -- blurred image
|
| 360 |
+
"""
|
| 361 |
+
# convert to RGB
|
| 362 |
+
image = image.convert(mode="RGB")
|
| 363 |
+
|
| 364 |
+
conv_mode = "valid"
|
| 365 |
+
if keep_image_dim:
|
| 366 |
+
conv_mode = "same"
|
| 367 |
+
|
| 368 |
+
result_bands = ()
|
| 369 |
+
|
| 370 |
+
for band in image.split():
|
| 371 |
+
|
| 372 |
+
# convolve each band individually with kernel
|
| 373 |
+
result_band = convolve(
|
| 374 |
+
band, self.kernelMatrix, mode=conv_mode).astype("uint8")
|
| 375 |
+
|
| 376 |
+
# collect bands
|
| 377 |
+
result_bands += result_band,
|
| 378 |
+
|
| 379 |
+
# stack bands back together
|
| 380 |
+
result = np.dstack(result_bands)
|
| 381 |
+
|
| 382 |
+
# Get image
|
| 383 |
+
return Image.fromarray(result)
|
| 384 |
+
|
| 385 |
+
# If image is Path
|
| 386 |
+
if isinstance(image, str) or isinstance(image, Path):
|
| 387 |
+
|
| 388 |
+
# open image as Image class
|
| 389 |
+
image_path = Path(image)
|
| 390 |
+
image = Image.open(image_path)
|
| 391 |
+
|
| 392 |
+
return applyToPIL(image, keep_image_dim)
|
| 393 |
+
|
| 394 |
+
elif isinstance(image, Image.Image):
|
| 395 |
+
|
| 396 |
+
# apply kernel
|
| 397 |
+
return applyToPIL(image, keep_image_dim)
|
| 398 |
+
|
| 399 |
+
elif isinstance(image, np.ndarray):
|
| 400 |
+
|
| 401 |
+
# ASSUMES we have an array of the form (H, W, 3)
|
| 402 |
+
###
|
| 403 |
+
|
| 404 |
+
# initiate Image object from array
|
| 405 |
+
image = Image.fromarray(image)
|
| 406 |
+
|
| 407 |
+
return applyToPIL(image, keep_image_dim)
|
| 408 |
+
|
| 409 |
+
else:
|
| 410 |
+
|
| 411 |
+
raise ValueError("Cannot apply kernel to this type.")
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
if __name__ == '__main__':
|
| 415 |
+
image = Image.open("./images/moon.png")
|
| 416 |
+
image.show()
|
| 417 |
+
k = Kernel()
|
| 418 |
+
|
| 419 |
+
k.applyTo(image, keep_image_dim=True).show()
|
lib/rain_gen.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import scipy
|
| 3 |
+
import random
|
| 4 |
+
import numpy as np
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from lib.gen_utils import (
|
| 7 |
+
generate_noisy_image,
|
| 8 |
+
centreCrop,
|
| 9 |
+
binarizeImage,
|
| 10 |
+
bwAreaFilter,
|
| 11 |
+
apply_motion_blur,
|
| 12 |
+
zoom_image_and_crop,
|
| 13 |
+
get_otsu_threshold,
|
| 14 |
+
color_level_adjustment,
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class RainGenUsingNoise:
|
| 19 |
+
def genRainLayer(
|
| 20 |
+
self,
|
| 21 |
+
h,
|
| 22 |
+
w,
|
| 23 |
+
noise_scale=0.5,
|
| 24 |
+
noise_amount=0.25,
|
| 25 |
+
zoom_layer=2.0,
|
| 26 |
+
blur_kernel_size=15,
|
| 27 |
+
blur_angle=-60,
|
| 28 |
+
):
|
| 29 |
+
layer = generate_noisy_image(h, w, sigma=noise_scale, p=noise_amount)
|
| 30 |
+
|
| 31 |
+
if blur_kernel_size > 0:
|
| 32 |
+
layer = apply_motion_blur(layer.copy(), blur_kernel_size, int(blur_angle))
|
| 33 |
+
|
| 34 |
+
if zoom_layer > 1:
|
| 35 |
+
layer = zoom_image_and_crop(layer.copy(), r=zoom_layer)
|
| 36 |
+
|
| 37 |
+
th = get_otsu_threshold(layer.copy())
|
| 38 |
+
layer = color_level_adjustment(
|
| 39 |
+
layer.copy(), inBlack=th, inWhite=th + 100, outWhite=250, inGamma=1.0
|
| 40 |
+
)
|
| 41 |
+
return layer
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class RainGenUsingMasks:
|
| 45 |
+
def __init__(self, mask_folder: str, ext="png"):
|
| 46 |
+
self._mask_path_list = sorted(Path(mask_folder).glob("*." + ext))
|
| 47 |
+
|
| 48 |
+
def genSingleLayer(self, scale=4, area=(10, 500), blur=False, rotate=0):
|
| 49 |
+
streak_file = random.choice(self._mask_path_list)
|
| 50 |
+
streak = cv2.cvtColor(cv2.imread(str(streak_file)), cv2.COLOR_BGR2GRAY)
|
| 51 |
+
hs, ws = streak.shape
|
| 52 |
+
if scale > 1:
|
| 53 |
+
streak = cv2.resize(streak, (int(ws * scale), int(hs * scale)))
|
| 54 |
+
|
| 55 |
+
if rotate != 0:
|
| 56 |
+
M = cv2.getRotationMatrix2D(
|
| 57 |
+
(int(ws * scale) / 2, int(hs * scale) / 2), rotate, 1
|
| 58 |
+
)
|
| 59 |
+
streak = cv2.warpAffine(streak, M, (int(ws * scale), int(hs * scale)))
|
| 60 |
+
|
| 61 |
+
binarized_streak = binarizeImage(streak)
|
| 62 |
+
mask = bwAreaFilter(binarized_streak, area_range=area)
|
| 63 |
+
|
| 64 |
+
# radius=2*ceil(2*sigma)+1
|
| 65 |
+
streak_masked = streak * mask
|
| 66 |
+
if blur:
|
| 67 |
+
streak_masked = scipy.ndimage.gaussian_filter(
|
| 68 |
+
streak_masked, sigma=1, mode="reflect", radius=5
|
| 69 |
+
)
|
| 70 |
+
return streak_masked
|
| 71 |
+
|
| 72 |
+
def genStreaks(
|
| 73 |
+
self,
|
| 74 |
+
reqH=720,
|
| 75 |
+
reqW=1280,
|
| 76 |
+
rotate=0,
|
| 77 |
+
num_itr=10,
|
| 78 |
+
scale=2,
|
| 79 |
+
area=(50, 150),
|
| 80 |
+
blur=False,
|
| 81 |
+
resize=False,
|
| 82 |
+
inGamma=1.0,
|
| 83 |
+
):
|
| 84 |
+
layer = np.zeros((reqH, reqW))
|
| 85 |
+
|
| 86 |
+
blur_kernel_size = 3
|
| 87 |
+
blur_angle = np.random.randint(-60, 60)
|
| 88 |
+
|
| 89 |
+
for i in range(num_itr):
|
| 90 |
+
streak = self.genSingleLayer(scale=scale, area=area, rotate=rotate)
|
| 91 |
+
if blur:
|
| 92 |
+
streak = apply_motion_blur(
|
| 93 |
+
streak.astype(float), blur_kernel_size, blur_angle
|
| 94 |
+
)
|
| 95 |
+
if resize:
|
| 96 |
+
streak = cv2.resize(streak.astype(float), (reqW, reqH))
|
| 97 |
+
streak = centreCrop(streak, reqH, reqW)
|
| 98 |
+
tr = random.random() * 0.2 + 0.25
|
| 99 |
+
layer = layer + streak * tr
|
| 100 |
+
|
| 101 |
+
layer = color_level_adjustment(
|
| 102 |
+
layer.copy(),
|
| 103 |
+
inBlack=10,
|
| 104 |
+
inWhite=100,
|
| 105 |
+
inGamma=inGamma,
|
| 106 |
+
outBlack=0,
|
| 107 |
+
outWhite=200,
|
| 108 |
+
)
|
| 109 |
+
return layer
|
| 110 |
+
|
| 111 |
+
def genRainEffect(self, intensnity):
|
| 112 |
+
rotate = random.randint(-30, 30)
|
| 113 |
+
if intensnity == "high":
|
| 114 |
+
layer_far = self.genStreaks(
|
| 115 |
+
reqH=720,
|
| 116 |
+
reqW=1280,
|
| 117 |
+
rotate=rotate,
|
| 118 |
+
num_itr=random.randint(40, 75),
|
| 119 |
+
scale=1,
|
| 120 |
+
area=(5, 150),
|
| 121 |
+
blur=False,
|
| 122 |
+
resize=False,
|
| 123 |
+
inGamma=1.0,
|
| 124 |
+
)
|
| 125 |
+
layer_close = self.genStreaks(
|
| 126 |
+
reqH=720,
|
| 127 |
+
reqW=1280,
|
| 128 |
+
rotate=rotate,
|
| 129 |
+
num_itr=random.randint(15, 30),
|
| 130 |
+
scale=1,
|
| 131 |
+
area=(150, 450),
|
| 132 |
+
blur=False,
|
| 133 |
+
resize=False,
|
| 134 |
+
inGamma=1.0,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
if intensnity == "mod":
|
| 138 |
+
layer_far = self.genStreaks(
|
| 139 |
+
reqH=720,
|
| 140 |
+
reqW=1280,
|
| 141 |
+
rotate=rotate,
|
| 142 |
+
num_itr=random.randint(15, 25),
|
| 143 |
+
scale=1,
|
| 144 |
+
area=(75, 150),
|
| 145 |
+
blur=False,
|
| 146 |
+
resize=False,
|
| 147 |
+
inGamma=2.0,
|
| 148 |
+
)
|
| 149 |
+
layer_close = self.genStreaks(
|
| 150 |
+
reqH=720,
|
| 151 |
+
reqW=1280,
|
| 152 |
+
rotate=rotate,
|
| 153 |
+
num_itr=random.randint(4, 10),
|
| 154 |
+
scale=1,
|
| 155 |
+
area=(150, 500),
|
| 156 |
+
blur=False,
|
| 157 |
+
resize=False,
|
| 158 |
+
inGamma=2.0,
|
| 159 |
+
)
|
| 160 |
+
tr = random.random() * 0.2 + 0.25
|
| 161 |
+
layer = layer_far + layer_close * tr
|
| 162 |
+
return layer
|
lib/snow_gen.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import numpy as np
|
| 3 |
+
from lib.gen_utils import (generate_noisy_image, zoom_image_and_crop, get_otsu_threshold,
|
| 4 |
+
apply_motion_blur, color_level_adjustment, repeat_and_combine, crystallize,
|
| 5 |
+
layer_blend)
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class SnowGenUsingNoise:
|
| 9 |
+
def __init__(self):
|
| 10 |
+
self._noise_scale_range = {
|
| 11 |
+
# 'small': (0.24, 0.45), 'large': (0.45, 0.65)
|
| 12 |
+
'small': (0.1, 0.2), 'large': (0.3, 0.5)
|
| 13 |
+
}
|
| 14 |
+
self._noise_amount_range = {
|
| 15 |
+
# 'small': (0.35, 0.65), 'large': (0.05, 0.15)
|
| 16 |
+
'small': (0.25, 0.45), 'large': (0.05, 0.15)
|
| 17 |
+
}
|
| 18 |
+
# self._zoom_range = {'small': (1.75, 3.0), 'large': (7, 10)}
|
| 19 |
+
self._zoom_range = {'small': (1.5, 2.0), 'large': (4, 6)}
|
| 20 |
+
self._blur_kernel_range = {'small': [3, 5, 7], 'large': [9, 11, 13]}
|
| 21 |
+
self._repeat_scale = {'small': [0], 'large': [0]}
|
| 22 |
+
self._max_level = {'small': (100, 150), 'large': (200, 250)}
|
| 23 |
+
self._cyrstalize_range = (0.55, 0.75)
|
| 24 |
+
|
| 25 |
+
def genSnowLayer(self,
|
| 26 |
+
h,
|
| 27 |
+
w,
|
| 28 |
+
noise_scale=0.5,
|
| 29 |
+
noise_amount=0.25,
|
| 30 |
+
zoom_layer=2.0,
|
| 31 |
+
blur_kernel_size=15,
|
| 32 |
+
blur_angle=-60,
|
| 33 |
+
max_level=250,
|
| 34 |
+
compress_scale=0,
|
| 35 |
+
cyrstalize_amount=0.5
|
| 36 |
+
):
|
| 37 |
+
im_noisy = generate_noisy_image(
|
| 38 |
+
h, w, sigma=noise_scale, p=noise_amount)
|
| 39 |
+
im_zoom = zoom_image_and_crop(im_noisy, r=zoom_layer)
|
| 40 |
+
im_blurr = apply_motion_blur(im_zoom, blur_kernel_size, blur_angle)
|
| 41 |
+
|
| 42 |
+
ret = get_otsu_threshold(im_blurr)
|
| 43 |
+
layer = color_level_adjustment(
|
| 44 |
+
im_blurr.copy(), inBlack=ret, inWhite=max_level, inGamma=1.0)
|
| 45 |
+
|
| 46 |
+
if compress_scale > 0:
|
| 47 |
+
layer = repeat_and_combine(layer, compress_scale)
|
| 48 |
+
|
| 49 |
+
if cyrstalize_amount > 0:
|
| 50 |
+
layer = crystallize(np.flipud(layer), r=0.75)
|
| 51 |
+
|
| 52 |
+
return layer.astype(np.uint8)
|
| 53 |
+
|
| 54 |
+
def genSnowMultiLayer(self, h, w, blur_angle=75, intensity="large", num_itr=2):
|
| 55 |
+
noise_scale_range = self._noise_scale_range[intensity]
|
| 56 |
+
noise_amount_range = self._noise_amount_range[intensity]
|
| 57 |
+
zoom_range = self._zoom_range[intensity]
|
| 58 |
+
blur_kernel_range = self._blur_kernel_range[intensity]
|
| 59 |
+
repeat_scale = self._repeat_scale[intensity][0]
|
| 60 |
+
max_level = self._max_level[intensity]
|
| 61 |
+
|
| 62 |
+
layer = np.zeros((h, w), dtype=np.uint8)
|
| 63 |
+
for _ in range(num_itr):
|
| 64 |
+
l = self.genSnowLayer(h, w,
|
| 65 |
+
noise_scale=random.uniform(
|
| 66 |
+
noise_scale_range[0], noise_scale_range[1]),
|
| 67 |
+
noise_amount=random.uniform(
|
| 68 |
+
noise_amount_range[0], noise_amount_range[1]),
|
| 69 |
+
zoom_layer=random.uniform(
|
| 70 |
+
zoom_range[0], zoom_range[1]),
|
| 71 |
+
blur_kernel_size=random.choice(
|
| 72 |
+
blur_kernel_range),
|
| 73 |
+
blur_angle=blur_angle,
|
| 74 |
+
max_level=random.randint(
|
| 75 |
+
max_level[0], max_level[1]),
|
| 76 |
+
compress_scale=repeat_scale,
|
| 77 |
+
cyrstalize_amount=random.uniform(
|
| 78 |
+
self._cyrstalize_range[0], self._cyrstalize_range[1])
|
| 79 |
+
)
|
| 80 |
+
# tr = 0.25 + random.random()*0.5
|
| 81 |
+
# layer = layer + tr*l
|
| 82 |
+
layer = layer_blend(layer, l)
|
| 83 |
+
return layer
|
lib/style_transfer_utils.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from PIL import Image
|
| 4 |
+
from tqdm.auto import tqdm
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
import torchvision.models as models
|
| 7 |
+
import torchvision.transforms as transforms
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def pil2tensor(pil: Image) -> torch.Tensor:
|
| 11 |
+
return transforms.functional.to_tensor(pil)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def tensor2pil(tensor: torch.Tensor) -> Image:
|
| 15 |
+
return transforms.functional.to_pil_image(tensor)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_style_transfer_model(pretrained: str = None) -> nn.Module:
|
| 19 |
+
if pretrained:
|
| 20 |
+
print(f"Loading VGG with {pretrained} weights.")
|
| 21 |
+
cnn = models.vgg19(weights=None).features
|
| 22 |
+
state_dict = torch.load(pretrained)
|
| 23 |
+
state_dict = {
|
| 24 |
+
k.replace("features.", ""): v
|
| 25 |
+
for k, v in state_dict.items()
|
| 26 |
+
if "features" in k
|
| 27 |
+
}
|
| 28 |
+
cnn.load_state_dict(state_dict)
|
| 29 |
+
else:
|
| 30 |
+
print(f"Loading VGG with IMAGENET1K weights.")
|
| 31 |
+
cnn = models.vgg19(weights=models.VGG19_Weights.IMAGENET1K_V1).features
|
| 32 |
+
cnn.eval()
|
| 33 |
+
return cnn
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def style_content_image_loader(content_path, style_path):
|
| 37 |
+
wreq = 640
|
| 38 |
+
|
| 39 |
+
content_img = Image.open(content_path)
|
| 40 |
+
wc, hc = content_img.size
|
| 41 |
+
wc_new, hc_new = wreq, int(hc * wreq / wc)
|
| 42 |
+
content_img = content_img.resize((wc_new, hc_new))
|
| 43 |
+
|
| 44 |
+
style_img = Image.open(style_path)
|
| 45 |
+
ws, hs = style_img.size
|
| 46 |
+
|
| 47 |
+
ws_new = wreq
|
| 48 |
+
hs_new = int(hs * ws_new / ws)
|
| 49 |
+
|
| 50 |
+
if hs_new < hc_new:
|
| 51 |
+
hs_new = hc_new
|
| 52 |
+
|
| 53 |
+
style_img = style_img.resize((ws_new, hs_new))
|
| 54 |
+
|
| 55 |
+
if hs_new > hc_new:
|
| 56 |
+
top = int((hs_new - hc_new) * 0.5)
|
| 57 |
+
bottom = top + hc_new
|
| 58 |
+
style_img = style_img.crop((0, top, ws_new, bottom))
|
| 59 |
+
|
| 60 |
+
assert style_img.size == content_img.size
|
| 61 |
+
|
| 62 |
+
style_img = pil2tensor(style_img).unsqueeze(0)
|
| 63 |
+
content_img = pil2tensor(content_img).unsqueeze(0)
|
| 64 |
+
return content_img, style_img
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class ContentLoss(nn.Module):
|
| 68 |
+
def __init__(
|
| 69 |
+
self,
|
| 70 |
+
target,
|
| 71 |
+
):
|
| 72 |
+
super(ContentLoss, self).__init__()
|
| 73 |
+
# we 'detach' the target content from the tree used
|
| 74 |
+
# to dynamically compute the gradient: this is a stated value,
|
| 75 |
+
# not a variable. Otherwise the forward method of the criterion
|
| 76 |
+
# will throw an error.
|
| 77 |
+
# self.target = target.detach()
|
| 78 |
+
self.register_buffer("target", target.detach())
|
| 79 |
+
|
| 80 |
+
def forward(self, input):
|
| 81 |
+
self.loss = F.mse_loss(input, self.target)
|
| 82 |
+
return input
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def gram_matrix(input):
|
| 86 |
+
a, b, c, d = input.size() # a=batch size(=1)
|
| 87 |
+
# b=number of feature maps
|
| 88 |
+
# (c,d)=dimensions of a f. map (N=c*d)
|
| 89 |
+
|
| 90 |
+
features = input.view(a * b, c * d) # resise F_XL into \hat F_XL
|
| 91 |
+
|
| 92 |
+
G = torch.mm(features, features.t()) # compute the gram product
|
| 93 |
+
|
| 94 |
+
# we 'normalize' the values of the gram matrix
|
| 95 |
+
# by dividing by the number of element in each feature maps.
|
| 96 |
+
return G.div(a * b * c * d)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class StyleLoss(nn.Module):
|
| 100 |
+
def __init__(self, target_feature):
|
| 101 |
+
super(StyleLoss, self).__init__()
|
| 102 |
+
# self.target = gram_matrix(target_feature).detach()
|
| 103 |
+
self.register_buffer("target", gram_matrix(target_feature).detach())
|
| 104 |
+
|
| 105 |
+
def forward(self, input):
|
| 106 |
+
G = gram_matrix(input)
|
| 107 |
+
sup = ((G**2).sum() + self.target.sum()) / input.numel()
|
| 108 |
+
self.loss = F.mse_loss(G, self.target) / sup
|
| 109 |
+
return input
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def get_style_model_and_losses(cnn, style_img, content_img, device="cpu"):
|
| 113 |
+
# desired depth layers to compute style/content losses :
|
| 114 |
+
content_layers = ["conv_4"]
|
| 115 |
+
style_layers = ["conv_1", "conv_2", "conv_3", "conv_4", "conv_5"]
|
| 116 |
+
|
| 117 |
+
# just in order to have an iterable access to or list of content/syle losses
|
| 118 |
+
content_losses = []
|
| 119 |
+
style_losses = []
|
| 120 |
+
|
| 121 |
+
# assuming that cnn is a nn.Sequential, so we make a new nn.Sequential
|
| 122 |
+
# to put in modules that are supposed to be activated sequentially
|
| 123 |
+
mean = torch.tensor([0.485, 0.456, 0.406])
|
| 124 |
+
std = torch.tensor([0.229, 0.224, 0.225])
|
| 125 |
+
model = nn.Sequential(transforms.Normalize(mean=mean, std=std))
|
| 126 |
+
|
| 127 |
+
i = 0 # increment every time we see a conv
|
| 128 |
+
for layer in cnn.children():
|
| 129 |
+
if isinstance(layer, nn.Conv2d):
|
| 130 |
+
i += 1
|
| 131 |
+
name = "conv_{}".format(i)
|
| 132 |
+
elif isinstance(layer, nn.ReLU):
|
| 133 |
+
name = "relu_{}".format(i)
|
| 134 |
+
# The in-place version doesn't play very nicely with the ContentLoss
|
| 135 |
+
# and StyleLoss we insert below. So we replace with out-of-place
|
| 136 |
+
# ones here.
|
| 137 |
+
layer = nn.ReLU(inplace=False)
|
| 138 |
+
elif isinstance(layer, nn.MaxPool2d):
|
| 139 |
+
name = "pool_{}".format(i)
|
| 140 |
+
elif isinstance(layer, nn.BatchNorm2d):
|
| 141 |
+
name = "bn_{}".format(i)
|
| 142 |
+
else:
|
| 143 |
+
raise RuntimeError(
|
| 144 |
+
"Unrecognized layer: {}".format(layer.__class__.__name__)
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
model.add_module(name, layer)
|
| 148 |
+
|
| 149 |
+
if name in content_layers:
|
| 150 |
+
# add content loss:
|
| 151 |
+
target = model(content_img).detach()
|
| 152 |
+
content_loss = ContentLoss(target)
|
| 153 |
+
model.add_module("content_loss_{}".format(i), content_loss)
|
| 154 |
+
content_losses.append(content_loss)
|
| 155 |
+
|
| 156 |
+
if name in style_layers:
|
| 157 |
+
# add style loss:
|
| 158 |
+
target_feature = model(style_img).detach()
|
| 159 |
+
style_loss = StyleLoss(target_feature)
|
| 160 |
+
model.add_module("style_loss_{}".format(i), style_loss)
|
| 161 |
+
style_losses.append(style_loss)
|
| 162 |
+
|
| 163 |
+
# now we trim off the layers after the last content and style losses
|
| 164 |
+
for i in range(len(model) - 1, -1, -1):
|
| 165 |
+
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
|
| 166 |
+
break
|
| 167 |
+
|
| 168 |
+
model = model[: (i + 1)]
|
| 169 |
+
for sl in style_losses:
|
| 170 |
+
sl.to(device)
|
| 171 |
+
for sl in content_losses:
|
| 172 |
+
sl.to(device)
|
| 173 |
+
return model.to(device), style_losses, content_losses
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def get_input_optimizer(input_img):
|
| 177 |
+
# this line to show that input is a parameter that requires a gradient
|
| 178 |
+
optimizer = torch.optim.LBFGS([input_img], lr=1) # , lr=1e-2
|
| 179 |
+
return optimizer
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
def run_style_transfer(
|
| 183 |
+
cnn,
|
| 184 |
+
content_img,
|
| 185 |
+
style_img,
|
| 186 |
+
input_img,
|
| 187 |
+
num_steps=300,
|
| 188 |
+
style_weight=1000000,
|
| 189 |
+
content_weight=1,
|
| 190 |
+
device="cpu",
|
| 191 |
+
):
|
| 192 |
+
"""Run the style transfer."""
|
| 193 |
+
# print('Building the style transfer model..')
|
| 194 |
+
model, style_losses, content_losses = get_style_model_and_losses(
|
| 195 |
+
cnn, style_img, content_img, device=device
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
# We want to optimize the input and not the model parameters so we
|
| 199 |
+
# update all the requires_grad fields accordingly
|
| 200 |
+
input_img.requires_grad_(True)
|
| 201 |
+
model.requires_grad_(False)
|
| 202 |
+
|
| 203 |
+
optimizer = get_input_optimizer(input_img)
|
| 204 |
+
|
| 205 |
+
for run in tqdm(range(num_steps)):
|
| 206 |
+
|
| 207 |
+
def closure():
|
| 208 |
+
# correct the values of updated input image
|
| 209 |
+
with torch.no_grad():
|
| 210 |
+
input_img.clamp_(0, 1)
|
| 211 |
+
|
| 212 |
+
optimizer.zero_grad()
|
| 213 |
+
model(input_img)
|
| 214 |
+
style_score = 0
|
| 215 |
+
content_score = 0
|
| 216 |
+
|
| 217 |
+
for sl in style_losses:
|
| 218 |
+
style_score += sl.loss
|
| 219 |
+
for cl in content_losses:
|
| 220 |
+
content_score += cl.loss
|
| 221 |
+
|
| 222 |
+
style_score *= style_weight
|
| 223 |
+
content_score *= content_weight
|
| 224 |
+
|
| 225 |
+
print(
|
| 226 |
+
f"Style Loss: {style_score.item()} Content Loss: {content_score.item()}"
|
| 227 |
+
)
|
| 228 |
+
|
| 229 |
+
loss = style_score + content_score
|
| 230 |
+
loss.backward()
|
| 231 |
+
return style_score + content_score
|
| 232 |
+
|
| 233 |
+
optimizer.step(closure)
|
| 234 |
+
|
| 235 |
+
# a last correction...
|
| 236 |
+
with torch.no_grad():
|
| 237 |
+
input_img.clamp_(0, 1)
|
| 238 |
+
|
| 239 |
+
return input_img
|
presentation.ipynb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa13d18e69b36e587c5b0bd4509954fddbf3fef9bf8c8918db9d9265ffa558e9
|
| 3 |
+
size 12779382
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
matplotlib
|
| 3 |
+
opencv-python
|
| 4 |
+
scikit-image
|
| 5 |
+
scikit-learn
|
| 6 |
+
torchsummary
|
resources/error_0.png
ADDED

|
resources/error_1.png
ADDED

|
resources/error_2.png
ADDED

|
resources/exploding_gradient.png
ADDED

|
resources/rain_0.jpg
ADDED

|
resources/rain_1.jpg
ADDED

|
resources/resnet_gan.png
ADDED
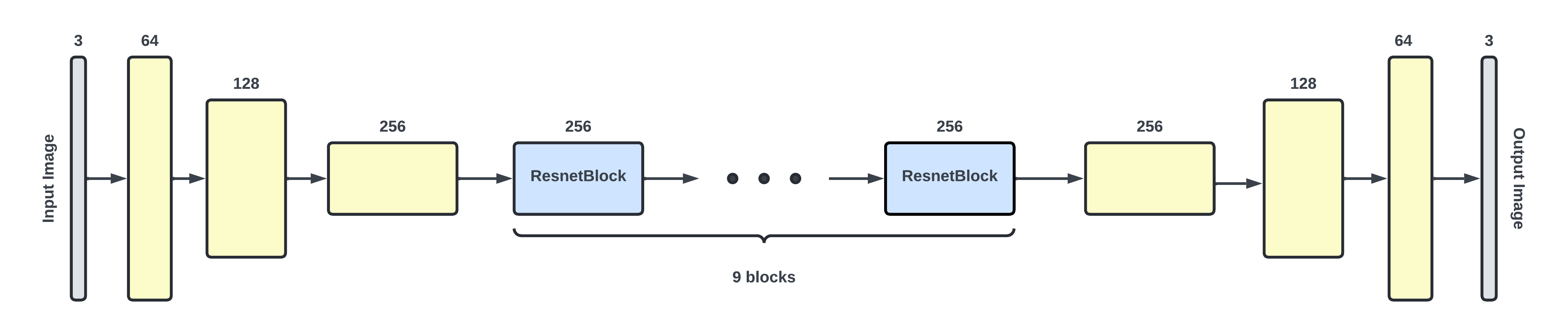
|
resources/snow_0.jpg
ADDED

|
resources/snow_1.jpg
ADDED

|