
End of training
Browse files- README.md +47 -0
- checkpoint-90000/controlnet/config.json +51 -0
- checkpoint-90000/controlnet/diffusion_pytorch_model.safetensors +3 -0
- checkpoint-90000/optimizer.bin +3 -0
- checkpoint-90000/random_states_0.pkl +3 -0
- checkpoint-90000/scheduler.bin +3 -0
- config.json +51 -0
- diffusion_pytorch_model.safetensors +3 -0
- image_control.png +0 -0
- images_0.png +0 -0
- images_1.png +0 -0
- images_2.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
|
| 3 |
+
library_name: diffusers
|
| 4 |
+
license: creativeml-openrail-m
|
| 5 |
+
tags:
|
| 6 |
+
- stable-diffusion
|
| 7 |
+
- stable-diffusion-diffusers
|
| 8 |
+
- text-to-image
|
| 9 |
+
- diffusers
|
| 10 |
+
- controlnet
|
| 11 |
+
- diffusers-training
|
| 12 |
+
inference: true
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
<!-- This model card has been generated automatically according to the information the training script had access to. You
|
| 16 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# controlnet-maxpmx/output_biosr_128
|
| 20 |
+
|
| 21 |
+
These are controlnet weights trained on stable-diffusion-v1-5/stable-diffusion-v1-5 with new type of conditioning.
|
| 22 |
+
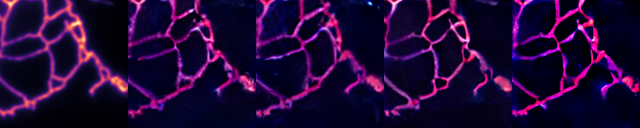
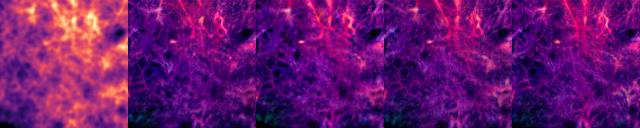
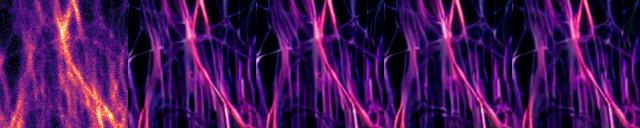
You can find some example images below.
|
| 23 |
+
|
| 24 |
+
prompt: Super-resolution ER image
|
| 25 |
+

|
| 26 |
+
prompt: Super-resolution F-actin image
|
| 27 |
+

|
| 28 |
+
prompt: Super-resolution Microtubules image
|
| 29 |
+

|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Intended uses & limitations
|
| 34 |
+
|
| 35 |
+
#### How to use
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
# TODO: add an example code snippet for running this diffusion pipeline
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
#### Limitations and bias
|
| 42 |
+
|
| 43 |
+
[TODO: provide examples of latent issues and potential remediations]
|
| 44 |
+
|
| 45 |
+
## Training details
|
| 46 |
+
|
| 47 |
+
[TODO: describe the data used to train the model]
|
checkpoint-90000/controlnet/config.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "ControlNetModel",
|
| 3 |
+
"_diffusers_version": "0.31.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"addition_embed_type": null,
|
| 6 |
+
"addition_embed_type_num_heads": 64,
|
| 7 |
+
"addition_time_embed_dim": null,
|
| 8 |
+
"attention_head_dim": 8,
|
| 9 |
+
"block_out_channels": [
|
| 10 |
+
320,
|
| 11 |
+
640,
|
| 12 |
+
1280,
|
| 13 |
+
1280
|
| 14 |
+
],
|
| 15 |
+
"class_embed_type": null,
|
| 16 |
+
"conditioning_channels": 3,
|
| 17 |
+
"conditioning_embedding_out_channels": [
|
| 18 |
+
16,
|
| 19 |
+
32,
|
| 20 |
+
96,
|
| 21 |
+
256
|
| 22 |
+
],
|
| 23 |
+
"controlnet_conditioning_channel_order": "rgb",
|
| 24 |
+
"cross_attention_dim": 768,
|
| 25 |
+
"down_block_types": [
|
| 26 |
+
"CrossAttnDownBlock2D",
|
| 27 |
+
"CrossAttnDownBlock2D",
|
| 28 |
+
"CrossAttnDownBlock2D",
|
| 29 |
+
"DownBlock2D"
|
| 30 |
+
],
|
| 31 |
+
"downsample_padding": 1,
|
| 32 |
+
"encoder_hid_dim": null,
|
| 33 |
+
"encoder_hid_dim_type": null,
|
| 34 |
+
"flip_sin_to_cos": true,
|
| 35 |
+
"freq_shift": 0,
|
| 36 |
+
"global_pool_conditions": false,
|
| 37 |
+
"in_channels": 4,
|
| 38 |
+
"layers_per_block": 2,
|
| 39 |
+
"mid_block_scale_factor": 1,
|
| 40 |
+
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
| 41 |
+
"norm_eps": 1e-05,
|
| 42 |
+
"norm_num_groups": 32,
|
| 43 |
+
"num_attention_heads": null,
|
| 44 |
+
"num_class_embeds": null,
|
| 45 |
+
"only_cross_attention": false,
|
| 46 |
+
"projection_class_embeddings_input_dim": null,
|
| 47 |
+
"resnet_time_scale_shift": "default",
|
| 48 |
+
"transformer_layers_per_block": 1,
|
| 49 |
+
"upcast_attention": false,
|
| 50 |
+
"use_linear_projection": false
|
| 51 |
+
}
|
checkpoint-90000/controlnet/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f9142ef623678293ad796937c6c505ae6258d1813083a84cdb27430493204c99
|
| 3 |
+
size 1445157120
|
checkpoint-90000/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:657dba15746fbd6022185afc654d66bccf14baddf41e39cca3a4ec4751a8c961
|
| 3 |
+
size 2890518478
|
checkpoint-90000/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:87e939f6dfc05a1acb28a844954735bb981055a5f541bab4f0d87acaaa1ab140
|
| 3 |
+
size 15124
|
checkpoint-90000/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6ae091356352dfcfe87bb80e59139e12a2ca12e2559d0092b0e5896cef936bc6
|
| 3 |
+
size 1000
|
config.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "ControlNetModel",
|
| 3 |
+
"_diffusers_version": "0.31.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"addition_embed_type": null,
|
| 6 |
+
"addition_embed_type_num_heads": 64,
|
| 7 |
+
"addition_time_embed_dim": null,
|
| 8 |
+
"attention_head_dim": 8,
|
| 9 |
+
"block_out_channels": [
|
| 10 |
+
320,
|
| 11 |
+
640,
|
| 12 |
+
1280,
|
| 13 |
+
1280
|
| 14 |
+
],
|
| 15 |
+
"class_embed_type": null,
|
| 16 |
+
"conditioning_channels": 3,
|
| 17 |
+
"conditioning_embedding_out_channels": [
|
| 18 |
+
16,
|
| 19 |
+
32,
|
| 20 |
+
96,
|
| 21 |
+
256
|
| 22 |
+
],
|
| 23 |
+
"controlnet_conditioning_channel_order": "rgb",
|
| 24 |
+
"cross_attention_dim": 768,
|
| 25 |
+
"down_block_types": [
|
| 26 |
+
"CrossAttnDownBlock2D",
|
| 27 |
+
"CrossAttnDownBlock2D",
|
| 28 |
+
"CrossAttnDownBlock2D",
|
| 29 |
+
"DownBlock2D"
|
| 30 |
+
],
|
| 31 |
+
"downsample_padding": 1,
|
| 32 |
+
"encoder_hid_dim": null,
|
| 33 |
+
"encoder_hid_dim_type": null,
|
| 34 |
+
"flip_sin_to_cos": true,
|
| 35 |
+
"freq_shift": 0,
|
| 36 |
+
"global_pool_conditions": false,
|
| 37 |
+
"in_channels": 4,
|
| 38 |
+
"layers_per_block": 2,
|
| 39 |
+
"mid_block_scale_factor": 1,
|
| 40 |
+
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
| 41 |
+
"norm_eps": 1e-05,
|
| 42 |
+
"norm_num_groups": 32,
|
| 43 |
+
"num_attention_heads": null,
|
| 44 |
+
"num_class_embeds": null,
|
| 45 |
+
"only_cross_attention": false,
|
| 46 |
+
"projection_class_embeddings_input_dim": null,
|
| 47 |
+
"resnet_time_scale_shift": "default",
|
| 48 |
+
"transformer_layers_per_block": 1,
|
| 49 |
+
"upcast_attention": false,
|
| 50 |
+
"use_linear_projection": false
|
| 51 |
+
}
|
diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fc44e189f15fe114bf66f09286dae1fa14fee1a78cad47e35f3643dd61d39bb3
|
| 3 |
+
size 1445157120
|
image_control.png
ADDED

|
images_0.png
ADDED
|
images_1.png
ADDED
|
images_2.png
ADDED
|