
question
dict | answers
listlengths 1
27
| url
stringlengths 66
601
| tags
sequencelengths 1
15
⌀ |
|---|---|---|---|
{
"author": "yogev ch",
"title": "Is there a way to know in a plan's final stage the build status?",
"body": "I want to perform some cleaning of an external resource, so I've created a stage, which is a final stage of a plan. \nAccording to Bamboo it should run no matter what.\n\nIs there a way to know in that final stage, if all stages until that stage succeeded or at least one failed?\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Yogev,\n\nWelcome to Atlassian community\n\nYou can look at the Buildresult of that run and see what stages passed and what failed, in this particular run, we can see Stage 2 Job 2 failed and Final stage was run successfully.\n\n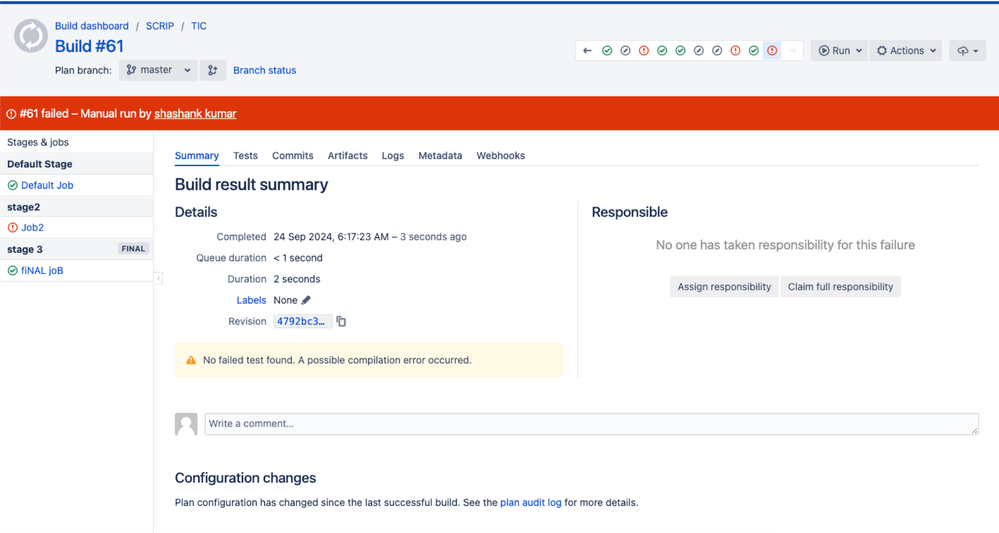\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "yogev ch",
"body": "Thanks for your response.\n\nMaybe I didn't clarify myself: I meant that I want to check programmatically in a script task of the final stage, if the build failed or not.\n\nI want to be able to perform some cleanups in case the build failed, automatically in a task within the final stage.\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Yogev,\n\nYou can use the REST API to get the details, refer [api-api-latest-result-projectkey-buildkey-get](https://developer.atlassian.com/server/bamboo/rest/api-group-api/#api-api-latest-result-projectkey-buildkey-get) for more details.\n\nYou'll need to use the expand parameter for stages, see example below\n\n\n\nThe result would look something like below when you expand the stages, it would print the status of the stage and you can see if your previous stage was successful or failed.\n\n \nRegards, \nShashank Kumar\n"
},
{
"author": "yogev ch",
"body": "Thank you \nHmm, for some reason I get\n\n```\ncurl: (56) Recv failure: Connection reset by peer\n```\n\nMy request is\n\n```\ncurl -X GET -H 'Authorization: Bearer Mddd' -H 'Accept: application/json' --url 'http://bamboo:8085/rest/api/latest/result/PPP-AO-123?expand=stages'\n```\n"
},
{
"author": "Shashank Kumar",
"body": "Seems to be a network/Proxy/Firewall Issue, Have a read at at <https://github.com/curl/curl/issues/1016>\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "yogev ch",
"body": "Thanks. I think it doesn't help though.\n\nBecause this one (without a build number) does work.\n\n```\ncurl -X GET -H 'Authorization: Bearer Mddd' -H 'Accept: application/json' --url 'http://bamboo:8085/rest/api/latest/result/PPP-AO?expand=stages'\n```\n\n```\n{\n\"results\": {\n\"size\": 25,\n\"start-index\": 0,\n\"max-result\": 25\n},\n\"expand\": \"results\",\n\"link\": {\n\"href\": \"http://bamboo:8085/rest/api/latest/result/PPP-AO\",\n\"rel\": \"self\"\n}\n}\n```\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Yogev,\n\nIt won't work without the build number, because you are trying to fetch the results data which is available per build.\n\nYou can use **bamboo.buildNumber** variable to pass to the API, read [Bamboo variables](https://confluence.atlassian.com/bamboo/bamboo-variables-289277087.html) for more details\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "yogev ch",
"body": "In my last response when I added the example\n\n```\ncurl -X GET -H 'Authorization: Bearer Mddd' -H 'Accept: application/json' --url 'http://bamboo:8085/rest/api/latest/result/PPP-AO?expand=stages'\n```\n\nI meant to show that other requests does work.\n\nAnyway... I restarted my computer and it now works, I have no idea how. \nThank you! \n\n<br />\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Is-there-a-way-to-know-in-a-plan-s-final-stage-the-build-status/qaq-p/2819642 | null |
{
"author": "Ramchandra Chintala",
"title": "Accidentally, deleted a bamboo plan",
"body": "Hi,\n\nI accidenally deleted a bamboo plan, please asssit me in recovering it back.\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Ram,\n\nYou can follow the steps at <https://confluence.atlassian.com/bamkb/how-to-restore-a-deleted-plan-in-bamboo-1116287934.html> to try and recover the deleted plan.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
},
{
"author": "Valerie Knapp",
"body": "Hi [@Ramchandra Chintala](/t5/user/viewprofilepage/user-id/5590620) , welcome to the Atlassian Community and thanks for your question.\n\nPlease open a support ticket for this with Atlassian - <https://support.atlassian.com/contact/>\n\nCheers\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Accidentally-deleted-a-bamboo-plan/qaq-p/2810139 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Bill Parlock",
"title": "How to migrate Single Bamboo project to another Instance",
"body": "I would like to migrate a single Bamboo project / plans to another instance of Bamboo. The destination Bamboo instance already has projects/plans so I do not want to overwrite any of the existing projects. I have been searching for documentation but what I am coming across is moving an entire Bamboo instance to another server. I just want to move a single Bamboo project to another instance that also contains other Bamboo projects.\n"
} | [
{
"author": "Anik Sengupta",
"body": "Unfortunately you cannot do selective copy/clone of the projects to new instance . Its either full or nothing.\n\nFor the single plan under a project you can may be , view the plan as specs (Edit plan configuration-\\>View plan as specs) and use java or yaml specs to generate the new plans. Else you need to manually create those plans in the new instance\n\nRegards,\n\nAnik Sengupta\n\n\\*\\*please don't forget to Accept the answer if your query was answered\\*\\*\n",
"comments": null
},
{
"author": "Bill Parlock",
"body": "Thank you.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-migrate-Single-Bamboo-project-to-another-Instance/qaq-p/2807187 | [
"bamboo-server",
"server"
] |
{
"author": "Kamran Alipoursimakani",
"title": "Moving Plan Y from Project Y to Project X fails!",
"body": "Hi there!\n\nWe're currently using Bamboo 7.1.2 and need to move some plans between projects due to changes in ownership and for cleanup purposes.\n\nWhen we attempt to move a newly created plan, Plan Y (key: PLANY), from a freshly created Project Y (key: PY) --- which contains only a single shell script task in its default job to list the contents of the working directory (this task runs successfully) --- to another newly created and completely empty Project X (key: PX), it fails with the error: *\"String \\[PX-JOB1\\] is not a job key.\"*\n\nDoes anyone have any tips or suggestions for us? ?\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Kamran,\n\nWelcome to Atlassian community\n\nLooking at the key ***PX-JOB1***for the job, it seems wrong, it should be projectkey-plankey-jobkey.\n\nI did a quick test in Bamboo 9 with the above scenario and I don't see the error, Can you try to open the Job from the moved plan and check what is the Job key it will be displayed in the browser.\n\nAlso do validate if you have followed the steps from <https://confluence.atlassian.com/bamboo/moving-plans-to-a-different-project-289277189.html>\n\nRegards,\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "Kamran Alipoursimakani",
"body": "Hi Shashank ?\n\nThanks for quick reply!\n\nHere is what I get in the browser address bar when I go to the **Default Job** inside **Plan Y** belonging to **Project Y** \n\n.../build/admin/edit/editBuildTasks.action?buildKey=PY-PLANY-JOB1\n\nBut when trying to move the plan, it seems to be dropping the plan ID ?\n"
},
{
"author": "Shashank Kumar",
"body": "Hi Kamran,\n\nThis is the original scenario when the Default Job is under **Plan Y** and **Project Y**\n\nCan you confirm what is the Job key when this is moved to**Project PX.**\n\nIf your project does not contain any sensitive info can you share the YAML Specification after the plan is moved to **Project PX** , this will clear all the doubts, refer [YAML specification](https://confluence.atlassian.com/bamboo/exporting-existing-plan-configuration-to-bamboo-yaml-specs-1018270696.html) for more details on how to do this.\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "Kamran Alipoursimakani",
"body": "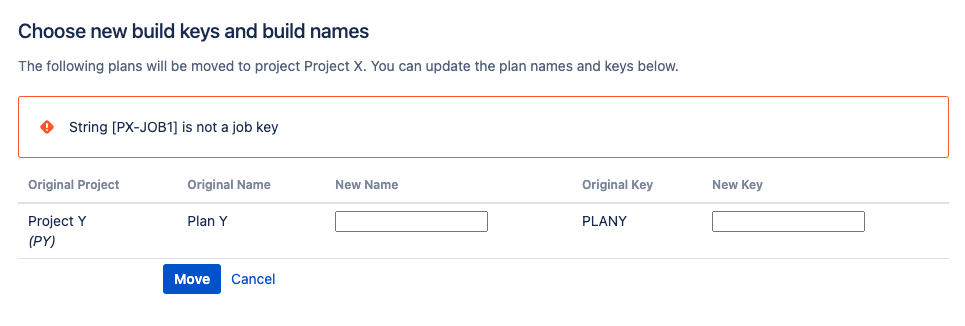\n\nThat's the problem, I can not move it at all, it fails when I click the Move button with the error message you see in the screenshot which is referring to a wrong job key which doesn't have the Plan ID in it! ?\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Moving-Plan-Y-from-Project-Y-to-Project-X-fails/qaq-p/2812978 | [
"data-center",
"fail",
"move",
"plan"
] |
{
"author": "Alejandro Carretero Trejo",
"title": "How to migrate Bamboo local agents to Ephemereal Agents with AWS ECS",
"body": "Good morning,\n\nIn our company, we are planning to upgrade our current version of Bamboo Data Center from 9.4.2 to 9.6.5 LTS in order to solve a recent vulnerability reported in your monthly Security Bulletins.\n\nHowever, we have an important trouble with that, because we are currently working in our instance with several Local Agents that are going to be unable from 9.6x versions.\n\nDue to this problem, we have analyzed the best workaround for us and we have decided to migrate from Local Agents to Ephemereal Agents for budget reasons.\n\nWe have several questions about Ephemereal Agents that we want to know:\n\n1 - ?It is possible to use a current AWS ECS engine in our AWS account as a Kubernetes cluster in where Ephemereal Agents and pods could be mount?\n\n2 - ?How much will it cost to have two or three Ephemeral Agents working on and enable for concurrency purposes? ?It is necessary to increase our currently license (1 remote agent license)?\n\n3 - In a scenario where currently we have three Local Agents working and we need to migrate to a similar scenario with Ephemereal or Elastic Agents, ?which one of the two options will be the cheaper without increase our 1 Remote Agente License?\n\nWe are looking forward to your help. Thanks in advance.\n\nKind regards.\n"
} | [
{
"author": "Yevhen",
"body": "[@Alejandro Carretero Trejo](/t5/user/viewprofilepage/user-id/5589579) while I can't answer your licensing questions, I can answer your ephemeral agents questions. Ephemeral agents are deployed to a Kubernetes cluster. AWS ECS is not a Kubernetes engine. Perhaps you mean AWS EKS?\n",
"comments": [
{
"author": "Alejandro Carretero Trejo",
"body": "Hi [@Yevhen](/t5/user/viewprofilepage/user-id/3965218)\n\nYes, I meant AWS EKS. We have an AWS EKS already configured in our AWS account where the Bamboo EC2 instance is deployed with the Bamboo Data Center installation\n"
},
{
"author": "Yevhen",
"body": "Ephemeral agents work just fine on EKS (in fact, they are vendor/cloud agnostic and will work on any K8S cluster really)\n"
},
{
"author": "Alejandro Carretero Trejo",
"body": "Thanks [@Yevhen](/t5/user/viewprofilepage/user-id/3965218)\n\nDo you have any documentation of how to start building templates and pods through EKS with Bamboo Ephemereal Agents? Any example configuration that can works fine?\n"
},
{
"author": "Yevhen",
"body": "I don't think I can share more than what's in official docs: <https://confluence.atlassian.com/bamboo/ephemeral-agents-1236444139.html>\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-migrate-Bamboo-local-agents-to-Ephemereal-Agents-with-AWS/qaq-p/2809022 | [
"agents",
"aws",
"ecs",
"kubernetes",
"migrate"
] |
{
"author": "???SA",
"title": "Bamboo Server 7.1.4 failing to connect to Bitbucket Cloud repositories",
"body": "We're using Bamboo Server 7.1.4. As of today, Sap 30th 2024, any repositories configured to use the \"Bitbucket Cloud\" repository type are failing to connect to Bitbucket. Hitting the \"Test Connection\" button results in this error message:\n\n\"We couldn't connect to the repository. The details you provided were invalid.\"\n\nThis happens regardless of whether I attempt to use SSH or username/password to connect. I confirmed that username/password is valid.\n\nWhat might be causing this?\n"
} | [
{
"author": "TS",
"body": "Same problem here! \nUnable to add a new repository using either app password or SSH key. \nAlready existing repositories are working fine, dropdown shows available branches, however pressing \nthe test button results in the message: \"We couldn't connect to the repository. The details you provided were invalid.\" \nWe are also using Bamboo server 7.1.4\n",
"comments": [
{
"author": "Anik Sengupta",
"body": "Looks like you may be hitting this bug- <https://jira.atlassian.com/browse/BAM-20988>\n"
},
{
"author": "???SA",
"body": "Hi, [@TS](/t5/user/viewprofilepage/user-id/3146178) \nthe issue occurred because the API used to check the personal space during the test connection was failing due to the personal space being deleted. To resolve this, I customized the internal Bamboo source so that the API process retrieves the current workspace instead of the personal space.\n"
}
]
},
{
"author": "Anik Sengupta",
"body": "I hope you are using an app password to connect .\n\nPlease refer-https://confluence.atlassian.com/bamkb/how-to-get-the-credential-details-user_name-and-app_password-to-connect-bamboo-to-bitbucket-cloud-1188411501.html\n\nRegards,\n\nAnik Sengupta\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "???SA",
"body": "I am already using an app password, and this app password can get the repository from Bitbucket Cloud, but the issue occurs when running the test connection.\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Bamboo-Server-7-1-4-failing-to-connect-to-Bitbucket-Cloud/qaq-p/2807522 | null |
{
"author": "Nathan Iwanski",
"title": "Yaml Specs: branch-overrides[*].other",
"body": "It would appear you can not override \"other\" configs with branch-overrides. The docs lead me to believe all configuration is valid and should be merged appropriately, however my experiences have shown otherwise. \n\nFor instance, the main plan has \\`other.concurrent-build-plugin: 1\\` and a branch override has 8 configured instead. Only the base plan's config is used. Is this to be expected or is it a bug? \n\nThank you \n\n<br />\n\nEdit: I guess going back, the note to the side of the docs says \"Miscellaneous plugins configuration on a plan level.\" which could be taken to mean only the top level config is used. I don't find that very clear in expectations, but maybe that's on me. It would be fantastic if this weren't the case...\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Nathan,\n\nWelcome to Atlassian community.\n\nYou can look at <https://docs.atlassian.com/bamboo-specs-docs/9.6.5/specs.html?yaml#overriding-branch-settings-using-bamboo-specs> to understand what configs can be changed.\n\nCan you give one example which you trying to change for your branch which is not working?\n\nRegards,\n\nShashank Kumar\n",
"comments": [
{
"author": "Nathan Iwanski",
"body": "Thank you, however those are the docs I'm referencing and they don't appear to communicate the issue at hand. Or that section doesn't, the Miscellaneous Plugins section may allude to it in a note on the side of the yaml documentation.\n\n**tl;dr:**If you override something for a branch, you would expect it to be overridden. It appears there are configurations that can not be overridden, and I do not believe that is clearly communicated if it is the intended behavior.\n\nAn example config which would result in a concurrency limit of 1, even on the \"main\" branch that supposedly overrides this to 8: \n\n```\n---\nversion: 2\nplan:\n project-key: LOCAL\n key: PLAN\n name: Test Plan\ntriggers:\n - remote\nbranches:\n create:\n for-new-branch: .*\nother:\n concurrent-build-plugin: 1\nstages:\n - Build Stage:\n manual: false\n final: false\n jobs:\n - Build Job\n - Test Stage:\n manual: true\n final: false\n jobs:\n - Test Job\n\nBuild Job:\n !include \"shared/jobs/build.yaml\"\n\nTest Job:\n !include \"shared/jobs/test.yaml\"\n\nbranch-overrides:\n - main:\n other:\n concurrent-build-plugin: 8\n stages:\n - Build Stage:\n manual: false\n final: true\n jobs:\n - Build Job\n - Test Stage:\n manual: false\n final: true\n jobs:\n - Test Job\n - Release Stage:\n manual: false\n final: true\n jobs:\n - Release Job\n Build Job:\n !include \"shared/jobs/build.yaml\"\n Test Job:\n !include \"shared/jobs/test.yaml\"\n Release Job:\n !include \"shared/jobs/release.yaml\"\n```\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Nathan,\n\nYes you are right. There are few properties which you cannot override like the one example which you specified.\n\nI don't know if this is a bug or a intended behaviour, I will check this internally with the right people and provide an update here.\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Nathan,\n\nI did check this internally and feedback is that **branch-override** will override only the attributes for branches which you are able to change from GUI for a plan branches, see the below screen. Anything which gets tagged to the default plan configuration will not get changed via branch override.\n\nFor this you can probably use Specs branches and modify the individual specs file for each branch if you wish to have specific configuration for each branch but that will work after the branch is created.\n\nI agree the documentation is not very clear about this, probably this can be improved a little\n\n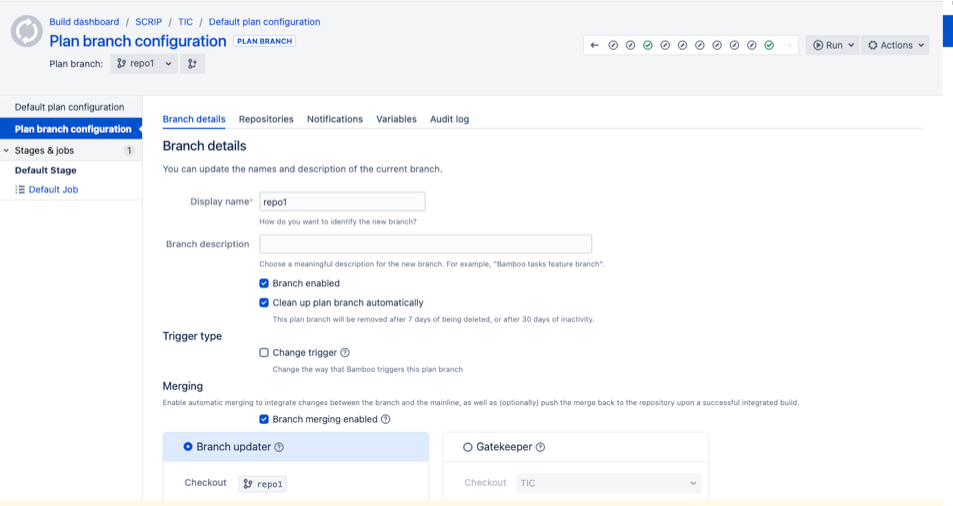\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Yaml-Specs-branch-overrides-other/qaq-p/2802186 | [
"bug",
"spec",
"yaml"
] |
{
"author": "UA UA",
"title": "Failed task fails stage",
"body": "Hey team,\n\nWe have below configuration in Bamboo:\n\nStage 1:\n\nTask 1 : Build\n\nTask 2 : Maven test suite 1\n\nTask 3 : Maven Test suite 2\n\nWith above configuration, when test suite 1 fails, I want test suite 2 to still execute as they are independent of each other. However, what I see happening is that when test suite 1 fails, the whole stage fails and it won't execute test suite 2. Any advice would be much appreciated. Thanks\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Team,\n\nWelcome to Atlassian community.\n\nBamboo tasks runs sequentially, so one task fails it will fail the whole Job.\n\nIf you want Test 2 to execute and as you mentioned they are independent of each other, you can move them to different Jobs as Jobs execute in parallel. Refer <https://confluence.atlassian.com/bamboo/jobs-and-tasks-289277035.html> for more details.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Failed-task-fails-stage/qaq-p/2800526 | null |
{
"author": "Arya Kumar",
"title": "Bamboo DC 9.6 - Why is there an \"unknown\" tag along with the release version ?",
"body": "Recently i upgraded our bamboo server from 6.3.1 server version to 9.6 data center version.I followed the documentation and did a step by step upgrade. After the upgrade, I am able to build and deploy successfully but i haven't been able to figure why and from where this \"unknown\" tag is coming from. I don't see any errors in the logs.Any help on this is appreciated.png\")\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Arya,\n\nWelcome to Atlassian community.\n\nIn Bamboo [9.4 release](https://confluence.atlassian.com/bambooreleases/bamboo-9-4-release-notes-1312161836.html#Bamboo9.4releasenotes-Safeguardyourdeploymentenvironmentsagainstunapprovedreleases) there was a new feature introduced to Safeguard your deployment environments against unapproved releases.\n> To help you make sure that a bad release never takes down your whole production environment (or never does that again), deployment environments now let you set their release approval policy. The policy lets you define the conditions a release must meet before it can be deployed. That is, which environments accept all releases, which ones accept approved releases, and which ones only accept releases that haven't been marked as broken. If you change your mind later, just update the environment's settings and you're good to go.\n>\n> [Learn more about the release approval policy for deployment environments](https://confluence.atlassian.com/bamboo0904/release-approval-policy-for-deployment-environments-1299917924.html)\n\nBecause of this the releases have now got a extra tag associated with them. UNKNOWN basically means that the release is neither **approved** nor **broken** , see example below \n\n\n**++Case 1:++**\n\nHere release 1 is showing as **UNKNOWN** because I have neither approved it nor made in broken but I have deployed it to some environment, see below. \n\n\n++**Case 2:**++\n\nHere release 2 is showing as Approved because I have approved it's status after it was deployed. \n \n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "Arya Kumar",
"body": "Thanks Shashank .I missed this part completely.\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Bamboo-DC-9-6-Why-is-there-an-quot-unknown-quot-tag-along-with/qaq-p/2801325 | null |
{
"author": "Norbert",
"title": "How to determine the last supported Version of Bamboo",
"body": "Hi\n\nOur Bamboo Maintenance expired beginning of this year\n\ncurrently we are useing version 9.3.x\n\nBut which is the latest supported version for us? \nHow to find this information?\n\nregards\n\nNorbert\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Norbert,\n\nWelcome to Atlassian community.\n\n\\* If you are asking about Technical support then it depends upon the License ( SEN ) validity, if you have a valid SEN then you are entitled for support, you can refer [Finding Your Bamboo Support Entitlement Number (SEN)](https://confluence.atlassian.com/bamboo/finding-your-bamboo-support-entitlement-number-sen-289277234.html) for more details\n\n\\* If you asking about the end of life of your current Bamboo version, you can refer [Atlassian Support End of Life Policy](https://confluence.atlassian.com/support/atlassian-support-end-of-life-policy-201851003.html) for more details\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "Norbert",
"body": "No\n\nI'm asking which is the latest version I can use. \nCan i use 9.6 with this license?\n\nI'm not able to ask Atlassian Support directly because as mentioned above the SEN already expired.\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Norbert,\n\nYou can't update to latest 9.6 version as the License is already expired, you'll see an error during the upgrade process that the license is expired.\n\nDepending upon if you are using Server or Data center version of the license you can refer [What happens when a Bamboo license expires](https://confluence.atlassian.com/bamkb/what-happens-when-a-bamboo-license-expires-1114804458.html) for your use case\n\nRegards,\n\nShashank Kumar\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-determine-the-last-supported-Version-of-Bamboo/qaq-p/2800539 | [
"bamboo-server",
"server"
] |
{
"author": "???SA",
"title": "Issue with Bamboo and Bitbucket Cloud Repository Registration Using Shared Credentials",
"body": "### Environment {#toc-hId--2125328245}\n\n* Bamboo Server 7.1.4\n* Bitbucket Cloud\n\n### Issue Description {#toc-hId-362184588}\n\nWhile configuring a Bamboo plan environment, the repository to be used was added under the Default plan configuration \\> Repositories menu. \nCurrently, the method to connect Bamboo to Bitbucket Cloud involves adding an app password from the Bitbucket Cloud account and then adding this key under the Bamboo Shared Credentials menu, which allowed successful registration. \nHowever, as of September 6th, repository registration is failing for all IDs except for a specific ID's Shared Credentials. My account has admin privileges on both Bitbucket and Bamboo, but I am still unable to register repositories (this was previously working without any issues). \nThe currently applied plans are still functional, but there is a problem when trying to register additional repositories. \nHow can this be resolved?\n\n#### **Error Details** {#toc-hId-1052746062}\n\n2024-09-09 14:04:12,477 WARN \\[http-nio-8085-exec-280\\] \\[AuthorizationLoggerListener\\] Authorization failed: org.acegisecurity.AccessDeniedException: Access is denied; authenticated principal: org.acegisecurity.providers.anonymous.AnonymousAuthenticationToken@90556c3e: Username: anonymousUser; Password: \\[PROTECTED\\]; Authenticated: true; Details: org.acegisecurity.ui.WebAuthenticationDetails@1de6: RemoteIpAddress: 10.13.11.148; SessionId: null; Granted Authorities: ROLE_ANONYMOUS; secure object: com.atlassian.bamboo.webwork.StarterAction@2acba534; configuration attributes: \\[WW_READ, GLOBAL_READ\\]\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello [???SA](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5152256),\n\nWelcome to Atlassian community.\n\n1. Can you provide a screen shot of the error which you are seeing ?\n\n2. Is there anything else in the logs apart from the Warning message when you try to save the repository.\n\nRegards,\n\nShashank Kumar\n",
"comments": [
{
"author": "???SA",
"body": "Hi [@Shashank Kumar](/t5/user/viewprofilepage/user-id/4693340) ,\n\n1. \n\n2. Here is some additional information. \n\n#### Error Details2024-09-11 11:09:31,999 WARN \\[http-nio-8085-exec-26\\] \\[RESTCall\\] Response from GET <https://api.bitbucket.org/2.0/workspaces/sreom/> (404)**2024-09-11 11:09:32,688 WARN \\[http-nio-8085-exec-26\\] \\[RESTCall\\] Response from GET <https://api.bitbucket.org/2.0/users/sreom/> (404)\n2024-09-11 11:09:33,378 WARN \\[http-nio-8085-exec-26\\] \\[RESTCall\\] Response from GET <https://api.bitbucket.org/2.0/teams/sreom/> (404)\n2024-09-11 11:09:33,636 WARN \\[http-nio-8085-exec-9\\] \\[AuthorizationLoggerListener\\] Authorization failed: org.acegisecurity.AccessDeniedException: Access is denied; authenticated principal: org.acegisecurity.providers.anonymous.AnonymousAuthenticationToken@90556c3e: Username: anonymousUser; Password: \\[PROTECTED\\]; Authenticated: true; Details: org.acegisecurity.ui.WebAuthenticationDetails@1de6: RemoteIpAddress: 10.13.11.148; SessionId: null; Granted Authorities: ROLE_ANONYMOUS; secure object: com.atlassian.bamboo.webwork.StarterAction@50dba756; configuration attributes: \\[WW_READ, GLOBAL_READ\\]** {#toc-hId-372751119}\n"
},
{
"author": "Shashank Kumar",
"body": "I think you are affected by this bug \\> [BAM-20988 Invalid username when attempting to save a Bitbucket Cloud repository when no workspace exists that matches username](https://jira.atlassian.com/browse/BAM-20988)\n\nEither you'll need to upgrade Bamboo or refer the workaround.\n\nRegards,\n\nShashank Kumar\n\n**\\*please don't forget to Accept the answer if your query was answered\\*\\***\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Issue-with-Bamboo-and-Bitbucket-Cloud-Repository-Registration/qaq-p/2806347 | [
"bitbucket-cloud"
] |
{
"author": "Mark Wolff",
"title": "Changing the default branch on the initial plan page",
"body": "On the initial page for a plan it says \"master\" as the branch and has a pull-down to choose a different branch.\n\nWe are never going to use master again. How do we get some other branch to be shown as the default. People are getting confused because they follow a link from another use and that link sends them to the default branch. So now the two users aren't looking at the same thing. (Canned laughter from the 80s sitcom here.) I can't be the only person struggling with this.\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Mark,\n\nWelcome to Atlassian community.\n\nWell you are not the only one having this problem :), this question has been asked previously in the community.\n\nCan you check this link <https://community.atlassian.com/t5/Bamboo-questions/Is-there-a-way-to-set-the-default-branch-in-Bamboo-that-is-NOT/qaq-p/1074965> and see if this helps you answer your query.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Changing-the-default-branch-on-the-initial-plan-page/qaq-p/2796085 | [
"bamboo-server",
"server"
] |
{
"author": "Rilwan Ahmed",
"title": "Bamboo upgrade steps",
"body": "We are using **Bamboo** data center 7.2.1 in **windows** server. As per the [upgrade path](https://confluence.atlassian.com/bamboo/bamboo-upgrade-guide-720411366.html#Bambooupgradeguide-Determinethecorrectupgradepath) , to upgrade to version 9.6.5, We need to follow the path 7.2.1 ? 8.0.12 ? 9.6.5. As I am new to Bamboo, can someone let me know full process to upgrade this.\n\n**Please note:**\n\n1. We are using database **Microsoft SQL server 2016** (version 13.00.7024) and **Java version 1.8.0_191**\n2. I have the upgrade steps link <https://confluence.atlassian.com/bamboo0906/bamboo-upgrade-guide-1376027576.html> . So wanted to know if there are any steps or instructions I need to follow during upgrade other than in the link mentioned\n"
} | [
{
"author": "Anik Sengupta",
"body": "Adding to what [@Charlie Misonne](/t5/user/viewprofilepage/user-id/502263) mentioned please check for the supported platforms as an when you plan to upgrade to the required Bamboo version. Below are the links for Bamboo 7, Bamboo 8.0.12 and Bamboo 9.6\n\n<https://confluence.atlassian.com/bamboo0700/supported-platforms-1014681701.html>\n\n<https://confluence.atlassian.com/bamboo0800/supported-platforms-1077778398.html>\n\n<https://confluence.atlassian.com/bamboo0906/supported-platforms-1376027552.html>\n",
"comments": null
},
{
"author": "Charlie Misonne",
"body": "Hi [@Rilwan Ahmed](/t5/user/viewprofilepage/user-id/716861) and welcome to the Atlassian Community!\n\nYes you can follow those steps. You basically need to perform it twice. Once for the intermediate version and then for your final target version.\n\nOf course there can be things to consider specifically for your environment. \nTherefore I strongly recommend performing this upgrade on a test environment first.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Bamboo-upgrade-steps/qaq-p/2791558 | [
"data-center",
"upgrade"
] |
{
"author": "Ruben Calderon",
"title": "unable to download artifact shared artifact: [build variables], pattern:[**/build variables.txt]",
"body": "Hello, I have this error on my bamboo 6.3.2 since May of this year:\n\n\"unable to download artifact shared artifact: \\[build variables\\], pattern:\\[\\*\\*/build variables.txt\\]\"\n\nAnd the only solution we have found is to do another build The error has now escalated to management to the point that they are evaluating removing bamboo.\n\nPlease, could you guide me in this case?\n\nBest Regards\n\nRub?n\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Ruben,\n\nWelcome to Atlassian community.\n\nCan you give me some clarity on your plan structure, Where are the artifacts generated and how are you downloading them.\n\nI believe as this is urgent for you, you can probably raise a support ticket with Atlassian Support if you have a valid SEN and they'll be able to assist you better.\n\nRegards,\n\nShashank Kumar\n",
"comments": null
},
{
"author": "Ruben Calderon",
"body": "2024-08-15 15:27:53,366 WARN \\[http-nio-8085-exec-19\\] \\[AuthorizationLoggerListener\\] Authorization failed: org.acegisecurity.AccessDeniedException: Access is denied; authenticated principal: org.acegisecurity.providers.anonymous.AnonymousAuthenticationToken@6faab5ec: Username: anonymousUser; Password: \\[PROTECTED\\]; Authenticated: true; Details: org.acegisecurity.ui.WebAuthenticationDetails@ffffc434: RemoteIpAddress: 10.255.0.2; SessionId: null; Granted Authorities: ROLE_ANONYMOUS; secure object: FilterInvocation: URL: /plugins/servlet/streams?use-accept-lang=true\\&streams=user+IS+CONT-LValdes\\&authOnly=true\\&local=true\\&maxResults=10; configuration attributes: \\[GLOBAL_READ\\]\n",
"comments": [
{
"author": "Shashank Kumar",
"body": "This warning is not related to the Artifact download error!\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/unable-to-download-artifact-shared-artifact-build-variables/qaq-p/2789432 | null |
{
"author": "jasna stefanovic",
"title": "integrate bamboo with jira cloud",
"body": "Is anyone using bamboo with the cloud version of jira? How easy or hard is it to manage?\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Jasna,\n\nWelcome to Atlassian community.\n\nSince Bamboo 9.3 Bamboo can be connected to Jira cloud via application tunnels, which removes all the complexities of initial setup, You can probably have a look at this and in my opinion these are very easy to connect to each other.\n\nRegards,\n\nShashank Kumar\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/integrate-bamboo-with-jira-cloud/qaq-p/2785028 | [
"atlassian-cloud"
] |
{
"author": "Margie Mounce",
"title": "Digicert USB token integration with Bamboo",
"body": "Hello,\n\nWe need to sign our executables using a physical **Digicert USB token** for the certificate. If I initiate the signing script manually, the code signs properly; however, if the same script is initiated from Bamboo, the signing fails with the following error:\n\n**SignTool Error: No certificates were found that met all the given criteria.**\n\nNote that the EKU and expiry filters found **1** cert; however, when the Private Key filter was applied, **0** certs were left.\n\n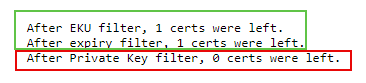\n\nIt seems that the automated Bamboo is seeing the *public* certificate, but doesn't have access to the *private* certificate (which is only available after the token is unlocked). If the token is not unlocked, the Digicert Authentication Client should be triggering a login dialog, which never happens. When running the script manually, the login dialog will appear.\n"
} | [
{
"author": "Sergey Podobry _Stellarity Software_",
"body": "It's tricky as Bamboo is running in a non-interactive session 0 and under another user than yours. I'm not sure that a USB token supports such scenario. Nowadays certificate vendors provide code signing in the cloud that works well with CI/CD. You can take a look into that direction.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Digicert-USB-token-integration-with-Bamboo/qaq-p/2782417 | null |
{
"author": "Nikola_Toshkov",
"title": "bamboo server huge temporary directory",
"body": "Hi can someone explain why is the\n\nTemporary directory C:\\\\Atlassian-bamboo\\\\Bamboo\\\\temp grown to about 180GB ?\n\nAnd how safe is it to delete it completely currently finding mixed opinion on the case...\n"
} | [
{
"author": "Eduardo Alvarenga",
"body": "Hello [@Nikola_Toshkov](/t5/user/viewprofilepage/user-id/5562019)\n\nWelcome to **Atlassian Community**!\n\nLarge temporary directories are a symptom of builds running in local agents, which may be using the temporary folder to store data that is not being removed after builds are finished.\n\nIt is usually safe to stop the application and clean up that folder, but be mindful that your builds may require content that is present in that location and force that to be recreated, which may impose a slowdown on your pipelines.\n\nCheers,\n\nEduardo Alvarenga \nAtlassian Support APAC\n\n**--please don't forget to Accept the answer if the reply is helpful--**\n",
"comments": [
{
"author": "Nikola_Toshkov",
"body": "Honestly very green at this, is there something i can ask the developers to add to their plans to clean up after their builds, or something i can change in the bamboo configuration ?\n"
}
]
},
{
"author": "Shashank Kumar",
"body": "Hello Nikola,\n\nWelcome to Atlassian Community.\n\nBamboo places some temporary files in this location for example during the source code checkout task it will create a temporary .bat or .sh file and it would be removed post the task completion.\n\nIdeally this location should not contain files amounting to 180 GB, in my opinion you can cleanup this directory, but make sure you have stopped your Bamboo Instance while you are doing it.\n\nBTW have you looked at the content of these files and when were these created/modified?\n\nThere was a feature request raised to clean this up automatically but it was never implemented, <https://jira.atlassian.com/browse/BAM-8521>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "Nikola_Toshkov",
"body": "Hi yes most of them are \\~18mb, folders named \"binary-number\" -\\> binary with a folder plugins with few .jar from pluings xray and jira and allure reports?\n\nAllure Report {#toc-hId--349710130}\n-----------------------------------\n\nConfigure Allure Reporting {#toc-hId-2137802703}\n------------------------------------------------\n\nin the config all are checked\\[\\\\/\\] \nDownload if no executable present \nEnable report custom logo \nBuild Allure for all builds by default\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Nikola,\n\nThis is coming from the External plugin Installed in your Bamboo Instance, [https://marketplace.atlassian.com/apps/1217177/allure-report-for-bamboo?tab=overview\\&hosting=datacenter](https://marketplace.atlassian.com/apps/1217177/allure-report-for-bamboo?tab=overview&hosting=datacenter).\n\nProbably you'll need to check the settings for this plugin and check why the files are being generate in /tmp location and can it be changed.\n\nRegards,\n\nShashank kumar\n"
},
{
"author": "Nikola_Toshkov",
"body": "A little digging turns out it has about 150k folders \\~17mb containing plugins .jar not just allure, still looking around at the settings what is causing it :\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/bamboo-server-huge-temporary-directory/qaq-p/2783013 | null |
{
"author": "wangwei",
"title": "bamboo installation fails with \" Cannot invoke \"com.atlassian.bamboo.plugin.OsgiServiceProxyFactory\"",
"body": "Bamboo installation fails after going through the **Configure database**step\n\nversion: **9.5.4** on windows 10\n\ndatabaseurl is\n\njdbc:mysql://222.92.152.106:3305/bamboo?useUnicode=true\\&characterEncoding=utf8\\&autoReconnect=true\n\nI'm sure database config is right.\n\n```\n?\n```\n\nio.atlassian.util.concurrent.LazyReference$InitializationException: java.lang.NullPointerException: Cannot invoke \"com.atlassian.bamboo.plugin.OsgiServiceProxyFactory.createNonIsolatingProxy(java.lang.Class, long)\" because \"this.this$0.osgiServiceProxyFactory\" is null at io.atlassian.util.concurrent.LazyReference.getInterruptibly(LazyReference.java:156) at io.atlassian.util.concurrent.LazyReference.get(LazyReference.java:116) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.renderNoCache(BambooFreemarkerManagerSoyHelpers.java:98) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.render(BambooFreemarkerManagerSoyHelpers.java:88) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.render(BambooFreemarkerManagerSoyHelpers.java:80) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:568) at freemarker.ext.beans.BeansWrapper.invokeMethod(BeansWrapper.java:1553) at freemarker.ext.beans.ReflectionCallableMemberDescriptor.invokeMethod(ReflectionCallableMemberDescriptor.java:56) at freemarker.ext.beans.MemberAndArguments.invokeMethod(MemberAndArguments.java:51) at freemarker.ext.beans.OverloadedMethodsModel.exec(OverloadedMethodsModel.java:64) at freemarker.core.MethodCall._eval(MethodCall.java:75) at freemarker.core.Expression.eval(Expression.java:101) at freemarker.core.DollarVariable.calculateInterpolatedStringOrMarkup(DollarVariable.java:100) at freemarker.core.DollarVariable.accept(DollarVariable.java:63) at freemarker.core.Environment.visit(Environment.java:347) at freemarker.core.Environment.visit(Environment.java:353) at freemarker.core.Environment.process(Environment.java:326) at freemarker.template.Template.process(Template.java:383) at com.atlassian.bamboo.ww2.FreemarkerRequestDispatcherPageFilter.applyDecorator(FreemarkerRequestDispatcherPageFilter.java:123) at org.apache.struts2.sitemesh.TemplatePageFilter.applyDecorator(TemplatePageFilter.java:116) at com.atlassian.bamboo.ww2.FreemarkerRequestDispatcherPageFilter.access$000(FreemarkerRequestDispatcherPageFilter.java:46) at com.atlassian.bamboo.ww2.FreemarkerRequestDispatcherPageFilter$BambooSitemeshDecorator.render(FreemarkerRequestDispatcherPageFilter.java:245) at com.opensymphony.sitemesh.webapp.decorator.BaseWebAppDecorator.render(BaseWebAppDecorator.java:33) at com.opensymphony.sitemesh.webapp.SiteMeshFilter.doFilter(SiteMeshFilter.java:92) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.SessionCreationForAnonymousUserFilter.doFilter(SessionCreationForAnonymousUserFilter.java:40) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.NewRelicTransactionNamingFilter.doFilter(NewRelicTransactionNamingFilter.java:28) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.ww2.StrutsPrepareFilter$1.doFilter(StrutsPrepareFilter.java:72) at org.apache.struts2.dispatcher.filter.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:96) at com.atlassian.bamboo.ww2.StrutsPrepareFilter.handleRequest(StrutsPrepareFilter.java:46) at com.atlassian.bamboo.ww2.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:38) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.BambooProfilingFilter.doFilter(BambooProfilingFilter.java:73) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:50) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.AccessLogFilter.doFilter(AccessLogFilter.java:93) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.BambooAcegiProxyFilter.doFilter(BambooAcegiProxyFilter.java:17) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.johnson.filters.AbstractJohnsonFilter.doFilter(AbstractJohnsonFilter.java:59) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.seraph.filter.SecurityFilter.doFilter(SecurityFilter.java:88) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.seraph.filter.BaseLoginFilter.doFilter(BaseLoginFilter.java:148) at com.atlassian.seraph.filter.BambooLoginFilter.doFilter(BambooLoginFilter.java:36) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:50) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.persistence.BambooSessionInViewFilter.doFilterInternal(BambooSessionInViewFilter.java:29) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.BambooCompressingFilter.doFilter(BambooCompressingFilter.java:39) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.RequestCacheThreadLocalFilter.doFilter(RequestCacheThreadLocalFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.ClickjackingAndMimeTypeSniffingPreventionFilter.doFilter(ClickjackingAndMimeTypeSniffingPreventionFilter.java:36) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.CookieCacheControlFilter.doFilter(CookieCacheControlFilter.java:56) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.core.filters.HeaderSanitisingFilter.doFilter(HeaderSanitisingFilter.java:37) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:50) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.TrafficThroughPrimaryNodeOnlyFilter.doFilter(TrafficThroughPrimaryNodeOnlyFilter.java:62) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:168) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:90) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:481) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:130) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:93) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74) at org.apache.catalina.valves.StuckThreadDetectionValve.invoke(StuckThreadDetectionValve.java:185) at org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:670) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:346) at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:390) at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:63) at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:928) at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1786) at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:52) at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1191) at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:63) at java.base/java.lang.Thread.run(Thread.java:842) Caused by: java.lang.NullPointerException: Cannot invoke \"com.atlassian.bamboo.plugin.OsgiServiceProxyFactory.createNonIsolatingProxy(java.lang.Class, long)\" because \"this.this$0.osgiServiceProxyFactory\" is null at com.atlassian.bamboo.ww2.BambooFreemarkerManager$1.get(BambooFreemarkerManager.java:127) at com.atlassian.bamboo.ww2.BambooFreemarkerManager$1.get(BambooFreemarkerManager.java:124) at io.atlassian.util.concurrent.Lazy$Strong.create(Lazy.java:98) at io.atlassian.util.concurrent.LazyReference$Sync.run(LazyReference.java:332) at io.atlassian.util.concurrent.LazyReference.getInterruptibly(LazyReference.java:150) ... 115 more \n[Continuous integration](http://www.atlassian.com/software/bamboo/) powered by [Atlassian Bamboo](http://www.atlassian.com/software/bamboo/) version 9.5.4 build 90510 - io.atlassian.util.concurrent.LazyReference$InitializationException: java.lang.NullPointerException: Cannot invoke \"com.atlassian.bamboo.plugin.OsgiServiceProxyFactory.createNonIsolatingProxy(java.lang.Class, long)\" because \"this.this$0.osgiServiceProxyFactory\" is null at io.atlassian.util.concurrent.LazyReference.getInterruptibly(LazyReference.java:156) at io.atlassian.util.concurrent.LazyReference.get(LazyReference.java:116) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.renderNoCache(BambooFreemarkerManagerSoyHelpers.java:98) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.render(BambooFreemarkerManagerSoyHelpers.java:88) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.render(BambooFreemarkerManagerSoyHelpers.java:80) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:568) at freemarker.ext.beans.BeansWrapper.invokeMethod(BeansWrapper.java:1553) at freemarker.ext.beans.ReflectionCallableMemberDescriptor.invokeMethod(ReflectionCallableMemberDescriptor.java:56) at freemarker.ext.beans.MemberAndArguments.invokeMethod(MemberAndArguments.java:51) at freemarker.ext.beans.OverloadedMethodsModel.exec(OverloadedMethodsModel.java:64) at freemarker.core.MethodCall._eval(MethodCall.java:75) at freemarker.core.Expression.eval(Expression.java:101) at freemarker.core.DollarVariable.calculateInterpolatedStringOrMarkup(DollarVariable.java:100) at freemarker.core.DollarVariable.accept(DollarVariable.java:63) at freemarker.core.Environment.visit(Environment.java:347) at freemarker.core.Environment.visit(Environment.java:353) at freemarker.core.Environment.visit(Environment.java:389) at freemarker.core.Environment.invokeMacroOrFunctionCommonPart(Environment.java:889) at freemarker.core.Environment.invokeMacro(Environment.java:825) at freemarker.core.UnifiedCall.accept(UnifiedCall.java:87) at freemarker.core.Environment.visit(Environment.java:347) at freemarker.core.Environment.visit(Environment.java:353) at freemarker.core.Environment.visit(Environment.java:353) at freemarker.core.Environment.include(Environment.java:2955) at freemarker.core.Include.accept(Include.java:171) at freemarker.core.Environment.visit(Environment.java:347) at freemarker.core.Environment.visit(Environment.java:353) at freemarker.core.Environment.process(Environment.java:326) at freemarker.template.Template.process(Template.java:383) at com.atlassian.bamboo.ww2.FreemarkerRequestDispatcherPageFilter.applyDecorator(FreemarkerRequestDispatcherPageFilter.java:123) at org.apache.struts2.sitemesh.TemplatePageFilter.applyDecorator(TemplatePageFilter.java:116) at com.atlassian.bamboo.ww2.FreemarkerRequestDispatcherPageFilter.access$000(FreemarkerRequestDispatcherPageFilter.java:46) at com.atlassian.bamboo.ww2.FreemarkerRequestDispatcherPageFilter$BambooSitemeshDecorator.render(FreemarkerRequestDispatcherPageFilter.java:245) at com.opensymphony.sitemesh.webapp.decorator.BaseWebAppDecorator.render(BaseWebAppDecorator.java:33) at com.opensymphony.sitemesh.webapp.SiteMeshFilter.doFilter(SiteMeshFilter.java:92) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.SessionCreationForAnonymousUserFilter.doFilter(SessionCreationForAnonymousUserFilter.java:40) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.NewRelicTransactionNamingFilter.doFilter(NewRelicTransactionNamingFilter.java:28) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.ww2.StrutsPrepareFilter$1.doFilter(StrutsPrepareFilter.java:72) at org.apache.struts2.dispatcher.filter.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:96) at com.atlassian.bamboo.ww2.StrutsPrepareFilter.handleRequest(StrutsPrepareFilter.java:46) at com.atlassian.bamboo.ww2.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:38) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.BambooProfilingFilter.doFilter(BambooProfilingFilter.java:73) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:50) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.AccessLogFilter.doFilter(AccessLogFilter.java:93) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.BambooAcegiProxyFilter.doFilter(BambooAcegiProxyFilter.java:17) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.johnson.filters.AbstractJohnsonFilter.doFilter(AbstractJohnsonFilter.java:59) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.seraph.filter.SecurityFilter.doFilter(SecurityFilter.java:88) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.seraph.filter.BaseLoginFilter.doFilter(BaseLoginFilter.java:148) at com.atlassian.seraph.filter.BambooLoginFilter.doFilter(BambooLoginFilter.java:36) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:50) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.persistence.BambooSessionInViewFilter.doFilterInternal(BambooSessionInViewFilter.java:29) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.BambooCompressingFilter.doFilter(BambooCompressingFilter.java:39) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.RequestCacheThreadLocalFilter.doFilter(RequestCacheThreadLocalFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.ClickjackingAndMimeTypeSniffingPreventionFilter.doFilter(ClickjackingAndMimeTypeSniffingPreventionFilter.java:36) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.CookieCacheControlFilter.doFilter(CookieCacheControlFilter.java:56) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.core.filters.HeaderSanitisingFilter.doFilter(HeaderSanitisingFilter.java:37) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:50) at com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:44) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at com.atlassian.bamboo.filter.TrafficThroughPrimaryNodeOnlyFilter.doFilter(TrafficThroughPrimaryNodeOnlyFilter.java:62) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:179) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:154) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:168) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:90) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:481) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:130) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:93) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74) at org.apache.catalina.valves.StuckThreadDetectionValve.invoke(StuckThreadDetectionValve.java:185) at org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:670) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:346) at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:390) at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:63) at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:928) at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1786) at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:52) at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1191) at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:63) at java.base/java.lang.Thread.run(Thread.java:842) Caused by: java.lang.NullPointerException: Cannot invoke \"com.atlassian.bamboo.plugin.OsgiServiceProxyFactory.createNonIsolatingProxy(java.lang.Class, long)\" because \"this.this$0.osgiServiceProxyFactory\" is null at com.atlassian.bamboo.ww2.BambooFreemarkerManager$1.get(BambooFreemarkerManager.java:127) at com.atlassian.bamboo.ww2.BambooFreemarkerManager$1.get(BambooFreemarkerManager.java:124) at io.atlassian.util.concurrent.Lazy$Strong.create(Lazy.java:98) at io.atlassian.util.concurrent.LazyReference$Sync.run(LazyReference.java:332) at io.atlassian.util.concurrent.LazyReference.getInterruptibly(LazyReference.java:150) at io.atlassian.util.concurrent.LazyReference.get(LazyReference.java:116) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.renderNoCache(BambooFreemarkerManagerSoyHelpers.java:98) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.render(BambooFreemarkerManagerSoyHelpers.java:88) at com.atlassian.bamboo.ww2.BambooFreemarkerManagerSoyHelpers$SoyHelper.render(BambooFreemarkerManagerSoyHelpers.java:80) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:568) at freemarker.ext.beans.BeansWrapper.invokeMethod(BeansWrapper.java:1553) at freemarker.ext.beans.ReflectionCallableMemberDescriptor.invokeMethod(ReflectionCallableMemberDescriptor.java:56) at freemarker.ext.beans.MemberAndArguments.invokeMethod(MemberAndArguments.java:51) at freemarker.ext.beans.OverloadedMethodsModel.exec(OverloadedMethodsModel.java:64) at freemarker.core.MethodCall._eval(MethodCall.java:75) at freemarker.core.Expression.eval(Expression.java:101) at freemarker.core.DollarVariable.calculateInterpolatedStringOrMarkup(DollarVariable.java:100) at freemarker.core.DollarVariable.accept(DollarVariable.java:63) ... 99 more\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello [wangwei](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5564416)\n\nWelcome to Atlassian community.\n\nCan you recheck the user which is running Bamboo has full read/write access on the Bamboo server, once you provide the read/write access, start everything from scratch and see if it works.\n\nRead more about it at <https://confluence.atlassian.com/bamkb/errors-in-the-database-setup-screen-during-the-bamboo-wizard's-setup-1114817309.html>\n\nRegards,\n\nShashaNK kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/bamboo-installation-fails-with-quot-Cannot-invoke-quot-com/qaq-p/2780243 | [
"osgi"
] |
{
"author": "yogev ch",
"title": "How to share pulled source code with several remote agent",
"body": "Hi, \nIn an older Bamboo version there was a local agent which was able to run several \"workers\" at the same time. \nThese workers shared resources, one of them is the storage. \nSo, if I had a \"check out\" stage in the beginning of a plan that pulled source code from git, any local agent worker was able to run the following stages and use the same source code.\n\nI have a \"heavy\" source code checkout which takes a lot of time. For that reason I wanted to run it once in the beginning in the 1'st stage.\n\nIn today's Bamboo version there aren't local agents anymore.\n\nI can still run a remote agent on the local bamboo device, for example, but that's one \"worker\" only.\n\nIf I start another remote agent, even if it's on the same device as the 1'st one, the don't share the pulled source code because each has a different \\`bamboo home\\`.\n\nAlso, I don't know which remote agent will run each stage. \nSo, for my plan which has several stages, a solution might be to add a \"check out\" job for each for the stages, which is quite cumbersome.\n\nPlease advise with a solution to this issue, \nThank you\n\nPlan example:\n\n```\nStage: checkout\n\n? Job: checkout\n\nStage: tests\n\n? Job: build1 + test1\n\n? Job: build2 + test2\n```\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello [yogev ch](https://community.atlassian.com/t5/user/viewprofilepage/user-id/4213474),\n\nWelcome to Atlassian community.\n\nYou can read [Why it is not advisable to share a common build working directory for Bamboo Remote agents](https://confluence.atlassian.com/bamkb/why-it-is-not-advisable-to-share-a-common-build-working-directory-for-bamboo-remote-agents-1387866726.html) to understand why remote agents don't share common working directories.\n\nAccording to Bamboo architecture Stage runs sequentially which means Stage 2 will only be called when Stage 1 is completed. if your case Stage tests will be run only when Stage checkout is completed.\n\nI can understand the problem here let's say Job : checkout was run by remote agent 1 but Job : build + test 1 can be run by remote agent 2 and Job : build2 + test 2 can be run by remote agent 3 and they will fails as they won't have access to checkout which contains the test files.\n\nIf all your Jobs are dependent upon each other then probably the better idea is to move everything under one stage and One Job which will be executed by the agent at one go, the final state would look like\n\n```\nStage: checkout + test\n\n? Job: \n\n Task checkout\n\n Task build1 + test1\n\n? Task build2 + test2\n```\n\nThis is one way to achieve what you are looking for.\n\nRegards,\n\nShashank kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "yogev ch",
"body": "Thank you for your reply.\n\nI tried to simplify my plan. \nMy actual plan has a lot of stages.\n\n```\n- Stage checkout\n - Job checkout\n - Task checkout\n - Task some commands and scripts\n- Stage tests\n - Job test1\n - Task build1\n - Task test1\n - Task test2\n - ...\n - Job test2\n - Task build2\n - Task test2_1\n - ...\nStage Build product 1\n - Job product 1\n - Task build\nStage Build product 2\n - Job product 2\n - Task build\n...\n```\n\nAs you can see, trying to move the task checkout will cause this plan to look worse :/\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Yogev,\n\nTo confirm your approach on the local agents, to understand the approach properly.\n\n1. In the first stage you were checking out the code into during the Job run into the build working directory of that particular Job or you used a shared build working directory which was accesible for other agents as well ?\n\n2. With the remote agents as I had earlier explained you can't have shared build working directory for multiple agents. Probably you can use dedicated agents for this particular plan so that the same agent runs all the Jobs from checkout until test and can access the source code checkout from the other Job.\n\n3. Have you enabled the caching on the linked repository and see if it makes any difference during the checkout tasks.\n\n4. Logically on remote agents if anyone of your tasks are depended upon the the output of another task, both of them should be part of the same Job.\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "yogev ch",
"body": "Hi,\n\n1. I am using the regular check out task. I'm pulling the code into the job's directory.\n\nNow, because these are 2 workers of the local agent, and they share the file system, on the next job I could use the directory where I pulled the code to.\n\nThat is quite a hack we can't use anymore.\n\n2. Right. That's my problem. I can't run 2 jobs of the same stage in parallel and I have to have a dedicated agent.\n\n3. I didn't. We want each time to pull everything from scratch to make sure it's a clean build. Also, even if I enable caching, and the next step is pull in each job, it means I'll have the git repo multiplied by the number of jobs I have, right? My repos are quite big so I don't really like that.\n\n4. Mm ok. By that you mean that I need to checkout each job, right? That returns me to the issue that our code takes a lot of time to pull, and it's big.\n\nLong time to pull \\> you day use cache \\> I say it's big and multiplied by the number of jobs that have a checkout task.\n\nThank you\n"
},
{
"author": "Shashank Kumar",
"body": "Hi Yogev,\n\nWith the current Design of the remote agent and your requirement of just checking out the code once , the best possible solution I can think of is that you'll have to move all your Jobs and tasks under one stage.\n\nI would let anyone else in the community opine if they have any alternate solution.\n\nRegards,\n\nShashank Kumar\n"
}
]
},
{
"author": "yogev ch",
"body": ".\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-share-pulled-source-code-with-several-remote-agent/qaq-p/2771256 | [
"agent",
"git",
"remote-agent",
"share",
"stage"
] |
{
"author": "Paul Moors",
"title": "Error occurred while running Task 'Checkout Default Repository(1)",
"body": "Anyone seen this before? \n\n```\nCaused by: com.atlassian.bamboo.plugins.git.GitCommandException: command ['C:\\Program Files\\Git\\cmd\\git.exe' submodule update --init --recursive] failed with code 128. Working directory was [D:\\Bamboo\\Build\\AAAA-V70-BP]., stderr:Warning: Permanently added '[127.0.0.1]:50231' (RSA) to the list of known [email protected]: Permission denied (password).fatal: Could not read from remote repository.Please make sure you have the correct access rightsand the repository exists.Unable to fetch in submodule path 'XXX'; trying to directly fetch 120a9635f4051b1d00f02de3048f0b77dde6e4f8:Warning: Permanently added '[127.0.0.1]:50231' (RSA) to the list of known [email protected]: Permission denied (password).fatal: Could not read from remote repository.\n```\n\nNote: these are plans with submodules! \n\nWe see these kind of errors on multiple agents at irregular intervals and with multiple buildplans. \n\nSo for a single buildplan, the builds are successful and others fail due to the failure mentioned above.\n"
} | [
{
"author": "Eduardo Alvarenga",
"body": "Hello [@Paul Moors](/t5/user/viewprofilepage/user-id/5516798)\n\nWelcome to the **Atlassian Community**!\n\nThe error relates to the SSH connection to the Git repository. As Bamboo uses a local SSH-PROXY, it will first connect to 127.0.0.1 at a random port, and then a Java thread will connect to the final Git Server.\n\nIn your case, it appears you have some SSH configuration that may be interfering with the connection. Please check your **$HOME/.ssh/config** and validate that no special configurations are causing the issue.\n\nIt's possible that the Git repository designated as a submodule doesn't have the credentials that Bamboo uses to connect to the main repository, as explained [here](https://confluence.atlassian.com/bambooreleases/bamboo-8-1-release-notes-1189793877.html#id=Bamboo8.1releasenotes-sshTheprimaryrepository%E2%80%99sSSHkeyisnowsharedwithsubmodules). To address this, you should check your default Repository Settings in Bamboo, navigate to Advanced Options, and then copy and add the provided SSH public key to the Repository configuration used as a submodule. If you're using a version of Bamboo earlier than 8.1.1, you can find an alternative setup in this KB.\n\n* [Checkout of Git repository with submodules failed in Bamboo](https://confluence.atlassian.com/bamkb/checkout-of-git-repository-with-submodules-failed-in-bamboo-586056672.html).\n\nKind regards,\n\nEduardo Alvarenga \nAtlassian Support APAC\n\n**--please don't forget to Accept the answer if the reply is helpful--**\n",
"comments": [
{
"author": "Paul Moors",
"body": "Hi Eduardo, \n\nThank you for your reply. \n\nI will do all the checks you mentioned to verify if the configuration is not interfering with the connection. \n\nStill I'm a bit confused at this moment: when I enable 'Force Clean Build' option with the 'Source Code Checkout' task, the problem seems solved. \nCan you explain that?\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Error-occurred-while-running-Task-Checkout-Default-Repository-1/qaq-p/2770243 | null |
{
"author": "Devops",
"title": "Want to change the Product Admins and Owners for DepotFinity status page",
"body": "Hi Team,\n\nWe want to update the users in Depotfinity Status page as few users have moved out of the project.\n\n<https://manage.statuspage.io/organizations/4ghctcqf74zd/team>\n\nPlease replace [email protected] and [email protected] with\n\[email protected] and [email protected] \n\nAlso advise on the process of adding more users(atleast 10) when opting for licensed version.\n"
} | [
{
"author": "Dave Mathijs",
"body": "Hi [@Devops](/t5/user/viewprofilepage/user-id/4654524) welcome to the Atlassian Community!\n\nFirst of all, community members don't have access to your Statuspage settings.\n\nAs I don't completely understand your question, this documentation article (and its child pages) might help you:\n\n[Manage user accounts and authentication](https://support.atlassian.com/statuspage/docs/manage-user-accounts-and-single-sign/)\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Want-to-change-the-Product-Admins-and-Owners-for-DepotFinity/qaq-p/2822449 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "First Last",
"title": "integration Third Party Components",
"body": "We are integration Third Party Components, wanted to get more documentation on existing components specifically for APIGEEX \nCurrent components under APIGEE seems to be for EDGE \nwe use APIGEEX from GCP \nBelow are the components we are interested to add for third party\n\n* Virtual Private Cloud (VPC)\n* Apigee\n* Google Compute Engine\n* Cloud Load Balancing\n* google compute engine\n* Google Cloud Networking\n\nIf we have to add them to our status page, do we need to reach out to vendor page owners to get it added? How else can we get this done? \nI am the owner of the status page and I don't see any option to add new components into existing page. \n"
} | [
{
"author": "Jesse Klein",
"body": "Hello there,\n\nThanks for reaching out about adding some of these third party components. We do have a few of the Google third party components including the Compute Engine and Cloud Networking. That would be under the Google Cloud Platform for third party components.\n\nFor the other things, it would likely be required to reach out to Apigee to see if they are able to add these to their Statuspage as they manage their own page and components.\n\nFor the Google Cloud Platform, we are a little more limited as Google doesn't have a Statuspage page. We actually take some of their information and manage it internally. We actually have an internal feature request within our private Jira. It's currently gathering interest so I'll add this community post to it to show that there is more interest.\n\nBesides the feature request, you may also be able to pull in data using the API. I would look at the <https://status.cloud.google.com/index.html> page and take a look at their JSON to see if it's something you can pull into Statuspage using the API.\n\nHopefully, this gets you pointed to the right resources.\n\nRegards, \nJesse\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/integration-Third-Party-Components/qaq-p/2819442 | null |
{
"author": "Mandy Martell",
"title": "Why am I getting this error?",
"body": "Something went wrong {#toc-hId--327365081}\n------------------------------------------\n\nTry reloading the page, then check our [Statuspage](https://status.atlassian.com/) for any current outages. If there are no relevant outages, create a [support request](https://support.atlassian.com/contact/) so we can help you out.\n\nIf you create a request, include the following so we can help you as fast as possible:\n\n* Error type: **429 - Too many requests**\n* Log reference: **61397d1e-e310-4f63-9228-f4d26ce20e42**\n"
} | [
{
"author": "Dave Mathijs",
"body": "Hi [@Mandy Martell](/t5/user/viewprofilepage/user-id/5599345) welcome to the Atlassian Community!\n\nI'm afraid I cannot add anymore information than what is listed in the error message, besides some basic troubleshooting:\n\n* Has it ever worked before?\n* If yes, since when do you have the issue?\n* When trying to reproduce the issue, what steps are you taking on which site before you get this error message?\n* Do you have the same issue with other browsers?\n* Do other users have the same issue?\n* Have you created a support request?\n",
"comments": null
},
{
"author": "Nikola Perisic",
"body": "Welcome to the community [@Mandy Martell](/t5/user/viewprofilepage/user-id/5599345)\n\nThis code usually resembles the API limit that is being used. You can find more information here: <https://developer.atlassian.com/cloud/jira/platform/rate-limiting/>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Why-am-I-getting-this-error/qaq-p/2819203 | null |
{
"author": "Chris Brownbridge",
"title": "Components Set to Major Outage During Scheduled Maintenance",
"body": "So our upstream provider has maintenance every Saturday during a set period. \nThis causes many of our components to have a partial outage which is expected.\n\nI've set up a lambda/scheduler to call the status page API every Monday and create an \"incident\" (scheduled maintenance) for the following Saturday. The reason for this is that the UI has no option for \"reoccurring\" scheduled maintenance (why not?)\n\nI mark the components which are affected by this weekly maintenance.\n\nThe annoying part is, the components affected always appear as having a \"Major Outage\" during the maintenance period...even though it understands this is part of a scheduled maintenance.\n\nMy question is - when components undergo an expected scheduled maintenance, can we set them, **in advance, via API** to have the status of something other than \"Major Outage\" **during the maintenance period**?\n"
} | [
{
"author": "Howard Nedd",
"body": "Hi [@Chris Brownbridge](/t5/user/viewprofilepage/user-id/5596046) ,\n\nIn Atlassian Statuspage, there isn't a built-in feature to set components to a status other than \"Major Outage\" during scheduled maintenance periods. However, you may be able to work around this limitation by leveraging the Incident API and Incident Updates API to manually update the status of the affected components during the maintenance period.\n\nHere's an approach you could consider:\n\n1. Create a scheduled maintenance incident using the Incident API for the upcoming maintenance period. \n2. Update the status of the affected components to a custom status (e.g., \"Scheduled Maintenance\") using the Incident Updates API at the start of the maintenance period. \n3. Update the status of the affected components back to their normal status (e.g., \"Operational\") once the maintenance period is over.\n\nThat is how I work with Statuspage in these cases.\n\nHope that helps.\n\nRegards,\n\nHoward\n",
"comments": [
{
"author": "Chris Brownbridge",
"body": "Thank you very much [@Howard Nedd](/t5/user/viewprofilepage/user-id/4566707) for confirming that.\n\nThe swift response is very much appreciated!\n\nI'll take the approach you have mentioned.\n"
}
]
},
{
"author": "Chris Brownbridge",
"body": "example:\n\n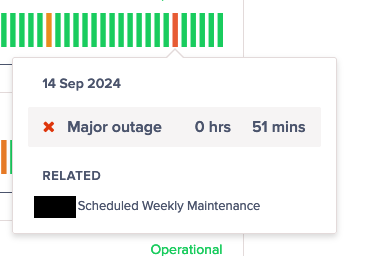\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Components-Set-to-Major-Outage-During-Scheduled-Maintenance/qaq-p/2815863 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Kenny Tran",
"title": "StatusPage - Editing uptime/downtime BULK update",
"body": "Hello, we have these red downtime ticks and so far we have to edit them one-by-one. Is there a way to BULK edit these instead of editing each tick one-by-one? \n\nLooking for a way to save some time editing these. \n\n\n"
} | [
{
"author": "Howard Nedd",
"body": "Hi [@Kenny Tran](/t5/user/viewprofilepage/user-id/5595955) ,\n\nAtlassian Statuspage does not currently have a built-in feature for bulk editing downtime.\n\nYou might need to create a script which interacts via API but you will have to ask yourself if it is worth the hassle.\n\nRegards\n\nHoward\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/StatusPage-Editing-uptime-downtime-BULK-update/qaq-p/2815703 | [
"downtime",
"uptime"
] |
{
"author": "Akash Ashok Kondekar",
"title": "Paid plans offer more Third-Party integration options for Status Page?",
"body": "We are currently utilizing the Free plan of Atlassian's Status Page and have explored the automation options available. While we see limited automation for third-party services that we want hence I am curious about the additional functionalities and integrations that might be available under the paid plans.\n\nI checked the pricing section as well, but I didn't find any information about it included in any of the plans hence Could anyone confirm/know if upgrading to a **paid plan would offer more third-party integration options ++(For example: Azure, MongoDB, etc)++, or if the list remains the same across all plans?**\n"
} | [
{
"author": "Tejaswi G",
"body": "Hi [@Akash Ashok Kondekar](/t5/user/viewprofilepage/user-id/3993249)\n\nThis is Tejaswi from the Atlassian Support Team and happy to help.\n\nWe don't have any other integrations with monitoring tools apart from the list [here](https://support.atlassian.com/statuspage/docs/what-are-system-metrics/) irrespective of the plan. You can use the [statuspage API](https://developer.statuspage.io/) and create a custom script to integrate with the statuspage.\n\nKind Regards, \nTejaswi\n",
"comments": [
{
"author": "Akash Ashok Kondekar",
"body": "Noted. Thank you!\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Paid-plans-offer-more-Third-Party-integration-options-for-Status/qaq-p/2815029 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "A C",
"title": "Post Mortem Summary",
"body": "When an incident is resolved, and a post mortem is published. Would it be shipped via emails or will it be posted on the Trust portal? And to whom would it be delivered to?\n"
} | [
{
"author": "Jesse Klein",
"body": "Hello there!\n\nThis is Jesse from the Statuspage support team. Welcome to the community! If you want to learn more about postmortems, I recommend checking out the following:\n\n<https://support.atlassian.com/statuspage/docs/create-a-postmortem/>\n\nYou can choose to send the postmortem to your subscribers by clicking the checkbox in the postmortem screen. It will also show in the incident itself. Hopefully, this helps you out!\n\nRegards, \nJesse\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Post-Mortem-Summary/qaq-p/2809400 | [
"cloud"
] |
{
"author": "Thor Kristian Sortevik",
"title": "Max amount of subscribers on multiple pages",
"body": "Hi, \n\nWe have 3 statuspages, 2 of then are on the business plan and 1 is on the hobby plan.\n\nPage1: Business plan, staus on our productin enviroments. This page will most likely pass 5000 subscribers.\n\nPage2: Business plan, a QA page to test our custom HTML, this page has 5 subscribers.\n\nPage 3: Hobby plan, stauspage for our test-enviroments.\n\nMy question is, if we exceed the 5000 subscriber limit, what will happen?\n\n<br />\n\nWe have almost 5000 \"available\" subscribers on page2, can these be transfered to page1?\n"
} | [
{
"author": "Howard Nedd",
"body": "Hi [@Thor Kristian Sortevik](/t5/user/viewprofilepage/user-id/4182967) ,\n\nWhen you exceed the 5,000 subscriber limit on a Statuspage that is on the Business plan, Atlassian typically handles this situation by preventing new subscribers from being added until you upgrade your plan to accommodate a higher number of subscribers.\n\nUnfortunately, Atlassian does not provide a way to transfer subscribers between different Statuspages directly. Each Statuspage operates independently, and its subscriber list is managed separately.\n\nPotential Solutions \n1. **Upgrade Your Plan**: The most straightforward solution is to upgrade Page1 to a plan that supports more subscribers. You can contact Atlassian sales or support for details on upgrading your plan to accommodate a higher number of subscribers.\n\n2. **Remove Inactive Subscribers**: If upgrading is not immediately feasible, you can manage your current subscriber list by removing inactive or less critical subscribers to make room for new ones. This can be done via the Statuspage dashboard.\n\nIf you're unsure about the best approach or need assistance with upgrading your plan, it's a good idea to reach out to Atlassian support. They can provide specific guidance based on your current usage and future needs.\n\n<https://support.atlassian.com/contact/>\n\nregards\n\nHoward\n",
"comments": [
{
"author": "Thor Kristian Sortevik",
"body": "Thank you Howard :)\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Max-amount-of-subscribers-on-multiple-pages/qaq-p/2809136 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Ben Sabine",
"title": "Maintenance has not posted",
"body": "I created a maintenance for next Tuesday. Upon confirming the details were correct I got a pop-up saying \"Success, Maintenance successfully created\", however, I do not see it as scheduled in our Admin area. \nWe already have a scheduled maintenance for Sunday evening, can we only have one scheduled at a time?\n\n\n"
} | [
{
"author": "Alan Violada",
"body": "Hey Ben, Alan from the Statuspage Support team here.\n\nYou can have multiple scheduled maintenances at the same time, and it should show up in your panel after creation.\n\nCan you please check if even after clearing browser cache/cookies it still does not show up? Also, does it show up in the user-facing page?\n\nIf the issue persists, please open a ticket at [Atlassian Support](https://support.atlassian.com/) so that we may get access to your instance and investigate.\n\nRegards,\n\nAlan\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Maintenance-has-not-posted/qaq-p/2809000 | [
"cloud"
] |
{
"author": "Robert Nichols",
"title": "Change the default end of maintenance text",
"body": "Is there a way to change the text used in the end of maintenance, without ending it manually. \n\nAt the moment if I let the maintenance window run the full time, then the end will update and send out the standard text\n\n***The scheduled maintenance has been completed.*** \n\nI can see a way that if I end the window earlier, I can use a template with some bespoke text, but can't see a way I can edit the default message if I'm not around and want the window to close naturally. \n"
} | [
{
"author": "Howard Nedd",
"body": "Hi [@Robert Nichols](/t5/user/viewprofilepage/user-id/5363551) ,\n\nAtlassian Statuspage does not offer a built-in feature to customize the automatic \"The scheduled maintenance has been completed\" message. However, there are a few workarounds you might consider:\n\n1. Scheduled Updates: You can pre-schedule an update with your custom message for the end of the maintenance window. This way, even if you're not around, the scheduled update will be posted at the designated time. Unfortunately, this won't prevent the standard message from being sent, but it ensures your custom message is also communicated.\n\n2. Automation with API: You could use the Statuspage API to automate the process. By creating a script that runs at the end of your maintenance window and posts a custom message, you could effectively bypass the need to manually end the window. This would require some technical setup and familiarity with the Statuspage API.\n\n3. Monitoring and Notification Tools: If you have monitoring tools in place, you could leverage them to trigger a custom notification or message at the end of the maintenance window. This again involves some setup and integration work but provides a more automated approach.\n\n4. Manual End with Templates: As you mentioned, manually ending the maintenance window allows you to use a template with bespoke text. If possible, you might schedule someone to manually close the window, ensuring the correct message is sent out.\n\nThose are the options that I am aware of.\n\nHope that helps.\n\nRegards\n\nHoward\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Change-the-default-end-of-maintenance-text/qaq-p/2807883 | [
"cloud",
"maintenance",
"statuspage-cloud"
] |
{
"author": "First Last",
"title": "We are integrating Third Party Components, wanted to get more documentation on existing components",
"body": "We are integration Third Party Components, wanted to get more documentation on existing components specifically for APIGEEX \nCurrent components under APIGEE seems to be for EDGE \nwe use APIGEEX from GCP \nBelow are the components we are interested to add for third party\n\n* Virtual Private Cloud (VPC)\n* Apigee\n* Google Compute Engine\n* Cloud Load Balancing\n* google compute engine\n* Google Cloud Networking\n\nAlso could you please provide more documentation on how do we know each of the component belongs to which third party provider \nhow do we add more third party components ? \nwhat will be the license for same?\n"
} | [
{
"author": "Egor",
"body": "Hi There, \nThanks for reaching out to Atlassian Community. \n\nPlease see the following article explaining how third-party components are working - <https://support.atlassian.com/statuspage/docs/add-a-third-party-component/> \n\nPlease note, in case you want to add a third-party component of the page that you do not own, then you need to contact the owners of the page and ask them to raise it with us to become a third-party component. \n\nI hope this helps.\n\nBest Regards, \nEgor\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/We-are-integrating-Third-Party-Components-wanted-to-get-more/qaq-p/2808851 | [
"cloud"
] |
{
"author": "Luca de Petris",
"title": "Email notifications with attributes",
"body": "Hello Atlassian community!\n\nI was trying to manage and customize email templates for the status page, to send something like:\n\n 5.01.04 p.m..png\")\\*\n\nIs there an easy way to send attributes or to get to a point of building something similar in an easy way?\n\n\\*The attributes highlighted in purple are internal.\n"
} | [
{
"author": "Agaci Avinas",
"body": "Hi Luca,\n\nI am Agaci from Statuspage support. This [document](https://support.atlassian.com/statuspage/docs/customize-email-notifications/) contains the currently available customizations to the email template. It'll allow you to add messages to the footer of the email.\n\nHaving said that, we have an active feature request for the requirement to make changes directly to the template, like adding variables. You can use the feature ID below for your reference.\n\nSTATUS-589\n\nCurrently, feature requests are not externally accessible for the Statuspage. However, you can refer to the feature ID to us to know the status. The feature request is in \"Gathering Interest\" status. It'll be executed based on the [feature policy here](https://confluence.atlassian.com/support/implementation-of-new-features-policy-201294576.html).\n\nRegards,\n\nAgaci\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Email-notifications-with-attributes/qaq-p/2807341 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Anna Siassios",
"title": "Can I bulk upload subscribers to a status page?",
"body": "As a incident manager I am looking at whether or not Confluence, status page is the right option for us. \n\nWe are currently looking to change systems from an internally managed notification system and would need to transfer those who have opted in to received notifications into our new status page. \n\nProblem: Can I upload bulk contacts to be subscribers of a status page?\n"
} | [
{
"author": "Howard Nedd",
"body": "Hi,\n\nYes, Atlassian's Statuspage allows for bulk uploading of contacts to be subscribers of your status page. This can be very useful when transitioning from an internally managed notification system. Here's a general outline of how you can do this:\n\n1. Prepare Your Contact List: \n- Ensure your contact list is in a CSV (Comma-Separated Values) file format. The CSV should include necessary fields like email addresses and names, depending on what information you want to import.\n\n2. Access Statuspage: \n- Log in to your Atlassian Statuspage account.\n\n3. Navigate to Subscribers: \n- Go to the \"Subscribers\" section in the Statuspage admin interface.\n\n4. Bulk Import: \n- Look for an option to import subscribers. This is usually found under the \"Manage Subscribers\" section. \n- Select the option to upload a CSV file. \n- Follow the instructions to upload your CSV file. You might need to map the columns in your CSV to the appropriate fields in Statuspage.\n\n5. Verify and Confirm: \n- After uploading, verify that the contacts have been correctly imported. \n- You may need to confirm the import or run a test notification to ensure everything is working as expected.\n\nHoping that this helps.\n\nRegards\n\nHoward\n",
"comments": [
{
"author": "Anna Siassios",
"body": "Thank you Howard.\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Can-I-bulk-upload-subscribers-to-a-status-page/qaq-p/2801297 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Altintas Murat",
"title": "Access to Statuspage without login",
"body": "Hello dear experts,\n\nI am looking for a Statuspage solution (SaaS), which should be accessible only from our intranet / network and without a login. That means it should also be accessible for employess who dont have an Atlassian account / subscription.\n\nIs this possible with the Atlassian Statuspage?\n\nKindly regards\n\nMurat\n"
} | [
{
"author": "Howard Nedd",
"body": "Hi Murat,\n\nAtlassian Statuspage does not have the capability to be accessible only from your intranet/network without a login but you can restrict access to your Statuspage by setting up IP allowlisting or using a VPN to ensure that only users within your network can access the page.\n\nRegards\n\nHoward\n",
"comments": [
{
"author": "Altintas Murat",
"body": "Hi Howard, thank you very much for the immediate feedback. I already thought about the IP Allowlisting but after feedback from our network team, unfortunately it will be not working for us.\n\nIs it possible to host the Atlassian status page on our AWS resources (under our AWS account)?\n"
},
{
"author": "Howard Nedd",
"body": "Hi [@Altintas Murat](/t5/user/viewprofilepage/user-id/5587548) ,\n\nAtlassian Statuspage is a fully managed Software-as-a-Service (SaaS) solution and does not provide an option to host it on your own infrastructure, including AWS. The service is designed to be hosted and managed entirely by Atlassian, which means you cannot directly deploy it on your AWS resources or under your AWS account.\n\nRegards\n\nHoward\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Access-to-Statuspage-without-login/qaq-p/2806787 | [
"cloud"
] |
{
"author": "SANDRA PARTRIDGE",
"title": "Status Page - Maintenance Notification Enhancement/hiccup",
"body": "Hi there, I have some Maintenance Notifications that I need to send out but I need an explanation on what the Scheduled Time affects, what date should be entered, and the HOURS/MINUTES Boxes. Shouldn't the SCHEDULED AUTOMATION tab/section be available before hitting SCHEDULE NOW? It only appears to me after I have sent the notification...seems like this should be entered/filled out before selecting SCHEDULE NOW.\n\nIs there someone who can reach out for a quick 5-minute Q\\&A?\n\nThank in advance\n"
} | [
{
"author": "Muhammad Zeeshan",
"body": "Hey [@SANDRA PARTRIDGE](/t5/user/viewprofilepage/user-id/5579040)\n\nThe Scheduled Maintenance allows you to schedule a maintenance period for your component(s) and that is what the date/time section entails. You define the date and time for when the maintenance period will start and for how long it will last and all of this is done before you hit the 'Schedule now' button as expected:\n\n\n\nIf that is not the case and you see a different UI where you are asked to enter the date and time after clicking 'Schedule Now' button please feel free to reach out to our Support Team via <https://support.atlassian.com/contact/> so we may assist you further on this.\n\nBR,\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Status-Page-Maintenance-Notification-Enhancement-hiccup/qaq-p/2797367 | [
"cloud",
"opsgenie",
"opsgenie-cloud"
] |
{
"author": "Tony Albus",
"title": "Templates for maintainance not working.",
"body": "Somehow when i create a scheduled maintanance i can not select my templates anymore, \nthey seems to be only available with incidents, this worked before. \ni did not create any template groups. \nDoes anyone have a solution or the same problem? \n\nKind regards \nTony\n"
} | [
{
"author": "Robert Nichols",
"body": "I found since a recent change you need a template group before you can use templates. I'm not sure why, but I just created a group, added the templates to the group. Then I could select both those in the group, and those not in the group. \n\nSeems strange, but has worked for me on several instances. \n",
"comments": [
{
"author": "Mark Preudhomme",
"body": "This worked for me. Thank you!\n"
},
{
"author": "Tony Albus",
"body": "Thanks!\n"
}
]
},
{
"author": "AnswerFirst Admin",
"body": "We are also having this exact same issue. Templates do not show up when scheduling a maintenance. This only started occurring this month.\n",
"comments": null
},
{
"author": "Tony Albus",
"body": "Thanks,\n\ni know how it works, i just can't select any template in maintanance while i can in Incidents,\n\nbut its okey its only a few times i year i need this.\n",
"comments": null
},
{
"author": "Rafael Meira",
"body": "Hey [@Tony Albus](/t5/user/viewprofilepage/user-id/5582134) \n\nIf you are following theses documentations and you are not able to accomplish what you need: \n\n<https://support.atlassian.com/statuspage/docs/create-an-incident-template/> \n\n<https://support.atlassian.com/statuspage/docs/incident-template-library/> \n\n<br />\n\nMy suggestion to you is for you to open a formal ticket with our support so we can better assist you: \n\n<https://support.atlassian.com/contact/>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Templates-for-maintainance-not-working/qaq-p/2800801 | [
"cloud",
"maintanance",
"template"
] |
{
"author": "Alex_flinchum",
"title": "Looking to Export Incidents",
"body": "Hey all I am hoping to find a way to export Incidents from our Statuspage from the past \\~2 years. Do I need to use an external software or is there a way to gather a CSV or PDF of this data somewhere? \n\nThank you in advance!\n"
} | [
{
"author": "Howard Nedd",
"body": "Hi [@Alex_flinchum](/t5/user/viewprofilepage/user-id/5577834) ,\n\nAs far as I know there currently isn't a way to export incidents in a csv format, but you can use the \"[Get a list of incidents](https://developer.statuspage.io/#operation/postPagesPageIdIncidents)\" API to fetch all incidents. The limit to fetch is 100, but you can use the page offset query parameter to query specific pages.\n\nHopefully that helps.\n",
"comments": [
{
"author": "Lynn Munro",
"body": "I want to do this too. I don't have the knowledge to use the API call. Is there no other way to extract data simply to Excel?\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Looking-to-Export-Incidents/qaq-p/2795839 | [
"analytics",
"cloud",
"export",
"pdf-export"
] |
{
"author": "Roydon Pereira",
"title": "Prometheus & Statuspage Integration",
"body": "I am trying to use Statuspage to have a Service Dashboard, where I am crawling Prometheus blackbox data using Python script and pushing to Statuspage (\\`api.statuspage.io\\`)\n\nI am able to submit metric to System Metrics as following\n\n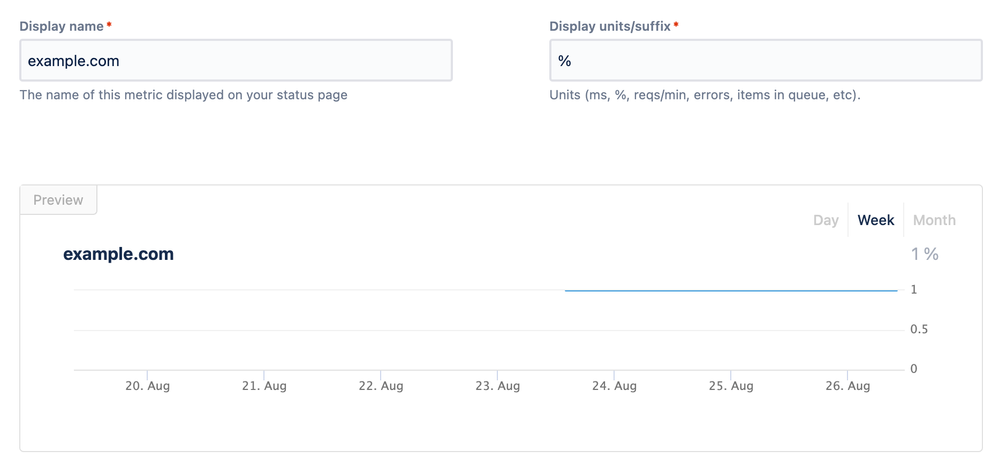\n\nbut need help with getting following view\n\n\n"
} | [
{
"author": "Jesse Klein",
"body": "Hello Roydon,\n\nI'm Jesse from the Statuspage support team. Welcome to the community, and thanks for the question. The screenshot you sent is related to components and the uptime showcase. You would need to create a Prometheus component, and then if the component went down, you could update the component manually or use the API to show whether it was in an outage state. This would update the uptime showcase.\n\nThe issue you would run into is trying to change the past state of the component. This is not possible for the API. Instead, you can go to the component and manually edit the days in the past if needed. Moving forward, you can automate it if that is your desire.\n\nHopefully that helps point you in the right direction.\n\nRegards, \nJesse\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Prometheus-amp-Statuspage-Integration/qaq-p/2793336 | [
"cloud",
"prometheus",
"statuspage-cloud"
] |
{
"author": "Bart van der Meijden",
"title": "Audience-specific tiering question",
"body": "My company is checking if audience-specific pages is the way to go. I have been looking at this [pricing page](https://support.atlassian.com/statuspage/docs/audience-specific-page-pricing/) but from what I read I can't decide which way to go.\n\nCan you elaborate on the pricing tiers? Is it a simple calculation, based on total numbers of users? For instance when my company expects 1500 users to be notified, do we need to opt for pricing tier 3? Or is it more complicated to determine the tiers?\n\nIt would be nice if the documentation regarding this topic would be more detailed with examples of how the tiering works.\n\nThanks in advance\n"
} | [
{
"author": "Muhammad Zeeshan",
"body": "Hey [@Bart van der Meijden](/t5/user/viewprofilepage/user-id/1313169)\n\nWill be happy to answer your query and thank you for your valuable feedback! :)\n\nThe pricing is based primarily on the number of groups. It starts at **$300/month for 10 groups** (effectively $30/group/month), and then incrementally scales in tiers of 10 additional groups (the price per group goes down as you purchase more tiers). For example, for your 11th through 100th group, the monthly price would be $200 purchased in tiers of 10 groups, meaning $20/group/month.\n\nEach tier of **10 Groups comes with 25 Team Members, 500 Page Access Users, and 30 Metrics.** These numbers are cumulative; for example, if you have 30 groups, you have 1,500 page access users total that you can distribute among those groups however you want.\n\nSo to simply answer your query, yes you will need Tier 3 for 1500 Page Access Users which should cost you a total of $700/month.\n\nBR,\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Audience-specific-tiering-question/qaq-p/2791741 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Bart van der Meijden",
"title": "Webinar missing",
"body": "Would it be possible to post the proper link to the webinar mentioned [here](https://www.atlassian.com/software/statuspage/public-pages)?\n\nI am curious about which status page is best for my company, but unfortunately the link is not active at the moment, and I haven't been able to find the webinar in the youtube channel either.\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@Bart van der Meijden](/t5/user/viewprofilepage/user-id/1313169) ,\n\nI also did not see a detailed video on their youtube channel discussing this topic. There is a short video by Kate Clavet on the Atlassian youtube channel that briefly touches on the page types around the 4 minute mark of the video. <https://www.youtube.com/watch?v=KshB1tdxqis>\n\nIf you post the use case your company has here in the community we can try and point you in the right direction for StatusPage Type and pricing Tier for your organization.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Webinar-missing/qaq-p/2791748 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "shivam_singla",
"title": "Component Wise Subscription Feature",
"body": "In many cases, a client may not be subscribed to all the services provided by the company. Is there a feature or configuration setup that allows subscribing to only specific components or groups of components? Currently, as I understand it, subscribing results in receiving notifications for all components, regardless of the specific ones the client is interested in.\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@shivam_singla](/t5/user/viewprofilepage/user-id/5538502) ,\n\nYes, with the Business and Enterprise tiers of Atlassian Statuspage, users have the ability to subscribe to specific components rather than the entire page. This feature allows users to receive notifications only for the components that are relevant to them.\n\nKP\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Component-Wise-Subscription-Feature/qaq-p/2788846 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Karthik Balakrishnan",
"title": "Show incidents of last 3 months",
"body": "Hi Team,\n\nI have couple of queries, Looking for quick help.\n\n1. By default the status page displays the incidents of last 15 days. Can we configure it to list down the incidents of last 3 months?\n\n2. The incident timestamp is being displayed without year. Can we show the year as well?\n\n\n\nThanks in advance!..\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@Karthik Balakrishnan](/t5/user/viewprofilepage/user-id/5570995) ,\n\nWhile this is not something you can do in the GUI, this can be done with HTML/CSS overrides available in Statuspage for your first use case. Atlassian published a document with common use cases scroll down to \"Show fewer days of history on the main status page\" section.\n\n<https://support.atlassian.com/statuspage/docs/css-and-javascript-snippets-for-customizations/>\n\nI suspect it is also possible to provide the year via an override to solve your second use case as well, but it is not something I have had the need to solve for yet myself.\n\nKP\n",
"comments": [
{
"author": "Karthik Balakrishnan",
"body": "Thanks Kevin,\n\nBut thats not helped. The script/css is used to reduce the number of days.\n\nThe expectation is to fetch more days of incidents.\n"
},
{
"author": "Kevin Patterson",
"body": "I see, I usually work with clients that want to Trim the days, not increase so I defaulted to this page out of habit. Thank you for correcting me Karthik.\n\nI'm sure you have seen it but the link at the bottom of the page \"incident history\" will redirect to the /history page in statuspage shows that will show all incidents. What I have seen most clients do is minimize the days on the main page (usually 7 days or less) and keep the link at the bottom that redirects to the history page. That said if you are wanting more to be shown on the main page it might be possible with the combination of an embedded javascript and html/css override to properly display the data.\n\nThe approach I would try would be to embed a javascript in the HTML footer that retrieves the incidents from the history page (/history) over the last 90 days. Then edit the HTML override section to display the results in an unordered list (ul). you will probably have to filter to account for the days that are already there by default.\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Show-incidents-of-last-3-months/qaq-p/2787792 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Abdel-Adhime Benhassine",
"title": "Alias or same number for SMS notifications to France",
"body": "Hello,\n\nWe are experiencing quite a spam issue with our incident notifications.\n\nIt seems that for every SMS notification (even for the same incident), we are receiving messages from different numbers.\n\nIs it possible to configure the same number or to set up an alias?\n\nThanks a lot.\n"
} | [
{
"author": "Jesse Klein",
"body": "Hello there,\n\nThis is Jesse from the Statuspage support team. Thanks for reaching out about SMS notification phone numbers for France being from different numbers.\n\nThere are no settings to change where SMS notifications are coming from. Typically, in our supported countries, the number is consistent and might use a shortcode instead of a long number for delivering notifications.\n\nFrance is not on our list of supported countries: <https://support.atlassian.com/statuspage/docs/sms-delivery-supported-countries/>\n\nIt may be because we aren't able to get the same consistency with numbers or there's regulatory issues blocking this but there wouldn't be a way to get that consistent number at this time. We do have feature requests to add greater availability for messaging so I'll add this community post to that feature request in our private Jira. Thanks for letting us know!\n\nRegards, \nJesse\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Alias-or-same-number-for-SMS-notifications-to-France/qaq-p/2784336 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Bertrand Mbanwi",
"title": "How does Component Grouping work",
"body": "If I have a couple of endpoints and I decide to group them, do they all get an overall status based on each component status? For example, if I let's say I have 3 components in a group, and all of them have the same Operational Status, Does the group which holds those three components have its own status that reflects the three components as operational, and if so, what happens when one of the components status changes, let's say to degraded or major outage, does it also affect the group overall status or is it just for each component? \n\nMy second question is which plan supports component grouping? I already have a process setup for individual components, but I've been asked to inquire and upgrade on the solution since some of our API's have multiple endpoints that capture different services, and we want to be able to capture all at once through component grouping and be able to get an overall status for each group based on its subcomponents.\n"
} | [
{
"author": "Egor",
"body": "Hey Bertrand, \nThanks for reaching out to Atlassian Community! \n\nWhen you group components in Statuspage, the overall status of the group is determined by the statuses of the individual components within it. Here's how it works:\n\n?**Operational Status:** If all components within a group are marked as \"Operational,\" the group itself will also display an \"Operational\" status.\n\n?**Status Change Impact:** If one of the components in the group changes its status (e.g., to \"Degraded Performance\" or \"Major Outage\"), this will affect the overall status of the group. The group will reflect the most severe status among its components. For instance, if one component has a \"Major Outage,\" the group will display that status, even if the other components are still operational.\n\nThis means that the group status acts as an aggregate representation of the individual statuses of the components within it, always reflecting the most severe status at any given time.\n\nComponent grouping is available in the **Business** and **Enterprise** plans of Statuspage. These plans allow you to group multiple components together and manage their statuses as a collective group. If you're looking to upgrade your plan to support component grouping, you would need to consider upgrading to one of these plans.\n\nI hope this helps!\n\nBest Regards, \nEgor\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-does-Component-Grouping-work/qaq-p/2784026 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Monizlorry15",
"title": "PCA lorrymoniz, for Lorraine amaral.441409 consumer code.",
"body": "PCA lorrymoniz , take ing care of Lorraine Amaral.441409 consumer code. Date of birth. My mom 11/ 21/ 37.\n"
} | [
{
"author": "Monizlorry15",
"body": "PCA lorrymoniz, taking care of my mother Lorraine Amaral .\n",
"comments": [
{
"author": "Monizlorry15",
"body": "PCA lorrymoniz take care my mother Lorraine Amaral. 86 year old.\n"
}
]
},
{
"author": "Monizlorry15",
"body": "PCA lorrymoniz taking care my mother Lorraine Amaral. Doing everything for my mother Lorraine Amaral..\n",
"comments": null
},
{
"author": "Monizlorry15",
"body": "PCA lorrymoniz caring for my mother Lorraine Amaral.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/PCA-lorrymoniz-for-Lorraine-amaral-441409-consumer-code/qaq-p/2821780 | [
"atlassian-accounts",
"not-applicable"
] |
{
"author": "vasanth",
"title": "how to pull crowd local groups not in active directory",
"body": "Hi All\n\nhow to pull crowd local groups not in the Active directory\n\nlike JIRA internal Groups\n"
} | [
{
"author": "Fabio Racobaldo _Herzum_",
"body": "Hi [@vasanth](/t5/user/viewprofilepage/user-id/3447449) ,\n\ncrowd has a specific internal directory. Please go to group and select CROWD as directory. All local groups created within crowd will be listed there.\n\nHope this helps,\n\nFabio\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/how-to-pull-crowd-local-groups-not-in-active-directory/qaq-p/2804366 | null |
{
"author": "isher",
"title": "Configuring SSL for Crowd 5.2 with Tomcat 9",
"body": "Hey Community!\n\nI'm having trouble configuring SSL for Crowd 5.2, which now uses Tomcat 9. Can anyone provide guidance or tips on how to properly configure the server.xml file in Tomcat 9 to support SSL for Crowd 5.2?\n\nTill 5.2 version release my server.xml looks like this:\n\n*** ** * ** ***\n\n\\<?xml version=\"1.0\" encoding=\"UTF-8\"?\\> \n\\<Server port=\"8020\" shutdown=\"SHUTDOWN\"\\> \n\\<Service name=\"Catalina\"\\> \n\\<Connector \nport=\"443\" \nprotocol=\"org.apache.coyote.http11.Http11Protocol\" \nmaxThreads=\"150\" \nSSLEnabled=\"true\" \nscheme=\"https\" \nsecure=\"true\" \nclientAuth=\"false\" \nsslProtocol=\"TLS\" \nkeystoreFile=\"${user.home}/.keystore/keystore.jks\" \nkeystorePass=\"myPass\" \n/\\> \n\\<Connector \nacceptCount=\"100\" \nconnectionTimeout=\"20000\" \ndisableUploadTimeout=\"true\" \nenableLookups=\"false\" \nprotocol=\"HTTP/1.1\" \nmaxHttpHeaderSize=\"8192\" \nmaxThreads=\"150\" \nminSpareThreads=\"25\" \nport=\"80\" \nsecure=\"false\" \nscheme=\"http\" \nredirectPort=\"443\" \nuseBodyEncodingForURI=\"true\" \nURIEncoding=\"UTF-8\" \ncompression=\"on\" \nsendReasonPhrase=\"true\" \ncompressableMimeType=\"text/html,text/xml,application/xml,text/plain,text/css,application/json,application/javascript,application/x-javascript\" \n/\\> \n\\<Engine defaultHost=\"localhost\" name=\"Catalina\"\\> \n\\<Host appBase=\"webapps\" autoDeploy=\"true\" name=\"localhost\" unpackWARs=\"true\"/\\> \n\\<Valve className=\"org.apache.catalina.valves.AccessLogValve\" directory=\"logs\" prefix=\"localhost_access_log.\" suffix=\".log\" pattern=\"%t %{User-Agent}i %h %m %r %b %s %I %{X-AUSERNAME}o %{X-AAPPNAME}o\" /\\> \n\\<Valve className=\"org.apache.catalina.valves.RemoteIpValve\" remoteIpHeader=\"x-forwarded-for\" protocolHeader=\"x-forwarded-proto\" /\\> \n\\</Engine\\> \n\\<!-- To connect to an external web server (typically Apache) --\\> \n\\<!-- Define an AJP 1.3 Connector on port 8009 --\\> \n\\<!-- \n\\<Connector port=\"8009\" enableLookups=\"false\" redirectPort=\"8443\" protocol=\"AJP/1.3\" /\\> \n--\\> \n\\</Service\\> \n\\<!-- Security listener. Documentation at /docs/config/listeners.html \n\\<Listener className=\"org.apache.catalina.security.SecurityListener\" /\\> \n--\\> \n\\<!--APR library loader. Documentation at /docs/apr.html --\\> \n\\<Listener className=\"org.apache.catalina.core.AprLifecycleListener\" SSLEngine=\"on\" /\\> \n\\<!-- Prevent memory leaks due to use of particular java/javax APIs--\\> \n\\<Listener className=\"org.apache.catalina.core.JreMemoryLeakPreventionListener\" /\\> \n\\<Listener className=\"org.apache.catalina.mbeans.GlobalResourcesLifecycleListener\" /\\> \n\\<Listener className=\"org.apache.catalina.core.ThreadLocalLeakPreventionListener\" /\\> \n\\</Server\\> \n\n*** ** * ** ***\n\nAny help or insights would be greatly appreciated!\n"
} | [
{
"author": "isher",
"body": "Weird, spend so much time on solving this, but solution was simple. Maybe someone will find it usefull:\n\n*** ** * ** ***\n\n\\<Connector port=\"443\" protocol=\"org.apache.coyote.http11.Http11NioProtocol\" SSLEnabled=\"true\" \nmaxThreads=\"150\" scheme=\"https\" secure=\"true\" \nsslProtocol=\"TLS\" \nkeystoreFile=\"${user.home}/.keystore/keystore.jks\" \nkeystorePass=\"myPass\" \n/\\>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/Configuring-SSL-for-Crowd-5-2-with-Tomcat-9/qaq-p/2647965 | null |
{
"author": "Jonathan Smith",
"title": "User Management: When deactivated, automatically remove the user from space permissions?",
"body": "Does anyone know a way to **automatically** remove users from spaces permissions (if listed individually) when they become deactivated?\n\nWe don't want to see a bunch of deactivated users listed when reviewing space permissions.\n\nSuggestions / recommendations?\n\nCheers,\n\nJonathan\n"
} | [
{
"author": "Ste Wright",
"body": "Hi [@Jonathan Smith](/t5/user/viewprofilepage/user-id/1254033)\n\nThere isn't a native option as far as I know.\n\nIt might be possible using an App which provides scripting capabilities in Confluence, such as...\n\n* [Scriptrunner for Confluence](https://marketplace.atlassian.com/apps/1215215/scriptrunner-for-confluence?hosting=cloud&tab=overview)\n* [Confluence Command Line Interface (CLI)](https://marketplace.atlassian.com/apps/284/confluence-command-line-interface-cli?hosting=cloud&tab=overview)\n* ...or another App from the [Marketplace](https://marketplace.atlassian.com/)\n\nI'm not sure how you'd build this specific function, but I'd contact Marketplace vendors ahead of purchasing an App, and see if they can advise if it's possible :)\n\nSte\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/User-Management-When-deactivated-automatically-remove-the-user/qaq-p/2641984 | [
"atlassian-guard",
"confluence-cloud"
] |
{
"author": "Till Hannemann",
"title": "Can I use Crowd Server for Jira Data Center or Confluence Data Center",
"body": "Hello,\n\nI would like to know if it is possible to connect Crowd Server to Jira or Confluence Data Center. I did some searching myself but the only thing I found is that connecting Crowd Data Center with Jira Server is a supported setup.\n\nThank you in advance\n\nTill\n"
} | [
{
"author": "BHUSHAN PATIL",
"body": "Hi [@Till Hannemann](/t5/user/viewprofilepage/user-id/980387) ,\n\nYes, It is possible to connect Crowd Server to Jira Data Center or Confluence Data Center for user management.\n\nHere's are some kb articles by using that you can set up the connection:\n\n* [Connecting a Jira application to Crowd](https://confluence.atlassian.com/adminjiraserver/connecting-to-crowd-or-another-jira-application-for-user-management-938847056.html#:~:text=.-,Connecting%20a%20Jira%20application%20to%20Crowd,-Atlassian%20Crowd%20is)\n* [Connecting Confluence to Crowd for User Management](https://confluence.atlassian.com/doc/connecting-to-crowd-or-jira-for-user-management-229838465.html#:~:text=for%20user%20management.-,Connecting%20Confluence%20to%20Crowd%20for%20User%20Management,-Atlassian%20Crowd%20is)\n* [Integrating Crowd with Atlassian Jira](https://confluence.atlassian.com/crowd/integrating-crowd-with-atlassian-jira-192625.html#:~:text=and%20Server%205.2-,Integrating%20Crowd%20with%20Atlassian%20Jira,-Currently%20Crowd%20supports)\n* [Integrating Crowd with Atlassian Confluence](https://confluence.atlassian.com/crowd/integrating-crowd-with-atlassian-confluence-198573.html#:~:text=and%20Server%205.2-,Integrating%20Crowd%20with%20Atlassian%20Confluence,-Atlassian%27s%20popular%20Confluence)\n\nBy following steps mention in above documents, you can connect Crowd Server to Jira Data Center or Confluence Data Center for user management.\n\nAlso, if you feel my input help you please accept the answer.\n\nRegards, \nBhushan\n",
"comments": [
{
"author": "Till Hannemann",
"body": "Hello Bhushan,\n\nthank you very much for your fast answer.\n\nBest regards\n\nTill\n"
}
]
}
] | https://community.atlassian.com/t5/Crowd-questions/Can-I-use-Crowd-Server-for-Jira-Data-Center-or-Confluence-Data/qaq-p/2579795 | [
"server"
] |
{
"author": "Jongho Jung",
"title": "How to remove bulk users from specific group.",
"body": "I want to remove more than 200 users from some specific group in Crowd.\n\nThere are more than 500 users in that group and direct members only - no nested members.\n\nIs there any way to run this bulk operation?\n\nThanks.\n"
} | [
{
"author": "Harshit bhagat",
"body": "Hello, \n\nI hope this message finds you well. \n\nI'm Harshit from the miniOrange team, and we have exactly what you need. \n\nIf you're looking to streamline the process of removing over 200 users from a specific group in Crowd, our plugin, **[Crowd Bulk User Management](https://marketplace.atlassian.com/apps/1225025/bulk-user-management-for-crowd?hosting=datacenter&tab=overview),** listed on the Atlassian Marketplace, can help you achieve this seamlessly. \n\nWith our plugin, you can efficiently manage your users and large groups, making tasks like user removal hassle-free. \n\nIf you're interested in learning more about how our plugin can benefit your user management processes, feel free to reach out to us [email protected]. I'd be happy to provide further details and assistance. \n\nThanks, \nHarshit.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/How-to-remove-bulk-users-from-specific-group/qaq-p/2608852 | null |
{
"author": "Martin Dowie",
"title": "Jenkins plugin Crowd2 pulled - can Atlassian help to reinstate this?",
"body": "We use Jenkins with our Atlassian stacks and the Crowd integration is really useful...but has recently been pulled from the Jenkins plugin site: [crowd2 \\| Jenkins plugin](https://plugins.jenkins.io/crowd2/)\n\nThis seems to be because of the license associated with the REST API, which isn't 'open' or 'open enough' for Jenkins/Github.\n\nCould Atlassian do something about this? e.g. adopt more open licenses?\n\nMore details here: [doc: add info about distribution restoration ? jenkinsci/crowd2-plugin@34daf89 (github.com)](https://github.com/jenkinsci/crowd2-plugin/commit/34daf89e4b144b6461df1a352d9732d8c1456dfe)\n"
} | [
{
"author": "Mark Hubers",
"body": "It's the same problem here, and we pay a lot more for DC software and get a lot less from Atalassian. The only reason we pay for the crowd and now we may not be able to use it anymore.\n",
"comments": [
{
"author": "Jaedo Aum",
"body": "me too. We may not renew our subscription to Crowd DC next year because we're not using the Crowd2 addon, we're using it directly with AD.\n"
}
]
},
{
"author": "Ashwini_More _miniOrange",
"body": "[@Martin Dowie](/t5/user/viewprofilepage/user-id/5370233)\n\nI would like to suggest miniOrange's Jenkins Crowd SSO App. We have developed an innovative solution to perform SSO with Crowd, allowing you to log in to Jenkins using Crowd credentials.\n\nPlease raise a service request [here](https://miniorange.atlassian.net/servicedesk/customer/portal/2) and a miniOrange representative will help you with all the details.\n\nPS: I work for miniOrange, One of the SSO vendors in Atlassian Marketplace.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/Jenkins-plugin-Crowd2-pulled-can-Atlassian-help-to-reinstate/qaq-p/2574376 | [
"crowd-administration",
"jenkins",
"server"
] |
{
"author": "Jongho Jung",
"title": "How to find different username using same email address.",
"body": "Hello,\n\nI want to find users has more than two accounts.\n\nAt first, I am trying to make user list using same email address.\n\nIs there any SQL to find user with same email address.\n\nThanks.\n"
} | [
{
"author": "Fabio Racobaldo _Herzum_",
"body": "Hi [@Jongho Jung](/t5/user/viewprofilepage/user-id/4595172) ,\n\nthe following article could help you finding users with the same email address <https://confluence.atlassian.com/jirakb/how-to-find-jira-users-with-duplicate-email-address-1376031383.html>\n\nHope this helps,\n\nFabio\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/How-to-find-different-username-using-same-email-address/qaq-p/2571231 | null |
{
"author": "Ashok Shembde",
"title": "The Approver needs to get a reminder for approval and SLA.?",
"body": "How can I build the requirement where the approver needs to get a reminder for approval and SLA in Jira Service Management? Does anyone have an idea?\n"
} | [
{
"author": "Cristian IONESCU",
"body": "Hi Ashok,\n\nYou can use: Automation for Jira and build an automation.\n\neg.\n\nWhen: SLA threshold breached ( here you can set time prior or after breach)\n\nThen: Send Email ( To: you ca set Pending Approvers)\n\nHope this helps.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/The-Approver-needs-to-get-a-reminder-for-approval-and-SLA/qaq-p/2822500 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Ashok Shembde",
"title": "In Jira Service Management (JSM), when I'm creating a ticket, it shows \"No Request Type\". I want to",
"body": "\n\nIn Jira Service Management (JSM), when I'm creating a ticket, it shows \"No Request Type.\" I want to remove this option. I have attached a screenshot here. Can anyone guide me on how to resolve this issue?\n"
} | [
{
"author": "Dave Mathijs",
"body": "Hi [@Ashok Shembde](/t5/user/viewprofilepage/user-id/5289317)\n\nProTip: Don't create a JSM request via the Create button, but use the portal instead (like customers do).\n\nThis option is only visible when using the Create button (being an JSM agent), and you can't remove it.\n",
"comments": null
},
{
"author": "Vijay Dadi",
"body": "Hello,\n\nWe do not have option to remove that option. Encourage your users to create issues via portal not via create button.\n\nVijay\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/In-Jira-Service-Management-JSM-when-I-m-creating-a-ticket-it/qaq-p/2822568 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Petru Negrusa",
"title": "Limit use automation per task",
"body": "Hello community. I hope you are all well\n\nCan anyone help me with advice?\n\nI have automation that works but.... I need to limit it to 1 launch per task. My parent task has 5 sub tasks and I need when the sub task transits from one status to another, the parent task itself changes its status. Because there are 5 sub tasks, it works once and the rest give an error because the parent task is already in the required status.\n\nSorry for my English.\n"
} | [
{
"author": "Petru Negrusa",
"body": "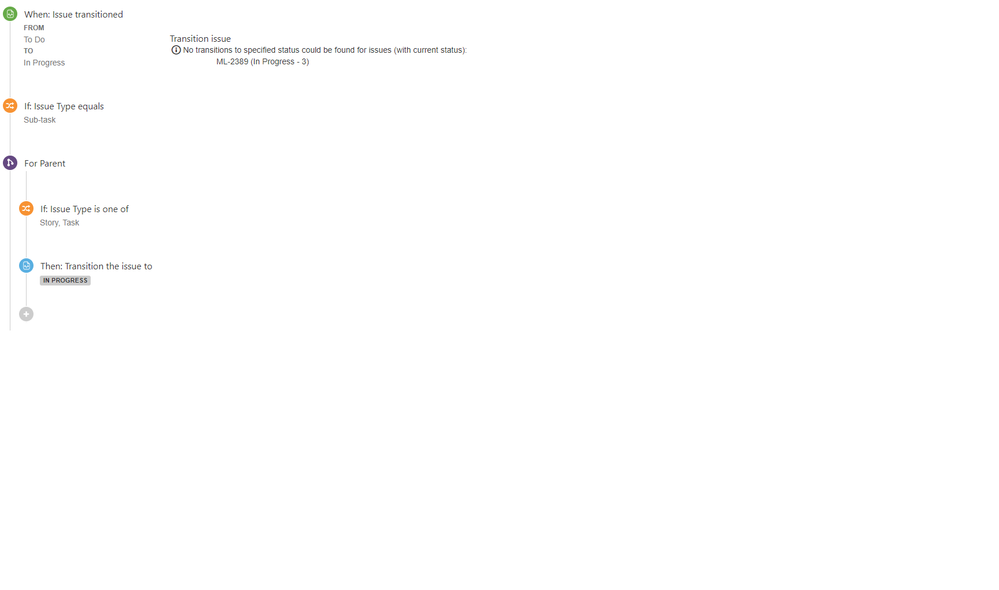\n",
"comments": [
{
"author": "Muhammad Moazzam Hassan",
"body": "Just add one condition. \n\nFor Parent \n\n**Refetch Issue Data** \n\nIf issue Type is one of Story, Task **and status != In Progress.** \n\nthen Transition the issue to In Progress\n"
},
{
"author": "Petru Negrusa",
"body": "Thank you!!!\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Limit-use-automation-per-task/qaq-p/2822468 | [
"jira-service-management",
"jira-service-management-server",
"jira-software",
"server"
] |
{
"author": "Leslie Loo",
"title": "Report: Time to resolution - No Data",
"body": "Everything shows 0.00 minutes. Was working before migrating to cloud. Anyone have any ideas how to fix this report. Thanks in advance\n"
} | [
{
"author": "Benjamin",
"body": "HI [@Leslie Loo](/t5/user/viewprofilepage/user-id/5601970) ,\n\nFor additional context:\n\nAre you referring to the SLA report? Has any of your SLA configuration when migrated changed? Is it only the request that were created on-prem affected or even the request that are recently in cloud impacted as well.\n\nThanks!\n",
"comments": null
},
{
"author": "Alex Ortiz",
"body": "[@Leslie Loo](/t5/user/viewprofilepage/user-id/5601970) Welcome to the Atlassian Community.\n\nDo you have any other details, maybe some screenshots that can help us troubleshoot with you? Are you looking in a queue, dashboard? Thanks!\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Report-Time-to-resolution-No-Data/qaq-p/2822318 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"jira-software"
] |
{
"author": "Maximiliano Julio",
"title": "Deterioration of Jira's performance",
"body": "**Hi community**,\n\nWe are experiencing a lot of slowness when using Jira, this is across all users of a particular project.\n\n<br />\n\nWe think this may be due to the fact that on many tickets, there are more than 100 attachments, but we are not sure.\n\nIs it possible that this is the cause or is there some other aspect that we are not considering?\n\nDoes anyone have any idea what might be going on?\n\nThank y'all in advance :)\n"
} | [
{
"author": "Alex Ortiz",
"body": "[@Maximiliano Julio](/t5/user/viewprofilepage/user-id/5577750)\n\nPerformance in the cloud isn't quite like it is on DC/Server. Cloud is usually very performant.\n\nI would recommend next time you experience sluggish behavior, check out: <https://status.atlassian.com/>\n\nYour region might be experiencing problems and that website would tell you.\n",
"comments": [
{
"author": "Alex Ortiz",
"body": "Also, have you checked your internet connection speed? Are other sites being slow for you?\n"
}
]
},
{
"author": "Joseph Chung Yin",
"body": "[@Maximiliano Julio](/t5/user/viewprofilepage/user-id/5577750) -\n\nPlease advise what you meant by \"all users\"? Are you referring to customers over their access to issues via the portal? or you are referring to your agents/users who are accessing the issues for JSM project UI?\n\nIn addition, what operations are you seeing the performance issue?\n\nIt is worth to know that issues with many attachments should not be an issue since by default an issue in JSM can have up to 2000 attachments by default. On the other hand, JSM is not meant for file storage purpose.\n\nPerformance issues are typically dealing on-prems instance of Jira/JSM (Data Center).\n\nYou can also contact Atlassian Support (<https://support.atlassian.com>) for their assistances on your performance problem when dealing with the Cloud env.\n\nPlease advise, so can further assist you.\n\nBest, Joseph Chung Yin\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Deterioration-of-Jira-s-performance/qaq-p/2822204 | [
"attachment",
"cloud",
"jira-cloud",
"jira-performance",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Bill Martin",
"title": "Trying to combine 2 automations into one",
"body": "In our Jira queue, we have 2 sources of tickets. One being tickets created in slack that generate tickets to our Jira queue and another where tickets are re-routed to us when created in the wrong place.\n\nWe currently have 2 workflows in place to auto-assign out these issue based on a Round robin assignment, but I'd like to combine these into one automation. As it stands, when we need to make changes to the round robin queue, we have to change two different rules. That is what I'd love to eliminate.\n"
} | [
{
"author": "Joseph Chung Yin",
"body": "[@Bill Martin](/t5/user/viewprofilepage/user-id/5601823) -\n\nWelcome to the community. Please provide more details of your existing automation rules, so we can further assist you.\n\nBest, Joseph Chung Yin\n",
"comments": null
},
{
"author": "Samuel Gatica",
"body": "Hi [@Bill Martin](/t5/user/viewprofilepage/user-id/5601823)\n\nWelcome to the community!\n\nWhen the tickets get re-routed, are you using the Move feature, or is a new issue being created (cloned) in your project?\n\nBest regards\n\nSam\n",
"comments": null
},
{
"author": "Josh Costella",
"body": "Hi [@Bill Martin](/t5/user/viewprofilepage/user-id/5601823)\n\nAre you able to post screenshots of your current automations? Feel free to sanitize as needed.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Trying-to-combine-2-automations-into-one/qaq-p/2822075 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "jakub_gajda",
"title": "How to show Attached Form in a linked Jira ticket",
"body": "When a user fills out a form on our JSM customer portal, the JSM ticket that gets created has the Attached Form. A linked ticket in Jira also gets created. However, it does not have the Attached Form. Is there a way to synchronize the form to show up both in JSM and Jira? \n\nThank you for info\n"
} | [
{
"author": "Manoj Gangwar",
"body": "Hi [@jakub_gajda](/t5/user/viewprofilepage/user-id/5601811) Welcome to the community!\n\nTo copy the form you can add an action after create linked issue.\n\naction: copy forms from the trigger issue\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/How-to-show-Attached-Form-in-a-linked-Jira-ticket/qaq-p/2822058 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Shelton Adams",
"title": "Will all of my Jira Service Desk projects and data transfer to Jira Service Management?",
"body": "Our team has made the jump from our old, outdated standalone server to Data Center. Our service desk projects, and info was transferred also, but we do not have service desk anymore which was a mistake made by procurement. My question is if we upgrade to JSM because I understand Service Desk is no more will we be able to function like normal?\n"
} | [
{
"author": "Mikael Sandberg",
"body": "The short answer is yes. The change was just a name change from Service Desk to Service Management, you would still be able to function as normal.\n",
"comments": [
{
"author": "Shelton Adams",
"body": "Ok all of the service desk permission schemes transferred over and are present when we do get JSM will they be able to see their old permission schemes and created forms? As of now they are present but blank due to us not having the application.\n"
},
{
"author": "Shelton Adams",
"body": "Also [@Mikael Sandberg](/t5/user/viewprofilepage/user-id/853579) thank you. I have come across your answers on other problems, and I just realized the legend himself is dropping knowledge. Thank you.\n"
},
{
"author": "Mikael Sandberg",
"body": "Yes, once you have the license it should all be there.\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Will-all-of-my-Jira-Service-Desk-projects-and-data-transfer-to/qaq-p/2822004 | [
"data-center",
"jira-service-management",
"jira-service-management-data-center"
] |
{
"author": "CCC IT Helpdesk",
"title": "system replying to inbound messages",
"body": "Hello,\n\nCurrently using the Free version of jira helpdesk\n\nodd thing.. i had disabled all repsonses to customer inbound messages while we were setting up the system., i re-enabled 3 responses, but not messsages are being recieved\n\ni checked my email settings everything is good, when i do a manual test of a template i receive the message. I ama receiving messages into the system, so i know the email account is working..\n\nbut did notice this:\n\n#### Bulk Emails are disabled {#toc-hId-374391447}\n\nYou can enable it by navigating to Outgoing mail setting from the side navigation or by clicking on the button below.\n\nwhen i check the outgoing mail servers:\n\nthe option Outgoing Mail is enabled. not sure why it continoulsy displays the disabled mesage.\n\nchecked my spam/quarantine, nothing there.. just crickets\n\nI have enabled:\n\nPublic comment added\n\nRequest created\n\nPublic comment edited\n\ni have a bunch of blacklisted domains and emails, i checked if my domain was listed and its not there.\n\nbut receive nothing..\n\nany insight appreciated!\n\nthanks,\n\nPeter\n"
} | [
{
"author": "Benjamin",
"body": "HI [@CCC IT Helpdesk](/t5/user/viewprofilepage/user-id/5601699) ,\n\nI'm not sure what are all the limits of the free plan but I assume that it can do most of the features as other subscriptions but with limits.\n\nThe e-mail should be straight forward if you use the one built into JSM. Would start there first to make sure all works before integrating with your own e-mail service. This way you know the mechanism works on the Atlassian side. Once that works, proceed with e-mail integration. If you are having with the integration, the JSM e-mail log will give you clues and errors of what is possible cause of the issue.\n\nWhen you say system, what is enable to respond to those messages? Are you using the customer notifications or something else.\n\nThanks!\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/system-replying-to-inbound-messages/qaq-p/2821912 | [
"cloud",
"email",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Daniil Kharatian",
"title": "When I try to rename Email request I have a error.",
"body": "1. Go to project settings.\n\n2. Open Request types.\n\n3. Select Email request.\n\n4. Change the name of the Email request to Question.\n\n5. Click Save changes.\n\n**Result:**An error message:\n\n\"We couldn't save your changes We couldn't update the \"Email request\" issue type. Refresh and try again.\"\n\nDoes anybody know why this basic operation returns a error? I've tried to search or the answer, but I didn't see anything related.\n\nThanks in advance.\n"
} | [
{
"author": "Chris Rainey",
"body": "Hi there,\n\nCan't say I've heard of this error before. Have you tried doing the same in a different web browser?\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/When-I-try-to-rename-Email-request-I-have-a-error/qaq-p/2821848 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Povilas Pamarnackas",
"title": "Phishing acounts on Atlasssian.net",
"body": "Fake accounts created pretending to be a company. under the links hide fishing scripts that collect information. Atlassian's platform is used to spread malicious activity. please block the accounts.\n\n<https://grigeouab.atlassian.net>\n\n<https://grigeoab.atlassian.net/>\n"
} | [
{
"author": "Jim Knepley - ReleaseTEAM",
"body": "I think this is the wrong place to request these accounts be investigated.\n\nI would either contact support or email [email protected]\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Phishing-acounts-on-Atlasssian-net/qaq-p/2821776 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Caroline Lussier",
"title": "Drop down list not populating properly in custom field",
"body": "I have a custom field in our service management portal for ticket categorization. Never mind the fact that you can't add more than two tiers to this drop down field out of the box, it's been bugging out recently and wont populate the second tier for any of our agents unless the first tier is selected, then unselected, then selected again. It would appear to be a bug, not a major issue, but it's difficult enough to encourage my employees to categorize tickets thoughtfully without having them to go through all of these extra steps. Anyone else noticing similar issues or have any suggestions of what to try?\n"
} | [
{
"author": "Christopher Yen",
"body": "Hi [@Caroline Lussier](/t5/user/viewprofilepage/user-id/5601562) welcome to the community. Unfortunately I don't have a great solution but what's worked for me is sticking to a 1 tier \"service catalog\" which is really just a service field with our applications and a few generic services and then use different request types to have a quasi 2nd tier. Not the best coming from using Service \\> Category \\>Subcategory in the past but customers and agents are filling it out consistently for the most part, we just have a large service list customers can search from, issue type is set by request type to determine if they have an incident or request and whether it's for hardware or applications.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Drop-down-list-not-populating-properly-in-custom-field/qaq-p/2821700 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Boris S",
"title": "Team-managed business",
"body": "Is available to create project with type \"team-managed business\" on a free plan? How?\n"
} | [
{
"author": "Boris S",
"body": "found this in marketing -\\> go-to-market template for example\n",
"comments": null
},
{
"author": "Alex Koxaras _Relational_",
"body": "Hi [@Boris S](/t5/user/viewprofilepage/user-id/5601500) and welcome to the community,\n\nYou should be able to create team managed project in a free plan, right out of the box. <https://support.atlassian.com/jira-software-cloud/docs/create-edit-and-delete-team-managed-projects/>\n",
"comments": [
{
"author": "Boris S",
"body": "i mean exactly ++business++ team-managed project\n"
},
{
"author": "Alex Koxaras _Relational_",
"body": "You can choose the type of project from the advance setting when creating a project. You will not see a \"Business project\" as you suggest since Jira Work Management and Jira Software are now plain Jira.\n"
},
{
"author": "Boris S",
"body": "found this in marketing -\\> go-to-market template for example\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Team-managed-business/qaq-p/2821600 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Rocco De Angelis",
"title": "JSM Cloud Migration Assistent - Internal comments will be visible to customer",
"body": "Hi All,\n\nWe are in the process of migrating one of our JSM projects from our Data Center instance to JSM Cloud. Now we're facing the issue that comments that were previously marked as internal have been migrated with the visibility set to \"Reply to customer\" instead of being marked as \"Internal note\" in JSM Cloud. As a result, all internal comments are now visible to our customers after the migration, which is a major concern.\n\nDoes anyone have an idea or a workaround to fix this issue?\n\nThank you in advance!\n"
} | [
{
"author": "Alex Koxaras _Relational_",
"body": "Hi [@Rocco De Angelis](/t5/user/viewprofilepage/user-id/5558218)\n\nQuick question: You are migrating from DC to Cloud, but are these JSM projects or Jira projects? Usually I've seen this problem when migrating Jira projects to JSM projects, where comments are public and attachements are not visible to customer. Can you please clarify this?\n",
"comments": [
{
"author": "Rocco De Angelis",
"body": "Hi [@Alex Koxaras _Relational_](/t5/user/viewprofilepage/user-id/4150197) JSM DC project to JSM Cloud project. \nAs far I know the feature of internal comments exists only in JSM projects.\n"
},
{
"author": "Alex Koxaras _Relational_",
"body": "Yes, that's why is strange. This feature is supported in both platforms. So I wonder why dc internal comments are made public on cloud. Have you requested help from a partner or move atlassian's support?\n"
},
{
"author": "Rocco De Angelis",
"body": "I contacted Atlassian support today and am still waiting for a response. However, I would also like to raise this question in the community.\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/JSM-Cloud-Migration-Assistent-Internal-comments-will-be-visible/qaq-p/2821598 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "christophe repulles",
"title": "Visibility problem on the portal versus requests by email",
"body": "I would like to deploy the portal for my users. On the portal, I don't want all the available projects, only the ones I select. For projects that do not appear on the portal, I want to retain the ability to create tickets and users via email. Is this possible?\n"
} | [
{
"author": "Susan Waldrip",
"body": "Hi [@christophe repulles](/t5/user/viewprofilepage/user-id/192361) , welcome to the community!\n\nTo follow on what [@Alex Koxaras _Relational_](/t5/user/viewprofilepage/user-id/4150197) said, you can absolutely hide projects from the portal and still email them! As a Jira admin, open the portal in a browser window and click your **avatar** (upper right), then click **Page Layout**.\n\n\n\nOn any of the projects you do NOT want showing on the portal page, click the star.\n\n\n\nIt will then be hidden, but you can always expand the Hidden project cards and click the eye (upper right) to \"star\" them again and show them. This just changes the visibility on the portal, not the ability to email them to create and process issues. Hope that helps!\n",
"comments": null
},
{
"author": "Alex Koxaras _Relational_",
"body": "Hi [@christophe repulles](/t5/user/viewprofilepage/user-id/192361) and welcome to the community,\n\nYes, you should be able to do that. Portal visibility concerns only the Help Desk and not its functionality. But even if you hide them, customers should be able to visit them and view their tickets. I would suggest to remove any link for viewing the issue on the portal from the customers notifications.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Visibility-problem-on-the-portal-versus-requests-by-email/qaq-p/2821590 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"jira-software"
] |
{
"author": "Rana Muhammad Naveed",
"title": "Dynamic SLA with JIRA native reports or dashboard",
"body": "I have used \"Time to SLA\" and \"SLA PowerBox for Jira,\" both of which provide custom fields for agents to add SLA times in the issue view. However, I also need the SLA data to be available in Jira's native dashboards or reports.\n"
} | [
{
"author": "Robert Dzido _Almarise_",
"body": "Hi,\n\n\"SLA PowerBox\"'s next release will include feature to use jira-native custom fields, so you will be able to see such data in native dashboards.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Dynamic-SLA-with-JIRA-native-reports-or-dashboard/qaq-p/2821468 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Vera Valshonok",
"title": "Why I dont succeed adding new Origination to Customer Organizations?",
"body": "Hi!\n\nI dont succeed adding new Origination to Customer Organizations (please see screenshot). I am only suggested to add already excistent organizations.\n"
} | [
{
"author": "Ivan Bilobrk",
"body": "[@Vera Valshonok](/t5/user/viewprofilepage/user-id/5174542)\n\nYou are actually offered the options \"Choose or create\". Just type the name of the new organization, it will appear in the drop-down list with the extension \"(create new)\", select it, and then hit Add.\n\nYou can also go to **Settings \\> Products \\> Jira Service Management \\> Organizations** where you will have a Create organization button.\n",
"comments": [
{
"author": "Vera Valshonok",
"body": "Worked! Thank you, Ivan.\n"
},
{
"author": "Vera Valshonok",
"body": "[@Ivan Bilobrk](/t5/user/viewprofilepage/user-id/4941573) Now I add people to this customer organization, I see that they are aded, but when i reload a page, there is only one user\n"
},
{
"author": "G?tz H",
"body": "[@Vera Valshonok](/t5/user/viewprofilepage/user-id/5174542) If you go back to the organization overview page and click on the organization again, you should be able to see all the users in that organization\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Why-I-dont-succeed-adding-new-Origination-to-Customer/qaq-p/2821369 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Richard Turnbull",
"title": "Auto Add Comment when Assignee Changes",
"body": "Hi there\n\nAny help appreciated!\n\nWe are using Jira Cloud; oftentimes the Assignee of a ticket may change. Is there a way to track these changes - I'm thinking some way to auto add an internal comment to the ticket to say \"Assignee changed from XXX to YYY\" or similar.\n\nOr maybe this information already sits somewhere that I am unaware of.\n\nThanks in advance for any clues...\n\nRichard\n"
} | [
{
"author": "Manoj Gangwar",
"body": "> Hi [@Richard Turnbull](/t5/user/viewprofilepage/user-id/4545571)\n\nWelcome to the community!\n\nHere's how to set up an automation rule to log changes in the Assignee:\n\n1. **Navigate to Project Settings** : Go to your project and select **Project settings** in the sidebar.\n\n2. **Select Automation** : Find and click on the **Automation** option.\n\n3. **Create a New Rule** : Click on **Create rule**.\n\n4. **Select Trigger** : Choose the **Field value changed** trigger and select **Assignee** as the field.\n\n5. **Add Condition (Optional)**: You can add a condition to check if the issue is in a specific status or project, depending on your needs.\n\n6. **Add Action** : Choose the **Add comment** action. In the comment field, you can use smart values to include the old and new Assignee values. For example: \n\n Assignee changed from {{changelog.assignee.last}} to {{assignee.displayName}}. \n\n7. **Save the Rule**: Give your rule a name and save it.\n\n8. **Test the Rule**: Change the Assignee on an issue to see if the comment gets added as expected.\n",
"comments": [
{
"author": "Kelly Arrey",
"body": "Changes to the assignee (and everything else) live in the Issue History. What do you want to do with it? \n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Auto-Add-Comment-when-Assignee-Changes/qaq-p/2820029 | null |
{
"author": "Philip Kroos - TEAM XALT",
"title": "how to copy a jira issue description to a Confluence page",
"body": "Hi community,\n\nI'm trying to create a confluence page via Jira Automation and webhooks, where I want to include only the correctly formatted content of the \"description\" field from Jira, just like when you go to the jira issue copy and then paste the description to a confluence page.\n\nIn this first screenshot, you can see a bulleted list in the description field.\n\n\n\nThis screenshot is my current automation webhook. To explain a bit further, all the \"add value to the audit log\" actions are only for debugging purposes. The webhook is using the \"create page\" API endpoint ([see the official doc](https://developer.atlassian.com/cloud/confluence/rest/v2/api-group-page/#api-pages-post)) and works as expected\n\n\n\nThis is the page that is created via API, and its title is simply made from the issue key and summary. In the \"body\" section, I'm setting the content of the page that is being created. In this case, I only want the issue description as the content, but I'm using the smart value as you can see in the screenshot (\"{{description.urlEncode.replaceAll etc}}\")\n\n\n\nHowever, this is how I would like the page to look. I created this page manually and simply copied the description from the jira issue and pasted it\n\n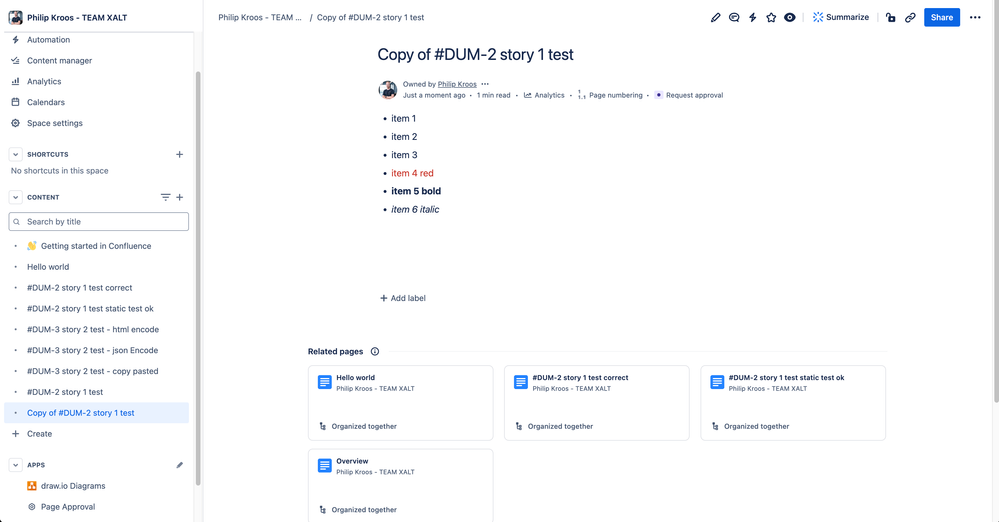\n\nThis screenshot includes the log of the automation, where I tried different operations/functions with my smart value:\n\n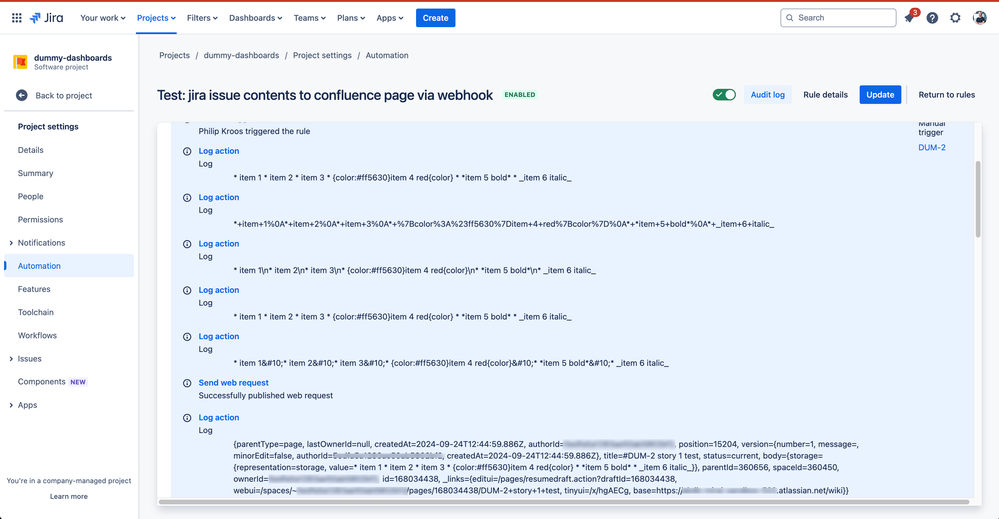\n\nI'm missing something about the content of the Jira issue description being converted to a format that can't be interpreted correctly by Confluence. I'm also new to REST API and webhooks in general, so maybe I'm missing something obvious\n"
} | [
{
"author": "Darryl Lee",
"body": "Hi [@Philip Kroos - TEAM XALT](/t5/user/viewprofilepage/user-id/3965067)\n\nSo from a quick test, it looks like {{description}} returns what looks like **wiki** format. My audit log (which doesn't include linefeeds) shows:\n\n```\nThis is a list * A * B * C [https://somejiralink|https://somejiralink|smartcard]\n```\n\nThe Confluence API accepts data in **wiki** format. So I would try this:\n\n```\n\"body\": {\n \"storage\": {\n \"value\": \"{{description}}\",\n \"representation\": \"wiki\"\n }\n}\n```\n",
"comments": [
{
"author": "Philip Kroos - TEAM XALT",
"body": "Hi [@Darryl Lee](/t5/user/viewprofilepage/user-id/1365322)\n\nunfortunately, using \"representation\": \"wiki\" doesn't work with the POST request for the page create endpoint. However, I found some more information about the \"Upate page\" PUT request here: <https://developer.atlassian.com/cloud/confluence/rest/v2/api-group-page/#api-pages-id-put>\n\nI will try to find a way to create the page first and then update the page content accordingly, maybe this is a possibility.\n"
},
{
"author": "Darryl Lee",
"body": "Hi [@Philip Kroos - TEAM XALT](/t5/user/viewprofilepage/user-id/3965067) - actually the POST can accept wiki just fine. Here's how I was able to create a page with a curl command:\n\n```\ncurl --request POST \\\n --url 'https://MYSITE.atlassian.net/wiki/api/v2/pages' \\\n --user '[email protected]:<api_token>' \\ \n --header 'Accept: application/json' \\\n --header 'Content-Type: application/json' \\\n --data '{\n \"spaceId\": \"753666\",\n \"status\": \"current\",\n \"title\": \"Test 2\",\n \"parentId\": \"950274\",\n \"body\": {\n \"representation\": \"wiki\",\n \"value\": \"This is a list\\n* foo\\n* bar\\n* C\"\n }\n}'\n```\n\n\n\nThe \\\\n is a linefeed. I'm gonna see if I can do this with an Automation....\n"
},
{
"author": "Darryl Lee",
"body": "Ah, needed a bit of encoding. Tested and validated it works:\n\nCustom data:\n\n```\n{ \n \"spaceId\": \"753666\",\n \"status\": \"current\",\n \"title\": \"{{issue.key}} {{issue.summary}}\",\n \"parentId\": \"950274\",\n \"body\": {\n \"representation\": \"wiki\",\n \"value\": \"{{issue.description.jsonEncode}}\"\n }\n}\n```\n\n* [jsonEncode() documentation](https://support.atlassian.com/cloud-automation/docs/jira-smart-values-text-fields/#jsonEncode--)\n\nThe example from there is actually {{issue.summary.jsonEncode}}, and now that I think about it, yeah, if you happen to have foreign characters or emojis in your Summaries, then that's probably a good idea.\n\nBut mainly I think I needed it to handle the linefeeds.\n"
},
{
"author": "Philip Kroos - TEAM XALT",
"body": "This works like a charm, you're my savior! Thank you so much\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/how-to-copy-a-jira-issue-description-to-a-Confluence-page/qaq-p/2820447 | [
"api",
"confluence-cloud",
"jira-cloud",
"rest-api",
"webhook"
] |
{
"author": "Shivani Saran",
"title": "Clone issue containing form submission details from one project to another",
"body": "I created two projects; I want to clone issue from one project to another with form submission detail\n"
} | [
{
"author": "Clara Belin-Brosseau",
"body": "Hello [@Shivani Saran](/t5/user/viewprofilepage/user-id/5597298) and welcome to Atlassian Community :)\n\nIf you're seeking for an easy way to **clone an issue across projects including form submission details,** I suggest trying our app [Elements Copy \\& Sync](https://marketplace.atlassian.com/apps/1211111/elements-copy-sync-clone-jira-issues?tab=overview&hosting=cloud?&utm_source=community&utm_medium=answer&utm_campaign=question_2818794&utm_keyword=CS&utm_vendorID=4952) that allows you to clone and sync a full hierarchy of issues with all their content (summary, description, custom fields, comments, attachments, etc).\n\nYou can check our guide [here](https://doc.elements-apps.com/copy-and-sync-jira-cloud/jira-fields-copy-and-synchronisation#Jirafieldscopyandsynchronisation-Otherdataandadd-ons?&utm_source=community&utm_medium=answer&utm_campaign=question_2818794&utm_keyword=CS&utm_vendorID=4952).\n\nThe app is for **free during 30 days** (and it stays free under 10 users).\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Clone-issue-containing-form-submission-details-from-one-project/qaq-p/2818794 | null |
{
"author": "Saneeta Galbow",
"title": "I need help to create a dashboard which would show one main epic and the sub epics linked to it",
"body": "I want to have an Epic which would be the main epic and then the sub epics that are linked to it.\n\nI need help to create a dashboard which would show one main epic and the sub epics linked to it, however i am not getting any two dimension view for it.\n\nCan anyone support me in solving this?\n"
} | [
{
"author": "Valerie Knapp",
"body": "Hi [@Saneeta Galbow](/t5/user/viewprofilepage/user-id/5597752) , welcome to the Atlassian Community and thanks for your question.\n\nThis visualisation you want to obtain, does it have to be a dashboard? The reason I ask is because I think you could use the Timeline for this, to show the Epics and their dependencies between each other.\n\nPlease check out the documentation here and share your feedback. <https://support.atlassian.com/jira-work-management/docs/what-is-the-timeline-view-and-how-do-i-use-it/>\n\nCheers\n",
"comments": [
{
"author": "Saneeta Galbow",
"body": "Thank you [@Valerie Knapp](/t5/user/viewprofilepage/user-id/4929946) for the warm welcome and the feedback. However the view i want to see is epic which has epic linked to it (more like a child epic- i know there is no concept called child epic).\n\nBut the add button only only child issues to it, which does not allow epic.\n\nHope i didn't confuse you more. :)\n\n\n"
},
{
"author": "Saneeta Galbow",
"body": "In the above example, Mega Epic is my main epic, i want epic of epics to be the child of Mega Epic\n"
},
{
"author": "Valerie Knapp",
"body": "Hi [@Saneeta Galbow](/t5/user/viewprofilepage/user-id/5597752) , thanks for your explanation.\n\nIf you have the Timeline enabled in your instance, it should mean you can also have a custom issue hierarchy, where you can create another level above the Epics for your Mega Epics.\n\n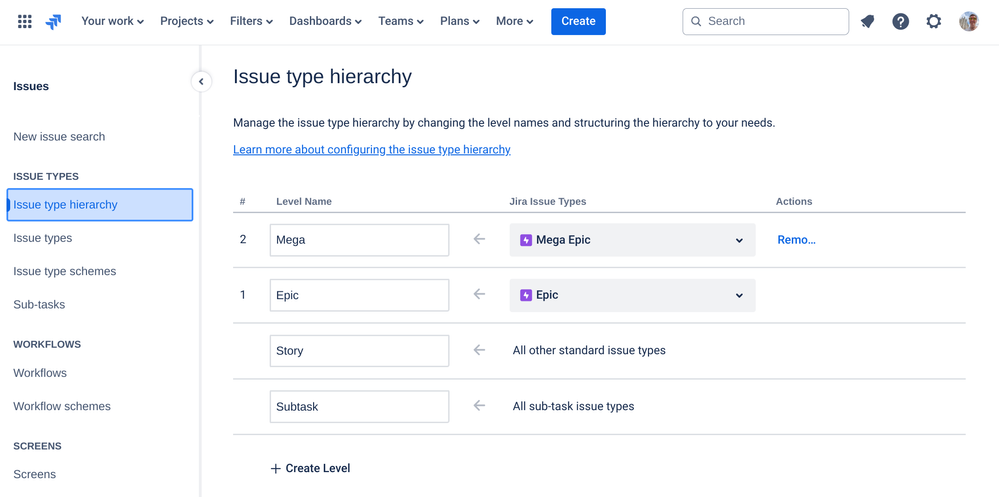\n\n\n\nAs you can see here, I was able to obtain the configuration of a Mega Epic that has other Epics under it.\n\nThe only thing I would say about the custom issue hierarchy is that it is a global configuration, for the whole instance, so you will need to evaluate if this will interfere with the work that anyone else is doing.\n\nI hope this helps you but if you have any other questions or feedback, please just let me know.\n\nCheers\n"
},
{
"author": "Saneeta Galbow",
"body": "Thank you [@Valerie Knapp](/t5/user/viewprofilepage/user-id/4929946) I do not have the custom issue hierarchy, have to check with the admins here. Thank you for your support for the steps explained.\n\nHowever, do you think is there any other way to get this mega epic view? Apologies in advance if i am over asking here. Just trying to understand if we have any other options.\n\nIf not, thank you for the support :)\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/I-need-help-to-create-a-dashboard-which-would-show-one-main-epic/qaq-p/2817666 | [
"dashboard",
"epics"
] |
{
"author": "Remya_Rajanandan",
"title": "how do I add up story points value for all child stories to a feature using JIRA automation",
"body": "please assist to form a rule to add up changes story points of child issues to the parent\n"
} | [
{
"author": "Jack Brickey",
"body": "Hi [@Remya_Rajanandan](/t5/user/viewprofilepage/user-id/5597476) , there are a number of existing posts that might help you out so I recommend researching it a bit. Here are a couple I found.\n\n[How-do-you-sum-up-story-points-to-the-epic-using-jira-automation](https://community.atlassian.com/t5/Automation-questions/How-do-you-sum-up-story-points-to-the-epic-using-jira-automation/qaq-p/1731595)\n\n[Sum-up-story-points-to-an-epic](https://community.atlassian.com/t5/Jira-questions/Sum-up-story-points-to-an-epic/qaq-p/2515666)\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/how-do-I-add-up-story-points-value-for-all-child-stories-to-a/qaq-p/2817330 | null |
{
"author": "Lior Efraim",
"title": "Automation for Jira DC smart value formula not working",
"body": "Hello,\n\ni have a field called \"Start Date\", a date field (no time)\n\nanother field \"Sprints Estimation\" which is number field.\n\ni want to set a value of another date field - \"Finish Date\" to be:\n\nFinish date = Start date + (Sprint estimation) \\* 21\n\nthis is what i tries and getting error parsing from automation:\n\noption 1: {{#=}}{{issue.startDate.plusDays({{issue.sprintsEstimation}} \\* 21)}}{{/}}\n\noption 2: {{issue.startDate.plusDays({{#=}}{{issue.sprintsEstimation}} \\* 21{{/}})}}\n\nany ideas?\n\nthanks im advance to any answer.\n"
} | [
{
"author": "Lior Nesher",
"body": "Hi Lior, \nOne small correction you used custom field \"Start Date\" and call it to \"StartDate\" you can use the space. \nthat error might be happen again in [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) solution isn't worked for you, you used 'sprintsEstimation' together, and my guess the field called 'Sprints Estimation'. \n\n{{issue.Start Date.plusDays(issue.Sprints Estimation.multiply(21))}}\n\n<br />\n\nto avoid those kind of mistakes my tip is using the custom field id\n\n{{issue.customfield_xxxxx.plusDays(issue.customfield_xxxxx.multiply(21))}}\n",
"comments": [
{
"author": "Lior Efraim",
"body": "Thanks Lior!\n\nwhat worked for me was:\n\n```\n{{issue.Start Date.plusDays(issue.customfield_17909.multiply(21))}}\n```\n\njust need to remember changing the number in customfield_xxxxx when moving this to prod.\n\nthanks again!\n"
}
]
},
{
"author": "Bill Sheboy",
"body": "Hi [@Lior Efraim](/t5/user/viewprofilepage/user-id/4520606)\n\nPlease review the [math expression syntaxes](https://confluence.atlassian.com/automation/jira-smart-values-math-expressions-993924866.html), and then try this one:\n\n```\n{{issue.startDate.plusDays(issue.sprintsEstimation.multiply(21))}}\n```\n\nAnd, when using a smart value nested within another function, the extra curly brackets are usually not needed.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Lior Efraim",
"body": "Thank you Bill.\n\nresult is \"success\" from the automation, and \"Issues edited successfully\" but \"Finish Date\" stays empty.\n\ni tried add \"jiraDate\" to the statement as i saw in documentation:\n\n```\n{{issue.startDate.plusDays(issue.sprintsEstimation.multiply(21)).jiraDate}}\n```\n\nbut still same thing, i get success with no value in the field it stays empty.\n"
},
{
"author": "Kelly Arrey",
"body": "Hi [@Lior Efraim](/t5/user/viewprofilepage/user-id/4520606) can you show us the details of the part of the rule where you set the Finish Date value? Thanks!\n"
},
{
"author": "Lior Efraim",
"body": "sure. please see screenshot\n\n\n"
},
{
"author": "Kelly Arrey",
"body": "LGTM. [@Lior Efraim](/t5/user/viewprofilepage/user-id/4520606)\n\n1. You might want to put some \"Add value to audit log\" actions in there to print some intermediate results of the smart value expression to the logs to help understand what's happening a little better.\n2. One other thing that sometimes bites people is, are there two fields named \"Finish Date\" on your system?\n"
},
{
"author": "Bill Sheboy",
"body": "Yes, and...have you confirmed you have the correct smart value for your custom field sprintsEstimation? You can do that using this how-to article:\n\n<https://confluence.atlassian.com/automation/find-the-smart-value-for-a-field-993924665.html>\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Automation-for-Jira-DC-smart-value-formula-not-working/qaq-p/2818486 | [
"formula",
"smart-value"
] |
{
"author": "Nithin Revanna",
"title": "Adding Work Notes as a Comment to Existing Issues via Incoming Email in Jira Service Management (JSM",
"body": "**Context:** I'm setting up an automation rule in Jira Service Management (JSM) to handle incoming emails. The objective is to check if the email body contains a specific issue key (formatted as `JSM Number: VPLSRV-xxxxx`). If the issue key is found, I want to add the **work notes** from the email as a comment on the existing issue. If no issue key is found, a new issue should be created.\n\n### **Specific Requirements:** {#toc-hId--2124375958}\n\n### **Email Format Example**: {#toc-hId-363136875}\n\nNumber: ABC123\n\nJSM Number: ABCD-149\n\nWork_notes: More info added \n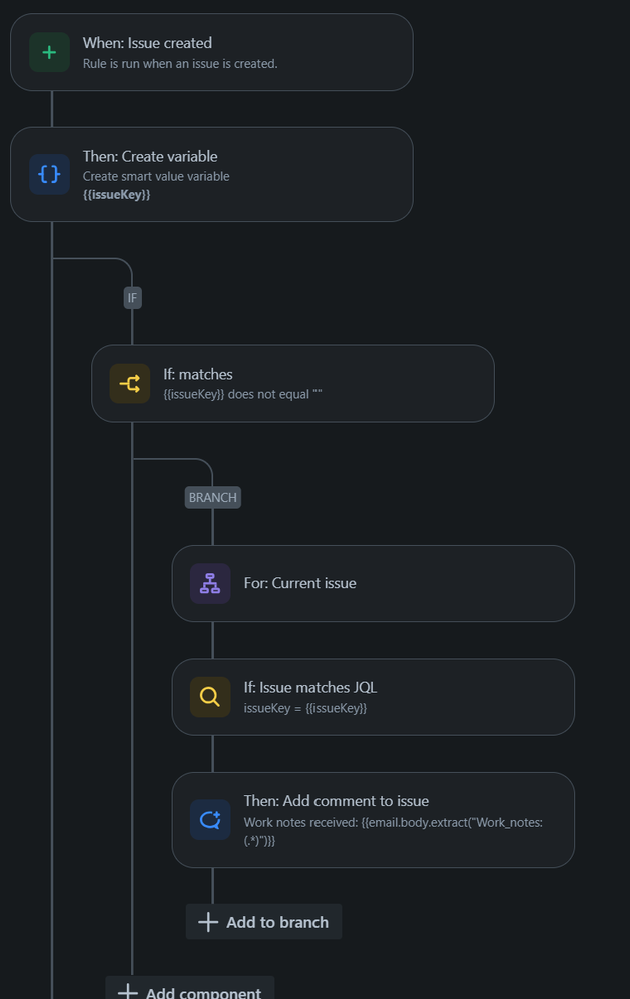\n\n### **Objective**: {#toc-hId--1444317588}\n\n1. **If the email contains an issue key** :\n * I want to check if an issue with that key already exists in JSM.\n * If the issue exists, I want to add the content under `Work_notes:` as a comment on the issue.\n * If the issue doesn't exist, I want to create a new issue.\n2. **If no issue key is found in the email** :\n * I need to create a new issue in JSM using the email details.\n\n### **Steps I've Taken So Far**: {#toc-hId-1043195245}\n\n1. **Triggered the Rule** when an incoming email is received.\n2. I use a **custom automation rule** to extract the issue key (formatted as `ABCD-xxxxx`) from the email body.\n3. I use this issue key to search for an existing issue in JSM.\n4. **If an issue is found** , I add the content of `Work_notes` from the email as a comment on the existing issue.\n5. **If no issue is found**, I create a new issue with the details from the email.\n\n### **Challenges**: {#toc-hId--764259218}\n\n1. **Issue with Searching for Existing Issue by Key**: When I try to use the extracted issue key to search for the issue in JSM, I'm getting errors related to the search query being incomplete or invalid.\n2. **Handling of Empty Issue Key**: I want to make sure that if no issue key is found in the email, the rule falls back to creating a new issue rather than failing.\n\n### **Questions for the Community**: {#toc-hId-1723253615}\n\n1. What is the best way to **extract the issue key** from the email body and use it in automation to check for an existing issue?\n2. How can I ensure that the search for an issue by the extracted issue key works reliably?\n3. Are there any **best practices** for handling cases where the issue key is missing from the email body?\n4. What would be the best approach to **add the work notes** as a comment on the existing issue, once it is found?\n"
} | [
{
"author": "Walter Buggenhout",
"body": "Hi [@Nithin Revanna](/t5/user/viewprofilepage/user-id/4706101) and welcome to the Community!\n\nCould you take a step back for a second and explain how you got to the idea of trying to write an automation rule for this?\n\nYou seem to be trying to replicate the behaviour Jira's email handler is doing by default. If an email arrives in a connected mailbox, Jira will check if it references an existing issue and - if so - attach the email body as a comment to that existing issue. If no reference to an issue is found in the email, a new issue will be created.\n\nAs far as I know, there is no such thing in Jira automation as a trigger on *email received* . In your screenshot, you reference the *Issue created* event. If this was indeed an issue raised from an email channel, that means that there was no reference to an existing issue found in the first place and everything else you are trying to do after that has no point anymore, since you will never find a related issue in there. Unless of course people add random references to issue keys in emails about other issues. And that would be the part I am interested to understand ?\n\nHope this helps!\n",
"comments": [
{
"author": "Walter Buggenhout",
"body": "Adding to the above; when you want to add a comment to a related issue, you need to use a branch on related issues, not to the current issue. The following frame setup might work (though it would probably require some tweaking for checking the condition):\n\n\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Adding-Work-Notes-as-a-Comment-to-Existing-Issues-via-Incoming/qaq-p/2817225 | null |
{
"author": "Akhila Rao",
"title": "Send Web Request to a Python Server through JIRA Automation",
"body": "Hello,\n\nI have a Python server running with Flask. Currently it is running in my local machine.\n\nWhenever there is a change in the due date, I want to send a web request to the server by sending some custom message.\n\nWhen, i try to validate it gives me 408 error and when the automation is triggered, it gives me \"Webhook request was sent, but timed out after 30 seconds on the remote host so the result is unknown (but most likely successful).\"\n\nWhen i send this via Rest Client, i recieve the message.\n\nDoes the endpoint have to be another Jira Rest End point or any endpoint can be used?\n\nMy webhook URL for the webrequest endpoint goes like this: <http://IP_Address:5000/post>\n"
} | [
{
"author": "Rick Westbrock",
"body": "I would start by checking the log on the Flask side to see what it received in the web request from the automation rule and compare that to what the log shows from a successful request from a REST client (I assume that by client you mean something like cURL or Postman).\n\nIt would also be helpful if you share the configuration of your automation rule web request action including headers and body.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Send-Web-Request-to-a-Python-Server-through-JIRA-Automation/qaq-p/2817085 | null |
{
"author": "David",
"title": "How to link multiple issues together on issue creation?",
"body": "Is it possible to automatically link tickets created by automation?\n\nFor example, when Ticket A is created, it generates Tickets B, C, and D. Establishing links between A and B, C, D is not an issue, but how can I create links between B, C, and D themselves?\n"
} | [
{
"author": "Ashok Shembde",
"body": "Hi [@David](/t5/user/viewprofilepage/user-id/5596125) ,\n\nPlease review this add-on to determine if it is useful for your issue. Let me know your thoughts! [linking https://marketplace.atlassian.com/apps/1212259/bigpicture-project-management-ppm?tab=overview\\&hosting=cloud](https://marketplace.atlassian.com/apps/1212259/bigpicture-project-management-ppm?tab=overview&hosting=cloud)\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/How-to-link-multiple-issues-together-on-issue-creation/qaq-p/2815924 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"jira-work-management-cloud"
] |
{
"author": "Yossi Geretz",
"title": "Having trouble with custom field in Automation JQL",
"body": "I have a field named StandupFlag which we use to flag items for discussion at the upcoming standup. I'm trying to write an automation script which will clear these flags en masse after we finish our standup meeting.\n\n\n\nThis little elegant snippet is what I finally found. I have no idea what it means, but it's the first thing I found which parses OK. The ID of the field is 10038. That is confirmed.\n\n{{#issue.customfield_10038}}\"{{.}}\"{{\\^first}} ,{{/}}{{/}} = \"Standup\"\n\nHere's the error I'm getting:\n\nDEV-54: \"((**\"Standup\"** = \"Standup\") AND (key != DEV-54)) AND (project in (10001)) AND (updated \\>= -3m)\" - Field 'Standup' does not exist or you do not have permission to view it.\n\nNote that the elegant little snippet of JQL has resolved to the string literal \"Standup\". Yes! This is the value of the StandupFlag field so obviously the StandupFlag was interrogated properly for that ticket to produce its value. So what's with the error message? I'm not referencing a field named Standup. I'm comparing a string literal \"Standup\" to the match string \"Standup\". This should evaluate to true!\n\nThanks for your advice!\n"
} | [
{
"author": "Trudy Claspill",
"body": "I believe that the problem is in your JQL in the left side where you put the field name you have entered **Standup** but you have otherwise stated that the field name is **StandupFlag** . In the JQL you are not comparing two values to each other. You are telling Jira to compare the value you supplied on the right side to the value in the **field you identify by field name**on the left side.\n",
"comments": [
{
"author": "Darryl Lee",
"body": "I think Trudy's nailed it. Maybe try flipping it around:\n\n```\n\"StandupFlag\" = {{#issue.customfield_10038}}\"{{.}}\"{{^first}} ,{{/}}{{/}}\n```\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Having-trouble-with-custom-field-in-Automation-JQL/qaq-p/2815868 | [
"custom-field",
"jql"
] |
{
"author": "Albert Edidiong",
"title": "How do i get the Original Estimate for the Task to sum up the original estimates for the subtasks?",
"body": "I have tried this option, and it still does not work for me. Please help me\n\n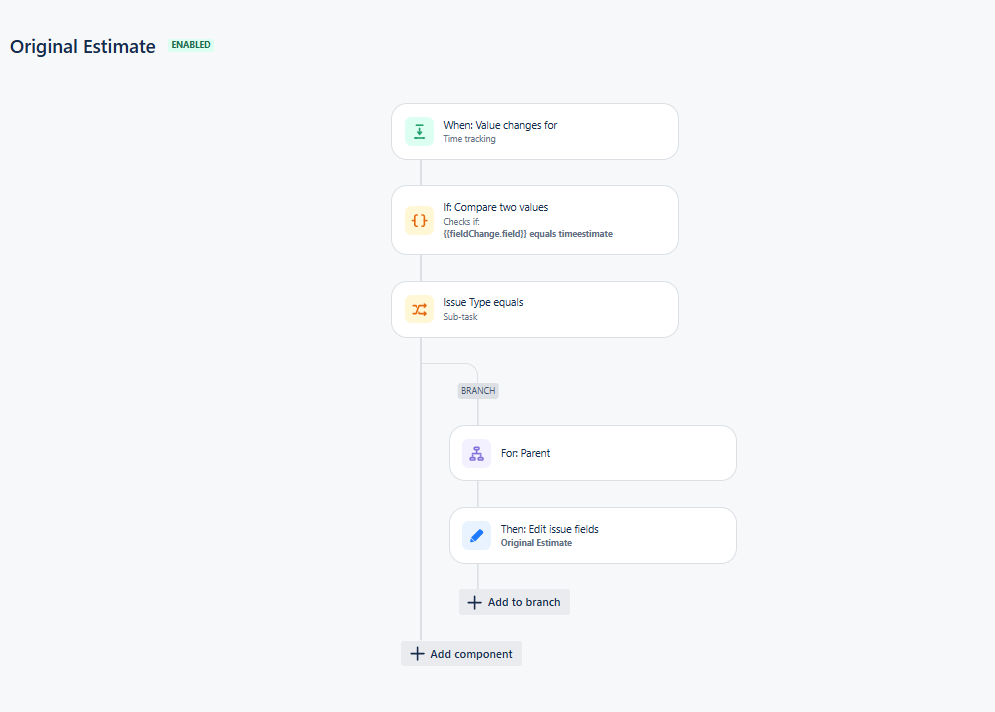\n"
} | [
{
"author": "Trudy Claspill",
"body": "Hello [@Albert Edidiong](/t5/user/viewprofilepage/user-id/5563535)\n\nWelcome to the Atlassian community.\n\nWhat are the details of your Edit Issue action?\n",
"comments": [
{
"author": "Albert Edidiong",
"body": "Hello [@Trudy Claspill](/t5/user/viewprofilepage/user-id/3569011) \n\nThese are the details for Original Estimate, that i used \n{{issue.subtasks.Original Estimate.sum.divide(3600)}}m \n\n<br />\n"
},
{
"author": "Trudy Claspill",
"body": "In what way is that not working?\n\nWhat value do you actually get in the field?\n\nWhat value do you expect to get in the field?\n\nWhat is the output in the rule execution log when the rule executes?\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/How-do-i-get-the-Original-Estimate-for-the-Task-to-sum-up-the/qaq-p/2814899 | null |
{
"author": "Ian Herzing",
"title": "When Engagement End in \"Past\" change status to \"SEND NPS\"",
"body": "Hi there! I want to build an automation that moves my Jira ticket from the status: \n\n\"ENGAGEMENT ACTIVE\" to the status \"SEND NPS\" \n\nWhen my \"Engagement End\" is in the past (i.e. less than 'Today')\n\nAny help is appreciated thank you!\n\n\n"
} | [
{
"author": "Bill Sheboy",
"body": "Hi [@Ian Herzing](/t5/user/viewprofilepage/user-id/5594592) -- Welcome to the Atlassian Community!\n\nWhat have you tried thus far to solve this need?\n\nIf you have created a rule and it is not working as expected, please post images of your complete rule and the audit log details showing the rule execution, and explain what is not working. Those will provide context for the community to offer better suggestions.\n\nIf you have not yet started a rule, I recommend you try to do so. Successfully using automation requires learning and experimentation. If you run into challenges, post images of the rule and audit log so the community can offer help.\n\nYour rule could use JQL with a Scheduled Trigger to find the issues, and then a Transition Issue action for the update.\n\nAnd to get you started on creating your rule, please refer to these documentation and example sources:\n\n* <https://www.atlassian.com/software/jira/guides/automation/overview#what-is-automation>\n* [https://www.atlassian.com/software/jira/automation-template-library#/rule-list?systemLabelId=all\\&page=1\\&pageSize=20\\&sortKey=name\\&sortOrder=ASC](https://www.atlassian.com/software/jira/automation-template-library#/rule-list?systemLabelId=all&page=1&pageSize=20&sortKey=name&sortOrder=ASC)\n* <https://support.atlassian.com/cloud-automation/docs/jira-smart-values-issues/>\n* <https://support.atlassian.com/jira-software-cloud/docs/use-advanced-search-with-jira-query-language-jql/>\n\nKind regards, \nBill\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/When-Engagement-End-in-quot-Past-quot-change-status-to-quot-SEND/qaq-p/2814331 | null |
{
"author": "Pamela Hein",
"title": "Manual trigger vs Issue created trigger",
"body": "Scenario:\n\nCreate a form for 'Deboarding Employee' that captures : Employee Name , Last Work Day and Location. Using Automation - when the form is submitted -- email specific employees (based on location) of the 'Deboarding Employee'.\n\nIf I run the automation manually (against a previous created ticket with the deboard form attached) checking for Summary condition contains 'Employee Deboard' and status is one of 'Waiting for support' -- the automation works fine and will run as expected -- sends an email with 'Employee Name, Last work day and location' to specific employees that need to know of the 'Deboarding employee'. (Location is checked as to ensure what group of people need to be emailed)\n\n* I've written to the audit log 'Employee Name' , 'Last work day' and 'Location' -- and the correct information is displayed there.\n\nWhen I change the automation to trigger on 'When: issue created' checking the same conditions listed above -- the automation does not work as expected. Summary and Status are correct. When I check 'Location' to send email -- the location is blank (along with Employee Name and Last work day). Location is a custom field and a screen field. (both Employee Name and Last work day are also custom fields). I have referenced these fields as a 'named' field and as a custom field in the automation (issue.customfield_xxxxx). The audit log does not show any information in the fields. I am able to edit the 'description' field and add 'Deboarding Employee' without the employee name. I've also tried 'Re-fetch' -- 5 times for 5 seconds each -- and still no information in the 3 fields.\n\nAny help is appreciated.\n\nPlease see attached screen shots.\n\nJSM / Data Center - on prem\n\nService Mgmt 5.9.1\n"
} | [
{
"author": "Bill Sheboy",
"body": "Hi [@Pamela Hein](/t5/user/viewprofilepage/user-id/5419111)\n\nWithout seeing the specifics of your rule or the audit log details, this symptom does seem like a delay / racetrack error.\n\nIf you look at an example issue's history, *when* do you see the fields populated: when the issue is created or at some time later?\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Pamela Hein",
"body": "I've uploaded screen shots of the automation\n"
},
{
"author": "Pamela Hein",
"body": "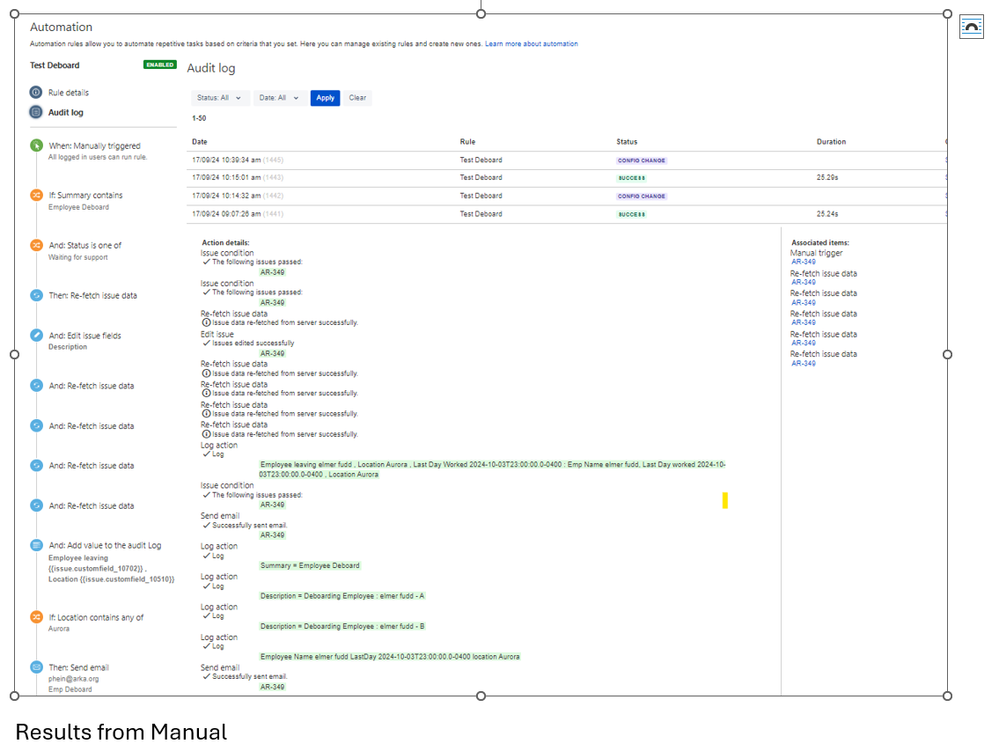\n"
},
{
"author": "Bill Sheboy",
"body": "Thanks for those screen images.\n\nDid you look at the issue history for AR-349 to observe when the Location and other custom fields were set?\n"
},
{
"author": "Pamela Hein",
"body": "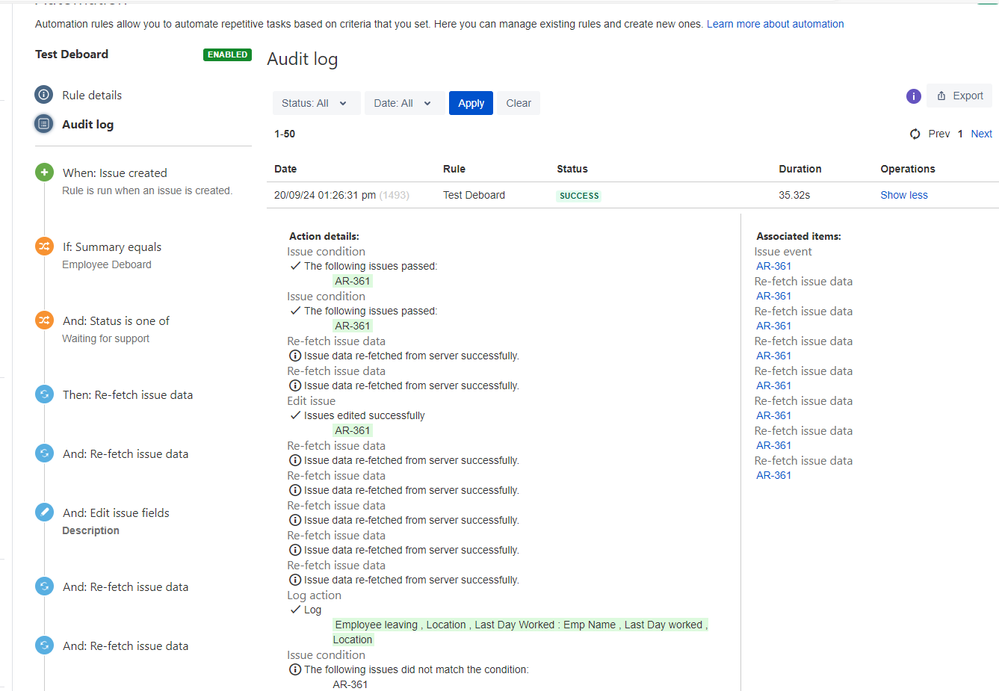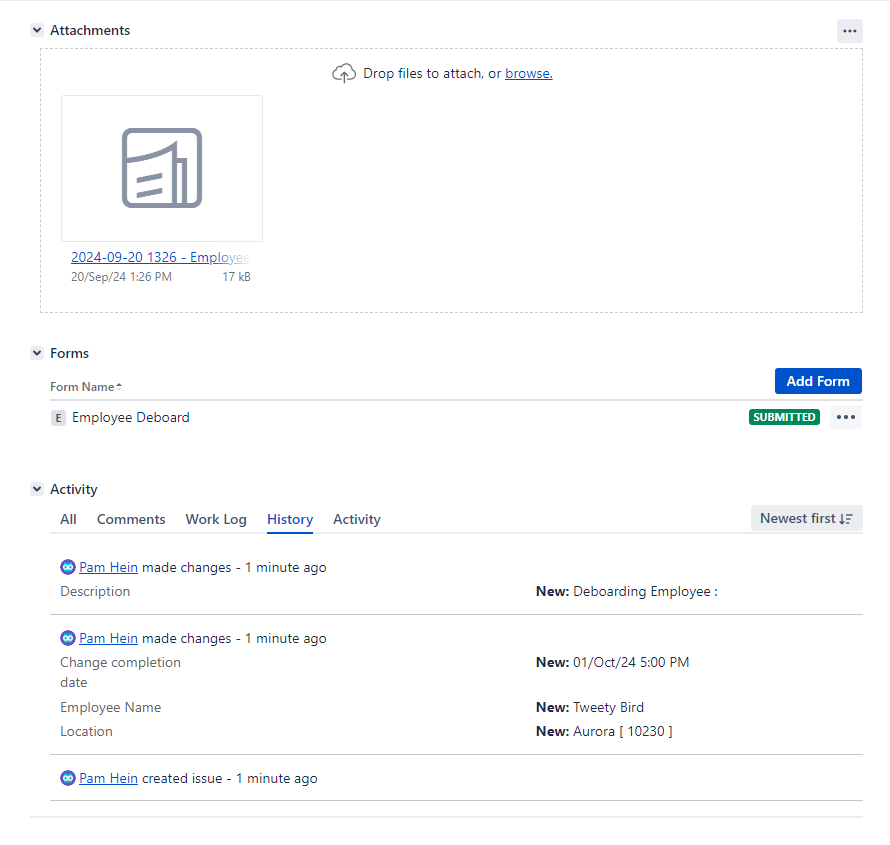\n"
},
{
"author": "Pamela Hein",
"body": "Bill,\n\nI just re-ran the form and when issue created automation. Is it possible to add a delay from when the form is submitted to when the automation is launched?\n\nthank you,\n\nPam\n"
},
{
"author": "Bill Sheboy",
"body": "That does appear to be a timing problem, and I would have expected a single Re-fetch Issue action after the trigger to have resolved this (given what the history shows).\n\nI recommend working with your Site Admin to contact Atlassian Support to learn what they suggest: <https://support.atlassian.com/contact/#/>\n\nWhile waiting for them to respond...you might try calling the REST API to get the form data directly using the Send Web Request action.\n"
},
{
"author": "Pamela Hein",
"body": "Bill,\n\nThank you for your time. I will contact Atlassian for suggestions.\n\nPam\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Manual-trigger-vs-Issue-created-trigger/qaq-p/2814315 | [
"jira-data-center"
] |
{
"author": "AB",
"title": "How can I trigger an event, if an issue is not updated for a given time?",
"body": "Is there is a way in JSM to send some reminder notifications to reporter? \n\nUse Case :\n\n- we set a ticket as Waiting for customer (T0) to get feedback\n\n- Notification to be sent if no comment received from reporter since 7 days -- 1st reminder\n\n- Notification to be sent if no comment received from reporter since 14 days -- 2nd reminder\n\n- Notification to be sent if no comment received from reporter for 21 days -- Last reminder\n\nThanks.\n"
} | [
{
"author": "Trudy Claspill",
"body": "Hello [@AB](/t5/user/viewprofilepage/user-id/5183787)\n\nIs it possible that people besides the reporter will enter comments during those time periods?\n\nOne possible solution involves multiple Automation rules.\n\nRule #1 would be triggered by a comment being added to the issue. The rule would compare the comment Author to the issue Reporter. If they are the same, then the rule would update a custom field (that you would need to add to the issue) with the current date to note that is the most recent comment from the reporter.\n\nYou would then set up additional scheduled rules to use JQL to select the the issues that need a reminder. There would be one rule for each time period (7 days, 14 days, 21 days). The rules would be scheduled to run daily. The JQL would include at least this criteria\n\n\"Last Reporter Comment Date\" = -7d\n\n...where each rule would use one of the time period values.\n\nYou would probably want additional criteria, such as\n\nstatus = \"Waiting for customer (T0) to get feedback\"\n\nYou could either have the rule then send an email directly to the Reporter, or add another comment to the issue which would generate an email being sent to the Reporter.\n\nWould you care when the issue status was set to \"Waiting for customer (T0) to get feedback\" vs. when the reporter last commented? For example:\n\n1. Reporter enters a comment on 1 Jan 2024\n2. Status is changed to \"Waiting for customer (T0) to get feedback\" on 3 Jan 2024\n3. As of 8 Jan 2024 the Reporter has not posted any new comments and the status is \"Waiting for customer (T0) to get feedback\", therefore the 7-days reminder will be sent.\n\nOr would the rule need to consider the date of the status change (3 Jan 2024) and start the clock from that date instead?\n",
"comments": [
{
"author": "AB",
"body": "7 Days timer should start from the date of status change, Jan 3rd in the example. Also i don't see \"Scheduled\" trigger in Automation. Is it something to do with the permissions?\n"
},
{
"author": "Trudy Claspill",
"body": "Are you working with a Cloud product or a self-hosted Server/Data Center product?\n\nHow did you navigate to the Automation feature?\n"
},
{
"author": "AB",
"body": "I am still learning and very new to JSM config, so my apologies in advance for any dumb question. I don't know why but I have two different screens for automation in QA environment and Prod. I am enclosing screenshots for reference. And Yes, It is data center. \n"
},
{
"author": "Trudy Claspill",
"body": "Everybody is new to Jira at some point. ?\n\nIn Data Center, Jira Service Management had its own Automation feature. That is what your first image shows. With later versions an Automation feature that works with both Jira Software and Jira Service Management was introduced. That is what your second image shows.\n\nYou can find documentation for that second one here:\n\n<https://confluence.atlassian.com/automation/>\n\nThe Schedule trigger will be available in the second Automation feature.\n\nYou may also benefit from looking at the documentation for creating JQL statements:\n\n<https://confluence.atlassian.com/jirasoftwareserver/advanced-searching-939938733.html>\n\nAre you a Jira Application Admin, or only a Project Administrator? If you click the gear icon near your avatar on the right end of the application menu bar? I ask that so that I know what other questions you'll be able to answer on your own versus needing to ask somebody else.\n\nTo factor in the date the issue changed to the specified status you will need to include another criteria in you JQL:\n\nStatus was changed to \"Waiting for customer\" on startOfDay(-7d) and Status was not changed after startOfDay(-7d)\n\nInsert the full status name between the quotes.\n\n\"was\" and \"changed\" are special operators that can be used with just a few fields. You can find more information about the in the JQL documentation I mentioned above.\n\nSee if you can work out the automation with the information I provided. If you have additional questions let me know.\n"
},
{
"author": "AB",
"body": "Thank you for all the explanation. I will go through it but just to let you know I am only the project admin\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/How-can-I-trigger-an-event-if-an-issue-is-not-updated-for-a/qaq-p/2814308 | [
"jsm",
"notification",
"reminder",
"schedule",
"send-email"
] |
{
"author": "Anna",
"title": "capture scheduler time in variable in jira automation",
"body": "Hi there,\n\ni have a scheduled trigger that checks for statuses of specific issues.\n\nThe trigger runs as per CRON expression\n\nevery **0 0 9-14 ? \\* THU.**\n\nThe last run should happen at 2 PM as per the scheduler. Is it possible to capture 2 PM as variable and use it in condition to see if it is a last run for the day? How we can capture the last run for the scheduled trigger in this case?\n\nI need to implement logic of checking the statuses of relevant issues at last run and send email with final statuses at 2 PM.\n\nThanks,\n\nAnna\n"
} | [
{
"author": "Bill Sheboy",
"body": "Hi [@Anna](/t5/user/viewprofilepage/user-id/5337719)\n\nShort answer: I do not believe that is possible, and even if it was, it may be unreliable.\n\nThe {{rule}} smart value provides the rule's name and the actor: {{rule.name}} and {{rule.actor}}. It does not provide other information about the rule. And, there is no public REST API yet to query the rule for other information.\n\nAnd even if such information was present, there could be occasional cloud outages from Atlassian preventing the rule running exactly when you expected. Indeed, information from Atlassian about what happens to the execution of scheduled rules after an outage resolves is undocumented.\n\nI suggest there are a couple of **workarounds** for your scenario, which are based on knowing what values are defined in the trigger:\n\n1. Using {{now}} check if the rule is running on / after some time around 2 pm, and then perform your final status checks.\n2. Better still, use a second rule, triggered at some time after 2 pm to capture the final information for the day. One advantage of this approach is the rule can be run manually after an Atlassian outage, regardless of the current time of day.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Anna",
"body": "Hi Bill,\n\nI was also thinking on using {{now}} as there are some date function for automation to try. I will try your suggestions. Really surprised on how deep your knowledge runs on these topics. Thanks a lot for your response!\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/capture-scheduler-time-in-variable-in-jira-automation/qaq-p/2813320 | null |
{
"author": "Anna Nguyen",
"title": "Create automation for auto closed",
"body": "Hi everyone,\n\nPlease help me this case for Jira Service Management\n\nI would like to create an automation, specifically: The status of a ticket will be automatically changed from Resolved to Closed after 3 days, and when customers reply to those Closed tickets, the system will automatically create a new Jira ticket for that issue to have the correct contact reasons.\n\nThanks\n"
} | [
{
"author": "Jakub Koc",
"body": "Hi Anna, \n\n[This article](https://confluence.atlassian.com/jirakb/automation:-issue-inactivity-follow-ups-and-closure-1130375679.html#:~:text=Using%20Automation%20and%20Service%20Level%20Agreements%20(SLAs)) should help you customize your automation, and [this](https://confluence.atlassian.com/jirakb/configuring-jira-to-prevent-comments-on-closed-issues-1387599245.html#:~:text=This%20behavior%20is%20due%20to,permission.) should help you set up creating new ticket when commented on closed.\n\nHope that helps:)\n",
"comments": [
{
"author": "Anna Nguyen",
"body": "Thanks a lot [@Jakub Koc](/t5/user/viewprofilepage/user-id/5446949)\n\nThis is exactly what I need, I will follow the instructions, and If I have any inquiries, please help me :)\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Create-automation-for-auto-closed/qaq-p/2812863 | null |
{
"author": "Vivek J",
"title": "Is it possible to use Jira automation to transition a ops sub task to DEPLOYED IN PROD.",
"body": "I want to create a Jira automation that automatically deploys an ops sub-task to push Bitbucket changes to production without manual intervention. This automation should run twice a week in scrum board.\n\nThe steps for the automation are as follows:\n\n1. Use the scheduler to create a Non-Development Work ticket.\n2. Create an ops sub-task linked to the Non-Development Work ticket as the parent issue. Both the task and the ops sub-task need to be visible in the current sprint for visibility purposes.\n3. Transition the ops sub-task to 'Ready for Prod' and then to 'Deployed in Prod' (if possible, directly transitioning to 'Deployed in Prod' to trigger deployment).\n4. Once the ops sub-task is deployed to production, it should trigger the Bitbucket deployment.\n5. Send an email to my team indicating that the automation has been triggered and requesting confirmation.\n6. Transition the Non-Development Work ticket to 'Done'.\n\nThe screenshot I provided is the automation I tired to make myself, it currently only creates the Non-Development work ticket only, rest of the automation fails.  \n"
} | [
{
"author": "Manoj Gangwar",
"body": "Hi [@Vivek J](/t5/user/viewprofilepage/user-id/5593887) Welcome to the community!\n\nTo create this Jira automation for deploying a Bitbucket change, follow these steps. You will need both Jira automation rules and potentially integrations with Bitbucket pipelines or APIs.\n\nSteps:\n\nCreate a scheduled trigger:\n\nIn Jira Automation, create a rule with the trigger \"Scheduled\" and set it to run twice a week (e.g., on specific days or intervals).\n\nCreate a Non-Development Work ticket:\n\nAfter the trigger, use the \"Create Issue\" action to create a new ticket (Non-Development Work).\n\nSet necessary fields like the project, issue type, summary, and any custom fields.\n\nCreate an ops sub-task linked to the parent issue:\n\nAdd another \"Create Issue\" action to create a sub-task. Link it to the previously created Non-Development Work ticket using the \"Parent Issue\" field.\n\nEnsure that both tickets (task and sub-task) are assigned to the current sprint by using the \"Edit Issue\" action to update the sprint field.\n\nTransition the ops sub-task:\n\nAdd a \"Transition Issue\" action to move the ops sub-task to 'Ready for Prod.'\n\nAfter this, add another transition to move the sub-task to 'Deployed in Prod.'\n\nIf your workflow supports direct transitions, you can combine these into one step. If not, use two transition actions.\n\nTrigger Bitbucket deployment:\n\nUse the \"Send web request\" action to trigger a Bitbucket deployment via its API or a webhook. Ensure the correct API token and endpoints are used to execute the deployment to production.\n\nSend an email notification:\n\nAdd an action to \"Send Email\" to notify your team. Include key information, like which issue was moved to production and when. Optionally request confirmation from the team.\n\nTransition the Non-Development Work ticket:\n\nAfter the Bitbucket deployment, transition the Non-Development Work ticket to 'Done' using the \"Transition Issue\" action.\n",
"comments": [
{
"author": "Vivek J",
"body": "Hi [@Manoj Gangwar](/t5/user/viewprofilepage/user-id/4484987), if I use the scheduler to automate the 'send web request' for the Bitbucket deployment, can I skip creating the tasks and ops sub-tasks altogether?\n"
},
{
"author": "Manoj Gangwar",
"body": "Yes, you can skip.\n"
},
{
"author": "Vivek J",
"body": "Hi [@Manoj Gangwar](/t5/user/viewprofilepage/user-id/4484987) we couldn't get the web request to work so I went back to using transitions to deploy the ops sub task, I broke the automation into 2 parts for simplicity. Part 1 is the creation of non-dev work task and ops sub task(This automation works), and part 2 is the transition of the ops sub task I'm getting an error for that I'm not sure how to fix the error do you have any ideas how I can fix this issue that can be seen in audit log. \n"
},
{
"author": "Manoj Gangwar",
"body": "Hi [@Vivek J](/t5/user/viewprofilepage/user-id/5593887)\n\nPlease check your workflow, i think there is no direct transition from ready for prod to deployed in prod. If not then add the transition\n"
},
{
"author": "Vivek J",
"body": "Hi [@Manoj Gangwar](/t5/user/viewprofilepage/user-id/4484987) this is my current workflow, based on what I see we don't have the direct transition. Can you show me an example of what the workflow would look like for my automation to work? I don't have access to creating workflow since it's a company managed project, so I would need to send the admin a screenshot of what it should be most likely to see if they can create it. \n"
},
{
"author": "Manoj Gangwar",
"body": "Hi [@Vivek J](/t5/user/viewprofilepage/user-id/5593887) workflow looks good. Could you please check if you are able to chane the status from In development to Ready for prod manually?\n\nIf ready for prod status transition option is not showing then check with admin there could be some validator Or condition are applied on the workflow.\n"
},
{
"author": "Vivek J",
"body": "Hi [@Manoj Gangwar](/t5/user/viewprofilepage/user-id/4484987) I can change it from in development to ready for prod manually, which is why it's weird that I got that error since I'm trying to move it from in development to ready for prod to deployed in prod, which we have a workflow for.\n"
},
{
"author": "Manoj Gangwar",
"body": "Hi [@Vivek J](/t5/user/viewprofilepage/user-id/5593887) could you please replace the rule actor with your name and then test?\n"
},
{
"author": "Vivek J",
"body": "Hi [@Manoj Gangwar](/t5/user/viewprofilepage/user-id/4484987) it worked once I changed the rule actor to myself, thank you for all the help.\n"
},
{
"author": "Manoj Gangwar",
"body": "Gald to help. Please accept the answer.\n"
},
{
"author": "Vivek J",
"body": "Done, thank you.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Is-it-possible-to-use-Jira-automation-to-transition-a-ops-sub/qaq-p/2813577 | [
"cloud"
] |
{
"author": "May Ovdat",
"title": "Automatically transition parent when child and grandchild are transitioning",
"body": "Hi community\n\nI have the following hierarchy -\n\nEpic called A (hierarchy 1) \nTask called B (hierarchy 0) \nSubtask called C (hierarchy -1)\n\nI opt to have automation, that once an issue of any hierarchy level (besides 1) transitions to in progress, the issue above it transitions as well.\n\nThis is the automation I created -\n\n\n\nOnce I transition subtask C, Task B transitioned as well, but it didn't transition Epic A as I hoped it would. \n\nI assume it didnt work since the transition of B was triggered by automation and not actual transition by user?\n\nPlease help me create an automation that will cover grandchild -\\> grandparent \n\nThanks!\n"
} | [
{
"author": "Arkadiusz Inglot",
"body": "Hi,\n\nPlease navigate to Rule details, and make sure:\n\n*Check to allow other rule actions to trigger this rule. Only enable this if you need this rule to execute in response to another rule.*\n\nis checked. This allows a automation rule trigger another rule.\n",
"comments": [
{
"author": "May Ovdat",
"body": "great thank you!!!!!!\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Automatically-transition-parent-when-child-and-grandchild-are/qaq-p/2810550 | [
"cloud"
] |
{
"author": "Dorene Watson",
"title": "Configure outgoing webhook using Automation for JIRA",
"body": "Hello,\n\nI'm trying to set up an Outgoing Webhook to an external system using Jira Automation. Webhook gets posted successfully, but I get an error message that the webhook is not registered.\n\nDoes anyone know if this means that it's not registered on the Jira side or on the external system?\n\nScreen shot with details is below. Thanks in advance!\n\nDorene\n\n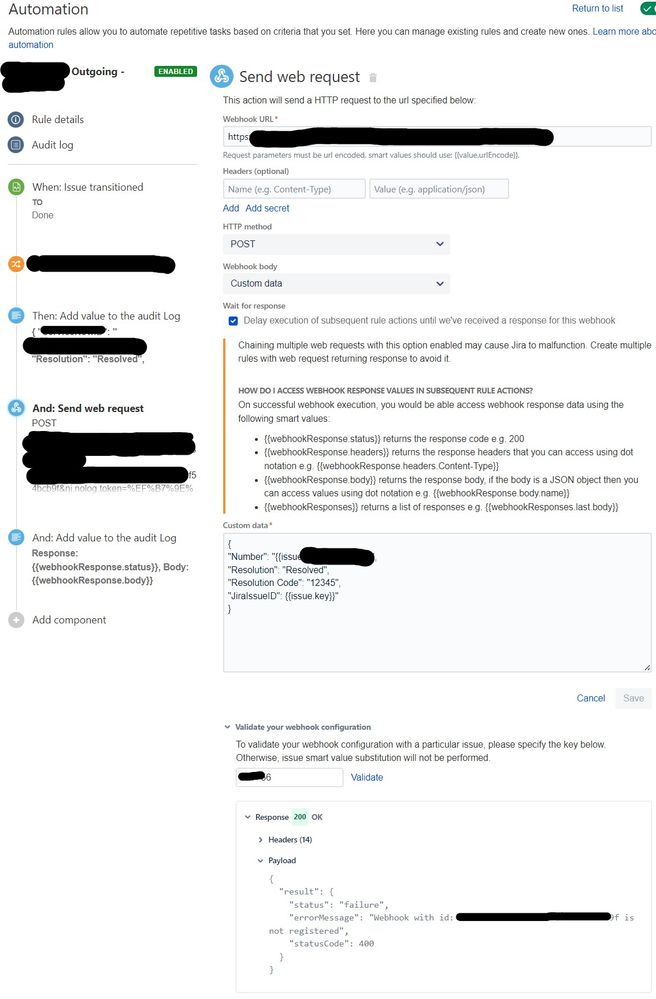\n"
} | [
{
"author": "Rick Westbrock",
"body": "I think that must mean the webhook on the external system since the Send Web Request action in the automation is not a webhook but is making an outbound call. Based on the HTTP 400 response my first thought is to check the URL of the external system's webhook to see if there's a typo.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Configure-outgoing-webhook-using-Automation-for-JIRA/qaq-p/2809869 | [
"datacenter",
"jira-software",
"webhooks"
] |
{
"author": "Julia Casciato",
"title": "How can I use Jira Automation Send Web Request to Update an Existing Confluence Page?",
"body": "I have a Jira Automation that creates a new Confluence page and this works well, but I want to edit/add content to an existing Confluence page with a web request.\n\nI'm running into an issue where my original content on the page is completely deleted, but I only want to add content, not remove it. Is this possible?\n\nI'm using a PUT method with Custom data request body: \n\n{ \"version\": \n{ \"number\": \"{{#=}}{{webResponse.body.version.number}} + 1{{/}}\" }, \n\"type\": \"page\", \n\"status\":\"current\", \n\"title\": \"Test Page\", \n\"body\": { \n\"storage\": { \n\"value\": \"\\<p\\>sample text\\</p\\>{{webResponse.body.body.storage.value}}\", \n\"representation\": \"storage\" \n} \n} \n}\n"
} | [
{
"author": "Rick Westbrock",
"body": "From what I have seen there is no way to add content to an existing page. Instead you would have to retrieve the current body of the page into a variable, update the variable to insert the additional content then make the API call to Confluence passing the modified body content to update the page.\n\nThis is a technical constraint that we ran into in the past and it's unfortunate that they don't provide an API to append to the end of the page body.\n",
"comments": [
{
"author": "Julia Casciato",
"body": "Do you know how I could retrieve the current body and set as a variable to reuse?\n\nAnd I agree, it would be super useful if they had an API call for this.\n"
},
{
"author": "Rick Westbrock",
"body": "The [Get page by id](https://developer.atlassian.com/cloud/confluence/rest/v2/api-group-page/#api-pages-id-get) API will return a **body** element which has three child elements:\n\n* storage\n* atlas_doc_format\n* view\n\nEach of those children has two child elements (string):\n\n* representation\n* value\n\nIt looks like the [Get pages](https://developer.atlassian.com/cloud/confluence/rest/v2/api-group-page/#api-pages-get) API also returns the **body** element but it only has the storage and atlas_doc_format children.\n\nI haven't personally used either of these APIs so I can't speak to how you would use the different body child elements.\n"
}
]
},
{
"author": "Jyoti Mane",
"body": "Hello [@Julia Casciato](/t5/user/viewprofilepage/user-id/5590348)\n\nTo update the existing page :-\n\n1) you need custom field (short text type ) in your jira project to capture confluece page ID. in my case it is (issue.customfield_15715)\n\n2)In your automation rule you first need to get the confluece page that you need to update and then PUT/update page\n\n\n\nIn \"PUT\" web request, custom data should be like :-\n\n{ \n\"id\":\"{{issue.customfield_15715}}\", \n\"version\": { \n\"number\": {{webresponse.body.version.number.plus(1)}} \n}, \n\"spaceId\": \"space_id\", \n\"status\": \"current\", \n\"title\": \"xyz\", \n\"parentId\":\"xyz\", \n\"body\":{ \n\"representation\": \"storage\", \n\"value\": \"\\<p\\> \\</p\\>\n\n}\n\n}\n\nAlso, make sure to select \"Delay execution of subsequent rule actions until we've received a response for this web request\"\n",
"comments": [
{
"author": "Julia Casciato",
"body": "I'm not sure how to get this custom field ID for a Confluence Page. I was using the Page ID, and I realized it was missing from the second request but the same issue happens.\n\nFirst request: GET\n\nhttps://\\[URL\\].atlassian.net/wiki/rest/api/content/2641690627\n\nDelay option is checked\n\nSecond request: PUT\n\nhttps://\\[URL\\].atlassian.net/wiki/rest/api/content/2641690627 \n\n{ \n\"id\": \"2641690627\", \n\"version\": { \n\"number\": \"{{#=}}{{webResponse.body.version.number}} + 1{{/}}\" \n}, \n\"type\": \"page\", \n\"status\":\"current\", \n\"title\": \"Hotfixes 2024\", \n\"body\": { \n\"storage\": { \n\"value\": \"{{webResponse.body.body.storage.value}}\\<p\\>Updated Content\\</p\\> \", \n\"representation\": \"storage\" \n} \n} \n}\n"
},
{
"author": "Rick Westbrock",
"body": "It looks like Jyoti was suggesting that you store the Confluence page ID in the Jira custom field but I think if you already know the page ID you could just hard-code it instead.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/How-can-I-use-Jira-Automation-Send-Web-Request-to-Update-an/qaq-p/2809903 | [
"confluence",
"web-request"
] |
{
"author": "Stuart Wosika",
"title": "I want to create a total (sum) for a custom field (Jira Data Center version)",
"body": "Hi guys,\n\n* I have a custom field called \"Risk Score\" which holds a number\n* This custom field is linked to an issuetype = Risk\n* On triggering of an update to this issuetype\n* I want to get all risks\n* I want to then add up the total for all of the risks \"Risk Score\"\n* Then use this total to update a field or pass to an email for example\n\nSo I:\n\n* I tried to create a branch (For JQL)\n * I tried smart value \"lookupIssues\" with sum but although I do not get an error when running the rule, sum does not seem to do anything:\n * {{lookupIssues.customfield_11139.sum}}\n * I created a variable to store the total but could not get this to work as could not work out how to update the variable\n\nJust trying to do something I thought would be simple. I must be missing something. Can anyone help me with an example rule please?\n"
} | [
{
"author": "Stuart Wosika",
"body": "Hi guys, the documentation suggests the following but is not clear. You cannot use properties such as sum and max with custom fields in a Jira Automation rule (Jira Data Center platform). There is a ticket open with Atlassian that relates to this issue but even that is not clear on which properties are not supported.\n\nI found another article that identified a possible workaround is to use the ACTION \"send web request\". This is where (in my use case) I use the search method (API) and JQL to query Jira via the API. I have now got this working and I am now able to sum up a field (value) for a number of issues successfully.\n\nFYI\n\n1. Action : Send web request\n\n2. \"Send web request\" configuration:\n\nWebhook URL : https://\\<your domain\\>/rest/api/2/search/\n\nHeaders: Authorization Bearer \\<PAT id you have created in Jira\\>\n\nAccept application/json\n\nHTTP Method: Post\n\nWebhook Body (custom data):\n\n{\n\n\"fields\": \\[\n\n\"summary\",\n\n\"status\",\n\n\"customfield_11139\"\n\n\\],\n\n\"jql\": \"project=NPR and issuetype=risk\"\n\n}\n\nNOTE: You can use any API call GET or POST. The above returns all issues of type risk\n\nfor a specific project\n\n3. Now sum up the custom field \"Score Risk\" which is field customfield_11139. There are\n\nmultiple actions where you can do this. I am showing example using \"Send email\"\n\nContent:\n\nTotal Risk Score = {{webhookResponse.body.issues.fields.customfield_11139.sum}}\n\nComplete Payload Response =\n\n{{webhookResponses}}\n\nHope this helps someone in the future.\n\nRegards.\n\nStuart.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/I-want-to-create-a-total-sum-for-a-custom-field-Jira-Data-Center/qaq-p/2809379 | null |
{
"author": "Stefano De Santis",
"title": "Initiative sets in canceled - also all tickets related get the same status",
"body": "I need a global automation that if I set the status \"canceled\" to an initiative then all the children, both work packages and epics and stories, take the status canceled\n"
} | [
{
"author": "Manoj Gangwar",
"body": "Hi [@Stefano De Santis](/t5/user/viewprofilepage/user-id/5303184)\n\nYou can create an automation like below example:\n\n**Example of Automation Rule Configuration:**\n\n* **Trigger:** Issue Transitioned\n\n * Status: Canceled\n* **Condition:** Issue Fields Condition\n\n * Field: Issue Type\n * Condition: equals\n * Value: Initiative\n* **Action:** Branch rule / related issues\n\n * Branch: Children\n* **Action within Branch:** Edit Issue\n\n * Field: Status\n * Value: Canceled\n",
"comments": [
{
"author": "Trudy Claspill",
"body": "Adding to this...\n\n[@Stefano De Santis](/t5/user/viewprofilepage/user-id/5303184)\n\nDo you use only Company Managed projects in your instance or do you also use Team Managed projects?\n\nIf you use Team Managed projects do you expect the issues in those projects to be transitioned also?\n"
},
{
"author": "Stefano De Santis",
"body": "I want to spread the rule also to Team Managed projects. Thank you\n"
},
{
"author": "Trudy Claspill",
"body": "I do not believe you can use a Global rule to change statuses on issues in Team Managed projects.\n\nWithin an Automation rule when you use a Transition Issue action and select a specific status, in the backend the automation rule is finding the unique ID associated with that Status.\n\nCompany Managed projects use globally defined status values, so the \"Canceled\" status in them is the same single Status in the backend.\n\nTeam Managed project have project specific statuses. Even if the Team Managed project uses a status named \"Canceled\" it is a different status the the \"Canceled\" status used in Company Managed projects and different from any \"Canceled\" status used in another Team Managed project. The backend ID for each of those Canceled statuses will be different. A Global automation rule won't be able to determine which one it should actually use.\n\nYou mentioned \"initiatives\" as the trigger issue.\n\nAre you using a Premium or Enterprise subscription where you have extended the Issue Type Hierarchy to include level(s) above Epics for Initiative and potentially other issues? That would add another wrinkle to the use the creation of the rule(s) since the issue hierarchy can't be extended directly in Team Managed projects. Instead you have to have the issues for those additional levels in a Company Managed project, and make the TM issues children of those CM project issues.\n\nI think that you would have to have multiple rules, with rules specifically for each Team Managed project.\n"
},
{
"author": "Stefano De Santis",
"body": "I use an Enterprise subscription\n"
},
{
"author": "Trudy Claspill",
"body": "Are you cross-project-parenting the issues so that Team Managed project issue might be descendants under Initiatives?\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Initiative-sets-in-canceled-also-all-tickets-related-get-the/qaq-p/2809089 | null |
{
"author": "Tim Larkman",
"title": "Automation to send an email when the renewal date is approaching",
"body": "We have a Team Managed project in Jira that tracks the status of all our vendors.\n\nSome of the notable fields we have include the following:\n\nBusiness Owner (people field) - The person who has the relationship with the vendor\n\nRenewal date (date field) - This is the date that the contract with the vendor is set to renew\n\nNotice period (dropdown list) - The is the number of days required to give notice for the cancelation of the contract. Available options include, 30 days, 60 days, 90 days\n\nI would like to create an automation rule which will send an email reminder to the business owner stating that the contract is due for renewal soon. The notification should go based on the notice period.\n\nAs an example. If the renewal date is 30 Nov and the notice period is 30 days, Then i should be able to send an email reminder to the business owner say 45 days prior to the renewal date. \n\nis this possible using Automation and if so how would i do that?\n"
} | [
{
"author": "Manon Soubies-Camy",
"body": "Hi [@Tim Larkman](/t5/user/viewprofilepage/user-id/5589667),\n\nI agree with [@Trudy Claspill](/t5/user/viewprofilepage/user-id/3569011), you need a Scheduled trigger and conditions to compare dates. I would also add that:\n\n* Team-managed projects have a limitation where People custom fields, such as your Business Owner one, aren't supported by Jira Cloud automations at the moment ([see more info here](https://support.atlassian.com/cloud-automation/docs/limitations-in-team-managed-projects-for-automation-rules/)). You could use the Assignee field instead of the Business Owner one.\n* I would recommend adding a comment to the Jira issue rather than sending an email. This will help tracking renewal history and decisions.\n* I would also recommend having a dedicated workflow status, for example \"Renewal evaluation\".\n\nThis is what your automation rule would look like:\n\n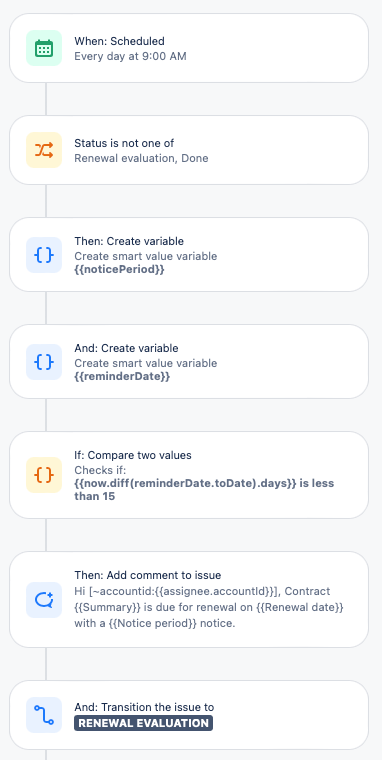\n\nBelow are the smart values I'm using:\n\n* noticePeriod variable: {{Notice period.value.split(\" \").first}}\n* reminderDate variable: {{Renewal date.minusDays(noticePeriod.asNumber)}}\n* Condition: {{now.diff(reminderDate.toDate).days}}\n* Assignee mention: \\[\\~accountid:{{assignee.accountId}}\\]\n\nHope this helps!\n\n- Manon\n",
"comments": [
{
"author": "Tim Larkman",
"body": "Hi [@Manon Soubies-Camy](/t5/user/viewprofilepage/user-id/1215212) \nthanks for your very detailed response. \nI have created a new \"Service management\" project to handle my vendors. I found it gave me more flexibility. \nIn your automation field for \"if Compare two values\" is it taking the reminder date and subtracting 15 days to it? So for example. \nRenewal date = 30 November \nNotice Period = 30 days \nReminder date is thus 31 Oct. It then subtracts 15 days which takes us to 16 Oct. \nThe comment will then get sent on 16 Oct to the business owner? Is my understanding correct? \n\nAlso, Not sure why the rule doesn't like my \"Status is not one of\" Policy? Any Ideas? 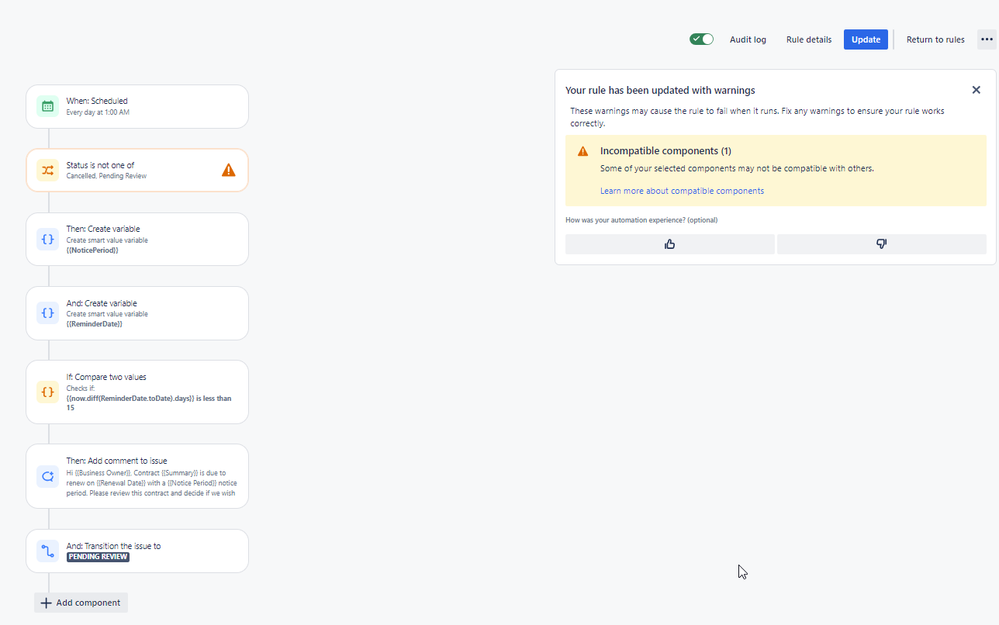\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Hi [@Tim Larkman](/t5/user/viewprofilepage/user-id/5589667), yes, you're correct! Notice period = 30/60/90 days, and 15 is the number of days you want add on top of that to get your reminder on time.\n\nFor the \"Incompatible component\" error, it might be due to your Scheduled trigger, did you filter with a JQL query?\n\n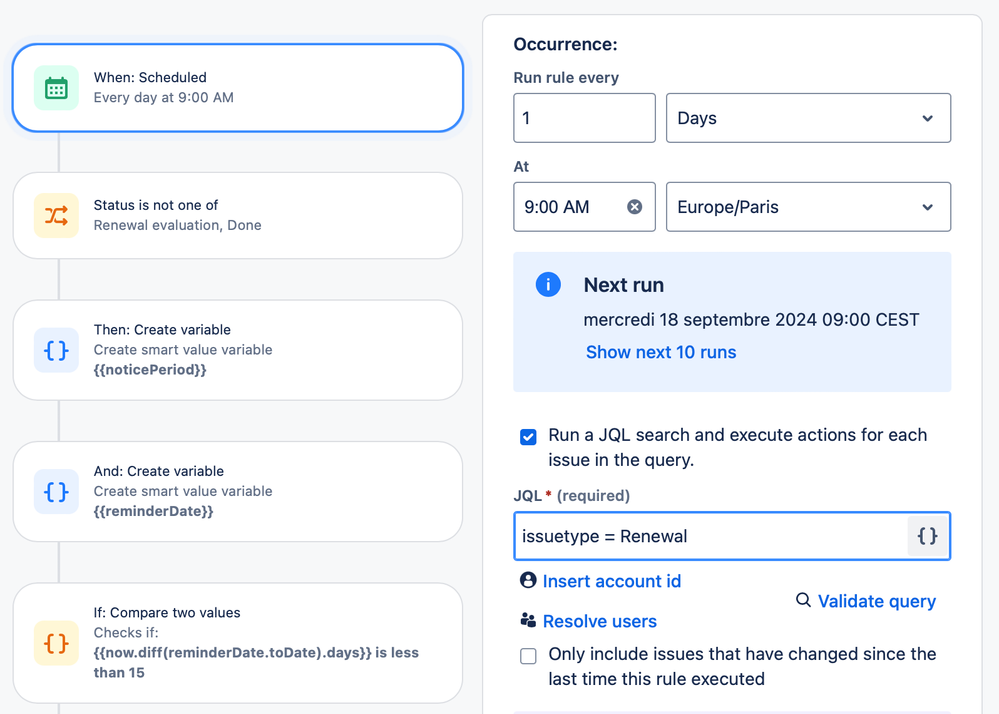\n"
},
{
"author": "Tim Larkman",
"body": "Hi [@Manon Soubies-Camy](/t5/user/viewprofilepage/user-id/1215212)\n\nWith your help i have managed to get this mostly working with only one hiccup remaining.\n\nThe \"if: Compare two values\" doesn't seem to want to work. \n\nThe audit log shows the following.\n\n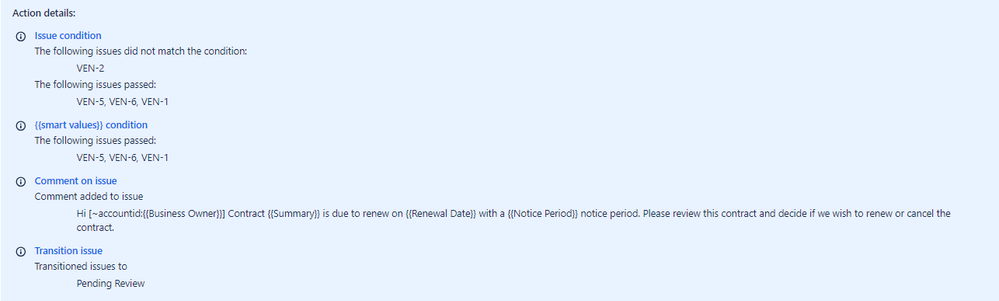\n\nThe issue condition part works perfectly.\n\nThe problem is in the Smart Values condition.\n\nI would expect a comment to get generated for VEN-5 and VEN-1 but VEN-6 has a renewal date of 28 Aug 2025 so i would expect not to get a comment generated for this Vendor but regretfully i do. Not sure what im doing wrong here.\n\n<br />\n\nThis is the comment i would expect not to receive. \n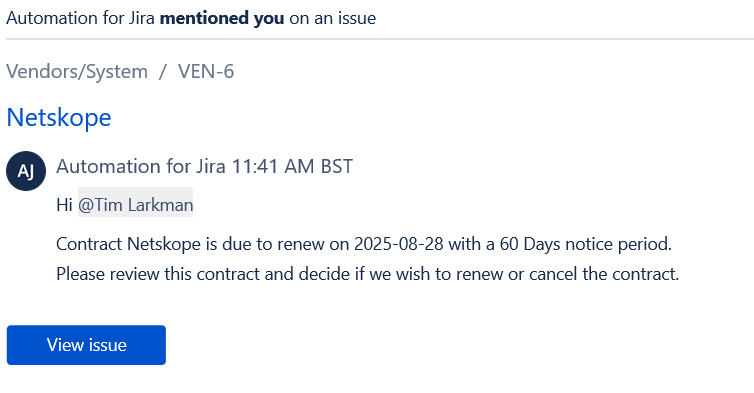\n\nThis is the rule details.\n\n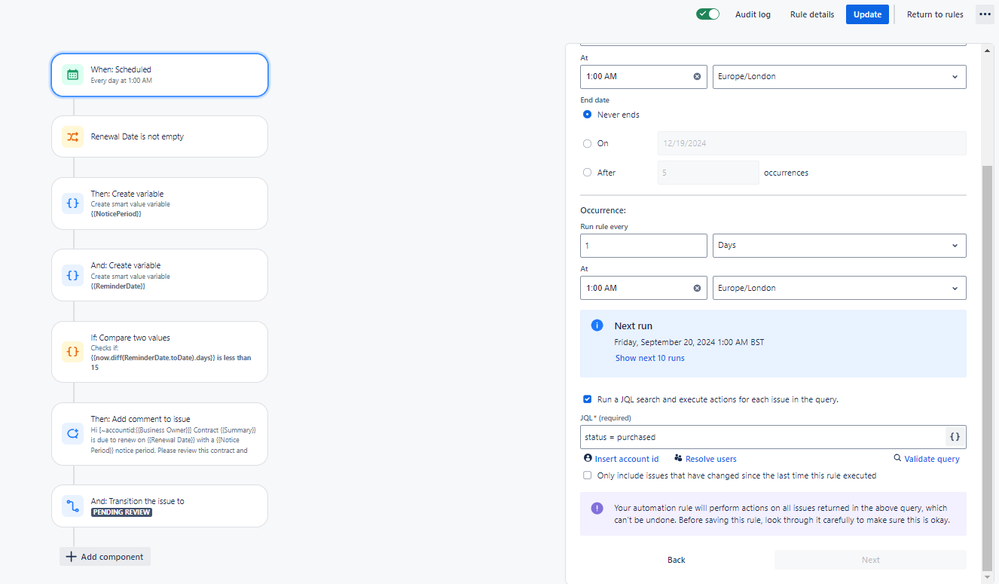\n\nAs always, many thanks for your help on this issue.\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Hi [@Tim Larkman](/t5/user/viewprofilepage/user-id/5589667),\n\nThanks for the detailed screenshots! That's very weird because I tried using your values (renewal in August 2025 with a 60 days notice period), and it works as expected on my end: no comment is triggered for that issue.\n\n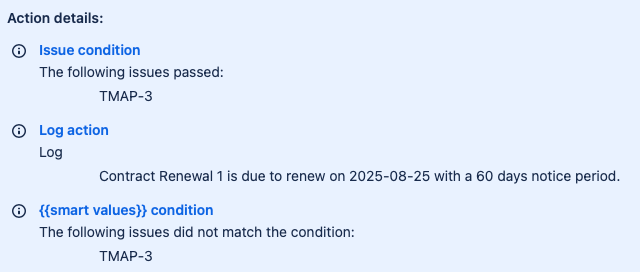\n\nCan you share a screenshot of your reminderDate and noticePeriod variables' configuration?\n"
},
{
"author": "Tim Larkman",
"body": "Hi [@Manon Soubies-Camy](/t5/user/viewprofilepage/user-id/1215212)\n\nSure thing, Please see below screen shots\n\n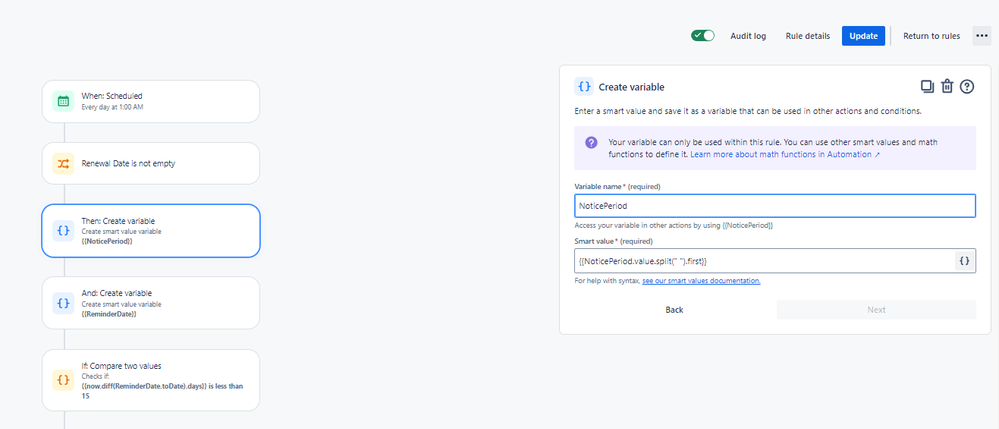\n\n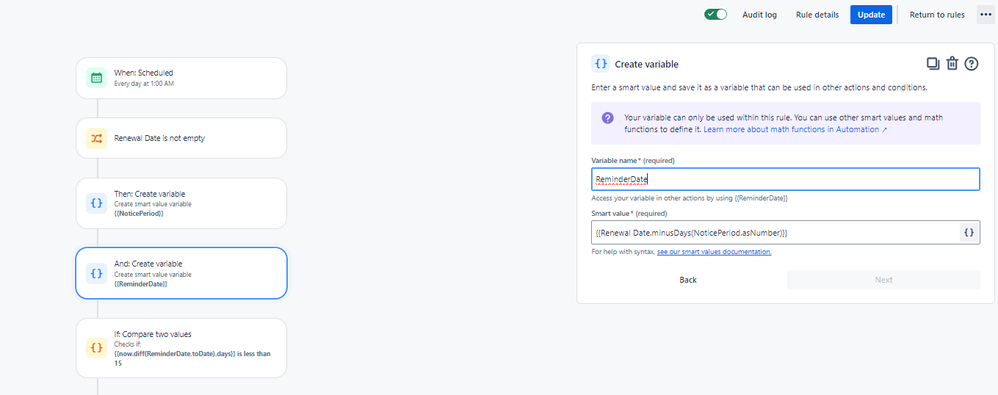\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Ah, I found a typo in your noticePeriod variable: can you try and add a space in the smart value? You should type in the name of your custom field (which has a space), instead of the variable (which doesn't have a space):\n\n\n"
},
{
"author": "Tim Larkman",
"body": "Thanks [@Manon Soubies-Camy](/t5/user/viewprofilepage/user-id/1215212)\n\nYou're a legend! it works perfectly now.\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Very happy to hear it's now working! :)\n"
}
]
},
{
"author": "Bill Sheboy",
"body": "Hi [@Tim Larkman](/t5/user/viewprofilepage/user-id/5589667) -- Welcome to the Atlassian Community!\n\nAdding to the other suggestions provided:\n\nPeople-type fields (e.g., your Business Owner field) do not provide the email address to automation rules at this time: <https://jira.atlassian.com/browse/AUTO-519>\n\nThe two possible workarounds are:\n\n1. Using the accountId from the user field, call the REST API endpoint with the Send Web Request action to get the user's data, including the email address: <https://community.atlassian.com/t5/Jira-articles/Automation-for-Jira-Send-web-request-using-Jira-REST-API/ba-p/1443828>\n2. Replace your team-managed project's People-type field with a global / company-managed user-picker field. Team-managed projects now allow using those shared fields to help ensure consistency across team-managed projects (and to solve limitations like with the People fields).\n\nKind regards, \nBill\n",
"comments": null
},
{
"author": "Trudy Claspill",
"body": "Hello [@Tim Larkman](/t5/user/viewprofilepage/user-id/5589667)\n\nWelcome to the Atlassian community.\n\nYes, it is possible. You could use an Automation Rule with a Scheduled trigger. The trigger could include a JQL to select the issues that match criteria. Perhaps you want to select all the issues for which the renewal date is in the future, or where the renewal date in sometime in the next 365 days.\n\nYou would schedule the rule to run daily.\n\nYou would then use conditions to determine if an email should be sent. The specifics of the conditions require clarification:\n\nHow do you determine that when the notice period is X days then you want to send the email at X+n days before the renewal date? How do you determine what \"n\" should be?\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Automation-to-send-an-email-when-the-renewal-date-is-approaching/qaq-p/2809086 | null |
{
"author": "Wiryono",
"title": "Restricting creating branch by push",
"body": "Hi is there a way to restrict pushing new branch unless specify in the branch permission ?\n\n<br />\n\nLets say I have this branch specify in the branch restriction\n\nmain\n\ntest\n\ndev/\\*\n\nfeature/\\*\n\nrelease/\\*\n\nHow do I make sure they not pushing \"my-custom-unknwon-branch\" to this repo\n"
} | [
{
"author": "Ulrich Kuhnhardt _IzymesCo_",
"body": "If you were on Bitbucket *server* you could add a custom server side pre-receive hook.\n\nSince you're on Bitbucket cloud there is no such mechanism in place.\n\nThere is a 10-year old feature request - <https://jira.atlassian.com/browse/BCLOUD-10471> - for allowing server-side pre-receive hook. You are welcome to vote for and watch this issue.\n\nAtlassian [proposes a work-around](https://jira.atlassian.com/browse/BCLOUD-10471?focusedId=3407404&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-3407404) of using custom merge-checks based on the Forge platform. I think you could create a custom merge-check that check the PR source branch pattern and veto the PR if the PR source branch pattern is not valid, i.e. 'my-custom-----'\n\nThis is not exactly what you are asking for, but it would discourage users to push random branch names because the PRs that they create, won't get merged.\n\nMerge-checks allow you to display a message, which you could use to 'educate' the person that pushed the custom branch name.\n\nHope that helps\n\nBest, Ulrich\n\n// [Izymes](https://marketplace.atlassian.com/vendors/1210584/izymes-pty-ltd)\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Restricting-creating-branch-by-push/qaq-p/2822292 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Yossi Geretz",
"title": "I can't install Angular inside my pipeline",
"body": "I am trying to execute the following command so that I can build my Angular application within the pipeline:\n\n- npm install -g @angular/cli\n\nBut this throws an error:\n\n+ npm install -g @angular/cli npm\n\nERR! code EUNSUPPORTEDPROTOCOL npm\n\nERR! Unsupported URL Type \"npm:\": npm:string-width@\\^4.2.0 npm\n\nERR! A complete log of this run can be found in: npm\n\nERR! /root/.npm/_logs/2024-09-25T19_58_43_985Z-debug.log npm\n\nERR! code EUNSUPPORTEDPROTOCOL npm\n\nERR! Unsupported URL Type \"npm:\": npm:string-width@\\^4.2.0 npm\n\nERR! A complete log of this run can be found in: npm\n\nERR! /root/.npm/_logs/2024-09-25T19_58_43_985Z-debug.log\n\nHere is the yaml:\n\n(The indentation got lost on the paste.)\n\n- step: \nname: Web Admin Portal Deployment \ncaches: \n- node \nscript: \n- cd Admin \n- npm cache clean --force \n- npm install -g \n- npm install -g @angular/cli \n- ng build --configuration staging \n- cd dist/lightning-admin \n- pipe: atlassian/aws-s3-deploy:1.6.1 \nvariables: \nAWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID \nAWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY \nAWS_DEFAULT_REGION: $AWS_DEFAULT_REGION \nS3_BUCKET: 's3-web-stg-0' \nLOCAL_PATH: '/dist/lightning-admin/'\n"
} | [
{
"author": "Yossi Geretz",
"body": "This might be a clue. I threw a command in there to output the version of node:\n\nnode -v\n\nv8.9.4\n\nYikes! That's quite old! On my workstation I am running v20.15.1\n\nHow can I get a more recent version of Node installed in the pipeline?\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/I-can-t-install-Angular-inside-my-pipeline/qaq-p/2822210 | [
"angular",
"bitbucket-cloud",
"bitbucket-pipelines",
"cloud",
"node.js"
] |
{
"author": "huanqiu",
"title": "use bitbucket api to get and create repository",
"body": "I want use python to get and create repository, and i have create a new App passwords with full auth. I always get wrong status code 401, please help me.\n\nmy python code:\n\nusername = \"xxx\"\n\napp_password = \"xxx\"\n\nbitbucket_api_url = \"<https://api.bitbucket.org/2.0/repositories/>\"\n\ndef check_bitbucket_repo(repo_slug):\n\nresponse = requests.get(urljoin(bitbucket_api_url, f\"{bitbucket_workspace}/{repo_slug}\"), auth=(username, app_password)) #, proxies=proxies #return response.status_code == 200\n\nif response.status_code == 200:\n\nlog_message(f\"Repository {repo_slug} exists in Bitbucket\")\n\nreturn True\n\nelse:\n\nlog_message(f\"Repository {repo_slug} does not exist in Bitbucket. Status code: {response.status_code}\")\n\nreturn False\n"
} | [
{
"author": "huanqiu",
"body": "new question, i use right username and app_password, the 401 issue is fixed, but i got status:404 when i create repository\n\nFailed to create repository test-bitbucket . Status code: 404\n\nYou may not have access to this repository or it no longer exists in this workspace. If you think this repository exists and you have access, make sure you are authenticated.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/use-bitbucket-api-to-get-and-create-repository/qaq-p/2821238 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Mohan Kona",
"title": "Use the Variable in definitions",
"body": "I'm trying to send variable to image in services, bit it seems like the variable is not being accepted and it throws error in the line where image with variable is defined.\n\nPlease find the yaml file below\n\n```\nimage: image:latest definitions: steps: - step: &udpateEnvVariable name: Populate Environment script: - export ENV=dev - if [ \"$FRONTEND_IMAGE\" = \"release\" ]; then export ENV=qa; elif [ \"$FRONTEND_IMAGE\" = \"daily\" ]; then export ENV=dev; else export ENV=dev; fi services: frontend: image: name: image_name:$IMAGE options: docker: true pipelines: custom: dummy: - variables: - name: IMAGE default: daily allowed-values: - daily - release - misc - step: *udpateEnvVariable - step: name: Dummy services: - frontend script: - echo \"ENV is $ENV\" \n```\n\nand below is the error thrown\n\n\n"
} | [
{
"author": "Aron Gombas _Midori_",
"body": "I don't think that the YAML above is valid at all. Validate this with an online validator before anything else.\n\nYAML is very sensitive to indentation and line-breaks, those have important meaning.\n",
"comments": [
{
"author": "Mohan Kona",
"body": "I couldn't paste the code in yaml format, but to make it simple, i'm trying to provide service value as a variable, something like \n\n```\ndefinitions: \n services:\n frontend:\n image:\n name: $docker_image\n```\n\nOR\n\n```\nservices:\n - $docker_image\n```\n"
},
{
"author": "Aron Gombas _Midori_",
"body": "The variable in this case is a regular Bitbucket pipeline variable?\n\nAlso, I don't know, but I guess it is rather likely that variable names are case-sensitive.\n"
},
{
"author": "Mohan Kona",
"body": "no, the variable here is the user defined one.\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Use-the-Variable-in-definitions/qaq-p/2820474 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Rupesh Rokade",
"title": "payment couldnt process or Bitbucket (workspace-id-redacted)",
"body": "Hi Team,\n\nI received the mail form atalassina stating payment for Bitbucket (workspace-id-redacted) due to a problem with your payment details.\n\nCan you please help me on this. As after checking we unable to make the payment.\n\nRegards,\n\nRupesh Rokade\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Rupesh and welcome to the community!\n\nI see that you have contacted our Customer Advocate team as well for this issue. The payment failed because there was an issue with the credit card on file. You will need to contact your credit card provider for more info on how to resolve the issue.\n\nIf you have any further questions, you can reach out via the support ticket you created.\n\nJust a heads up, I removed the workspace ID from your post to protect your privacy.\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/payment-couldnt-process-or-Bitbucket-workspace-id-redacted/qaq-p/2820122 | [
"bitbucket-cloud",
"cloud",
"not-applicable",
"subscriptions-and-billing"
] |
{
"author": "Christophe Verdot",
"title": "error: src refspec master does not match any",
"body": "I have a lot of repo on bitbucket and never had an issue but today, when trying to create a new one, i seem to cannnot set a default master branch, i set it in the repo creation but when i try to push my local code to the repo i get the following: \n\n```\ngit push origin master \nerror: src refspec master does not match any \nerror: failed to push some refs to 'https://bitbucket.org/******/frontend.git'\n```\n\n<br />\n\nIf i go to my repo setting i see the master as default but let's say i try change the repo name, i get an error related to the default branch (see attached screen). \n\nAny idea what is happening? This seem very new, never had such issue before.\n\n<br />\n\n\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Christophe and welcome to the community!\n\nHave you added the changes in the local repo with the following command?\n\n```\ngit add .\n```\n\nAfter that, did you commit the changes with the following command?\n\n```\ngit commit -m \"some commit message\"\n```\n\nI can reproduce the error if I attempt to push from a local repo that doesn't have any commits yet.\n\nDo the following commands show any commits and branches respectively, if you execute them in the directory of you local clone?\n\n```\ngit log\n```\n\n```\ngit branch\n```\n\nRegarding the inability to change the repository details from the website, this is because of a bug that occurs when the repo is empty:\n\n* <https://jira.atlassian.com/browse/BCLOUD-23139>\n\nOnce commits are pushed to the repo, you will be able to change the repo's details.\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/error-src-refspec-master-does-not-match-any/qaq-p/2819808 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Kimberly Anderson",
"title": "Can you use workspace variables in a custom pipe without passing the variable name?",
"body": "We're trying to use a custom pipe that builds its own workspace variable names. In the past, we've always declared the deployment and workspace variables in the variables block for the pipe and we've just been able to use them by name. Is there another way to do it that doesn't require passing the names? We're okay with the pipe getting access to all workspace/deployment variables.\n\nThanks!\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Kimberly and welcome to the community!\n\nThis is possible the following way:\n\n1. You will need to describe the variables in the pipe.yml file of the pipe's repo\n2. Then, you will need to load them in the pipe\n\nAn example of this can be found in the following pipe:\n\n* <https://bitbucket.org/atlassian/aws-cloudformation-deploy/src/master/>\n\nThe variables AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and AWS_DEFAULT_REGION can also be configured as workspace, repository, or deployment variables and then it is not necessary to use them in the pipe's variables block.\n\nFor that to work, the variables are described in the pipe.yml file of the repo:\n\n* <https://bitbucket.org/atlassian/aws-cloudformation-deploy/src/8a0b36184b9b04229a50d3852186c9e0c5f0ed41/pipe.yml#lines-5>\n\nAnd then they are loaded in the pipe in the main.py file (line 529):\n\n* <https://bitbucket.org/atlassian/aws-cloudformation-deploy/src/8a0b36184b9b04229a50d3852186c9e0c5f0ed41/pipe/main.py#lines-529>\n\nPlease note that this will work if you later refer to the pipe in the bitbucket-pipelines.yml of another repo with **- pipe atlassian/aws-cloudformation-deploy:0.20.1** , so the format should be **- pipe: BB_workspace/BB_repo:tag**.\n\nIt will not work if you refer to the pipe by using theDocker image with **- pipe: docker://docker_acct/docker_repo:tag**.\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Can-you-use-workspace-variables-in-a-custom-pipe-without-passing/qaq-p/2819737 | [
"bitbucket-cloud",
"bitbucket-pipelines",
"cloud",
"pipes",
"variable",
"workspace"
] |
{
"author": "Jonathan Duncan",
"title": "Unknown New Bitbucket Pipeline IP Address",
"body": "I have a script that runs in Pipelines. It accesses a resource that is blocked by my load-balancers unless the request is from a known IP address. I have the lists of known Bitbucket IP addresses, so this request usually works. Today it stopped working and the IP that was reported is: \\`44.198.171.117\\`\n\nIs this a new IP that has not made it onto the official lists? A \\`whois\\` shows that it belongs to Amazon.\n\nThat Address is not in any of the lists that I have found:\n\n- <https://support.atlassian.com/organization-administration/docs/ip-addresses-and-domains-for-atlassian-cloud-products/#AtlassiancloudIPrangesanddomains-OutgoingConnections>\n\n- <https://support.atlassian.com/bitbucket-cloud/docs/what-are-the-bitbucket-cloud-ip-addresses-i-should-use-to-configure-my-corporate-firewall/>\n\n- <https://ip-ranges.atlassian.com/>\n"
} | [
{
"author": "Syahrul",
"body": "G'day,\n\nWe have recently [updated our 1x/2x size option builds](https://bitbucket.org/blog/migrating-pipelines-1-2x-steps-to-our-new-ci-cd-runtime) to operate from a new, [broader IP range](https://support.atlassian.com/bitbucket-cloud/docs/what-are-the-bitbucket-cloud-ip-addresses-i-should-use-to-configure-my-corporate-firewall/). To access the complete list of IP addresses, you can use [this endpoint](https://ip-ranges.amazonaws.com/ip-ranges.json) to filter results specifically for **EC2** resources located in **us-east1** and **us-west2**.\n\n**Important Note:** The IP addresses provided via this endpoint are managed by Amazon and are subject to change. We recommend regularly checking this endpoint and updating your firewall's IP list accordingly. Additionally, consider exploring automation options to streamline updating IPs in response to changes.\n\n If you require your builds to run from a more limited set of IP addresses, you must use the atlassian-ip-ranges runtime configuration available on **4x/8x steps** . This configuration is [documented here](https://support.atlassian.com/bitbucket-cloud/docs/step-options/#Runtime).\n\n**Please Note:** Using larger step sizes may have billing implications. Please review the related documentation on step sizes that are [available here](https://support.atlassian.com/bitbucket-cloud/docs/step-options/#Size).\n\nI hope this helps. \n\nRegards, \nSyahrul\n",
"comments": [
{
"author": "Jonathan Duncan",
"body": "I searched for all of the IP addresses that myself and other commenters have specified on this thread. I did not find any of them listed at either of the endpoints that you mentioned:\n\n- <https://ip-ranges.atlassian.com/> \n- <https://ip-ranges.amazonaws.com/ip-ranges.json>\n"
},
{
"author": "Syahrul",
"body": "Hey [@Jonathan Duncan](/t5/user/viewprofilepage/user-id/1170081)\n\nYou can use <https://thameera.com/awsip/> to check for the IPs subnet. It should give you the correct subnet that you can use to allowlist.\n\nRegards, \nSyahrul\n"
}
]
},
{
"author": "Zach Robert",
"body": "Also confirming this - had a few users with deployment issues this morning, found the following 3 IPs being blocked as they weren't part of our Bitbucket Pipeline policy:\n\n44.199.196.217 \n44.211.80.122 \n52.23.252.59\n",
"comments": [
{
"author": "Syahrul",
"body": "Hey [@Zach Robert](/t5/user/viewprofilepage/user-id/5600544)\n\nThese IP addresses are part of the broader IP range listed at [AWS IP Ranges](https://ip-ranges.amazonaws.com/ip-ranges.json).\n\nTo verify the IP addresses you encounter and allowlist specific subnets, you can use [this tool](https://thameera.com/awsip/).\n\nHowever, I recommend filtering for services equal to EC2 or S3 and focusing on the us-east-1 and us-west-2 regions.\n\nRegards, \nSyahrul\n"
}
]
},
{
"author": "Tim Spiekermann",
"body": "I can confirm this.\n\nWe have rsync deployment problems since yesterday and are debugging right now. It seems, there are some new undocumented IP addresses in use:\n\n3.231.55.79 \n44.192.120.9\n",
"comments": [
{
"author": "Syahrul",
"body": "Hey [@Tim Spiekermann](/t5/user/viewprofilepage/user-id/5599211)\n\nThese IP addresses are part of the broader IP range listed at [AWS IP Ranges](https://ip-ranges.amazonaws.com/ip-ranges.json).\n\nTo verify the IP addresses you encounter and allowlist specific subnets, you can use [this tool](https://thameera.com/awsip/).\n\nHowever, I recommend filtering for services equal to EC2 or S3 and focusing on the us-east-1 and us-west-2 regions.\n\nRegards, \nSyahrul\n"
},
{
"author": "Tim Spiekermann",
"body": "Thank you,\n\nwe are using atlassian-ip-range: true and size: x4 config now and it works.\n"
}
]
},
{
"author": "Tim Spiekermann",
"body": "See answer here:\n\n<https://community.atlassian.com/t5/Bitbucket-questions/bitbucket-new-pipline-ip-address-list/qaq-p/2817058>\n\nThey are using a lot of AWS IP ranges per default now, but you can configure your x4/x8 pipeline with atlassian-ip-ranges: true.\n\nJust tested it and it works (it does not without size: 4x)\n",
"comments": [
{
"author": "Corey Mohler",
"body": "I tried adding that to my pipeline but I'm still getting new ips.\n"
}
]
},
{
"author": "Renato Lima",
"body": "There is this blog post regarding the change <https://bitbucket.org/blog/evolving-bitbucket-pipelines-to-unlock-faster-performance-and-larger-builds>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Unknown-New-Bitbucket-Pipeline-IP-Address/qaq-p/2819738 | [
"bitbucket-cloud",
"cloud"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.