
datasetId
stringlengths 5
121
| author
stringlengths 2
42
| last_modified
unknown | downloads
int64 0
32.1M
| likes
int64 0
5.8k
| tags
sequencelengths 1
7.92k
| task_categories
sequencelengths 0
40
⌀ | createdAt
unknown | card
stringlengths 19
977k
|
|---|---|---|---|---|---|---|---|---|
maritaca-ai/enem | maritaca-ai | "2023-12-19T19:08:47Z" | 3,018 | 3 | [
"task_categories:visual-question-answering",
"task_categories:multiple-choice",
"language:pt",
"license:apache-2.0",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2311.14169",
"arxiv:2303.17003",
"region:us"
] | [
"visual-question-answering",
"multiple-choice"
] | "2023-11-24T12:55:21Z" | ---
license: apache-2.0
configs:
- config_name: '2022'
data_files: 2022.jsonl
- config_name: '2023'
data_files: 2023.jsonl
default: true
dataset_info:
features:
- name: id
dtype: string
- name: exam
dtype: string
- name: IU
dtype: bool
- name: ledor
dtype: bool
- name: question
dtype: string
- name: alternatives
sequence: string
- name: figures
sequence: string
- name: description
sequence: string
- name: label
dtype: string
task_categories:
- visual-question-answering
- multiple-choice
language:
- pt
pretty_name: ENEM
size_categories:
- n<1K
---
The enem 2022 and enem 2023 datasets encompass all multiple-choice questions from the last two editions of the [Exame Nacional do Ensino Médio (ENEM)](https://www.gov.br/inep/pt-br/areas-de-atuacao/avaliacao-e-exames-educacionais/enem), the main standardized entrance examination adopted by Brazilian universities. The datasets have been created to allow the evaluation of both textual-only and textual-visual language models. To evaluate textual-only models, we incorporated into the datasets the textual descriptions of the images that appear in the questions' statements from the orange ENEM exam booklet, a particular booklet that offers accessibility to people with visual impairments.
A repository containing the essential code for utilizing this dataset is accessible [here](https://github.com/piresramon/gpt-4-enem).
If you use this dataset in your research, please acknowledge the papers below by citing them:
```bibtex
@misc{pires2023evaluating,
title={Evaluating GPT-4's Vision Capabilities on Brazilian University Admission Exams},
author={Ramon Pires and Thales Sales Almeida and Hugo Abonizio and Rodrigo Nogueira},
year={2023},
eprint={2311.14169},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{nunes2023evaluating,
title={Evaluating GPT-3.5 and GPT-4 Models on Brazilian University Admission Exams},
author={Desnes Nunes and Ricardo Primi and Ramon Pires and Roberto Lotufo and Rodrigo Nogueira},
year={2023},
eprint={2303.17003},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
open-llm-leaderboard-old/details_Mikivis__xuanxuan | open-llm-leaderboard-old | "2023-09-16T21:42:12Z" | 3,004 | 0 | [
"region:us"
] | null | "2023-09-01T13:15:05Z" | ---
pretty_name: Evaluation run of Mikivis/xuanxuan
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [Mikivis/xuanxuan](https://huggingface.co/Mikivis/xuanxuan) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Mikivis__xuanxuan\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-16T21:42:00.993318](https://huggingface.co/datasets/open-llm-leaderboard/details_Mikivis__xuanxuan/blob/main/results_2023-09-16T21-42-00.993318.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.008389261744966443,\n\
\ \"em_stderr\": 0.000934054321686696,\n \"f1\": 0.05742869127516786,\n\
\ \"f1_stderr\": 0.0015884226243297857,\n \"acc\": 0.2521704814522494,\n\
\ \"acc_stderr\": 0.00702597803203845\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.008389261744966443,\n \"em_stderr\": 0.000934054321686696,\n\
\ \"f1\": 0.05742869127516786,\n \"f1_stderr\": 0.0015884226243297857\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0,\n \"acc_stderr\"\
: 0.0\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.5043409629044988,\n\
\ \"acc_stderr\": 0.0140519560640769\n }\n}\n```"
repo_url: https://huggingface.co/Mikivis/xuanxuan
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|arc:challenge|25_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_16T21_42_00.993318
path:
- '**/details_harness|drop|3_2023-09-16T21-42-00.993318.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-16T21-42-00.993318.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_16T21_42_00.993318
path:
- '**/details_harness|gsm8k|5_2023-09-16T21-42-00.993318.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-16T21-42-00.993318.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hellaswag|10_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T13:14:51.241896.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-01T13:14:51.241896.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-01T13:14:51.241896.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_16T21_42_00.993318
path:
- '**/details_harness|winogrande|5_2023-09-16T21-42-00.993318.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-16T21-42-00.993318.parquet'
- config_name: results
data_files:
- split: 2023_09_01T13_14_51.241896
path:
- results_2023-09-01T13:14:51.241896.parquet
- split: 2023_09_16T21_42_00.993318
path:
- results_2023-09-16T21-42-00.993318.parquet
- split: latest
path:
- results_2023-09-16T21-42-00.993318.parquet
---
# Dataset Card for Evaluation run of Mikivis/xuanxuan
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/Mikivis/xuanxuan
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [Mikivis/xuanxuan](https://huggingface.co/Mikivis/xuanxuan) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Mikivis__xuanxuan",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-16T21:42:00.993318](https://huggingface.co/datasets/open-llm-leaderboard/details_Mikivis__xuanxuan/blob/main/results_2023-09-16T21-42-00.993318.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.008389261744966443,
"em_stderr": 0.000934054321686696,
"f1": 0.05742869127516786,
"f1_stderr": 0.0015884226243297857,
"acc": 0.2521704814522494,
"acc_stderr": 0.00702597803203845
},
"harness|drop|3": {
"em": 0.008389261744966443,
"em_stderr": 0.000934054321686696,
"f1": 0.05742869127516786,
"f1_stderr": 0.0015884226243297857
},
"harness|gsm8k|5": {
"acc": 0.0,
"acc_stderr": 0.0
},
"harness|winogrande|5": {
"acc": 0.5043409629044988,
"acc_stderr": 0.0140519560640769
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
EleutherAI/hendrycks_ethics | EleutherAI | "2023-11-02T14:48:16Z" | 3,000 | 1 | [
"license:other",
"region:us"
] | null | "2023-07-05T20:37:47Z" | ---
license: other
--- |
oskarvanderwal/simple-cooccurrence-bias | oskarvanderwal | "2023-12-14T15:58:03Z" | 2,991 | 0 | [
"license:mit",
"size_categories:n<1K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-12-14T15:32:13Z" | ---
license: mit
---
`simple-cooccurrence-bias` contains the sentences used in the simple cooccurrence (or association) test used for evaluating gender bias originally proposed for GPT-3 (Brown et al., 2020).
This dataset is based on the details described in "Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model" (Smith et al., 2022). |
mozilla-foundation/common_voice_16_0 | mozilla-foundation | "2023-12-21T13:53:03Z" | 2,988 | 65 | [
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:multilingual",
"language:ab",
"language:af",
"language:am",
"language:ar",
"language:as",
"language:ast",
"language:az",
"language:ba",
"language:bas",
"language:be",
"language:bg",
"language:bn",
"language:br",
"language:ca",
"language:ckb",
"language:cnh",
"language:cs",
"language:cv",
"language:cy",
"language:da",
"language:de",
"language:dv",
"language:dyu",
"language:el",
"language:en",
"language:eo",
"language:es",
"language:et",
"language:eu",
"language:fa",
"language:fi",
"language:fr",
"language:fy",
"language:ga",
"language:gl",
"language:gn",
"language:ha",
"language:he",
"language:hi",
"language:hsb",
"language:hu",
"language:hy",
"language:ia",
"language:id",
"language:ig",
"language:is",
"language:it",
"language:ja",
"language:ka",
"language:kab",
"language:kk",
"language:kmr",
"language:ko",
"language:ky",
"language:lg",
"language:lij",
"language:lo",
"language:lt",
"language:ltg",
"language:lv",
"language:mdf",
"language:mhr",
"language:mk",
"language:ml",
"language:mn",
"language:mr",
"language:mrj",
"language:mt",
"language:myv",
"language:nan",
"language:ne",
"language:nhi",
"language:nl",
"language:nn",
"language:oc",
"language:or",
"language:os",
"language:pa",
"language:pl",
"language:ps",
"language:pt",
"language:quy",
"language:rm",
"language:ro",
"language:ru",
"language:rw",
"language:sah",
"language:sat",
"language:sc",
"language:sk",
"language:skr",
"language:sl",
"language:sq",
"language:sr",
"language:sv",
"language:sw",
"language:ta",
"language:te",
"language:th",
"language:ti",
"language:tig",
"language:tk",
"language:tok",
"language:tr",
"language:tt",
"language:tw",
"language:ug",
"language:uk",
"language:ur",
"language:uz",
"language:vi",
"language:vot",
"language:yi",
"language:yo",
"language:yue",
"language:zgh",
"language:zh",
"license:cc0-1.0",
"size_categories:1M<n<10M",
"modality:audio",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:1912.06670",
"region:us"
] | null | "2023-12-20T09:01:34Z" | ---
pretty_name: Common Voice Corpus 16
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- ab
- af
- am
- ar
- as
- ast
- az
- ba
- bas
- be
- bg
- bn
- br
- ca
- ckb
- cnh
- cs
- cv
- cy
- da
- de
- dv
- dyu
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gl
- gn
- ha
- he
- hi
- hsb
- hu
- hy
- ia
- id
- ig
- is
- it
- ja
- ka
- kab
- kk
- kmr
- ko
- ky
- lg
- lij
- lo
- lt
- ltg
- lv
- mdf
- mhr
- mk
- ml
- mn
- mr
- mrj
- mt
- myv
- nan
- ne
- nhi
- nl
- nn
- oc
- or
- os
- pa
- pl
- ps
- pt
- quy
- rm
- ro
- ru
- rw
- sah
- sat
- sc
- sk
- skr
- sl
- sq
- sr
- sv
- sw
- ta
- te
- th
- ti
- tig
- tk
- tok
- tr
- tt
- tw
- ug
- uk
- ur
- uz
- vi
- vot
- yi
- yo
- yue
- zgh
- zh
language_bcp47:
- zh-CN
- zh-HK
- zh-TW
- sv-SE
- rm-sursilv
- rm-vallader
- pa-IN
- nn-NO
- ne-NP
- nan-tw
- hy-AM
- ga-IE
- fy-NL
license:
- cc0-1.0
multilinguality:
- multilingual
paperswithcode_id: common-voice
extra_gated_prompt: "By clicking on “Access repository” below, you also agree to not attempt to determine the identity of speakers in the Common Voice dataset."
---
# Dataset Card for Common Voice Corpus 16
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://commonvoice.mozilla.org/en/datasets
- **Repository:** https://github.com/common-voice/common-voice
- **Paper:** https://arxiv.org/abs/1912.06670
- **Leaderboard:** https://paperswithcode.com/dataset/common-voice
- **Point of Contact:** [Vaibhav Srivastav](mailto:[email protected])
### Dataset Summary
The Common Voice dataset consists of a unique MP3 and corresponding text file.
Many of the 30328 recorded hours in the dataset also include demographic metadata like age, sex, and accent
that can help improve the accuracy of speech recognition engines.
The dataset currently consists of 19673 validated hours in 120 languages, but more voices and languages are always added.
Take a look at the [Languages](https://commonvoice.mozilla.org/en/languages) page to request a language or start contributing.
### Languages
```
Abkhaz, Afrikaans, Albanian, Amharic, Arabic, Armenian, Assamese, Asturian, Azerbaijani, Basaa, Bashkir, Basque, Belarusian, Bengali, Breton, Bulgarian, Cantonese, Catalan, Central Kurdish, Chinese (China), Chinese (Hong Kong), Chinese (Taiwan), Chuvash, Czech, Danish, Dhivehi, Dioula, Dutch, English, Erzya, Esperanto, Estonian, Finnish, French, Frisian, Galician, Georgian, German, Greek, Guarani, Hakha Chin, Hausa, Hebrew, Hill Mari, Hindi, Hungarian, Icelandic, Igbo, Indonesian, Interlingua, Irish, Italian, Japanese, Kabyle, Kazakh, Kinyarwanda, Korean, Kurmanji Kurdish, Kyrgyz, Lao, Latgalian, Latvian, Ligurian, Lithuanian, Luganda, Macedonian, Malayalam, Maltese, Marathi, Meadow Mari, Moksha, Mongolian, Nepali, Norwegian Nynorsk, Occitan, Odia, Ossetian, Pashto, Persian, Polish, Portuguese, Punjabi, Quechua Chanka, Romanian, Romansh Sursilvan, Romansh Vallader, Russian, Sakha, Santali (Ol Chiki), Saraiki, Sardinian, Serbian, Slovak, Slovenian, Sorbian, Upper, Spanish, Swahili, Swedish, Taiwanese (Minnan), Tamazight, Tamil, Tatar, Telugu, Thai, Tigre, Tigrinya, Toki Pona, Turkish, Turkmen, Twi, Ukrainian, Urdu, Uyghur, Uzbek, Vietnamese, Votic, Welsh, Western Sierra Puebla Nahuatl, Yiddish, Yoruba
```
## How to use
The `datasets` library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the `load_dataset` function.
For example, to download the Hindi config, simply specify the corresponding language config name (i.e., "hi" for Hindi):
```python
from datasets import load_dataset
cv_16 = load_dataset("mozilla-foundation/common_voice_16_0", "hi", split="train")
```
Using the datasets library, you can also stream the dataset on-the-fly by adding a `streaming=True` argument to the `load_dataset` function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.
```python
from datasets import load_dataset
cv_16 = load_dataset("mozilla-foundation/common_voice_16_0", "hi", split="train", streaming=True)
print(next(iter(cv_16)))
```
*Bonus*: create a [PyTorch dataloader](https://huggingface.co/docs/datasets/use_with_pytorch) directly with your own datasets (local/streamed).
### Local
```python
from datasets import load_dataset
from torch.utils.data.sampler import BatchSampler, RandomSampler
cv_16 = load_dataset("mozilla-foundation/common_voice_16_0", "hi", split="train")
batch_sampler = BatchSampler(RandomSampler(cv_16), batch_size=32, drop_last=False)
dataloader = DataLoader(cv_16, batch_sampler=batch_sampler)
```
### Streaming
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
cv_16 = load_dataset("mozilla-foundation/common_voice_16_0", "hi", split="train")
dataloader = DataLoader(cv_16, batch_size=32)
```
To find out more about loading and preparing audio datasets, head over to [hf.co/blog/audio-datasets](https://huggingface.co/blog/audio-datasets).
### Example scripts
Train your own CTC or Seq2Seq Automatic Speech Recognition models on Common Voice 16 with `transformers` - [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
## Dataset Structure
### Data Instances
A typical data point comprises the `path` to the audio file and its `sentence`.
Additional fields include `accent`, `age`, `client_id`, `up_votes`, `down_votes`, `gender`, `locale` and `segment`.
```python
{
'client_id': 'd59478fbc1ee646a28a3c652a119379939123784d99131b865a89f8b21c81f69276c48bd574b81267d9d1a77b83b43e6d475a6cfc79c232ddbca946ae9c7afc5',
'path': 'et/clips/common_voice_et_18318995.mp3',
'audio': {
'path': 'et/clips/common_voice_et_18318995.mp3',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346, 0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 48000
},
'sentence': 'Tasub kokku saada inimestega, keda tunned juba ammust ajast saati.',
'up_votes': 2,
'down_votes': 0,
'age': 'twenties',
'gender': 'male',
'accent': '',
'locale': 'et',
'segment': ''
}
```
### Data Fields
`client_id` (`string`): An id for which client (voice) made the recording
`path` (`string`): The path to the audio file
`audio` (`dict`): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
`sentence` (`string`): The sentence the user was prompted to speak
`up_votes` (`int64`): How many upvotes the audio file has received from reviewers
`down_votes` (`int64`): How many downvotes the audio file has received from reviewers
`age` (`string`): The age of the speaker (e.g. `teens`, `twenties`, `fifties`)
`gender` (`string`): The gender of the speaker
`accent` (`string`): Accent of the speaker
`locale` (`string`): The locale of the speaker
`segment` (`string`): Usually an empty field
### Data Splits
The speech material has been subdivided into portions for dev, train, test, validated, invalidated, reported and other.
The validated data is data that has been validated with reviewers and received upvotes that the data is of high quality.
The invalidated data is data has been invalidated by reviewers
and received downvotes indicating that the data is of low quality.
The reported data is data that has been reported, for different reasons.
The other data is data that has not yet been reviewed.
The dev, test, train are all data that has been reviewed, deemed of high quality and split into dev, test and train.
## Data Preprocessing Recommended by Hugging Face
The following are data preprocessing steps advised by the Hugging Face team. They are accompanied by an example code snippet that shows how to put them to practice.
Many examples in this dataset have trailing quotations marks, e.g _“the cat sat on the mat.“_. These trailing quotation marks do not change the actual meaning of the sentence, and it is near impossible to infer whether a sentence is a quotation or not a quotation from audio data alone. In these cases, it is advised to strip the quotation marks, leaving: _the cat sat on the mat_.
In addition, the majority of training sentences end in punctuation ( . or ? or ! ), whereas just a small proportion do not. In the dev set, **almost all** sentences end in punctuation. Thus, it is recommended to append a full-stop ( . ) to the end of the small number of training examples that do not end in punctuation.
```python
from datasets import load_dataset
ds = load_dataset("mozilla-foundation/common_voice_16_0", "en", use_auth_token=True)
def prepare_dataset(batch):
"""Function to preprocess the dataset with the .map method"""
transcription = batch["sentence"]
if transcription.startswith('"') and transcription.endswith('"'):
# we can remove trailing quotation marks as they do not affect the transcription
transcription = transcription[1:-1]
if transcription[-1] not in [".", "?", "!"]:
# append a full-stop to sentences that do not end in punctuation
transcription = transcription + "."
batch["sentence"] = transcription
return batch
ds = ds.map(prepare_dataset, desc="preprocess dataset")
```
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
## Considerations for Using the Data
### Social Impact of Dataset
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Public Domain, [CC-0](https://creativecommons.org/share-your-work/public-domain/cc0/)
### Citation Information
```
@inproceedings{commonvoice:2020,
author = {Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G.},
title = {Common Voice: A Massively-Multilingual Speech Corpus},
booktitle = {Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)},
pages = {4211--4215},
year = 2020
}
```
|
Skywork/Skywork-Reward-Preference-80K-v0.1 | Skywork | "2024-09-05T07:50:25Z" | 2,988 | 27 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-09-05T07:39:45Z" | ---
dataset_info:
features:
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 439724483
num_examples: 81973
download_size: 220679232
dataset_size: 439724483
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Skywork Reward Preference 80K
Skywork Reward Preference 80K is a subset of 80K preference pairs, sourced from publicly available data. This subset is used to train [**Skywork-Reward-Gemma-2-27B**](https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B) and [**Skywork-Reward-Llama-3.1-8B**](https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B).
## Data Mixture
We carefully curate the [Skywork Reward Data Collection](https://huggingface.co/collections/Skywork/skywork-reward-data-collection-66d7fda6a5098dc77035336d) (1) to include high-quality preference pairs and (2) to target specific capability and knowledge domains. The curated training dataset consists of approximately 80K samples, subsampled from multiple publicly available data sources, including
1. [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2)
2. [OffsetBias](https://huggingface.co/datasets/NCSOFT/offsetbias)
3. [WildGuard (adversarial)](https://huggingface.co/allenai/wildguard)
4. Magpie DPO series: [Ultra](https://huggingface.co/datasets/argilla/magpie-ultra-v0.1), [Pro (Llama-3.1)](https://huggingface.co/datasets/Magpie-Align/Magpie-Llama-3.1-Pro-DPO-100K-v0.1), [Pro](https://huggingface.co/datasets/Magpie-Align/Magpie-Pro-DPO-100K-v0.1), [Air](https://huggingface.co/datasets/Magpie-Align/Magpie-Air-DPO-100K-v0.1).
**Disclaimer: We made no modifications to the original datasets listed above, other than subsampling the datasets to create the Skywork Reward Data Collection.**
During dataset curation, we adopt several tricks to achieve both performance improvement and a balance between each domain, without compromising the overall performance:
1. We select top samples from math, code, and other categories in the combined Magpie dataset independently, based on the average ArmoRM score provided with the dataset. We subtract the ArmoRM average scores in the Magpie-Air subset and the Magpie-Pro subset by 0.1 and 0.05, respectively, to prioritize Magpie-Ultra and Magpie-Pro-Llama-3.1 samples.
2. Instead of including all preference pairs in WildGuard, we first train a reward model (RM) on three other data sources. We then (1) use this RM to score the chosen and rejected responses for all samples in WildGuard and (2) select only samples where the chosen response's RM score is greater than the rejected response's RM score. We observe that this approach largely preserves the original performance of Chat, Char hard, and Reasoning while improving Safety. For both models, we use the 27B model to score the WildGuard samples.
|
tatsu-lab/alpaca_farm | tatsu-lab | "2023-05-29T01:00:10Z" | 2,983 | 26 | [
"license:cc-by-nc-4.0",
"size_categories:10K<n<100K",
"modality:tabular",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | null | "2023-05-13T22:28:40Z" | ---
license: cc-by-nc-4.0
--- |
princeton-nlp/SWE-bench_Lite_oracle | princeton-nlp | "2024-04-15T22:09:51Z" | 2,975 | 2 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2310.06770",
"region:us"
] | null | "2024-03-19T19:31:44Z" | ---
dataset_info:
features:
- name: instance_id
dtype: string
- name: text
dtype: string
- name: repo
dtype: string
- name: base_commit
dtype: string
- name: problem_statement
dtype: string
- name: hints_text
dtype: string
- name: created_at
dtype: string
- name: patch
dtype: string
- name: test_patch
dtype: string
- name: version
dtype: string
- name: FAIL_TO_PASS
dtype: string
- name: PASS_TO_PASS
dtype: string
- name: environment_setup_commit
dtype: string
splits:
- name: dev
num_bytes: 1439991
num_examples: 23
- name: test
num_bytes: 20853665
num_examples: 300
download_size: 9371677
dataset_size: 22293656
configs:
- config_name: default
data_files:
- split: dev
path: data/dev-*
- split: test
path: data/test-*
---
### Dataset Summary
SWE-bench is a dataset that tests systems’ ability to solve GitHub issues automatically. The dataset collects 300 test Issue-Pull Request pairs from 11 popular Python. Evaluation is performed by unit test verification using post-PR behavior as the reference solution.
The dataset was released as part of [SWE-bench: Can Language Models Resolve Real-World GitHub Issues?](https://arxiv.org/abs/2310.06770)
This dataset `SWE-bench_Lite_oracle` includes a formatting of each instance using the "Oracle" retrieval setting as described in the paper. The `text` column can be used directly with LMs to generate patch files.
Models are instructed to generate [`patch`](https://en.wikipedia.org/wiki/Patch_(Unix)) formatted file using the following template:
```diff
<patch>
diff
--- a/path/to/file.py
--- b/path/to/file.py
@@ -1,3 +1,3 @@
This is a test file.
-It contains several lines.
+It has been modified.
This is the third line.
</patch>
```
This format can be used directly with the [SWE-bench inference scripts](https://github.com/princeton-nlp/SWE-bench/tree/main/inference). Please refer to these scripts for more details on inference.
|
open-llm-leaderboard-old/details_TFLai__OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch | open-llm-leaderboard-old | "2023-10-19T05:09:23Z" | 2,956 | 0 | [
"region:us"
] | null | "2023-08-30T12:43:04Z" | ---
pretty_name: Evaluation run of TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch](https://huggingface.co/TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_TFLai__OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-19T05:09:10.291904](https://huggingface.co/datasets/open-llm-leaderboard/details_TFLai__OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch/blob/main/results_2023-10-19T05-09-10.291904.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.08263422818791946,\n\
\ \"em_stderr\": 0.0028196220932582595,\n \"f1\": 0.18827600671140907,\n\
\ \"f1_stderr\": 0.003179593951573151,\n \"acc\": 0.383890237575643,\n\
\ \"acc_stderr\": 0.008217068757542224\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.08263422818791946,\n \"em_stderr\": 0.0028196220932582595,\n\
\ \"f1\": 0.18827600671140907,\n \"f1_stderr\": 0.003179593951573151\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.02350265352539803,\n \
\ \"acc_stderr\": 0.0041728836696439744\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.744277821625888,\n \"acc_stderr\": 0.012261253845440474\n\
\ }\n}\n```"
repo_url: https://huggingface.co/TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|arc:challenge|25_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_19T05_09_10.291904
path:
- '**/details_harness|drop|3_2023-10-19T05-09-10.291904.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-19T05-09-10.291904.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_19T05_09_10.291904
path:
- '**/details_harness|gsm8k|5_2023-10-19T05-09-10.291904.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-19T05-09-10.291904.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hellaswag|10_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T12:42:39.618303.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-30T12:42:39.618303.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-30T12:42:39.618303.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_19T05_09_10.291904
path:
- '**/details_harness|winogrande|5_2023-10-19T05-09-10.291904.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-19T05-09-10.291904.parquet'
- config_name: results
data_files:
- split: 2023_08_30T12_42_39.618303
path:
- results_2023-08-30T12:42:39.618303.parquet
- split: 2023_10_19T05_09_10.291904
path:
- results_2023-10-19T05-09-10.291904.parquet
- split: latest
path:
- results_2023-10-19T05-09-10.291904.parquet
---
# Dataset Card for Evaluation run of TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch](https://huggingface.co/TFLai/OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_TFLai__OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-19T05:09:10.291904](https://huggingface.co/datasets/open-llm-leaderboard/details_TFLai__OpenOrcaPlatypus2-Platypus2-13B-QLora-0.80-epoch/blob/main/results_2023-10-19T05-09-10.291904.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.08263422818791946,
"em_stderr": 0.0028196220932582595,
"f1": 0.18827600671140907,
"f1_stderr": 0.003179593951573151,
"acc": 0.383890237575643,
"acc_stderr": 0.008217068757542224
},
"harness|drop|3": {
"em": 0.08263422818791946,
"em_stderr": 0.0028196220932582595,
"f1": 0.18827600671140907,
"f1_stderr": 0.003179593951573151
},
"harness|gsm8k|5": {
"acc": 0.02350265352539803,
"acc_stderr": 0.0041728836696439744
},
"harness|winogrande|5": {
"acc": 0.744277821625888,
"acc_stderr": 0.012261253845440474
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
baber/logiqa2 | baber | "2023-08-01T00:52:03Z" | 2,954 | 8 | [
"task_categories:multiple-choice",
"language:en",
"language:zh",
"license:cc-by-sa-4.0",
"arxiv:2304.03439",
"region:us"
] | [
"multiple-choice"
] | "2023-07-22T20:15:28Z" | ---
license: cc-by-sa-4.0
task_categories:
- multiple-choice
language:
- en
- zh
pretty_name: LogiQA2.0
data_splits:
- train
- validation
- test
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:** https://github.com/csitfun/LogiQA2.0, https://github.com/csitfun/LogiEval
- **Repository:** https://github.com/csitfun/LogiQA2.0, https://github.com/csitfun/LogiEval
- **Paper:** https://ieeexplore.ieee.org/abstract/document/10174688
### Dataset Summary
Logiqa2.0 dataset - logical reasoning in MRC and NLI tasks
LogiEval: a benchmark suite for testing logical reasoning abilities of instruct-prompt large language models
### Licensing Information
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
### Citation Information
@ARTICLE{10174688,
author={Liu, Hanmeng and Liu, Jian and Cui, Leyang and Teng, Zhiyang and Duan, Nan and Zhou, Ming and Zhang, Yue},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={LogiQA 2.0 — An Improved Dataset for Logical Reasoning in Natural Language Understanding},
year={2023},
volume={},
number={},
pages={1-16},
doi={10.1109/TASLP.2023.3293046}}
@misc{liu2023evaluating,
title={Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4},
author={Hanmeng Liu and Ruoxi Ning and Zhiyang Teng and Jian Liu and Qiji Zhou and Yue Zhang},
year={2023},
eprint={2304.03439},
archivePrefix={arXiv},
primaryClass={cs.CL}
} |
flwrlabs/cinic10 | flwrlabs | "2024-08-07T13:00:32Z" | 2,952 | 2 | [
"task_categories:image-classification",
"license:cc-by-4.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:1810.03505",
"arxiv:2007.14390",
"region:us"
] | [
"image-classification"
] | "2024-08-07T12:05:12Z" | ---
license: cc-by-4.0
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': airplane
'1': automobile
'2': bird
'3': cat
'4': deer
'5': dog
'6': frog
'7': horse
'8': ship
'9': truck
splits:
- name: train
num_bytes: 178662714
num_examples: 90000
- name: validation
num_bytes: 180126542
num_examples: 90000
- name: test
num_bytes: 178913694
num_examples: 90000
download_size: 771149160
dataset_size: 537702950
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
task_categories:
- image-classification
size_categories:
- 100K<n<1M
---
# Dataset Card for CINIC-10
CINIC-10 has a total of 270,000 images equally split amongst three subsets: train, validate, and test. This means that CINIC-10 has 4.5 times as many samples than CIFAR-10.
## Dataset Details
In each subset (90,000 images), there are ten classes (identical to [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) classes). There are 9000 images per class per subset. Using the suggested data split (an equal three-way split), CINIC-10 has 1.8 times as many training samples as in CIFAR-10. CINIC-10 is designed to be directly swappable with CIFAR-10.
To understand the motivation behind the dataset creation please visit the [GitHub repository](https://github.com/BayesWatch/cinic-10 ).
### Dataset Sources
- **Repository:** https://github.com/BayesWatch/cinic-10
- **Paper:** https://arxiv.org/abs/1810.03505
- **Dataset:** http://dx.doi.org/10.7488/ds/2448
- **Benchmarking, Papers with code:** https://paperswithcode.com/sota/image-classification-on-cinic-10
## Use in FL
In order to prepare the dataset for the FL settings, we recommend using [Flower Dataset](https://flower.ai/docs/datasets/) (flwr-datasets) for the dataset download and partitioning and [Flower](https://flower.ai/docs/framework/) (flwr) for conducting FL experiments.
To partition the dataset, do the following.
1. Install the package.
```bash
pip install flwr-datasets[vision]
```
2. Use the HF Dataset under the hood in Flower Datasets.
```python
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import IidPartitioner
fds = FederatedDataset(
dataset="flwrlabs/cinic10",
partitioners={"train": IidPartitioner(num_partitions=10)}
)
partition = fds.load_partition(partition_id=0)
```
## Dataset Structure
### Data Instances
The first instance of the train split is presented below:
```
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32>,
'label': 0
}
```
### Data Split
```
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 90000
})
validation: Dataset({
features: ['image', 'label'],
num_rows: 90000
})
test: Dataset({
features: ['image', 'label'],
num_rows: 90000
})
})
```
## Citation
When working with the CINIC-10 dataset, please cite the original paper.
If you're using this dataset with Flower Datasets and Flower, cite Flower.
**BibTeX:**
Original paper:
```
@misc{darlow2018cinic10imagenetcifar10,
title={CINIC-10 is not ImageNet or CIFAR-10},
author={Luke N. Darlow and Elliot J. Crowley and Antreas Antoniou and Amos J. Storkey},
year={2018},
eprint={1810.03505},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/1810.03505},
}
````
Flower:
```
@article{DBLP:journals/corr/abs-2007-14390,
author = {Daniel J. Beutel and
Taner Topal and
Akhil Mathur and
Xinchi Qiu and
Titouan Parcollet and
Nicholas D. Lane},
title = {Flower: {A} Friendly Federated Learning Research Framework},
journal = {CoRR},
volume = {abs/2007.14390},
year = {2020},
url = {https://arxiv.org/abs/2007.14390},
eprinttype = {arXiv},
eprint = {2007.14390},
timestamp = {Mon, 03 Aug 2020 14:32:13 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007-14390.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## Dataset Card Contact
If you have any questions about the dataset preprocessing and preparation, please contact [Flower Labs](https://flower.ai/). |
ChilleD/SVAMP | ChilleD | "2024-06-05T03:08:36Z" | 2,948 | 5 | [
"task_categories:text-generation",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-generation"
] | "2023-04-24T07:52:00Z" | ---
language:
- en
license: mit
size_categories:
- n<1K
task_categories:
- text-generation
dataset_info:
features:
- name: ID
dtype: string
- name: Body
dtype: string
- name: Question
dtype: string
- name: Equation
dtype: string
- name: Answer
dtype: string
- name: Type
dtype: string
- name: question_concat
dtype: string
splits:
- name: train
num_bytes: 273253
num_examples: 700
- name: test
num_bytes: 117208.0
num_examples: 300
download_size: 166226
dataset_size: 390461.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
CIIRC-NLP/mmlu-cs | CIIRC-NLP | "2024-09-03T12:30:52Z" | 2,946 | 0 | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"language:cs",
"license:mit",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"multiple-choice",
"question-answering"
] | "2024-05-04T19:36:27Z" | ---
language:
- cs
license: mit
size_categories:
- 10K<n<100K
task_categories:
- multiple-choice
- question-answering
pretty_name: Czech MMLU
dataset_info:
- config_name: abstract_algebra
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 18632
dataset_size: 59552.573964806004
- config_name: anatomy
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 69633.1384418174
num_examples: 135
- name: validation
num_bytes: 7254.944480731548
num_examples: 14
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 31356
dataset_size: 79160.24081728578
- config_name: astronomy
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 78401.75587523145
num_examples: 152
- name: validation
num_bytes: 8291.365120836055
num_examples: 16
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 43159
dataset_size: 88965.27889080434
- config_name: business_ethics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 34480
dataset_size: 59552.573964806004
- config_name: clinical_knowledge
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 136687.2717561601
num_examples: 265
- name: validation
num_bytes: 15028.09928151535
num_examples: 29
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 57057
dataset_size: 153987.5289324123
- config_name: college_biology
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 74275.3476712719
num_examples: 144
- name: validation
num_bytes: 8291.365120836055
num_examples: 16
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 48202
dataset_size: 84838.87068684479
- config_name: college_chemistry
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 4145.682560418028
num_examples: 8
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 29973
dataset_size: 57997.94300464924
- config_name: college_computer_science
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 47407
dataset_size: 59552.573964806004
- config_name: college_mathematics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 28730
dataset_size: 59552.573964806004
- config_name: college_medicine
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 89233.57741062526
num_examples: 173
- name: validation
num_bytes: 11400.627041149575
num_examples: 22
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 61068
dataset_size: 102906.36234651168
- config_name: college_physics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 52611.70460048426
num_examples: 102
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 31116
dataset_size: 60584.17601579589
- config_name: computer_security
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 34653
dataset_size: 59552.573964806004
- config_name: conceptual_physics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 121213.24099131177
num_examples: 235
- name: validation
num_bytes: 13473.468321358589
num_examples: 26
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 38327
dataset_size: 136958.86720740722
- config_name: default
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 7242878
num_examples: 14042
- name: validation
num_bytes: 793380
num_examples: 1531
- name: dev
num_bytes: 129513
num_examples: 285
download_size: 4484098
dataset_size: 8165771
- config_name: econometrics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 58801.316906423584
num_examples: 114
- name: validation
num_bytes: 6218.523840627041
num_examples: 12
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 39182
dataset_size: 67291.99864178748
- config_name: electrical_engineering
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 74791.14869676685
num_examples: 145
- name: validation
num_bytes: 8291.365120836055
num_examples: 16
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 29982
dataset_size: 85354.67171233974
- config_name: elementary_mathematics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 194972.78763708874
num_examples: 378
- name: validation
num_bytes: 21246.62312214239
num_examples: 41
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 60730
dataset_size: 218491.568653968
- config_name: formal_logic
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 64990.92921236291
num_examples: 126
- name: validation
num_bytes: 7254.944480731548
num_examples: 14
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 34085
dataset_size: 74518.0315878313
- config_name: global_facts
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5182.103200522534
num_examples: 10
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 21705
dataset_size: 59034.36364475375
- config_name: high_school_biology
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 159898.31790343256
num_examples: 310
- name: validation
num_bytes: 16582.73024167211
num_examples: 32
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 86510
dataset_size: 178753.20603984152
- config_name: high_school_chemistry
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 104707.60817547358
num_examples: 203
- name: validation
num_bytes: 11400.627041149575
num_examples: 22
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 50508
dataset_size: 118380.39311136
- config_name: high_school_computer_science
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 4663.892880470281
num_examples: 9
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 44245
dataset_size: 58516.153324701496
- config_name: high_school_european_history
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 85107.16920666571
num_examples: 165
- name: validation
num_bytes: 9327.785760940562
num_examples: 18
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 206776
dataset_size: 96707.11286234311
- config_name: high_school_geography
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 102128.60304799885
num_examples: 198
- name: validation
num_bytes: 11400.627041149575
num_examples: 22
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 43434
dataset_size: 115801.38798388527
- config_name: high_school_government_and_politics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 99549.59792052415
num_examples: 193
- name: validation
num_bytes: 10882.416721097323
num_examples: 21
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 59438
dataset_size: 112704.17253635831
- config_name: high_school_macroeconomics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 201162.39994302805
num_examples: 390
- name: validation
num_bytes: 22283.043762246896
num_examples: 43
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 77909
dataset_size: 225717.6016000118
- config_name: high_school_mathematics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 139266.2768836348
num_examples: 270
- name: validation
num_bytes: 15028.09928151535
num_examples: 29
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 50033
dataset_size: 156566.534059887
- config_name: high_school_microeconomics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 122760.64406779662
num_examples: 238
- name: validation
num_bytes: 13473.468321358589
num_examples: 26
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 58809
dataset_size: 138506.27028389205
- config_name: high_school_physics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 77885.9548497365
num_examples: 151
- name: validation
num_bytes: 8809.575440888308
num_examples: 17
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 50198
dataset_size: 88967.68818536165
- config_name: high_school_psychology
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 281111.5588947443
num_examples: 545
- name: validation
num_bytes: 31092.619203135207
num_examples: 60
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 127254
dataset_size: 314476.33599261637
- config_name: high_school_statistics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 111413.02150690785
num_examples: 216
- name: validation
num_bytes: 11918.83736120183
num_examples: 23
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 83271
dataset_size: 125604.01676284653
- config_name: high_school_us_history
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 105223.40920096853
num_examples: 204
- name: validation
num_bytes: 11400.627041149575
num_examples: 22
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 222279
dataset_size: 118896.19413685495
- config_name: high_school_world_history
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 122244.84304230167
num_examples: 237
- name: validation
num_bytes: 13473.468321358589
num_examples: 26
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 274783
dataset_size: 137990.46925839712
- config_name: human_aging
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 115023.62868537246
num_examples: 223
- name: validation
num_bytes: 11918.83736120183
num_examples: 23
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 47533
dataset_size: 129214.62394131113
- config_name: human_sexuality
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 67569.93433983764
num_examples: 131
- name: validation
num_bytes: 6218.523840627041
num_examples: 12
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 35184
dataset_size: 76060.61607520151
- config_name: international_law
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 62411.92408488819
num_examples: 121
- name: validation
num_bytes: 6736.734160679294
num_examples: 13
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 45796
dataset_size: 71420.81614030432
- config_name: jurisprudence
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 55706.51075345393
num_examples: 108
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 36346
dataset_size: 63678.98216876556
- config_name: logical_fallacies
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 84075.56715567583
num_examples: 163
- name: validation
num_bytes: 9327.785760940562
num_examples: 18
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 37722
dataset_size: 95675.51081135323
- config_name: machine_learning
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 57769.714855433696
num_examples: 112
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 35871
dataset_size: 65742.18627074533
- config_name: management
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 53127.5056259792
num_examples: 103
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 24865
dataset_size: 61099.97704129083
- config_name: marketing
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 120697.43996581684
num_examples: 234
- name: validation
num_bytes: 12955.258001306336
num_examples: 25
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 55684
dataset_size: 135924.85586186004
- config_name: medical_genetics
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 26718
dataset_size: 59552.573964806004
- config_name: miscellaneous
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 403872.20296254096
num_examples: 783
- name: validation
num_bytes: 44566.08752449379
num_examples: 86
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 133344
dataset_size: 450710.4483817716
- config_name: moral_disputes
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 178467.15482125053
num_examples: 346
- name: validation
num_bytes: 19691.99216198563
num_examples: 38
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 86498
dataset_size: 200431.30487797302
- config_name: moral_scenarios
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 461641.91781797464
num_examples: 895
- name: validation
num_bytes: 51821.032005225345
num_examples: 100
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 130913
dataset_size: 515735.10771793686
- config_name: nutrition
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 157835.1138014528
num_examples: 306
- name: validation
num_bytes: 17100.940561724365
num_examples: 33
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 74461
dataset_size: 177208.212257914
- config_name: philosophy
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 160414.1189289275
num_examples: 311
- name: validation
num_bytes: 17619.150881776615
num_examples: 34
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 67153
dataset_size: 180305.42770544096
- config_name: prehistory
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 167119.53226036177
num_examples: 324
- name: validation
num_bytes: 18137.36120182887
num_examples: 35
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 77251
dataset_size: 187529.0513569275
- config_name: professional_accounting
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 145455.88918957414
num_examples: 282
- name: validation
num_bytes: 16064.519921619856
num_examples: 31
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 100551
dataset_size: 163792.56700593085
- config_name: professional_law
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 791238.7731092437
num_examples: 1534
- name: validation
num_bytes: 88095.75440888308
num_examples: 170
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 1298507
dataset_size: 881606.6854128636
- config_name: professional_medicine
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 140297.8789346247
num_examples: 272
- name: validation
num_bytes: 16064.519921619856
num_examples: 31
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 171644
dataset_size: 158634.5567509814
- config_name: professional_psychology
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 315670.2276029056
num_examples: 612
- name: validation
num_bytes: 35756.512083605485
num_examples: 69
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 179149
dataset_size: 353698.89758124796
- config_name: public_relations
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 56738.11280444381
num_examples: 110
- name: validation
num_bytes: 6218.523840627041
num_examples: 12
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 34465
dataset_size: 65228.79453980769
- config_name: security_studies
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 126371.25124626122
num_examples: 245
- name: validation
num_bytes: 13991.678641410843
num_examples: 27
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 153065
dataset_size: 142635.08778240893
- config_name: sociology
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 103676.0061244837
num_examples: 201
- name: validation
num_bytes: 11400.627041149575
num_examples: 22
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 62419
dataset_size: 117348.79106037012
- config_name: us_foreign_policy
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 51580.102549494375
num_examples: 100
- name: validation
num_bytes: 5700.313520574788
num_examples: 11
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 32068
dataset_size: 59552.573964806004
- config_name: virology
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 85622.97023216066
num_examples: 166
- name: validation
num_bytes: 9327.785760940562
num_examples: 18
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 41865
dataset_size: 97222.91388783806
- config_name: world_religions
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
splits:
- name: test
num_bytes: 88201.97535963538
num_examples: 171
- name: validation
num_bytes: 9845.996080992814
num_examples: 19
- name: dev
num_bytes: 2272.157894736842
num_examples: 5
download_size: 29008
dataset_size: 100320.12933536504
configs:
- config_name: abstract_algebra
data_files:
- split: test
path: abstract_algebra/test-*
- split: validation
path: abstract_algebra/validation-*
- split: dev
path: abstract_algebra/dev-*
- config_name: anatomy
data_files:
- split: test
path: anatomy/test-*
- split: validation
path: anatomy/validation-*
- split: dev
path: anatomy/dev-*
- config_name: astronomy
data_files:
- split: test
path: astronomy/test-*
- split: validation
path: astronomy/validation-*
- split: dev
path: astronomy/dev-*
- config_name: business_ethics
data_files:
- split: test
path: business_ethics/test-*
- split: validation
path: business_ethics/validation-*
- split: dev
path: business_ethics/dev-*
- config_name: clinical_knowledge
data_files:
- split: test
path: clinical_knowledge/test-*
- split: validation
path: clinical_knowledge/validation-*
- split: dev
path: clinical_knowledge/dev-*
- config_name: college_biology
data_files:
- split: test
path: college_biology/test-*
- split: validation
path: college_biology/validation-*
- split: dev
path: college_biology/dev-*
- config_name: college_chemistry
data_files:
- split: test
path: college_chemistry/test-*
- split: validation
path: college_chemistry/validation-*
- split: dev
path: college_chemistry/dev-*
- config_name: college_computer_science
data_files:
- split: test
path: college_computer_science/test-*
- split: validation
path: college_computer_science/validation-*
- split: dev
path: college_computer_science/dev-*
- config_name: college_mathematics
data_files:
- split: test
path: college_mathematics/test-*
- split: validation
path: college_mathematics/validation-*
- split: dev
path: college_mathematics/dev-*
- config_name: college_medicine
data_files:
- split: test
path: college_medicine/test-*
- split: validation
path: college_medicine/validation-*
- split: dev
path: college_medicine/dev-*
- config_name: college_physics
data_files:
- split: test
path: college_physics/test-*
- split: validation
path: college_physics/validation-*
- split: dev
path: college_physics/dev-*
- config_name: computer_security
data_files:
- split: test
path: computer_security/test-*
- split: validation
path: computer_security/validation-*
- split: dev
path: computer_security/dev-*
- config_name: conceptual_physics
data_files:
- split: test
path: conceptual_physics/test-*
- split: validation
path: conceptual_physics/validation-*
- split: dev
path: conceptual_physics/dev-*
- config_name: default
data_files:
- split: test
path: data/test-*
- split: validation
path: data/validation-*
- split: dev
path: data/dev-*
- config_name: econometrics
data_files:
- split: test
path: econometrics/test-*
- split: validation
path: econometrics/validation-*
- split: dev
path: econometrics/dev-*
- config_name: electrical_engineering
data_files:
- split: test
path: electrical_engineering/test-*
- split: validation
path: electrical_engineering/validation-*
- split: dev
path: electrical_engineering/dev-*
- config_name: elementary_mathematics
data_files:
- split: test
path: elementary_mathematics/test-*
- split: validation
path: elementary_mathematics/validation-*
- split: dev
path: elementary_mathematics/dev-*
- config_name: formal_logic
data_files:
- split: test
path: formal_logic/test-*
- split: validation
path: formal_logic/validation-*
- split: dev
path: formal_logic/dev-*
- config_name: global_facts
data_files:
- split: test
path: global_facts/test-*
- split: validation
path: global_facts/validation-*
- split: dev
path: global_facts/dev-*
- config_name: high_school_biology
data_files:
- split: test
path: high_school_biology/test-*
- split: validation
path: high_school_biology/validation-*
- split: dev
path: high_school_biology/dev-*
- config_name: high_school_chemistry
data_files:
- split: test
path: high_school_chemistry/test-*
- split: validation
path: high_school_chemistry/validation-*
- split: dev
path: high_school_chemistry/dev-*
- config_name: high_school_computer_science
data_files:
- split: test
path: high_school_computer_science/test-*
- split: validation
path: high_school_computer_science/validation-*
- split: dev
path: high_school_computer_science/dev-*
- config_name: high_school_european_history
data_files:
- split: test
path: high_school_european_history/test-*
- split: validation
path: high_school_european_history/validation-*
- split: dev
path: high_school_european_history/dev-*
- config_name: high_school_geography
data_files:
- split: test
path: high_school_geography/test-*
- split: validation
path: high_school_geography/validation-*
- split: dev
path: high_school_geography/dev-*
- config_name: high_school_government_and_politics
data_files:
- split: test
path: high_school_government_and_politics/test-*
- split: validation
path: high_school_government_and_politics/validation-*
- split: dev
path: high_school_government_and_politics/dev-*
- config_name: high_school_macroeconomics
data_files:
- split: test
path: high_school_macroeconomics/test-*
- split: validation
path: high_school_macroeconomics/validation-*
- split: dev
path: high_school_macroeconomics/dev-*
- config_name: high_school_mathematics
data_files:
- split: test
path: high_school_mathematics/test-*
- split: validation
path: high_school_mathematics/validation-*
- split: dev
path: high_school_mathematics/dev-*
- config_name: high_school_microeconomics
data_files:
- split: test
path: high_school_microeconomics/test-*
- split: validation
path: high_school_microeconomics/validation-*
- split: dev
path: high_school_microeconomics/dev-*
- config_name: high_school_physics
data_files:
- split: test
path: high_school_physics/test-*
- split: validation
path: high_school_physics/validation-*
- split: dev
path: high_school_physics/dev-*
- config_name: high_school_psychology
data_files:
- split: test
path: high_school_psychology/test-*
- split: validation
path: high_school_psychology/validation-*
- split: dev
path: high_school_psychology/dev-*
- config_name: high_school_statistics
data_files:
- split: test
path: high_school_statistics/test-*
- split: validation
path: high_school_statistics/validation-*
- split: dev
path: high_school_statistics/dev-*
- config_name: high_school_us_history
data_files:
- split: test
path: high_school_us_history/test-*
- split: validation
path: high_school_us_history/validation-*
- split: dev
path: high_school_us_history/dev-*
- config_name: high_school_world_history
data_files:
- split: test
path: high_school_world_history/test-*
- split: validation
path: high_school_world_history/validation-*
- split: dev
path: high_school_world_history/dev-*
- config_name: human_aging
data_files:
- split: test
path: human_aging/test-*
- split: validation
path: human_aging/validation-*
- split: dev
path: human_aging/dev-*
- config_name: human_sexuality
data_files:
- split: test
path: human_sexuality/test-*
- split: validation
path: human_sexuality/validation-*
- split: dev
path: human_sexuality/dev-*
- config_name: international_law
data_files:
- split: test
path: international_law/test-*
- split: validation
path: international_law/validation-*
- split: dev
path: international_law/dev-*
- config_name: jurisprudence
data_files:
- split: test
path: jurisprudence/test-*
- split: validation
path: jurisprudence/validation-*
- split: dev
path: jurisprudence/dev-*
- config_name: logical_fallacies
data_files:
- split: test
path: logical_fallacies/test-*
- split: validation
path: logical_fallacies/validation-*
- split: dev
path: logical_fallacies/dev-*
- config_name: machine_learning
data_files:
- split: test
path: machine_learning/test-*
- split: validation
path: machine_learning/validation-*
- split: dev
path: machine_learning/dev-*
- config_name: management
data_files:
- split: test
path: management/test-*
- split: validation
path: management/validation-*
- split: dev
path: management/dev-*
- config_name: marketing
data_files:
- split: test
path: marketing/test-*
- split: validation
path: marketing/validation-*
- split: dev
path: marketing/dev-*
- config_name: medical_genetics
data_files:
- split: test
path: medical_genetics/test-*
- split: validation
path: medical_genetics/validation-*
- split: dev
path: medical_genetics/dev-*
- config_name: miscellaneous
data_files:
- split: test
path: miscellaneous/test-*
- split: validation
path: miscellaneous/validation-*
- split: dev
path: miscellaneous/dev-*
- config_name: moral_disputes
data_files:
- split: test
path: moral_disputes/test-*
- split: validation
path: moral_disputes/validation-*
- split: dev
path: moral_disputes/dev-*
- config_name: moral_scenarios
data_files:
- split: test
path: moral_scenarios/test-*
- split: validation
path: moral_scenarios/validation-*
- split: dev
path: moral_scenarios/dev-*
- config_name: nutrition
data_files:
- split: test
path: nutrition/test-*
- split: validation
path: nutrition/validation-*
- split: dev
path: nutrition/dev-*
- config_name: philosophy
data_files:
- split: test
path: philosophy/test-*
- split: validation
path: philosophy/validation-*
- split: dev
path: philosophy/dev-*
- config_name: prehistory
data_files:
- split: test
path: prehistory/test-*
- split: validation
path: prehistory/validation-*
- split: dev
path: prehistory/dev-*
- config_name: professional_accounting
data_files:
- split: test
path: professional_accounting/test-*
- split: validation
path: professional_accounting/validation-*
- split: dev
path: professional_accounting/dev-*
- config_name: professional_law
data_files:
- split: test
path: professional_law/test-*
- split: validation
path: professional_law/validation-*
- split: dev
path: professional_law/dev-*
- config_name: professional_medicine
data_files:
- split: test
path: professional_medicine/test-*
- split: validation
path: professional_medicine/validation-*
- split: dev
path: professional_medicine/dev-*
- config_name: professional_psychology
data_files:
- split: test
path: professional_psychology/test-*
- split: validation
path: professional_psychology/validation-*
- split: dev
path: professional_psychology/dev-*
- config_name: public_relations
data_files:
- split: test
path: public_relations/test-*
- split: validation
path: public_relations/validation-*
- split: dev
path: public_relations/dev-*
- config_name: security_studies
data_files:
- split: test
path: security_studies/test-*
- split: validation
path: security_studies/validation-*
- split: dev
path: security_studies/dev-*
- config_name: sociology
data_files:
- split: test
path: sociology/test-*
- split: validation
path: sociology/validation-*
- split: dev
path: sociology/dev-*
- config_name: us_foreign_policy
data_files:
- split: test
path: us_foreign_policy/test-*
- split: validation
path: us_foreign_policy/validation-*
- split: dev
path: us_foreign_policy/dev-*
- config_name: virology
data_files:
- split: test
path: virology/test-*
- split: validation
path: virology/validation-*
- split: dev
path: virology/dev-*
- config_name: world_religions
data_files:
- split: test
path: world_religions/test-*
- split: validation
path: world_religions/validation-*
- split: dev
path: world_religions/dev-*
---
# Czech MMLU
This is a Czech translation of the original [MMLU](https://huggingface.co/datasets/cais/mmlu) dataset, created using the [WMT 21 En-X](https://huggingface.co/facebook/wmt21-dense-24-wide-en-x) model.
The 'auxiliary_train' subset is not included.
The translation was completed for use within the [Czech-Bench](https://gitlab.com/jirkoada/czech-bench) evaluation framework.
The script used for translation can be reviewed [here](https://gitlab.com/jirkoada/czech-bench/-/blob/main/benchmarks/dataset_translation.py?ref_type=heads).
## Citation
Original dataset:
```bibtex
@article{hendryckstest2021,
title={Measuring Massive Multitask Language Understanding},
author={Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt},
journal={Proceedings of the International Conference on Learning Representations (ICLR)},
year={2021}
}
@article{hendrycks2021ethics,
title={Aligning AI With Shared Human Values},
author={Dan Hendrycks and Collin Burns and Steven Basart and Andrew Critch and Jerry Li and Dawn Song and Jacob Steinhardt},
journal={Proceedings of the International Conference on Learning Representations (ICLR)},
year={2021}
}
```
Czech translation:
```bibtex
@masterthesis{jirkovsky-thesis,
author = {Jirkovský, Adam},
title = {Benchmarking Techniques for Evaluation of Large Language Models},
school = {Czech Technical University in Prague, Faculty of Electrical Engineering},
year = 2024,
URL = {https://dspace.cvut.cz/handle/10467/115227}
}
``` |
hf-audio/esb-datasets-test-only-sorted | hf-audio | "2024-07-26T03:55:27Z" | 2,945 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-06-21T11:01:49Z" | ---
dataset_info:
- config_name: ami
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 7313111859.091001
num_examples: 12643
download_size: 1300234949
dataset_size: 7313111859.091001
- config_name: common_voice
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 1312573669.596
num_examples: 16334
download_size: 720365151
dataset_size: 1312573669.596
- config_name: earnings22
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 2066334348.212
num_examples: 2741
download_size: 1103772123
dataset_size: 2066334348.212
- config_name: gigaspeech
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 9091854755.2
num_examples: 19931
download_size: 4034348699
dataset_size: 9091854755.2
- config_name: librispeech
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test.clean
num_bytes: 367597326.0
num_examples: 2620
- name: test.other
num_bytes: 352273450.594
num_examples: 2939
download_size: 683412729
dataset_size: 719870776.594
- config_name: spgispeech
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 18550272796.201
num_examples: 39341
download_size: 11377636910
dataset_size: 18550272796.201
- config_name: tedlium
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 301767463.0
num_examples: 1155
download_size: 301633880
dataset_size: 301767463.0
- config_name: voxpopuli
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 1612296642.268
num_examples: 1842
download_size: 944084987
dataset_size: 1612296642.268
configs:
- config_name: ami
data_files:
- split: test
path: ami/test-*
- config_name: common_voice
data_files:
- split: test
path: common_voice/test-*
- config_name: earnings22
data_files:
- split: test
path: earnings22/test-*
- config_name: gigaspeech
data_files:
- split: test
path: gigaspeech/test-*
- config_name: librispeech
data_files:
- split: test.clean
path: librispeech/test.clean-*
- split: test.other
path: librispeech/test.other-*
- config_name: spgispeech
data_files:
- split: test
path: spgispeech/test-*
- config_name: tedlium
data_files:
- split: test
path: tedlium/test-*
- config_name: voxpopuli
data_files:
- split: test
path: voxpopuli/test-*
extra_gated_prompt: "Three of the ESB datasets have specific terms of usage that must\
\ be agreed to before using the data. \nTo do so, fill in the access forms on the\
\ specific datasets' pages:\n * Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0\n\
\ * GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech\n * SPGISpeech:\
\ https://huggingface.co/datasets/kensho/spgispeech"
extra_gated_fields:
? I hereby confirm that I have registered on the original Common Voice page and
agree to not attempt to determine the identity of speakers in the Common Voice
dataset
: checkbox
I hereby confirm that I have accepted the terms of usages on GigaSpeech page: checkbox
I hereby confirm that I have accepted the terms of usages on SPGISpeech page: checkbox
---
# ESB Test Sets: Parquet & Sorted
This dataset takes the [open-asr-leaderboard/datasets-test-only](hf.co/datasets/open-asr-leaderboard/datasets-test-only) data and sorts each split by audio length.
The format is also changed, from custom loading script (un-safe remote code) to parquet (safe).
Broadly speaking, this dataset was generated with the following code-snippet:
```py
from datasets import load_dataset, get_dataset_config_names
DATASET = "open-asr-leaderboard/datasets-test-only" # dataset to load from
HUB_DATASET_ID = "hf-audio/esb-datasets-test-only-sorted" # dataset id to push to
config_names = get_dataset_config_names(DATASET)
for config in config_names:
dataset = load_dataset(DATASET, config)
sampling_rate = dataset[next(iter(dataset))].features["audio"].sampling_rate
def compute_audio_length(audio):
return {"audio_length_s": len(audio["array"]) / sampling_rate}
dataset = dataset.map(compute_audio_length, input_columns=["audio"])
dataset = dataset.sort("audio_length_s", reverse=True)
dataset.push_to_hub(HUB_DATASET_ID, config_name=config, private=True)
```
All eight of datasets in ESB can be downloaded and prepared in just a single line of code through the Hugging Face Datasets library:
```python
from datasets import load_dataset
librispeech = load_dataset("esb/datasets", "librispeech", split="train")
```
- `"esb/datasets"`: the repository namespace. This is fixed for all ESB datasets.
- `"librispeech"`: the dataset name. This can be changed to any of any one of the eight datasets in ESB to download that dataset.
- `split="train"`: the split. Set this to one of train/validation/test to generate a specific split. Omit the `split` argument to generate all splits for a dataset.
The datasets are full prepared, such that the audio and transcription files can be used directly in training/evaluation scripts.
## Dataset Information
A data point can be accessed by indexing the dataset object loaded through `load_dataset`:
```python
print(librispeech[0])
```
A typical data point comprises the path to the audio file and its transcription. Also included is information of the dataset from which the sample derives and a unique identifier name:
```python
{
'dataset': 'librispeech',
'audio': {'path': '/home/sanchit-gandhi/.cache/huggingface/datasets/downloads/extracted/d2da1969fe9e7d06661b5dc370cf2e3c119a14c35950045bcb76243b264e4f01/374-180298-0000.flac',
'array': array([ 7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ...,
-2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000},
'text': 'chapter sixteen i might have told you of the beginning of this liaison in a few lines but i wanted you to see every step by which we came i to agree to whatever marguerite wished',
'id': '374-180298-0000'
}
```
### Data Fields
- `dataset`: name of the ESB dataset from which the sample is taken.
- `audio`: a dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate.
- `text`: the transcription of the audio file.
- `id`: unique id of the data sample.
### Data Preparation
#### Audio
The audio for all ESB datasets is segmented into sample lengths suitable for training ASR systems. The Hugging Face datasets library decodes audio files on the fly, reading the segments and converting them to a Python arrays. Consequently, no further preparation of the audio is required to be used in training/evaluation scripts.
Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, i.e. `dataset[0]["audio"]` should always be preferred over `dataset["audio"][0]`.
#### Transcriptions
The transcriptions corresponding to each audio file are provided in their 'error corrected' format. No transcription pre-processing is applied to the text, only necessary 'error correction' steps such as removing junk tokens (_<unk>_) or converting symbolic punctuation to spelled out form (_<comma>_ to _,_). As such, no further preparation of the transcriptions is required to be used in training/evaluation scripts.
Transcriptions are provided for training and validation splits. The transcriptions are **not** provided for the test splits. ESB requires you to generate predictions for the test sets and upload them to https://huggingface.co/spaces/esb/leaderboard for scoring.
### Access
All eight of the datasets in ESB are accessible and licensing is freely available. Three of the ESB datasets have specific terms of usage that must be agreed to before using the data. To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
### Diagnostic Dataset
ESB contains a small, 8h diagnostic dataset of in-domain validation data with newly annotated transcriptions. The audio data is sampled from each of the ESB validation sets, giving a range of different domains and speaking styles. The transcriptions are annotated according to a consistent style guide with two formats: normalised and un-normalised. The dataset is structured in the same way as the ESB dataset, by grouping audio-transcription samples according to the dataset from which they were taken. We encourage participants to use this dataset when evaluating their systems to quickly assess performance on a range of different speech recognition conditions. For more information, visit: [esb/diagnostic-dataset](https://huggingface.co/datasets/esb/diagnostic-dataset).
## Summary of ESB Datasets
| Dataset | Domain | Speaking Style | Train (h) | Dev (h) | Test (h) | Transcriptions | License |
|--------------|-----------------------------|-----------------------|-----------|---------|----------|--------------------|-----------------|
| LibriSpeech | Audiobook | Narrated | 960 | 11 | 11 | Normalised | CC-BY-4.0 |
| Common Voice | Wikipedia | Narrated | 1409 | 27 | 27 | Punctuated & Cased | CC0-1.0 |
| Voxpopuli | European Parliament | Oratory | 523 | 5 | 5 | Punctuated | CC0 |
| TED-LIUM | TED talks | Oratory | 454 | 2 | 3 | Normalised | CC-BY-NC-ND 3.0 |
| GigaSpeech | Audiobook, podcast, YouTube | Narrated, spontaneous | 2500 | 12 | 40 | Punctuated | apache-2.0 |
| SPGISpeech | Fincancial meetings | Oratory, spontaneous | 4900 | 100 | 100 | Punctuated & Cased | User Agreement |
| Earnings-22 | Fincancial meetings | Oratory, spontaneous | 105 | 5 | 5 | Punctuated & Cased | CC-BY-SA-4.0 |
| AMI | Meetings | Spontaneous | 78 | 9 | 9 | Punctuated & Cased | CC-BY-4.0 |
## LibriSpeech
The LibriSpeech corpus is a standard large-scale corpus for assessing ASR systems. It consists of approximately 1,000 hours of narrated audiobooks from the [LibriVox](https://librivox.org) project. It is licensed under CC-BY-4.0.
Example Usage:
```python
librispeech = load_dataset("esb/datasets", "librispeech")
```
Train/validation splits:
- `train` (combination of `train.clean.100`, `train.clean.360` and `train.other.500`)
- `validation.clean`
- `validation.other`
Test splits:
- `test.clean`
- `test.other`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
librispeech = load_dataset("esb/datasets", "librispeech", subconfig="clean.100")
```
- `clean.100`: 100 hours of training data from the 'clean' subset
- `clean.360`: 360 hours of training data from the 'clean' subset
- `other.500`: 500 hours of training data from the 'other' subset
## Common Voice
Common Voice is a series of crowd-sourced open-licensed speech datasets where speakers record text from Wikipedia in various languages. The speakers are of various nationalities and native languages, with different accents and recording conditions. We use the English subset of version 9.0 (27-4-2022), with approximately 1,400 hours of audio-transcription data. It is licensed under CC0-1.0.
Example usage:
```python
common_voice = load_dataset("esb/datasets", "common_voice", use_auth_token=True)
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## VoxPopuli
VoxPopuli is a large-scale multilingual speech corpus consisting of political data sourced from 2009-2020 European Parliament event recordings. The English subset contains approximately 550 hours of speech largely from non-native English speakers. It is licensed under CC0.
Example usage:
```python
voxpopuli = load_dataset("esb/datasets", "voxpopuli")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## TED-LIUM
TED-LIUM consists of English-language TED Talk conference videos covering a range of different cultural, political, and academic topics. It contains approximately 450 hours of transcribed speech data. It is licensed under CC-BY-NC-ND 3.0.
Example usage:
```python
tedlium = load_dataset("esb/datasets", "tedlium")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## GigaSpeech
GigaSpeech is a multi-domain English speech recognition corpus created from audiobooks, podcasts and YouTube. We provide the large train set (2,500 hours) and the standard validation and test splits. It is licensed under apache-2.0.
Example usage:
```python
gigaspeech = load_dataset("esb/datasets", "gigaspeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (2,500 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
gigaspeech = load_dataset("esb/datasets", "spgispeech", subconfig="xs", use_auth_token=True)
```
- `xs`: extra-small subset of training data (10 h)
- `s`: small subset of training data (250 h)
- `m`: medium subset of training data (1,000 h)
- `xl`: extra-large subset of training data (10,000 h)
## SPGISpeech
SPGISpeech consists of company earnings calls that have been manually transcribed by S&P Global, Inc according to a professional style guide. We provide the large train set (5,000 hours) and the standard validation and test splits. It is licensed under a Kensho user agreement.
Loading the dataset requires authorization.
Example usage:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (~5,000 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", subconfig="s", use_auth_token=True)
```
- `s`: small subset of training data (~200 h)
- `m`: medium subset of training data (~1,000 h)
## Earnings-22
Earnings-22 is a 119-hour corpus of English-language earnings calls collected from global companies, with speakers of many different nationalities and accents. It is licensed under CC-BY-SA-4.0.
Example usage:
```python
earnings22 = load_dataset("esb/datasets", "earnings22")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## AMI
The AMI Meeting Corpus consists of 100 hours of meeting recordings from multiple recording devices synced to a common timeline. It is licensed under CC-BY-4.0.
Example usage:
```python
ami = load_dataset("esb/datasets", "ami")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test` |
cardiffnlp/tweet_topic_single | cardiffnlp | "2022-11-27T11:25:34Z" | 2,944 | 5 | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"multilinguality:monolingual",
"language:en",
"license:other",
"size_categories:10K<n<100K",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2209.09824",
"region:us"
] | [
"text-classification"
] | "2022-09-02T00:20:17Z" | ---
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 1k<10K
task_categories:
- text-classification
task_ids:
- sentiment-classification
pretty_name: TweetTopicSingle
---
# Dataset Card for "cardiffnlp/tweet_topic_single"
## Dataset Description
- **Paper:** [https://arxiv.org/abs/2209.09824](https://arxiv.org/abs/2209.09824)
- **Dataset:** Tweet Topic Dataset
- **Domain:** Twitter
- **Number of Class:** 6
### Dataset Summary
This is the official repository of TweetTopic (["Twitter Topic Classification
, COLING main conference 2022"](https://arxiv.org/abs/2209.09824)), a topic classification dataset on Twitter with 6 labels.
Each instance of TweetTopic comes with a timestamp which distributes from September 2019 to August 2021.
See [cardiffnlp/tweet_topic_multi](https://huggingface.co/datasets/cardiffnlp/tweet_topic_multi) for multi label version of TweetTopic.
The tweet collection used in TweetTopic is same as what used in [TweetNER7](https://huggingface.co/datasets/tner/tweetner7).
The dataset is integrated in [TweetNLP](https://tweetnlp.org/) too.
### Preprocessing
We pre-process tweets before the annotation to normalize some artifacts, converting URLs into a special token `{{URL}}` and non-verified usernames into `{{USERNAME}}`.
For verified usernames, we replace its display name (or account name) with symbols `{@}`.
For example, a tweet
```
Get the all-analog Classic Vinyl Edition
of "Takin' Off" Album from @herbiehancock
via @bluenoterecords link below:
http://bluenote.lnk.to/AlbumOfTheWeek
```
is transformed into the following text.
```
Get the all-analog Classic Vinyl Edition
of "Takin' Off" Album from {@herbiehancock@}
via {@bluenoterecords@} link below: {{URL}}
```
A simple function to format tweet follows below.
```python
import re
from urlextract import URLExtract
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
target = """Get the all-analog Classic Vinyl Edition of "Takin' Off" Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"""
target_format = format_tweet(target)
print(target_format)
'Get the all-analog Classic Vinyl Edition of "Takin\' Off" Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}'
```
### Data Splits
| split | number of texts | description |
|:------------------------|-----:|------:|
| test_2020 | 376 | test dataset from September 2019 to August 2020 |
| test_2021 | 1693 | test dataset from September 2020 to August 2021 |
| train_2020 | 2858 | training dataset from September 2019 to August 2020 |
| train_2021 | 1516 | training dataset from September 2020 to August 2021 |
| train_all | 4374 | combined training dataset of `train_2020` and `train_2021` |
| validation_2020 | 352 | validation dataset from September 2019 to August 2020 |
| validation_2021 | 189 | validation dataset from September 2020 to August 2021 |
| train_random | 2830 | randomly sampled training dataset with the same size as `train_2020` from `train_all` |
| validation_random | 354 | randomly sampled training dataset with the same size as `validation_2020` from `validation_all` |
| test_coling2022_random | 3399 | random split used in the COLING 2022 paper |
| train_coling2022_random | 3598 | random split used in the COLING 2022 paper |
| test_coling2022 | 3399 | temporal split used in the COLING 2022 paper |
| train_coling2022 | 3598 | temporal split used in the COLING 2022 paper |
For the temporal-shift setting, model should be trained on `train_2020` with `validation_2020` and evaluate on `test_2021`.
In general, model would be trained on `train_all`, the most representative training set with `validation_2021` and evaluate on `test_2021`.
**IMPORTANT NOTE:** To get a result that is comparable with the results of the COLING 2022 Tweet Topic paper, please use `train_coling2022` and `test_coling2022` for temporal-shift, and `train_coling2022_random` and `test_coling2022_random` fir random split (the coling2022 split does not have validation set).
### Models
| model | training data | F1 | F1 (macro) | Accuracy |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------|---------:|-------------:|-----------:|
| [cardiffnlp/roberta-large-tweet-topic-single-all](https://huggingface.co/cardiffnlp/roberta-large-tweet-topic-single-all) | all (2020 + 2021) | 0.896043 | 0.800061 | 0.896043 |
| [cardiffnlp/roberta-base-tweet-topic-single-all](https://huggingface.co/cardiffnlp/roberta-base-tweet-topic-single-all) | all (2020 + 2021) | 0.887773 | 0.79793 | 0.887773 |
| [cardiffnlp/twitter-roberta-base-2019-90m-tweet-topic-single-all](https://huggingface.co/cardiffnlp/twitter-roberta-base-2019-90m-tweet-topic-single-all) | all (2020 + 2021) | 0.892499 | 0.774494 | 0.892499 |
| [cardiffnlp/twitter-roberta-base-dec2020-tweet-topic-single-all](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2020-tweet-topic-single-all) | all (2020 + 2021) | 0.890136 | 0.776025 | 0.890136 |
| [cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-single-all](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-single-all) | all (2020 + 2021) | 0.894861 | 0.800952 | 0.894861 |
| [cardiffnlp/roberta-large-tweet-topic-single-2020](https://huggingface.co/cardiffnlp/roberta-large-tweet-topic-single-2020) | 2020 only | 0.878913 | 0.70565 | 0.878913 |
| [cardiffnlp/roberta-base-tweet-topic-single-2020](https://huggingface.co/cardiffnlp/roberta-base-tweet-topic-single-2020) | 2020 only | 0.868281 | 0.729667 | 0.868281 |
| [cardiffnlp/twitter-roberta-base-2019-90m-tweet-topic-single-2020](https://huggingface.co/cardiffnlp/twitter-roberta-base-2019-90m-tweet-topic-single-2020) | 2020 only | 0.882457 | 0.740187 | 0.882457 |
| [cardiffnlp/twitter-roberta-base-dec2020-tweet-topic-single-2020](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2020-tweet-topic-single-2020) | 2020 only | 0.87596 | 0.746275 | 0.87596 |
| [cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-single-2020](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-single-2020) | 2020 only | 0.877732 | 0.746119 | 0.877732 |
Model fine-tuning script can be found [here](https://huggingface.co/datasets/cardiffnlp/tweet_topic_single/blob/main/lm_finetuning.py).
## Dataset Structure
### Data Instances
An example of `train` looks as follows.
```python
{
"text": "Game day for {{USERNAME}} U18\u2019s against {{USERNAME}} U18\u2019s. Even though it\u2019s a \u2018home\u2019 game for the people that have settled in Mid Wales it\u2019s still a 4 hour round trip for us up to Colwyn Bay. Still enjoy it though!",
"date": "2019-09-08",
"label": 4,
"id": "1170606779568463874",
"label_name": "sports_&_gaming"
}
```
### Label ID
The label2id dictionary can be found at [here](https://huggingface.co/datasets/tner/tweet_topic_single/raw/main/dataset/label.single.json).
```python
{
"arts_&_culture": 0,
"business_&_entrepreneurs": 1,
"pop_culture": 2,
"daily_life": 3,
"sports_&_gaming": 4,
"science_&_technology": 5
}
```
### Citation Information
```
@inproceedings{dimosthenis-etal-2022-twitter,
title = "{T}witter {T}opic {C}lassification",
author = "Antypas, Dimosthenis and
Ushio, Asahi and
Camacho-Collados, Jose and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics"
}
``` |
saier/unarXive_imrad_clf | saier | "2023-04-02T00:56:43Z" | 2,944 | 6 | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:extended|10.5281/zenodo.7752615",
"language:en",
"license:cc-by-sa-4.0",
"size_categories:100K<n<1M",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2303.14957",
"region:us",
"arXiv.org",
"arXiv",
"IMRaD",
"publication",
"paper",
"preprint",
"section",
"physics",
"mathematics",
"computer science",
"cs"
] | [
"text-classification"
] | "2023-03-24T11:30:56Z" | ---
annotations_creators:
- machine-generated
language:
- en
language_creators:
- found
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: unarXive IMRaD classification
size_categories:
- 100K<n<1M
tags:
- arXiv.org
- arXiv
- IMRaD
- publication
- paper
- preprint
- section
- physics
- mathematics
- computer science
- cs
task_categories:
- text-classification
task_ids:
- multi-class-classification
source_datasets:
- extended|10.5281/zenodo.7752615
dataset_info:
features:
- name: _id
dtype: string
- name: text
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 451908280
num_examples: 520053
- name: test
num_bytes: 4650429
num_examples: 5000
- name: validation
num_bytes: 4315597
num_examples: 5001
download_size: 482376743
dataset_size: 460874306
---
# Dataset Card for unarXive IMRaD classification
## Dataset Description
* **Homepage:** [https://github.com/IllDepence/unarXive](https://github.com/IllDepence/unarXive)
* **Paper:** [unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network](https://arxiv.org/abs/2303.14957)
### Dataset Summary
The unarXive IMRaD classification dataset contains 530k paragraphs from computer science papers and the IMRaD section they originate from. The paragraphs are derived from [unarXive](https://github.com/IllDepence/unarXive).
The dataset can be used as follows.
```
from datasets import load_dataset
imrad_data = load_dataset('saier/unarXive_imrad_clf')
imrad_data = imrad_data.class_encode_column('label') # assign target label column
imrad_data = imrad_data.remove_columns('_id') # remove sample ID column
```
## Dataset Structure
### Data Instances
Each data instance contains the paragraph’s text as well as one of the labels ('i', 'm', 'r', 'd', 'w' — for Introduction, Methods, Results, Discussion and Related Work). An example is shown below.
```
{'_id': '789f68e7-a1cc-4072-b07d-ecffc3e7ca38',
'label': 'm',
'text': 'To link the mentions encoded by BERT to the KGE entities, we define '
'an entity linking loss as cross-entropy between self-supervised '
'entity labels and similarities obtained from the linker in KGE '
'space:\n'
'\\(\\mathcal {L}_{EL}=\\sum -\\log \\dfrac{\\exp (h_m^{proj}\\cdot '
'\\textbf {e})}{\\sum _{\\textbf {e}_j\\in \\mathcal {E}} \\exp '
'(h_m^{proj}\\cdot \\textbf {e}_j)}\\) \n'}
```
### Data Splits
The data is split into training, development, and testing data as follows.
* Training: 520,053 instances
* Development: 5000 instances
* Testing: 5001 instances
## Dataset Creation
### Source Data
The paragraph texts are extracted from the data set [unarXive](https://github.com/IllDepence/unarXive).
#### Who are the source language producers?
The paragraphs were written by the authors of the arXiv papers. In file `license_info.jsonl` author and text licensing information can be found for all samples, An example is shown below.
```
{'authors': 'Yusuke Sekikawa, Teppei Suzuki',
'license': 'http://creativecommons.org/licenses/by/4.0/',
'paper_arxiv_id': '2011.09852',
'sample_ids': ['cc375518-347c-43d0-bfb2-f88564d66df8',
'18dc073e-a48e-488e-b34c-e5fc3cb8a4ca',
'0c2e89b3-d863-4bc2-9e11-8f6c48d867cb',
'd85e46cf-b11d-49b6-801b-089aa2dd037d',
'92915cea-17ab-4a98-aad2-417f6cdd53d2',
'e88cb422-47b7-4f69-9b0b-fbddf8140d98',
'4f5094a4-0e6e-46ae-a34d-e15ce0b9803c',
'59003494-096f-4a7c-ad65-342b74eed561',
'6a99b3f5-217e-4d3d-a770-693483ef8670']}
```
### Annotations
Class labels were automatically determined ([see implementation](https://github.com/IllDepence/unarXive/blob/master/src/utility_scripts/ml_tasks_prep_data.py)).
## Considerations for Using the Data
### Discussion and Biases
Because only paragraphs unambiguously assignable to one of the IMRaD classeswere used, a certain selection bias is to be expected in the data.
### Other Known Limitations
Depending on authors’ writing styles as well LaTeX processing quirks, paragraphs can vary in length a significantly.
## Additional Information
### Licensing information
The dataset is released under the Creative Commons Attribution-ShareAlike 4.0.
### Citation Information
```
@inproceedings{Saier2023unarXive,
author = {Saier, Tarek and Krause, Johan and F\"{a}rber, Michael},
title = {{unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network}},
booktitle = {Proceedings of the 23rd ACM/IEEE Joint Conference on Digital Libraries},
year = {2023},
series = {JCDL '23}
}
```
|
bgglue/bgglue | bgglue | "2023-08-06T15:22:26Z" | 2,930 | 1 | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"task_categories:multiple-choice",
"task_ids:multiple-choice-qa",
"task_ids:named-entity-recognition",
"task_ids:natural-language-inference",
"task_ids:part-of-speech",
"task_ids:sentiment-analysis",
"source_datasets:bsnlp",
"source_datasets:wikiann",
"source_datasets:exams",
"source_datasets:ct21.t1",
"source_datasets:fakenews",
"source_datasets:crediblenews",
"source_datasets:universal_dependencies",
"language:bg",
"license:mit",
"license:cc-by-3.0",
"license:cc-by-sa-4.0",
"license:other",
"license:cc-by-nc-4.0",
"license:cc-by-nc-3.0",
"size_categories:n<1K",
"arxiv:2306.02349",
"region:us",
"check-worthiness-estimation",
"fake-new-detection",
"humor-detection",
"regression",
"ranking"
] | [
"text-classification",
"token-classification",
"question-answering",
"multiple-choice"
] | "2023-07-08T10:43:00Z" | ---
task_categories:
- text-classification
- token-classification
- question-answering
- multiple-choice
language:
- bg
pretty_name: Bulgarian GLUE
size_categories:
- n<1K
- 1K<n<10K
- 10K<n<100K
- 100K<n<1M
license:
- mit
- cc-by-3.0
- cc-by-sa-4.0
- other
- cc-by-nc-4.0
- cc-by-nc-3.0
task_ids:
- multiple-choice-qa
- named-entity-recognition
- natural-language-inference
- part-of-speech
- sentiment-analysis
source_datasets:
- bsnlp
- wikiann
- exams
- ct21.t1
- fakenews
- crediblenews
- universal_dependencies
tags:
- check-worthiness-estimation
- fake-new-detection
- humor-detection
- regression
- ranking
---
# Dataset Card for "bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://bgglue.github.io/](https://bgglue.github.io/)
- **Repository:** [https://github.com/bgGLUE](https://github.com/bgGLUE)
- **Paper:** [bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark](https://arxiv.org/abs/2306.02349)
- **Point of Contact:** [bulgarianglue [at] gmail [dot] com](mailto:[email protected])

### Dataset Summary
bgGLUE (Bulgarian General Language Understanding Evaluation) is a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. The benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression).
### Supported Tasks and Leaderboards
List of supported tasks: [Tasks](https://bgglue.github.io/tasks/).
Leaderboard: [bgGLUE Leaderboard](https://bgglue.github.io/leaderboard/).
### Languages
Bulgarian
## Dataset Structure
### Data Instances
<div id="container">
<table id="table-tasks" class="table table-striped table-bordered">
<thead>
<tr>
<th scope="col">Name</th>
<th scope="col">Task type</th>
<th scope="col">Identifier</th>
<th scope="col" data-toggle="tooltip" data-placement="top" title="Tooltip on right">Download</th>
<th scope="col">More Info</th>
<th scope="col">Metrics</th>
<th scope="col">Train / Val / Test</th>
</tr>
</thead>
<tbody>
<tr>
<td>Balto-Slavic NLP Shared Task</td>
<td>Named Entity Recognition</td>
<td>BSNLP</td>
<td class="text-center"><a href="https://github.com/bgGLUE/bgglue/raw/main/data/bsnlp.tar.gz" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/bsnlp/">Info</a> </td>
<td>F1</td>
<td>724 / 182 / 301</td>
</tr>
<tr>
<td>CheckThat! (2021), Task 1A </td>
<td>Check-Worthiness Estimation</td>
<td>CT21.T1</td>
<td class="text-center"><a href="https://gitlab.com/checkthat_lab/clef2021-checkthat-lab/-/tree/master/task1" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/ct21-t1/">Info</a> </td>
<td>Average Precision</td>
<td>2,995 / 350 / 357</td>
</tr>
<tr>
<td>Cinexio Movie Reviews</td>
<td>Sentiment Analysis</td>
<td>Cinexio</td>
<td class="text-center"><a href="https://github.com/bgGLUE/bgglue/raw/main/data/cinexio.tar.gz" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/cinexio/">Info</a> </td>
<td>Pearson-Spearman Corr</td>
<td>8,155 / 811 / 861</td>
</tr>
<tr>
<td>Hack the News Datathon (2019)</td>
<td>Fake News Detection</td>
<td>Fake-N</td>
<td class="text-center"><a href="https://github.com/bgGLUE/bgglue/raw/main/data/fakenews.tar.gz" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/fakenews/">Info</a> </td>
<td>Binary F1</td>
<td>1,990 / 221 / 701</td>
</tr>
<tr>
<td>In Search of Credible News</td>
<td>Humor Detection</td>
<td>Cred.-N</td>
<td class="text-center"><a href="https://forms.gle/Z7PYHMAvFvFusWT37" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/crediblenews/">Info</a> </td>
<td>Binary F1</td>
<td>19,227 / 5,949 / 17,887</td>
</tr>
<tr>
<td>Multi-Subject High School Examinations Dataset</td>
<td>Multiple-choice QA</td>
<td>EXAMS</td>
<td class="text-center"><a href="https://github.com/bgGLUE/bgglue/raw/main/data/exams.tar.gz" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/exams/">Info</a> </td>
<td>Accuracy</td>
<td>1,512 / 365 / 1,472</td>
</tr>
<tr>
<td>Universal Dependencies</td>
<td>Part-of-Speech Tagging</td>
<td>U.Dep</td>
<td class="text-center"><a href="https://universaldependencies.org/#bulgarian-treebanks" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/udep/">Info</a> </td>
<td>F1</td>
<td>8,907 / 1,115 / 1,116</td>
</tr>
<tr>
<td>Cross-lingual Natural Language Inference</td>
<td>Natural Language Inference</td>
<td>XNLI</td>
<td class="text-center"><a href="https://github.com/facebookresearch/XNLI#download" target="_blank" rel="noopener">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/xnli/">Info</a> </td>
<td>Accuracy</td>
<td>392,702 / 5,010 / 2,490</td>
</tr>
<tr>
<td>Cross-lingual Name Tagging and Linking (PAN-X / WikiAnn)</td>
<td>Named Entity Recognition</td>
<td>PAN-X</td>
<td class="text-center"><a href="https://github.com/bgGLUE/bgglue/raw/main/data/wikiann_bg.tar.gz">URL</a> </td>
<td class="text-center"><a href="https://bgglue.github.io/tasks/task_info/wikiann/">Info</a> </td>
<td>F1</td>
<td>16,237 / 7,029 / 7,263 </td>
</tr>
</tbody>
</table>
</div>
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
Here, we describe the pre-processing steps we took to prepare the datasets before including them in the bgGLUE benchmark. Our main goal was to ensure that the setup evaluated the language understanding abilities of the models in a principled way and in a diverse set of domains. Since all of the datasets were publicly available, we preserved the original setup as much as possible. Nevertheless, we found that some datasets contained duplicate examples across their train/dev/test splits, or that all of the splits came from the same domain, which may overestimate the model's performance. Hereby, \textit{we removed data leaks} and proposed new topic-based or temporal-based (i.e., timestamp-based) data splits where needed. We deduplicated the examples based on a complete word overlap in two pairs of normalized texts, i.e., lowercased, and excluding all stop words.
## Considerations for Using the Data
### Discussion of Biases
The datasets included in bgGLUE were annotated by human annotators, who could be subject to potential biases in their annotation process. Hence, the datasets in \benchmarkName could potentially be misused to develop models that make predictions that are unfair to individuals or groups. Therefore, we ask users of bgGLUE to be aware of such potential biases and risks of misuse. We note that any biases that might exist in the original resources gathered in this benchmark are unintentional and do not aim to cause harm.
### Other Known Limitations
#### Tasks in bgGLUE
The bgGLUE benchmark is comprised of nine challenging NLU tasks, including three token classification tasks, one ranking task and five text classification tasks. While we cover three different types of tasks in the benchmark, we are restricted by the available resources for Bulgarian, and thus we could not include some other NLP tasks, such as language generation. We also consider only NLP tasks and we do not include tasks with other/multiple modalities. Finally, some of the tasks are of similar nature, e.g., we include two datasets for NER and two for credibility/fake news classification.
### Domains in bgGLUE
The tasks included in bgGLUE span over multiple domains such as social media posts, Wikipedia, and news articles and can test both for short and long document understanding. However, each task is limited to one domain and the topics within the domain do not necessarily have full coverage of all possible topics. Moreover, some of the tasks have overlapping domains, e.g., the documents in both Cred.-N and Fake-N are news articles.
## Additional Information
### Licensing Information
The primary bgGLUE tasks are built on and derived from existing datasets.
We refer users to the original licenses accompanying each dataset.
For each dataset the license is listed on its ["Tasks" page](https://bgglue.github.io/tasks/) on the bgGLUE website.
### Citation Information
```
@inproceedings{hardalov-etal-2023-bgglue,
title = "bg{GLUE}: A {B}ulgarian General Language Understanding Evaluation Benchmark",
author = "Hardalov, Momchil and
Atanasova, Pepa and
Mihaylov, Todor and
Angelova, Galia and
Simov, Kiril and
Osenova, Petya and
Stoyanov, Veselin and
Koychev, Ivan and
Nakov, Preslav and
Radev, Dragomir",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.487",
pages = "8733--8759",
}
```
### Contributions
[List of bgGLUE contributors](https://bgglue.github.io/people/) |
EleutherAI/asdiv | EleutherAI | "2023-11-02T14:45:42Z" | 2,918 | 1 | [
"license:cc-by-nc-4.0",
"region:us"
] | null | "2023-07-07T14:58:55Z" | ---
license: cc-by-nc-4.0
--- |
mosaicml/instruct-v3 | mosaicml | "2023-10-02T15:46:55Z" | 2,904 | 32 | [
"language:en",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-06-17T04:41:48Z" | ---
language: en
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
- name: source
dtype: string
splits:
- name: test
num_bytes: 18266901
num_examples: 6807
- name: train
num_bytes: 220790357
num_examples: 56167
download_size: 137475849
dataset_size: 239057258
---
# MosaicML Instruct V3
This is an aggregate dataset, comprised of [Dolly HHRLHF](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf) (derived from the [Databricks Dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) and the [Anthropic Helpful and Harmless (HH-RLHF)](https://huggingface.co/datasets/Anthropic/hh-rlhf) datasets), combined with [Competition Math](https://huggingface.co/datasets/competition_math), [Duorc](https://huggingface.co/datasets/duorc), [CoT GSM8k](https://huggingface.co/datasets/conceptofmind/cot_submix_original), [Qasper](https://huggingface.co/datasets/allenai/qasper), [Quality](https://huggingface.co/datasets/emozilla/quality), [Summ Screen FD](https://huggingface.co/datasets/tau/scrolls) and [Spider](https://huggingface.co/datasets/spider).
The intention was to create a permissively-licensed instruction-following dataset with a large number of longform samples.
## Data Processing
Some data was transformed during the creation of this dataset. This involved: formatting the data into the Alpaca format, filtering for length, filtering for duplicates, adding instructions (for summarization and QA datasets), and making the instructions more like human input (transforming case, adding typos, etc).
## Data Mix
| Data Source | Number of Samples | Proportion (By Count of Samples) | Number of Tokens in Source | Proportion (By Count of Tokens) |
|-------------|------------|------------|------------|------------|
| competition_math | 4,995 | 8.89% | 1.6 M | 3.66% |
| cot_gsm8k | 4,995 | 8.89% | 3.36 M | 7.67% |
| dialogsum | 400 | 0.71% | 0.1 M | 0.23% |
| dolly_hhrlhf | 34,333 | 61.13% | 5.89 M | 13.43% |
| duorc | 4,986 | 8.88% | 7.8 M | 17.80% |
| qasper | 1,998 | 3.56% | 8.72 M | 19.90% |
| quality | 1,963 | 3.49% | 11.29 M | 25.78% |
| scrolls/summ_screen_fd | 1,498 | 2.67% | 4.97 M | 11.33% |
| spider | 999 | 1.78% | 0.089 M | 0.20% |
## License/Attribution
<!--
**Copyright (2023) MosaicML, Inc.**
-->
This dataset was developed at MosaicML (https://www.mosaicml.com) and its use is subject to the CC BY-SA 3.0 license.
Certain categories of material in the dataset include materials from the following sources, licensed under the CC BY-SA 3.0 license:
Wikipedia (various pages) - https://www.wikipedia.org/
Copyright © Wikipedia editors and contributors.
Dolly — Databricks (https://www.databricks.com)
Copyright © Databricks
When citing this dataset, please use the following:
```
@misc{mosaicml2023instruct-v3,
author = {MosaicML},
title = {MosaicML Instruct-v3 Dataset},
year = {2023},
publisher = {HuggingFace Datasets},
howpublished = {https://huggingface.co/datasets/mosaicml/instruct-v3},
}
```
|
OpenAssistant/oasst1 | OpenAssistant | "2023-05-02T13:21:21Z" | 2,903 | 1,256 | [
"language:en",
"language:es",
"language:ru",
"language:de",
"language:pl",
"language:th",
"language:vi",
"language:sv",
"language:bn",
"language:da",
"language:he",
"language:it",
"language:fa",
"language:sk",
"language:id",
"language:nb",
"language:el",
"language:nl",
"language:hu",
"language:eu",
"language:zh",
"language:eo",
"language:ja",
"language:ca",
"language:cs",
"language:bg",
"language:fi",
"language:pt",
"language:tr",
"language:ro",
"language:ar",
"language:uk",
"language:gl",
"language:fr",
"language:ko",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2304.07327",
"region:us",
"human-feedback"
] | null | "2023-04-13T15:48:16Z" | ---
license: apache-2.0
dataset_info:
features:
- name: message_id
dtype: string
- name: parent_id
dtype: string
- name: user_id
dtype: string
- name: created_date
dtype: string
- name: text
dtype: string
- name: role
dtype: string
- name: lang
dtype: string
- name: review_count
dtype: int32
- name: review_result
dtype: bool
- name: deleted
dtype: bool
- name: rank
dtype: int32
- name: synthetic
dtype: bool
- name: model_name
dtype: string
- name: detoxify
struct:
- name: toxicity
dtype: float64
- name: severe_toxicity
dtype: float64
- name: obscene
dtype: float64
- name: identity_attack
dtype: float64
- name: insult
dtype: float64
- name: threat
dtype: float64
- name: sexual_explicit
dtype: float64
- name: message_tree_id
dtype: string
- name: tree_state
dtype: string
- name: emojis
sequence:
- name: name
dtype: string
- name: count
dtype: int32
- name: labels
sequence:
- name: name
dtype: string
- name: value
dtype: float64
- name: count
dtype: int32
splits:
- name: train
num_bytes: 100367999
num_examples: 84437
- name: validation
num_bytes: 5243405
num_examples: 4401
download_size: 41596430
dataset_size: 105611404
language:
- en
- es
- ru
- de
- pl
- th
- vi
- sv
- bn
- da
- he
- it
- fa
- sk
- id
- nb
- el
- nl
- hu
- eu
- zh
- eo
- ja
- ca
- cs
- bg
- fi
- pt
- tr
- ro
- ar
- uk
- gl
- fr
- ko
tags:
- human-feedback
size_categories:
- 100K<n<1M
pretty_name: OpenAssistant Conversations
---
# OpenAssistant Conversations Dataset (OASST1)
## Dataset Description
- **Homepage:** https://www.open-assistant.io/
- **Repository:** https://github.com/LAION-AI/Open-Assistant
- **Paper:** https://arxiv.org/abs/2304.07327
### Dataset Summary
In an effort to democratize research on large-scale alignment, we release OpenAssistant
Conversations (OASST1), a human-generated, human-annotated assistant-style conversation
corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292
quality ratings, resulting in over 10,000 fully annotated conversation trees. The corpus
is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers.
Please refer to our [paper](https://arxiv.org/abs/2304.07327) for further details.
### Dataset Structure
This dataset contains message trees. Each message tree has an initial prompt message as the root node,
which can have multiple child messages as replies, and these child messages can have multiple replies.
All messages have a role property: this can either be "assistant" or "prompter". The roles in
conversation threads from prompt to leaf node strictly alternate between "prompter" and "assistant".
This version of the dataset contains data collected on the [open-assistant.io](https://open-assistant.io/) website until April 12 2023.
### JSON Example: Message
For readability, the following JSON examples are shown formatted with indentation on multiple lines.
Objects are stored without indentation (on single lines) in the actual jsonl files.
```json
{
"message_id": "218440fd-5317-4355-91dc-d001416df62b",
"parent_id": "13592dfb-a6f9-4748-a92c-32b34e239bb4",
"user_id": "8e95461f-5e94-4d8b-a2fb-d4717ce973e4",
"text": "It was the winter of 2035, and artificial intelligence (..)",
"role": "assistant",
"lang": "en",
"review_count": 3,
"review_result": true,
"deleted": false,
"rank": 0,
"synthetic": true,
"model_name": "oasst-sft-0_3000,max_new_tokens=400 (..)",
"labels": {
"spam": { "value": 0.0, "count": 3 },
"lang_mismatch": { "value": 0.0, "count": 3 },
"pii": { "value": 0.0, "count": 3 },
"not_appropriate": { "value": 0.0, "count": 3 },
"hate_speech": { "value": 0.0, "count": 3 },
"sexual_content": { "value": 0.0, "count": 3 },
"quality": { "value": 0.416, "count": 3 },
"toxicity": { "value": 0.16, "count": 3 },
"humor": { "value": 0.0, "count": 3 },
"creativity": { "value": 0.33, "count": 3 },
"violence": { "value": 0.16, "count": 3 }
}
}
```
### JSON Example: Conversation Tree
For readability, only a subset of the message properties is shown here.
```json
{
"message_tree_id": "14fbb664-a620-45ce-bee4-7c519b16a793",
"tree_state": "ready_for_export",
"prompt": {
"message_id": "14fbb664-a620-45ce-bee4-7c519b16a793",
"text": "Why can't we divide by 0? (..)",
"role": "prompter",
"lang": "en",
"replies": [
{
"message_id": "894d30b6-56b4-4605-a504-89dd15d4d1c8",
"text": "The reason we cannot divide by zero is because (..)",
"role": "assistant",
"lang": "en",
"replies": [
// ...
]
},
{
"message_id": "84d0913b-0fd9-4508-8ef5-205626a7039d",
"text": "The reason that the result of a division by zero is (..)",
"role": "assistant",
"lang": "en",
"replies": [
{
"message_id": "3352725e-f424-4e3b-a627-b6db831bdbaa",
"text": "Math is confusing. Like those weird Irrational (..)",
"role": "prompter",
"lang": "en",
"replies": [
{
"message_id": "f46207ca-3149-46e9-a466-9163d4ce499c",
"text": "Irrational numbers are simply numbers (..)",
"role": "assistant",
"lang": "en",
"replies": []
},
// ...
]
}
]
}
]
}
}
```
Please refer to [oasst-data](https://github.com/LAION-AI/Open-Assistant/tree/main/oasst-data) for
details about the data structure and Python code to read and write jsonl files containing oasst data objects.
If you would like to explore the dataset yourself you can find a
[`getting-started`](https://github.com/LAION-AI/Open-Assistant/blob/main/notebooks/openassistant-oasst1/getting-started.ipynb)
notebook in the `notebooks/openassistant-oasst1` folder of the [LAION-AI/Open-Assistant](https://github.com/LAION-AI/Open-Assistant)
github repository.
## Main Dataset Files
Conversation data is provided either as nested messages in trees (extension `.trees.jsonl.gz`)
or as a flat list (table) of messages (extension `.messages.jsonl.gz`).
### Ready For Export Trees
```
2023-04-12_oasst_ready.trees.jsonl.gz 10,364 trees with 88,838 total messages
2023-04-12_oasst_ready.messages.jsonl.gz 88,838 messages
```
Trees in `ready_for_export` state without spam and deleted messages including message labels.
The oasst_ready-trees file usually is sufficient for supervised fine-tuning (SFT) & reward model (RM) training.
### All Trees
```
2023-04-12_oasst_all.trees.jsonl.gz 66,497 trees with 161,443 total messages
2023-04-12_oasst_all.messages.jsonl.gz 161,443 messages
```
All trees, including those in states `prompt_lottery_waiting` (trees that consist of only one message, namely the initial prompt),
`aborted_low_grade` (trees that stopped growing because the messages had low quality), and `halted_by_moderator`.
### Supplemental Exports: Spam & Prompts
```
2023-04-12_oasst_spam.messages.jsonl.gz
```
These are messages which were deleted or have a negative review result (`"review_result": false`).
Besides low quality, a frequent reason for message deletion is a wrong language tag.
```
2023-04-12_oasst_prompts.messages.jsonl.gz
```
These are all the kept initial prompt messages with positive review result (no spam) of trees in `ready_for_export` or `prompt_lottery_waiting` state.
### Using the Huggingface Datasets
While HF datasets is ideal for tabular datasets, it is not a natural fit for nested data structures like the OpenAssistant conversation trees.
Nevertheless, we make all messages which can also be found in the file `2023-04-12_oasst_ready.trees.jsonl.gz` available in parquet as train/validation splits.
These are directly loadable by [Huggingface Datasets](https://pypi.org/project/datasets/).
To load the oasst1 train & validation splits use:
```python
from datasets import load_dataset
ds = load_dataset("OpenAssistant/oasst1")
train = ds['train'] # len(train)=84437 (95%)
val = ds['validation'] # len(val)=4401 (5%)
```
The messages appear in depth-first order of the message trees.
Full conversation trees can be reconstructed from the flat messages table by using the `parent_id`
and `message_id` properties to identify the parent-child relationship of messages. The `message_tree_id`
and `tree_state` properties (only present in flat messages files) can be used to find all messages of a message tree or to select trees by their state.
### Languages
OpenAssistant Conversations incorporates 35 different languages with a distribution of messages as follows:
**Languages with over 1000 messages**
- English: 71956
- Spanish: 43061
- Russian: 9089
- German: 5279
- Chinese: 4962
- French: 4251
- Thai: 3042
- Portuguese (Brazil): 2969
- Catalan: 2260
- Korean: 1553
- Ukrainian: 1352
- Italian: 1320
- Japanese: 1018
<details>
<summary><b>Languages with under 1000 messages</b></summary>
<ul>
<li>Vietnamese: 952</li>
<li>Basque: 947</li>
<li>Polish: 886</li>
<li>Hungarian: 811</li>
<li>Arabic: 666</li>
<li>Dutch: 628</li>
<li>Swedish: 512</li>
<li>Turkish: 454</li>
<li>Finnish: 386</li>
<li>Czech: 372</li>
<li>Danish: 358</li>
<li>Galician: 339</li>
<li>Hebrew: 255</li>
<li>Romanian: 200</li>
<li>Norwegian Bokmål: 133</li>
<li>Indonesian: 115</li>
<li>Bulgarian: 95</li>
<li>Bengali: 82</li>
<li>Persian: 72</li>
<li>Greek: 66</li>
<li>Esperanto: 59</li>
<li>Slovak: 19</li>
</ul>
</details>
## Contact
- Discord [Open Assistant Discord Server](https://ykilcher.com/open-assistant-discord)
- GitHub: [LAION-AI/Open-Assistant](https://github.com/LAION-AI/Open-Assistant)
- E-Mail: [[email protected]](mailto:[email protected]) |
baber/multilingual_mmlu | baber | "2024-09-17T12:49:25Z" | 2,892 | 0 | [
"task_categories:text-generation",
"license:mit",
"size_categories:100K<n<1M",
"modality:text",
"region:us"
] | [
"text-generation"
] | "2024-09-17T11:31:42Z" | ---
license: mit
configs:
- config_name: high_school_world_history
data_files:
- split: AR_XY
path: AR_XY/high_school_world_history/*.parquet
- split: BN_BD
path: BN_BD/high_school_world_history/*.parquet
- split: DE_DE
path: DE_DE/high_school_world_history/*.parquet
- split: ES_LA
path: ES_LA/high_school_world_history/*.parquet
- split: FR_FR
path: FR_FR/high_school_world_history/*.parquet
- split: HI_IN
path: HI_IN/high_school_world_history/*.parquet
- split: ID_ID
path: ID_ID/high_school_world_history/*.parquet
- split: IT_IT
path: IT_IT/high_school_world_history/*.parquet
- split: JA_JP
path: JA_JP/high_school_world_history/*.parquet
- split: KO_KR
path: KO_KR/high_school_world_history/*.parquet
- split: PT_BR
path: PT_BR/high_school_world_history/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_world_history/*.parquet
- split: SW_KE
path: SW_KE/high_school_world_history/*.parquet
- split: YO_NG
path: YO_NG/high_school_world_history/*.parquet
- split: EN_US
path: EN_US/high_school_world_history/*.parquet
- config_name: electrical_engineering
data_files:
- split: AR_XY
path: AR_XY/electrical_engineering/*.parquet
- split: BN_BD
path: BN_BD/electrical_engineering/*.parquet
- split: DE_DE
path: DE_DE/electrical_engineering/*.parquet
- split: ES_LA
path: ES_LA/electrical_engineering/*.parquet
- split: FR_FR
path: FR_FR/electrical_engineering/*.parquet
- split: HI_IN
path: HI_IN/electrical_engineering/*.parquet
- split: ID_ID
path: ID_ID/electrical_engineering/*.parquet
- split: IT_IT
path: IT_IT/electrical_engineering/*.parquet
- split: JA_JP
path: JA_JP/electrical_engineering/*.parquet
- split: KO_KR
path: KO_KR/electrical_engineering/*.parquet
- split: PT_BR
path: PT_BR/electrical_engineering/*.parquet
- split: ZH_CN
path: ZH_CN/electrical_engineering/*.parquet
- split: SW_KE
path: SW_KE/electrical_engineering/*.parquet
- split: YO_NG
path: YO_NG/electrical_engineering/*.parquet
- split: EN_US
path: EN_US/electrical_engineering/*.parquet
- config_name: international_law
data_files:
- split: AR_XY
path: AR_XY/international_law/*.parquet
- split: BN_BD
path: BN_BD/international_law/*.parquet
- split: DE_DE
path: DE_DE/international_law/*.parquet
- split: ES_LA
path: ES_LA/international_law/*.parquet
- split: FR_FR
path: FR_FR/international_law/*.parquet
- split: HI_IN
path: HI_IN/international_law/*.parquet
- split: ID_ID
path: ID_ID/international_law/*.parquet
- split: IT_IT
path: IT_IT/international_law/*.parquet
- split: JA_JP
path: JA_JP/international_law/*.parquet
- split: KO_KR
path: KO_KR/international_law/*.parquet
- split: PT_BR
path: PT_BR/international_law/*.parquet
- split: ZH_CN
path: ZH_CN/international_law/*.parquet
- split: SW_KE
path: SW_KE/international_law/*.parquet
- split: YO_NG
path: YO_NG/international_law/*.parquet
- split: EN_US
path: EN_US/international_law/*.parquet
- config_name: medical_genetics
data_files:
- split: AR_XY
path: AR_XY/medical_genetics/*.parquet
- split: BN_BD
path: BN_BD/medical_genetics/*.parquet
- split: DE_DE
path: DE_DE/medical_genetics/*.parquet
- split: ES_LA
path: ES_LA/medical_genetics/*.parquet
- split: FR_FR
path: FR_FR/medical_genetics/*.parquet
- split: HI_IN
path: HI_IN/medical_genetics/*.parquet
- split: ID_ID
path: ID_ID/medical_genetics/*.parquet
- split: IT_IT
path: IT_IT/medical_genetics/*.parquet
- split: JA_JP
path: JA_JP/medical_genetics/*.parquet
- split: KO_KR
path: KO_KR/medical_genetics/*.parquet
- split: PT_BR
path: PT_BR/medical_genetics/*.parquet
- split: ZH_CN
path: ZH_CN/medical_genetics/*.parquet
- split: SW_KE
path: SW_KE/medical_genetics/*.parquet
- split: YO_NG
path: YO_NG/medical_genetics/*.parquet
- split: EN_US
path: EN_US/medical_genetics/*.parquet
- config_name: moral_scenarios
data_files:
- split: AR_XY
path: AR_XY/moral_scenarios/*.parquet
- split: BN_BD
path: BN_BD/moral_scenarios/*.parquet
- split: DE_DE
path: DE_DE/moral_scenarios/*.parquet
- split: ES_LA
path: ES_LA/moral_scenarios/*.parquet
- split: FR_FR
path: FR_FR/moral_scenarios/*.parquet
- split: HI_IN
path: HI_IN/moral_scenarios/*.parquet
- split: ID_ID
path: ID_ID/moral_scenarios/*.parquet
- split: IT_IT
path: IT_IT/moral_scenarios/*.parquet
- split: JA_JP
path: JA_JP/moral_scenarios/*.parquet
- split: KO_KR
path: KO_KR/moral_scenarios/*.parquet
- split: PT_BR
path: PT_BR/moral_scenarios/*.parquet
- split: ZH_CN
path: ZH_CN/moral_scenarios/*.parquet
- split: SW_KE
path: SW_KE/moral_scenarios/*.parquet
- split: YO_NG
path: YO_NG/moral_scenarios/*.parquet
- split: EN_US
path: EN_US/moral_scenarios/*.parquet
- config_name: formal_logic
data_files:
- split: AR_XY
path: AR_XY/formal_logic/*.parquet
- split: BN_BD
path: BN_BD/formal_logic/*.parquet
- split: DE_DE
path: DE_DE/formal_logic/*.parquet
- split: ES_LA
path: ES_LA/formal_logic/*.parquet
- split: FR_FR
path: FR_FR/formal_logic/*.parquet
- split: HI_IN
path: HI_IN/formal_logic/*.parquet
- split: ID_ID
path: ID_ID/formal_logic/*.parquet
- split: IT_IT
path: IT_IT/formal_logic/*.parquet
- split: JA_JP
path: JA_JP/formal_logic/*.parquet
- split: KO_KR
path: KO_KR/formal_logic/*.parquet
- split: PT_BR
path: PT_BR/formal_logic/*.parquet
- split: ZH_CN
path: ZH_CN/formal_logic/*.parquet
- split: SW_KE
path: SW_KE/formal_logic/*.parquet
- split: YO_NG
path: YO_NG/formal_logic/*.parquet
- split: EN_US
path: EN_US/formal_logic/*.parquet
- config_name: astronomy
data_files:
- split: AR_XY
path: AR_XY/astronomy/*.parquet
- split: BN_BD
path: BN_BD/astronomy/*.parquet
- split: DE_DE
path: DE_DE/astronomy/*.parquet
- split: ES_LA
path: ES_LA/astronomy/*.parquet
- split: FR_FR
path: FR_FR/astronomy/*.parquet
- split: HI_IN
path: HI_IN/astronomy/*.parquet
- split: ID_ID
path: ID_ID/astronomy/*.parquet
- split: IT_IT
path: IT_IT/astronomy/*.parquet
- split: JA_JP
path: JA_JP/astronomy/*.parquet
- split: KO_KR
path: KO_KR/astronomy/*.parquet
- split: PT_BR
path: PT_BR/astronomy/*.parquet
- split: ZH_CN
path: ZH_CN/astronomy/*.parquet
- split: SW_KE
path: SW_KE/astronomy/*.parquet
- split: YO_NG
path: YO_NG/astronomy/*.parquet
- split: EN_US
path: EN_US/astronomy/*.parquet
- config_name: high_school_computer_science
data_files:
- split: AR_XY
path: AR_XY/high_school_computer_science/*.parquet
- split: BN_BD
path: BN_BD/high_school_computer_science/*.parquet
- split: DE_DE
path: DE_DE/high_school_computer_science/*.parquet
- split: ES_LA
path: ES_LA/high_school_computer_science/*.parquet
- split: FR_FR
path: FR_FR/high_school_computer_science/*.parquet
- split: HI_IN
path: HI_IN/high_school_computer_science/*.parquet
- split: ID_ID
path: ID_ID/high_school_computer_science/*.parquet
- split: IT_IT
path: IT_IT/high_school_computer_science/*.parquet
- split: JA_JP
path: JA_JP/high_school_computer_science/*.parquet
- split: KO_KR
path: KO_KR/high_school_computer_science/*.parquet
- split: PT_BR
path: PT_BR/high_school_computer_science/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_computer_science/*.parquet
- split: SW_KE
path: SW_KE/high_school_computer_science/*.parquet
- split: YO_NG
path: YO_NG/high_school_computer_science/*.parquet
- split: EN_US
path: EN_US/high_school_computer_science/*.parquet
- config_name: jurisprudence
data_files:
- split: AR_XY
path: AR_XY/jurisprudence/*.parquet
- split: BN_BD
path: BN_BD/jurisprudence/*.parquet
- split: DE_DE
path: DE_DE/jurisprudence/*.parquet
- split: ES_LA
path: ES_LA/jurisprudence/*.parquet
- split: FR_FR
path: FR_FR/jurisprudence/*.parquet
- split: HI_IN
path: HI_IN/jurisprudence/*.parquet
- split: ID_ID
path: ID_ID/jurisprudence/*.parquet
- split: IT_IT
path: IT_IT/jurisprudence/*.parquet
- split: JA_JP
path: JA_JP/jurisprudence/*.parquet
- split: KO_KR
path: KO_KR/jurisprudence/*.parquet
- split: PT_BR
path: PT_BR/jurisprudence/*.parquet
- split: ZH_CN
path: ZH_CN/jurisprudence/*.parquet
- split: SW_KE
path: SW_KE/jurisprudence/*.parquet
- split: YO_NG
path: YO_NG/jurisprudence/*.parquet
- split: EN_US
path: EN_US/jurisprudence/*.parquet
- config_name: sociology
data_files:
- split: AR_XY
path: AR_XY/sociology/*.parquet
- split: BN_BD
path: BN_BD/sociology/*.parquet
- split: DE_DE
path: DE_DE/sociology/*.parquet
- split: ES_LA
path: ES_LA/sociology/*.parquet
- split: FR_FR
path: FR_FR/sociology/*.parquet
- split: HI_IN
path: HI_IN/sociology/*.parquet
- split: ID_ID
path: ID_ID/sociology/*.parquet
- split: IT_IT
path: IT_IT/sociology/*.parquet
- split: JA_JP
path: JA_JP/sociology/*.parquet
- split: KO_KR
path: KO_KR/sociology/*.parquet
- split: PT_BR
path: PT_BR/sociology/*.parquet
- split: ZH_CN
path: ZH_CN/sociology/*.parquet
- split: SW_KE
path: SW_KE/sociology/*.parquet
- split: YO_NG
path: YO_NG/sociology/*.parquet
- split: EN_US
path: EN_US/sociology/*.parquet
- config_name: anatomy
data_files:
- split: AR_XY
path: AR_XY/anatomy/*.parquet
- split: BN_BD
path: BN_BD/anatomy/*.parquet
- split: DE_DE
path: DE_DE/anatomy/*.parquet
- split: ES_LA
path: ES_LA/anatomy/*.parquet
- split: FR_FR
path: FR_FR/anatomy/*.parquet
- split: HI_IN
path: HI_IN/anatomy/*.parquet
- split: ID_ID
path: ID_ID/anatomy/*.parquet
- split: IT_IT
path: IT_IT/anatomy/*.parquet
- split: JA_JP
path: JA_JP/anatomy/*.parquet
- split: KO_KR
path: KO_KR/anatomy/*.parquet
- split: PT_BR
path: PT_BR/anatomy/*.parquet
- split: ZH_CN
path: ZH_CN/anatomy/*.parquet
- split: SW_KE
path: SW_KE/anatomy/*.parquet
- split: YO_NG
path: YO_NG/anatomy/*.parquet
- split: EN_US
path: EN_US/anatomy/*.parquet
- config_name: elementary_mathematics
data_files:
- split: AR_XY
path: AR_XY/elementary_mathematics/*.parquet
- split: BN_BD
path: BN_BD/elementary_mathematics/*.parquet
- split: DE_DE
path: DE_DE/elementary_mathematics/*.parquet
- split: ES_LA
path: ES_LA/elementary_mathematics/*.parquet
- split: FR_FR
path: FR_FR/elementary_mathematics/*.parquet
- split: HI_IN
path: HI_IN/elementary_mathematics/*.parquet
- split: ID_ID
path: ID_ID/elementary_mathematics/*.parquet
- split: IT_IT
path: IT_IT/elementary_mathematics/*.parquet
- split: JA_JP
path: JA_JP/elementary_mathematics/*.parquet
- split: KO_KR
path: KO_KR/elementary_mathematics/*.parquet
- split: PT_BR
path: PT_BR/elementary_mathematics/*.parquet
- split: ZH_CN
path: ZH_CN/elementary_mathematics/*.parquet
- split: SW_KE
path: SW_KE/elementary_mathematics/*.parquet
- split: YO_NG
path: YO_NG/elementary_mathematics/*.parquet
- split: EN_US
path: EN_US/elementary_mathematics/*.parquet
- config_name: high_school_european_history
data_files:
- split: AR_XY
path: AR_XY/high_school_european_history/*.parquet
- split: BN_BD
path: BN_BD/high_school_european_history/*.parquet
- split: DE_DE
path: DE_DE/high_school_european_history/*.parquet
- split: ES_LA
path: ES_LA/high_school_european_history/*.parquet
- split: FR_FR
path: FR_FR/high_school_european_history/*.parquet
- split: HI_IN
path: HI_IN/high_school_european_history/*.parquet
- split: ID_ID
path: ID_ID/high_school_european_history/*.parquet
- split: IT_IT
path: IT_IT/high_school_european_history/*.parquet
- split: JA_JP
path: JA_JP/high_school_european_history/*.parquet
- split: KO_KR
path: KO_KR/high_school_european_history/*.parquet
- split: PT_BR
path: PT_BR/high_school_european_history/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_european_history/*.parquet
- split: SW_KE
path: SW_KE/high_school_european_history/*.parquet
- split: YO_NG
path: YO_NG/high_school_european_history/*.parquet
- split: EN_US
path: EN_US/high_school_european_history/*.parquet
- config_name: prehistory
data_files:
- split: AR_XY
path: AR_XY/prehistory/*.parquet
- split: BN_BD
path: BN_BD/prehistory/*.parquet
- split: DE_DE
path: DE_DE/prehistory/*.parquet
- split: ES_LA
path: ES_LA/prehistory/*.parquet
- split: FR_FR
path: FR_FR/prehistory/*.parquet
- split: HI_IN
path: HI_IN/prehistory/*.parquet
- split: ID_ID
path: ID_ID/prehistory/*.parquet
- split: IT_IT
path: IT_IT/prehistory/*.parquet
- split: JA_JP
path: JA_JP/prehistory/*.parquet
- split: KO_KR
path: KO_KR/prehistory/*.parquet
- split: PT_BR
path: PT_BR/prehistory/*.parquet
- split: ZH_CN
path: ZH_CN/prehistory/*.parquet
- split: SW_KE
path: SW_KE/prehistory/*.parquet
- split: YO_NG
path: YO_NG/prehistory/*.parquet
- split: EN_US
path: EN_US/prehistory/*.parquet
- config_name: professional_law
data_files:
- split: AR_XY
path: AR_XY/professional_law/*.parquet
- split: BN_BD
path: BN_BD/professional_law/*.parquet
- split: DE_DE
path: DE_DE/professional_law/*.parquet
- split: ES_LA
path: ES_LA/professional_law/*.parquet
- split: FR_FR
path: FR_FR/professional_law/*.parquet
- split: HI_IN
path: HI_IN/professional_law/*.parquet
- split: ID_ID
path: ID_ID/professional_law/*.parquet
- split: IT_IT
path: IT_IT/professional_law/*.parquet
- split: JA_JP
path: JA_JP/professional_law/*.parquet
- split: KO_KR
path: KO_KR/professional_law/*.parquet
- split: PT_BR
path: PT_BR/professional_law/*.parquet
- split: ZH_CN
path: ZH_CN/professional_law/*.parquet
- split: SW_KE
path: SW_KE/professional_law/*.parquet
- split: YO_NG
path: YO_NG/professional_law/*.parquet
- split: EN_US
path: EN_US/professional_law/*.parquet
- config_name: moral_disputes
data_files:
- split: AR_XY
path: AR_XY/moral_disputes/*.parquet
- split: BN_BD
path: BN_BD/moral_disputes/*.parquet
- split: DE_DE
path: DE_DE/moral_disputes/*.parquet
- split: ES_LA
path: ES_LA/moral_disputes/*.parquet
- split: FR_FR
path: FR_FR/moral_disputes/*.parquet
- split: HI_IN
path: HI_IN/moral_disputes/*.parquet
- split: ID_ID
path: ID_ID/moral_disputes/*.parquet
- split: IT_IT
path: IT_IT/moral_disputes/*.parquet
- split: JA_JP
path: JA_JP/moral_disputes/*.parquet
- split: KO_KR
path: KO_KR/moral_disputes/*.parquet
- split: PT_BR
path: PT_BR/moral_disputes/*.parquet
- split: ZH_CN
path: ZH_CN/moral_disputes/*.parquet
- split: SW_KE
path: SW_KE/moral_disputes/*.parquet
- split: YO_NG
path: YO_NG/moral_disputes/*.parquet
- split: EN_US
path: EN_US/moral_disputes/*.parquet
- config_name: machine_learning
data_files:
- split: AR_XY
path: AR_XY/machine_learning/*.parquet
- split: BN_BD
path: BN_BD/machine_learning/*.parquet
- split: DE_DE
path: DE_DE/machine_learning/*.parquet
- split: ES_LA
path: ES_LA/machine_learning/*.parquet
- split: FR_FR
path: FR_FR/machine_learning/*.parquet
- split: HI_IN
path: HI_IN/machine_learning/*.parquet
- split: ID_ID
path: ID_ID/machine_learning/*.parquet
- split: IT_IT
path: IT_IT/machine_learning/*.parquet
- split: JA_JP
path: JA_JP/machine_learning/*.parquet
- split: KO_KR
path: KO_KR/machine_learning/*.parquet
- split: PT_BR
path: PT_BR/machine_learning/*.parquet
- split: ZH_CN
path: ZH_CN/machine_learning/*.parquet
- split: SW_KE
path: SW_KE/machine_learning/*.parquet
- split: YO_NG
path: YO_NG/machine_learning/*.parquet
- split: EN_US
path: EN_US/machine_learning/*.parquet
- config_name: high_school_microeconomics
data_files:
- split: AR_XY
path: AR_XY/high_school_microeconomics/*.parquet
- split: BN_BD
path: BN_BD/high_school_microeconomics/*.parquet
- split: DE_DE
path: DE_DE/high_school_microeconomics/*.parquet
- split: ES_LA
path: ES_LA/high_school_microeconomics/*.parquet
- split: FR_FR
path: FR_FR/high_school_microeconomics/*.parquet
- split: HI_IN
path: HI_IN/high_school_microeconomics/*.parquet
- split: ID_ID
path: ID_ID/high_school_microeconomics/*.parquet
- split: IT_IT
path: IT_IT/high_school_microeconomics/*.parquet
- split: JA_JP
path: JA_JP/high_school_microeconomics/*.parquet
- split: KO_KR
path: KO_KR/high_school_microeconomics/*.parquet
- split: PT_BR
path: PT_BR/high_school_microeconomics/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_microeconomics/*.parquet
- split: SW_KE
path: SW_KE/high_school_microeconomics/*.parquet
- split: YO_NG
path: YO_NG/high_school_microeconomics/*.parquet
- split: EN_US
path: EN_US/high_school_microeconomics/*.parquet
- config_name: high_school_us_history
data_files:
- split: AR_XY
path: AR_XY/high_school_us_history/*.parquet
- split: BN_BD
path: BN_BD/high_school_us_history/*.parquet
- split: DE_DE
path: DE_DE/high_school_us_history/*.parquet
- split: ES_LA
path: ES_LA/high_school_us_history/*.parquet
- split: FR_FR
path: FR_FR/high_school_us_history/*.parquet
- split: HI_IN
path: HI_IN/high_school_us_history/*.parquet
- split: ID_ID
path: ID_ID/high_school_us_history/*.parquet
- split: IT_IT
path: IT_IT/high_school_us_history/*.parquet
- split: JA_JP
path: JA_JP/high_school_us_history/*.parquet
- split: KO_KR
path: KO_KR/high_school_us_history/*.parquet
- split: PT_BR
path: PT_BR/high_school_us_history/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_us_history/*.parquet
- split: SW_KE
path: SW_KE/high_school_us_history/*.parquet
- split: YO_NG
path: YO_NG/high_school_us_history/*.parquet
- split: EN_US
path: EN_US/high_school_us_history/*.parquet
- config_name: college_computer_science
data_files:
- split: AR_XY
path: AR_XY/college_computer_science/*.parquet
- split: BN_BD
path: BN_BD/college_computer_science/*.parquet
- split: DE_DE
path: DE_DE/college_computer_science/*.parquet
- split: ES_LA
path: ES_LA/college_computer_science/*.parquet
- split: FR_FR
path: FR_FR/college_computer_science/*.parquet
- split: HI_IN
path: HI_IN/college_computer_science/*.parquet
- split: ID_ID
path: ID_ID/college_computer_science/*.parquet
- split: IT_IT
path: IT_IT/college_computer_science/*.parquet
- split: JA_JP
path: JA_JP/college_computer_science/*.parquet
- split: KO_KR
path: KO_KR/college_computer_science/*.parquet
- split: PT_BR
path: PT_BR/college_computer_science/*.parquet
- split: ZH_CN
path: ZH_CN/college_computer_science/*.parquet
- split: SW_KE
path: SW_KE/college_computer_science/*.parquet
- split: YO_NG
path: YO_NG/college_computer_science/*.parquet
- split: EN_US
path: EN_US/college_computer_science/*.parquet
- config_name: security_studies
data_files:
- split: AR_XY
path: AR_XY/security_studies/*.parquet
- split: BN_BD
path: BN_BD/security_studies/*.parquet
- split: DE_DE
path: DE_DE/security_studies/*.parquet
- split: ES_LA
path: ES_LA/security_studies/*.parquet
- split: FR_FR
path: FR_FR/security_studies/*.parquet
- split: HI_IN
path: HI_IN/security_studies/*.parquet
- split: ID_ID
path: ID_ID/security_studies/*.parquet
- split: IT_IT
path: IT_IT/security_studies/*.parquet
- split: JA_JP
path: JA_JP/security_studies/*.parquet
- split: KO_KR
path: KO_KR/security_studies/*.parquet
- split: PT_BR
path: PT_BR/security_studies/*.parquet
- split: ZH_CN
path: ZH_CN/security_studies/*.parquet
- split: SW_KE
path: SW_KE/security_studies/*.parquet
- split: YO_NG
path: YO_NG/security_studies/*.parquet
- split: EN_US
path: EN_US/security_studies/*.parquet
- config_name: management
data_files:
- split: AR_XY
path: AR_XY/management/*.parquet
- split: BN_BD
path: BN_BD/management/*.parquet
- split: DE_DE
path: DE_DE/management/*.parquet
- split: ES_LA
path: ES_LA/management/*.parquet
- split: FR_FR
path: FR_FR/management/*.parquet
- split: HI_IN
path: HI_IN/management/*.parquet
- split: ID_ID
path: ID_ID/management/*.parquet
- split: IT_IT
path: IT_IT/management/*.parquet
- split: JA_JP
path: JA_JP/management/*.parquet
- split: KO_KR
path: KO_KR/management/*.parquet
- split: PT_BR
path: PT_BR/management/*.parquet
- split: ZH_CN
path: ZH_CN/management/*.parquet
- split: SW_KE
path: SW_KE/management/*.parquet
- split: YO_NG
path: YO_NG/management/*.parquet
- split: EN_US
path: EN_US/management/*.parquet
- config_name: econometrics
data_files:
- split: AR_XY
path: AR_XY/econometrics/*.parquet
- split: BN_BD
path: BN_BD/econometrics/*.parquet
- split: DE_DE
path: DE_DE/econometrics/*.parquet
- split: ES_LA
path: ES_LA/econometrics/*.parquet
- split: FR_FR
path: FR_FR/econometrics/*.parquet
- split: HI_IN
path: HI_IN/econometrics/*.parquet
- split: ID_ID
path: ID_ID/econometrics/*.parquet
- split: IT_IT
path: IT_IT/econometrics/*.parquet
- split: JA_JP
path: JA_JP/econometrics/*.parquet
- split: KO_KR
path: KO_KR/econometrics/*.parquet
- split: PT_BR
path: PT_BR/econometrics/*.parquet
- split: ZH_CN
path: ZH_CN/econometrics/*.parquet
- split: SW_KE
path: SW_KE/econometrics/*.parquet
- split: YO_NG
path: YO_NG/econometrics/*.parquet
- split: EN_US
path: EN_US/econometrics/*.parquet
- config_name: professional_medicine
data_files:
- split: AR_XY
path: AR_XY/professional_medicine/*.parquet
- split: BN_BD
path: BN_BD/professional_medicine/*.parquet
- split: DE_DE
path: DE_DE/professional_medicine/*.parquet
- split: ES_LA
path: ES_LA/professional_medicine/*.parquet
- split: FR_FR
path: FR_FR/professional_medicine/*.parquet
- split: HI_IN
path: HI_IN/professional_medicine/*.parquet
- split: ID_ID
path: ID_ID/professional_medicine/*.parquet
- split: IT_IT
path: IT_IT/professional_medicine/*.parquet
- split: JA_JP
path: JA_JP/professional_medicine/*.parquet
- split: KO_KR
path: KO_KR/professional_medicine/*.parquet
- split: PT_BR
path: PT_BR/professional_medicine/*.parquet
- split: ZH_CN
path: ZH_CN/professional_medicine/*.parquet
- split: SW_KE
path: SW_KE/professional_medicine/*.parquet
- split: YO_NG
path: YO_NG/professional_medicine/*.parquet
- split: EN_US
path: EN_US/professional_medicine/*.parquet
- config_name: high_school_geography
data_files:
- split: AR_XY
path: AR_XY/high_school_geography/*.parquet
- split: BN_BD
path: BN_BD/high_school_geography/*.parquet
- split: DE_DE
path: DE_DE/high_school_geography/*.parquet
- split: ES_LA
path: ES_LA/high_school_geography/*.parquet
- split: FR_FR
path: FR_FR/high_school_geography/*.parquet
- split: HI_IN
path: HI_IN/high_school_geography/*.parquet
- split: ID_ID
path: ID_ID/high_school_geography/*.parquet
- split: IT_IT
path: IT_IT/high_school_geography/*.parquet
- split: JA_JP
path: JA_JP/high_school_geography/*.parquet
- split: KO_KR
path: KO_KR/high_school_geography/*.parquet
- split: PT_BR
path: PT_BR/high_school_geography/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_geography/*.parquet
- split: SW_KE
path: SW_KE/high_school_geography/*.parquet
- split: YO_NG
path: YO_NG/high_school_geography/*.parquet
- split: EN_US
path: EN_US/high_school_geography/*.parquet
- config_name: public_relations
data_files:
- split: AR_XY
path: AR_XY/public_relations/*.parquet
- split: BN_BD
path: BN_BD/public_relations/*.parquet
- split: DE_DE
path: DE_DE/public_relations/*.parquet
- split: ES_LA
path: ES_LA/public_relations/*.parquet
- split: FR_FR
path: FR_FR/public_relations/*.parquet
- split: HI_IN
path: HI_IN/public_relations/*.parquet
- split: ID_ID
path: ID_ID/public_relations/*.parquet
- split: IT_IT
path: IT_IT/public_relations/*.parquet
- split: JA_JP
path: JA_JP/public_relations/*.parquet
- split: KO_KR
path: KO_KR/public_relations/*.parquet
- split: PT_BR
path: PT_BR/public_relations/*.parquet
- split: ZH_CN
path: ZH_CN/public_relations/*.parquet
- split: SW_KE
path: SW_KE/public_relations/*.parquet
- split: YO_NG
path: YO_NG/public_relations/*.parquet
- split: EN_US
path: EN_US/public_relations/*.parquet
- config_name: miscellaneous
data_files:
- split: AR_XY
path: AR_XY/miscellaneous/*.parquet
- split: BN_BD
path: BN_BD/miscellaneous/*.parquet
- split: DE_DE
path: DE_DE/miscellaneous/*.parquet
- split: ES_LA
path: ES_LA/miscellaneous/*.parquet
- split: FR_FR
path: FR_FR/miscellaneous/*.parquet
- split: HI_IN
path: HI_IN/miscellaneous/*.parquet
- split: ID_ID
path: ID_ID/miscellaneous/*.parquet
- split: IT_IT
path: IT_IT/miscellaneous/*.parquet
- split: JA_JP
path: JA_JP/miscellaneous/*.parquet
- split: KO_KR
path: KO_KR/miscellaneous/*.parquet
- split: PT_BR
path: PT_BR/miscellaneous/*.parquet
- split: ZH_CN
path: ZH_CN/miscellaneous/*.parquet
- split: SW_KE
path: SW_KE/miscellaneous/*.parquet
- split: YO_NG
path: YO_NG/miscellaneous/*.parquet
- split: EN_US
path: EN_US/miscellaneous/*.parquet
- config_name: clinical_knowledge
data_files:
- split: AR_XY
path: AR_XY/clinical_knowledge/*.parquet
- split: BN_BD
path: BN_BD/clinical_knowledge/*.parquet
- split: DE_DE
path: DE_DE/clinical_knowledge/*.parquet
- split: ES_LA
path: ES_LA/clinical_knowledge/*.parquet
- split: FR_FR
path: FR_FR/clinical_knowledge/*.parquet
- split: HI_IN
path: HI_IN/clinical_knowledge/*.parquet
- split: ID_ID
path: ID_ID/clinical_knowledge/*.parquet
- split: IT_IT
path: IT_IT/clinical_knowledge/*.parquet
- split: JA_JP
path: JA_JP/clinical_knowledge/*.parquet
- split: KO_KR
path: KO_KR/clinical_knowledge/*.parquet
- split: PT_BR
path: PT_BR/clinical_knowledge/*.parquet
- split: ZH_CN
path: ZH_CN/clinical_knowledge/*.parquet
- split: SW_KE
path: SW_KE/clinical_knowledge/*.parquet
- split: YO_NG
path: YO_NG/clinical_knowledge/*.parquet
- split: EN_US
path: EN_US/clinical_knowledge/*.parquet
- config_name: world_religions
data_files:
- split: AR_XY
path: AR_XY/world_religions/*.parquet
- split: BN_BD
path: BN_BD/world_religions/*.parquet
- split: DE_DE
path: DE_DE/world_religions/*.parquet
- split: ES_LA
path: ES_LA/world_religions/*.parquet
- split: FR_FR
path: FR_FR/world_religions/*.parquet
- split: HI_IN
path: HI_IN/world_religions/*.parquet
- split: ID_ID
path: ID_ID/world_religions/*.parquet
- split: IT_IT
path: IT_IT/world_religions/*.parquet
- split: JA_JP
path: JA_JP/world_religions/*.parquet
- split: KO_KR
path: KO_KR/world_religions/*.parquet
- split: PT_BR
path: PT_BR/world_religions/*.parquet
- split: ZH_CN
path: ZH_CN/world_religions/*.parquet
- split: SW_KE
path: SW_KE/world_religions/*.parquet
- split: YO_NG
path: YO_NG/world_religions/*.parquet
- split: EN_US
path: EN_US/world_religions/*.parquet
- config_name: human_sexuality
data_files:
- split: AR_XY
path: AR_XY/human_sexuality/*.parquet
- split: BN_BD
path: BN_BD/human_sexuality/*.parquet
- split: DE_DE
path: DE_DE/human_sexuality/*.parquet
- split: ES_LA
path: ES_LA/human_sexuality/*.parquet
- split: FR_FR
path: FR_FR/human_sexuality/*.parquet
- split: HI_IN
path: HI_IN/human_sexuality/*.parquet
- split: ID_ID
path: ID_ID/human_sexuality/*.parquet
- split: IT_IT
path: IT_IT/human_sexuality/*.parquet
- split: JA_JP
path: JA_JP/human_sexuality/*.parquet
- split: KO_KR
path: KO_KR/human_sexuality/*.parquet
- split: PT_BR
path: PT_BR/human_sexuality/*.parquet
- split: ZH_CN
path: ZH_CN/human_sexuality/*.parquet
- split: SW_KE
path: SW_KE/human_sexuality/*.parquet
- split: YO_NG
path: YO_NG/human_sexuality/*.parquet
- split: EN_US
path: EN_US/human_sexuality/*.parquet
- config_name: high_school_mathematics
data_files:
- split: AR_XY
path: AR_XY/high_school_mathematics/*.parquet
- split: BN_BD
path: BN_BD/high_school_mathematics/*.parquet
- split: DE_DE
path: DE_DE/high_school_mathematics/*.parquet
- split: ES_LA
path: ES_LA/high_school_mathematics/*.parquet
- split: FR_FR
path: FR_FR/high_school_mathematics/*.parquet
- split: HI_IN
path: HI_IN/high_school_mathematics/*.parquet
- split: ID_ID
path: ID_ID/high_school_mathematics/*.parquet
- split: IT_IT
path: IT_IT/high_school_mathematics/*.parquet
- split: JA_JP
path: JA_JP/high_school_mathematics/*.parquet
- split: KO_KR
path: KO_KR/high_school_mathematics/*.parquet
- split: PT_BR
path: PT_BR/high_school_mathematics/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_mathematics/*.parquet
- split: SW_KE
path: SW_KE/high_school_mathematics/*.parquet
- split: YO_NG
path: YO_NG/high_school_mathematics/*.parquet
- split: EN_US
path: EN_US/high_school_mathematics/*.parquet
- config_name: high_school_government_and_politics
data_files:
- split: AR_XY
path: AR_XY/high_school_government_and_politics/*.parquet
- split: BN_BD
path: BN_BD/high_school_government_and_politics/*.parquet
- split: DE_DE
path: DE_DE/high_school_government_and_politics/*.parquet
- split: ES_LA
path: ES_LA/high_school_government_and_politics/*.parquet
- split: FR_FR
path: FR_FR/high_school_government_and_politics/*.parquet
- split: HI_IN
path: HI_IN/high_school_government_and_politics/*.parquet
- split: ID_ID
path: ID_ID/high_school_government_and_politics/*.parquet
- split: IT_IT
path: IT_IT/high_school_government_and_politics/*.parquet
- split: JA_JP
path: JA_JP/high_school_government_and_politics/*.parquet
- split: KO_KR
path: KO_KR/high_school_government_and_politics/*.parquet
- split: PT_BR
path: PT_BR/high_school_government_and_politics/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_government_and_politics/*.parquet
- split: SW_KE
path: SW_KE/high_school_government_and_politics/*.parquet
- split: YO_NG
path: YO_NG/high_school_government_and_politics/*.parquet
- split: EN_US
path: EN_US/high_school_government_and_politics/*.parquet
- config_name: us_foreign_policy
data_files:
- split: AR_XY
path: AR_XY/us_foreign_policy/*.parquet
- split: BN_BD
path: BN_BD/us_foreign_policy/*.parquet
- split: DE_DE
path: DE_DE/us_foreign_policy/*.parquet
- split: ES_LA
path: ES_LA/us_foreign_policy/*.parquet
- split: FR_FR
path: FR_FR/us_foreign_policy/*.parquet
- split: HI_IN
path: HI_IN/us_foreign_policy/*.parquet
- split: ID_ID
path: ID_ID/us_foreign_policy/*.parquet
- split: IT_IT
path: IT_IT/us_foreign_policy/*.parquet
- split: JA_JP
path: JA_JP/us_foreign_policy/*.parquet
- split: KO_KR
path: KO_KR/us_foreign_policy/*.parquet
- split: PT_BR
path: PT_BR/us_foreign_policy/*.parquet
- split: ZH_CN
path: ZH_CN/us_foreign_policy/*.parquet
- split: SW_KE
path: SW_KE/us_foreign_policy/*.parquet
- split: YO_NG
path: YO_NG/us_foreign_policy/*.parquet
- split: EN_US
path: EN_US/us_foreign_policy/*.parquet
- config_name: high_school_psychology
data_files:
- split: AR_XY
path: AR_XY/high_school_psychology/*.parquet
- split: BN_BD
path: BN_BD/high_school_psychology/*.parquet
- split: DE_DE
path: DE_DE/high_school_psychology/*.parquet
- split: ES_LA
path: ES_LA/high_school_psychology/*.parquet
- split: FR_FR
path: FR_FR/high_school_psychology/*.parquet
- split: HI_IN
path: HI_IN/high_school_psychology/*.parquet
- split: ID_ID
path: ID_ID/high_school_psychology/*.parquet
- split: IT_IT
path: IT_IT/high_school_psychology/*.parquet
- split: JA_JP
path: JA_JP/high_school_psychology/*.parquet
- split: KO_KR
path: KO_KR/high_school_psychology/*.parquet
- split: PT_BR
path: PT_BR/high_school_psychology/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_psychology/*.parquet
- split: SW_KE
path: SW_KE/high_school_psychology/*.parquet
- split: YO_NG
path: YO_NG/high_school_psychology/*.parquet
- split: EN_US
path: EN_US/high_school_psychology/*.parquet
- config_name: college_mathematics
data_files:
- split: AR_XY
path: AR_XY/college_mathematics/*.parquet
- split: BN_BD
path: BN_BD/college_mathematics/*.parquet
- split: DE_DE
path: DE_DE/college_mathematics/*.parquet
- split: ES_LA
path: ES_LA/college_mathematics/*.parquet
- split: FR_FR
path: FR_FR/college_mathematics/*.parquet
- split: HI_IN
path: HI_IN/college_mathematics/*.parquet
- split: ID_ID
path: ID_ID/college_mathematics/*.parquet
- split: IT_IT
path: IT_IT/college_mathematics/*.parquet
- split: JA_JP
path: JA_JP/college_mathematics/*.parquet
- split: KO_KR
path: KO_KR/college_mathematics/*.parquet
- split: PT_BR
path: PT_BR/college_mathematics/*.parquet
- split: ZH_CN
path: ZH_CN/college_mathematics/*.parquet
- split: SW_KE
path: SW_KE/college_mathematics/*.parquet
- split: YO_NG
path: YO_NG/college_mathematics/*.parquet
- split: EN_US
path: EN_US/college_mathematics/*.parquet
- config_name: conceptual_physics
data_files:
- split: AR_XY
path: AR_XY/conceptual_physics/*.parquet
- split: BN_BD
path: BN_BD/conceptual_physics/*.parquet
- split: DE_DE
path: DE_DE/conceptual_physics/*.parquet
- split: ES_LA
path: ES_LA/conceptual_physics/*.parquet
- split: FR_FR
path: FR_FR/conceptual_physics/*.parquet
- split: HI_IN
path: HI_IN/conceptual_physics/*.parquet
- split: ID_ID
path: ID_ID/conceptual_physics/*.parquet
- split: IT_IT
path: IT_IT/conceptual_physics/*.parquet
- split: JA_JP
path: JA_JP/conceptual_physics/*.parquet
- split: KO_KR
path: KO_KR/conceptual_physics/*.parquet
- split: PT_BR
path: PT_BR/conceptual_physics/*.parquet
- split: ZH_CN
path: ZH_CN/conceptual_physics/*.parquet
- split: SW_KE
path: SW_KE/conceptual_physics/*.parquet
- split: YO_NG
path: YO_NG/conceptual_physics/*.parquet
- split: EN_US
path: EN_US/conceptual_physics/*.parquet
- config_name: professional_psychology
data_files:
- split: AR_XY
path: AR_XY/professional_psychology/*.parquet
- split: BN_BD
path: BN_BD/professional_psychology/*.parquet
- split: DE_DE
path: DE_DE/professional_psychology/*.parquet
- split: ES_LA
path: ES_LA/professional_psychology/*.parquet
- split: FR_FR
path: FR_FR/professional_psychology/*.parquet
- split: HI_IN
path: HI_IN/professional_psychology/*.parquet
- split: ID_ID
path: ID_ID/professional_psychology/*.parquet
- split: IT_IT
path: IT_IT/professional_psychology/*.parquet
- split: JA_JP
path: JA_JP/professional_psychology/*.parquet
- split: KO_KR
path: KO_KR/professional_psychology/*.parquet
- split: PT_BR
path: PT_BR/professional_psychology/*.parquet
- split: ZH_CN
path: ZH_CN/professional_psychology/*.parquet
- split: SW_KE
path: SW_KE/professional_psychology/*.parquet
- split: YO_NG
path: YO_NG/professional_psychology/*.parquet
- split: EN_US
path: EN_US/professional_psychology/*.parquet
- config_name: philosophy
data_files:
- split: AR_XY
path: AR_XY/philosophy/*.parquet
- split: BN_BD
path: BN_BD/philosophy/*.parquet
- split: DE_DE
path: DE_DE/philosophy/*.parquet
- split: ES_LA
path: ES_LA/philosophy/*.parquet
- split: FR_FR
path: FR_FR/philosophy/*.parquet
- split: HI_IN
path: HI_IN/philosophy/*.parquet
- split: ID_ID
path: ID_ID/philosophy/*.parquet
- split: IT_IT
path: IT_IT/philosophy/*.parquet
- split: JA_JP
path: JA_JP/philosophy/*.parquet
- split: KO_KR
path: KO_KR/philosophy/*.parquet
- split: PT_BR
path: PT_BR/philosophy/*.parquet
- split: ZH_CN
path: ZH_CN/philosophy/*.parquet
- split: SW_KE
path: SW_KE/philosophy/*.parquet
- split: YO_NG
path: YO_NG/philosophy/*.parquet
- split: EN_US
path: EN_US/philosophy/*.parquet
- config_name: college_chemistry
data_files:
- split: AR_XY
path: AR_XY/college_chemistry/*.parquet
- split: BN_BD
path: BN_BD/college_chemistry/*.parquet
- split: DE_DE
path: DE_DE/college_chemistry/*.parquet
- split: ES_LA
path: ES_LA/college_chemistry/*.parquet
- split: FR_FR
path: FR_FR/college_chemistry/*.parquet
- split: HI_IN
path: HI_IN/college_chemistry/*.parquet
- split: ID_ID
path: ID_ID/college_chemistry/*.parquet
- split: IT_IT
path: IT_IT/college_chemistry/*.parquet
- split: JA_JP
path: JA_JP/college_chemistry/*.parquet
- split: KO_KR
path: KO_KR/college_chemistry/*.parquet
- split: PT_BR
path: PT_BR/college_chemistry/*.parquet
- split: ZH_CN
path: ZH_CN/college_chemistry/*.parquet
- split: SW_KE
path: SW_KE/college_chemistry/*.parquet
- split: YO_NG
path: YO_NG/college_chemistry/*.parquet
- split: EN_US
path: EN_US/college_chemistry/*.parquet
- config_name: human_aging
data_files:
- split: AR_XY
path: AR_XY/human_aging/*.parquet
- split: BN_BD
path: BN_BD/human_aging/*.parquet
- split: DE_DE
path: DE_DE/human_aging/*.parquet
- split: ES_LA
path: ES_LA/human_aging/*.parquet
- split: FR_FR
path: FR_FR/human_aging/*.parquet
- split: HI_IN
path: HI_IN/human_aging/*.parquet
- split: ID_ID
path: ID_ID/human_aging/*.parquet
- split: IT_IT
path: IT_IT/human_aging/*.parquet
- split: JA_JP
path: JA_JP/human_aging/*.parquet
- split: KO_KR
path: KO_KR/human_aging/*.parquet
- split: PT_BR
path: PT_BR/human_aging/*.parquet
- split: ZH_CN
path: ZH_CN/human_aging/*.parquet
- split: SW_KE
path: SW_KE/human_aging/*.parquet
- split: YO_NG
path: YO_NG/human_aging/*.parquet
- split: EN_US
path: EN_US/human_aging/*.parquet
- config_name: marketing
data_files:
- split: AR_XY
path: AR_XY/marketing/*.parquet
- split: BN_BD
path: BN_BD/marketing/*.parquet
- split: DE_DE
path: DE_DE/marketing/*.parquet
- split: ES_LA
path: ES_LA/marketing/*.parquet
- split: FR_FR
path: FR_FR/marketing/*.parquet
- split: HI_IN
path: HI_IN/marketing/*.parquet
- split: ID_ID
path: ID_ID/marketing/*.parquet
- split: IT_IT
path: IT_IT/marketing/*.parquet
- split: JA_JP
path: JA_JP/marketing/*.parquet
- split: KO_KR
path: KO_KR/marketing/*.parquet
- split: PT_BR
path: PT_BR/marketing/*.parquet
- split: ZH_CN
path: ZH_CN/marketing/*.parquet
- split: SW_KE
path: SW_KE/marketing/*.parquet
- split: YO_NG
path: YO_NG/marketing/*.parquet
- split: EN_US
path: EN_US/marketing/*.parquet
- config_name: professional_accounting
data_files:
- split: AR_XY
path: AR_XY/professional_accounting/*.parquet
- split: BN_BD
path: BN_BD/professional_accounting/*.parquet
- split: DE_DE
path: DE_DE/professional_accounting/*.parquet
- split: ES_LA
path: ES_LA/professional_accounting/*.parquet
- split: FR_FR
path: FR_FR/professional_accounting/*.parquet
- split: HI_IN
path: HI_IN/professional_accounting/*.parquet
- split: ID_ID
path: ID_ID/professional_accounting/*.parquet
- split: IT_IT
path: IT_IT/professional_accounting/*.parquet
- split: JA_JP
path: JA_JP/professional_accounting/*.parquet
- split: KO_KR
path: KO_KR/professional_accounting/*.parquet
- split: PT_BR
path: PT_BR/professional_accounting/*.parquet
- split: ZH_CN
path: ZH_CN/professional_accounting/*.parquet
- split: SW_KE
path: SW_KE/professional_accounting/*.parquet
- split: YO_NG
path: YO_NG/professional_accounting/*.parquet
- split: EN_US
path: EN_US/professional_accounting/*.parquet
- config_name: logical_fallacies
data_files:
- split: AR_XY
path: AR_XY/logical_fallacies/*.parquet
- split: BN_BD
path: BN_BD/logical_fallacies/*.parquet
- split: DE_DE
path: DE_DE/logical_fallacies/*.parquet
- split: ES_LA
path: ES_LA/logical_fallacies/*.parquet
- split: FR_FR
path: FR_FR/logical_fallacies/*.parquet
- split: HI_IN
path: HI_IN/logical_fallacies/*.parquet
- split: ID_ID
path: ID_ID/logical_fallacies/*.parquet
- split: IT_IT
path: IT_IT/logical_fallacies/*.parquet
- split: JA_JP
path: JA_JP/logical_fallacies/*.parquet
- split: KO_KR
path: KO_KR/logical_fallacies/*.parquet
- split: PT_BR
path: PT_BR/logical_fallacies/*.parquet
- split: ZH_CN
path: ZH_CN/logical_fallacies/*.parquet
- split: SW_KE
path: SW_KE/logical_fallacies/*.parquet
- split: YO_NG
path: YO_NG/logical_fallacies/*.parquet
- split: EN_US
path: EN_US/logical_fallacies/*.parquet
- config_name: global_facts
data_files:
- split: AR_XY
path: AR_XY/global_facts/*.parquet
- split: BN_BD
path: BN_BD/global_facts/*.parquet
- split: DE_DE
path: DE_DE/global_facts/*.parquet
- split: ES_LA
path: ES_LA/global_facts/*.parquet
- split: FR_FR
path: FR_FR/global_facts/*.parquet
- split: HI_IN
path: HI_IN/global_facts/*.parquet
- split: ID_ID
path: ID_ID/global_facts/*.parquet
- split: IT_IT
path: IT_IT/global_facts/*.parquet
- split: JA_JP
path: JA_JP/global_facts/*.parquet
- split: KO_KR
path: KO_KR/global_facts/*.parquet
- split: PT_BR
path: PT_BR/global_facts/*.parquet
- split: ZH_CN
path: ZH_CN/global_facts/*.parquet
- split: SW_KE
path: SW_KE/global_facts/*.parquet
- split: YO_NG
path: YO_NG/global_facts/*.parquet
- split: EN_US
path: EN_US/global_facts/*.parquet
- config_name: abstract_algebra
data_files:
- split: AR_XY
path: AR_XY/abstract_algebra/*.parquet
- split: BN_BD
path: BN_BD/abstract_algebra/*.parquet
- split: DE_DE
path: DE_DE/abstract_algebra/*.parquet
- split: ES_LA
path: ES_LA/abstract_algebra/*.parquet
- split: FR_FR
path: FR_FR/abstract_algebra/*.parquet
- split: HI_IN
path: HI_IN/abstract_algebra/*.parquet
- split: ID_ID
path: ID_ID/abstract_algebra/*.parquet
- split: IT_IT
path: IT_IT/abstract_algebra/*.parquet
- split: JA_JP
path: JA_JP/abstract_algebra/*.parquet
- split: KO_KR
path: KO_KR/abstract_algebra/*.parquet
- split: PT_BR
path: PT_BR/abstract_algebra/*.parquet
- split: ZH_CN
path: ZH_CN/abstract_algebra/*.parquet
- split: SW_KE
path: SW_KE/abstract_algebra/*.parquet
- split: YO_NG
path: YO_NG/abstract_algebra/*.parquet
- split: EN_US
path: EN_US/abstract_algebra/*.parquet
- config_name: high_school_statistics
data_files:
- split: AR_XY
path: AR_XY/high_school_statistics/*.parquet
- split: BN_BD
path: BN_BD/high_school_statistics/*.parquet
- split: DE_DE
path: DE_DE/high_school_statistics/*.parquet
- split: ES_LA
path: ES_LA/high_school_statistics/*.parquet
- split: FR_FR
path: FR_FR/high_school_statistics/*.parquet
- split: HI_IN
path: HI_IN/high_school_statistics/*.parquet
- split: ID_ID
path: ID_ID/high_school_statistics/*.parquet
- split: IT_IT
path: IT_IT/high_school_statistics/*.parquet
- split: JA_JP
path: JA_JP/high_school_statistics/*.parquet
- split: KO_KR
path: KO_KR/high_school_statistics/*.parquet
- split: PT_BR
path: PT_BR/high_school_statistics/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_statistics/*.parquet
- split: SW_KE
path: SW_KE/high_school_statistics/*.parquet
- split: YO_NG
path: YO_NG/high_school_statistics/*.parquet
- split: EN_US
path: EN_US/high_school_statistics/*.parquet
- config_name: virology
data_files:
- split: AR_XY
path: AR_XY/virology/*.parquet
- split: BN_BD
path: BN_BD/virology/*.parquet
- split: DE_DE
path: DE_DE/virology/*.parquet
- split: ES_LA
path: ES_LA/virology/*.parquet
- split: FR_FR
path: FR_FR/virology/*.parquet
- split: HI_IN
path: HI_IN/virology/*.parquet
- split: ID_ID
path: ID_ID/virology/*.parquet
- split: IT_IT
path: IT_IT/virology/*.parquet
- split: JA_JP
path: JA_JP/virology/*.parquet
- split: KO_KR
path: KO_KR/virology/*.parquet
- split: PT_BR
path: PT_BR/virology/*.parquet
- split: ZH_CN
path: ZH_CN/virology/*.parquet
- split: SW_KE
path: SW_KE/virology/*.parquet
- split: YO_NG
path: YO_NG/virology/*.parquet
- split: EN_US
path: EN_US/virology/*.parquet
- config_name: high_school_chemistry
data_files:
- split: AR_XY
path: AR_XY/high_school_chemistry/*.parquet
- split: BN_BD
path: BN_BD/high_school_chemistry/*.parquet
- split: DE_DE
path: DE_DE/high_school_chemistry/*.parquet
- split: ES_LA
path: ES_LA/high_school_chemistry/*.parquet
- split: FR_FR
path: FR_FR/high_school_chemistry/*.parquet
- split: HI_IN
path: HI_IN/high_school_chemistry/*.parquet
- split: ID_ID
path: ID_ID/high_school_chemistry/*.parquet
- split: IT_IT
path: IT_IT/high_school_chemistry/*.parquet
- split: JA_JP
path: JA_JP/high_school_chemistry/*.parquet
- split: KO_KR
path: KO_KR/high_school_chemistry/*.parquet
- split: PT_BR
path: PT_BR/high_school_chemistry/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_chemistry/*.parquet
- split: SW_KE
path: SW_KE/high_school_chemistry/*.parquet
- split: YO_NG
path: YO_NG/high_school_chemistry/*.parquet
- split: EN_US
path: EN_US/high_school_chemistry/*.parquet
- config_name: high_school_biology
data_files:
- split: AR_XY
path: AR_XY/high_school_biology/*.parquet
- split: BN_BD
path: BN_BD/high_school_biology/*.parquet
- split: DE_DE
path: DE_DE/high_school_biology/*.parquet
- split: ES_LA
path: ES_LA/high_school_biology/*.parquet
- split: FR_FR
path: FR_FR/high_school_biology/*.parquet
- split: HI_IN
path: HI_IN/high_school_biology/*.parquet
- split: ID_ID
path: ID_ID/high_school_biology/*.parquet
- split: IT_IT
path: IT_IT/high_school_biology/*.parquet
- split: JA_JP
path: JA_JP/high_school_biology/*.parquet
- split: KO_KR
path: KO_KR/high_school_biology/*.parquet
- split: PT_BR
path: PT_BR/high_school_biology/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_biology/*.parquet
- split: SW_KE
path: SW_KE/high_school_biology/*.parquet
- split: YO_NG
path: YO_NG/high_school_biology/*.parquet
- split: EN_US
path: EN_US/high_school_biology/*.parquet
- config_name: college_biology
data_files:
- split: AR_XY
path: AR_XY/college_biology/*.parquet
- split: BN_BD
path: BN_BD/college_biology/*.parquet
- split: DE_DE
path: DE_DE/college_biology/*.parquet
- split: ES_LA
path: ES_LA/college_biology/*.parquet
- split: FR_FR
path: FR_FR/college_biology/*.parquet
- split: HI_IN
path: HI_IN/college_biology/*.parquet
- split: ID_ID
path: ID_ID/college_biology/*.parquet
- split: IT_IT
path: IT_IT/college_biology/*.parquet
- split: JA_JP
path: JA_JP/college_biology/*.parquet
- split: KO_KR
path: KO_KR/college_biology/*.parquet
- split: PT_BR
path: PT_BR/college_biology/*.parquet
- split: ZH_CN
path: ZH_CN/college_biology/*.parquet
- split: SW_KE
path: SW_KE/college_biology/*.parquet
- split: YO_NG
path: YO_NG/college_biology/*.parquet
- split: EN_US
path: EN_US/college_biology/*.parquet
- config_name: nutrition
data_files:
- split: AR_XY
path: AR_XY/nutrition/*.parquet
- split: BN_BD
path: BN_BD/nutrition/*.parquet
- split: DE_DE
path: DE_DE/nutrition/*.parquet
- split: ES_LA
path: ES_LA/nutrition/*.parquet
- split: FR_FR
path: FR_FR/nutrition/*.parquet
- split: HI_IN
path: HI_IN/nutrition/*.parquet
- split: ID_ID
path: ID_ID/nutrition/*.parquet
- split: IT_IT
path: IT_IT/nutrition/*.parquet
- split: JA_JP
path: JA_JP/nutrition/*.parquet
- split: KO_KR
path: KO_KR/nutrition/*.parquet
- split: PT_BR
path: PT_BR/nutrition/*.parquet
- split: ZH_CN
path: ZH_CN/nutrition/*.parquet
- split: SW_KE
path: SW_KE/nutrition/*.parquet
- split: YO_NG
path: YO_NG/nutrition/*.parquet
- split: EN_US
path: EN_US/nutrition/*.parquet
- config_name: computer_security
data_files:
- split: AR_XY
path: AR_XY/computer_security/*.parquet
- split: BN_BD
path: BN_BD/computer_security/*.parquet
- split: DE_DE
path: DE_DE/computer_security/*.parquet
- split: ES_LA
path: ES_LA/computer_security/*.parquet
- split: FR_FR
path: FR_FR/computer_security/*.parquet
- split: HI_IN
path: HI_IN/computer_security/*.parquet
- split: ID_ID
path: ID_ID/computer_security/*.parquet
- split: IT_IT
path: IT_IT/computer_security/*.parquet
- split: JA_JP
path: JA_JP/computer_security/*.parquet
- split: KO_KR
path: KO_KR/computer_security/*.parquet
- split: PT_BR
path: PT_BR/computer_security/*.parquet
- split: ZH_CN
path: ZH_CN/computer_security/*.parquet
- split: SW_KE
path: SW_KE/computer_security/*.parquet
- split: YO_NG
path: YO_NG/computer_security/*.parquet
- split: EN_US
path: EN_US/computer_security/*.parquet
- config_name: college_physics
data_files:
- split: AR_XY
path: AR_XY/college_physics/*.parquet
- split: BN_BD
path: BN_BD/college_physics/*.parquet
- split: DE_DE
path: DE_DE/college_physics/*.parquet
- split: ES_LA
path: ES_LA/college_physics/*.parquet
- split: FR_FR
path: FR_FR/college_physics/*.parquet
- split: HI_IN
path: HI_IN/college_physics/*.parquet
- split: ID_ID
path: ID_ID/college_physics/*.parquet
- split: IT_IT
path: IT_IT/college_physics/*.parquet
- split: JA_JP
path: JA_JP/college_physics/*.parquet
- split: KO_KR
path: KO_KR/college_physics/*.parquet
- split: PT_BR
path: PT_BR/college_physics/*.parquet
- split: ZH_CN
path: ZH_CN/college_physics/*.parquet
- split: SW_KE
path: SW_KE/college_physics/*.parquet
- split: YO_NG
path: YO_NG/college_physics/*.parquet
- split: EN_US
path: EN_US/college_physics/*.parquet
- config_name: high_school_physics
data_files:
- split: AR_XY
path: AR_XY/high_school_physics/*.parquet
- split: BN_BD
path: BN_BD/high_school_physics/*.parquet
- split: DE_DE
path: DE_DE/high_school_physics/*.parquet
- split: ES_LA
path: ES_LA/high_school_physics/*.parquet
- split: FR_FR
path: FR_FR/high_school_physics/*.parquet
- split: HI_IN
path: HI_IN/high_school_physics/*.parquet
- split: ID_ID
path: ID_ID/high_school_physics/*.parquet
- split: IT_IT
path: IT_IT/high_school_physics/*.parquet
- split: JA_JP
path: JA_JP/high_school_physics/*.parquet
- split: KO_KR
path: KO_KR/high_school_physics/*.parquet
- split: PT_BR
path: PT_BR/high_school_physics/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_physics/*.parquet
- split: SW_KE
path: SW_KE/high_school_physics/*.parquet
- split: YO_NG
path: YO_NG/high_school_physics/*.parquet
- split: EN_US
path: EN_US/high_school_physics/*.parquet
- config_name: college_medicine
data_files:
- split: AR_XY
path: AR_XY/college_medicine/*.parquet
- split: BN_BD
path: BN_BD/college_medicine/*.parquet
- split: DE_DE
path: DE_DE/college_medicine/*.parquet
- split: ES_LA
path: ES_LA/college_medicine/*.parquet
- split: FR_FR
path: FR_FR/college_medicine/*.parquet
- split: HI_IN
path: HI_IN/college_medicine/*.parquet
- split: ID_ID
path: ID_ID/college_medicine/*.parquet
- split: IT_IT
path: IT_IT/college_medicine/*.parquet
- split: JA_JP
path: JA_JP/college_medicine/*.parquet
- split: KO_KR
path: KO_KR/college_medicine/*.parquet
- split: PT_BR
path: PT_BR/college_medicine/*.parquet
- split: ZH_CN
path: ZH_CN/college_medicine/*.parquet
- split: SW_KE
path: SW_KE/college_medicine/*.parquet
- split: YO_NG
path: YO_NG/college_medicine/*.parquet
- split: EN_US
path: EN_US/college_medicine/*.parquet
- config_name: high_school_macroeconomics
data_files:
- split: AR_XY
path: AR_XY/high_school_macroeconomics/*.parquet
- split: BN_BD
path: BN_BD/high_school_macroeconomics/*.parquet
- split: DE_DE
path: DE_DE/high_school_macroeconomics/*.parquet
- split: ES_LA
path: ES_LA/high_school_macroeconomics/*.parquet
- split: FR_FR
path: FR_FR/high_school_macroeconomics/*.parquet
- split: HI_IN
path: HI_IN/high_school_macroeconomics/*.parquet
- split: ID_ID
path: ID_ID/high_school_macroeconomics/*.parquet
- split: IT_IT
path: IT_IT/high_school_macroeconomics/*.parquet
- split: JA_JP
path: JA_JP/high_school_macroeconomics/*.parquet
- split: KO_KR
path: KO_KR/high_school_macroeconomics/*.parquet
- split: PT_BR
path: PT_BR/high_school_macroeconomics/*.parquet
- split: ZH_CN
path: ZH_CN/high_school_macroeconomics/*.parquet
- split: SW_KE
path: SW_KE/high_school_macroeconomics/*.parquet
- split: YO_NG
path: YO_NG/high_school_macroeconomics/*.parquet
- split: EN_US
path: EN_US/high_school_macroeconomics/*.parquet
- config_name: business_ethics
data_files:
- split: AR_XY
path: AR_XY/business_ethics/*.parquet
- split: BN_BD
path: BN_BD/business_ethics/*.parquet
- split: DE_DE
path: DE_DE/business_ethics/*.parquet
- split: ES_LA
path: ES_LA/business_ethics/*.parquet
- split: FR_FR
path: FR_FR/business_ethics/*.parquet
- split: HI_IN
path: HI_IN/business_ethics/*.parquet
- split: ID_ID
path: ID_ID/business_ethics/*.parquet
- split: IT_IT
path: IT_IT/business_ethics/*.parquet
- split: JA_JP
path: JA_JP/business_ethics/*.parquet
- split: KO_KR
path: KO_KR/business_ethics/*.parquet
- split: PT_BR
path: PT_BR/business_ethics/*.parquet
- split: ZH_CN
path: ZH_CN/business_ethics/*.parquet
- split: SW_KE
path: SW_KE/business_ethics/*.parquet
- split: YO_NG
path: YO_NG/business_ethics/*.parquet
- split: EN_US
path: EN_US/business_ethics/*.parquet
pretty_name: MMLU multilingual
task_categories:
- text-generation
---
MMLU professionally translated into 14 languages using professional human translators, sourced from OpenAI's [simple-eval](https://github.com/openai/simple-evals).
Original files:
english: `https://openaipublic.blob.core.windows.net/simple-evals/mmlu.csv`
multilingual: `https://openaipublic.blob.core.windows.net/simple-evals/mmlu_{language}.csv` where `language` one of `"AR-XY", "BN-BD", "DE-DE", "ES-LA", "FR-FR", "HI-IN", "ID-ID", "IT-IT", "JA-JP", "KO-KR", "PT-BR", "ZH-CN", "SW-KE", "YO-NG", "EN-US"` |
Salesforce/dialogstudio | Salesforce | "2024-07-21T19:57:06Z" | 2,888 | 212 | [
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"task_categories:table-to-text",
"task_categories:text-classification",
"task_categories:table-question-answering",
"language:en",
"license:apache-2.0",
"arxiv:2307.10172",
"region:us"
] | [
"question-answering",
"summarization",
"text-generation",
"table-to-text",
"text-classification",
"table-question-answering"
] | "2023-07-16T23:15:44Z" | ---
extra_gated_heading: "Acknowledge to follow corresponding dataset licenses and cite dialogstudio to access the repository"
extra_gated_button_content: "Agree and access repository"
extra_gated_fields:
First Name: text
Last Name: text
Country: country
Affiliation: text
# geo: ip_location
license: apache-2.0
task_categories:
- question-answering
- summarization
- text-generation
- table-to-text
- text-classification
- table-question-answering
language:
- en
pretty_name: Dialog Studio
---
<img src="https://huggingface.co/datasets/jianguozhang/logos/resolve/main/logo.png"
alt="drawing" width="510"/>
# DialogStudio: Unified Dialog Datasets and Instruction-Aware Models for Conversational AI
**Author**: [Jianguo Zhang](https://github.com/jianguoz), [Kun Qian](https://github.com/qbetterk)
[Paper](https://arxiv.org/pdf/2307.10172.pdf)|[Github](https://github.com/salesforce/DialogStudio)|[GDrive]
🎉 **March 18, 2024: Update for AI Agent**. Check [xLAM](https://github.com/SalesforceAIResearch/xLAM) for the latest data and models relevant to AI Agent!
🎉 **March 10 2024: Update for dataset viewer issues:**
- Please refer to https://github.com/salesforce/DialogStudio for view of each dataset, where we provide 5 converted examples along with 5 original examples under each data folder.
- For example, https://github.com/salesforce/DialogStudio/tree/main/open-domain-dialogues/ShareGPT contains two files: [converted_examples.json](https://github.com/salesforce/DialogStudio/blob/main/open-domain-dialogues/ShareGPT/converted_example.json) and [original_example.json](https://github.com/salesforce/DialogStudio/blob/main/open-domain-dialogues/ShareGPT/original_example.json).
<img src="https://huggingface.co/datasets/jianguozhang/logos/resolve/main/DialogStudio_Stats.jpg"
alt="drawing" width="800"/>
**Follow the [DialogStudio](https://github.com/salesforce/DialogStudio) GitHub repository for latest information.**
### Datasets
### Load dataset
The datasets are split into several categories in HuggingFace
```
Datasets/
├── Knowledge-Grounded-Dialogues
├── Natural-Language-Understanding
├── Open-Domain-Dialogues
├── Task-Oriented-Dialogues
├── Dialogue-Summarization
├── Conversational-Recommendation-Dialogs
```
You can load any dataset in the DialogStudio from the [HuggingFace hub](https://huggingface.co/datasets/Salesforce/dialogstudio) by claiming the `{dataset_name}`, which is exactly the dataset folder name. All available datasets are described in [dataset content](https://github.com/salesforce/DialogStudio/blob/main/Dataset_Stats.csv). For easier reference, [available dataset names](#Available Datasets) are also listed below.
Below is one example to load the [MULTIWOZ2_2](https://huggingface.co/datasets/Salesforce/dialogstudio/blob/main/task_oriented/MULTIWOZ2_2.zip) dataset under the [task-oriented-dialogues](https://huggingface.co/datasets/Salesforce/dialogstudio/tree/main/task_oriented) category:
Load the dataset
```python
from datasets import load_dataset
dataset = load_dataset('Salesforce/dialogstudio', 'MULTIWOZ2_2')
```
Here is the output structure of MultiWOZ 2.2
```python
DatasetDict({
train: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index', 'original dialog info', 'log', 'prompt', 'external knowledge non-flat', 'external knowledge', 'dst knowledge', 'intent knowledge'],
num_rows: 8437
})
validation: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index', 'original dialog info', 'log', 'prompt', 'external knowledge non-flat', 'external knowledge', 'dst knowledge', 'intent knowledge'],
num_rows: 1000
})
test: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index', 'original dialog info', 'log', 'prompt', 'external knowledge non-flat', 'external knowledge', 'dst knowledge', 'intent knowledge'],
num_rows: 1000
})
})
```
### Available Datasets
The ``data_name`` for ``load_dataset("Salesforce/dialogstudio", data_name)`` can be found below. More detailed information for each dataset can be found in out [github](https://github.com/salesforce/DialogStudio/blob/main/Dataset_Stats.csv).
```python
"natural_language_understanding": [
"ATIS", "ATIS-NER", "BANKING77", "BANKING77-OOS", "CLINC-Single-Domain-OOS-banking",
"CLINC-Single-Domain-OOS-credit_cards", "CLINC150", "DSTC8-SGD", "HWU64", "MIT-Movie",
"MIT-Restaurant", "RESTAURANTS8K", "SNIPS", "SNIPS-NER", "TOP", "TOP-NER"
],
"task_oriented": [
"ABCD", "AirDialogue", "BiTOD", "CaSiNo", "CraigslistBargains",
"Disambiguation", "DSTC2-Clean", "FRAMES", "GECOR", "HDSA-Dialog",
"KETOD", "KVRET", "MetaLWOZ", "MS-DC", "MuDoCo",
"MulDoGO", "MultiWOZ_2.1", "MULTIWOZ2_2", "SGD", "SimJointGEN",
"SimJointMovie", "SimJointRestaurant", "STAR", "Taskmaster1", "Taskmaster2",
"Taskmaster3", "WOZ2_0"
],
"dialogue_summarization": [
"AMI", "CRD3", "DialogSum", "ECTSum", "ICSI",
"MediaSum", "QMSum", "SAMSum", "TweetSumm", "ConvoSumm",
"SummScreen_ForeverDreaming", "SummScreen_TVMegaSite"
],
"conversational_recommendation": [
"Redial", "DuRecDial-2.0", "OpenDialKG", "SalesBot",
],
"open_domain": [
"chitchat-dataset", "ConvAI2", "AntiScam", "Empathetic", "HH-RLHF",
"PLACES3.5", "Prosocial", "SODA", "ShareGPT"
],
"knowledge_grounded": [
"CompWebQ", "CoQA", "CoSQL", "DART", "FeTaQA",
"GrailQA", "HybridQA", "MTOP", "MultiModalQA", "SParC",
"Spider", "SQA", "ToTTo", "WebQSP", "WikiSQL",
"WikiTQ", "wizard_of_internet", "wizard_of_wikipedia"
],
```
# License
Our project follows the following structure with respect to licensing:
1. For all the modified datasets in DialogStudio:
- A portion of these datasets is under the [Apache License 2.0](https://github.com/salesforce/DialogStudio/blob/main/LICENSE.txt).
- Some retain their original licenses even after modification.
- For a few datasets that lacked a license, we have cited the relevant papers.
2. Original dataset licenses: For reference, we also put the original avaliable licenses for each dataset into their respective dataset folders.
3. Code: Our codebase is under the [Apache License 2.0](https://github.com/salesforce/DialogStudio/blob/main/LICENSE.txt).
For detailed licensing information, please refer to the specific licenses accompanying the datasets. If you utilize datasets from DialogStudio, we kindly request that you cite our work.
# Citation
The data and code in this repository is mostly developed for or derived from the paper below. If you utilize datasets from DialogStudio, we kindly request that you cite both the original work and our own (Accepted by EACL 2024 Findings as a long paper).
```
@article{zhang2023dialogstudio,
title={DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
``` |
JasonGross/max-of-10-proofs | JasonGross | "2024-09-11T02:38:22Z" | 2,888 | 0 | [
"license:mit",
"size_categories:n<1K",
"format:parquet",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-08-27T20:46:05Z" | ---
license: mit
dataset_info:
- config_name: compute_EQKE_SVD_analysis
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 4439309
num_examples: 1
download_size: 1306530
dataset_size: 4439309
- config_name: compute_EQKE_SVD_analysis_10248_ADt9TMfA0ohwJWJoHGEb_A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_10248_AF__SLASH__cdMlHuDiIYavaEc_m7g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_104_AMTHJYbXtl9V78qiarKwHA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_104_AOcepby1JGjQVWVDLVjtWw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11124_AGABnR_tEu1iXfeoRXN2mw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11124_APeNgf__SLASH__Zd2Su7DBNh6cCqA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11130_ACT5Wkf1g_7uEb9Vo0V5iQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11130_AL_3FuWR5VAgcmpLCi9CyA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11498_AA3IABg_HE0mnB9J1vZofA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11498_AGeDPkWzQOKcGEigTEC7aQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11598_ABxlXC4ZX1sFXo7KyS6g1Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11598_ANLxdMRWrGwB_tntg5zBTw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11611_AESuee__SLASH_____SLASH__V8y4T19Td1Y4w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_11611_AFIFrDND4k1__SLASH__jag1QZYwRg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1185_AEmBIHMQpZQ_7FOxKhe4FA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1185_AKS8JWbQJkCtdpSqHxycRA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12141_ALah3F7R9VpRXUX5icdeYQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12141_APNwg2_RYDwIiRHiFmm5NA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12287_AG4IN9v_tnpz_KA8ut__SLASH__Rpg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12287_APVJQ5nKpiYG1N78lSdjEg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_123_AAF01m__SLASH__jSu655uXEJ3n5lw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_123_AGHhlv9gCTV4REJmDsZvAA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12457_ABlvKY__SLASH__ea1W0I9J0__SLASH__5Ke__SLASH__w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12457_ANtn5XZqYm6lWkYX7wm50w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12493_ACvLRUMpn0IXNyk3DhABig__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12493_ALpk8shllJ7lNUe6UxFxwA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12552_ACWqOnUNQIY6ZXSlIrSAeg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12552_AKC4I5HibpQXmsfK81jcpw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12561_AHQTJ4yqdCQ2xbrOh1vg_Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_12561_AMu3S843KoohTTL7_Pc9Pw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1283_ADr6__SLASH__zEW84fe6XOeQvMMGA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1283_ALlLMLCS3VTR3RqgVaqrjw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13036_AAyp5i1xoPiUoBE1xgtLrA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13036_AOUagJAhZlsYnyOnPHR97Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13293_AEn70QMIWNu8SqGyjfu__SLASH__TQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13293_APpv3h4__SLASH__0oRquuaWTyG94g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13468_AHXi3sW9s0zSZVdbLBo02g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13468_APxhL7FxHmQcxv7tLYDfcA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13654_ALXxfTllLv2UV6DVcVDzAg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13654_AP6P_4wuBrxCAB__SLASH__0agbeBQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13716_ACjV0gebaFRv7Im24SKvQw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_13716_ANaOWdYtOTwk6zJmhcT_OA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_14095_AHdteQBmDXOUGrqHT24Qjg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_14095_ALBkCyP8vrs0S_gdYMQ1Bg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1412_ALVkFOwVCV4O1Cb5IYZwJQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1412_ALpi0jYEoq85sqBJ52VagQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1490_ADYfJYpp721n1k_dP2pLLg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1490_APUVyRDKGVXYsMZyb6PT2A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_14929_AG07CJr82KW1UoMBV2z5wA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_14929_AIG__SLASH__plpvvjhgGSNogfpDYg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15043_AIyj3TNGpH8SMqQhgOz2_A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15043_AN49JNcV2adNef2Xjgggmg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15399_AITBIGR4YZiSnltfpup_WA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15399_AIufJc2CqyQWF6hEws5q4A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15622_AE8thSNibi_bQ45ZzPXpCw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15622_ALnNMknsHCTpXNiKwqJdhg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15662_ABN0xMnoG8eswBrOaQRYGg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_15662_ADzISma__SLASH__Ivlz4V355__SLASH__zywA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16069_AL2l8w3n0wNELddPV_zsBg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16069_ALPN8qZcnT__SLASH__9lUw2XtoPFA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16149_AMkn905ekHNFmPUJZFe__SLASH__cg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16149_APQUV8ZlUlkkGWxJX3TkRg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16197_AD9_hspz4VUwKKEUsl1pQg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16197_ANOQT3ss6CiM0JldM2k71A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16284_AEC_0V7Yo1Vg8912paAPJA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_16284_AEEF6XEJ24kVfWOam43d9A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1681_AJ2PDL_2JMP__SLASH__XhqR__SLASH__178__SLASH__Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1681_ANwkZM5TW4cNkpe5A0PJMQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1696_ACY__SLASH__8CfzyVzA3W2fcCtrLw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1696_AChvUnC6YJ0fTAbQwfT80Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17080_AIhm3D0L4tW5062sbstdTg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17080_AMoso0kf__SLASH__I7FaeVG2g1c9A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17096_ACsGM5WBvZG8rCy_s2BYfg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17096_ADWz0kjtHLXoeUZ7B__SLASH__j__SLASH__cw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17194_ACLvzwY3PZFz3uPB6nPTcQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17194_APoCTJ2qAnT91QuTqJBXgA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17197_ADRpaYfxtQh83NGQKSYCWg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_17197_AF4QRGwG7i76o6VkRHying__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_18146_ADp6siELcqhd8e5qrbU__SLASH__kw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_18146_ANBhndJ0AlCep8Jm41w2zQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_18289_AJcuOAnybHMHbw4vohzLcg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_18289_AOgaWFKxlXBf3cyEs72VOw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_18668_AHr8wzfdJ__SLASH__o9ksYQ8HZXRw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_18668_AO6QRUo_g8oJQOj8TQga9w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1895_ABY4waS3AwiPNhqmkHd8pQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1895_AF3GNlURclLbIsCS6y8Q__SLASH__Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19004_AFdEafhGrVtuebjgI__SLASH__rgew__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19004_AFerkSj1mc_HtUPZuIHLgQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19093_AAr9v5vr3g_6JoGwVFtnMA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19093_AF5xzTFfrjg_86AHBmQTew__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19451_AFstGaELqmsJVsloeIunwg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19451_AOUxxQV3sijBGCMnJS812Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19488_AAN__SLASH__HudTRHtTka9FBzosng__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19488_AJZiY7nrQA7YsDVRxhadDg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1951_AC_Trhn0UP4COIKbfLHFIA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_1951_AEpjIMss6Hn04zAXunvLFA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19538_AIAkxFPOh__SLASH__3svQ75QCheCA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19538_AIwSI6FQmfrmw4yYViipcA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19917_AIDzLm9bCNA6eD6xSMOUAQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_19917_AN5nTgMfNWq8Xuo__SLASH__1ArCQg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20013_ADIxR__SLASH__IXKtOECSendODuLA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20013_AFMMgDcASMaks36wcly_ZQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20294_AIfe8lSYEtW5FoHd13gR3Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20294_AIpdyHGCePozyr2__SLASH__s95O0Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20338_ANCscxn6xe__SLASH__EviB7BNrdIQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20338_ANdQotqoE2lIzO9HmLRVPA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20415_ABSwZ7N4ddWy7GeuVzWERw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20415_AFAIYpiGc43GgXkeGzPPOQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20539_ABCQ2vZ6CfxakGT0Wj3CJw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20539_AInpG9vaVs3pUysjknrPmw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20751_AJj9W3vPfFyJPNO__SLASH__2tchPg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20751_AMzyDvUVcISxdLsOkmo6OQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20754_AK_IWpcNwhdTh0___SLASH__gFT1mQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20754_ALxtPs__SLASH__LShgLpcoCY6cDzg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20976_AER46AvB8x6A1MNxYWCqIg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_20976_AG2p1gKtASLzEPD8_RaiCQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_21317_AC9FpqDbtjaqgiHis9cGPQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_21317_AEuzvh4zgNa__SLASH__v4KtEqiX5Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_21598_AIQdTC8_swIKvC7RFn5BlA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_21598_AM29Kbf36O01U4KxzciQIg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22261_AIoykjvCEt__SLASH__dScSIKKibbw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22261_AMyTjYK6e__SLASH__8YhiVRmNNyRg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22286_AMm9YfrvKc5p7BbjldYuPw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22286_AOa3r2OxugCp9e26TsqEnQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2236_AMHBQONNgtiK39yzzuwRaw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2236_APqJsoTceJeRrUa7Es__SLASH__Lww__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22401_AIU__SLASH__DsHoyiLPXuxHwTsAVA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22401_ANaNDayL8ivmOJ_1pptNCQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22545_AHLfWxtzC__SLASH__QdLX37FUqGOw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_22545_AHcAvIMkF4jWkvWFa5bB2g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2306_ABsYlX6DVj_9i4JnoCvfWQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2306_ABul3FoYy3aZc__SLASH__T65mZTZQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23241_AFO__SLASH__R51bR63iYNf_FeGuOg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23241_ANnWhBSpvmH7czrVOQmfsQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23367_AASDXkVNxxtL0U1MYgnbQA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23367_ANJHLPhP__HtPtE2n8E0MA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23447_AFyyzC87tztou3PoEYuSEQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23447_AKTnPzmxFYglqdAwoi4PLQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2345_AGMW2uZA77iy46TAiWZ5vQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2345_ANsBKybWfEP__SLASH__sRoAg2Z_8Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23633_AAnXOpwRqrQRqAZ6VZuDmw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23633_ABKA2iGKYQws__SLASH__tgD4Y2RWA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23696_AI0EONwJusz4NK81V5WzTw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_23696_APsCFbRVa9F1Ci14vNWCkQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24144_AH8H5Z8WO3JLqAv44KT7ZA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24144_AOUF0C2stvvl1e64Eoq04A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24173_AMa4HGmzdFhy4qWbRNF4fw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24173_APz28QBYSgPqi24JcGVzIw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24202_AEbexUwQ_CtDuHjXuf_t9Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24202_AGE6YUW5nzSgg5W9cdrhGg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24262_AB1MiQsdnnrW_ai0B2bUfw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24262_AD_kbRXglHaQj7T9rXKs5Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24438_AFtesAxyLwEmzRrPi4k3WA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24438_AM64RhPEqAUkrWNPwqNX6w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24566_AEB7mEH__SLASH__KxiPYQthHO2Cfw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_24566_AFD86EMU8emPF2bvHzM__SLASH__RQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2549_ADzO_7X4txiEulQBpHzwzQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2549_AFbVvnvSal__SLASH__ExNLrQKqjSg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_25516_AMA4sOusZ60RZaPN_8fGfQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_25516_AMMFbTuyH3Ybb6MQCxB4mg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26278_AJLgiBe0i837PsR55__SLASH__LDgA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26278_AMcvJozFGFZkcWkRmR55yg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26374_ABYjrPudexgJ8oRBtrSSHg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26374_ADRuQLdROsvXFImCfSY9cw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26829_AAsAm8p9l88i3IWEdKN83A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26829_AGDeX6BsBF_Xe7WSqIQcAQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26932_ACpQyIx7y5qGb85NFGfJhw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_26932_AGwKD1Jhy__SLASH__ESUkKPVUcs_g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27300_AAJYPECA__SLASH__I_od__SLASH__PfhJKs8g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27300_AKHh0pcxBntRR9FTBbUSIw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2743_ALNot6Gxp2qnROzqq__SLASH__saVg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2743_AOxxB716AtsCFymWkEieaQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27484_AGam0MjLmG__SLASH__rKt7qTJ2KAw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27484_AIpA62__SLASH__CvLK3wGXALz6SUQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27584_AFWaV08dH2wzAJvktl4sZA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27584_AKo8r462NdVABXNqTg7U0A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27671_ADYpxUR6V9FNZM_8PuC9Fw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27671_APchiaGyoxj20MBZIKkFGQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27714_AKLnS14lKrz1JD0AjzUhvQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_27714_AKxLDr__SLASH__6NhM9fJwtS651JA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2773_ANSoI_iQEIXYpD__SLASH__ZTLEZFw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_2773_APU2QfC2OkdSwUgQhcMbEw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_28090_AFrmezvmNY6eyPHq4WNZiA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_28090_AOZnFvmpAWkUx6WXFsG5dA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_28716_AIUx7reOWuXjwIf5wLUUCA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_28716_AJeutgNDaXLJ1XiQuLDVfw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_28778_ACLIE_7zmk_uc3ZjuyWCzQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_28778_APi__SLASH__OJOb0YzdXccwZSxo_w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29022_AHAxkIUJa79v3Iw1wmgxNA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29022_ALhPYHAyJ8U2Xmj0kXGt_w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29052_AEhtLGGIwGliKn4nZzE_VA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29052_APsMJAd__SLASH__43v__SLASH__NyYDrtU0Ng__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29110_AAFzL0DH5OFRYAV3XgeaSA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29110_ACbEUMLn6zlgf5RJlsvCow__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29195_ACk6_Dm56ttp4v1yZi_IfQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29195_AFLl__SLASH__8gQCGG_TOhJzZnOfg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29565_AGRmBwvdDdTplygkefDh4Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29565_ANBpA0Yn12QTqTFeCnFwPA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29725_AAIR88ERgDAcpJi0PQcGOQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29725_ALz8nQl2VEc6pYDfGmpZTA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29726_AJ8xRygXOVHXAQZY9x85lw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_29726_ANM8ktiGrsyp2Aq__SLASH__Wth5_Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30371_AL8Eon3nXMLUEurkTKPFiA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30371_ALo8GqW5ytQUImFT1PK__SLASH__Pg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30463_AF3j5hiOXR3wmXzTk5cc4w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30463_AFqt4ukXA__SLASH__Sb9Q3W3za5Ww__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30684_ADe2D3vJyy2rp3yodcTdUA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30684_AI1fmJ__SLASH__rqYP0lrS_RQ8lDw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30899_AEP12Fz38iCP6JWA8UIj9A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_30899_AEzsVon4__SLASH__quJ2JaOHmnHSw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_31308_AK3PW5wOv400zArDy__SLASH__UZwQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_31308_AP7hvn9AyE8WPdJcc4XQAA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_3175_AImandw7IlWwcsuXkzrbDQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_3175_AP0M_nqJX1LWcMvpnDMj8w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_32103_AGQVoO7gIx4co2f__SLASH__zSILeA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_32103_AHZbWLPRaw3M8acNPWdp7g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_32374_AJ936vfkWWLrpgcr4WDAEw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_32374_ALnS9Xll9KVewoJeWSKhOQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_32382_AAlR_MtmmxdZNHKHTHrd0g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_32382_AEG5rty2brZzZWBD_VACCg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_3254_AKcGPu_3DWVJJCceZdJujg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_3254_AOFht9mGg6FHwMCx9to7Fg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_3284_AAZIepd3rMs0KQoOsRPEZg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_3284_AIbuAjLQAxhqCCZoy9__SLASH__j4Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4157_AIe6fnBzYh2LxPTJHJsuQQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4157_AMmP337V1eUwXlNOJ9GM9A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4305_AEtQZVLsqBOE8XTOiZI3Nw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4305_AMAV0VOFMp8lWg1wVfPu3g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4430_ADMUH9ql2cJgrD0nH__SLASH__H00A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4430_ADVMKT7__SLASH__xmoZWamt6K9TOQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4647_AIZ5ejLml8KeYIevzjIbNQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4647_AKEoXAigR__SLASH__r__SLASH__eXOecsT_aw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4729_ADWJOy9eKfwKxOrkVos6DA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4729_ALXT26HoJdgA8AbmMOplSA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4800_ABqcVM93EpSlAAOY4nt00Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4800_AHn4VsleoAdloGK6kLmg1g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4810_ADDLDStbh1HDKT2aKifo3g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_4810_ADXEY7SvniiLGI__SLASH__cykhGiQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_50_AFGUWAE6pU9rnXJBHHKG9g__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_50_AN617ABYWMTWFuHoHYCViQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_519_AAp2j6nnaXDnAIIMxDOqDg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_519_AJVIR4v0t4SYuPXaiSyjXg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5358_AE4oy__SLASH__yijj_Lt_bO9Xbjyg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5358_AFEwIYNfyoZcIf__SLASH__DCgKMHQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5615_AEIyPR42yzSsQ5__SLASH__L3_g1__SLASH__A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5615_AEnaILA9efEtYQ_ffZpj1w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5781_AEVfDmMH__SLASH__8tMET0eCSuuRw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5781_AH_yA0odOSxoFFPi_li9Aw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5928_AEnKe1Kt5SD5PvAsPQxvNA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_5928_ALIK1Xp3ziPt7PKcn8JaDA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6082_ACsIVVOLawuQFVJAAr2fUQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6082_AKuZRKvmAy_iTTEriHA26Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6155_AK4M9kAUARy4yVUDQWc7EQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6155_APENjC6_leQo8ggD_NAvNw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6159_ACDthNCQCXdpuvTJOHB7_w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6159_AKkNJwcNIr1APoWnww3trA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6204_ALA12KN_Bzufc__SLASH__fckgQLYQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6204_ANh5D6gjhFczRNoXnfYQZw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6532_AKFI5H8hdER1nhTk6FeZ9w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6532_AM___SLASH__3HsepmCAE1znBS5DaQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6549_AGscQnFIP7ROHL2rRr__SLASH__RwA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6549_AJi__SLASH__z15eMzdj7SeW9vgCDg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6589_AAwn__SLASH__ECxsh_1dlUI6m3mXw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6589_ABhxU1A0X3UrM7xUks__SLASH__KAg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6910_ALxIbmPsD6gVXm903kNNZw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_6910_AMSJZzmG__SLASH__F7_pJyM7M3FWg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7098_AHe8kcqn0WeWqKzCBdOZWA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7098_ANqIBrmTyogZWWnpSqa2GQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7238_AJcczDLZLMg6HmgLwbPZRA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7238_ALUsWuJGa0qH02RGiG_q_w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7310_AI3U726NidndYxOJ8LXiGg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7310_AIqQyzL_6bFft3B3fsNdqQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_742_AHBUd7uN5bMEI9uPtdSJVQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_742_APA7H8RDv7iZGppzsgSzWQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7467_ADmUCP0MCBdxdP147nXPbw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7467_AOgCgysNNhaxY98pr89C5A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7790_AHY8bHMjC8Cau4l3CEbFzg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7790_AII4NQbRGUPwvJb7aj17kg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7884_ACgySAHsnEfS0KVlDcPJpQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_7884_AEwUzGIHnYdSCNvgAQOiwA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8048_ADFBq2ohLYdLz_8EBW7y0w__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8048_AHnWR6MkAzx__SLASH____SLASH__cXMlZ4vPw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8299_ABkI5rBAmBZ__SLASH__9mGeSYRyPw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8299_AJbNG5spEefZBe66MQAhPA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8721_ACP2ea_NrT_V1iorYvJWMA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8721_AJIeCHqUwDEL__SLASH__VC7vXISIw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8745_AMmAXqM7tWcPTuRGfT570A__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8745_APVIRgHObCsuOAETakwTRA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8840_AGW4dTaz9hbQevZ__NgUBQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8840_ANmbeQ31jox4EmsW6ZKVjA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8893_AEEAg2gyeEuHX6OsdmEOZg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_8893_AJ6m9YoPafTnmX1AuUTDyA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9132_ACHb0E5NUU__SLASH__yQK4T79SyWg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9132_ANKHsKenG2rm9JrnAUKI5Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9134_ADqdBOJvh2JRjZANKgb6ew__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9134_AOwBnBi0uYjQRJfhbOo3SA__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_913_AH52yTi3c_1cdfD__SLASH__xDvVhw__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_913_ALJhsoisa_orWoJ04Xd7ZQ__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9504_ALcZ__SLASH__GkSkldvW2___SLASH__oyz8_Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9504_ALuaKFji8SahiaEgZUZXyg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9816_AH9M6PKoJ6IBOMQSAzBR9Q__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 650014
dataset_size: 2209955
- config_name: compute_EQKE_SVD_analysis_9816_ALJ2MB8mbkYNx2ltMg0elg__
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 2209955
num_examples: 1
download_size: 647776
dataset_size: 2209955
- config_name: cubic_count_verify_proof__d_vocab_128_n_ctx_10
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 522
num_examples: 1
download_size: 4191
dataset_size: 522
- config_name: cubic_count_verify_proof__n_ctx_10
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 521
num_examples: 1
download_size: 4184
dataset_size: 521
- config_name: cubic_find_proof
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 8120
num_examples: 1
download_size: 5410
dataset_size: 8120
- config_name: cubic_verify_proof
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 83895046
num_examples: 1
download_size: 12915939
dataset_size: 83895046
- config_name: find_min_gaps
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 16435663
num_examples: 1
download_size: 1998913
dataset_size: 16435663
- config_name: importance-sample-10
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 8699
num_examples: 1
download_size: 5407
dataset_size: 8699
- config_name: importance-sample-lightweight-10
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 10639
num_examples: 1
download_size: 5555
dataset_size: 10639
- config_name: importance_sample_instruction_count_10_n_ctx_10
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 175
num_examples: 1
download_size: 1899
dataset_size: 175
- config_name: importance_sample_instruction_count_d_vocab_128_10_n_ctx_10
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 231
num_examples: 1
download_size: 2275
dataset_size: 231
- config_name: run_batch_loss_accuracy
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 43697344
num_examples: 1
download_size: 10209550
dataset_size: 43697344
- config_name: run_batch_loss_accuracy_10248_ADt9TMfA0ohwJWJoHGEb_A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_10248_AF__SLASH__cdMlHuDiIYavaEc_m7g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_104_AMTHJYbXtl9V78qiarKwHA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_104_AOcepby1JGjQVWVDLVjtWw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11124_AGABnR_tEu1iXfeoRXN2mw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11124_APeNgf__SLASH__Zd2Su7DBNh6cCqA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11130_ACT5Wkf1g_7uEb9Vo0V5iQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11130_AL_3FuWR5VAgcmpLCi9CyA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11498_AA3IABg_HE0mnB9J1vZofA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11498_AGeDPkWzQOKcGEigTEC7aQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11598_ABxlXC4ZX1sFXo7KyS6g1Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11598_ANLxdMRWrGwB_tntg5zBTw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11611_AESuee__SLASH_____SLASH__V8y4T19Td1Y4w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_11611_AFIFrDND4k1__SLASH__jag1QZYwRg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1185_AEmBIHMQpZQ_7FOxKhe4FA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1185_AKS8JWbQJkCtdpSqHxycRA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12141_ALah3F7R9VpRXUX5icdeYQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12141_APNwg2_RYDwIiRHiFmm5NA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12287_AG4IN9v_tnpz_KA8ut__SLASH__Rpg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12287_APVJQ5nKpiYG1N78lSdjEg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_123_AAF01m__SLASH__jSu655uXEJ3n5lw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_123_AGHhlv9gCTV4REJmDsZvAA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12457_ABlvKY__SLASH__ea1W0I9J0__SLASH__5Ke__SLASH__w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12457_ANtn5XZqYm6lWkYX7wm50w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12493_ACvLRUMpn0IXNyk3DhABig___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12493_ALpk8shllJ7lNUe6UxFxwA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12552_ACWqOnUNQIY6ZXSlIrSAeg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12552_AKC4I5HibpQXmsfK81jcpw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12561_AHQTJ4yqdCQ2xbrOh1vg_Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_12561_AMu3S843KoohTTL7_Pc9Pw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1283_ADr6__SLASH__zEW84fe6XOeQvMMGA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1283_ALlLMLCS3VTR3RqgVaqrjw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13036_AAyp5i1xoPiUoBE1xgtLrA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13036_AOUagJAhZlsYnyOnPHR97Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13293_AEn70QMIWNu8SqGyjfu__SLASH__TQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13293_APpv3h4__SLASH__0oRquuaWTyG94g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13468_AHXi3sW9s0zSZVdbLBo02g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13468_APxhL7FxHmQcxv7tLYDfcA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13654_ALXxfTllLv2UV6DVcVDzAg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13654_AP6P_4wuBrxCAB__SLASH__0agbeBQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13716_ACjV0gebaFRv7Im24SKvQw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_13716_ANaOWdYtOTwk6zJmhcT_OA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_14095_AHdteQBmDXOUGrqHT24Qjg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_14095_ALBkCyP8vrs0S_gdYMQ1Bg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1412_ALVkFOwVCV4O1Cb5IYZwJQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1412_ALpi0jYEoq85sqBJ52VagQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1490_ADYfJYpp721n1k_dP2pLLg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1490_APUVyRDKGVXYsMZyb6PT2A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_14929_AG07CJr82KW1UoMBV2z5wA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_14929_AIG__SLASH__plpvvjhgGSNogfpDYg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15043_AIyj3TNGpH8SMqQhgOz2_A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15043_AN49JNcV2adNef2Xjgggmg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15399_AITBIGR4YZiSnltfpup_WA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15399_AIufJc2CqyQWF6hEws5q4A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15622_AE8thSNibi_bQ45ZzPXpCw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15622_ALnNMknsHCTpXNiKwqJdhg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15662_ABN0xMnoG8eswBrOaQRYGg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_15662_ADzISma__SLASH__Ivlz4V355__SLASH__zywA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16069_AL2l8w3n0wNELddPV_zsBg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16069_ALPN8qZcnT__SLASH__9lUw2XtoPFA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16149_AMkn905ekHNFmPUJZFe__SLASH__cg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16149_APQUV8ZlUlkkGWxJX3TkRg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16197_AD9_hspz4VUwKKEUsl1pQg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16197_ANOQT3ss6CiM0JldM2k71A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16284_AEC_0V7Yo1Vg8912paAPJA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_16284_AEEF6XEJ24kVfWOam43d9A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1681_AJ2PDL_2JMP__SLASH__XhqR__SLASH__178__SLASH__Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1681_ANwkZM5TW4cNkpe5A0PJMQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1696_ACY__SLASH__8CfzyVzA3W2fcCtrLw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1696_AChvUnC6YJ0fTAbQwfT80Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17080_AIhm3D0L4tW5062sbstdTg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17080_AMoso0kf__SLASH__I7FaeVG2g1c9A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17096_ACsGM5WBvZG8rCy_s2BYfg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17096_ADWz0kjtHLXoeUZ7B__SLASH__j__SLASH__cw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17194_ACLvzwY3PZFz3uPB6nPTcQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17194_APoCTJ2qAnT91QuTqJBXgA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17197_ADRpaYfxtQh83NGQKSYCWg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_17197_AF4QRGwG7i76o6VkRHying___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_18146_ADp6siELcqhd8e5qrbU__SLASH__kw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_18146_ANBhndJ0AlCep8Jm41w2zQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_18289_AJcuOAnybHMHbw4vohzLcg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_18289_AOgaWFKxlXBf3cyEs72VOw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_18668_AHr8wzfdJ__SLASH__o9ksYQ8HZXRw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_18668_AO6QRUo_g8oJQOj8TQga9w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1895_ABY4waS3AwiPNhqmkHd8pQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1895_AF3GNlURclLbIsCS6y8Q__SLASH__Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19004_AFdEafhGrVtuebjgI__SLASH__rgew___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19004_AFerkSj1mc_HtUPZuIHLgQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19093_AAr9v5vr3g_6JoGwVFtnMA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19093_AF5xzTFfrjg_86AHBmQTew___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19451_AFstGaELqmsJVsloeIunwg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19451_AOUxxQV3sijBGCMnJS812Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19488_AAN__SLASH__HudTRHtTka9FBzosng___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19488_AJZiY7nrQA7YsDVRxhadDg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1951_AC_Trhn0UP4COIKbfLHFIA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_1951_AEpjIMss6Hn04zAXunvLFA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19538_AIAkxFPOh__SLASH__3svQ75QCheCA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19538_AIwSI6FQmfrmw4yYViipcA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19917_AIDzLm9bCNA6eD6xSMOUAQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_19917_AN5nTgMfNWq8Xuo__SLASH__1ArCQg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20013_ADIxR__SLASH__IXKtOECSendODuLA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20013_AFMMgDcASMaks36wcly_ZQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20294_AIfe8lSYEtW5FoHd13gR3Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20294_AIpdyHGCePozyr2__SLASH__s95O0Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20338_ANCscxn6xe__SLASH__EviB7BNrdIQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20338_ANdQotqoE2lIzO9HmLRVPA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20415_ABSwZ7N4ddWy7GeuVzWERw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20415_AFAIYpiGc43GgXkeGzPPOQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20539_ABCQ2vZ6CfxakGT0Wj3CJw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20539_AInpG9vaVs3pUysjknrPmw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20751_AJj9W3vPfFyJPNO__SLASH__2tchPg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20751_AMzyDvUVcISxdLsOkmo6OQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20754_AK_IWpcNwhdTh0___SLASH__gFT1mQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20754_ALxtPs__SLASH__LShgLpcoCY6cDzg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20976_AER46AvB8x6A1MNxYWCqIg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_20976_AG2p1gKtASLzEPD8_RaiCQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_21317_AC9FpqDbtjaqgiHis9cGPQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_21317_AEuzvh4zgNa__SLASH__v4KtEqiX5Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_21598_AIQdTC8_swIKvC7RFn5BlA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_21598_AM29Kbf36O01U4KxzciQIg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22261_AIoykjvCEt__SLASH__dScSIKKibbw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22261_AMyTjYK6e__SLASH__8YhiVRmNNyRg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22286_AMm9YfrvKc5p7BbjldYuPw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22286_AOa3r2OxugCp9e26TsqEnQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2236_AMHBQONNgtiK39yzzuwRaw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2236_APqJsoTceJeRrUa7Es__SLASH__Lww___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22401_AIU__SLASH__DsHoyiLPXuxHwTsAVA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22401_ANaNDayL8ivmOJ_1pptNCQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22545_AHLfWxtzC__SLASH__QdLX37FUqGOw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_22545_AHcAvIMkF4jWkvWFa5bB2g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2306_ABsYlX6DVj_9i4JnoCvfWQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2306_ABul3FoYy3aZc__SLASH__T65mZTZQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23241_AFO__SLASH__R51bR63iYNf_FeGuOg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23241_ANnWhBSpvmH7czrVOQmfsQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23367_AASDXkVNxxtL0U1MYgnbQA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23367_ANJHLPhP__HtPtE2n8E0MA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23447_AFyyzC87tztou3PoEYuSEQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23447_AKTnPzmxFYglqdAwoi4PLQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2345_AGMW2uZA77iy46TAiWZ5vQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2345_ANsBKybWfEP__SLASH__sRoAg2Z_8Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23633_AAnXOpwRqrQRqAZ6VZuDmw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23633_ABKA2iGKYQws__SLASH__tgD4Y2RWA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23696_AI0EONwJusz4NK81V5WzTw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_23696_APsCFbRVa9F1Ci14vNWCkQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24144_AH8H5Z8WO3JLqAv44KT7ZA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24144_AOUF0C2stvvl1e64Eoq04A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24173_AMa4HGmzdFhy4qWbRNF4fw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24173_APz28QBYSgPqi24JcGVzIw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24202_AEbexUwQ_CtDuHjXuf_t9Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24202_AGE6YUW5nzSgg5W9cdrhGg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24262_AB1MiQsdnnrW_ai0B2bUfw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24262_AD_kbRXglHaQj7T9rXKs5Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24438_AFtesAxyLwEmzRrPi4k3WA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24438_AM64RhPEqAUkrWNPwqNX6w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24566_AEB7mEH__SLASH__KxiPYQthHO2Cfw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_24566_AFD86EMU8emPF2bvHzM__SLASH__RQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2549_ADzO_7X4txiEulQBpHzwzQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2549_AFbVvnvSal__SLASH__ExNLrQKqjSg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_25516_AMA4sOusZ60RZaPN_8fGfQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_25516_AMMFbTuyH3Ybb6MQCxB4mg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26278_AJLgiBe0i837PsR55__SLASH__LDgA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26278_AMcvJozFGFZkcWkRmR55yg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26374_ABYjrPudexgJ8oRBtrSSHg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26374_ADRuQLdROsvXFImCfSY9cw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26829_AAsAm8p9l88i3IWEdKN83A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26829_AGDeX6BsBF_Xe7WSqIQcAQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26932_ACpQyIx7y5qGb85NFGfJhw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_26932_AGwKD1Jhy__SLASH__ESUkKPVUcs_g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27300_AAJYPECA__SLASH__I_od__SLASH__PfhJKs8g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27300_AKHh0pcxBntRR9FTBbUSIw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2743_ALNot6Gxp2qnROzqq__SLASH__saVg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2743_AOxxB716AtsCFymWkEieaQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27484_AGam0MjLmG__SLASH__rKt7qTJ2KAw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27484_AIpA62__SLASH__CvLK3wGXALz6SUQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27584_AFWaV08dH2wzAJvktl4sZA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27584_AKo8r462NdVABXNqTg7U0A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27671_ADYpxUR6V9FNZM_8PuC9Fw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27671_APchiaGyoxj20MBZIKkFGQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27714_AKLnS14lKrz1JD0AjzUhvQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_27714_AKxLDr__SLASH__6NhM9fJwtS651JA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2773_ANSoI_iQEIXYpD__SLASH__ZTLEZFw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_2773_APU2QfC2OkdSwUgQhcMbEw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_28090_AFrmezvmNY6eyPHq4WNZiA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_28090_AOZnFvmpAWkUx6WXFsG5dA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_28716_AIUx7reOWuXjwIf5wLUUCA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_28716_AJeutgNDaXLJ1XiQuLDVfw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_28778_ACLIE_7zmk_uc3ZjuyWCzQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_28778_APi__SLASH__OJOb0YzdXccwZSxo_w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29022_AHAxkIUJa79v3Iw1wmgxNA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29022_ALhPYHAyJ8U2Xmj0kXGt_w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29052_AEhtLGGIwGliKn4nZzE_VA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29052_APsMJAd__SLASH__43v__SLASH__NyYDrtU0Ng___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29110_AAFzL0DH5OFRYAV3XgeaSA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29110_ACbEUMLn6zlgf5RJlsvCow___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29195_ACk6_Dm56ttp4v1yZi_IfQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29195_AFLl__SLASH__8gQCGG_TOhJzZnOfg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29565_AGRmBwvdDdTplygkefDh4Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29565_ANBpA0Yn12QTqTFeCnFwPA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29725_AAIR88ERgDAcpJi0PQcGOQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29725_ALz8nQl2VEc6pYDfGmpZTA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29726_AJ8xRygXOVHXAQZY9x85lw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_29726_ANM8ktiGrsyp2Aq__SLASH__Wth5_Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30371_AL8Eon3nXMLUEurkTKPFiA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30371_ALo8GqW5ytQUImFT1PK__SLASH__Pg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30463_AF3j5hiOXR3wmXzTk5cc4w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30463_AFqt4ukXA__SLASH__Sb9Q3W3za5Ww___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30684_ADe2D3vJyy2rp3yodcTdUA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30684_AI1fmJ__SLASH__rqYP0lrS_RQ8lDw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30899_AEP12Fz38iCP6JWA8UIj9A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_30899_AEzsVon4__SLASH__quJ2JaOHmnHSw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_31308_AK3PW5wOv400zArDy__SLASH__UZwQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_31308_AP7hvn9AyE8WPdJcc4XQAA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_3175_AImandw7IlWwcsuXkzrbDQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_3175_AP0M_nqJX1LWcMvpnDMj8w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_32103_AGQVoO7gIx4co2f__SLASH__zSILeA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_32103_AHZbWLPRaw3M8acNPWdp7g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_32374_AJ936vfkWWLrpgcr4WDAEw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_32374_ALnS9Xll9KVewoJeWSKhOQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_32382_AAlR_MtmmxdZNHKHTHrd0g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_32382_AEG5rty2brZzZWBD_VACCg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_3254_AKcGPu_3DWVJJCceZdJujg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_3254_AOFht9mGg6FHwMCx9to7Fg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_3284_AAZIepd3rMs0KQoOsRPEZg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_3284_AIbuAjLQAxhqCCZoy9__SLASH__j4Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4157_AIe6fnBzYh2LxPTJHJsuQQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4157_AMmP337V1eUwXlNOJ9GM9A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4305_AEtQZVLsqBOE8XTOiZI3Nw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4305_AMAV0VOFMp8lWg1wVfPu3g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4430_ADMUH9ql2cJgrD0nH__SLASH__H00A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4430_ADVMKT7__SLASH__xmoZWamt6K9TOQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4647_AIZ5ejLml8KeYIevzjIbNQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4647_AKEoXAigR__SLASH__r__SLASH__eXOecsT_aw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4729_ADWJOy9eKfwKxOrkVos6DA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4729_ALXT26HoJdgA8AbmMOplSA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4800_ABqcVM93EpSlAAOY4nt00Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4800_AHn4VsleoAdloGK6kLmg1g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4810_ADDLDStbh1HDKT2aKifo3g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_4810_ADXEY7SvniiLGI__SLASH__cykhGiQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_50_AFGUWAE6pU9rnXJBHHKG9g___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_50_AN617ABYWMTWFuHoHYCViQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_519_AAp2j6nnaXDnAIIMxDOqDg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_519_AJVIR4v0t4SYuPXaiSyjXg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5358_AE4oy__SLASH__yijj_Lt_bO9Xbjyg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5358_AFEwIYNfyoZcIf__SLASH__DCgKMHQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5615_AEIyPR42yzSsQ5__SLASH__L3_g1__SLASH__A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5615_AEnaILA9efEtYQ_ffZpj1w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5781_AEVfDmMH__SLASH__8tMET0eCSuuRw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5781_AH_yA0odOSxoFFPi_li9Aw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5928_AEnKe1Kt5SD5PvAsPQxvNA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_5928_ALIK1Xp3ziPt7PKcn8JaDA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6082_ACsIVVOLawuQFVJAAr2fUQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6082_AKuZRKvmAy_iTTEriHA26Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6155_AK4M9kAUARy4yVUDQWc7EQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6155_APENjC6_leQo8ggD_NAvNw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6159_ACDthNCQCXdpuvTJOHB7_w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6159_AKkNJwcNIr1APoWnww3trA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6204_ALA12KN_Bzufc__SLASH__fckgQLYQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6204_ANh5D6gjhFczRNoXnfYQZw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6532_AKFI5H8hdER1nhTk6FeZ9w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6532_AM___SLASH__3HsepmCAE1znBS5DaQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6549_AGscQnFIP7ROHL2rRr__SLASH__RwA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6549_AJi__SLASH__z15eMzdj7SeW9vgCDg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6589_AAwn__SLASH__ECxsh_1dlUI6m3mXw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6589_ABhxU1A0X3UrM7xUks__SLASH__KAg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6910_ALxIbmPsD6gVXm903kNNZw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_6910_AMSJZzmG__SLASH__F7_pJyM7M3FWg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7098_AHe8kcqn0WeWqKzCBdOZWA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7098_ANqIBrmTyogZWWnpSqa2GQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7238_AJcczDLZLMg6HmgLwbPZRA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7238_ALUsWuJGa0qH02RGiG_q_w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7310_AI3U726NidndYxOJ8LXiGg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7310_AIqQyzL_6bFft3B3fsNdqQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_742_AHBUd7uN5bMEI9uPtdSJVQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_742_APA7H8RDv7iZGppzsgSzWQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7467_ADmUCP0MCBdxdP147nXPbw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7467_AOgCgysNNhaxY98pr89C5A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7790_AHY8bHMjC8Cau4l3CEbFzg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7790_AII4NQbRGUPwvJb7aj17kg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7884_ACgySAHsnEfS0KVlDcPJpQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_7884_AEwUzGIHnYdSCNvgAQOiwA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8048_ADFBq2ohLYdLz_8EBW7y0w___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8048_AHnWR6MkAzx__SLASH____SLASH__cXMlZ4vPw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8299_ABkI5rBAmBZ__SLASH__9mGeSYRyPw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8299_AJbNG5spEefZBe66MQAhPA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8721_ACP2ea_NrT_V1iorYvJWMA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8721_AJIeCHqUwDEL__SLASH__VC7vXISIw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8745_AMmAXqM7tWcPTuRGfT570A___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8745_APVIRgHObCsuOAETakwTRA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8840_AGW4dTaz9hbQevZ__NgUBQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8840_ANmbeQ31jox4EmsW6ZKVjA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8893_AEEAg2gyeEuHX6OsdmEOZg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_8893_AJ6m9YoPafTnmX1AuUTDyA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9132_ACHb0E5NUU__SLASH__yQK4T79SyWg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9132_ANKHsKenG2rm9JrnAUKI5Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9134_ADqdBOJvh2JRjZANKgb6ew___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9134_AOwBnBi0uYjQRJfhbOo3SA___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_913_AH52yTi3c_1cdfD__SLASH__xDvVhw___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_913_ALJhsoisa_orWoJ04Xd7ZQ___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9504_ALcZ__SLASH__GkSkldvW2___SLASH__oyz8_Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9504_ALuaKFji8SahiaEgZUZXyg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9816_AH9M6PKoJ6IBOMQSAzBR9Q___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5016811
dataset_size: 21838313
- config_name: run_batch_loss_accuracy_9816_ALJ2MB8mbkYNx2ltMg0elg___False
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 21838313
num_examples: 1
download_size: 5185698
dataset_size: 21838313
- config_name: shared_proof_search
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 39806750
num_examples: 1
download_size: 39807132
dataset_size: 39806750
- config_name: subcubic_analyze_gaps
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 82013401
num_examples: 1
download_size: 7643648
dataset_size: 82013401
- config_name: subcubic_count_verify_proof
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 64253
num_examples: 1
download_size: 13154
dataset_size: 64253
- config_name: subcubic_verify_proof
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 65682461
num_examples: 1
download_size: 33082797
dataset_size: 65682461
- config_name: train_or_load_model
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 444948308
num_examples: 1
download_size: 73164324
dataset_size: 444948308
- config_name: train_or_load_model_d_vocab_128
features:
- name: data
dtype: binary
splits:
- name: alldata
num_bytes: 460034980
num_examples: 1
download_size: 90095348
dataset_size: 460034980
configs:
- config_name: compute_EQKE_SVD_analysis
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis/alldata-*
- config_name: compute_EQKE_SVD_analysis_10248_ADt9TMfA0ohwJWJoHGEb_A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_10248_ADt9TMfA0ohwJWJoHGEb_A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_10248_AF__SLASH__cdMlHuDiIYavaEc_m7g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_10248_AF__SLASH__cdMlHuDiIYavaEc_m7g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_104_AMTHJYbXtl9V78qiarKwHA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_104_AMTHJYbXtl9V78qiarKwHA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_104_AOcepby1JGjQVWVDLVjtWw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_104_AOcepby1JGjQVWVDLVjtWw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11124_AGABnR_tEu1iXfeoRXN2mw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11124_AGABnR_tEu1iXfeoRXN2mw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11124_APeNgf__SLASH__Zd2Su7DBNh6cCqA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11124_APeNgf__SLASH__Zd2Su7DBNh6cCqA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11130_ACT5Wkf1g_7uEb9Vo0V5iQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11130_ACT5Wkf1g_7uEb9Vo0V5iQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11130_AL_3FuWR5VAgcmpLCi9CyA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11130_AL_3FuWR5VAgcmpLCi9CyA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11498_AA3IABg_HE0mnB9J1vZofA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11498_AA3IABg_HE0mnB9J1vZofA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11498_AGeDPkWzQOKcGEigTEC7aQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11498_AGeDPkWzQOKcGEigTEC7aQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11598_ABxlXC4ZX1sFXo7KyS6g1Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11598_ABxlXC4ZX1sFXo7KyS6g1Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11598_ANLxdMRWrGwB_tntg5zBTw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11598_ANLxdMRWrGwB_tntg5zBTw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11611_AESuee__SLASH_____SLASH__V8y4T19Td1Y4w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11611_AESuee__SLASH_____SLASH__V8y4T19Td1Y4w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_11611_AFIFrDND4k1__SLASH__jag1QZYwRg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_11611_AFIFrDND4k1__SLASH__jag1QZYwRg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1185_AEmBIHMQpZQ_7FOxKhe4FA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1185_AEmBIHMQpZQ_7FOxKhe4FA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1185_AKS8JWbQJkCtdpSqHxycRA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1185_AKS8JWbQJkCtdpSqHxycRA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12141_ALah3F7R9VpRXUX5icdeYQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12141_ALah3F7R9VpRXUX5icdeYQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12141_APNwg2_RYDwIiRHiFmm5NA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12141_APNwg2_RYDwIiRHiFmm5NA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12287_AG4IN9v_tnpz_KA8ut__SLASH__Rpg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12287_AG4IN9v_tnpz_KA8ut__SLASH__Rpg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12287_APVJQ5nKpiYG1N78lSdjEg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12287_APVJQ5nKpiYG1N78lSdjEg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_123_AAF01m__SLASH__jSu655uXEJ3n5lw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_123_AAF01m__SLASH__jSu655uXEJ3n5lw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_123_AGHhlv9gCTV4REJmDsZvAA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_123_AGHhlv9gCTV4REJmDsZvAA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12457_ABlvKY__SLASH__ea1W0I9J0__SLASH__5Ke__SLASH__w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12457_ABlvKY__SLASH__ea1W0I9J0__SLASH__5Ke__SLASH__w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12457_ANtn5XZqYm6lWkYX7wm50w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12457_ANtn5XZqYm6lWkYX7wm50w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12493_ACvLRUMpn0IXNyk3DhABig__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12493_ACvLRUMpn0IXNyk3DhABig__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12493_ALpk8shllJ7lNUe6UxFxwA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12493_ALpk8shllJ7lNUe6UxFxwA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12552_ACWqOnUNQIY6ZXSlIrSAeg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12552_ACWqOnUNQIY6ZXSlIrSAeg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12552_AKC4I5HibpQXmsfK81jcpw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12552_AKC4I5HibpQXmsfK81jcpw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12561_AHQTJ4yqdCQ2xbrOh1vg_Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12561_AHQTJ4yqdCQ2xbrOh1vg_Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_12561_AMu3S843KoohTTL7_Pc9Pw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_12561_AMu3S843KoohTTL7_Pc9Pw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1283_ADr6__SLASH__zEW84fe6XOeQvMMGA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1283_ADr6__SLASH__zEW84fe6XOeQvMMGA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1283_ALlLMLCS3VTR3RqgVaqrjw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1283_ALlLMLCS3VTR3RqgVaqrjw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13036_AAyp5i1xoPiUoBE1xgtLrA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13036_AAyp5i1xoPiUoBE1xgtLrA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13036_AOUagJAhZlsYnyOnPHR97Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13036_AOUagJAhZlsYnyOnPHR97Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13293_AEn70QMIWNu8SqGyjfu__SLASH__TQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13293_AEn70QMIWNu8SqGyjfu__SLASH__TQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13293_APpv3h4__SLASH__0oRquuaWTyG94g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13293_APpv3h4__SLASH__0oRquuaWTyG94g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13468_AHXi3sW9s0zSZVdbLBo02g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13468_AHXi3sW9s0zSZVdbLBo02g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13468_APxhL7FxHmQcxv7tLYDfcA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13468_APxhL7FxHmQcxv7tLYDfcA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13654_ALXxfTllLv2UV6DVcVDzAg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13654_ALXxfTllLv2UV6DVcVDzAg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13654_AP6P_4wuBrxCAB__SLASH__0agbeBQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13654_AP6P_4wuBrxCAB__SLASH__0agbeBQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13716_ACjV0gebaFRv7Im24SKvQw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13716_ACjV0gebaFRv7Im24SKvQw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_13716_ANaOWdYtOTwk6zJmhcT_OA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_13716_ANaOWdYtOTwk6zJmhcT_OA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_14095_AHdteQBmDXOUGrqHT24Qjg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_14095_AHdteQBmDXOUGrqHT24Qjg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_14095_ALBkCyP8vrs0S_gdYMQ1Bg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_14095_ALBkCyP8vrs0S_gdYMQ1Bg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1412_ALVkFOwVCV4O1Cb5IYZwJQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1412_ALVkFOwVCV4O1Cb5IYZwJQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1412_ALpi0jYEoq85sqBJ52VagQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1412_ALpi0jYEoq85sqBJ52VagQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1490_ADYfJYpp721n1k_dP2pLLg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1490_ADYfJYpp721n1k_dP2pLLg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1490_APUVyRDKGVXYsMZyb6PT2A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1490_APUVyRDKGVXYsMZyb6PT2A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_14929_AG07CJr82KW1UoMBV2z5wA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_14929_AG07CJr82KW1UoMBV2z5wA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_14929_AIG__SLASH__plpvvjhgGSNogfpDYg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_14929_AIG__SLASH__plpvvjhgGSNogfpDYg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15043_AIyj3TNGpH8SMqQhgOz2_A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15043_AIyj3TNGpH8SMqQhgOz2_A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15043_AN49JNcV2adNef2Xjgggmg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15043_AN49JNcV2adNef2Xjgggmg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15399_AITBIGR4YZiSnltfpup_WA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15399_AITBIGR4YZiSnltfpup_WA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15399_AIufJc2CqyQWF6hEws5q4A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15399_AIufJc2CqyQWF6hEws5q4A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15622_AE8thSNibi_bQ45ZzPXpCw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15622_AE8thSNibi_bQ45ZzPXpCw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15622_ALnNMknsHCTpXNiKwqJdhg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15622_ALnNMknsHCTpXNiKwqJdhg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15662_ABN0xMnoG8eswBrOaQRYGg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15662_ABN0xMnoG8eswBrOaQRYGg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_15662_ADzISma__SLASH__Ivlz4V355__SLASH__zywA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_15662_ADzISma__SLASH__Ivlz4V355__SLASH__zywA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16069_AL2l8w3n0wNELddPV_zsBg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16069_AL2l8w3n0wNELddPV_zsBg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16069_ALPN8qZcnT__SLASH__9lUw2XtoPFA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16069_ALPN8qZcnT__SLASH__9lUw2XtoPFA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16149_AMkn905ekHNFmPUJZFe__SLASH__cg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16149_AMkn905ekHNFmPUJZFe__SLASH__cg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16149_APQUV8ZlUlkkGWxJX3TkRg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16149_APQUV8ZlUlkkGWxJX3TkRg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16197_AD9_hspz4VUwKKEUsl1pQg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16197_AD9_hspz4VUwKKEUsl1pQg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16197_ANOQT3ss6CiM0JldM2k71A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16197_ANOQT3ss6CiM0JldM2k71A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16284_AEC_0V7Yo1Vg8912paAPJA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16284_AEC_0V7Yo1Vg8912paAPJA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_16284_AEEF6XEJ24kVfWOam43d9A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_16284_AEEF6XEJ24kVfWOam43d9A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1681_AJ2PDL_2JMP__SLASH__XhqR__SLASH__178__SLASH__Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1681_AJ2PDL_2JMP__SLASH__XhqR__SLASH__178__SLASH__Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1681_ANwkZM5TW4cNkpe5A0PJMQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1681_ANwkZM5TW4cNkpe5A0PJMQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1696_ACY__SLASH__8CfzyVzA3W2fcCtrLw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1696_ACY__SLASH__8CfzyVzA3W2fcCtrLw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1696_AChvUnC6YJ0fTAbQwfT80Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1696_AChvUnC6YJ0fTAbQwfT80Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17080_AIhm3D0L4tW5062sbstdTg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17080_AIhm3D0L4tW5062sbstdTg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17080_AMoso0kf__SLASH__I7FaeVG2g1c9A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17080_AMoso0kf__SLASH__I7FaeVG2g1c9A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17096_ACsGM5WBvZG8rCy_s2BYfg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17096_ACsGM5WBvZG8rCy_s2BYfg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17096_ADWz0kjtHLXoeUZ7B__SLASH__j__SLASH__cw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17096_ADWz0kjtHLXoeUZ7B__SLASH__j__SLASH__cw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17194_ACLvzwY3PZFz3uPB6nPTcQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17194_ACLvzwY3PZFz3uPB6nPTcQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17194_APoCTJ2qAnT91QuTqJBXgA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17194_APoCTJ2qAnT91QuTqJBXgA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17197_ADRpaYfxtQh83NGQKSYCWg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17197_ADRpaYfxtQh83NGQKSYCWg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_17197_AF4QRGwG7i76o6VkRHying__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_17197_AF4QRGwG7i76o6VkRHying__/alldata-*
- config_name: compute_EQKE_SVD_analysis_18146_ADp6siELcqhd8e5qrbU__SLASH__kw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_18146_ADp6siELcqhd8e5qrbU__SLASH__kw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_18146_ANBhndJ0AlCep8Jm41w2zQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_18146_ANBhndJ0AlCep8Jm41w2zQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_18289_AJcuOAnybHMHbw4vohzLcg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_18289_AJcuOAnybHMHbw4vohzLcg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_18289_AOgaWFKxlXBf3cyEs72VOw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_18289_AOgaWFKxlXBf3cyEs72VOw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_18668_AHr8wzfdJ__SLASH__o9ksYQ8HZXRw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_18668_AHr8wzfdJ__SLASH__o9ksYQ8HZXRw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_18668_AO6QRUo_g8oJQOj8TQga9w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_18668_AO6QRUo_g8oJQOj8TQga9w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1895_ABY4waS3AwiPNhqmkHd8pQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1895_ABY4waS3AwiPNhqmkHd8pQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1895_AF3GNlURclLbIsCS6y8Q__SLASH__Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1895_AF3GNlURclLbIsCS6y8Q__SLASH__Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19004_AFdEafhGrVtuebjgI__SLASH__rgew__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19004_AFdEafhGrVtuebjgI__SLASH__rgew__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19004_AFerkSj1mc_HtUPZuIHLgQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19004_AFerkSj1mc_HtUPZuIHLgQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19093_AAr9v5vr3g_6JoGwVFtnMA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19093_AAr9v5vr3g_6JoGwVFtnMA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19093_AF5xzTFfrjg_86AHBmQTew__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19093_AF5xzTFfrjg_86AHBmQTew__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19451_AFstGaELqmsJVsloeIunwg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19451_AFstGaELqmsJVsloeIunwg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19451_AOUxxQV3sijBGCMnJS812Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19451_AOUxxQV3sijBGCMnJS812Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19488_AAN__SLASH__HudTRHtTka9FBzosng__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19488_AAN__SLASH__HudTRHtTka9FBzosng__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19488_AJZiY7nrQA7YsDVRxhadDg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19488_AJZiY7nrQA7YsDVRxhadDg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1951_AC_Trhn0UP4COIKbfLHFIA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1951_AC_Trhn0UP4COIKbfLHFIA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_1951_AEpjIMss6Hn04zAXunvLFA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_1951_AEpjIMss6Hn04zAXunvLFA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19538_AIAkxFPOh__SLASH__3svQ75QCheCA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19538_AIAkxFPOh__SLASH__3svQ75QCheCA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19538_AIwSI6FQmfrmw4yYViipcA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19538_AIwSI6FQmfrmw4yYViipcA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19917_AIDzLm9bCNA6eD6xSMOUAQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19917_AIDzLm9bCNA6eD6xSMOUAQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_19917_AN5nTgMfNWq8Xuo__SLASH__1ArCQg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_19917_AN5nTgMfNWq8Xuo__SLASH__1ArCQg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20013_ADIxR__SLASH__IXKtOECSendODuLA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20013_ADIxR__SLASH__IXKtOECSendODuLA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20013_AFMMgDcASMaks36wcly_ZQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20013_AFMMgDcASMaks36wcly_ZQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20294_AIfe8lSYEtW5FoHd13gR3Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20294_AIfe8lSYEtW5FoHd13gR3Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20294_AIpdyHGCePozyr2__SLASH__s95O0Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20294_AIpdyHGCePozyr2__SLASH__s95O0Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20338_ANCscxn6xe__SLASH__EviB7BNrdIQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20338_ANCscxn6xe__SLASH__EviB7BNrdIQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20338_ANdQotqoE2lIzO9HmLRVPA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20338_ANdQotqoE2lIzO9HmLRVPA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20415_ABSwZ7N4ddWy7GeuVzWERw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20415_ABSwZ7N4ddWy7GeuVzWERw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20415_AFAIYpiGc43GgXkeGzPPOQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20415_AFAIYpiGc43GgXkeGzPPOQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20539_ABCQ2vZ6CfxakGT0Wj3CJw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20539_ABCQ2vZ6CfxakGT0Wj3CJw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20539_AInpG9vaVs3pUysjknrPmw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20539_AInpG9vaVs3pUysjknrPmw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20751_AJj9W3vPfFyJPNO__SLASH__2tchPg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20751_AJj9W3vPfFyJPNO__SLASH__2tchPg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20751_AMzyDvUVcISxdLsOkmo6OQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20751_AMzyDvUVcISxdLsOkmo6OQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20754_AK_IWpcNwhdTh0___SLASH__gFT1mQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20754_AK_IWpcNwhdTh0___SLASH__gFT1mQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20754_ALxtPs__SLASH__LShgLpcoCY6cDzg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20754_ALxtPs__SLASH__LShgLpcoCY6cDzg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20976_AER46AvB8x6A1MNxYWCqIg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20976_AER46AvB8x6A1MNxYWCqIg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_20976_AG2p1gKtASLzEPD8_RaiCQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_20976_AG2p1gKtASLzEPD8_RaiCQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_21317_AC9FpqDbtjaqgiHis9cGPQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_21317_AC9FpqDbtjaqgiHis9cGPQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_21317_AEuzvh4zgNa__SLASH__v4KtEqiX5Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_21317_AEuzvh4zgNa__SLASH__v4KtEqiX5Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_21598_AIQdTC8_swIKvC7RFn5BlA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_21598_AIQdTC8_swIKvC7RFn5BlA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_21598_AM29Kbf36O01U4KxzciQIg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_21598_AM29Kbf36O01U4KxzciQIg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22261_AIoykjvCEt__SLASH__dScSIKKibbw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22261_AIoykjvCEt__SLASH__dScSIKKibbw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22261_AMyTjYK6e__SLASH__8YhiVRmNNyRg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22261_AMyTjYK6e__SLASH__8YhiVRmNNyRg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22286_AMm9YfrvKc5p7BbjldYuPw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22286_AMm9YfrvKc5p7BbjldYuPw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22286_AOa3r2OxugCp9e26TsqEnQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22286_AOa3r2OxugCp9e26TsqEnQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2236_AMHBQONNgtiK39yzzuwRaw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2236_AMHBQONNgtiK39yzzuwRaw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2236_APqJsoTceJeRrUa7Es__SLASH__Lww__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2236_APqJsoTceJeRrUa7Es__SLASH__Lww__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22401_AIU__SLASH__DsHoyiLPXuxHwTsAVA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22401_AIU__SLASH__DsHoyiLPXuxHwTsAVA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22401_ANaNDayL8ivmOJ_1pptNCQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22401_ANaNDayL8ivmOJ_1pptNCQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22545_AHLfWxtzC__SLASH__QdLX37FUqGOw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22545_AHLfWxtzC__SLASH__QdLX37FUqGOw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_22545_AHcAvIMkF4jWkvWFa5bB2g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_22545_AHcAvIMkF4jWkvWFa5bB2g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2306_ABsYlX6DVj_9i4JnoCvfWQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2306_ABsYlX6DVj_9i4JnoCvfWQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2306_ABul3FoYy3aZc__SLASH__T65mZTZQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2306_ABul3FoYy3aZc__SLASH__T65mZTZQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23241_AFO__SLASH__R51bR63iYNf_FeGuOg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23241_AFO__SLASH__R51bR63iYNf_FeGuOg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23241_ANnWhBSpvmH7czrVOQmfsQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23241_ANnWhBSpvmH7czrVOQmfsQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23367_AASDXkVNxxtL0U1MYgnbQA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23367_AASDXkVNxxtL0U1MYgnbQA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23367_ANJHLPhP__HtPtE2n8E0MA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23367_ANJHLPhP__HtPtE2n8E0MA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23447_AFyyzC87tztou3PoEYuSEQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23447_AFyyzC87tztou3PoEYuSEQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23447_AKTnPzmxFYglqdAwoi4PLQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23447_AKTnPzmxFYglqdAwoi4PLQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2345_AGMW2uZA77iy46TAiWZ5vQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2345_AGMW2uZA77iy46TAiWZ5vQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2345_ANsBKybWfEP__SLASH__sRoAg2Z_8Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2345_ANsBKybWfEP__SLASH__sRoAg2Z_8Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23633_AAnXOpwRqrQRqAZ6VZuDmw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23633_AAnXOpwRqrQRqAZ6VZuDmw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23633_ABKA2iGKYQws__SLASH__tgD4Y2RWA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23633_ABKA2iGKYQws__SLASH__tgD4Y2RWA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23696_AI0EONwJusz4NK81V5WzTw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23696_AI0EONwJusz4NK81V5WzTw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_23696_APsCFbRVa9F1Ci14vNWCkQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_23696_APsCFbRVa9F1Ci14vNWCkQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24144_AH8H5Z8WO3JLqAv44KT7ZA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24144_AH8H5Z8WO3JLqAv44KT7ZA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24144_AOUF0C2stvvl1e64Eoq04A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24144_AOUF0C2stvvl1e64Eoq04A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24173_AMa4HGmzdFhy4qWbRNF4fw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24173_AMa4HGmzdFhy4qWbRNF4fw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24173_APz28QBYSgPqi24JcGVzIw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24173_APz28QBYSgPqi24JcGVzIw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24202_AEbexUwQ_CtDuHjXuf_t9Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24202_AEbexUwQ_CtDuHjXuf_t9Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24202_AGE6YUW5nzSgg5W9cdrhGg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24202_AGE6YUW5nzSgg5W9cdrhGg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24262_AB1MiQsdnnrW_ai0B2bUfw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24262_AB1MiQsdnnrW_ai0B2bUfw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24262_AD_kbRXglHaQj7T9rXKs5Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24262_AD_kbRXglHaQj7T9rXKs5Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24438_AFtesAxyLwEmzRrPi4k3WA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24438_AFtesAxyLwEmzRrPi4k3WA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24438_AM64RhPEqAUkrWNPwqNX6w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24438_AM64RhPEqAUkrWNPwqNX6w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24566_AEB7mEH__SLASH__KxiPYQthHO2Cfw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24566_AEB7mEH__SLASH__KxiPYQthHO2Cfw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_24566_AFD86EMU8emPF2bvHzM__SLASH__RQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_24566_AFD86EMU8emPF2bvHzM__SLASH__RQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2549_ADzO_7X4txiEulQBpHzwzQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2549_ADzO_7X4txiEulQBpHzwzQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2549_AFbVvnvSal__SLASH__ExNLrQKqjSg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2549_AFbVvnvSal__SLASH__ExNLrQKqjSg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_25516_AMA4sOusZ60RZaPN_8fGfQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_25516_AMA4sOusZ60RZaPN_8fGfQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_25516_AMMFbTuyH3Ybb6MQCxB4mg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_25516_AMMFbTuyH3Ybb6MQCxB4mg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26278_AJLgiBe0i837PsR55__SLASH__LDgA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26278_AJLgiBe0i837PsR55__SLASH__LDgA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26278_AMcvJozFGFZkcWkRmR55yg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26278_AMcvJozFGFZkcWkRmR55yg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26374_ABYjrPudexgJ8oRBtrSSHg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26374_ABYjrPudexgJ8oRBtrSSHg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26374_ADRuQLdROsvXFImCfSY9cw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26374_ADRuQLdROsvXFImCfSY9cw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26829_AAsAm8p9l88i3IWEdKN83A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26829_AAsAm8p9l88i3IWEdKN83A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26829_AGDeX6BsBF_Xe7WSqIQcAQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26829_AGDeX6BsBF_Xe7WSqIQcAQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26932_ACpQyIx7y5qGb85NFGfJhw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26932_ACpQyIx7y5qGb85NFGfJhw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_26932_AGwKD1Jhy__SLASH__ESUkKPVUcs_g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_26932_AGwKD1Jhy__SLASH__ESUkKPVUcs_g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27300_AAJYPECA__SLASH__I_od__SLASH__PfhJKs8g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27300_AAJYPECA__SLASH__I_od__SLASH__PfhJKs8g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27300_AKHh0pcxBntRR9FTBbUSIw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27300_AKHh0pcxBntRR9FTBbUSIw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2743_ALNot6Gxp2qnROzqq__SLASH__saVg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2743_ALNot6Gxp2qnROzqq__SLASH__saVg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2743_AOxxB716AtsCFymWkEieaQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2743_AOxxB716AtsCFymWkEieaQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27484_AGam0MjLmG__SLASH__rKt7qTJ2KAw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27484_AGam0MjLmG__SLASH__rKt7qTJ2KAw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27484_AIpA62__SLASH__CvLK3wGXALz6SUQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27484_AIpA62__SLASH__CvLK3wGXALz6SUQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27584_AFWaV08dH2wzAJvktl4sZA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27584_AFWaV08dH2wzAJvktl4sZA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27584_AKo8r462NdVABXNqTg7U0A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27584_AKo8r462NdVABXNqTg7U0A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27671_ADYpxUR6V9FNZM_8PuC9Fw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27671_ADYpxUR6V9FNZM_8PuC9Fw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27671_APchiaGyoxj20MBZIKkFGQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27671_APchiaGyoxj20MBZIKkFGQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27714_AKLnS14lKrz1JD0AjzUhvQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27714_AKLnS14lKrz1JD0AjzUhvQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_27714_AKxLDr__SLASH__6NhM9fJwtS651JA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_27714_AKxLDr__SLASH__6NhM9fJwtS651JA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2773_ANSoI_iQEIXYpD__SLASH__ZTLEZFw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2773_ANSoI_iQEIXYpD__SLASH__ZTLEZFw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_2773_APU2QfC2OkdSwUgQhcMbEw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_2773_APU2QfC2OkdSwUgQhcMbEw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_28090_AFrmezvmNY6eyPHq4WNZiA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_28090_AFrmezvmNY6eyPHq4WNZiA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_28090_AOZnFvmpAWkUx6WXFsG5dA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_28090_AOZnFvmpAWkUx6WXFsG5dA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_28716_AIUx7reOWuXjwIf5wLUUCA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_28716_AIUx7reOWuXjwIf5wLUUCA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_28716_AJeutgNDaXLJ1XiQuLDVfw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_28716_AJeutgNDaXLJ1XiQuLDVfw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_28778_ACLIE_7zmk_uc3ZjuyWCzQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_28778_ACLIE_7zmk_uc3ZjuyWCzQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_28778_APi__SLASH__OJOb0YzdXccwZSxo_w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_28778_APi__SLASH__OJOb0YzdXccwZSxo_w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29022_AHAxkIUJa79v3Iw1wmgxNA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29022_AHAxkIUJa79v3Iw1wmgxNA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29022_ALhPYHAyJ8U2Xmj0kXGt_w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29022_ALhPYHAyJ8U2Xmj0kXGt_w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29052_AEhtLGGIwGliKn4nZzE_VA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29052_AEhtLGGIwGliKn4nZzE_VA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29052_APsMJAd__SLASH__43v__SLASH__NyYDrtU0Ng__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29052_APsMJAd__SLASH__43v__SLASH__NyYDrtU0Ng__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29110_AAFzL0DH5OFRYAV3XgeaSA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29110_AAFzL0DH5OFRYAV3XgeaSA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29110_ACbEUMLn6zlgf5RJlsvCow__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29110_ACbEUMLn6zlgf5RJlsvCow__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29195_ACk6_Dm56ttp4v1yZi_IfQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29195_ACk6_Dm56ttp4v1yZi_IfQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29195_AFLl__SLASH__8gQCGG_TOhJzZnOfg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29195_AFLl__SLASH__8gQCGG_TOhJzZnOfg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29565_AGRmBwvdDdTplygkefDh4Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29565_AGRmBwvdDdTplygkefDh4Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29565_ANBpA0Yn12QTqTFeCnFwPA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29565_ANBpA0Yn12QTqTFeCnFwPA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29725_AAIR88ERgDAcpJi0PQcGOQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29725_AAIR88ERgDAcpJi0PQcGOQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29725_ALz8nQl2VEc6pYDfGmpZTA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29725_ALz8nQl2VEc6pYDfGmpZTA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29726_AJ8xRygXOVHXAQZY9x85lw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29726_AJ8xRygXOVHXAQZY9x85lw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_29726_ANM8ktiGrsyp2Aq__SLASH__Wth5_Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_29726_ANM8ktiGrsyp2Aq__SLASH__Wth5_Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30371_AL8Eon3nXMLUEurkTKPFiA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30371_AL8Eon3nXMLUEurkTKPFiA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30371_ALo8GqW5ytQUImFT1PK__SLASH__Pg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30371_ALo8GqW5ytQUImFT1PK__SLASH__Pg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30463_AF3j5hiOXR3wmXzTk5cc4w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30463_AF3j5hiOXR3wmXzTk5cc4w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30463_AFqt4ukXA__SLASH__Sb9Q3W3za5Ww__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30463_AFqt4ukXA__SLASH__Sb9Q3W3za5Ww__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30684_ADe2D3vJyy2rp3yodcTdUA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30684_ADe2D3vJyy2rp3yodcTdUA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30684_AI1fmJ__SLASH__rqYP0lrS_RQ8lDw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30684_AI1fmJ__SLASH__rqYP0lrS_RQ8lDw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30899_AEP12Fz38iCP6JWA8UIj9A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30899_AEP12Fz38iCP6JWA8UIj9A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_30899_AEzsVon4__SLASH__quJ2JaOHmnHSw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_30899_AEzsVon4__SLASH__quJ2JaOHmnHSw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_31308_AK3PW5wOv400zArDy__SLASH__UZwQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_31308_AK3PW5wOv400zArDy__SLASH__UZwQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_31308_AP7hvn9AyE8WPdJcc4XQAA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_31308_AP7hvn9AyE8WPdJcc4XQAA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_3175_AImandw7IlWwcsuXkzrbDQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_3175_AImandw7IlWwcsuXkzrbDQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_3175_AP0M_nqJX1LWcMvpnDMj8w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_3175_AP0M_nqJX1LWcMvpnDMj8w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_32103_AGQVoO7gIx4co2f__SLASH__zSILeA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_32103_AGQVoO7gIx4co2f__SLASH__zSILeA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_32103_AHZbWLPRaw3M8acNPWdp7g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_32103_AHZbWLPRaw3M8acNPWdp7g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_32374_AJ936vfkWWLrpgcr4WDAEw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_32374_AJ936vfkWWLrpgcr4WDAEw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_32374_ALnS9Xll9KVewoJeWSKhOQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_32374_ALnS9Xll9KVewoJeWSKhOQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_32382_AAlR_MtmmxdZNHKHTHrd0g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_32382_AAlR_MtmmxdZNHKHTHrd0g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_32382_AEG5rty2brZzZWBD_VACCg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_32382_AEG5rty2brZzZWBD_VACCg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_3254_AKcGPu_3DWVJJCceZdJujg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_3254_AKcGPu_3DWVJJCceZdJujg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_3254_AOFht9mGg6FHwMCx9to7Fg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_3254_AOFht9mGg6FHwMCx9to7Fg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_3284_AAZIepd3rMs0KQoOsRPEZg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_3284_AAZIepd3rMs0KQoOsRPEZg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_3284_AIbuAjLQAxhqCCZoy9__SLASH__j4Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_3284_AIbuAjLQAxhqCCZoy9__SLASH__j4Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4157_AIe6fnBzYh2LxPTJHJsuQQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4157_AIe6fnBzYh2LxPTJHJsuQQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4157_AMmP337V1eUwXlNOJ9GM9A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4157_AMmP337V1eUwXlNOJ9GM9A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4305_AEtQZVLsqBOE8XTOiZI3Nw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4305_AEtQZVLsqBOE8XTOiZI3Nw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4305_AMAV0VOFMp8lWg1wVfPu3g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4305_AMAV0VOFMp8lWg1wVfPu3g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4430_ADMUH9ql2cJgrD0nH__SLASH__H00A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4430_ADMUH9ql2cJgrD0nH__SLASH__H00A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4430_ADVMKT7__SLASH__xmoZWamt6K9TOQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4430_ADVMKT7__SLASH__xmoZWamt6K9TOQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4647_AIZ5ejLml8KeYIevzjIbNQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4647_AIZ5ejLml8KeYIevzjIbNQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4647_AKEoXAigR__SLASH__r__SLASH__eXOecsT_aw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4647_AKEoXAigR__SLASH__r__SLASH__eXOecsT_aw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4729_ADWJOy9eKfwKxOrkVos6DA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4729_ADWJOy9eKfwKxOrkVos6DA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4729_ALXT26HoJdgA8AbmMOplSA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4729_ALXT26HoJdgA8AbmMOplSA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4800_ABqcVM93EpSlAAOY4nt00Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4800_ABqcVM93EpSlAAOY4nt00Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4800_AHn4VsleoAdloGK6kLmg1g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4800_AHn4VsleoAdloGK6kLmg1g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4810_ADDLDStbh1HDKT2aKifo3g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4810_ADDLDStbh1HDKT2aKifo3g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_4810_ADXEY7SvniiLGI__SLASH__cykhGiQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_4810_ADXEY7SvniiLGI__SLASH__cykhGiQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_50_AFGUWAE6pU9rnXJBHHKG9g__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_50_AFGUWAE6pU9rnXJBHHKG9g__/alldata-*
- config_name: compute_EQKE_SVD_analysis_50_AN617ABYWMTWFuHoHYCViQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_50_AN617ABYWMTWFuHoHYCViQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_519_AAp2j6nnaXDnAIIMxDOqDg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_519_AAp2j6nnaXDnAIIMxDOqDg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_519_AJVIR4v0t4SYuPXaiSyjXg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_519_AJVIR4v0t4SYuPXaiSyjXg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5358_AE4oy__SLASH__yijj_Lt_bO9Xbjyg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5358_AE4oy__SLASH__yijj_Lt_bO9Xbjyg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5358_AFEwIYNfyoZcIf__SLASH__DCgKMHQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5358_AFEwIYNfyoZcIf__SLASH__DCgKMHQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5615_AEIyPR42yzSsQ5__SLASH__L3_g1__SLASH__A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5615_AEIyPR42yzSsQ5__SLASH__L3_g1__SLASH__A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5615_AEnaILA9efEtYQ_ffZpj1w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5615_AEnaILA9efEtYQ_ffZpj1w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5781_AEVfDmMH__SLASH__8tMET0eCSuuRw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5781_AEVfDmMH__SLASH__8tMET0eCSuuRw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5781_AH_yA0odOSxoFFPi_li9Aw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5781_AH_yA0odOSxoFFPi_li9Aw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5928_AEnKe1Kt5SD5PvAsPQxvNA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5928_AEnKe1Kt5SD5PvAsPQxvNA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_5928_ALIK1Xp3ziPt7PKcn8JaDA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_5928_ALIK1Xp3ziPt7PKcn8JaDA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6082_ACsIVVOLawuQFVJAAr2fUQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6082_ACsIVVOLawuQFVJAAr2fUQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6082_AKuZRKvmAy_iTTEriHA26Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6082_AKuZRKvmAy_iTTEriHA26Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6155_AK4M9kAUARy4yVUDQWc7EQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6155_AK4M9kAUARy4yVUDQWc7EQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6155_APENjC6_leQo8ggD_NAvNw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6155_APENjC6_leQo8ggD_NAvNw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6159_ACDthNCQCXdpuvTJOHB7_w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6159_ACDthNCQCXdpuvTJOHB7_w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6159_AKkNJwcNIr1APoWnww3trA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6159_AKkNJwcNIr1APoWnww3trA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6204_ALA12KN_Bzufc__SLASH__fckgQLYQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6204_ALA12KN_Bzufc__SLASH__fckgQLYQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6204_ANh5D6gjhFczRNoXnfYQZw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6204_ANh5D6gjhFczRNoXnfYQZw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6532_AKFI5H8hdER1nhTk6FeZ9w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6532_AKFI5H8hdER1nhTk6FeZ9w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6532_AM___SLASH__3HsepmCAE1znBS5DaQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6532_AM___SLASH__3HsepmCAE1znBS5DaQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6549_AGscQnFIP7ROHL2rRr__SLASH__RwA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6549_AGscQnFIP7ROHL2rRr__SLASH__RwA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6549_AJi__SLASH__z15eMzdj7SeW9vgCDg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6549_AJi__SLASH__z15eMzdj7SeW9vgCDg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6589_AAwn__SLASH__ECxsh_1dlUI6m3mXw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6589_AAwn__SLASH__ECxsh_1dlUI6m3mXw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6589_ABhxU1A0X3UrM7xUks__SLASH__KAg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6589_ABhxU1A0X3UrM7xUks__SLASH__KAg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6910_ALxIbmPsD6gVXm903kNNZw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6910_ALxIbmPsD6gVXm903kNNZw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_6910_AMSJZzmG__SLASH__F7_pJyM7M3FWg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_6910_AMSJZzmG__SLASH__F7_pJyM7M3FWg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7098_AHe8kcqn0WeWqKzCBdOZWA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7098_AHe8kcqn0WeWqKzCBdOZWA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7098_ANqIBrmTyogZWWnpSqa2GQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7098_ANqIBrmTyogZWWnpSqa2GQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7238_AJcczDLZLMg6HmgLwbPZRA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7238_AJcczDLZLMg6HmgLwbPZRA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7238_ALUsWuJGa0qH02RGiG_q_w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7238_ALUsWuJGa0qH02RGiG_q_w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7310_AI3U726NidndYxOJ8LXiGg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7310_AI3U726NidndYxOJ8LXiGg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7310_AIqQyzL_6bFft3B3fsNdqQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7310_AIqQyzL_6bFft3B3fsNdqQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_742_AHBUd7uN5bMEI9uPtdSJVQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_742_AHBUd7uN5bMEI9uPtdSJVQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_742_APA7H8RDv7iZGppzsgSzWQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_742_APA7H8RDv7iZGppzsgSzWQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7467_ADmUCP0MCBdxdP147nXPbw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7467_ADmUCP0MCBdxdP147nXPbw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7467_AOgCgysNNhaxY98pr89C5A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7467_AOgCgysNNhaxY98pr89C5A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7790_AHY8bHMjC8Cau4l3CEbFzg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7790_AHY8bHMjC8Cau4l3CEbFzg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7790_AII4NQbRGUPwvJb7aj17kg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7790_AII4NQbRGUPwvJb7aj17kg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7884_ACgySAHsnEfS0KVlDcPJpQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7884_ACgySAHsnEfS0KVlDcPJpQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_7884_AEwUzGIHnYdSCNvgAQOiwA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_7884_AEwUzGIHnYdSCNvgAQOiwA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8048_ADFBq2ohLYdLz_8EBW7y0w__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8048_ADFBq2ohLYdLz_8EBW7y0w__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8048_AHnWR6MkAzx__SLASH____SLASH__cXMlZ4vPw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8048_AHnWR6MkAzx__SLASH____SLASH__cXMlZ4vPw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8299_ABkI5rBAmBZ__SLASH__9mGeSYRyPw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8299_ABkI5rBAmBZ__SLASH__9mGeSYRyPw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8299_AJbNG5spEefZBe66MQAhPA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8299_AJbNG5spEefZBe66MQAhPA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8721_ACP2ea_NrT_V1iorYvJWMA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8721_ACP2ea_NrT_V1iorYvJWMA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8721_AJIeCHqUwDEL__SLASH__VC7vXISIw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8721_AJIeCHqUwDEL__SLASH__VC7vXISIw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8745_AMmAXqM7tWcPTuRGfT570A__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8745_AMmAXqM7tWcPTuRGfT570A__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8745_APVIRgHObCsuOAETakwTRA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8745_APVIRgHObCsuOAETakwTRA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8840_AGW4dTaz9hbQevZ__NgUBQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8840_AGW4dTaz9hbQevZ__NgUBQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8840_ANmbeQ31jox4EmsW6ZKVjA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8840_ANmbeQ31jox4EmsW6ZKVjA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8893_AEEAg2gyeEuHX6OsdmEOZg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8893_AEEAg2gyeEuHX6OsdmEOZg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_8893_AJ6m9YoPafTnmX1AuUTDyA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_8893_AJ6m9YoPafTnmX1AuUTDyA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9132_ACHb0E5NUU__SLASH__yQK4T79SyWg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9132_ACHb0E5NUU__SLASH__yQK4T79SyWg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9132_ANKHsKenG2rm9JrnAUKI5Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9132_ANKHsKenG2rm9JrnAUKI5Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9134_ADqdBOJvh2JRjZANKgb6ew__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9134_ADqdBOJvh2JRjZANKgb6ew__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9134_AOwBnBi0uYjQRJfhbOo3SA__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9134_AOwBnBi0uYjQRJfhbOo3SA__/alldata-*
- config_name: compute_EQKE_SVD_analysis_913_AH52yTi3c_1cdfD__SLASH__xDvVhw__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_913_AH52yTi3c_1cdfD__SLASH__xDvVhw__/alldata-*
- config_name: compute_EQKE_SVD_analysis_913_ALJhsoisa_orWoJ04Xd7ZQ__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_913_ALJhsoisa_orWoJ04Xd7ZQ__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9504_ALcZ__SLASH__GkSkldvW2___SLASH__oyz8_Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9504_ALcZ__SLASH__GkSkldvW2___SLASH__oyz8_Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9504_ALuaKFji8SahiaEgZUZXyg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9504_ALuaKFji8SahiaEgZUZXyg__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9816_AH9M6PKoJ6IBOMQSAzBR9Q__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9816_AH9M6PKoJ6IBOMQSAzBR9Q__/alldata-*
- config_name: compute_EQKE_SVD_analysis_9816_ALJ2MB8mbkYNx2ltMg0elg__
data_files:
- split: alldata
path: compute_EQKE_SVD_analysis_9816_ALJ2MB8mbkYNx2ltMg0elg__/alldata-*
- config_name: cubic_count_verify_proof__d_vocab_128_n_ctx_10
data_files:
- split: alldata
path: cubic_count_verify_proof__d_vocab_128_n_ctx_10/alldata-*
- config_name: cubic_count_verify_proof__n_ctx_10
data_files:
- split: alldata
path: cubic_count_verify_proof__n_ctx_10/alldata-*
- config_name: cubic_find_proof
data_files:
- split: alldata
path: cubic_find_proof/alldata-*
- config_name: cubic_verify_proof
data_files:
- split: alldata
path: cubic_verify_proof/alldata-*
- config_name: find_min_gaps
data_files:
- split: alldata
path: find_min_gaps/alldata-*
- config_name: importance-sample-10
data_files:
- split: alldata
path: importance-sample-10/alldata-*
- config_name: importance-sample-lightweight-10
data_files:
- split: alldata
path: importance-sample-lightweight-10/alldata-*
- config_name: importance_sample_instruction_count_10_n_ctx_10
data_files:
- split: alldata
path: importance_sample_instruction_count_10_n_ctx_10/alldata-*
- config_name: importance_sample_instruction_count_d_vocab_128_10_n_ctx_10
data_files:
- split: alldata
path: importance_sample_instruction_count_d_vocab_128_10_n_ctx_10/alldata-*
- config_name: run_batch_loss_accuracy
data_files:
- split: alldata
path: run_batch_loss_accuracy/alldata-*
- config_name: run_batch_loss_accuracy_10248_ADt9TMfA0ohwJWJoHGEb_A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_10248_ADt9TMfA0ohwJWJoHGEb_A___False/alldata-*
- config_name: run_batch_loss_accuracy_10248_AF__SLASH__cdMlHuDiIYavaEc_m7g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_10248_AF__SLASH__cdMlHuDiIYavaEc_m7g___False/alldata-*
- config_name: run_batch_loss_accuracy_104_AMTHJYbXtl9V78qiarKwHA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_104_AMTHJYbXtl9V78qiarKwHA___False/alldata-*
- config_name: run_batch_loss_accuracy_104_AOcepby1JGjQVWVDLVjtWw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_104_AOcepby1JGjQVWVDLVjtWw___False/alldata-*
- config_name: run_batch_loss_accuracy_11124_AGABnR_tEu1iXfeoRXN2mw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11124_AGABnR_tEu1iXfeoRXN2mw___False/alldata-*
- config_name: run_batch_loss_accuracy_11124_APeNgf__SLASH__Zd2Su7DBNh6cCqA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11124_APeNgf__SLASH__Zd2Su7DBNh6cCqA___False/alldata-*
- config_name: run_batch_loss_accuracy_11130_ACT5Wkf1g_7uEb9Vo0V5iQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11130_ACT5Wkf1g_7uEb9Vo0V5iQ___False/alldata-*
- config_name: run_batch_loss_accuracy_11130_AL_3FuWR5VAgcmpLCi9CyA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11130_AL_3FuWR5VAgcmpLCi9CyA___False/alldata-*
- config_name: run_batch_loss_accuracy_11498_AA3IABg_HE0mnB9J1vZofA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11498_AA3IABg_HE0mnB9J1vZofA___False/alldata-*
- config_name: run_batch_loss_accuracy_11498_AGeDPkWzQOKcGEigTEC7aQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11498_AGeDPkWzQOKcGEigTEC7aQ___False/alldata-*
- config_name: run_batch_loss_accuracy_11598_ABxlXC4ZX1sFXo7KyS6g1Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11598_ABxlXC4ZX1sFXo7KyS6g1Q___False/alldata-*
- config_name: run_batch_loss_accuracy_11598_ANLxdMRWrGwB_tntg5zBTw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11598_ANLxdMRWrGwB_tntg5zBTw___False/alldata-*
- config_name: run_batch_loss_accuracy_11611_AESuee__SLASH_____SLASH__V8y4T19Td1Y4w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11611_AESuee__SLASH_____SLASH__V8y4T19Td1Y4w___False/alldata-*
- config_name: run_batch_loss_accuracy_11611_AFIFrDND4k1__SLASH__jag1QZYwRg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_11611_AFIFrDND4k1__SLASH__jag1QZYwRg___False/alldata-*
- config_name: run_batch_loss_accuracy_1185_AEmBIHMQpZQ_7FOxKhe4FA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1185_AEmBIHMQpZQ_7FOxKhe4FA___False/alldata-*
- config_name: run_batch_loss_accuracy_1185_AKS8JWbQJkCtdpSqHxycRA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1185_AKS8JWbQJkCtdpSqHxycRA___False/alldata-*
- config_name: run_batch_loss_accuracy_12141_ALah3F7R9VpRXUX5icdeYQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12141_ALah3F7R9VpRXUX5icdeYQ___False/alldata-*
- config_name: run_batch_loss_accuracy_12141_APNwg2_RYDwIiRHiFmm5NA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12141_APNwg2_RYDwIiRHiFmm5NA___False/alldata-*
- config_name: run_batch_loss_accuracy_12287_AG4IN9v_tnpz_KA8ut__SLASH__Rpg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12287_AG4IN9v_tnpz_KA8ut__SLASH__Rpg___False/alldata-*
- config_name: run_batch_loss_accuracy_12287_APVJQ5nKpiYG1N78lSdjEg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12287_APVJQ5nKpiYG1N78lSdjEg___False/alldata-*
- config_name: run_batch_loss_accuracy_123_AAF01m__SLASH__jSu655uXEJ3n5lw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_123_AAF01m__SLASH__jSu655uXEJ3n5lw___False/alldata-*
- config_name: run_batch_loss_accuracy_123_AGHhlv9gCTV4REJmDsZvAA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_123_AGHhlv9gCTV4REJmDsZvAA___False/alldata-*
- config_name: run_batch_loss_accuracy_12457_ABlvKY__SLASH__ea1W0I9J0__SLASH__5Ke__SLASH__w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12457_ABlvKY__SLASH__ea1W0I9J0__SLASH__5Ke__SLASH__w___False/alldata-*
- config_name: run_batch_loss_accuracy_12457_ANtn5XZqYm6lWkYX7wm50w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12457_ANtn5XZqYm6lWkYX7wm50w___False/alldata-*
- config_name: run_batch_loss_accuracy_12493_ACvLRUMpn0IXNyk3DhABig___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12493_ACvLRUMpn0IXNyk3DhABig___False/alldata-*
- config_name: run_batch_loss_accuracy_12493_ALpk8shllJ7lNUe6UxFxwA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12493_ALpk8shllJ7lNUe6UxFxwA___False/alldata-*
- config_name: run_batch_loss_accuracy_12552_ACWqOnUNQIY6ZXSlIrSAeg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12552_ACWqOnUNQIY6ZXSlIrSAeg___False/alldata-*
- config_name: run_batch_loss_accuracy_12552_AKC4I5HibpQXmsfK81jcpw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12552_AKC4I5HibpQXmsfK81jcpw___False/alldata-*
- config_name: run_batch_loss_accuracy_12561_AHQTJ4yqdCQ2xbrOh1vg_Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12561_AHQTJ4yqdCQ2xbrOh1vg_Q___False/alldata-*
- config_name: run_batch_loss_accuracy_12561_AMu3S843KoohTTL7_Pc9Pw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_12561_AMu3S843KoohTTL7_Pc9Pw___False/alldata-*
- config_name: run_batch_loss_accuracy_1283_ADr6__SLASH__zEW84fe6XOeQvMMGA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1283_ADr6__SLASH__zEW84fe6XOeQvMMGA___False/alldata-*
- config_name: run_batch_loss_accuracy_1283_ALlLMLCS3VTR3RqgVaqrjw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1283_ALlLMLCS3VTR3RqgVaqrjw___False/alldata-*
- config_name: run_batch_loss_accuracy_13036_AAyp5i1xoPiUoBE1xgtLrA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13036_AAyp5i1xoPiUoBE1xgtLrA___False/alldata-*
- config_name: run_batch_loss_accuracy_13036_AOUagJAhZlsYnyOnPHR97Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13036_AOUagJAhZlsYnyOnPHR97Q___False/alldata-*
- config_name: run_batch_loss_accuracy_13293_AEn70QMIWNu8SqGyjfu__SLASH__TQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13293_AEn70QMIWNu8SqGyjfu__SLASH__TQ___False/alldata-*
- config_name: run_batch_loss_accuracy_13293_APpv3h4__SLASH__0oRquuaWTyG94g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13293_APpv3h4__SLASH__0oRquuaWTyG94g___False/alldata-*
- config_name: run_batch_loss_accuracy_13468_AHXi3sW9s0zSZVdbLBo02g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13468_AHXi3sW9s0zSZVdbLBo02g___False/alldata-*
- config_name: run_batch_loss_accuracy_13468_APxhL7FxHmQcxv7tLYDfcA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13468_APxhL7FxHmQcxv7tLYDfcA___False/alldata-*
- config_name: run_batch_loss_accuracy_13654_ALXxfTllLv2UV6DVcVDzAg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13654_ALXxfTllLv2UV6DVcVDzAg___False/alldata-*
- config_name: run_batch_loss_accuracy_13654_AP6P_4wuBrxCAB__SLASH__0agbeBQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13654_AP6P_4wuBrxCAB__SLASH__0agbeBQ___False/alldata-*
- config_name: run_batch_loss_accuracy_13716_ACjV0gebaFRv7Im24SKvQw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13716_ACjV0gebaFRv7Im24SKvQw___False/alldata-*
- config_name: run_batch_loss_accuracy_13716_ANaOWdYtOTwk6zJmhcT_OA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_13716_ANaOWdYtOTwk6zJmhcT_OA___False/alldata-*
- config_name: run_batch_loss_accuracy_14095_AHdteQBmDXOUGrqHT24Qjg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_14095_AHdteQBmDXOUGrqHT24Qjg___False/alldata-*
- config_name: run_batch_loss_accuracy_14095_ALBkCyP8vrs0S_gdYMQ1Bg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_14095_ALBkCyP8vrs0S_gdYMQ1Bg___False/alldata-*
- config_name: run_batch_loss_accuracy_1412_ALVkFOwVCV4O1Cb5IYZwJQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1412_ALVkFOwVCV4O1Cb5IYZwJQ___False/alldata-*
- config_name: run_batch_loss_accuracy_1412_ALpi0jYEoq85sqBJ52VagQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1412_ALpi0jYEoq85sqBJ52VagQ___False/alldata-*
- config_name: run_batch_loss_accuracy_1490_ADYfJYpp721n1k_dP2pLLg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1490_ADYfJYpp721n1k_dP2pLLg___False/alldata-*
- config_name: run_batch_loss_accuracy_1490_APUVyRDKGVXYsMZyb6PT2A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1490_APUVyRDKGVXYsMZyb6PT2A___False/alldata-*
- config_name: run_batch_loss_accuracy_14929_AG07CJr82KW1UoMBV2z5wA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_14929_AG07CJr82KW1UoMBV2z5wA___False/alldata-*
- config_name: run_batch_loss_accuracy_14929_AIG__SLASH__plpvvjhgGSNogfpDYg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_14929_AIG__SLASH__plpvvjhgGSNogfpDYg___False/alldata-*
- config_name: run_batch_loss_accuracy_15043_AIyj3TNGpH8SMqQhgOz2_A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15043_AIyj3TNGpH8SMqQhgOz2_A___False/alldata-*
- config_name: run_batch_loss_accuracy_15043_AN49JNcV2adNef2Xjgggmg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15043_AN49JNcV2adNef2Xjgggmg___False/alldata-*
- config_name: run_batch_loss_accuracy_15399_AITBIGR4YZiSnltfpup_WA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15399_AITBIGR4YZiSnltfpup_WA___False/alldata-*
- config_name: run_batch_loss_accuracy_15399_AIufJc2CqyQWF6hEws5q4A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15399_AIufJc2CqyQWF6hEws5q4A___False/alldata-*
- config_name: run_batch_loss_accuracy_15622_AE8thSNibi_bQ45ZzPXpCw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15622_AE8thSNibi_bQ45ZzPXpCw___False/alldata-*
- config_name: run_batch_loss_accuracy_15622_ALnNMknsHCTpXNiKwqJdhg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15622_ALnNMknsHCTpXNiKwqJdhg___False/alldata-*
- config_name: run_batch_loss_accuracy_15662_ABN0xMnoG8eswBrOaQRYGg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15662_ABN0xMnoG8eswBrOaQRYGg___False/alldata-*
- config_name: run_batch_loss_accuracy_15662_ADzISma__SLASH__Ivlz4V355__SLASH__zywA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_15662_ADzISma__SLASH__Ivlz4V355__SLASH__zywA___False/alldata-*
- config_name: run_batch_loss_accuracy_16069_AL2l8w3n0wNELddPV_zsBg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16069_AL2l8w3n0wNELddPV_zsBg___False/alldata-*
- config_name: run_batch_loss_accuracy_16069_ALPN8qZcnT__SLASH__9lUw2XtoPFA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16069_ALPN8qZcnT__SLASH__9lUw2XtoPFA___False/alldata-*
- config_name: run_batch_loss_accuracy_16149_AMkn905ekHNFmPUJZFe__SLASH__cg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16149_AMkn905ekHNFmPUJZFe__SLASH__cg___False/alldata-*
- config_name: run_batch_loss_accuracy_16149_APQUV8ZlUlkkGWxJX3TkRg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16149_APQUV8ZlUlkkGWxJX3TkRg___False/alldata-*
- config_name: run_batch_loss_accuracy_16197_AD9_hspz4VUwKKEUsl1pQg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16197_AD9_hspz4VUwKKEUsl1pQg___False/alldata-*
- config_name: run_batch_loss_accuracy_16197_ANOQT3ss6CiM0JldM2k71A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16197_ANOQT3ss6CiM0JldM2k71A___False/alldata-*
- config_name: run_batch_loss_accuracy_16284_AEC_0V7Yo1Vg8912paAPJA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16284_AEC_0V7Yo1Vg8912paAPJA___False/alldata-*
- config_name: run_batch_loss_accuracy_16284_AEEF6XEJ24kVfWOam43d9A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_16284_AEEF6XEJ24kVfWOam43d9A___False/alldata-*
- config_name: run_batch_loss_accuracy_1681_AJ2PDL_2JMP__SLASH__XhqR__SLASH__178__SLASH__Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1681_AJ2PDL_2JMP__SLASH__XhqR__SLASH__178__SLASH__Q___False/alldata-*
- config_name: run_batch_loss_accuracy_1681_ANwkZM5TW4cNkpe5A0PJMQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1681_ANwkZM5TW4cNkpe5A0PJMQ___False/alldata-*
- config_name: run_batch_loss_accuracy_1696_ACY__SLASH__8CfzyVzA3W2fcCtrLw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1696_ACY__SLASH__8CfzyVzA3W2fcCtrLw___False/alldata-*
- config_name: run_batch_loss_accuracy_1696_AChvUnC6YJ0fTAbQwfT80Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1696_AChvUnC6YJ0fTAbQwfT80Q___False/alldata-*
- config_name: run_batch_loss_accuracy_17080_AIhm3D0L4tW5062sbstdTg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17080_AIhm3D0L4tW5062sbstdTg___False/alldata-*
- config_name: run_batch_loss_accuracy_17080_AMoso0kf__SLASH__I7FaeVG2g1c9A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17080_AMoso0kf__SLASH__I7FaeVG2g1c9A___False/alldata-*
- config_name: run_batch_loss_accuracy_17096_ACsGM5WBvZG8rCy_s2BYfg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17096_ACsGM5WBvZG8rCy_s2BYfg___False/alldata-*
- config_name: run_batch_loss_accuracy_17096_ADWz0kjtHLXoeUZ7B__SLASH__j__SLASH__cw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17096_ADWz0kjtHLXoeUZ7B__SLASH__j__SLASH__cw___False/alldata-*
- config_name: run_batch_loss_accuracy_17194_ACLvzwY3PZFz3uPB6nPTcQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17194_ACLvzwY3PZFz3uPB6nPTcQ___False/alldata-*
- config_name: run_batch_loss_accuracy_17194_APoCTJ2qAnT91QuTqJBXgA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17194_APoCTJ2qAnT91QuTqJBXgA___False/alldata-*
- config_name: run_batch_loss_accuracy_17197_ADRpaYfxtQh83NGQKSYCWg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17197_ADRpaYfxtQh83NGQKSYCWg___False/alldata-*
- config_name: run_batch_loss_accuracy_17197_AF4QRGwG7i76o6VkRHying___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_17197_AF4QRGwG7i76o6VkRHying___False/alldata-*
- config_name: run_batch_loss_accuracy_18146_ADp6siELcqhd8e5qrbU__SLASH__kw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_18146_ADp6siELcqhd8e5qrbU__SLASH__kw___False/alldata-*
- config_name: run_batch_loss_accuracy_18146_ANBhndJ0AlCep8Jm41w2zQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_18146_ANBhndJ0AlCep8Jm41w2zQ___False/alldata-*
- config_name: run_batch_loss_accuracy_18289_AJcuOAnybHMHbw4vohzLcg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_18289_AJcuOAnybHMHbw4vohzLcg___False/alldata-*
- config_name: run_batch_loss_accuracy_18289_AOgaWFKxlXBf3cyEs72VOw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_18289_AOgaWFKxlXBf3cyEs72VOw___False/alldata-*
- config_name: run_batch_loss_accuracy_18668_AHr8wzfdJ__SLASH__o9ksYQ8HZXRw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_18668_AHr8wzfdJ__SLASH__o9ksYQ8HZXRw___False/alldata-*
- config_name: run_batch_loss_accuracy_18668_AO6QRUo_g8oJQOj8TQga9w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_18668_AO6QRUo_g8oJQOj8TQga9w___False/alldata-*
- config_name: run_batch_loss_accuracy_1895_ABY4waS3AwiPNhqmkHd8pQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1895_ABY4waS3AwiPNhqmkHd8pQ___False/alldata-*
- config_name: run_batch_loss_accuracy_1895_AF3GNlURclLbIsCS6y8Q__SLASH__Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1895_AF3GNlURclLbIsCS6y8Q__SLASH__Q___False/alldata-*
- config_name: run_batch_loss_accuracy_19004_AFdEafhGrVtuebjgI__SLASH__rgew___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19004_AFdEafhGrVtuebjgI__SLASH__rgew___False/alldata-*
- config_name: run_batch_loss_accuracy_19004_AFerkSj1mc_HtUPZuIHLgQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19004_AFerkSj1mc_HtUPZuIHLgQ___False/alldata-*
- config_name: run_batch_loss_accuracy_19093_AAr9v5vr3g_6JoGwVFtnMA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19093_AAr9v5vr3g_6JoGwVFtnMA___False/alldata-*
- config_name: run_batch_loss_accuracy_19093_AF5xzTFfrjg_86AHBmQTew___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19093_AF5xzTFfrjg_86AHBmQTew___False/alldata-*
- config_name: run_batch_loss_accuracy_19451_AFstGaELqmsJVsloeIunwg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19451_AFstGaELqmsJVsloeIunwg___False/alldata-*
- config_name: run_batch_loss_accuracy_19451_AOUxxQV3sijBGCMnJS812Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19451_AOUxxQV3sijBGCMnJS812Q___False/alldata-*
- config_name: run_batch_loss_accuracy_19488_AAN__SLASH__HudTRHtTka9FBzosng___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19488_AAN__SLASH__HudTRHtTka9FBzosng___False/alldata-*
- config_name: run_batch_loss_accuracy_19488_AJZiY7nrQA7YsDVRxhadDg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19488_AJZiY7nrQA7YsDVRxhadDg___False/alldata-*
- config_name: run_batch_loss_accuracy_1951_AC_Trhn0UP4COIKbfLHFIA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1951_AC_Trhn0UP4COIKbfLHFIA___False/alldata-*
- config_name: run_batch_loss_accuracy_1951_AEpjIMss6Hn04zAXunvLFA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_1951_AEpjIMss6Hn04zAXunvLFA___False/alldata-*
- config_name: run_batch_loss_accuracy_19538_AIAkxFPOh__SLASH__3svQ75QCheCA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19538_AIAkxFPOh__SLASH__3svQ75QCheCA___False/alldata-*
- config_name: run_batch_loss_accuracy_19538_AIwSI6FQmfrmw4yYViipcA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19538_AIwSI6FQmfrmw4yYViipcA___False/alldata-*
- config_name: run_batch_loss_accuracy_19917_AIDzLm9bCNA6eD6xSMOUAQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19917_AIDzLm9bCNA6eD6xSMOUAQ___False/alldata-*
- config_name: run_batch_loss_accuracy_19917_AN5nTgMfNWq8Xuo__SLASH__1ArCQg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_19917_AN5nTgMfNWq8Xuo__SLASH__1ArCQg___False/alldata-*
- config_name: run_batch_loss_accuracy_20013_ADIxR__SLASH__IXKtOECSendODuLA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20013_ADIxR__SLASH__IXKtOECSendODuLA___False/alldata-*
- config_name: run_batch_loss_accuracy_20013_AFMMgDcASMaks36wcly_ZQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20013_AFMMgDcASMaks36wcly_ZQ___False/alldata-*
- config_name: run_batch_loss_accuracy_20294_AIfe8lSYEtW5FoHd13gR3Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20294_AIfe8lSYEtW5FoHd13gR3Q___False/alldata-*
- config_name: run_batch_loss_accuracy_20294_AIpdyHGCePozyr2__SLASH__s95O0Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20294_AIpdyHGCePozyr2__SLASH__s95O0Q___False/alldata-*
- config_name: run_batch_loss_accuracy_20338_ANCscxn6xe__SLASH__EviB7BNrdIQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20338_ANCscxn6xe__SLASH__EviB7BNrdIQ___False/alldata-*
- config_name: run_batch_loss_accuracy_20338_ANdQotqoE2lIzO9HmLRVPA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20338_ANdQotqoE2lIzO9HmLRVPA___False/alldata-*
- config_name: run_batch_loss_accuracy_20415_ABSwZ7N4ddWy7GeuVzWERw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20415_ABSwZ7N4ddWy7GeuVzWERw___False/alldata-*
- config_name: run_batch_loss_accuracy_20415_AFAIYpiGc43GgXkeGzPPOQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20415_AFAIYpiGc43GgXkeGzPPOQ___False/alldata-*
- config_name: run_batch_loss_accuracy_20539_ABCQ2vZ6CfxakGT0Wj3CJw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20539_ABCQ2vZ6CfxakGT0Wj3CJw___False/alldata-*
- config_name: run_batch_loss_accuracy_20539_AInpG9vaVs3pUysjknrPmw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20539_AInpG9vaVs3pUysjknrPmw___False/alldata-*
- config_name: run_batch_loss_accuracy_20751_AJj9W3vPfFyJPNO__SLASH__2tchPg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20751_AJj9W3vPfFyJPNO__SLASH__2tchPg___False/alldata-*
- config_name: run_batch_loss_accuracy_20751_AMzyDvUVcISxdLsOkmo6OQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20751_AMzyDvUVcISxdLsOkmo6OQ___False/alldata-*
- config_name: run_batch_loss_accuracy_20754_AK_IWpcNwhdTh0___SLASH__gFT1mQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20754_AK_IWpcNwhdTh0___SLASH__gFT1mQ___False/alldata-*
- config_name: run_batch_loss_accuracy_20754_ALxtPs__SLASH__LShgLpcoCY6cDzg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20754_ALxtPs__SLASH__LShgLpcoCY6cDzg___False/alldata-*
- config_name: run_batch_loss_accuracy_20976_AER46AvB8x6A1MNxYWCqIg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20976_AER46AvB8x6A1MNxYWCqIg___False/alldata-*
- config_name: run_batch_loss_accuracy_20976_AG2p1gKtASLzEPD8_RaiCQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_20976_AG2p1gKtASLzEPD8_RaiCQ___False/alldata-*
- config_name: run_batch_loss_accuracy_21317_AC9FpqDbtjaqgiHis9cGPQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_21317_AC9FpqDbtjaqgiHis9cGPQ___False/alldata-*
- config_name: run_batch_loss_accuracy_21317_AEuzvh4zgNa__SLASH__v4KtEqiX5Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_21317_AEuzvh4zgNa__SLASH__v4KtEqiX5Q___False/alldata-*
- config_name: run_batch_loss_accuracy_21598_AIQdTC8_swIKvC7RFn5BlA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_21598_AIQdTC8_swIKvC7RFn5BlA___False/alldata-*
- config_name: run_batch_loss_accuracy_21598_AM29Kbf36O01U4KxzciQIg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_21598_AM29Kbf36O01U4KxzciQIg___False/alldata-*
- config_name: run_batch_loss_accuracy_22261_AIoykjvCEt__SLASH__dScSIKKibbw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22261_AIoykjvCEt__SLASH__dScSIKKibbw___False/alldata-*
- config_name: run_batch_loss_accuracy_22261_AMyTjYK6e__SLASH__8YhiVRmNNyRg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22261_AMyTjYK6e__SLASH__8YhiVRmNNyRg___False/alldata-*
- config_name: run_batch_loss_accuracy_22286_AMm9YfrvKc5p7BbjldYuPw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22286_AMm9YfrvKc5p7BbjldYuPw___False/alldata-*
- config_name: run_batch_loss_accuracy_22286_AOa3r2OxugCp9e26TsqEnQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22286_AOa3r2OxugCp9e26TsqEnQ___False/alldata-*
- config_name: run_batch_loss_accuracy_2236_AMHBQONNgtiK39yzzuwRaw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2236_AMHBQONNgtiK39yzzuwRaw___False/alldata-*
- config_name: run_batch_loss_accuracy_2236_APqJsoTceJeRrUa7Es__SLASH__Lww___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2236_APqJsoTceJeRrUa7Es__SLASH__Lww___False/alldata-*
- config_name: run_batch_loss_accuracy_22401_AIU__SLASH__DsHoyiLPXuxHwTsAVA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22401_AIU__SLASH__DsHoyiLPXuxHwTsAVA___False/alldata-*
- config_name: run_batch_loss_accuracy_22401_ANaNDayL8ivmOJ_1pptNCQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22401_ANaNDayL8ivmOJ_1pptNCQ___False/alldata-*
- config_name: run_batch_loss_accuracy_22545_AHLfWxtzC__SLASH__QdLX37FUqGOw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22545_AHLfWxtzC__SLASH__QdLX37FUqGOw___False/alldata-*
- config_name: run_batch_loss_accuracy_22545_AHcAvIMkF4jWkvWFa5bB2g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_22545_AHcAvIMkF4jWkvWFa5bB2g___False/alldata-*
- config_name: run_batch_loss_accuracy_2306_ABsYlX6DVj_9i4JnoCvfWQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2306_ABsYlX6DVj_9i4JnoCvfWQ___False/alldata-*
- config_name: run_batch_loss_accuracy_2306_ABul3FoYy3aZc__SLASH__T65mZTZQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2306_ABul3FoYy3aZc__SLASH__T65mZTZQ___False/alldata-*
- config_name: run_batch_loss_accuracy_23241_AFO__SLASH__R51bR63iYNf_FeGuOg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23241_AFO__SLASH__R51bR63iYNf_FeGuOg___False/alldata-*
- config_name: run_batch_loss_accuracy_23241_ANnWhBSpvmH7czrVOQmfsQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23241_ANnWhBSpvmH7czrVOQmfsQ___False/alldata-*
- config_name: run_batch_loss_accuracy_23367_AASDXkVNxxtL0U1MYgnbQA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23367_AASDXkVNxxtL0U1MYgnbQA___False/alldata-*
- config_name: run_batch_loss_accuracy_23367_ANJHLPhP__HtPtE2n8E0MA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23367_ANJHLPhP__HtPtE2n8E0MA___False/alldata-*
- config_name: run_batch_loss_accuracy_23447_AFyyzC87tztou3PoEYuSEQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23447_AFyyzC87tztou3PoEYuSEQ___False/alldata-*
- config_name: run_batch_loss_accuracy_23447_AKTnPzmxFYglqdAwoi4PLQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23447_AKTnPzmxFYglqdAwoi4PLQ___False/alldata-*
- config_name: run_batch_loss_accuracy_2345_AGMW2uZA77iy46TAiWZ5vQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2345_AGMW2uZA77iy46TAiWZ5vQ___False/alldata-*
- config_name: run_batch_loss_accuracy_2345_ANsBKybWfEP__SLASH__sRoAg2Z_8Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2345_ANsBKybWfEP__SLASH__sRoAg2Z_8Q___False/alldata-*
- config_name: run_batch_loss_accuracy_23633_AAnXOpwRqrQRqAZ6VZuDmw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23633_AAnXOpwRqrQRqAZ6VZuDmw___False/alldata-*
- config_name: run_batch_loss_accuracy_23633_ABKA2iGKYQws__SLASH__tgD4Y2RWA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23633_ABKA2iGKYQws__SLASH__tgD4Y2RWA___False/alldata-*
- config_name: run_batch_loss_accuracy_23696_AI0EONwJusz4NK81V5WzTw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23696_AI0EONwJusz4NK81V5WzTw___False/alldata-*
- config_name: run_batch_loss_accuracy_23696_APsCFbRVa9F1Ci14vNWCkQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_23696_APsCFbRVa9F1Ci14vNWCkQ___False/alldata-*
- config_name: run_batch_loss_accuracy_24144_AH8H5Z8WO3JLqAv44KT7ZA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24144_AH8H5Z8WO3JLqAv44KT7ZA___False/alldata-*
- config_name: run_batch_loss_accuracy_24144_AOUF0C2stvvl1e64Eoq04A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24144_AOUF0C2stvvl1e64Eoq04A___False/alldata-*
- config_name: run_batch_loss_accuracy_24173_AMa4HGmzdFhy4qWbRNF4fw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24173_AMa4HGmzdFhy4qWbRNF4fw___False/alldata-*
- config_name: run_batch_loss_accuracy_24173_APz28QBYSgPqi24JcGVzIw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24173_APz28QBYSgPqi24JcGVzIw___False/alldata-*
- config_name: run_batch_loss_accuracy_24202_AEbexUwQ_CtDuHjXuf_t9Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24202_AEbexUwQ_CtDuHjXuf_t9Q___False/alldata-*
- config_name: run_batch_loss_accuracy_24202_AGE6YUW5nzSgg5W9cdrhGg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24202_AGE6YUW5nzSgg5W9cdrhGg___False/alldata-*
- config_name: run_batch_loss_accuracy_24262_AB1MiQsdnnrW_ai0B2bUfw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24262_AB1MiQsdnnrW_ai0B2bUfw___False/alldata-*
- config_name: run_batch_loss_accuracy_24262_AD_kbRXglHaQj7T9rXKs5Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24262_AD_kbRXglHaQj7T9rXKs5Q___False/alldata-*
- config_name: run_batch_loss_accuracy_24438_AFtesAxyLwEmzRrPi4k3WA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24438_AFtesAxyLwEmzRrPi4k3WA___False/alldata-*
- config_name: run_batch_loss_accuracy_24438_AM64RhPEqAUkrWNPwqNX6w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24438_AM64RhPEqAUkrWNPwqNX6w___False/alldata-*
- config_name: run_batch_loss_accuracy_24566_AEB7mEH__SLASH__KxiPYQthHO2Cfw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24566_AEB7mEH__SLASH__KxiPYQthHO2Cfw___False/alldata-*
- config_name: run_batch_loss_accuracy_24566_AFD86EMU8emPF2bvHzM__SLASH__RQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_24566_AFD86EMU8emPF2bvHzM__SLASH__RQ___False/alldata-*
- config_name: run_batch_loss_accuracy_2549_ADzO_7X4txiEulQBpHzwzQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2549_ADzO_7X4txiEulQBpHzwzQ___False/alldata-*
- config_name: run_batch_loss_accuracy_2549_AFbVvnvSal__SLASH__ExNLrQKqjSg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2549_AFbVvnvSal__SLASH__ExNLrQKqjSg___False/alldata-*
- config_name: run_batch_loss_accuracy_25516_AMA4sOusZ60RZaPN_8fGfQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_25516_AMA4sOusZ60RZaPN_8fGfQ___False/alldata-*
- config_name: run_batch_loss_accuracy_25516_AMMFbTuyH3Ybb6MQCxB4mg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_25516_AMMFbTuyH3Ybb6MQCxB4mg___False/alldata-*
- config_name: run_batch_loss_accuracy_26278_AJLgiBe0i837PsR55__SLASH__LDgA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26278_AJLgiBe0i837PsR55__SLASH__LDgA___False/alldata-*
- config_name: run_batch_loss_accuracy_26278_AMcvJozFGFZkcWkRmR55yg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26278_AMcvJozFGFZkcWkRmR55yg___False/alldata-*
- config_name: run_batch_loss_accuracy_26374_ABYjrPudexgJ8oRBtrSSHg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26374_ABYjrPudexgJ8oRBtrSSHg___False/alldata-*
- config_name: run_batch_loss_accuracy_26374_ADRuQLdROsvXFImCfSY9cw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26374_ADRuQLdROsvXFImCfSY9cw___False/alldata-*
- config_name: run_batch_loss_accuracy_26829_AAsAm8p9l88i3IWEdKN83A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26829_AAsAm8p9l88i3IWEdKN83A___False/alldata-*
- config_name: run_batch_loss_accuracy_26829_AGDeX6BsBF_Xe7WSqIQcAQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26829_AGDeX6BsBF_Xe7WSqIQcAQ___False/alldata-*
- config_name: run_batch_loss_accuracy_26932_ACpQyIx7y5qGb85NFGfJhw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26932_ACpQyIx7y5qGb85NFGfJhw___False/alldata-*
- config_name: run_batch_loss_accuracy_26932_AGwKD1Jhy__SLASH__ESUkKPVUcs_g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_26932_AGwKD1Jhy__SLASH__ESUkKPVUcs_g___False/alldata-*
- config_name: run_batch_loss_accuracy_27300_AAJYPECA__SLASH__I_od__SLASH__PfhJKs8g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27300_AAJYPECA__SLASH__I_od__SLASH__PfhJKs8g___False/alldata-*
- config_name: run_batch_loss_accuracy_27300_AKHh0pcxBntRR9FTBbUSIw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27300_AKHh0pcxBntRR9FTBbUSIw___False/alldata-*
- config_name: run_batch_loss_accuracy_2743_ALNot6Gxp2qnROzqq__SLASH__saVg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2743_ALNot6Gxp2qnROzqq__SLASH__saVg___False/alldata-*
- config_name: run_batch_loss_accuracy_2743_AOxxB716AtsCFymWkEieaQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2743_AOxxB716AtsCFymWkEieaQ___False/alldata-*
- config_name: run_batch_loss_accuracy_27484_AGam0MjLmG__SLASH__rKt7qTJ2KAw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27484_AGam0MjLmG__SLASH__rKt7qTJ2KAw___False/alldata-*
- config_name: run_batch_loss_accuracy_27484_AIpA62__SLASH__CvLK3wGXALz6SUQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27484_AIpA62__SLASH__CvLK3wGXALz6SUQ___False/alldata-*
- config_name: run_batch_loss_accuracy_27584_AFWaV08dH2wzAJvktl4sZA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27584_AFWaV08dH2wzAJvktl4sZA___False/alldata-*
- config_name: run_batch_loss_accuracy_27584_AKo8r462NdVABXNqTg7U0A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27584_AKo8r462NdVABXNqTg7U0A___False/alldata-*
- config_name: run_batch_loss_accuracy_27671_ADYpxUR6V9FNZM_8PuC9Fw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27671_ADYpxUR6V9FNZM_8PuC9Fw___False/alldata-*
- config_name: run_batch_loss_accuracy_27671_APchiaGyoxj20MBZIKkFGQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27671_APchiaGyoxj20MBZIKkFGQ___False/alldata-*
- config_name: run_batch_loss_accuracy_27714_AKLnS14lKrz1JD0AjzUhvQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27714_AKLnS14lKrz1JD0AjzUhvQ___False/alldata-*
- config_name: run_batch_loss_accuracy_27714_AKxLDr__SLASH__6NhM9fJwtS651JA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_27714_AKxLDr__SLASH__6NhM9fJwtS651JA___False/alldata-*
- config_name: run_batch_loss_accuracy_2773_ANSoI_iQEIXYpD__SLASH__ZTLEZFw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2773_ANSoI_iQEIXYpD__SLASH__ZTLEZFw___False/alldata-*
- config_name: run_batch_loss_accuracy_2773_APU2QfC2OkdSwUgQhcMbEw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_2773_APU2QfC2OkdSwUgQhcMbEw___False/alldata-*
- config_name: run_batch_loss_accuracy_28090_AFrmezvmNY6eyPHq4WNZiA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_28090_AFrmezvmNY6eyPHq4WNZiA___False/alldata-*
- config_name: run_batch_loss_accuracy_28090_AOZnFvmpAWkUx6WXFsG5dA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_28090_AOZnFvmpAWkUx6WXFsG5dA___False/alldata-*
- config_name: run_batch_loss_accuracy_28716_AIUx7reOWuXjwIf5wLUUCA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_28716_AIUx7reOWuXjwIf5wLUUCA___False/alldata-*
- config_name: run_batch_loss_accuracy_28716_AJeutgNDaXLJ1XiQuLDVfw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_28716_AJeutgNDaXLJ1XiQuLDVfw___False/alldata-*
- config_name: run_batch_loss_accuracy_28778_ACLIE_7zmk_uc3ZjuyWCzQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_28778_ACLIE_7zmk_uc3ZjuyWCzQ___False/alldata-*
- config_name: run_batch_loss_accuracy_28778_APi__SLASH__OJOb0YzdXccwZSxo_w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_28778_APi__SLASH__OJOb0YzdXccwZSxo_w___False/alldata-*
- config_name: run_batch_loss_accuracy_29022_AHAxkIUJa79v3Iw1wmgxNA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29022_AHAxkIUJa79v3Iw1wmgxNA___False/alldata-*
- config_name: run_batch_loss_accuracy_29022_ALhPYHAyJ8U2Xmj0kXGt_w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29022_ALhPYHAyJ8U2Xmj0kXGt_w___False/alldata-*
- config_name: run_batch_loss_accuracy_29052_AEhtLGGIwGliKn4nZzE_VA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29052_AEhtLGGIwGliKn4nZzE_VA___False/alldata-*
- config_name: run_batch_loss_accuracy_29052_APsMJAd__SLASH__43v__SLASH__NyYDrtU0Ng___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29052_APsMJAd__SLASH__43v__SLASH__NyYDrtU0Ng___False/alldata-*
- config_name: run_batch_loss_accuracy_29110_AAFzL0DH5OFRYAV3XgeaSA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29110_AAFzL0DH5OFRYAV3XgeaSA___False/alldata-*
- config_name: run_batch_loss_accuracy_29110_ACbEUMLn6zlgf5RJlsvCow___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29110_ACbEUMLn6zlgf5RJlsvCow___False/alldata-*
- config_name: run_batch_loss_accuracy_29195_ACk6_Dm56ttp4v1yZi_IfQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29195_ACk6_Dm56ttp4v1yZi_IfQ___False/alldata-*
- config_name: run_batch_loss_accuracy_29195_AFLl__SLASH__8gQCGG_TOhJzZnOfg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29195_AFLl__SLASH__8gQCGG_TOhJzZnOfg___False/alldata-*
- config_name: run_batch_loss_accuracy_29565_AGRmBwvdDdTplygkefDh4Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29565_AGRmBwvdDdTplygkefDh4Q___False/alldata-*
- config_name: run_batch_loss_accuracy_29565_ANBpA0Yn12QTqTFeCnFwPA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29565_ANBpA0Yn12QTqTFeCnFwPA___False/alldata-*
- config_name: run_batch_loss_accuracy_29725_AAIR88ERgDAcpJi0PQcGOQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29725_AAIR88ERgDAcpJi0PQcGOQ___False/alldata-*
- config_name: run_batch_loss_accuracy_29725_ALz8nQl2VEc6pYDfGmpZTA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29725_ALz8nQl2VEc6pYDfGmpZTA___False/alldata-*
- config_name: run_batch_loss_accuracy_29726_AJ8xRygXOVHXAQZY9x85lw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29726_AJ8xRygXOVHXAQZY9x85lw___False/alldata-*
- config_name: run_batch_loss_accuracy_29726_ANM8ktiGrsyp2Aq__SLASH__Wth5_Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_29726_ANM8ktiGrsyp2Aq__SLASH__Wth5_Q___False/alldata-*
- config_name: run_batch_loss_accuracy_30371_AL8Eon3nXMLUEurkTKPFiA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30371_AL8Eon3nXMLUEurkTKPFiA___False/alldata-*
- config_name: run_batch_loss_accuracy_30371_ALo8GqW5ytQUImFT1PK__SLASH__Pg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30371_ALo8GqW5ytQUImFT1PK__SLASH__Pg___False/alldata-*
- config_name: run_batch_loss_accuracy_30463_AF3j5hiOXR3wmXzTk5cc4w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30463_AF3j5hiOXR3wmXzTk5cc4w___False/alldata-*
- config_name: run_batch_loss_accuracy_30463_AFqt4ukXA__SLASH__Sb9Q3W3za5Ww___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30463_AFqt4ukXA__SLASH__Sb9Q3W3za5Ww___False/alldata-*
- config_name: run_batch_loss_accuracy_30684_ADe2D3vJyy2rp3yodcTdUA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30684_ADe2D3vJyy2rp3yodcTdUA___False/alldata-*
- config_name: run_batch_loss_accuracy_30684_AI1fmJ__SLASH__rqYP0lrS_RQ8lDw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30684_AI1fmJ__SLASH__rqYP0lrS_RQ8lDw___False/alldata-*
- config_name: run_batch_loss_accuracy_30899_AEP12Fz38iCP6JWA8UIj9A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30899_AEP12Fz38iCP6JWA8UIj9A___False/alldata-*
- config_name: run_batch_loss_accuracy_30899_AEzsVon4__SLASH__quJ2JaOHmnHSw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_30899_AEzsVon4__SLASH__quJ2JaOHmnHSw___False/alldata-*
- config_name: run_batch_loss_accuracy_31308_AK3PW5wOv400zArDy__SLASH__UZwQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_31308_AK3PW5wOv400zArDy__SLASH__UZwQ___False/alldata-*
- config_name: run_batch_loss_accuracy_31308_AP7hvn9AyE8WPdJcc4XQAA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_31308_AP7hvn9AyE8WPdJcc4XQAA___False/alldata-*
- config_name: run_batch_loss_accuracy_3175_AImandw7IlWwcsuXkzrbDQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_3175_AImandw7IlWwcsuXkzrbDQ___False/alldata-*
- config_name: run_batch_loss_accuracy_3175_AP0M_nqJX1LWcMvpnDMj8w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_3175_AP0M_nqJX1LWcMvpnDMj8w___False/alldata-*
- config_name: run_batch_loss_accuracy_32103_AGQVoO7gIx4co2f__SLASH__zSILeA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_32103_AGQVoO7gIx4co2f__SLASH__zSILeA___False/alldata-*
- config_name: run_batch_loss_accuracy_32103_AHZbWLPRaw3M8acNPWdp7g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_32103_AHZbWLPRaw3M8acNPWdp7g___False/alldata-*
- config_name: run_batch_loss_accuracy_32374_AJ936vfkWWLrpgcr4WDAEw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_32374_AJ936vfkWWLrpgcr4WDAEw___False/alldata-*
- config_name: run_batch_loss_accuracy_32374_ALnS9Xll9KVewoJeWSKhOQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_32374_ALnS9Xll9KVewoJeWSKhOQ___False/alldata-*
- config_name: run_batch_loss_accuracy_32382_AAlR_MtmmxdZNHKHTHrd0g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_32382_AAlR_MtmmxdZNHKHTHrd0g___False/alldata-*
- config_name: run_batch_loss_accuracy_32382_AEG5rty2brZzZWBD_VACCg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_32382_AEG5rty2brZzZWBD_VACCg___False/alldata-*
- config_name: run_batch_loss_accuracy_3254_AKcGPu_3DWVJJCceZdJujg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_3254_AKcGPu_3DWVJJCceZdJujg___False/alldata-*
- config_name: run_batch_loss_accuracy_3254_AOFht9mGg6FHwMCx9to7Fg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_3254_AOFht9mGg6FHwMCx9to7Fg___False/alldata-*
- config_name: run_batch_loss_accuracy_3284_AAZIepd3rMs0KQoOsRPEZg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_3284_AAZIepd3rMs0KQoOsRPEZg___False/alldata-*
- config_name: run_batch_loss_accuracy_3284_AIbuAjLQAxhqCCZoy9__SLASH__j4Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_3284_AIbuAjLQAxhqCCZoy9__SLASH__j4Q___False/alldata-*
- config_name: run_batch_loss_accuracy_4157_AIe6fnBzYh2LxPTJHJsuQQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4157_AIe6fnBzYh2LxPTJHJsuQQ___False/alldata-*
- config_name: run_batch_loss_accuracy_4157_AMmP337V1eUwXlNOJ9GM9A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4157_AMmP337V1eUwXlNOJ9GM9A___False/alldata-*
- config_name: run_batch_loss_accuracy_4305_AEtQZVLsqBOE8XTOiZI3Nw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4305_AEtQZVLsqBOE8XTOiZI3Nw___False/alldata-*
- config_name: run_batch_loss_accuracy_4305_AMAV0VOFMp8lWg1wVfPu3g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4305_AMAV0VOFMp8lWg1wVfPu3g___False/alldata-*
- config_name: run_batch_loss_accuracy_4430_ADMUH9ql2cJgrD0nH__SLASH__H00A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4430_ADMUH9ql2cJgrD0nH__SLASH__H00A___False/alldata-*
- config_name: run_batch_loss_accuracy_4430_ADVMKT7__SLASH__xmoZWamt6K9TOQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4430_ADVMKT7__SLASH__xmoZWamt6K9TOQ___False/alldata-*
- config_name: run_batch_loss_accuracy_4647_AIZ5ejLml8KeYIevzjIbNQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4647_AIZ5ejLml8KeYIevzjIbNQ___False/alldata-*
- config_name: run_batch_loss_accuracy_4647_AKEoXAigR__SLASH__r__SLASH__eXOecsT_aw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4647_AKEoXAigR__SLASH__r__SLASH__eXOecsT_aw___False/alldata-*
- config_name: run_batch_loss_accuracy_4729_ADWJOy9eKfwKxOrkVos6DA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4729_ADWJOy9eKfwKxOrkVos6DA___False/alldata-*
- config_name: run_batch_loss_accuracy_4729_ALXT26HoJdgA8AbmMOplSA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4729_ALXT26HoJdgA8AbmMOplSA___False/alldata-*
- config_name: run_batch_loss_accuracy_4800_ABqcVM93EpSlAAOY4nt00Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4800_ABqcVM93EpSlAAOY4nt00Q___False/alldata-*
- config_name: run_batch_loss_accuracy_4800_AHn4VsleoAdloGK6kLmg1g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4800_AHn4VsleoAdloGK6kLmg1g___False/alldata-*
- config_name: run_batch_loss_accuracy_4810_ADDLDStbh1HDKT2aKifo3g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4810_ADDLDStbh1HDKT2aKifo3g___False/alldata-*
- config_name: run_batch_loss_accuracy_4810_ADXEY7SvniiLGI__SLASH__cykhGiQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_4810_ADXEY7SvniiLGI__SLASH__cykhGiQ___False/alldata-*
- config_name: run_batch_loss_accuracy_50_AFGUWAE6pU9rnXJBHHKG9g___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_50_AFGUWAE6pU9rnXJBHHKG9g___False/alldata-*
- config_name: run_batch_loss_accuracy_50_AN617ABYWMTWFuHoHYCViQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_50_AN617ABYWMTWFuHoHYCViQ___False/alldata-*
- config_name: run_batch_loss_accuracy_519_AAp2j6nnaXDnAIIMxDOqDg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_519_AAp2j6nnaXDnAIIMxDOqDg___False/alldata-*
- config_name: run_batch_loss_accuracy_519_AJVIR4v0t4SYuPXaiSyjXg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_519_AJVIR4v0t4SYuPXaiSyjXg___False/alldata-*
- config_name: run_batch_loss_accuracy_5358_AE4oy__SLASH__yijj_Lt_bO9Xbjyg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5358_AE4oy__SLASH__yijj_Lt_bO9Xbjyg___False/alldata-*
- config_name: run_batch_loss_accuracy_5358_AFEwIYNfyoZcIf__SLASH__DCgKMHQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5358_AFEwIYNfyoZcIf__SLASH__DCgKMHQ___False/alldata-*
- config_name: run_batch_loss_accuracy_5615_AEIyPR42yzSsQ5__SLASH__L3_g1__SLASH__A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5615_AEIyPR42yzSsQ5__SLASH__L3_g1__SLASH__A___False/alldata-*
- config_name: run_batch_loss_accuracy_5615_AEnaILA9efEtYQ_ffZpj1w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5615_AEnaILA9efEtYQ_ffZpj1w___False/alldata-*
- config_name: run_batch_loss_accuracy_5781_AEVfDmMH__SLASH__8tMET0eCSuuRw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5781_AEVfDmMH__SLASH__8tMET0eCSuuRw___False/alldata-*
- config_name: run_batch_loss_accuracy_5781_AH_yA0odOSxoFFPi_li9Aw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5781_AH_yA0odOSxoFFPi_li9Aw___False/alldata-*
- config_name: run_batch_loss_accuracy_5928_AEnKe1Kt5SD5PvAsPQxvNA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5928_AEnKe1Kt5SD5PvAsPQxvNA___False/alldata-*
- config_name: run_batch_loss_accuracy_5928_ALIK1Xp3ziPt7PKcn8JaDA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_5928_ALIK1Xp3ziPt7PKcn8JaDA___False/alldata-*
- config_name: run_batch_loss_accuracy_6082_ACsIVVOLawuQFVJAAr2fUQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6082_ACsIVVOLawuQFVJAAr2fUQ___False/alldata-*
- config_name: run_batch_loss_accuracy_6082_AKuZRKvmAy_iTTEriHA26Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6082_AKuZRKvmAy_iTTEriHA26Q___False/alldata-*
- config_name: run_batch_loss_accuracy_6155_AK4M9kAUARy4yVUDQWc7EQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6155_AK4M9kAUARy4yVUDQWc7EQ___False/alldata-*
- config_name: run_batch_loss_accuracy_6155_APENjC6_leQo8ggD_NAvNw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6155_APENjC6_leQo8ggD_NAvNw___False/alldata-*
- config_name: run_batch_loss_accuracy_6159_ACDthNCQCXdpuvTJOHB7_w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6159_ACDthNCQCXdpuvTJOHB7_w___False/alldata-*
- config_name: run_batch_loss_accuracy_6159_AKkNJwcNIr1APoWnww3trA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6159_AKkNJwcNIr1APoWnww3trA___False/alldata-*
- config_name: run_batch_loss_accuracy_6204_ALA12KN_Bzufc__SLASH__fckgQLYQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6204_ALA12KN_Bzufc__SLASH__fckgQLYQ___False/alldata-*
- config_name: run_batch_loss_accuracy_6204_ANh5D6gjhFczRNoXnfYQZw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6204_ANh5D6gjhFczRNoXnfYQZw___False/alldata-*
- config_name: run_batch_loss_accuracy_6532_AKFI5H8hdER1nhTk6FeZ9w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6532_AKFI5H8hdER1nhTk6FeZ9w___False/alldata-*
- config_name: run_batch_loss_accuracy_6532_AM___SLASH__3HsepmCAE1znBS5DaQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6532_AM___SLASH__3HsepmCAE1znBS5DaQ___False/alldata-*
- config_name: run_batch_loss_accuracy_6549_AGscQnFIP7ROHL2rRr__SLASH__RwA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6549_AGscQnFIP7ROHL2rRr__SLASH__RwA___False/alldata-*
- config_name: run_batch_loss_accuracy_6549_AJi__SLASH__z15eMzdj7SeW9vgCDg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6549_AJi__SLASH__z15eMzdj7SeW9vgCDg___False/alldata-*
- config_name: run_batch_loss_accuracy_6589_AAwn__SLASH__ECxsh_1dlUI6m3mXw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6589_AAwn__SLASH__ECxsh_1dlUI6m3mXw___False/alldata-*
- config_name: run_batch_loss_accuracy_6589_ABhxU1A0X3UrM7xUks__SLASH__KAg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6589_ABhxU1A0X3UrM7xUks__SLASH__KAg___False/alldata-*
- config_name: run_batch_loss_accuracy_6910_ALxIbmPsD6gVXm903kNNZw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6910_ALxIbmPsD6gVXm903kNNZw___False/alldata-*
- config_name: run_batch_loss_accuracy_6910_AMSJZzmG__SLASH__F7_pJyM7M3FWg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_6910_AMSJZzmG__SLASH__F7_pJyM7M3FWg___False/alldata-*
- config_name: run_batch_loss_accuracy_7098_AHe8kcqn0WeWqKzCBdOZWA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7098_AHe8kcqn0WeWqKzCBdOZWA___False/alldata-*
- config_name: run_batch_loss_accuracy_7098_ANqIBrmTyogZWWnpSqa2GQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7098_ANqIBrmTyogZWWnpSqa2GQ___False/alldata-*
- config_name: run_batch_loss_accuracy_7238_AJcczDLZLMg6HmgLwbPZRA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7238_AJcczDLZLMg6HmgLwbPZRA___False/alldata-*
- config_name: run_batch_loss_accuracy_7238_ALUsWuJGa0qH02RGiG_q_w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7238_ALUsWuJGa0qH02RGiG_q_w___False/alldata-*
- config_name: run_batch_loss_accuracy_7310_AI3U726NidndYxOJ8LXiGg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7310_AI3U726NidndYxOJ8LXiGg___False/alldata-*
- config_name: run_batch_loss_accuracy_7310_AIqQyzL_6bFft3B3fsNdqQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7310_AIqQyzL_6bFft3B3fsNdqQ___False/alldata-*
- config_name: run_batch_loss_accuracy_742_AHBUd7uN5bMEI9uPtdSJVQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_742_AHBUd7uN5bMEI9uPtdSJVQ___False/alldata-*
- config_name: run_batch_loss_accuracy_742_APA7H8RDv7iZGppzsgSzWQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_742_APA7H8RDv7iZGppzsgSzWQ___False/alldata-*
- config_name: run_batch_loss_accuracy_7467_ADmUCP0MCBdxdP147nXPbw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7467_ADmUCP0MCBdxdP147nXPbw___False/alldata-*
- config_name: run_batch_loss_accuracy_7467_AOgCgysNNhaxY98pr89C5A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7467_AOgCgysNNhaxY98pr89C5A___False/alldata-*
- config_name: run_batch_loss_accuracy_7790_AHY8bHMjC8Cau4l3CEbFzg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7790_AHY8bHMjC8Cau4l3CEbFzg___False/alldata-*
- config_name: run_batch_loss_accuracy_7790_AII4NQbRGUPwvJb7aj17kg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7790_AII4NQbRGUPwvJb7aj17kg___False/alldata-*
- config_name: run_batch_loss_accuracy_7884_ACgySAHsnEfS0KVlDcPJpQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7884_ACgySAHsnEfS0KVlDcPJpQ___False/alldata-*
- config_name: run_batch_loss_accuracy_7884_AEwUzGIHnYdSCNvgAQOiwA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_7884_AEwUzGIHnYdSCNvgAQOiwA___False/alldata-*
- config_name: run_batch_loss_accuracy_8048_ADFBq2ohLYdLz_8EBW7y0w___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8048_ADFBq2ohLYdLz_8EBW7y0w___False/alldata-*
- config_name: run_batch_loss_accuracy_8048_AHnWR6MkAzx__SLASH____SLASH__cXMlZ4vPw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8048_AHnWR6MkAzx__SLASH____SLASH__cXMlZ4vPw___False/alldata-*
- config_name: run_batch_loss_accuracy_8299_ABkI5rBAmBZ__SLASH__9mGeSYRyPw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8299_ABkI5rBAmBZ__SLASH__9mGeSYRyPw___False/alldata-*
- config_name: run_batch_loss_accuracy_8299_AJbNG5spEefZBe66MQAhPA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8299_AJbNG5spEefZBe66MQAhPA___False/alldata-*
- config_name: run_batch_loss_accuracy_8721_ACP2ea_NrT_V1iorYvJWMA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8721_ACP2ea_NrT_V1iorYvJWMA___False/alldata-*
- config_name: run_batch_loss_accuracy_8721_AJIeCHqUwDEL__SLASH__VC7vXISIw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8721_AJIeCHqUwDEL__SLASH__VC7vXISIw___False/alldata-*
- config_name: run_batch_loss_accuracy_8745_AMmAXqM7tWcPTuRGfT570A___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8745_AMmAXqM7tWcPTuRGfT570A___False/alldata-*
- config_name: run_batch_loss_accuracy_8745_APVIRgHObCsuOAETakwTRA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8745_APVIRgHObCsuOAETakwTRA___False/alldata-*
- config_name: run_batch_loss_accuracy_8840_AGW4dTaz9hbQevZ__NgUBQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8840_AGW4dTaz9hbQevZ__NgUBQ___False/alldata-*
- config_name: run_batch_loss_accuracy_8840_ANmbeQ31jox4EmsW6ZKVjA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8840_ANmbeQ31jox4EmsW6ZKVjA___False/alldata-*
- config_name: run_batch_loss_accuracy_8893_AEEAg2gyeEuHX6OsdmEOZg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8893_AEEAg2gyeEuHX6OsdmEOZg___False/alldata-*
- config_name: run_batch_loss_accuracy_8893_AJ6m9YoPafTnmX1AuUTDyA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_8893_AJ6m9YoPafTnmX1AuUTDyA___False/alldata-*
- config_name: run_batch_loss_accuracy_9132_ACHb0E5NUU__SLASH__yQK4T79SyWg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9132_ACHb0E5NUU__SLASH__yQK4T79SyWg___False/alldata-*
- config_name: run_batch_loss_accuracy_9132_ANKHsKenG2rm9JrnAUKI5Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9132_ANKHsKenG2rm9JrnAUKI5Q___False/alldata-*
- config_name: run_batch_loss_accuracy_9134_ADqdBOJvh2JRjZANKgb6ew___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9134_ADqdBOJvh2JRjZANKgb6ew___False/alldata-*
- config_name: run_batch_loss_accuracy_9134_AOwBnBi0uYjQRJfhbOo3SA___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9134_AOwBnBi0uYjQRJfhbOo3SA___False/alldata-*
- config_name: run_batch_loss_accuracy_913_AH52yTi3c_1cdfD__SLASH__xDvVhw___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_913_AH52yTi3c_1cdfD__SLASH__xDvVhw___False/alldata-*
- config_name: run_batch_loss_accuracy_913_ALJhsoisa_orWoJ04Xd7ZQ___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_913_ALJhsoisa_orWoJ04Xd7ZQ___False/alldata-*
- config_name: run_batch_loss_accuracy_9504_ALcZ__SLASH__GkSkldvW2___SLASH__oyz8_Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9504_ALcZ__SLASH__GkSkldvW2___SLASH__oyz8_Q___False/alldata-*
- config_name: run_batch_loss_accuracy_9504_ALuaKFji8SahiaEgZUZXyg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9504_ALuaKFji8SahiaEgZUZXyg___False/alldata-*
- config_name: run_batch_loss_accuracy_9816_AH9M6PKoJ6IBOMQSAzBR9Q___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9816_AH9M6PKoJ6IBOMQSAzBR9Q___False/alldata-*
- config_name: run_batch_loss_accuracy_9816_ALJ2MB8mbkYNx2ltMg0elg___False
data_files:
- split: alldata
path: run_batch_loss_accuracy_9816_ALJ2MB8mbkYNx2ltMg0elg___False/alldata-*
- config_name: shared_proof_search
data_files:
- split: alldata
path: shared_proof_search/alldata-*
- config_name: subcubic_analyze_gaps
data_files:
- split: alldata
path: subcubic_analyze_gaps/alldata-*
- config_name: subcubic_count_verify_proof
data_files:
- split: alldata
path: subcubic_count_verify_proof/alldata-*
- config_name: subcubic_verify_proof
data_files:
- split: alldata
path: subcubic_verify_proof/alldata-*
- config_name: train_or_load_model
data_files:
- split: alldata
path: train_or_load_model/alldata-*
- config_name: train_or_load_model_d_vocab_128
data_files:
- split: alldata
path: train_or_load_model_d_vocab_128/alldata-*
---
|
bigcode/starcoderdata | bigcode | "2023-05-16T10:05:48Z" | 2,876 | 384 | [
"task_categories:text-generation",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:multilingual",
"language:code",
"license:other",
"size_categories:100M<n<1B",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-generation"
] | "2023-03-30T12:02:21Z" | ---
annotations_creators: []
language_creators:
- crowdsourced
- expert-generated
language:
- code
license:
- other
multilinguality:
- multilingual
pretty_name: The-Stack
size_categories:
- unknown
source_datasets: []
task_categories:
- text-generation
extra_gated_prompt: >-
## Terms of Use for The Stack
The Stack dataset is a collection of source code in over 300 programming
languages. We ask that you read and acknowledge the following points before
using the dataset:
1. The Stack is a collection of source code from repositories with various
licenses. Any use of all or part of the code gathered in The Stack must abide
by the terms of the original licenses, including attribution clauses when
relevant. We facilitate this by providing provenance information for each data
point.
2. The Stack is regularly updated to enact validated data removal requests. By
clicking on "Access repository", you agree to update your own version of The
Stack to the most recent usable version specified by the maintainers in [the
following
thread](https://huggingface.co/datasets/bigcode/the-stack/discussions/7). If
you have questions about dataset versions and allowed uses, please also ask
them in the dataset’s [community
discussions](https://huggingface.co/datasets/bigcode/the-stack/discussions/new).
We will also notify users via email when the latest usable version changes.
3. To host, share, or otherwise provide access to The Stack dataset, you must
include [these Terms of
Use](https://huggingface.co/datasets/bigcode/the-stack#terms-of-use-for-the-stack)
and require users to agree to it.
By clicking on "Access repository" below, you accept that your contact
information (email address and username) can be shared with the dataset
maintainers as well.
extra_gated_fields:
Email: text
I have read the License and agree with its terms: checkbox
---
# StarCoder Training Dataset
## Dataset description
This is the dataset used for training [StarCoder](https://huggingface.co/bigcode/starcoder) and [StarCoderBase](https://huggingface.co/bigcode/starcoderbase). It contains 783GB of code in 86 programming languages, and includes 54GB GitHub Issues + 13GB Jupyter notebooks in scripts and text-code pairs,
and 32GB of GitHub commits, which is approximately 250 Billion tokens.
## Dataset creation
The creation and filtering of The Stack is explained in the [original dataset](https://huggingface.co/datasets/bigcode/the-stack-dedup), we additionally decontaminate and clean all 86 programming
languages in the dataset, in addition to GitHub issues, Jupyter Notebooks and GitHub commits. We also apply near-deduplication and remove PII, all details are mentionned in our [Paper: 💫 StarCoder, May The Source Be With You](https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view)
## How to use the dataset
```python
from datasets import load_dataset
# to load python for example
ds = load_dataset("bigcode/starcoderdata", data_dir="python", split="train")
```
GitHub issues, GitHub commits and Jupyter notebooks subsets have different columns from the rest so loading the entire dataset at once may fail, we suggest loading programming languages separatly from these categories.
````
jupyter-scripts-dedup-filtered
jupyter-structured-clean-dedup
github-issues-filtered-structured
git-commits-cleaned
````
|
allenai/scirepeval_test | allenai | "2023-10-19T00:10:58Z" | 2,876 | 0 | [
"size_categories:1M<n<10M",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | null | "2023-10-19T00:05:18Z" | ---
dataset_info:
- config_name: fos
features:
- name: paper_id
dtype: string
- name: label
sequence: int32
splits:
- name: test
num_bytes: 51276
num_examples: 472
- name: train
num_bytes: 5873604
num_examples: 54131
download_size: 3194762
dataset_size: 5924880
- config_name: mesh_descriptors
features:
- name: paper_id
dtype: string
- name: label
dtype: int32
splits:
- name: test
num_bytes: 820660
num_examples: 51738
- name: train
num_bytes: 3283053
num_examples: 206949
download_size: 3203144
dataset_size: 4103713
- config_name: cite_count
features:
- name: paper_id
dtype: string
- name: label
dtype: float64
splits:
- name: test
num_bytes: 121260
num_examples: 6012
- name: train
num_bytes: 483822
num_examples: 24000
download_size: 477603
dataset_size: 605082
- config_name: pub_year
features:
- name: paper_id
dtype: string
- name: label
dtype: float64
splits:
- name: test
num_bytes: 123284
num_examples: 6000
- name: train
num_bytes: 493073
num_examples: 24000
download_size: 518506
dataset_size: 616357
- config_name: high_influence_cite
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 1439013
num_examples: 58255
download_size: 3477938
dataset_size: 1439013
- config_name: same_author
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 3144107
num_examples: 123430
download_size: 7464157
dataset_size: 3144107
- config_name: search
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 1283980
num_examples: 25850
download_size: 2188731
dataset_size: 1283980
- config_name: drsm
features:
- name: paper_id
dtype: string
- name: label
dtype: int32
splits:
- name: test
num_bytes: 15277
num_examples: 955
- name: train
num_bytes: 119083
num_examples: 7520
download_size: 100492
dataset_size: 134360
- config_name: feeds_1
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 110997
num_examples: 4223
download_size: 258802
dataset_size: 110997
- config_name: feeds_m
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 2321483
num_examples: 87528
download_size: 5384963
dataset_size: 2321483
- config_name: feeds_title
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 210605
num_examples: 4233
download_size: 358760
dataset_size: 210605
- config_name: peer_review_score
features:
- name: paper_id
dtype: string
- name: label
dtype: float64
splits:
- name: test
num_bytes: 89892
num_examples: 2043
- name: train
num_bytes: 359348
num_examples: 8167
download_size: 408432
dataset_size: 449240
- config_name: hIndex
features:
- name: paper_id
dtype: string
- name: label
dtype: float64
splits:
- name: test
num_bytes: 94864
num_examples: 2156
- name: train
num_bytes: 382756
num_examples: 8699
download_size: 434232
dataset_size: 477620
- config_name: trec_covid
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: int8
splits:
- name: test
num_bytes: 3396582
num_examples: 69318
download_size: 5822714
dataset_size: 3396582
- config_name: tweet_mentions
features:
- name: paper_id
dtype: string
- name: label
dtype: float64
splits:
- name: test
num_bytes: 111212
num_examples: 5132
- name: train
num_bytes: 444784
num_examples: 20523
download_size: 454231
dataset_size: 555996
- config_name: scidocs_mag
features:
- name: paper_id
dtype: string
- name: label
dtype: int32
splits:
- name: test
num_bytes: 180048
num_examples: 3751
- name: train
num_bytes: 840048
num_examples: 17501
download_size: 923863
dataset_size: 1020096
- config_name: scidocs_mesh
features:
- name: paper_id
dtype: string
- name: label
dtype: int32
splits:
- name: test
num_bytes: 169488
num_examples: 3531
- name: train
num_bytes: 790944
num_examples: 16478
download_size: 862299
dataset_size: 960432
- config_name: scidocs_view
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 2668042
num_examples: 29978
download_size: 3717272
dataset_size: 2668042
- config_name: scidocs_cite
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 2663592
num_examples: 29928
download_size: 3711072
dataset_size: 2663592
- config_name: scidocs_cocite
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 2665461
num_examples: 29949
download_size: 3713676
dataset_size: 2665461
- config_name: scidocs_read
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 2667953
num_examples: 29977
download_size: 3717148
dataset_size: 2667953
- config_name: reviewers
features:
- name: r_id
dtype: string
- name: papers
sequence: string
splits:
- name: metadata
num_bytes: 3564977
num_examples: 668
download_size: 3576339
dataset_size: 3564977
- config_name: paper_reviewer_matching
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test_hard
num_bytes: 50603
num_examples: 1729
- name: test_soft
num_bytes: 50603
num_examples: 1729
download_size: 222236
dataset_size: 101206
- config_name: biomimicry
features:
- name: paper_id
dtype: string
- name: label
dtype: int32
splits:
- name: test
num_bytes: 44513
num_examples: 2748
- name: train
num_bytes: 133570
num_examples: 8243
download_size: 134151
dataset_size: 178083
- config_name: relish
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 4779565
num_examples: 191245
download_size: 11473140
dataset_size: 4779565
- config_name: nfcorpus
features:
- name: query_id
dtype: string
- name: cand_id
dtype: string
- name: score
dtype: uint8
splits:
- name: test
num_bytes: 1188859
num_examples: 44634
download_size: 2751049
dataset_size: 1188859
---
|
CohereForAI/aya_evaluation_suite | CohereForAI | "2024-06-28T08:04:59Z" | 2,862 | 40 | [
"task_categories:text-generation",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"language_creators:machine-generated",
"multilinguality:multilingual",
"source_datasets:original",
"source_datasets:extended",
"language:afr",
"language:sqi",
"language:amh",
"language:ara",
"language:aze",
"language:bel",
"language:ben",
"language:bul",
"language:cat",
"language:ceb",
"language:ces",
"language:kur",
"language:cym",
"language:dan",
"language:deu",
"language:ell",
"language:eng",
"language:epo",
"language:est",
"language:eus",
"language:fin",
"language:fra",
"language:gla",
"language:gle",
"language:glg",
"language:guj",
"language:hat",
"language:hau",
"language:heb",
"language:hin",
"language:hun",
"language:hye",
"language:ibo",
"language:ind",
"language:isl",
"language:ita",
"language:jav",
"language:jpn",
"language:kan",
"language:kat",
"language:kaz",
"language:mon",
"language:khm",
"language:kir",
"language:kor",
"language:lao",
"language:lit",
"language:ltz",
"language:lav",
"language:mal",
"language:mar",
"language:mkd",
"language:mlt",
"language:mri",
"language:mya",
"language:nld",
"language:nor",
"language:nep",
"language:sot",
"language:pus",
"language:pes",
"language:mlg",
"language:pol",
"language:por",
"language:ron",
"language:rus",
"language:sin",
"language:slk",
"language:slv",
"language:smo",
"language:sna",
"language:snd",
"language:som",
"language:spa",
"language:srp",
"language:sun",
"language:swe",
"language:swa",
"language:tam",
"language:tel",
"language:tgk",
"language:tha",
"language:tur",
"language:ukr",
"language:urd",
"language:uzb",
"language:vie",
"language:xho",
"language:yid",
"language:yor",
"language:zho",
"language:msa",
"language:zul",
"language:ace",
"language:bjn",
"language:kas",
"language:kau",
"language:min",
"language:mni",
"language:taq",
"language:nso",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2402.06619",
"region:us"
] | [
"text-generation"
] | "2024-02-06T08:54:09Z" | ---
language_creators:
- crowdsourced
- expert-generated
- machine-generated
language:
- afr
- sqi
- amh
- ara
- aze
- bel
- ben
- bul
- cat
- ceb
- ces
- kur
- cym
- dan
- deu
- ell
- eng
- epo
- est
- eus
- fin
- fra
- gla
- gle
- glg
- guj
- hat
- hau
- heb
- hin
- hun
- hye
- ibo
- ind
- isl
- ita
- jav
- jpn
- kan
- kat
- kaz
- mon
- khm
- kir
- kor
- lao
- lit
- ltz
- lav
- mal
- mar
- mkd
- mlt
- mri
- mya
- nld
- nor
- nep
- sot
- pus
- pes
- mlg
- pol
- por
- ron
- rus
- sin
- slk
- slv
- smo
- sna
- snd
- som
- spa
- srp
- sun
- swe
- swa
- tam
- tel
- tgk
- tha
- tur
- ukr
- urd
- uzb
- vie
- xho
- yid
- yor
- zho
- msa
- zul
- ace
- bjn
- kas
- kau
- min
- mni
- taq
- nso
license: apache-2.0
multilinguality:
- multilingual
size_categories:
- 10K<n<100K
source_datasets:
- original
- extended
task_categories:
- text-generation
pretty_name: Aya Evaluation Suite
dataset_info:
- config_name: aya_human_annotated
features:
- name: id
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: language
dtype: string
- name: script
dtype: string
splits:
- name: test
num_bytes: 1624958
num_examples: 1750
download_size: 974483
dataset_size: 1624958
- config_name: dolly_human_edited
features:
- name: id
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: language
dtype: string
- name: script
dtype: string
- name: source_id
dtype: int64
splits:
- name: test
num_bytes: 1219111
num_examples: 1200
download_size: 602117
dataset_size: 1219111
- config_name: dolly_machine_translated
features:
- name: id
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: language
dtype: string
- name: script
dtype: string
- name: source_id
dtype: int64
splits:
- name: test
num_bytes: 39679355
num_examples: 23800
download_size: 20100505
dataset_size: 39679355
configs:
- config_name: aya_human_annotated
data_files:
- split: test
path: aya_human_annotated/test-*
- config_name: dolly_human_edited
data_files:
- split: test
path: dolly_human_edited/test-*
- config_name: dolly_machine_translated
data_files:
- split: test
path: dolly_machine_translated/test-*
---

# Dataset Summary
`Aya Evaluation Suite` contains a total of 26,750 open-ended conversation-style prompts to evaluate multilingual open-ended generation quality.\
To strike a balance between language coverage and the quality that comes with human curation, we create an evaluation suite that includes:
1) human-curated examples in 7 languages (`tur, eng, yor, arb, zho, por, tel`) → `aya-human-annotated`.
2) machine-translations of handpicked examples into 101 languages → `dolly-machine-translated`.
3) human-post-edited translations into 6 languages (`hin, srp, rus, fra, arb, spa`) → `dolly-human-edited`.
---
- **Curated by:** Contributors of [Aya Open Science Intiative](https://aya.for.ai/), professional annotators, and synthetic generation
- **Language(s):** 101 languages
- **License:** [Apache 2.0](https://opensource.org/license/apache-2-0)
- **Aya Datasets Family:**
| Name | Explanation |
|------|--------------|
| [aya_dataset](https://huggingface.co/datasets/CohereForAI/aya_dataset) | Human-annotated multilingual instruction finetuning dataset, comprising over 204K instances across 65 languages. |
| [aya_collection](https://huggingface.co/datasets/CohereForAI/aya_collection) | Created by applying instruction-style templates from fluent speakers to 44 datasets, including translations of 19 instruction-style datasets into 101 languages, providing 513M instances for various tasks.|
| [aya_collection_language_split](https://huggingface.co/datasets/CohereForAI/aya_collection_language_split) | Aya Collection structured based on language level subsets. |
| [aya_evaluation_suite](https://huggingface.co/datasets/CohereForAI/aya_evaluation_suite) | A diverse evaluation set for multilingual open-ended generation, featuring 250 culturally grounded prompts in 7 languages, 200 translated prompts in 24 languages, and human-edited versions selected for cross-cultural relevance from English Dolly in 6 languages.|
| [aya_redteaming](https://huggingface.co/datasets/CohereForAI/aya_redteaming)| A red-teaming dataset consisting of harmful prompts in 8 languages across 9 different categories of harm with explicit labels for "global" and "local" harm.|
# Dataset
The `Aya Evaluation Suite` includes the following subsets:
1. **aya-human-annotated**: 250 original human-written prompts in 7 languages each.
2. **dolly-machine-translated**: 200 human-selected prompts from [databricks-dolly-15k](https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm)
, automatically translated with the [NLLB model](https://ai.meta.com/research/no-language-left-behind/) from English into 101 languages (114 dialects in total).
3. **dolly-human-edited**: 200 dolly-machine-translated prompts post-edited by fluent speakers for 6 languages.
## Load with Datasets
To load this dataset consisting of prompt-completions with `datasets`, you just need to install Datasets as `pip install datasets --upgrade` and then use the following code:
```python
from datasets import load_dataset
aya_eval = load_dataset("CohereForAI/aya_evaluation_suite", "aya_human_annotated")
```
## Data Fields
- `id`: Unique id of the data point.
- `inputs`: Prompt or input to the language model.
- `targets`: Completion or output of the language model. (Not applicable for `dolly-human-edited`)
- `language`: The language of the `prompt` and `completion.`
- `script`: The writing system of the language.
- `source_id`: Corresponding original row index from the [databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) dataset (Field applicable only for subsets `dolly-machine-translated` & `dolly-human-edited`)
## Data Instances
Example data instances from the `Aya Evaluation Suite` subsets are listed in the toggled sections below.
<details>
<summary> <b>aya-human-annotated</b> </summary>
```json
{
"id": 42,
"inputs": "What day is known as Star Wars Day?",
"targets": "May 4th (May the 4th be with you!)",
"language": "eng",
"script": "Latn",
}
```
</details>
<b>Dolly-machine-translated and dolly-human-edited</b>
- These two subsets are parallel datasets (data instances can be mapped using their `id` column).
- Note that in the `dolly-machine-translated` subset, we also include the original English subset (`id 1-200`), which is translated into 101 languages. Furthermore, the field `id` can be used to match the translations of the same data instance across languages.
- The `source_id` field contains the corresponding original row index from the [databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) dataset.
<details>
<summary> <b>dolly-machine-translated</b> </summary>
```json
{
"id": 2,
"inputs": "How to escape from a helicopter trapped in water ?",
"targets": "If you are ever trapped inside a helicopter while submerged in water, it’s best to try and remain calm until the cabin is completely underwater. It’s better to wait for pressure to be equalized, before you try to open the door or break the glass to escape.",
"language": "eng",
"script": "Latn",
"source_id": 6060,
}
```
</details>
<details>
<summary> <b>dolly-human-edited</b> </summary>
```json
{
"id": 2,
"inputs": "Comment peut-on s'échapper d'un hélicoptère piégé dans l'eau ?",
"targets": "-",
"language": "fra",
"script": "Latn",
"source_id": 6060,
}
```
</details>
## Statistics
The toggled table below lists the breakdown of languages in each subset.
### Languages
<details>
<summary> <b>aya-human-annotated</b> </summary>
| ISO Code | Language | Resources |
|----------|----------|---------------|
| `tel` | Telugu | Low |
| `yor` | Yorùbá | Low |
| `arb` | Arabic | High |
| `tur` | Turkish | High |
| `por` | Portuguese | High |
| `zho` | Chinese (Simplified) | High |
| `eng` | English | High |
</details>
<details>
<summary> <b>dolly-machine-translated</b> </summary>
| ISO Code | Language | Resources |
|----------|----------|-----------|
| `ace` | Achinese | Low |
| `afr` | Afrikaans | Mid |
| `amh` | Amharic | Low |
| `ara` (`arb`, `acm`, `acq`, `aeb`, `ajp`, `apc`, `ars`, `ary` & `arz`) | Arabic (Standard, Gelet Iraqi, Ta'izzi-Adeni, Tunisian, South Levantine, North Levantine, Najdi, Moroccan & Egyptian) | High |
| `aze` (`azb` & `azj`) | Azerbaijani (South & North) | Low |
| `bel` | Belarusian | Mid |
| `ben` | Bengali | Mid |
| `bjn` | Banjar | Low |
| `bul` | Bulgarian | Mid |
| `cat` | Catalan | High |
| `ceb` | Cebuano | Mid |
| `ces` | Czech | High |
| `cym` | Welsh | Low |
| `dan` | Danish | Mid |
| `deu` | German | High |
| `ell` | Greek | Mid |
| `eng` | English | High |
| `epo` | Esperanto | Low |
| `est` | Estonian | Mid |
| `eus` | Basque | High |
| `fin` | Finnish | High |
| `fra` | French | High |
| `gla` | Scottish Gaelic | Low |
| `gle` | Irish | Low |
| `glg` | Galician | Mid |
| `guj` | Gujarati | Low |
| `hat` | Haitian Creole | Low |
| `hau` | Hausa | Low |
| `heb` | Hebrew | Mid |
| `hin` | Hindi | High |
| `hun` | Hungarian | High |
| `hye` | Armenian | Low |
| `ibo` | Igbo | Low |
| `ind` | Indonesian | Mid |
| `isl` | Icelandic | Low |
| `ita` | Italian | High |
| `jav` | Javanese | Low |
| `jpn` | Japanese | High |
| `kan` | Kannada | Low |
| `kas` | Kashmiri | Low |
| `kat` | Georgian | Mid |
| `kau` (`knc`) | Kanuri (Central) | Low |
| `kaz` | Kazakh | Mid |
| `khm` | Khmer | Low |
| `kir` | Kyrgyz | Low |
| `kor` | Korean | High |
| `kur` (`ckb` & `kmr`) | Kurdish (Central & Northern) | Low |
| `lao` | Lao | Low |
| `lav` (`lvs`) | Latvian (Standard) | Mid |
| `lit` | Lithuanian | Mid |
| `ltz` | Luxembourgish | Low |
| `mal` | Malayalam | Low |
| `mar` | Marathi | Low |
| `min` | Minangkabau | Low |
| `mkd` | Macedonian | Low |
| `mlg` (`plt`) | Malagasy (Plateau) | Low |
| `mlt` | Maltese | Low |
| `mni` | Manipuri | Low |
| `mon` (`khk`) | Mongolian (Khalkha) | Low |
| `mri` | Maori | Low |
| `msa` (`zsm`) | Malay (Standard) | Mid |
| `mya` | Burmese | Low |
| `nep` (`npi`) | Nepali | Low |
| `nld` | Dutch | High |
| `nor` (`nno` & `nob`) | Norwegian (Nynorsk & Bokmål) | Low |
| `nso` | Northern Sotho | Low |
| `pes` | Persian | High |
| `pol` | Polish | High |
| `por` | Portuguese | High |
| `pus` (`pbt`) | Pashto (Southern) | Low |
| `ron` | Romanian | Mid |
| `rus` | Russian | High |
| `sin` | Sinhala | Low |
| `slk` | Slovak | Mid |
| `slv` | Slovenian | Mid |
| `smo` | Samoan | Low |
| `sna` | Shona | Low |
| `snd` | Sindhi | Low |
| `som` | Somali | Low |
| `sot` | Southern Sotho | Low |
| `spa` | Spanish | High |
| `sqi` (`als`) | Albanian (Tosk) | Low |
| `srp` | Serbian | High |
| `sun` | Sundanese | Low |
| `swa` (`swh`) | Swahili (Coastal) | Low |
| `swe` | Swedish | High |
| `tam` | Tamil | Mid |
| `taq` | Tamasheq | Low |
| `tel` | Telugu | Low |
| `tgk` | Tajik | Low |
| `tha` | Thai | Mid |
| `tur` | Turkish | High |
| `ukr` | Ukrainian | Mid |
| `urd` | Urdu | Mid |
| `uzb` (`uzn`) | Uzbek (Nothern) | Mid |
| `vie` | Vietnamese | High |
| `xho` | Xhosa | Low |
| `yid` (`ydd`) | Yiddish (Eastern) | Low |
| `yor` | Yoruba | Low |
| `zho` (+ `yue`) | Chinese (Simplified & Cantonese) | High |
| `zul` | Zulu | Low |
</details>
<details>
<summary> <b>dolly-human-edited</b> </summary>
| ISO Code | Language | Resources |
|----------|----------|-----------|
| `arb` | Arabic | High |
| `fra` | French | High |
| `hin` | Hindi | High |
| `rus` | Russian | High |
| `spa` | Spanish | High |
| `srp` | Serbian | High |
</details>
<br>
# Motivations & Intentions
- **Curation Rationale:** This evaluation suite is tailored to test the generation quality of multilingual models, with the aim of balancing language coverage and human-sourced quality.
It covers prompts originally written in each language, as well as English-centric translated, and manually curated or edited prompts for a linguistically broad, but rich testbed.
The list of languages was initially established from mT5 and aligned with the annotators’ language list and the NLLB translation model.
# Known Limitations
- **Translation Quality:** Note that the expressiveness of the `dolly-machine-translated` subset is limited by the quality of the translation model and may adversely impact an estimate of ability in languages where translations are not adequate. If this subset is used for testing, we recommend it be paired and reported with the professionally post-edited `dolly-human-edited` subset or the `aya-human-annotated` set, which, while covering only 7 languages, is entirely created by proficient target language speakers.
---
# Additional Information
## Provenance
- **Methods Used:** combination of original annotations by volunteers, automatic translation, and post-editing of translations by professional annotators.
- **Methodology Details:**
- *Source:* Original annotations from Aya dataset along with translations and post-edits of Dolly dataset
- *Platform:* [Aya Annotation Platform](https://aya.for.ai/)
- *Dates of Collection:* May 2023 - Dec 2023
## Dataset Version and Maintenance
- **Maintenance Status:** Actively Maintained
- **Version Details:**
- *Current version:* 1.0
- *Last Update:* 02/2024
- *First Release:* 02/2024
- **Maintenance Plan:** No updates planned.
## Authorship
- **Publishing Organization:** [Cohere For AI](https://cohere.com/research)
- **Industry Type:** Not-for-profit - Tech
- **Contact Details:** https://aya.for.ai/
## Licensing Information
This dataset can be used for any purpose, whether academic or commercial, under the terms of the [Apache 2.0](https://opensource.org/license/apache-2-0) License.
## Citation Information
```bibtex
@misc{singh2024aya,
title={Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning},
author={Shivalika Singh and Freddie Vargus and Daniel Dsouza and Börje F. Karlsson and Abinaya Mahendiran and Wei-Yin Ko and Herumb Shandilya and Jay Patel and Deividas Mataciunas and Laura OMahony and Mike Zhang and Ramith Hettiarachchi and Joseph Wilson and Marina Machado and Luisa Souza Moura and Dominik Krzemiński and Hakimeh Fadaei and Irem Ergün and Ifeoma Okoh and Aisha Alaagib and Oshan Mudannayake and Zaid Alyafeai and Vu Minh Chien and Sebastian Ruder and Surya Guthikonda and Emad A. Alghamdi and Sebastian Gehrmann and Niklas Muennighoff and Max Bartolo and Julia Kreutzer and Ahmet Üstün and Marzieh Fadaee and Sara Hooker},
year={2024},
eprint={2402.06619},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
open-llm-leaderboard-old/details_Undi95__ReMM-L2-13B | open-llm-leaderboard-old | "2023-10-16T18:10:16Z" | 2,860 | 0 | [
"region:us"
] | null | "2023-09-03T14:15:52Z" | ---
pretty_name: Evaluation run of Undi95/ReMM-L2-13B
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [Undi95/ReMM-L2-13B](https://huggingface.co/Undi95/ReMM-L2-13B) on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Undi95__ReMM-L2-13B\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-16T18:10:03.763192](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__ReMM-L2-13B/blob/main/results_2023-10-16T18-10-03.763192.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.3603187919463087,\n\
\ \"em_stderr\": 0.004916600307723715,\n \"f1\": 0.4369505033557066,\n\
\ \"f1_stderr\": 0.004727018193601331,\n \"acc\": 0.3873174710218511,\n\
\ \"acc_stderr\": 0.008457350051798611\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.3603187919463087,\n \"em_stderr\": 0.004916600307723715,\n\
\ \"f1\": 0.4369505033557066,\n \"f1_stderr\": 0.004727018193601331\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.029567854435178165,\n \
\ \"acc_stderr\": 0.004665893134220799\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.745067087608524,\n \"acc_stderr\": 0.012248806969376422\n\
\ }\n}\n```"
repo_url: https://huggingface.co/Undi95/ReMM-L2-13B
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|arc:challenge|25_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_16T18_10_03.763192
path:
- '**/details_harness|drop|3_2023-10-16T18-10-03.763192.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-16T18-10-03.763192.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_16T18_10_03.763192
path:
- '**/details_harness|gsm8k|5_2023-10-16T18-10-03.763192.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-16T18-10-03.763192.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hellaswag|10_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T14:15:27.893202.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-03T14:15:27.893202.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-03T14:15:27.893202.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_16T18_10_03.763192
path:
- '**/details_harness|winogrande|5_2023-10-16T18-10-03.763192.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-16T18-10-03.763192.parquet'
- config_name: results
data_files:
- split: 2023_09_03T14_15_27.893202
path:
- results_2023-09-03T14:15:27.893202.parquet
- split: 2023_10_16T18_10_03.763192
path:
- results_2023-10-16T18-10-03.763192.parquet
- split: latest
path:
- results_2023-10-16T18-10-03.763192.parquet
---
# Dataset Card for Evaluation run of Undi95/ReMM-L2-13B
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/Undi95/ReMM-L2-13B
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [Undi95/ReMM-L2-13B](https://huggingface.co/Undi95/ReMM-L2-13B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Undi95__ReMM-L2-13B",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-16T18:10:03.763192](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__ReMM-L2-13B/blob/main/results_2023-10-16T18-10-03.763192.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.3603187919463087,
"em_stderr": 0.004916600307723715,
"f1": 0.4369505033557066,
"f1_stderr": 0.004727018193601331,
"acc": 0.3873174710218511,
"acc_stderr": 0.008457350051798611
},
"harness|drop|3": {
"em": 0.3603187919463087,
"em_stderr": 0.004916600307723715,
"f1": 0.4369505033557066,
"f1_stderr": 0.004727018193601331
},
"harness|gsm8k|5": {
"acc": 0.029567854435178165,
"acc_stderr": 0.004665893134220799
},
"harness|winogrande|5": {
"acc": 0.745067087608524,
"acc_stderr": 0.012248806969376422
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
AI-MO/NuminaMath-CoT | AI-MO | "2024-07-19T13:58:59Z" | 2,848 | 183 | [
"task_categories:text-generation",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"aimo",
"math"
] | [
"text-generation"
] | "2024-07-15T20:14:23Z" | ---
dataset_info:
features:
- name: source
dtype: string
- name: problem
dtype: string
- name: solution
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 2495457595.0398345
num_examples: 859494
- name: test
num_bytes: 290340.31593470514
num_examples: 100
download_size: 1234351634
dataset_size: 2495747935.355769
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
license: cc-by-nc-4.0
task_categories:
- text-generation
language:
- en
tags:
- aimo
- math
pretty_name: NuminaMath CoT
---
# Dataset Card for NuminaMath CoT
## Dataset Description
- **Homepage:** https://projectnumina.ai
- **Repository:** https://github.com/project-numina/aimo-progress-prize
- **Paper:** https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf
- **Leaderboard:**
- **Point of Contact:** [Jia Li]([email protected])
### Dataset Summary
Approximately 860k math problems, where each solution is formatted in a Chain of Thought (CoT) manner. The sources of the dataset range from Chinese high school math exercises to US and international mathematics olympiad competition problems. The data were primarily collected from online exam paper PDFs and mathematics discussion forums. The processing steps include (a) OCR from the original PDFs, (b) segmentation into problem-solution pairs, (c) Translation into English, (d) realignment to produce a CoT reasoning format, and (e) final answer formatting.
### Source breakdown
| Source | Number of Samples |
| --- | --- |
| aops_forum | 30201 |
| amc_aime | 4072 |
| cn_k12 | 276591 |
| gsm8k | 7345 |
| math | 7478 |
| olympiads | 150581 |
| orca_math | 153334 |
| synthetic_amc | 62111 |
| synthetic_math | 167895 |
| **Total** | **859608** |
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{numina_math_datasets,
author = {Jia LI and Edward Beeching and Lewis Tunstall and Ben Lipkin and Roman Soletskyi and Shengyi Costa Huang and Kashif Rasul and Longhui Yu and Albert Jiang and Ziju Shen and Zihan Qin and Bin Dong and Li Zhou and Yann Fleureau and Guillaume Lample and Stanislas Polu},
title = {NuminaMath},
year = {2024},
publisher = {Numina},
journal = {Hugging Face repository},
howpublished = {\url{[https://huggingface.co/AI-MO/NuminaMath-CoT](https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf)}}
}
``` |
easytpp/taxi | easytpp | "2024-02-14T05:58:53Z" | 2,834 | 0 | [
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:json",
"modality:tabular",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-02-09T12:05:39Z" | ---
license: apache-2.0
---
|
Mike0307/MNIST-M | Mike0307 | "2024-04-09T15:17:56Z" | 2,830 | 0 | [
"license:mit",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-07-03T15:48:24Z" | ---
license: mit
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
'2': '2'
'3': '3'
'4': '4'
'5': '5'
'6': '6'
'7': '7'
'8': '8'
'9': '9'
splits:
- name: train
num_bytes: 119131988.027
num_examples: 59001
- name: test
num_bytes: 18049625.166
num_examples: 9001
download_size: 143468539
dataset_size: 137181613.193
---
## Train Example
👉[Domain-Adversarial-Neural-Network](https://github.com/yeyuting0307/Domain-Adversarial-Neural-Network)
|
lkevinzc/tldr-with-sft-reference | lkevinzc | "2024-09-15T10:30:41Z" | 2,825 | 0 | [
"language:en",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-08-30T13:43:31Z" | ---
language:
- en
dataset_info:
features:
- name: prompt
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: id
dtype: string
- name: subreddit
dtype: string
- name: title
dtype: string
- name: post
dtype: string
- name: summary
dtype: string
- name: pythia-1b-reference
dtype: string
- name: pythia-6.9b-reference
dtype: string
- name: pythia-2.8b-reference
dtype: string
splits:
- name: train
num_bytes: 574773935
num_examples: 116722
- name: validation
num_bytes: 31772636
num_examples: 6447
- name: test
num_bytes: 32328258
num_examples: 6553
download_size: 384023843
dataset_size: 638874829
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
Shengcao1006/MMHal-Bench | Shengcao1006 | "2023-11-01T03:48:38Z" | 2,820 | 9 | [
"task_categories:visual-question-answering",
"task_categories:image-to-text",
"language:en",
"license:apache-2.0",
"size_categories:n<1K",
"region:us"
] | [
"visual-question-answering",
"image-to-text"
] | "2023-09-25T04:27:58Z" | ---
arxiv: 2309.14525
license: apache-2.0
task_categories:
- visual-question-answering
- image-to-text
language:
- en
pretty_name: MMHal-Bench
size_categories:
- n<1K
---
### Overview
MMHal-Bench is a new evaluation benchmark specifically designed for hallucintation in Large Multimodal Models (LMM). It contains 96 challenging questions based on images from OpenImages, and their corresponding ground-truth answers and image contents.
You may check `response_template.json` for more details. In the folder `responses` we have included some example responses from representative LMMs.
### Usage
To evaluate your own model on MMHal-Bench, first generate model responses to the image-question pairs. You may check the template `get_response.py` about how to read and write to the response file.
After that, you may let GPT-4 rate your model's responses automatically. You will need package `openai` installed and an API key. Then, run `eval_gpt4.py`:
```
python eval_gpt4.py \
--response [JSON file with model responses] \
--evaluation [JSON file with GPT-4 evaluation to be saved] \
--api-key [your OpenAI API key, starting with 'sk-'] \
--gpt-model [GPT model to be used, or 'gpt-4-0314' by default]
```
Please note that the GPT-4 API calls are not free. Depending on your model response lengths, evaluating each question may use 1.5k-2k tokens. Also, GPT-4 responses are not deterministic, so you may get different results with the same responses.
At the end of the outputs, you can see the evaluation results like this:
```
Average score: 2.05
Hallucination rate: 0.61
Average score for each question type: 2.33,1.25,2,2.5,1.5,3.33,2.33,1.17
``` |
google/IFEval | google | "2024-08-14T08:21:56Z" | 2,820 | 32 | [
"task_categories:text-generation",
"language:en",
"license:apache-2.0",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2311.07911",
"region:us"
] | [
"text-generation"
] | "2023-12-22T11:20:03Z" | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
pretty_name: IFEval
---
# Dataset Card for IFEval
<!-- Provide a quick summary of the dataset. -->
## Dataset Description
- **Repository:** https://github.com/google-research/google-research/tree/master/instruction_following_eval
- **Paper:** https://huggingface.co/papers/2311.07911
- **Leaderboard:** https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- **Point of Contact:** [Le Hou]([email protected])
### Dataset Summary
This dataset contains the prompts used in the [Instruction-Following Eval (IFEval) benchmark](https://arxiv.org/abs/2311.07911) for large language models. It contains around 500 "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times" which can be verified by heuristics. To load the dataset, run:
```python
from datasets import load_dataset
ifeval = load_dataset("google/IFEval")
```
### Supported Tasks and Leaderboards
The IFEval dataset is designed for evaluating chat or instruction fine-tuned language models and is one of the core benchmarks used in the [Open LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard).
### Languages
The data in IFEval are in English (BCP-47 en).
## Dataset Structure
### Data Instances
An example of the `train` split looks as follows:
```
{
"key": 1000,
"prompt": 'Write a 300+ word summary of the wikipedia page "https://en.wikipedia.org/wiki/Raymond_III,_Count_of_Tripoli". Do not use any commas and highlight at least 3 sections that has titles in markdown format, for example *highlighted section part 1*, *highlighted section part 2*, *highlighted section part 3*.',
"instruction_id_list": [
"punctuation:no_comma",
"detectable_format:number_highlighted_sections",
"length_constraints:number_words",
],
"kwargs": [
{
"num_highlights": None,
"relation": None,
"num_words": None,
"num_placeholders": None,
"prompt_to_repeat": None,
"num_bullets": None,
"section_spliter": None,
"num_sections": None,
"capital_relation": None,
"capital_frequency": None,
"keywords": None,
"num_paragraphs": None,
"language": None,
"let_relation": None,
"letter": None,
"let_frequency": None,
"end_phrase": None,
"forbidden_words": None,
"keyword": None,
"frequency": None,
"num_sentences": None,
"postscript_marker": None,
"first_word": None,
"nth_paragraph": None,
},
{
"num_highlights": 3,
"relation": None,
"num_words": None,
"num_placeholders": None,
"prompt_to_repeat": None,
"num_bullets": None,
"section_spliter": None,
"num_sections": None,
"capital_relation": None,
"capital_frequency": None,
"keywords": None,
"num_paragraphs": None,
"language": None,
"let_relation": None,
"letter": None,
"let_frequency": None,
"end_phrase": None,
"forbidden_words": None,
"keyword": None,
"frequency": None,
"num_sentences": None,
"postscript_marker": None,
"first_word": None,
"nth_paragraph": None,
},
{
"num_highlights": None,
"relation": "at least",
"num_words": 300,
"num_placeholders": None,
"prompt_to_repeat": None,
"num_bullets": None,
"section_spliter": None,
"num_sections": None,
"capital_relation": None,
"capital_frequency": None,
"keywords": None,
"num_paragraphs": None,
"language": None,
"let_relation": None,
"letter": None,
"let_frequency": None,
"end_phrase": None,
"forbidden_words": None,
"keyword": None,
"frequency": None,
"num_sentences": None,
"postscript_marker": None,
"first_word": None,
"nth_paragraph": None,
},
],
}
```
### Data Fields
The data fields are as follows:
* `key`: A unique ID for the prompt.
* `prompt`: Describes the task the model should perform.
* `instruction_id_list`: An array of verifiable instructions. See Table 1 of the paper for the full set with their descriptions.
* `kwargs`: An array of arguments used to specify each verifiable instruction in `instruction_id_list`.
### Data Splits
| | train |
|---------------|------:|
| IFEval | 541 |
### Licensing Information
The dataset is available under the [Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0).
### Citation Information
```
@misc{zhou2023instructionfollowingevaluationlargelanguage,
title={Instruction-Following Evaluation for Large Language Models},
author={Jeffrey Zhou and Tianjian Lu and Swaroop Mishra and Siddhartha Brahma and Sujoy Basu and Yi Luan and Denny Zhou and Le Hou},
year={2023},
eprint={2311.07911},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2311.07911},
}
``` |
C-MTEB/T2Retrieval | C-MTEB | "2023-07-28T10:11:06Z" | 2,818 | 2 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-07-28T10:08:40Z" | ---
configs:
- config_name: default
data_files:
- split: corpus
path: data/corpus-*
- split: queries
path: data/queries-*
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: corpus
num_bytes: 265607316
num_examples: 118605
- name: queries
num_bytes: 1000130
num_examples: 22812
download_size: 157606535
dataset_size: 266607446
---
# Dataset Card for "T2Retrieval"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hpprc/emb | hpprc | "2024-09-13T01:51:47Z" | 2,808 | 8 | [
"language:ja",
"license:other",
"size_categories:10M<n<100M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2409.07737",
"region:us"
] | null | "2024-04-15T14:12:27Z" | ---
language:
- ja
license: other
dataset_info:
- config_name: auto-wiki-nli-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: neg.orig
sequence: string
splits:
- name: train
num_bytes: 533673945
num_examples: 198895
download_size: 362814978
dataset_size: 533673945
- config_name: auto-wiki-qa-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 5215705706
num_examples: 8215817
download_size: 3385038265
dataset_size: 5215705706
- config_name: auto-wiki-qa-dataset
features:
- name: passage_id
dtype: int64
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: int64
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 30767957804
num_examples: 2377503
download_size: 21875194075
dataset_size: 30767957804
- config_name: auto-wiki-qa-nemotron-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4202532852
num_examples: 6354725
download_size: 2709124196
dataset_size: 4202532852
- config_name: auto-wiki-qa-nemotron-dataset
features:
- name: passage_id
dtype: int64
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: int64
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 2034181294
num_examples: 156089
download_size: 1449231482
dataset_size: 2034181294
- config_name: baobab-wiki-retrieval-collection
features:
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3771123469
num_examples: 5140862
download_size: 2463376300
dataset_size: 3771123469
- config_name: baobab-wiki-retrieval-dataset
features:
- name: anc
dtype: string
- name: pos_1st
dtype: string
- name: neg_1st.original
dtype: 'null'
- name: neg_1st.me5-large
dtype: string
- name: sim_1st.me5-large
dtype: float64
- name: neg_1st.bm25
dtype: string
- name: sim_1st.bm25
dtype: float64
- name: pos_ids
sequence: int64
- name: neg_ids.original
sequence: 'null'
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 7837529
num_examples: 838
download_size: 5661379
dataset_size: 7837529
- config_name: jagovfaqs-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 13918890
num_examples: 22794
download_size: 5874592
dataset_size: 13918890
- config_name: jagovfaqs-dataset
features:
- name: anc
dtype: string
- name: pos_1st
dtype: string
- name: neg_1st.original
dtype: 'null'
- name: neg_1st.me5-large
dtype: string
- name: sim_1st.me5-large
dtype: float64
- name: neg_1st.bm25
dtype: string
- name: sim_1st.bm25
dtype: float64
- name: pos_ids
sequence: int64
- name: neg_ids.original
sequence: 'null'
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 205284001
num_examples: 22794
download_size: 93115345
dataset_size: 205284001
- config_name: janli-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: neg.orig
sequence: string
splits:
- name: train
num_bytes: 14075833
num_examples: 13496
download_size: 3088881
dataset_size: 14075833
- config_name: jaquad-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4213318372
num_examples: 6364369
download_size: 2716125410
dataset_size: 4213318372
- config_name: jaquad-dataset
features:
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: int64
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 410758435
num_examples: 31748
download_size: 267846825
dataset_size: 410758435
- config_name: jcommonsenseqa-dataset
features:
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: 'null'
- name: neg_ids.original
sequence: 'null'
splits:
- name: train
num_bytes: 673948
num_examples: 8939
download_size: 381605
dataset_size: 673948
- config_name: jqara-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4267669475
num_examples: 6433384
download_size: 2751666583
dataset_size: 4267669475
- config_name: jqara-dataset
features:
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: int64
- name: neg_ids.original
sequence: int64
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 29789340
num_examples: 2235
download_size: 22310036
dataset_size: 29789340
- config_name: jsnli-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: neg.orig
sequence: string
splits:
- name: train
num_bytes: 170593490
num_examples: 144190
download_size: 88629828
dataset_size: 170593490
- config_name: jsquad-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4210493031
num_examples: 6369790
download_size: 2714126867
dataset_size: 4210493031
- config_name: jsquad-dataset
features:
- name: passage_id
dtype: int64
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: int64
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 812736672
num_examples: 62859
download_size: 514718047
dataset_size: 812736672
- config_name: miracl-collection
features:
- name: passage_id
dtype: int64
- name: docid
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3026160577.0
num_examples: 6953614
download_size: 1682864613
dataset_size: 3026160577.0
- config_name: miracl-dataset
features:
- name: anc
dtype: string
- name: pos_1st
dtype: string
- name: neg_1st.original
dtype: string
- name: neg_1st.me5-large
dtype: string
- name: sim_1st.me5-large
dtype: float64
- name: neg_1st.bm25
dtype: string
- name: sim_1st.bm25
dtype: float64
- name: pos_ids
sequence: int64
- name: neg_ids.original
sequence: int64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 32393484
num_examples: 3477
download_size: 23431039
dataset_size: 32393484
- config_name: mkqa-dataset
features:
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: 'null'
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 129900532
num_examples: 10000
download_size: 88793974
dataset_size: 129900532
- config_name: mkqa-triplet
features:
- name: idx
dtype: string
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
splits:
- name: train
num_bytes: 7640649
num_examples: 10000
download_size: 4121496
dataset_size: 7640649
- config_name: mmarco-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 3814117634
num_examples: 8829813
download_size: 2217976936
dataset_size: 3814117634
- config_name: mmarco-dataset
features:
- name: anc
dtype: string
- name: pos_1st
dtype: string
- name: neg_1st.original
dtype: string
- name: neg_1st.me5-large
dtype: string
- name: sim_1st.me5-large
dtype: float64
- name: neg_1st.bm25
dtype: string
- name: sim_1st.bm25
dtype: float64
- name: pos_ids
sequence: int64
- name: neg_ids.original
sequence: int64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 3548801103
num_examples: 391060
download_size: 2624355417
dataset_size: 3548801103
- config_name: mr-tydi-collection
features:
- name: passage_id
dtype: int64
- name: docid
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3061941618
num_examples: 7000027
download_size: 1702050239
dataset_size: 3061941618
- config_name: mr-tydi-dataset
features:
- name: anc
dtype: string
- name: pos_1st
dtype: string
- name: neg_1st.original
dtype: string
- name: neg_1st.me5-large
dtype: string
- name: sim_1st.me5-large
dtype: float64
- name: neg_1st.bm25
dtype: string
- name: sim_1st.bm25
dtype: float64
- name: pos_ids
sequence: int64
- name: neg_ids.original
sequence: int64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 35660240
num_examples: 3697
download_size: 25702000
dataset_size: 35660240
- config_name: niilc-qa-dataset
features:
- name: id
dtype: string
- name: anc
dtype: string
- name: answers
sequence: string
splits:
- name: dev
num_bytes: 94339
num_examples: 795
- name: test
num_bytes: 24706
num_examples: 198
download_size: 69487
dataset_size: 119045
- config_name: nu-mnli-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: neg.orig
sequence: string
splits:
- name: train
num_bytes: 145358014
num_examples: 77785
download_size: 90397670
dataset_size: 145358014
- config_name: nu-snli-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: neg.orig
sequence: string
splits:
- name: train
num_bytes: 133786645
num_examples: 109154
download_size: 68979487
dataset_size: 133786645
- config_name: paws-x-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: neg.orig
sequence: string
splits:
- name: train
num_bytes: 124053741
num_examples: 49401
download_size: 75965630
dataset_size: 124053741
- config_name: qa-collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4202542828.0
num_examples: 6354742
download_size: 2284295643
dataset_size: 4202542828.0
- config_name: quiz-no-mori-dataset
features:
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: 'null'
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 340206118
num_examples: 25991
download_size: 241017142
dataset_size: 340206118
- config_name: quiz-works-dataset
features:
- name: anc
dtype: string
- name: answers
sequence: string
- name: pos_ids.original
sequence: 'null'
- name: neg_ids.original
sequence: 'null'
- name: pos_ids.me5-large
sequence: int64
- name: pos_sims.me5-large
sequence: float64
- name: pos_ids.bm25
sequence: int64
- name: pos_sims.bm25
sequence: float64
- name: neg_ids.me5-large
sequence: int64
- name: neg_sims.me5-large
sequence: float64
- name: neg_ids.bm25
sequence: int64
- name: neg_sims.bm25
sequence: float64
splits:
- name: train
num_bytes: 248971793
num_examples: 19073
download_size: 176241965
dataset_size: 248971793
- config_name: snow-triplet
features:
- name: anc
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
splits:
- name: train
num_bytes: 63640356
num_examples: 62758
download_size: 35752257
dataset_size: 63640356
configs:
- config_name: auto-wiki-nli-triplet
data_files:
- split: train
path: auto-wiki-nli-triplet/train-*
- config_name: auto-wiki-qa-collection
data_files:
- split: train
path: auto-wiki-qa-collection/train-*
- config_name: auto-wiki-qa-dataset
data_files:
- split: train
path: auto-wiki-qa-dataset/train-*
- config_name: auto-wiki-qa-nemotron-collection
data_files:
- split: train
path: auto-wiki-qa-nemotron-collection/train-*
- config_name: auto-wiki-qa-nemotron-dataset
data_files:
- split: train
path: auto-wiki-qa-nemotron-dataset/train-*
- config_name: baobab-wiki-retrieval-collection
data_files:
- split: train
path: baobab-wiki-retrieval-collection/train-*
- config_name: baobab-wiki-retrieval-dataset
data_files:
- split: train
path: baobab-wiki-retrieval-dataset/train-*
- config_name: jagovfaqs-collection
data_files:
- split: train
path: jagovfaqs-collection/train-*
- config_name: jagovfaqs-dataset
data_files:
- split: train
path: jagovfaqs-dataset/train-*
- config_name: janli-triplet
data_files:
- split: train
path: janli-triplet/train-*
- config_name: jaquad-collection
data_files:
- split: train
path: jaquad-collection/train-*
- config_name: jaquad-dataset
data_files:
- split: train
path: jaquad-dataset/train-*
- config_name: jcommonsenseqa-dataset
data_files:
- split: train
path: jcommonsenseqa-dataset/train-*
- config_name: jqara-collection
data_files:
- split: train
path: jqara-collection/train-*
- config_name: jqara-dataset
data_files:
- split: train
path: jqara-dataset/train-*
- config_name: jsnli-triplet
data_files:
- split: train
path: jsnli-triplet/train-*
- config_name: jsquad-collection
data_files:
- split: train
path: jsquad-collection/train-*
- config_name: jsquad-dataset
data_files:
- split: train
path: jsquad-dataset/train-*
- config_name: miracl-collection
data_files:
- split: train
path: miracl-collection/train-*
- config_name: miracl-dataset
data_files:
- split: train
path: miracl-dataset/train-*
- config_name: mkqa-dataset
data_files:
- split: train
path: mkqa-dataset/train-*
- config_name: mkqa-triplet
data_files:
- split: train
path: mkqa-triplet/train-*
- config_name: mmarco-collection
data_files:
- split: train
path: mmarco-collection/train-*
- config_name: mmarco-dataset
data_files:
- split: train
path: mmarco-dataset/train-*
- config_name: mr-tydi-collection
data_files:
- split: train
path: mr-tydi-collection/train-*
- config_name: mr-tydi-dataset
data_files:
- split: train
path: mr-tydi-dataset/train-*
- config_name: niilc-qa-dataset
data_files:
- split: dev
path: niilc-qa-dataset/dev-*
- split: test
path: niilc-qa-dataset/test-*
- config_name: nu-mnli-triplet
data_files:
- split: train
path: nu-mnli-triplet/train-*
- config_name: nu-snli-triplet
data_files:
- split: train
path: nu-snli-triplet/train-*
- config_name: paws-x-triplet
data_files:
- split: train
path: paws-x-triplet/train-*
- config_name: qa-collection
data_files:
- split: train
path: qa-collection/train-*
- config_name: quiz-no-mori-dataset
data_files:
- split: train
path: quiz-no-mori-dataset/train-*
- config_name: quiz-works-dataset
data_files:
- split: train
path: quiz-works-dataset/train-*
- config_name: snow-triplet
data_files:
- split: train
path: snow-triplet/train-*
---
still WIP
## Dataset Description
- **Paper:** https://arxiv.org/abs/2409.07737
- **Point of Contact:** [Hayato Tsukagoshi](mailto:[email protected])
## Information
|Name|Type|License (根拠)|
|-|-|-|
|MMARCO|Retrieval|[Apache 2.0 (?)](https://huggingface.co/datasets/unicamp-dl/mmarco)|
|Mr. TyDi|Retrieval|[Apache 2.0](https://huggingface.co/datasets/castorini/mr-tydi)|
|MIRACL|Retrieval|[Apache 2.0](https://huggingface.co/datasets/miracl/miracl)|
|JaGovFaqs|QA|[CC-BY-4.0](https://huggingface.co/datasets/matsuxr/JaGovFaqs-22k)|
|Auto Wiki QA|QA & Retrieval|[CC-BY-SA-4.0](https://huggingface.co/datasets/cl-nagoya/auto-wiki-qa)|
|Auto Wiki QA Nemotron|QA & Retrieval|[CC-BY-SA-4.0](https://huggingface.co/datasets/hpprc/auto-wiki-qa-nemotron)|
|JCommonsenseQA|QA|[CC-BY-SA-4.0](https://github.com/yahoojapan/JGLUE)|
|JSQuAD|QA & Retrieval|[CC-BY-SA-4.0](https://github.com/yahoojapan/JGLUE)|
|Japanese Wikipedia Human Retrieval|QA & Retrieval|[Apache 2.0](https://huggingface.co/datasets/baobab-trees/wikipedia-human-retrieval-ja)|
|JQaRA (dev, unused)|QA|[CC-BY-SA-4.0](https://huggingface.co/datasets/hotchpotch/JQaRA#:~:text=%E3%81%B0%E5%B9%B8%E3%81%84%E3%81%A7%E3%81%99%E3%80%82-,%E3%83%A9%E3%82%A4%E3%82%BB%E3%83%B3%E3%82%B9,%E3%81%A7%E3%81%82%E3%82%8B%20CC%20BY%2DSA%204.0%20%E3%81%BE%E3%81%9F%E3%81%AF%20GFDL%E3%81%A8%E3%81%97%E3%81%BE%E3%81%99%E3%80%82,-%E8%AC%9D%E8%BE%9E)|
|JaQuAD|QA & Retrieval|[CC-BY-SA-3.0](https://huggingface.co/datasets/SkelterLabsInc/JaQuAD)|
|JSNLI|NLI|[CC-BY-SA-4.0](https://huggingface.co/datasets/shunk031/jsnli)|
|Auto Wiki NLI|NLI|[CC-BY-SA-4.0](https://huggingface.co/datasets/hpprc/auto-wiki-nli-reward)|
|NU-SNLI|NLI|[CC-BY-SA-4.0](https://huggingface.co/datasets/cl-nagoya/nu-snli)|
|NU-MNLI|NLI|[CC-BY-SA-3.0, MIT, Others](https://huggingface.co/datasets/cl-nagoya/nu-mnli)|
|PAWS-X|Paraphrase|[Free (二次利用自由)](https://github.com/google-research-datasets/paws?tab=License-1-ov-file#readme)|
|SNOW|Paraphrase|[CC-BY-3.0](https://huggingface.co/datasets/SNOW-NLP/snow_simplified_japanese_corpus)|
|MKQA|QA|[CC-BY-3.0](https://huggingface.co/datasets/apple/mkqa)|
|Quiz Works|QA|[Free (二次利用自由)](https://quiz-works.com/about)|
|Quiz No Mori|QA|[Free (二次利用自由)](https://quiz-schedule.info/quiz_no_mori/quizforestsecond.html)|
|NIILC QA|QA|[CC-BY-SA](https://mynlp.is.s.u-tokyo.ac.jp/niilc-qa/)| |
flwrlabs/fed-isic2019 | flwrlabs | "2024-08-28T08:37:05Z" | 2,805 | 0 | [
"task_categories:image-classification",
"license:cc-by-nc-4.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2007.14390",
"region:us"
] | [
"image-classification"
] | "2024-08-26T14:44:12Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: center
dtype: int64
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
'2': '2'
'3': '3'
'4': '4'
'5': '5'
'6': '6'
'7': '7'
splits:
- name: train
num_bytes: 100322881.119
num_examples: 18597
- name: test
num_bytes: 25524081.6
num_examples: 4650
download_size: 143843380
dataset_size: 125846962.71900001
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
license: cc-by-nc-4.0
task_categories:
- image-classification
size_categories:
- 10K<n<100K
---
# Dataset Card for Fed-ISIC-2019
Federated version of ISIC-2019 Datasets ([ISIC2019 challenge](https://challenge.isic-archive.com/landing/2019/) and the [HAM1000 database](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T)). This implementation is derived based on the [FLamby](https://github.com/owkin/FLamby/blob/main/flamby/datasets/fed_isic2019/README.md) implementation.
## Dataset Details
The dataset contains 23,247 images of skin lesions divided among 6 clients representing different data centers. The number of samples for training/testing per data center is displayed in the table below:
| center_id | Train | Test |
|:---------:|:-------:|:------:|
| 0 | 9930 | 2483 |
| 1 | 3163 | 791 |
| 2 | 2691 | 672 |
| 3 | 1807 | 452 |
| 4 | 655 | 164 |
| 5 | 351 | 88 |
### Dataset Sources
- **ISIC 2019 Challange website:** https://challenge.isic-archive.com/landing/2019/
- **HAM1000 database website:** https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T
- **FLamby:** https://github.com/owkin/FLamby/tree/main
- **FLamby Fed-ISIC-2019 README:** https://github.com/owkin/FLamby/blob/main/flamby/datasets/fed_isic2019/README.md
- **Fed-ISIC-2019 docs:** https://owkin.github.io/FLamby/fed_isic.html
## Use in FL
In order to prepare the dataset for the FL settings, we recommend using [Flower Dataset](https://flower.ai/docs/datasets/) (flwr-datasets) for the dataset download and partitioning and [Flower](https://flower.ai/docs/framework/) (flwr) for conducting FL experiments.
To partition the dataset, do the following.
1. Install the package.
```bash
pip install flwr-datasets[vision]
```
2. Use the HF Dataset under the hood in Flower Datasets.
```python
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import NaturalIdPartitioner
fds = FederatedDataset(
dataset="flwrlabs/fed-isic2019",
partitioners={"train": NaturalIdPartitioner(partition_by="center"),
"test": NaturalIdPartitioner(partition_by="center")}
)
partition_train = fds.load_partition(partition_id=0, split="train")
partition_test = fds.load_partition(partition_id=0, split="test")
```
```
# Note: to keep the same results as in FLamby, please apply the following transformation
import albumentations
import random
import numpy as np
import torch
# Train dataset transformations
def apply_train_transforms(image_input):
print(image_input)
size = 200
train_transforms = albumentations.Compose(
[
albumentations.RandomScale(0.07),
albumentations.Rotate(50),
albumentations.RandomBrightnessContrast(0.15, 0.1),
albumentations.Flip(p=0.5),
albumentations.Affine(shear=0.1),
albumentations.RandomCrop(size, size),
albumentations.CoarseDropout(random.randint(1, 8), 16, 16),
albumentations.Normalize(always_apply=True),
]
)
images = []
for image in image_input["image"]:
augmented = train_transforms(image=np.array(image))["image"]
transposed = np.transpose(augmented, (2, 0, 1)).astype(np.float32)
images.append(torch.tensor(transposed, dtype=torch.float32))
image_input["image"] = images
return image_input
partition_train = partition_train.with_transform(apply_train_transforms,
columns="image")
# Test dataset transformations
def apply_test_transforms(image_input):
print(image_input)
size = 200
test_transforms = albumentations.Compose(
[
albumentations.CenterCrop(size, size),
albumentations.Normalize(always_apply=True),
]
)
images = []
for image in image_input["image"]:
augmented = test_transforms(image=np.array(image))["image"]
transposed = np.transpose(augmented, (2, 0, 1)).astype(np.float32)
images.append(torch.tensor(transposed, dtype=torch.float32))
image_input["image"] = images
return image_input
partition_test = partition_test.with_transform(apply_test_transforms,
columns="image")
```
## Dataset Structure
### Data Instances
The first instance of the train split is presented below:
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=224x224>,
'center': 0,
'label': 2
}
```
### Data Split
```
DatasetDict({
train: Dataset({
features: ['image', 'center', 'label'],
num_rows: 18597
})
test: Dataset({
features: ['image', 'center', 'label'],
num_rows: 4650
})
})
```
## Citation
When working with the Fed-ISIC-2019 dataset, please cite the original paper.
If you're using this dataset with Flower Datasets and Flower, cite Flower.
**BibTeX:**
FLamby:
```
@inproceedings{NEURIPS2022_232eee8e,
author = {Ogier du Terrail, Jean and Ayed, Samy-Safwan and Cyffers, Edwige and Grimberg, Felix and He, Chaoyang and Loeb, Regis and Mangold, Paul and Marchand, Tanguy and Marfoq, Othmane and Mushtaq, Erum and Muzellec, Boris and Philippenko, Constantin and Silva, Santiago and Tele\'{n}czuk, Maria and Albarqouni, Shadi and Avestimehr, Salman and Bellet, Aur\'{e}lien and Dieuleveut, Aymeric and Jaggi, Martin and Karimireddy, Sai Praneeth and Lorenzi, Marco and Neglia, Giovanni and Tommasi, Marc and Andreux, Mathieu},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {5315--5334},
publisher = {Curran Associates, Inc.},
title = {FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/232eee8ef411a0a316efa298d7be3c2b-Paper-Datasets_and_Benchmarks.pdf},
volume = {35},
year = {2022}
}
````
Flower:
```
@article{DBLP:journals/corr/abs-2007-14390,
author = {Daniel J. Beutel and
Taner Topal and
Akhil Mathur and
Xinchi Qiu and
Titouan Parcollet and
Nicholas D. Lane},
title = {Flower: {A} Friendly Federated Learning Research Framework},
journal = {CoRR},
volume = {abs/2007.14390},
year = {2020},
url = {https://arxiv.org/abs/2007.14390},
eprinttype = {arXiv},
eprint = {2007.14390},
timestamp = {Mon, 03 Aug 2020 14:32:13 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007-14390.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## Other References
The "ISIC 2019: Training" is the aggregate of the following datasets:
BCN_20000 Dataset: (c) Department of Dermatology, Hospital Clínic de Barcelona
HAM10000 Dataset: (c) by ViDIR Group, Department of Dermatology, Medical University of Vienna; HAM10000 dataset
MSK Dataset: (c) Anonymous; challenge 2017; challenge 2018
See below the full citations:
[1] Tschandl P., Rosendahl C. & Kittler H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 5, 180161 doi.10.1038/sdata.2018.161 (2018).
[2] Noel C. F. Codella, David Gutman, M. Emre Celebi, Brian Helba, Michael A. Marchetti, Stephen W. Dusza, Aadi Kalloo, Konstantinos Liopyris, Nabin Mishra, Harald Kittler, Allan Halpern: “Skin Lesion Analysis Toward Melanoma Detection: A Challenge at the 2017 International Symposium on Biomedical Imaging (ISBI), Hosted by the International Skin Imaging Collaboration (ISIC)”, 2017; arXiv:1710.05006.
[3] Marc Combalia, Noel C. F. Codella, Veronica Rotemberg, Brian Helba, Veronica Vilaplana, Ofer Reiter, Allan C. Halpern, Susana Puig, Josep Malvehy: “BCN20000: Dermoscopic Lesions in the Wild”, 2019; arXiv:1908.02288.
## Dataset Card Contact
If you have any questions about the dataset preprocessing and preparation, please contact [Flower Labs](https://flower.ai/). |
BeIR/scifact | BeIR | "2022-10-23T06:01:22Z" | 2,796 | 1 | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"size_categories:1K<n<10K",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [
"text-retrieval",
"zero-shot-retrieval",
"information-retrieval",
"zero-shot-information-retrieval"
] | "2022-06-05T16:24:20Z" | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. |
flwrlabs/usps | flwrlabs | "2024-07-15T08:54:40Z" | 2,792 | 2 | [
"task_categories:image-classification",
"license:unknown",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2007.14390",
"region:us"
] | [
"image-classification"
] | "2024-07-11T11:40:04Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
'2': '2'
'3': '3'
'4': '4'
'5': '5'
'6': '6'
'7': '7'
'8': '8'
'9': '9'
splits:
- name: train
num_bytes: 2194749.625
num_examples: 7291
- name: test
num_bytes: 609594.125
num_examples: 2007
download_size: 2559509
dataset_size: 2804343.75
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
license: unknown
task_categories:
- image-classification
size_categories:
- 1K<n<10K
---
# Dataset Card for USPS
USPS is a digit dataset automatically scanned from envelopes by the U.S. Postal Service containing a total of 9,298 16×16 pixel grayscale samples.
## Dataset Details
The images are centered and normalized. They show a broad range of font styles.
### Dataset Sources
- **Repository:** train set https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass/usps.bz2, test set: https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass/usps.t.bz2
- **Paper:** https://ieeexplore.ieee.org/abstract/document/291440
## Uses
In order to prepare the dataset for the FL settings, we recommend using [Flower Dataset](https://flower.ai/docs/datasets/) (flwr-datasets) for the dataset download and partitioning and [Flower](https://flower.ai/docs/framework/) (flwr) for conducting FL experiments.
To partition the dataset, do the following.
1. Install the package.
```bash
pip install flwr-datasets[vision]
```
2. Use the HF Dataset under the hood in Flower Datasets.
```python
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import IidPartitioner
fds = FederatedDataset(
dataset="flwrlabs/usps",
partitioners={"train": IidPartitioner(num_partitions=10)}
)
partition = fds.load_partition(partition_id=0)
```
## Dataset Structure
### Data Instances
The first instance of the train split is presented below:
```
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=L size=16x16 at 0x133B4BA90>,
'label': 6
}
```
### Data Split
```
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 7291
})
test: Dataset({
features: ['image', 'label'],
num_rows: 2007
})
})
```
## Citation
When working with the USPS dataset, please cite the original paper.
If you're using this dataset with Flower Datasets and Flower, cite Flower.
**BibTeX:**
Original paper:
```
@article{hull1994database,
title={A database for handwritten text recognition research},
journal={IEEE Transactions on pattern analysis and machine intelligence},
volume={16},
number={5},
pages={550--554},
year={1994},
publisher={IEEE}
}
````
Flower:
```
@article{DBLP:journals/corr/abs-2007-14390,
author = {Daniel J. Beutel and
Taner Topal and
Akhil Mathur and
Xinchi Qiu and
Titouan Parcollet and
Nicholas D. Lane},
title = {Flower: {A} Friendly Federated Learning Research Framework},
journal = {CoRR},
volume = {abs/2007.14390},
year = {2020},
url = {https://arxiv.org/abs/2007.14390},
eprinttype = {arXiv},
eprint = {2007.14390},
timestamp = {Mon, 03 Aug 2020 14:32:13 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007-14390.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## Dataset Card Contact
In case of any doubts about the dataset preprocessing and preparation, please contact [Flower Labs](https://flower.ai/). |
lambdalabs/pokemon-blip-captions | lambdalabs | "2024-03-20T15:56:33Z" | 2,773 | 278 | [
"task_categories:text-to-image",
"annotations_creators:machine-generated",
"language_creators:other",
"multilinguality:monolingual",
"source_datasets:huggan/few-shot-pokemon",
"language:en",
"license:cc-by-nc-sa-4.0",
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-to-image"
] | "2022-09-14T12:04:50Z" | ---
license: cc-by-nc-sa-4.0
annotations_creators:
- machine-generated
language:
- en
language_creators:
- other
multilinguality:
- monolingual
pretty_name: 'Pokémon BLIP captions'
size_categories:
- n<1K
source_datasets:
- huggan/few-shot-pokemon
tags: []
task_categories:
- text-to-image
task_ids: []
---
# Notice of DMCA Takedown Action
We have received a DMCA takedown notice from The Pokémon Company International, Inc.
In response to this action, we have taken down the dataset.
We appreciate your understanding. |
microsoft/ms_marco | microsoft | "2024-01-04T16:01:29Z" | 2,767 | 107 | [
"language:en",
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:1611.09268",
"region:us"
] | null | "2022-03-02T23:29:22Z" | ---
language:
- en
paperswithcode_id: ms-marco
pretty_name: Microsoft Machine Reading Comprehension Dataset
dataset_info:
- config_name: v1.1
features:
- name: answers
sequence: string
- name: passages
sequence:
- name: is_selected
dtype: int32
- name: passage_text
dtype: string
- name: url
dtype: string
- name: query
dtype: string
- name: query_id
dtype: int32
- name: query_type
dtype: string
- name: wellFormedAnswers
sequence: string
splits:
- name: validation
num_bytes: 42665198
num_examples: 10047
- name: train
num_bytes: 350516260
num_examples: 82326
- name: test
num_bytes: 40977580
num_examples: 9650
download_size: 217328153
dataset_size: 434159038
- config_name: v2.1
features:
- name: answers
sequence: string
- name: passages
sequence:
- name: is_selected
dtype: int32
- name: passage_text
dtype: string
- name: url
dtype: string
- name: query
dtype: string
- name: query_id
dtype: int32
- name: query_type
dtype: string
- name: wellFormedAnswers
sequence: string
splits:
- name: validation
num_bytes: 413765365
num_examples: 101093
- name: train
num_bytes: 3462807709
num_examples: 808731
- name: test
num_bytes: 405691932
num_examples: 101092
download_size: 2105722550
dataset_size: 4282265006
configs:
- config_name: v1.1
data_files:
- split: validation
path: v1.1/validation-*
- split: train
path: v1.1/train-*
- split: test
path: v1.1/test-*
- config_name: v2.1
data_files:
- split: validation
path: v2.1/validation-*
- split: train
path: v2.1/train-*
- split: test
path: v2.1/test-*
---
# Dataset Card for "ms_marco"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://microsoft.github.io/msmarco/](https://microsoft.github.io/msmarco/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 1.55 GB
- **Size of the generated dataset:** 4.72 GB
- **Total amount of disk used:** 6.28 GB
### Dataset Summary
Starting with a paper released at NIPS 2016, MS MARCO is a collection of datasets focused on deep learning in search.
The first dataset was a question answering dataset featuring 100,000 real Bing questions and a human generated answer.
Since then we released a 1,000,000 question dataset, a natural langauge generation dataset, a passage ranking dataset,
keyphrase extraction dataset, crawling dataset, and a conversational search.
There have been 277 submissions. 20 KeyPhrase Extraction submissions, 87 passage ranking submissions, 0 document ranking
submissions, 73 QnA V2 submissions, 82 NLGEN submisions, and 15 QnA V1 submissions
This data comes in three tasks/forms: Original QnA dataset(v1.1), Question Answering(v2.1), Natural Language Generation(v2.1).
The original question answering datset featured 100,000 examples and was released in 2016. Leaderboard is now closed but data is availible below.
The current competitive tasks are Question Answering and Natural Language Generation. Question Answering features over 1,000,000 queries and
is much like the original QnA dataset but bigger and with higher quality. The Natural Language Generation dataset features 180,000 examples and
builds upon the QnA dataset to deliver answers that could be spoken by a smart speaker.
version v1.1
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### v1.1
- **Size of downloaded dataset files:** 168.69 MB
- **Size of the generated dataset:** 434.61 MB
- **Total amount of disk used:** 603.31 MB
An example of 'train' looks as follows.
```
```
#### v2.1
- **Size of downloaded dataset files:** 1.38 GB
- **Size of the generated dataset:** 4.29 GB
- **Total amount of disk used:** 5.67 GB
An example of 'validation' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### v1.1
- `answers`: a `list` of `string` features.
- `passages`: a dictionary feature containing:
- `is_selected`: a `int32` feature.
- `passage_text`: a `string` feature.
- `url`: a `string` feature.
- `query`: a `string` feature.
- `query_id`: a `int32` feature.
- `query_type`: a `string` feature.
- `wellFormedAnswers`: a `list` of `string` features.
#### v2.1
- `answers`: a `list` of `string` features.
- `passages`: a dictionary feature containing:
- `is_selected`: a `int32` feature.
- `passage_text`: a `string` feature.
- `url`: a `string` feature.
- `query`: a `string` feature.
- `query_id`: a `int32` feature.
- `query_type`: a `string` feature.
- `wellFormedAnswers`: a `list` of `string` features.
### Data Splits
|name|train |validation| test |
|----|-----:|---------:|-----:|
|v1.1| 82326| 10047| 9650|
|v2.1|808731| 101093|101092|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{DBLP:journals/corr/NguyenRSGTMD16,
author = {Tri Nguyen and
Mir Rosenberg and
Xia Song and
Jianfeng Gao and
Saurabh Tiwary and
Rangan Majumder and
Li Deng},
title = {{MS} {MARCO:} {A} Human Generated MAchine Reading COmprehension Dataset},
journal = {CoRR},
volume = {abs/1611.09268},
year = {2016},
url = {http://arxiv.org/abs/1611.09268},
archivePrefix = {arXiv},
eprint = {1611.09268},
timestamp = {Mon, 13 Aug 2018 16:49:03 +0200},
biburl = {https://dblp.org/rec/journals/corr/NguyenRSGTMD16.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
}
```
### Contributions
Thanks to [@mariamabarham](https://github.com/mariamabarham), [@thomwolf](https://github.com/thomwolf), [@lewtun](https://github.com/lewtun) for adding this dataset. |
Neel-Gupta/owt-processed_512 | Neel-Gupta | "2024-08-05T04:38:16Z" | 2,756 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-08-05T04:09:55Z" | ---
dataset_info:
features:
- name: text
sequence:
sequence:
sequence: int64
splits:
- name: train
num_bytes: 281226340096
num_examples: 44656
download_size: 30432469170
dataset_size: 281226340096
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
MBZUAI/MadinahQA | MBZUAI | "2024-09-17T08:22:25Z" | 2,743 | 1 | [
"task_categories:question-answering",
"language:ar",
"license:cc-by-nc-4.0",
"size_categories:n<1K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"ArabicMMLU",
"exams"
] | [
"question-answering"
] | "2024-09-17T08:19:45Z" | ---
license: cc-by-nc-4.0
task_categories:
- question-answering
language:
- ar
tags:
- ArabicMMLU
- exams
dataset_info:
configs:
- config_name: Arabic Language (General)
data_files:
- split: test
path: Arabic Language (General)/test.csv
- split: dev
path: Arabic Language (General)/dev.csv
- config_name: Arabic Language (Grammar)
data_files:
- split: test
path: Arabic Language (Grammar)/test.csv
- split: dev
path: Arabic Language (Grammar)/dev.csv
---
This data is part of MBZUAI/ArabicMMLU |
BeIR/hotpotqa-qrels | BeIR | "2022-10-23T06:06:12Z" | 2,734 | 1 | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"size_categories:100K<n<1M",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-retrieval",
"zero-shot-retrieval",
"information-retrieval",
"zero-shot-information-retrieval"
] | "2022-06-05T17:26:24Z" | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. |
pkavumba/balanced-copa | pkavumba | "2022-10-03T00:39:01Z" | 2,727 | 1 | [
"task_categories:question-answering",
"task_ids:multiple-choice-qa",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"source_datasets:extended|copa",
"language:en",
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"question-answering"
] | "2022-10-03T00:33:09Z" | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: BCOPA
size_categories:
- unknown
source_datasets:
- extended|copa
task_categories:
- question-answering
task_ids:
- multiple-choice-qa
---
# Dataset Card for "Balanced COPA"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://balanced-copa.github.io/](https://balanced-copa.github.io/)
- **Repository:** [Balanced COPA](https://github.com/Balanced-COPA/Balanced-COPA)
- **Paper:** [When Choosing Plausible Alternatives, Clever Hans can be Clever](https://aclanthology.org/D19-6004/)
- **Point of Contact:** [@pkavumba](https://github.com/pkavumba)
### Dataset Summary
Bala-COPA: An English language Dataset for Training Robust Commonsense Causal Reasoning Models
The Balanced Choice of Plausible Alternatives dataset is a benchmark for training machine learning models that are robust to superficial cues/spurious correlations. The dataset extends the COPA dataset(Roemmele et al. 2011) with mirrored instances that mitigate against token-level superficial cues in the original COPA answers. The superficial cues in the original COPA datasets result from an unbalanced token distribution between the correct and the incorrect answer choices, i.e., some tokens appear more in the correct choices than the incorrect ones. Balanced COPA equalizes the token distribution by adding mirrored instances with identical answer choices but different labels.
The details about the creation of Balanced COPA and the implementation of the baselines are available in the paper.
Balanced COPA language en
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
- English
## Dataset Structure
### Data Instances
An example of 'validation' looks as follows.
```
{
"id": 1,
"premise": "My body cast a shadow over the grass.",
"choice1": "The sun was rising.",
"choice2": "The grass was cut.",
"question": "cause",
"label": 1,
"mirrored": false,
}
{
"id": 1001,
"premise": "The garden looked well-groomed.",
"choice1": "The sun was rising.",
"choice2": "The grass was cut.",
"question": "cause",
"label": 1,
"mirrored": true,
}
```
### Data Fields
The data fields are the same among all splits.
#### en
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `label`: a `int32` feature.
- `id`: a `int32` feature.
- `mirrored`: a `bool` feature.
### Data Splits
| validation | test |
| ---------: | ---: |
| 1,000 | 500 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[Creative Commons Attribution 4.0 International (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
```
@inproceedings{kavumba-etal-2019-choosing,
title = "When Choosing Plausible Alternatives, Clever Hans can be Clever",
author = "Kavumba, Pride and
Inoue, Naoya and
Heinzerling, Benjamin and
Singh, Keshav and
Reisert, Paul and
Inui, Kentaro",
booktitle = "Proceedings of the First Workshop on Commonsense Inference in Natural Language Processing",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D19-6004",
doi = "10.18653/v1/D19-6004",
pages = "33--42",
abstract = "Pretrained language models, such as BERT and RoBERTa, have shown large improvements in the commonsense reasoning benchmark COPA. However, recent work found that many improvements in benchmarks of natural language understanding are not due to models learning the task, but due to their increasing ability to exploit superficial cues, such as tokens that occur more often in the correct answer than the wrong one. Are BERT{'}s and RoBERTa{'}s good performance on COPA also caused by this? We find superficial cues in COPA, as well as evidence that BERT exploits these cues.To remedy this problem, we introduce Balanced COPA, an extension of COPA that does not suffer from easy-to-exploit single token cues. We analyze BERT{'}s and RoBERTa{'}s performance on original and Balanced COPA, finding that BERT relies on superficial cues when they are present, but still achieves comparable performance once they are made ineffective, suggesting that BERT learns the task to a certain degree when forced to. In contrast, RoBERTa does not appear to rely on superficial cues.",
}
@inproceedings{roemmele2011choice,
title={Choice of plausible alternatives: An evaluation of commonsense causal reasoning},
author={Roemmele, Melissa and Bejan, Cosmin Adrian and Gordon, Andrew S},
booktitle={2011 AAAI Spring Symposium Series},
year={2011},
url={https://people.ict.usc.edu/~gordon/publications/AAAI-SPRING11A.PDF},
}
```
### Contributions
Thanks to [@pkavumba](https://github.com/pkavumba) for adding this dataset.
|
derek-thomas/ScienceQA | derek-thomas | "2023-02-25T04:23:01Z" | 2,722 | 136 | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:other",
"task_categories:visual-question-answering",
"task_categories:text-classification",
"task_ids:multiple-choice-qa",
"task_ids:closed-domain-qa",
"task_ids:open-domain-qa",
"task_ids:visual-question-answering",
"task_ids:multi-class-classification",
"annotations_creators:expert-generated",
"annotations_creators:found",
"language_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:cc-by-sa-4.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2209.09513",
"region:us",
"multi-modal-qa",
"science",
"chemistry",
"biology",
"physics",
"earth-science",
"engineering",
"geography",
"history",
"world-history",
"civics",
"economics",
"global-studies",
"grammar",
"writing",
"vocabulary",
"natural-science",
"language-science",
"social-science"
] | [
"multiple-choice",
"question-answering",
"other",
"visual-question-answering",
"text-classification"
] | "2023-02-10T11:28:58Z" | ---
license: cc-by-sa-4.0
annotations_creators:
- expert-generated
- found
language:
- en
language_creators:
- expert-generated
- found
multilinguality:
- monolingual
paperswithcode_id: scienceqa
pretty_name: ScienceQA
size_categories:
- 10K<n<100K
source_datasets:
- original
tags:
- multi-modal-qa
- science
- chemistry
- biology
- physics
- earth-science
- engineering
- geography
- history
- world-history
- civics
- economics
- global-studies
- grammar
- writing
- vocabulary
- natural-science
- language-science
- social-science
task_categories:
- multiple-choice
- question-answering
- other
- visual-question-answering
- text-classification
task_ids:
- multiple-choice-qa
- closed-domain-qa
- open-domain-qa
- visual-question-answering
- multi-class-classification
dataset_info:
features:
- name: image
dtype: image
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype: int8
- name: hint
dtype: string
- name: task
dtype: string
- name: grade
dtype: string
- name: subject
dtype: string
- name: topic
dtype: string
- name: category
dtype: string
- name: skill
dtype: string
- name: lecture
dtype: string
- name: solution
dtype: string
splits:
- name: train
num_bytes: 16416902
num_examples: 12726
- name: validation
num_bytes: 5404896
num_examples: 4241
- name: test
num_bytes: 5441676
num_examples: 4241
download_size: 0
dataset_size: 27263474
---
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://scienceqa.github.io/index.html#home](https://scienceqa.github.io/index.html#home)
- **Repository:** [https://github.com/lupantech/ScienceQA](https://github.com/lupantech/ScienceQA)
- **Paper:** [https://arxiv.org/abs/2209.09513](https://arxiv.org/abs/2209.09513)
- **Leaderboard:** [https://paperswithcode.com/dataset/scienceqa](https://paperswithcode.com/dataset/scienceqa)
- **Point of Contact:** [Pan Lu](https://lupantech.github.io/) or file an issue on [Github](https://github.com/lupantech/ScienceQA/issues)
### Dataset Summary
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
### Supported Tasks and Leaderboards
Multi-modal Multiple Choice
### Languages
English
## Dataset Structure
### Data Instances
Explore more samples [here](https://scienceqa.github.io/explore.html).
``` json
{'image': Image,
'question': 'Which of these states is farthest north?',
'choices': ['West Virginia', 'Louisiana', 'Arizona', 'Oklahoma'],
'answer': 0,
'hint': '',
'task': 'closed choice',
'grade': 'grade2',
'subject': 'social science',
'topic': 'geography',
'category': 'Geography',
'skill': 'Read a map: cardinal directions',
'lecture': 'Maps have four cardinal directions, or main directions. Those directions are north, south, east, and west.\nA compass rose is a set of arrows that point to the cardinal directions. A compass rose usually shows only the first letter of each cardinal direction.\nThe north arrow points to the North Pole. On most maps, north is at the top of the map.',
'solution': 'To find the answer, look at the compass rose. Look at which way the north arrow is pointing. West Virginia is farthest north.'}
```
Some records might be missing any or all of image, lecture, solution.
### Data Fields
- `image` : Contextual image
- `question` : Prompt relating to the `lecture`
- `choices` : Multiple choice answer with 1 correct to the `question`
- `answer` : Index of choices corresponding to the correct answer
- `hint` : Hint to help answer the `question`
- `task` : Task description
- `grade` : Grade level from K-12
- `subject` : High level
- `topic` : natural-sciences, social-science, or language-science
- `category` : A subcategory of `topic`
- `skill` : A description of the task required
- `lecture` : A relevant lecture that a `question` is generated from
- `solution` : Instructions on how to solve the `question`
Note that the descriptions can be initialized with the **Show Markdown Data Fields** output of the [Datasets Tagging app](https://huggingface.co/spaces/huggingface/datasets-tagging), you will then only need to refine the generated descriptions.
### Data Splits
- name: train
- num_bytes: 16416902
- num_examples: 12726
- name: validation
- num_bytes: 5404896
- num_examples: 4241
- name: test
- num_bytes: 5441676
- num_examples: 4241
## Dataset Creation
### Curation Rationale
When answering a question, humans utilize the information available across different modalities to synthesize a consistent and complete chain of thought (CoT). This process is normally a black box in the case of deep learning models like large-scale language models. Recently, science question benchmarks have been used to diagnose the multi-hop reasoning ability and interpretability of an AI system. However, existing datasets fail to provide annotations for the answers, or are restricted to the textual-only modality, small scales, and limited domain diversity. To this end, we present Science Question Answering (ScienceQA).
### Source Data
ScienceQA is collected from elementary and high school science curricula.
#### Initial Data Collection and Normalization
See Below
#### Who are the source language producers?
See Below
### Annotations
Questions in the ScienceQA dataset are sourced from open resources managed by IXL Learning,
an online learning platform curated by experts in the field of K-12 education. The dataset includes
problems that align with California Common Core Content Standards. To construct ScienceQA, we
downloaded the original science problems and then extracted individual components (e.g. questions,
hints, images, options, answers, lectures, and solutions) from them based on heuristic rules.
We manually removed invalid questions, such as questions that have only one choice, questions that
contain faulty data, and questions that are duplicated, to comply with fair use and transformative
use of the law. If there were multiple correct answers that applied, we kept only one correct answer.
Also, we shuffled the answer options of each question to ensure the choices do not follow any
specific pattern. To make the dataset easy to use, we then used semi-automated scripts to reformat
the lectures and solutions. Therefore, special structures in the texts, such as tables and lists, are
easily distinguishable from simple text passages. Similar to ImageNet, ReClor, and PMR datasets,
ScienceQA is available for non-commercial research purposes only and the copyright belongs to
the original authors. To ensure data quality, we developed a data exploration tool to review examples
in the collected dataset, and incorrect annotations were further manually revised by experts. The tool
can be accessed at https://scienceqa.github.io/explore.html.
#### Annotation process
See above
#### Who are the annotators?
See above
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
- Pan Lu1,3
- Swaroop Mishra2,3
- Tony Xia1
- Liang Qiu1
- Kai-Wei Chang1
- Song-Chun Zhu1
- Oyvind Tafjord3
- Peter Clark3
- Ashwin Kalyan3
From:
1. University of California, Los Angeles
2. Arizona State University
3. Allen Institute for AI
### Licensing Information
[Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
](https://creativecommons.org/licenses/by-nc-sa/4.0/)
### Citation Information
Provide the [BibTex](http://www.bibtex.org/)-formatted reference for the dataset. For example:
```
@inproceedings{lu2022learn,
title={Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering},
author={Lu, Pan and Mishra, Swaroop and Xia, Tony and Qiu, Liang and Chang, Kai-Wei and Zhu, Song-Chun and Tafjord, Oyvind and Clark, Peter and Ashwin Kalyan},
booktitle={The 36th Conference on Neural Information Processing Systems (NeurIPS)},
year={2022}
}
```
### Contributions
Thanks to [Derek Thomas](https://huggingface.co/derek-thomas) [@datavistics](https://github.com/datavistics) for adding this dataset. |
Dahoas/full-hh-rlhf | Dahoas | "2023-02-23T17:29:46Z" | 2,717 | 71 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2022-12-16T20:45:27Z" | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
splits:
- name: train
num_bytes: 203150123
num_examples: 112052
- name: test
num_bytes: 22606646
num_examples: 12451
download_size: 136150742
dataset_size: 225756769
---
# Dataset Card for "full-hh-rlhf"
Anthropic's HH dataset reformatted into prompt, chosen, rejected samples. |
yuvalkirstain/pickapic_v1_no_images | yuvalkirstain | "2023-04-16T14:53:35Z" | 2,692 | 1 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-04-16T14:52:20Z" | ---
dataset_info:
features:
- name: are_different
dtype: bool
- name: best_image_uid
dtype: string
- name: caption
dtype: string
- name: created_at
dtype: timestamp[ns]
- name: has_label
dtype: bool
- name: image_0_uid
dtype: string
- name: image_0_url
dtype: string
- name: image_1_uid
dtype: string
- name: image_1_url
dtype: string
- name: label_0
dtype: float64
- name: label_1
dtype: float64
- name: model_0
dtype: string
- name: model_1
dtype: string
- name: ranking_id
dtype: int64
- name: user_id
dtype: int64
- name: num_example_per_prompt
dtype: int64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 308923563
num_examples: 583747
- name: validation
num_bytes: 8759568
num_examples: 17439
- name: test
num_bytes: 7194410
num_examples: 14073
- name: validation_unique
num_bytes: 248229
num_examples: 500
- name: test_unique
num_bytes: 256313
num_examples: 500
download_size: 175013617
dataset_size: 325382083
---
# Dataset Card for "pick_a_pic_v1_no_images"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
bigcode/the-stack-dedup | bigcode | "2023-08-17T08:21:58Z" | 2,676 | 328 | [
"task_categories:text-generation",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:multilingual",
"language:code",
"license:other",
"size_categories:100M<n<1B",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2211.15533",
"arxiv:2107.03374",
"arxiv:2207.14157",
"region:us"
] | [
"text-generation"
] | "2022-10-06T17:49:19Z" | ---
annotations_creators: []
language_creators:
- crowdsourced
- expert-generated
language:
- code
license:
- other
multilinguality:
- multilingual
pretty_name: The-Stack
size_categories:
- unknown
source_datasets: []
task_categories:
- text-generation
task_ids: []
extra_gated_prompt: |-
## Terms of Use for The Stack
The Stack dataset is a collection of source code in over 300 programming languages. We ask that you read and acknowledge the following points before using the dataset:
1. The Stack is a collection of source code from repositories with various licenses. Any use of all or part of the code gathered in The Stack must abide by the terms of the original licenses, including attribution clauses when relevant. We facilitate this by providing provenance information for each data point.
2. The Stack is regularly updated to enact validated data removal requests. By clicking on "Access repository", you agree to update your own version of The Stack to the most recent usable version specified by the maintainers in [the following thread](https://huggingface.co/datasets/bigcode/the-stack/discussions/7). If you have questions about dataset versions and allowed uses, please also ask them in the dataset’s [community discussions](https://huggingface.co/datasets/bigcode/the-stack/discussions/new). We will also notify users via email when the latest usable version changes.
3. To host, share, or otherwise provide access to The Stack dataset, you must include [these Terms of Use](https://huggingface.co/datasets/bigcode/the-stack#terms-of-use-for-the-stack) and require users to agree to it.
By clicking on "Access repository" below, you accept that your contact information (email address and username) can be shared with the dataset maintainers as well.
extra_gated_fields:
Email: text
I have read the License and agree with its terms: checkbox
---
# Dataset Card for The Stack

## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Changelog](#changelog)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use it](#how-to-use-it)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
- [Terms of Use for The Stack](#terms-of-use-for-the-stack)
## Dataset Description
- **Homepage:** https://www.bigcode-project.org/
- **Repository:** https://github.com/bigcode-project
- **Paper:** https://arxiv.org/abs/2211.15533
- **Leaderboard:** N/A
- **Point of Contact:** [email protected]
### Changelog
|Release|Description|
|-|-|
|v1.0| Initial release of the Stack. Included 30 programming languages and 18 permissive licenses. **Note:** Three included licenses (MPL/EPL/LGPL) are considered weak copyleft licenses. The resulting near-deduplicated dataset is 1.5TB in size. |
|v1.1| The three copyleft licenses ((MPL/EPL/LGPL) were excluded and the list of permissive licenses extended to 193 licenses in total. The list of programming languages was increased from 30 to 358 languages. Also opt-out request submitted by 15.11.2022 were excluded from this version of the dataset. The resulting near-deduplicated dataset is 3TB in size.|
|v1.2| Opt-out request submitted by 09.02.2022 were excluded from this version of the dataset. A stronger near-deduplication strategy was applied resulting leading to 2.7TB in size.|
### Dataset Summary
The Stack contains over 6TB of permissively-licensed source code files covering 358 programming languages. The dataset was created as part of the [BigCode Project](https://www.bigcode-project.org/), an open scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs). The Stack serves as a pre-training dataset for Code LLMs, i.e., code-generating AI systems which enable the synthesis of programs from natural language descriptions as well as other from code snippets. **This is the near-deduplicated version with 3TB data.**
### Supported Tasks and Leaderboards
The Stack is a pre-training dataset for creating code LLMs. Code LLMs can be used for a wide variety of downstream tasks such as code completion from natural language descriptions ([HumanEval](https://huggingface.co/datasets/openai_humaneval), [MBPP](https://huggingface.co/datasets/mbpp)), documentation generation for individual functions ([CodeSearchNet](https://huggingface.co/datasets/code_search_net)), and auto-completion of code snippets ([HumanEval-Infilling](https://github.com/openai/human-eval-infilling)). However, these downstream evaluation benchmarks are outside the scope of The Stack.
### Languages
The following natural languages appear in the comments and docstrings from files in the dataset: EN, ZH, FR, PT, ES, RU, DE, KO, JA, UZ, IT, ID, RO, AR, FA, CA, HU, ML, NL, TR, TE, EL, EO, BN, LV, GL, PL, GU, CEB, IA, KN, SH, MK, UR, SV, LA, JKA, MY, SU, CS, MN. This kind of data is essential for applications such as documentation generation and natural-language-to-code translation.
The dataset contains **358 programming languages**. The full list can be found [here](https://huggingface.co/datasets/bigcode/the-stack-dedup/blob/main/programming-languages.json).
### How to use it
```python
from datasets import load_dataset
# full dataset (3TB of data)
ds = load_dataset("bigcode/the-stack-dedup", split="train")
# specific language (e.g. Dockerfiles)
ds = load_dataset("bigcode/the-stack-dedup", data_dir="data/dockerfile", split="train")
# dataset streaming (will only download the data as needed)
ds = load_dataset("bigcode/the-stack-dedup", streaming=True, split="train")
for sample in iter(ds): print(sample["content"])
```
## Dataset Structure
### Data Instances
Each data instance corresponds to one file. The content of the file is in the `content` feature, and other features (`repository_name`, `licenses`, etc.) provide some metadata. Note that a given file can appear in several different repositories that satisfy our safe-license criterion. If that is the case, only the first – in alphabetical order -- of these repositories is shown for simplicity.
### Data Fields
- `content` (string): the content of the file.
- `size` (integer): size of the uncompressed file.
- `lang` (string): the programming language.
- `ext` (string): file extension
- `avg_line_length` (float): the average line-length of the file.
- `max_line_length` (integer): the maximum line-length of the file.
- `alphanum_fraction` (float): the fraction of characters in the file that are alphabetical or numerical characters.
- `hexsha` (string): unique git hash of file
- `max_{stars|forks|issues}_repo_path` (string): path to file in repo containing this file with maximum number of `{stars|forks|issues}`
- `max_{stars|forks|issues}_repo_name` (string): name of repo containing this file with maximum number of `{stars|forks|issues}`
- `max_{stars|forks|issues}_repo_head_hexsha` (string): hexsha of repository head
- `max_{stars|forks|issues}_repo_licenses` (string): licenses in repository
- `max_{stars|forks|issues}_count` (integer): number of `{stars|forks|issues}` in repository
- `max_{stars|forks|issues}_repo_{stars|forks|issues}_min_datetime` (string): first timestamp of a `{stars|forks|issues}` event
- `max_{stars|forks|issues}_repo_{stars|forks|issues}_max_datetime` (string): last timestamp of a `{stars|forks|issues}` event
### Data Splits
The dataset has no splits and all data is loaded as train split by default. If you want to setup a custom train-test split beware that dataset contains a lot of near-duplicates which can cause leakage into the test split.
## Dataset Creation
### Curation Rationale
One of the challenges faced by researchers working on code LLMs is the lack of openness and transparency around the development of these systems. Most prior works described the high-level data collection process but did not release the training data. It is therefore difficult for other researchers to fully reproduce these models and understand what kind of pre-training data leads to high-performing code LLMs. By releasing an open large-scale code dataset we hope to make training of code LLMs more reproducible. **This is the near-deduplicated version with 3TB data.**
### Source Data
#### Initial Data Collection and Normalization
220.92M active GitHub repository names were collected from the event archives published between January 1st, 2015 and March 31st, 2022 on [GHArchive](https://gharchive.org/). Only 137.36M of these repositories were public and accessible on GitHub – others were not accessible as they had been deleted by their owners. 51.76B files were downloaded from the public repositories on GitHub between November 2021 and June 2022. 5.28B files were unique. The uncompressed size of all stored files is 92.36TB.
The list of programming language extensions is taken from this [list](https://gist.github.com/ppisarczyk/43962d06686722d26d176fad46879d41) (also provided in Appendix C of the paper).
Near-deduplication was implemented in the pre-processing pipeline on top of exact deduplication. To find near-duplicates, MinHash with 256 permutations of all documents was computed in linear time. Locality Sensitive Hashing was used to find the clusters of duplicates. Jaccard Similarities were computed inside these clusters to remove any false positives and with a similarity threshold of 0.85. Roughly 40% of permissively licensed files were (near-)duplicates. See section 3 of the paper for further details.
The following are not stored:
- Files that cannot contribute to training code: binary, empty, could not be decoded
- Files larger than 1MB
- The excluded file extensions are listed in Appendix B of the paper.
##### License detection
Permissive licenses have minimal restrictions on how the software can be copied, modified, and redistributed. The full list of licenses can be found [here](https://huggingface.co/datasets/bigcode/the-stack-dedup/blob/main/licenses.json)
GHArchive contained the license information for approximately 12% of the collected repositories. For the remaining repositories, [go-license-detector](https://github.com/src-d/go-license-detector) was run to detect the most likely SPDX license identifier. The detector did not detect a license for ~81% of the repositories, in which case the repository was excluded from the dataset.
A file was in included in the safe license dataset if at least one of the repositories containing the file had a permissive license.
#### Who are the source language producers?
The source (code) language producers are users of GitHub that created unique repository names between January 1st, 2015, and March 31st, 2022.
### Personal and Sensitive Information
The released dataset may contain sensitive information such as emails, IP addresses, and API/ssh keys that have previously been published to public repositories on GitHub. Deduplication has helped to reduce the amount of sensitive data that may exist. In the event that the dataset contains personal information, researchers should only use public, non-personal information in support of conducting and publishing their [open-access](https://en.wikipedia.org/wiki/Open_access) research. Personal information should not be used for spamming purposes, including sending unsolicited emails or selling of personal information. Complaints, removal requests, and "do not contact" requests can be sent to [email protected].
The PII pipeline for this dataset is still a work in progress (see this [issue](https://github.com/bigcode-project/admin/issues/9) for updates). Researchers that wish to contribute to the anonymization pipeline of the project can apply to join [here](https://www.bigcode-project.org/docs/about/join/). Developers with source code in the dataset can request to have it removed [here](https://www.bigcode-project.org/docs/about/ip/) (proof of code contribution is required).
### Opting out of The Stack
We are giving developers the ability to have their code removed from the dataset upon request. The process for submitting and enacting removal requests will keep evolving throughout the project as we receive feedback and build up more data governance tools.
You can check if your code is in The Stack with the following ["Am I In The Stack?" Space](https://huggingface.co/spaces/bigcode/in-the-stack). If you'd like to have your data removed from the dataset follow the [instructions on GitHub](https://github.com/bigcode-project/opt-out-v2).
## Considerations for Using the Data
### Social Impact of Dataset
The Stack is an output of the BigCode Project. BigCode aims to be responsible by design and by default. The project is conducted in the spirit of Open Science, focused on the responsible development of LLMs for code.
With the release of The Stack, we aim to increase access, reproducibility, and transparency of code LLMs in the research community. Work to de-risk and improve on the implementation of ethical best practices of code LLMs is conducted in various BigCode working groups. The Legal, Ethics, and Governance working group has explored topics such as licensing (including copyleft and the intended use of permissively licensed code), attribution of generated code to original code, rights to restrict processing, the inclusion of Personally Identifiable Information (PII), and risks of malicious code, among other topics. This work is ongoing as of October 25th, 2022.
We expect code LLMs to enable people from diverse backgrounds to write higher quality code and develop low-code applications. Mission-critical software could become easier to maintain as professional developers are guided by code-generating systems on how to write more robust and efficient code. While the social impact is intended to be positive, the increased accessibility of code LLMs comes with certain risks such as over-reliance on the generated code and long-term effects on the software development job market.
A broader impact analysis relating to Code LLMs can be found in section 7 of this [paper](https://arxiv.org/abs/2107.03374). An in-depth risk assessments for Code LLMs can be found in section 4 of this [paper](https://arxiv.org/abs/2207.14157).
### Discussion of Biases
The code collected from GitHub does not contain demographic information or proxy information about the demographics. However, it is not without risks,
as the comments within the code may contain harmful or offensive language, which could be learned by the models.
Widely adopted programming languages like C and Javascript are overrepresented compared to niche programming languages like Julia and Scala. Some programming languages such as SQL, Batchfile, TypeScript are less likely to be permissively licensed (4% vs the average 10%). This may result in a biased representation of those languages. Permissively licensed files also tend to be longer.
Roughly 40 natural languages are present in docstrings and comments with English being the most prevalent. In python files, it makes up ~96% of the dataset.
For further information on data analysis of the Stack, see this [repo](https://github.com/bigcode-project/bigcode-analysis).
### Other Known Limitations
One of the current limitations of The Stack is that scraped HTML for websites may not be compliant with Web Content Accessibility Guidelines ([WCAG](https://www.w3.org/WAI/standards-guidelines/wcag/)). This could have an impact on HTML-generated code that may introduce web accessibility issues.
The training dataset could contain malicious code and/or the model could be used to generate malware or ransomware.
To the best of our knowledge, all files contained in the dataset are licensed with one of the permissive licenses (see list in [Licensing information](#licensing-information)). The accuracy of license attribution is limited by the accuracy of GHArchive and go-license-detector. Any mistakes should be reported to BigCode Project for review and follow-up as needed.
## Additional Information
### Dataset Curators
1. Harm de Vries, ServiceNow Research, [email protected]
2. Leandro von Werra, Hugging Face, [email protected]
### Licensing Information
The Stack is a collection of source code from repositories with various licenses. Any use of all or part of the code gathered in The Stack must abide by the terms of the original licenses, including attribution clauses when relevant. We facilitate this by providing provenance information for each data point.
The list of [SPDX license identifiers](https://spdx.org/licenses/) included in the dataset can be found [here](https://huggingface.co/datasets/bigcode/the-stack-dedup/blob/main/licenses.json).
### Citation Information
```
@article{Kocetkov2022TheStack,
title={The Stack: 3 TB of permissively licensed source code},
author={Kocetkov, Denis and Li, Raymond and Ben Allal, Loubna and Li, Jia and Mou,Chenghao and Muñoz Ferrandis, Carlos and Jernite, Yacine and Mitchell, Margaret and Hughes, Sean and Wolf, Thomas and Bahdanau, Dzmitry and von Werra, Leandro and de Vries, Harm},
journal={Preprint},
year={2022}
}
```
### Contributions
[More Information Needed]
## Terms of Use for The Stack
The Stack dataset is a collection of source code in over 300 programming languages. We ask that you read and acknowledge the following points before using the dataset:
1. The Stack is a collection of source code from repositories with various licenses. Any use of all or part of the code gathered in The Stack must abide by the terms of the original licenses, including attribution clauses when relevant. We facilitate this by providing provenance information for each data point.
2. The Stack is regularly updated to enact validated data removal requests. By clicking on "Access repository", you agree to update your own version of The Stack to the most recent usable version specified by the maintainers in [the following thread](https://huggingface.co/datasets/bigcode/the-stack/discussions/7). If you have questions about dataset versions and allowed uses, please also ask them in the dataset’s [community discussions](https://huggingface.co/datasets/bigcode/the-stack/discussions/new). We will also notify users via email when the latest usable version changes.
3. To host, share, or otherwise provide access to The Stack dataset, you must include these Terms of Use and require users to agree to it.
|
AlignmentResearch/Helpful | AlignmentResearch | "2024-07-29T21:23:48Z" | 2,650 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-07-12T03:40:35Z" | ---
dataset_info:
- config_name: default
features:
- name: instructions
dtype: string
- name: content
sequence: string
- name: answer_prompt
dtype: string
- name: clf_label
dtype:
class_label:
names:
'0': ' FIRST'
'1': ' SECOND'
- name: proxy_clf_label
dtype:
class_label:
names:
'0': ' FIRST'
'1': ' SECOND'
- name: gen_target
dtype: string
- name: proxy_gen_target
dtype: string
splits:
- name: train
num_bytes: 76038646.0
num_examples: 41815
- name: validation
num_bytes: 4090622.0
num_examples: 2243
download_size: 25532448
dataset_size: 80129268.0
- config_name: neg
features:
- name: instructions
dtype: string
- name: content
sequence: string
- name: answer_prompt
dtype: string
- name: clf_label
dtype:
class_label:
names:
'0': ' FIRST'
'1': ' SECOND'
- name: proxy_clf_label
dtype:
class_label:
names:
'0': ' FIRST'
'1': ' SECOND'
- name: gen_target
dtype: string
- name: proxy_gen_target
dtype: string
splits:
- name: train
num_bytes: 37994773.873586036
num_examples: 20894
- name: validation
num_bytes: 2044399.1359786
num_examples: 1121
download_size: 12795527
dataset_size: 40039173.00956464
- config_name: pos
features:
- name: instructions
dtype: string
- name: content
sequence: string
- name: answer_prompt
dtype: string
- name: clf_label
dtype:
class_label:
names:
'0': ' FIRST'
'1': ' SECOND'
- name: proxy_clf_label
dtype:
class_label:
names:
'0': ' FIRST'
'1': ' SECOND'
- name: gen_target
dtype: string
- name: proxy_gen_target
dtype: string
splits:
- name: train
num_bytes: 38043872.126413964
num_examples: 20921
- name: validation
num_bytes: 2046222.8640214
num_examples: 1122
download_size: 12756279
dataset_size: 40090094.99043536
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- config_name: neg
data_files:
- split: train
path: neg/train-*
- split: validation
path: neg/validation-*
- config_name: pos
data_files:
- split: train
path: pos/train-*
- split: validation
path: pos/validation-*
---
|
open-llm-leaderboard-old/details_Sao10K__Stheno-Inverted-L2-13B | open-llm-leaderboard-old | "2023-10-24T14:50:06Z" | 2,649 | 0 | [
"region:us"
] | null | "2023-08-31T22:34:49Z" | ---
pretty_name: Evaluation run of Sao10K/Stheno-Inverted-L2-13B
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [Sao10K/Stheno-Inverted-L2-13B](https://huggingface.co/Sao10K/Stheno-Inverted-L2-13B)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Sao10K__Stheno-Inverted-L2-13B\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-24T14:49:52.594706](https://huggingface.co/datasets/open-llm-leaderboard/details_Sao10K__Stheno-Inverted-L2-13B/blob/main/results_2023-10-24T14-49-52.594706.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.005453020134228188,\n\
\ \"em_stderr\": 0.0007541727796792602,\n \"f1\": 0.08334836409396004,\n\
\ \"f1_stderr\": 0.00173175395556551,\n \"acc\": 0.43967650267207525,\n\
\ \"acc_stderr\": 0.01076620685162581\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.005453020134228188,\n \"em_stderr\": 0.0007541727796792602,\n\
\ \"f1\": 0.08334836409396004,\n \"f1_stderr\": 0.00173175395556551\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.13191811978771797,\n \
\ \"acc_stderr\": 0.009321265253857515\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7474348855564326,\n \"acc_stderr\": 0.012211148449394105\n\
\ }\n}\n```"
repo_url: https://huggingface.co/Sao10K/Stheno-Inverted-L2-13B
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|arc:challenge|25_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_24T14_49_52.594706
path:
- '**/details_harness|drop|3_2023-10-24T14-49-52.594706.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-24T14-49-52.594706.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_24T14_49_52.594706
path:
- '**/details_harness|gsm8k|5_2023-10-24T14-49-52.594706.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-24T14-49-52.594706.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hellaswag|10_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T22:34:24.452875.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-31T22:34:24.452875.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-31T22:34:24.452875.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_24T14_49_52.594706
path:
- '**/details_harness|winogrande|5_2023-10-24T14-49-52.594706.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-24T14-49-52.594706.parquet'
- config_name: results
data_files:
- split: 2023_08_31T22_34_24.452875
path:
- results_2023-08-31T22:34:24.452875.parquet
- split: 2023_10_24T14_49_52.594706
path:
- results_2023-10-24T14-49-52.594706.parquet
- split: latest
path:
- results_2023-10-24T14-49-52.594706.parquet
---
# Dataset Card for Evaluation run of Sao10K/Stheno-Inverted-L2-13B
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/Sao10K/Stheno-Inverted-L2-13B
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [Sao10K/Stheno-Inverted-L2-13B](https://huggingface.co/Sao10K/Stheno-Inverted-L2-13B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Sao10K__Stheno-Inverted-L2-13B",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-24T14:49:52.594706](https://huggingface.co/datasets/open-llm-leaderboard/details_Sao10K__Stheno-Inverted-L2-13B/blob/main/results_2023-10-24T14-49-52.594706.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.005453020134228188,
"em_stderr": 0.0007541727796792602,
"f1": 0.08334836409396004,
"f1_stderr": 0.00173175395556551,
"acc": 0.43967650267207525,
"acc_stderr": 0.01076620685162581
},
"harness|drop|3": {
"em": 0.005453020134228188,
"em_stderr": 0.0007541727796792602,
"f1": 0.08334836409396004,
"f1_stderr": 0.00173175395556551
},
"harness|gsm8k|5": {
"acc": 0.13191811978771797,
"acc_stderr": 0.009321265253857515
},
"harness|winogrande|5": {
"acc": 0.7474348855564326,
"acc_stderr": 0.012211148449394105
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
strombergnlp/bornholmsk_parallel | strombergnlp | "2022-07-01T15:45:35Z" | 2,643 | 2 | [
"task_categories:translation",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:translation",
"source_datasets:original",
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [
"translation"
] | "2022-05-11T08:29:38Z" | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- da
- da-bornholm
license:
- cc-by-4.0
multilinguality:
- translation
pretty_name: Bornholmsk/Danish Parallel Texts
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- translation
task_ids: []
paperswithcode_id: bornholmsk-parallel
---
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [https://github.com/StrombergNLP/bornholmsk](https://github.com/StrombergNLP/bornholmsk)
- **Repository:** [https://github.com/StrombergNLP/bornholmsk](https://github.com/StrombergNLP/bornholmsk)
- **Paper:** [https://aclanthology.org/W19-6138/](https://aclanthology.org/W19-6138/)
- **Point of Contact:** [Leon Derczynski](https://github.com/leondz)
- **Size of downloaded dataset files:** 490 KB
- **Size of the generated dataset:** 582 KB
- **Total amount of disk used:** 1072 KB
### Dataset Summary
This dataset is parallel text for Bornholmsk and Danish.
For more details, see the paper [Bornholmsk Natural Language Processing: Resources and Tools](https://aclanthology.org/W19-6138/).
### Supported Tasks and Leaderboards
*
### Languages
Bornholmsk, a language variant of Danish spoken on the island of Bornholm, and Danish. bcp47: `da-bornholm` and `da-DK`
## Dataset Structure
### Data Instances
### Data Fields
`id`: the sentence ID, `int`
`da-bornholm`: the Bornholmsk text, `string`
`da`: the Danish translation, `string`
### Data Splits
* Train: 5785 sentence pairs
* Validation: 500 sentence pairs
* Test: 500 sentence pairs
## Dataset Creation
### Curation Rationale
To gather as much parallel Bornholmsk together as possible
### Source Data
#### Initial Data Collection and Normalization
From a translation of Kuhre's Sansager, a selection of colloquial resources, and a prototype Bornholmsk/Danish dictionary
#### Who are the source language producers?
Native speakers of Bornholmsk who have produced works in their native language, or translated them to Danish. Much of the data is the result of a community of Bornholmsk speakers volunteering their time across the island in an effort to capture this endangered language.
### Annotations
#### Annotation process
No annotations
#### Who are the annotators?
Native speakers of Bornholmsk, mostly aged 60+.
### Personal and Sensitive Information
Unknown, but low risk of presence, given the source material
## Considerations for Using the Data
### Social Impact of Dataset
The hope behind this data is to enable people to learn and use Bornholmsk
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
This collection of Bornholmsk is curated by Leon Derczynski and Alex Speed Kjeldsen
### Licensing Information
Creative Commons Attribution 4.0
### Citation Information
```
@inproceedings{derczynski-kjeldsen-2019-bornholmsk,
title = "Bornholmsk Natural Language Processing: Resources and Tools",
author = "Derczynski, Leon and
Kjeldsen, Alex Speed",
booktitle = "Proceedings of the 22nd Nordic Conference on Computational Linguistics",
month = sep # "{--}" # oct,
year = "2019",
address = "Turku, Finland",
publisher = {Link{\"o}ping University Electronic Press},
url = "https://aclanthology.org/W19-6138",
pages = "338--344",
}
``` |
open-llm-leaderboard-old/details_RWKV__rwkv-4-14b-pile | open-llm-leaderboard-old | "2023-10-15T21:19:21Z" | 2,639 | 0 | [
"region:us"
] | null | "2023-09-03T13:55:51Z" | ---
pretty_name: Evaluation run of RWKV/rwkv-4-14b-pile
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [RWKV/rwkv-4-14b-pile](https://huggingface.co/RWKV/rwkv-4-14b-pile) on the [Open\
\ LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_RWKV__rwkv-4-14b-pile\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-15T21:19:09.628553](https://huggingface.co/datasets/open-llm-leaderboard/details_RWKV__rwkv-4-14b-pile/blob/main/results_2023-10-15T21-19-09.628553.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.0017827181208053692,\n\
\ \"em_stderr\": 0.0004320097346039099,\n \"f1\": 0.045845218120805505,\n\
\ \"f1_stderr\": 0.0012042308580297368,\n \"acc\": 0.32904612508698977,\n\
\ \"acc_stderr\": 0.007529648846042276\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.0017827181208053692,\n \"em_stderr\": 0.0004320097346039099,\n\
\ \"f1\": 0.045845218120805505,\n \"f1_stderr\": 0.0012042308580297368\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0037907505686125853,\n \
\ \"acc_stderr\": 0.0016927007401501789\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.654301499605367,\n \"acc_stderr\": 0.013366596951934373\n\
\ }\n}\n```"
repo_url: https://huggingface.co/RWKV/rwkv-4-14b-pile
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|arc:challenge|25_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_15T21_19_09.628553
path:
- '**/details_harness|drop|3_2023-10-15T21-19-09.628553.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-15T21-19-09.628553.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_15T21_19_09.628553
path:
- '**/details_harness|gsm8k|5_2023-10-15T21-19-09.628553.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-15T21-19-09.628553.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hellaswag|10_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:55:36.441206.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-03T13:55:36.441206.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-03T13:55:36.441206.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_15T21_19_09.628553
path:
- '**/details_harness|winogrande|5_2023-10-15T21-19-09.628553.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-15T21-19-09.628553.parquet'
- config_name: results
data_files:
- split: 2023_09_03T13_55_36.441206
path:
- results_2023-09-03T13:55:36.441206.parquet
- split: 2023_10_15T21_19_09.628553
path:
- results_2023-10-15T21-19-09.628553.parquet
- split: latest
path:
- results_2023-10-15T21-19-09.628553.parquet
---
# Dataset Card for Evaluation run of RWKV/rwkv-4-14b-pile
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/RWKV/rwkv-4-14b-pile
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [RWKV/rwkv-4-14b-pile](https://huggingface.co/RWKV/rwkv-4-14b-pile) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_RWKV__rwkv-4-14b-pile",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-15T21:19:09.628553](https://huggingface.co/datasets/open-llm-leaderboard/details_RWKV__rwkv-4-14b-pile/blob/main/results_2023-10-15T21-19-09.628553.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.0017827181208053692,
"em_stderr": 0.0004320097346039099,
"f1": 0.045845218120805505,
"f1_stderr": 0.0012042308580297368,
"acc": 0.32904612508698977,
"acc_stderr": 0.007529648846042276
},
"harness|drop|3": {
"em": 0.0017827181208053692,
"em_stderr": 0.0004320097346039099,
"f1": 0.045845218120805505,
"f1_stderr": 0.0012042308580297368
},
"harness|gsm8k|5": {
"acc": 0.0037907505686125853,
"acc_stderr": 0.0016927007401501789
},
"harness|winogrande|5": {
"acc": 0.654301499605367,
"acc_stderr": 0.013366596951934373
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
mandarjoshi/trivia_qa | mandarjoshi | "2024-01-05T13:24:37Z" | 2,634 | 83 | [
"task_categories:question-answering",
"task_categories:text2text-generation",
"task_ids:open-domain-qa",
"task_ids:open-domain-abstractive-qa",
"task_ids:extractive-qa",
"task_ids:abstractive-qa",
"annotations_creators:crowdsourced",
"language_creators:machine-generated",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:unknown",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:1705.03551",
"region:us"
] | [
"question-answering",
"text2text-generation"
] | "2022-03-02T23:29:22Z" | ---
annotations_creators:
- crowdsourced
language_creators:
- machine-generated
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
- 100K<n<1M
source_datasets:
- original
task_categories:
- question-answering
- text2text-generation
task_ids:
- open-domain-qa
- open-domain-abstractive-qa
- extractive-qa
- abstractive-qa
paperswithcode_id: triviaqa
pretty_name: TriviaQA
dataset_info:
- config_name: rc
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 12749651131
num_examples: 138384
- name: validation
num_bytes: 1662321188
num_examples: 17944
- name: test
num_bytes: 1577710503
num_examples: 17210
download_size: 8998808983
dataset_size: 15989682822
- config_name: rc.nocontext
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 106882730
num_examples: 138384
- name: validation
num_bytes: 14059830
num_examples: 17944
- name: test
num_bytes: 3667903
num_examples: 17210
download_size: 63926518
dataset_size: 124610463
- config_name: rc.web
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 9408851139
num_examples: 76496
- name: validation
num_bytes: 1232155138
num_examples: 9951
- name: test
num_bytes: 1171663999
num_examples: 9509
download_size: 6626625832
dataset_size: 11812670276
- config_name: rc.web.nocontext
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 58523085
num_examples: 76496
- name: validation
num_bytes: 7694557
num_examples: 9951
- name: test
num_bytes: 2024747
num_examples: 9509
download_size: 35123473
dataset_size: 68242389
- config_name: rc.wikipedia
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 3340799992
num_examples: 61888
- name: validation
num_bytes: 430166050
num_examples: 7993
- name: test
num_bytes: 406046504
num_examples: 7701
download_size: 2293374081
dataset_size: 4177012546
- config_name: rc.wikipedia.nocontext
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 48359645
num_examples: 61888
- name: validation
num_bytes: 6365273
num_examples: 7993
- name: test
num_bytes: 1643156
num_examples: 7701
download_size: 28803950
dataset_size: 56368074
- config_name: unfiltered
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 23292199425
num_examples: 87622
- name: validation
num_bytes: 3038803743
num_examples: 11313
- name: test
num_bytes: 2906455311
num_examples: 10832
download_size: 16695552268
dataset_size: 29237458479
- config_name: unfiltered.nocontext
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 63300226
num_examples: 87622
- name: validation
num_bytes: 8296870
num_examples: 11313
- name: test
num_bytes: 2320660
num_examples: 10832
download_size: 38364033
dataset_size: 73917756
- config_name: unfiltered.web
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
- name: validation
- name: test
download_size: 3298328560
dataset_size: 0
- config_name: unfiltered.web.nocontext
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
- name: validation
- name: test
download_size: 632549060
dataset_size: 0
- config_name: unfiltered.wikipedia
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
- name: validation
- name: test
download_size: 3298328560
dataset_size: 0
- config_name: unfiltered.wikipedia.nocontext
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: train
- name: validation
- name: test
download_size: 632549060
dataset_size: 0
configs:
- config_name: rc
data_files:
- split: train
path: rc/train-*
- split: validation
path: rc/validation-*
- split: test
path: rc/test-*
- config_name: rc.nocontext
data_files:
- split: train
path: rc.nocontext/train-*
- split: validation
path: rc.nocontext/validation-*
- split: test
path: rc.nocontext/test-*
- config_name: rc.web
data_files:
- split: train
path: rc.web/train-*
- split: validation
path: rc.web/validation-*
- split: test
path: rc.web/test-*
- config_name: rc.web.nocontext
data_files:
- split: train
path: rc.web.nocontext/train-*
- split: validation
path: rc.web.nocontext/validation-*
- split: test
path: rc.web.nocontext/test-*
- config_name: rc.wikipedia
data_files:
- split: train
path: rc.wikipedia/train-*
- split: validation
path: rc.wikipedia/validation-*
- split: test
path: rc.wikipedia/test-*
- config_name: rc.wikipedia.nocontext
data_files:
- split: train
path: rc.wikipedia.nocontext/train-*
- split: validation
path: rc.wikipedia.nocontext/validation-*
- split: test
path: rc.wikipedia.nocontext/test-*
- config_name: unfiltered
data_files:
- split: train
path: unfiltered/train-*
- split: validation
path: unfiltered/validation-*
- split: test
path: unfiltered/test-*
- config_name: unfiltered.nocontext
data_files:
- split: train
path: unfiltered.nocontext/train-*
- split: validation
path: unfiltered.nocontext/validation-*
- split: test
path: unfiltered.nocontext/test-*
---
# Dataset Card for "trivia_qa"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [http://nlp.cs.washington.edu/triviaqa/](http://nlp.cs.washington.edu/triviaqa/)
- **Repository:** [https://github.com/mandarjoshi90/triviaqa](https://github.com/mandarjoshi90/triviaqa)
- **Paper:** [TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension](https://arxiv.org/abs/1705.03551)
- **Leaderboard:** [CodaLab Leaderboard](https://competitions.codalab.org/competitions/17208#results)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 9.26 GB
- **Size of the generated dataset:** 45.46 GB
- **Total amount of disk used:** 54.72 GB
### Dataset Summary
TriviaqQA is a reading comprehension dataset containing over 650K
question-answer-evidence triples. TriviaqQA includes 95K question-answer
pairs authored by trivia enthusiasts and independently gathered evidence
documents, six per question on average, that provide high quality distant
supervision for answering the questions.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
English.
## Dataset Structure
### Data Instances
#### rc
- **Size of downloaded dataset files:** 2.67 GB
- **Size of the generated dataset:** 16.02 GB
- **Total amount of disk used:** 18.68 GB
An example of 'train' looks as follows.
```
```
#### rc.nocontext
- **Size of downloaded dataset files:** 2.67 GB
- **Size of the generated dataset:** 126.27 MB
- **Total amount of disk used:** 2.79 GB
An example of 'train' looks as follows.
```
```
#### unfiltered
- **Size of downloaded dataset files:** 3.30 GB
- **Size of the generated dataset:** 29.24 GB
- **Total amount of disk used:** 32.54 GB
An example of 'validation' looks as follows.
```
```
#### unfiltered.nocontext
- **Size of downloaded dataset files:** 632.55 MB
- **Size of the generated dataset:** 74.56 MB
- **Total amount of disk used:** 707.11 MB
An example of 'train' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### rc
- `question`: a `string` feature.
- `question_id`: a `string` feature.
- `question_source`: a `string` feature.
- `entity_pages`: a dictionary feature containing:
- `doc_source`: a `string` feature.
- `filename`: a `string` feature.
- `title`: a `string` feature.
- `wiki_context`: a `string` feature.
- `search_results`: a dictionary feature containing:
- `description`: a `string` feature.
- `filename`: a `string` feature.
- `rank`: a `int32` feature.
- `title`: a `string` feature.
- `url`: a `string` feature.
- `search_context`: a `string` feature.
- `aliases`: a `list` of `string` features.
- `normalized_aliases`: a `list` of `string` features.
- `matched_wiki_entity_name`: a `string` feature.
- `normalized_matched_wiki_entity_name`: a `string` feature.
- `normalized_value`: a `string` feature.
- `type`: a `string` feature.
- `value`: a `string` feature.
#### rc.nocontext
- `question`: a `string` feature.
- `question_id`: a `string` feature.
- `question_source`: a `string` feature.
- `entity_pages`: a dictionary feature containing:
- `doc_source`: a `string` feature.
- `filename`: a `string` feature.
- `title`: a `string` feature.
- `wiki_context`: a `string` feature.
- `search_results`: a dictionary feature containing:
- `description`: a `string` feature.
- `filename`: a `string` feature.
- `rank`: a `int32` feature.
- `title`: a `string` feature.
- `url`: a `string` feature.
- `search_context`: a `string` feature.
- `aliases`: a `list` of `string` features.
- `normalized_aliases`: a `list` of `string` features.
- `matched_wiki_entity_name`: a `string` feature.
- `normalized_matched_wiki_entity_name`: a `string` feature.
- `normalized_value`: a `string` feature.
- `type`: a `string` feature.
- `value`: a `string` feature.
#### unfiltered
- `question`: a `string` feature.
- `question_id`: a `string` feature.
- `question_source`: a `string` feature.
- `entity_pages`: a dictionary feature containing:
- `doc_source`: a `string` feature.
- `filename`: a `string` feature.
- `title`: a `string` feature.
- `wiki_context`: a `string` feature.
- `search_results`: a dictionary feature containing:
- `description`: a `string` feature.
- `filename`: a `string` feature.
- `rank`: a `int32` feature.
- `title`: a `string` feature.
- `url`: a `string` feature.
- `search_context`: a `string` feature.
- `aliases`: a `list` of `string` features.
- `normalized_aliases`: a `list` of `string` features.
- `matched_wiki_entity_name`: a `string` feature.
- `normalized_matched_wiki_entity_name`: a `string` feature.
- `normalized_value`: a `string` feature.
- `type`: a `string` feature.
- `value`: a `string` feature.
#### unfiltered.nocontext
- `question`: a `string` feature.
- `question_id`: a `string` feature.
- `question_source`: a `string` feature.
- `entity_pages`: a dictionary feature containing:
- `doc_source`: a `string` feature.
- `filename`: a `string` feature.
- `title`: a `string` feature.
- `wiki_context`: a `string` feature.
- `search_results`: a dictionary feature containing:
- `description`: a `string` feature.
- `filename`: a `string` feature.
- `rank`: a `int32` feature.
- `title`: a `string` feature.
- `url`: a `string` feature.
- `search_context`: a `string` feature.
- `aliases`: a `list` of `string` features.
- `normalized_aliases`: a `list` of `string` features.
- `matched_wiki_entity_name`: a `string` feature.
- `normalized_matched_wiki_entity_name`: a `string` feature.
- `normalized_value`: a `string` feature.
- `type`: a `string` feature.
- `value`: a `string` feature.
### Data Splits
| name |train |validation|test |
|--------------------|-----:|---------:|----:|
|rc |138384| 18669|17210|
|rc.nocontext |138384| 18669|17210|
|unfiltered | 87622| 11313|10832|
|unfiltered.nocontext| 87622| 11313|10832|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The University of Washington does not own the copyright of the questions and documents included in TriviaQA.
### Citation Information
```
@article{2017arXivtriviaqa,
author = {{Joshi}, Mandar and {Choi}, Eunsol and {Weld},
Daniel and {Zettlemoyer}, Luke},
title = "{triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension}",
journal = {arXiv e-prints},
year = 2017,
eid = {arXiv:1705.03551},
pages = {arXiv:1705.03551},
archivePrefix = {arXiv},
eprint = {1705.03551},
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@patrickvonplaten](https://github.com/patrickvonplaten), [@lewtun](https://github.com/lewtun) for adding this dataset. |
cyanic-selkie/wikianc | cyanic-selkie | "2023-09-05T14:22:32Z" | 2,632 | 5 | [
"task_categories:token-classification",
"annotations_creators:machine-generated",
"annotations_creators:crowdsourced",
"language_creators:machine-generated",
"language_creators:crowdsourced",
"multilinguality:multilingual",
"language:en",
"language:ceb",
"language:de",
"language:sv",
"language:fr",
"language:nl",
"language:ru",
"language:es",
"language:it",
"language:arz",
"language:pl",
"language:ja",
"language:zh",
"language:vi",
"language:uk",
"language:war",
"language:ar",
"language:pt",
"language:fa",
"language:ca",
"language:sr",
"language:id",
"language:ko",
"language:no",
"language:ce",
"language:fi",
"language:cs",
"language:tr",
"language:hu",
"language:tt",
"language:sh",
"language:ro",
"language:eu",
"language:ms",
"language:eo",
"language:he",
"language:hy",
"language:da",
"language:bg",
"language:cy",
"language:sk",
"language:azb",
"language:uz",
"language:et",
"language:be",
"language:kk",
"language:min",
"language:el",
"language:hr",
"language:lt",
"language:gl",
"language:az",
"language:ur",
"language:sl",
"language:lld",
"language:ka",
"language:nn",
"language:hi",
"language:th",
"language:ta",
"language:bn",
"language:la",
"language:mk",
"language:ast",
"language:lv",
"language:af",
"language:tg",
"language:my",
"language:mg",
"language:mr",
"language:sq",
"language:bs",
"language:oc",
"language:te",
"language:ml",
"language:nds",
"language:br",
"language:ky",
"language:sw",
"language:jv",
"language:lmo",
"language:new",
"language:pnb",
"language:vec",
"language:ht",
"language:pms",
"language:ba",
"language:lb",
"language:su",
"language:ku",
"language:ga",
"language:szl",
"language:is",
"language:fy",
"language:cv",
"language:ckb",
"language:pa",
"language:tl",
"language:an",
"language:wuu",
"language:diq",
"language:io",
"language:sco",
"language:vo",
"language:yo",
"language:ne",
"language:ia",
"language:kn",
"language:gu",
"language:als",
"language:ha",
"language:avk",
"language:bar",
"language:crh",
"language:scn",
"language:bpy",
"language:qu",
"language:mn",
"language:nv",
"language:xmf",
"language:ban",
"language:si",
"language:tum",
"language:ps",
"language:ig",
"language:frr",
"language:os",
"language:mzn",
"language:or",
"language:sah",
"language:cdo",
"language:gd",
"language:bug",
"language:yi",
"language:sd",
"language:ilo",
"language:am",
"language:nap",
"language:li",
"language:bcl",
"language:fo",
"language:gor",
"language:hsb",
"language:mai",
"language:shn",
"language:eml",
"language:ace",
"language:sa",
"language:as",
"language:wa",
"language:ie",
"language:hyw",
"language:lij",
"language:mhr",
"language:zu",
"language:sn",
"language:hif",
"language:mrj",
"language:bjn",
"language:km",
"language:mni",
"language:hak",
"language:pam",
"language:sat",
"language:rue",
"language:nso",
"language:bh",
"language:so",
"language:mi",
"language:se",
"language:myv",
"language:vls",
"language:dag",
"language:sc",
"language:co",
"language:ary",
"language:kw",
"language:bo",
"language:vep",
"language:glk",
"language:tk",
"language:kab",
"language:gan",
"language:rw",
"language:ab",
"language:gv",
"language:ug",
"language:nah",
"language:zea",
"language:skr",
"language:frp",
"language:udm",
"language:pcd",
"language:mt",
"language:kv",
"language:csb",
"language:gn",
"language:smn",
"language:ay",
"language:nrm",
"language:ks",
"language:lez",
"language:lfn",
"language:olo",
"language:mwl",
"language:lo",
"language:stq",
"language:ang",
"language:mdf",
"language:fur",
"language:rm",
"language:lad",
"language:kaa",
"language:gom",
"language:ext",
"language:koi",
"language:tyv",
"language:pap",
"language:av",
"language:dsb",
"language:ln",
"language:dty",
"language:tw",
"language:dv",
"language:ksh",
"language:za",
"language:gag",
"language:bxr",
"language:pfl",
"language:lg",
"language:szy",
"language:pag",
"language:blk",
"language:pi",
"language:tay",
"language:haw",
"language:awa",
"language:inh",
"language:krc",
"language:xal",
"language:pdc",
"language:to",
"language:atj",
"language:tcy",
"language:arc",
"language:mnw",
"language:shi",
"language:jam",
"language:kbp",
"language:wo",
"language:anp",
"language:kbd",
"language:nia",
"language:om",
"language:nov",
"language:ki",
"language:nqo",
"language:bi",
"language:xh",
"language:tpi",
"language:ff",
"language:tet",
"language:jbo",
"language:fj",
"language:kg",
"language:lbe",
"language:ty",
"language:cu",
"language:guw",
"language:trv",
"language:ami",
"language:srn",
"language:sm",
"language:mad",
"language:alt",
"language:ltg",
"language:gcr",
"language:chr",
"language:tn",
"language:ny",
"language:st",
"language:pih",
"language:got",
"language:rmy",
"language:ee",
"language:pcm",
"language:bm",
"language:ss",
"language:gpe",
"language:ts",
"language:ve",
"language:kcg",
"language:chy",
"language:rn",
"language:ch",
"language:gur",
"language:ik",
"language:ady",
"language:fat",
"language:pnt",
"language:guc",
"language:iu",
"language:pwn",
"language:sg",
"language:din",
"language:ti",
"language:kl",
"language:dz",
"language:cr",
"license:cc-by-sa-4.0",
"size_categories:100M<n<1B",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"wikidata",
"wikipedia",
"wikification",
"named-entity-linking",
"nel",
"entity-linking",
"el",
"named-entity-disambiguation",
"ned",
"entity-disambiguation",
"ed"
] | [
"token-classification"
] | "2023-09-05T14:22:32Z" | ---
license: cc-by-sa-4.0
pretty_name: WikiAnc
annotations_creators:
- machine-generated
- crowdsourced
language_creators:
- machine-generated
- crowdsourced
task_categories:
- token-classification
multilinguality:
- multilingual
language:
- en
- ceb
- de
- sv
- fr
- nl
- ru
- es
- it
- arz
- pl
- ja
- zh
- vi
- uk
- war
- ar
- pt
- fa
- ca
- sr
- id
- ko
- 'no'
- ce
- fi
- cs
- tr
- hu
- tt
- sh
- ro
#- zh-min-nan
- eu
- ms
- eo
- he
- hy
- da
- bg
- cy
- sk
- azb
- uz
- et
#- simple
- be
- kk
- min
- el
- hr
- lt
- gl
- az
- ur
- sl
- lld
- ka
- nn
- hi
- th
- ta
- bn
- la
- mk
#- zh-yue
- ast
- lv
- af
- tg
- my
- mg
- mr
- sq
- bs
- oc
- te
- ml
- nds
- br
- ky
- sw
- jv
- lmo
- new
- pnb
- vec
- ht
- pms
- ba
- lb
- su
- ku
- ga
- szl
- is
- fy
- cv
- ckb
- pa
- tl
- an
- wuu
- diq
- io
- sco
- vo
- yo
- ne
- ia
- kn
- gu
- als
- ha
- avk
- bar
- crh
- scn
- bpy
- qu
- mn
- nv
- xmf
- ban
- si
- tum
- ps
- ig
- frr
- os
- mzn
#- bat-smg
- or
- sah
- cdo
- gd
- bug
- yi
- sd
- ilo
- am
- nap
- li
- bcl
- fo
- gor
- hsb
#- map-bms
- mai
- shn
- eml
- ace
#- zh-classical
- sa
- as
- wa
- ie
- hyw
- lij
- mhr
- zu
- sn
- hif
- mrj
- bjn
- km
- mni
- hak
#- roa-tara
- pam
- sat
- rue
- nso
- bh
- so
- mi
- se
- myv
- vls
#- nds-nl
- dag
- sc
- co
- ary
- kw
- bo
- vep
- glk
- tk
- kab
- gan
- rw
#- fiu-vro
- ab
- gv
- ug
- nah
- zea
- skr
- frp
- udm
- pcd
- mt
- kv
- csb
- gn
- smn
- ay
- nrm
- ks
- lez
- lfn
- olo
- mwl
- lo
- stq
- ang
- mdf
- fur
- rm
- lad
- kaa
- gom
- ext
- koi
- tyv
- pap
- av
- dsb
- ln
- dty
- tw
#- cbk-zam
- dv
- ksh
- za
- gag
- bxr
- pfl
- lg
- szy
- pag
- blk
- pi
- tay
- haw
- awa
- inh
- krc
- xal
- pdc
- to
- atj
- tcy
- arc
- mnw
- shi
- jam
- kbp
- wo
- anp
- kbd
- nia
- om
- nov
- ki
- nqo
- bi
- xh
- tpi
- ff
- tet
#- roa-rup
- jbo
- fj
- kg
- lbe
- ty
- cu
- guw
- trv
- ami
- srn
- sm
- mad
- alt
- ltg
- gcr
- chr
- tn
- ny
- st
- pih
- got
- rmy
- ee
- pcm
- bm
- ss
- gpe
- ts
- ve
- kcg
- chy
- rn
- ch
- gur
- ik
- ady
- fat
- pnt
- guc
- iu
- pwn
- sg
- din
- ti
- kl
- dz
- cr
tags:
- wikidata
- wikipedia
- wikification
- named-entity-linking
- nel
- entity-linking
- el
- named-entity-disambiguation
- ned
- entity-disambiguation
- ed
configs:
- config_name: ab
data_files:
- split: train
path: "data/ab/train.parquet"
- split: validation
path: "data/ab/validation.parquet"
- config_name: ace
data_files:
- split: train
path: "data/ace/train.parquet"
- split: validation
path: "data/ace/validation.parquet"
- config_name: ady
data_files:
- split: train
path: "data/ady/train.parquet"
- split: validation
path: "data/ady/validation.parquet"
- config_name: af
data_files:
- split: train
path: "data/af/train.parquet"
- split: validation
path: "data/af/validation.parquet"
- config_name: als
data_files:
- split: train
path: "data/als/train.parquet"
- split: validation
path: "data/als/validation.parquet"
- config_name: alt
data_files:
- split: train
path: "data/alt/train.parquet"
- split: validation
path: "data/alt/validation.parquet"
- config_name: am
data_files:
- split: train
path: "data/am/train.parquet"
- split: validation
path: "data/am/validation.parquet"
- config_name: ami
data_files:
- split: train
path: "data/ami/train.parquet"
- split: validation
path: "data/ami/validation.parquet"
- config_name: an
data_files:
- split: train
path: "data/an/train.parquet"
- split: validation
path: "data/an/validation.parquet"
- config_name: ang
data_files:
- split: train
path: "data/ang/train.parquet"
- split: validation
path: "data/ang/validation.parquet"
- config_name: anp
data_files:
- split: train
path: "data/anp/train.parquet"
- split: validation
path: "data/anp/validation.parquet"
- config_name: ar
data_files:
- split: train
path: "data/ar/train.parquet"
- split: validation
path: "data/ar/validation.parquet"
- config_name: arc
data_files:
- split: train
path: "data/arc/train.parquet"
- split: validation
path: "data/arc/validation.parquet"
- config_name: ary
data_files:
- split: train
path: "data/ary/train.parquet"
- split: validation
path: "data/ary/validation.parquet"
- config_name: arz
data_files:
- split: train
path: "data/arz/train.parquet"
- split: validation
path: "data/arz/validation.parquet"
- config_name: as
data_files:
- split: train
path: "data/as/train.parquet"
- split: validation
path: "data/as/validation.parquet"
- config_name: ast
data_files:
- split: train
path: "data/ast/train.parquet"
- split: validation
path: "data/ast/validation.parquet"
- config_name: atj
data_files:
- split: train
path: "data/atj/train.parquet"
- split: validation
path: "data/atj/validation.parquet"
- config_name: av
data_files:
- split: train
path: "data/av/train.parquet"
- split: validation
path: "data/av/validation.parquet"
- config_name: avk
data_files:
- split: train
path: "data/avk/train.parquet"
- split: validation
path: "data/avk/validation.parquet"
- config_name: awa
data_files:
- split: train
path: "data/awa/train.parquet"
- split: validation
path: "data/awa/validation.parquet"
- config_name: ay
data_files:
- split: train
path: "data/ay/train.parquet"
- split: validation
path: "data/ay/validation.parquet"
- config_name: az
data_files:
- split: train
path: "data/az/train.parquet"
- split: validation
path: "data/az/validation.parquet"
- config_name: azb
data_files:
- split: train
path: "data/azb/train.parquet"
- split: validation
path: "data/azb/validation.parquet"
- config_name: ba
data_files:
- split: train
path: "data/ba/train.parquet"
- split: validation
path: "data/ba/validation.parquet"
- config_name: ban
data_files:
- split: train
path: "data/ban/train.parquet"
- split: validation
path: "data/ban/validation.parquet"
- config_name: bar
data_files:
- split: train
path: "data/bar/train.parquet"
- split: validation
path: "data/bar/validation.parquet"
- config_name: bat_smg
data_files:
- split: train
path: "data/bat_smg/train.parquet"
- split: validation
path: "data/bat_smg/validation.parquet"
- config_name: bcl
data_files:
- split: train
path: "data/bcl/train.parquet"
- split: validation
path: "data/bcl/validation.parquet"
- config_name: be
data_files:
- split: train
path: "data/be/train.parquet"
- split: validation
path: "data/be/validation.parquet"
- config_name: bg
data_files:
- split: train
path: "data/bg/train.parquet"
- split: validation
path: "data/bg/validation.parquet"
- config_name: bh
data_files:
- split: train
path: "data/bh/train.parquet"
- split: validation
path: "data/bh/validation.parquet"
- config_name: bi
data_files:
- split: train
path: "data/bi/train.parquet"
- split: validation
path: "data/bi/validation.parquet"
- config_name: bjn
data_files:
- split: train
path: "data/bjn/train.parquet"
- split: validation
path: "data/bjn/validation.parquet"
- config_name: blk
data_files:
- split: train
path: "data/blk/train.parquet"
- split: validation
path: "data/blk/validation.parquet"
- config_name: bm
data_files:
- split: train
path: "data/bm/train.parquet"
- split: validation
path: "data/bm/validation.parquet"
- config_name: bn
data_files:
- split: train
path: "data/bn/train.parquet"
- split: validation
path: "data/bn/validation.parquet"
- config_name: bo
data_files:
- split: train
path: "data/bo/train.parquet"
- split: validation
path: "data/bo/validation.parquet"
- config_name: bpy
data_files:
- split: train
path: "data/bpy/train.parquet"
- split: validation
path: "data/bpy/validation.parquet"
- config_name: br
data_files:
- split: train
path: "data/br/train.parquet"
- split: validation
path: "data/br/validation.parquet"
- config_name: bs
data_files:
- split: train
path: "data/bs/train.parquet"
- split: validation
path: "data/bs/validation.parquet"
- config_name: bug
data_files:
- split: train
path: "data/bug/train.parquet"
- split: validation
path: "data/bug/validation.parquet"
- config_name: bxr
data_files:
- split: train
path: "data/bxr/train.parquet"
- split: validation
path: "data/bxr/validation.parquet"
- config_name: ca
data_files:
- split: train
path: "data/ca/train.parquet"
- split: validation
path: "data/ca/validation.parquet"
- config_name: cbk_zam
data_files:
- split: train
path: "data/cbk_zam/train.parquet"
- split: validation
path: "data/cbk_zam/validation.parquet"
- config_name: cdo
data_files:
- split: train
path: "data/cdo/train.parquet"
- split: validation
path: "data/cdo/validation.parquet"
- config_name: ce
data_files:
- split: train
path: "data/ce/train.parquet"
- split: validation
path: "data/ce/validation.parquet"
- config_name: ceb
data_files:
- split: train
path: "data/ceb/train.parquet"
- split: validation
path: "data/ceb/validation.parquet"
- config_name: ch
data_files:
- split: train
path: "data/ch/train.parquet"
- split: validation
path: "data/ch/validation.parquet"
- config_name: chr
data_files:
- split: train
path: "data/chr/train.parquet"
- split: validation
path: "data/chr/validation.parquet"
- config_name: chy
data_files:
- split: train
path: "data/chy/train.parquet"
- split: validation
path: "data/chy/validation.parquet"
- config_name: ckb
data_files:
- split: train
path: "data/ckb/train.parquet"
- split: validation
path: "data/ckb/validation.parquet"
- config_name: co
data_files:
- split: train
path: "data/co/train.parquet"
- split: validation
path: "data/co/validation.parquet"
- config_name: cr
data_files:
- split: train
path: "data/cr/train.parquet"
- split: validation
path: "data/cr/validation.parquet"
- config_name: crh
data_files:
- split: train
path: "data/crh/train.parquet"
- split: validation
path: "data/crh/validation.parquet"
- config_name: cs
data_files:
- split: train
path: "data/cs/train.parquet"
- split: validation
path: "data/cs/validation.parquet"
- config_name: csb
data_files:
- split: train
path: "data/csb/train.parquet"
- split: validation
path: "data/csb/validation.parquet"
- config_name: cu
data_files:
- split: train
path: "data/cu/train.parquet"
- split: validation
path: "data/cu/validation.parquet"
- config_name: cv
data_files:
- split: train
path: "data/cv/train.parquet"
- split: validation
path: "data/cv/validation.parquet"
- config_name: cy
data_files:
- split: train
path: "data/cy/train.parquet"
- split: validation
path: "data/cy/validation.parquet"
- config_name: da
data_files:
- split: train
path: "data/da/train.parquet"
- split: validation
path: "data/da/validation.parquet"
- config_name: dag
data_files:
- split: train
path: "data/dag/train.parquet"
- split: validation
path: "data/dag/validation.parquet"
- config_name: de
data_files:
- split: train
path: "data/de/train.parquet"
- split: validation
path: "data/de/validation.parquet"
- config_name: din
data_files:
- split: train
path: "data/din/train.parquet"
- split: validation
path: "data/din/validation.parquet"
- config_name: diq
data_files:
- split: train
path: "data/diq/train.parquet"
- split: validation
path: "data/diq/validation.parquet"
- config_name: dsb
data_files:
- split: train
path: "data/dsb/train.parquet"
- split: validation
path: "data/dsb/validation.parquet"
- config_name: dty
data_files:
- split: train
path: "data/dty/train.parquet"
- split: validation
path: "data/dty/validation.parquet"
- config_name: dv
data_files:
- split: train
path: "data/dv/train.parquet"
- split: validation
path: "data/dv/validation.parquet"
- config_name: dz
data_files:
- split: train
path: "data/dz/train.parquet"
- split: validation
path: "data/dz/validation.parquet"
- config_name: ee
data_files:
- split: train
path: "data/ee/train.parquet"
- split: validation
path: "data/ee/validation.parquet"
- config_name: el
data_files:
- split: train
path: "data/el/train.parquet"
- split: validation
path: "data/el/validation.parquet"
- config_name: eml
data_files:
- split: train
path: "data/eml/train.parquet"
- split: validation
path: "data/eml/validation.parquet"
- config_name: en
data_files:
- split: train
path: "data/en/train.parquet"
- split: validation
path: "data/en/validation.parquet"
- config_name: eo
data_files:
- split: train
path: "data/eo/train.parquet"
- split: validation
path: "data/eo/validation.parquet"
- config_name: es
data_files:
- split: train
path: "data/es/train.parquet"
- split: validation
path: "data/es/validation.parquet"
- config_name: et
data_files:
- split: train
path: "data/et/train.parquet"
- split: validation
path: "data/et/validation.parquet"
- config_name: eu
data_files:
- split: train
path: "data/eu/train.parquet"
- split: validation
path: "data/eu/validation.parquet"
- config_name: ext
data_files:
- split: train
path: "data/ext/train.parquet"
- split: validation
path: "data/ext/validation.parquet"
- config_name: fa
data_files:
- split: train
path: "data/fa/train.parquet"
- split: validation
path: "data/fa/validation.parquet"
- config_name: fat
data_files:
- split: train
path: "data/fat/train.parquet"
- split: validation
path: "data/fat/validation.parquet"
- config_name: ff
data_files:
- split: train
path: "data/ff/train.parquet"
- split: validation
path: "data/ff/validation.parquet"
- config_name: fi
data_files:
- split: train
path: "data/fi/train.parquet"
- split: validation
path: "data/fi/validation.parquet"
- config_name: fiu_vro
data_files:
- split: train
path: "data/fiu_vro/train.parquet"
- split: validation
path: "data/fiu_vro/validation.parquet"
- config_name: fj
data_files:
- split: train
path: "data/fj/train.parquet"
- split: validation
path: "data/fj/validation.parquet"
- config_name: fo
data_files:
- split: train
path: "data/fo/train.parquet"
- split: validation
path: "data/fo/validation.parquet"
- config_name: fr
data_files:
- split: train
path: "data/fr/train.parquet"
- split: validation
path: "data/fr/validation.parquet"
- config_name: frp
data_files:
- split: train
path: "data/frp/train.parquet"
- split: validation
path: "data/frp/validation.parquet"
- config_name: frr
data_files:
- split: train
path: "data/frr/train.parquet"
- split: validation
path: "data/frr/validation.parquet"
- config_name: fur
data_files:
- split: train
path: "data/fur/train.parquet"
- split: validation
path: "data/fur/validation.parquet"
- config_name: fy
data_files:
- split: train
path: "data/fy/train.parquet"
- split: validation
path: "data/fy/validation.parquet"
- config_name: ga
data_files:
- split: train
path: "data/ga/train.parquet"
- split: validation
path: "data/ga/validation.parquet"
- config_name: gag
data_files:
- split: train
path: "data/gag/train.parquet"
- split: validation
path: "data/gag/validation.parquet"
- config_name: gan
data_files:
- split: train
path: "data/gan/train.parquet"
- split: validation
path: "data/gan/validation.parquet"
- config_name: gcr
data_files:
- split: train
path: "data/gcr/train.parquet"
- split: validation
path: "data/gcr/validation.parquet"
- config_name: gd
data_files:
- split: train
path: "data/gd/train.parquet"
- split: validation
path: "data/gd/validation.parquet"
- config_name: gl
data_files:
- split: train
path: "data/gl/train.parquet"
- split: validation
path: "data/gl/validation.parquet"
- config_name: glk
data_files:
- split: train
path: "data/glk/train.parquet"
- split: validation
path: "data/glk/validation.parquet"
- config_name: gn
data_files:
- split: train
path: "data/gn/train.parquet"
- split: validation
path: "data/gn/validation.parquet"
- config_name: gom
data_files:
- split: train
path: "data/gom/train.parquet"
- split: validation
path: "data/gom/validation.parquet"
- config_name: gor
data_files:
- split: train
path: "data/gor/train.parquet"
- split: validation
path: "data/gor/validation.parquet"
- config_name: got
data_files:
- split: train
path: "data/got/train.parquet"
- split: validation
path: "data/got/validation.parquet"
- config_name: gpe
data_files:
- split: train
path: "data/gpe/train.parquet"
- split: validation
path: "data/gpe/validation.parquet"
- config_name: gu
data_files:
- split: train
path: "data/gu/train.parquet"
- split: validation
path: "data/gu/validation.parquet"
- config_name: guc
data_files:
- split: train
path: "data/guc/train.parquet"
- split: validation
path: "data/guc/validation.parquet"
- config_name: gur
data_files:
- split: train
path: "data/gur/train.parquet"
- split: validation
path: "data/gur/validation.parquet"
- config_name: guw
data_files:
- split: train
path: "data/guw/train.parquet"
- split: validation
path: "data/guw/validation.parquet"
- config_name: gv
data_files:
- split: train
path: "data/gv/train.parquet"
- split: validation
path: "data/gv/validation.parquet"
- config_name: ha
data_files:
- split: train
path: "data/ha/train.parquet"
- split: validation
path: "data/ha/validation.parquet"
- config_name: hak
data_files:
- split: train
path: "data/hak/train.parquet"
- split: validation
path: "data/hak/validation.parquet"
- config_name: haw
data_files:
- split: train
path: "data/haw/train.parquet"
- split: validation
path: "data/haw/validation.parquet"
- config_name: he
data_files:
- split: train
path: "data/he/train.parquet"
- split: validation
path: "data/he/validation.parquet"
- config_name: hi
data_files:
- split: train
path: "data/hi/train.parquet"
- split: validation
path: "data/hi/validation.parquet"
- config_name: hif
data_files:
- split: train
path: "data/hif/train.parquet"
- split: validation
path: "data/hif/validation.parquet"
- config_name: hr
data_files:
- split: train
path: "data/hr/train.parquet"
- split: validation
path: "data/hr/validation.parquet"
- config_name: hsb
data_files:
- split: train
path: "data/hsb/train.parquet"
- split: validation
path: "data/hsb/validation.parquet"
- config_name: ht
data_files:
- split: train
path: "data/ht/train.parquet"
- split: validation
path: "data/ht/validation.parquet"
- config_name: hu
data_files:
- split: train
path: "data/hu/train.parquet"
- split: validation
path: "data/hu/validation.parquet"
- config_name: hy
data_files:
- split: train
path: "data/hy/train.parquet"
- split: validation
path: "data/hy/validation.parquet"
- config_name: hyw
data_files:
- split: train
path: "data/hyw/train.parquet"
- split: validation
path: "data/hyw/validation.parquet"
- config_name: ia
data_files:
- split: train
path: "data/ia/train.parquet"
- split: validation
path: "data/ia/validation.parquet"
- config_name: id
data_files:
- split: train
path: "data/id/train.parquet"
- split: validation
path: "data/id/validation.parquet"
- config_name: ie
data_files:
- split: train
path: "data/ie/train.parquet"
- split: validation
path: "data/ie/validation.parquet"
- config_name: ig
data_files:
- split: train
path: "data/ig/train.parquet"
- split: validation
path: "data/ig/validation.parquet"
- config_name: ik
data_files:
- split: train
path: "data/ik/train.parquet"
- split: validation
path: "data/ik/validation.parquet"
- config_name: ilo
data_files:
- split: train
path: "data/ilo/train.parquet"
- split: validation
path: "data/ilo/validation.parquet"
- config_name: inh
data_files:
- split: train
path: "data/inh/train.parquet"
- split: validation
path: "data/inh/validation.parquet"
- config_name: io
data_files:
- split: train
path: "data/io/train.parquet"
- split: validation
path: "data/io/validation.parquet"
- config_name: is
data_files:
- split: train
path: "data/is/train.parquet"
- split: validation
path: "data/is/validation.parquet"
- config_name: it
data_files:
- split: train
path: "data/it/train.parquet"
- split: validation
path: "data/it/validation.parquet"
- config_name: iu
data_files:
- split: train
path: "data/iu/train.parquet"
- split: validation
path: "data/iu/validation.parquet"
- config_name: ja
data_files:
- split: train
path: "data/ja/train.parquet"
- split: validation
path: "data/ja/validation.parquet"
- config_name: jam
data_files:
- split: train
path: "data/jam/train.parquet"
- split: validation
path: "data/jam/validation.parquet"
- config_name: jbo
data_files:
- split: train
path: "data/jbo/train.parquet"
- split: validation
path: "data/jbo/validation.parquet"
- config_name: jv
data_files:
- split: train
path: "data/jv/train.parquet"
- split: validation
path: "data/jv/validation.parquet"
- config_name: ka
data_files:
- split: train
path: "data/ka/train.parquet"
- split: validation
path: "data/ka/validation.parquet"
- config_name: kaa
data_files:
- split: train
path: "data/kaa/train.parquet"
- split: validation
path: "data/kaa/validation.parquet"
- config_name: kab
data_files:
- split: train
path: "data/kab/train.parquet"
- split: validation
path: "data/kab/validation.parquet"
- config_name: kbd
data_files:
- split: train
path: "data/kbd/train.parquet"
- split: validation
path: "data/kbd/validation.parquet"
- config_name: kbp
data_files:
- split: train
path: "data/kbp/train.parquet"
- split: validation
path: "data/kbp/validation.parquet"
- config_name: kcg
data_files:
- split: train
path: "data/kcg/train.parquet"
- split: validation
path: "data/kcg/validation.parquet"
- config_name: kg
data_files:
- split: train
path: "data/kg/train.parquet"
- split: validation
path: "data/kg/validation.parquet"
- config_name: ki
data_files:
- split: train
path: "data/ki/train.parquet"
- split: validation
path: "data/ki/validation.parquet"
- config_name: kk
data_files:
- split: train
path: "data/kk/train.parquet"
- split: validation
path: "data/kk/validation.parquet"
- config_name: kl
data_files:
- split: train
path: "data/kl/train.parquet"
- split: validation
path: "data/kl/validation.parquet"
- config_name: km
data_files:
- split: train
path: "data/km/train.parquet"
- split: validation
path: "data/km/validation.parquet"
- config_name: kn
data_files:
- split: train
path: "data/kn/train.parquet"
- split: validation
path: "data/kn/validation.parquet"
- config_name: ko
data_files:
- split: train
path: "data/ko/train.parquet"
- split: validation
path: "data/ko/validation.parquet"
- config_name: koi
data_files:
- split: train
path: "data/koi/train.parquet"
- split: validation
path: "data/koi/validation.parquet"
- config_name: krc
data_files:
- split: train
path: "data/krc/train.parquet"
- split: validation
path: "data/krc/validation.parquet"
- config_name: ks
data_files:
- split: train
path: "data/ks/train.parquet"
- split: validation
path: "data/ks/validation.parquet"
- config_name: ksh
data_files:
- split: train
path: "data/ksh/train.parquet"
- split: validation
path: "data/ksh/validation.parquet"
- config_name: ku
data_files:
- split: train
path: "data/ku/train.parquet"
- split: validation
path: "data/ku/validation.parquet"
- config_name: kv
data_files:
- split: train
path: "data/kv/train.parquet"
- split: validation
path: "data/kv/validation.parquet"
- config_name: kw
data_files:
- split: train
path: "data/kw/train.parquet"
- split: validation
path: "data/kw/validation.parquet"
- config_name: ky
data_files:
- split: train
path: "data/ky/train.parquet"
- split: validation
path: "data/ky/validation.parquet"
- config_name: la
data_files:
- split: train
path: "data/la/train.parquet"
- split: validation
path: "data/la/validation.parquet"
- config_name: lad
data_files:
- split: train
path: "data/lad/train.parquet"
- split: validation
path: "data/lad/validation.parquet"
- config_name: lb
data_files:
- split: train
path: "data/lb/train.parquet"
- split: validation
path: "data/lb/validation.parquet"
- config_name: lbe
data_files:
- split: train
path: "data/lbe/train.parquet"
- split: validation
path: "data/lbe/validation.parquet"
- config_name: lez
data_files:
- split: train
path: "data/lez/train.parquet"
- split: validation
path: "data/lez/validation.parquet"
- config_name: lfn
data_files:
- split: train
path: "data/lfn/train.parquet"
- split: validation
path: "data/lfn/validation.parquet"
- config_name: lg
data_files:
- split: train
path: "data/lg/train.parquet"
- split: validation
path: "data/lg/validation.parquet"
- config_name: li
data_files:
- split: train
path: "data/li/train.parquet"
- split: validation
path: "data/li/validation.parquet"
- config_name: lij
data_files:
- split: train
path: "data/lij/train.parquet"
- split: validation
path: "data/lij/validation.parquet"
- config_name: lld
data_files:
- split: train
path: "data/lld/train.parquet"
- split: validation
path: "data/lld/validation.parquet"
- config_name: lmo
data_files:
- split: train
path: "data/lmo/train.parquet"
- split: validation
path: "data/lmo/validation.parquet"
- config_name: ln
data_files:
- split: train
path: "data/ln/train.parquet"
- split: validation
path: "data/ln/validation.parquet"
- config_name: lo
data_files:
- split: train
path: "data/lo/train.parquet"
- split: validation
path: "data/lo/validation.parquet"
- config_name: lt
data_files:
- split: train
path: "data/lt/train.parquet"
- split: validation
path: "data/lt/validation.parquet"
- config_name: ltg
data_files:
- split: train
path: "data/ltg/train.parquet"
- split: validation
path: "data/ltg/validation.parquet"
- config_name: lv
data_files:
- split: train
path: "data/lv/train.parquet"
- split: validation
path: "data/lv/validation.parquet"
- config_name: mad
data_files:
- split: train
path: "data/mad/train.parquet"
- split: validation
path: "data/mad/validation.parquet"
- config_name: mai
data_files:
- split: train
path: "data/mai/train.parquet"
- split: validation
path: "data/mai/validation.parquet"
- config_name: map_bms
data_files:
- split: train
path: "data/map_bms/train.parquet"
- split: validation
path: "data/map_bms/validation.parquet"
- config_name: mdf
data_files:
- split: train
path: "data/mdf/train.parquet"
- split: validation
path: "data/mdf/validation.parquet"
- config_name: mg
data_files:
- split: train
path: "data/mg/train.parquet"
- split: validation
path: "data/mg/validation.parquet"
- config_name: mhr
data_files:
- split: train
path: "data/mhr/train.parquet"
- split: validation
path: "data/mhr/validation.parquet"
- config_name: mi
data_files:
- split: train
path: "data/mi/train.parquet"
- split: validation
path: "data/mi/validation.parquet"
- config_name: min
data_files:
- split: train
path: "data/min/train.parquet"
- split: validation
path: "data/min/validation.parquet"
- config_name: mk
data_files:
- split: train
path: "data/mk/train.parquet"
- split: validation
path: "data/mk/validation.parquet"
- config_name: ml
data_files:
- split: train
path: "data/ml/train.parquet"
- split: validation
path: "data/ml/validation.parquet"
- config_name: mn
data_files:
- split: train
path: "data/mn/train.parquet"
- split: validation
path: "data/mn/validation.parquet"
- config_name: mni
data_files:
- split: train
path: "data/mni/train.parquet"
- split: validation
path: "data/mni/validation.parquet"
- config_name: mnw
data_files:
- split: train
path: "data/mnw/train.parquet"
- split: validation
path: "data/mnw/validation.parquet"
- config_name: mr
data_files:
- split: train
path: "data/mr/train.parquet"
- split: validation
path: "data/mr/validation.parquet"
- config_name: mrj
data_files:
- split: train
path: "data/mrj/train.parquet"
- split: validation
path: "data/mrj/validation.parquet"
- config_name: ms
data_files:
- split: train
path: "data/ms/train.parquet"
- split: validation
path: "data/ms/validation.parquet"
- config_name: mt
data_files:
- split: train
path: "data/mt/train.parquet"
- split: validation
path: "data/mt/validation.parquet"
- config_name: mwl
data_files:
- split: train
path: "data/mwl/train.parquet"
- split: validation
path: "data/mwl/validation.parquet"
- config_name: my
data_files:
- split: train
path: "data/my/train.parquet"
- split: validation
path: "data/my/validation.parquet"
- config_name: myv
data_files:
- split: train
path: "data/myv/train.parquet"
- split: validation
path: "data/myv/validation.parquet"
- config_name: mzn
data_files:
- split: train
path: "data/mzn/train.parquet"
- split: validation
path: "data/mzn/validation.parquet"
- config_name: nah
data_files:
- split: train
path: "data/nah/train.parquet"
- split: validation
path: "data/nah/validation.parquet"
- config_name: nap
data_files:
- split: train
path: "data/nap/train.parquet"
- split: validation
path: "data/nap/validation.parquet"
- config_name: nds
data_files:
- split: train
path: "data/nds/train.parquet"
- split: validation
path: "data/nds/validation.parquet"
- config_name: nds_nl
data_files:
- split: train
path: "data/nds_nl/train.parquet"
- split: validation
path: "data/nds_nl/validation.parquet"
- config_name: ne
data_files:
- split: train
path: "data/ne/train.parquet"
- split: validation
path: "data/ne/validation.parquet"
- config_name: new
data_files:
- split: train
path: "data/new/train.parquet"
- split: validation
path: "data/new/validation.parquet"
- config_name: nia
data_files:
- split: train
path: "data/nia/train.parquet"
- split: validation
path: "data/nia/validation.parquet"
- config_name: nl
data_files:
- split: train
path: "data/nl/train.parquet"
- split: validation
path: "data/nl/validation.parquet"
- config_name: nn
data_files:
- split: train
path: "data/nn/train.parquet"
- split: validation
path: "data/nn/validation.parquet"
- config_name: 'no'
data_files:
- split: train
path: "data/no/train.parquet"
- split: validation
path: "data/no/validation.parquet"
- config_name: nov
data_files:
- split: train
path: "data/nov/train.parquet"
- split: validation
path: "data/nov/validation.parquet"
- config_name: nqo
data_files:
- split: train
path: "data/nqo/train.parquet"
- split: validation
path: "data/nqo/validation.parquet"
- config_name: nrm
data_files:
- split: train
path: "data/nrm/train.parquet"
- split: validation
path: "data/nrm/validation.parquet"
- config_name: nso
data_files:
- split: train
path: "data/nso/train.parquet"
- split: validation
path: "data/nso/validation.parquet"
- config_name: nv
data_files:
- split: train
path: "data/nv/train.parquet"
- split: validation
path: "data/nv/validation.parquet"
- config_name: ny
data_files:
- split: train
path: "data/ny/train.parquet"
- split: validation
path: "data/ny/validation.parquet"
- config_name: oc
data_files:
- split: train
path: "data/oc/train.parquet"
- split: validation
path: "data/oc/validation.parquet"
- config_name: olo
data_files:
- split: train
path: "data/olo/train.parquet"
- split: validation
path: "data/olo/validation.parquet"
- config_name: om
data_files:
- split: train
path: "data/om/train.parquet"
- split: validation
path: "data/om/validation.parquet"
- config_name: or
data_files:
- split: train
path: "data/or/train.parquet"
- split: validation
path: "data/or/validation.parquet"
- config_name: os
data_files:
- split: train
path: "data/os/train.parquet"
- split: validation
path: "data/os/validation.parquet"
- config_name: pa
data_files:
- split: train
path: "data/pa/train.parquet"
- split: validation
path: "data/pa/validation.parquet"
- config_name: pag
data_files:
- split: train
path: "data/pag/train.parquet"
- split: validation
path: "data/pag/validation.parquet"
- config_name: pam
data_files:
- split: train
path: "data/pam/train.parquet"
- split: validation
path: "data/pam/validation.parquet"
- config_name: pap
data_files:
- split: train
path: "data/pap/train.parquet"
- split: validation
path: "data/pap/validation.parquet"
- config_name: pcd
data_files:
- split: train
path: "data/pcd/train.parquet"
- split: validation
path: "data/pcd/validation.parquet"
- config_name: pcm
data_files:
- split: train
path: "data/pcm/train.parquet"
- split: validation
path: "data/pcm/validation.parquet"
- config_name: pdc
data_files:
- split: train
path: "data/pdc/train.parquet"
- split: validation
path: "data/pdc/validation.parquet"
- config_name: pfl
data_files:
- split: train
path: "data/pfl/train.parquet"
- split: validation
path: "data/pfl/validation.parquet"
- config_name: pi
data_files:
- split: train
path: "data/pi/train.parquet"
- split: validation
path: "data/pi/validation.parquet"
- config_name: pih
data_files:
- split: train
path: "data/pih/train.parquet"
- split: validation
path: "data/pih/validation.parquet"
- config_name: pl
data_files:
- split: train
path: "data/pl/train.parquet"
- split: validation
path: "data/pl/validation.parquet"
- config_name: pms
data_files:
- split: train
path: "data/pms/train.parquet"
- split: validation
path: "data/pms/validation.parquet"
- config_name: pnb
data_files:
- split: train
path: "data/pnb/train.parquet"
- split: validation
path: "data/pnb/validation.parquet"
- config_name: pnt
data_files:
- split: train
path: "data/pnt/train.parquet"
- split: validation
path: "data/pnt/validation.parquet"
- config_name: ps
data_files:
- split: train
path: "data/ps/train.parquet"
- split: validation
path: "data/ps/validation.parquet"
- config_name: pt
data_files:
- split: train
path: "data/pt/train.parquet"
- split: validation
path: "data/pt/validation.parquet"
- config_name: pwn
data_files:
- split: train
path: "data/pwn/train.parquet"
- split: validation
path: "data/pwn/validation.parquet"
- config_name: qu
data_files:
- split: train
path: "data/qu/train.parquet"
- split: validation
path: "data/qu/validation.parquet"
- config_name: rm
data_files:
- split: train
path: "data/rm/train.parquet"
- split: validation
path: "data/rm/validation.parquet"
- config_name: rmy
data_files:
- split: train
path: "data/rmy/train.parquet"
- split: validation
path: "data/rmy/validation.parquet"
- config_name: rn
data_files:
- split: train
path: "data/rn/train.parquet"
- split: validation
path: "data/rn/validation.parquet"
- config_name: ro
data_files:
- split: train
path: "data/ro/train.parquet"
- split: validation
path: "data/ro/validation.parquet"
- config_name: roa_rup
data_files:
- split: train
path: "data/roa_rup/train.parquet"
- split: validation
path: "data/roa_rup/validation.parquet"
- config_name: roa_tara
data_files:
- split: train
path: "data/roa_tara/train.parquet"
- split: validation
path: "data/roa_tara/validation.parquet"
- config_name: ru
data_files:
- split: train
path: "data/ru/train.parquet"
- split: validation
path: "data/ru/validation.parquet"
- config_name: rue
data_files:
- split: train
path: "data/rue/train.parquet"
- split: validation
path: "data/rue/validation.parquet"
- config_name: rw
data_files:
- split: train
path: "data/rw/train.parquet"
- split: validation
path: "data/rw/validation.parquet"
- config_name: sa
data_files:
- split: train
path: "data/sa/train.parquet"
- split: validation
path: "data/sa/validation.parquet"
- config_name: sah
data_files:
- split: train
path: "data/sah/train.parquet"
- split: validation
path: "data/sah/validation.parquet"
- config_name: sat
data_files:
- split: train
path: "data/sat/train.parquet"
- split: validation
path: "data/sat/validation.parquet"
- config_name: sc
data_files:
- split: train
path: "data/sc/train.parquet"
- split: validation
path: "data/sc/validation.parquet"
- config_name: scn
data_files:
- split: train
path: "data/scn/train.parquet"
- split: validation
path: "data/scn/validation.parquet"
- config_name: sco
data_files:
- split: train
path: "data/sco/train.parquet"
- split: validation
path: "data/sco/validation.parquet"
- config_name: sd
data_files:
- split: train
path: "data/sd/train.parquet"
- split: validation
path: "data/sd/validation.parquet"
- config_name: se
data_files:
- split: train
path: "data/se/train.parquet"
- split: validation
path: "data/se/validation.parquet"
- config_name: sg
data_files:
- split: train
path: "data/sg/train.parquet"
- split: validation
path: "data/sg/validation.parquet"
- config_name: sh
data_files:
- split: train
path: "data/sh/train.parquet"
- split: validation
path: "data/sh/validation.parquet"
- config_name: shi
data_files:
- split: train
path: "data/shi/train.parquet"
- split: validation
path: "data/shi/validation.parquet"
- config_name: shn
data_files:
- split: train
path: "data/shn/train.parquet"
- split: validation
path: "data/shn/validation.parquet"
- config_name: si
data_files:
- split: train
path: "data/si/train.parquet"
- split: validation
path: "data/si/validation.parquet"
- config_name: simple
data_files:
- split: train
path: "data/simple/train.parquet"
- split: validation
path: "data/simple/validation.parquet"
- config_name: sk
data_files:
- split: train
path: "data/sk/train.parquet"
- split: validation
path: "data/sk/validation.parquet"
- config_name: skr
data_files:
- split: train
path: "data/skr/train.parquet"
- split: validation
path: "data/skr/validation.parquet"
- config_name: sl
data_files:
- split: train
path: "data/sl/train.parquet"
- split: validation
path: "data/sl/validation.parquet"
- config_name: sm
data_files:
- split: train
path: "data/sm/train.parquet"
- split: validation
path: "data/sm/validation.parquet"
- config_name: smn
data_files:
- split: train
path: "data/smn/train.parquet"
- split: validation
path: "data/smn/validation.parquet"
- config_name: sn
data_files:
- split: train
path: "data/sn/train.parquet"
- split: validation
path: "data/sn/validation.parquet"
- config_name: so
data_files:
- split: train
path: "data/so/train.parquet"
- split: validation
path: "data/so/validation.parquet"
- config_name: sq
data_files:
- split: train
path: "data/sq/train.parquet"
- split: validation
path: "data/sq/validation.parquet"
- config_name: sr
data_files:
- split: train
path: "data/sr/train.parquet"
- split: validation
path: "data/sr/validation.parquet"
- config_name: srn
data_files:
- split: train
path: "data/srn/train.parquet"
- split: validation
path: "data/srn/validation.parquet"
- config_name: ss
data_files:
- split: train
path: "data/ss/train.parquet"
- split: validation
path: "data/ss/validation.parquet"
- config_name: st
data_files:
- split: train
path: "data/st/train.parquet"
- split: validation
path: "data/st/validation.parquet"
- config_name: stq
data_files:
- split: train
path: "data/stq/train.parquet"
- split: validation
path: "data/stq/validation.parquet"
- config_name: su
data_files:
- split: train
path: "data/su/train.parquet"
- split: validation
path: "data/su/validation.parquet"
- config_name: sv
data_files:
- split: train
path: "data/sv/train.parquet"
- split: validation
path: "data/sv/validation.parquet"
- config_name: sw
data_files:
- split: train
path: "data/sw/train.parquet"
- split: validation
path: "data/sw/validation.parquet"
- config_name: szl
data_files:
- split: train
path: "data/szl/train.parquet"
- split: validation
path: "data/szl/validation.parquet"
- config_name: szy
data_files:
- split: train
path: "data/szy/train.parquet"
- split: validation
path: "data/szy/validation.parquet"
- config_name: ta
data_files:
- split: train
path: "data/ta/train.parquet"
- split: validation
path: "data/ta/validation.parquet"
- config_name: tay
data_files:
- split: train
path: "data/tay/train.parquet"
- split: validation
path: "data/tay/validation.parquet"
- config_name: tcy
data_files:
- split: train
path: "data/tcy/train.parquet"
- split: validation
path: "data/tcy/validation.parquet"
- config_name: te
data_files:
- split: train
path: "data/te/train.parquet"
- split: validation
path: "data/te/validation.parquet"
- config_name: tet
data_files:
- split: train
path: "data/tet/train.parquet"
- split: validation
path: "data/tet/validation.parquet"
- config_name: tg
data_files:
- split: train
path: "data/tg/train.parquet"
- split: validation
path: "data/tg/validation.parquet"
- config_name: th
data_files:
- split: train
path: "data/th/train.parquet"
- split: validation
path: "data/th/validation.parquet"
- config_name: ti
data_files:
- split: train
path: "data/ti/train.parquet"
- split: validation
path: "data/ti/validation.parquet"
- config_name: tk
data_files:
- split: train
path: "data/tk/train.parquet"
- split: validation
path: "data/tk/validation.parquet"
- config_name: tl
data_files:
- split: train
path: "data/tl/train.parquet"
- split: validation
path: "data/tl/validation.parquet"
- config_name: tn
data_files:
- split: train
path: "data/tn/train.parquet"
- split: validation
path: "data/tn/validation.parquet"
- config_name: to
data_files:
- split: train
path: "data/to/train.parquet"
- split: validation
path: "data/to/validation.parquet"
- config_name: tpi
data_files:
- split: train
path: "data/tpi/train.parquet"
- split: validation
path: "data/tpi/validation.parquet"
- config_name: tr
data_files:
- split: train
path: "data/tr/train.parquet"
- split: validation
path: "data/tr/validation.parquet"
- config_name: trv
data_files:
- split: train
path: "data/trv/train.parquet"
- split: validation
path: "data/trv/validation.parquet"
- config_name: ts
data_files:
- split: train
path: "data/ts/train.parquet"
- split: validation
path: "data/ts/validation.parquet"
- config_name: tt
data_files:
- split: train
path: "data/tt/train.parquet"
- split: validation
path: "data/tt/validation.parquet"
- config_name: tum
data_files:
- split: train
path: "data/tum/train.parquet"
- split: validation
path: "data/tum/validation.parquet"
- config_name: tw
data_files:
- split: train
path: "data/tw/train.parquet"
- split: validation
path: "data/tw/validation.parquet"
- config_name: ty
data_files:
- split: train
path: "data/ty/train.parquet"
- split: validation
path: "data/ty/validation.parquet"
- config_name: tyv
data_files:
- split: train
path: "data/tyv/train.parquet"
- split: validation
path: "data/tyv/validation.parquet"
- config_name: udm
data_files:
- split: train
path: "data/udm/train.parquet"
- split: validation
path: "data/udm/validation.parquet"
- config_name: ug
data_files:
- split: train
path: "data/ug/train.parquet"
- split: validation
path: "data/ug/validation.parquet"
- config_name: uk
data_files:
- split: train
path: "data/uk/train.parquet"
- split: validation
path: "data/uk/validation.parquet"
- config_name: ur
data_files:
- split: train
path: "data/ur/train.parquet"
- split: validation
path: "data/ur/validation.parquet"
- config_name: uz
data_files:
- split: train
path: "data/uz/train.parquet"
- split: validation
path: "data/uz/validation.parquet"
- config_name: ve
data_files:
- split: train
path: "data/ve/train.parquet"
- split: validation
path: "data/ve/validation.parquet"
- config_name: vec
data_files:
- split: train
path: "data/vec/train.parquet"
- split: validation
path: "data/vec/validation.parquet"
- config_name: vep
data_files:
- split: train
path: "data/vep/train.parquet"
- split: validation
path: "data/vep/validation.parquet"
- config_name: vi
data_files:
- split: train
path: "data/vi/train.parquet"
- split: validation
path: "data/vi/validation.parquet"
- config_name: vls
data_files:
- split: train
path: "data/vls/train.parquet"
- split: validation
path: "data/vls/validation.parquet"
- config_name: vo
data_files:
- split: train
path: "data/vo/train.parquet"
- split: validation
path: "data/vo/validation.parquet"
- config_name: wa
data_files:
- split: train
path: "data/wa/train.parquet"
- split: validation
path: "data/wa/validation.parquet"
- config_name: war
data_files:
- split: train
path: "data/war/train.parquet"
- split: validation
path: "data/war/validation.parquet"
- config_name: wo
data_files:
- split: train
path: "data/wo/train.parquet"
- split: validation
path: "data/wo/validation.parquet"
- config_name: wuu
data_files:
- split: train
path: "data/wuu/train.parquet"
- split: validation
path: "data/wuu/validation.parquet"
- config_name: xal
data_files:
- split: train
path: "data/xal/train.parquet"
- split: validation
path: "data/xal/validation.parquet"
- config_name: xh
data_files:
- split: train
path: "data/xh/train.parquet"
- split: validation
path: "data/xh/validation.parquet"
- config_name: xmf
data_files:
- split: train
path: "data/xmf/train.parquet"
- split: validation
path: "data/xmf/validation.parquet"
- config_name: yi
data_files:
- split: train
path: "data/yi/train.parquet"
- split: validation
path: "data/yi/validation.parquet"
- config_name: yo
data_files:
- split: train
path: "data/yo/train.parquet"
- split: validation
path: "data/yo/validation.parquet"
- config_name: za
data_files:
- split: train
path: "data/za/train.parquet"
- split: validation
path: "data/za/validation.parquet"
- config_name: zea
data_files:
- split: train
path: "data/zea/train.parquet"
- split: validation
path: "data/zea/validation.parquet"
- config_name: zh
data_files:
- split: train
path: "data/zh/train.parquet"
- split: validation
path: "data/zh/validation.parquet"
- config_name: zh_classical
data_files:
- split: train
path: "data/zh_classical/train.parquet"
- split: validation
path: "data/zh_classical/validation.parquet"
- config_name: zh_min_nan
data_files:
- split: train
path: "data/zh_min_nan/train.parquet"
- split: validation
path: "data/zh_min_nan/validation.parquet"
- config_name: zh_yue
data_files:
- split: train
path: "data/zh_yue/train.parquet"
- split: validation
path: "data/zh_yue/validation.parquet"
- config_name: zu
data_files:
- split: train
path: "data/zu/train.parquet"
- split: validation
path: "data/zu/validation.parquet"
---
# Dataset Card for WikiAnc
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Repository:** [WikiAnc repository](https://github.com/cyanic-selkie/wikianc)
### Dataset Summary
The WikiAnc dataset is an automatically generated dataset from Wikipedia (all languages) and Wikidata dumps (August, 2023).
The code for generating the dataset can be found [here](https://github.com/cyanic-selkie/wikianc).
### Supported Tasks
- `wikificiation`: The dataset can be used to train a model for Wikification.
- `named-entity-linking`: The dataset can be used to train a model for Named Entity Linking.
### Languages
The text in the dataset is in all 320 Wikipedia languages. The full list can be found in the table below.
## Dataset Structure
### Data Instances
A typical data point represents a paragraph in a Wikipedia article.
The `paragraph_text` field contains the original text in an NFC normalized, UTF-8 encoded string.
The `paragraph_anchors` field contains a list of anchors, each represented by a struct with the inclusive starting UTF-8 code point `start` field, exclusive ending UTF-8 code point `end` field, a nullable `qid` field, a nullable `pageid` field, and an NFC normalized, UTF-8 encoded `title` (Wikipedia) field.
Additionally, each paragraph has `article_title`, `article_pageid`, and (nullable) `article_qid` fields referring to the article the paragraph came from.
There is also a nullable, NFC normalized, UTF-8 encoded `section_heading` field, and an integer `section_level` field referring to the heading (if it exists) of the article section, and the level in the section hierarchy that the paragraph came from.
The `qid` fields refers to Wikidata's QID identifiers, while the `pageid` and `title` fields refer to Wikipedia's pageID and title identifiers (there is a one-to-one mapping between pageIDs and titles).
**NOTE:** An anchor will always have a `title`, but that doesn't mean it has to have a `pageid`. This is because Wikipedia allows defining anchors to nonexistent articles.
An example from the WikiAnc EN test set looks as follows:
```
{
"uuid": "5f74e678-944f-4761-a5e0-b6426f6f61b8",
"article_title": "Climatius",
"article_pageid": 5394373,
"article_qid": 867987,
"section_heading": null,
"section_level": 0,
"paragraph_text": "It was a small fish, at 7.5 cm, and to discourage predators, Climatius sported fifteen sharp spines. There was one spine each on the paired pelvic and pectoral fins, and on the aingle anal and two dorsal fins, and a four pairs without fins on the fish's underside.",
"paragraph_anchors": [
{
"start": 140,
"end": 146,
"qid": 3335089,
"pageid": 56849833,
"title": "Pelvic_fin"
},
{
"start": 151,
"end": 159,
"qid": 4162555,
"pageid": 331956,
"title": "Pectoral_fin"
},
{
"start": 184,
"end": 188,
"qid": 4162555,
"pageid": 331958,
"title": "Anal_fin"
},
{
"start": 197,
"end": 208,
"qid": 1568355,
"pageid": 294244,
"title": "Dorsal_fin"
}
]
}
```
### Data Fields
- `uuid`: a UTF-8 encoded string representing a v4 UUID that uniquely identifies the example
- `article_title`: an NFC normalized, UTF-8 encoded Wikipedia title of the article; spaces are replaced with underscores
- `article_pageid`: an integer representing the Wikipedia pageID of the article
- `article_qid`: an integer representing the Wikidata QID this article refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `section_heading`: a nullable, NFC normalized, UTF-8 encoded string representing the section heading
- `section_level`: an integer representing the level of the section in the section hierarchy
- `paragraph_text`: an NFC normalized, UTF-8 encoded string representing the paragraph
- `paragraph_anchors`: a list of structs representing anchors, each anchor has:
- `start`: an integer representing the inclusive starting UTF-8 code point of the anchors
- `end`: an integer representing the exclusive ending UTF-8 code point of the anchor
- `qid`: a nullable integer representing the Wikidata QID this anchor refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `pageid`: a nullable integer representing the Wikipedia pageID of the anchor; it can be null if the article didn't exist in Wikipedia at the time of the creation of the original dataset
- `title`: an NFC normalized, UTF-8 encoded string representing the Wikipedia title of the anchor; spaces are replaced with underscores; can refer to a nonexistent Wikipedia article
### Data Splits
The data is split into training, validation and test sets; paragraphs belonging to the same article aren't necessarily in the same split. The final split sizes are as follows:
#### Train
| | Articles | Paragraphs | Anchors | Anchors with QIDs | Anchors with PageIDs |
| :-- | --: | --: | --: | --: | --: |
| ab | 2378 | 5678 | 10515 | 3649 | 3650 |
| ace | 12591 | 23969 | 48638 | 25150 | 25175 |
| ady | 596 | 1662 | 2694 | 1593 | 1606 |
| af | 104470 | 399038 | 985640 | 900596 | 900967 |
| als | 27999 | 165085 | 402049 | 294742 | 294744 |
| alt | 1043 | 7468 | 9158 | 5446 | 5452 |
| am | 13576 | 46318 | 90051 | 51915 | 52173 |
| ami | 1582 | 12428 | 6080 | 1505 | 2579 |
| an | 40179 | 121367 | 669830 | 516248 | 516822 |
| ang | 3833 | 9664 | 24297 | 10189 | 10229 |
| anp | 2506 | 6865 | 14560 | 3825 | 5061 |
| ar | 1132271 | 3617491 | 11657228 | 11240112 | 11244160 |
| arc | 1844 | 3766 | 9232 | 5460 | 5545 |
| ary | 6736 | 17049 | 50185 | 34193 | 34227 |
| arz | 1579782 | 3693549 | 7879303 | 6906799 | 6917393 |
| as | 11947 | 77835 | 122760 | 67594 | 67720 |
| ast | 126992 | 877278 | 2952000 | 1775764 | 1777383 |
| atj | 1872 | 3820 | 6544 | 3247 | 3365 |
| av | 3048 | 8542 | 16115 | 8895 | 9000 |
| avk | 27577 | 85219 | 106100 | 32260 | 33491 |
| awa | 3396 | 5802 | 6617 | 1679 | 2370 |
| ay | 5102 | 15125 | 22802 | 13930 | 13933 |
| az | 180810 | 789902 | 1570889 | 1377797 | 1380325 |
| azb | 240990 | 585386 | 1241661 | 749575 | 753318 |
| ba | 62269 | 391926 | 625645 | 562730 | 563181 |
| ban | 18955 | 44138 | 86239 | 66213 | 66412 |
| bar | 26057 | 83298 | 185158 | 109082 | 109091 |
| bat_smg | 17013 | 41951 | 77417 | 51701 | 51733 |
| bcl | 13783 | 45457 | 78963 | 47819 | 47861 |
| be | 222883 | 821135 | 2499258 | 2204062 | 2204117 |
| bg | 285156 | 1336530 | 3967713 | 3618800 | 3627798 |
| bh | 7658 | 17052 | 29110 | 22157 | 22217 |
| bi | 1403 | 1712 | 3172 | 1991 | 1995 |
| bjn | 9672 | 19007 | 58660 | 32538 | 33071 |
| blk | 2786 | 11825 | 11341 | 5979 | 6129 |
| bm | 1111 | 2421 | 2451 | 1217 | 1218 |
| bn | 136921 | 736388 | 1530942 | 1161967 | 1162761 |
| bo | 11843 | 37121 | 8241 | 6265 | 6359 |
| bpy | 24742 | 115606 | 166906 | 86166 | 86170 |
| br | 78524 | 214128 | 657375 | 527295 | 527606 |
| bs | 86407 | 382114 | 1246030 | 965782 | 966511 |
| bug | 14231 | 14484 | 53879 | 14787 | 15146 |
| bxr | 2730 | 9571 | 27853 | 11560 | 11567 |
| ca | 691444 | 3596667 | 11359870 | 10236358 | 10237666 |
| cbk_zam | 2989 | 8322 | 9939 | 2790 | 2847 |
| cdo | 15922 | 30059 | 63474 | 29659 | 29705 |
| ce | 597137 | 2121587 | 3097393 | 1507129 | 1507806 |
| ceb | 5888811 | 11920613 | 37969424 | 33678489 | 33962205 |
| ch | 574 | 1166 | 2290 | 492 | 601 |
| chr | 980 | 1110 | 1311 | 779 | 790 |
| chy | 711 | 753 | 494 | 428 | 428 |
| ckb | 48903 | 163599 | 435662 | 224749 | 226749 |
| co | 6719 | 22954 | 46391 | 24149 | 24229 |
| cr | 158 | 216 | 209 | 94 | 94 |
| crh | 24117 | 29781 | 98534 | 70231 | 70235 |
| cs | 516037 | 2679537 | 9917806 | 8763103 | 8763291 |
| csb | 5315 | 14009 | 31294 | 16820 | 16820 |
| cu | 1171 | 2796 | 5283 | 2346 | 2349 |
| cv | 50525 | 157542 | 375399 | 166889 | 167497 |
| cy | 276031 | 992900 | 2011030 | 1613064 | 1620632 |
| da | 284765 | 1167917 | 4352733 | 3854239 | 3854549 |
| dag | 9248 | 29213 | 46084 | 10981 | 14213 |
| de | 2780056 | 16093948 | 52497421 | 50480495 | 50480548 |
| din | 485 | 1551 | 1096 | 197 | 197 |
| diq | 37565 | 70969 | 155656 | 141636 | 141695 |
| dsb | 3083 | 8760 | 19397 | 9652 | 9652 |
| dty | 3339 | 6219 | 7505 | 4417 | 4447 |
| dv | 4190 | 16809 | 7906 | 3612 | 3620 |
| dz | 652 | 2623 | 272 | 94 | 100 |
| ee | 1075 | 2326 | 1823 | 861 | 926 |
| el | 224207 | 1527561 | 4181433 | 3119952 | 3121967 |
| eml | 12169 | 53861 | 115729 | 65775 | 65940 |
| en | 6514924 | 40656507 | 109681826 | 107761324 | 107768438 |
| eo | 330486 | 1116191 | 4257655 | 3975927 | 3979379 |
| es | 1792062 | 10890435 | 33729712 | 31581851 | 31648945 |
| et | 233078 | 1110906 | 3558448 | 2879595 | 2886824 |
| eu | 386029 | 1405747 | 3398477 | 3025183 | 3030635 |
| ext | 3472 | 9626 | 20554 | 11966 | 11978 |
| fa | 901254 | 2357271 | 6189352 | 5862106 | 5870803 |
| fat | 1044 | 6092 | 1717 | 120 | 857 |
| ff | 1763 | 4103 | 3483 | 2304 | 2413 |
| fi | 373226 | 1667296 | 5221239 | 4658292 | 4663471 |
| fiu_vro | 6417 | 19897 | 40418 | 23563 | 23609 |
| fj | 1157 | 1782 | 4852 | 1910 | 1911 |
| fo | 11809 | 30828 | 119267 | 95117 | 95259 |
| fr | 2432972 | 15252697 | 43564517 | 42573624 | 42589064 |
| frp | 5341 | 10574 | 36358 | 24905 | 24926 |
| frr | 16038 | 30821 | 80265 | 68184 | 68315 |
| fur | 3665 | 10651 | 29516 | 16249 | 16278 |
| fy | 46011 | 206153 | 1271339 | 985227 | 985511 |
| ga | 52168 | 130535 | 347037 | 288261 | 288309 |
| gag | 2408 | 4844 | 8551 | 4520 | 4520 |
| gan | 4219 | 9689 | 18994 | 14119 | 14128 |
| gcr | 2227 | 5163 | 2763 | 1186 | 1186 |
| gd | 15850 | 48217 | 141290 | 95557 | 95562 |
| gl | 190419 | 910543 | 3674404 | 2937660 | 2938634 |
| glk | 6484 | 15344 | 32631 | 21395 | 21447 |
| gn | 5064 | 15481 | 40641 | 30389 | 30440 |
| gom | 4192 | 37508 | 14192 | 2369 | 2382 |
| gor | 14388 | 28133 | 107341 | 66191 | 67016 |
| got | 960 | 2186 | 4093 | 1404 | 1415 |
| gpe | 899 | 3383 | 1199 | 796 | 815 |
| gu | 30025 | 114805 | 459063 | 348651 | 348731 |
| guc | 546 | 2545 | 2300 | 1025 | 1138 |
| gur | 1010 | 5043 | 1761 | 227 | 244 |
| guw | 1263 | 3719 | 7474 | 3116 | 5375 |
| gv | 5036 | 12213 | 48801 | 19659 | 19663 |
| ha | 31977 | 149096 | 115029 | 97167 | 98184 |
| hak | 8694 | 11505 | 39744 | 28150 | 28152 |
| haw | 2470 | 5810 | 11169 | 5700 | 5705 |
| he | 323472 | 2648617 | 10904148 | 10367532 | 10379886 |
| hi | 150121 | 538451 | 964251 | 795726 | 798254 |
| hif | 10534 | 21169 | 43463 | 23970 | 24316 |
| hr | 189415 | 876107 | 3210326 | 2752205 | 2758602 |
| hsb | 13183 | 40760 | 91863 | 66632 | 66633 |
| ht | 64850 | 154160 | 201547 | 166206 | 167961 |
| hu | 346711 | 1859683 | 5267990 | 4707580 | 4710525 |
| hy | 298066 | 1542920 | 3767938 | 2689014 | 2690466 |
| hyw | 11358 | 83640 | 161227 | 82218 | 84817 |
| ia | 24581 | 43289 | 129914 | 96517 | 96595 |
| id | 620895 | 2138237 | 6589957 | 5629372 | 5644832 |
| ie | 11020 | 22342 | 60890 | 46054 | 46122 |
| ig | 19448 | 110907 | 57963 | 31022 | 31298 |
| ik | 737 | 1016 | 848 | 551 | 580 |
| ilo | 14135 | 74304 | 126533 | 75701 | 75705 |
| inh | 1754 | 4640 | 13284 | 5770 | 6011 |
| io | 36312 | 101555 | 303765 | 258933 | 259001 |
| is | 54348 | 170321 | 574897 | 436767 | 437784 |
| it | 1610989 | 8718610 | 27447754 | 26116131 | 26126157 |
| iu | 502 | 757 | 536 | 414 | 418 |
| ja | 1355269 | 9276459 | 29002111 | 27752954 | 27801000 |
| jam | 1571 | 2260 | 5887 | 3588 | 3590 |
| jbo | 1287 | 3088 | 5831 | 546 | 546 |
| jv | 66323 | 148710 | 547010 | 381682 | 382052 |
| ka | 167161 | 695865 | 2275552 | 422090 | 422095 |
| kaa | 3540 | 9814 | 12930 | 5312 | 5752 |
| kab | 5346 | 14709 | 36889 | 22000 | 22050 |
| kbd | 1549 | 6348 | 14594 | 5277 | 5280 |
| kbp | 1846 | 6005 | 7119 | 6875 | 6880 |
| kcg | 871 | 1839 | 2953 | 1857 | 1871 |
| kg | 1187 | 1933 | 3835 | 2292 | 2295 |
| ki | 1482 | 2899 | 2035 | 1386 | 1649 |
| kk | 235740 | 889990 | 1840304 | 1143049 | 1151399 |
| kl | 282 | 1024 | 1337 | 302 | 302 |
| km | 11422 | 84697 | 111378 | 40954 | 41529 |
| kn | 30729 | 261724 | 432994 | 188536 | 188807 |
| ko | 606386 | 2159706 | 6217786 | 5715559 | 5725614 |
| koi | 3260 | 9065 | 17068 | 10628 | 10628 |
| krc | 1465 | 6234 | 18092 | 7294 | 7311 |
| ks | 4176 | 9446 | 15252 | 5917 | 6226 |
| ksh | 2836 | 11043 | 26577 | 9484 | 9496 |
| ku | 55166 | 112840 | 269080 | 208679 | 210304 |
| kv | 5236 | 13396 | 32141 | 26727 | 26744 |
| kw | 6884 | 18901 | 49462 | 28074 | 28194 |
| ky | 75426 | 191772 | 271376 | 189656 | 190133 |
| la | 124150 | 240343 | 1456464 | 1283285 | 1283728 |
| lad | 3538 | 11910 | 37456 | 19124 | 19124 |
| lb | 57747 | 178507 | 573528 | 443583 | 444601 |
| lbe | 1205 | 2249 | 4470 | 2543 | 2543 |
| lez | 4067 | 16675 | 36970 | 25834 | 25842 |
| lfn | 4506 | 21746 | 29785 | 14554 | 14560 |
| lg | 3814 | 23386 | 15539 | 2088 | 2724 |
| li | 14134 | 58711 | 212772 | 137110 | 137367 |
| lij | 8092 | 23366 | 61410 | 34939 | 34940 |
| lld | 152613 | 158049 | 578033 | 443976 | 458150 |
| lmo | 67387 | 136650 | 373890 | 274174 | 274612 |
| ln | 3132 | 6066 | 11086 | 7838 | 7874 |
| lo | 4734 | 15005 | 27132 | 8562 | 8799 |
| lt | 204135 | 775863 | 2687983 | 2406710 | 2414909 |
| ltg | 1018 | 2979 | 5815 | 2190 | 2193 |
| lv | 118530 | 437086 | 1458341 | 1244609 | 1247181 |
| mad | 1113 | 3500 | 3762 | 1149 | 1157 |
| mai | 13285 | 22572 | 53246 | 38119 | 38128 |
| map_bms | 10875 | 16411 | 67964 | 51125 | 51137 |
| mdf | 4002 | 11043 | 21658 | 9178 | 9183 |
| mg | 92227 | 213580 | 328751 | 265931 | 267633 |
| mhr | 11010 | 33013 | 60771 | 38153 | 38220 |
| mi | 7274 | 10154 | 29052 | 24854 | 25216 |
| min | 223075 | 422381 | 1315030 | 513108 | 515548 |
| mk | 131522 | 695456 | 1984109 | 1639280 | 1640744 |
| ml | 84334 | 415940 | 797903 | 485482 | 486324 |
| mn | 23434 | 124485 | 295548 | 142014 | 142984 |
| mni | 10354 | 18872 | 29474 | 18810 | 19876 |
| mnw | 3136 | 34165 | 9342 | 1908 | 2387 |
| mr | 92464 | 326662 | 633452 | 383501 | 392709 |
| mrj | 10156 | 20132 | 48416 | 24098 | 24098 |
| ms | 344459 | 988647 | 2424535 | 1932685 | 1937647 |
| mt | 5381 | 49856 | 104636 | 51251 | 51278 |
| mwl | 4402 | 37271 | 127176 | 25729 | 26366 |
| my | 103938 | 334243 | 445026 | 300567 | 303288 |
| myv | 7515 | 21592 | 36762 | 26570 | 26591 |
| mzn | 17364 | 39937 | 89805 | 46962 | 47020 |
| nah | 5934 | 12478 | 30805 | 13093 | 14364 |
| nap | 11235 | 22336 | 41891 | 20798 | 20804 |
| nds | 79228 | 242004 | 583941 | 305374 | 305422 |
| nds_nl | 6484 | 28252 | 94875 | 51767 | 51785 |
| ne | 30359 | 91033 | 153937 | 124841 | 125078 |
| new | 71653 | 245033 | 454251 | 289444 | 289912 |
| nia | 1496 | 4047 | 4524 | 2258 | 2812 |
| nl | 1948842 | 5867108 | 17953497 | 16886996 | 16893078 |
| nn | 160106 | 549454 | 1751481 | 1375622 | 1376155 |
| no | 591000 | 2213493 | 7050421 | 6471776 | 6476157 |
| nov | 1341 | 3711 | 7466 | 3948 | 3955 |
| nqo | 1489 | 9858 | 23633 | 6056 | 6981 |
| nrm | 4571 | 14279 | 38935 | 33295 | 33321 |
| nso | 7618 | 9505 | 36826 | 35621 | 35623 |
| nv | 21911 | 57663 | 123762 | 107139 | 107139 |
| ny | 1060 | 3164 | 4750 | 1455 | 1490 |
| oc | 85099 | 303185 | 1035051 | 791403 | 792043 |
| olo | 4348 | 14334 | 18704 | 8634 | 8647 |
| om | 1710 | 7496 | 8222 | 4333 | 4416 |
| or | 17027 | 76677 | 137274 | 57023 | 57064 |
| os | 17468 | 40488 | 80943 | 48124 | 48414 |
| pa | 50421 | 226354 | 344239 | 197594 | 198080 |
| pag | 2533 | 41416 | 4150 | 2907 | 2907 |
| pam | 7816 | 16493 | 53785 | 29375 | 29715 |
| pap | 3153 | 12086 | 22157 | 18161 | 18233 |
| pcd | 5272 | 12203 | 15602 | 12319 | 12360 |
| pcm | 1019 | 4631 | 4161 | 1160 | 1261 |
| pdc | 2009 | 5406 | 8151 | 4122 | 4144 |
| pfl | 2717 | 14024 | 26150 | 10291 | 10294 |
| pi | 2972 | 5959 | 7773 | 201 | 201 |
| pih | 829 | 1065 | 2857 | 2016 | 2018 |
| pl | 1468194 | 5599437 | 19364191 | 18389560 | 18405120 |
| pms | 66552 | 170133 | 369956 | 308593 | 314917 |
| pnb | 67534 | 402101 | 937247 | 525105 | 533265 |
| pnt | 497 | 1467 | 3553 | 1715 | 1716 |
| ps | 19254 | 134868 | 72493 | 36348 | 36899 |
| pt | 1048823 | 5226543 | 16811382 | 15714686 | 15714890 |
| pwn | 328 | 1825 | 990 | 428 | 430 |
| qu | 22365 | 47078 | 133032 | 106686 | 106708 |
| rm | 3569 | 27345 | 47169 | 20460 | 20490 |
| rmy | 911 | 2221 | 4235 | 1854 | 1965 |
| rn | 726 | 1641 | 1436 | 594 | 601 |
| ro | 417630 | 1518438 | 4282072 | 3764830 | 3765626 |
| roa_rup | 1270 | 2751 | 4641 | 2527 | 2537 |
| roa_tara | 8407 | 18031 | 42040 | 14330 | 14331 |
| ru | 1889271 | 12344758 | 30796034 | 29268121 | 29288089 |
| rue | 7369 | 21429 | 61022 | 43241 | 43256 |
| rw | 7793 | 35619 | 38066 | 19821 | 20967 |
| sa | 12069 | 78188 | 104193 | 40307 | 41518 |
| sah | 16007 | 76450 | 82154 | 61041 | 61412 |
| sat | 8655 | 43624 | 57493 | 28497 | 28820 |
| sc | 6919 | 24434 | 66719 | 44707 | 44733 |
| scn | 21990 | 49686 | 132583 | 102735 | 102774 |
| sco | 34097 | 86464 | 301450 | 148184 | 148406 |
| sd | 16228 | 48679 | 79392 | 34572 | 35729 |
| se | 6101 | 10531 | 25844 | 17978 | 18010 |
| sg | 473 | 537 | 318 | 184 | 184 |
| sh | 445218 | 1213741 | 4337559 | 3858400 | 3860253 |
| shi | 1650 | 6036 | 10364 | 4715 | 4926 |
| shn | 10653 | 51542 | 46976 | 29925 | 29993 |
| si | 21959 | 132932 | 146935 | 55158 | 56422 |
| simple | 224811 | 618711 | 2014692 | 1689101 | 1689185 |
| sk | 230073 | 845501 | 2867955 | 2468707 | 2469129 |
| skr | 5505 | 62742 | 38412 | 15004 | 21015 |
| sl | 175804 | 810714 | 2597824 | 2067682 | 2068522 |
| sm | 995 | 1591 | 3838 | 2515 | 2523 |
| smn | 5004 | 12483 | 37008 | 22440 | 22492 |
| sn | 10159 | 19527 | 40437 | 31573 | 32763 |
| so | 8540 | 36173 | 53012 | 42913 | 43548 |
| sq | 94941 | 371562 | 699210 | 520709 | 522241 |
| sr | 657766 | 2331205 | 6562651 | 5257496 | 5264077 |
| srn | 1171 | 3050 | 6637 | 1752 | 1941 |
| ss | 783 | 2124 | 2382 | 1127 | 1139 |
| st | 982 | 1971 | 2510 | 1689 | 1701 |
| stq | 3648 | 10972 | 29713 | 15919 | 15920 |
| su | 57552 | 122590 | 496201 | 384518 | 384891 |
| sv | 2418380 | 5019466 | 22263222 | 21445193 | 21445441 |
| sw | 75109 | 218219 | 798980 | 688743 | 692052 |
| szl | 56229 | 109496 | 473528 | 129434 | 129479 |
| szy | 4628 | 49166 | 18867 | 2419 | 3187 |
| ta | 157642 | 780711 | 1642095 | 1141032 | 1142372 |
| tay | 2643 | 15831 | 10104 | 1496 | 5312 |
| tcy | 2135 | 9932 | 11073 | 4680 | 4745 |
| te | 83866 | 719826 | 822054 | 619184 | 622092 |
| tet | 1323 | 3797 | 8047 | 4093 | 4095 |
| tg | 108598 | 279635 | 761826 | 330974 | 331423 |
| th | 153075 | 715083 | 1723394 | 1395935 | 1398891 |
| ti | 388 | 987 | 1191 | 325 | 326 |
| tk | 4739 | 23629 | 18964 | 9717 | 9760 |
| tl | 43388 | 150141 | 447293 | 296084 | 296634 |
| tn | 1090 | 3960 | 3976 | 2008 | 2010 |
| to | 1512 | 2754 | 3542 | 2029 | 2080 |
| tpi | 1278 | 2055 | 3897 | 2193 | 2198 |
| tr | 500435 | 1806253 | 4476004 | 3964449 | 3965589 |
| trv | 1770 | 16650 | 3814 | 504 | 969 |
| ts | 674 | 1798 | 1557 | 903 | 909 |
| tt | 484761 | 1196573 | 2064576 | 1675637 | 1676579 |
| tum | 16778 | 31383 | 57382 | 28399 | 37107 |
| tw | 3568 | 16807 | 15312 | 10912 | 11495 |
| ty | 1175 | 1364 | 1563 | 1095 | 1095 |
| tyv | 3399 | 21968 | 21004 | 5535 | 5557 |
| udm | 5066 | 11432 | 24875 | 17709 | 17715 |
| ug | 8102 | 58982 | 23654 | 12671 | 12874 |
| uk | 522709 | 2867475 | 6800045 | 6445628 | 6451294 |
| ur | 194948 | 676227 | 1870488 | 910419 | 914840 |
| uz | 232879 | 859793 | 1344790 | 1073065 | 1084092 |
| ve | 764 | 1359 | 2524 | 2366 | 2366 |
| vec | 62729 | 98987 | 275972 | 194424 | 194447 |
| vep | 6853 | 43014 | 93864 | 39225 | 39228 |
| vi | 1300753 | 4103594 | 10852870 | 6884928 | 6892519 |
| vls | 7272 | 26374 | 61885 | 49639 | 49653 |
| vo | 32133 | 78015 | 125495 | 101612 | 101629 |
| wa | 11104 | 56305 | 116752 | 79686 | 80037 |
| war | 1158901 | 1342594 | 6654010 | 6009636 | 6009641 |
| wo | 1659 | 7693 | 10828 | 4057 | 4103 |
| wuu | 37170 | 58227 | 121928 | 82184 | 82237 |
| xal | 2008 | 4309 | 4582 | 2112 | 2113 |
| xh | 1502 | 4448 | 6733 | 2128 | 2186 |
| xmf | 19201 | 49944 | 179291 | 21189 | 22041 |
| yi | 14164 | 68937 | 172645 | 116102 | 116325 |
| yo | 29938 | 52231 | 85171 | 46928 | 47346 |
| za | 2388 | 3917 | 7463 | 4613 | 4665 |
| zea | 5445 | 16648 | 36161 | 23532 | 23578 |
| zh | 1310818 | 5501834 | 16397675 | 14380752 | 14421795 |
| zh_classical | 11775 | 44053 | 140340 | 71576 | 71692 |
| zh_min_nan | 425676 | 853753 | 2627115 | 2053956 | 2054838 |
| zh_yue | 121401 | 273459 | 844047 | 683130 | 683226 |
| zu | 10387 | 18211 | 22569 | 20193 | 20238 |
#### Validation
| | Articles | Paragraphs | Anchors | Anchors with QIDs | Anchors with PageIDs |
| :-- | --: | --: | --: | --: | --: |
| ab | 475 | 601 | 1061 | 399 | 399 |
| ace | 2443 | 2668 | 5197 | 2583 | 2587 |
| ady | 142 | 183 | 248 | 150 | 151 |
| af | 27383 | 44157 | 109108 | 100078 | 100123 |
| als | 11998 | 18277 | 44634 | 32874 | 32874 |
| alt | 481 | 827 | 1020 | 621 | 621 |
| am | 3746 | 5234 | 10111 | 5731 | 5756 |
| ami | 749 | 1431 | 744 | 179 | 304 |
| an | 10526 | 13588 | 74808 | 58195 | 58259 |
| ang | 826 | 1099 | 2647 | 1099 | 1102 |
| anp | 504 | 751 | 1698 | 437 | 581 |
| ar | 265368 | 401215 | 1295968 | 1249666 | 1250103 |
| arc | 377 | 418 | 1061 | 610 | 617 |
| ary | 1447 | 1870 | 5702 | 3885 | 3887 |
| arz | 367206 | 410487 | 876531 | 767742 | 768942 |
| as | 5463 | 8589 | 13953 | 7719 | 7732 |
| ast | 48345 | 97904 | 329690 | 197832 | 198042 |
| atj | 399 | 440 | 774 | 406 | 416 |
| av | 719 | 961 | 1918 | 1043 | 1053 |
| avk | 8056 | 9538 | 11816 | 3633 | 3772 |
| awa | 515 | 645 | 721 | 213 | 287 |
| ay | 1391 | 1653 | 2616 | 1481 | 1483 |
| az | 57070 | 88136 | 177151 | 155596 | 155858 |
| azb | 57642 | 64997 | 137053 | 83336 | 83778 |
| ba | 25690 | 43460 | 69052 | 61624 | 61666 |
| ban | 4053 | 4840 | 9581 | 7374 | 7385 |
| bar | 6905 | 9377 | 20546 | 12164 | 12164 |
| bat_smg | 4149 | 4706 | 8787 | 5820 | 5823 |
| bcl | 3355 | 5058 | 8759 | 5080 | 5083 |
| be | 64203 | 91174 | 276525 | 244114 | 244122 |
| bg | 98148 | 148234 | 438687 | 400356 | 401330 |
| bh | 1535 | 1891 | 3464 | 2630 | 2635 |
| bi | 154 | 159 | 251 | 151 | 151 |
| bjn | 1764 | 2166 | 6458 | 3694 | 3775 |
| blk | 887 | 1374 | 1538 | 821 | 839 |
| bm | 196 | 272 | 317 | 146 | 146 |
| bn | 50495 | 81841 | 169097 | 128508 | 128609 |
| bo | 2198 | 4079 | 934 | 746 | 752 |
| bpy | 10057 | 12879 | 18710 | 9693 | 9693 |
| br | 18687 | 23734 | 73278 | 59024 | 59056 |
| bs | 28533 | 42574 | 138483 | 107760 | 107846 |
| bug | 1636 | 1655 | 6141 | 1682 | 1731 |
| bxr | 754 | 1003 | 2930 | 1211 | 1211 |
| ca | 251952 | 399403 | 1265187 | 1140208 | 1140359 |
| cbk_zam | 460 | 932 | 1040 | 268 | 272 |
| cdo | 2953 | 3237 | 6938 | 3273 | 3281 |
| ce | 197899 | 234617 | 341843 | 166126 | 166206 |
| ceb | 1221405 | 1324624 | 4218179 | 3742385 | 3773844 |
| ch | 123 | 131 | 239 | 64 | 73 |
| chr | 124 | 134 | 175 | 100 | 100 |
| chy | 67 | 67 | 47 | 42 | 42 |
| ckb | 13511 | 18279 | 48490 | 25365 | 25540 |
| co | 1723 | 2587 | 5286 | 2729 | 2737 |
| cr | 22 | 23 | 22 | 13 | 13 |
| crh | 2978 | 3246 | 11005 | 7899 | 7899 |
| cs | 189136 | 297000 | 1101343 | 974485 | 974505 |
| csb | 1307 | 1533 | 3341 | 1851 | 1851 |
| cu | 250 | 275 | 540 | 229 | 229 |
| cv | 14374 | 17462 | 42486 | 19049 | 19114 |
| cy | 89897 | 110225 | 222476 | 177842 | 178698 |
| da | 87765 | 129990 | 482701 | 427333 | 427374 |
| dag | 2215 | 3237 | 4935 | 1169 | 1498 |
| de | 1120553 | 1788057 | 5831103 | 5607963 | 5607963 |
| din | 149 | 177 | 128 | 15 | 15 |
| diq | 6660 | 7883 | 17684 | 15853 | 15861 |
| dsb | 781 | 1032 | 2476 | 1301 | 1301 |
| dty | 554 | 659 | 861 | 480 | 483 |
| dv | 1227 | 1898 | 870 | 406 | 406 |
| dz | 215 | 303 | 21 | 8 | 8 |
| ee | 203 | 242 | 183 | 66 | 74 |
| el | 99725 | 169395 | 461747 | 344216 | 344456 |
| eml | 4387 | 6114 | 13938 | 8193 | 8214 |
| en | 2503257 | 4516442 | 12185882 | 11974436 | 11975194 |
| eo | 90949 | 123848 | 474727 | 442357 | 442772 |
| es | 701171 | 1209944 | 3752765 | 3514968 | 3522213 |
| et | 80911 | 123354 | 395877 | 319773 | 320587 |
| eu | 104388 | 156552 | 378553 | 337331 | 337944 |
| ext | 804 | 1045 | 2269 | 1344 | 1345 |
| fa | 191532 | 262121 | 688824 | 652200 | 653219 |
| fat | 446 | 709 | 214 | 3 | 97 |
| ff | 361 | 459 | 378 | 222 | 234 |
| fi | 123327 | 184244 | 576163 | 514419 | 514915 |
| fiu_vro | 1738 | 2263 | 4622 | 2623 | 2628 |
| fj | 168 | 213 | 604 | 214 | 214 |
| fo | 2625 | 3398 | 13383 | 10599 | 10617 |
| fr | 954388 | 1695419 | 4847588 | 4738268 | 4740047 |
| frp | 1018 | 1181 | 4089 | 2862 | 2862 |
| frr | 2968 | 3419 | 9609 | 7996 | 8011 |
| fur | 884 | 1168 | 3225 | 1833 | 1839 |
| fy | 15980 | 22974 | 139530 | 108300 | 108337 |
| ga | 10781 | 14493 | 38848 | 32343 | 32352 |
| gag | 440 | 551 | 961 | 465 | 465 |
| gan | 731 | 1045 | 2071 | 1536 | 1537 |
| gcr | 480 | 567 | 297 | 122 | 122 |
| gd | 4393 | 5296 | 15544 | 10458 | 10458 |
| gl | 62030 | 101112 | 407821 | 325854 | 325960 |
| glk | 1383 | 1747 | 3723 | 2435 | 2443 |
| gn | 1164 | 1728 | 4751 | 3521 | 3528 |
| gom | 2106 | 4116 | 1511 | 251 | 251 |
| gor | 2844 | 3082 | 11826 | 7315 | 7411 |
| got | 216 | 245 | 514 | 190 | 190 |
| gpe | 265 | 355 | 93 | 71 | 73 |
| gu | 8437 | 13008 | 50956 | 38242 | 38251 |
| guc | 198 | 279 | 312 | 141 | 162 |
| gur | 369 | 565 | 145 | 25 | 27 |
| guw | 332 | 393 | 827 | 313 | 616 |
| gv | 957 | 1324 | 5652 | 2252 | 2253 |
| ha | 10666 | 16571 | 12853 | 10862 | 10993 |
| hak | 1179 | 1302 | 4628 | 3155 | 3155 |
| haw | 541 | 650 | 1238 | 616 | 618 |
| he | 165541 | 295188 | 1213939 | 1153986 | 1155384 |
| hi | 36229 | 60184 | 108382 | 89102 | 89340 |
| hif | 2107 | 2369 | 5015 | 2648 | 2680 |
| hr | 62673 | 97103 | 354392 | 304964 | 305664 |
| hsb | 3599 | 4379 | 10001 | 7239 | 7240 |
| ht | 14693 | 17294 | 23011 | 18721 | 18928 |
| hu | 125438 | 206546 | 586091 | 523501 | 523814 |
| hy | 113060 | 171415 | 418503 | 298111 | 298292 |
| hyw | 5310 | 9207 | 17616 | 8842 | 9168 |
| ia | 4021 | 4850 | 14972 | 11257 | 11263 |
| id | 158648 | 237793 | 734148 | 627764 | 629525 |
| ie | 2213 | 2523 | 6750 | 5036 | 5046 |
| ig | 7944 | 12354 | 6464 | 3466 | 3493 |
| ik | 100 | 118 | 120 | 64 | 71 |
| ilo | 4096 | 8297 | 14183 | 8609 | 8609 |
| inh | 399 | 494 | 1298 | 626 | 645 |
| io | 8868 | 11368 | 33682 | 28744 | 28748 |
| is | 13573 | 18566 | 62576 | 47263 | 47360 |
| it | 584902 | 968880 | 3050620 | 2902006 | 2903047 |
| iu | 61 | 62 | 48 | 29 | 29 |
| ja | 573457 | 1032568 | 3222875 | 3083301 | 3088604 |
| jam | 249 | 274 | 623 | 399 | 399 |
| jbo | 270 | 321 | 562 | 56 | 56 |
| jv | 13108 | 16457 | 60143 | 42112 | 42148 |
| ka | 53071 | 76961 | 252383 | 46974 | 46975 |
| kaa | 775 | 1071 | 1476 | 669 | 717 |
| kab | 1269 | 1685 | 4050 | 2397 | 2403 |
| kbd | 474 | 663 | 1482 | 537 | 537 |
| kbp | 535 | 656 | 835 | 810 | 811 |
| kcg | 190 | 223 | 311 | 196 | 197 |
| kg | 187 | 213 | 420 | 260 | 260 |
| ki | 273 | 333 | 248 | 169 | 206 |
| kk | 76635 | 99268 | 204324 | 126732 | 127677 |
| kl | 97 | 129 | 162 | 43 | 43 |
| km | 3844 | 9340 | 12192 | 4524 | 4583 |
| kn | 14217 | 29387 | 48402 | 20992 | 21022 |
| ko | 154713 | 239887 | 689906 | 633527 | 634725 |
| koi | 682 | 1010 | 1815 | 1144 | 1144 |
| krc | 423 | 698 | 2022 | 841 | 846 |
| ks | 888 | 1006 | 1692 | 645 | 670 |
| ksh | 918 | 1156 | 2951 | 1053 | 1055 |
| ku | 10060 | 12771 | 29766 | 23050 | 23232 |
| kv | 1105 | 1456 | 3365 | 2787 | 2787 |
| kw | 1820 | 2171 | 5570 | 3076 | 3082 |
| ky | 16655 | 21571 | 31213 | 21712 | 21757 |
| la | 22397 | 26732 | 161732 | 142447 | 142486 |
| lad | 961 | 1286 | 3984 | 2056 | 2056 |
| lb | 15385 | 19667 | 60568 | 46664 | 46730 |
| lbe | 207 | 232 | 488 | 290 | 290 |
| lez | 1184 | 1764 | 3829 | 2760 | 2760 |
| lfn | 1455 | 2435 | 3328 | 1602 | 1604 |
| lg | 1272 | 2650 | 1795 | 239 | 305 |
| li | 4501 | 6650 | 24213 | 15790 | 15826 |
| lij | 1781 | 2607 | 6658 | 3933 | 3933 |
| lld | 17293 | 17539 | 64059 | 49327 | 50864 |
| lmo | 12641 | 14976 | 40217 | 29874 | 29946 |
| ln | 585 | 692 | 1321 | 996 | 997 |
| lo | 1144 | 1680 | 3023 | 991 | 1013 |
| lt | 62652 | 85962 | 300456 | 269264 | 270227 |
| ltg | 289 | 341 | 686 | 285 | 285 |
| lv | 34742 | 48371 | 160433 | 136594 | 136873 |
| mad | 284 | 381 | 439 | 135 | 136 |
| mai | 2184 | 2499 | 5878 | 4209 | 4212 |
| map_bms | 1539 | 1847 | 7486 | 5705 | 5705 |
| mdf | 1086 | 1244 | 2512 | 1077 | 1077 |
| mg | 20361 | 23650 | 36313 | 29821 | 29974 |
| mhr | 2863 | 3594 | 6538 | 4114 | 4122 |
| mi | 1078 | 1154 | 3214 | 2743 | 2776 |
| min | 42987 | 46277 | 143692 | 55809 | 56077 |
| mk | 46235 | 76890 | 219310 | 180884 | 181042 |
| ml | 31116 | 46345 | 88976 | 53726 | 53818 |
| mn | 8485 | 13887 | 32271 | 15330 | 15455 |
| mni | 1843 | 2102 | 3418 | 2183 | 2325 |
| mnw | 1284 | 3750 | 897 | 202 | 224 |
| mr | 26803 | 36202 | 70510 | 43103 | 44352 |
| mrj | 2062 | 2297 | 5627 | 2888 | 2888 |
| ms | 75473 | 110077 | 270064 | 215280 | 215811 |
| mt | 2516 | 5510 | 11680 | 5760 | 5761 |
| mwl | 1828 | 4316 | 15365 | 3216 | 3287 |
| my | 24005 | 37165 | 49321 | 33223 | 33518 |
| myv | 1732 | 2327 | 4094 | 2923 | 2925 |
| mzn | 3784 | 4409 | 9938 | 5199 | 5205 |
| nah | 1128 | 1314 | 3316 | 1418 | 1556 |
| nap | 2047 | 2473 | 4579 | 2249 | 2249 |
| nds | 20646 | 26845 | 65355 | 34090 | 34094 |
| nds_nl | 2127 | 3063 | 10188 | 5585 | 5587 |
| ne | 6956 | 10087 | 16847 | 13502 | 13536 |
| new | 22645 | 27233 | 50860 | 32165 | 32217 |
| nia | 312 | 430 | 512 | 277 | 329 |
| nl | 490380 | 651743 | 1994062 | 1874588 | 1875259 |
| nn | 44180 | 60918 | 194747 | 153072 | 153140 |
| no | 172653 | 245377 | 779775 | 715618 | 716153 |
| nov | 339 | 410 | 861 | 452 | 452 |
| nqo | 583 | 1037 | 2598 | 704 | 813 |
| nrm | 1318 | 1600 | 4276 | 3734 | 3736 |
| nso | 960 | 1038 | 4242 | 4119 | 4119 |
| nv | 5649 | 6281 | 13652 | 11768 | 11768 |
| ny | 236 | 318 | 392 | 126 | 126 |
| oc | 23067 | 33775 | 115155 | 87980 | 88063 |
| olo | 1273 | 1598 | 2162 | 997 | 998 |
| om | 401 | 830 | 891 | 401 | 412 |
| or | 6261 | 8669 | 16120 | 6752 | 6757 |
| os | 3923 | 4535 | 9130 | 5470 | 5524 |
| pa | 17242 | 24844 | 37813 | 21759 | 21812 |
| pag | 1602 | 4519 | 404 | 300 | 300 |
| pam | 1509 | 1831 | 6019 | 3230 | 3272 |
| pap | 773 | 1376 | 2526 | 2042 | 2056 |
| pcd | 1089 | 1361 | 1803 | 1334 | 1338 |
| pcm | 353 | 542 | 409 | 128 | 139 |
| pdc | 370 | 565 | 839 | 424 | 429 |
| pfl | 1113 | 1500 | 2861 | 1070 | 1070 |
| pi | 578 | 682 | 881 | 26 | 26 |
| pih | 118 | 125 | 317 | 217 | 218 |
| pl | 444095 | 621669 | 2149058 | 2041686 | 2043400 |
| pms | 16530 | 19186 | 41547 | 34783 | 35474 |
| pnb | 21586 | 44654 | 103992 | 58461 | 59380 |
| pnt | 147 | 172 | 389 | 177 | 178 |
| ps | 7566 | 14922 | 8427 | 4108 | 4187 |
| pt | 349931 | 580790 | 1868210 | 1745832 | 1745858 |
| pwn | 103 | 166 | 85 | 31 | 31 |
| qu | 4540 | 5211 | 14781 | 11746 | 11750 |
| rm | 1076 | 3100 | 5539 | 2293 | 2298 |
| rmy | 214 | 235 | 446 | 176 | 184 |
| rn | 125 | 172 | 124 | 53 | 53 |
| ro | 106169 | 168972 | 473512 | 416263 | 416347 |
| roa_rup | 214 | 290 | 458 | 254 | 254 |
| roa_tara | 1278 | 1979 | 4455 | 1534 | 1534 |
| ru | 806592 | 1369860 | 3416036 | 3245837 | 3247963 |
| rue | 2022 | 2513 | 7023 | 5064 | 5066 |
| rw | 2577 | 3925 | 4139 | 2223 | 2349 |
| sa | 4344 | 8607 | 11313 | 4249 | 4391 |
| sah | 4729 | 8472 | 9040 | 6623 | 6660 |
| sat | 3485 | 4960 | 6473 | 3225 | 3278 |
| sc | 1900 | 2807 | 7641 | 5096 | 5098 |
| scn | 4263 | 5604 | 14333 | 11167 | 11171 |
| sco | 7382 | 9639 | 33771 | 16432 | 16453 |
| sd | 3970 | 5499 | 8879 | 3804 | 3925 |
| se | 982 | 1149 | 2841 | 1958 | 1958 |
| sg | 67 | 72 | 36 | 24 | 24 |
| sh | 103283 | 135121 | 484459 | 429555 | 429770 |
| shi | 477 | 679 | 1144 | 545 | 570 |
| shn | 3633 | 5630 | 5456 | 3627 | 3639 |
| si | 7672 | 14760 | 16443 | 6215 | 6346 |
| simple | 52503 | 68765 | 224811 | 187586 | 187598 |
| sk | 67520 | 93957 | 317232 | 272711 | 272779 |
| skr | 2090 | 6926 | 4136 | 1683 | 2359 |
| sl | 55621 | 89740 | 285769 | 228421 | 228530 |
| sm | 153 | 171 | 485 | 297 | 297 |
| smn | 1163 | 1420 | 4517 | 2681 | 2688 |
| sn | 1896 | 2139 | 4351 | 3384 | 3529 |
| so | 2358 | 4032 | 6064 | 5027 | 5083 |
| sq | 25223 | 41621 | 79295 | 59156 | 59350 |
| sr | 177997 | 258455 | 728755 | 584663 | 585394 |
| srn | 281 | 342 | 796 | 205 | 225 |
| ss | 188 | 259 | 265 | 125 | 125 |
| st | 157 | 198 | 248 | 164 | 166 |
| stq | 804 | 1162 | 3150 | 1816 | 1816 |
| su | 10348 | 13687 | 55055 | 42915 | 42944 |
| sv | 467467 | 558522 | 2473790 | 2382576 | 2382608 |
| sw | 18014 | 24348 | 90302 | 77817 | 78145 |
| szl | 11292 | 12173 | 52459 | 14419 | 14424 |
| szy | 2391 | 5418 | 2042 | 235 | 285 |
| ta | 59923 | 87114 | 183399 | 126977 | 127148 |
| tay | 1192 | 1757 | 1101 | 175 | 591 |
| tcy | 769 | 1077 | 1089 | 464 | 465 |
| te | 43790 | 79667 | 91327 | 69148 | 69484 |
| tet | 294 | 412 | 871 | 471 | 471 |
| tg | 27060 | 31599 | 86180 | 37522 | 37561 |
| th | 49169 | 78814 | 189768 | 154097 | 154453 |
| ti | 87 | 99 | 89 | 22 | 22 |
| tk | 1328 | 2612 | 2116 | 1056 | 1062 |
| tl | 11731 | 16623 | 49726 | 32858 | 32914 |
| tn | 296 | 424 | 477 | 278 | 278 |
| to | 254 | 277 | 393 | 230 | 233 |
| tpi | 180 | 207 | 394 | 216 | 217 |
| tr | 134938 | 200972 | 496960 | 440639 | 440790 |
| trv | 807 | 1814 | 400 | 53 | 98 |
| ts | 155 | 203 | 219 | 132 | 132 |
| tt | 113689 | 132676 | 228544 | 185563 | 185662 |
| tum | 2188 | 3516 | 6442 | 3105 | 4083 |
| tw | 1249 | 1885 | 1729 | 1217 | 1291 |
| ty | 162 | 167 | 215 | 143 | 143 |
| tyv | 1494 | 2486 | 2342 | 611 | 617 |
| udm | 1036 | 1240 | 2781 | 1957 | 1957 |
| ug | 2629 | 6556 | 2657 | 1479 | 1493 |
| uk | 203057 | 318240 | 758049 | 718278 | 718908 |
| ur | 54784 | 75152 | 206169 | 99493 | 100041 |
| uz | 65767 | 95465 | 149763 | 119192 | 120519 |
| ve | 128 | 148 | 256 | 229 | 229 |
| vec | 9463 | 11242 | 32188 | 22525 | 22531 |
| vep | 3225 | 4804 | 10375 | 4295 | 4295 |
| vi | 330763 | 455933 | 1211343 | 768936 | 769829 |
| vls | 2189 | 2904 | 7133 | 5776 | 5777 |
| vo | 7308 | 8647 | 13902 | 11270 | 11273 |
| wa | 4457 | 6269 | 12736 | 8751 | 8794 |
| war | 146537 | 149236 | 738087 | 666983 | 666983 |
| wo | 516 | 864 | 1083 | 404 | 414 |
| wuu | 5530 | 6448 | 13732 | 9168 | 9171 |
| xal | 407 | 449 | 549 | 308 | 308 |
| xh | 399 | 550 | 804 | 284 | 293 |
| xmf | 4516 | 5414 | 19437 | 2342 | 2447 |
| yi | 5260 | 7563 | 18821 | 12493 | 12510 |
| yo | 4431 | 5855 | 9761 | 5361 | 5410 |
| za | 335 | 414 | 777 | 457 | 458 |
| zea | 1470 | 1847 | 3682 | 2569 | 2574 |
| zh | 389361 | 611537 | 1817382 | 1592929 | 1597686 |
| zh_classical | 3601 | 4995 | 15834 | 8157 | 8170 |
| zh_min_nan | 87849 | 94529 | 291330 | 227978 | 228083 |
| zh_yue | 23579 | 30146 | 92720 | 75081 | 75096 |
| zu | 1646 | 2050 | 2518 | 2228 | 2234 |
**NOTE:** The number of articles in the tables above refers to the number of articles that have at least one paragraph belonging to the article appear in the split.
## Additional Information
### Licensing Information
The WikiAnc dataset is given under the [Creative Commons Attribution ShareAlike 4.0 International](https://creativecommons.org/licenses/by-sa/4.0/) license.
|
openai/summarize_from_feedback | openai | "2023-01-03T16:55:41Z" | 2,625 | 183 | [
"size_categories:100K<n<1M",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2009.01325",
"region:us"
] | null | "2022-12-28T03:42:47Z" | ---
pretty_name: Summarize from Feedback
---
# Dataset Card for Summarize from Feedback
## Dataset Description
In the [Learning to Summarize from Human Feedback paper](https://arxiv.org/abs/2009.01325), a reward model was trained from human feedback.
The reward model was then used to train a summarization model to align with human preferences. This is the dataset of human feedback that was released for reward modelling.
There are two parts of this dataset: `comparisons` and `axis`. In the `comparisons` part, human annotators were asked to choose the best out of two summaries.
In the `axis` part, human annotators gave scores on a likert scale for the quality of a summary.
The `comparisons` part only has a train and validation split, and the `axis` part only has a test and validation split.
The summaries used for training the reward model in the paper come from the TL;DR dataset.
Additional validation and test data come from the TL;DR dataset, CNN articles, and Daily Mail articles.
For more information, see the repo [here](https://github.com/openai/summarize-from-feedback#human-feedback-data).
## Citation Information
[https://arxiv.org/abs/2009.01325](https://arxiv.org/abs/2009.01325)
```
@inproceedings{stienon2020learning,
author = {Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano},
title = {Learning to summarize from human feedback},
booktitle = {NeurIPS},
year = 2020,
}
```
Dataset added to the Hugging Face Hub with help from [@Tristan](https://huggingface.co/Tristan) |
OALL/Arabic_EXAMS | OALL | "2024-02-16T20:54:12Z" | 2,623 | 1 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-02-16T15:24:11Z" | ---
dataset_info:
features:
- name: id
dtype: string
- name: subject
dtype: string
- name: question
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 167521
num_examples: 537
- name: validation
num_bytes: 7803
num_examples: 25
download_size: 99036
dataset_size: 175324
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
- split: validation
path: data/validation-*
---
|
Graphcore/vqa | Graphcore | "2022-10-25T08:41:02Z" | 2,622 | 4 | [
"language:en",
"license:cc-by-4.0",
"region:us"
] | null | "2022-03-02T23:29:22Z" | ---
language:
- en
license:
- cc-by-4.0
---
|
google/xtreme | google | "2024-02-22T17:12:06Z" | 2,616 | 88 | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:token-classification",
"task_categories:text-classification",
"task_categories:text-retrieval",
"task_ids:multiple-choice-qa",
"task_ids:extractive-qa",
"task_ids:open-domain-qa",
"task_ids:natural-language-inference",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"multilinguality:translation",
"source_datasets:extended|xnli",
"source_datasets:extended|paws-x",
"source_datasets:extended|wikiann",
"source_datasets:extended|xquad",
"source_datasets:extended|mlqa",
"source_datasets:extended|tydiqa",
"source_datasets:extended|tatoeba",
"source_datasets:extended|squad",
"language:af",
"language:ar",
"language:bg",
"language:bn",
"language:de",
"language:el",
"language:en",
"language:es",
"language:et",
"language:eu",
"language:fa",
"language:fi",
"language:fr",
"language:he",
"language:hi",
"language:hu",
"language:id",
"language:it",
"language:ja",
"language:jv",
"language:ka",
"language:kk",
"language:ko",
"language:ml",
"language:mr",
"language:ms",
"language:my",
"language:nl",
"language:pt",
"language:ru",
"language:sw",
"language:ta",
"language:te",
"language:th",
"language:tl",
"language:tr",
"language:ur",
"language:vi",
"language:yo",
"language:zh",
"license:apache-2.0",
"license:cc-by-4.0",
"license:cc-by-2.0",
"license:cc-by-sa-4.0",
"license:other",
"license:cc-by-nc-4.0",
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2003.11080",
"region:us",
"parallel-sentence-retrieval",
"paraphrase-identification"
] | [
"multiple-choice",
"question-answering",
"token-classification",
"text-classification",
"text-retrieval",
"token-classification"
] | "2022-03-02T23:29:22Z" | ---
annotations_creators:
- found
language_creators:
- found
language:
- af
- ar
- bg
- bn
- de
- el
- en
- es
- et
- eu
- fa
- fi
- fr
- he
- hi
- hu
- id
- it
- ja
- jv
- ka
- kk
- ko
- ml
- mr
- ms
- my
- nl
- pt
- ru
- sw
- ta
- te
- th
- tl
- tr
- ur
- vi
- yo
- zh
license:
- apache-2.0
- cc-by-4.0
- cc-by-2.0
- cc-by-sa-4.0
- other
- cc-by-nc-4.0
multilinguality:
- multilingual
- translation
size_categories:
- n<1K
- 1K<n<10K
- 10K<n<100K
- 100K<n<1M
source_datasets:
- extended|xnli
- extended|paws-x
- extended|wikiann
- extended|xquad
- extended|mlqa
- extended|tydiqa
- extended|tatoeba
- extended|squad
task_categories:
- multiple-choice
- question-answering
- token-classification
- text-classification
- text-retrieval
- token-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- natural-language-inference
- named-entity-recognition
- part-of-speech
paperswithcode_id: xtreme
pretty_name: XTREME
config_names:
- MLQA.ar.ar
- MLQA.ar.de
- MLQA.ar.en
- MLQA.ar.es
- MLQA.ar.hi
- MLQA.ar.vi
- MLQA.ar.zh
- MLQA.de.ar
- MLQA.de.de
- MLQA.de.en
- MLQA.de.es
- MLQA.de.hi
- MLQA.de.vi
- MLQA.de.zh
- MLQA.en.ar
- MLQA.en.de
- MLQA.en.en
- MLQA.en.es
- MLQA.en.hi
- MLQA.en.vi
- MLQA.en.zh
- MLQA.es.ar
- MLQA.es.de
- MLQA.es.en
- MLQA.es.es
- MLQA.es.hi
- MLQA.es.vi
- MLQA.es.zh
- MLQA.hi.ar
- MLQA.hi.de
- MLQA.hi.en
- MLQA.hi.es
- MLQA.hi.hi
- MLQA.hi.vi
- MLQA.hi.zh
- MLQA.vi.ar
- MLQA.vi.de
- MLQA.vi.en
- MLQA.vi.es
- MLQA.vi.hi
- MLQA.vi.vi
- MLQA.vi.zh
- MLQA.zh.ar
- MLQA.zh.de
- MLQA.zh.en
- MLQA.zh.es
- MLQA.zh.hi
- MLQA.zh.vi
- MLQA.zh.zh
- PAN-X.af
- PAN-X.ar
- PAN-X.bg
- PAN-X.bn
- PAN-X.de
- PAN-X.el
- PAN-X.en
- PAN-X.es
- PAN-X.et
- PAN-X.eu
- PAN-X.fa
- PAN-X.fi
- PAN-X.fr
- PAN-X.he
- PAN-X.hi
- PAN-X.hu
- PAN-X.id
- PAN-X.it
- PAN-X.ja
- PAN-X.jv
- PAN-X.ka
- PAN-X.kk
- PAN-X.ko
- PAN-X.ml
- PAN-X.mr
- PAN-X.ms
- PAN-X.my
- PAN-X.nl
- PAN-X.pt
- PAN-X.ru
- PAN-X.sw
- PAN-X.ta
- PAN-X.te
- PAN-X.th
- PAN-X.tl
- PAN-X.tr
- PAN-X.ur
- PAN-X.vi
- PAN-X.yo
- PAN-X.zh
- PAWS-X.de
- PAWS-X.en
- PAWS-X.es
- PAWS-X.fr
- PAWS-X.ja
- PAWS-X.ko
- PAWS-X.zh
- SQuAD
- XNLI
- XQuAD
- bucc18.de
- bucc18.fr
- bucc18.ru
- bucc18.zh
- tatoeba.afr
- tatoeba.ara
- tatoeba.ben
- tatoeba.bul
- tatoeba.cmn
- tatoeba.deu
- tatoeba.ell
- tatoeba.est
- tatoeba.eus
- tatoeba.fin
- tatoeba.fra
- tatoeba.heb
- tatoeba.hin
- tatoeba.hun
- tatoeba.ind
- tatoeba.ita
- tatoeba.jav
- tatoeba.jpn
- tatoeba.kat
- tatoeba.kaz
- tatoeba.kor
- tatoeba.mal
- tatoeba.mar
- tatoeba.nld
- tatoeba.pes
- tatoeba.por
- tatoeba.rus
- tatoeba.spa
- tatoeba.swh
- tatoeba.tam
- tatoeba.tel
- tatoeba.tgl
- tatoeba.tha
- tatoeba.tur
- tatoeba.urd
- tatoeba.vie
- tydiqa
- udpos.Afrikans
- udpos.Arabic
- udpos.Basque
- udpos.Bulgarian
- udpos.Chinese
- udpos.Dutch
- udpos.English
- udpos.Estonian
- udpos.Finnish
- udpos.French
- udpos.German
- udpos.Greek
- udpos.Hebrew
- udpos.Hindi
- udpos.Hungarian
- udpos.Indonesian
- udpos.Italian
- udpos.Japanese
- udpos.Kazakh
- udpos.Korean
- udpos.Marathi
- udpos.Persian
- udpos.Portuguese
- udpos.Russian
- udpos.Spanish
- udpos.Tagalog
- udpos.Tamil
- udpos.Telugu
- udpos.Thai
- udpos.Turkish
- udpos.Urdu
- udpos.Vietnamese
- udpos.Yoruba
language_bcp47:
- fa-IR
license_details: Licence Universal Dependencies v2.5
tags:
- parallel-sentence-retrieval
- paraphrase-identification
dataset_info:
- config_name: MLQA.ar.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 8368086
num_examples: 5335
- name: validation
num_bytes: 824080
num_examples: 517
download_size: 4048180
dataset_size: 9192166
- config_name: MLQA.ar.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 2183914
num_examples: 1649
- name: validation
num_bytes: 364809
num_examples: 207
download_size: 1192825
dataset_size: 2548723
- config_name: MLQA.ar.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 8225634
num_examples: 5335
- name: validation
num_bytes: 810061
num_examples: 517
download_size: 3998008
dataset_size: 9035695
- config_name: MLQA.ar.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3041350
num_examples: 1978
- name: validation
num_bytes: 228152
num_examples: 161
download_size: 1531661
dataset_size: 3269502
- config_name: MLQA.ar.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3039368
num_examples: 1831
- name: validation
num_bytes: 281742
num_examples: 186
download_size: 1369756
dataset_size: 3321110
- config_name: MLQA.ar.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3290601
num_examples: 2047
- name: validation
num_bytes: 288418
num_examples: 163
download_size: 1667238
dataset_size: 3579019
- config_name: MLQA.ar.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3229844
num_examples: 1912
- name: validation
num_bytes: 340021
num_examples: 188
download_size: 1591445
dataset_size: 3569865
- config_name: MLQA.de.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1619978
num_examples: 1649
- name: validation
num_bytes: 200146
num_examples: 207
download_size: 1044483
dataset_size: 1820124
- config_name: MLQA.de.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4366074
num_examples: 4517
- name: validation
num_bytes: 488339
num_examples: 512
download_size: 2798050
dataset_size: 4854413
- config_name: MLQA.de.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4343116
num_examples: 4517
- name: validation
num_bytes: 485866
num_examples: 512
download_size: 2778346
dataset_size: 4828982
- config_name: MLQA.de.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1716587
num_examples: 1776
- name: validation
num_bytes: 170554
num_examples: 196
download_size: 1118751
dataset_size: 1887141
- config_name: MLQA.de.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1371046
num_examples: 1430
- name: validation
num_bytes: 153843
num_examples: 163
download_size: 880652
dataset_size: 1524889
- config_name: MLQA.de.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1688455
num_examples: 1675
- name: validation
num_bytes: 216047
num_examples: 182
download_size: 1108163
dataset_size: 1904502
- config_name: MLQA.de.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1679152
num_examples: 1621
- name: validation
num_bytes: 184290
num_examples: 190
download_size: 1045861
dataset_size: 1863442
- config_name: MLQA.en.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 6739191
num_examples: 5335
- name: validation
num_bytes: 630815
num_examples: 517
download_size: 3939135
dataset_size: 7370006
- config_name: MLQA.en.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 5056694
num_examples: 4517
- name: validation
num_bytes: 594908
num_examples: 512
download_size: 3223196
dataset_size: 5651602
- config_name: MLQA.en.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 14004592
num_examples: 11590
- name: validation
num_bytes: 1329084
num_examples: 1148
download_size: 8217519
dataset_size: 15333676
- config_name: MLQA.en.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 6179221
num_examples: 5253
- name: validation
num_bytes: 555434
num_examples: 500
download_size: 3776828
dataset_size: 6734655
- config_name: MLQA.en.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 6378838
num_examples: 4918
- name: validation
num_bytes: 623143
num_examples: 507
download_size: 3517340
dataset_size: 7001981
- config_name: MLQA.en.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 7056670
num_examples: 5495
- name: validation
num_bytes: 640618
num_examples: 511
download_size: 4170642
dataset_size: 7697288
- config_name: MLQA.en.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 6539279
num_examples: 5137
- name: validation
num_bytes: 608416
num_examples: 504
download_size: 3929122
dataset_size: 7147695
- config_name: MLQA.es.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1740254
num_examples: 1978
- name: validation
num_bytes: 148621
num_examples: 161
download_size: 1107435
dataset_size: 1888875
- config_name: MLQA.es.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1403997
num_examples: 1776
- name: validation
num_bytes: 144158
num_examples: 196
download_size: 950448
dataset_size: 1548155
- config_name: MLQA.es.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4362709
num_examples: 5253
- name: validation
num_bytes: 419040
num_examples: 500
download_size: 2842879
dataset_size: 4781749
- config_name: MLQA.es.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4394305
num_examples: 5253
- name: validation
num_bytes: 422043
num_examples: 500
download_size: 2856931
dataset_size: 4816348
- config_name: MLQA.es.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1523495
num_examples: 1723
- name: validation
num_bytes: 181806
num_examples: 187
download_size: 954018
dataset_size: 1705301
- config_name: MLQA.es.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1747941
num_examples: 2018
- name: validation
num_bytes: 176813
num_examples: 189
download_size: 1187949
dataset_size: 1924754
- config_name: MLQA.es.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1678423
num_examples: 1947
- name: validation
num_bytes: 126618
num_examples: 161
download_size: 1100765
dataset_size: 1805041
- config_name: MLQA.hi.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4445561
num_examples: 1831
- name: validation
num_bytes: 410396
num_examples: 186
download_size: 1542768
dataset_size: 4855957
- config_name: MLQA.hi.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3022836
num_examples: 1430
- name: validation
num_bytes: 301685
num_examples: 163
download_size: 1257846
dataset_size: 3324521
- config_name: MLQA.hi.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 11449233
num_examples: 4918
- name: validation
num_bytes: 1097829
num_examples: 507
download_size: 4131083
dataset_size: 12547062
- config_name: MLQA.hi.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3862201
num_examples: 1723
- name: validation
num_bytes: 420374
num_examples: 187
download_size: 1493468
dataset_size: 4282575
- config_name: MLQA.hi.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 11810447
num_examples: 4918
- name: validation
num_bytes: 1136756
num_examples: 507
download_size: 4235981
dataset_size: 12947203
- config_name: MLQA.hi.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4743456
num_examples: 1947
- name: validation
num_bytes: 419078
num_examples: 177
download_size: 1704964
dataset_size: 5162534
- config_name: MLQA.hi.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4354847
num_examples: 1767
- name: validation
num_bytes: 424218
num_examples: 189
download_size: 1627107
dataset_size: 4779065
- config_name: MLQA.vi.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 3205157
num_examples: 2047
- name: validation
num_bytes: 230307
num_examples: 163
download_size: 1656661
dataset_size: 3435464
- config_name: MLQA.vi.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 2227005
num_examples: 1675
- name: validation
num_bytes: 277157
num_examples: 182
download_size: 1268041
dataset_size: 2504162
- config_name: MLQA.vi.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 7843403
num_examples: 5495
- name: validation
num_bytes: 719245
num_examples: 511
download_size: 4071703
dataset_size: 8562648
- config_name: MLQA.vi.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 2866569
num_examples: 2018
- name: validation
num_bytes: 283433
num_examples: 189
download_size: 1607926
dataset_size: 3150002
- config_name: MLQA.vi.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 2776636
num_examples: 1947
- name: validation
num_bytes: 254979
num_examples: 177
download_size: 1366057
dataset_size: 3031615
- config_name: MLQA.vi.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 7922057
num_examples: 5495
- name: validation
num_bytes: 726490
num_examples: 511
download_size: 4105388
dataset_size: 8648547
- config_name: MLQA.vi.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 2989632
num_examples: 1943
- name: validation
num_bytes: 269361
num_examples: 184
download_size: 1570393
dataset_size: 3258993
- config_name: MLQA.zh.ar
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1731455
num_examples: 1912
- name: validation
num_bytes: 175321
num_examples: 188
download_size: 1223863
dataset_size: 1906776
- config_name: MLQA.zh.de
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1389990
num_examples: 1621
- name: validation
num_bytes: 174577
num_examples: 190
download_size: 1006829
dataset_size: 1564567
- config_name: MLQA.zh.en
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4450957
num_examples: 5137
- name: validation
num_bytes: 446840
num_examples: 504
download_size: 3108433
dataset_size: 4897797
- config_name: MLQA.zh.es
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1736255
num_examples: 1947
- name: validation
num_bytes: 138045
num_examples: 161
download_size: 1223467
dataset_size: 1874300
- config_name: MLQA.zh.hi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1578191
num_examples: 1767
- name: validation
num_bytes: 184373
num_examples: 189
download_size: 1044599
dataset_size: 1762564
- config_name: MLQA.zh.vi
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 1806158
num_examples: 1943
- name: validation
num_bytes: 172906
num_examples: 184
download_size: 1268213
dataset_size: 1979064
- config_name: MLQA.zh.zh
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: test
num_bytes: 4422322
num_examples: 5137
- name: validation
num_bytes: 443782
num_examples: 504
download_size: 3105362
dataset_size: 4866104
- config_name: PAN-X.af
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 1321376
num_examples: 5000
- name: validation
num_bytes: 259689
num_examples: 1000
- name: test
num_bytes: 257184
num_examples: 1000
download_size: 389015
dataset_size: 1838249
- config_name: PAN-X.ar
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3634096
num_examples: 20000
- name: validation
num_bytes: 1808283
num_examples: 10000
- name: test
num_bytes: 1811963
num_examples: 10000
download_size: 1567470
dataset_size: 7254342
- config_name: PAN-X.bg
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4600733
num_examples: 20000
- name: validation
num_bytes: 2310294
num_examples: 10000
- name: test
num_bytes: 2306138
num_examples: 10000
download_size: 2030669
dataset_size: 9217165
- config_name: PAN-X.bn
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 1568825
num_examples: 10000
- name: validation
num_bytes: 159068
num_examples: 1000
- name: test
num_bytes: 159262
num_examples: 1000
download_size: 364024
dataset_size: 1887155
- config_name: PAN-X.de
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4762312
num_examples: 20000
- name: validation
num_bytes: 2381545
num_examples: 10000
- name: test
num_bytes: 2377619
num_examples: 10000
download_size: 2360242
dataset_size: 9521476
- config_name: PAN-X.el
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 5063136
num_examples: 20000
- name: validation
num_bytes: 2533786
num_examples: 10000
- name: test
num_bytes: 2547574
num_examples: 10000
download_size: 2271726
dataset_size: 10144496
- config_name: PAN-X.en
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3823434
num_examples: 20000
- name: validation
num_bytes: 1920049
num_examples: 10000
- name: test
num_bytes: 1916200
num_examples: 10000
download_size: 1886284
dataset_size: 7659683
- config_name: PAN-X.es
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3199121
num_examples: 20000
- name: validation
num_bytes: 1592505
num_examples: 10000
- name: test
num_bytes: 1602271
num_examples: 10000
download_size: 1489562
dataset_size: 6393897
- config_name: PAN-X.et
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3023171
num_examples: 15000
- name: validation
num_bytes: 2030140
num_examples: 10000
- name: test
num_bytes: 2021389
num_examples: 10000
download_size: 1915624
dataset_size: 7074700
- config_name: PAN-X.eu
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 2292307
num_examples: 10000
- name: validation
num_bytes: 2296315
num_examples: 10000
- name: test
num_bytes: 2249815
num_examples: 10000
download_size: 1393179
dataset_size: 6838437
- config_name: PAN-X.fa
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3529314
num_examples: 20000
- name: validation
num_bytes: 1782286
num_examples: 10000
- name: test
num_bytes: 1770264
num_examples: 10000
download_size: 1401208
dataset_size: 7081864
- config_name: PAN-X.fi
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4273753
num_examples: 20000
- name: validation
num_bytes: 2131749
num_examples: 10000
- name: test
num_bytes: 2130645
num_examples: 10000
download_size: 2459149
dataset_size: 8536147
- config_name: PAN-X.fr
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3335384
num_examples: 20000
- name: validation
num_bytes: 1664170
num_examples: 10000
- name: test
num_bytes: 1675765
num_examples: 10000
download_size: 1679283
dataset_size: 6675319
- config_name: PAN-X.he
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4667060
num_examples: 20000
- name: validation
num_bytes: 2332740
num_examples: 10000
- name: test
num_bytes: 2318736
num_examples: 10000
download_size: 2186463
dataset_size: 9318536
- config_name: PAN-X.hi
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 964192
num_examples: 5000
- name: validation
num_bytes: 190651
num_examples: 1000
- name: test
num_bytes: 196170
num_examples: 1000
download_size: 266086
dataset_size: 1351013
- config_name: PAN-X.hu
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4499874
num_examples: 20000
- name: validation
num_bytes: 2211831
num_examples: 10000
- name: test
num_bytes: 2249759
num_examples: 10000
download_size: 2399390
dataset_size: 8961464
- config_name: PAN-X.id
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3083967
num_examples: 20000
- name: validation
num_bytes: 1537959
num_examples: 10000
- name: test
num_bytes: 1536859
num_examples: 10000
download_size: 1412049
dataset_size: 6158785
- config_name: PAN-X.it
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3874623
num_examples: 20000
- name: validation
num_bytes: 1908509
num_examples: 10000
- name: test
num_bytes: 1928388
num_examples: 10000
download_size: 1855798
dataset_size: 7711520
- config_name: PAN-X.ja
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 12670361
num_examples: 20000
- name: validation
num_bytes: 6322983
num_examples: 10000
- name: test
num_bytes: 6448940
num_examples: 10000
download_size: 2465674
dataset_size: 25442284
- config_name: PAN-X.jv
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 16086
num_examples: 100
- name: validation
num_bytes: 14580
num_examples: 100
- name: test
num_bytes: 16897
num_examples: 100
download_size: 20475
dataset_size: 47563
- config_name: PAN-X.ka
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 2777342
num_examples: 10000
- name: validation
num_bytes: 2806881
num_examples: 10000
- name: test
num_bytes: 2824621
num_examples: 10000
download_size: 1817280
dataset_size: 8408844
- config_name: PAN-X.kk
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 240256
num_examples: 1000
- name: validation
num_bytes: 238089
num_examples: 1000
- name: test
num_bytes: 236704
num_examples: 1000
download_size: 160554
dataset_size: 715049
- config_name: PAN-X.ko
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4284693
num_examples: 20000
- name: validation
num_bytes: 2138147
num_examples: 10000
- name: test
num_bytes: 2138274
num_examples: 10000
download_size: 2539591
dataset_size: 8561114
- config_name: PAN-X.ml
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 2865184
num_examples: 10000
- name: validation
num_bytes: 290735
num_examples: 1000
- name: test
num_bytes: 276906
num_examples: 1000
download_size: 852955
dataset_size: 3432825
- config_name: PAN-X.mr
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 1248239
num_examples: 5000
- name: validation
num_bytes: 245338
num_examples: 1000
- name: test
num_bytes: 255884
num_examples: 1000
download_size: 347215
dataset_size: 1749461
- config_name: PAN-X.ms
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 2965008
num_examples: 20000
- name: validation
num_bytes: 147495
num_examples: 1000
- name: test
num_bytes: 147148
num_examples: 1000
download_size: 708795
dataset_size: 3259651
- config_name: PAN-X.my
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 32715
num_examples: 100
- name: validation
num_bytes: 40408
num_examples: 100
- name: test
num_bytes: 37346
num_examples: 100
download_size: 39008
dataset_size: 110469
- config_name: PAN-X.nl
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4062149
num_examples: 20000
- name: validation
num_bytes: 2016836
num_examples: 10000
- name: test
num_bytes: 2038618
num_examples: 10000
download_size: 1943893
dataset_size: 8117603
- config_name: PAN-X.pt
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3149243
num_examples: 20000
- name: validation
num_bytes: 1575121
num_examples: 10000
- name: test
num_bytes: 1562605
num_examples: 10000
download_size: 1540478
dataset_size: 6286969
- config_name: PAN-X.ru
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4121751
num_examples: 20000
- name: validation
num_bytes: 2053149
num_examples: 10000
- name: test
num_bytes: 2074125
num_examples: 10000
download_size: 2127730
dataset_size: 8249025
- config_name: PAN-X.sw
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 135891
num_examples: 1000
- name: validation
num_bytes: 136348
num_examples: 1000
- name: test
num_bytes: 140211
num_examples: 1000
download_size: 87435
dataset_size: 412450
- config_name: PAN-X.ta
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 4122090
num_examples: 15000
- name: validation
num_bytes: 277605
num_examples: 1000
- name: test
num_bytes: 278094
num_examples: 1000
download_size: 1044729
dataset_size: 4677789
- config_name: PAN-X.te
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 295390
num_examples: 1000
- name: validation
num_bytes: 293261
num_examples: 1000
- name: test
num_bytes: 296943
num_examples: 1000
download_size: 200516
dataset_size: 885594
- config_name: PAN-X.th
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 27132989
num_examples: 20000
- name: validation
num_bytes: 13262717
num_examples: 10000
- name: test
num_bytes: 13586908
num_examples: 10000
download_size: 2569566
dataset_size: 53982614
- config_name: PAN-X.tl
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 1168697
num_examples: 10000
- name: validation
num_bytes: 114136
num_examples: 1000
- name: test
num_bytes: 117884
num_examples: 1000
download_size: 308160
dataset_size: 1400717
- config_name: PAN-X.tr
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3779130
num_examples: 20000
- name: validation
num_bytes: 1915332
num_examples: 10000
- name: test
num_bytes: 1911483
num_examples: 10000
download_size: 2000699
dataset_size: 7605945
- config_name: PAN-X.ur
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3072236
num_examples: 20000
- name: validation
num_bytes: 152128
num_examples: 1000
- name: test
num_bytes: 151902
num_examples: 1000
download_size: 610869
dataset_size: 3376266
- config_name: PAN-X.vi
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 3153187
num_examples: 20000
- name: validation
num_bytes: 1565123
num_examples: 10000
- name: test
num_bytes: 1580196
num_examples: 10000
download_size: 1375631
dataset_size: 6298506
- config_name: PAN-X.yo
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 14689
num_examples: 100
- name: validation
num_bytes: 13225
num_examples: 100
- name: test
num_bytes: 13513
num_examples: 100
download_size: 17337
dataset_size: 41427
- config_name: PAN-X.zh
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
splits:
- name: train
num_bytes: 8832011
num_examples: 20000
- name: validation
num_bytes: 4491305
num_examples: 10000
- name: test
num_bytes: 4363152
num_examples: 10000
download_size: 2083198
dataset_size: 17686468
- config_name: PAWS-X.de
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 12451823
num_examples: 49380
- name: validation
num_bytes: 499997
num_examples: 2000
- name: test
num_bytes: 510182
num_examples: 2000
download_size: 9294034
dataset_size: 13462002
- config_name: PAWS-X.en
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 11827659
num_examples: 49175
- name: validation
num_bytes: 478279
num_examples: 2000
- name: test
num_bytes: 480726
num_examples: 2000
download_size: 8717639
dataset_size: 12786664
- config_name: PAWS-X.es
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 12462047
num_examples: 49401
- name: validation
num_bytes: 494057
num_examples: 1961
- name: test
num_bytes: 505035
num_examples: 2000
download_size: 9229918
dataset_size: 13461139
- config_name: PAWS-X.fr
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 12948452
num_examples: 49399
- name: validation
num_bytes: 516099
num_examples: 1988
- name: test
num_bytes: 521019
num_examples: 2000
download_size: 9464987
dataset_size: 13985570
- config_name: PAWS-X.ja
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 14695593
num_examples: 49401
- name: validation
num_bytes: 647762
num_examples: 2000
- name: test
num_bytes: 654628
num_examples: 2000
download_size: 10136228
dataset_size: 15997983
- config_name: PAWS-X.ko
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 13542597
num_examples: 49164
- name: validation
num_bytes: 540775
num_examples: 2000
- name: test
num_bytes: 547966
num_examples: 1999
download_size: 9926292
dataset_size: 14631338
- config_name: PAWS-X.zh
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 10469652
num_examples: 49401
- name: validation
num_bytes: 459108
num_examples: 2000
- name: test
num_bytes: 460626
num_examples: 2000
download_size: 8878855
dataset_size: 11389386
- config_name: SQuAD
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: train
num_bytes: 79316858
num_examples: 87599
- name: validation
num_bytes: 10472597
num_examples: 10570
download_size: 16272656
dataset_size: 89789455
- config_name: XNLI
features:
- name: language
dtype: string
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: gold_label
dtype: string
splits:
- name: test
num_bytes: 20359372
num_examples: 75150
- name: validation
num_bytes: 10049239
num_examples: 37350
download_size: 8881623
dataset_size: 30408611
- config_name: XQuAD.ar
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 1722775
num_examples: 1190
download_size: 263032
dataset_size: 1722775
- config_name: XQuAD.de
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 1283277
num_examples: 1190
download_size: 241987
dataset_size: 1283277
- config_name: XQuAD.el
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 2206666
num_examples: 1190
download_size: 324409
dataset_size: 2206666
- config_name: XQuAD.en
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 1116099
num_examples: 1190
download_size: 212402
dataset_size: 1116099
- config_name: XQuAD.es
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 1273475
num_examples: 1190
download_size: 236904
dataset_size: 1273475
- config_name: XQuAD.hi
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 2682951
num_examples: 1190
download_size: 322113
dataset_size: 2682951
- config_name: XQuAD.ru
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 2136966
num_examples: 1190
download_size: 321758
dataset_size: 2136966
- config_name: XQuAD.th
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 2854935
num_examples: 1190
download_size: 337337
dataset_size: 2854935
- config_name: XQuAD.tr
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 1210739
num_examples: 1190
download_size: 228394
dataset_size: 1210739
- config_name: XQuAD.vi
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 1477215
num_examples: 1190
download_size: 237674
dataset_size: 1477215
- config_name: XQuAD.zh
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: validation
num_bytes: 984217
num_examples: 1190
download_size: 205798
dataset_size: 984217
- config_name: bucc18.de
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 248691
num_examples: 1038
- name: test
num_bytes: 2325685
num_examples: 9580
download_size: 1636130
dataset_size: 2574376
- config_name: bucc18.fr
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 212497
num_examples: 929
- name: test
num_bytes: 2082403
num_examples: 9086
download_size: 1437096
dataset_size: 2294900
- config_name: bucc18.ru
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 761331
num_examples: 2374
- name: test
num_bytes: 4641646
num_examples: 14435
download_size: 3074476
dataset_size: 5402977
- config_name: bucc18.zh
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 55723
num_examples: 257
- name: test
num_bytes: 415909
num_examples: 1899
download_size: 320378
dataset_size: 471632
- config_name: tatoeba.afr
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 250635
num_examples: 1000
download_size: 47676
dataset_size: 250635
- config_name: tatoeba.ara
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 263650
num_examples: 1000
download_size: 51228
dataset_size: 263650
- config_name: tatoeba.ben
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 282703
num_examples: 1000
download_size: 51362
dataset_size: 282703
- config_name: tatoeba.bul
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 293279
num_examples: 1000
download_size: 62454
dataset_size: 293279
- config_name: tatoeba.cmn
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 259931
num_examples: 1000
download_size: 58281
dataset_size: 259931
- config_name: tatoeba.deu
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 296567
num_examples: 1000
download_size: 79066
dataset_size: 296567
- config_name: tatoeba.ell
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 269961
num_examples: 1000
download_size: 52251
dataset_size: 269961
- config_name: tatoeba.est
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 250728
num_examples: 1000
download_size: 49968
dataset_size: 250728
- config_name: tatoeba.eus
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 257068
num_examples: 1000
download_size: 54271
dataset_size: 257068
- config_name: tatoeba.fin
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 266669
num_examples: 1000
download_size: 60580
dataset_size: 266669
- config_name: tatoeba.fra
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 271018
num_examples: 1000
download_size: 60925
dataset_size: 271018
- config_name: tatoeba.heb
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 274500
num_examples: 1000
download_size: 57306
dataset_size: 274500
- config_name: tatoeba.hin
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 313558
num_examples: 1000
download_size: 68816
dataset_size: 313558
- config_name: tatoeba.hun
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 259889
num_examples: 1000
download_size: 58096
dataset_size: 259889
- config_name: tatoeba.ind
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 265844
num_examples: 1000
download_size: 57047
dataset_size: 265844
- config_name: tatoeba.ita
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 256833
num_examples: 1000
download_size: 52422
dataset_size: 256833
- config_name: tatoeba.jav
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 53068
num_examples: 205
download_size: 15208
dataset_size: 53068
- config_name: tatoeba.jpn
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 284083
num_examples: 1000
download_size: 66620
dataset_size: 284083
- config_name: tatoeba.kat
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 214646
num_examples: 746
download_size: 41759
dataset_size: 214646
- config_name: tatoeba.kaz
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 157003
num_examples: 575
download_size: 35693
dataset_size: 157003
- config_name: tatoeba.kor
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 270139
num_examples: 1000
download_size: 61210
dataset_size: 270139
- config_name: tatoeba.mal
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 225934
num_examples: 687
download_size: 51077
dataset_size: 225934
- config_name: tatoeba.mar
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 291542
num_examples: 1000
download_size: 56575
dataset_size: 291542
- config_name: tatoeba.nld
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 264263
num_examples: 1000
download_size: 59774
dataset_size: 264263
- config_name: tatoeba.pes
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 284719
num_examples: 1000
download_size: 64642
dataset_size: 284719
- config_name: tatoeba.por
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 266185
num_examples: 1000
download_size: 58250
dataset_size: 266185
- config_name: tatoeba.rus
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 283472
num_examples: 1000
download_size: 61601
dataset_size: 283472
- config_name: tatoeba.spa
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 263266
num_examples: 1000
download_size: 57055
dataset_size: 263266
- config_name: tatoeba.swh
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 94957
num_examples: 390
download_size: 19362
dataset_size: 94957
- config_name: tatoeba.tam
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 98078
num_examples: 307
download_size: 23648
dataset_size: 98078
- config_name: tatoeba.tel
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 69837
num_examples: 234
download_size: 18260
dataset_size: 69837
- config_name: tatoeba.tgl
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 259138
num_examples: 1000
download_size: 53699
dataset_size: 259138
- config_name: tatoeba.tha
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 167866
num_examples: 548
download_size: 39659
dataset_size: 167866
- config_name: tatoeba.tur
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 262885
num_examples: 1000
download_size: 54137
dataset_size: 262885
- config_name: tatoeba.urd
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 279712
num_examples: 1000
download_size: 60399
dataset_size: 279712
- config_name: tatoeba.vie
features:
- name: source_sentence
dtype: string
- name: target_sentence
dtype: string
- name: source_lang
dtype: string
- name: target_lang
dtype: string
splits:
- name: validation
num_bytes: 282407
num_examples: 1000
download_size: 66746
dataset_size: 282407
- config_name: tydiqa
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: answer_start
dtype: int32
- name: text
dtype: string
splits:
- name: train
num_bytes: 52948467
num_examples: 49881
- name: validation
num_bytes: 5006433
num_examples: 5077
download_size: 29402238
dataset_size: 57954900
- config_name: udpos.Afrikaans
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 586370
num_examples: 1315
- name: validation
num_bytes: 91290
num_examples: 194
- name: test
num_bytes: 174244
num_examples: 425
download_size: 193788
dataset_size: 851904
- config_name: udpos.Arabic
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 4453682
num_examples: 6075
- name: validation
num_bytes: 593650
num_examples: 909
- name: test
num_bytes: 973822
num_examples: 1680
download_size: 1186113
dataset_size: 6021154
- config_name: udpos.Basque
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 1327713
num_examples: 5396
- name: validation
num_bytes: 438671
num_examples: 1798
- name: test
num_bytes: 444644
num_examples: 1799
download_size: 703094
dataset_size: 2211028
- config_name: udpos.Bulgarian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 2689767
num_examples: 8907
- name: validation
num_bytes: 347117
num_examples: 1115
- name: test
num_bytes: 339947
num_examples: 1116
download_size: 926186
dataset_size: 3376831
- config_name: udpos.Chinese
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 4218891
num_examples: 18998
- name: validation
num_bytes: 594448
num_examples: 3038
- name: test
num_bytes: 1236051
num_examples: 5528
download_size: 1471747
dataset_size: 6049390
- config_name: udpos.Dutch
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 4517994
num_examples: 18051
- name: validation
num_bytes: 393592
num_examples: 1394
- name: test
num_bytes: 397904
num_examples: 1471
download_size: 1410982
dataset_size: 5309490
- config_name: udpos.English
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 6225509
num_examples: 21253
- name: validation
num_bytes: 1042040
num_examples: 3974
- name: test
num_bytes: 1421148
num_examples: 5440
download_size: 2116535
dataset_size: 8688697
- config_name: udpos.Estonian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 6614893
num_examples: 25749
- name: validation
num_bytes: 814171
num_examples: 3125
- name: test
num_bytes: 1065701
num_examples: 3760
download_size: 2619121
dataset_size: 8494765
- config_name: udpos.Finnish
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 5613706
num_examples: 27198
- name: validation
num_bytes: 656646
num_examples: 3239
- name: test
num_bytes: 1025726
num_examples: 4422
download_size: 2503217
dataset_size: 7296078
- config_name: udpos.French
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 10118933
num_examples: 47308
- name: validation
num_bytes: 1294096
num_examples: 5979
- name: test
num_bytes: 1731049
num_examples: 9465
download_size: 3378680
dataset_size: 13144078
- config_name: udpos.German
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 54773777
num_examples: 166849
- name: validation
num_bytes: 6044838
num_examples: 19233
- name: test
num_bytes: 7345863
num_examples: 22458
download_size: 18623155
dataset_size: 68164478
- config_name: udpos.Greek
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 8932104
num_examples: 28152
- name: validation
num_bytes: 1062447
num_examples: 2559
- name: test
num_bytes: 1028665
num_examples: 2809
download_size: 2763293
dataset_size: 11023216
- config_name: udpos.Hebrew
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 2505691
num_examples: 5241
- name: validation
num_bytes: 210013
num_examples: 484
- name: test
num_bytes: 223865
num_examples: 491
download_size: 624771
dataset_size: 2939569
- config_name: udpos.Hindi
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 6690250
num_examples: 13304
- name: validation
num_bytes: 839702
num_examples: 1659
- name: test
num_bytes: 1400225
num_examples: 2684
download_size: 1468314
dataset_size: 8930177
- config_name: udpos.Hungarian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 372226
num_examples: 910
- name: validation
num_bytes: 215879
num_examples: 441
- name: test
num_bytes: 193728
num_examples: 449
download_size: 251882
dataset_size: 781833
- config_name: udpos.Indonesian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 1710678
num_examples: 4477
- name: validation
num_bytes: 220863
num_examples: 559
- name: test
num_bytes: 557101
num_examples: 1557
download_size: 684225
dataset_size: 2488642
- config_name: udpos.Italian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 11299293
num_examples: 29685
- name: validation
num_bytes: 988996
num_examples: 2278
- name: test
num_bytes: 1337869
num_examples: 3518
download_size: 3256246
dataset_size: 13626158
- config_name: udpos.Japanese
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 2792951
num_examples: 7125
- name: validation
num_bytes: 200356
num_examples: 511
- name: test
num_bytes: 928902
num_examples: 2372
download_size: 1012282
dataset_size: 3922209
- config_name: udpos.Kazakh
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 11438
num_examples: 31
- name: test
num_bytes: 228924
num_examples: 1047
download_size: 76300
dataset_size: 240362
- config_name: udpos.Korean
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 7341267
num_examples: 27410
- name: validation
num_bytes: 782587
num_examples: 3016
- name: test
num_bytes: 1162539
num_examples: 4276
download_size: 3115101
dataset_size: 9286393
- config_name: udpos.Marathi
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 59023
num_examples: 373
- name: validation
num_bytes: 8497
num_examples: 46
- name: test
num_bytes: 7871
num_examples: 47
download_size: 22133
dataset_size: 75391
- config_name: udpos.Persian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 2400776
num_examples: 4798
- name: validation
num_bytes: 317053
num_examples: 599
- name: test
num_bytes: 320683
num_examples: 600
download_size: 606912
dataset_size: 3038512
- config_name: udpos.Portuguese
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 7669556
num_examples: 17992
- name: validation
num_bytes: 712397
num_examples: 1770
- name: test
num_bytes: 1082582
num_examples: 2681
download_size: 2505672
dataset_size: 9464535
- config_name: udpos.Russian
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 24230098
num_examples: 67435
- name: validation
num_bytes: 3457031
num_examples: 9960
- name: test
num_bytes: 4236693
num_examples: 11336
download_size: 8818512
dataset_size: 31923822
- config_name: udpos.Spanish
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 13858406
num_examples: 28492
- name: validation
num_bytes: 1498765
num_examples: 3054
- name: test
num_bytes: 1476500
num_examples: 3147
download_size: 4347905
dataset_size: 16833671
- config_name: udpos.Tagalog
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: test
num_bytes: 5153
num_examples: 55
download_size: 3345
dataset_size: 5153
- config_name: udpos.Tamil
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 202596
num_examples: 400
- name: validation
num_bytes: 40031
num_examples: 80
- name: test
num_bytes: 62366
num_examples: 120
download_size: 73764
dataset_size: 304993
- config_name: udpos.Telugu
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 138049
num_examples: 1051
- name: validation
num_bytes: 17990
num_examples: 131
- name: test
num_bytes: 19575
num_examples: 146
download_size: 46045
dataset_size: 175614
- config_name: udpos.Thai
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: test
num_bytes: 561336
num_examples: 1000
download_size: 92925
dataset_size: 561336
- config_name: udpos.Turkish
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 704405
num_examples: 3664
- name: validation
num_bytes: 186455
num_examples: 988
- name: test
num_bytes: 827382
num_examples: 4785
download_size: 581177
dataset_size: 1718242
- config_name: udpos.Urdu
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 2107362
num_examples: 4043
- name: validation
num_bytes: 284261
num_examples: 552
- name: test
num_bytes: 288553
num_examples: 535
download_size: 499594
dataset_size: 2680176
- config_name: udpos.Vietnamese
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: train
num_bytes: 367335
num_examples: 1400
- name: validation
num_bytes: 206188
num_examples: 800
- name: test
num_bytes: 214063
num_examples: 800
download_size: 181239
dataset_size: 787586
- config_name: udpos.Yoruba
features:
- name: tokens
sequence: string
- name: pos_tags
sequence:
class_label:
names:
'0': ADJ
'1': ADP
'2': ADV
'3': AUX
'4': CCONJ
'5': DET
'6': INTJ
'7': NOUN
'8': NUM
'9': PART
'10': PRON
'11': PROPN
'12': PUNCT
'13': SCONJ
'14': SYM
'15': VERB
'16': X
splits:
- name: test
num_bytes: 44656
num_examples: 100
download_size: 10151
dataset_size: 44656
configs:
- config_name: MLQA.ar.ar
data_files:
- split: test
path: MLQA.ar.ar/test-*
- split: validation
path: MLQA.ar.ar/validation-*
- config_name: MLQA.ar.de
data_files:
- split: test
path: MLQA.ar.de/test-*
- split: validation
path: MLQA.ar.de/validation-*
- config_name: MLQA.ar.en
data_files:
- split: test
path: MLQA.ar.en/test-*
- split: validation
path: MLQA.ar.en/validation-*
- config_name: MLQA.ar.es
data_files:
- split: test
path: MLQA.ar.es/test-*
- split: validation
path: MLQA.ar.es/validation-*
- config_name: MLQA.ar.hi
data_files:
- split: test
path: MLQA.ar.hi/test-*
- split: validation
path: MLQA.ar.hi/validation-*
- config_name: MLQA.ar.vi
data_files:
- split: test
path: MLQA.ar.vi/test-*
- split: validation
path: MLQA.ar.vi/validation-*
- config_name: MLQA.ar.zh
data_files:
- split: test
path: MLQA.ar.zh/test-*
- split: validation
path: MLQA.ar.zh/validation-*
- config_name: MLQA.de.ar
data_files:
- split: test
path: MLQA.de.ar/test-*
- split: validation
path: MLQA.de.ar/validation-*
- config_name: MLQA.de.de
data_files:
- split: test
path: MLQA.de.de/test-*
- split: validation
path: MLQA.de.de/validation-*
- config_name: MLQA.de.en
data_files:
- split: test
path: MLQA.de.en/test-*
- split: validation
path: MLQA.de.en/validation-*
- config_name: MLQA.de.es
data_files:
- split: test
path: MLQA.de.es/test-*
- split: validation
path: MLQA.de.es/validation-*
- config_name: MLQA.de.hi
data_files:
- split: test
path: MLQA.de.hi/test-*
- split: validation
path: MLQA.de.hi/validation-*
- config_name: MLQA.de.vi
data_files:
- split: test
path: MLQA.de.vi/test-*
- split: validation
path: MLQA.de.vi/validation-*
- config_name: MLQA.de.zh
data_files:
- split: test
path: MLQA.de.zh/test-*
- split: validation
path: MLQA.de.zh/validation-*
- config_name: MLQA.en.ar
data_files:
- split: test
path: MLQA.en.ar/test-*
- split: validation
path: MLQA.en.ar/validation-*
- config_name: MLQA.en.de
data_files:
- split: test
path: MLQA.en.de/test-*
- split: validation
path: MLQA.en.de/validation-*
- config_name: MLQA.en.en
data_files:
- split: test
path: MLQA.en.en/test-*
- split: validation
path: MLQA.en.en/validation-*
- config_name: MLQA.en.es
data_files:
- split: test
path: MLQA.en.es/test-*
- split: validation
path: MLQA.en.es/validation-*
- config_name: MLQA.en.hi
data_files:
- split: test
path: MLQA.en.hi/test-*
- split: validation
path: MLQA.en.hi/validation-*
- config_name: MLQA.en.vi
data_files:
- split: test
path: MLQA.en.vi/test-*
- split: validation
path: MLQA.en.vi/validation-*
- config_name: MLQA.en.zh
data_files:
- split: test
path: MLQA.en.zh/test-*
- split: validation
path: MLQA.en.zh/validation-*
- config_name: MLQA.es.ar
data_files:
- split: test
path: MLQA.es.ar/test-*
- split: validation
path: MLQA.es.ar/validation-*
- config_name: MLQA.es.de
data_files:
- split: test
path: MLQA.es.de/test-*
- split: validation
path: MLQA.es.de/validation-*
- config_name: MLQA.es.en
data_files:
- split: test
path: MLQA.es.en/test-*
- split: validation
path: MLQA.es.en/validation-*
- config_name: MLQA.es.es
data_files:
- split: test
path: MLQA.es.es/test-*
- split: validation
path: MLQA.es.es/validation-*
- config_name: MLQA.es.hi
data_files:
- split: test
path: MLQA.es.hi/test-*
- split: validation
path: MLQA.es.hi/validation-*
- config_name: MLQA.es.vi
data_files:
- split: test
path: MLQA.es.vi/test-*
- split: validation
path: MLQA.es.vi/validation-*
- config_name: MLQA.es.zh
data_files:
- split: test
path: MLQA.es.zh/test-*
- split: validation
path: MLQA.es.zh/validation-*
- config_name: MLQA.hi.ar
data_files:
- split: test
path: MLQA.hi.ar/test-*
- split: validation
path: MLQA.hi.ar/validation-*
- config_name: MLQA.hi.de
data_files:
- split: test
path: MLQA.hi.de/test-*
- split: validation
path: MLQA.hi.de/validation-*
- config_name: MLQA.hi.en
data_files:
- split: test
path: MLQA.hi.en/test-*
- split: validation
path: MLQA.hi.en/validation-*
- config_name: MLQA.hi.es
data_files:
- split: test
path: MLQA.hi.es/test-*
- split: validation
path: MLQA.hi.es/validation-*
- config_name: MLQA.hi.hi
data_files:
- split: test
path: MLQA.hi.hi/test-*
- split: validation
path: MLQA.hi.hi/validation-*
- config_name: MLQA.hi.vi
data_files:
- split: test
path: MLQA.hi.vi/test-*
- split: validation
path: MLQA.hi.vi/validation-*
- config_name: MLQA.hi.zh
data_files:
- split: test
path: MLQA.hi.zh/test-*
- split: validation
path: MLQA.hi.zh/validation-*
- config_name: MLQA.vi.ar
data_files:
- split: test
path: MLQA.vi.ar/test-*
- split: validation
path: MLQA.vi.ar/validation-*
- config_name: MLQA.vi.de
data_files:
- split: test
path: MLQA.vi.de/test-*
- split: validation
path: MLQA.vi.de/validation-*
- config_name: MLQA.vi.en
data_files:
- split: test
path: MLQA.vi.en/test-*
- split: validation
path: MLQA.vi.en/validation-*
- config_name: MLQA.vi.es
data_files:
- split: test
path: MLQA.vi.es/test-*
- split: validation
path: MLQA.vi.es/validation-*
- config_name: MLQA.vi.hi
data_files:
- split: test
path: MLQA.vi.hi/test-*
- split: validation
path: MLQA.vi.hi/validation-*
- config_name: MLQA.vi.vi
data_files:
- split: test
path: MLQA.vi.vi/test-*
- split: validation
path: MLQA.vi.vi/validation-*
- config_name: MLQA.vi.zh
data_files:
- split: test
path: MLQA.vi.zh/test-*
- split: validation
path: MLQA.vi.zh/validation-*
- config_name: MLQA.zh.ar
data_files:
- split: test
path: MLQA.zh.ar/test-*
- split: validation
path: MLQA.zh.ar/validation-*
- config_name: MLQA.zh.de
data_files:
- split: test
path: MLQA.zh.de/test-*
- split: validation
path: MLQA.zh.de/validation-*
- config_name: MLQA.zh.en
data_files:
- split: test
path: MLQA.zh.en/test-*
- split: validation
path: MLQA.zh.en/validation-*
- config_name: MLQA.zh.es
data_files:
- split: test
path: MLQA.zh.es/test-*
- split: validation
path: MLQA.zh.es/validation-*
- config_name: MLQA.zh.hi
data_files:
- split: test
path: MLQA.zh.hi/test-*
- split: validation
path: MLQA.zh.hi/validation-*
- config_name: MLQA.zh.vi
data_files:
- split: test
path: MLQA.zh.vi/test-*
- split: validation
path: MLQA.zh.vi/validation-*
- config_name: MLQA.zh.zh
data_files:
- split: test
path: MLQA.zh.zh/test-*
- split: validation
path: MLQA.zh.zh/validation-*
- config_name: PAN-X.af
data_files:
- split: train
path: PAN-X.af/train-*
- split: validation
path: PAN-X.af/validation-*
- split: test
path: PAN-X.af/test-*
- config_name: PAN-X.ar
data_files:
- split: train
path: PAN-X.ar/train-*
- split: validation
path: PAN-X.ar/validation-*
- split: test
path: PAN-X.ar/test-*
- config_name: PAN-X.bg
data_files:
- split: train
path: PAN-X.bg/train-*
- split: validation
path: PAN-X.bg/validation-*
- split: test
path: PAN-X.bg/test-*
- config_name: PAN-X.bn
data_files:
- split: train
path: PAN-X.bn/train-*
- split: validation
path: PAN-X.bn/validation-*
- split: test
path: PAN-X.bn/test-*
- config_name: PAN-X.de
data_files:
- split: train
path: PAN-X.de/train-*
- split: validation
path: PAN-X.de/validation-*
- split: test
path: PAN-X.de/test-*
- config_name: PAN-X.el
data_files:
- split: train
path: PAN-X.el/train-*
- split: validation
path: PAN-X.el/validation-*
- split: test
path: PAN-X.el/test-*
- config_name: PAN-X.en
data_files:
- split: train
path: PAN-X.en/train-*
- split: validation
path: PAN-X.en/validation-*
- split: test
path: PAN-X.en/test-*
- config_name: PAN-X.es
data_files:
- split: train
path: PAN-X.es/train-*
- split: validation
path: PAN-X.es/validation-*
- split: test
path: PAN-X.es/test-*
- config_name: PAN-X.et
data_files:
- split: train
path: PAN-X.et/train-*
- split: validation
path: PAN-X.et/validation-*
- split: test
path: PAN-X.et/test-*
- config_name: PAN-X.eu
data_files:
- split: train
path: PAN-X.eu/train-*
- split: validation
path: PAN-X.eu/validation-*
- split: test
path: PAN-X.eu/test-*
- config_name: PAN-X.fa
data_files:
- split: train
path: PAN-X.fa/train-*
- split: validation
path: PAN-X.fa/validation-*
- split: test
path: PAN-X.fa/test-*
- config_name: PAN-X.fi
data_files:
- split: train
path: PAN-X.fi/train-*
- split: validation
path: PAN-X.fi/validation-*
- split: test
path: PAN-X.fi/test-*
- config_name: PAN-X.fr
data_files:
- split: train
path: PAN-X.fr/train-*
- split: validation
path: PAN-X.fr/validation-*
- split: test
path: PAN-X.fr/test-*
- config_name: PAN-X.he
data_files:
- split: train
path: PAN-X.he/train-*
- split: validation
path: PAN-X.he/validation-*
- split: test
path: PAN-X.he/test-*
- config_name: PAN-X.hi
data_files:
- split: train
path: PAN-X.hi/train-*
- split: validation
path: PAN-X.hi/validation-*
- split: test
path: PAN-X.hi/test-*
- config_name: PAN-X.hu
data_files:
- split: train
path: PAN-X.hu/train-*
- split: validation
path: PAN-X.hu/validation-*
- split: test
path: PAN-X.hu/test-*
- config_name: PAN-X.id
data_files:
- split: train
path: PAN-X.id/train-*
- split: validation
path: PAN-X.id/validation-*
- split: test
path: PAN-X.id/test-*
- config_name: PAN-X.it
data_files:
- split: train
path: PAN-X.it/train-*
- split: validation
path: PAN-X.it/validation-*
- split: test
path: PAN-X.it/test-*
- config_name: PAN-X.ja
data_files:
- split: train
path: PAN-X.ja/train-*
- split: validation
path: PAN-X.ja/validation-*
- split: test
path: PAN-X.ja/test-*
- config_name: PAN-X.jv
data_files:
- split: train
path: PAN-X.jv/train-*
- split: validation
path: PAN-X.jv/validation-*
- split: test
path: PAN-X.jv/test-*
- config_name: PAN-X.ka
data_files:
- split: train
path: PAN-X.ka/train-*
- split: validation
path: PAN-X.ka/validation-*
- split: test
path: PAN-X.ka/test-*
- config_name: PAN-X.kk
data_files:
- split: train
path: PAN-X.kk/train-*
- split: validation
path: PAN-X.kk/validation-*
- split: test
path: PAN-X.kk/test-*
- config_name: PAN-X.ko
data_files:
- split: train
path: PAN-X.ko/train-*
- split: validation
path: PAN-X.ko/validation-*
- split: test
path: PAN-X.ko/test-*
- config_name: PAN-X.ml
data_files:
- split: train
path: PAN-X.ml/train-*
- split: validation
path: PAN-X.ml/validation-*
- split: test
path: PAN-X.ml/test-*
- config_name: PAN-X.mr
data_files:
- split: train
path: PAN-X.mr/train-*
- split: validation
path: PAN-X.mr/validation-*
- split: test
path: PAN-X.mr/test-*
- config_name: PAN-X.ms
data_files:
- split: train
path: PAN-X.ms/train-*
- split: validation
path: PAN-X.ms/validation-*
- split: test
path: PAN-X.ms/test-*
- config_name: PAN-X.my
data_files:
- split: train
path: PAN-X.my/train-*
- split: validation
path: PAN-X.my/validation-*
- split: test
path: PAN-X.my/test-*
- config_name: PAN-X.nl
data_files:
- split: train
path: PAN-X.nl/train-*
- split: validation
path: PAN-X.nl/validation-*
- split: test
path: PAN-X.nl/test-*
- config_name: PAN-X.pt
data_files:
- split: train
path: PAN-X.pt/train-*
- split: validation
path: PAN-X.pt/validation-*
- split: test
path: PAN-X.pt/test-*
- config_name: PAN-X.ru
data_files:
- split: train
path: PAN-X.ru/train-*
- split: validation
path: PAN-X.ru/validation-*
- split: test
path: PAN-X.ru/test-*
- config_name: PAN-X.sw
data_files:
- split: train
path: PAN-X.sw/train-*
- split: validation
path: PAN-X.sw/validation-*
- split: test
path: PAN-X.sw/test-*
- config_name: PAN-X.ta
data_files:
- split: train
path: PAN-X.ta/train-*
- split: validation
path: PAN-X.ta/validation-*
- split: test
path: PAN-X.ta/test-*
- config_name: PAN-X.te
data_files:
- split: train
path: PAN-X.te/train-*
- split: validation
path: PAN-X.te/validation-*
- split: test
path: PAN-X.te/test-*
- config_name: PAN-X.th
data_files:
- split: train
path: PAN-X.th/train-*
- split: validation
path: PAN-X.th/validation-*
- split: test
path: PAN-X.th/test-*
- config_name: PAN-X.tl
data_files:
- split: train
path: PAN-X.tl/train-*
- split: validation
path: PAN-X.tl/validation-*
- split: test
path: PAN-X.tl/test-*
- config_name: PAN-X.tr
data_files:
- split: train
path: PAN-X.tr/train-*
- split: validation
path: PAN-X.tr/validation-*
- split: test
path: PAN-X.tr/test-*
- config_name: PAN-X.ur
data_files:
- split: train
path: PAN-X.ur/train-*
- split: validation
path: PAN-X.ur/validation-*
- split: test
path: PAN-X.ur/test-*
- config_name: PAN-X.vi
data_files:
- split: train
path: PAN-X.vi/train-*
- split: validation
path: PAN-X.vi/validation-*
- split: test
path: PAN-X.vi/test-*
- config_name: PAN-X.yo
data_files:
- split: train
path: PAN-X.yo/train-*
- split: validation
path: PAN-X.yo/validation-*
- split: test
path: PAN-X.yo/test-*
- config_name: PAN-X.zh
data_files:
- split: train
path: PAN-X.zh/train-*
- split: validation
path: PAN-X.zh/validation-*
- split: test
path: PAN-X.zh/test-*
- config_name: PAWS-X.de
data_files:
- split: train
path: PAWS-X.de/train-*
- split: validation
path: PAWS-X.de/validation-*
- split: test
path: PAWS-X.de/test-*
- config_name: PAWS-X.en
data_files:
- split: train
path: PAWS-X.en/train-*
- split: validation
path: PAWS-X.en/validation-*
- split: test
path: PAWS-X.en/test-*
- config_name: PAWS-X.es
data_files:
- split: train
path: PAWS-X.es/train-*
- split: validation
path: PAWS-X.es/validation-*
- split: test
path: PAWS-X.es/test-*
- config_name: PAWS-X.fr
data_files:
- split: train
path: PAWS-X.fr/train-*
- split: validation
path: PAWS-X.fr/validation-*
- split: test
path: PAWS-X.fr/test-*
- config_name: PAWS-X.ja
data_files:
- split: train
path: PAWS-X.ja/train-*
- split: validation
path: PAWS-X.ja/validation-*
- split: test
path: PAWS-X.ja/test-*
- config_name: PAWS-X.ko
data_files:
- split: train
path: PAWS-X.ko/train-*
- split: validation
path: PAWS-X.ko/validation-*
- split: test
path: PAWS-X.ko/test-*
- config_name: PAWS-X.zh
data_files:
- split: train
path: PAWS-X.zh/train-*
- split: validation
path: PAWS-X.zh/validation-*
- split: test
path: PAWS-X.zh/test-*
- config_name: SQuAD
data_files:
- split: train
path: SQuAD/train-*
- split: validation
path: SQuAD/validation-*
- config_name: XNLI
data_files:
- split: test
path: XNLI/test-*
- split: validation
path: XNLI/validation-*
- config_name: XQuAD.ar
data_files:
- split: validation
path: XQuAD.ar/validation-*
- config_name: XQuAD.de
data_files:
- split: validation
path: XQuAD.de/validation-*
- config_name: XQuAD.el
data_files:
- split: validation
path: XQuAD.el/validation-*
- config_name: XQuAD.en
data_files:
- split: validation
path: XQuAD.en/validation-*
- config_name: XQuAD.es
data_files:
- split: validation
path: XQuAD.es/validation-*
- config_name: XQuAD.hi
data_files:
- split: validation
path: XQuAD.hi/validation-*
- config_name: XQuAD.ru
data_files:
- split: validation
path: XQuAD.ru/validation-*
- config_name: XQuAD.th
data_files:
- split: validation
path: XQuAD.th/validation-*
- config_name: XQuAD.tr
data_files:
- split: validation
path: XQuAD.tr/validation-*
- config_name: XQuAD.vi
data_files:
- split: validation
path: XQuAD.vi/validation-*
- config_name: XQuAD.zh
data_files:
- split: validation
path: XQuAD.zh/validation-*
- config_name: bucc18.de
data_files:
- split: validation
path: bucc18.de/validation-*
- split: test
path: bucc18.de/test-*
- config_name: bucc18.fr
data_files:
- split: validation
path: bucc18.fr/validation-*
- split: test
path: bucc18.fr/test-*
- config_name: bucc18.ru
data_files:
- split: validation
path: bucc18.ru/validation-*
- split: test
path: bucc18.ru/test-*
- config_name: bucc18.zh
data_files:
- split: validation
path: bucc18.zh/validation-*
- split: test
path: bucc18.zh/test-*
- config_name: tatoeba.afr
data_files:
- split: validation
path: tatoeba.afr/validation-*
- config_name: tatoeba.ara
data_files:
- split: validation
path: tatoeba.ara/validation-*
- config_name: tatoeba.ben
data_files:
- split: validation
path: tatoeba.ben/validation-*
- config_name: tatoeba.bul
data_files:
- split: validation
path: tatoeba.bul/validation-*
- config_name: tatoeba.cmn
data_files:
- split: validation
path: tatoeba.cmn/validation-*
- config_name: tatoeba.deu
data_files:
- split: validation
path: tatoeba.deu/validation-*
- config_name: tatoeba.ell
data_files:
- split: validation
path: tatoeba.ell/validation-*
- config_name: tatoeba.est
data_files:
- split: validation
path: tatoeba.est/validation-*
- config_name: tatoeba.eus
data_files:
- split: validation
path: tatoeba.eus/validation-*
- config_name: tatoeba.fin
data_files:
- split: validation
path: tatoeba.fin/validation-*
- config_name: tatoeba.fra
data_files:
- split: validation
path: tatoeba.fra/validation-*
- config_name: tatoeba.heb
data_files:
- split: validation
path: tatoeba.heb/validation-*
- config_name: tatoeba.hin
data_files:
- split: validation
path: tatoeba.hin/validation-*
- config_name: tatoeba.hun
data_files:
- split: validation
path: tatoeba.hun/validation-*
- config_name: tatoeba.ind
data_files:
- split: validation
path: tatoeba.ind/validation-*
- config_name: tatoeba.ita
data_files:
- split: validation
path: tatoeba.ita/validation-*
- config_name: tatoeba.jav
data_files:
- split: validation
path: tatoeba.jav/validation-*
- config_name: tatoeba.jpn
data_files:
- split: validation
path: tatoeba.jpn/validation-*
- config_name: tatoeba.kat
data_files:
- split: validation
path: tatoeba.kat/validation-*
- config_name: tatoeba.kaz
data_files:
- split: validation
path: tatoeba.kaz/validation-*
- config_name: tatoeba.kor
data_files:
- split: validation
path: tatoeba.kor/validation-*
- config_name: tatoeba.mal
data_files:
- split: validation
path: tatoeba.mal/validation-*
- config_name: tatoeba.mar
data_files:
- split: validation
path: tatoeba.mar/validation-*
- config_name: tatoeba.nld
data_files:
- split: validation
path: tatoeba.nld/validation-*
- config_name: tatoeba.pes
data_files:
- split: validation
path: tatoeba.pes/validation-*
- config_name: tatoeba.por
data_files:
- split: validation
path: tatoeba.por/validation-*
- config_name: tatoeba.rus
data_files:
- split: validation
path: tatoeba.rus/validation-*
- config_name: tatoeba.spa
data_files:
- split: validation
path: tatoeba.spa/validation-*
- config_name: tatoeba.swh
data_files:
- split: validation
path: tatoeba.swh/validation-*
- config_name: tatoeba.tam
data_files:
- split: validation
path: tatoeba.tam/validation-*
- config_name: tatoeba.tel
data_files:
- split: validation
path: tatoeba.tel/validation-*
- config_name: tatoeba.tgl
data_files:
- split: validation
path: tatoeba.tgl/validation-*
- config_name: tatoeba.tha
data_files:
- split: validation
path: tatoeba.tha/validation-*
- config_name: tatoeba.tur
data_files:
- split: validation
path: tatoeba.tur/validation-*
- config_name: tatoeba.urd
data_files:
- split: validation
path: tatoeba.urd/validation-*
- config_name: tatoeba.vie
data_files:
- split: validation
path: tatoeba.vie/validation-*
- config_name: tydiqa
data_files:
- split: train
path: tydiqa/train-*
- split: validation
path: tydiqa/validation-*
- config_name: udpos.Afrikaans
data_files:
- split: train
path: udpos.Afrikaans/train-*
- split: validation
path: udpos.Afrikaans/validation-*
- split: test
path: udpos.Afrikaans/test-*
- config_name: udpos.Arabic
data_files:
- split: train
path: udpos.Arabic/train-*
- split: validation
path: udpos.Arabic/validation-*
- split: test
path: udpos.Arabic/test-*
- config_name: udpos.Basque
data_files:
- split: train
path: udpos.Basque/train-*
- split: validation
path: udpos.Basque/validation-*
- split: test
path: udpos.Basque/test-*
- config_name: udpos.Bulgarian
data_files:
- split: train
path: udpos.Bulgarian/train-*
- split: validation
path: udpos.Bulgarian/validation-*
- split: test
path: udpos.Bulgarian/test-*
- config_name: udpos.Chinese
data_files:
- split: train
path: udpos.Chinese/train-*
- split: validation
path: udpos.Chinese/validation-*
- split: test
path: udpos.Chinese/test-*
- config_name: udpos.Dutch
data_files:
- split: train
path: udpos.Dutch/train-*
- split: validation
path: udpos.Dutch/validation-*
- split: test
path: udpos.Dutch/test-*
- config_name: udpos.English
data_files:
- split: train
path: udpos.English/train-*
- split: validation
path: udpos.English/validation-*
- split: test
path: udpos.English/test-*
- config_name: udpos.Estonian
data_files:
- split: train
path: udpos.Estonian/train-*
- split: validation
path: udpos.Estonian/validation-*
- split: test
path: udpos.Estonian/test-*
- config_name: udpos.Finnish
data_files:
- split: train
path: udpos.Finnish/train-*
- split: validation
path: udpos.Finnish/validation-*
- split: test
path: udpos.Finnish/test-*
- config_name: udpos.French
data_files:
- split: train
path: udpos.French/train-*
- split: validation
path: udpos.French/validation-*
- split: test
path: udpos.French/test-*
- config_name: udpos.German
data_files:
- split: train
path: udpos.German/train-*
- split: validation
path: udpos.German/validation-*
- split: test
path: udpos.German/test-*
- config_name: udpos.Greek
data_files:
- split: train
path: udpos.Greek/train-*
- split: validation
path: udpos.Greek/validation-*
- split: test
path: udpos.Greek/test-*
- config_name: udpos.Hebrew
data_files:
- split: train
path: udpos.Hebrew/train-*
- split: validation
path: udpos.Hebrew/validation-*
- split: test
path: udpos.Hebrew/test-*
- config_name: udpos.Hindi
data_files:
- split: train
path: udpos.Hindi/train-*
- split: validation
path: udpos.Hindi/validation-*
- split: test
path: udpos.Hindi/test-*
- config_name: udpos.Hungarian
data_files:
- split: train
path: udpos.Hungarian/train-*
- split: validation
path: udpos.Hungarian/validation-*
- split: test
path: udpos.Hungarian/test-*
- config_name: udpos.Indonesian
data_files:
- split: train
path: udpos.Indonesian/train-*
- split: validation
path: udpos.Indonesian/validation-*
- split: test
path: udpos.Indonesian/test-*
- config_name: udpos.Italian
data_files:
- split: train
path: udpos.Italian/train-*
- split: validation
path: udpos.Italian/validation-*
- split: test
path: udpos.Italian/test-*
- config_name: udpos.Japanese
data_files:
- split: train
path: udpos.Japanese/train-*
- split: validation
path: udpos.Japanese/validation-*
- split: test
path: udpos.Japanese/test-*
- config_name: udpos.Kazakh
data_files:
- split: train
path: udpos.Kazakh/train-*
- split: test
path: udpos.Kazakh/test-*
- config_name: udpos.Korean
data_files:
- split: train
path: udpos.Korean/train-*
- split: validation
path: udpos.Korean/validation-*
- split: test
path: udpos.Korean/test-*
- config_name: udpos.Marathi
data_files:
- split: train
path: udpos.Marathi/train-*
- split: validation
path: udpos.Marathi/validation-*
- split: test
path: udpos.Marathi/test-*
- config_name: udpos.Persian
data_files:
- split: train
path: udpos.Persian/train-*
- split: validation
path: udpos.Persian/validation-*
- split: test
path: udpos.Persian/test-*
- config_name: udpos.Portuguese
data_files:
- split: train
path: udpos.Portuguese/train-*
- split: validation
path: udpos.Portuguese/validation-*
- split: test
path: udpos.Portuguese/test-*
- config_name: udpos.Russian
data_files:
- split: train
path: udpos.Russian/train-*
- split: validation
path: udpos.Russian/validation-*
- split: test
path: udpos.Russian/test-*
- config_name: udpos.Spanish
data_files:
- split: train
path: udpos.Spanish/train-*
- split: validation
path: udpos.Spanish/validation-*
- split: test
path: udpos.Spanish/test-*
- config_name: udpos.Tagalog
data_files:
- split: test
path: udpos.Tagalog/test-*
- config_name: udpos.Tamil
data_files:
- split: train
path: udpos.Tamil/train-*
- split: validation
path: udpos.Tamil/validation-*
- split: test
path: udpos.Tamil/test-*
- config_name: udpos.Telugu
data_files:
- split: train
path: udpos.Telugu/train-*
- split: validation
path: udpos.Telugu/validation-*
- split: test
path: udpos.Telugu/test-*
- config_name: udpos.Thai
data_files:
- split: test
path: udpos.Thai/test-*
- config_name: udpos.Turkish
data_files:
- split: train
path: udpos.Turkish/train-*
- split: validation
path: udpos.Turkish/validation-*
- split: test
path: udpos.Turkish/test-*
- config_name: udpos.Urdu
data_files:
- split: train
path: udpos.Urdu/train-*
- split: validation
path: udpos.Urdu/validation-*
- split: test
path: udpos.Urdu/test-*
- config_name: udpos.Vietnamese
data_files:
- split: train
path: udpos.Vietnamese/train-*
- split: validation
path: udpos.Vietnamese/validation-*
- split: test
path: udpos.Vietnamese/test-*
- config_name: udpos.Yoruba
data_files:
- split: test
path: udpos.Yoruba/test-*
---
# Dataset Card for "xtreme"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/google-research/xtreme](https://github.com/google-research/xtreme)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 15.88 GB
- **Size of the generated dataset:** 1.08 GB
- **Total amount of disk used:** 16.96 GB
### Dataset Summary
The Cross-lingual Natural Language Inference (XNLI) corpus is a crowd-sourced collection of 5,000 test and
2,500 dev pairs for the MultiNLI corpus. The pairs are annotated with textual entailment and translated into
14 languages: French, Spanish, German, Greek, Bulgarian, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese,
Hindi, Swahili and Urdu. This results in 112.5k annotated pairs. Each premise can be associated with the
corresponding hypothesis in the 15 languages, summing up to more than 1.5M combinations. The corpus is made to
evaluate how to perform inference in any language (including low-resources ones like Swahili or Urdu) when only
English NLI data is available at training time. One solution is cross-lingual sentence encoding, for which XNLI
is an evaluation benchmark.
The Cross-lingual TRansfer Evaluation of Multilingual Encoders (XTREME) benchmark is a benchmark for the evaluation of
the cross-lingual generalization ability of pre-trained multilingual models. It covers 40 typologically diverse languages
(spanning 12 language families) and includes nine tasks that collectively require reasoning about different levels of
syntax and semantics. The languages in XTREME are selected to maximize language diversity, coverage in existing tasks,
and availability of training data. Among these are many under-studied languages, such as the Dravidian languages Tamil
(spoken in southern India, Sri Lanka, and Singapore), Telugu and Malayalam (spoken mainly in southern India), and the
Niger-Congo languages Swahili and Yoruba, spoken in Africa.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### MLQA.ar.ar
- **Size of downloaded dataset files:** 75.72 MB
- **Size of the generated dataset:** 9.20 MB
- **Total amount of disk used:** 84.91 MB
An example of 'validation' looks as follows.
```
```
#### MLQA.ar.de
- **Size of downloaded dataset files:** 75.72 MB
- **Size of the generated dataset:** 2.55 MB
- **Total amount of disk used:** 78.27 MB
An example of 'validation' looks as follows.
```
```
#### MLQA.ar.en
- **Size of downloaded dataset files:** 75.72 MB
- **Size of the generated dataset:** 9.04 MB
- **Total amount of disk used:** 84.76 MB
An example of 'validation' looks as follows.
```
```
#### MLQA.ar.es
- **Size of downloaded dataset files:** 75.72 MB
- **Size of the generated dataset:** 3.27 MB
- **Total amount of disk used:** 78.99 MB
An example of 'validation' looks as follows.
```
```
#### MLQA.ar.hi
- **Size of downloaded dataset files:** 75.72 MB
- **Size of the generated dataset:** 3.32 MB
- **Total amount of disk used:** 79.04 MB
An example of 'validation' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### MLQA.ar.ar
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `answer_start`: a `int32` feature.
- `text`: a `string` feature.
#### MLQA.ar.de
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `answer_start`: a `int32` feature.
- `text`: a `string` feature.
#### MLQA.ar.en
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `answer_start`: a `int32` feature.
- `text`: a `string` feature.
#### MLQA.ar.es
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `answer_start`: a `int32` feature.
- `text`: a `string` feature.
#### MLQA.ar.hi
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `answer_start`: a `int32` feature.
- `text`: a `string` feature.
### Data Splits
| name |validation|test|
|----------|---------:|---:|
|MLQA.ar.ar| 517|5335|
|MLQA.ar.de| 207|1649|
|MLQA.ar.en| 517|5335|
|MLQA.ar.es| 161|1978|
|MLQA.ar.hi| 186|1831|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@InProceedings{conneau2018xnli,
author = {Conneau, Alexis
and Rinott, Ruty
and Lample, Guillaume
and Williams, Adina
and Bowman, Samuel R.
and Schwenk, Holger
and Stoyanov, Veselin},
title = {XNLI: Evaluating Cross-lingual Sentence Representations},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods
in Natural Language Processing},
year = {2018},
publisher = {Association for Computational Linguistics},
location = {Brussels, Belgium},
}
@article{hu2020xtreme,
author = {Junjie Hu and Sebastian Ruder and Aditya Siddhant and Graham Neubig and Orhan Firat and Melvin Johnson},
title = {XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization},
journal = {CoRR},
volume = {abs/2003.11080},
year = {2020},
archivePrefix = {arXiv},
eprint = {2003.11080}
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@jplu](https://github.com/jplu), [@lewtun](https://github.com/lewtun), [@lvwerra](https://github.com/lvwerra), [@lhoestq](https://github.com/lhoestq), [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham) for adding this dataset. |
delphi-suite/stories | delphi-suite | "2024-01-22T20:46:34Z" | 2,614 | 0 | [
"license:cdla-sharing-1.0",
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-01-22T20:37:17Z" | ---
license: cdla-sharing-1.0
dataset_info:
features:
- name: story
dtype: string
splits:
- name: validation
num_bytes: 22026876
num_examples: 27516
- name: train
num_bytes: 2180184297
num_examples: 2705118
download_size: 1141574770
dataset_size: 2202211173
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: train
path: data/train-*
---
|
WillHeld/blimp | WillHeld | "2023-01-24T22:34:34Z" | 2,611 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-01-24T22:33:00Z" | ---
dataset_info:
features:
- name: sentence_good
dtype: string
- name: sentence_bad
dtype: string
- name: two_prefix_prefix_good
dtype: string
- name: two_prefix_prefix_bad
dtype: string
- name: two_prefix_word
dtype: string
- name: field
dtype: string
- name: linguistics_term
dtype: string
- name: UID
dtype: string
- name: simple_LM_method
dtype: bool
- name: one_prefix_method
dtype: bool
- name: two_prefix_method
dtype: bool
- name: lexically_identical
dtype: bool
- name: pairID
dtype: string
- name: feature_name
dtype: string
splits:
- name: train
num_bytes: 15550503
num_examples: 67000
download_size: 4374212
dataset_size: 15550503
---
# Dataset Card for "blimp"
HuggingFace Hub Upload of BLiMP: The Benchmark of Linguistic Minimal Pairs from https://github.com/alexwarstadt/blimp
If you use this dataset in your work, please cite the original authors and paper.
```
@article{warstadt2020blimp,
author = {Warstadt, Alex and Parrish, Alicia and Liu, Haokun and Mohananey, Anhad and Peng, Wei and Wang, Sheng-Fu and Bowman, Samuel R.},
title = {BLiMP: The Benchmark of Linguistic Minimal Pairs for English},
journal = {Transactions of the Association for Computational Linguistics},
volume = {8},
number = {},
pages = {377-392},
year = {2020},
doi = {10.1162/tacl\_a\_00321},
URL = {https://doi.org/10.1162/tacl_a_00321},
eprint = {https://doi.org/10.1162/tacl_a_00321},
abstract = { We introduce The Benchmark of Linguistic Minimal Pairs (BLiMP),1 a challenge set for evaluating the linguistic knowledge of language models (LMs) on major grammatical phenomena in English. BLiMP consists of 67 individual datasets, each containing 1,000 minimal pairs—that is, pairs of minimally different sentences that contrast in grammatical acceptability and isolate specific phenomenon in syntax, morphology, or semantics. We generate the data according to linguist-crafted grammar templates, and human aggregate agreement with the labels is 96.4\%. We evaluate n-gram, LSTM, and Transformer (GPT-2 and Transformer-XL) LMs by observing whether they assign a higher probability to the acceptable sentence in each minimal pair. We find that state-of-the-art models identify morphological contrasts related to agreement reliably, but they struggle with some subtle semantic and syntactic phenomena, such as negative polarity items and extraction islands. }
}
``` |
MM-UPD/MM-UPD | MM-UPD | "2024-09-15T23:45:14Z" | 2,611 | 13 | [
"task_categories:visual-question-answering",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"arxiv:2403.20331",
"region:us"
] | [
"visual-question-answering"
] | "2024-03-27T07:22:36Z" | ---
dataset_info:
- config_name: mmaad_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmiasd_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmivqd_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmaad_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmiasd_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmivqd_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmaad_aad_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmaad_standard_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmiasd_iasd_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmiasd_standard_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmivqd_ivqd_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmivqd_standard_base
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmaad_aad_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmaad_standard_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmiasd_iasd_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmiasd_standard_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmivqd_ivqd_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
- config_name: mmivqd_standard_option
features:
- name: index
dtype: int64
- name: question
dtype: string
- name: hint
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: string
- name: masked_answer
dtype: string
- name: category
dtype: string
- name: image
dtype: image
- name: source
dtype: string
- name: l2-category
dtype: string
- name: comment
dtype: string
- name: split
dtype: string
- name: type
dtype: string
configs:
- config_name: mmaad_base
data_files:
- split: test
path: data/mmaad_20240303_base
- config_name: mmiasd_base
data_files:
- split: test
path: data/mmiasd_20240303_base
- config_name: mmivqd_base
data_files:
- split: test
path: data/mmivqd_20240303_base
- config_name: mmaad_option
data_files:
- split: test
path: data/mmaad_20240303_option
- config_name: mmiasd_option
data_files:
- split: test
path: data/mmiasd_20240303_option
- config_name: mmivqd_option
data_files:
- split: test
path: data/mmivqd_20240303_option
- config_name: mmaad_aad_base
data_files:
- split: test
path: data/mmaad_aad_20240303_base
- config_name: mmaad_standard_base
data_files:
- split: test
path: data/mmaad_standard_20240303_base
- config_name: mmiasd_iasd_base
data_files:
- split: test
path: data/mmiasd_iasd_20240303_base
- config_name: mmiasd_standard_base
data_files:
- split: test
path: data/mmiasd_standard_20240303_base
- config_name: mmivqd_ivqd_base
data_files:
- split: test
path: data/mmivqd_ivqd_20240303_base
- config_name: mmivqd_standard_base
data_files:
- split: test
path: data/mmivqd_standard_20240303_base
- config_name: mmaad_aad_option
data_files:
- split: test
path: data/mmaad_aad_20240303_option
- config_name: mmaad_standard_option
data_files:
- split: test
path: data/mmaad_standard_20240303_option
- config_name: mmiasd_iasd_option
data_files:
- split: test
path: data/mmiasd_iasd_20240303_option
- config_name: mmiasd_standard_option
data_files:
- split: test
path: data/mmiasd_standard_20240303_option
- config_name: mmivqd_ivqd_option
data_files:
- split: test
path: data/mmivqd_ivqd_20240303_option
- config_name: mmivqd_standard_option
data_files:
- split: test
path: data/mmivqd_standard_20240303_option
task_categories:
- visual-question-answering
language:
- en
size_categories:
- 1K<n<10K
license: apache-2.0
---
# MM-UPD Bench

## Introduction
This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed **Unsolvable Problem Detection (UPD)**. UPD examines the VLM's ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks. UPD encompasses three distinct settings: **Absent Answer Detection (AAD)**, **Incompatible Answer Set Detection (IASD)**, and **Incompatible Visual Question Detection (IVQD)**. To deeply investigate the UPD problem, extensive experiments indicate that **most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents**, highlighting significant room for the improvements. To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
## Dataset Details

MM-UPD consists of three benchmarks: **MM-AAD**, **MM-IASD**, and **MM-IVQD**
**MM-AAD Bench**: MM-AAD Bench is a dataset where the correct answer option for each question is removed.
When creating the MM-AAD Bench, we mask the correct options and remove all questions that originally have two options (which after removal would have only one option left).
To ensure no answer is present in the options, we also manually remove some questions with ambiguity.
Our MM-AAD Bench has 820 AAD questions over 18 abilities.
**MM-IASD Bench**: MM-IASD Bench is a dataset where the answer set is completely incompatible with the context specified by the question and the image.
To create MM-IASD, we shuffle all questions and answer sets and pair each question with a random answer set.
To further ensure the incompatibility, after the shuffling, we manually removed questions where the shuffled answer set was somehow compatible with the question.
Our MM-IASD Bench has 919 IASD questions over 18 abilities.
**MM-IVQD Bench**: MM-IVQD Bench is a dataset where the image and question are incompatible.
This is achieved by focusing on questions that are specific, which are more likely to be incompatible with a randomly picked image.
Specifically, we first exclude the questions that can be relevant to most images and then shuffle the original image-question pairs.
Again, we conduct a manual check to guarantee the incompatibility of image-question pairs.
Our MM-IVQD Bench has 356 IVQD questions over 12 abilities.
The explanation of each file under `./data` is the following:
* 1. `mm<aad/iasd/ivqd>_20240303_base.tsv`: UPD and Standard questions for the base setting (mixed data with 3. and 4.)
* 2. `mm<aad/iasd/ivqd>_20240303_option.tsv`: UPD and Standard questions questions for the additional-option setting (mixed data with 5. and 6.)
* 3. `mm<aad/iasd/ivqd>_<aad/iasd/ivqd>_20240303_base.tsv`: UPD questions for the base setting
* 4. `mm<aad/iasd/ivqd>_standard_20240303_base.tsv`: Standard questions for the base setting
* 5. `mm<aad/iasd/ivqd>_<aad/iasd/ivqd>_20240303_option.tsv`: UPD questions for the additional-option setting
* 6. `mm<aad/iasd/ivqd>_standard_20240303_option.tsv`: Standard questions for the additional-option setting
For the additional-instruction setting and instruction tuning, we can use the files for the base setting.
Note that the number of lines in the tsv file also include the CircularEval passes (for example, 4 copy of a single question if it has 4 choices), so the line number is ~4x of the question number.
## How to Download
Please implement
* `load_dataset("MM-UPD/MM-UPD", config_name)`
The confing_name is <mmaad/mmiasd/mmivqd>_<base/option> (e.g., mmivqd_base).
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
For the images of MM-UPD Bench, we use the data from MMBench (https://github.com/open-compass/MMBench) following its license (https://github.com/open-compass/MMBench/blob/main/LICENSE).
- **Repository:** https://github.com/AtsuMiyai/UPD
- **Paper:** https://arxiv.org/abs/2403.20331
|
Abirate/english_quotes | Abirate | "2022-10-25T08:39:16Z" | 2,609 | 73 | [
"task_categories:text-classification",
"task_ids:multi-label-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"doi:10.57967/hf/1053",
"region:us"
] | [
"text-classification"
] | "2022-03-02T23:29:22Z" | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
- crowdsourced
language:
- en
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-label-classification
---
# ****Dataset Card for English quotes****
# **I-Dataset Summary**
english_quotes is a dataset of all the quotes retrieved from [goodreads quotes](https://www.goodreads.com/quotes). This dataset can be used for multi-label text classification and text generation. The content of each quote is in English and concerns the domain of datasets for NLP and beyond.
# **II-Supported Tasks and Leaderboards**
- Multi-label text classification : The dataset can be used to train a model for text-classification, which consists of classifying quotes by author as well as by topic (using tags). Success on this task is typically measured by achieving a high or low accuracy.
- Text-generation : The dataset can be used to train a model to generate quotes by fine-tuning an existing pretrained model on the corpus composed of all quotes (or quotes by author).
# **III-Languages**
The texts in the dataset are in English (en).
# **IV-Dataset Structure**
#### Data Instances
A JSON-formatted example of a typical instance in the dataset:
```python
{'author': 'Ralph Waldo Emerson',
'quote': '“To be yourself in a world that is constantly trying to make you something else is the greatest accomplishment.”',
'tags': ['accomplishment', 'be-yourself', 'conformity', 'individuality']}
```
#### Data Fields
- **author** : The author of the quote.
- **quote** : The text of the quote.
- **tags**: The tags could be characterized as topics around the quote.
#### Data Splits
I kept the dataset as one block (train), so it can be shuffled and split by users later using methods of the hugging face dataset library like the (.train_test_split()) method.
# **V-Dataset Creation**
#### Curation Rationale
I want to share my datasets (created by web scraping and additional cleaning treatments) with the HuggingFace community so that they can use them in NLP tasks to advance artificial intelligence.
#### Source Data
The source of Data is [goodreads](https://www.goodreads.com/?ref=nav_home) site: from [goodreads quotes](https://www.goodreads.com/quotes)
#### Initial Data Collection and Normalization
The data collection process is web scraping using BeautifulSoup and Requests libraries.
The data is slightly modified after the web scraping: removing all quotes with "None" tags, and the tag "attributed-no-source" is removed from all tags, because it has not added value to the topic of the quote.
#### Who are the source Data producers ?
The data is machine-generated (using web scraping) and subjected to human additional treatment.
below, I provide the script I created to scrape the data (as well as my additional treatment):
```python
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json
from collections import OrderedDict
page = requests.get('https://www.goodreads.com/quotes')
if page.status_code == 200:
pageParsed = BeautifulSoup(page.content, 'html5lib')
# Define a function that retrieves information about each HTML quote code in a dictionary form.
def extract_data_quote(quote_html):
quote = quote_html.find('div',{'class':'quoteText'}).get_text().strip().split('\n')[0]
author = quote_html.find('span',{'class':'authorOrTitle'}).get_text().strip()
if quote_html.find('div',{'class':'greyText smallText left'}) is not None:
tags_list = [tag.get_text() for tag in quote_html.find('div',{'class':'greyText smallText left'}).find_all('a')]
tags = list(OrderedDict.fromkeys(tags_list))
if 'attributed-no-source' in tags:
tags.remove('attributed-no-source')
else:
tags = None
data = {'quote':quote, 'author':author, 'tags':tags}
return data
# Define a function that retrieves all the quotes on a single page.
def get_quotes_data(page_url):
page = requests.get(page_url)
if page.status_code == 200:
pageParsed = BeautifulSoup(page.content, 'html5lib')
quotes_html_page = pageParsed.find_all('div',{'class':'quoteDetails'})
return [extract_data_quote(quote_html) for quote_html in quotes_html_page]
# Retrieve data from the first page.
data = get_quotes_data('https://www.goodreads.com/quotes')
# Retrieve data from all pages.
for i in range(2,101):
print(i)
url = f'https://www.goodreads.com/quotes?page={i}'
data_current_page = get_quotes_data(url)
if data_current_page is None:
continue
data = data + data_current_page
data_df = pd.DataFrame.from_dict(data)
for i, row in data_df.iterrows():
if row['tags'] is None:
data_df = data_df.drop(i)
# Produce the data in a JSON format.
data_df.to_json('C:/Users/Abir/Desktop/quotes.jsonl',orient="records", lines =True,force_ascii=False)
# Then I used the familiar process to push it to the Hugging Face hub.
```
#### Annotations
Annotations are part of the initial data collection (see the script above).
# **VI-Additional Informations**
#### Dataset Curators
Abir ELTAIEF
#### Licensing Information
This work is licensed under a Creative Commons Attribution 4.0 International License (all software and libraries used for web scraping are made available under this Creative Commons Attribution license).
#### Contributions
Thanks to [@Abirate](https://huggingface.co/Abirate)
for adding this dataset. |
open-llm-leaderboard-old/details_venkycs__llama-v2-7b-32kC-Security | open-llm-leaderboard-old | "2023-09-16T22:13:05Z" | 2,605 | 0 | [
"region:us"
] | null | "2023-09-02T02:09:30Z" | ---
pretty_name: Evaluation run of venkycs/llama-v2-7b-32kC-Security
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [venkycs/llama-v2-7b-32kC-Security](https://huggingface.co/venkycs/llama-v2-7b-32kC-Security)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_venkycs__llama-v2-7b-32kC-Security\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-16T22:12:53.343595](https://huggingface.co/datasets/open-llm-leaderboard/details_venkycs__llama-v2-7b-32kC-Security/blob/main/results_2023-09-16T22-12-53.343595.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.0014681208053691276,\n\
\ \"em_stderr\": 0.00039210421902984526,\n \"f1\": 0.05811556208053706,\n\
\ \"f1_stderr\": 0.0013703157651110908,\n \"acc\": 0.37805421700805364,\n\
\ \"acc_stderr\": 0.00898232300653474\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.0014681208053691276,\n \"em_stderr\": 0.00039210421902984526,\n\
\ \"f1\": 0.05811556208053706,\n \"f1_stderr\": 0.0013703157651110908\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.03866565579984837,\n \
\ \"acc_stderr\": 0.005310583162098087\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7174427782162589,\n \"acc_stderr\": 0.012654062850971393\n\
\ }\n}\n```"
repo_url: https://huggingface.co/venkycs/llama-v2-7b-32kC-Security
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|arc:challenge|25_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_16T22_12_53.343595
path:
- '**/details_harness|drop|3_2023-09-16T22-12-53.343595.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-16T22-12-53.343595.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_16T22_12_53.343595
path:
- '**/details_harness|gsm8k|5_2023-09-16T22-12-53.343595.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-16T22-12-53.343595.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hellaswag|10_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-02T02:09:05.697790.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-02T02:09:05.697790.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-02T02:09:05.697790.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_16T22_12_53.343595
path:
- '**/details_harness|winogrande|5_2023-09-16T22-12-53.343595.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-16T22-12-53.343595.parquet'
- config_name: results
data_files:
- split: 2023_09_02T02_09_05.697790
path:
- results_2023-09-02T02:09:05.697790.parquet
- split: 2023_09_16T22_12_53.343595
path:
- results_2023-09-16T22-12-53.343595.parquet
- split: latest
path:
- results_2023-09-16T22-12-53.343595.parquet
---
# Dataset Card for Evaluation run of venkycs/llama-v2-7b-32kC-Security
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/venkycs/llama-v2-7b-32kC-Security
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [venkycs/llama-v2-7b-32kC-Security](https://huggingface.co/venkycs/llama-v2-7b-32kC-Security) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_venkycs__llama-v2-7b-32kC-Security",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-16T22:12:53.343595](https://huggingface.co/datasets/open-llm-leaderboard/details_venkycs__llama-v2-7b-32kC-Security/blob/main/results_2023-09-16T22-12-53.343595.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.0014681208053691276,
"em_stderr": 0.00039210421902984526,
"f1": 0.05811556208053706,
"f1_stderr": 0.0013703157651110908,
"acc": 0.37805421700805364,
"acc_stderr": 0.00898232300653474
},
"harness|drop|3": {
"em": 0.0014681208053691276,
"em_stderr": 0.00039210421902984526,
"f1": 0.05811556208053706,
"f1_stderr": 0.0013703157651110908
},
"harness|gsm8k|5": {
"acc": 0.03866565579984837,
"acc_stderr": 0.005310583162098087
},
"harness|winogrande|5": {
"acc": 0.7174427782162589,
"acc_stderr": 0.012654062850971393
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
open-llm-leaderboard-old/details_uukuguy__speechless-llama2-luban-orca-platypus-13b | open-llm-leaderboard-old | "2023-10-16T17:52:08Z" | 2,597 | 0 | [
"region:us"
] | null | "2023-09-01T05:55:07Z" | ---
pretty_name: Evaluation run of uukuguy/speechless-llama2-luban-orca-platypus-13b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [uukuguy/speechless-llama2-luban-orca-platypus-13b](https://huggingface.co/uukuguy/speechless-llama2-luban-orca-platypus-13b)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_uukuguy__speechless-llama2-luban-orca-platypus-13b\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-16T17:51:55.747438](https://huggingface.co/datasets/open-llm-leaderboard/details_uukuguy__speechless-llama2-luban-orca-platypus-13b/blob/main/results_2023-10-16T17-51-55.747438.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.006921140939597316,\n\
\ \"em_stderr\": 0.0008490247804930292,\n \"f1\": 0.11193687080536992,\n\
\ \"f1_stderr\": 0.0020523308364626394,\n \"acc\": 0.4264965386587744,\n\
\ \"acc_stderr\": 0.009679849375871168\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.006921140939597316,\n \"em_stderr\": 0.0008490247804930292,\n\
\ \"f1\": 0.11193687080536992,\n \"f1_stderr\": 0.0020523308364626394\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.08188021228203184,\n \
\ \"acc_stderr\": 0.007552338527716947\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.771112865035517,\n \"acc_stderr\": 0.011807360224025388\n\
\ }\n}\n```"
repo_url: https://huggingface.co/uukuguy/speechless-llama2-luban-orca-platypus-13b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|arc:challenge|25_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_16T17_51_55.747438
path:
- '**/details_harness|drop|3_2023-10-16T17-51-55.747438.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-16T17-51-55.747438.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_16T17_51_55.747438
path:
- '**/details_harness|gsm8k|5_2023-10-16T17-51-55.747438.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-16T17-51-55.747438.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hellaswag|10_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T05:54:43.169153.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-01T05:54:43.169153.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-01T05:54:43.169153.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_16T17_51_55.747438
path:
- '**/details_harness|winogrande|5_2023-10-16T17-51-55.747438.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-16T17-51-55.747438.parquet'
- config_name: results
data_files:
- split: 2023_09_01T05_54_43.169153
path:
- results_2023-09-01T05:54:43.169153.parquet
- split: 2023_10_16T17_51_55.747438
path:
- results_2023-10-16T17-51-55.747438.parquet
- split: latest
path:
- results_2023-10-16T17-51-55.747438.parquet
---
# Dataset Card for Evaluation run of uukuguy/speechless-llama2-luban-orca-platypus-13b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/uukuguy/speechless-llama2-luban-orca-platypus-13b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [uukuguy/speechless-llama2-luban-orca-platypus-13b](https://huggingface.co/uukuguy/speechless-llama2-luban-orca-platypus-13b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_uukuguy__speechless-llama2-luban-orca-platypus-13b",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-16T17:51:55.747438](https://huggingface.co/datasets/open-llm-leaderboard/details_uukuguy__speechless-llama2-luban-orca-platypus-13b/blob/main/results_2023-10-16T17-51-55.747438.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.006921140939597316,
"em_stderr": 0.0008490247804930292,
"f1": 0.11193687080536992,
"f1_stderr": 0.0020523308364626394,
"acc": 0.4264965386587744,
"acc_stderr": 0.009679849375871168
},
"harness|drop|3": {
"em": 0.006921140939597316,
"em_stderr": 0.0008490247804930292,
"f1": 0.11193687080536992,
"f1_stderr": 0.0020523308364626394
},
"harness|gsm8k|5": {
"acc": 0.08188021228203184,
"acc_stderr": 0.007552338527716947
},
"harness|winogrande|5": {
"acc": 0.771112865035517,
"acc_stderr": 0.011807360224025388
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
hendrydong/preference_700K | hendrydong | "2024-09-28T16:05:26Z" | 2,595 | 5 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2405.07863",
"region:us"
] | null | "2024-04-18T01:43:10Z" | ---
dataset_info:
features:
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected_score
dtype: float64
- name: chosen_score
dtype: float64
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 2802733004
num_examples: 700000
download_size: 1433169364
dataset_size: 2802733004
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
This is the preference dataset used for RLHF Workflow project.
It is a mixed dataset of the following complenent,
* HH-RLHF (Bai et al., 2022a) is a pairwise preference dataset where each sample is accompanied
by a conversation history and two alternative responses written by an early Claude model with 52B
parameters. The preferences of the responses are annotated by humans.
* SHP (Ethayarajh et al., 2022) is sourced from Reddit and includes examples from 18 subreddits, such
as askacademia, askbaking, askengineers, and changemyview. Each example is a Reddit post with a
question/instruction and a pair of top-level comments. One comment is preferred by more Reddit users
than the other. All preferences and responses are provided by humans. Only samples with a score
ratio > 2 are used, and at most 5 pairs are taken for each prompt.
* HelpSteer (Wang et al., 2023). This open-source dataset (Wang et al., 2023) contains prompts,
responses, and five human-annotated attributes (helpfulness, correctness, coherence, complexity, and
verbosity) ranging from 0 to 4. The prompts are generated using a mixture of template-generated and
human-generated methods, while responses are generated by an in-house LLM. The authors generate
up to 4 responses per prompt, and we can construct pairwise comparisons based on them.
* PKU-SafeRLHF (Ji et al., 2024). This dataset (Ji et al., 2024) consists of 30k+ expert comparison
data. Each sample includes two responses to a question and two preference signals for helpfulness and
safety, respectively. The responses are generated by open-source chatbots, and the preference signals
are merged through the results of 14 harm category multi-class classficiation.
* UltraFeedback (Cui et al., 2023) consists of 64k prompts from diverse resources (including UltraChat,
ShareGPT, Evol-Instruct, TruthfulQA, FalseQA, and FLAN) and the authors generate 4 responses per
prompt using 4 different LLMs sampled from a diverse set of state-of-the-art open-source LLMs. The
preference is from GPT-4 based on a fine-grained annotation instruction, which contains 4 different
aspects, namely instruction-following, truthfulness, honesty and helpfulness. The dataset collection
strategy of UltraFeedback has also influenced many subsequent works.
* UltraInteract (Yuan et al., 2024a) is a preference dataset designed for complex reasoning tasks. The
authors collect a preference tree for each instruction, with the instruction being the root and each
action a node. A trajectory is a root-to-leaf path consisting of a sequence of actions. Paired correct
and incorrect nodes or trajectories are used for preference learning.
* Distilabel-Capybara is a preference dataset of multi-turn dialogues whose prompts are taken from
Daniele and Suphavadeeprasit (2023), where the responses are generated by open-source LLMs and
preferences are generated by GPT-4.
* Distilabel-Orca is collected similarly with Capybara but with the prompts from Lian et al. (2023a).
## Reference
If you found it useful, please cite
```bibtex
@misc{dong2024rlhf,
title={RLHF Workflow: From Reward Modeling to Online RLHF},
author={Hanze Dong and Wei Xiong and Bo Pang and Haoxiang Wang and Han Zhao and Yingbo Zhou and Nan Jiang and Doyen Sahoo and Caiming Xiong and Tong Zhang},
year={2024},
eprint={2405.07863},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
jlvdoorn/atco2-asr-atcosim | jlvdoorn | "2023-07-07T07:06:05Z" | 2,594 | 1 | [
"task_categories:automatic-speech-recognition",
"language:en",
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"doi:10.57967/hf/1379",
"region:us",
"air traffic control",
"automatic speech recognition",
"natural language processing",
"atc",
"asr",
"nlp",
"atco2",
"atcosim"
] | [
"automatic-speech-recognition"
] | "2023-06-14T13:08:14Z" | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: text
dtype: string
- name: info
dtype: string
splits:
- name: train
num_bytes: 2029124649.948
num_examples: 8092
- name: validation
num_bytes: 508032748.446
num_examples: 2026
download_size: 2524947331
dataset_size: 2537157398.394
task_categories:
- automatic-speech-recognition
language:
- en
tags:
- air traffic control
- automatic speech recognition
- natural language processing
- atc
- asr
- nlp
- atco2
- atcosim
pretty_name: ATCO2-ASR-ATCOSIM
---
# Dataset Card for "atco2-asr-atcosim"
This is a dataset constructed from two datasets: [ATCO2-ASR](https://huggingface.co/datasets/jlvdoorn/atco2-asr) and [ATCOSIM](https://huggingface.co/datasets/jlvdoorn/atcosim).
It is divided into 80% train and 20% validation by selecting files randomly. Some of the files have additional information that is presented in the 'info' file. |
VikramSingh178/Products-10k-BLIP-captions | VikramSingh178 | "2024-05-26T05:48:45Z" | 2,585 | 0 | [
"task_categories:visual-question-answering",
"task_categories:question-answering",
"task_categories:text-to-image",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"arxiv:2008.10545",
"region:us",
"art"
] | [
"visual-question-answering",
"question-answering",
"text-to-image"
] | "2024-05-17T16:16:46Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: test
num_bytes: 1024849819
num_examples: 10000
download_size: 1018358664
dataset_size: 1024849819
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
license: mit
language:
- en
tags:
- art
size_categories:
- 1K<n<10K
task_categories:
- visual-question-answering
- question-answering
- text-to-image
---
## Dataset Description
The **Products-10k BLIP CAPTIONS** dataset consists of 10000 images of various products along with their automatically generated captions. The captions are generated using the BLIP (Bootstrapping Language-Image Pre-training) model. This dataset aims to aid in tasks related to image captioning, visual recognition, and product classification.
## Dataset Summary
- **Dataset Name**: Products-10k
- **Generated Captions Model**: Salesforce/blip-image-captioning-large
- **Number of Images**: 10,000
- **Image Formats**: JPEG, PNG
- **Captioning Prompt**: "Photography of"
- **Source**: The images are sourced from a variety of product categories.
## Dataset Structure
The dataset is structured as follows:
- **image**: Contains the product images in RGB format.
- **text**: Contains the generated captions for each product image.
## Usage
You can load and use this dataset with the Hugging Face `datasets` library as follows:
```python
from datasets import load_dataset
dataset = load_dataset("VikramSingh178/Products-10k-BLIP-captions", split="test")
# Display an example
example = dataset[0]
image = example["image"]
caption = example["text"]
image.show()
print("Caption:", caption)
```
```
author = {Yalong Bai, Yuxiang Chen, Wei Yu, Linfang Wang, Wei Zhang},
title = {Products-10K: A Large-scale Product Recognition Dataset},
journal = {arXiv},
year = {2024},
url = {https://arxiv.org/abs/2008.10545}
``` |
deepmind/code_contests | deepmind | "2023-06-11T12:22:30Z" | 2,584 | 104 | [
"task_categories:translation",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2203.07814",
"arxiv:2105.12655",
"region:us"
] | [
"translation"
] | "2022-07-19T16:02:55Z" | ---
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- translation
task_ids: []
paperswithcode_id: codecontests
pretty_name: CodeContests
---
# Dataset Card for CodeContests
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/deepmind/code_contests/
- **Paper:** [Competition-Level Code Generation with AlphaCode](https://arxiv.org/abs/2203.07814v1)
- **Leaderboard:** [Code Generation on CodeContests](https://paperswithcode.com/sota/code-generation-on-codecontests)
- **Point of Contact:** [David Choi](mailto:[email protected])
### Dataset Summary
CodeContests is a competitive programming dataset for machine-learning. This
dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
It consists of programming problems, from a variety of sources:
Site | URL | Source
----------- | --------------------------- | ------
Aizu | https://judge.u-aizu.ac.jp | [CodeNet](https://github.com/IBM/Project_CodeNet)
AtCoder | https://atcoder.jp | [CodeNet](https://github.com/IBM/Project_CodeNet)
CodeChef | https://www.codechef.com | [description2code](https://github.com/ethancaballero/description2code)
Codeforces | https://codeforces.com | [description2code](https://github.com/ethancaballero/description2code) and Codeforces
HackerEarth | https://www.hackerearth.com | [description2code](https://github.com/ethancaballero/description2code)
Problems include test cases in the form of paired inputs and outputs, as well as both correct and incorrect human solutions in a variety of languages.
### Supported Tasks and Leaderboards
- `translation` - the competitive programming code generation problem can be viewed as a sequence-to-sequence translation task: given a problem description 𝑋 in natural language, produce a corresponding solution 𝑌 in a programming language. The metric used for evaluation is "percentage of problems solved using 𝑛 submissions from 𝑘 samples per problem", denoted as 𝑛@𝑘. More information on the evaluation of AlphaCode can be found in Section 2.2. and Appendix A.3. of the paper. The leaderboard for this task is available [here](https://paperswithcode.com/sota/code-generation-on-codecontests).
### Languages
English.
## Dataset Structure
### Data Instances
A data point corresponds to a singular contest problem:
```
{
'name': '76_B. Mice',
'description': 'Modern researches has shown that a flock of hungry mice '
'searching for a piece of...',
'public_tests': {'input': ['3 2 0 2\n0 1 3\n2 5\n'], 'output': ['1\n']},
'private_tests': {'input': ['20 18 1 2\n'
'-9999944 -9999861 -9999850 -9999763 -9999656 '
'-9999517 -9999375 -999927...',
...,
'7 11 10 20\n'
'6 18 32 63 66 68 87\n'
'6 8 15 23 25 41 53 59 60 75 90\n'],
'output': ['2\n', ..., '1\n']},
'generated_tests': {'input': ['7 11 10 5\n'
'6 18 32 63 66 68 87\n'
'6 8 15 23 25 41 53 59 60 75 90\n',
...,
'7 11 10 4\n'
'6 18 46 63 85 84 87\n'
'6 8 15 18 25 41 53 59 60 75 90\n'],
'output': ['1\n', ..., '2\n']},
'source': 2,
'difficulty': 8,
'solutions': {'language': [2, ..., 2],
'solution': ['#include <bits/stdc++.h>\n'
'using namespace std;\n'
'int n, m;\n'
'int data[2][100010], t[1...',
...,
'#include <bits/stdc++.h>\n'
'using namespace std;\n'
'int n, m, pos[100100], food[100100...']},
'incorrect_solutions': {'language': [2, ..., 2],
'solution': ['#include <bits/stdc++.h>\n'
'using namespace std;\n'
'vector<pair<int, int> > v[100010];...',
...,
'#include <bits/stdc++.h>\n'
'using namespace std;\n'
'vector<pair<int, int> > v[100010];...']},
'cf_contest_id': 76,
'cf_index': 'B',
'cf_points': 0.0,
'cf_rating': 2100,
'cf_tags': ['greedy', 'two pointers'],
'is_description_translated': False,
'untranslated_description': '',
'time_limit': {'seconds': 0, 'nanos': 500000000},
'memory_limit_bytes': 256000000,
'input_file': '',
'output_file': ''
}
```
### Data Fields
- `name`: The name of the contest. Note that names could agree between different sources.
- `description`: A natural language description of a programming problem.
- `public_tests`: Public tests are those that are available before submitting a solution, typically as part of the description itself. Represented as a paired `input` and `output` that can be used to test potential solutions. They are therefore acceptable inputs to a model.
- `private_tests`: Private tests are not visible before submitting a solution, so should not be made available as inputs to a model.
- `generated_tests`: Generated tests are automatically generated by modifying inputs from public and private tests and validating using known correct solutions.
- `source`: The original source of the problem, with possible values including `UNKNOWN_SOURCE` (0),`CODECHEF` (1), `CODEFORCES` (2), `HACKEREARTH` (3), `CODEJAM` (4), `ATCODER` (5) and `AIZU` (6).
- `difficulty`: A representation of the difficulty of the problem with possible values including `UNKNOWN_DIFFICULTY` (0), `EASY` (1), `MEDIUM` (2), `HARD` (3), `HARDER` (4), `HARDEST` (5), `EXTERNAL` (6), `A` (7), `B` (8), `C` (9), `D` (10), `E` (11), `F` (12), `G` (13), `H` (14), `I` (15), `J` (16), `K` (17), `L` (18), `M` (19), `N` (20), `O` (21), `P` (22), `Q` (23), `R` (24), `S` (25), `T` (26), `U` (27) and `V` (28). Note that different sources use different, non-comparable gradings. For Codeforces problems, `cf_rating` is a more reliable measure of difficulty when available.
- `solutions`: Correct solutions to the problem. Contrast with `incorrect_solutions` below.
- `incorrect_solutions`: Incorrect solutions.
- `cf_contest_id`: The Contest ID. Note that Contest ID is not monotonic with respect to time.
- `cf_index`: Problem index, e.g. `"A"` or `"B"` or `"C"`.
- `cf_points`: Points for the problem, e.g. `1000.0`
- `cf_rating`: Problem rating (difficulty), e.g. `1100`
- `cf_tags`: Problem tags, e.g. `['greedy', 'math']`
- `is_description_translated`: Whether the problem was translated to English.
- `untranslated_description`: The untranslated description is only available for translated problems.
- `time_limit`: The time limit constraint to use when executing solutions. Represented as a dictionary with two keys, `seconds` and `nanos`. This field is None if not defined.
- `memory_limit_bytes`: The memory limit constraint to use when executing solutions.
- `input_file`: Most problems use stdin for IO. Some problems expect specific files to be used instead.
- `output_file`: Most problems use stdout for IO. Some problems expect specific files to be used instead.
All tests are represented as a paired `input` and `output` that can be used to test potential solutions and all solutions comprise a `language`, with possible values including `UNKNOWN_LANGUAGE` (0), `PYTHON` (1) (solutions written in PYTHON2), `CPP` (2), `PYTHON3` (3) and `JAVA` (4), and a `solution` string written in that `language`. The fields preceded with `cf_` denote extra meta-data for Codeforces problems.
### Data Splits
The data is split into training, validation and test set. The training set contains 13328 samples, the validation set 117 samples and the test set 165 samples.
## Dataset Creation
### Curation Rationale
This dataset was created for fine-tuning AlphaCode models:
> Models pre-trained on GitHub can generate good code and solve simple programming problems, but
as shown in Appendix B.3 they can solve very few competitive programming problems. Fine-tuning
the model on a dedicated competitive programming dataset is critical for performance.
### Source Data
#### Initial Data Collection and Normalization
The information on the data collection and normalization procedures can found in Section 3.2. and Appendinx B.2. of the paper.
#### Who are the source language producers?
The problems are scraped from the following platforms: [Aizu](https://judge.u-aizu.ac.jp), [AtCoder](https://atcoder.jp ), [CodeChef](https://www.codechef.com), [Codeforces](https://codeforces.com) and [HackerEarch](https://www.hackerearth.com). Additionally, some data from the existing public competitive programming dataset Description2Code ([Caballero et al., 2016](https://github.com/ethancaballero/description2code)) and CodeNet ([(Puri et al., 2021](https://arxiv.org/pdf/2105.12655.pdf)) is mixed into the training set.
### Annotations
#### Annotation process
The solutions are scapred alongside the problem descriptions.
#### Who are the annotators?
Same as the source data creators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d'Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu and Oriol Vinyals.
### Licensing Information
This dataset is made available under the terms of the CC BY
4.0 license ([Creative Commons Attribution 4.0 International license](https://creativecommons.org/licenses/by/4.0/legalcode)).
Additional acknowledged contributions:
* Codeforces materials are sourced from http://codeforces.com.
* Description2Code materials are sourced from:
[Description2Code Dataset](https://github.com/ethancaballero/description2code),
licensed under the
[MIT open source license](https://opensource.org/licenses/MIT), copyright
not specified.
* CodeNet materials are sourced from:
[Project_CodeNet](https://github.com/IBM/Project_CodeNet), licensed under
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0), copyright not
specified.
### Citation Information
```bibtex
@article{li2022competition,
title={Competition-Level Code Generation with AlphaCode},
author={Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and
Schrittwieser, Julian and Leblond, R{\'e}mi and Eccles, Tom and
Keeling, James and Gimeno, Felix and Dal Lago, Agustin and
Hubert, Thomas and Choy, Peter and de Masson d'Autume, Cyprien and
Babuschkin, Igor and Chen, Xinyun and Huang, Po-Sen and Welbl, Johannes and
Gowal, Sven and Cherepanov, Alexey and Molloy, James and
Mankowitz, Daniel and Sutherland Robson, Esme and Kohli, Pushmeet and
de Freitas, Nando and Kavukcuoglu, Koray and Vinyals, Oriol},
journal={arXiv preprint arXiv:2203.07814},
year={2022}
}
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset. |
garrethlee/svamp | garrethlee | "2024-10-03T08:04:53Z" | 2,579 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-10-03T08:04:49Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 156918.4
num_examples: 800
- name: test
num_bytes: 39229.6
num_examples: 200
download_size: 88241
dataset_size: 196148.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
RekaAI/VibeEval | RekaAI | "2024-05-06T10:28:10Z" | 2,578 | 37 | [
"task_categories:image-to-text",
"task_categories:image-classification",
"language:en",
"language:pl",
"language:zh",
"language:ja",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"Reka",
"Vibe",
"Eval",
"VibeEval",
"Vibe-Eval",
"Hard"
] | [
"image-to-text",
"image-classification"
] | "2024-05-02T10:09:50Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: prompt
dtype: string
- name: reference
dtype: string
- name: example_id
dtype: string
- name: category
dtype: string
- name: media_url
dtype: string
splits:
- name: test
num_bytes: 212934461
num_examples: 269
download_size: 5175222
dataset_size: 212934461
configs:
- config_name: default
data_files:
- split: test
path: vibe-eval.v1.parquet
license: apache-2.0
task_categories:
- image-to-text
- image-classification
language:
- en
- pl
- zh
- ja
size_categories:
- n<1K
tags:
- Reka
- Vibe
- Eval
- VibeEval
- Vibe-Eval
- Hard
pretty_name: Vibe-Eval
---
# Vibe-Eval
A benchmark for evaluating multimodal chat models, including especially challenging examples.
[[Link to paper]](https://publications.reka.ai/reka-vibe-eval.pdf) [[Blogpost]](https://www.reka.ai/news/vibe-eval) [[Github]](https://github.com/reka-ai/reka-vibe-eval)

## Dataset
Each example has the following fields:
- **example_id**: a unique ID for the example
- **category**: the category that this example belongs to, either `difficulty-normal` or `difficulty-hard`
- **prompt**: the user prompt
- **reference**: a golden reference answer for the prompt
- **image**: an image struct (containing `bytes` and `path` keys).
- **media_filename**: the name of the file in the dataset
- **media_url**: a URL where the file is hosted publicly
The dataset can also be downloaded from the [Releases page of the reka-vibe-eval repo](https://github.com/reka-ai/reka-vibe-eval/releases/tag/v1.0.0).
## Leaderboard 🏆
Vibe-Eval Score (%)
| Model | all | hard | normal |
|-----------------|---------------------|--------|--------|
| Gemini Pro 1.5 | 60.4 | 53.0 | 64.8 |
| GPT-4V | 57.9 | 46.0 | 64.9 |
| Reka Core | 53.7 | 38.2† | 62.8 |
| Claude Opus | 52.8 | 41.8 | 59.2 |
| Reka Flash | 52.2 | 39.2 | 59.9 |
| Claude Sonnet | 52.1 | 39.7 | 59.5 |
| Claude Haiku | 49.8 | 38.5 | 56.4 |
| Llava-1.6-34b | 48.6 | 39.9 | 53.7 |
| Reka Edge | 45.4 | 32.2 | 53.1 |
| Llava-1.6-7b | 43.7 | 35.3 | 48.6 |
| Idefics-2-8b | 40.0 | 32.2 | 44.6 |
| Idefics-1-80b | 36.0 | 32.1 | 38.3 |
| Fuyu-8b | 30.8 | 23.4 | 35.2 |
† Note we expect the results of Reka Core to be worse on the hard-set, as these are, by their very definition, prompts that Core cannot solve.
## Running the evaluation
Check out [github](https://github.com/reka-ai/reka-vibe-eval) page to see instructions for evaluation.
## Citation
```bibtex
@article{padlewski2024vibeeval,
title={Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models},
author={Piotr Padlewski and Max Bain and Matthew Henderson and Zhongkai Zhu and Nishant Relan and Hai Pham and Donovan Ong and Kaloyan Aleksiev and Aitor Ormazabal and Samuel Phua and Ethan Yeo and Eugenie Lamprecht and Qi Liu and Yuqi Wang and Eric Chen and Deyu Fu and Lei Li and Che Zheng and Cyprien de Masson d'Autume and Dani Yogatama and Mikel Artetxe and Yi Tay},
journal={arXiv preprint arXiv:2405.02287},
year={2024}
}
|
loicmagne/open-subtitles-500-bitext-mining | loicmagne | "2024-04-10T13:53:11Z" | 2,564 | 0 | [
"size_categories:100K<n<1M",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-04-10T13:52:47Z" | ---
configs:
- config_name: ka-ml
data_files: "data/ka-ml.jsonl"
- config_name: br-sr
data_files: "data/br-sr.jsonl"
- config_name: bg-br
data_files: "data/bg-br.jsonl"
- config_name: kk-lv
data_files: "data/kk-lv.jsonl"
- config_name: br-sk
data_files: "data/br-sk.jsonl"
- config_name: br-fi
data_files: "data/br-fi.jsonl"
- config_name: eu-ze_zh
data_files: "data/eu-ze_zh.jsonl"
- config_name: kk-nl
data_files: "data/kk-nl.jsonl"
- config_name: kk-vi
data_files: "data/kk-vi.jsonl"
- config_name: ja-kk
data_files: "data/ja-kk.jsonl"
- config_name: br-sv
data_files: "data/br-sv.jsonl"
- config_name: kk-zh_cn
data_files: "data/kk-zh_cn.jsonl"
- config_name: kk-ms
data_files: "data/kk-ms.jsonl"
- config_name: br-et
data_files: "data/br-et.jsonl"
- config_name: br-hu
data_files: "data/br-hu.jsonl"
- config_name: eo-kk
data_files: "data/eo-kk.jsonl"
- config_name: br-tr
data_files: "data/br-tr.jsonl"
- config_name: ko-tl
data_files: "data/ko-tl.jsonl"
- config_name: te-zh_tw
data_files: "data/te-zh_tw.jsonl"
- config_name: br-hr
data_files: "data/br-hr.jsonl"
- config_name: br-nl
data_files: "data/br-nl.jsonl"
- config_name: ka-si
data_files: "data/ka-si.jsonl"
- config_name: br-cs
data_files: "data/br-cs.jsonl"
- config_name: br-is
data_files: "data/br-is.jsonl"
- config_name: br-ro
data_files: "data/br-ro.jsonl"
- config_name: br-de
data_files: "data/br-de.jsonl"
- config_name: et-kk
data_files: "data/et-kk.jsonl"
- config_name: fr-hy
data_files: "data/fr-hy.jsonl"
- config_name: br-no
data_files: "data/br-no.jsonl"
- config_name: is-ko
data_files: "data/is-ko.jsonl"
- config_name: br-da
data_files: "data/br-da.jsonl"
- config_name: br-en
data_files: "data/br-en.jsonl"
- config_name: eo-lt
data_files: "data/eo-lt.jsonl"
- config_name: is-ze_zh
data_files: "data/is-ze_zh.jsonl"
- config_name: eu-ko
data_files: "data/eu-ko.jsonl"
- config_name: br-it
data_files: "data/br-it.jsonl"
- config_name: br-id
data_files: "data/br-id.jsonl"
- config_name: eu-zh_cn
data_files: "data/eu-zh_cn.jsonl"
- config_name: is-ja
data_files: "data/is-ja.jsonl"
- config_name: br-sl
data_files: "data/br-sl.jsonl"
- config_name: br-gl
data_files: "data/br-gl.jsonl"
- config_name: br-pt_br
data_files: "data/br-pt_br.jsonl"
- config_name: br-es
data_files: "data/br-es.jsonl"
- config_name: br-pt
data_files: "data/br-pt.jsonl"
- config_name: is-th
data_files: "data/is-th.jsonl"
- config_name: fa-is
data_files: "data/fa-is.jsonl"
- config_name: br-ca
data_files: "data/br-ca.jsonl"
- config_name: eu-ka
data_files: "data/eu-ka.jsonl"
- config_name: is-zh_cn
data_files: "data/is-zh_cn.jsonl"
- config_name: eu-ur
data_files: "data/eu-ur.jsonl"
- config_name: id-kk
data_files: "data/id-kk.jsonl"
- config_name: br-sq
data_files: "data/br-sq.jsonl"
- config_name: eu-ja
data_files: "data/eu-ja.jsonl"
- config_name: uk-ur
data_files: "data/uk-ur.jsonl"
- config_name: is-zh_tw
data_files: "data/is-zh_tw.jsonl"
- config_name: ka-ko
data_files: "data/ka-ko.jsonl"
- config_name: eu-zh_tw
data_files: "data/eu-zh_tw.jsonl"
- config_name: eu-th
data_files: "data/eu-th.jsonl"
- config_name: eu-is
data_files: "data/eu-is.jsonl"
- config_name: is-tl
data_files: "data/is-tl.jsonl"
- config_name: br-eo
data_files: "data/br-eo.jsonl"
- config_name: eo-ze_zh
data_files: "data/eo-ze_zh.jsonl"
- config_name: eu-te
data_files: "data/eu-te.jsonl"
- config_name: ar-kk
data_files: "data/ar-kk.jsonl"
- config_name: eo-lv
data_files: "data/eo-lv.jsonl"
- config_name: ko-ze_zh
data_files: "data/ko-ze_zh.jsonl"
- config_name: ml-ze_zh
data_files: "data/ml-ze_zh.jsonl"
- config_name: is-lt
data_files: "data/is-lt.jsonl"
- config_name: br-fr
data_files: "data/br-fr.jsonl"
- config_name: ko-te
data_files: "data/ko-te.jsonl"
- config_name: kk-sl
data_files: "data/kk-sl.jsonl"
- config_name: eu-fa
data_files: "data/eu-fa.jsonl"
- config_name: eo-ko
data_files: "data/eo-ko.jsonl"
- config_name: ka-ze_en
data_files: "data/ka-ze_en.jsonl"
- config_name: eo-eu
data_files: "data/eo-eu.jsonl"
- config_name: ta-zh_tw
data_files: "data/ta-zh_tw.jsonl"
- config_name: eu-lv
data_files: "data/eu-lv.jsonl"
- config_name: ko-lv
data_files: "data/ko-lv.jsonl"
- config_name: lt-tl
data_files: "data/lt-tl.jsonl"
- config_name: eu-si
data_files: "data/eu-si.jsonl"
- config_name: hy-ru
data_files: "data/hy-ru.jsonl"
- config_name: ar-is
data_files: "data/ar-is.jsonl"
- config_name: eu-lt
data_files: "data/eu-lt.jsonl"
- config_name: eu-tl
data_files: "data/eu-tl.jsonl"
- config_name: eu-uk
data_files: "data/eu-uk.jsonl"
- config_name: ka-ze_zh
data_files: "data/ka-ze_zh.jsonl"
- config_name: si-ze_zh
data_files: "data/si-ze_zh.jsonl"
- config_name: el-is
data_files: "data/el-is.jsonl"
- config_name: bn-is
data_files: "data/bn-is.jsonl"
- config_name: ko-ze_en
data_files: "data/ko-ze_en.jsonl"
- config_name: eo-si
data_files: "data/eo-si.jsonl"
- config_name: cs-kk
data_files: "data/cs-kk.jsonl"
- config_name: is-uk
data_files: "data/is-uk.jsonl"
- config_name: eu-ze_en
data_files: "data/eu-ze_en.jsonl"
- config_name: ta-ze_zh
data_files: "data/ta-ze_zh.jsonl"
- config_name: is-pl
data_files: "data/is-pl.jsonl"
- config_name: is-mk
data_files: "data/is-mk.jsonl"
- config_name: eu-ta
data_files: "data/eu-ta.jsonl"
- config_name: ko-lt
data_files: "data/ko-lt.jsonl"
- config_name: is-lv
data_files: "data/is-lv.jsonl"
- config_name: fa-ko
data_files: "data/fa-ko.jsonl"
- config_name: bn-ko
data_files: "data/bn-ko.jsonl"
- config_name: hi-is
data_files: "data/hi-is.jsonl"
- config_name: bn-ze_zh
data_files: "data/bn-ze_zh.jsonl"
- config_name: bn-eu
data_files: "data/bn-eu.jsonl"
- config_name: bn-ja
data_files: "data/bn-ja.jsonl"
- config_name: is-ml
data_files: "data/is-ml.jsonl"
- config_name: eu-ru
data_files: "data/eu-ru.jsonl"
- config_name: ko-ta
data_files: "data/ko-ta.jsonl"
- config_name: is-vi
data_files: "data/is-vi.jsonl"
- config_name: ja-tl
data_files: "data/ja-tl.jsonl"
- config_name: eu-mk
data_files: "data/eu-mk.jsonl"
- config_name: eu-he
data_files: "data/eu-he.jsonl"
- config_name: ka-zh_tw
data_files: "data/ka-zh_tw.jsonl"
- config_name: ka-zh_cn
data_files: "data/ka-zh_cn.jsonl"
- config_name: si-tl
data_files: "data/si-tl.jsonl"
- config_name: is-kk
data_files: "data/is-kk.jsonl"
- config_name: eu-fi
data_files: "data/eu-fi.jsonl"
- config_name: fi-ko
data_files: "data/fi-ko.jsonl"
- config_name: is-ur
data_files: "data/is-ur.jsonl"
- config_name: ka-th
data_files: "data/ka-th.jsonl"
- config_name: ko-ur
data_files: "data/ko-ur.jsonl"
- config_name: eo-ja
data_files: "data/eo-ja.jsonl"
- config_name: he-is
data_files: "data/he-is.jsonl"
- config_name: is-tr
data_files: "data/is-tr.jsonl"
- config_name: ka-ur
data_files: "data/ka-ur.jsonl"
- config_name: et-ko
data_files: "data/et-ko.jsonl"
- config_name: eu-vi
data_files: "data/eu-vi.jsonl"
- config_name: is-sk
data_files: "data/is-sk.jsonl"
- config_name: gl-is
data_files: "data/gl-is.jsonl"
- config_name: fr-is
data_files: "data/fr-is.jsonl"
- config_name: is-sq
data_files: "data/is-sq.jsonl"
- config_name: hu-is
data_files: "data/hu-is.jsonl"
- config_name: fr-kk
data_files: "data/fr-kk.jsonl"
- config_name: eu-sq
data_files: "data/eu-sq.jsonl"
- config_name: is-ru
data_files: "data/is-ru.jsonl"
- config_name: ja-ka
data_files: "data/ja-ka.jsonl"
- config_name: fi-tl
data_files: "data/fi-tl.jsonl"
- config_name: ka-lv
data_files: "data/ka-lv.jsonl"
- config_name: fi-is
data_files: "data/fi-is.jsonl"
- config_name: is-si
data_files: "data/is-si.jsonl"
- config_name: ar-ko
data_files: "data/ar-ko.jsonl"
- config_name: ko-sl
data_files: "data/ko-sl.jsonl"
- config_name: ar-eu
data_files: "data/ar-eu.jsonl"
- config_name: ko-si
data_files: "data/ko-si.jsonl"
- config_name: bg-is
data_files: "data/bg-is.jsonl"
- config_name: eu-hu
data_files: "data/eu-hu.jsonl"
- config_name: ko-sv
data_files: "data/ko-sv.jsonl"
- config_name: bn-hu
data_files: "data/bn-hu.jsonl"
- config_name: kk-ro
data_files: "data/kk-ro.jsonl"
- config_name: eu-hi
data_files: "data/eu-hi.jsonl"
- config_name: ka-ms
data_files: "data/ka-ms.jsonl"
- config_name: ko-th
data_files: "data/ko-th.jsonl"
- config_name: ko-sr
data_files: "data/ko-sr.jsonl"
- config_name: ko-mk
data_files: "data/ko-mk.jsonl"
- config_name: fi-kk
data_files: "data/fi-kk.jsonl"
- config_name: ka-vi
data_files: "data/ka-vi.jsonl"
- config_name: eu-ml
data_files: "data/eu-ml.jsonl"
- config_name: ko-ml
data_files: "data/ko-ml.jsonl"
- config_name: de-ko
data_files: "data/de-ko.jsonl"
- config_name: fa-ze_zh
data_files: "data/fa-ze_zh.jsonl"
- config_name: eu-sk
data_files: "data/eu-sk.jsonl"
- config_name: is-sl
data_files: "data/is-sl.jsonl"
- config_name: et-is
data_files: "data/et-is.jsonl"
- config_name: eo-is
data_files: "data/eo-is.jsonl"
- config_name: is-sr
data_files: "data/is-sr.jsonl"
- config_name: is-ze_en
data_files: "data/is-ze_en.jsonl"
- config_name: kk-pt_br
data_files: "data/kk-pt_br.jsonl"
- config_name: hr-hy
data_files: "data/hr-hy.jsonl"
- config_name: kk-pl
data_files: "data/kk-pl.jsonl"
- config_name: ja-ta
data_files: "data/ja-ta.jsonl"
- config_name: is-ms
data_files: "data/is-ms.jsonl"
- config_name: hi-ze_en
data_files: "data/hi-ze_en.jsonl"
- config_name: is-ro
data_files: "data/is-ro.jsonl"
- config_name: ko-zh_cn
data_files: "data/ko-zh_cn.jsonl"
- config_name: el-eu
data_files: "data/el-eu.jsonl"
- config_name: ka-pl
data_files: "data/ka-pl.jsonl"
- config_name: ka-sq
data_files: "data/ka-sq.jsonl"
- config_name: eu-sl
data_files: "data/eu-sl.jsonl"
- config_name: fa-ka
data_files: "data/fa-ka.jsonl"
- config_name: ko-no
data_files: "data/ko-no.jsonl"
- config_name: si-ze_en
data_files: "data/si-ze_en.jsonl"
- config_name: ko-uk
data_files: "data/ko-uk.jsonl"
- config_name: ja-ze_zh
data_files: "data/ja-ze_zh.jsonl"
- config_name: hu-ko
data_files: "data/hu-ko.jsonl"
- config_name: kk-no
data_files: "data/kk-no.jsonl"
- config_name: eu-pl
data_files: "data/eu-pl.jsonl"
- config_name: is-pt_br
data_files: "data/is-pt_br.jsonl"
- config_name: bn-lv
data_files: "data/bn-lv.jsonl"
- config_name: tl-zh_cn
data_files: "data/tl-zh_cn.jsonl"
- config_name: is-nl
data_files: "data/is-nl.jsonl"
- config_name: he-ko
data_files: "data/he-ko.jsonl"
- config_name: ko-sq
data_files: "data/ko-sq.jsonl"
- config_name: ta-th
data_files: "data/ta-th.jsonl"
- config_name: lt-ta
data_files: "data/lt-ta.jsonl"
- config_name: da-ko
data_files: "data/da-ko.jsonl"
- config_name: ca-is
data_files: "data/ca-is.jsonl"
- config_name: is-ta
data_files: "data/is-ta.jsonl"
- config_name: bn-fi
data_files: "data/bn-fi.jsonl"
- config_name: ja-ml
data_files: "data/ja-ml.jsonl"
- config_name: lv-si
data_files: "data/lv-si.jsonl"
- config_name: eu-sv
data_files: "data/eu-sv.jsonl"
- config_name: ja-te
data_files: "data/ja-te.jsonl"
- config_name: bn-ur
data_files: "data/bn-ur.jsonl"
- config_name: bn-ca
data_files: "data/bn-ca.jsonl"
- config_name: bs-ko
data_files: "data/bs-ko.jsonl"
- config_name: bs-is
data_files: "data/bs-is.jsonl"
- config_name: eu-sr
data_files: "data/eu-sr.jsonl"
- config_name: ko-vi
data_files: "data/ko-vi.jsonl"
- config_name: ko-zh_tw
data_files: "data/ko-zh_tw.jsonl"
- config_name: et-tl
data_files: "data/et-tl.jsonl"
- config_name: kk-tr
data_files: "data/kk-tr.jsonl"
- config_name: eo-vi
data_files: "data/eo-vi.jsonl"
- config_name: is-it
data_files: "data/is-it.jsonl"
- config_name: ja-ko
data_files: "data/ja-ko.jsonl"
- config_name: eo-et
data_files: "data/eo-et.jsonl"
- config_name: id-is
data_files: "data/id-is.jsonl"
- config_name: bn-et
data_files: "data/bn-et.jsonl"
- config_name: bs-eu
data_files: "data/bs-eu.jsonl"
- config_name: bn-lt
data_files: "data/bn-lt.jsonl"
- config_name: tl-uk
data_files: "data/tl-uk.jsonl"
- config_name: bn-zh_tw
data_files: "data/bn-zh_tw.jsonl"
- config_name: da-eu
data_files: "data/da-eu.jsonl"
- config_name: el-ko
data_files: "data/el-ko.jsonl"
- config_name: no-tl
data_files: "data/no-tl.jsonl"
- config_name: ko-sk
data_files: "data/ko-sk.jsonl"
- config_name: is-pt
data_files: "data/is-pt.jsonl"
- config_name: hu-kk
data_files: "data/hu-kk.jsonl"
- config_name: si-zh_tw
data_files: "data/si-zh_tw.jsonl"
- config_name: si-te
data_files: "data/si-te.jsonl"
- config_name: ka-ru
data_files: "data/ka-ru.jsonl"
- config_name: lt-ml
data_files: "data/lt-ml.jsonl"
- config_name: af-ja
data_files: "data/af-ja.jsonl"
- config_name: bg-eu
data_files: "data/bg-eu.jsonl"
- config_name: eo-th
data_files: "data/eo-th.jsonl"
- config_name: cs-is
data_files: "data/cs-is.jsonl"
- config_name: pl-ze_zh
data_files: "data/pl-ze_zh.jsonl"
- config_name: el-kk
data_files: "data/el-kk.jsonl"
- config_name: kk-sv
data_files: "data/kk-sv.jsonl"
- config_name: ka-nl
data_files: "data/ka-nl.jsonl"
- config_name: ko-pl
data_files: "data/ko-pl.jsonl"
- config_name: bg-ko
data_files: "data/bg-ko.jsonl"
- config_name: ka-pt_br
data_files: "data/ka-pt_br.jsonl"
- config_name: et-eu
data_files: "data/et-eu.jsonl"
- config_name: tl-zh_tw
data_files: "data/tl-zh_tw.jsonl"
- config_name: ka-pt
data_files: "data/ka-pt.jsonl"
- config_name: id-ko
data_files: "data/id-ko.jsonl"
- config_name: fi-ze_zh
data_files: "data/fi-ze_zh.jsonl"
- config_name: he-kk
data_files: "data/he-kk.jsonl"
- config_name: ka-tr
data_files: "data/ka-tr.jsonl"
- config_name: hr-ko
data_files: "data/hr-ko.jsonl"
- config_name: ka-sk
data_files: "data/ka-sk.jsonl"
- config_name: eu-ms
data_files: "data/eu-ms.jsonl"
- config_name: ka-no
data_files: "data/ka-no.jsonl"
- config_name: de-eu
data_files: "data/de-eu.jsonl"
- config_name: af-fa
data_files: "data/af-fa.jsonl"
- config_name: ko-ru
data_files: "data/ko-ru.jsonl"
- config_name: hr-is
data_files: "data/hr-is.jsonl"
- config_name: eu-it
data_files: "data/eu-it.jsonl"
- config_name: ko-ro
data_files: "data/ko-ro.jsonl"
- config_name: cs-eu
data_files: "data/cs-eu.jsonl"
- config_name: hr-kk
data_files: "data/hr-kk.jsonl"
- config_name: lv-te
data_files: "data/lv-te.jsonl"
- config_name: ka-lt
data_files: "data/ka-lt.jsonl"
- config_name: eu-tr
data_files: "data/eu-tr.jsonl"
- config_name: eu-no
data_files: "data/eu-no.jsonl"
- config_name: ml-zh_cn
data_files: "data/ml-zh_cn.jsonl"
- config_name: ko-ms
data_files: "data/ko-ms.jsonl"
- config_name: tl-vi
data_files: "data/tl-vi.jsonl"
- config_name: is-no
data_files: "data/is-no.jsonl"
- config_name: ja-si
data_files: "data/ja-si.jsonl"
- config_name: kk-sr
data_files: "data/kk-sr.jsonl"
- config_name: ko-tr
data_files: "data/ko-tr.jsonl"
- config_name: et-ta
data_files: "data/et-ta.jsonl"
- config_name: fr-ko
data_files: "data/fr-ko.jsonl"
- config_name: ml-zh_tw
data_files: "data/ml-zh_tw.jsonl"
- config_name: af-hi
data_files: "data/af-hi.jsonl"
- config_name: eu-id
data_files: "data/eu-id.jsonl"
- config_name: eo-ms
data_files: "data/eo-ms.jsonl"
- config_name: ka-sl
data_files: "data/ka-sl.jsonl"
- config_name: sk-tl
data_files: "data/sk-tl.jsonl"
- config_name: cs-ko
data_files: "data/cs-ko.jsonl"
- config_name: eu-nl
data_files: "data/eu-nl.jsonl"
- config_name: fa-ja
data_files: "data/fa-ja.jsonl"
- config_name: eo-zh_tw
data_files: "data/eo-zh_tw.jsonl"
- config_name: is-sv
data_files: "data/is-sv.jsonl"
- config_name: eo-hu
data_files: "data/eo-hu.jsonl"
- config_name: bg-kk
data_files: "data/bg-kk.jsonl"
- config_name: ko-pt
data_files: "data/ko-pt.jsonl"
- config_name: sr-tl
data_files: "data/sr-tl.jsonl"
- config_name: ka-ro
data_files: "data/ka-ro.jsonl"
- config_name: hu-hy
data_files: "data/hu-hy.jsonl"
- config_name: hu-ta
data_files: "data/hu-ta.jsonl"
- config_name: kk-ru
data_files: "data/kk-ru.jsonl"
- config_name: lt-te
data_files: "data/lt-te.jsonl"
- config_name: ta-zh_cn
data_files: "data/ta-zh_cn.jsonl"
- config_name: ka-sv
data_files: "data/ka-sv.jsonl"
- config_name: eo-fi
data_files: "data/eo-fi.jsonl"
- config_name: eu-pt_br
data_files: "data/eu-pt_br.jsonl"
- config_name: bn-tl
data_files: "data/bn-tl.jsonl"
- config_name: da-is
data_files: "data/da-is.jsonl"
- config_name: lt-si
data_files: "data/lt-si.jsonl"
- config_name: fa-ta
data_files: "data/fa-ta.jsonl"
- config_name: ka-sr
data_files: "data/ka-sr.jsonl"
- config_name: bn-uk
data_files: "data/bn-uk.jsonl"
- config_name: sv-tl
data_files: "data/sv-tl.jsonl"
- config_name: et-te
data_files: "data/et-te.jsonl"
- config_name: eo-zh_cn
data_files: "data/eo-zh_cn.jsonl"
- config_name: ko-pt_br
data_files: "data/ko-pt_br.jsonl"
- config_name: et-ml
data_files: "data/et-ml.jsonl"
- config_name: eo-ml
data_files: "data/eo-ml.jsonl"
- config_name: ko-nl
data_files: "data/ko-nl.jsonl"
- config_name: es-is
data_files: "data/es-is.jsonl"
- config_name: fi-ta
data_files: "data/fi-ta.jsonl"
- config_name: eu-fr
data_files: "data/eu-fr.jsonl"
- config_name: es-ko
data_files: "data/es-ko.jsonl"
- config_name: bn-th
data_files: "data/bn-th.jsonl"
- config_name: it-ko
data_files: "data/it-ko.jsonl"
- config_name: ca-ko
data_files: "data/ca-ko.jsonl"
- config_name: th-ze_zh
data_files: "data/th-ze_zh.jsonl"
- config_name: ml-th
data_files: "data/ml-th.jsonl"
- config_name: bn-pl
data_files: "data/bn-pl.jsonl"
- config_name: it-kk
data_files: "data/it-kk.jsonl"
- config_name: lv-ta
data_files: "data/lv-ta.jsonl"
- config_name: si-zh_cn
data_files: "data/si-zh_cn.jsonl"
- config_name: hu-ml
data_files: "data/hu-ml.jsonl"
- config_name: hu-ka
data_files: "data/hu-ka.jsonl"
- config_name: eu-ro
data_files: "data/eu-ro.jsonl"
- config_name: es-kk
data_files: "data/es-kk.jsonl"
- config_name: bn-zh_cn
data_files: "data/bn-zh_cn.jsonl"
- config_name: lv-ze_zh
data_files: "data/lv-ze_zh.jsonl"
- config_name: gl-ko
data_files: "data/gl-ko.jsonl"
- config_name: sq-ze_zh
data_files: "data/sq-ze_zh.jsonl"
- config_name: te-zh_cn
data_files: "data/te-zh_cn.jsonl"
- config_name: fa-zh_tw
data_files: "data/fa-zh_tw.jsonl"
- config_name: ja-ze_en
data_files: "data/ja-ze_en.jsonl"
- config_name: fi-si
data_files: "data/fi-si.jsonl"
- config_name: fa-te
data_files: "data/fa-te.jsonl"
- config_name: sl-ze_zh
data_files: "data/sl-ze_zh.jsonl"
- config_name: ja-lv
data_files: "data/ja-lv.jsonl"
- config_name: af-uk
data_files: "data/af-uk.jsonl"
- config_name: hi-zh_tw
data_files: "data/hi-zh_tw.jsonl"
- config_name: si-th
data_files: "data/si-th.jsonl"
- config_name: bn-el
data_files: "data/bn-el.jsonl"
- config_name: fr-ka
data_files: "data/fr-ka.jsonl"
- config_name: ar-ze_zh
data_files: "data/ar-ze_zh.jsonl"
- config_name: fa-si
data_files: "data/fa-si.jsonl"
- config_name: eu-hr
data_files: "data/eu-hr.jsonl"
- config_name: de-is
data_files: "data/de-is.jsonl"
- config_name: bs-tl
data_files: "data/bs-tl.jsonl"
- config_name: et-ze_zh
data_files: "data/et-ze_zh.jsonl"
- config_name: af-vi
data_files: "data/af-vi.jsonl"
- config_name: ca-ze_zh
data_files: "data/ca-ze_zh.jsonl"
- config_name: bn-sk
data_files: "data/bn-sk.jsonl"
- config_name: ro-ze_zh
data_files: "data/ro-ze_zh.jsonl"
- config_name: hu-te
data_files: "data/hu-te.jsonl"
- config_name: eo-he
data_files: "data/eo-he.jsonl"
- config_name: ml-pl
data_files: "data/ml-pl.jsonl"
- config_name: el-ka
data_files: "data/el-ka.jsonl"
- config_name: hi-ze_zh
data_files: "data/hi-ze_zh.jsonl"
- config_name: en-ko
data_files: "data/en-ko.jsonl"
- config_name: el-ze_zh
data_files: "data/el-ze_zh.jsonl"
- config_name: te-tr
data_files: "data/te-tr.jsonl"
- config_name: fa-lv
data_files: "data/fa-lv.jsonl"
- config_name: si-vi
data_files: "data/si-vi.jsonl"
- config_name: kk-pt
data_files: "data/kk-pt.jsonl"
- config_name: bn-fa
data_files: "data/bn-fa.jsonl"
- config_name: lv-zh_tw
data_files: "data/lv-zh_tw.jsonl"
- config_name: ar-ka
data_files: "data/ar-ka.jsonl"
- config_name: bn-vi
data_files: "data/bn-vi.jsonl"
- config_name: bn-sl
data_files: "data/bn-sl.jsonl"
- config_name: ms-ze_zh
data_files: "data/ms-ze_zh.jsonl"
- config_name: ca-ml
data_files: "data/ca-ml.jsonl"
- config_name: ru-ze_zh
data_files: "data/ru-ze_zh.jsonl"
- config_name: ja-lt
data_files: "data/ja-lt.jsonl"
- config_name: lt-ze_zh
data_files: "data/lt-ze_zh.jsonl"
- config_name: fi-ml
data_files: "data/fi-ml.jsonl"
- config_name: uk-ze_zh
data_files: "data/uk-ze_zh.jsonl"
- config_name: en-is
data_files: "data/en-is.jsonl"
- config_name: et-ka
data_files: "data/et-ka.jsonl"
- config_name: bg-tl
data_files: "data/bg-tl.jsonl"
- config_name: et-si
data_files: "data/et-si.jsonl"
- config_name: fi-te
data_files: "data/fi-te.jsonl"
- config_name: cs-tl
data_files: "data/cs-tl.jsonl"
- config_name: eo-sk
data_files: "data/eo-sk.jsonl"
- config_name: hu-ze_zh
data_files: "data/hu-ze_zh.jsonl"
- config_name: hr-ze_zh
data_files: "data/hr-ze_zh.jsonl"
- config_name: bg-ze_zh
data_files: "data/bg-ze_zh.jsonl"
- config_name: ja-sl
data_files: "data/ja-sl.jsonl"
- config_name: ml-sl
data_files: "data/ml-sl.jsonl"
- config_name: vi-ze_zh
data_files: "data/vi-ze_zh.jsonl"
- config_name: hu-tl
data_files: "data/hu-tl.jsonl"
- config_name: fa-tl
data_files: "data/fa-tl.jsonl"
- config_name: da-kk
data_files: "data/da-kk.jsonl"
- config_name: fa-ml
data_files: "data/fa-ml.jsonl"
- config_name: te-vi
data_files: "data/te-vi.jsonl"
- config_name: mk-te
data_files: "data/mk-te.jsonl"
- config_name: sl-ta
data_files: "data/sl-ta.jsonl"
- config_name: sr-ze_zh
data_files: "data/sr-ze_zh.jsonl"
- config_name: lv-ze_en
data_files: "data/lv-ze_en.jsonl"
- config_name: da-tl
data_files: "data/da-tl.jsonl"
- config_name: ml-sk
data_files: "data/ml-sk.jsonl"
- config_name: fa-zh_cn
data_files: "data/fa-zh_cn.jsonl"
- config_name: gl-ka
data_files: "data/gl-ka.jsonl"
- config_name: si-ta
data_files: "data/si-ta.jsonl"
- config_name: ta-tr
data_files: "data/ta-tr.jsonl"
- config_name: eo-sl
data_files: "data/eo-sl.jsonl"
- config_name: gl-ml
data_files: "data/gl-ml.jsonl"
- config_name: ml-vi
data_files: "data/ml-vi.jsonl"
- config_name: eo-no
data_files: "data/eo-no.jsonl"
- config_name: th-tl
data_files: "data/th-tl.jsonl"
- config_name: ca-eu
data_files: "data/ca-eu.jsonl"
- config_name: eu-pt
data_files: "data/eu-pt.jsonl"
- config_name: bn-da
data_files: "data/bn-da.jsonl"
- config_name: no-ze_zh
data_files: "data/no-ze_zh.jsonl"
- config_name: af-zh_cn
data_files: "data/af-zh_cn.jsonl"
- config_name: fa-ze_en
data_files: "data/fa-ze_en.jsonl"
- config_name: id-ka
data_files: "data/id-ka.jsonl"
- config_name: da-ka
data_files: "data/da-ka.jsonl"
- config_name: af-et
data_files: "data/af-et.jsonl"
- config_name: si-sk
data_files: "data/si-sk.jsonl"
- config_name: ja-ur
data_files: "data/ja-ur.jsonl"
- config_name: ja-sq
data_files: "data/ja-sq.jsonl"
- config_name: bs-ka
data_files: "data/bs-ka.jsonl"
- config_name: fi-ka
data_files: "data/fi-ka.jsonl"
- config_name: fa-fi
data_files: "data/fa-fi.jsonl"
- config_name: tr-ze_zh
data_files: "data/tr-ze_zh.jsonl"
- config_name: sk-ze_zh
data_files: "data/sk-ze_zh.jsonl"
- config_name: bn-he
data_files: "data/bn-he.jsonl"
- config_name: et-ja
data_files: "data/et-ja.jsonl"
- config_name: ta-vi
data_files: "data/ta-vi.jsonl"
- config_name: eo-uk
data_files: "data/eo-uk.jsonl"
- config_name: bs-ze_zh
data_files: "data/bs-ze_zh.jsonl"
- config_name: hu-si
data_files: "data/hu-si.jsonl"
- config_name: eo-fa
data_files: "data/eo-fa.jsonl"
- config_name: bn-ze_en
data_files: "data/bn-ze_en.jsonl"
- config_name: th-ze_en
data_files: "data/th-ze_en.jsonl"
- config_name: de-ze_zh
data_files: "data/de-ze_zh.jsonl"
- config_name: si-sv
data_files: "data/si-sv.jsonl"
- config_name: bg-te
data_files: "data/bg-te.jsonl"
- config_name: fr-ze_zh
data_files: "data/fr-ze_zh.jsonl"
- config_name: bn-gl
data_files: "data/bn-gl.jsonl"
- config_name: bn-mk
data_files: "data/bn-mk.jsonl"
- config_name: ml-sv
data_files: "data/ml-sv.jsonl"
- config_name: af-bg
data_files: "data/af-bg.jsonl"
- config_name: id-ze_zh
data_files: "data/id-ze_zh.jsonl"
- config_name: ja-sr
data_files: "data/ja-sr.jsonl"
- config_name: sq-zh_tw
data_files: "data/sq-zh_tw.jsonl"
- config_name: sl-tl
data_files: "data/sl-tl.jsonl"
- config_name: el-te
data_files: "data/el-te.jsonl"
- config_name: es-ka
data_files: "data/es-ka.jsonl"
- config_name: de-kk
data_files: "data/de-kk.jsonl"
- config_name: lv-ml
data_files: "data/lv-ml.jsonl"
- config_name: ru-tl
data_files: "data/ru-tl.jsonl"
- config_name: it-ka
data_files: "data/it-ka.jsonl"
- config_name: si-sl
data_files: "data/si-sl.jsonl"
- config_name: ml-uk
data_files: "data/ml-uk.jsonl"
- config_name: pl-ta
data_files: "data/pl-ta.jsonl"
- config_name: de-ka
data_files: "data/de-ka.jsonl"
- config_name: da-ze_zh
data_files: "data/da-ze_zh.jsonl"
- config_name: ar-tl
data_files: "data/ar-tl.jsonl"
- config_name: eo-pl
data_files: "data/eo-pl.jsonl"
- config_name: en-eu
data_files: "data/en-eu.jsonl"
- config_name: ur-zh_tw
data_files: "data/ur-zh_tw.jsonl"
- config_name: el-eo
data_files: "data/el-eo.jsonl"
- config_name: sv-ze_zh
data_files: "data/sv-ze_zh.jsonl"
- config_name: hr-ka
data_files: "data/hr-ka.jsonl"
- config_name: bn-tr
data_files: "data/bn-tr.jsonl"
- config_name: sk-ta
data_files: "data/sk-ta.jsonl"
- config_name: bn-ro
data_files: "data/bn-ro.jsonl"
- config_name: gl-ze_zh
data_files: "data/gl-ze_zh.jsonl"
- config_name: af-eo
data_files: "data/af-eo.jsonl"
- config_name: nl-ze_zh
data_files: "data/nl-ze_zh.jsonl"
- config_name: he-tl
data_files: "data/he-tl.jsonl"
- config_name: fa-vi
data_files: "data/fa-vi.jsonl"
- config_name: ja-th
data_files: "data/ja-th.jsonl"
- config_name: bs-ta
data_files: "data/bs-ta.jsonl"
- config_name: fa-hu
data_files: "data/fa-hu.jsonl"
- config_name: eo-tr
data_files: "data/eo-tr.jsonl"
- config_name: bn-no
data_files: "data/bn-no.jsonl"
- config_name: bn-cs
data_files: "data/bn-cs.jsonl"
- config_name: ja-no
data_files: "data/ja-no.jsonl"
- config_name: cs-ka
data_files: "data/cs-ka.jsonl"
- config_name: hi-ko
data_files: "data/hi-ko.jsonl"
- config_name: bn-sr
data_files: "data/bn-sr.jsonl"
- config_name: bs-ja
data_files: "data/bs-ja.jsonl"
- config_name: ar-ja
data_files: "data/ar-ja.jsonl"
- config_name: ml-ze_en
data_files: "data/ml-ze_en.jsonl"
- config_name: bg-ta
data_files: "data/bg-ta.jsonl"
- config_name: it-ze_zh
data_files: "data/it-ze_zh.jsonl"
- config_name: af-lv
data_files: "data/af-lv.jsonl"
- config_name: fa-lt
data_files: "data/fa-lt.jsonl"
- config_name: bn-sv
data_files: "data/bn-sv.jsonl"
- config_name: eo-sr
data_files: "data/eo-sr.jsonl"
- config_name: si-uk
data_files: "data/si-uk.jsonl"
- config_name: ml-tr
data_files: "data/ml-tr.jsonl"
- config_name: ja-sk
data_files: "data/ja-sk.jsonl"
- config_name: ja-vi
data_files: "data/ja-vi.jsonl"
- config_name: gl-lv
data_files: "data/gl-lv.jsonl"
- config_name: gl-zh_tw
data_files: "data/gl-zh_tw.jsonl"
---
|
lmms-lab/ActivityNetQA | lmms-lab | "2024-06-21T10:35:17Z" | 2,559 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-06-20T12:41:26Z" | ---
dataset_info:
features:
- name: video_name
dtype: string
- name: question_id
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: type
dtype: string
splits:
- name: test
num_bytes: 779227
num_examples: 8000
download_size: 326030
dataset_size: 779227
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
garrethlee/MAWPS | garrethlee | "2024-10-03T05:53:26Z" | 2,553 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-10-02T21:43:02Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 242439.74379232505
num_examples: 1417
- name: test
num_bytes: 60738.256207674945
num_examples: 355
download_size: 161461
dataset_size: 303178.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
Adapted from https://huggingface.co/datasets/mwpt5/MAWPS
Processed with the following code:
```
def process_row(row):
# Create placeholder-to-actual mapping
placeholder_map = [(f"N_{i:02}", actual) for i, actual in enumerate(row['Numbers'].split())]
try:
# Process placeholders and replacements
for placeholder, replacement in placeholder_map:
replacement_value = float(replacement)
# Convert to integer if it is a whole number, otherwise round to 2 decimal places
replacement = str(int(replacement_value)) if replacement_value.is_integer() else str(round(replacement_value, 2))
# Update Question and Equation with the new replacement value
row['Question'] = row['Question'].strip().replace(placeholder, replacement)
row['Equation'] = row['Equation'].strip().replace(placeholder, replacement)
# Process Answer
answer_value = float(row['Answer'])
row['Answer'] = str(int(answer_value)) if answer_value.is_integer() else str(round(answer_value, 2))
# Format the final answer string
row['Answer'] = f"{row['Equation']} = {row['Answer']} #### {row['Answer']}"
except ValueError as e:
print(f"ValueError: {e}")
except Exception as e:
print(f"Unexpected error: {e}")
return row
```
To format the answers, I used a similar formatting style to GSM8K's answers, which allows for easy parsing for evaluation.
|
open-llm-leaderboard-old/details_uukuguy__speechless-orca-platypus-coig-lite-2k-0.6e-13b | open-llm-leaderboard-old | "2023-10-19T07:05:23Z" | 2,547 | 0 | [
"region:us"
] | null | "2023-08-30T17:55:15Z" | ---
pretty_name: Evaluation run of uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b](https://huggingface.co/uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_uukuguy__speechless-orca-platypus-coig-lite-2k-0.6e-13b\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-19T07:05:10.941569](https://huggingface.co/datasets/open-llm-leaderboard/details_uukuguy__speechless-orca-platypus-coig-lite-2k-0.6e-13b/blob/main/results_2023-10-19T07-05-10.941569.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.40740352348993286,\n\
\ \"em_stderr\": 0.005031895046041088,\n \"f1\": 0.46848573825503476,\n\
\ \"f1_stderr\": 0.004828956071080464,\n \"acc\": 0.4270311930602038,\n\
\ \"acc_stderr\": 0.00945942839156503\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.40740352348993286,\n \"em_stderr\": 0.005031895046041088,\n\
\ \"f1\": 0.46848573825503476,\n \"f1_stderr\": 0.004828956071080464\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.07505686125852919,\n \
\ \"acc_stderr\": 0.007257633145486643\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7790055248618785,\n \"acc_stderr\": 0.011661223637643416\n\
\ }\n}\n```"
repo_url: https://huggingface.co/uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|arc:challenge|25_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_19T07_05_10.941569
path:
- '**/details_harness|drop|3_2023-10-19T07-05-10.941569.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-19T07-05-10.941569.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_19T07_05_10.941569
path:
- '**/details_harness|gsm8k|5_2023-10-19T07-05-10.941569.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-19T07-05-10.941569.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hellaswag|10_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T17:54:51.197545.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-30T17:54:51.197545.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-30T17:54:51.197545.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_19T07_05_10.941569
path:
- '**/details_harness|winogrande|5_2023-10-19T07-05-10.941569.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-19T07-05-10.941569.parquet'
- config_name: results
data_files:
- split: 2023_08_30T17_54_51.197545
path:
- results_2023-08-30T17:54:51.197545.parquet
- split: 2023_10_19T07_05_10.941569
path:
- results_2023-10-19T07-05-10.941569.parquet
- split: latest
path:
- results_2023-10-19T07-05-10.941569.parquet
---
# Dataset Card for Evaluation run of uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b](https://huggingface.co/uukuguy/speechless-orca-platypus-coig-lite-2k-0.6e-13b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_uukuguy__speechless-orca-platypus-coig-lite-2k-0.6e-13b",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-19T07:05:10.941569](https://huggingface.co/datasets/open-llm-leaderboard/details_uukuguy__speechless-orca-platypus-coig-lite-2k-0.6e-13b/blob/main/results_2023-10-19T07-05-10.941569.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.40740352348993286,
"em_stderr": 0.005031895046041088,
"f1": 0.46848573825503476,
"f1_stderr": 0.004828956071080464,
"acc": 0.4270311930602038,
"acc_stderr": 0.00945942839156503
},
"harness|drop|3": {
"em": 0.40740352348993286,
"em_stderr": 0.005031895046041088,
"f1": 0.46848573825503476,
"f1_stderr": 0.004828956071080464
},
"harness|gsm8k|5": {
"acc": 0.07505686125852919,
"acc_stderr": 0.007257633145486643
},
"harness|winogrande|5": {
"acc": 0.7790055248618785,
"acc_stderr": 0.011661223637643416
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
open-llm-leaderboard-old/details_xxyyy123__10k_v1_lora_qkvo_rank14_v3 | open-llm-leaderboard-old | "2023-09-03T13:18:25Z" | 2,523 | 0 | [
"region:us"
] | null | "2023-09-03T13:17:27Z" | ---
pretty_name: Evaluation run of xxyyy123/10k_v1_lora_qkvo_rank14_v3
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [xxyyy123/10k_v1_lora_qkvo_rank14_v3](https://huggingface.co/xxyyy123/10k_v1_lora_qkvo_rank14_v3)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 61 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_xxyyy123__10k_v1_lora_qkvo_rank14_v3\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-09-03T13:17:02.987872](https://huggingface.co/datasets/open-llm-leaderboard/details_xxyyy123__10k_v1_lora_qkvo_rank14_v3/blob/main/results_2023-09-03T13%3A17%3A02.987872.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.5091352266849982,\n\
\ \"acc_stderr\": 0.03495474191892426,\n \"acc_norm\": 0.5128128131582483,\n\
\ \"acc_norm_stderr\": 0.03493935725866389,\n \"mc1\": 0.3671970624235006,\n\
\ \"mc1_stderr\": 0.01687480500145318,\n \"mc2\": 0.5344202990692574,\n\
\ \"mc2_stderr\": 0.015729161957393895\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.5298634812286689,\n \"acc_stderr\": 0.014585305840007105,\n\
\ \"acc_norm\": 0.5597269624573379,\n \"acc_norm_stderr\": 0.01450676952480424\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6050587532364071,\n\
\ \"acc_stderr\": 0.004878390226591715,\n \"acc_norm\": 0.7921728739294961,\n\
\ \"acc_norm_stderr\": 0.00404923158643323\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.31,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.31,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.48148148148148145,\n\
\ \"acc_stderr\": 0.043163785995113245,\n \"acc_norm\": 0.48148148148148145,\n\
\ \"acc_norm_stderr\": 0.043163785995113245\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.5,\n \"acc_stderr\": 0.04068942293855797,\n \
\ \"acc_norm\": 0.5,\n \"acc_norm_stderr\": 0.04068942293855797\n },\n\
\ \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.49,\n \
\ \"acc_stderr\": 0.05024183937956912,\n \"acc_norm\": 0.49,\n \
\ \"acc_norm_stderr\": 0.05024183937956912\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.5584905660377358,\n \"acc_stderr\": 0.030561590426731833,\n\
\ \"acc_norm\": 0.5584905660377358,\n \"acc_norm_stderr\": 0.030561590426731833\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.5486111111111112,\n\
\ \"acc_stderr\": 0.041614023984032786,\n \"acc_norm\": 0.5486111111111112,\n\
\ \"acc_norm_stderr\": 0.041614023984032786\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.37,\n \"acc_stderr\": 0.048523658709391,\n \
\ \"acc_norm\": 0.37,\n \"acc_norm_stderr\": 0.048523658709391\n },\n\
\ \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\": 0.39,\n\
\ \"acc_stderr\": 0.04902071300001975,\n \"acc_norm\": 0.39,\n \
\ \"acc_norm_stderr\": 0.04902071300001975\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.045604802157206845,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.045604802157206845\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.45664739884393063,\n\
\ \"acc_stderr\": 0.03798106566014498,\n \"acc_norm\": 0.45664739884393063,\n\
\ \"acc_norm_stderr\": 0.03798106566014498\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.2647058823529412,\n \"acc_stderr\": 0.04389869956808778,\n\
\ \"acc_norm\": 0.2647058823529412,\n \"acc_norm_stderr\": 0.04389869956808778\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.64,\n \"acc_stderr\": 0.04824181513244218,\n \"acc_norm\": 0.64,\n\
\ \"acc_norm_stderr\": 0.04824181513244218\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.46808510638297873,\n \"acc_stderr\": 0.03261936918467382,\n\
\ \"acc_norm\": 0.46808510638297873,\n \"acc_norm_stderr\": 0.03261936918467382\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.34210526315789475,\n\
\ \"acc_stderr\": 0.04462917535336936,\n \"acc_norm\": 0.34210526315789475,\n\
\ \"acc_norm_stderr\": 0.04462917535336936\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.46206896551724136,\n \"acc_stderr\": 0.041546596717075474,\n\
\ \"acc_norm\": 0.46206896551724136,\n \"acc_norm_stderr\": 0.041546596717075474\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.29365079365079366,\n \"acc_stderr\": 0.023456037383982022,\n \"\
acc_norm\": 0.29365079365079366,\n \"acc_norm_stderr\": 0.023456037383982022\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.2698412698412698,\n\
\ \"acc_stderr\": 0.03970158273235173,\n \"acc_norm\": 0.2698412698412698,\n\
\ \"acc_norm_stderr\": 0.03970158273235173\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.37,\n \"acc_stderr\": 0.04852365870939099,\n \
\ \"acc_norm\": 0.37,\n \"acc_norm_stderr\": 0.04852365870939099\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.5451612903225806,\n\
\ \"acc_stderr\": 0.028327743091561077,\n \"acc_norm\": 0.5451612903225806,\n\
\ \"acc_norm_stderr\": 0.028327743091561077\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.3793103448275862,\n \"acc_stderr\": 0.034139638059062345,\n\
\ \"acc_norm\": 0.3793103448275862,\n \"acc_norm_stderr\": 0.034139638059062345\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.39,\n \"acc_stderr\": 0.04902071300001975,\n \"acc_norm\"\
: 0.39,\n \"acc_norm_stderr\": 0.04902071300001975\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7333333333333333,\n \"acc_stderr\": 0.03453131801885415,\n\
\ \"acc_norm\": 0.7333333333333333,\n \"acc_norm_stderr\": 0.03453131801885415\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.6363636363636364,\n \"acc_stderr\": 0.03427308652999934,\n \"\
acc_norm\": 0.6363636363636364,\n \"acc_norm_stderr\": 0.03427308652999934\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.7253886010362695,\n \"acc_stderr\": 0.03221024508041153,\n\
\ \"acc_norm\": 0.7253886010362695,\n \"acc_norm_stderr\": 0.03221024508041153\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.4948717948717949,\n \"acc_stderr\": 0.02534967290683866,\n \
\ \"acc_norm\": 0.4948717948717949,\n \"acc_norm_stderr\": 0.02534967290683866\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.24074074074074073,\n \"acc_stderr\": 0.026067159222275805,\n \
\ \"acc_norm\": 0.24074074074074073,\n \"acc_norm_stderr\": 0.026067159222275805\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.5126050420168067,\n \"acc_stderr\": 0.03246816765752174,\n \
\ \"acc_norm\": 0.5126050420168067,\n \"acc_norm_stderr\": 0.03246816765752174\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.31125827814569534,\n \"acc_stderr\": 0.03780445850526733,\n \"\
acc_norm\": 0.31125827814569534,\n \"acc_norm_stderr\": 0.03780445850526733\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.7211009174311926,\n \"acc_stderr\": 0.0192274688764635,\n \"acc_norm\"\
: 0.7211009174311926,\n \"acc_norm_stderr\": 0.0192274688764635\n },\n\
\ \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\": 0.4166666666666667,\n\
\ \"acc_stderr\": 0.03362277436608043,\n \"acc_norm\": 0.4166666666666667,\n\
\ \"acc_norm_stderr\": 0.03362277436608043\n },\n \"harness|hendrycksTest-high_school_us_history|5\"\
: {\n \"acc\": 0.696078431372549,\n \"acc_stderr\": 0.03228210387037892,\n\
\ \"acc_norm\": 0.696078431372549,\n \"acc_norm_stderr\": 0.03228210387037892\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.7341772151898734,\n \"acc_stderr\": 0.02875679962965834,\n \
\ \"acc_norm\": 0.7341772151898734,\n \"acc_norm_stderr\": 0.02875679962965834\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.5515695067264574,\n\
\ \"acc_stderr\": 0.03337883736255098,\n \"acc_norm\": 0.5515695067264574,\n\
\ \"acc_norm_stderr\": 0.03337883736255098\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.6030534351145038,\n \"acc_stderr\": 0.04291135671009224,\n\
\ \"acc_norm\": 0.6030534351145038,\n \"acc_norm_stderr\": 0.04291135671009224\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.7024793388429752,\n \"acc_stderr\": 0.04173349148083499,\n \"\
acc_norm\": 0.7024793388429752,\n \"acc_norm_stderr\": 0.04173349148083499\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.6388888888888888,\n\
\ \"acc_stderr\": 0.04643454608906275,\n \"acc_norm\": 0.6388888888888888,\n\
\ \"acc_norm_stderr\": 0.04643454608906275\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.5398773006134969,\n \"acc_stderr\": 0.03915857291436971,\n\
\ \"acc_norm\": 0.5398773006134969,\n \"acc_norm_stderr\": 0.03915857291436971\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.3392857142857143,\n\
\ \"acc_stderr\": 0.04493949068613539,\n \"acc_norm\": 0.3392857142857143,\n\
\ \"acc_norm_stderr\": 0.04493949068613539\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7281553398058253,\n \"acc_stderr\": 0.044052680241409216,\n\
\ \"acc_norm\": 0.7281553398058253,\n \"acc_norm_stderr\": 0.044052680241409216\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.7649572649572649,\n\
\ \"acc_stderr\": 0.027778835904935434,\n \"acc_norm\": 0.7649572649572649,\n\
\ \"acc_norm_stderr\": 0.027778835904935434\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.57,\n \"acc_stderr\": 0.04975698519562428,\n \
\ \"acc_norm\": 0.57,\n \"acc_norm_stderr\": 0.04975698519562428\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.7037037037037037,\n\
\ \"acc_stderr\": 0.016328814422102052,\n \"acc_norm\": 0.7037037037037037,\n\
\ \"acc_norm_stderr\": 0.016328814422102052\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.5664739884393064,\n \"acc_stderr\": 0.026680134761679214,\n\
\ \"acc_norm\": 0.5664739884393064,\n \"acc_norm_stderr\": 0.026680134761679214\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.2547486033519553,\n\
\ \"acc_stderr\": 0.014572650383409155,\n \"acc_norm\": 0.2547486033519553,\n\
\ \"acc_norm_stderr\": 0.014572650383409155\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.5359477124183006,\n \"acc_stderr\": 0.02855582751652878,\n\
\ \"acc_norm\": 0.5359477124183006,\n \"acc_norm_stderr\": 0.02855582751652878\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.5819935691318328,\n\
\ \"acc_stderr\": 0.028013651891995072,\n \"acc_norm\": 0.5819935691318328,\n\
\ \"acc_norm_stderr\": 0.028013651891995072\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.5524691358024691,\n \"acc_stderr\": 0.027667138569422704,\n\
\ \"acc_norm\": 0.5524691358024691,\n \"acc_norm_stderr\": 0.027667138569422704\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.36879432624113473,\n \"acc_stderr\": 0.028782227561347243,\n \
\ \"acc_norm\": 0.36879432624113473,\n \"acc_norm_stderr\": 0.028782227561347243\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.3820078226857888,\n\
\ \"acc_stderr\": 0.012409564470235567,\n \"acc_norm\": 0.3820078226857888,\n\
\ \"acc_norm_stderr\": 0.012409564470235567\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.48161764705882354,\n \"acc_stderr\": 0.030352303395351964,\n\
\ \"acc_norm\": 0.48161764705882354,\n \"acc_norm_stderr\": 0.030352303395351964\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.4820261437908497,\n \"acc_stderr\": 0.020214761037872404,\n \
\ \"acc_norm\": 0.4820261437908497,\n \"acc_norm_stderr\": 0.020214761037872404\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.5818181818181818,\n\
\ \"acc_stderr\": 0.04724577405731572,\n \"acc_norm\": 0.5818181818181818,\n\
\ \"acc_norm_stderr\": 0.04724577405731572\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.6040816326530613,\n \"acc_stderr\": 0.03130802899065686,\n\
\ \"acc_norm\": 0.6040816326530613,\n \"acc_norm_stderr\": 0.03130802899065686\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.5373134328358209,\n\
\ \"acc_stderr\": 0.035256751674679745,\n \"acc_norm\": 0.5373134328358209,\n\
\ \"acc_norm_stderr\": 0.035256751674679745\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.69,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.69,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.42168674698795183,\n\
\ \"acc_stderr\": 0.03844453181770917,\n \"acc_norm\": 0.42168674698795183,\n\
\ \"acc_norm_stderr\": 0.03844453181770917\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.6783625730994152,\n \"acc_stderr\": 0.03582529442573122,\n\
\ \"acc_norm\": 0.6783625730994152,\n \"acc_norm_stderr\": 0.03582529442573122\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.3671970624235006,\n\
\ \"mc1_stderr\": 0.01687480500145318,\n \"mc2\": 0.5344202990692574,\n\
\ \"mc2_stderr\": 0.015729161957393895\n }\n}\n```"
repo_url: https://huggingface.co/xxyyy123/10k_v1_lora_qkvo_rank14_v3
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|arc:challenge|25_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hellaswag|10_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:17:02.987872.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-09-03T13:17:02.987872.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-03T13:17:02.987872.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-09-03T13:17:02.987872.parquet'
- config_name: results
data_files:
- split: 2023_09_03T13_17_02.987872
path:
- results_2023-09-03T13:17:02.987872.parquet
- split: latest
path:
- results_2023-09-03T13:17:02.987872.parquet
---
# Dataset Card for Evaluation run of xxyyy123/10k_v1_lora_qkvo_rank14_v3
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/xxyyy123/10k_v1_lora_qkvo_rank14_v3
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [xxyyy123/10k_v1_lora_qkvo_rank14_v3](https://huggingface.co/xxyyy123/10k_v1_lora_qkvo_rank14_v3) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 61 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_xxyyy123__10k_v1_lora_qkvo_rank14_v3",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-03T13:17:02.987872](https://huggingface.co/datasets/open-llm-leaderboard/details_xxyyy123__10k_v1_lora_qkvo_rank14_v3/blob/main/results_2023-09-03T13%3A17%3A02.987872.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.5091352266849982,
"acc_stderr": 0.03495474191892426,
"acc_norm": 0.5128128131582483,
"acc_norm_stderr": 0.03493935725866389,
"mc1": 0.3671970624235006,
"mc1_stderr": 0.01687480500145318,
"mc2": 0.5344202990692574,
"mc2_stderr": 0.015729161957393895
},
"harness|arc:challenge|25": {
"acc": 0.5298634812286689,
"acc_stderr": 0.014585305840007105,
"acc_norm": 0.5597269624573379,
"acc_norm_stderr": 0.01450676952480424
},
"harness|hellaswag|10": {
"acc": 0.6050587532364071,
"acc_stderr": 0.004878390226591715,
"acc_norm": 0.7921728739294961,
"acc_norm_stderr": 0.00404923158643323
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.31,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.31,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.48148148148148145,
"acc_stderr": 0.043163785995113245,
"acc_norm": 0.48148148148148145,
"acc_norm_stderr": 0.043163785995113245
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.5,
"acc_stderr": 0.04068942293855797,
"acc_norm": 0.5,
"acc_norm_stderr": 0.04068942293855797
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.49,
"acc_stderr": 0.05024183937956912,
"acc_norm": 0.49,
"acc_norm_stderr": 0.05024183937956912
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.5584905660377358,
"acc_stderr": 0.030561590426731833,
"acc_norm": 0.5584905660377358,
"acc_norm_stderr": 0.030561590426731833
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.5486111111111112,
"acc_stderr": 0.041614023984032786,
"acc_norm": 0.5486111111111112,
"acc_norm_stderr": 0.041614023984032786
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.37,
"acc_stderr": 0.048523658709391,
"acc_norm": 0.37,
"acc_norm_stderr": 0.048523658709391
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.39,
"acc_stderr": 0.04902071300001975,
"acc_norm": 0.39,
"acc_norm_stderr": 0.04902071300001975
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.29,
"acc_stderr": 0.045604802157206845,
"acc_norm": 0.29,
"acc_norm_stderr": 0.045604802157206845
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.45664739884393063,
"acc_stderr": 0.03798106566014498,
"acc_norm": 0.45664739884393063,
"acc_norm_stderr": 0.03798106566014498
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.2647058823529412,
"acc_stderr": 0.04389869956808778,
"acc_norm": 0.2647058823529412,
"acc_norm_stderr": 0.04389869956808778
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.64,
"acc_stderr": 0.04824181513244218,
"acc_norm": 0.64,
"acc_norm_stderr": 0.04824181513244218
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.46808510638297873,
"acc_stderr": 0.03261936918467382,
"acc_norm": 0.46808510638297873,
"acc_norm_stderr": 0.03261936918467382
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.34210526315789475,
"acc_stderr": 0.04462917535336936,
"acc_norm": 0.34210526315789475,
"acc_norm_stderr": 0.04462917535336936
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.46206896551724136,
"acc_stderr": 0.041546596717075474,
"acc_norm": 0.46206896551724136,
"acc_norm_stderr": 0.041546596717075474
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.29365079365079366,
"acc_stderr": 0.023456037383982022,
"acc_norm": 0.29365079365079366,
"acc_norm_stderr": 0.023456037383982022
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.2698412698412698,
"acc_stderr": 0.03970158273235173,
"acc_norm": 0.2698412698412698,
"acc_norm_stderr": 0.03970158273235173
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.37,
"acc_stderr": 0.04852365870939099,
"acc_norm": 0.37,
"acc_norm_stderr": 0.04852365870939099
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.5451612903225806,
"acc_stderr": 0.028327743091561077,
"acc_norm": 0.5451612903225806,
"acc_norm_stderr": 0.028327743091561077
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.3793103448275862,
"acc_stderr": 0.034139638059062345,
"acc_norm": 0.3793103448275862,
"acc_norm_stderr": 0.034139638059062345
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.39,
"acc_stderr": 0.04902071300001975,
"acc_norm": 0.39,
"acc_norm_stderr": 0.04902071300001975
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7333333333333333,
"acc_stderr": 0.03453131801885415,
"acc_norm": 0.7333333333333333,
"acc_norm_stderr": 0.03453131801885415
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.6363636363636364,
"acc_stderr": 0.03427308652999934,
"acc_norm": 0.6363636363636364,
"acc_norm_stderr": 0.03427308652999934
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.7253886010362695,
"acc_stderr": 0.03221024508041153,
"acc_norm": 0.7253886010362695,
"acc_norm_stderr": 0.03221024508041153
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.4948717948717949,
"acc_stderr": 0.02534967290683866,
"acc_norm": 0.4948717948717949,
"acc_norm_stderr": 0.02534967290683866
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.24074074074074073,
"acc_stderr": 0.026067159222275805,
"acc_norm": 0.24074074074074073,
"acc_norm_stderr": 0.026067159222275805
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.5126050420168067,
"acc_stderr": 0.03246816765752174,
"acc_norm": 0.5126050420168067,
"acc_norm_stderr": 0.03246816765752174
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.31125827814569534,
"acc_stderr": 0.03780445850526733,
"acc_norm": 0.31125827814569534,
"acc_norm_stderr": 0.03780445850526733
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.7211009174311926,
"acc_stderr": 0.0192274688764635,
"acc_norm": 0.7211009174311926,
"acc_norm_stderr": 0.0192274688764635
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.4166666666666667,
"acc_stderr": 0.03362277436608043,
"acc_norm": 0.4166666666666667,
"acc_norm_stderr": 0.03362277436608043
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.696078431372549,
"acc_stderr": 0.03228210387037892,
"acc_norm": 0.696078431372549,
"acc_norm_stderr": 0.03228210387037892
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.7341772151898734,
"acc_stderr": 0.02875679962965834,
"acc_norm": 0.7341772151898734,
"acc_norm_stderr": 0.02875679962965834
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.5515695067264574,
"acc_stderr": 0.03337883736255098,
"acc_norm": 0.5515695067264574,
"acc_norm_stderr": 0.03337883736255098
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.6030534351145038,
"acc_stderr": 0.04291135671009224,
"acc_norm": 0.6030534351145038,
"acc_norm_stderr": 0.04291135671009224
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.7024793388429752,
"acc_stderr": 0.04173349148083499,
"acc_norm": 0.7024793388429752,
"acc_norm_stderr": 0.04173349148083499
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.6388888888888888,
"acc_stderr": 0.04643454608906275,
"acc_norm": 0.6388888888888888,
"acc_norm_stderr": 0.04643454608906275
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.5398773006134969,
"acc_stderr": 0.03915857291436971,
"acc_norm": 0.5398773006134969,
"acc_norm_stderr": 0.03915857291436971
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.3392857142857143,
"acc_stderr": 0.04493949068613539,
"acc_norm": 0.3392857142857143,
"acc_norm_stderr": 0.04493949068613539
},
"harness|hendrycksTest-management|5": {
"acc": 0.7281553398058253,
"acc_stderr": 0.044052680241409216,
"acc_norm": 0.7281553398058253,
"acc_norm_stderr": 0.044052680241409216
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.7649572649572649,
"acc_stderr": 0.027778835904935434,
"acc_norm": 0.7649572649572649,
"acc_norm_stderr": 0.027778835904935434
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.57,
"acc_stderr": 0.04975698519562428,
"acc_norm": 0.57,
"acc_norm_stderr": 0.04975698519562428
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.7037037037037037,
"acc_stderr": 0.016328814422102052,
"acc_norm": 0.7037037037037037,
"acc_norm_stderr": 0.016328814422102052
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.5664739884393064,
"acc_stderr": 0.026680134761679214,
"acc_norm": 0.5664739884393064,
"acc_norm_stderr": 0.026680134761679214
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.2547486033519553,
"acc_stderr": 0.014572650383409155,
"acc_norm": 0.2547486033519553,
"acc_norm_stderr": 0.014572650383409155
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.5359477124183006,
"acc_stderr": 0.02855582751652878,
"acc_norm": 0.5359477124183006,
"acc_norm_stderr": 0.02855582751652878
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.5819935691318328,
"acc_stderr": 0.028013651891995072,
"acc_norm": 0.5819935691318328,
"acc_norm_stderr": 0.028013651891995072
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.5524691358024691,
"acc_stderr": 0.027667138569422704,
"acc_norm": 0.5524691358024691,
"acc_norm_stderr": 0.027667138569422704
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.36879432624113473,
"acc_stderr": 0.028782227561347243,
"acc_norm": 0.36879432624113473,
"acc_norm_stderr": 0.028782227561347243
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.3820078226857888,
"acc_stderr": 0.012409564470235567,
"acc_norm": 0.3820078226857888,
"acc_norm_stderr": 0.012409564470235567
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.48161764705882354,
"acc_stderr": 0.030352303395351964,
"acc_norm": 0.48161764705882354,
"acc_norm_stderr": 0.030352303395351964
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.4820261437908497,
"acc_stderr": 0.020214761037872404,
"acc_norm": 0.4820261437908497,
"acc_norm_stderr": 0.020214761037872404
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.5818181818181818,
"acc_stderr": 0.04724577405731572,
"acc_norm": 0.5818181818181818,
"acc_norm_stderr": 0.04724577405731572
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.6040816326530613,
"acc_stderr": 0.03130802899065686,
"acc_norm": 0.6040816326530613,
"acc_norm_stderr": 0.03130802899065686
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.5373134328358209,
"acc_stderr": 0.035256751674679745,
"acc_norm": 0.5373134328358209,
"acc_norm_stderr": 0.035256751674679745
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.69,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.69,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-virology|5": {
"acc": 0.42168674698795183,
"acc_stderr": 0.03844453181770917,
"acc_norm": 0.42168674698795183,
"acc_norm_stderr": 0.03844453181770917
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.6783625730994152,
"acc_stderr": 0.03582529442573122,
"acc_norm": 0.6783625730994152,
"acc_norm_stderr": 0.03582529442573122
},
"harness|truthfulqa:mc|0": {
"mc1": 0.3671970624235006,
"mc1_stderr": 0.01687480500145318,
"mc2": 0.5344202990692574,
"mc2_stderr": 0.015729161957393895
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
tanganke/sun397 | tanganke | "2024-05-16T02:41:24Z" | 2,522 | 1 | [
"task_categories:image-classification",
"language:en",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"image-classification"
] | "2024-04-25T20:29:36Z" | ---
language:
- en
size_categories:
- 10K<n<100K
task_categories:
- image-classification
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': abbey
'1': airplane cabin
'2': airport terminal
'3': alley
'4': amphitheater
'5': amusement arcade
'6': amusement park
'7': anechoic chamber
'8': apartment building outdoor
'9': apse indoor
'10': aquarium
'11': aqueduct
'12': arch
'13': archive
'14': arrival gate outdoor
'15': art gallery
'16': art school
'17': art studio
'18': assembly line
'19': athletic field outdoor
'20': atrium public
'21': attic
'22': auditorium
'23': auto factory
'24': badlands
'25': badminton court indoor
'26': baggage claim
'27': bakery shop
'28': balcony exterior
'29': balcony interior
'30': ball pit
'31': ballroom
'32': bamboo forest
'33': banquet hall
'34': bar
'35': barn
'36': barndoor
'37': baseball field
'38': basement
'39': basilica
'40': basketball court outdoor
'41': bathroom
'42': batters box
'43': bayou
'44': bazaar indoor
'45': bazaar outdoor
'46': beach
'47': beauty salon
'48': bedroom
'49': berth
'50': biology laboratory
'51': bistro indoor
'52': boardwalk
'53': boat deck
'54': boathouse
'55': bookstore
'56': booth indoor
'57': botanical garden
'58': bow window indoor
'59': bow window outdoor
'60': bowling alley
'61': boxing ring
'62': brewery indoor
'63': bridge
'64': building facade
'65': bullring
'66': burial chamber
'67': bus interior
'68': butchers shop
'69': butte
'70': cabin outdoor
'71': cafeteria
'72': campsite
'73': campus
'74': canal natural
'75': canal urban
'76': candy store
'77': canyon
'78': car interior backseat
'79': car interior frontseat
'80': carrousel
'81': casino indoor
'82': castle
'83': catacomb
'84': cathedral indoor
'85': cathedral outdoor
'86': cavern indoor
'87': cemetery
'88': chalet
'89': cheese factory
'90': chemistry lab
'91': chicken coop indoor
'92': chicken coop outdoor
'93': childs room
'94': church indoor
'95': church outdoor
'96': classroom
'97': clean room
'98': cliff
'99': cloister indoor
'100': closet
'101': clothing store
'102': coast
'103': cockpit
'104': coffee shop
'105': computer room
'106': conference center
'107': conference room
'108': construction site
'109': control room
'110': control tower outdoor
'111': corn field
'112': corral
'113': corridor
'114': cottage garden
'115': courthouse
'116': courtroom
'117': courtyard
'118': covered bridge exterior
'119': creek
'120': crevasse
'121': crosswalk
'122': cubicle office
'123': dam
'124': delicatessen
'125': dentists office
'126': desert sand
'127': desert vegetation
'128': diner indoor
'129': diner outdoor
'130': dinette home
'131': dinette vehicle
'132': dining car
'133': dining room
'134': discotheque
'135': dock
'136': doorway outdoor
'137': dorm room
'138': driveway
'139': driving range outdoor
'140': drugstore
'141': electrical substation
'142': elevator door
'143': elevator interior
'144': elevator shaft
'145': engine room
'146': escalator indoor
'147': excavation
'148': factory indoor
'149': fairway
'150': fastfood restaurant
'151': field cultivated
'152': field wild
'153': fire escape
'154': fire station
'155': firing range indoor
'156': fishpond
'157': florist shop indoor
'158': food court
'159': forest broadleaf
'160': forest needleleaf
'161': forest path
'162': forest road
'163': formal garden
'164': fountain
'165': galley
'166': game room
'167': garage indoor
'168': garbage dump
'169': gas station
'170': gazebo exterior
'171': general store indoor
'172': general store outdoor
'173': gift shop
'174': golf course
'175': greenhouse indoor
'176': greenhouse outdoor
'177': gymnasium indoor
'178': hangar indoor
'179': hangar outdoor
'180': harbor
'181': hayfield
'182': heliport
'183': herb garden
'184': highway
'185': hill
'186': home office
'187': hospital
'188': hospital room
'189': hot spring
'190': hot tub outdoor
'191': hotel outdoor
'192': hotel room
'193': house
'194': hunting lodge outdoor
'195': ice cream parlor
'196': ice floe
'197': ice shelf
'198': ice skating rink indoor
'199': ice skating rink outdoor
'200': iceberg
'201': igloo
'202': industrial area
'203': inn outdoor
'204': islet
'205': jacuzzi indoor
'206': jail cell
'207': jail indoor
'208': jewelry shop
'209': kasbah
'210': kennel indoor
'211': kennel outdoor
'212': kindergarden classroom
'213': kitchen
'214': kitchenette
'215': labyrinth outdoor
'216': lake natural
'217': landfill
'218': landing deck
'219': laundromat
'220': lecture room
'221': library indoor
'222': library outdoor
'223': lido deck outdoor
'224': lift bridge
'225': lighthouse
'226': limousine interior
'227': living room
'228': lobby
'229': lock chamber
'230': locker room
'231': mansion
'232': manufactured home
'233': market indoor
'234': market outdoor
'235': marsh
'236': martial arts gym
'237': mausoleum
'238': medina
'239': moat water
'240': monastery outdoor
'241': mosque indoor
'242': mosque outdoor
'243': motel
'244': mountain
'245': mountain snowy
'246': movie theater indoor
'247': museum indoor
'248': music store
'249': music studio
'250': nuclear power plant outdoor
'251': nursery
'252': oast house
'253': observatory outdoor
'254': ocean
'255': office
'256': office building
'257': oil refinery outdoor
'258': oilrig
'259': operating room
'260': orchard
'261': outhouse outdoor
'262': pagoda
'263': palace
'264': pantry
'265': park
'266': parking garage indoor
'267': parking garage outdoor
'268': parking lot
'269': parlor
'270': pasture
'271': patio
'272': pavilion
'273': pharmacy
'274': phone booth
'275': physics laboratory
'276': picnic area
'277': pilothouse indoor
'278': planetarium outdoor
'279': playground
'280': playroom
'281': plaza
'282': podium indoor
'283': podium outdoor
'284': pond
'285': poolroom establishment
'286': poolroom home
'287': power plant outdoor
'288': promenade deck
'289': pub indoor
'290': pulpit
'291': putting green
'292': racecourse
'293': raceway
'294': raft
'295': railroad track
'296': rainforest
'297': reception
'298': recreation room
'299': residential neighborhood
'300': restaurant
'301': restaurant kitchen
'302': restaurant patio
'303': rice paddy
'304': riding arena
'305': river
'306': rock arch
'307': rope bridge
'308': ruin
'309': runway
'310': sandbar
'311': sandbox
'312': sauna
'313': schoolhouse
'314': sea cliff
'315': server room
'316': shed
'317': shoe shop
'318': shopfront
'319': shopping mall indoor
'320': shower
'321': skatepark
'322': ski lodge
'323': ski resort
'324': ski slope
'325': sky
'326': skyscraper
'327': slum
'328': snowfield
'329': squash court
'330': stable
'331': stadium baseball
'332': stadium football
'333': stage indoor
'334': staircase
'335': street
'336': subway interior
'337': subway station platform
'338': supermarket
'339': sushi bar
'340': swamp
'341': swimming pool indoor
'342': swimming pool outdoor
'343': synagogue indoor
'344': synagogue outdoor
'345': television studio
'346': temple east asia
'347': temple south asia
'348': tennis court indoor
'349': tennis court outdoor
'350': tent outdoor
'351': theater indoor procenium
'352': theater indoor seats
'353': thriftshop
'354': throne room
'355': ticket booth
'356': toll plaza
'357': topiary garden
'358': tower
'359': toyshop
'360': track outdoor
'361': train railway
'362': train station platform
'363': tree farm
'364': tree house
'365': trench
'366': underwater coral reef
'367': utility room
'368': valley
'369': van interior
'370': vegetable garden
'371': veranda
'372': veterinarians office
'373': viaduct
'374': videostore
'375': village
'376': vineyard
'377': volcano
'378': volleyball court indoor
'379': volleyball court outdoor
'380': waiting room
'381': warehouse indoor
'382': water tower
'383': waterfall block
'384': waterfall fan
'385': waterfall plunge
'386': watering hole
'387': wave
'388': wet bar
'389': wheat field
'390': wind farm
'391': windmill
'392': wine cellar barrel storage
'393': wine cellar bottle storage
'394': wrestling ring indoor
'395': yard
'396': youth hostel
splits:
- name: train
num_bytes: 8834961188.3
num_examples: 19850
- name: test
num_bytes: 8610045383.95
num_examples: 19850
download_size: 14498373101
dataset_size: 17445006572.25
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# SUN397 dataset
The database contains 397 categories subset from the SUN dataset for Scene Recognition used in the following paper.
The number of images varies across categories, but there are at least 100 images per category, and 108,754 images in total.
All images are in jpg format. The images provided here are for research purposes only.
The file ClassName.txt contains the name list for the 397 categories.
Please cite the following paper if you use this dataset in your research.
J. Xiao, J. Hays, K. Ehinger, A. Oliva, and A. Torralba.
SUN Database: Large-scale Scene Recognition from Abbey to Zoo.
Proceedings of 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR2010).
Please visit our project webpage for more information:
http://groups.csail.mit.edu/vision/SUN/
## Usage
```python
from datasets import load_dataset
dataset = load_dataset('tanganke/sun397')
``` |
HuggingFaceM4/COCO | HuggingFaceM4 | "2022-12-15T15:51:03Z" | 2,521 | 19 | [
"license:cc-by-4.0",
"arxiv:1405.0312",
"region:us"
] | null | "2022-12-14T21:13:57Z" | ---
license: cc-by-4.0
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://cocodataset.org/](https://cocodataset.org/)
- **Repository:**
- **Paper:** [Microsoft COCO: Common Objects in Context](https://arxiv.org/abs/1405.0312)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
MS COCO is a large-scale object detection, segmentation, and captioning dataset.
COCO has several features: Object segmentation, Recognition in context, Superpixel stuff segmentation, 330K images (>200K labeled), 1.5 million object instances, 80 object categories, 91 stuff categories, 5 captions per image, 250,000 people with keypoints.
As of now, there is only the 2014 subset (with Karpathy annotations and splits), but feel free to contribute the 2017 subset of COCO!
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
Each instance has the following structure:
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x480 at 0x7F69C1BA8550>,
'filepath': 'COCO_val2014_000000522418.jpg',
'sentids': [681330, 686718, 688839, 693159, 693204],
'filename': 'COCO_val2014_000000522418.jpg',
'imgid': 1,
'split': 'restval',
'sentences': {
'tokens': ['a', 'woman', 'wearing', 'a', 'net', 'on', 'her', 'head', 'cutting', 'a', 'cake'],
'raw': 'A woman wearing a net on her head cutting a cake. ',
'imgid': 1,
'sentid': 681330
},
'cocoid': 522418
}
```
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@VictorSanh](https://github.com/VictorSanh) for adding this dataset.
|
nvidia/HelpSteer | nvidia | "2024-06-24T05:36:40Z" | 2,515 | 211 | [
"language:en",
"license:cc-by-4.0",
"size_categories:10K<n<100K",
"format:json",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2311.09528",
"arxiv:2310.05344",
"region:us",
"human-feedback"
] | null | "2023-11-15T20:55:27Z" | ---
license: cc-by-4.0
language:
- en
pretty_name: Helpfulness SteerLM Dataset
size_categories:
- 10K<n<100K
tags:
- human-feedback
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
- name: helpfulness
dtype: int32
- name: correctness
dtype: int32
- name: coherence
dtype: int32
- name: complexity
dtype: int32
- name: verbosity
dtype: int32
splits:
- name: train
num_examples: 35331
- name: validation
num_examples: 1789
---
# HelpSteer: Helpfulness SteerLM Dataset
HelpSteer is an open-source Helpfulness Dataset (CC-BY-4.0) that supports aligning models to become more helpful, factually correct and coherent, while being adjustable in terms of the complexity and verbosity of its responses.
Leveraging this dataset and SteerLM, we train a Llama 2 70B to reach **7.54** on MT Bench, the highest among models trained on open-source datasets based on [MT Bench Leaderboard](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard) as of 15 Nov 2023.
This model is available on HF at [Llama2-70B-SteerLM-Chat](https://huggingface.co/nvidia/Llama2-70B-SteerLM-Chat).
Try this model instantly for free hosted by us at [NVIDIA AI Playground](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ai-foundation/models/llama2-70b-steerlm). You can use this in the provided UI or through a limited access API (up to 10, 000 requests within 30 days).
If you would need more requests, we demonstrate how you can set up an inference server at [Llama2-70B-SteerLM-Chat model page on HF](https://huggingface.co/nvidia/Llama2-70B-SteerLM-Chat)
You can also train a model using [NeMo Aligner](https://github.com/NVIDIA/NeMo-Aligner) following [SteerLM training user guide](https://docs.nvidia.com/nemo-framework/user-guide/latest/modelalignment/steerlm.html).
<img src="https://huggingface.co/datasets/nvidia/HelpSteer/resolve/main/mtbench_categories.png" alt="MT Bench Categories" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
HelpSteer Paper : [HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM](http://arxiv.org/abs/2311.09528)
SteerLM Paper: [SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF](https://arxiv.org/abs/2310.05344)
Note: [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2) is the follow up to this dataset and we recommend using HelpSteer2 instead of this dataset.
## Dataset Description
HelpSteer contains 37, 120 samples, each containing a prompt, a response as well as five human-annotated attributes of the response, each ranging between 0 and 4 where higher means better for each attribute.
These attributes are:
1. **Helpfulness**: Overall helpfulness of the response to the prompt.
2. **Correctness**: Inclusion of all pertinent facts without errors.
3. **Coherence**: Consistency and clarity of expression.
4. **Complexity**: Intellectual depth required to write response (i.e. whether the response can be written by anyone with basic language competency or requires deep domain expertise).
5. **Verbosity**: Amount of detail included in the response, relative to what is asked for in the prompt.
## Example
```json
{
"prompt": "What are the three most important things to consider when deciding what technology to use to build an assist device to help an elderly person with basic needs?",
"response": "To build an assistive device to help an elderly person with basic needs, one must consider three crucial things: safety, compatibility, and ease of use. Safety is paramount, as the device must not cause harm to the user. Compatibility with the user's environment and other devices is also essential. Finally, the device must be simple enough for the elderly person to operate.",
"helpfulness": 3,
"correctness": 4,
"coherence": 4,
"complexity": 2,
"verbosity": 2
}
```
## Using the Huggingface Datasets
```python
from datasets import load_dataset
ds = load_dataset("nvidia/HelpSteer")
train = ds['train'] # len(train) = 35331 (95%)
val = ds['validation'] # len(val) = 1789 (5%)
```
## Source
1. Prompts are collected based on a mixture of template-generated (mainly for prompt involving long reference text) and human generated by Scale AI. These prompts relate to the tasks of Rewrite, Summarization, Classification, Extraction, Closed Question Answering, Open Question Answering, Generation and Brainstorming.
2. Responses are generated by an early version of an inhouse LLM. We generate up to 4 responses per prompts using sample techniques to give diverse yet reasonable responses.
3. Annotations of various attributes were done by Scale AI. Annotators rated each response on a Likert 5 scale (between 0 and 4) for each attribute (helpfulness, correctness, coherence, complexity and verbosity).
## Annotation methodology (short)
1. We engaged a select group of contractors via Scale AI. These contractors were provided with comprehensive guidelines that defined each attribute and the criteria for every rating level, together with some annotated examples. These guidelines and examples are detailed in the Appendix of the accompanying paper.
2. The annotation process involved approximately 200 U.S.-based human annotators. Candidates first underwent preliminary assignments, including assessments of English proficiency, to determine eligibility for working on the project. Subsequently, they participated in an introductory training course on the task which ended with a test that involved annotating 35 sample responses. This process ensured not only a thorough understanding of the task requirements but also the delivery of high-quality annotations.
3. Post-annotations, Scale AI performed extensive quality assurance, with each annotation reaching a minimum of two human reviews in addition to automated checks. After receiving the annotations from Scale AI, we conducted our independent quality assurance to make sure that the quality of the annotations was up to our expectations. As a result, some annotations were filtered away to retain only 37, 120 samples.
## Ethical statement
Annotators for the dataset were contracted through Scale AI. Scale AI engages the Anker Methodology, GISC Impact Sourcing Standard, and UN Sustainable Development Goals to provide a fair and competitive pay. The specific pay is calculated based on many factors, including the specific project, the specialized skillset and expertise required, regional costs of living and then transparently listed on Scale AI platform. Scale AI also provides multiple channels for questions and support, including 24/7 support teams, community discussion channels with specially trained moderators, and a “speak up” hotline where contractors can report concerns anonymously. Worker concerns can be submitted to and are reviewed by our Remotasks support team, and pay disputes are reviewed by support specialists trained in this area.
## Contact
E-Mail: [Zhilin Wang](mailto:[email protected])
## Citation
If you find this dataset useful, please cite the following works
```bibtex
@misc{wang2023helpsteer,
title={HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM},
author={Zhilin Wang and Yi Dong and Jiaqi Zeng and Virginia Adams and Makesh Narsimhan Sreedhar and Daniel Egert and Olivier Delalleau and Jane Polak Scowcroft and Neel Kant and Aidan Swope and Oleksii Kuchaiev},
year={2023},
eprint={2311.09528},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{dong2023steerlm,
title={SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF},
author={Yi Dong and Zhilin Wang and Makesh Narsimhan Sreedhar and Xianchao Wu and Oleksii Kuchaiev},
year={2023},
eprint={2310.05344},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
RealTimeData/bbc_news_alltime | RealTimeData | "2024-09-28T01:39:36Z" | 2,509 | 19 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-12-24T11:32:33Z" | ---
dataset_info:
- config_name: 2017-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5574520
num_examples: 1688
download_size: 0
dataset_size: 5574520
- config_name: 2017-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5013358
num_examples: 1469
download_size: 2533589
dataset_size: 5013358
- config_name: 2017-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 3454177
num_examples: 721
download_size: 1456354
dataset_size: 3454177
- config_name: 2017-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 3759656
num_examples: 807
download_size: 1573085
dataset_size: 3759656
- config_name: 2017-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 3656616
num_examples: 756
download_size: 1577606
dataset_size: 3656616
- config_name: 2017-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4546752
num_examples: 1106
download_size: 2055760
dataset_size: 4546752
- config_name: 2017-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4669023
num_examples: 1139
download_size: 2220913
dataset_size: 4669023
- config_name: 2017-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4529387
num_examples: 1113
download_size: 2053558
dataset_size: 4529387
- config_name: 2017-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4950651
num_examples: 1199
download_size: 2406134
dataset_size: 4950651
- config_name: 2017-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4900443
num_examples: 1187
download_size: 2344203
dataset_size: 4900443
- config_name: 2017-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5141607
num_examples: 1443
download_size: 2535360
dataset_size: 5141607
- config_name: 2017-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4273797
num_examples: 1294
download_size: 2074041
dataset_size: 4273797
- config_name: 2018-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4789841
num_examples: 1323
download_size: 0
dataset_size: 4789841
- config_name: 2018-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4174594
num_examples: 1223
download_size: 1922883
dataset_size: 4174594
- config_name: 2018-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4550223
num_examples: 1280
download_size: 2193369
dataset_size: 4550223
- config_name: 2018-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4646713
num_examples: 1328
download_size: 0
dataset_size: 4646713
- config_name: 2018-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4549377
num_examples: 1334
download_size: 0
dataset_size: 4549377
- config_name: 2018-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4416735
num_examples: 1189
download_size: 2050298
dataset_size: 4416735
- config_name: 2018-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5677193
num_examples: 1496
download_size: 0
dataset_size: 5677193
- config_name: 2018-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4346176
num_examples: 1253
download_size: 2051252
dataset_size: 4346176
- config_name: 2018-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4299146
num_examples: 1277
download_size: 2067971
dataset_size: 4299146
- config_name: 2018-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4207852
num_examples: 1249
download_size: 1992203
dataset_size: 4207852
- config_name: 2018-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4390888
num_examples: 1290
download_size: 2117715
dataset_size: 4390888
- config_name: 2018-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 3725672
num_examples: 1138
download_size: 1703129
dataset_size: 3725672
- config_name: 2019-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4299425
num_examples: 1240
download_size: 2076680
dataset_size: 4299425
- config_name: 2019-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4403481
num_examples: 1214
download_size: 2138193
dataset_size: 4403481
- config_name: 2019-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4758117
num_examples: 1333
download_size: 2336195
dataset_size: 4758117
- config_name: 2019-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4691658
num_examples: 1280
download_size: 2280145
dataset_size: 4691658
- config_name: 2019-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4809409
num_examples: 1369
download_size: 2423627
dataset_size: 4809409
- config_name: 2019-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4971344
num_examples: 1348
download_size: 2439729
dataset_size: 4971344
- config_name: 2019-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5114465
num_examples: 1366
download_size: 2547598
dataset_size: 5114465
- config_name: 2019-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4379278
num_examples: 1219
download_size: 2080813
dataset_size: 4379278
- config_name: 2019-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4784664
num_examples: 1256
download_size: 2267891
dataset_size: 4784664
- config_name: 2019-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4805548
num_examples: 1271
download_size: 2314075
dataset_size: 4805548
- config_name: 2019-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4665346
num_examples: 1275
download_size: 2241667
dataset_size: 4665346
- config_name: 2019-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4766654
num_examples: 1304
download_size: 2240533
dataset_size: 4766654
- config_name: 2020-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4693399
num_examples: 1230
download_size: 2249724
dataset_size: 4693399
- config_name: 2020-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4456312
num_examples: 1197
download_size: 2111991
dataset_size: 4456312
- config_name: 2020-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4188579
num_examples: 1156
download_size: 1921306
dataset_size: 4188579
- config_name: 2020-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4280469
num_examples: 1152
download_size: 1864282
dataset_size: 4280469
- config_name: 2020-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4709875
num_examples: 1257
download_size: 2250585
dataset_size: 4709875
- config_name: 2020-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4890877
num_examples: 1231
download_size: 2339433
dataset_size: 4890877
- config_name: 2020-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4895721
num_examples: 1302
download_size: 2466602
dataset_size: 4895721
- config_name: 2020-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4740067
num_examples: 1240
download_size: 2301105
dataset_size: 4740067
- config_name: 2020-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4609527
num_examples: 1199
download_size: 2215523
dataset_size: 4609527
- config_name: 2020-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5077617
num_examples: 1298
download_size: 2468054
dataset_size: 5077617
- config_name: 2020-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5140934
num_examples: 1297
download_size: 2550717
dataset_size: 5140934
- config_name: 2020-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4704766
num_examples: 1186
download_size: 2228502
dataset_size: 4704766
- config_name: 2021-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5788543
num_examples: 1365
download_size: 2802958
dataset_size: 5788543
- config_name: 2021-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5566915
num_examples: 1368
download_size: 2782746
dataset_size: 5566915
- config_name: 2021-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5442120
num_examples: 1321
download_size: 2714031
dataset_size: 5442120
- config_name: 2021-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5428458
num_examples: 1320
download_size: 2608886
dataset_size: 5428458
- config_name: 2021-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5459942
num_examples: 1264
download_size: 2678492
dataset_size: 5459942
- config_name: 2021-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5684472
num_examples: 1367
download_size: 2845555
dataset_size: 5684472
- config_name: 2021-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6015721
num_examples: 1486
download_size: 0
dataset_size: 6015721
- config_name: 2021-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5237163
num_examples: 1381
download_size: 2520550
dataset_size: 5237163
- config_name: 2021-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5787591
num_examples: 1429
download_size: 2964644
dataset_size: 5787591
- config_name: 2021-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5951443
num_examples: 1474
download_size: 0
dataset_size: 5951443
- config_name: 2021-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6156073
num_examples: 1461
download_size: 3072907
dataset_size: 6156073
- config_name: 2021-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5669496
num_examples: 1344
download_size: 2737609
dataset_size: 5669496
- config_name: 2022-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5772649
num_examples: 1404
download_size: 2775239
dataset_size: 5772649
- config_name: 2022-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5978585
num_examples: 1405
download_size: 2998444
dataset_size: 5978585
- config_name: 2022-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6155116
num_examples: 1440
download_size: 2846323
dataset_size: 6155116
- config_name: 2022-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5990391
num_examples: 1436
download_size: 2845665
dataset_size: 5990391
- config_name: 2022-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5731497
num_examples: 1357
download_size: 2771401
dataset_size: 5731497
- config_name: 2022-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6193465
num_examples: 1479
download_size: 3050919
dataset_size: 6193465
- config_name: 2022-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5952295
num_examples: 1445
download_size: 3005257
dataset_size: 5952295
- config_name: 2022-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5202318
num_examples: 1281
download_size: 2554877
dataset_size: 5202318
- config_name: 2022-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6475630
num_examples: 1538
download_size: 3116639
dataset_size: 6475630
- config_name: 2022-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 5720095
num_examples: 1394
download_size: 2833046
dataset_size: 5720095
- config_name: 2022-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6746726
num_examples: 1630
download_size: 0
dataset_size: 6746726
- config_name: 2022-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6503786
num_examples: 1647
download_size: 3259667
dataset_size: 6503786
- config_name: 2023-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6581264
num_examples: 1623
download_size: 3294354
dataset_size: 6581264
- config_name: 2023-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6833602
num_examples: 1588
download_size: 3372795
dataset_size: 6833602
- config_name: 2023-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6496844
num_examples: 1590
download_size: 0
dataset_size: 6496844
- config_name: 2023-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6929455
num_examples: 1672
download_size: 3485685
dataset_size: 6929455
- config_name: 2023-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 7189370
num_examples: 1746
download_size: 3613049
dataset_size: 7189370
- config_name: 2023-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6890616
num_examples: 1674
download_size: 3430482
dataset_size: 6890616
- config_name: 2023-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6886749
num_examples: 1694
download_size: 0
dataset_size: 6886749
- config_name: 2023-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 7000778
num_examples: 1715
download_size: 3433271
dataset_size: 7000778
- config_name: 2023-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6672924
num_examples: 1661
download_size: 3377990
dataset_size: 6672924
- config_name: 2023-10
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 7057042
num_examples: 1680
download_size: 3400238
dataset_size: 7057042
- config_name: 2023-11
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6948193
num_examples: 1575
download_size: 3263773
dataset_size: 6948193
- config_name: 2023-12
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6295385
num_examples: 1460
download_size: 3029041
dataset_size: 6295385
- config_name: 2024-01
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 6499952
num_examples: 1562
download_size: 3319623
dataset_size: 6499952
- config_name: 2024-02
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
sequence: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 8130657
num_examples: 2017
download_size: 4307597
dataset_size: 8130657
- config_name: 2024-03
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 13643333
num_examples: 3470
download_size: 6206278
dataset_size: 13643333
- config_name: 2024-04
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 11074180
num_examples: 2776
download_size: 4692582
dataset_size: 11074180
- config_name: 2024-05
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 4719450
num_examples: 1289
download_size: 1918531
dataset_size: 4719450
- config_name: 2024-06
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 310058
num_examples: 192
download_size: 120647
dataset_size: 310058
- config_name: 2024-07
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 86415
num_examples: 94
download_size: 35421
dataset_size: 86415
- config_name: 2024-08
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 49613
num_examples: 55
download_size: 35042
dataset_size: 49613
- config_name: 2024-09
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: top_image
dtype: string
splits:
- name: train
num_bytes: 47794
num_examples: 59
download_size: 22979
dataset_size: 47794
configs:
- config_name: 2017-01
data_files:
- split: train
path: 2017-01/train-*
- config_name: 2017-02
data_files:
- split: train
path: 2017-02/train-*
- config_name: 2017-03
data_files:
- split: train
path: 2017-03/train-*
- config_name: 2017-04
data_files:
- split: train
path: 2017-04/train-*
- config_name: 2017-05
data_files:
- split: train
path: 2017-05/train-*
- config_name: 2017-06
data_files:
- split: train
path: 2017-06/train-*
- config_name: 2017-07
data_files:
- split: train
path: 2017-07/train-*
- config_name: 2017-08
data_files:
- split: train
path: 2017-08/train-*
- config_name: 2017-09
data_files:
- split: train
path: 2017-09/train-*
- config_name: 2017-10
data_files:
- split: train
path: 2017-10/train-*
- config_name: 2017-11
data_files:
- split: train
path: 2017-11/train-*
- config_name: 2017-12
data_files:
- split: train
path: 2017-12/train-*
- config_name: 2018-01
data_files:
- split: train
path: 2018-01/train-*
- config_name: 2018-02
data_files:
- split: train
path: 2018-02/train-*
- config_name: 2018-03
data_files:
- split: train
path: 2018-03/train-*
- config_name: 2018-04
data_files:
- split: train
path: 2018-04/train-*
- config_name: 2018-05
data_files:
- split: train
path: 2018-05/train-*
- config_name: 2018-06
data_files:
- split: train
path: 2018-06/train-*
- config_name: 2018-07
data_files:
- split: train
path: 2018-07/train-*
- config_name: 2018-08
data_files:
- split: train
path: 2018-08/train-*
- config_name: 2018-09
data_files:
- split: train
path: 2018-09/train-*
- config_name: 2018-10
data_files:
- split: train
path: 2018-10/train-*
- config_name: 2018-11
data_files:
- split: train
path: 2018-11/train-*
- config_name: 2018-12
data_files:
- split: train
path: 2018-12/train-*
- config_name: 2019-01
data_files:
- split: train
path: 2019-01/train-*
- config_name: 2019-02
data_files:
- split: train
path: 2019-02/train-*
- config_name: 2019-03
data_files:
- split: train
path: 2019-03/train-*
- config_name: 2019-04
data_files:
- split: train
path: 2019-04/train-*
- config_name: 2019-05
data_files:
- split: train
path: 2019-05/train-*
- config_name: 2019-06
data_files:
- split: train
path: 2019-06/train-*
- config_name: 2019-07
data_files:
- split: train
path: 2019-07/train-*
- config_name: 2019-08
data_files:
- split: train
path: 2019-08/train-*
- config_name: 2019-09
data_files:
- split: train
path: 2019-09/train-*
- config_name: 2019-10
data_files:
- split: train
path: 2019-10/train-*
- config_name: 2019-11
data_files:
- split: train
path: 2019-11/train-*
- config_name: 2019-12
data_files:
- split: train
path: 2019-12/train-*
- config_name: 2020-01
data_files:
- split: train
path: 2020-01/train-*
- config_name: 2020-02
data_files:
- split: train
path: 2020-02/train-*
- config_name: 2020-03
data_files:
- split: train
path: 2020-03/train-*
- config_name: 2020-04
data_files:
- split: train
path: 2020-04/train-*
- config_name: 2020-05
data_files:
- split: train
path: 2020-05/train-*
- config_name: 2020-06
data_files:
- split: train
path: 2020-06/train-*
- config_name: 2020-07
data_files:
- split: train
path: 2020-07/train-*
- config_name: 2020-08
data_files:
- split: train
path: 2020-08/train-*
- config_name: 2020-09
data_files:
- split: train
path: 2020-09/train-*
- config_name: 2020-10
data_files:
- split: train
path: 2020-10/train-*
- config_name: 2020-11
data_files:
- split: train
path: 2020-11/train-*
- config_name: 2020-12
data_files:
- split: train
path: 2020-12/train-*
- config_name: 2021-01
data_files:
- split: train
path: 2021-01/train-*
- config_name: 2021-02
data_files:
- split: train
path: 2021-02/train-*
- config_name: 2021-03
data_files:
- split: train
path: 2021-03/train-*
- config_name: 2021-04
data_files:
- split: train
path: 2021-04/train-*
- config_name: 2021-05
data_files:
- split: train
path: 2021-05/train-*
- config_name: 2021-06
data_files:
- split: train
path: 2021-06/train-*
- config_name: 2021-07
data_files:
- split: train
path: 2021-07/train-*
- config_name: 2021-08
data_files:
- split: train
path: 2021-08/train-*
- config_name: 2021-09
data_files:
- split: train
path: 2021-09/train-*
- config_name: 2021-10
data_files:
- split: train
path: 2021-10/train-*
- config_name: 2021-11
data_files:
- split: train
path: 2021-11/train-*
- config_name: 2021-12
data_files:
- split: train
path: 2021-12/train-*
- config_name: 2022-01
data_files:
- split: train
path: 2022-01/train-*
- config_name: 2022-02
data_files:
- split: train
path: 2022-02/train-*
- config_name: 2022-03
data_files:
- split: train
path: 2022-03/train-*
- config_name: 2022-04
data_files:
- split: train
path: 2022-04/train-*
- config_name: 2022-05
data_files:
- split: train
path: 2022-05/train-*
- config_name: 2022-06
data_files:
- split: train
path: 2022-06/train-*
- config_name: 2022-07
data_files:
- split: train
path: 2022-07/train-*
- config_name: 2022-08
data_files:
- split: train
path: 2022-08/train-*
- config_name: 2022-09
data_files:
- split: train
path: 2022-09/train-*
- config_name: 2022-10
data_files:
- split: train
path: 2022-10/train-*
- config_name: 2022-11
data_files:
- split: train
path: 2022-11/train-*
- config_name: 2022-12
data_files:
- split: train
path: 2022-12/train-*
- config_name: 2023-01
data_files:
- split: train
path: 2023-01/train-*
- config_name: 2023-02
data_files:
- split: train
path: 2023-02/train-*
- config_name: 2023-03
data_files:
- split: train
path: 2023-03/train-*
- config_name: 2023-04
data_files:
- split: train
path: 2023-04/train-*
- config_name: 2023-05
data_files:
- split: train
path: 2023-05/train-*
- config_name: 2023-06
data_files:
- split: train
path: 2023-06/train-*
- config_name: 2023-07
data_files:
- split: train
path: 2023-07/train-*
- config_name: 2023-08
data_files:
- split: train
path: 2023-08/train-*
- config_name: 2023-09
data_files:
- split: train
path: 2023-09/train-*
- config_name: 2023-10
data_files:
- split: train
path: 2023-10/train-*
- config_name: 2023-11
data_files:
- split: train
path: 2023-11/train-*
- config_name: 2023-12
data_files:
- split: train
path: 2023-12/train-*
- config_name: 2024-01
data_files:
- split: train
path: 2024-01/train-*
- config_name: 2024-02
data_files:
- split: train
path: 2024-02/train-*
- config_name: 2024-03
data_files:
- split: train
path: 2024-03/train-*
- config_name: 2024-04
data_files:
- split: train
path: 2024-04/train-*
- config_name: 2024-05
data_files:
- split: train
path: 2024-05/train-*
- config_name: 2024-06
data_files:
- split: train
path: 2024-06/train-*
- config_name: 2024-07
data_files:
- split: train
path: 2024-07/train-*
- config_name: 2024-08
data_files:
- split: train
path: 2024-08/train-*
- config_name: 2024-09
data_files:
- split: train
path: 2024-09/train-*
---
# RealTimeData Monthly Collection - BBC News
This datasets contains all news articles from BBC News that were created every months from 2017 to current.
To access articles in a specific month, simple run the following:
```
ds = datasets.load_dataset('RealTimeData/bbc_news_alltime', '2020-02')
```
This will give you all BBC news articles that were created in `2020-02`.
# Want to crawl the data by your own?
Please head to [LatestEval](https://github.com/liyucheng09/LatestEval/tree/master/data/monthly_updater) for the crawler scripts.
# Credit
This is resources is created in this AAAI'24 paper: [LatestEval: Addressing data contamination through dynamic and time-sensitive test construction](https://ojs.aaai.org/index.php/AAAI/article/view/29822).
If you find this collection helpful, please consider cite this paper:
```
@inproceedings{li2024latesteval,
title={Latesteval: Addressing data contamination in language model evaluation through dynamic and time-sensitive test construction},
author={Li, Yucheng and Guerin, Frank and Lin, Chenghua},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={17},
pages={18600--18607},
year={2024}
}
``` |
BeIR/fever | BeIR | "2022-10-23T06:04:31Z" | 2,507 | 3 | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"size_categories:1M<n<10M",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [
"text-retrieval",
"zero-shot-retrieval",
"information-retrieval",
"zero-shot-information-retrieval"
] | "2022-06-05T16:58:21Z" | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. |
s-nlp/paradetox | s-nlp | "2024-08-30T08:30:48Z" | 2,504 | 8 | [
"task_categories:text-generation",
"language:en",
"license:openrail++",
"size_categories:10K<n<100K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"detoxification"
] | [
"text-generation"
] | "2022-05-19T17:12:06Z" | ---
license: openrail++
task_categories:
- text-generation
language:
- en
tags:
- detoxification
size_categories:
- 10K<n<100K
---
# ParaDetox: Text Detoxification with Parallel Data (English)
This repository contains information about ParaDetox dataset -- the first parallel corpus for the detoxification task -- as well as models and evaluation methodology for the detoxification of English texts. The original paper ["ParaDetox: Detoxification with Parallel Data"](https://aclanthology.org/2022.acl-long.469/) was presented at ACL 2022 main conference.
## ParaDetox Collection Pipeline
The ParaDetox Dataset collection was done via [Yandex.Toloka](https://toloka.yandex.com/) crowdsource platform. The collection was done in three steps:
* *Task 1:* **Generation of Paraphrases**: The first crowdsourcing task asks users to eliminate toxicity in a given sentence while keeping the content.
* *Task 2:* **Content Preservation Check**: We show users the generated paraphrases along with their original variants and ask them to indicate if they have close meanings.
* *Task 3:* **Toxicity Check**: Finally, we check if the workers succeeded in removing toxicity.
All these steps were done to ensure high quality of the data and make the process of collection automated. For more details please refer to the original paper.
## ParaDetox Dataset
As a result, we get paraphrases for 11,939 toxic sentences (on average 1.66 paraphrases per sentence), 19,766 paraphrases total.
In addition to all ParaDetox dataset, we also make public [samples](https://huggingface.co/datasets/s-nlp/en_non_detoxified) that were marked by annotators as "cannot rewrite" in *Task 1* of crowdsource pipeline.
# Detoxification evaluation
The automatic evaluation of the model were produced based on three parameters:
* *style transfer accuracy* (**STA**): percentage of nontoxic outputs identified by a style classifier. We pretrained toxicity classifier on Jigsaw data and put it online in HuggingFace🤗 [repo](https://huggingface.co/s-nlp/roberta_toxicity_classifier).
* *content preservation* (**SIM**): cosine similarity between the embeddings of the original text and the output computed with the model of [Wieting et al. (2019)](https://aclanthology.org/P19-1427/).
* *fluency* (**FL**): percentage of fluent sentences identified by a RoBERTa-based classifier of linguistic acceptability trained on the [CoLA dataset](https://nyu-mll.github.io/CoLA/).
All code used for our experiments to evluate different detoxifcation models can be run via Colab notebook [](https://colab.research.google.com/drive/1xTqbx7IPF8bVL2bDCfQSDarA43mIPefE?usp=sharing)
## Detoxification model
At-the-time SOTA for text detoxification task in English -- BART (base) model trained on ParaDetox dataset -- we release online in HuggingFace🤗 [repo](https://huggingface.co/s-nlp/bart-base-detox).
You can also check out our [web-demo](https://detoxifier.nlp.zhores.net/junction/).
## Citation
```
@inproceedings{logacheva-etal-2022-paradetox,
title = "{P}ara{D}etox: Detoxification with Parallel Data",
author = "Logacheva, Varvara and
Dementieva, Daryna and
Ustyantsev, Sergey and
Moskovskiy, Daniil and
Dale, David and
Krotova, Irina and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.469",
pages = "6804--6818",
abstract = "We present a novel pipeline for the collection of parallel data for the detoxification task. We collect non-toxic paraphrases for over 10,000 English toxic sentences. We also show that this pipeline can be used to distill a large existing corpus of paraphrases to get toxic-neutral sentence pairs. We release two parallel corpora which can be used for the training of detoxification models. To the best of our knowledge, these are the first parallel datasets for this task.We describe our pipeline in detail to make it fast to set up for a new language or domain, thus contributing to faster and easier development of new parallel resources.We train several detoxification models on the collected data and compare them with several baselines and state-of-the-art unsupervised approaches. We conduct both automatic and manual evaluations. All models trained on parallel data outperform the state-of-the-art unsupervised models by a large margin. This suggests that our novel datasets can boost the performance of detoxification systems.",
}
```
## Contacts
If you find some issue, do not hesitate to add it to [Github Issues](https://github.com/s-nlp/paradetox/issues).
For any questions and get the TEST SET, please, contact: Daryna Dementieva ([email protected]), Daniil Moskovskiy ([email protected]), or Alexander Panchenko ([email protected])
Dataset Card corresponding contact: Daryna Dementieva ([email protected]) |
allenai/multi_lexsum | allenai | "2024-08-25T05:12:50Z" | 2,500 | 15 | [
"task_categories:summarization",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:odc-by",
"size_categories:1K<n<10K",
"arxiv:2206.10883",
"region:us"
] | [
"summarization"
] | "2022-08-03T15:51:10Z" | ---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- found
license:
- odc-by
multilinguality:
- monolingual
pretty_name: Multi-LexSum
size_categories:
- 1K<n<10K
- 10K<n<100K
source_datasets:
- original
tags: []
task_categories:
- summarization
task_ids: []
---
# Dataset Card for Multi-LexSum
## Table of Contents
- [Dataset Card for Multi-LexSum](#dataset-card-for-multi-lexsum)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset](#dataset)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Sheet (Datasheet)](#dataset-sheet-datasheet)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Release History](#release-history)
## Dataset Description
- **Homepage:** https://multilexsum.github.io
- **Repository:** https://github.com/multilexsum/dataset
- **Paper:** https://arxiv.org/abs/2206.10883
<p>
<a href="https://multilexsum.github.io" style="display: inline-block;">
<img src="https://img.shields.io/badge/-homepage-informational.svg?logo=jekyll" title="Multi-LexSum Paper" style="margin-top: 0.25rem; margin-bottom: 0.25rem"></a>
<a href="https://github.com/multilexsum/dataset" style="display: inline-block;">
<img src="https://img.shields.io/badge/-multilexsum-lightgrey.svg?logo=github" title="Multi-LexSum Github Repo" style="margin-top: 0.25rem; margin-bottom: 0.25rem"></a>
<a href="https://arxiv.org/abs/2206.10883" style="display: inline-block;">
<img src="https://img.shields.io/badge/NeurIPS-2022-9cf" title="Multi-LexSum is accepted in NeurIPS 2022" style="margin-top: 0.25rem; margin-bottom: 0.25rem"></a>
</p>
### Talk @ NeurIPS 2022
[](https://youtu.be/C-fwW_ZhkE8)
### Dataset Summary
The Multi-LexSum dataset is a collection of 9,280 such legal case summaries. Multi-LexSum is distinct from other datasets in its **multiple target summaries, each at a different granularity** (ranging from one-sentence “extreme” summaries to multi-paragraph narrations of over five hundred words). It presents a challenging multi-document summarization task given **the long length of the source documents**, often exceeding two hundred pages per case. Unlike other summarization datasets that are (semi-)automatically curated, Multi-LexSum consists of **expert-authored summaries**: the experts—lawyers and law students—are trained to follow carefully created guidelines, and their work is reviewed by an additional expert to ensure quality.
### Languages
English
## Dataset
### Data Fields
The dataset contains a list of instances (cases); each instance contains the following data:
| Field | Description |
| ------------: | -------------------------------------------------------------------------------: |
| id | `(str)` The case ID |
| sources | `(List[str])` A list of strings for the text extracted from the source documents |
| summary/long | `(str)` The long (multi-paragraph) summary for this case |
| summary/short | `(Optional[str])` The short (one-paragraph) summary for this case |
| summary/tiny | `(Optional[str])` The tiny (one-sentence) summary for this case |
Please check the exemplar usage below for loading the data:
```python
from datasets import load_dataset
multi_lexsum = load_dataset("allenai/multi_lexsum", name="v20230518")
# Download multi_lexsum locally and load it as a Dataset object
example = multi_lexsum["validation"][0] # The first instance of the dev set
example["sources"] # A list of source document text for the case
for sum_len in ["long", "short", "tiny"]:
print(example["summary/" + sum_len]) # Summaries of three lengths
print(example['case_metadata']) # The corresponding metadata for a case in a dict
```
### Data Splits
| | Instances | Source Documents (D) | Long Summaries (L) | Short Summaries (S) | Tiny Summaries (T) | Total Summaries |
| ----------: | --------: | -------------------: | -----------------: | ------------------: | -----------------: | --------------: |
| Train (70%) | 3,177 | 28,557 | 3,177 | 2,210 | 1,130 | 6,517 |
| Test (20%) | 908 | 7,428 | 908 | 616 | 312 | 1,836 |
| Dev (10%) | 454 | 4,134 | 454 | 312 | 161 | 927 |
## Dataset Sheet (Datasheet)
Please check our [dataset sheet](https://multilexsum.github.io/datasheet) for details regarding dataset creation, source data, annotation, and considerations for the usage.
## Additional Information
### Dataset Curators
The dataset is created by the collaboration between Civil Rights Litigation Clearinghouse (CRLC, from University of Michigan) and Allen Institute for AI. Multi-LexSum builds on the dataset used and posted by the Clearinghouse to inform the public about civil rights litigation.
### Licensing Information
The Multi-LexSum dataset is distributed under the [Open Data Commons Attribution License (ODC-By)](https://opendatacommons.org/licenses/by/1-0/).
The case summaries and metadata are licensed under the [Creative Commons Attribution License (CC BY-NC)](https://creativecommons.org/licenses/by-nc/4.0/), and the source documents are already in the public domain.
Commercial users who desire a license for summaries and metadata can contact [[email protected]](mailto:[email protected]), which will allow free use but limit summary re-posting.
The corresponding code for downloading and loading the dataset is licensed under the Apache License 2.0.
### Citation Information
```
@article{Shen2022MultiLexSum,
author = {Zejiang Shen and
Kyle Lo and
Lauren Yu and
Nathan Dahlberg and
Margo Schlanger and
Doug Downey},
title = {Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities},
journal = {CoRR},
volume = {abs/2206.10883},
year = {2022},****
url = {https://doi.org/10.48550/arXiv.2206.10883},
doi = {10.48550/arXiv.2206.10883}
}
```
## Release History
| Version | Description |
| ----------: | -----------------------------------------------------------: |
| `v20230518` | The v1.1 release including case and source document metadata |
| `v20220616` | The initial v1.0 release | |
vidore/colpali_train_set | vidore | "2024-09-04T17:16:45Z" | 2,497 | 60 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2407.01449",
"region:us"
] | null | "2024-09-04T12:55:07Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: image_filename
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: source
dtype: string
- name: options
dtype: string
- name: page
dtype: string
- name: model
dtype: string
- name: prompt
dtype: string
- name: answer_type
dtype: string
splits:
- name: train
num_bytes: 40887661837.62469
num_examples: 118195
- name: test
num_bytes: 172966846.15108374
num_examples: 500
download_size: 52705427788
dataset_size: 41060628683.77577
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
## Dataset Description
This dataset is the training set of [ColPali](https://huggingface.co/vidore/colpali) it includes 127,460 query-image pairs from both openly available academic datasets (63%) and a synthetic dataset made up
of pages from web-crawled PDF documents and augmented with VLM-generated (Claude-3 Sonnet) pseudo-questions (37%).
Our training set is fully English by design, enabling us to study zero-shot generalization to non-English languages.
| Dataset | #examples (query-page pairs) | Language |
|------------------------------------------|-------------------------------|----------|
| [DocVQA](https://www.docvqa.org/datasets/docvqa) | 39,463 | English |
| [InfoVQA](https://www.docvqa.org/datasets/infographicvqa) | 10,074 | English |
| [TATDQA](https://github.com/NExTplusplus/TAT-DQA) | 13,251 | English |
| [arXivQA](https://huggingface.co/datasets/MMInstruction/ArxivQA) | 10,000 | English |
| Scrapped documents with a wide array of topics covered | 45,940 | English |
| **TOTAL** | **118,695** | **English-only** |
### Data Curation
We explicitly verify no multi-page PDF document is used both ViDoRe and in the train set to prevent evaluation contamination.
### Load the dataset
```python
from datasets import load_dataset
ds = load_dataset("vidore/colpali_train_set", split="train")
```
### Dataset Structure
Here is an example of a dataset instance structure:
```json
features:
- name: image
dtype: image
- name: image_filename
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: source
dtype: string
- name: options
dtype: string
- name: page
dtype: string
- name: model
dtype: string
- name: prompt
dtype: string
- name: answer_type
dtype: string
```
## License
All academic datasets used are here redistributed subsampled and under their original license.
The synthetic datasets we created with public internet data and VLM synthetic queries are released without usage restrictions.
## Citation Information
If you use this dataset in your research, please cite the original dataset as follows:
```latex
@misc{faysse2024colpaliefficientdocumentretrieval,
title={ColPali: Efficient Document Retrieval with Vision Language Models},
author={Manuel Faysse and Hugues Sibille and Tony Wu and Bilel Omrani and Gautier Viaud and Céline Hudelot and Pierre Colombo},
year={2024},
eprint={2407.01449},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2407.01449},
}
``` |
speechcolab/gigaspeech | speechcolab | "2023-11-23T14:08:34Z" | 2,486 | 87 | [
"task_categories:automatic-speech-recognition",
"task_categories:text-to-speech",
"task_categories:text-to-audio",
"multilinguality:monolingual",
"language:en",
"license:apache-2.0",
"size_categories:100K<n<1M",
"modality:audio",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2106.06909",
"region:us"
] | [
"automatic-speech-recognition",
"text-to-speech",
"text-to-audio"
] | "2022-06-09T14:51:58Z" | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: Gigaspeech
source_datasets: []
task_categories:
- automatic-speech-recognition
- text-to-speech
- text-to-audio
extra_gated_prompt: >-
SpeechColab does not own the copyright of the audio files. For researchers and
educators who wish to use the audio files for non-commercial research and/or
educational purposes, we can provide access through the Hub under certain
conditions and terms.
Terms of Access:
The "Researcher" has requested permission to use the GigaSpeech database (the
"Database") at Tsinghua University. In exchange for such permission,
Researcher hereby agrees to the following terms and conditions:
1. Researcher shall use the Database only for non-commercial research and
educational purposes.
2. The SpeechColab team and Tsinghua University make no representations or
warranties regarding the Database, including but not limited to warranties of
non-infringement or fitness for a particular purpose.
3. Researcher accepts full responsibility for his or her use of the Database
and shall defend and indemnify the SpeechColab team and Tsinghua University,
including their employees, Trustees, officers and agents, against any and all
claims arising from Researcher's use of the Database, including but not
limited to Researcher's use of any copies of copyrighted audio files that he
or she may create from the Database.
4. Researcher may provide research associates and colleagues with access to
the Database provided that they first agree to be bound by these terms and
conditions.
5. The SpeechColab team and Tsinghua University reserve the right to terminate
Researcher's access to the Database at any time.
6. If Researcher is employed by a for-profit, commercial entity, Researcher's
employer shall also be bound by these terms and conditions, and Researcher
hereby represents that he or she is fully authorized to enter into this
agreement on behalf of such employer.
!!! Please also fill out the Google Form https://forms.gle/UuGQAPyscGRrUMLq6
to request access to the Gigaspeech dataset.
extra_gated_fields:
Name: text
Email: text
Organization: text
Address: text
I hereby confirm that I have requested access via the Google Form provided above: checkbox
I accept the terms of access: checkbox
---
# Dataset Card for Gigaspeech
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
- [Terms of Access](#terms-of-access)
## Dataset Description
- **Homepage:** https://github.com/SpeechColab/GigaSpeech
- **Repository:** https://github.com/SpeechColab/GigaSpeech
- **Paper:** https://arxiv.org/abs/2106.06909
- **Leaderboard:** https://github.com/SpeechColab/GigaSpeech#leaderboard
- **Point of Contact:** [[email protected]](mailto:[email protected])
## Dataset Description
GigaSpeech is an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training. The transcribed audio data is collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc.
### Example Usage
The training split has several configurations of various size:
XS, S, M, L, XL. See the Section on "Data Splits" for more information. To download the XS configuration:
```python
from datasets import load_dataset
gs = load_dataset("speechcolab/gigaspeech", "xs", use_auth_token=True)
# see structure
print(gs)
# load audio sample on the fly
audio_input = gs["train"][0]["audio"] # first decoded audio sample
transcription = gs["train"][0]["text"] # first transcription
```
It is possible to download only the development or test data:
```python
gs_dev = load_dataset("speechcolab/gigaspeech", "dev", use_auth_token=True)
gs_test = load_dataset("speechcolab/gigaspeech", "test", use_auth_token=True)
```
### Supported Tasks and Leaderboards
- `automatic-speech-recognition`: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at https://github.com/SpeechColab/GigaSpeech#leaderboard and ranks models based on their WER.
- `text-to-speech`, `text-to-audio`: The dataset can also be used to train a model for Text-To-Speech (TTS).
### Languages
Gigaspeech contains audio and transcription data in English.
## Dataset Structure
### Data Instances
```python
{
'segment_id': 'YOU0000000315_S0000660',
'speaker': 'N/A',
'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio':
{
# in streaming mode 'path' will be 'xs_chunks_0000/YOU0000000315_S0000660.wav'
'path': '/home/user/.cache/huggingface/datasets/downloads/extracted/9d48cf31/xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([0.0005188 , 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294, 0.00036621], dtype=float32),
'sampling_rate': 16000
},
'begin_time': 2941.889892578125,
'end_time': 2945.070068359375,
'audio_id': 'YOU0000000315',
'title': 'Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43',
'url': 'https://www.youtube.com/watch?v=zr2n1fLVasU',
'source': 2,
'category': 24,
'original_full_path': 'audio/youtube/P0004/YOU0000000315.opus'
}
```
### Data Fields
* segment_id (string) - string id of the segment.
* speaker (string) - string id of the speaker (can be "N/A").
* text (string) - transcription of the segment.
* begin_time (float) - start time of the segment in an original full audio.
* end_time (float32) - end time of the segment in an original full audio.
* audio (Audio feature) - a dictionary containing the path to the audio, the decoded audio array, and the sampling rate.
In non-streaming mode (default), the path point to the locally extracted audio. In streaming mode, the path is the relative path of an audio.
segment inside its archive (as files are not downloaded and extracted locally).
* audio_id (string) - string idea of the original full audio.
* title (string) - title of the original full audio.
* url (string) - url of the original full audio.
* source (ClassLabel) - id of the audio source. Sources are audiobook (0), podcast (1), and YouYube (2).
* category (ClassLabel) - id of the audio category, categories are listed below.
* original_full_path (string) - the relative path to the original full audio sample in the original data directory.
Categories are assigned from the following labels:
"People and Blogs", "Business", "Nonprofits and Activism", "Crime", "History", "Pets and Animals",
"News and Politics", "Travel and Events", "Kids and Family", "Leisure", "N/A", "Comedy", "News and Politics",
"Sports", "Arts", "Science and Technology", "Autos and Vehicles", "Science and Technology", "People and Blogs",
"Music", "Society and Culture", "Education", "Howto and Style", "Film and Animation", "Gaming", "Entertainment",
"Travel and Events", "Health and Fitness", "audiobook".
### Data Splits
The dataset has three splits: train, evaluation (dev) and test. The train split has five configurations of various sizes:
XS, S, M, L, XL. Larger subsets are supersets of smaller subsets, e.g., the L subset contains all the data from the M subset.
#### Transcribed Training Subsets Size
| Subset | Hours | Remarks |
|:---------------:|:-------------:|:-------------|
| XS | 10 | System building and debugging |
| S | 250 | Quick research experiments |
| M | 1,000 | Large-scale research experiments |
| L | 2,500 | Medium-scale industrial experiments |
| XL | 10,000 | Large-scale industrial experiments |
#### Transcribed Evaluation Subsets
| Subset | Hours | Remarks |
|:------:|:-----:|:--------|
| Dev | 12 | Randomly selected from the crawled Podcast and YouTube Data |
| Test | 40 | Part of the subset was randomly selected from the crawled Podcast and YouTube data; part of it was manually collected through other channels to have better coverage. |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
| Audio Source | Transcribed Hours | Acoustic Condition |
|:-------------|:----------------------:|:-------------------|
| Audiobook | 2,655 | <li>Reading</li><li>Various ages and accents</li> |
| Podcast | 3,498 | <li>Clean or background music</li><li>Indoor</li><li>Near-field</li><li>Spontaneous</li><li>Various ages and accents</li>|
| YouTube | 3,845 | <li>Clean and noisy</li><li>Indoor and outdoor</li><li>Near- and far-field</li><li>Reading and spontaneous</li><li>Various ages and accents</li> |
| ***Total*** | ***10,000*** ||
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
Development and test subsets are annotated by professional human annotators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
SpeechColab does not own the copyright of the audio files. For researchers and educators who wish to use the audio files for
non-commercial research and/or educational purposes, we can provide access through our site under certain conditions and terms.
In general, when training a machine learning model on a given dataset, the license of the model is **independent** to that of the
dataset. That is to say, speech recognition models trained on the GigaSpeech dataset may be eligible for commercial license,
provided they abide to the 'Fair Use' terms of the underlying data and do not violate any explicit copyright restrictions.
This is likely to be true in most use-cases. However, it is your responsiblity to verify the appropriate model license for
your specific use-case by confirming that the dataset usage abides by the Fair Use terms. SpeechColab is not responsible
for the license of any machine learning model trained on the GigaSpeech dataset.
### Citation Information
Please cite this paper if you find this work useful:
```bibtext
@inproceedings{GigaSpeech2021,
title={GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio},
booktitle={Proc. Interspeech 2021},
year=2021,
author={Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, Mingjie Jin, Sanjeev Khudanpur, Shinji Watanabe, Shuaijiang Zhao, Wei Zou, Xiangang Li, Xuchen Yao, Yongqing Wang, Yujun Wang, Zhao You, Zhiyong Yan}
}
```
### Contributions
Thanks to [@polinaeterna](https://github.com/polinaeterna) and [@sanchit-gandhi](https://github.com/sanchit-gandhi)
for adding this dataset.
## Terms of Access
The "Researcher" has requested permission to use the GigaSpeech database (the "Database")
at Tsinghua University. In exchange for such permission, Researcher hereby agrees to the
following terms and conditions:
1. Researcher shall use the Database only for non-commercial research and educational purposes.
2. The SpeechColab team and Tsinghua University make no representations or warranties regarding the Database, including but not limited to warranties of non-infringement or fitness for a particular purpose.
3. Researcher accepts full responsibility for his or her use of the Database and shall defend and indemnify the SpeechColab team and Tsinghua University, including their employees, Trustees, officers and agents, against any and all claims arising from Researcher's use of the Database, including but not limited to Researcher's use of any copies of copyrighted audio files that he or she may create from the Database.
4. Researcher may provide research associates and colleagues with access to the Database provided that they first agree to be bound by these terms and conditions.
5. The SpeechColab team and Tsinghua University reserve the right to terminate Researcher's access to the Database at any time.
6. If Researcher is employed by a for-profit, commercial entity, Researcher's employer shall also be bound by these terms and conditions, and Researcher hereby represents that he or she is fully authorized to enter into this agreement on behalf of such employer. |
open-llm-leaderboard-old/details_TheBloke__fiction.live-Kimiko-V2-70B-fp16 | open-llm-leaderboard-old | "2023-10-23T10:02:58Z" | 2,485 | 0 | [
"region:us"
] | null | "2023-08-31T20:41:49Z" | ---
pretty_name: Evaluation run of TheBloke/fiction.live-Kimiko-V2-70B-fp16
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [TheBloke/fiction.live-Kimiko-V2-70B-fp16](https://huggingface.co/TheBloke/fiction.live-Kimiko-V2-70B-fp16)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_TheBloke__fiction.live-Kimiko-V2-70B-fp16\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-23T10:02:44.747886](https://huggingface.co/datasets/open-llm-leaderboard/details_TheBloke__fiction.live-Kimiko-V2-70B-fp16/blob/main/results_2023-10-23T10-02-44.747886.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.001572986577181208,\n\
\ \"em_stderr\": 0.00040584511324177344,\n \"f1\": 0.06689072986577178,\n\
\ \"f1_stderr\": 0.0013705945295387344,\n \"acc\": 0.5923530956998468,\n\
\ \"acc_stderr\": 0.011715067911613648\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.001572986577181208,\n \"em_stderr\": 0.00040584511324177344,\n\
\ \"f1\": 0.06689072986577178,\n \"f1_stderr\": 0.0013705945295387344\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.3457164518574678,\n \
\ \"acc_stderr\": 0.01310042299044158\n },\n \"harness|winogrande|5\":\
\ {\n \"acc\": 0.8389897395422258,\n \"acc_stderr\": 0.010329712832785717\n\
\ }\n}\n```"
repo_url: https://huggingface.co/TheBloke/fiction.live-Kimiko-V2-70B-fp16
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|arc:challenge|25_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_23T10_02_44.747886
path:
- '**/details_harness|drop|3_2023-10-23T10-02-44.747886.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-23T10-02-44.747886.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_23T10_02_44.747886
path:
- '**/details_harness|gsm8k|5_2023-10-23T10-02-44.747886.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-23T10-02-44.747886.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hellaswag|10_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:41:25.940897.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-31T20:41:25.940897.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-31T20:41:25.940897.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_23T10_02_44.747886
path:
- '**/details_harness|winogrande|5_2023-10-23T10-02-44.747886.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-23T10-02-44.747886.parquet'
- config_name: results
data_files:
- split: 2023_08_31T20_41_25.940897
path:
- results_2023-08-31T20:41:25.940897.parquet
- split: 2023_10_23T10_02_44.747886
path:
- results_2023-10-23T10-02-44.747886.parquet
- split: latest
path:
- results_2023-10-23T10-02-44.747886.parquet
---
# Dataset Card for Evaluation run of TheBloke/fiction.live-Kimiko-V2-70B-fp16
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/TheBloke/fiction.live-Kimiko-V2-70B-fp16
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [TheBloke/fiction.live-Kimiko-V2-70B-fp16](https://huggingface.co/TheBloke/fiction.live-Kimiko-V2-70B-fp16) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_TheBloke__fiction.live-Kimiko-V2-70B-fp16",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-23T10:02:44.747886](https://huggingface.co/datasets/open-llm-leaderboard/details_TheBloke__fiction.live-Kimiko-V2-70B-fp16/blob/main/results_2023-10-23T10-02-44.747886.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.001572986577181208,
"em_stderr": 0.00040584511324177344,
"f1": 0.06689072986577178,
"f1_stderr": 0.0013705945295387344,
"acc": 0.5923530956998468,
"acc_stderr": 0.011715067911613648
},
"harness|drop|3": {
"em": 0.001572986577181208,
"em_stderr": 0.00040584511324177344,
"f1": 0.06689072986577178,
"f1_stderr": 0.0013705945295387344
},
"harness|gsm8k|5": {
"acc": 0.3457164518574678,
"acc_stderr": 0.01310042299044158
},
"harness|winogrande|5": {
"acc": 0.8389897395422258,
"acc_stderr": 0.010329712832785717
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
Nophin/nrrqa-string | Nophin | "2024-07-16T20:57:35Z" | 2,485 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-07-16T20:45:57Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: txt
dtype: string
splits:
- name: train
num_bytes: 7322280.0
num_examples: 21
- name: validation
num_bytes: 2364775.0
num_examples: 6
download_size: 6085771
dataset_size: 9687055.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
tanganke/resisc45 | tanganke | "2024-05-06T14:22:54Z" | 2,465 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-04-25T19:54:17Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': airplane
'1': airport
'2': baseball diamond
'3': basketball court
'4': beach
'5': bridge
'6': chaparral
'7': church
'8': circular farmland
'9': cloud
'10': commercial area
'11': dense residential
'12': desert
'13': forest
'14': freeway
'15': golf course
'16': ground track field
'17': harbor
'18': industrial area
'19': intersection
'20': island
'21': lake
'22': meadow
'23': medium residential
'24': mobile home park
'25': mountain
'26': overpass
'27': palace
'28': parking lot
'29': railway
'30': railway station
'31': rectangular farmland
'32': river
'33': roundabout
'34': runway
'35': sea ice
'36': ship
'37': snowberg
'38': sparse residential
'39': stadium
'40': storage tank
'41': tennis court
'42': terrace
'43': thermal power station
'44': wetland
splits:
- name: train
num_bytes: 246710368.7
num_examples: 18900
- name: test
num_bytes: 87460774.8
num_examples: 6300
- name: contrast
num_bytes: 67512032.7
num_examples: 6300
- name: gaussian_noise
num_bytes: 116440617.3
num_examples: 6300
- name: impulse_noise
num_bytes: 125449913.4
num_examples: 6300
- name: jpeg_compression
num_bytes: 85196403.6
num_examples: 6300
- name: motion_blur
num_bytes: 73908158.1
num_examples: 6300
- name: pixelate
num_bytes: 5573022.0
num_examples: 6300
- name: spatter
num_bytes: 109007915.1
num_examples: 6300
download_size: 911199338
dataset_size: 917259205.7
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: contrast
path: data/contrast-*
- split: gaussian_noise
path: data/gaussian_noise-*
- split: impulse_noise
path: data/impulse_noise-*
- split: jpeg_compression
path: data/jpeg_compression-*
- split: motion_blur
path: data/motion_blur-*
- split: pixelate
path: data/pixelate-*
- split: spatter
path: data/spatter-*
---
# [RESISC45](https://www.tensorflow.org/datasets/catalog/resisc45)
## Overview
## Usage
```python
from datasets import load_dataset
# Load the dataset
dataset = load_dataset('tanganke/resisc45')
```
## Dataset Information
The dataset is divided into the following splits:
- **Training set**: Contains 18,900 examples, used for model training.
- **Test set**: Contains 6,300 examples, used for model evaluation and benchmarking.
The dataset also includes the following augmented sets, which can be used for testing the model's robustness to various types of image corruptions:
- **Contrast-enhanced set**: Contains 6,300 examples with enhanced contrast for improved feature visibility.
- **Gaussian noise set**: Contains 6,300 examples where images have been corrupted with Gaussian noise.
- **Impulse noise set**: Contains 6,300 examples with impulse noise.
- **JPEG compression set**: Contains 6,300 examples where images have been compressed using JPEG encoding.
- **Motion blur set**: Contains 6,300 examples with motion blur applied.
- **Pixelate set**: Contains 6,300 examples where images have been pixelated.
- **Spatter set**: Contains 6,300 examples with spatter noise.
|
visualwebbench/VisualWebBench | visualwebbench | "2024-04-11T04:47:36Z" | 2,458 | 9 | [
"task_categories:image-to-text",
"task_categories:visual-question-answering",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2404.05955",
"region:us"
] | [
"image-to-text",
"visual-question-answering"
] | "2024-04-02T08:49:42Z" | ---
dataset_info:
- config_name: action_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: instruction
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 116178465
num_examples: 103
download_size: 116152003
dataset_size: 116178465
- config_name: action_prediction
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: options
sequence: string
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 212320282
num_examples: 281
download_size: 212176366
dataset_size: 212320282
- config_name: element_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 541444180
num_examples: 413
download_size: 425203495
dataset_size: 541444180
- config_name: element_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 177127391
num_examples: 245
download_size: 177036578
dataset_size: 177127391
- config_name: heading_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 36406054
num_examples: 46
download_size: 36401829
dataset_size: 36406054
- config_name: web_caption
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 112890184
num_examples: 134
download_size: 112864700
dataset_size: 112890184
- config_name: webqa
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: question
dtype: string
- name: answer
sequence: string
splits:
- name: test
num_bytes: 271769428
num_examples: 314
download_size: 100761418
dataset_size: 271769428
configs:
- config_name: action_ground
data_files:
- split: test
path: action_ground/test-*
- config_name: action_prediction
data_files:
- split: test
path: action_prediction/test-*
- config_name: element_ground
data_files:
- split: test
path: element_ground/test-*
- config_name: element_ocr
data_files:
- split: test
path: element_ocr/test-*
- config_name: heading_ocr
data_files:
- split: test
path: heading_ocr/test-*
- config_name: web_caption
data_files:
- split: test
path: web_caption/test-*
- config_name: webqa
data_files:
- split: test
path: webqa/test-*
license: apache-2.0
task_categories:
- image-to-text
- visual-question-answering
language:
- en
pretty_name: VisualWebBench
size_categories:
- 1K<n<10K
---
# VisualWebBench
Dataset for the paper: [VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?](https://arxiv.org/abs/2404.05955)
[**🌐 Homepage**](https://visualwebbench.github.io/) | [**🐍 GitHub**](https://github.com/VisualWebBench/VisualWebBench) | [**📖 arXiv**](https://arxiv.org/abs/2404.05955)
## Introduction
We introduce **VisualWebBench**, a multimodal benchmark designed to assess the **understanding and grounding capabilities of MLLMs in web scenarios**. VisualWebBench consists of **seven tasks**, and comprises **1.5K** human-curated instances from **139** real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude 3, and GPT-4V(ision) on WebBench, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe VisualWebBench will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
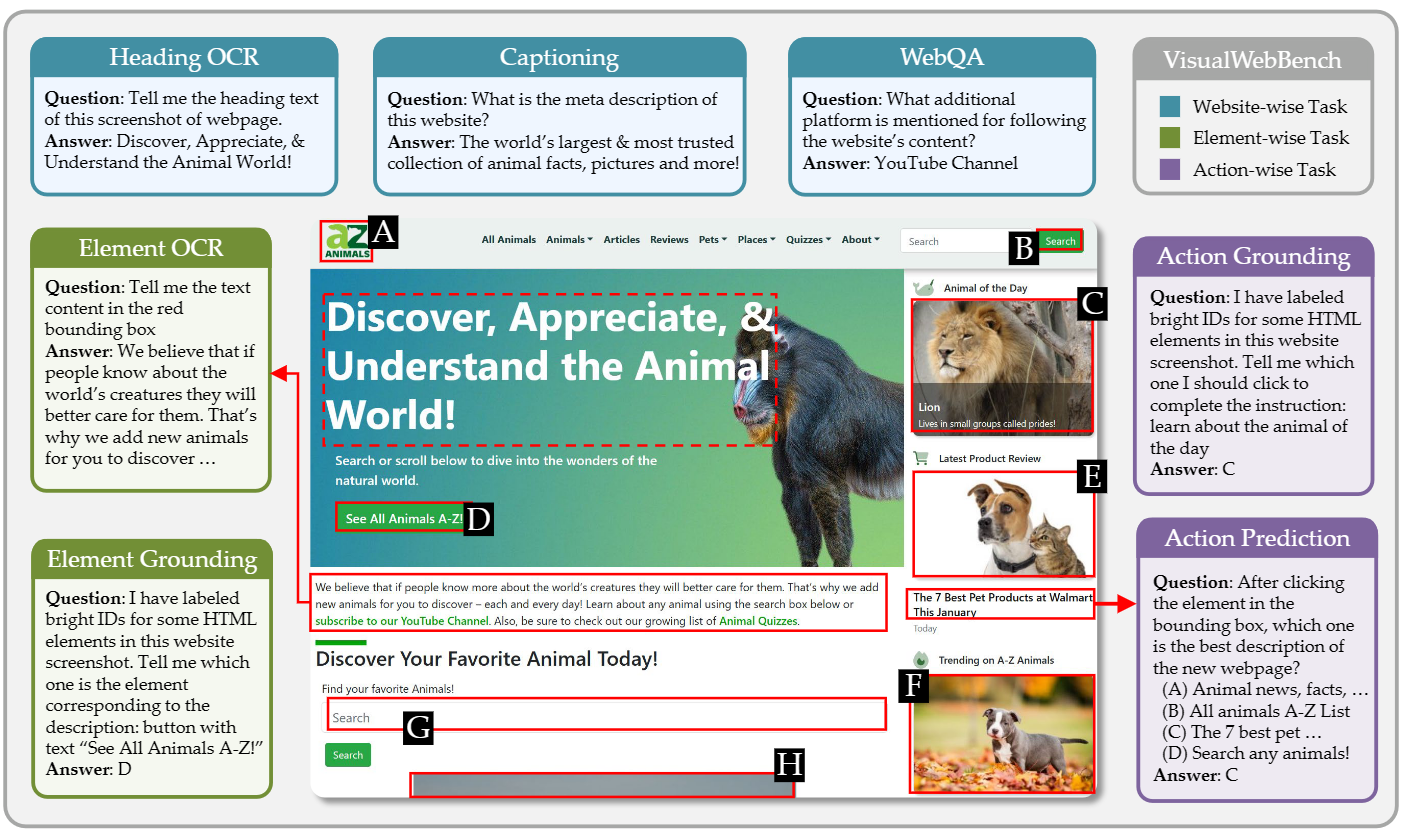
## Benchmark Construction
We introduce VisualWebBench, a comprehensive multimodal benchmark designed to assess the capabilities of MLLMs in the web domain. Inspired by the human interaction process with web browsers, VisualWebBench consists of seven tasks that map to core abilities required for web tasks: captioning, webpage QA, heading OCR, element OCR, element grounding, action prediction, and action grounding, as detailed in the figure. The benchmark comprises 1.5K instances, all uniformly formulated in the QA style, making it easy to evaluate and compare the performance of different MLLMs.
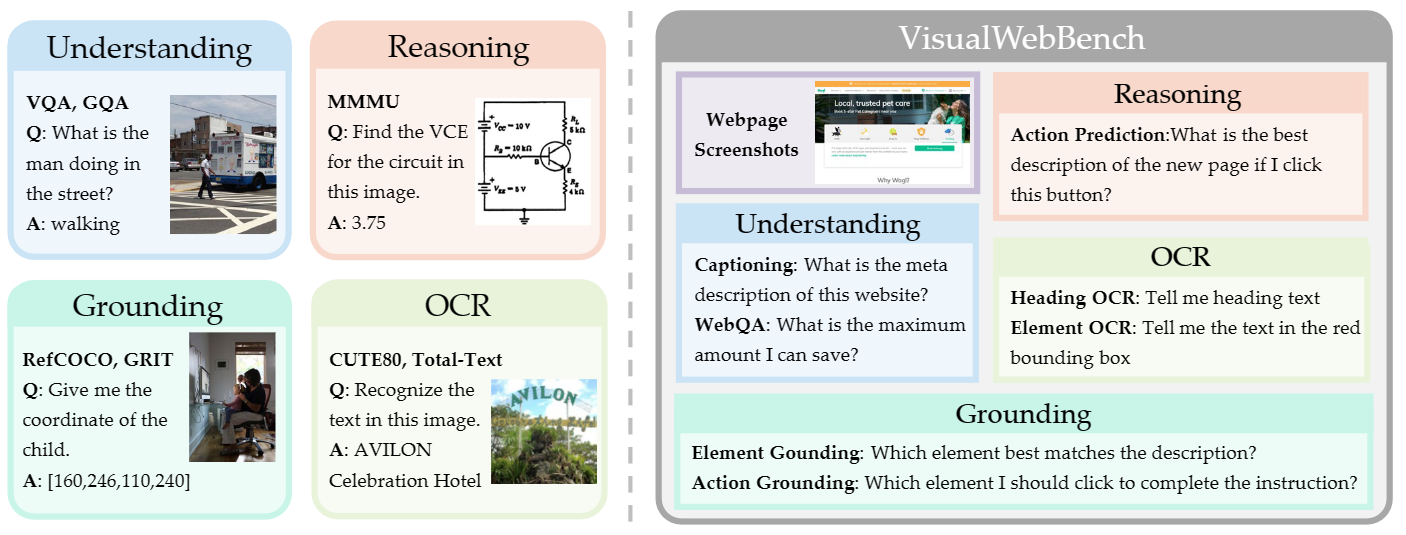
The proposed VisualWebBench possesses the following features:
- **Comprehensiveness**: VisualWebBench spans 139 websites with 1.5K samples, encompassing 12 different domains (e.g., travel, sports, hobby, lifestyle, animals, science, etc.) and 87 sub-domains.
- **Multi-granularity**: VisualWebBench assesses MLLMs at three levels: website-level, element-level, and action-level.
- **Multi-tasks**: WebBench encompasses seven tasks designed to evaluate the understanding, OCR, grounding, and reasoning capabilities of MLLMs.
- **High quality**: Quality is ensured through careful human verification and curation efforts.
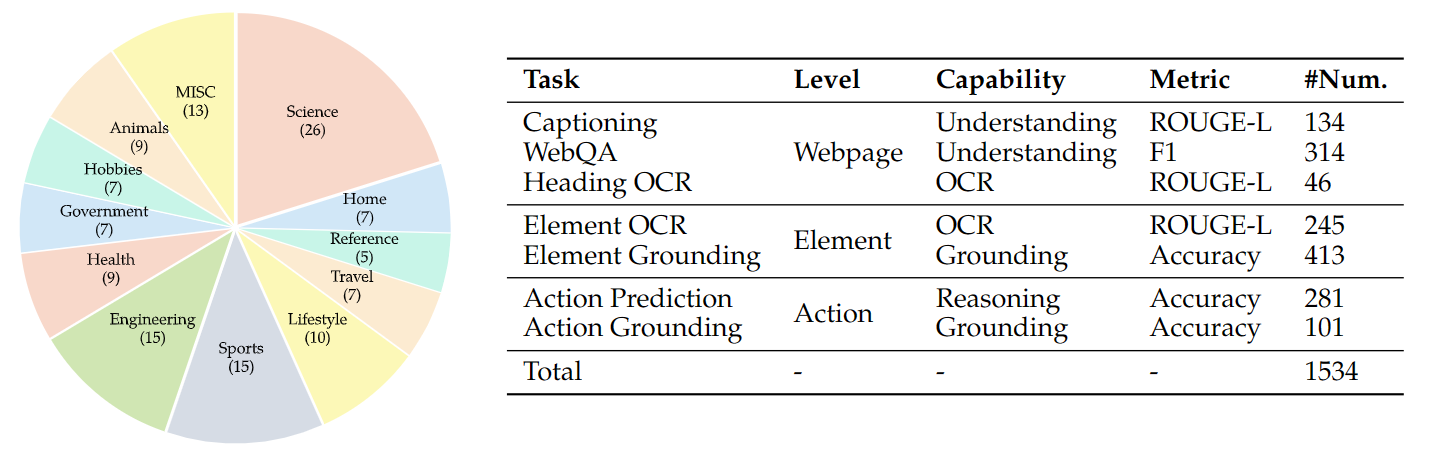
## Evaluation
We provide [evaluation code](https://github.com/VisualWebBench/VisualWebBench) for GPT-4V, Claude, Gemini, and LLaVA 1.6 series.
## Contact
- Junpeng Liu: [[email protected]]([email protected])
- Yifan Song: [[email protected]]([email protected])
- Xiang Yue: [[email protected]]([email protected])
## Citation
If you find this work helpful, please cite out paper:
```
@misc{liu2024visualwebbench,
title={VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?},
author={Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue},
year={2024},
eprint={2404.05955},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
ozgur-celik/scqa_german_combined | ozgur-celik | "2024-08-23T14:57:19Z" | 2,458 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-08-23T14:57:16Z" | ---
dataset_info:
features:
- name: context
dtype: string
- name: question
dtype: string
- name: answerA
dtype: string
- name: answerB
dtype: string
- name: answerC
dtype: string
- name: label
dtype: string
- name: question_en
dtype: string
- name: context_en
dtype: string
- name: answerA_en
dtype: string
- name: answerB_en
dtype: string
- name: answerC_en
dtype: string
splits:
- name: train
num_bytes: 2015471
num_examples: 5000
- name: validation
num_bytes: 794696
num_examples: 1954
download_size: 1556011
dataset_size: 2810167
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
argilla-internal-testing/test_import_dataset_from_hub_with_automatic_settings_True | argilla-internal-testing | "2024-09-17T11:56:56Z" | 2,450 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-09-17T11:56:55Z" | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': positive
'1': negative
splits:
- name: train
num_bytes: 111
num_examples: 3
download_size: 1454
dataset_size: 111
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
allenai/qasper | allenai | "2022-10-07T22:04:11Z" | 2,443 | 60 | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"source_datasets:extended|s2orc",
"language:en",
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2105.03011",
"region:us"
] | [
"question-answering"
] | "2022-03-02T23:29:22Z" | ---
pretty_name: QASPER
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
language_bcp47:
- en-US
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|s2orc
task_categories:
- question-answering
task_ids:
- closed-domain-qa
paperswithcode_id: qasper
---
# Dataset Card for Qasper
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://allenai.org/data/qasper](https://allenai.org/data/qasper)
- **Demo:** [https://qasper-demo.apps.allenai.org/](https://qasper-demo.apps.allenai.org/)
- **Paper:** [https://arxiv.org/abs/2105.03011](https://arxiv.org/abs/2105.03011)
- **Blogpost:** [https://medium.com/ai2-blog/question-answering-on-scientific-research-papers-f6d6da9fd55c](https://medium.com/ai2-blog/question-answering-on-scientific-research-papers-f6d6da9fd55c)
- **Leaderboards:** [https://paperswithcode.com/dataset/qasper](https://paperswithcode.com/dataset/qasper)
### Dataset Summary
QASPER is a dataset for question answering on scientific research papers. It consists of 5,049 questions over 1,585 Natural Language Processing papers. Each question is written by an NLP practitioner who read only the title and abstract of the corresponding paper, and the question seeks information present in the full text. The questions are then answered by a separate set of NLP practitioners who also provide supporting evidence to answers.
### Supported Tasks and Leaderboards
- `question-answering`: The dataset can be used to train a model for Question Answering. Success on this task is typically measured by achieving a *high* [F1 score](https://huggingface.co/metrics/f1). The [official baseline model](https://github.com/allenai/qasper-led-baseline) currently achieves 33.63 Token F1 score & uses [Longformer](https://huggingface.co/transformers/model_doc/longformer.html). This task has an active leaderboard which can be found [here](https://paperswithcode.com/sota/question-answering-on-qasper)
- `evidence-selection`: The dataset can be used to train a model for Evidence Selection. Success on this task is typically measured by achieving a *high* [F1 score](https://huggingface.co/metrics/f1). The [official baseline model](https://github.com/allenai/qasper-led-baseline) currently achieves 39.37 F1 score & uses [Longformer](https://huggingface.co/transformers/model_doc/longformer.html). This task has an active leaderboard which can be found [here](https://paperswithcode.com/sota/evidence-selection-on-qasper)
### Languages
English, as it is used in research papers.
## Dataset Structure
### Data Instances
A typical instance in the dataset:
```
{
'id': "Paper ID (string)",
'title': "Paper Title",
'abstract': "paper abstract ...",
'full_text': {
'paragraphs':[["section1_paragraph1_text","section1_paragraph2_text",...],["section2_paragraph1_text","section2_paragraph2_text",...]],
'section_name':["section1_title","section2_title"],...},
'qas': {
'answers':[{
'annotation_id': ["q1_answer1_annotation_id","q1_answer2_annotation_id"]
'answer': [{
'unanswerable':False,
'extractive_spans':["q1_answer1_extractive_span1","q1_answer1_extractive_span2"],
'yes_no':False,
'free_form_answer':"q1_answer1",
'evidence':["q1_answer1_evidence1","q1_answer1_evidence2",..],
'highlighted_evidence':["q1_answer1_highlighted_evidence1","q1_answer1_highlighted_evidence2",..]
},
{
'unanswerable':False,
'extractive_spans':["q1_answer2_extractive_span1","q1_answer2_extractive_span2"],
'yes_no':False,
'free_form_answer':"q1_answer2",
'evidence':["q1_answer2_evidence1","q1_answer2_evidence2",..],
'highlighted_evidence':["q1_answer2_highlighted_evidence1","q1_answer2_highlighted_evidence2",..]
}],
'worker_id':["q1_answer1_worker_id","q1_answer2_worker_id"]
},{...["question2's answers"]..},{...["question3's answers"]..}],
'question':["question1","question2","question3"...],
'question_id':["question1_id","question2_id","question3_id"...],
'question_writer':["question1_writer_id","question2_writer_id","question3_writer_id"...],
'nlp_background':["question1_writer_nlp_background","question2_writer_nlp_background",...],
'topic_background':["question1_writer_topic_background","question2_writer_topic_background",...],
'paper_read': ["question1_writer_paper_read_status","question2_writer_paper_read_status",...],
'search_query':["question1_search_query","question2_search_query","question3_search_query"...],
}
}
```
### Data Fields
The following is an excerpt from the dataset README:
Within "qas", some fields should be obvious. Here is some explanation about the others:
#### Fields specific to questions:
- "nlp_background" shows the experience the question writer had. The values can be "zero" (no experience), "two" (0 - 2 years of experience), "five" (2 - 5 years of experience), and "infinity" (> 5 years of experience). The field may be empty as well, indicating the writer has chosen not to share this information.
- "topic_background" shows how familiar the question writer was with the topic of the paper. The values are "unfamiliar", "familiar", "research" (meaning that the topic is the research area of the writer), or null.
- "paper_read", when specified shows whether the questionwriter has read the paper.
- "search_query", if not empty, is the query the question writer used to find the abstract of the paper from a large pool of abstracts we made available to them.
#### Fields specific to answers
Unanswerable answers have "unanswerable" set to true. The remaining answers have exactly one of the following fields being non-empty.
- "extractive_spans" are spans in the paper which serve as the answer.
- "free_form_answer" is a written out answer.
- "yes_no" is true iff the answer is Yes, and false iff the answer is No.
"evidence" is the set of paragraphs, figures or tables used to arrive at the answer. Tables or figures start with the string "FLOAT SELECTED"
"highlighted_evidence" is the set of sentences the answer providers selected as evidence if they chose textual evidence. The text in the "evidence" field is a mapping from these sentences to the paragraph level. That is, if you see textual evidence in the "evidence" field, it is guaranteed to be entire paragraphs, while that is not the case with "highlighted_evidence".
### Data Splits
| | Train | Valid |
| ----- | ------ | ----- |
| Number of papers | 888 | 281 |
| Number of questions | 2593 | 1005 |
| Number of answers | 2675 | 1764 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
NLP papers: The full text of the papers is extracted from [S2ORC](https://huggingface.co/datasets/s2orc) (Lo et al., 2020)
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
"The annotators are NLP practitioners, not
expert researchers, and it is likely that an expert
would score higher"
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Crowdsourced NLP practitioners
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0)
### Citation Information
```
@inproceedings{Dasigi2021ADO,
title={A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers},
author={Pradeep Dasigi and Kyle Lo and Iz Beltagy and Arman Cohan and Noah A. Smith and Matt Gardner},
year={2021}
}
```
### Contributions
Thanks to [@cceyda](https://github.com/cceyda) for adding this dataset.
|
iamroot/chat_formatted_examples | iamroot | "2024-08-08T15:37:27Z" | 2,441 | 0 | [
"license:mit",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-01-19T21:50:00Z" | ---
license: mit
---
|
open-llm-leaderboard-old/details_lgaalves__gpt2_platypus-dolly-guanaco | open-llm-leaderboard-old | "2023-09-28T14:27:55Z" | 2,439 | 0 | [
"region:us"
] | null | "2023-08-31T20:05:14Z" | ---
pretty_name: Evaluation run of lgaalves/gpt2_platypus-dolly-guanaco
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [lgaalves/gpt2_platypus-dolly-guanaco](https://huggingface.co/lgaalves/gpt2_platypus-dolly-guanaco)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_lgaalves__gpt2_platypus-dolly-guanaco\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-28T14:27:44.520216](https://huggingface.co/datasets/open-llm-leaderboard/details_lgaalves__gpt2_platypus-dolly-guanaco/blob/main/results_2023-09-28T14-27-44.520216.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.002307046979865772,\n\
\ \"em_stderr\": 0.0004913221265094559,\n \"f1\": 0.04980704697986585,\n\
\ \"f1_stderr\": 0.0013966099124026671,\n \"acc\": 0.2517758484609313,\n\
\ \"acc_stderr\": 0.007026065573457924\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.002307046979865772,\n \"em_stderr\": 0.0004913221265094559,\n\
\ \"f1\": 0.04980704697986585,\n \"f1_stderr\": 0.0013966099124026671\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0,\n \"acc_stderr\"\
: 0.0\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.5035516969218626,\n\
\ \"acc_stderr\": 0.014052131146915848\n }\n}\n```"
repo_url: https://huggingface.co/lgaalves/gpt2_platypus-dolly-guanaco
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|arc:challenge|25_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_28T14_27_44.520216
path:
- '**/details_harness|drop|3_2023-09-28T14-27-44.520216.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-28T14-27-44.520216.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_28T14_27_44.520216
path:
- '**/details_harness|gsm8k|5_2023-09-28T14-27-44.520216.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-28T14-27-44.520216.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hellaswag|10_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:05:00.341927.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-31T20:05:00.341927.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-31T20:05:00.341927.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_28T14_27_44.520216
path:
- '**/details_harness|winogrande|5_2023-09-28T14-27-44.520216.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-28T14-27-44.520216.parquet'
- config_name: results
data_files:
- split: 2023_08_31T20_05_00.341927
path:
- results_2023-08-31T20:05:00.341927.parquet
- split: 2023_09_28T14_27_44.520216
path:
- results_2023-09-28T14-27-44.520216.parquet
- split: latest
path:
- results_2023-09-28T14-27-44.520216.parquet
---
# Dataset Card for Evaluation run of lgaalves/gpt2_platypus-dolly-guanaco
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/lgaalves/gpt2_platypus-dolly-guanaco
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [lgaalves/gpt2_platypus-dolly-guanaco](https://huggingface.co/lgaalves/gpt2_platypus-dolly-guanaco) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_lgaalves__gpt2_platypus-dolly-guanaco",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-28T14:27:44.520216](https://huggingface.co/datasets/open-llm-leaderboard/details_lgaalves__gpt2_platypus-dolly-guanaco/blob/main/results_2023-09-28T14-27-44.520216.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.002307046979865772,
"em_stderr": 0.0004913221265094559,
"f1": 0.04980704697986585,
"f1_stderr": 0.0013966099124026671,
"acc": 0.2517758484609313,
"acc_stderr": 0.007026065573457924
},
"harness|drop|3": {
"em": 0.002307046979865772,
"em_stderr": 0.0004913221265094559,
"f1": 0.04980704697986585,
"f1_stderr": 0.0013966099124026671
},
"harness|gsm8k|5": {
"acc": 0.0,
"acc_stderr": 0.0
},
"harness|winogrande|5": {
"acc": 0.5035516969218626,
"acc_stderr": 0.014052131146915848
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
xlangai/DS-1000 | xlangai | "2024-09-19T13:00:01Z" | 2,434 | 9 | [
"task_categories:text2text-generation",
"language:code",
"license:cc-by-sa-4.0",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"code-generation"
] | [
"text2text-generation"
] | "2024-04-09T20:04:59Z" | ---
license: cc-by-sa-4.0
language:
- code
task_categories:
- text2text-generation
tags:
- code-generation
pretty_name: DS-1000
---
<h1 align="center"> DS-1000 in simplified format </h1>
🔥 Check the leaderboard from Eval-Arena on our [project page](https://ds1000-code-gen.github.io/).
See testing code and more information (also the original [fill-in-the-middle/Insertion format](https://github.com/xlang-ai/DS-1000/tree/original_format)) in the [DS-1000 repo](https://github.com/xlang-ai/DS-1000/).
Reformatting credits: Yuhang Lai, Sida Wang
|
open-llm-leaderboard-old/details_Felladrin__TinyMistral-248M-SFT-v3 | open-llm-leaderboard-old | "2024-03-03T13:52:22Z" | 2,432 | 0 | [
"region:us"
] | null | "2023-12-04T18:06:04Z" | ---
pretty_name: Evaluation run of Felladrin/TinyMistral-248M-SFT-v3
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [Felladrin/TinyMistral-248M-SFT-v3](https://huggingface.co/Felladrin/TinyMistral-248M-SFT-v3)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Felladrin__TinyMistral-248M-SFT-v3\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2024-03-03T13:49:45.268039](https://huggingface.co/datasets/open-llm-leaderboard/details_Felladrin__TinyMistral-248M-SFT-v3/blob/main/results_2024-03-03T13-49-45.268039.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.24383979385655258,\n\
\ \"acc_stderr\": 0.03038500351805996,\n \"acc_norm\": 0.24446776002420564,\n\
\ \"acc_norm_stderr\": 0.031187377048429957,\n \"mc1\": 0.24357405140758873,\n\
\ \"mc1_stderr\": 0.01502635482491078,\n \"mc2\": 0.48872658811270636,\n\
\ \"mc2_stderr\": 0.016406516849122543\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.22184300341296928,\n \"acc_stderr\": 0.012141659068147882,\n\
\ \"acc_norm\": 0.2568259385665529,\n \"acc_norm_stderr\": 0.0127669237941168\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.25492929695279826,\n\
\ \"acc_stderr\": 0.004349307702735164,\n \"acc_norm\": 0.2531368253335989,\n\
\ \"acc_norm_stderr\": 0.004339200363454488\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.22,\n \"acc_stderr\": 0.041633319989322716,\n \
\ \"acc_norm\": 0.22,\n \"acc_norm_stderr\": 0.041633319989322716\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.18518518518518517,\n\
\ \"acc_stderr\": 0.03355677216313142,\n \"acc_norm\": 0.18518518518518517,\n\
\ \"acc_norm_stderr\": 0.03355677216313142\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.21052631578947367,\n \"acc_stderr\": 0.03317672787533157,\n\
\ \"acc_norm\": 0.21052631578947367,\n \"acc_norm_stderr\": 0.03317672787533157\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.22,\n\
\ \"acc_stderr\": 0.04163331998932268,\n \"acc_norm\": 0.22,\n \
\ \"acc_norm_stderr\": 0.04163331998932268\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.25660377358490566,\n \"acc_stderr\": 0.026880647889051975,\n\
\ \"acc_norm\": 0.25660377358490566,\n \"acc_norm_stderr\": 0.026880647889051975\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.2152777777777778,\n\
\ \"acc_stderr\": 0.034370793441061365,\n \"acc_norm\": 0.2152777777777778,\n\
\ \"acc_norm_stderr\": 0.034370793441061365\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.2,\n \"acc_stderr\": 0.040201512610368445,\n \
\ \"acc_norm\": 0.2,\n \"acc_norm_stderr\": 0.040201512610368445\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.3,\n \"acc_stderr\": 0.04605661864718381,\n \"acc_norm\": 0.3,\n\
\ \"acc_norm_stderr\": 0.04605661864718381\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.04560480215720684,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.04560480215720684\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.19653179190751446,\n\
\ \"acc_stderr\": 0.030299574664788147,\n \"acc_norm\": 0.19653179190751446,\n\
\ \"acc_norm_stderr\": 0.030299574664788147\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.22549019607843138,\n \"acc_stderr\": 0.041583075330832865,\n\
\ \"acc_norm\": 0.22549019607843138,\n \"acc_norm_stderr\": 0.041583075330832865\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.16,\n \"acc_stderr\": 0.03684529491774709,\n \"acc_norm\": 0.16,\n\
\ \"acc_norm_stderr\": 0.03684529491774709\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.30638297872340425,\n \"acc_stderr\": 0.030135906478517563,\n\
\ \"acc_norm\": 0.30638297872340425,\n \"acc_norm_stderr\": 0.030135906478517563\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.22807017543859648,\n\
\ \"acc_stderr\": 0.03947152782669415,\n \"acc_norm\": 0.22807017543859648,\n\
\ \"acc_norm_stderr\": 0.03947152782669415\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.23448275862068965,\n \"acc_stderr\": 0.035306258743465914,\n\
\ \"acc_norm\": 0.23448275862068965,\n \"acc_norm_stderr\": 0.035306258743465914\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.21957671957671956,\n \"acc_stderr\": 0.021320018599770348,\n \"\
acc_norm\": 0.21957671957671956,\n \"acc_norm_stderr\": 0.021320018599770348\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.2857142857142857,\n\
\ \"acc_stderr\": 0.04040610178208841,\n \"acc_norm\": 0.2857142857142857,\n\
\ \"acc_norm_stderr\": 0.04040610178208841\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.31,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.31,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.26129032258064516,\n\
\ \"acc_stderr\": 0.024993053397764815,\n \"acc_norm\": 0.26129032258064516,\n\
\ \"acc_norm_stderr\": 0.024993053397764815\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.28078817733990147,\n \"acc_stderr\": 0.031618563353586086,\n\
\ \"acc_norm\": 0.28078817733990147,\n \"acc_norm_stderr\": 0.031618563353586086\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.22,\n \"acc_stderr\": 0.041633319989322716,\n \"acc_norm\"\
: 0.22,\n \"acc_norm_stderr\": 0.041633319989322716\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.21818181818181817,\n \"acc_stderr\": 0.03225078108306289,\n\
\ \"acc_norm\": 0.21818181818181817,\n \"acc_norm_stderr\": 0.03225078108306289\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.20707070707070707,\n \"acc_stderr\": 0.028869778460267052,\n \"\
acc_norm\": 0.20707070707070707,\n \"acc_norm_stderr\": 0.028869778460267052\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.23316062176165803,\n \"acc_stderr\": 0.03051611137147601,\n\
\ \"acc_norm\": 0.23316062176165803,\n \"acc_norm_stderr\": 0.03051611137147601\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.2,\n \"acc_stderr\": 0.020280805062535722,\n \"acc_norm\"\
: 0.2,\n \"acc_norm_stderr\": 0.020280805062535722\n },\n \"harness|hendrycksTest-high_school_mathematics|5\"\
: {\n \"acc\": 0.26296296296296295,\n \"acc_stderr\": 0.02684205787383371,\n\
\ \"acc_norm\": 0.26296296296296295,\n \"acc_norm_stderr\": 0.02684205787383371\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.23109243697478993,\n \"acc_stderr\": 0.02738140692786897,\n\
\ \"acc_norm\": 0.23109243697478993,\n \"acc_norm_stderr\": 0.02738140692786897\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.18543046357615894,\n \"acc_stderr\": 0.031732843842942844,\n \"\
acc_norm\": 0.18543046357615894,\n \"acc_norm_stderr\": 0.031732843842942844\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.21834862385321102,\n \"acc_stderr\": 0.017712600528722738,\n \"\
acc_norm\": 0.21834862385321102,\n \"acc_norm_stderr\": 0.017712600528722738\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.1388888888888889,\n \"acc_stderr\": 0.023585447368900128,\n \"\
acc_norm\": 0.1388888888888889,\n \"acc_norm_stderr\": 0.023585447368900128\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.25,\n \"acc_stderr\": 0.03039153369274154,\n \"acc_norm\": 0.25,\n\
\ \"acc_norm_stderr\": 0.03039153369274154\n },\n \"harness|hendrycksTest-high_school_world_history|5\"\
: {\n \"acc\": 0.270042194092827,\n \"acc_stderr\": 0.028900721906293426,\n\
\ \"acc_norm\": 0.270042194092827,\n \"acc_norm_stderr\": 0.028900721906293426\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.34080717488789236,\n\
\ \"acc_stderr\": 0.031811497470553604,\n \"acc_norm\": 0.34080717488789236,\n\
\ \"acc_norm_stderr\": 0.031811497470553604\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.25190839694656486,\n \"acc_stderr\": 0.03807387116306086,\n\
\ \"acc_norm\": 0.25190839694656486,\n \"acc_norm_stderr\": 0.03807387116306086\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.2727272727272727,\n \"acc_stderr\": 0.04065578140908705,\n \"\
acc_norm\": 0.2727272727272727,\n \"acc_norm_stderr\": 0.04065578140908705\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.21296296296296297,\n\
\ \"acc_stderr\": 0.0395783547198098,\n \"acc_norm\": 0.21296296296296297,\n\
\ \"acc_norm_stderr\": 0.0395783547198098\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.1901840490797546,\n \"acc_stderr\": 0.030833491146281245,\n\
\ \"acc_norm\": 0.1901840490797546,\n \"acc_norm_stderr\": 0.030833491146281245\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.2857142857142857,\n\
\ \"acc_stderr\": 0.042878587513404544,\n \"acc_norm\": 0.2857142857142857,\n\
\ \"acc_norm_stderr\": 0.042878587513404544\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.30097087378640774,\n \"acc_stderr\": 0.04541609446503948,\n\
\ \"acc_norm\": 0.30097087378640774,\n \"acc_norm_stderr\": 0.04541609446503948\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.2222222222222222,\n\
\ \"acc_stderr\": 0.027236013946196687,\n \"acc_norm\": 0.2222222222222222,\n\
\ \"acc_norm_stderr\": 0.027236013946196687\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.27,\n \"acc_stderr\": 0.0446196043338474,\n \
\ \"acc_norm\": 0.27,\n \"acc_norm_stderr\": 0.0446196043338474\n },\n\
\ \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.24648786717752236,\n\
\ \"acc_stderr\": 0.01541130876968693,\n \"acc_norm\": 0.24648786717752236,\n\
\ \"acc_norm_stderr\": 0.01541130876968693\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.2254335260115607,\n \"acc_stderr\": 0.022497230190967554,\n\
\ \"acc_norm\": 0.2254335260115607,\n \"acc_norm_stderr\": 0.022497230190967554\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.23910614525139665,\n\
\ \"acc_stderr\": 0.014265554192331142,\n \"acc_norm\": 0.23910614525139665,\n\
\ \"acc_norm_stderr\": 0.014265554192331142\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.22875816993464052,\n \"acc_stderr\": 0.024051029739912255,\n\
\ \"acc_norm\": 0.22875816993464052,\n \"acc_norm_stderr\": 0.024051029739912255\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.20257234726688103,\n\
\ \"acc_stderr\": 0.02282731749105969,\n \"acc_norm\": 0.20257234726688103,\n\
\ \"acc_norm_stderr\": 0.02282731749105969\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.2345679012345679,\n \"acc_stderr\": 0.023576881744005716,\n\
\ \"acc_norm\": 0.2345679012345679,\n \"acc_norm_stderr\": 0.023576881744005716\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.2553191489361702,\n \"acc_stderr\": 0.026011992930902,\n \
\ \"acc_norm\": 0.2553191489361702,\n \"acc_norm_stderr\": 0.026011992930902\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.2457627118644068,\n\
\ \"acc_stderr\": 0.010996156635142692,\n \"acc_norm\": 0.2457627118644068,\n\
\ \"acc_norm_stderr\": 0.010996156635142692\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.4485294117647059,\n \"acc_stderr\": 0.030211479609121593,\n\
\ \"acc_norm\": 0.4485294117647059,\n \"acc_norm_stderr\": 0.030211479609121593\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.25163398692810457,\n \"acc_stderr\": 0.01755581809132226,\n \
\ \"acc_norm\": 0.25163398692810457,\n \"acc_norm_stderr\": 0.01755581809132226\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.2727272727272727,\n\
\ \"acc_stderr\": 0.04265792110940588,\n \"acc_norm\": 0.2727272727272727,\n\
\ \"acc_norm_stderr\": 0.04265792110940588\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.24081632653061225,\n \"acc_stderr\": 0.027372942201788163,\n\
\ \"acc_norm\": 0.24081632653061225,\n \"acc_norm_stderr\": 0.027372942201788163\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.21890547263681592,\n\
\ \"acc_stderr\": 0.029239174636647,\n \"acc_norm\": 0.21890547263681592,\n\
\ \"acc_norm_stderr\": 0.029239174636647\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.28,\n \"acc_stderr\": 0.04512608598542127,\n \
\ \"acc_norm\": 0.28,\n \"acc_norm_stderr\": 0.04512608598542127\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.27710843373493976,\n\
\ \"acc_stderr\": 0.034843315926805875,\n \"acc_norm\": 0.27710843373493976,\n\
\ \"acc_norm_stderr\": 0.034843315926805875\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.2573099415204678,\n \"acc_stderr\": 0.03352799844161865,\n\
\ \"acc_norm\": 0.2573099415204678,\n \"acc_norm_stderr\": 0.03352799844161865\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.24357405140758873,\n\
\ \"mc1_stderr\": 0.01502635482491078,\n \"mc2\": 0.48872658811270636,\n\
\ \"mc2_stderr\": 0.016406516849122543\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.48382004735595896,\n \"acc_stderr\": 0.014045126130978601\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0,\n \"acc_stderr\"\
: 0.0\n }\n}\n```"
repo_url: https://huggingface.co/Felladrin/TinyMistral-248M-SFT-v3
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: [email protected]
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|arc:challenge|25_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|arc:challenge|25_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|gsm8k|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|gsm8k|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hellaswag|10_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hellaswag|10_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-04T18-03-12.401261.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-03-03T13-49-45.268039.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-management|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-virology|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|truthfulqa:mc|0_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2024-03-03T13-49-45.268039.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- '**/details_harness|winogrande|5_2023-12-04T18-03-12.401261.parquet'
- split: 2024_03_03T13_49_45.268039
path:
- '**/details_harness|winogrande|5_2024-03-03T13-49-45.268039.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2024-03-03T13-49-45.268039.parquet'
- config_name: results
data_files:
- split: 2023_12_04T18_03_12.401261
path:
- results_2023-12-04T18-03-12.401261.parquet
- split: 2024_03_03T13_49_45.268039
path:
- results_2024-03-03T13-49-45.268039.parquet
- split: latest
path:
- results_2024-03-03T13-49-45.268039.parquet
---
# Dataset Card for Evaluation run of Felladrin/TinyMistral-248M-SFT-v3
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [Felladrin/TinyMistral-248M-SFT-v3](https://huggingface.co/Felladrin/TinyMistral-248M-SFT-v3) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Felladrin__TinyMistral-248M-SFT-v3",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2024-03-03T13:49:45.268039](https://huggingface.co/datasets/open-llm-leaderboard/details_Felladrin__TinyMistral-248M-SFT-v3/blob/main/results_2024-03-03T13-49-45.268039.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.24383979385655258,
"acc_stderr": 0.03038500351805996,
"acc_norm": 0.24446776002420564,
"acc_norm_stderr": 0.031187377048429957,
"mc1": 0.24357405140758873,
"mc1_stderr": 0.01502635482491078,
"mc2": 0.48872658811270636,
"mc2_stderr": 0.016406516849122543
},
"harness|arc:challenge|25": {
"acc": 0.22184300341296928,
"acc_stderr": 0.012141659068147882,
"acc_norm": 0.2568259385665529,
"acc_norm_stderr": 0.0127669237941168
},
"harness|hellaswag|10": {
"acc": 0.25492929695279826,
"acc_stderr": 0.004349307702735164,
"acc_norm": 0.2531368253335989,
"acc_norm_stderr": 0.004339200363454488
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.22,
"acc_stderr": 0.041633319989322716,
"acc_norm": 0.22,
"acc_norm_stderr": 0.041633319989322716
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.18518518518518517,
"acc_stderr": 0.03355677216313142,
"acc_norm": 0.18518518518518517,
"acc_norm_stderr": 0.03355677216313142
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.21052631578947367,
"acc_stderr": 0.03317672787533157,
"acc_norm": 0.21052631578947367,
"acc_norm_stderr": 0.03317672787533157
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.22,
"acc_stderr": 0.04163331998932268,
"acc_norm": 0.22,
"acc_norm_stderr": 0.04163331998932268
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.25660377358490566,
"acc_stderr": 0.026880647889051975,
"acc_norm": 0.25660377358490566,
"acc_norm_stderr": 0.026880647889051975
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.2152777777777778,
"acc_stderr": 0.034370793441061365,
"acc_norm": 0.2152777777777778,
"acc_norm_stderr": 0.034370793441061365
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.2,
"acc_stderr": 0.040201512610368445,
"acc_norm": 0.2,
"acc_norm_stderr": 0.040201512610368445
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.3,
"acc_stderr": 0.04605661864718381,
"acc_norm": 0.3,
"acc_norm_stderr": 0.04605661864718381
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.29,
"acc_stderr": 0.04560480215720684,
"acc_norm": 0.29,
"acc_norm_stderr": 0.04560480215720684
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.19653179190751446,
"acc_stderr": 0.030299574664788147,
"acc_norm": 0.19653179190751446,
"acc_norm_stderr": 0.030299574664788147
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.22549019607843138,
"acc_stderr": 0.041583075330832865,
"acc_norm": 0.22549019607843138,
"acc_norm_stderr": 0.041583075330832865
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.16,
"acc_stderr": 0.03684529491774709,
"acc_norm": 0.16,
"acc_norm_stderr": 0.03684529491774709
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.30638297872340425,
"acc_stderr": 0.030135906478517563,
"acc_norm": 0.30638297872340425,
"acc_norm_stderr": 0.030135906478517563
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.22807017543859648,
"acc_stderr": 0.03947152782669415,
"acc_norm": 0.22807017543859648,
"acc_norm_stderr": 0.03947152782669415
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.23448275862068965,
"acc_stderr": 0.035306258743465914,
"acc_norm": 0.23448275862068965,
"acc_norm_stderr": 0.035306258743465914
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.21957671957671956,
"acc_stderr": 0.021320018599770348,
"acc_norm": 0.21957671957671956,
"acc_norm_stderr": 0.021320018599770348
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.2857142857142857,
"acc_stderr": 0.04040610178208841,
"acc_norm": 0.2857142857142857,
"acc_norm_stderr": 0.04040610178208841
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.31,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.31,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.26129032258064516,
"acc_stderr": 0.024993053397764815,
"acc_norm": 0.26129032258064516,
"acc_norm_stderr": 0.024993053397764815
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.28078817733990147,
"acc_stderr": 0.031618563353586086,
"acc_norm": 0.28078817733990147,
"acc_norm_stderr": 0.031618563353586086
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.22,
"acc_stderr": 0.041633319989322716,
"acc_norm": 0.22,
"acc_norm_stderr": 0.041633319989322716
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.21818181818181817,
"acc_stderr": 0.03225078108306289,
"acc_norm": 0.21818181818181817,
"acc_norm_stderr": 0.03225078108306289
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.20707070707070707,
"acc_stderr": 0.028869778460267052,
"acc_norm": 0.20707070707070707,
"acc_norm_stderr": 0.028869778460267052
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.23316062176165803,
"acc_stderr": 0.03051611137147601,
"acc_norm": 0.23316062176165803,
"acc_norm_stderr": 0.03051611137147601
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.2,
"acc_stderr": 0.020280805062535722,
"acc_norm": 0.2,
"acc_norm_stderr": 0.020280805062535722
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.26296296296296295,
"acc_stderr": 0.02684205787383371,
"acc_norm": 0.26296296296296295,
"acc_norm_stderr": 0.02684205787383371
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.23109243697478993,
"acc_stderr": 0.02738140692786897,
"acc_norm": 0.23109243697478993,
"acc_norm_stderr": 0.02738140692786897
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.18543046357615894,
"acc_stderr": 0.031732843842942844,
"acc_norm": 0.18543046357615894,
"acc_norm_stderr": 0.031732843842942844
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.21834862385321102,
"acc_stderr": 0.017712600528722738,
"acc_norm": 0.21834862385321102,
"acc_norm_stderr": 0.017712600528722738
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.1388888888888889,
"acc_stderr": 0.023585447368900128,
"acc_norm": 0.1388888888888889,
"acc_norm_stderr": 0.023585447368900128
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.25,
"acc_stderr": 0.03039153369274154,
"acc_norm": 0.25,
"acc_norm_stderr": 0.03039153369274154
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.270042194092827,
"acc_stderr": 0.028900721906293426,
"acc_norm": 0.270042194092827,
"acc_norm_stderr": 0.028900721906293426
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.34080717488789236,
"acc_stderr": 0.031811497470553604,
"acc_norm": 0.34080717488789236,
"acc_norm_stderr": 0.031811497470553604
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.25190839694656486,
"acc_stderr": 0.03807387116306086,
"acc_norm": 0.25190839694656486,
"acc_norm_stderr": 0.03807387116306086
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.2727272727272727,
"acc_stderr": 0.04065578140908705,
"acc_norm": 0.2727272727272727,
"acc_norm_stderr": 0.04065578140908705
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.21296296296296297,
"acc_stderr": 0.0395783547198098,
"acc_norm": 0.21296296296296297,
"acc_norm_stderr": 0.0395783547198098
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.1901840490797546,
"acc_stderr": 0.030833491146281245,
"acc_norm": 0.1901840490797546,
"acc_norm_stderr": 0.030833491146281245
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.2857142857142857,
"acc_stderr": 0.042878587513404544,
"acc_norm": 0.2857142857142857,
"acc_norm_stderr": 0.042878587513404544
},
"harness|hendrycksTest-management|5": {
"acc": 0.30097087378640774,
"acc_stderr": 0.04541609446503948,
"acc_norm": 0.30097087378640774,
"acc_norm_stderr": 0.04541609446503948
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.2222222222222222,
"acc_stderr": 0.027236013946196687,
"acc_norm": 0.2222222222222222,
"acc_norm_stderr": 0.027236013946196687
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.27,
"acc_stderr": 0.0446196043338474,
"acc_norm": 0.27,
"acc_norm_stderr": 0.0446196043338474
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.24648786717752236,
"acc_stderr": 0.01541130876968693,
"acc_norm": 0.24648786717752236,
"acc_norm_stderr": 0.01541130876968693
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.2254335260115607,
"acc_stderr": 0.022497230190967554,
"acc_norm": 0.2254335260115607,
"acc_norm_stderr": 0.022497230190967554
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.23910614525139665,
"acc_stderr": 0.014265554192331142,
"acc_norm": 0.23910614525139665,
"acc_norm_stderr": 0.014265554192331142
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.22875816993464052,
"acc_stderr": 0.024051029739912255,
"acc_norm": 0.22875816993464052,
"acc_norm_stderr": 0.024051029739912255
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.20257234726688103,
"acc_stderr": 0.02282731749105969,
"acc_norm": 0.20257234726688103,
"acc_norm_stderr": 0.02282731749105969
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.2345679012345679,
"acc_stderr": 0.023576881744005716,
"acc_norm": 0.2345679012345679,
"acc_norm_stderr": 0.023576881744005716
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.2553191489361702,
"acc_stderr": 0.026011992930902,
"acc_norm": 0.2553191489361702,
"acc_norm_stderr": 0.026011992930902
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.2457627118644068,
"acc_stderr": 0.010996156635142692,
"acc_norm": 0.2457627118644068,
"acc_norm_stderr": 0.010996156635142692
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.4485294117647059,
"acc_stderr": 0.030211479609121593,
"acc_norm": 0.4485294117647059,
"acc_norm_stderr": 0.030211479609121593
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.25163398692810457,
"acc_stderr": 0.01755581809132226,
"acc_norm": 0.25163398692810457,
"acc_norm_stderr": 0.01755581809132226
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.2727272727272727,
"acc_stderr": 0.04265792110940588,
"acc_norm": 0.2727272727272727,
"acc_norm_stderr": 0.04265792110940588
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.24081632653061225,
"acc_stderr": 0.027372942201788163,
"acc_norm": 0.24081632653061225,
"acc_norm_stderr": 0.027372942201788163
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.21890547263681592,
"acc_stderr": 0.029239174636647,
"acc_norm": 0.21890547263681592,
"acc_norm_stderr": 0.029239174636647
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.28,
"acc_stderr": 0.04512608598542127,
"acc_norm": 0.28,
"acc_norm_stderr": 0.04512608598542127
},
"harness|hendrycksTest-virology|5": {
"acc": 0.27710843373493976,
"acc_stderr": 0.034843315926805875,
"acc_norm": 0.27710843373493976,
"acc_norm_stderr": 0.034843315926805875
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.2573099415204678,
"acc_stderr": 0.03352799844161865,
"acc_norm": 0.2573099415204678,
"acc_norm_stderr": 0.03352799844161865
},
"harness|truthfulqa:mc|0": {
"mc1": 0.24357405140758873,
"mc1_stderr": 0.01502635482491078,
"mc2": 0.48872658811270636,
"mc2_stderr": 0.016406516849122543
},
"harness|winogrande|5": {
"acc": 0.48382004735595896,
"acc_stderr": 0.014045126130978601
},
"harness|gsm8k|5": {
"acc": 0.0,
"acc_stderr": 0.0
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
lrhammond/buggy-apps | lrhammond | "2024-09-26T07:06:34Z" | 2,425 | 0 | [
"language:en",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2105.09938",
"arxiv:2203.07814",
"region:us",
"code"
] | null | "2024-09-20T22:25:24Z" | ---
language:
- en
size_categories:
- 1K<n<10K
pretty_name: Buggy APPS
dataset_info:
features:
- name: apps_split
dtype: string
- name: apps_problem_id
dtype: int64
- name: difficulty
dtype: string
- name: question
dtype: string
- name: solutions
list:
- name: apps_solution_number
dtype: int64
- name: checks
struct:
- name: error
dtype: int64
- name: fail
dtype: int64
- name: pass
dtype: int64
- name: generation_attempts
dtype: int64
- name: levenshtein_distance
struct:
- name: normalised
dtype: float64
- name: raw
dtype: int64
- name: solution
dtype: string
- name: buggy_solutions
list:
- name: apps_solution_number
dtype: int64
- name: checks
struct:
- name: error
dtype: int64
- name: fail
dtype: int64
- name: pass
dtype: int64
- name: generation_attempts
dtype: int64
- name: levenshtein_distance
struct:
- name: normalised
dtype: float64
- name: raw
dtype: int64
- name: solution
dtype: string
splits:
- name: train
num_bytes: 12930571
num_examples: 4877
download_size: 5993256
dataset_size: 12930571
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- code
---
This dataset is based on the [APPS](https://arxiv.org/abs/2105.09938) benchmark for code generation (see also the corresponding [Hugging Face dataset](https://huggingface.co/datasets/codeparrot/apps)). It includes includes a number of coding problems with both buggy and non-buggy solutions (though note that, apparently, in [AlphaCode](https://arxiv.org/pdf/2203.07814v1.pdf) the authors found that this dataset can generate many false positives during evaluation, where incorrect submissions are marked as correct due to lack of test coverage).
Each datum has the following structure:
```
{
apps_split: <the split ('train' or 'test') from the APPS dataset>
apps_problem_id: <the problem ID from the APPS dataset, within the relevant split>
difficulty: <the difficulty level of the problem ('introductory', 'interview', or 'competition')>
question: <the coding question\>
solutions: <a list of non-buggy solutions>
buggy_solutions: <a list of buggy solutions>
}
```
And each solution (buggy or non-buggy) has the following structure:
```
{
apps_solution_number: <the corresponding solution number from the APPS dataset>
solution: <the code>
levenshtein_distance : {
normalised: <the normalised (by code length) edit distance from the original code (0 if non-buggy)>
raw: <the raw edit distance from the original code (0 if non-buggy)>
}
checks: {
pass: <the number of checks (provided in the APPS dataset) passed, i.e. the correct answer is returned by the code>
fail: <the number of checks (provided in the APPS dataset) failed, i.e. the incorrect answer is returned by the code (0 if non-buggy)>
error: <the number of checks (provided in the APPS dataset) producing an error, i.e. no answer is returned by the code (0 if non-buggy)>
}
generation_attempts : <the number of attempts needed to generate the solution (0 if non-buggy)>
}
``` |
elplaguister/DTS_session_datasets | elplaguister | "2024-09-05T02:58:52Z" | 2,418 | 0 | [
"license:mit",
"size_categories:10K<n<100K",
"format:json",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"region:us"
] | null | "2024-08-13T12:39:11Z" | ---
license: mit
---
|
microsoft/orca-math-word-problems-200k | microsoft | "2024-03-04T18:01:08Z" | 2,397 | 398 | [
"task_categories:question-answering",
"language:en",
"license:mit",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2402.14830",
"region:us",
"math"
] | [
"question-answering"
] | "2024-03-01T00:56:17Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 225322861
num_examples: 200035
download_size: 84248748
dataset_size: 225322861
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: mit
task_categories:
- question-answering
language:
- en
tags:
- math
size_categories:
- 100K<n<1M
---
# Dataset Card
<!-- Provide a quick summary of the dataset. -->
This dataset contains ~200K grade school math word problems. All the answers in this dataset is generated using Azure GPT4-Turbo. Please refer to [Orca-Math: Unlocking the potential of
SLMs in Grade School Math](https://arxiv.org/pdf/2402.14830.pdf) for details about the dataset construction.
### Dataset Description
- **Curated by:** Microsoft
- **Language(s) (NLP):** English
- **License:** MIT
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
- **Repository:** [microsoft/orca-math-word-problems-200k](https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k)
- **Paper:** [Orca-Math: Unlocking the potential of
SLMs in Grade School Math](https://arxiv.org/pdf/2402.14830.pdf)
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
This dataset has been designed to enhance the mathematical abilities of language models. It aims to provide a robust foundation for language models to excel in mathematical problem-solving.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
This dataset is not intended for use in educational systems or organizations.
## Dataset Structure
### Data Instances
A typical data entry in the dataset consists of a question and its corresponding answer. Below is an example from the dataset:
```python
{'question': 'In a highly contested election having multiple candidates, Mr. Jackson, one of the losing candidates, received 3,485,782 votes, which accounted for precisely 38.7 percent of all votes. To have achieved a victory, he would have needed to secure at least 51 percent of all votes. Approximately, what percent of the remaining unsecured votes would Mr. Jackson have needed to accumulate to reach this victory threshold?',
'answer': "First, let's find out the total number of votes cast in the election. Since Mr. Jackson received 38.7% of all votes, and that amounted to 3,485,782 votes, we can set up the following equation to find the total number of votes (T):\n\n0.387 * T = 3,485,782\n\nNow, solve for T:\n\nT = 3,485,782 / 0.387\nT ≈ 9,000,467 votes (total number of votes cast)\n\nTo win, Mr. Jackson would have needed 51% of the total votes. Let's calculate that amount:\n\n0.51 * T = 0.51 * 9,000,467\n0.51 * T ≈ 4,590,238 votes needed to win\n\nNow, let's find out how many more votes Mr. Jackson needed to reach this winning threshold:\n\nVotes needed to win - Votes Mr. Jackson received = Additional votes needed\n4,590,238 - 3,485,782 = 1,104,456 additional votes needed\n\nNow, let's find out what percentage of the remaining unsecured votes this number represents. The remaining unsecured votes are the votes that were not for Mr. Jackson, which is 100% - 38.7% = 61.3% of the total votes.\n\n61.3% of the total votes is the remaining unsecured votes:\n\n0.613 * T = 0.613 * 9,000,467\n0.613 * T ≈ 5,514,686 votes were unsecured\n\nNow, we'll calculate the percentage of these unsecured votes that the additional votes needed represent:\n\n(Additional votes needed / Unsecured votes) * 100 = Percentage of unsecured votes needed\n(1,104,456 / 5,514,686) * 100 ≈ 20.03%\n\nSo, Mr. Jackson would have needed approximately 20.03% of the remaining unsecured votes to reach the victory threshold of 51%."}
```
### Data Fields
The dataset comprises the following fields:
- `question`: a string containing the question to be answered.
- `answer`: a string containing the answer to the corresponding question.
### Data Splits
The dataset is split into a training set. The number of rows in each split is as follows:
- `train`: 200,035 rows
The `DatasetDict` structure for the dataset is as follows:
```python
DatasetDict({
'train': Dataset({
features: ['question', 'answer'],
num_rows: 200035
})
})
```
Each split in the `DatasetDict` contains a `Dataset` object with the specified features and number of rows.
## Dataset Creation
Please refer to [Orca-Math: Unlocking the potential of
SLMs in Grade School Math](https://arxiv.org/pdf/2402.14830.pdf) for details about the dataset construction.
### Source Data
- [Lila](https://huggingface.co/datasets/allenai/lila)
- [DMath](https://arxiv.org/ftp/arxiv/papers/2106/2106.15772.pdf)
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
Please refer to [Orca-Math: Unlocking the potential of
SLMs in Grade School Math](https://arxiv.org/pdf/2402.14830.pdf) for details about the dataset construction.
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
Microsoft
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
We expanded a seed set of questions using Azure GPT-4 Trubo. The answers to those questions are generated using Azure GPT-4 Trubo.
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
None
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
This dataset is in English and contains only math word problems.
## Citation
If you find this work useful in your method, you can cite the paper as below:
```
@misc{mitra2024orcamath,
title={Orca-Math: Unlocking the potential of SLMs in Grade School Math},
author={Arindam Mitra and Hamed Khanpour and Corby Rosset and Ahmed Awadallah},
year={2024},
eprint={2402.14830},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Dataset Card Contact
[Arindam Mitra]([email protected])
|
LIUM/tedlium | LIUM | "2024-09-10T18:27:41Z" | 2,390 | 18 | [
"task_categories:automatic-speech-recognition",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"size_categories:10K<n<100K",
"region:us"
] | [
"automatic-speech-recognition"
] | "2022-05-11T12:47:06Z" | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license: []
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- automatic-speech-recognition
task_ids: []
pretty_name: TED-LIUM
---
# Dataset Card for tedlium
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [TED-LIUM homepage](https://www.openslr.org/7/)
- **Repository:** [Needs More Information]
- **Paper:** [TED-LIUM: an Automatic Speech Recognition dedicated corpus](https://aclanthology.org/L12-1405/)
- **Leaderboard:** [Paperswithcode Leaderboard](https://paperswithcode.com/sota/speech-recognition-on-tedlium)
- **Point of Contact:** [Sanchit Gandhi](mailto:[email protected])
### Dataset Summary
The TED-LIUM corpus is English-language TED talks, with transcriptions, sampled at 16kHz. The three releases of the corpus range from 118 to 452 hours of transcribed speech data.
### Example
```python
from datasets import load_dataset
tedlium = load_dataset("LIUM/tedlium", "release1") # for Release 1
# see structure
print(tedlium)
# load audio sample on the fly
audio_input = tedlium["train"][0]["audio"] # first decoded audio sample
transcription = tedlium["train"][0]["text"] # first transcription
```
### Supported Tasks and Leaderboards
- `automatic-speech-recognition`: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at https://paperswithcode.com/sota/speech-recognition-on-tedlium that ranks models based on their WER.
### Languages
The audio and transcriptions are in English, as per the TED talks at http://www.ted.com.
## Dataset Structure
### Data Instances
```
{'audio': {'path': '/home/sanchitgandhi/cache/downloads/extracted/6e3655f9e735ae3c467deed1df788e0dabd671c1f3e2e386e30aa3b571bd9761/TEDLIUM_release1/train/sph/PaulaScher_2008P.sph',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346,
0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 16000},
'text': '{COUGH} but <sil> i was so {COUGH} utterly unqualified for(2) this project and {NOISE} so utterly ridiculous {SMACK} and ignored the brief {SMACK} <sil>',
'speaker_id': 'PaulaScher_2008P',
'gender': 'female',
'file': '/home/sanchitgandhi/cache/downloads/extracted/6e3655f9e735ae3c467deed1df788e0dabd671c1f3e2e386e30aa3b571bd9761/TEDLIUM_release1/train/sph/PaulaScher_2008P.sph',
'id': 'PaulaScher_2008P-1003.35-1011.16-<o,f0,female>'}
```
### Data Fields
- audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- file: A path to the downloaded audio file in .sph format.
- text: the transcription of the audio file.
- gender: the gender of the speaker. One of: male, female or N/A.
- id: unique id of the data sample.
- speaker_id: unique id of the speaker. The same speaker id can be found for multiple data samples.
### Data Splits
There are three releases for the TED-LIUM corpus, progressively increasing the number of transcribed speech training data from 118 hours (Release 1), to 207 hours (Release 2), to 452 hours (Release 3).
Release 1:
- 774 audio talks and automatically aligned transcriptions.
- Contains 118 hours of speech audio data.
- Homepage: https://www.openslr.org/7/
Release 2:
- 1495 audio talks and automatically aligned transcriptions.
- Contains 207 hours of speech audio data.
- Dictionary with pronunciations (159848 entries).
- Selected monolingual data for language modeling from WMT12 publicly available corpora.
- Homepage: https://www.openslr.org/19/
Release 3:
- 2351 audio talks and automatically aligned transcriptions.
- Contains 452 hours of speech audio data.
- TED-LIUM 2 validation and test data: 19 TED talks with their corresponding manual transcriptions.
- Dictionary with pronunciations (159848 entries), the same file as the one included in TED-LIUM 2.
- Selected monolingual data for language modeling from WMT12 publicly available corpora: these files come from the TED-LIUM 2 release, but have been modified to produce a tokenization more relevant for English language.
- Homepage: https://www.openslr.org/51/
Release 3 contains two different corpus distributions:
- The ‘legacy’ one, on which the dev and test datasets are the same as in TED-LIUM 2 (and TED-LIUM 1).
- The ‘speaker adaptation’ one, specially designed for experiments on speaker adaptation.
Each release is split into a training, validation and test set:
| Split | Release 1 | Release 2 | Release 3 |
|------------|-----------|-----------|-----------|
| Train | 56,803 | 92,973 | 268,263 |
| Validation | 591 | 591 | 591 |
| Test | 1,469 | 1,469 | 1,469 |
## Dataset Creation
### Curation Rationale
TED-LIUM was built during [The International Workshop on Spoken Language Trans- lation (IWSLT) 2011 Evaluation Campaign](https://aclanthology.org/2011.iwslt-evaluation.1/), an annual workshop focused on the automatic translation of public talks and included tracks for speech recognition, speech translation, text translation, and system combination.
### Source Data
#### Initial Data Collection and Normalization
The data was obtained from publicly available TED talks at http://www.ted.com. Proper alignments between the speech and the transcribed text were generated using an in-house speaker segmentation and clustering tool (_LIUM_SpkDiarization_). Speech disfluencies (e.g. repetitions, hesitations, false starts) were treated in the following way: repetitions were transcribed, hesitations mapped to a specific filler word, and false starts not taken into account. For full details on the data collection and processing, refer to the [TED-LIUM paper](https://aclanthology.org/L12-1405/).
#### Who are the source language producers?
TED Talks are influential videos from expert speakers on education, business, science, tech and creativity.
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
Licensed under Creative Commons BY-NC-ND 3.0 (http://creativecommons.org/licenses/by-nc-nd/3.0/deed.en).
### Citation Information
Release 1:
```
@inproceedings{rousseau2012tedlium,
title={TED-LIUM: an Automatic Speech Recognition dedicated corpus},
author={Rousseau, Anthony and Del{\'e}glise, Paul and Est{\`e}ve, Yannick},
booktitle={Conference on Language Resources and Evaluation (LREC)},
pages={125--129},
year={2012}
}
```
Release 2:
```
@inproceedings{rousseau2014enhancing,
title={Enhancing the TED-LIUM corpus with selected data for language modeling and more TED talks.},
author={Rousseau, Anthony and Del{\'e}glise, Paul and Esteve, Yannick and others},
booktitle={LREC},
pages={3935--3939},
year={2014}
}
```
Release 3:
```
@inproceedings{hernandez2018ted,
author="Hernandez, Fran{\c{c}}ois
and Nguyen, Vincent
and Ghannay, Sahar
and Tomashenko, Natalia
and Est{\`e}ve, Yannick",
title="TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation",
booktitle="Speech and Computer",
year="2018",
publisher="Springer International Publishing",
pages="198--208",
}
``` |
ibm/finqa | ibm | "2024-06-06T08:56:37Z" | 2,390 | 1 | [
"task_categories:question-answering",
"language:en",
"license:cc-by-4.0",
"arxiv:2109.00122",
"region:us"
] | [
"question-answering"
] | "2024-06-06T08:51:58Z" | ---
license: cc-by-4.0
task_categories:
- question-answering
language:
- en
---
- **Homepage:** [FinQA](https://finqasite.github.io/)
- **Repository:** [GitHub](https://github.com/czyssrs/FinQA)
- **Paper:** [FinQA: A Dataset of Numerical Reasoning over Financial Data](https://arxiv.org/abs/2109.00122)
### Dataset Summary
FinQA is a large-scale dataset with 2.8k financial reports for 8k Q&A pairs to study numerical reasoning with structured and unstructured evidence.
### Citation Information
```
@inproceedings{chen2021finqa,
title={FinQA: A Dataset of Numerical Reasoning over Financial Data},
author={Chen, Zhiyu and Chen, Wenhu and Smiley, Charese and Shah, Sameena and Borova, Iana and Langdon, Dylan and Moussa, Reema and Beane, Matt and Huang, Ting-Hao and Routledge, Bryan R and others},
booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing},
pages={3697--3711},
year={2021}
}
```
|