Datasets:

Tasks:
Multiple Choice
Modalities:
Text
Formats:
parquet
Languages:
English
Size:
10K - 100K
ArXiv:
Tags:
theory-of-mind
License:
metadata
size_categories:
- 10K<n<100K
task_categories:
- multiple-choice
configs:
- config_name: tom-in-amc
default: true
data_files:
- split: train
path: data/train.parquet
- split: dev
path: data/dev.parquet
- split: test
path: data/test.parquet
- split: dev_human_subset
path: data/dev_human_subset.parquet
- split: test_human_subset
path: data/test_human_subset.parquet
license: apache-2.0
language:
- en
tags:
- theory-of-mind
Dataset Card for ToM-in-AMC
The dataset consists of ∼1,000 parsed movie scripts from IMSDb, each corresponding to a character understanding task.
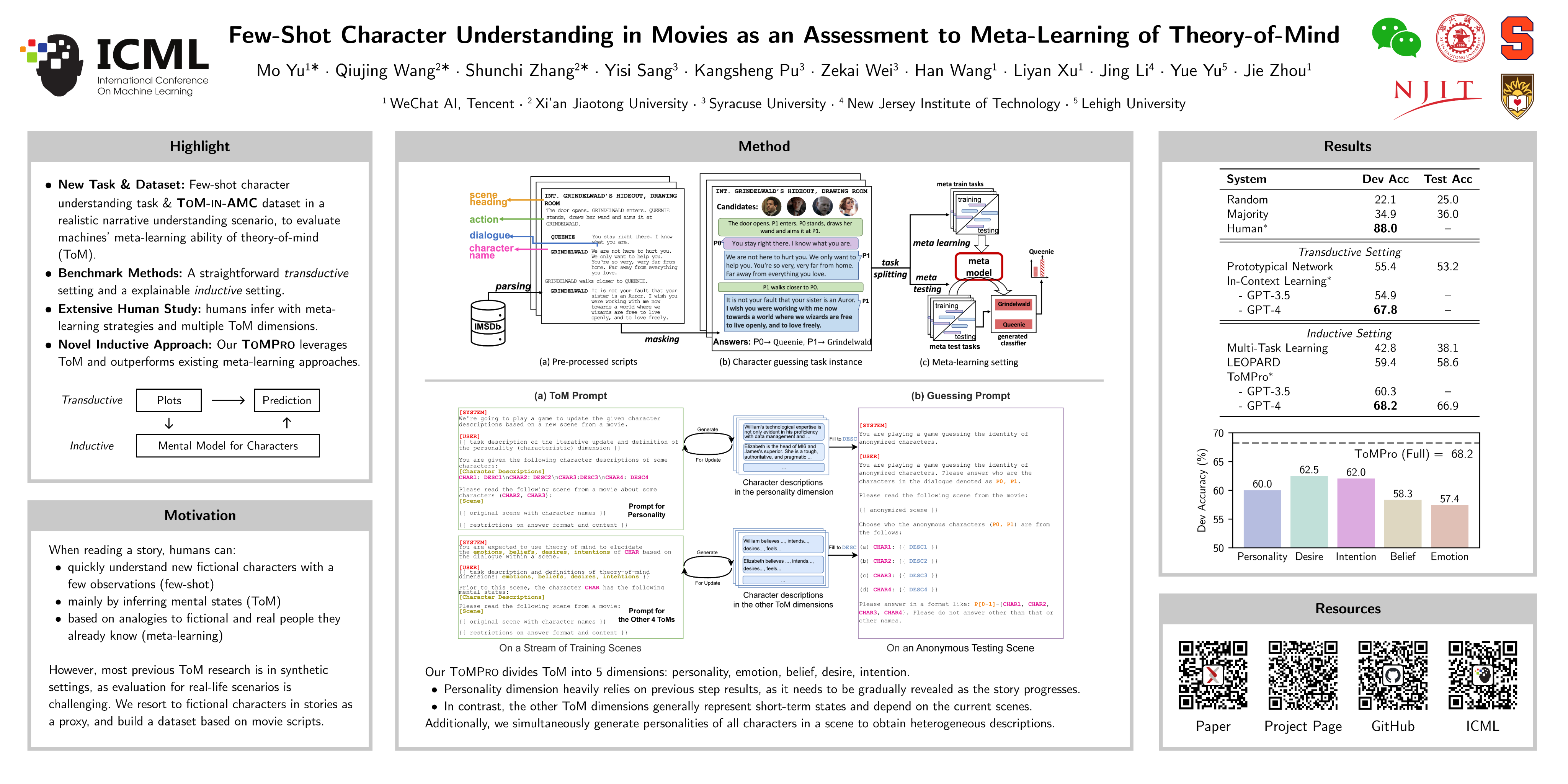
Dataset Description
- Homepage: https://shunchizhang.github.io/tom-in-amc/
- Repository: https://github.com/ShunchiZhang/ToM-in-AMC
- Paper: https://huggingface.co/papers/2211.04684
- Point of Contact: [email protected]
Citation
BibTeX:
@inproceedings{yu2024few,
title = {Few-Shot Character Understanding in Movies as an Assessment to Meta-Learning of Theory-of-Mind},
author = {Yu, Mo and Wang, Qiujing and Zhang, Shunchi and Sang, Yisi and Pu, Kangsheng and Wei, Zekai and Wang, Han and Xu, Liyan and Li, Jing and Yu, Yue and Zhou, Jie},
booktitle = {Proceedings of the 41st International Conference on Machine Learning},
year = {2024}
}
Dataset Card Authors
Mo Yu*, Qiujing Wang*, Shunchi Zhang*, Yisi Sang, Kangsheng Pu, Zekai Wei, Han Wang, Liyan Xu, Jing Li, Yue Yu, and Jie Zhou.