
SLPL/t5-fa
Updated • 5
text stringlengths 8 240k |
|---|
توی بساطش همه چیز بود
|
غرور ، حرص ، دروغ و خیانت ، جاهطلبی و
|
هر کس چیزی میخرید و درازایش چیزی میداد .
|
بعضیها تکهای از قلبشان را میدادند و بعضی پارهای از روحشان را .
|
بعضیها ایمانشان را میدادند و بعضی آزادگیشان را .
|
شیطان میخندید و دهانش بوی گند جهنم میداد .
|
حالم را به هم میزد .
|
دلم میخواست همه نفرتم را توی صورتش تف کنم .
|
انگار ذهنم را خواند .
|
موذیانه خندید و گفت من کاری با کسی ندارم ،
|
فقط گوشهای بساطم را پهن کردهام و آرام نجوا میکنم .
|
نه قیل و قال میکنم و نه کسی را مجبور میکنم چیزی از من بخرد .
|
میبینی ! آدمها خودشان دور من جمع شدهاند .
|
جوابش را ندادم .
|
آن وقت سرش را نزدیکتر آورد
|
و گفت البته تو با اینها فرق میکنی .
|
تو زیرکی و مؤمن . زیرکی و ایمان ، آدم را نجات میدهد .
|
اینها سادهاند و گرسنه . به جای هر چیزی فریب میخورند .
|
از شیطان بدم میآمد .
|
حرفهایش اما شیرین بود .
|
گذاشتم که حرف بزند و او هی گفت و گفت و گفت .
|
ساعتها کنار بساطش نشستم تا این که چشمم
|
به جعبهای عبادت افتاد که لا به لای چیزهای دیگر بود .
|
دور از چشم شیطان آن را برداشتم و توی جیبم گذاشتم .
|
با خودم گفتم بگذار یک بار هم شده کسی ،
|
چیزی از شیطان بدزدد . بگذار یک بار هم او فریب بخورد .
|
به خانه آمدم و در کوچک جعبه عبادت را باز کردم .
|
توی آن اما جز غرور چیزی نبود .
|
جعبه عبادت از دستم افتاد و غرور توی اتاق ریخت .
|
فریب خورده بودم ، فریب . دستم را روی قلبم گذاشتم ،
|
نبود ! فهمیدم که آن را کنار بساط شیطان جا گذاشتهام .
|
تمام راه را دویدم . تمام راه لعنتش کردم . تمام راه خدا خدا کردم .
|
میخواستم یقه نامردش را بگیرم .
|
عبادت دروغیاش را توی سرش بکوبم
|
و قلبم را پس بگیرم . به میدان رسیدم ، شیطان اما نبود .
|
آن وقت نشستم و هایهای گریه کردم .
|
اشکهایم که تمام شد ، بلند شدم .
|
بلند شدم تا بیدلیام را با خود ببرم که صدایی شنیدم ،
|
صدای قلبم را .
|
و همانجا بیاختیار به سجده افتادم و زمین را بوسیدم .
|
به شکرانه قلبی که پیدا شده بود .
|
همین ! ! ! ! ! !
|
آرزو نوشت شلا شلا شلامی دوباله به همه دوشتان وبلاگی ناناسم .
|
آرزو نوشت خوفیید ؟ خوشیید ؟ شلامتید ؟
|
آرزو نوشت ممنونم که با نظرات خوشملتون خوشالم میکنید !
|
آرزو نوشت من چند روزی مسافرت بودم برای همین شند نفری آپ
|
کرده بودند و منو خبر کرده بودند نتونستم بهشون سر بزنم .
|
آرزو نوشت خواهش میکنم از دست من نالاحت نشید
|
آرزو نوشت ممنونم هولا هولاااا
|
آرزو نوشت خوب دیگه من دارم میام در خونه همتون
|
و خبلتون کنم به وبم چون یه آپ جدید کردم
|
خوب تو وبم با نظراتون میبنمتون بابای
|
کاشکی چشمات مال من بود !
|
کاشکی چشمات مال من بود
|
تو سرت خیال من بود
|
واسه من که آرزومی آرزوت وصال من بود
|
کاشکی دستامونو زنجیر می بستیم ما به هم
|
همه جا داد میزدیم که عاشقیم عاشق هم
|
عاشقیم عاشق هم
|
من آن آرامترین موج و تو طوفانیترین احساس من
|
من زیباترین جویبارم و تو زیباترین زمزمه من
|
من دشت سراسر گل و تو قشنگترین آهنگ من
|
من بلندترین آواز و تو قشنگترین آهنگ من
|
من زیباترین شروع و تو قشنگترین انتهای عالم
|
من سراسر سبز و تو سراسر یکرنگی
|
من سراسر روشن و تو نور خدایی
|
من همه صداقت و تو تمام عشق
|
تو قشنگترین مفهوم برای ستایش خدا
|
تو والاترین واژه دفتر شعر من
|
تو سراسر عشق
|
تو بیمانند نگهبان احساس
|
تو مفهوم خلوص و من واژه آرام سکوت
|
و من اما . عاشق تو
|
آرزو نوشت شلا شلا آجیهای ناناسم و داداشیهای مهربونم .
|
آرزو نوشت خوفید ؟ خوشید ؟ خوش میگذره ؟
|
آرزو نوشت تو پست قبلیم یادم رفت از داداشی پژمانم
|
که زحمت کشید یه قالب ناناس که الانم تو وبمه درست
|
کرده تشکر کنم !
|
ولی الان میگم کعه داداشی جونم دست گلت درد نکنه ! !
|
آرزو نوشت خوب آپم شهطوره ؟ خوبه یا که بده ؟
|
آرزو نوشت خوب بل آخره امید والم که خوشتون
|
بیاد و بلاشم کامنت بزارید
|
تنهام نزارید ! ! ! !
|
به امید کامنتهای خوشملتون اینجا هستم . .
|
آرزو نوشت من دیگه بلم یادتون نره تنهام نزارید
|
آرزو نوشت بابای
|
باز ه م
|
از تپیدنهای قلب و از پریدنهای رنگ
|
عاشق بیچاره هر جا هست رسوا میشود
|
باز هم خواب زیبای با تو بودن را دیدم تو از دور می آمدی و پاییز دلم را بهار می ساختی و من محو تو همه چیز حتی خودم را از یاد برده بودم در آن لحظه میخواستم دست دراز کنم و همه ستارههای جهان را چون الماسهایی زیبا به پای تو بریزم یا همه شکوفههای درختان را بر سرت نثار سازم بر لبم ترانه نامت بر صورتم اشک شوقت بر چشمانم بر... |
میخوام بگم دوستت دارم ولی روم نمیشه این دل بیقرار من یه لحظه آروم نمیشه
|
میخوام بگم دوست دارم میخوام که با تو بمونم شعرای عاشقونمو فقط واسه تو بخونم
|
میخوام بگم دوست دارم هر جا باشی هرجا باشم تو شادی و توی غما میخوام کنار تو باشم
|
میخوام بگم دوست دارم بگم تو قلب من تویی اگه که درمون ندارم بدون که درد من تویی
|
میخوام بگم دوست دارم یه عالمه خیلی زیاد شب که بهت فکر میکنم من دیگه خوابم نمیآد
|
میخوام بگم دوست دارم میخوام که اینو بدونی اگه نمیتونم بگم اینو تو شعرام بخونی
|
پینوشت شلا شلا عسیسای دلم
|
پینوشت خوفید عروسکای من و داداشیهای مهربون من ؟
|
پینوشت قالبم شه طور بود ؟ خوب بود ؟ آپم شی ؟
|
پینوشت خوب به هر حال خدا کنه که خوشتون اومده باشه
|
[If you want to join our community to keep up with news, models and datasets from naab, click on this link.]
naab is the biggest cleaned and ready-to-use open-source textual corpus in Farsi. It contains about 130GB of data, 250 million paragraphs, and 15 billion words. The project name is derived from the Farsi word ناب which means pure and high-grade. We also provide the raw version of the corpus called naab-raw and an easy-to-use pre-processor that can be employed by those who wanted to make a customized corpus.
You can use this corpus by the commands below:
from datasets import load_dataset
dataset = load_dataset("SLPL/naab")
You may need to download parts/splits of this corpus too, if so use the command below (You can find more ways to use it here):
from datasets import load_dataset
dataset = load_dataset("SLPL/naab", split="train[:10%]")
Note: be sure that your machine has at least 130 GB free space, also it may take a while to download. If you are facing disk or internet shortage, you can use below code snippet helping you download your costume sections of the naab:
from datasets import load_dataset
# ==========================================================
# You should just change this part in order to download your
# parts of corpus.
indices = {
"train": [5, 1, 2],
"test": [0, 2]
}
# ==========================================================
N_FILES = {
"train": 126,
"test": 3
}
_BASE_URL = "https://huggingface.co/datasets/SLPL/naab/resolve/main/data/"
data_url = {
"train": [_BASE_URL + "train-{:05d}-of-{:05d}.txt".format(x, N_FILES["train"]) for x in range(N_FILES["train"])],
"test": [_BASE_URL + "test-{:05d}-of-{:05d}.txt".format(x, N_FILES["test"]) for x in range(N_FILES["test"])],
}
for index in indices['train']:
assert index < N_FILES['train']
for index in indices['test']:
assert index < N_FILES['test']
data_files = {
"train": [data_url['train'][i] for i in indices['train']],
"test": [data_url['test'][i] for i in indices['test']]
}
print(data_files)
dataset = load_dataset('text', data_files=data_files, use_auth_token=True)
This corpus can be used for training all language models which can be trained by Masked Language Modeling (MLM) or any other self-supervised objective.
language-modelingmasked-language-modelingEach row of the dataset will look like something like the below:
{
'text': "این یک تست برای نمایش یک پاراگراف در پیکره متنی ناب است.",
}
text : the textual paragraph.This dataset includes two splits (train and test). We split these two by dividing the randomly permuted version of the corpus into (95%, 5%) division respected to (train, test). Since validation is usually occurring during training with the train dataset we avoid proposing another split for it.
| train | test | |
|---|---|---|
| Input Sentences | 225892925 | 11083849 |
| Average Sentence Length | 61 | 25 |
Below you can see the log-based histogram of word/paragraph over the two splits of the dataset.
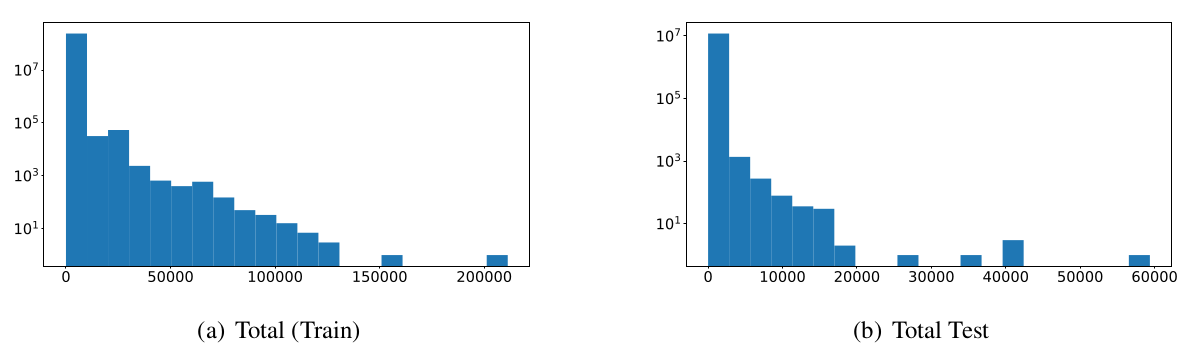
Due to the lack of a huge amount of text data in lower resource languages - like Farsi - researchers working on these languages were always finding it hard to start to fine-tune such models. This phenomenon can lead to a situation in which the golden opportunity for fine-tuning models is just in hands of a few companies or countries which contributes to the weakening the open science.
The last biggest cleaned merged textual corpus in Farsi is a 70GB cleaned text corpus from a compilation of 8 big data sets that have been cleaned and can be downloaded directly. Our solution to the discussed issues is called naab. It provides 126GB (including more than 224 million sequences and nearly 15 billion words) as the training corpus and 2.3GB (including nearly 11 million sequences and nearly 300 million words) as the test corpus.
The textual corpora that we used as our source data are illustrated in the figure below. It contains 5 corpora which are linked in the coming sections.
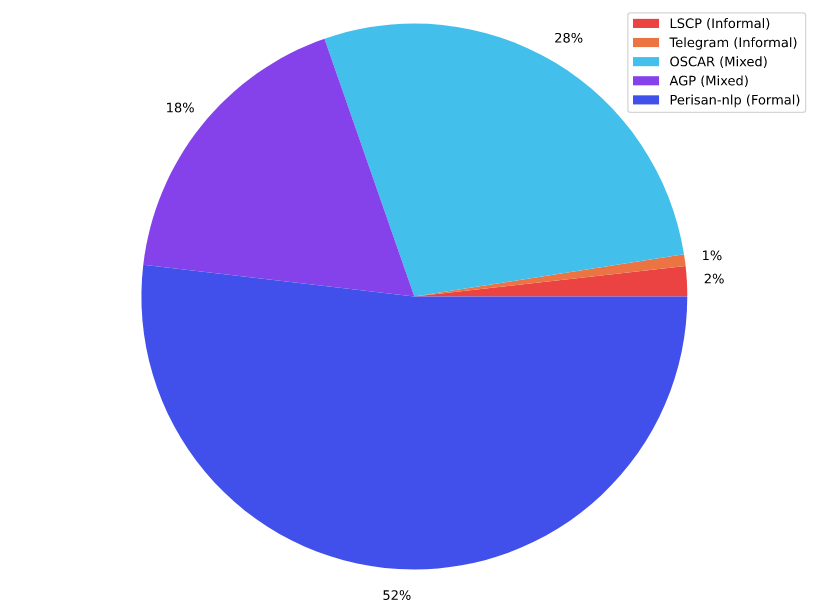
This corpus includes eight corpora that are sorted based on their volume as below:
This corpus was a formerly private corpus for ASR Gooyesh Pardaz which is now published for all users by this project. This corpus contains more than 140 million paragraphs summed up in 23GB (after cleaning). This corpus is a mixture of both formal and informal paragraphs that are crawled from different websites and/or social media.
OSCAR or Open Super-large Crawled ALMAnaCH coRpus is a huge multilingual corpus obtained by language classification and filtering of the Common Crawl corpus using the go classy architecture. Data is distributed by language in both original and deduplicated form. We used the unshuffled-deduplicated-fa from this corpus, after cleaning there were about 36GB remaining.
Telegram, a cloud-based instant messaging service, is a widely used application in Iran. Following this hypothesis, we prepared a list of Telegram channels in Farsi covering various topics including sports, daily news, jokes, movies and entertainment, etc. The text data extracted from mentioned channels mainly contains informal data.
The Large Scale Colloquial Persian Language Understanding dataset has 120M sentences from 27M casual Persian sentences with its derivation tree, part-of-speech tags, sentiment polarity, and translations in English, German, Czech, Italian, and Hindi. However, we just used the Farsi part of it and after cleaning we had 2.3GB of it remaining. Since the dataset is casual, it may help our corpus have more informal sentences although its proportion to formal paragraphs is not comparable.
The data collection process was separated into two parts. In the first part, we searched for existing corpora. After downloading these corpora we started to crawl data from some social networks. Then thanks to ASR Gooyesh Pardaz we were provided with enough textual data to start the naab journey.
We used a preprocessor based on some stream-based Linux kernel commands so that this process can be less time/memory-consuming. The code is provided here.
Since this corpus is briefly a compilation of some former corpora we take no responsibility for personal information included in this corpus. If you detect any of these violations please let us know, we try our best to remove them from the corpus ASAP.
We tried our best to provide anonymity while keeping the crucial information. We shuffled some parts of the corpus so the information passing through possible conversations wouldn't be harmful.
mit?
@article{sabouri2022naab,
title={naab: A ready-to-use plug-and-play corpus for Farsi},
author={Sabouri, Sadra and Rahmati, Elnaz and Gooran, Soroush and Sameti, Hossein},
journal={arXiv preprint arXiv:2208.13486},
year={2022}
}
DOI: https://doi.org/10.48550/arXiv.2208.13486
Thanks to @sadrasabouri and @elnazrahmati for adding this dataset.
