
description
stringlengths 38
154k
| category
stringclasses 5
values | solutions
stringlengths 13
289k
| name
stringlengths 3
179
| id
stringlengths 24
24
| tags
listlengths 0
13
| url
stringlengths 54
54
| rank_name
stringclasses 8
values |
|---|---|---|---|---|---|---|---|
<link href="https://fonts.googleapis.com/css?family=Comfortaa&effect=canvas-print" rel="stylesheet">
<style>
.task {
background: #fff;
color: #333;
padding: 25px;
box-sizing: border-box;
font-family: Comfortaa, sans-serif !important;
position: relative;
}
.task code, .task_code {
display: inline-block;
padding: 0;
border-radius: 2px;
margin: 0;
position: relative;
top: 6px;
background: bisque;
border: 1px solid #f9d2a4;
padding: 3px;
line-height: 1em;
}
.task_code {
top: -1px;
}
.task_header {
color: #333 !important;
margin-top: 0;
font-size: 30px !important;
}
.task_inner {
box-shadow: 0 2px 11px -3px rgba(0,0,0,.6);
padding: 20px;
border-radius: 3px;
}
.task_devil {
float: right;
margin-left: 15px;
shape-outside: circle(150px);
}
.task_devil img {
max-width: 150px;
}
.task_part-header {
font-size: 20px !important;
font-weight: 800;
color: #333;
padding: 20px 0 10px;
}
.task_part-header:first-of-type {
padding-top: 0;
}
.task_list {
padding: 0;
margin: 10px 0;
padding-left: 30px;
}
.task_list ul {
padding: 0;
margin: 0;
}
.font-effect-canvas-print { color: black; }
</style>
<div class="task">
<h1 class="task_header font-effect-canvas-print">Devil's Sequence</h1>
<div class="task_inner">
<div class="task_part-header font-effect-canvas-print">Problem</div>
<div class="task_devil">
<img src="https://cloud.githubusercontent.com/assets/1553519/20080980/c85a971e-a55d-11e6-8cff-bd10cbc81aa7.png"></img>
</div>
Robodevil likes to do some mathematics between rehearsals of his orchestra. Today he invented devilish sequence No. 1729:
<div class="task_list">
<ul>
<li>x<sub>0</sub> = 0,</li>
<li>x<sub>1</sub> = 1,</li>
<li>x<sub>n</sub> = (x<sub>n - 1</sub> + x<sub>n - 2</sub>) / 2.</li>
</ul>
</div>
For example, <span class="task_code">x<sub>10</sub> = 0.666015625</span>. Robodevil became interested at once how many `sixes` there were at the beginning of an arbitrary x<sub>n</sub>. In 6 nanoseconds, he had a formula. Can you do the same?
<div class="task_part-header font-effect-canvas-print">Input</div>
You are given an integer n; `2 ≤ n ≤ 100000`.
<div class="task_part-header font-effect-canvas-print">Output</div>
Output the number of sixes at the beginning of x<sub>n</sub> in decimal notation.
<div class="task_part-header font-effect-canvas-print">Example</div>
<div class="task_table">
<table>
<tr>
<th class="font-effect-canvas-print">Input</th>
<th class="font-effect-canvas-print">Output</th>
</tr>
<tr>
<td>10</td>
<td>3</td>
</tr>
</table>
</div>
</div>
</div> | algorithms | from math import floor, log
def count_sixes(n):
return floor((n - n % 2) * log(2, 10))
| Devil's Sequence | 582110dc2fd420bf7f00117b | [
"Mathematics",
"Algorithms"
]
| https://www.codewars.com/kata/582110dc2fd420bf7f00117b | 5 kyu |
Looking at consecutive powers of `2`, starting with `2^1`:
`2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, 32768, ...`
Note that out of all the digits `0-9`, the last one ever to appear is `7`. It only shows up for the first time in the number `32768 (= 2^15)`.
So let us define LAST DIGIT TO APPEAR as the last digit to be written down when writing down all the powers of `n`, starting with `n^1`.
## Your task
You'll be given a positive integer ```1 =< n <= 10000```, and must return the last digit to appear, as an integer.
If for any reason there are digits which never appear in the sequence of powers, return `None`/`nil`.
Please note: The Last digit to appear can be in the same number as the penultimate one. For example for `n = 8`, the last digit to appear is `7`, although `3` appears slightly before it, in the same number:
`8, 64, 512, 4096, 32768, ...` | reference | def digits(x): return set(str(x))
def LDTA(n):
if digits(n) == digits(n * n):
return None
seen = []
x = n
while len(seen) < 10:
for d in str(x):
if d not in seen:
seen . append(d)
x *= n
return int(seen[- 1])
| Last Digit to Appear in Sequence of Powers | 5ccfcfad7306d900269da53f | [
"Fundamentals"
]
| https://www.codewars.com/kata/5ccfcfad7306d900269da53f | 7 kyu |
A stem-and-leaf plot groups data points that have the same leading digit, resembling a histogram. For example, for the input `[11, 35, 14, 9, 39, 23, 35]`, it might look something like this:
```
stem | leaf
-----------
0 | 9
1 | 1 4
2 | 3
3 | 5 5 9
```
Some important things to notice:
* Any single-digit number, such as `9`, has `0` as its stem;
* The leaves are presented in ascending order;
* Leaves can be repeated (as with the two 5's in the last row).
Create a function called `stem_and_leaf` that, given a list of integers `i` as input (`0 <= i <= 99`), returns a Python dictionary containing a stem-and-leaf plot. Each key of the dictionary should be a stem and each value should be a list of leaves, following the format above.
For the example above, the output would be:
```
{0: [9], 1: [1, 4], 2: [3], 3: [5, 5, 9]}
``` | reference | from collections import defaultdict
def stem_and_leaf(a):
d = defaultdict(list)
for x in a:
d[x / / 10]. append(x % 10)
return {x: sorted(y) for x, y in d . items()}
| Stem-and-leaf plot | 5cc80fbe701f0d001136e5eb | [
"Fundamentals",
"Lists"
]
| https://www.codewars.com/kata/5cc80fbe701f0d001136e5eb | 7 kyu |
## Number pyramid
Number pyramid is a recursive structure where each next row is constructed by adding adjacent values of the current row. For example:
```
Row 1 [1 2 3 4]
Row 2 [3 5 7]
Row 3 [8 12]
Row 4 [20]
```
___
## Task
Given the first row of the number pyramid, find the value stored in its last row.
___
## Performance tests
```python
Number of tests: 10
List size: 10,000
```
```javascript
Number of tests: 5
Array size: 10,000
```
```ruby
Number of tests: 10
Array size: 10,000
```
```haskell
Number of tests: 5
List size: 10,000
``` | algorithms | from operator import mul
def reduce_pyramid(base):
return sum(map(mul, base, comb_n(len(base) - 1)))
def comb_n(n):
c = 1
for k in range(0, n + 1):
yield c
c = c * (n - k) / / (k + 1)
| Reducing a pyramid | 5cc2cd9628b4200020880248 | [
"Algorithms",
"Performance"
]
| https://www.codewars.com/kata/5cc2cd9628b4200020880248 | 6 kyu |
If this challenge is too easy for you, check out:
https://www.codewars.com/kata/5cc89c182777b00001b3e6a2
___
Upside-Down Pyramid Addition is the process of taking a list of numbers and consecutively adding them together until you reach one number.
When given the numbers `2, 1, 1` the following process occurs:
```
2 1 1
3 2
5
```
This ends in the number `5`.
___
### YOUR TASK
Given the right side of an Upside-Down Pyramid (Ascending), write a function that will return the original list.
### EXAMPLE
```javascript
reverse([5, 2, 1]) => [2, 1, 1]
```
```haskell
reversePyramid [5, 2, 1] -> [2, 1, 1]
```
```python
reverse([5, 2, 1]) == [2, 1, 1]
```
```ruby
reverse_pyramid([5, 2, 1]) == [2, 1, 1]
```
NOTE: The Upside-Down Pyramid will never be empty and will always consist of positive integers ONLY. | algorithms | def reverse(lst):
ret = []
while lst:
ret . append(lst[- 1])
lst = [a - b for a, b in zip(lst, lst[1:])]
return ret[:: - 1]
| Upside-Down Pyramid Addition...REVERSED! | 5cc1e284ece231001ccf7014 | [
"Mathematics",
"Algorithms"
]
| https://www.codewars.com/kata/5cc1e284ece231001ccf7014 | 6 kyu |
Hey, Path Finder, where are you?
## Path Finder Series:
- [#1: can you reach the exit?](https://www.codewars.com/kata/5765870e190b1472ec0022a2)
- [#2: shortest path](https://www.codewars.com/kata/57658bfa28ed87ecfa00058a)
- [#3: the Alpinist](https://www.codewars.com/kata/576986639772456f6f00030c)
- [#4: where are you?](https://www.codewars.com/kata/5a0573c446d8435b8e00009f)
- [#5: there's someone here](https://www.codewars.com/kata/5a05969cba2a14e541000129)
| games | import re
class Me (object):
def __init__(self): self . x, self . y, self . dx, self . dy = 0, 0, - 1, 0
def move(self, n): self . x += n * self . dx; self . y += n * self . dy
def back(self): self . dx *= - 1; self . dy *= - 1
def turn(self, d): self . dx, self . dy = (self . dy * (- 1) * * (d == 'l'), 0) if self . dy else (0, self . dx * (- 1) * * (d == 'r'))
def where(self): return [self . x, self . y]
def __str__(
self): return f'x,y= { self . x } , { self . y } (dx,dy= { self . dx } , { self . dy } )'
me = Me()
def i_am_here(path):
for v in re . findall(r'\d+|.', path):
if v in 'RL':
me . back()
elif v in 'rl':
me . turn(v)
else:
me . move(int(v))
return me . where()
| Path Finder #4: where are you? | 5a0573c446d8435b8e00009f | [
"Puzzles"
]
| https://www.codewars.com/kata/5a0573c446d8435b8e00009f | 4 kyu |
We define the function `f1(n,k)`, as the least multiple of `n` that has all its digits less than `k`.
We define the function `f2(n,k)`, as the least multiple of `n` that has all the digits that are less than `k`, and no others.
Each digit may occur more than once in both values of `f1(n,k)` and `f2(n,k)`.
The possible values for `n` and `k` according to these ranges for both functions `f1` and `f2` in this kata:
```
1 <= n <= 1.000.000.000.000
3 <= k <= 9
```
For example, let's see the value of both functions for `n = 71` and `k = 4`:
```
f1(71,4) == 213 # all its digits less than 4
f2(71,4) == 2130 # 0,1,2,3 all of them present
```
The integer `76` is the first integer that has the same values of `f1` and `f2` for `k = 4`.
```
f1(76,4) = f2(76,4) = 10032
```
Let's call these kind of numbers, **forgiving numbers**. (Let's continue with the fashion of attributing personality traits to numbers and, of course, an unknown one)
So, `76` is the smallest forgiving number of order `4`.
In the same way, `485` is the smallest forgiving number of order `5`.
Create a function that given an integer `n` and the order `k`, will output the higher and closest forgiving number to `n` of order `k`.
Let's see some examples:
```
find_f1_eq_f2(500,5) == 547
find_f1_eq_f2(1600,6) == 1799
find_f1_eq_f2(14900,7) == 14996
```
If the number `n` is a forgiving itself for a certain order `k`, the function will never output the same value, remember, closest and **higher** than `n`.
For example, `3456`, is a forgiving one of order `4`,
```
find_f1_eq_f2(3456,4) == 3462
```
**Features of the tests:**
* `n` and `k` will be always valid and positive integers.
* A total of 8 fixed tests.
* A total of 150 random tests in the ranges for `n` and `k` given above.
I'll be waiting your awesome solution. :) | reference | from itertools import count
def f1(n, k):
return next(n * m for m in count(1) if all(int(d) < k for d in str(n * m)))
def f2(n, k):
s = set(map(str, range(0, k)))
return next(n * m for m in count(1) if set(str(n * m)) == s)
def find_f1_eq_f2(n, k):
return next(m for m in count(n + 1) if f1(m, k) == f2(m, k))
| Forgiving Numbers | 5cb99d1a1e00460024827738 | [
"Fundamentals",
"Data Structures",
"Algorithms",
"Mathematics"
]
| https://www.codewars.com/kata/5cb99d1a1e00460024827738 | 7 kyu |
Alan is going to watch the Blood Moon (lunar eclipse) tonight for the first time in his life. But his
mother, who is a history teacher, thinks the Blood Moon comes with an evil intent. The ancient Inca
people interpreted the deep red coloring as a jaguar attacking and eating the moon. But who
believes in Inca myths these days? So, Alan decides to prove to her mom that there is no jaguar.
How? Well, only little Alan knows that. For now, he needs a small help from you. Help him solve the
following calculations so that he gets enough time to prove it before the eclipse starts.
<img src="https://i.ibb.co/jRd3Z1K/Screenshot-3.png" alt="Screenshot-3" border="0">
Three semicircles are drawn on `AB`, `AD`, and `AF`. Here `CD` is perpendicular to `AB` and `EF` is
perpendicular to `AD`.
## Task
Given the radius of the semicircle `ADBCA`, find out the area of the lune `AGFHA` (the shaded area). | algorithms | def blood_moon(r):
""" if AC = r = CD
then AD = r * root2
then AE = r * root 2 / 2 = EF
then AF = r
then area AEFH is pi r^2/ 8
area triangle AEF is bh/2 = 1/2r^2 / 2 = r^2 / 4
therefore area AFH = pir^2 / 8 - r^2 / 4 or pir^2 - 2r^2 all over 8
area AFG is pi (r/2)^2 / 2 which is pi r^2 / 8
thus area lune is pir^2 / 8 - (pir^2/8 - r^2 / 4) = r^2 / 4
"""
return r * * 2 / 4
| Blood Moon | 5cba04533e6dce000eaf6126 | [
"Mathematics",
"Geometry",
"Algorithms"
]
| https://www.codewars.com/kata/5cba04533e6dce000eaf6126 | 7 kyu |
## A Discovery
One fine day while tenaciously turning the soil of his fields, Farmer Arepo found a square stone tablet with letters carved into it... he knew such artifacts may '_show a message in four directions_', so he wisely kept it. As he continued to toil in his work with his favourite rotary plough, he found more such tablets, but with so many crops to sow he had no time to decipher them all.
## Your Task
Please help Farmer Arepo by inspecting each tablet to see if it forms a valid <a href="https://en.wikipedia.org/wiki/Sator_Square">Sator Square</a>!
<img src="https://i.imgur.com/DjVOjV4.jpeg" title="sator square" width="300"/>
## The Square
is a two-dimentional palindrome, made from words of equal length that can be read in these four ways:
```
1) left-to-right (across)
2) top-to-bottom (down)
3) bottom-to-top (up)
4) right-to-left (reverse)
```
## An Example
Considering this square:
```
B A T S
A B U T
T U B A
S T A B
```
Here are the four ways a word (in this case `"TUBA"`) can be read:
<pre style='background:black'>
down
↓
B A T S B A <span style='color:green'>T</span> S B <span style='color:green'>A</span> T S B A T S
A B U T A B <span style='color:green'>U</span> T A <span style='color:green'>B</span> U T <span style='color:green'>A B U T</span> ← reverse
across → <span style='color:green'>T U B A</span> T U <span style='color:green'>B</span> A T <span style='color:green'>U</span> B A T U B A
S T A B S T <span style='color:green'>A</span> B S <span style='color:green'>T</span> A B S T A B
↑
up
</pre>
IMPORTANT:
* In a `true` Sator Square, ALL of its words can be read in ALL four of these ways.
* If there is any deviation, it would be `false` to consider it a Sator Square.
## Some Details
* tablet (square) dimensions range from `2x2` to `33x33` inclusive
* all characters used will be upper-case alphabet letters
* there is no need to validate any input
## Input
* an N x N (square) two-dimentional matrix of uppercase letters
## Output
* boolean `true` or `false` whether or not the tablet is a Sator Square
## Enjoy!
You may consider one of the following kata to solve next:
* [Playing With Toy Blocks ~ Can you build a 4x4 square?](https://www.codewars.com/kata/5cab471da732b30018968071)
* [Four Letter Words ~ Mutations](https://www.codewars.com/kata/5cb5eb1f03c3ff4778402099)
* [Crossword Puzzle! (2x2)](https://www.codewars.com/kata/5c658c2dd1574532507da30b)
* [Interlocking Binary Pairs](https://www.codewars.com/kata/628e3ee2e1daf90030239e8a)
| algorithms | def is_sator_square(tablet):
A = {'' . join(lst) for lst in tablet}
B = {'' . join(lst)[:: - 1] for lst in tablet}
C = {'' . join(lst) for lst in zip(* tablet)}
D = {'' . join(lst)[:: - 1] for lst in zip(* tablet)}
return A == B == C == D
| Is Sator Square? | 5cb7baa989b1c50014a53333 | [
"Arrays",
"Data Structures",
"Algorithms"
]
| https://www.codewars.com/kata/5cb7baa989b1c50014a53333 | 7 kyu |
A pair of numbers has a unique LCM but a single number can be the LCM of more than one possible
pairs. For example `12` is the LCM of `(1, 12), (2, 12), (3,4)` etc. For a given positive integer N, the number of different integer pairs with LCM is equal to N can be called the LCM cardinality of that number N. In this kata your job is to find out the LCM cardinality of a number. | reference | from itertools import combinations
from math import gcd
def lcm_cardinality(n):
return 1 + sum(1 for a, b in combinations(divisors(n), 2) if lcm(a, b) == n)
def divisors(n):
d = {1, n}
for k in range(2, int(n * * 0.5) + 1):
if n % k == 0:
d . add(k)
d . add(n / / k)
return sorted(d)
def lcm(a, b):
return a * b / / gcd(a, b)
| LCM Cardinality | 5c45bef3b6adcb0001d3cc5f | [
"Fundamentals"
]
| https://www.codewars.com/kata/5c45bef3b6adcb0001d3cc5f | 6 kyu |
Your website is divided vertically in sections, and each can be of different size (height).
You need to establish the section index (starting at `0`) you are at, given the `scrollY` and `sizes` of all sections.
Sections start with `0`, so if first section is `200` high, it takes `0-199` "pixels" and second starts at `200`.
### Example:
~~~if-not:factor
With `scrollY = 300` and `sizes = [300,200,400,600,100]`
the result will be `1` as it's the second section.
With `scrollY = 1600` and `size = [300,200,400,600,100]`
the result will be `-1` as it's past last section.
~~~
~~~if:factor
With `scrollY = 300` and `sizes = { 300 200 400 600 100 }`
the result will be `1` as it's the second section.
With `scrollY = 1600` and `size = { 300 200 400 600 100 }`
the result will be `-1` as it's past last section.
~~~
Given the `scrollY` integer (always non-negative) and an array of non-negative integers (with at least one element), calculate the index (starting at `0`) or `-1` if `scrollY` falls beyond last section (indication of an error). | algorithms | def get_section_id(scroll, sizes):
c = 0
for idx, s in enumerate(sizes):
c += s
if scroll < c:
return idx
return - 1
| Which section did you scroll to? | 5cb05eee03c3ff002153d4ef | [
"Fundamentals",
"Algorithms"
]
| https://www.codewars.com/kata/5cb05eee03c3ff002153d4ef | 7 kyu |
A programmer that loves creating algorithms for security is doing a previous investigation of a special set of primes. Specially, he has to define ranges of values and to have the total number of the required primes.
These primes should fulfill the following requirements:
* The primes should have at least 3 digits.
* The primes can not include the digit 0.
* The sum of the digits should be a multiple of a perfect square number. (**Note:** even though 1 is a perfect square, **do not** consider it for obvious reasons)
* The product of the first digit by the last one cannot be 45, or in other words, if 5 is the first digit, the last one cannot be 9.
* The primes' digits should occur only once. Examples of this kind of primes are: `167, 359`. Cases like `113` and `331` have to be discarded because digits 1 and 3 that appear twice respectively.
Once he has these special primes, that fulfill the constraints listed above, he has to classify them in three subsets: bouncy, increasing and decreasing primes.
The increasing primes are the ones that have their digits in increasing order, for example : `157, 359, 569`.
The decreasing ones, on the other hand, have their digits in decreasing order, for example: `761, 953, 971`.
Finally, the bouncy primes are the ones that does not belong to any of both previous subsets: neither increasing nor decreasing ones, for example: `173, 193, 317`.
## Your Task
*Do you want to have the results of this investigation and accept the challenge? If your answer is affirmative, continue reading.*
Your function will accept an integer higher than 100 (and lower than 50000) as an upper bound of the range to work in, so all these special primes should be lower or equal to the given value of `n`.
The function should output a list of lists with the data in this order:
```
[ [data for _bouncy_ primes], [data for _increasing_ primes], [data for _decreasing_ primes] ]
```
The data required for each subset should be as follows:
```
[ min. prime found, max. prime found, number of primes in range ]
```
## Examples
Let's see some examples for some values of n:
```
special_primes(101) --> [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
```
No special primes at this value (obviously).
```
special_primes(200) --> [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
```
Still no special primes.
```
special_primes(457) --> [[251, 439, 2], [349, 457, 4], [431, 431, 1]]
```
Now we have some values:
* bouncy primes: `251, 439` (2 in total)
* increasing primes: `349, 367, 389, 457` (4)
* decreasing primes: `431` (1)
```
special_primes(1000) --> [[251, 947, 11], [349, 479, 5], [431, 983, 4]]
```
* bouncy primes: `251, 439, 547, 587, 619, 659, 673, 691, 839, 857, 947` (11)
* increasing primes: `349, 367, 389, 457, 479` (5)
* decreasing primes: `431, 521, 853, 983` (4)
Good Luck and happy coding!
---
Items the programmer has to think after the investigation:
- The highest possible prime, with these constraints, is ________.
- The larger subset of prime is _______.
- The smallest subset of primes is _______.
- The sum of the digits of these special primes are always multiples of the perfect squares: __________
If your code passed you have these answers!! | reference | def special_primes(n):
cat = [[] for _ in range(3)]
for x in range(101, n + 1, 2):
dig = list(map(int, str(x)))
sum_, set_ = sum(dig), set(dig)
if not sum_ % 3 or len(set_) != len(dig):
continue
if 0 in set_ or dig[0] * dig[- 1] == 45:
continue
if all(sum_ % k * * 2 for k in range(2, int(sum_ * * .5) + 1)):
continue
if not all(x % d for d in range(3, int(x * * .5) + 1, 2)):
continue
cat[sum({(a < b) - (a > b) for a, b in zip(dig, dig[1:])})]. append(x)
return [[len(l) and l[0], len(l) and l[- 1], len(l)] for l in cat]
| Special Subsets of Primes | 55d5f4aae676c3da53000024 | [
"Fundamentals",
"Algorithms",
"Mathematics",
"Data Structures"
]
| https://www.codewars.com/kata/55d5f4aae676c3da53000024 | 6 kyu |
Consider a pyramid made up of blocks. Each layer of the pyramid is a rectangle of blocks, and the dimensions of these rectangles increment as you descend the pyramid. So, if a layer is a `3x6` rectangle of blocks, then the next layer will be a `4x7` rectangle of blocks. A `1x10` layer will be on top of a `2x11` layer on top of a `3x12` layer, and so on.
## Task
Given the dimensions of a pyramid's topmost layer `w,l`, and its height `h` (aka the number of layers), return the total number of blocks in the pyramid.
## Examples
`num_blocks(1, 1, 2)` will return `5`. This pyramid starts with a `1x1` layer and has 2 layers total. So, there is 1 block in the first layer, and `2x2=4` blocks in the second. Thus, 5 is the total number of blocks.
`num_blocks(2, 4, 3)` will return `47`. This pyramid has 3 layers: `2x4`, `3x5`, and `4x6`. So, there are `47` blocks total.
## Notes
All parameters will always be postive nonzero integers.
Efficiency is important. There will be:
* 100 'small' cases with `w`, `l`, and `h` below `20`.
* 100 'big' cases with `w`, `l`, and `h` between `1e9` and `1e10`. | algorithms | def num_blocks(w, l, h):
return w * l * h + (w + l) * (h - 1) * h / / 2 + (h - 1) * h * (2 * h - 1) / / 6
"""
For those who wonder:
first layer being of size w*l, the total number of blocks, SB, is:
SB = w*l + (w+1)*(l+1) + (w+2)*(l+2) + ... + (w+h-1)*(l+h-1)
So: SB = " Sum from i=0 to h-1 of (w+i)*(l+i) "
Let's use the following notation for this: SB = S(i)[ (w+i)*(l+i) ]
Then:
SB = S(i)[ w*l + i(w+l) + i**2 ]
= S(i)[ w*l ] + S(i)[ i(w+l) ] + S(i)[ i**2 ]
= w*l*h + (w+l) * S(i)[ i ] + S(i)[ i**2 ]
Here, you find two classic sums of sequences (see wiki or equivalent for the demonstrations):
S(i)[ i ] = sum of all integers from 1 to x = x*(x+1) // 2
S(i)[ i**2 ] = sum of all squares of integers from 1 to x = x*(x+1)*(2*x+1) // 6
Since on our side we do the sum from 0 (which doesn't affect at all the result)
to h-1 in place of x, we get:
SB = w*l*h + (w+l) * (h-1)*h//2 + (h-1)*h*(2*h-1)//6
"""
| Blocks in an Irregular Pyramid | 5ca6c0a2783dec001da025ee | [
"Mathematics",
"Algorithms"
]
| https://www.codewars.com/kata/5ca6c0a2783dec001da025ee | 6 kyu |
A few years ago, <b>Aaron</b> left his old school and registered at another due to security reasons. Now he wishes to find <b>Jane</b>, one of his schoolmates and good friends.
There are `n` schools numbered from 1 to `n`. One can travel between each pair of schools by buying a ticket. The ticket between schools `i` and `j` costs `(i + j) modulo (n + 1)` and can be used multiple times. Help <b>Aaron</b> find the minimum total cost to visit all schools. He can start and finish at any school.
<b>Range : 1 ≤ n ≤ 10<sup>6</sup></b> | reference | def find_jane(n):
return (n - 1) / / 2
| Minimum Ticket Cost | 5bdc1558ab6bc57f47000b8e | [
"Fundamentals",
"Mathematics"
]
| https://www.codewars.com/kata/5bdc1558ab6bc57f47000b8e | 7 kyu |
Removed due to copyright infringement.
<!---
Fibsieve had a fantabulous (yes, it's an actual word) birthday party this year. He had so many gifts that he was actually thinking of not having a party next year.
Among these gifts there was an `N x N` glass chessboard that had a light in each of its cells. When the board was turned on a distinct cell would light up every second, and then go dark.
The cells would light up in the sequence shown in the diagram. Each cell is marked with the second in which it would light up:

In the first second the light at cell `(1, 1)` would be on. And in the 5th second the cell `(3, 1)` would be on. Now Fibsieve is trying to predict which cell will light up at a certain time (given in seconds).
**Output**: `(x, y)` - the column and the row number of a cell which would light up at the `N`'th second.
___
## Notes
* Column and row indices are `1-based`.
* `x` is the column index, and `y` is the row index.
* The cells are indexed from bottom-left corner.
* `N` will be large.
---> | algorithms | from math import ceil, sqrt
def fantabulous_birthday(n):
a = ceil(sqrt(n))
b = a * a - a + 1
c = a - abs(n - b)
return [a, c] if (n < b) ^ (a % 2) == 0 else [c, a]
| Fantabulous Birthday | 5be83eb488c754f304000185 | [
"Algorithms",
"Fundamentals",
"Mathematics",
"Logic",
"Numbers"
]
| https://www.codewars.com/kata/5be83eb488c754f304000185 | 6 kyu |
`{a, e, i, o, u, A, E, I, O, U}`
Natural Language Understanding is the subdomain of Natural Language Processing where people used to design AI based applications have ability to understand the human languages. HashInclude Speech Processing team has a project named Virtual Assistant. For this project they appointed you as a data engineer (who has good knowledge of creating clean datasets by writing efficient code). As a data engineer your first task is to make vowel recognition dataset. In this task you have to find the presence of vowels in all possible substrings of the given string. For each given string you have to return the total number of vowels.
## Example
Given a string `"baceb"` you can split it into substrings: `b, ba, bac, bace, baceb, a, ac, ace, aceb, c, ce, ceb, e, eb, b`. The number of vowels in each of these substrings is `0, 1, 1, 2, 2, 1, 1, 2, 2, 0, 1, 1, 1, 1, 0`; if you sum up these number, you get `16` - the expected output.
**Note**: your solution should have linear time complexity. | algorithms | def vowel_recognition(input):
vowels = set('aeiouAEIOU')
s = t = 0
for c, e in enumerate(input, 1):
if e in vowels:
t += c
s += t
return s
| Vowel Recognition | 5bed96b9a68c19d394000b1d | [
"Algorithms",
"Performance"
]
| https://www.codewars.com/kata/5bed96b9a68c19d394000b1d | 6 kyu |
## My problem
I'm currently applying/interviewing for jobs, and as graph problems are one of my weaker points, I'm working on leveling up on them. I noticed that Codewars didn't have a kata of the classic Clone Graph problem yet, so I thought I would fix that. :-)
## Your problem
In this kata you need to clone a connected undirected graph, and return the cloned node of the node orginally sent to your function. In Python (I'll add other languages later) each node in the graph is an instance of this GraphNode class, which is provided for you in the kata:
```
class GraphNode:
def __init__(self, val):
self.val = val # an integer
self.neighbors = [] # a list of GraphNode nodes
```
Here's a visualization of the graph in the fourth basic test, with some description below:
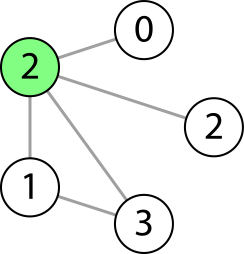
This image represents five GraphNode nodes forming a connected graph, with the gray lines indicating the neighbor relationships between the nodes. The node highlighted in green represents the node that your clone_graph function receives in the fourth basic test -- it has a value of 2, and it has all of the other four nodes as neighbors. Likewise, each of those other four nodes have the highlighted node as a neighbor. The nodes with values of 1 and 3 also have each other as neighbors. Like the highlighted node, the node shown in the rightmost position here also has a value of 2, but they are different nodes. Because it's an undirected graph, where each of a node's neighbors also has that node as its neighbor, you could traverse the graph no matter which node you had been given as a starting point, but an important thing here is that when you create a cloned graph with the same number of nodes having the same values and neighbor relationships to each other, the node your function returns needs to be the cloned node of the node it had received.
Note:
* As shown in the visualization above, nodes in a graph may contain duplicate values.
* Although the highlighted node in the visualization graph above has all the other nodes as its neighbors, don't assume that this will generally be the case -- all nodes in a graph will be connected, but they may be more sparsely connected.
* A node will never be its own neighbor.
* If your function receives None instead of a GraphNode, it should return None.
* You are not allowed to use `deepcopy` in this kata, you will have to do it yourself. :-)
Have fun! | reference | def clone_graph(node):
queue, mp = [node] if node else [], {}
while queue:
cur = queue . pop(0)
mp[cur] = GraphNode(cur . val)
for nd in cur . neighbors:
if nd not in mp:
queue . append(nd)
for k in mp:
mp[k]. neighbors = [mp[nd] for nd in k . neighbors]
return mp . get(node, None)
| Clone Graph | 5c9a6e225ae9822e70abc7c1 | [
"Fundamentals",
"Graph Theory"
]
| https://www.codewars.com/kata/5c9a6e225ae9822e70abc7c1 | 6 kyu |
# Task
In the city, a bus named Fibonacci runs on the road every day.
There are `n` stations on the route. The Bus runs from station<sub>1</sub> to station<sub>n</sub>.
At the departure station(station<sub>1</sub>), `k` passengers get on the bus.
At the second station(station<sub>2</sub>), a certain number of passengers get on and the same number get off. There are still `k` passengers on the bus.
From station<sub>3</sub> to station<sub>n-1</sub>, the number of boarding and alighting passengers follows the following rule:
- At station<sub>i</sub>, the number of people getting on is the sum of the number of people getting on at the two previous stations(station<sub>i-1</sub> and station<sub>i-2</sub>)
- The number of people getting off is equal to the number of people getting on at the previous station(station<sub>i-1</sub>).
At station<sub>n</sub>, all the passengers get off the bus.
Now, The numbers we know are: `k` passengers get on the bus at station<sub>1</sub>, `n` stations in total, `m` passengers get off the bus at station<sub>n</sub>.
We want to know: How many passengers on the bus when the bus runs out station<sub>x</sub>.
# Input
- `k`: The number of passengers get on the bus at station<sub>1</sub>.
- `1 <= k <= 100`
- `n`: The total number of stations(1-based).
- `6 <= n <= 30`
- `m`: The number of passengers get off the bus at station<sub>n</sub>.
- `1 <= m <= 10^10`
- `x`: Station<sub>x</sub>(1-based). The station we need to calculate.
- `3 <= m <= n-1`
- All inputs are valid integers.
# Output
An integer. The number of passengers on the bus when the bus runs out station<sub>x</sub>.
| algorithms | def sim(k, n, p):
r = [(k, k, 0), (k, p, p)]
for i in range(n - 2):
u, d = r[0][1] + r[1][1], r[1][1]
r = [r[1], (r[1][0] + u - d, u, d)]
return r[1][0]
def calc(k, n, m, x):
z, o = sim(k, n - 1, 0), sim(k, n - 1, 1)
return sim(k, x, (m - z) / / (o - z))
| Kata 2019: Fibonacci Bus | 5c2c0c5e2f172f0fae21729f | [
"Mathematics",
"Algorithms"
]
| https://www.codewars.com/kata/5c2c0c5e2f172f0fae21729f | 6 kyu |
*This kata is based on [Project Euler Problem #349](https://projecteuler.net/problem=349). You may want to start with solving [this kata](https://www.codewars.com/kata/langtons-ant) first.*
### Task
[Langton's ant](https://en.wikipedia.org/wiki/Langton%27s_ant) moves on a regular grid of squares that are coloured either black or white.
The ant is always oriented in one of the cardinal directions (left, right, up or down) and moves according to the following rules:
- if it is on a black square, it flips the colour of the square to white, rotates 90 degrees counterclockwise (left) and moves forward one square.
- if it is on a white square, it flips the colour of the square to black, rotates 90 degrees clockwise (right) and moves forward one square.
Starting with a grid that is **entirely white**, how many squares are black after `n` moves of the ant?
**Note:** `n` will go as high as 10<sup>20</sup>
---
### My other katas
If you enjoyed this kata then please try [my other katas](https://www.codewars.com/users/anter69/authored)! :-)
#### *Translations are welcome!* | algorithms | # precalculate results
LIMIT = 11000 # > 9977 + 104
CACHE = [0]
GRID = set() # empty grid
x, y = 0, 0 # ant's position
dx, dy = 1, 0 # direction
for _ in range(LIMIT + 1):
if (x, y) in GRID: # square is black
GRID . remove((x, y))
dx, dy = - dy, dx
else: # square is white
GRID . add((x, y))
dx, dy = dy, - dx
# move forward
x += dx
y += dy
# store number of black squares
CACHE . append(len(GRID))
def langtons_ant(n):
if n < LIMIT:
return CACHE[n]
# a(n+104) = a(n) + 12 for n > 9976
x = (n - LIMIT) / / 104 + 1
return CACHE[n - x * 104] + x * 12
| Langton's Ant - Advanced Version | 5c99553d5c67244b60cb5722 | [
"Mathematics",
"Performance",
"Algorithms"
]
| https://www.codewars.com/kata/5c99553d5c67244b60cb5722 | 5 kyu |
A Magic Square contains the integers 1 to n<sup>2</sup>, arranged in an n by n array such that the columns, rows and both main diagonals add up to the same number.<br/>For doubly even positive integers (multiples of 4) the following method can be used to create a magic square.<br/>
Fill an array with the numbers 1 to n<sup>2</sup> in succession. Then, for each 4 by 4 subarray, replace the entries on the blue and red diagonals by n<sup>2</sup>+1-a<sub>ij</sub>.<br/>
So, in the following example, a<sub>11</sub> (row 1, column 1) was initially 1 and is replaced by 8<sup>2</sup>+1-1 = 64
<style type="text/css">
tab1 { padding-left: 2em; }
fc1 { font color="blue"}
</style>
<h5><code>
n=8<br/><br/>
<font color="blue">64</font><tab1>2 <tab1>3 <tab1><font color="red">61</font><tab1><font color="blue">60</font><tab1>6 <tab1>7 <tab1><font color="red">57</font><br/>
9 <tab1><font color="blue">55</font><tab1><font color="red">54</font><tab1>12<tab1>13<tab1><font color="blue">51</font><tab1><font color="red">50</font><tab1>16<br/>
17<tab1><font color="red">47</font><tab1><font color="blue">46</font><tab1>20<tab1>21<tab1><font color="red">43</font><tab1><font color="blue">42</font><tab1>24<br/>
<font color="red">40</font><tab1>26<tab1>27<tab1><font color="blue">37</font><tab1><font color="red">36</font><tab1>30<tab1>31<tab1><font color="blue">33</font><br/>
<font color="blue">32</font><tab1>34<tab1>35<tab1><font color="red">29</font><tab1><font color="blue">28</font><tab1>38<tab1>39<tab1><font color="red">25</font><br/>
41<tab1><font color="blue">23</font><tab1><font color="red">22</font><tab1>44<tab1>45<tab1><font color="blue">19</font><tab1><font color="red">18</font><tab1>48<br/>
49<tab1><font color="red">15</font><tab1><font color="blue">14</font><tab1>52<tab1>53<tab1><font color="red">11</font><tab1><font color="blue">10</font><tab1>56<br/>
<font color="red">8 </font><tab1>58<tab1>59<tab1><font color="blue">5 </font><tab1><font color="red">4 </font><tab1>62<tab1>63<tab1><font color="blue">1</font> <br/>
</code></h5>
<br />The function even_magic() should return a 2D array as follows:-<br/>
Example:
<h5><code>n=4: Output: [[16,2,3,13],[5,11,10,8],[9,7,6,12],[4,14,15,1]]
<br /><br/>
16<tab1>2 <tab1>3 <tab1>13<br/>
5 <tab1>11<tab1>10<tab1>8 <br/>
9 <tab1>7 <tab1>6 <tab1>12<br/>
4 <tab1>14<tab1>15<tab1>1 <br/>
</code></h5>
Only doubly even numbers will be passed to the function in the tests.
See <a href="http://mathworld.wolfram.com/MagicSquare.html">mathworld.wolfram.com</a> for further details. | games | def even_magic(n):
return [[n * n - (y * n + x) if x % 4 == y % 4 or (x % 4 + y % 4) % 4 == 3 else y * n + x + 1 for x in range(n)] for y in range(n)]
| Double Even Magic Square | 570e0a6ce5c9a0a8c4000bbb | [
"Fundamentals",
"Puzzles",
"Arrays",
"Mathematics"
]
| https://www.codewars.com/kata/570e0a6ce5c9a0a8c4000bbb | 6 kyu |
*Based on this Numberphile video: https://www.youtube.com/watch?v=Wim9WJeDTHQ*
---
Multiply all the digits of a nonnegative integer `n` by each other, repeating with the product until a single digit is obtained. The number of steps required is known as the **multiplicative persistence**.
Create a function that calculates the individual results of each step, not including the original number, but including the single digit, and outputs the result as a list/array. If the input is a single digit, return an empty list/array.
## Examples
```
per(1) = []
per(10) = [0]
// 1*0 = 0
per(69) = [54, 20, 0]
// 6*9 = 54 --> 5*4 = 20 --> 2*0 = 0
per(277777788888899) = [4996238671872, 438939648, 4478976, 338688, 27648, 2688, 768, 336, 54, 20, 0]
// 2*7*7*7*7*7*7*8*8*8*8*8*8*9*9 = 4996238671872 --> 4*9*9*6*2*3*8*6*7*1*8*7*2 = 4478976 --> ...
``` | algorithms | def per(n):
r = []
while n >= 10:
p = 1
for i in str(n):
p = p * int(i)
r . append(p)
n = p
return r
| Multiplicative Persistence... What's special about 277777788888899? | 5c942f40bc4575001a3ea7ec | [
"Algorithms"
]
| https://www.codewars.com/kata/5c942f40bc4575001a3ea7ec | 7 kyu |
Given a string `s` and a character `c`, return an array of integers representing the shortest distance from the current character in `s` to `c`.
### Notes
* All letters will be lowercase.
* If the string is empty, return an empty array.
* If the character is not present, return an empty array.
## Examples
```
s = "lovecodewars"
c = "e"
result = [3, 2, 1, 0, 1, 2, 1, 0, 1, 2, 3, 4]
s = "aaaabbbb"
c = "b"
result = [4, 3, 2, 1, 0, 0, 0, 0]
s = ""
c = "b"
result = []
s = "abcde"
c = ""
result = []
```
___
If you liked it, please rate :D | algorithms | def shortest_to_char(s, c):
if not s or not c:
return []
indexes = [i for i, ch in enumerate(s) if ch == c]
if not indexes:
return []
return [min(abs(i - ic) for ic in indexes) for i in range(len(s))]
| Shortest Distance to a Character | 5c8bf3ec5048ca2c8e954bf3 | [
"Strings",
"Algorithms"
]
| https://www.codewars.com/kata/5c8bf3ec5048ca2c8e954bf3 | 6 kyu |
You have read the title: you must guess a sequence. It will have something to do with the number given.
## Example
```
x = 16
result = [1, 10, 11, 12, 13, 14, 15, 16, 2, 3, 4, 5, 6, 7, 8, 9]
```
Good luck!
| algorithms | def sequence(x):
return sorted(range(1, x + 1), key=str)
| Guess the Sequence | 5b45e4b3f41dd36bf9000090 | [
"Puzzles",
"Algorithms"
]
| https://www.codewars.com/kata/5b45e4b3f41dd36bf9000090 | 7 kyu |
*This kata is inspired by [Project Euler Problem #387](https://projecteuler.net/problem=387)*
### Description
A [Harshad number](https://en.wikipedia.org/wiki/Harshad_number) (or Niven number) is a number that is divisible by the sum of its digits. A *right truncatable Harshad number* is any Harshad number that, when recursively right-truncated, results in a Harshad number at each truncation. By definition, 1-digit numbers are **not** right truncatable Harshad numbers.
For example `201` (which is a Harshad number) yields `20`, then `2` when right-truncated, which are all Harshad numbers. Thus `201` is a *right truncatable Harshad number*.
### Your task
Given a range of numbers (`a..b`, both included), return the list of right truncatable Harshad numbers in this range.
```if-not:javascript
Note: there are `500` random tests, with 0 <= `a` <= `b` <= 10<sup>16</sup>
```
```if:javascript
Note: there are `500` random tests, with `0 <= a <= b <= Number.MAX_SAFE_INTEGER`
```
### Examples
```
0, 20 --> [10, 12, 18, 20]
30, 100 --> [30, 36, 40, 42, 45, 48, 50, 54, 60, 63, 70, 72, 80, 81, 84, 90, 100]
90, 200 --> [90, 100, 102, 108, 120, 126, 180, 200]
200, 210 --> [200, 201, 204, 207, 209, 210]
1000, 2000 --> [1000, 1002, 1008, 1020, 1026, 1080, 1088, 1200, 1204, 1206, 1260, 1800, 2000]
2200, 2300 --> []
9000002182976, 9000195371842 --> [9000004000000, 9000004000008]
```
---
### My other katas
If you enjoyed this kata then please try [my other katas](https://www.codewars.com/users/anter69/authored)! :-)
#### *Translations are welcome!* | algorithms | def gen(n):
if n >= 10 * * 16:
return
for i in range(10):
x = 10 * n + i
if x % sum(map(int, str(x))):
continue
yield x
for y in gen(x):
yield y
L = sorted(x for n in range(1, 10) for x in gen(n))
from bisect import bisect_left as bl, bisect_right as br
def rthn_between(a, b):
return L[bl(L, a): br(L, b)]
| Right Truncatable Harshad numbers | 5c824b7b9775761ada934500 | [
"Mathematics",
"Number Theory",
"Algorithms"
]
| https://www.codewars.com/kata/5c824b7b9775761ada934500 | 5 kyu |
[Haikus](https://en.wikipedia.org/wiki/Haiku_in_English) are short poems in a three-line format, with 17 syllables arranged in a 5–7–5 pattern. Your task is to check if the supplied text is a haiku or not.
#### About syllables
[Syllables](https://en.wikipedia.org/wiki/Syllable) are the phonological building blocks of words. *In this kata*, a syllable is a part of a word including a vowel ("a-e-i-o-u-y") or a group of vowels (e.g. "ou", "ee", "ay"). A few examples: *"tea", "can", "to·day", "week·end", "el·e·phant".*
**However**, silent "E"s **do not** create syllables. *In this kata*, an "E" is considered silent if it's alone at the end of the word, preceded by one (or more) consonant(s) and there is at least one other syllable in the word. Examples: *"age", "ar·range", "con·crete";* but not in *"she", "blue", "de·gree".*
Some more examples:
* one syllable words: *"cat", "cool", "sprout", "like", "eye", "squeeze"*
* two syllables words: *"ac·count", "hon·est", "beau·ty", "a·live", "be·cause", "re·store"*
### Examples
```
An old silent pond...
A frog jumps into the pond,
splash! Silence again.
```
...should return `True`, as this is a valid 5–7–5 haiku:
```
An old si·lent pond... # 5 syllables
A frog jumps in·to the pond, # 7
splash! Si·lence a·gain. # 5
```
Another example:
```
Autumn moonlight -
a worm digs silently
into the chestnut.
```
...should return `False`, because the number of syllables per line is not correct:
```
Au·tumn moon·light - # 4 syllables
a worm digs si·lent·ly # 6
in·to the chest·nut. # 5
```
---
### My other katas
If you enjoyed this kata then please try [my other katas](https://www.codewars.com/users/anter69/authored)! :-)
#### *Translations are welcome!* | algorithms | import re
PATTERN = re . compile(r'[aeyuio]+[^aeyuio ]*((?=e\b)e)?', flags=re . I)
def is_haiku(text):
return [5, 7, 5] == [check(s) for s in text . split("\n")]
def check(s):
return sum(1 for _ in PATTERN . finditer(s))
| Haiku Checker | 5c765a4f29e50e391e1414d4 | [
"Algorithms"
]
| https://www.codewars.com/kata/5c765a4f29e50e391e1414d4 | 5 kyu |
### Description
Lets imagine a yoga classroom as a Square 2D Array of Integers ```classroom```, with each integer representing a person, and the value representing their skill level.
```
classroom = [
[3,2,1,3],
[1,3,2,1],
[1,1,1,2],
]
poses = [1,7,5,9,10,21,4,3]
```
During a yoga class the instructor gives a list of integers ```poses``` representing a yoga pose that each person in the class will attempt to complete.
A person can complete a yoga pose if the sum of their row and their skill level is greater than or equal to the value of the pose.
### Task
Your task is to return the total amount poses completed for the entire ```classroom```.
### Example
```
classroom = [
[1,1,0,1], #sum = 3
[2,0,6,0], #sum = 8
[0,2,2,0], #sum = 4
]
poses = [4, 0, 20, 10]
3 people in row 1 can complete the first pose
Everybody in row 1 can complete the second pose
Nobody in row 1 can complete the third pose
Nobody in row 1 can complete the fourth pose
The total poses completed for row 1 is 7
You'll need to return the total for all rows and all poses.
```
Translations are welcomed! | algorithms | def yoga(classroom, poses):
total_poses = 0
for pose in poses:
for row in classroom:
for person in row:
if person + sum(row) >= pose:
total_poses += 1
return total_poses
| Yoga Class | 5c79c07b4ba1e100097f4e1a | [
"Mathematics",
"Fundamentals",
"Algorithms"
]
| https://www.codewars.com/kata/5c79c07b4ba1e100097f4e1a | 7 kyu |
Create a Regular Expression that matches a string with lowercase characters in alphabetical order, including any number of spaces. There can be NO whitespace between groups of the same letter. Leading and trailing whitespace is also allowed. An empty string should match.
Your regex should match:
```
""
"abc"
"aaabc "
"a bc"
" abcdefghijk"
"abdfkmnpstvxz"
"cxy"
"cdklstxy"
"bfrtw"
"a b c "
" acg jko pr"
"a z "
"v z"
"a b cdefg kl"
"uv xyz"
" ab de gh"
"x yz"
"abcdefghijklmnopqrstuvwxyz"
"a bcdefghijklmnopqrstuvwxyz"
```
It should NOT match:
```
"abcb"
"a ab"
"abccc cd"
"a bcdjkrza"
"qwerty"
"zyxcba"
"abcdfe"
"ab c dfe"
"a z a"
"asdfg"
"asd f g"
"poqwoieruytjhfg"
"\tab"
"abc\n"
```
____
This tools may help you:
* [Cheat sheet](https://www.rexegg.com/regex-quickstart.html)
* [Online tester](https://regex101.com/) | algorithms | REGEX = r'^ *a* *b* *c* *d* *e* *f* *g* *h* *i* *j* *k* *l* *m* *n* *o* *p* *q* *r* *s* *t* *u* *v* *w* *x* *y* *z* *\Z'
| RegEx Like a Boss #2: Alphabetical Order String | 5c1a334516537ccd450000d8 | [
"Regular Expressions",
"Algorithms"
]
| https://www.codewars.com/kata/5c1a334516537ccd450000d8 | 7 kyu |
Convert hex-encoded (https://en.wikipedia.org/wiki/Hexadecimal) string to base64 (https://en.wikipedia.org/wiki/Base64)
Example:
The string:
49276d206b696c6c696e6720796f757220627261696e206c696b65206120706f69736f6e6f7573206d757368726f6f6d
Should produce:
SSdtIGtpbGxpbmcgeW91ciBicmFpbiBsaWtlIGEgcG9pc29ub3VzIG11c2hyb29t
| algorithms | from base64 import b64encode
def hex_to_base64(h: str) - > str:
return b64encode(bytes . fromhex(h)). decode()
| Hex to base64 | 5b360fcc9212cb0cf300001f | [
"Strings",
"Algorithms"
]
| https://www.codewars.com/kata/5b360fcc9212cb0cf300001f | 6 kyu |
### Description
As hex values can include letters `A` through to `F`, certain English words can be spelled out, such as `CAFE`, `BEEF`, or `FACADE`.
This vocabulary can be extended by using numbers to represent other letters, such as `5EAF00D`, or `DEC0DE5`.
Given a string, your task is to return the decimal sum of all words in the string that can be interpreted as such hex values.
### Example
Working with the string `"BAG OF BEES"`:
```
"BAG" = 0, as it is not a valid hex value
"OF" = 0F = 15
"BEES" = BEE5 = 48869
```
So the result is the sum of these: 48884 (0 + 15 + 48869)
### Notes
* Inputs are all uppercase and contain no punctuation
* `0` can be substituted for `O`
* `5` can be substituted for `S`
| reference | def hex_word_sum(s):
return sum(int(w, 16) for w in s . translate(str . maketrans('OS', '05')). split() if set(w) <= set('0123456789ABCDEF'))
| Hex Word Sum | 5c46ea433dd41b19af1ca3b3 | [
"Fundamentals",
"Strings"
]
| https://www.codewars.com/kata/5c46ea433dd41b19af1ca3b3 | 7 kyu |
In some ranking people collects points. The challenge is sort by points and calulate position for every person. But remember if two or more persons have same number of points, they should have same position number and sorted by name (name is unique).
For example:
Input structure:
```javascript
[
{
name: "John",
points: 100,
},
{
name: "Bob",
points: 130,
},
{
name: "Mary",
points: 120,
},
{
name: "Kate",
points: 120,
},
]
```
```php
[
[
"name" => "John",
"points" => 100,
],
[
"name" => "Bob",
"points" => 130,
],
[
"name" => "Mary",
"points" => 120,
],
[
"name" => "Kate",
"points" => 120,
],
]
```
Output should be:
```javascript
[
{
name: "Bob",
points: 130,
position: 1,
},
{
name: "Kate",
points: 120,
position: 2,
},
{
name: "Mary",
points: 120,
position: 2,
},
{
name: "John",
points: 100,
position: 4,
},
]
```
```php
[
[
"name" => "Bob",
"points" => 130,
"position" => 1,
],
[
"name" => "Kate",
"points" => 120,
"position" => 2,
],
[
"name" => "Mary",
"points" => 120,
"position" => 2,
],
[
"name" => "John",
"points" => 100,
"position" => 4,
],
]
``` | algorithms | def ranking(a):
a . sort(key=lambda x: (- x["points"], x["name"]))
for i, x in enumerate(a):
x["position"] = i + 1 if not i or x["points"] < a[i -
1]["points"] else a[i - 1]["position"]
return a
| Ranking position | 5c784110bfe2ef660cb90369 | [
"Algorithms"
]
| https://www.codewars.com/kata/5c784110bfe2ef660cb90369 | 7 kyu |
___
### Background
Moving average of a set of values and a window size is a series of local averages.
```
Example:
Values: [1, 2, 3, 4, 5]
Window size: 3
Moving average is calculated as:
1, 2, 3, 4, 5
| |
^^^^^^^
(1+2+3)/3 = 2
1, 2, 3, 4, 5
| |
^^^^^^^
(2+3+4)/3 = 3
1, 2, 3, 4, 5
| |
^^^^^^^
(3+4+5)/3 = 4
Here, the moving average would be [2, 3, 4]
```
----
### Task
Given a list `values` of integers and an integer `n` representing size of the window, calculate and return the moving average.
When integer `n` is equal to zero or the size of `values` list is less than window's size, return `None`
---
Reference: [Moving average](https://en.wikipedia.org/wiki/Moving_average) | algorithms | def moving_average(a, n):
if 0 < n <= len(a):
return [sum(a[i: i + n]) / n for i in range(len(a) - n + 1)]
| Moving Average | 5c745b30f6216a301dc4dda5 | [
"Algorithms",
"Logic",
"Mathematics",
"Lists"
]
| https://www.codewars.com/kata/5c745b30f6216a301dc4dda5 | 7 kyu |
Given the current exchange rate between the USD and the EUR is 1.1363636 write a function that will accept the Curency type to be returned and a list of the amounts that need to be converted.
Don't forget this is a currency so the result will need to be rounded to the second decimal.
'USD' Return format should be `'$100,000.00'`
'EUR' Return format for this kata should be `'100,000.00€'`
`to_currency` is a string with values `'USD','EUR'` , `values_list` is a list of floats
`solution(to_currency,values)`
#EXAMPLES:
```
solution('USD',[1394.0, 250.85, 721.3, 911.25, 1170.67])
= ['$1,584.09', '$285.06', '$819.66', '$1,035.51', '$1,330.31']
solution('EUR',[109.45, 640.31, 1310.99, 669.51, 415.54])
= ['96.32€', '563.47€', '1,153.67€', '589.17€', '365.68€']
```
| reference | def solution(to, lst):
dolSym, eurSym, power = ('', '€', - 1) if to == 'EUR' else ('$', '', 1)
return [f" { dolSym }{ v * 1.1363636 * * power :, .2 f }{ eurSym } " for v in lst]
| Converting Currency II | 5c744111cb0cdd3206f96665 | [
"Lists",
"Mathematics",
"Fundamentals",
"Algorithms",
"Algebra",
"Strings"
]
| https://www.codewars.com/kata/5c744111cb0cdd3206f96665 | 7 kyu |
## Description
You've been working with a lot of different file types recently as your interests have broadened.
But what file types are you using the most? With this question in mind we look at the following problem.
Given a `List/Array` of Filenames (strings) `files` return a `List/Array of string(s)` containing the most common extension(s). If there is a tie, return a sorted list of all extensions.
### Important Info:
* Don't forget, you've been working with a lot of different file types, so expect some interesting extensions/file names/lengths in the random tests.
* Filenames and extensions will only contain letters (case sensitive), and numbers.
* If a file has multiple extensions (ie: `mysong.mp3.als`) only count the last extension (`.als` in this case)
## Examples
```
files = ['Lakey - Better days.mp3',
'Wheathan - Superlove.wav',
'groovy jam.als',
'#4 final mixdown.als',
'album cover.ps',
'good nights.mp3']
```
would return: `['.als', '.mp3']`, as both of the extensions appear two times in files.
```
files = ['Lakey - Better days.mp3',
'Fisher - Stop it.mp3',
'Fisher - Losing it.mp3',
'#4 final mixdown.als',
'album cover.ps',
'good nights.mp3']
```
would return `['.mp3']`, because it appears more times then any other extension, and no other extension has an equal amount of appearences. | reference | from collections import Counter
import re
def solve(files):
c = Counter(re . match('.*(\.[^.]+)$', fn). group(1) for fn in files)
m = max(c . values(), default=0)
return sorted(k for k in c if c[k] == m)
| Which filetypes are you using the most? | 5c7254fcaccda64d01907710 | [
"Fundamentals",
"Algorithms",
"Strings",
"Arrays"
]
| https://www.codewars.com/kata/5c7254fcaccda64d01907710 | 6 kyu |
# Echo Program
Write an <code>echoProgram</code> function (or <code>echo_program</code> depend on language) that returns your solution source code as a string.
~~~if:javascript
### Note:
`Function.prototype.toString` has been disabled.
~~~ | games | def echo_program():
return open(__file__). read()
| Echo | 5c6dc504abcd1628cd174bea | [
"Puzzles",
"Strings",
"Games"
]
| https://www.codewars.com/kata/5c6dc504abcd1628cd174bea | 7 kyu |
Koch curve is a simple geometric fractal.
This fractal is constructed as follows: take a segment divided into three equal parts. Instead of the middle part, two identical segments are inserted, set at an angle of 60 degrees to each other.
This process is repeated at each iteration: each segment is replaced by four.
You must write a program that takes the number n and returns an array of rotation angles when drawing a line from the starting point to the ending point. The rotation angle is positive in a counterclockwise direction.

Input: An integer `n` (`0 <= n <= 8`)
Output: An array of angles of rotation. The angle of rotation must be in the interval [-180; 180]. For example, for `n == 0` should return an empty array and for `n == 1` the answer should be `[60, -120, 60]` | reference | def koch_curve(n):
if not n:
return []
deep = koch_curve(n - 1)
return [* deep, 60, * deep, - 120, * deep, 60, * deep]
| Koch curve | 5c5abf56052d1c0001b22ce5 | [
"Algorithms",
"Fundamentals"
]
| https://www.codewars.com/kata/5c5abf56052d1c0001b22ce5 | 7 kyu |
You are given array of integers, your task will be to count all pairs in that array and return their count.
**Notes:**
* Array can be empty or contain only one value; in this case return `0`
* If there are more pairs of a certain number, count each pair only once. E.g.: for `[0, 0, 0, 0]` the return value is `2` (= 2 pairs of `0`s)
* Random tests: maximum array length is 1000, range of values in array is between 0 and 1000
## Examples
```
[1, 2, 5, 6, 5, 2] --> 2
```
...because there are 2 pairs: `2` and `5`
```
[1, 2, 2, 20, 6, 20, 2, 6, 2] --> 4
```
...because there are 4 pairs: `2`, `20`, `6` and `2` (again)
| reference | def duplicates(arr):
return sum(arr . count(i) / / 2 for i in set(arr))
| Find all pairs | 5c55ad8c9d76d41a62b4ede3 | [
"Fundamentals",
"Arrays"
]
| https://www.codewars.com/kata/5c55ad8c9d76d41a62b4ede3 | 7 kyu |
<h2> INTRODUCTION </h2>
<p> The Club Doorman will give you a word. To enter the Club you need to provide the right number according to provided the word.</p>
<p>Every given word has a doubled letter, like 'tt' in lettuce.</p>
<p>To answer the right number you need to find the doubled letter's position of the given word in the alphabet and multiply this number per 3.
<p>It will be given only words with one doubled letter.</p>
</p>
</br>
<pre><h2>EXAMPLE</h2></pre>
<code><p>
Lettuce is the given word. 't' is the doubled letter and it's position is 20 in the alphabet.</p>
<p>The answer to the Club Doorman is 20 * 3 = 60
</p></code>
</br>
<h2>TASK</h2>
<p>The function passTheDoorMan with a given string <code>word</code> shall return the right number. | reference | def pass_the_door_man(word):
for i in word:
if i * 2 in word:
return (ord(i) - 96) * 3
| Club Doorman | 5c563cb78dac1951c2d60f01 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5c563cb78dac1951c2d60f01 | 7 kyu |
Mr. Square is going on a holiday. He wants to bring 2 of his favorite squares with him, so he put them in his rectangle suitcase.
Write a function that, given the size of the squares and the suitcase, return whether the squares can fit inside the suitcase.
```Python
fit_in(a,b,m,n)
a,b are the sizes of the 2 squares
m,n are the sizes of the suitcase
```
# Example
```Python
fit_in(1,2,3,2) should return True
fit_in(1,2,2,1) should return False
fit_in(3,2,3,2) should return False
fit_in(1,2,1,2) should return False
```
| games | def fit_in(a, b, m, n):
return max(a, b) <= min(m, n) and a + b <= max(m, n)
| Suitcase packing | 5c556845d7e0334c74698706 | [
"Puzzles"
]
| https://www.codewars.com/kata/5c556845d7e0334c74698706 | 7 kyu |
There exist two zeroes: +0 (or just 0) and -0.
Write a function that returns `true` if the input number is -0 and `false` otherwise (`True` and `False` for Python).
In JavaScript / TypeScript / Coffeescript the input will be a number.
In Python / Java / C / NASM / Haskell / the input will be a float.
| reference | def is_negative_zero(n):
return str(n) == '-0.0'
| Is It Negative Zero (-0)? | 5c5086287bc6600001c7589a | [
"Fundamentals"
]
| https://www.codewars.com/kata/5c5086287bc6600001c7589a | 7 kyu |
## Description
For this Kata you will be given an array of numbers and another number `n`.
You have to find the **sum** of the `n` largest numbers of the array and the **product** of the `n` smallest numbers of the array, and compare the two.
If the sum of the `n` largest numbers is higher, return `"sum"`
If the product of the `n` smallest numbers is higher, return `"product"`
If the 2 values are equal, return `"same"`
**Note** The array will never be empty and `n` will always be smaller than the length of the array.
## Example
```javascript
sumOrProduct([10, 41, 8, 16, 20, 36, 9, 13, 20], 3) // => "product"
```
```haskell
productOrSum [10, 41, 8, 16, 20, 36, 9, 13, 20] 3 -> Product
```
```rust
sum_or_product(&[10, 41, 8, 16, 20, 36, 9, 13, 20], 3) // => "product"
```
```python
sum_or_product([10, 41, 8, 16, 20, 36, 9, 13, 20], 3) # => "product"
```
```julia
sumorproduct([10, 41, 8, 16, 20, 36, 9, 13, 20], 3) # => "product"
```
## Explanation
The sum of the 3 highest numbers is `41 + 36 + 20 = 97`
The product of the lowest 3 numbers is `8 x 9 x 10 = 720`
The product of the 3 lowest numbers is higher than the sum of the 3 highest numbers so the function returns `"product"`
~~~if:haskell
## Note
The return datatype has been Preloaded for you. It is
data ProductOrSum = Product | Same | Sum deriving (Eq,Ord,Enum,Bounded,Show)
~~~ | reference | from math import prod
def sum_or_product(array, n):
array . sort()
n_sum = sum(array[- n:])
n_prod = prod(array[: n])
return "sum" if n_sum > n_prod else "product" if n_sum < n_prod else "same"
| Larger Product or Sum | 5c4cb8fc3cf185147a5bdd02 | [
"Fundamentals",
"Mathematics",
"Algorithms"
]
| https://www.codewars.com/kata/5c4cb8fc3cf185147a5bdd02 | 7 kyu |
Given 2 elevators (named "left" and "right") in a building with 3 floors (numbered `0` to `2`), write a function `elevator` accepting 3 arguments (in order):
- `left` - The current floor of the left elevator
- `right` - The current floor of the right elevator
- `call` - The floor that called an elevator
It should return the name of the elevator closest to the called floor (`"left"`/`"right"`).
In the case where both elevators are equally distant from the called floor, choose the elevator to the right.
You can assume that the inputs will always be valid integers between 0-2.
Examples:
```javascript
elevator(0, 1, 0); // => "left"
elevator(0, 1, 1); // => "right"
elevator(0, 1, 2); // => "right"
elevator(0, 0, 0); // => "right"
elevator(0, 2, 1); // => "right"
```
```python
elevator(0, 1, 0) # => "left"
elevator(0, 1, 1) # => "right"
elevator(0, 1, 2) # => "right"
elevator(0, 0, 0) # => "right"
elevator(0, 2, 1) # => "right"
```
```kotlin
elevator(0, 1, 0) // => "left"
elevator(0, 1, 1) // => "right"
elevator(0, 1, 2) // => "right"
elevator(0, 0, 0) // => "right"
elevator(0, 2, 1) // => "right"
```
```purescript
elevator 0 1 0 -- => "left"
elevator 0 1 1 -- => "right"
elevator 0 1 2 -- => "right"
elevator 0 0 0 -- => "right"
elevator 0 2 1 -- => "right"
```
```racket
(elevator 0 1 0) ; "left"
(elevator 0 1 1) ; "right"
(elevator 0 1 2) ; "right"
(elevator 0 0 0) ; "right"
(elevator 0 2 1) ; "right"
``` | algorithms | def elevator(left, right, call):
return "left" if abs(call - left) < abs(call - right) else "right"
| Closest elevator | 5c374b346a5d0f77af500a5a | [
"Algorithms"
]
| https://www.codewars.com/kata/5c374b346a5d0f77af500a5a | 8 kyu |
Write a function that returns the number of arguments it received.
```
args_count() --> 0
args_count('a') --> 1
args_count('a', 'b') --> 2
```
```if:python,ruby
The function must work for keyword arguments too:
```
```if:python
~~~
args_count(x=10, y=20, 'z') --> 3
~~~
```
```if:ruby
~~~
args_count(x:10, y:20, 'z') --> 3
~~~
``` | reference | def args_count(* args, * * kwargs):
return len(args) + len(kwargs)
| How many arguments | 5c44b0b200ce187106452139 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5c44b0b200ce187106452139 | 7 kyu |
The dominoes in a full set come in a couple of types. For each number of pips there is a double domino, ranging from double blank represented `[0, 0]` up to double six, sometimes nine, fifteen, or in general `[n, n]`. Then there are all combinations of different numbers. For instance, a standard set has a single domino with a blank on one end and six pips on the other, which could be represented either as `[0, 6]` or equivalently `[6, 0]`.
Imagine you are given two identical sets of dominoes, except that the doubles from one set are removed. For instance, if the sets have at most `n=2` pips, then you have `[0, 1]`, `[0, 2]`, and `[1, 2]` from both sets, but you're given only a single `[0, 0]`, `[1, 1]`, and `[2, 2]`. In general there will be `(n + 1) * (n + 1)` dominoes to work with. Your task is to line up all these dominoes end to end such that the values on adjacent dominoes match where they meet. This sequence of dominoes is called a train.
The input is a single number, e.g. `n=2` as the max, and the output is a list such as `[0, 1, 1, 0, 2, 1, 2, 2, 0, 0]` which represents the values where dominoes meet, capped by the values at each end. In other words, this list is interpreted as the train `[0, 1]`, `[1, 1]`, `[1, 0]`, `[0, 2]`, `[2, 1]`, `[1, 2]`, `[2, 2]`, `[2, 0]`, `[0, 0]`. Other possibilities with all these dominoes in a different order could also be accepted as correct.
Graph theory proves there is always a valid solution, but neither a graph nor too much theory are needed to generate one quickly. Best of luck! `:~)` | games | def domino(n):
for a in range(n + 1):
for b in range(a):
yield b
yield a
yield a
yield 0
def domino_train(n):
return list(domino(n))
| Train of dominoes | 5c356d3977bd7254d7191403 | [
"Puzzles",
"Graph Theory"
]
| https://www.codewars.com/kata/5c356d3977bd7254d7191403 | 5 kyu |
Return the `n`th term of the Recamán's sequence.
```
a(0) = 0;
a(n-1) - n, if this value is positive and not yet in the sequence
/
a(n) <
\
a(n-1) + n, otherwise
```
Input range: 0 – 30,000
___
A video about Recamán's sequence by Numberphile: https://www.youtube.com/watch?v=FGC5TdIiT9U | algorithms | def recaman(n):
series, last = {0}, 0
for i in range(1, n + 1):
test = last - i
last = last + i if test < 0 or test in series else test
series . add(last)
return last
| Recaman Sequence | 5c3f31c2460e9b4020780aa2 | [
"Algorithms",
"Performance"
]
| https://www.codewars.com/kata/5c3f31c2460e9b4020780aa2 | 7 kyu |
# Task
John is an orchard worker.
There are `n` piles of fruits waiting to be transported. Each pile of fruit has a corresponding weight. John's job is to combine the fruits into a pile and wait for the truck to take them away.
Every time, John can combine any two piles(`may be adjacent piles, or not`), and the energy he costs is equal to the weight of the two piles of fruit.
For example, if there are two piles, pile1's weight is `1` and pile2's weight is `2`. After merging, the new pile's weight is `3`, and he consumed 3 units of energy.
John wants to combine all the fruits into 1 pile with the least energy.
Your task is to help John, calculate the minimum energy he costs.
# Input
- `fruits`: An array of positive integers. Each element represents the weight of a pile of fruit.
Javascript:
- 1 <= fruits.length <= 10000
- 1 <= fruits[i] <= 10000
Python:
- 1 <= len(fruits) <= 5000
- 1 <= fruits[i] <= 10000
# Output
An integer. the minimum energy John costs.
# Examples
For `fruits = [1,2,9]`, the output should be `15`.
```
3 piles: 1 2 9
combine 1 and 2 to 3, cost 3 units of energy.
2 piles: 3 9
combine 3 and 9 to 12, cost 12 units of energy.
1 pile: 12
The total units of energy is 3 + 12 = 15 units
```
For `fruits = [100]`, the output should be `0`.
There's only 1 pile. So no need combine it. | algorithms | from heapq import heappop, heappush
def comb(fruits):
total, heap = 0, sorted(fruits)
while len(heap) > 1:
cost = heappop(heap) + heappop(heap)
heappush(heap, cost)
total += cost
return total
| Kata 2019: Combine Fruits | 5c2ab63b1debff404a46bd12 | [
"Algorithms",
"Performance"
]
| https://www.codewars.com/kata/5c2ab63b1debff404a46bd12 | 6 kyu |
## Task
Given an array of strings, reverse them and their order in such way that their length stays the same as the length of the original inputs.
### Example:
```
Input: {"I", "like", "big", "butts", "and", "I", "cannot", "lie!"}
Output: {"!", "eilt", "onn", "acIdn", "ast", "t", "ubgibe", "kilI"}
```
Good luck! | reference | def reverse(a):
s = reversed('' . join(a))
return ['' . join(next(s) for _ in w) for w in a]
| Ultimate Array Reverser | 5c3433a4d828182e420f4197 | [
"Fundamentals",
"Algorithms"
]
| https://www.codewars.com/kata/5c3433a4d828182e420f4197 | 7 kyu |
Create a Regular Expression that matches a word consistent only of letter `x`. No other letters will be used. The word has to have prime numbers of letters.
Matching with `re.match()`
Should match:
```
xx
xxx
xxxxx
xxxxxxx
xxxxxxxxxxx
xxxxxxxxxxxxx
```
Should NOT match
```
xxxx
xxxxxx
xxxxxxxx
xxxxxxxxx
xxxxxxxxxx
xxxxxxxxxxxx
xxxxxxxxxxxxxx
xxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxx
```
# CodeGolf restriction
Your REGEX string should be not longer than 40 characters
____
This tools may help you:
[Cheat sheet](https://www.rexegg.com/regex-quickstart.html)
[Online tester](https://regex101.com)
| algorithms | REGEX = r'(?!(xx+)\1+$)xx+$'
| RegEx Like a Boss #4 CodeGolf : Prime length | 5c2cea87b0aea22f8181757c | [
"Regular Expressions",
"Strings",
"Restricted",
"Algorithms"
]
| https://www.codewars.com/kata/5c2cea87b0aea22f8181757c | 5 kyu |
# Task
Numpy has a function [numpy.fmax](https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.fmax.html) which computes the element-wise maximum for two arrays.
However, there are two problems with this: First, you don't want to get numpy just to use this function. Second, you want a *in-place* version of this function because turning an in-place function into one that creates a new object is trivially easy, but the opposite is not true.
In order to justify your rationale of not using numpy, you want to write the function as short as possible.
The function `fmax`, given arguments `a` and `b`, should compute the element-wise maximum of two arrays, and assign the maximum to `a` *in-place*. The return value of `fmax` is arbitrary as you don't care about it.
# Code Limit
At most `36` characters.
# Example
For `a = [1, 2, 3, 4, 5], b = [10, 0, 10, 0, 10]`, `a` should be `[10, 2, 10, 4, 10]` after executing `fmax(a,b)`.
# Input
```
len(a) = len(b)
0 <= len(a), len(b) <= 10000
```
You can guarantee that input arrays only contain integers. | reference | def fmax(a, b): a[:] = map(max, a, b)
| One Line Task: Element-wise Maximum | 5c2dbc63bfc6ec0001d2fcf9 | [
"Restricted",
"Fundamentals"
]
| https://www.codewars.com/kata/5c2dbc63bfc6ec0001d2fcf9 | 6 kyu |
<h2>Introduction</h2>
It's been more than 20 minutes since the negligent waiter has taken your order for the house special prime tofu steak with a side of chili fries.
Out of boredom, you start fiddling around with the condiments tray. To be efficient, you want to be familiar with the choice of sauces and spices before your order is finally served.
You also examine the toothpick holder and try to analyze its inner workings when - yikes - the holder's lid falls off and all 23 picks lay scattered on the table.
Being a good and hygiene oriented citizen, you decide not to just put them back in the holder. Instead of letting all the good wood go to waste, you start playing around with the picks.
In the first "round", you lay down one toothpick vertically. You've used a total of one toothpick.
In the second "round", at each end of the first toothpick, you add a perpendicular toothpick at its center point. You added two additional toothpicks for a total of three toothpicks.
In the next rounds, you continue to add perpendicular toothpicks to each free end of toothpicks already on the table.
With your 23 toothpicks, you can complete a total of six rounds:<br/>
<img src="http://codewars.smubo.ch/toothpicks_XYAdcRDzf.jpg">
You wonder if you'd be able to implement this sequence in your favorite programming language. Because your food still hasn't arrived, you decide to take out your laptop and start implementing...
<h2>Challenge</h2>
Implement a script that returns the amount of toothpicks needed to complete n amount of rounds of the toothpick sequence.
```
0 <= n <= 5000
```
<h2>Hint</h2>
You can attempt this brute force or get <a href="https://arxiv.org/abs/1004.3036">some inspiration</a> from the math department. | algorithms | from math import log2
def t(n):
if n == 0:
return 0
k = int(log2(n))
i = n - 2 * * k
if i == 0:
return (2 * * (2 * k + 1) + 1) / / 3
else:
return t(2 * * k) + 2 * t(i) + t(i + 1) - 1
toothpick = t
| Toothpick Sequence | 5c258f3c48925d030200014b | [
"Algorithms",
"Mathematics",
"Recursion"
]
| https://www.codewars.com/kata/5c258f3c48925d030200014b | 6 kyu |
Welcome to yet *another* kata on palindromes!
Your job is to return a string with 2 requirements:
1 . The first half of the string should represent a proper function expression in your chosen language.
2 . The string should be a palindrome.
Wait... that's too easy -- let's add one more requirement:
Call ```x``` the sum of the character codes of the full string we want to return.
To pass the kata, make sure the function represented in your string will return ```x``` when it is given as an input. | algorithms | def palindromic_expression():
return "intni"
| Palindromic Expression | 5c11c3f757415b1735000338 | [
"Algorithms"
]
| https://www.codewars.com/kata/5c11c3f757415b1735000338 | 7 kyu |
# Toggling Grid
You are given a grid (2d array) of 0/1's. All 1's represents a solved puzzle. Your job is to come up with a sequence of toggle moves that will solve a scrambled grid.
Solved:
```
[ [1, 1, 1],
[1, 1, 1],
[1, 1, 1] ]
```
"0" (first row) toggle:
```
[ [0, 0, 0],
[1, 1, 1],
[1, 1, 1] ]
```
then "3" (first column) toggle:
```
[ [1, 0, 0],
[0, 1, 1],
[0, 1, 1] ]
```
The numbers in quotes are codes for the row/column, and will be explained.
## Your task: findSolution()
Your task is to write a function, `findSolution()` (or `find_solution()`), which takes as input a 2d array, and returns an array of "steps" that represent a sequence of toggles to solve the puzzle.
For example:
```javascript
var puzzle = [
[1, 0, 0],
[0, 1, 1],
[0, 1, 1]
];
```
```javascript
var solution = findSolution(puzzle)
console.log(solution);
> [0, 3]
```
```python
solution = find_solution(puzzle)
print(solution);
> [0, 3]
```
Note that, in the above example, `[1, 2, 4, 5]` is also a valid solution! Any solution will pass the tests.
The solution is tested like this, for each number in the solution:
```python
if n < puzzle.size:
toggleRow(n)
else:
toggleCol(n - puzzle.size)
```
To elaborate, possible n's for a 3x3 puzzle:
```javascript
row toggles:
0, 1, or 2
column toggles:
3, 4, or 5 -> correspond to columns 0, 1, or 2
```
- Row numbers = (0 --> size - 1)
- Cols numbers = (size --> size * 2 - 1)
### Example of "2" toggle:
```javascript
before:
[
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]
]
after:
[
[1, 1, 1],
[1, 1, 1],
[0, 0, 0]
]
```
### Example of "4" toggle:
```javascript
before:
[
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]
]
after:
[
[1, 0, 1],
[1, 0, 1],
[1, 0, 1]
]
```
## More examples:
```javascript
var puzzle = [
[ 0, 1, 0 ],
[ 1, 0, 1 ],
[ 1, 0, 1 ]
];
var solution = findSolution(puzzle)
console.log(solution);
> [0, 4]
```
```python
puzzle = [
[ 0, 1, 0 ],
[ 1, 0, 1 ],
[ 1, 0, 1 ]
];
solution = find_solution(puzzle)
print(solution);
> [0, 4]
```
let's try some bigger puzzles:
```javascript
var puzzle = [
[ 1, 0, 1, 0, 0 ],
[ 0, 1, 0, 1, 1 ],
[ 0, 1, 0, 1, 1 ],
[ 0, 1, 0, 1, 1 ],
[ 1, 0, 1, 0, 0 ]
];
var solution = findSolution(puzzle)
console.log(solution);
> [ 0, 5, 4, 7 ]
```
```python
puzzle = [
[ 1, 0, 1, 0, 0 ],
[ 0, 1, 0, 1, 1 ],
[ 0, 1, 0, 1, 1 ],
[ 0, 1, 0, 1, 1 ],
[ 1, 0, 1, 0, 0 ]
];
solution = find_solution(puzzle)
print(solution);
> [ 0, 5, 4, 7 ]
```
```javascript
var puzzle = [
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 0, 0, 0, 1, 0, 0, 0 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ]
];
var solution = findSolution(puzzle)
console.log(solution);
> [ 3, 10 ]
```
```python
puzzle = [
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 0, 0, 0, 1, 0, 0, 0 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 1, 1, 1 ]
];
solution = find_solution(puzzle)
print(solution);
> [ 3, 10 ]
```
There are randomized tests with puzzles of up to 100x100 in size. Have fun!
| games | def findSolution(m):
return [j for j, r in enumerate(m) if r[0] ^ m[0][0]] + [len(m) + i for i, b in enumerate(m[0]) if not b]
| Solve the Grid! Binary Toggling Puzzle | 5bfc9bf3b20606b065000052 | [
"Binary",
"Puzzles",
"Arrays"
]
| https://www.codewars.com/kata/5bfc9bf3b20606b065000052 | 5 kyu |
In English, all words at the begining of a sentence should begin with a capital letter.
You will be given a paragraph that does not use capital letters. Your job is to capitalise the first letter of the first word of each sentence.
For example,
input:
`"hello. my name is inigo montoya. you killed my father. prepare to die."`
output:
`"Hello. My name is inigo montoya. You killed my father. Prepare to die."`
You may assume:
- there will be no punctuation besides full stops and spaces
- all but the last full stop will be followed by a space and at least one word
| reference | def fix(paragraph):
return '. ' . join(s . capitalize() for s in paragraph . split('. '))
| Sentences should start with capital letters. | 5bf774a81505a7413400006a | [
"Strings",
"Fundamentals"
]
| https://www.codewars.com/kata/5bf774a81505a7413400006a | 7 kyu |
Your task is to write a regular expression that matches positive decimal integers divisible by 4.
Negative numbers should be rejected, but leading zeroes are permitted.
Random tests can consist of numbers, ascii letters, some puctuation and brackets.
But no need to check for line breaks (\n) and non-ASCII chatracters, nothing that fancy in the tests.
There is 50 characters limit for this regex to avoid hardcoding and keep the "puzzle" status :)
Good luck!
| games | div_4 = '[048]$|\d*([02468][048]|[13579][26])$'
| Regex for a decimal number divisible by 4 | 5bf6bd7a3efceeda4700011f | [
"Regular Expressions",
"Puzzles"
]
| https://www.codewars.com/kata/5bf6bd7a3efceeda4700011f | 6 kyu |
In this kata we have to calculate products and sums using the values of an array with an arbitrary number of non-zero integers (positive and/or negative). Each number in the array occurs once, i.e. they are all unique.
You need to implement a function `eval_prod_sum(arr, num_fact, num_add, max_val)` that takes the following four arguments:
1. A list/array of integers `$[x_1, x_2, x_3, \dotsc, x_n]$` of arbitrary length `n` where `$ x_i \ne 0$`
2. A positive integer `num_fact`, which is the number of array elements that combine to form individual products.
For example, given an array `[a, b, c, d]` and `num_fact = 3`, the products would be `a*b*c, a*b*d, a*c*d, b*c*d`
3. A positive integer `num_add`, which is the number of previously produced products (see `2.`) that combine to form individual sums.
Continuing the previous example, given `num_add = 2`, the sums would be `a*b*c + a*b*d, a*b*c + a*c*d, ..., a*c*d + b*c*d`
4. An integer `max_val`, against which the previously produced sums will be compared to produce the following results:
- `smaller`, the number of sums that are **smaller** than `max_val`
- `equal`, the number of sums that are **equal** to `max_val`
- `larger`, the number of sums that are **larger** than `max_val`
The output should be a list of dictionaries with the following structure:
```python
[{"Below than max_val": smaller}, {"Equals to max_val": equal}, {"Higher than max_val": larger}]
```
```ruby
[{"Below than max_val" => smaller}, {"Equals to max_val" => equal}, {"Higher than max_val" => larger}]
```
## Example
```python
lst = [2, 10, 20, 15]
num_fact = 3
num_add = 2
max_val = 8
eval_prod_sum(lst, num_fact, num_add, max_val) == [{'Below than 8': 0}, {'Equals to 8': 0}, {'Higher than 8': 6}]
```
```ruby
lst = [2, 10, 20, 15]
num_fact = 3
num_add = 2
max_val = 8
eval_prod_sum(lst, num_fact, num_add, max_val) == [{'Below than 8'=> 0}, {'Equals to 8'=> 0}, {'Higher than 8'=> 6}]
```
```
Factors Products
(2, 10, 20) 400
(2, 10, 15) 300
(2, 20, 15) 600
(10, 20, 15) 3000
Addends Sums (Final Result)
(300, 400) 700 (larger than 8)
(300, 600) 900 (larger than 8)
(300, 3000) 3300 ( " " ")
(400, 600) 1000 ( " " ")
(400, 3000) 3400 ( " " ")
(600, 3000) 3600 ( " " ")
-> 6 sums of which 0 are smaller or equal to 8 and 6 are larger than 8
```
## Error handling
The function `eval_prod_sum` should return an error message under the following conditions:
- the given array contains a string or a float, or any of the arguments `num_fact`, `num_add `, `max_val` are strings, floats, negative integers or 0.
Output: `"Error. Unexpected entries"`
- `num_fact` is larger than the length of the array.
Output: `"Error. Number of factors too high"`
- `num_add` is larger than the number of product combinations obtainable from the given array with `num_fact`.
Output: `"Error. Number of addens too high"`
### Examples:
```python
lst = [2, 10, '20', 15]
num_fact = 3
num_add = 2
max_val = 8
eval_prod_sum(lst, num_fact, num_add, max_val) == "Error. Unexpected entries"
lst = [2, 10, 20, 15]
num_fact = 3
num_add = 2.0
max_val = '8'
eval_prod_sum(lst, num_fact, num_add, max_val) == "Error. Unexpected entries"
```
```ruby
lst = [2, 10, '20', 15]
num_fact = 3
num_add = 2
max_val = 8
eval_prod_sum(lst, num_fact, num_add, max_val) == "Error. Unexpected entries"
lst = [2, 10, 20, 15]
num_fact = 3
num_add = 2.0
max_val = '8'
eval_prod_sum(lst, num_fact, num_add, max_val) == "Error. Unexpected entries"
```
Enjoy! | reference | from itertools import combinations
from math import comb, prod
def eval_prod_sum(numbers: list, factor_count: int, addend_count: int, max_value: int) - > list or str:
if not (all(isinstance(i, int) for i in numbers) and
all(isinstance(i, int) and i > 0 for i in {factor_count, addend_count, max_value})):
return 'Error. Unexpected entries'
if factor_count > len(numbers):
return 'Error. Number of factors too high'
if addend_count > comb(len(numbers), factor_count):
return 'Error. Number of addens too high'
lower = equal = higher = 0
for sum_ in map(sum, combinations(map(prod, combinations(numbers, r=factor_count)), r=addend_count)):
if sum_ < max_value:
lower += 1
elif sum_ > max_value:
higher += 1
else:
equal += 1
return [{f'Below than { max_value } ': lower}, {f'Equals to { max_value } ': equal}, {f'Higher than { max_value } ': higher}]
| A Combinatorial Way to Get Products and Sums of an Array | 561f18d45df118e7c400000b | [
"Fundamentals",
"Mathematics",
"Data Structures",
"Algorithms"
]
| https://www.codewars.com/kata/561f18d45df118e7c400000b | 6 kyu |
Pythagoras(569-500 B.C.E.) discovered the relation ```a² + b² = c²``` for rectangle triangles,```a, b and c``` are the side values of these special triangles. A rectangle triangle has an angle of 90°. In the following animated image you can see a rectangle triangle with the side values of (a, b, c) = (3, 4, 5)
The pink square has an area equals to 9 (a² = 3²), the green square an area equals to 16 (b² = 4²) and the square with pink and green an area of 25 (c² = 5²)
Adding the pink area to the green one, we obtain ```9 + 16 = 25```
<a href="http://imgur.com/d0minUx"><img src="http://i.imgur.com/d0minUx.gif" title="source: imgur.com" /></a>
A Pythagorean Triple ```(a, b, c)``` is such that ```a ≤ b < c```, the three are integers, and ```a² + b² = c²```.
A Primitive Pythagorean Triple has another additional property: a, b and c are co-primes. Two numbers are co-primes when the Greatest Common Divisor of every pair of the triple is 1. So ```G.C.D.(a, b) = 1```, ```G.C.D.(b, c) = 1``` and ```G.C.D.(a, c) = 1```
Just to visualize the primitives triples, we may see them, each one represented like a rectangle triangle displayed in a 2D arrengement done by Adam Cunningham and John Ringland (March 2012):
<a href="http://imgur.com/1E5w7g3"><img src="http://i.imgur.com/1E5w7g3.jpg?1" title="source: imgur.com" /></a>
The perimeter for a pythagorean triple is: ```per = a + b + c```
The first 16 primitive pythagorean triples with their corresponding perimeter beside, having c below or equal 100 ```(c ≤ 100)``` are:
```python
(3, 4, 5), 12 (5, 12, 13), 30 (8, 15, 17), 40 (7, 24, 25), 56
(20, 21, 29), 70 (12, 35, 37), 84 (9, 40, 41), 90 (28, 45, 53), 126
(11, 60, 61), 132 (16, 63, 65), 144 (33, 56, 65), 154 (48, 55, 73), 176
(13, 84, 85), 182 (36, 77, 85), 198 (39, 80, 89), 208 (65, 72, 97), 234
```
The primitive triple that has the maximum perimeter, with c ≤ 100 is ```(65, 72, 97)``` with a perimeter equals to ```234```
Your task is to make a function that receives an argument returns the triple with the maximum perimeter having the side ```c``` below or equal its argument.
~~~if:ruby,python
The function will output a list of dictionaries as follows:
```[{"number triplets below-eq c_max": amount_triplets}, {"max perimeter": max_per}, {"largest triplet": (am, bm, cm)}]```
Let's see some cases:
```
find_max_triple(50) == [{'number triples below-eq 50': 7}, {'max perimeter': 90}, {'largest triplet': [(9, 40, 41)]}]
find_max_triple(100) == [{'number triples below-eq 100': 16}, {'max perimeter': 234}, {'largest triplet': [(65, 72, 97)]}]
find_max_triple(150) = [{'number triples below-eq 150': 24}, {'max perimeter': 340}, {'largest triplet': [(51, 140, 149)]}]
```
~~~
~~~if:javascript
The function will output a 2D array, see examples bellow
```javascript
findMaxTriple(50) ==[['number triples below-eq 50',7],['max perimeter', 90], ['largest triple', [[9, 40, 41]]]];
findMaxTriple(100) == [['number triples below-eq 100', 16], ['max perimeter', 234], ['largest triple', [[65, 72, 97]]]];
findMaxTriple(150) == [['number triples below-eq 150', 24], ['max perimeter', 340], ['largest triple', [[51, 140, 149]]]];
```
~~~
~~~if-not:javascript,python, ruby
The function will output a tuple / array (depending on the language; refer to solution set up for the exact format) of 3 elements in order: the number of triples below the argument, the maximum perimeter of those triples, and an array / tuple with the largest triple.
### Examples (input --> output)
50 --> (7, 90, (9, 40, 41))
100 --> (16, 234, (65, 72, 97))
150 --> (24, 340, (51, 140, 149))
~~~
Hint, see at: https://en.wikipedia.org/wiki/Formulas_for_generating_Pythagorean_triples
Your code will be tested for values of c_max up to `10000`.
(Memoizations is advisable)
| reference | from math import gcd
def find_max_triple(c_max):
triples = [(n * n - m * m, 2 * m * n, m * m + n * n)
for n in range(2, int(c_max * * 0.5) + 1)
for m in range(1 + n % 2, min(n, int((c_max - n * n) * * 0.5) + 1), 2)
if gcd(m, n) == 1]
largest = tuple(sorted(max(triples, key=sum)))
return [{f'number triples below-eq { c_max } ': len(triples)},
{'max perimeter': sum(largest)},
{'largest triple': [largest]}]
| Primitive Pythagorean Triples | 5622c008f0d21eb5ca000032 | [
"Fundamentals",
"Mathematics",
"Algorithms",
"Data Structures",
"Algebra",
"Geometry",
"Memoization"
]
| https://www.codewars.com/kata/5622c008f0d21eb5ca000032 | 5 kyu |
A specialist of statistics was hired to do an investigation about the people's voting intention for a certain candidate for the next elections.
Unfortunately, some of the interviewers, hired for the researches, are not honest and they want to modify the results because, some of them like the candidate too much, or others hate him.
The specialist suspects about the situation and will apply his own method named: Recursive 2.5 Standard Deviation Filter.
He does not know who of them are cheating and obviously, he doesn´t know the minimum or maximum possible votes for this candidate.
The method works with the following steps explained below:
1) The method calculates the mean, ``` μ```, and the standard deviation, ```σ``` for the received data that has ```n``` elements.
<a href="http://imgur.com/qi97XWq"><img src="http://i.imgur.com/qi97XWq.png?2" title="source: imgur.com" /></a>
2) A new data is obtained discarding all the values that are not in the range [μ - 2.5*σ, μ + 2.5*σ] (strictly lower or higher than these extremes)
3) The values of ``` μ``` and ```σ``` are recalculated and an all the values will be filtered by the new range with the updated values of ``` μ``` and ```σ``` and so on.
He receives the data from the interviewers. The data is the number of votes of samples less than 500 people per neighbourhood of a county.
Let's see a suspect data, the exaggerated data was left at the end on purpose, to see it clearly:
```
votes = [35, 34, 37, 32, 33, 36, 38, 32, 35, 35, 36, 34, 35, 100*, 85*, 70*]
```
The values marked with an (*) are suspect, too high perhaps.
```
Step Votes μ σ μ - 2.5*σ μ + 2.5*σ dicarded values
1 [35,34,37,32,33,36,38,32,35,35,36,34,35,100,85,70] 44.1875 20.3692 -6.7354 95.1104 100
2 [35,34,37,32,33,36,38,32,35,35,36,34,35,85,70] 40.4667 14.8677 3.2974 77.6359 85
3 [35,34,37,32,33,36,38,32,35,35,36,34,35,70] 37.2857 9.2229 14.2286 60.3429 70
4 [35,34,37,32,33,36,38,32,35,35,36,34,35] 34.7692 1.7166 30.4777 39.0608 ---
```
The final values that will be output are ```̅X```and ```s```, ```̅X = μ ``` and ```s = σ/√̅n``` because this will be consider a sample for another calculations.
In this case ```̅X = 34.7692``` and ```s = 1.7166/√̅13 = 0.4761```.
We need a function ```filter_val()```, that receives an array with the number of votes of different neighbourhoods of a county and may express the comparisson in the size of the data and the values of ```̅X``` and ```s```.
For our case:
```python
filter_val([35,34,37,32,33,36,38,32,35,35,36,34,35,100,85,70]) == [[16, 13], 34.76923076923077, 0.4761016021276081] # you don't have to round the results
# 16 was the length of the received array of votes, 13 is the length of the filtered data.
```
The assumptions for this kata: the honest interviwers are much more than the cheaters and the last ones do not agree about the number of votes they will add or subtract, so the modified values are not equal or almost equal.
Some "honest values" may be discarded with this process and all the "dishonest ones" will be eliminated in almost the total of cases but the method still gives a good result.
Enjoy it!! | reference | def avg(x):
return sum(x) / len(x)
def std(arr):
mu = avg(arr)
var = sum([(x - mu) * * 2 for x in arr]) / len(arr)
return var * * 0.5
def filter_val(lst):
len1 = len(lst)
while True:
mu = avg(lst)
s = std(lst)
ret = [x for x in lst if mu - 2.5 * s <= x <= mu + 2.5 * s]
if ret == lst:
break
else:
lst = ret
len2 = len(lst)
mean = avg(lst)
s = std(lst)
return [[len1, len2], mean, s]
| Filtering Values For an Election | 574b448ed27783868600004c | [
"Mathematics",
"Statistics",
"Recursion",
"Data Science"
]
| https://www.codewars.com/kata/574b448ed27783868600004c | 6 kyu |
A chain of car rental locals made a statistical research for each local in a city. They measure the average of clients for every day.
They used the Simpson model for probabilities:
<a href="http://imgur.com/LQWj8kM"><img src="http://i.imgur.com/LQWj8kM.png?1" title="source: imgur.com" /></a>
The number ```e``` is ```2,7182818284....```
Suposse that one of the locals has an average 8 clients per day.
The probability of having 12 clients, one of the goals of the manager, will be:
<a href="http://imgur.com/L7bNl2r"><img src="http://i.imgur.com/L7bNl2r.png?1" title="source: imgur.com" /></a>
It is a very low value, almost 5%. It shows that they have to work a lot for this increment.
And, how would it be if we want to know the sum of probabilities for values below ```12``` (cumulative probability)?
```
P(c < 12) = P(c=0) + P(c=1) + P(c=3) + P(c=4) + P(c=5) + P(c=6) + P(c=7) + P(c=8) + P(c=9) + P(c=10) + P(c=11)
P(c<12) = 0.00033546262790251196 + 0.0026837010232200957 + 0.010734804092880383 + 0.02862614424768102 + 0.05725228849536204 + 0.09160366159257927 + 0.12213821545677235 + 0.13958653195059698 + 0.13958653195059698 + 0.12407691728941954 + 0.09926153383153563 + 0.072190206422935 = 0.888075998981
```
But the probability of having below or equal the value ```12```, will be:
```
P(c≤12) = P(c=0) + P(c=1) + P(c=3) + P(c=4) + P(c=5) + P(c=6) + P(c=7) + P(c=8) + P(c=9) + P(c=10) + P(c=11) + P(c=12) = 0.936202803263
(P(c≤12) = P(12≥c))
```
The probability for having equal or more clients than 12 will be:
```
P(c>12) = P(c=13) + P(c=14) + P(c=15) + ........+ P(c=+∞)
(P(c>12) = P(12<c))
```
But the sum of the probabilities for c = 0 to +∞ is ```1```
So,
```
P(c>12) = 1 - P(c≤12) = 1 - 0.936202803263 = 0.063797196737
```
Make the function ```prob_simpson()```, that will receive 2 or 3 arguments.
1) Two arguments if we want to calculate the probability for a specific number, receives the average ```lamb``` and the variable ```x```.
2) Three arguments if we want the cumulative probability for a value, besides receiving ```lamb``` and ```x```, will receive one of the following operators in string format: ```<, <=, >, >=```.
Let's see some cases for probability at the number:
```python
prob_simpson(8, 12) == 0.04812680428195667
prob_simpson(8, 11) == 0.072190206422935
prob_simpson(8, 10) == 0.09926153383153563
```
And for cumulative probability:
```python
prob_simpson(8, 12, '>') == 0.888075998981 # or P(12>c)
prob_simpson(8, 12, '>=') == 0.936202803263 # or P(12≥c)
prob_simpson(8, 12, '<') == 0.063797196737 # or P(12<c)
prob_simpson(8, 12, '<=') == 0.111924001019 # or P(12≤c)
```
You may assume that you will not receive high values for ```lamb``` and ```x```
This kata will also have translations into Javascript and Ruby.
Enjoy it! | reference | from math import e, factorial
def poi(l, x): return e * * - l * l * * x / factorial(x)
def prob_simpson(l, x, op='='):
if op == '=':
return poi(l, x)
if op == '>=':
return sum(poi(l, e) for e in range(x + 1))
if op == '>':
return sum(poi(l, e) for e in range(x))
if op == '<=':
return 1 - sum(poi(l, e) for e in range(x))
if op == '<':
return 1 - sum(poi(l, e) for e in range(x + 1))
| Car Rental Business Needs Statistics and Programming | 570176b0d1acef5778000fbd | [
"Algorithms",
"Mathematics",
"Statistics",
"Probability",
"Data Science"
]
| https://www.codewars.com/kata/570176b0d1acef5778000fbd | 5 kyu |
Some languages like Chinese, Japanese, and Thai do not have spaces between words. However, most natural languages processing tasks like part-of-speech tagging require texts that have segmented words. A simple and reasonably effective algorithm to segment a sentence into its component words is called "MaxMatch".
## MaxMatch
MaxMatch starts at the first character of a sentence and tries to find the longest valid word starting from that character. If no word is found, the first character is deemed the longest "word", regardless of its validity. In order to find the rest of the words, MaxMatch is then recursively invoked on all of the remaining characters until no characters remain. A list of all of the words that were found is returned.
So for the string `"happyday"`, `"happy"` is found because `"happyday"` is not a valid word, nor is `"happyda"`, nor `"happyd"`. Then, MaxMatch is called on `"day"`, and `"day"` is found. The output is the list `["happy", "day"]` in that order.
## The Challenge
```if:javascript
Write `maxMatch`, which takes an alphanumeric, spaceless, lowercased `String` as input and returns an `Array` of all the words found, in the order they were found.
**All valid words are in the** `Set` `VALID_WORDS`, which only contains around 500 English words.
```
```if:haskell
Write `maxMatch`, which takes an alphanumeric, spaceless, lowercased `String` as input and returns a `[String]` of all the words found, in the order they were found. All valid words are in the `[String]` `validWords`, which only contains around 500 English words.
```
```if:java
Write `maxMatch`, which takes an alphanumeric, spaceless, lowercased `String` as input and returns a `List` of `String`s which are all the words found, in the order they were found. All valid words are in the `Set` `Preloaded.VALID_WORDS`, , which only contains around 500 English words.
```
```if:python
Write `max_match`, which takes an alphanumeric, spaceless, lowercased `String` as input and returns a `List` of `String`s of all the words found, in the order they were found. **All valid words are in the** `Set` `VALID_WORDS`, which only contains around 500 English words.
```
```if:ruby
Write `max_match`, which takes an alphanumeric, spaceless, lowercased `String` as input and returns an `Array` of `String`s of all the words found, in the order they were found. All valid words are in the `Array` `VALID_WORDS`, which only contains around 500 English words.
```
```if:kotlin
Write `maxMatch`, which takes an alphanumeric, spaceless, lowercased `String` as input and returns a `List` of `String`s which are all the words found, in the order they were found. All valid words are in the `Set` `VALID_WORDS`, which only contains around 500 English words.
```
**Note:** This algorithm is simple and operates better on Chinese text, so accept the fact that some words will be segmented wrongly.
Happy coding :) | algorithms | def max_match(s):
result = []
while s:
for size in range(len(s), 0, - 1):
word = s[: size]
if word in VALID_WORDS:
break
result . append(word)
s = s[size:]
return result
| Word Segmentation: MaxMatch | 5be350bcce5afad8020000d6 | [
"Parsing",
"Recursion",
"Strings",
"Arrays",
"Algorithms"
]
| https://www.codewars.com/kata/5be350bcce5afad8020000d6 | 6 kyu |
An **Almost Isosceles Integer Triangle** is a triangle that all its side lengths are integers and also,
two sides are almost equal, being their absolute difference `1` unit of length.
We are interested in the generation of the almost isosceles triangles by the diophantine equation (length sides of triangles are positive and not 0):
`x³-(x-1)³ = y²` Eq.1
So the first solution `(x,y)` for this equation is that may generate a real triangle and almost isosceles is `(8,13)`, being the first nearly isosceles triangle `(7,8,13)`.
Equation 1 has infinite solutions `(x,y)`, so the corresponding triangles will be `(x-1,x,y)`
We need a code that can find those triangles with huge sides.
You will be given an integer `p` (always valid and positive, and p ≠ 0) and your code should output the closest perimeter to p, let's name it p_, of the corresponding triangle.
Examples:
```python
find_closest_perim(500) === 390 # (104, 105, 181) is the triangle with the closest perimeter to 500
find_closest_perim(5000) === 5432 # perimeter of triangle (1455, 1456, 2521)
```
```javascript
findClosestPerimeter(500) === 390 # (104, 105, 181) is the triangle with the closest perimeter to 500
findClosestPerimeter(5000) === 5432 # perimeter of triangle (1455, 1456, 2521)
```
In the case that you have two possible solutions, `p_1` and `p_2` being `p_1 < p_2`, because `p = p_1 + (p_2 - p1)/2`, you select the highest solution `p_2`.
If `p` coincides with a perimeter of these triangles the output should be `p`.
Features of the random tests:
`1000 <= p <= 1e180`
Interesting cases in the example tests box with edge cases.
The sequence of triangles are almost similar with the two nearly same sides forming an angle of 120º (strictly, nearly 120º)
No hardcoded solutions are allowed for this kata.
Enjoy it! | reference | # A001921 + A001570, aka A011944
v = [0, 2]
while v[- 1] < 1e180:
v . append(14 * v[- 1] - v[- 2])
from bisect import bisect
def find_closest_perim(p):
i = bisect(v, p)
return v [2 ] if i == 2 else min ([v [i ], v [i - 1 ]], key = lambda t : ( abs ( t - p ), - t )) | Almost Isosceles Integer Triangles With Their Angles With Asymptotic Tendency | 5be4d000825f24623a0001e8 | [
"Algorithms",
"Performance",
"Number Theory",
"Recursion",
"Geometry",
"Fundamentals"
]
| https://www.codewars.com/kata/5be4d000825f24623a0001e8 | 5 kyu |
# Task
You are given a positive integer `n`. We intend to make some ascending sequences according to the following rules:
1. Make a sequence of length 1: [ n ]
2. Or, insert a number to the left side of the sequence. But this number can not exceed half of the first number of the sequence.
3. Follow rule 2, continue insert number to the left side of the sequence.
Your task is to count the number of all possible sequences, and return it.
If you do not understand the task, please read the rewritten version below:
You are given a positive integer `n`. Your task is to count the number of such sequences:
- It should be an ascending sequence;
- It should end with number `n`.
- Each number in the sequence should smaller or equals to the half of its right, except for the last number `n`.
- We define that a sequence containing only a number `n` is a valid ascending sequence.
# Examples
For `n = 6`, the output should be `6`.
All sequences we made are:
```
[6]
insert a number to the left:
[1,6]
[2,6]
[3,6]
continue insert number:
[1,2,6]
[1,3,6]
```
There are 6 sequences in total.
For `n = 10`, the output should be `14`.
All sequences we made are:
```
[10]
insert a number to the left:
[1,10]
[2,10]
[3,10]
[4,10]
[5,10]
continue insert number:
[1,2,10]
[1,3,10]
[1,4,10]
[2,4,10]
[1,5,10]
[2,5,10]
continue insert number:
[1,2,4,10]
[1,2,5,10]
```
There are 14 sequences in total.
# Note
- `1 <= n <= 1000`
- `3` fixed testcases
- `100` random testcases, testing for correctness of solution
- All inputs are valid.
~~~if:lambdacalc
# Encodings
purity: `LetRec`
numEncoding: `BinaryScott`
~~~ | algorithms | from functools import lru_cache
@ lru_cache(maxsize=None)
def make_sequences(n):
return 1 + sum(map(make_sequences, range(1, n / / 2 + 1)))
| Simple Fun #399: Make Ascending Sequences | 5be0f1786279697939000157 | [
"Fundamentals",
"Arrays",
"Algorithms"
]
| https://www.codewars.com/kata/5be0f1786279697939000157 | 7 kyu |
Ever wonder how many keystrokes any given string takes to type? No? Most normal people don't...but we're not normal! :D
Program a ```num_key_strokes (string)``` function that takes a string and returns a count of the number of keystrokes that it took to type that string.
For example, ```Hello, world!``` takes 15 key strokes to type.
This kata is expecting an EN-US keyboard mapping, specifically using the QWERTY layout.
## Rules
* This kata assumes that the string was only typed using the main keyboard and NOT a number-pad.
* We also assume that the user does not hold down the ```Shift``` key and thus has to press it once every time it's needed. In addition, the ```CAPS LOCK``` key is not used.
* Every character in the input string requires either ```1``` or ```2``` keystrokes. Your goal is to figure out which ones belong in which group and count the total number of keystrokes.
Here's a picture of the en-US QWERTY layout :
<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/5/51/KB_United_States-NoAltGr.svg/1920px-KB_United_States-NoAltGr.svg.png" title="the en-US QWERTY layout" alt="the en-US QWERTY layout" style = "width:85%">
| reference | def num_key_strokes(text):
return sum([1 if i in "abcdefghijklmnopqrestuvwxyz1234567890-=`];[',.\/ " else 2 for i in text])
| Keystroking | 5be085e418bcfd260b000028 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5be085e418bcfd260b000028 | 7 kyu |
The first positive integer, `n`, with its value `4n² + 1`, being divisible by `5` and `13` is `4`. (condition 1)
It can be demonstrated that we have infinite numbers that may satisfy the above condition.
If we name **<i>a</i><sub><i>i</i></sub>**, the different terms of the sequence of numbers with this property, we define `S(n)` as:
<a href="https://imgur.com/79h926t"><img src="https://i.imgur.com/79h926t.png?2" title="source: imgur.com" /></a>
We are interested in working with numbers of this sequence from 10 to 15 digits. Could you elaborate a solution for these results?
You will be given an integer value `m`(always valid an positive) and you should output the closest value of the sequence to `m`.
If the given value `m` is in the sequence, your solution should return the same value.
In the case that there are two possible solutions: `s1` and `s2`, (`s1 < s2`), because `|m - s1| = |m - s2|`, output the highest solution `s2`
No hardcoded solutions are allowed.
No misterious formulae are required, just good observation to discover hidden patterns.
See the example tests to see output format and useful examples, edge cases are included.
Features of the random tests
`1000 <= m <= 5.2 e14`
**Note** <i>Sierpinsky presented the numbers that satisfy condition (1)</i>
| reference | def sierpinski():
x = s = 0
while 1:
for a in 4, 9, 56, 61:
s += x + a
yield s
x += 65
s = sierpinski()
S = [next(s)]
from bisect import bisect_left
def find_closest_value(m):
while S[- 1] < m:
S . append(next(s))
i = bisect_left(S, m)
return min(S[i: i - 2: - 1], key=lambda n: abs(m - n))
| Following Sierpinski's Footprints | 5be0af91621daf08e1000185 | [
"Algorithms",
"Performance",
"Number Theory",
"Fundamentals"
]
| https://www.codewars.com/kata/5be0af91621daf08e1000185 | 5 kyu |
You are given two strings. In a single move, you can choose any of them, and delete the first (i.e. leftmost) character.
For Example:
* By applying a move to the string `"where"`, the result is the string `"here"`.
* By applying a move to the string `"a"`, the result is an empty string `""`.
Implement a function that calculates the minimum number of moves that should be performed to make the given strings equal.
## Notes
* Both strings consist of lowercase latin letters.
* If the string is already empty, you cannot perform any more delete operations. | reference | def shift_left(a, b):
r = len(a) + len(b)
for i in range(- 1, - min(len(a), len(b)) - 1, - 1):
if a[i] != b[i]:
break
r -= 2
return r
| Shift Left | 5bdc191306a8a678f6000187 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5bdc191306a8a678f6000187 | 7 kyu |
## Background
Those of you who have used spreadsheets will know that rows are identified by numbers and columns are identified by letters.
For example the top left square of a spreadsheet is identified as `A1`, and the start of the grid is labelled like so:
A1 | B1 | C1
---+----+---
A2 | B2 | C2
---+----+---
A3 | B3 | C3
The first 26 collums are labelled `A` to `Z`, then the label 27 becomes `AA` to 52 being `AZ`, then `BA` to `BZ`, and so on. `ZZ` rolls over to `AAA`
In this kata, our internal data structure uses zero-based indexing for both row and index like so:
(0,0) | (1,0) | (2,0)
------+-------+------
(0,1) | (1,1) | (2,1)
------+-------+------
(0,2) | (1,2) | (2,2)
## Kata
The kata is to write a class with the **static** helper routines to convert a cell's internal representation to its display representation and vice versa.
You can assume that your inputs are validated.
### Warning
*However the initial solution was supplied by your boss, and he hasn't coded since his glory days with COBOL, you can be reasonably sure that the starter code he has given you **will not work** ...*
Luckily, the unit tests supplied by your co-worker will work though, as he is so up-to-date with his skills he writes new languages because he knows everything about computing already...
| algorithms | class SpreadSheetHelper:
from string import ascii_uppercase
BASE26 = dict(zip(ascii_uppercase, range(len(ascii_uppercase))))
@ classmethod
def convert_to_display(cls, internal):
display = []
row, col = internal
row += 1
while row:
row -= 1
row, n = divmod(row, 26)
display . append(cls . ascii_uppercase[n])
return '' . join(reversed(display)) + str(col + 1)
@ classmethod
def convert_to_internal(cls, display):
first_digit = next(n for n, c in enumerate(display) if c . isdigit())
row, col = display[: first_digit], display[first_digit:]
internal = - 1
for c in row:
internal += 1
internal *= 26
internal += cls . BASE26[c]
return internal, int(col) - 1
| Spreadsheet Cell Name Conversions | 5540b8b79bb322607b000021 | [
"Strings",
"Algorithms"
]
| https://www.codewars.com/kata/5540b8b79bb322607b000021 | 5 kyu |
You are given a sequence of a journey in London, UK. The sequence will contain bus **numbers** and TFL tube names as **strings** e.g.
```javascript
['Northern', 'Central', 243, 1, 'Victoria']
```
```java
new Object[] {"Northern", "Central", 243, 1, "Victoria"}
```
```haskell
[ Tube "Northern", Tube "Central", Bus 243, Bus 1, Tube "Victoria" ]
```
```python
['Northern', 'Central', 243, 1, 'Victoria']
```
```kotlin
arrayOf("Northern", "Central", 243, 1, "Victoria")
```
Journeys will always only contain a combination of tube names and bus numbers. Each tube journey costs `£2.40` and each bus journey costs `£1.50`. If there are `2` or more adjacent bus journeys, the bus fare is capped for sets of two adjacent buses and calculated as one bus fare for each set.
For example:
`'Piccadilly', 56, 93, 243, 20, 14 -> "£6.90"`
Your task is to calculate the total cost of the journey and return the cost `rounded to 2 decimal places` in the format (where x is a number): `£x.xx`
| reference | def london_city_hacker(journey):
# your code here
tube = 2.40
bus = 1.50
total_cost = 0.00
count = 0
for link in journey:
if isinstance(link, str):
total_cost += tube
count = 0
else:
if count == 0:
total_cost += bus
count += 1
else:
count = 0
return '£{:.2f}' . format(total_cost)
| London CityHacker | 5bce125d3bb2adff0d000245 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5bce125d3bb2adff0d000245 | 7 kyu |
# Scenario
*the rhythm of beautiful musical notes is drawing a Pendulum*
**_Beautiful musical notes_** are the **_Numbers_**
___
# Task
**_Given_** an *array/list [] of n integers* , **_Arrange_** *them in a way similar to the to-and-fro movement of a Pendulum*
* **_The Smallest element_** of the list of integers , must come *in center position of array/list*.
* **_The Higher than smallest_** , *goes to the right* .
* **_The Next higher_** number goes *to the left of minimum number* and So on , in a to-and-fro manner similar to that of a Pendulum.

___
# Notes
* **_Array/list_** size is *at least **_3_*** .
* In **_Even array size_** , *The minimum element should be moved to (n-1)/2 index* (considering that indexes start from 0)
* **_Repetition_** of numbers in *the array/list could occur* , So **_(duplications are included when Arranging)_**.
____
# Input >> Output Examples:
```
pendulum ([6, 6, 8 ,5 ,10]) ==> [10, 6, 5, 6, 8]
```
## **_Explanation_**:
* **_Since_** , `5` is the **_The Smallest element_** of the list of integers , came *in The center position of array/list*
* **_The Higher than smallest_** is `6` *goes to the right* of `5` .
* **_The Next higher_** number goes *to the left of minimum number* and So on .
* Remember , **_Duplications are included when Arranging_** , Don't Delete Them .
____
```
pendulum ([-9, -2, -10, -6]) ==> [-6, -10, -9, -2]
```
## **_Explanation_**:
* **_Since_** , `-10` is the **_The Smallest element_** of the list of integers , came *in The center position of array/list*
* **_The Higher than smallest_** is `-9` *goes to the right* of it .
* **_The Next higher_** number goes *to the left of* `-10` , and So on .
* Remeber , In **_Even array size_** , *The minimum element moved to (n-1)/2 index* (considering that indexes start from 0) .
____
```
pendulum ([11, -16, -18, 13, -11, -12, 3, 18]) ==> [13, 3, -12, -18, -16, -11, 11, 18]
```
## **_Explanation_**:
* **_Since_** , `-18` is the **_The Smallest element_** of the list of integers , came *in The center position of array/list*
* **_The Higher than smallest_** is `-16` *goes to the right* of it .
* **_The Next higher_** number goes *to the left of* `-18` , and So on .
* Remember , In **_Even array size_** , *The minimum element moved to (n-1)/2 index* (considering that indexes start from 0) .
____
```if:rust,clojure,cobol
# Tune Your Code , There are 200 Assertions , 15.000 element For Each .
```
```if-not:rust,clojure,prolog,cobol
# Tune Your Code , There are 200 Assertions , 60.000 element For Each .
```
```if:prolog
# Tune Your Code , There are 100 Assertions , 1000 elements For Each .
```
___
# [Playing with Numbers Series](https://www.codewars.com/collections/playing-with-numbers)
# [Playing With Lists/Arrays Series](https://www.codewars.com/collections/playing-with-lists-slash-arrays)
# [Bizarre Sorting-katas](https://www.codewars.com/collections/bizarre-sorting-katas)
# [For More Enjoyable Katas](http://www.codewars.com/users/MrZizoScream/authored)
___
## ALL translations are welcomed
## Enjoy Learning !!
# Zizou
| reference | def pendulum(a):
a = sorted(a)
return a[:: 2][:: - 1] + a[1:: 2]
| The Poet And The Pendulum | 5bd776533a7e2720c40000e5 | [
"Fundamentals",
"Arrays",
"Algorithms",
"Performance"
]
| https://www.codewars.com/kata/5bd776533a7e2720c40000e5 | 7 kyu |
Given an array `[x1, x2, ..., xn]` determine whether it is possible to put `+` or `-` between the elements and get an expression equal to `sum`. Result is `boolean`
```
2 <= n <= 22
0 <= xi <= 20
-10 <= sum <= 10
```
## Example
`arr = [1, 3, 4, 6, 8]`
`sum = -2`
**1 + 3 - 4 + 6 - 8 = -2**
Result is: `true`
## Notes
If it is impossible to find a solution then you should return `false`.
| algorithms | def is_possible(nums, goal):
if not nums:
return False
sums = {nums[0]}
for i in range(1, len(nums)):
sums = {n + s for n in sums for s in (- nums[i], nums[i])}
return goal in sums
| Plus - minus - plus - plus - ... - Sum | 5bc463f7797b00b661000118 | [
"Algorithms"
]
| https://www.codewars.com/kata/5bc463f7797b00b661000118 | 6 kyu |
You've had a baby.
Well done. Nice isn't it? Life destroying... but in a good way.
Part of your new routine is lying awake at night worrying that you've either lost the baby... or that you have more than 1!
Given a string of words (x), you need to calculate how many babies are in it. To count as a baby you must have all of the letters in baby ('b', 'a', 'b', 'y'). That counts as 1. They do not need to be in order in the string. Upper and lower case letters count.
Examples:
```kotlin
"baby" = 1
"abby" = 1
"babybaby" = 2
"Why the hell are there so many babies?!" = 1
"Anyone remember life before babies?" = 1
"Happy babies boom ba by?" = 2
```
If there are no babies in the string - you lost the baby!! Return a different value, as shown below:
```if-not:kotlin
'none here' = "Where's the baby?!"
'' = "Where's the baby?!"
```
```if:kotlin
"none here" = null
"" = null
```
| reference | def baby_count(x):
x = x . lower()
return min(x . count('a'), x . count('b') / / 2, x . count('y')) or "Where's the baby?!"
| The Baby Years I - Baby Counting | 5bc9951026f1cdc77400011c | [
"Fundamentals",
"Strings"
]
| https://www.codewars.com/kata/5bc9951026f1cdc77400011c | 7 kyu |
# Story
OOP is a very useful paradigm which allows creating infinite amount of similar objects. On the contrary, "singleton pattern" limits it, so only 1 instance of a class can be created, and any future attempt to instantiate a new object returns the already existing one. But what if we want something in between?
___
# Task
Implement a decorator which limits the number of instances of a class which can exist at the same time.
It will take 3 values: `limit`, `unique`, `lookup`.
1) `Limit` specifies the number of instances which can exist at the same time.
2) `Unique` specifies which attribute will serve as a unique identifier in this class. If another object with the same value of `unique` attribute was created eariler, older instance should be returned.
3) `Lookup` specifies which object should be returned if the instance limit has been hit, and the value of `unique` attribute was not used earlier. `Lookup` may equal to 3 values: `"FIRST"` (the oldest object is returned), `"LAST"` (the newest object is returned), or `"RECENT"` (the object which was returned during the previous instantiation attempt is returned again).
___
## Examples:
```
@limiter(2, "ID", "FIRST")
class ExampleClass:
def __init__(self, ID, value): self.ID, self.value = ID, value
a = ExampleClass(1, 5) # unique ID=1
b = ExampleClass(2, 8) # unique ID=2
ExampleClass(1, 20).value == 5 # there's an instance with unique ID=1 memorized
ExampleClass(3, 0).value == 5 # no instance with ID=3, no more instances to remember, lookup type is
# "FIRST", so we should return the first object that was memorized -
# ExampleClass(1, 5)
@limiter(2, "ID", "LAST")
class ExampleClass:
def __init__(self, ID, value): self.ID, self.value = ID, value
a = ExampleClass(1, 5)
b = ExampleClass(2, 8)
ExampleClass(1, 20).value == 5 # there's an instance with unique ID=1 memorized
ExampleClass(3, 0).value == 8 # no instance with ID=3, no more instances to remember, lookup type is
# "LAST", so we should return the last object that was memorized -
# ExampleClass(2, 8)
@limiter(2, "value", "RECENT")
class ExampleClass:
def __init__(self, ID, value): self.ID, self.value = ID, value
a = ExampleClass(1, 5)
b = ExampleClass(2, 8)
ExampleClass(4, 5).ID == 1 # this time "value" attribute is unique among the instances, which is why
# we return ExampleClass(1, 5) - it has value=5
RecentInstance(1, 0).ID == 1 # no instance with value=0, no more instances to remember, lookup type is
# "RECENT", so we should return the last object that we accessed again -
# ExampleClass(1, 5)
``` | reference | def limiter(limit, unique, lookup):
def wrapper(class_):
instances = {}
lookups = {}
def getinstance(* args, * * kwargs):
new_obj = class_(* args, * * kwargs)
if "FIRST" not in lookups:
lookups["FIRST"] = new_obj
id = getattr(new_obj, unique)
if id in instances:
res = instances[id]
elif len(instances) < limit:
instances[id] = new_obj
res = lookups["LAST"] = new_obj
else:
res = lookups[lookup]
lookups["RECENT"] = res
return res
return getinstance
return wrapper
| Limited number of instances | 5bd36d5e03c3c4a37f0004f4 | [
"Object-oriented Programming",
"Metaprogramming"
]
| https://www.codewars.com/kata/5bd36d5e03c3c4a37f0004f4 | 5 kyu |
In this kata you will be given a random string of letters and tasked with returning them as a string of comma-separated sequences sorted alphabetically, with each sequence starting with an uppercase character followed by `n-1` lowercase characters, where `n` is the letter's alphabet position `1-26`.
## <span style="color: #f88">Example</span>
```javascript
alphaSeq("ZpglnRxqenU") -> "Eeeee,Ggggggg,Llllllllllll,Nnnnnnnnnnnnnn,Nnnnnnnnnnnnnn,Pppppppppppppppp,Qqqqqqqqqqqqqqqqq,Rrrrrrrrrrrrrrrrrr,Uuuuuuuuuuuuuuuuuuuuu,Xxxxxxxxxxxxxxxxxxxxxxxx,Zzzzzzzzzzzzzzzzzzzzzzzzzz"
```
```python
alpha_seq("ZpglnRxqenU") -> "Eeeee,Ggggggg,Llllllllllll,Nnnnnnnnnnnnnn,Nnnnnnnnnnnnnn,Pppppppppppppppp,Qqqqqqqqqqqqqqqqq,Rrrrrrrrrrrrrrrrrr,Uuuuuuuuuuuuuuuuuuuuu,Xxxxxxxxxxxxxxxxxxxxxxxx,Zzzzzzzzzzzzzzzzzzzzzzzzzz"
```
## <span style="color: #f88">Technical Details</span>
- The string will include only letters.
- The first letter of each sequence is uppercase followed by `n-1` lowercase.
- Each sequence is separated with a comma.
- Return value needs to be a string. | reference | def alpha_seq(s):
return "," . join((c * (ord(c) - 96)). capitalize() for c in sorted(s . lower()))
| Alphabetical Sequence | 5bd00c99dbc73908bb00057a | [
"Fundamentals",
"Strings",
"Arrays"
]
| https://www.codewars.com/kata/5bd00c99dbc73908bb00057a | 7 kyu |
## Story
As a part of your work on a project, you are supposed to implement a node-based calculator. Thinking that it is too much of a boring task, you decided to give it to a less experienced developer without telling the management. When he finished, you were astounded to see how poor and ugly his implementation is. To not lose your face in front of the higher-ups, you must rewrite it... as short as possible.
___
## Task
You will be given a ready solution passing all the tests. Unfortunately for you, it is very long and overly repetitive. Current code length is `901` characters. Your task is to shorten it to at most `300` characters.
**Note**: you can modify the implementation any way you want, as long as it is written using only OOP. | refactoring | import operator as o
class v:
def __init__(s, a, b): s . a, s . b = a, b
def compute(s): return getattr(o, type(s). __name__)(s . a, s . b)
class value (int):
pass
class add (v):
pass
class sub (v):
pass
class mul (v):
pass
class truediv (v):
pass
class mod (v):
pass
class pow (v):
pass
| Refactor a node-based calculator (DRY) | 5bcf52022f660cab19000300 | [
"Refactoring",
"Object-oriented Programming"
]
| https://www.codewars.com/kata/5bcf52022f660cab19000300 | 5 kyu |
### Story
Your company migrated the last 20 years of it's *very important data* to a new platform, in multiple phases. However, something went wrong: some of the essential time-stamps were messed up! It looks like that some servers were set to use the `dd/mm/yyyy` date format, while others were using the `mm/dd/yyyy` format during the migration. Unfortunately, the original database got corrupted in the process and there are no backups available... Now it's up to you to assess the damage.
### Task
You will receive a list of records as strings in the form of `[start_date, end_date]` given in the ISO `yyyy-mm-dd` format, and your task is to count how many of these records are:
* **correct**: there can be nothing wrong with the dates, the month/day cannot be mixed up, or it would not make a valid timestamp in any other way; e.g. `["2015-04-04", "2015-05-13"]`
* **recoverable**: invalid in its current form, but the original timestamp can be recovered, because there is only one valid combination possible; e.g. `["2011-10-08", "2011-08-14"]`
* **uncertain**: the original timestamp cannot be retrieved, because one or both dates are ambiguous and may generate multiple valid results, or can generate only invalid results; e.g. `["2002-02-07", "2002-12-10"]`
**Note:** the original records always defined a *non-negative* duration (i.e. `start_date ≤ end_date`)
Return your findings in an array: `[ correct_count, recoverable_count, uncertain_count ]`
### Examples
```ruby
["2015-04-04", "2015-05-13"] --> correct # nothing (could be) wrong here
["2013-06-18", "2013-08-05"] --> correct # end date is ambiguous, but this is
# the only possible valid version
["2001-02-07", "2001-03-01"] --> correct # both dates are ambiguous, but this is
# the only possible valid version
["2011-10-08", "2011-08-14"] --> recoverable # start date is wrong, but can be corrected
# because there is only one valid version possible
["2009-08-21", "2009-04-12"] --> recoverable # end date is wrong, but can be corrected
# because there is only one valid version possible
["1996-01-24", "1996-03-09"] --> uncertain # end date is ambiguous (could also be 1996-09-03)
["2000-10-09", "2000-11-20"] --> uncertain # start date is ambiguous (could also be 2000-09-10)
["2002-02-07", "2002-12-10"] --> uncertain # both dates are ambiguous, and there are
# multiple possible valid versions
```
---
### My other katas
If you enjoyed this kata then please try [my other katas](https://www.codewars.com/users/anter69/authored)! :-)
#### *Translations are welcome!* | algorithms | def candidates(ymd):
y, m, d = ymd . split('-')
return {ymd, f' { y } - { d } - { m } '}
def check_dates(records):
result = [0, 0, 0]
for start, end in records:
xs = [(dt1, dt2) for dt1 in candidates(start) for dt2 in candidates(end)
if dt1 <= dt2 and dt1[5: 7] <= '12' >= dt2[5: 7]]
i = 2 if len(xs) > 1 else xs[0] != (start, end)
result[i] += 1 # 2: uncertain, 1(True): recoverable, 0(False): correct
return result
| Data Analysis Following Migration | 5bc5cfc9d38567e29600019d | [
"Date Time",
"Algorithms",
"Data Science"
]
| https://www.codewars.com/kata/5bc5cfc9d38567e29600019d | 6 kyu |
# Task
You are given a string `s`. It's a string consist of letters, numbers or symbols.
Your task is to find the Longest substring consisting of unique characters in `s`, and return the length of it.
# Note
- `1 <= s.length <= 10^7`
- `5` fixed testcases
- `100` random testcases, testing for correctness of solution
- `100` random testcases, testing for performance of code
- All inputs are valid.
- Pay attention to code performance.
- If my reference solution gives the wrong result in the random tests, please let me know(post an issue).
# Example
For `s="baacab"`, the output should be `3`.
The non repeating substrings in `s` are:
```
"b","c","a","ba","ac","ca","ab","cab"
```
The longest one is `"cab"`, its length is `3`.
For `s="abcd"`, the output should be `4`.
The longest one is `"abcd"`, its length is `4`.
For `s="!@#$%^&^%$#@!"`, the output should be `7`.
The longest substring are `"!@#$%^&"` and `"&^%$#@!"`, their length both are `7`. | algorithms | def longest_substring(s: str) - > int:
start, memo, res = 0, {}, 0
for i, c in enumerate(s):
if c in memo and memo[c] >= start:
start, res = memo[c] + 1, max(res, i - start)
memo[c] = i
return max(res, len(s) - start)
| Simple Fun #396: Find the Longest Substring Consisting of Unique Characters | 5bcd90808f9726d0f6000091 | [
"Algorithms",
"Strings",
"Fundamentals"
]
| https://www.codewars.com/kata/5bcd90808f9726d0f6000091 | 6 kyu |
With one die of 6 sides we will have six different possible results:``` 1, 2, 3, 4, 5, 6``` .
With 2 dice of six sides, we will have 36 different possible results:
```
(1,1),(1,2),(2,1),(1,3),(3,1),(1,4),(4,1),(1,5),
(5,1), (1,6),(6,1),(2,2),(2,3),(3,2),(2,4),(4,2),
(2,5),(5,2)(2,6),(6,2),(3,3),(3,4),(4,3),(3,5),(5,3),
(3,6),(6,3),(4,4),(4,5),(5,4),(4,6),(6,4),(5,5),
(5,6),(6,5),(6,6)
```
So, with 2 dice of 6 sides we get 36 different events.
```
([6,6] ---> 36)
```
But with 2 different dice we can get for this case, the same number of events.
One die of ```4 sides``` and another of ```9 sides``` will produce the exact amount of events.
```
([4,9] ---> 36)
```
We say that the dice set ```[4,9]``` is equivalent to ```[6,6]``` because both produce the same number of events.
Also we may have an amount of three dice producing the same amount of events. It will be for:
```
[4,3,3] ---> 36
```
(One die of 4 sides and two dice of 3 sides each)
Perhaps you may think that the following set is equivalent: ```[6,3,2]``` but unfortunately dice have a **minimum of three sides** (well, really a
tetrahedron with one empty side)
The task for this kata is to get the amount of equivalent dice sets, having **2 dice at least**,for a given set.
For example, for the previous case: [6,6] we will have 3 equivalent sets that are: ``` [4, 3, 3], [12, 3], [9, 4]``` .
You may assume that dice are available from 3 and above for any value up to an icosahedral die (20 sides).
```
[5,6,4] ---> 5 (they are [10, 4, 3], [8, 5, 3], [20, 6], [15, 8], [12, 10])
```
For the cases we cannot get any equivalent set the result will be `0`.
For example for the set `[3,3]` we will not have equivalent dice.
Range of inputs for Random Tests:
```
3 <= sides <= 15
2 <= dices <= 7
```
See examples in the corresponding box.
Enjoy it!!
| reference | import numpy as np
def products(n, min_divisor, max_divisor):
if n == 1:
yield []
for divisor in range(min_divisor, max_divisor + 1):
if n % divisor == 0:
for product in products(n / / divisor, divisor, max_divisor):
yield product + [divisor]
def eq_dice(set):
product = np . prod(set)
lista = list(products(product, 3, min(product - 1, 20)))
return len(lista) - 1 if len(set) > 1 else len(lista)
| Equivalent Dice | 5b26047b9e40b9f4ec00002b | [
"Algorithms",
"Performance",
"Number Theory",
"Recursion",
"Fundamentals"
]
| https://www.codewars.com/kata/5b26047b9e40b9f4ec00002b | 5 kyu |
In this kata we are going to mimic a software versioning system.
```if:javascript
You have to implement a `vm` function returning an object.
```
```if:factor
You have to implement a `<version-manager>` constructor word, and some associated words.
```
```if:rust
You have to implement a `VersionManager` struct.
```
```if-not:javascript,factor,rust
You have to implement a `VersionManager` class.
```
It should accept an optional parameter that represents the initial version. The input will be in one of the following formats: `"{MAJOR}"`, `"{MAJOR}.{MINOR}"`, or `"{MAJOR}.{MINOR}.{PATCH}"`. More values may be provided after `PATCH` but they should be ignored. If these 3 parts are not decimal values, an exception with the message `"Error occured while parsing version!"` should be thrown. If the initial version is not provided or is an empty string, use `"0.0.1"` by default.
This class should support the following methods, all of which should be chainable (except `release`):
* `major()` - increase `MAJOR` by `1`, set `MINOR` and `PATCH` to `0`
* `minor()` - increase `MINOR` by `1`, set `PATCH` to `0`
* `patch()` - increase `PATCH` by `1`
* `rollback()` - return the `MAJOR`, `MINOR`, and `PATCH` to their values before the previous `major`/`minor`/`patch` call, or throw an exception with the message `"Cannot rollback!"` if there's no version to roll back to. Multiple calls to `rollback()` should be possible and restore the version history
* `release()` - return a string in the format `"{MAJOR}.{MINOR}.{PATCH}"`
~~~if:factor
***Note:** An error word has been preloaded for you, use it as follows: `msg version-error`.*
~~~
~~~if:cpp
**Note:** In C++, use preloaded `VersionException` class for throwing exceptions.
~~~
May the binary force be with you!
~~~if:rust
# Notes for Rust
### API
Rust is strictly typed and thus imposes restrictions and idioms that don't apply to some other languages, particularly for concepts like method chaining and optional parameters. To allow the tests to interface with your solution, an API has been chosen and set up in the initial solution which you **must not alter** (you are free to declare and use custom structs and methods outside and within the given API as you see fit).\
The constructor functions are as follows:
* `new`: takes no arguments and creates a VersionManager with the default initial version as described above
* `from_version`: takes a string representing the initial version and attempts to parse it into a VersionManager (see below)
### Errors
In Rust, we don't throw and (maybe) catch Exceptions, and as *competent* Rustaceans we certainly don't `panic!` when we encounter an error we can recover from. Accordingly, the two methods that can potentially fail return a `Result<VersionManager, VMError>`.\
The error type `VMError` has been preloaded for you and replaces the string messages in the original description:
```rust
pub enum VMError {
InvalidVersion, // for the `from_version` function
NoHistory, // for the `rollback` method
}
```
~~~
| algorithms | class VersionManager:
def __init__(self, version=None):
if not version:
version = '0.0.1'
self . __memory = []
try:
arr = [* map(int, version . split('.')[: 3])] + [0, 0, 0]
except:
raise Exception("Error occured while parsing version!")
del arr[3:]
self . __version = arr if any(arr) else [0, 0, 1]
def release(self):
return '.' . join(map(str, self . __version))
def rollback(self):
if not self . __memory:
raise Exception("Cannot rollback!")
self . __version = self . __memory . pop()
return self
def __update(self, i):
self . __memory . append([* self . __version])
self . __version[i] += 1
self . __version[i + 1:] = [0] * (len(self . __version) - 1 - i)
return self
def major(self): return self . __update(0)
def minor(self): return self . __update(1)
def patch(self): return self . __update(2)
| Versions manager | 5bc7bb444be9774f100000c3 | [
"Algorithms",
"Arrays",
"Strings",
"Object-oriented Programming"
]
| https://www.codewars.com/kata/5bc7bb444be9774f100000c3 | 6 kyu |
The leader of the village sends you to carry back exactly `c` litres from the mountain shrine holy water, but you can only bring back one of the 2 jars `a` or `b` (`a` and `b` are known values) in the shrine. You also have to do that in one travel... you can't risk going to the shrine and die trying to fill one of the jars with `c` litres. So help yourself by precalculating if it's possible to do that in any way and inform the leader about the possibility of you been able to achieve the task (You are very trustworthy and won't like to disappoint your leader) :)
<p>
* ****INPUT****<br>
`a, b` the volumes of jars you are given and `c` the volume of the water you have to carry back
* ****Output**** <br>
`true` or `false` depending upon if it's possible to fill one of the `a` or `b` litre jar with demand `c` litre.
* ****Example****<br>
<a href="https://www.youtube.com/watch?v=6cAbgAaEOVE">My favorite explanation </a> <br>
****OR (For those who like to read)**** ;) <br>
For `a = 3`, `b = 5` and `c = 4` litre
* Fill the jar `a` full and pour that in jar `b` now jar `a` contains 0 litres and jar `b` contains 3 litres of water
* Repeat 1st step once again and now you have jar `b` full with 5 litres and jar `a` left with 1 litre.
* Now empty the jar `b` and pour the water left in jar `a` (1 litre) into jar `b`, now jar `a` is empty and jar `b` contains `1` litre of water.
* Now just fill again the jar `a` and pour that back into jar `b` to get `4` litres (Hope you understand)
| algorithms | from math import gcd
def can_measure(a, b, c):
return not (a < c > b or c % gcd(a, b))
| 3 litres and 5 litres | 5bc8c9db40ecc7f792002308 | [
"Mathematics",
"Algorithms"
]
| https://www.codewars.com/kata/5bc8c9db40ecc7f792002308 | 7 kyu |
Baby is getting his frst tooth. This means more sleepless nights, but with the fun of feeling round his gums and trying to guess which will be first out!
Probably best have a sweepstake with your friends - because you have the best chance of knowing. You can feel the gums and see where the raised bits are - most raised, most likely tooth to come through first!
Given an array of numbers (t) to represent baby's gums, you need to return the index of the lump that is most pronounced.
The most pronounced lump is the one that has the biggest differential to its surrounding values. e.g.:
```
[1, 2, 4] = 2
index 0 has a differential of -1 to its right (it is lower so the figure is negative)
index 1 has a differential of +1 to its left, and -2 to its right. Total is -1.
index 2 has a differential of +2 to its left, and nothing to its right,
```
If there is no distinct highest value (more than one occurence of the largest differential), return -1. | reference | def first_tooth(lst):
gums = lst[: 1] + lst + lst[- 1:]
diff = [gums[i + 1] * 2 - gums[i] - gums[i + 2] for i in range(len(lst))]
m = max(diff)
return diff . index(m) if diff . count(m) == 1 else - 1
| The Baby Years III - First Tooth | 5bcac5a01cbff756e900003e | [
"Fundamentals",
"Strings",
"Arrays"
]
| https://www.codewars.com/kata/5bcac5a01cbff756e900003e | 7 kyu |
We have the array of string digits, ```arr = ["3", "7", "7", "7", "3", "3, "3", "7", "8", "8", "8"]```.
The string digit with the least frequency is "8" occurring three times.
We will pop the first element of the array three times (exactly the same value of the minimum frequency) and we get "377"
```
["3", "7", "7", "7", "3", "3, "3", "7", "8", "8", "8"] ---> "3"
["7", "7", "7", "3", "3, "3", "7", "8", "8", "8"] ---> "37"
["7", "7", "3", "3, "3", "7", "8", "8", "8"] ---> "377"
```
We change the order in the original array, arr, in a random way and we get another string number, in this case: ```"783"```
```
['7', '8', '3', '3', '7', '3', '8', '3', '7', '8', '7'] ---> "7"
['8', '3', '3', '7', '3', '8', '3', '7', '8', '7'] ---> "78"
['3', '3', '7', '3', '8', '3', '7', '8', '7'] ---> "783"
```
Repeating this process you will get all the possible string numbers of three digits we list them below in a random order:
```
['377', '783', '883', '887', '338', '337', '888', '333', '833', '837', '878', '877', '838', '873', '733', '737', '738', '777', '773', '778', '383', '387', '388', '787', '788', '378', '373'] (27 different string numbers) (I)
```
From the set above the following string numbers have at least one string digit occurring more than once:
```
['377','883','887','338','337','888','333','833','878','877','838','733','737','777','773','778','383','388','787','788','373'] (total of 21 numbers) (II)
```
From this above list, we get the integer 873, that is the highest number having digits occurring only once (pandigital). (III)
Having in mind the random process shown above that generates string numbers, we need a function ```proc_arrII()``` that receives an array of string digits and outputs the total maximum possible amount of string numbers (I), the amount of digits that have at least one digit occurring more than once (II) and the highest pandigital number(III).
The above case will be:
```python
proc_arrII(["3","7","7","7","3","3","3","7","8","8","8"]) == [27, 21, 873]
```
More cases in the example box.
The digit "0" may be included in the given array and is treated the same as any other digit.
If it is not possible to generate a pandigital number the function will output only the total number of generated numbers. See the case below:
```python
proc_arrII(['3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '1', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', '1', '3', '3', '3', '3', '3', '1', '3', '3']) = [8]
```
Features of the random tests:
```
Low Performance Tests:
Length of array between 6 and 200
Minimum occurrence of digits between 3 and 25
Number of tests: 100
```
| algorithms | from collections import Counter
from math import factorial as fact
def proc_arrII(arr):
c = Counter(arr)
l = min(c . values())
p = len(c) * * l
return [p] if len(c) < l else [p, p - fact(len(c)) / / fact(len(c) - l), int('' . join(sorted(c . keys(), reverse=True)[: l]))]
| Generate Numbers From Digits #2 | 584e936ae82520a397000027 | [
"Fundamentals",
"Logic",
"Strings",
"Data Structures",
"Algorithms",
"Mathematics",
"Number Theory",
"Permutations"
]
| https://www.codewars.com/kata/584e936ae82520a397000027 | 5 kyu |
There is no single treatment that works for every phobia, but some people cure it by being gradually exposed to the phobic situation or object. In this kata we will try curing arachnophobia by drawing primitive spiders.
Our spiders will have legs, body, eyes and a mouth. Here are some examples:
```
/\((OOwOO))/\
/╲(((0000w0000)))╱\
^(oWo)^
```
You will be given four values:
1) `leg size` where each value stands for its own leg type: `1 for "^ ^", 2 for "/\ /\", 3 for "/╲ ╱\", 4 for "╱╲ ╱╲"`
2) `body size` where each value stands for its own body type: `1 for "( )", 2 for "(( ))", 3 for "((( )))"`
3) `mouth` representing the spider's mouth
4) `eye` representing the spider's eye
**Note:** the eyes are symmetric, and their total amount is `2 to the power of body size`.
You will also be given only valid data. That's it for the instructions, you can start coding! | reference | def draw_spider(leg_size, body_size, mouth, eye):
lleg = ['', '^', '/\\', '/╲', '╱╲'][leg_size]
rleg = ['', '^', '/\\', '╱\\', '╱╲'][leg_size]
lbody = '(' * body_size
rbody = ')' * body_size
eye *= 2 * * (body_size - 1)
return f' { lleg }{ lbody }{ eye }{ mouth }{ eye }{ rbody }{ rleg } '
| Curing Arachnophobia | 5bc73331797b005d18000255 | [
"Strings",
"Fundamentals"
]
| https://www.codewars.com/kata/5bc73331797b005d18000255 | 7 kyu |
# Task
**Your task** is to implement function `printNumber` (`print_number` in C/C++ and Python `Kata.printNumber` in Java) that returns string that represents given number in text format (see examples below).
Arguments:
- `number` — Number that we need to print (`num` in C/C++/Java)
- `char` — Character for building number (`ch` in C/C++/Java)
# Examples
```javascript
printNumber(99, "$")
//Should return
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n
//$ $\n
//$ $$$$ $$$$ $$$$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$$$ $$$$ $$$$ $$ $$ $\n
//$ $\n
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
printNumber(12345, "*")
//Should return
//****************************************\n
//* *\n
//* ** **** **** ** ** ****** *\n
//* *** ** ** ** ** ** ** ** *\n
//* * ** ** ** ** ** ***** *\n
//* ** ** ** ***** ** *\n
//* ** ** ** ** ** ** *\n
//* ****** ****** **** ** ***** *\n
//* *\n
//****************************************
printNumber(67890, "@")
//Should return
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\n
//@ @\n
//@ @@ @@@@@@ @@@@ @@@@ @@@@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@ @@ @@ @\n
//@ @@ @@ @@ @@@@ @@@@ @@ @@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@@@ @\n
//@ @\n
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
```
```c,python
print_number(99, '$')
//Should return
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n
//$ $\n
//$ $$$$ $$$$ $$$$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$$$ $$$$ $$$$ $$ $$ $\n
//$ $\n
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
print_number(12345, '*')
//Should return
//****************************************\n
//* *\n
//* ** **** **** ** ** ****** *\n
//* *** ** ** ** ** ** ** ** *\n
//* * ** ** ** ** ** ***** *\n
//* ** ** ** ***** ** *\n
//* ** ** ** ** ** ** *\n
//* ****** ****** **** ** ***** *\n
//* *\n
//****************************************
print_number(67890, '@')
//Should return
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\n
//@ @\n
//@ @@ @@@@@@ @@@@ @@@@ @@@@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@ @@ @@ @\n
//@ @@ @@ @@ @@@@ @@@@ @@ @@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@@@ @\n
//@ @\n
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
```
```cpp
print_number(99, '$')
//Should return
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n
//$ $\n
//$ $$$$ $$$$ $$$$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$$$ $$$$ $$$$ $$ $$ $\n
//$ $\n
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
print_number(12345, '*')
//Should return
//****************************************\n
//* *\n
//* ** **** **** ** ** ****** *\n
//* *** ** ** ** ** ** ** ** *\n
//* * ** ** ** ** ** ***** *\n
//* ** ** ** ***** ** *\n
//* ** ** ** ** ** ** *\n
//* ****** ****** **** ** ***** *\n
//* *\n
//****************************************
print_number(67890, '@')
//Should return
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\n
//@ @\n
//@ @@ @@@@@@ @@@@ @@@@ @@@@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@ @@ @@ @\n
//@ @@ @@ @@ @@@@ @@@@ @@ @@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@@@ @\n
//@ @\n
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
```
```java
Kata.printNumber(99, '$')
//Should return
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n
//$ $\n
//$ $$$$ $$$$ $$$$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$ $$ $$ $$ $$ $$ $$$$ $$$$ $\n
//$ $$ $$ $$ $$ $$ $$ $$ $$ $\n
//$ $$$$ $$$$ $$$$ $$ $$ $\n
//$ $\n
//$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
Kata.printNumber(12345, '*')
//Should return
//****************************************\n
//* *\n
//* ** **** **** ** ** ****** *\n
//* *** ** ** ** ** ** ** ** *\n
//* * ** ** ** ** ** ***** *\n
//* ** ** ** ***** ** *\n
//* ** ** ** ** ** ** *\n
//* ****** ****** **** ** ***** *\n
//* *\n
//****************************************
Kata.printNumber(67890, '@')
//Should return
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\n
//@ @\n
//@ @@ @@@@@@ @@@@ @@@@ @@@@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@ @@ @@ @\n
//@ @@ @@ @@ @@@@ @@@@ @@ @@ @\n
//@ @@ @@ @@ @@ @@ @@ @@ @@ @\n
//@ @@@@ @@ @@@@ @@ @@@@ @\n
//@ @\n
//@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
```
>***Note, that***:
- Number should be `0 <= number <= 99999` and have `5 digits` (should have zeros at the start if needed)
- Test cases contains only valid values (integers that are 0 <= number <= 99999) and characters
- Numbers should have the same shape as in the examples (6x6 by the way)
- Returned string should be joined by `\n` character (except of the end)
- Returned string should have 1 character *(height)* border (use the same character as for number) + padding (1 character in height vertical and 2 horizontal with ` `) around borders and 1 character margin between "digits"
*Suggestions and translations are welcome.*
| reference | DIGITS = """
***************************************************************************
* *
* **** ** **** **** ** ** ****** ** ****** **** **** *
* ** ** *** ** ** ** ** ** ** ** ** ** ** ** ** ** ** *
* ** ** * ** ** ** ** ** ***** **** ** **** ** ** *
* ** ** ** ** ** ***** ** ** ** ** **** **** *
* ** ** ** ** ** ** ** ** ** ** ** ** ** ** *
* **** ****** ****** **** ** ***** **** ** **** ** *
* *
***************************************************************************
""" . strip(). splitlines()
def print_number(number, char):
ns = [* map(int, format(number, '05'))]
return '\n' . join(
ds[: 2] + '' . join(ds[n * 7 + 2: n * 7 + 9] for n in ns) + ds[- 3:]
for ds in DIGITS
). replace('*', char)
| Print number with character | 5bc5c0f8eba26e792400012a | [
"Fundamentals"
]
| https://www.codewars.com/kata/5bc5c0f8eba26e792400012a | 6 kyu |
# Silent Import
As part of your spy training, You were taught to be as stealthy as possible while carrying out missions. This time, you have to silently import modules from a without getting caught. Most of your peers are skeptical if you will be able to do this. But, you are the [G.O.A.T](https://www.urbandictionary.com/define.php?term=goat) and you always have a plan.
# Your Task
Write a function `silent_thief` that will import any module passed in to it and return it.
Your code must __NOT__:
1. Contain the word `import`
2. Contain any double underscores: `__`
3. Use either `eval` or `exec`.
## Extra info
This is kata 2 of my awesome [__spy__](https://www.codewars.com/collections/spy-series) series.
#### Please take time to give feedback on this kata. | games | def silent_thief(module_name):
return globals()['_' '_builtins_' '_']['_' '_imp' 'ort_' '_'](module_name)
| Silent Import | 5bc5c064eba26ef6ed000158 | [
"Puzzles",
"Language Features",
"Restricted"
]
| https://www.codewars.com/kata/5bc5c064eba26ef6ed000158 | 6 kyu |
## Task
You are given three non negative integers `a`, `b` and `n`, and making an infinite sequence just like fibonacci sequence, use the following rules:
- step 1: use `ab` as the initial sequence.
- step 2: calculate the sum of the last two digits of the sequence, and append it to the end of sequence.
- repeat step 2 until you have enough digits
Your task is to complete the function which returns the `n`th digit (0-based) of the sequence.
### Notes:
- `0 <= a, b <= 9`, `0 <= n <= 10^10`
- `16` fixed testcases
- `100` random testcases, testing for correctness of solution
- `100` random testcases, testing for performance of code
- All inputs are valid.
- Pay attention to code performance.
## Examples
For `a = 7, b = 8 and n = 9` the output should be `5`, because the sequence is:
```
78 -> 7815 -> 78156 -> 7815611 -> 78156112 -> 781561123 -> 7815611235 -> ...
```
and the 9th digit of the sequence is `5`.
---
For `a = 0, b = 0 and n = 100000000` the output should be `0`, because all the digits in this sequence are `0`.
| games | def find(a, b, n):
strng = str(a) + str(b)
# there are 10 and 4 long loops
if (n > 20):
n = n % 20 + 20
while len(strng) <= n:
next_ch = int(strng[- 1]) + int(strng[- 2])
strng = strng + str(next_ch)
return int(strng[n])
| Simple Fun #395: Fibonacci digit sequence | 5bc555bb62a4cec849000047 | [
"Puzzles",
"Fundamentals"
]
| https://www.codewars.com/kata/5bc555bb62a4cec849000047 | 6 kyu |
John has invited some friends. His list is:
```
s = "Fred:Corwill;Wilfred:Corwill;Barney:Tornbull;Betty:Tornbull;Bjon:Tornbull;Raphael:Corwill;Alfred:Corwill";
```
Could you make a program that
- makes this string uppercase
- gives it sorted in alphabetical order by last name.
When the last names are the same, sort them by first name.
Last name and first name of a guest come in the result between parentheses separated by a comma.
So the result of function `meeting(s)` will be:
```
"(CORWILL, ALFRED)(CORWILL, FRED)(CORWILL, RAPHAEL)(CORWILL, WILFRED)(TORNBULL, BARNEY)(TORNBULL, BETTY)(TORNBULL, BJON)"
```
It can happen that in two distinct families with the same family name two people have the same first name too.
#### Notes
- You can see another examples in the "Sample tests".
| reference | def meeting(s):
return '' . join(sorted('({1}, {0})' . format(* (x . split(':'))) for x in s . upper(). split(';')))
| Meeting | 59df2f8f08c6cec835000012 | [
"Fundamentals"
]
| https://www.codewars.com/kata/59df2f8f08c6cec835000012 | 6 kyu |
A rook is a piece used in the game of chess which is played on a board of square grids. A rook can only move vertically or horizontally from its current position and two rooks attack each other if one is on the path of the other. In the following figure, the dark squares represent the reachable locations for rook R<sub>1</sub> from its current position. The figure also shows that the rook R<sub>1</sub> and R<sub>2</sub> are in attacking positions where R<sub>1</sub> and R<sub>3</sub> are not. R<sub>2</sub> and R<sub>3</sub> are also in non-attacking positions.
<img src="https://image.ibb.co/ixj2op/Screenshot-2.png" alt="Screenshot-2" border="0"></a>
Now, given two numbers ``n`` and ``k``, your job is to determine the number of ways one can put ``k`` rooks on an ``n x n`` chessboard so that no two of them are in attacking positions.
**NOTE:** The `k` rooks are **indistinguishable** / **interchangeable** - this means that in the above illustration, for example, swapping rook R<sub>1</sub> with rook R<sub>2</sub> does **not** count as a new configuration - it is just a "relabelling" of the same configuration.
**Range:** (1 ≤ n ≤ 15) and (0 ≤ k ≤ n<sup>2</sup>) | reference | from math import factorial, comb
def rooks(n, k):
return factorial(k) * comb(n, k) * * 2
| Rooks | 5bc2c8e230031558900000b5 | [
"Algorithms",
"Mathematics",
"Fundamentals",
"Combinatorics"
]
| https://www.codewars.com/kata/5bc2c8e230031558900000b5 | 6 kyu |
We need a function that may receive a list of an unknown amount of points in the same plane, having each of them, cartesian coordinates of the form (x, y) and may find the biggest triangle (the one with the largest area) formed by all of the possible combinations of groups of three points of that given list.
Of course, we will have some combinations of three points that does not form a triangle, because the three points are aligned.
The function find_biggTriang(listOfPoints), will output a list with the following data in the order presented bellow:
```python
[(1), (2), (3), (4), 5]
(1) - Number of points received (You may assume that you will not receive duplicates)
(2) - Maximum possible amount of triangles that can be formed with the amount of received
points (number in data (1) above). It should be expressed as an integer, (no L for long type
variables)
(3) - Real Number of triangles that can be formed with the given points. (The function should have a
counter for all the cases of three points aligned). It should be expressedas as an integer.
(4) - The triangles that have maximum area in a sorted list.
If there are two triangles with the biggest area, the result will be presented in this way:
[[[xA1, yA1], [xB1, yB1], [xC1, yC1]], [[xA2, yA2], [xB2, yB2], [xC2, yC2]]]
But if we have only one triangle with max. area, there is no need of a spare level of braces,
so it will be as follows: [[xA1, yA1], [xB1, yB1], [xC1, yC1]]
(5) - The value of max. area (absolute value) that was found as a float. As we did not define the
units of length for the coordinates, the units for the area will be ignored.
```
It would be useful to apply the expression for the area of a triangle with vertices A, B, and C, is equal to the half of the determinant of the matrix, using the respective coordinates as follows:
```python
| xA yA 1|
Area Triangle(A, B, C) = 1/2 . | xB yB 1|
| xC yC 1|
```
The negative sign for the area should be ignored for the purpose of the exercise, and we will consider the absolute value for all cases.
See how to calculate the determinant of a matrix 3 x 3, rule of Sarrus.
https://en.wikipedia.org/wiki/Rule_of_Sarrus
Using this expression, it would be easy to detect the cases when three points are aligned.
Let's see some simple cases.
```python
listOfPoints1 = [(0, 1), (7, 3), (9, 0), (7, 10), (2, 9), (10, 7), (2, 8), (9, 8), (4, 4), (2, 10), (10, 1), (0, 4), (4, 3), (10, 0), (0, 3), (3, 4), (1, 1), (7, 2), (4, 0)] (19 points received)
find_biggTriang(listOfPoints1) --------> [19, 969, 953, [[0, 1], [7, 10], [10, 0]], 48.5]
/// Combinations (19, 3) = 969 (We do not have repeated points)
953 real cases for triangles because the function detected 16 cases when three points are
aligned.
The function found one triangle [[0, 1], [7, 10], [10, 0]] with its area equals to 49.5///
listOfPoints2 = [(7, 4), (0, 0), (9, 10), (5, 0), (8, 1), (7, 6), (9, 3), (2, 4), (6, 3), (5, 6), (3, 6), (10, 0), (9, 7), (3, 10), (10, 2)] (15 points received)
find_biggTriang(listOfPoints2) --------> [15, 455, 446, [[[0, 0], [9, 10], [10, 0]], [[0, 0], [10, 0], [3, 10]]], 50.0]
/// Combinations(15, 3) = 455 but there were only 446 real triangles
We found two triangles: [[0, 0], [9, 10], [10, 0]] and [[0, 0], [10, 0], [3, 10]] (both in a
sorted list. Both triangles have an area of 50.0///
```
Your code will be tested with lists created randomly up to 70 points.
Have a nice moment and enjoy it!!
| reference | from itertools import combinations
def find_biggTriang(listPoints):
def area(a, b, c): return 0.5 * abs(b[0] * c[1] - b[1] *
c[0] - a[0] * c[1] + a[1] * c[0] + a[0] * b[1] - a[1] * b[0])
triangls = [[[a, b, c], area(a, b, c)]
for a, b, c in combinations(map(list, listPoints), 3)]
np, mp, rp = len(listPoints), len(
triangls), sum(a != 0 for _, a in triangls)
mxt, mxa = max(triangls, key=lambda x: x[1])
mxtt = [t for t, a in triangls if a == mxa]
return [np, mp, rp, mxt if len(mxtt) == 1 else mxtt, mxa]
| Find the Biggest Triangle | 55f0a7d8c44c6f1438000013 | [
"Data Structures",
"Algorithms",
"Mathematics",
"Searching",
"Sorting",
"Fundamentals"
]
| https://www.codewars.com/kata/55f0a7d8c44c6f1438000013 | 6 kyu |
The conic curves may be obtained doing different sections of a cone and we may obtain the three principal groups: ellipse, hyperbola and parabola.
<a href="http://imgur.com/4NdOkgf"><img src="http://i.imgur.com/4NdOkgf.png?2" title="source: imgur.com" /></a>
The circle is a special case of ellipses.
In mathematics all the conics may be represented by the following equation:
<a href="http://imgur.com/SVTomxD"><img src="http://i.imgur.com/SVTomxD.jpg?1" title="source: imgur.com" /></a>
```A, B, C, D, E and F``` are coefficients that may have different values in the real numeric field.
Hesse in the nineteenth century, introduced the use of the invariants, useful tool in order to classify the different conic curves.
The invariants ```M, N, and S``` are:
<a href="http://imgur.com/v7xVjyX"><img src="http://i.imgur.com/v7xVjyX.png?1" title="source: imgur.com" /></a>
It may be proved that if the system of coordinates changes, for example moving the center of the system of coordinates or rotating the coordinates axes, or doing both things, the invariants will have the same value, even though the coefficients ```A, B, C, D, E, and F``` change.
The following chart shows how the values of ```M, N and S``` classify the gender of the conics and the special cases when the conics are degenerated (points or lines) or they are imaginary:
<a href="https://imgur.com/2hUJNeN"><img src="https://i.imgur.com/2hUJNeN.jpg?1" title="source: imgur.com" /></a>
The function ```classify_conic()``` will do this work.
This function will receive the different coefficients of the conic equation and will output the result of the classification as a string
```python
classify_conic(A, B, C, D, E, F) == result
```
```javascript
classifyConic(A, B, C, D, E, F) == result
```
```ruby
classify_conic(a, b, c, d, e, f) == result
```
Let's see some cases:
```
Case1
A = 1 , B = 1, C = 1, D = 2, E = 2, F = -4
classify_conic(A, B, C, D, E, F) == "A real ellipse"
Case2
A = 1 , B = 1, C = -1, D = 2, E = 2, F = 4
classify_conic(A, B, C, D, E, F) == "A real hyperbola"
Case3
A =1, B = 0, C = 0, D = 4; E = 4, F = 4
classify_conic(A, B, C, D, E, F) == "A real parabola"
```
```
Case1
A = 1 , B = 1, C = 1, D = 2, E = 2, F = -4
classifyConic(A, B, C, D, E, F) == "A real ellipse"
Case2
A = 1 , B = 1, C = -1, D = 2, E = 2, F = 4
classifyConic(A, B, C, D, E, F) == "A real hyperbola"
Case3
A =1, B = 0, C = 0, D = 4; E = 4, F = 4
classifyConic(A, B, C, D, E, F) == "A real parabola"
```
The graph showing the above three cases is the following:
<a href="http://imgur.com/nUE4mcM"><img src="http://i.imgur.com/nUE4mcM.png?1" title="source: imgur.com" /></a>
The messages for the special cases, having degenerated or imaginary conics will be:
```python
# For elliptic gender:
"An imaginary ellipse"
"A degenerated ellipse: One point"
# For hyperbolic gender:
"A degenerated hyperbola: two intersecting lines"
# For parabolic gender:
"A degenerated parabola: two parallel lines"
"A degenerated parabola: two coinciding lines"
"A degenerated parabola: two imaginary lines"
```
Enjoy it!!
#Note:
- The given coefficients `A`, `B`, `C`, `D`, `E and `F`, (`a`, `b`, `c`, `d`, `e` and `f` in Ruby) will be always integers.
- In order to avoid precision problems, the determinant values of `M` and `N` should be obtained by the rule of Sarrus. (See: https://en.wikipedia.org/wiki/Rule_of_Sarrus) | reference | def det(matrix: list) - > int:
if len(matrix) == 1:
return matrix[0][0]
return sum((- 1) * * i * matrix[0][i] * det([row[: i] + row[i + 1:] for row in matrix[1:]]) for i in range(len(matrix)))
def classify_conic(A: int, B: int, C: int, D: int, E: int, F: int) - > str:
M = det([[2 * A, B, D], [B, 2 * C, E], [D, E, 2 * F]])
N = det([[B, 2 * A], [2 * C, B]])
S = A + C
if N < 0: # elliptic
if M == 0:
return 'A degenerated ellipse: One point'
if M * S < 0:
return 'A real ellipse'
if M * S > 0:
return 'An imaginary ellipse'
if N > 0: # hyperbolic
if M == 0:
return 'A degenerated hyperbola: two intersecting lines'
if M != 0:
return 'A real hyperbola'
if N == 0: # parabolic
if M != 0:
return 'A real parabola'
delta = D * * 2 - 4 * A * F
if delta == 0:
return 'A degenerated parabola: two coinciding lines'
if delta > 0:
return 'A degenerated parabola: two parallel lines'
if delta < 0:
return 'A degenerated parabola: two imaginary lines'
| Conic Classification | 56546460730f15790b000075 | [
"Fundamentals",
"Logic",
"Data Structures",
"Mathematics",
"Geometry",
"Linear Algebra"
]
| https://www.codewars.com/kata/56546460730f15790b000075 | 6 kyu |
You will be given two strings `a` and `b` consisting of lower case letters, but `a` will have at most one asterix character. The asterix (if any) can be replaced with an arbitrary sequence (possibly empty) of lowercase letters. No other character of string `a` can be replaced. If it is possible to replace the asterix in `a` to obtain string `b`, then string `b` matches the pattern.
If the string matches, return `true` else `false`.
```
For example:
solve("code*s","codewars") = true, because we can replace the asterix(*) with "war" to match the second string.
solve("codewar*s","codewars") = true, because we can replace the asterix(*) with "" to match the second string.
solve("codewars","codewars") = true, because the strings already match.
solve("a","b") = false
solve("*", "codewars") = true
```
More examples in test cases.
Good luck! | reference | from fnmatch import fnmatch
def solve(a, b):
return fnmatch(b, a)
| Simple string matching | 5bc052f93f43de7054000188 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5bc052f93f43de7054000188 | 7 kyu |
Given an integer `n`, find two integers `a` and `b` such that:
```Pearl
A) a >= 0 and b >= 0
B) a + b = n
C) DigitSum(a) + Digitsum(b) is maximum of all possibilities.
```
You will return the digitSum(a) + digitsum(b).
```
For example:
solve(29) = 11. If we take 15 + 14 = 29 and digitSum = 1 + 5 + 1 + 4 = 11. There is no larger outcome.
```
`n` will not exceed `10e10`.
More examples in test cases.
Good luck! | reference | def solve(n):
if n < 10:
return n
a = int((len(str(n)) - 1) * '9')
b = n - a
return sum([int(i) for i in (list(str(a)) + list(str(b)))])
| Simple sum of pairs | 5bc027fccd4ec86c840000b7 | [
"Fundamentals",
"Performance"
]
| https://www.codewars.com/kata/5bc027fccd4ec86c840000b7 | 6 kyu |
We have an integer array with unique elements and we want to do the permutations that have an element fixed, in other words, these permutations should have a certain element at the same position than the original.
These permutations will be called: **permutations with one fixed point**.
Let's see an example with an array of four elements and we want the permutations that have a coincidence **only at index 0**, so these permutations are (the permutations between parenthesis):
```
arr = [1, 2, 3, 4]
(1, 3, 4, 2)
(1, 4, 2, 3)
Two permutations matching with arr only at index 0
```
Let's see the permutations of the same array with only one coincidence at index **1**:
```
arr = [1, 2, 3, 4]
(3, 2, 4, 1)
(4, 2, 1, 3)
Two permutations matching with arr only at index 1
```
Once again, let's see the permutations of the same array with only one coincidence at index **2**:
```
arr = [1, 2, 3, 4]
(2, 4, 3, 1)
(4, 1, 3, 2)
Two permutations matching with arr only at index 2
```
Finally, let's see the permutations of the same array with only one coincidence at index **3**:
```
arr = [1, 2, 3, 4]
(2, 3, 1, 4)
(3, 1, 2, 4)
Two permutations matching with arr only at index 3
```
For this array given above (arr) :
- We conclude that we have 8 permutations with one fixed point (two at each index of arr).
- We may do the same development for our array, `arr`, with two fixed points and we will get `6` permutations.
- There are no permutations with coincidences only at three indexes.
- It's good to know that the amount of permutations with no coincidences at all are `9`. See the kata <a href="https://www.codewars.com/kata/shuffle-it-up">Shuffle It Up!!</a>
In general:
- When the amount of fixed points is equal to the array length, there is only one permutation, the original array.
- When the amount of fixed points surpasses the length of the array, obvously, there are no permutations at all.
Create a function that receives the length of the array and the number of fixed points and may output the total amount of permutations for these constraints.
Features of the random tests:
```
length of the array = l
number of fixed points = k
10 ≤ k ≤ l ≤ 9000
```
See the example tests!
Enjoy it!!
Ruby versin will be released soon.
#Note: This kata was published previously but in a version not well optimized. | reference | def fixed_points_perms(n, k):
if k > n:
return 0
if k == n:
return 1
if k == 0:
def subf(n): return 1 if n == 0 else n * subf(n - 1) + (- 1) * * n
return subf(n)
return fixed_points_perms(n - 1, k - 1) * n / / k
| Shuffle It Up II | 5bbecf840441ca6d6a000126 | [
"Algorithms",
"Performance",
"Number Theory",
"Recursion",
"Fundamentals"
]
| https://www.codewars.com/kata/5bbecf840441ca6d6a000126 | 6 kyu |
This kata is an extension of "Combinations in a Set Using Boxes":https://www.codewars.com/kata/5b5f7f7607a266914200007c
The goal for this kata is to get all the possible combinations (or distributions) (with no empty boxes) of a certain number of balls, but now, **with different amount of boxes.** In the previous kata, the number of boxes was always the same
Just to figure the goal for this kata, we can see in the picture below the combinations for four balls using the diagram of Hasse:
<a href="https://imgur.com/1Eft913"><img src="https://i.imgur.com/1Eft913.png?1" title="source: imgur.com" /></a>
Points that are isolated represent balls that are unique in a box.
k points that are bonded in an area respresent a subset that is content in a box.
The unique square at the bottom of the diagram, means that there is only one possible combination for four balls in four boxes.
The above next line with 6 squares, means that we have 6 possible distributions of the four balls in 3 boxes. These six distributions have something in common, all of them have one box with 2 balls.
Going up one line more, we find the 7 possible distributions of the four balls in 2 boxes. As it is shown, we will have 7 distributions with: three balls in a box and only one ball in the another box, or two balls in each box.
Finally, we find again at the top, an unique square, that represents, the only possible distribution, having one box, the four balls together in the only available box.
So, for a set of 4 labeled balls, we have a total of 15 possible distributions (as always with no empty boxes) and with a maximum of 7 possible distributions for the case of two boxes.
Prepare a code that for a given number of balls (an integer), may output an array with required data in the following order:
```
[total_amount_distributions, maximum_amount_distributions_case_k_boxes, k_boxes]
```
Just see how it would be for the example given above:
```
combs_non_empty_boxesII(4) == [15, 7, 2] # A total of 15 combinations
#The case with maximum distributions is 7 using 2 boxes.
```
Features of the random tests:
```
1 < n <= 1800 (python)
1 < n <= 1200 (ruby)
```
You may see the example tests for more cases.
Enjoy it!
Ruby version will be published soon. | reference | MAX_BALL = 2 + 1800
DP, lst = [None], [0, 1]
for _ in range(MAX_BALL):
DP . append([sum(lst), * max((v, i) for i, v in enumerate(lst))])
lst . append(0)
lst = [v * i + lst[i - 1] for i, v in enumerate(lst)]
combs_non_empty_boxesII = DP . __getitem__
| Combinations in a Set Using Boxes II | 5b61e9306d0db7d097000632 | [
"Performance",
"Algorithms",
"Mathematics",
"Machine Learning",
"Combinatorics",
"Number Theory"
]
| https://www.codewars.com/kata/5b61e9306d0db7d097000632 | 5 kyu |
You have a set of four (4) balls labeled with different numbers: ball_1 (1), ball_2 (2), ball_3 (3) and ball(4) and we have 3 equal boxes for distribute them. The possible combinations of the balls, without having empty boxes, are:
```
(1) (2) (3)(4)
______ ______ _______
```
```
(1) (2)(4) (3)
______ ______ ______
```
```
(1)(4) (2) (3)
______ ______ ______
```
```
(1) (2)(3) (4)
_______ _______ ______
```
```
(1)(3) (2) (4)
_______ _______ ______
```
```
(1)(2) (3) (4)
_______ _______ ______
```
We have a total of **6** combinations.
Think how many combinations you will have with two boxes instead of three. You will obtain **7** combinations.
Obviously, the four balls in only box will give only one possible combination (the four balls in the unique box). Another particular case is the four balls in four boxes having again one possible combination(Each box having one ball).
What will be the reasonable result for a set of n elements with no boxes?
Think to create a function that may calculate the amount of these combinations of a set of ```n``` elements in ```k``` boxes.
You do no not have to check the inputs type that will be always valid integers.
The code should detect the cases when ```k > n```, returning "It cannot be possible!".
Features of the random tests:
```
1 <= k <= n <= 800
```
Ruby version will be published soon.
| reference | # Stirling numbers of second kind
# http://mathworld.wolfram.com/StirlingNumberoftheSecondKind.html
# S(n,k)=1/(k!)sum_(i=0)^k(-1)^i(k; i)(k-i)^n
from math import factorial as fact
def combs_non_empty_boxes(n, k):
if k < 0 or k > n:
return 'It cannot be possible!'
return sum([1, - 1][i % 2] * (k - i) * * n * fact(k) / / (fact(k - i) * fact(i)) for i in range(k + 1)) / / fact(k)
| Combinations in a Set Using Boxes | 5b5f7f7607a266914200007c | [
"Performance",
"Algorithms",
"Mathematics",
"Machine Learning",
"Combinatorics",
"Number Theory",
"Memoization"
]
| https://www.codewars.com/kata/5b5f7f7607a266914200007c | 5 kyu |
Cheesy Cheeseman just got a new monitor! He is happy with it, but he just discovered that his old desktop wallpaper no longer fits. He wants to find a new wallpaper, but does not know which size wallpaper he should be looking for, and alas, he just threw out the new monitor's box. Luckily he remembers the width and the aspect ratio of the monitor from when Bob Mortimer sold it to him. Can you help Cheesy out?
# The Challenge
Given an integer `width` and a string `ratio` written as `WIDTH:HEIGHT`, output the screen dimensions as a string written as `WIDTHxHEIGHT`.
**Note:** The calculated height should be represented as an integer. If the height is fractional, truncate it. | reference | def find_screen_height(width, ratio):
a, b = map(int, ratio . split(":"))
return f" { width } x { int ( width / a * b )} "
| Find Screen Size | 5bbd279c8f8bbd5ee500000f | [
"Fundamentals",
"Strings"
]
| https://www.codewars.com/kata/5bbd279c8f8bbd5ee500000f | 7 kyu |
<img src="https://i.imgur.com/ta6gv1i.png?1" title="weekly coding challenge" />
# Background
I have stacked some cannon balls in a triangle-based pyramid.
Like this,
<img src="https://i.imgur.com/ut4ejG1.png" title="cannon balls triangle base" />
# Kata Task
Given the number of `layers` of my stack, what is the total height?
Return the height as multiple of the ball diameter.
## Example
The image above shows a stack of 3 layers.
## Notes
* `layers` >= 0
* approximate answers (within 0.001) are good enough
---
*See Also*
* [Stacked Balls - 2D](https://www.codewars.com/kata/stacked-balls-2d)
* [Stacked Balls - 3D with square base](https://www.codewars.com/kata/stacked-balls-3d-square-base)
* [Stacked Balls - 3D with triangle base](https://www.codewars.com/kata/stacked-balls-3d-triangle-base)
| reference | def stack_height_3d(layers):
return 1 + (layers - 1) * (2 / 3) * * 0.5 if layers else 0
| Stacked Balls - 3D (triangle base) | 5bbad1082ce5333f8b000006 | [
"Mathematics",
"Fundamentals"
]
| https://www.codewars.com/kata/5bbad1082ce5333f8b000006 | 7 kyu |
Alice, Samantha, and Patricia are relaxing on the porch, when Alice suddenly says: _"I'm thinking of two numbers, both greater than or equal to 2. I shall tell Samantha the sum of the two numbers and Patricia the product of the two numbers."_
She takes Samantha aside and whispers in her ear the sum so that Patricia cannot hear it. Then she takes Patricia aside and whispers in her ear the product so that Samantha cannot hear it.
After a moment of reflection, Samantha says:
**Statement 1:** _"Patricia cannot know what the two numbers are."_
After which Patricia says:
**Statement 2:** _"In that case, I do know what the two numbers are."_
To which Samantha replies:
**Statement 3:** _"Then I too know what the two numbers are."_
Your first task is to write a function `statement1(s)` that takes an `int` argument `s` and returns `True` if and only if Samantha could have made statement 1 if given the number `s`. You may assume that `s` is the sum of two numbers both greater than or equal to 2.
Your second task is to write a function `statement2(p)` that takes an `int` argument `p` and returns `True` if and only if Patricia, when given the number `p`, could have made statement 2 after hearing Samantha make statement 1. You may assume that `p` is the product of two numbers both greater than or equal to 2 and that Patricia would not have been able to determine the two numbers by looking at `p` alone.
Your third task is to write a function `statement3(s)` that takes an `int` argument `s` and returns `True` if and only if Samantha, when given the number `s`, could have made statement 3 after hearing Patricia make statement 2.
Finally, it is to you to figure out what two numbers Alice was thinking of. Since there are multiple solutions, you must write a function `is_solution(a, b)` that returns `True` if and only if `a` and `b` could have been two numbers that Alice was thinking of.
Hint: To get you started, think of what Samantha's first statement implies. Samantha knows that Patricia was not given the product of two primes. That means that the sum that Samantha was given cannot be written as the sum of two primes. Goldbach's conjecture stipulates that every even number greater than 3 can be written as the sum of two primes. Although Goldbach's conjecture has not yet been proven, you may assume that it has been verified for all numbers involved in the test cases here. So we know that the sum that Samantha was given must be odd. The only way to write an odd number as the sum of two primes is when one of the primes is 2, the only even prime. This means that the number given to Samantha is not the sum of 2 and a prime. | games | def is_prime(n):
return n == 2 or n % 2 != 0 and all(n % k != 0 for k in xrange(3, root(n) + 1, 2))
def root(p):
return int(p * * 0.5)
def statement1(s):
return not (s % 2 == 0 or is_prime(s - 2))
def statement2(p):
return sum(statement1(i + p / i) for i in xrange(2, root(p) + 1) if p % i == 0) == 1
def statement3(s):
return sum(statement2(i * (s - i)) for i in xrange(2, s / 2 + 1)) == 1
def is_solution(a, b):
return statement1(a + b) and statement2(a * b) and statement3(a + b)
| Bridge Puzzle | 56f6380a690784f96e00045d | [
"Recursion",
"Puzzles"
]
| https://www.codewars.com/kata/56f6380a690784f96e00045d | 4 kyu |
# Background
I have stacked some cannon balls in a square pyramid.
Like this,
<img src="https://i.imgur.com/6d5Kpva.png" title="cannon balls" />
# Kata Task
Given the number of `layers` of my stack, what is the total height?
Return the height as multiple of the ball diameter.
## Example
The image above shows a stack of 4 layers.
## Notes
* `layers` >= 0
* approximate answers (within 0.001) are good enough
---
*See Also*
* [Stacked Balls - 2D](https://www.codewars.com/kata/stacked-balls-2d)
* [Stacked Balls - 3D with square base](https://www.codewars.com/kata/stacked-balls-3d-square-base)
* [Stacked Balls - 3D with triangle base](https://www.codewars.com/kata/stacked-balls-3d-triangle-base)
| reference | def stack_height_3d(layers):
return layers and 1 + (layers - 1) / 2 * * 0.5
| Stacked Balls - 3D (square base) | 5bb493932ce53339dc0000c2 | [
"Fundamentals"
]
| https://www.codewars.com/kata/5bb493932ce53339dc0000c2 | 7 kyu |

A [sliding puzzle](https://en.wikipedia.org/wiki/Sliding_puzzle) is a combination puzzle that challenges a player to slide (frequently flat) pieces along certain routes (usually on a board) to establish a certain end-configuration.
Your goal for this kata is to write a function that produces a sequence of tile movements that solves the puzzle.
## Input
An `n x n` array/list comprised of integer values ranging from `0` to `n^2 - 1` (inclusive), which represents a square grid of tiles. Note that there will always be one empty tile (represented by `0`) to allow for movement of adjacent tiles.
## Output
An array/list comprised of any (but not necessarily all) of the integers from `1` to `n^2 - 1`, inclusive. This represents the sequence of tile moves for a successful transition from the initial unsolved state to the solved state. If the puzzle is unsolvable, return `null`(JavaScript, Java, PHP) or `None`(Python) or the vector `{0}` (C++).
## Test Example
```javascript
let simpleExample = [
[ 1, 2, 3, 4],
[ 5, 0, 6, 8],
[ 9,10, 7,11],
[13,14,15,12]
];
slidePuzzle(simpleExample); // [6,7,11,12]
// TRANSITION SEQUENCE:
[ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4]
[ 5, 0, 6, 8] [ 5, 6, 0, 8] [ 5, 6, 7, 8] [ 5, 6, 7, 8] [ 5, 6, 7, 8]
[ 9,10, 7,11] -> [ 9,10, 7,11] -> [ 9,10, 0,11] -> [ 9,10,11, 0] -> [ 9,10,11,12]
[13,14,15,12] [13,14,15,12] [13,14,15,12] [13,14,15,12] [13,14,15, 0]
// NOTE: Your solution does not need to follow this exact sequence to pass
```
```python
simple_example = [
[ 1, 2, 3, 4],
[ 5, 0, 6, 8],
[ 9,10, 7,11],
[13,14,15,12]
]
slide_puzzle(simple_example) #[6,7,11,12]
# TRANSITION SEQUENCE:
[ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4]
[ 5, 0, 6, 8] [ 5, 6, 0, 8] [ 5, 6, 7, 8] [ 5, 6, 7, 8] [ 5, 6, 7, 8]
[ 9,10, 7,11] -> [ 9,10, 7,11] -> [ 9,10, 0,11] -> [ 9,10,11, 0] -> [ 9,10,11,12]
[13,14,15,12] [13,14,15,12] [13,14,15,12] [13,14,15,12] [13,14,15, 0]
# NOTE: Your solution does not need to follow this exact sequence to pass
```
```php
$simpleExample = [
[ 1, 2, 3, 4],
[ 5, 0, 6, 8],
[ 9,10, 7,11],
[13,14,15,12]
];
slidePuzzle($simpleExample); // [6,7,11,12]
// TRANSITION SEQUENCE:
[ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4] [ 1, 2, 3, 4]
[ 5, 0, 6, 8] [ 5, 6, 0, 8] [ 5, 6, 7, 8] [ 5, 6, 7, 8] [ 5, 6, 7, 8]
[ 9,10, 7,11] -> [ 9,10, 7,11] -> [ 9,10, 0,11] -> [ 9,10,11, 0] -> [ 9,10,11,12]
[13,14,15,12] [13,14,15,12] [13,14,15,12] [13,14,15,12] [13,14,15, 0]
// NOTE: Your solution does not need to follow this exact sequence to pass
```
## Technical Details
- Input will always be valid.
- The range of values for `n` are: `10 >= n >= 3`
If you enjoyed this kata, be sure to check out [my other katas](https://www.codewars.com/users/docgunthrop/authored). | algorithms | from itertools import chain, combinations, accumulate
from heapq import heappush, heappop
def slide_puzzle(arr):
def moveTargetTo(iX, i0, grid, target=None, lowLim=None):
""" iX: index in the grid of the position to work on
i0: blank index
grid: current grid state
target: value to place at iX
lowLim: value index under which the tiles cannot be/go (mostly optimization to avoid searching for inde'xes from the beginning)
"""
if target is None: target = iX+1 # Default VALUE of the tile to move
if lowLim is None: lowLim = iX # Default minimal index under
iT = grid.index(target, lowLim) # Current position of the target tile
xyX, xyT = divmod(iX,S), divmod(iT,S) # Coords converted to (x,y) format
dV,dH = [b-a for a,b in zip(xyT,xyX)] # Moves to do to reach the iX position, in (x,y) format
sV,sH = S * ((dV>0)-(dV<0)), (dH>0)-(dH<0) # "Amount to move", step by step, in each direction
paths = [ list(accumulate([iT] + [sH]*abs(dH) + [sV]*abs(dV))), # Build the two possible direct paths (dH->dV or dV->dH)
list(accumulate([iT] + [sV]*abs(dV) + [sH]*abs(dH))) ]
path = next(filter(lambda p: not set(p) & forbid, paths)) # Peek the first one that is fully allowed (at least one always exists)
for iT,iTnext in zip(path, path[1:]):
forbid.add(iT) # Set up the constraint
i0, grid = moveBlank(i0, iTnext, grid, lowLim)
forbid.remove(iT) # Relax"-relax... don't do it..."
i0, grid = gridSwapper(i0, iT, grid) # Final swap of blank and target
movesToParadise.append(target) # Register the moves needed
forbid.add(iX) # Archive iX as "definitively" done
return i0, grid
def conquerCorner(i0, grid, i1, i2, lowLim):
v1, v2 = i1+1, i2+1, # Target values
delta = i2-i1 # Step in idexes between i1 and i2
delta2nd = S if delta == 1 else 1 # Step in idexes in the orthogonal direction
shifted2 = i2+delta2nd # Temporary targeted index
i0, grid = moveTargetTo(i2, i0, grid, target=v1, lowLim=lowLim) # Place v1 at i2 for now
forbid.remove(i2) # Unlock to avoid impossible moves
i0, grid = moveTargetTo(shifted2, i0, grid, target=v2, lowLim=lowLim) # Place v2 next to v1, in the orthogonal direction
forbid.remove(shifted2) # Unlock the temporary point
i0, grid = moveBlank(i0, i1+2*delta2nd, grid, lowLim) # Try to move the blank away first (avoid to move v1 and v2 if they are correct)
i0, grid = moveBlank(i0, i1, grid, lowLim) # Move the blank at the ideal position for final 2x2 rotation
if grid[i2] == v1 and grid[shifted2] == v2: # The 3 tiles are still placed as expected/hoped for (blank IS): solve directly
movesToParadise.extend([v1,v2])
for i in (i2,shifted2): # Makes the two actual swaps in the grid
i0, grid = gridSwapper(i0, i, grid)
else: # Occasionally, something might go "wrong" (v1 or v2 moved again), so resolve instead a 3x2 subgrid with A*, to get the 2 target tiles at the right place (note, at this point, we are sure that the 3 tiles are in the subgrid)
subGrid_3x2 = {i1 + a*delta + b*delta2nd for a in range(2) for b in range(3)} # Grid to work on, in the appropriate orientation
blocking = set(range(lowLim+2, linS)) - subGrid_3x2 - forbid # Tiles to block (only those that are still free at this point and not in the subgrid)
(_,it1),(_,it2) = sorted((grid[i],i) for i in subGrid_3x2 if grid[i] in (v1,v2)) # Retrieve the index of each target
cost = manhattan(it1, i1) + manhattan(it2, i2) # Cost based on the positions of v1 and v2 only
def heuristic(cost, i, i0, grid): # Function updating the cost for each swap in A*
delta1 = manhattan(i0, i1) - manhattan(i, i1) if grid[i] == v1 else 0
delta2 = manhattan(i0, i2) - manhattan(i, i2) if grid[i] == v2 else 0
c = cost + delta1 + delta2
return c
forbid.update(blocking) # "Gendarmerie nationale, vos papiers siouplait..."
i0, grid, seq = modifiedAStar(grid, i0, heuristic, cost, forbid) # Move the blank to the right position (just "ahead" of the target)
forbid.difference_update(blocking) # Relax...
movesToParadise.extend(seq)
forbid.update({i1,i2}) # Block the two tiles that have been placed
return i0, grid
def moveBlank(i0, to, grid, lowLim):
cost = manhattan(i0, to) # Cost only related to the distance between the blank and the targeted position
heuristic = lambda _,i0,__,___: manhattan(i0, to)
i0, grid, seq = modifiedAStar(grid, i0, heuristic, cost, forbid) # Move the blank to the correct position (just "ahead" of the target)
movesToParadise.extend(seq) # Archive the moves
return i0, grid
def manhattan(i0, to): return sum( abs(b-a) for a,b in zip(divmod(i0,S),divmod(to,S)) ) # Distance between indexes
def manhattan2(i, v): return sum( abs(b-a) for a,b in zip(divmod(i,S), divmod((v-1)%linS,S)) ) # Distance current index of v/expected position of v
#-----------------------------------------------------------------------------------------
grid = tuple(chain.from_iterable(arr)) # Linearized
S,linS = len(arr), len(arr)**2 # Dimensions (square / linear)
i0 = grid.index(0) # Initial position
""" Check doability """
nInv = sum(a*b and a>b for a,b in combinations(chain.from_iterable(arr), 2)) # Number of inversions
r0Bot = S - grid.index(0) // S # Row containing the 0 (1-indexed, from bottom)
if S%2 and nInv%2 or not S%2 and not (nInv%2 ^ r0Bot%2): return None # Unsolvable!
""" Divide and conquer, up to 3x2 rectangle remaining """
forbid = set() # MUTATED: Archive all the indexes already done ON THE LEFT part (no tneeded for the upper part)
movesToParadise = [] # MUTATED: Moves applied to solve the puzzle
for z in range(S-2): # Up to the two last rows... (z moving on the diagonal):
for y in range(z, S-2): # Complete the current top line, until 2 squares are remaining (or 3 if that's the second to last row)
iX = z*S + y
i0, grid = moveTargetTo(iX, i0, grid)
i0, grid = conquerCorner(i0, grid, iX+1, iX+2, iX+1) # Places those two values at the end of the row z
lim = S*(z+1)
for x in range(z+1,S-2): # Left column, going down, leaving the two last free.
iX = x*S + z
i0, grid = moveTargetTo(iX, i0, grid, lowLim=lim) # Complete the current first column, until 2 squares remains
if z < S-3: # Place the two last squares on the column, unless they are for the last 3x2 grid ("z == S-3")
i1, i2 = iX+S, iX+2*S
i0, grid = conquerCorner(i0, grid, i1, i2, lowLim=lim) # Places those two tiles
""" Solve the 3x2 remaining grid with A* """
lowLim = linS-S-3 # Last tile completed + 1
cost = sum( manhattan2(i, grid[i]) for i in range(linS)) # Initial cost
def heuristic(cost, i, i0, grid):
a,b,c,d = (manhattan2(i0, grid[i]), manhattan2(i, grid[i0]), # Costs in the candidate grid
manhattan2(i0, grid[i0]), manhattan2(i, grid[i]) ) # Costs in the original grid
return cost+a+b-c-d
i0, grid, seq = modifiedAStar(grid, i0, heuristic, cost, forbid)
movesToParadise.extend(seq)
return movesToParadise
def display(grid, msg='',force=False):
if DEBUG or force:
linS, S = len(grid), int(len(grid)**.5)
if msg: print(msg)
print('\n'.join(' '.join(map('{: >2}'.format, grid[i:i+S])) for i in range(0,linS,S)).replace(' 0',' X'))
print('-'*S*2)
def gridSwapper(i0, other, grid):
a, b = (i0,other) if i0<other else (other,i0)
nextGrid = grid[:a] + (grid[b],) + grid[a+1:b] + (grid[a],) + grid[b+1:]
return other, nextGrid
def modifiedAStar(grid, i0, heuristic, cost, forbid):
""" "A*", but exit as soon as the end condition (cost==0) is reached, even if not
the shortest path. Returns the moves needed to to this final situation.
grid: linear version of the puzzle (as tuple).
i0: position of the blank at the beginning.
heuristic: function that computes the update the cost for each candidate grid.
Call in the form: f(cost, i, i0, grid).
cost: initial cost, has to reach 0 when the final configuration is reached.
forbid: Set of forbidden positions (as linearized indexes). This set is copied
right at the beginning to keep the source faithful.
@RETURN: tuple: (i0 at the end,
Final grid state (tuple),
sequence of moves to reach that state)
"""
S = int(len(grid)**.5)
linS = S**2
MOVES = (S, -S, 1, -1) # (down, up, right, left)
q = [(cost, grid, i0, 1j, (-1,))] # (cost, current state (as tuple), i0, last move, ans ('-1' is dummy))
seens = set()
forbidPos = set(forbid) # Use a copy
while q and q[0][0]:
cost, grid, i0, last, moves = heappop(q)
seens.add(grid)
for m in MOVES:
i = i0+m
if (m == -last or m==1 and i0%S==S-1 or m==-1 and not i0%S # Skip if: going back (opposite of the last move) or "wrapping" two rows ([i][-1] <-> [i+1][0])...
or not (0 <= i < linS) or i in forbidPos): # ... or not inside the correct area or in the forbidden positions)
continue
_,cnd = gridSwapper(i0, i, grid) # Build the candidate (making the swap)
if cnd not in seens: # Skip if already found
cndCost = heuristic(cost, i, i0, grid)
heappush(q, (cndCost, cnd, i, m, moves+(grid[i],)) )
if q:
return q[0][2], q[0][1], q[0][-1][1:] # Outputs (without the initial -1 in the moves, used to simplify/fasten the executions)
else:
raise Exception(display(grid) or "Aha... That's not going well... (A* ran out of possibilities!)") | Sliding Puzzle Solver | 5a20eeccee1aae3cbc000090 | [
"Puzzles",
"Genetic Algorithms",
"Game Solvers",
"Algorithms"
]
| https://www.codewars.com/kata/5a20eeccee1aae3cbc000090 | 1 kyu |
We want to obtain number ```π``` (```π = 3,1415926535897932384626433832795```) with an approximate fraction having a relative error of 1%
```
rel_error = (π - fraction_value) / π * 100 = ± 1
absolute_error = |± 1 / 100 * π| = 0.031416
```
Try to get the used algorithm to obtain the approximate fraction, observing the process bellow:
```
1/1 -----> 2/1 -----> 3/1 -----> 4/1 -----> 4/2 -----> 5/2 -----> 6/2 -----> 7/2 -----> 7/3 -----> 8/3 -----> 9/3 -----> 10/3 ----> 10/4 ----> 11/4 ----> 12/4 ----> 13/4 ----> 13/5 ----> 14/5 ----> 15/5 ----> 16/5 ----> 16/6 ----> 17/6 ----> 18/6 ----> 19/6
```
```|π - 19/6| = 0.02 < 0.031416```
So we obtain the fraction ```19/6``` (approximate to π) in ```23``` steps.
Make the function ```approx_fraction()```, that receives a float (an irrational number) and a relative error (as percentage) as arguments. The function should output a list with the fraction as a string and the number of steps needed.
Let's see some cases:
```python
float_ = math.pi
rel_error = 1
approx_fraction(float_, rel_error) == ['19/6', 23]
float_ = math.pi
rel_error = 0.01
approx_fraction(float_, rel_error) == ['289/92', 379]
```
Your code should handle negative floats.
```python
degrees = 130
float_ = math.cos(math.pi*degrees/180) # (= -0.6427876096865394)
rel_error = 0.001
approx_fraction(float_, rel_error) == ['-610/949', 1557]
```
If the float number does not have a decimal part, like this case:
```python
float_ = math.sqrt(361) #(= 19)
rel_error = 0.01
approx_fraction(float_, rel_error) == "There is no need to have a fraction for 19"
float_ = math.log(1)
rel_error = 0.01
approx_fraction(float_, rel_error) == "There is no need to have a fraction for 0"
```
Finally if the absolute difference with the given float and its integer part is less than 0.0000000001 (1* 10^-10), consider it as an integer
```python
degrees = 45
float_ = math.tan(math.pi*degrees/180) # (= 0.9999999999999999)
rel_error = 0.01
approx_fraction(float_, rel_error) == "There is no need to have a fraction for 1"
```
As irrational numbers, you will be given: 10-base logarithms, natural logarithms, trigonometric functions, square roots and nth-roots of numbers.
Do not worry about values like ± ∞ (positive, negative infinity) or complex numbers. For python: There is no need to import the math library.
Enjoy it!!
| reference | import math
def approx_fraction(target: float, rel_err_pct: float, eps: float = 1e-10) - > list[str, int] | str:
if math . isclose(round(target), target, rel_tol=eps):
return f'There is no need to have a fraction for { round ( target )} '
if target < 0:
a, b = approx_fraction(- target, rel_err_pct)
return [f'- { a } ', b]
rel_err_pct /= 100
i = 0
n = d = q = 1
while not math . isclose(q, target, rel_tol=rel_err_pct):
if q < target:
n += 1
else:
d += 1
q = n / d
i += 1
return [f' { n } / { d } ', i]
| Approximate Fractions | 56797325703d8b34a4000014 | [
"Fundamentals",
"Mathematics",
"Strings"
]
| https://www.codewars.com/kata/56797325703d8b34a4000014 | 6 kyu |
# A History Lesson
The <a href=https://en.wikipedia.org/wiki/Pony_Express>Pony Express</a> was a mail service operating in the US in 1859-60.
<img src="https://i.imgur.com/oEqUjpP.png" title="Pony Express" />
It reduced the time for messages to travel between the Atlantic and Pacific coasts to about 10 days, before it was made obsolete by the <a href=https://en.wikipedia.org/wiki/First_transcontinental_telegraph>transcontinental telegraph</a>.
# How it worked
There were a number of *stations*, where:
* The rider switched to a fresh horse and carried on, or
* The mail bag was handed over to the next rider
# Kata Task
`stations` is a list/array of distances (miles) from one station to the next along the Pony Express route.
Implement the `riders` method/function, to return how many riders are necessary to get the mail from one end to the other.
## Missing rider
In this version of the Kata a rider may go missing. In practice, this could be for a number of reasons - a lame horse, an accidental fall, foul play...
After some time, the rider's absence would be noticed at the **next** station, so the next designated rider from there would have to back-track the mail route to look for his missing colleague. The missing rider is then safely escorted back to the station he last came from, and the mail bags are handed to his rescuer (or another substitute rider if necessary).
`stationX` is the number (2..N) of the station where the rider's absence was noticed.
# Notes
* Each rider travels as far as he can, but never more than 100 miles.
# Example
GIven
* `stations = [43, 23, 40, 13]`
* `stationX = 4`
So
`S1` ... ... 43 ... ... `S2` ... ... 23 ... ... `S3` ... ... 40 ... ... `S4` ... ... 13 ... ... `S5`
* Rider 1 gets as far as Station S3
* Rider 2 (at station S3) takes mail bags from Rider 1
* Rider 2 never arrives at station S4
* Rider 3 goes back to find what happened to Rider 2
* Rider 2 and Rider 3 return together back to Station S3
* Rider 3 takes mail bags from Rider 2
* Rider 3 completes the journey to Station S5
**Answer:**
3 riders
<hr style="width:75%;margin-top:40px;margin-bottom:40px;height:1px;border:none;color:red;background-color:red;" />
*Good Luck.</br>
DM.*
---
See also
* <a href=https://www.codewars.com/kata/the-pony-express>The Pony Express</a>
* The Pony Express (missing rider)
| algorithms | def riders(stations, lost):
stations = stations[: lost - 1] + stations[lost - 2:]
rider, dist = 1, 0
for i, d in enumerate(stations):
rider += (dist + d > 100) + (i == lost - 2)
dist = dist * (dist + d <= 100 and i != lost - 2) + d
return rider
| The Pony Express (missing rider) | 5b204d1d9212cb6ef3000111 | [
"Algorithms"
]
| https://www.codewars.com/kata/5b204d1d9212cb6ef3000111 | 6 kyu |
Count how often sign changes in array.
### result
number from `0` to ... . Empty array returns `0`
### example
```javascript
const arr = [1, -3, -4, 0, 5];
/*
| elem | count |
|------|-------|
| 1 | 0 |
| -3 | 1 |
| -4 | 1 |
| 0 | 2 |
| 5 | 2 |
*/
catchSignChange(arr) == 2;
```
~~~if:lambdacalc
### encodings
purity: `LetRec`
numEncoding: <span style="color: aqua">extended</span> `binaryScott`
export constructors `nil, cons` for your `List` encoding
* <span style="color: aqua">negative numbers</span> are allowed, encoded as the bit-complement of the encoding of their absolute value
* e.g. `6 -> 011$ ; -6 -> 100$`
* non-negative number encoding is unchanged
* the normal invariant "MSB, if any, must be `1`" becomes "MSB must be `0`" for negative numbers
* you can use positive, zero and negative number literals in your code
* return value is a non-negative `Number`, in basic Binary Scott encoding
~~~ | reference | def catch_sign_change(lst):
count = 0
for i in range(1, len(lst)):
if lst[i] < 0 and lst[i - 1] >= 0:
count += 1
if lst[i] >= 0 and lst[i - 1] < 0:
count += 1
return count
| Plus - minus - plus - plus - ... - Count | 5bbb8887484fcd36fb0020ca | [
"Fundamentals"
]
| https://www.codewars.com/kata/5bbb8887484fcd36fb0020ca | 7 kyu |
## Description
"John, come here, we have to talk about the order form. Although I was drunk yesterday, today is not fully awake, but why do they look so strange?"
```
[
{"tire":1,"steeringWheel":2,"totalPrice":31.56},
{"tire":5,"steeringWheel":1,"totalPrice":73.69}
]
```
"Oh, my boss, all of these are based on the list you gave me yesterday."
"John, we sell the car parts, each order is the customer needs to be installed on a car. Have you ever seen a car with a wheel and two steering wheels? Or five tires of a car?"
"Oh, my boss, all of these are based on the list you gave me yesterday."
"Well, I was beaten by you. But don't you know I got drunk yesterday? I don't even know what I did yesterday. I thought you should know that a car has 4 wheels and 1 steering wheel."
"I'm sorry, boss, I think our company is an innovative enterprise, will produce some unusual car. And the boss is always right is my belief."
"Well, for your belief, I now order you to correct the number of tires and steering wheels for all orders, and calculate the correct total price."
"Sorry, boss, I don't know their unit price, you give me a list of only those. These tires and steering wheel have different models, their price is not the same."
"This is your job! Don't discuss anything with a drunken boss. The only thing I know now is that the end of the price of these tires is `.98`, the end of the unit price of the steering wheel is `.79`. Their prices are not less than $5, not more than $20. Your job is to figure out all the numbers, if you don't want to be fired!"
## Task
Complete function `correctOrder()` that accepts a arguments `list`, it's an array that contains some objects of order form. Calculation of the tire and the steering wheel unit price, in accordance with the 4 tires and a steering wheel to calculate the total price, return the results of the calculation.
The condition that we known:
The unit price range of the tire and steering wheel is `5-20(5.79 <= ? <= 19.98)`; The unit price of the steering wheel is `always higher than the price of the tire`, but `the difference is less than $3`; You can assume that all test cases `have and only have` a correct answer.
## Example
```
list=[
{"tire":1,"steeringWheel":2,"totalPrice":31.56},
{"tire":5,"steeringWheel":1,"totalPrice":73.69}]
correctOrder(list) should return:
[
{"tire":4,"steeringWheel":1,"totalPrice":50.71},
{"tire":4,"steeringWheel":1,"totalPrice":61.71}]
``` | games | def correct_order(orders):
result = []
for o in orders:
for t in range(5, 20):
for s in range(t + 1, t + 4):
if round((t + .98) * o["tire"] + (s + .79) * o["steeringWheel"], 2) == o["totalPrice"]:
result . append({"tire": 4, "steeringWheel": 1,
"totalPrice": round((t + .98) * 4 + (s + .79), 2)})
break
else:
continue
break
return result
| T.T.T.47: The boss is always right | 57be4f2e87e4483c800002ee | [
"Puzzles",
"Games"
]
| https://www.codewars.com/kata/57be4f2e87e4483c800002ee | 6 kyu |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.