

Commit
•
5aae7af
1
Parent(s):
c6bc3d8
Update README.md
Browse files
README.md
CHANGED
|
@@ -18,7 +18,8 @@ In June, we released the [IndustryCorpus](https://huggingface.co/datasets/BAAI/I
|
|
| 18 |
|
| 19 |
The data processing process is consistent with IndustryCorpus
|
| 20 |
|
| 21 |
-
|
|
|
|
| 22 |
|
| 23 |
## Data Perspective
|
| 24 |
|
|
@@ -48,7 +49,8 @@ The disk size of each industry data after full process processing is as follows
|
|
| 48 |
|
| 49 |
The industry data distribution chart in the summary data set is as follows
|
| 50 |
|
| 51 |
-
|
|
|
|
| 52 |
|
| 53 |
From the distribution chart, we can see that subject education, sports, current affairs, law, medical health, film and television entertainment account for most of the overall data. The data of these industries are widely available on the Internet and textbooks, and the high proportion of them is in line with expectations. It is worth mentioning that since we have supplemented the data of mathematics, we can see that the proportion of mathematics data is also high, which is inconsistent with the proportion of mathematics Internet corpus data.
|
| 54 |
|
|
@@ -97,7 +99,8 @@ All our data repos have a unified naming format, f"BAAI/IndustryCorpus2_{name}",
|
|
| 97 |
|
| 98 |
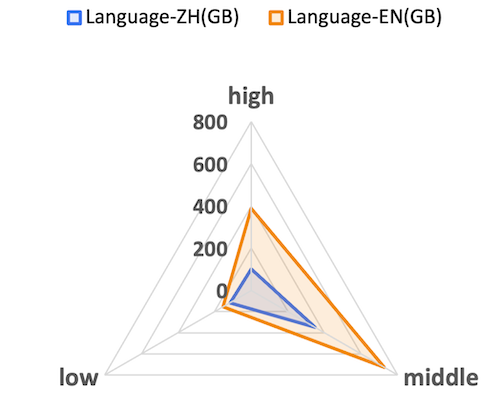
We filter the entire data according to data quality, remove extremely low-quality data, and divide the available data into three independent groups: Low, Middle, and Hight, to facilitate data matching and combination during model training. The distribution of data of different qualities is shown below. It can be seen that the data quality distribution trends of Chinese and English are basically the same, with the largest number of middle data, followed by middle data, and the least number of low data; in addition, it can be observed that the proportion of hight data in English is higher than that in Chinese (with a larger slope), which is also in line with the current trend of distribution of different languages.
|
| 99 |
|
| 100 |
-
|
|
|
|
| 101 |
|
| 102 |
## Industry Category Classification
|
| 103 |
|
|
@@ -116,7 +119,7 @@ In order to improve the coverage of industry classification in the data set to a
|
|
| 116 |
|
| 117 |
The overall process of data construction is as follows:
|
| 118 |
|
| 119 |
-
 project, which we will explain in detail there.
|
|
|
|
| 18 |
|
| 19 |
The data processing process is consistent with IndustryCorpus
|
| 20 |
|
| 21 |
+
|
| 22 |
+

|
| 23 |
|
| 24 |
## Data Perspective
|
| 25 |
|
|
|
|
| 49 |
|
| 50 |
The industry data distribution chart in the summary data set is as follows
|
| 51 |
|
| 52 |
+
|
| 53 |
+

|
| 54 |
|
| 55 |
From the distribution chart, we can see that subject education, sports, current affairs, law, medical health, film and television entertainment account for most of the overall data. The data of these industries are widely available on the Internet and textbooks, and the high proportion of them is in line with expectations. It is worth mentioning that since we have supplemented the data of mathematics, we can see that the proportion of mathematics data is also high, which is inconsistent with the proportion of mathematics Internet corpus data.
|
| 56 |
|
|
|
|
| 99 |
|
| 100 |
We filter the entire data according to data quality, remove extremely low-quality data, and divide the available data into three independent groups: Low, Middle, and Hight, to facilitate data matching and combination during model training. The distribution of data of different qualities is shown below. It can be seen that the data quality distribution trends of Chinese and English are basically the same, with the largest number of middle data, followed by middle data, and the least number of low data; in addition, it can be observed that the proportion of hight data in English is higher than that in Chinese (with a larger slope), which is also in line with the current trend of distribution of different languages.
|
| 101 |
|
| 102 |
+
|
| 103 |
+
|
| 104 |
|
| 105 |
## Industry Category Classification
|
| 106 |
|
|
|
|
| 119 |
|
| 120 |
The overall process of data construction is as follows:
|
| 121 |
|
| 122 |
+

|
| 123 |
|
| 124 |
- Model training:
|
| 125 |
|
|
|
|
| 129 |
|
| 130 |
Training hyperparameters: full parameter training, max_length = 2048, lr = 1e-5, batch_size = 64, validation set evaluation acc: 86%
|
| 131 |
|
| 132 |
+
|
| 133 |
+

|
| 134 |
|
| 135 |
## Data quality assessment
|
| 136 |
|
|
|
|
| 185 |
|
| 186 |
Model evaluation: On the validation set, the consistency rate of the model and GPT4 in sample quality judgment was 90%.
|
| 187 |
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+

|
| 191 |
|
| 192 |
- Training benefits from high-quality data
|
| 193 |
|
|
|
|
| 195 |
|
| 196 |
As can be seen from the curve, the 14B tokens of the model trained with high-quality data can achieve the performance of the model with 50B of ordinary data. High-quality data can greatly improve training efficiency.
|
| 197 |
|
| 198 |
+
|
| 199 |
+

|
| 200 |
|
| 201 |
In addition, high-quality data can be added to the model as data in the pre-training annealing stage to further improve the model effect. To verify this conjecture, when training the industry model, we added pre-training data converted from high-quality data after screening and some instruction data to the annealing stage of the model. It can be seen that the performance of the model has been greatly improved.
|
| 202 |
|
| 203 |
+

|
| 204 |
|
| 205 |
Finally, high-quality pre-training predictions contain a wealth of high-value knowledge content, from which instruction data can be extracted to further improve the richness and knowledge of instruction data. This also gave rise to the [BAAI/IndustryInstruction](https://huggingface.co/datasets/BAAI/IndustryInstruction) project, which we will explain in detail there.
|