
Jacobellis Dan (dgj335)
commited on
Commit
·
606c287
1
Parent(s):
3e130f9
readme
Browse files- README.ipynb +0 -0
- README.md +66 -44
README.ipynb
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
README.md
CHANGED
|
@@ -5,7 +5,7 @@ datasets:
|
|
| 5 |
# Wavelet Learned Lossy Compression (WaLLoC)
|
| 6 |
|
| 7 |
WaLLoC sandwiches a convolutional autoencoder between time-frequency analysis and synthesis transforms using
|
| 8 |
-
CDF 9/7 wavelet filters. The time-frequency transform increases the number of signal channels, but reduces the temporal or spatial resolution, resulting in lower GPU memory consumption and higher throughput. WaLLoC's training procedure is highly simplified compared to other $\beta$-VAEs, VQ-VAEs, and neural codecs, but still offers significant dimensionality reduction and compression. This makes it suitable for dataset storage and compressed-domain learning. It currently supports 2D signals
|
| 9 |
|
| 10 |
## Installation
|
| 11 |
|
|
@@ -30,32 +30,35 @@ import os
|
|
| 30 |
import torch
|
| 31 |
import matplotlib.pyplot as plt
|
| 32 |
import numpy as np
|
| 33 |
-
from PIL import Image
|
| 34 |
from IPython.display import display
|
| 35 |
from torchvision.transforms import ToPILImage, PILToTensor
|
| 36 |
from walloc import walloc
|
| 37 |
from walloc.walloc import latent_to_pil, pil_to_latent
|
| 38 |
-
class
|
| 39 |
```
|
| 40 |
|
| 41 |
### Load the model from a pre-trained checkpoint
|
| 42 |
|
| 43 |
-
```wget https://hf.co/danjacobellis/walloc/resolve/main/
|
| 44 |
|
| 45 |
|
| 46 |
```python
|
| 47 |
device = "cpu"
|
| 48 |
-
checkpoint = torch.load("
|
| 49 |
-
|
| 50 |
-
codec = walloc.
|
| 51 |
-
channels =
|
| 52 |
-
J =
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
|
|
|
|
|
|
| 56 |
)
|
| 57 |
codec.load_state_dict(checkpoint['model_state_dict'])
|
| 58 |
codec = codec.to(device)
|
|
|
|
| 59 |
```
|
| 60 |
|
| 61 |
### Load an example image
|
|
@@ -72,7 +75,7 @@ img
|
|
| 72 |
|
| 73 |
|
| 74 |
|
| 75 |
-

|
| 76 |
|
| 77 |
|
| 78 |
|
|
@@ -97,7 +100,7 @@ ToPILImage()(x_hat[0]+0.5)
|
|
| 97 |
|
| 98 |
|
| 99 |
|
| 100 |
-

|
| 101 |
|
| 102 |
|
| 103 |
|
|
@@ -116,7 +119,7 @@ with torch.no_grad():
|
|
| 116 |
print(f"dimensionality reduction: {x.numel()/Y.numel()}×")
|
| 117 |
```
|
| 118 |
|
| 119 |
-
dimensionality reduction:
|
| 120 |
|
| 121 |
|
| 122 |
|
|
@@ -127,9 +130,8 @@ Y.unique()
|
|
| 127 |
|
| 128 |
|
| 129 |
|
| 130 |
-
tensor([-
|
| 131 |
-
|
| 132 |
-
9., 10., 11., 12., 13., 14., 15.])
|
| 133 |
|
| 134 |
|
| 135 |
|
|
@@ -138,86 +140,106 @@ Y.unique()
|
|
| 138 |
plt.figure(figsize=(5,3),dpi=150)
|
| 139 |
plt.hist(
|
| 140 |
Y.flatten().numpy(),
|
| 141 |
-
range=(-
|
| 142 |
-
bins=
|
| 143 |
density=True,
|
| 144 |
-
width=0.
|
| 145 |
plt.title("Histogram of latents")
|
| 146 |
-
plt.xticks(range(-
|
|
|
|
| 147 |
```
|
| 148 |
|
| 149 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 150 |
|
| 151 |
-

|
| 158 |
|
| 159 |
|
| 160 |
```python
|
| 161 |
-
|
| 162 |
-
|
|
|
|
| 163 |
Y_pil[0].save('latent.png')
|
| 164 |
png = [Image.open("latent.png")]
|
| 165 |
-
Y_rec = pil_to_latent(png,
|
| 166 |
-
assert(Y_rec.equal(
|
| 167 |
print("compression_ratio: ", x.numel()/os.path.getsize("latent.png"))
|
| 168 |
```
|
| 169 |
|
| 170 |
|
| 171 |
|
| 172 |
-

|
| 180 |
|
| 181 |
|
| 182 |
```python
|
| 183 |
-
Y_pil = latent_to_pil(Y
|
| 184 |
-
display(Y_pil[0])
|
| 185 |
Y_pil[0].save('latent.webp',lossless=True)
|
| 186 |
webp = [Image.open("latent.webp")]
|
| 187 |
-
Y_rec = pil_to_latent(webp,
|
| 188 |
-
assert(Y_rec.equal(Y
|
| 189 |
-
print("compression_ratio: ",
|
| 190 |
```
|
| 191 |
|
| 192 |
|
| 193 |
|
| 194 |
-

|
| 202 |
|
| 203 |
|
| 204 |
```python
|
| 205 |
-
|
| 206 |
-
|
|
|
|
| 207 |
Y_pil[0].save('latent.tif',compression="tiff_adobe_deflate")
|
| 208 |
tif = [Image.open("latent.tif")]
|
| 209 |
-
Y_rec = pil_to_latent(tif,
|
| 210 |
-
assert(Y_rec.equal(
|
| 211 |
-
print("compression_ratio: ", x.numel()/os.path.getsize("latent.
|
| 212 |
```
|
| 213 |
|
| 214 |
|
| 215 |
|
| 216 |
-
/os.path.getsize("latent.png"))
|
|
| 228 |
[NbConvertApp] Converting notebook README.ipynb to markdown
|
| 229 |
[NbConvertApp] Support files will be in README_files/
|
| 230 |
[NbConvertApp] Making directory README_files
|
| 231 |
-
[NbConvertApp] Writing
|
| 232 |
|
| 233 |
|
| 234 |
|
|
|
|
| 5 |
# Wavelet Learned Lossy Compression (WaLLoC)
|
| 6 |
|
| 7 |
WaLLoC sandwiches a convolutional autoencoder between time-frequency analysis and synthesis transforms using
|
| 8 |
+
CDF 9/7 wavelet filters. The time-frequency transform increases the number of signal channels, but reduces the temporal or spatial resolution, resulting in lower GPU memory consumption and higher throughput. WaLLoC's training procedure is highly simplified compared to other $\beta$-VAEs, VQ-VAEs, and neural codecs, but still offers significant dimensionality reduction and compression. This makes it suitable for dataset storage and compressed-domain learning. It currently supports 1D and 2D signals, including mono, stereo, or multi-channel audio, and grayscale, RGB, or hyperspectral images.
|
| 9 |
|
| 10 |
## Installation
|
| 11 |
|
|
|
|
| 30 |
import torch
|
| 31 |
import matplotlib.pyplot as plt
|
| 32 |
import numpy as np
|
| 33 |
+
from PIL import Image, ImageEnhance
|
| 34 |
from IPython.display import display
|
| 35 |
from torchvision.transforms import ToPILImage, PILToTensor
|
| 36 |
from walloc import walloc
|
| 37 |
from walloc.walloc import latent_to_pil, pil_to_latent
|
| 38 |
+
class Config: pass
|
| 39 |
```
|
| 40 |
|
| 41 |
### Load the model from a pre-trained checkpoint
|
| 42 |
|
| 43 |
+
```wget https://hf.co/danjacobellis/walloc/resolve/main/RGB_Li_27c_J3_nf4_v1.0.2.pth```
|
| 44 |
|
| 45 |
|
| 46 |
```python
|
| 47 |
device = "cpu"
|
| 48 |
+
checkpoint = torch.load("RGB_Li_27c_J3_nf4_v1.0.2.pth",map_location="cpu",weights_only=False)
|
| 49 |
+
codec_config = checkpoint['config']
|
| 50 |
+
codec = walloc.Codec2D(
|
| 51 |
+
channels = codec_config.channels,
|
| 52 |
+
J = codec_config.J,
|
| 53 |
+
Ne = codec_config.Ne,
|
| 54 |
+
Nd = codec_config.Nd,
|
| 55 |
+
latent_dim = codec_config.latent_dim,
|
| 56 |
+
latent_bits = codec_config.latent_bits,
|
| 57 |
+
lightweight_encode = codec_config.lightweight_encode
|
| 58 |
)
|
| 59 |
codec.load_state_dict(checkpoint['model_state_dict'])
|
| 60 |
codec = codec.to(device)
|
| 61 |
+
codec.eval();
|
| 62 |
```
|
| 63 |
|
| 64 |
### Load an example image
|
|
|
|
| 75 |
|
| 76 |
|
| 77 |
|
| 78 |
+

|
| 79 |
|
| 80 |
|
| 81 |
|
|
|
|
| 100 |
|
| 101 |
|
| 102 |
|
| 103 |
+

|
| 104 |
|
| 105 |
|
| 106 |
|
|
|
|
| 119 |
print(f"dimensionality reduction: {x.numel()/Y.numel()}×")
|
| 120 |
```
|
| 121 |
|
| 122 |
+
dimensionality reduction: 7.111111111111111×
|
| 123 |
|
| 124 |
|
| 125 |
|
|
|
|
| 130 |
|
| 131 |
|
| 132 |
|
| 133 |
+
tensor([-7., -6., -5., -4., -3., -2., -1., -0., 1., 2., 3., 4., 5., 6.,
|
| 134 |
+
7.])
|
|
|
|
| 135 |
|
| 136 |
|
| 137 |
|
|
|
|
| 140 |
plt.figure(figsize=(5,3),dpi=150)
|
| 141 |
plt.hist(
|
| 142 |
Y.flatten().numpy(),
|
| 143 |
+
range=(-7.5,7.5),
|
| 144 |
+
bins=15,
|
| 145 |
density=True,
|
| 146 |
+
width=0.9);
|
| 147 |
plt.title("Histogram of latents")
|
| 148 |
+
plt.xticks(range(-7,8,1));
|
| 149 |
+
plt.xlim([-7.5,7.5])
|
| 150 |
```
|
| 151 |
|
| 152 |
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
(-7.5, 7.5)
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
|
| 160 |
|
| 161 |
+
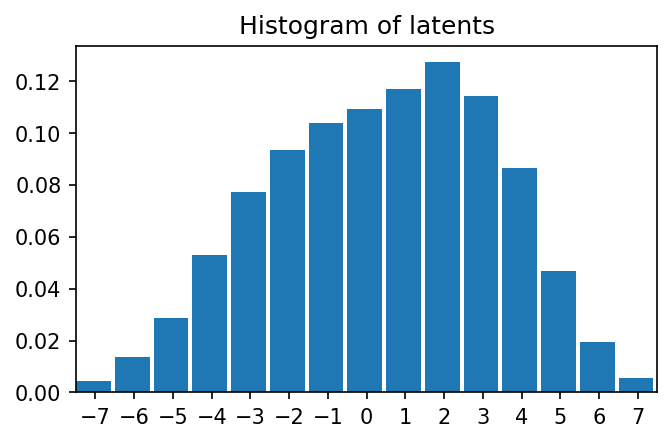
|
| 162 |
|
| 163 |
|
| 164 |
|
| 165 |
# Lossless compression of latents
|
| 166 |
|
| 167 |
+
|
| 168 |
+
```python
|
| 169 |
+
def scale_for_display(img, n_bits):
|
| 170 |
+
scale_factor = (2**8 - 1) / (2**n_bits - 1)
|
| 171 |
+
lut = [int(i * scale_factor) for i in range(2**n_bits)]
|
| 172 |
+
channels = img.split()
|
| 173 |
+
scaled_channels = [ch.point(lut * 2**(8-n_bits)) for ch in channels]
|
| 174 |
+
return Image.merge(img.mode, scaled_channels)
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
### Single channel PNG (L)
|
| 178 |
|
| 179 |
|
| 180 |
```python
|
| 181 |
+
Y_padded = torch.nn.functional.pad(Y, (0, 0, 0, 0, 0, 9))
|
| 182 |
+
Y_pil = latent_to_pil(Y_padded,codec.latent_bits,1)
|
| 183 |
+
display(scale_for_display(Y_pil[0], codec.latent_bits))
|
| 184 |
Y_pil[0].save('latent.png')
|
| 185 |
png = [Image.open("latent.png")]
|
| 186 |
+
Y_rec = pil_to_latent(png,36,codec.latent_bits,1)
|
| 187 |
+
assert(Y_rec.equal(Y_padded))
|
| 188 |
print("compression_ratio: ", x.numel()/os.path.getsize("latent.png"))
|
| 189 |
```
|
| 190 |
|
| 191 |
|
| 192 |
|
| 193 |
+

|
| 194 |
|
| 195 |
|
| 196 |
|
| 197 |
+
compression_ratio: 15.171345894154717
|
| 198 |
|
| 199 |
|
| 200 |
### Three channel WebP (RGB)
|
| 201 |
|
| 202 |
|
| 203 |
```python
|
| 204 |
+
Y_pil = latent_to_pil(Y,codec.latent_bits,3)
|
| 205 |
+
display(scale_for_display(Y_pil[0], codec.latent_bits))
|
| 206 |
Y_pil[0].save('latent.webp',lossless=True)
|
| 207 |
webp = [Image.open("latent.webp")]
|
| 208 |
+
Y_rec = pil_to_latent(webp,27,codec.latent_bits,3)
|
| 209 |
+
assert(Y_rec.equal(Y))
|
| 210 |
+
print("compression_ratio: ", x.numel()/os.path.getsize("latent.webp"))
|
| 211 |
```
|
| 212 |
|
| 213 |
|
| 214 |
|
| 215 |
+

|
| 216 |
|
| 217 |
|
| 218 |
|
| 219 |
+
compression_ratio: 16.451175633838172
|
| 220 |
|
| 221 |
|
| 222 |
### Four channel TIF (CMYK)
|
| 223 |
|
| 224 |
|
| 225 |
```python
|
| 226 |
+
Y_padded = torch.nn.functional.pad(Y, (0, 0, 0, 0, 0, 9))
|
| 227 |
+
Y_pil = latent_to_pil(Y_padded,codec.latent_bits,4)
|
| 228 |
+
display(scale_for_display(Y_pil[0], codec.latent_bits))
|
| 229 |
Y_pil[0].save('latent.tif',compression="tiff_adobe_deflate")
|
| 230 |
tif = [Image.open("latent.tif")]
|
| 231 |
+
Y_rec = pil_to_latent(tif,36,codec.latent_bits,4)
|
| 232 |
+
assert(Y_rec.equal(Y_padded))
|
| 233 |
+
print("compression_ratio: ", x.numel()/os.path.getsize("latent.tif"))
|
| 234 |
```
|
| 235 |
|
| 236 |
|
| 237 |
|
| 238 |
+

|
| 239 |
|
| 240 |
|
| 241 |
|
| 242 |
+
compression_ratio: 12.40611656815935
|
| 243 |
|
| 244 |
|
| 245 |
|
|
|
|
| 250 |
[NbConvertApp] Converting notebook README.ipynb to markdown
|
| 251 |
[NbConvertApp] Support files will be in README_files/
|
| 252 |
[NbConvertApp] Making directory README_files
|
| 253 |
+
[NbConvertApp] Writing 6024 bytes to README.md
|
| 254 |
|
| 255 |
|
| 256 |
|