
File size: 4,986 Bytes
fad58ef 7884e07 fad58ef 7884e07 fad58ef 1235916 abe3734 fad58ef abe3734 fad58ef 7884e07 fad58ef 7884e07 fad58ef 7884e07 fad58ef abe3734 fad58ef 7884e07 fad58ef 7884e07 fad58ef 7884e07 fad58ef 1235916 fad58ef 7884e07 fad58ef 7884e07 fad58ef 7884e07 fad58ef 7884e07 fad58ef 7884e07 fad58ef 7884e07 fad58ef abe3734 fad58ef abe3734 fad58ef 7884e07 fad58ef 5d6efd1 fad58ef abe3734 fad58ef 7884e07 fad58ef 7884e07 abe3734 7884e07 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
---
base_model: google/paligemma-3b-ft-docvqa-896
library_name: peft
license: apache-2.0
datasets:
- cmarkea/table-vqa
language:
- fr
- en
pipeline_tag: visual-question-answering
---
## Model Description
**paligemma-3b-ft-tablevqa-896-lora** is a fine-tuned version of the **[google/paligemma-3b-ft-docvqa-896](https://huggingface.co/google/paligemma-3b-ft-docvqa-896)** model,
trained specifically on the **[table-vqa](https://huggingface.co/datasets/cmarkea/table-vqa)** dataset published by Crédit Mutuel Arkéa. This model leverages the
**LoRA** (Low-Rank Adaptation) technique, which significantly reduces the computational complexity of fine-tuning while maintaining high performance. The model operates
in bfloat16 precision for efficiency, making it an ideal solution for resource-constrained environments.
This model is designed for multilingual environments (French and English) and excels in table-based visual question-answering (VQA) tasks. It is highly suitable for
extracting information from tables in documents, making it a strong candidate for applications in financial reporting, data analysis, or administrative document processing.
The model was fine-tuned over a span of 7 days using a single A100 40GB GPU.
## Key Features
- **Language:** Multilingual capabilities, optimized for French and English.
- **Model Type:** Multi-modal (image-text-to-text).
- **Precision:** bfloat16 for resource efficiency.
- **Training Duration:** 7 days on A100 40GB GPU.
- **Fine-Tuning Method:** LoRA (Low-Rank Adaptation).
- **Domain:** Table-based visual question answering.
## Model Architecture
This model was built on top of **[google/paligemma-3b-ft-docvqa-896](https://huggingface.co/google/paligemma-3b-ft-docvqa-896)**, using its pre-trained multi-modal
capabilities to process both text and images (e.g., document tables). LoRA was applied to reduce the size and complexity of fine-tuning while preserving accuracy,
allowing the model to excel in specific tasks such as table understanding and VQA.
## Usage
You can use this model for visual question answering with table-based data by following the steps below:
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "cmarkea/paligemma-3b-ft-tablevqa-896-lora"
# Sample image for inference
url = "https://datasets-server.huggingface.co/cached-assets/cmarkea/table-vqa/--/c26968da3346f92ab6bfc5fec85592f8250e23f5/--/default/train/22/image/image.jpg?Expires=1728915081&Signature=Zkrd9ZWt5b9XtY0UFrgfrTuqo58DHWIJ00ZwXAymmL-mrwqnWWmiwUPelYOOjPZZdlP7gAvt96M1PKeg9a2TFm7hDrnnRAEO~W89li~AKU2apA81M6AZgwMCxc2A0xBe6rnCPQumiCGD7IsFnFVwcxkgMQXyNEL7bEem6cT0Cief9DkURUDCC-kheQY1hhkiqLLUt3ITs6o2KwPdW97EAQ0~VBK1cERgABKXnzPfAImnvjw7L-5ZXCcMJLrvuxwgOQ~DYPs456ZVxQLbTxuDwlxvNbpSKoqoAQv0CskuQwTFCq2b5MOkCCp9zoqYJxhUhJ-aI3lhyIAjmnsL4bhe6A__&Key-Pair-Id=K3EI6M078Z3AC3"
image = Image.open(requests.get(url, stream=True).raw)
# Load the fine-tuned model and processor
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
processor = AutoProcessor.from_pretrained("google/paligemma-3b-ft-docvqa-896")
# Input prompt for table VQA
prompt = "How many rows are in this table?"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
# Generate the answer
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
```
## Performance
The model's performance was evaluated on 200 question-answer pairs, extracted from 100 tables from the test set of the
**[table-vqa](https://huggingface.co/datasets/cmarkea/table-vqa)** dataset. For each table, two pairs were selected: one in French and the other in English.
To evaluate the model’s responses, the **[LLM-as-Juries](https://arxiv.org/abs/2404.18796)** framework was employed using three judge models (GPT-4o, Gemini1.5 Pro,
and Claude 3.5-Sonnet). The evaluation was based on a scale from 0 to 5, tailored to the VQA context, ensuring accurate judgment of the model’s performance.
Here’s a visualization of the results:
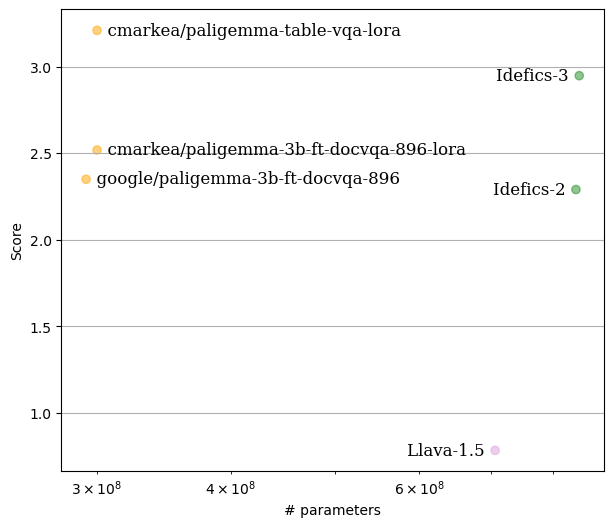
In comparison, this model outperforms **[HuggingFaceM4/Idefics3-8B-Llama3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3)** in terms of accuracy and efficiency,
despite having a smaller parameter size.
## Citation
```bibtex
@online{AgDePaligemmaTabVQA,
AUTHOR = {Tom Agonnoude, Cyrile Delestre},
URL = {https://huggingface.co/cmarkea/paligemma-tablevqa-896-lora},
YEAR = {2024},
KEYWORDS = {Multimodal, VQA, Table Understanding, LoRA},
} |